Guest Post by Willis Eschenbach
Let me start with a quick run through how mainstream climate scientists think the climate works, and then my hypothesis on how the climate works.
The central paradigm of modern climate science is that changes in the global temperature are a linear function of the “forcing”, the total energy input to the planetary surface. This is generally expressed as an equation:
∆T = λ ∆F
The delta “∆” means “change in”. The lambda “λ” is a constant called the “climate sensitivity”. “F” is the forcing, in watts per square meter. And “T” is the temperature. So the equation says:
The change in temperature ∆T is equal to the climate sensitivity λ times the change in forcing ∆F.
Me, I think that’s nonsense. If it were true, the global average temperature would go up and down like a yo-yo on steroids. But it doesn’t. Over the entire 20th century, the temperature increased by about 0.2%. Two-tenths of a percent. And this is despite monthly temperature variations at many locations varying by 30°C or more (~10%), so it cannot be from “thermal inertia” as many people claim.
My hypothesis is that this temperature stability is due to the thermoregulatory effect of a variety of different emergent phenomena. These include tropical cumulus cloud fields, thermally driven thunderstorms, dust devils, cyclones, and most relevant to this post … the El Nino phenomenon.
[UPDATE: What follows is a greatly simplified version of the circle of events of Nino Neutral/El Nino/La Nina and repeat. People wanting a detailed explanation can read Bob Tisdale’s 550 page book on the subject. Otherwise, here’s the TL;DR version.]
The El Nino phenomenon is a curious beast. When the Pacific Ocean gets hot off of the coast of Peru, this is called an “El Nino” condition. As it decays, it is succeeded by an increase in easterly trade winds. These winds blow the warm equatorial surface waters to the west, cooling the ocean surface. This is called a “La Nina” condition. Here is a graphic of a cross section of the ocean looking westward from 90° West, off of the coast of Peru.

Figure 1. 3-D views of the top 500 meters of the ocean, from 90° West (off the Peruvian coast) to 140°E (near the Asian mainland). Left graphic shows the El Nino condition, right graphic shows the La Nina condition. Colors indicate temperature.
In Figure 1, you can see how the wind literally scoops up the warm surface water and pushes it westward clear across the Pacific. Here are two images showing the changes in the sea level during the El Nino and La Nina alterations.


Figure 2. Changes in the sea surface elevation during El Nino (upper panel) and La Nina (lower panel)
Once the warm water arrives at the west Pacific islands and the Asian mainland, it strikes the land and divides in two, with part of the warm water heading towards the Arctic and the rest heading towards the Antarctic. Figure 3 shows the warmer tropical surface water being pushed polewards.

Figure 3. Sea surface temperature anomaly during the 1997-1998 La Nina.
The La Nina wind cool the equatorial Pacific, and thus the planet, in two ways.
First, as seen in Figure 3, it moves the warm water from the tropics toward the poles. There, because the air is dryer than in the moist tropics, more of the radiated heat from the warm water can escape to space.
And second, it exposes a large area of cooler sub-surface water (blue area in Figure 3) to the atmosphere. This cools the atmosphere.
So … if we accept my hypothesis that the El Nino/La Nina alteration is an emergent phenomenon that acts to cool the planet, an obvious question arises—if the earth is gradually warming, will the Pacific shift towards more El Nino conditions, more La Nina conditions, or remain unchanged?
Clearly, if my hypothesis is correct, it will shift towards more cooling La Nina conditions.
How can we measure this? Well, we have several indices that measure the state of the Pacific Ocean regarding El Nino.
The oldest of these is the Southern Ocean Index (SOI), which measures the difference in sea level pressure between Tahiti and Darwin, Australia. The change from El Nino to La Nina conditions affects the atmospheric pressure.
Next, we have the NINO34 Index. This is a measure of the sea surface temperature in the “NINO34” area, which goes from 5°N to 5°S and stretches across the Pacific from 120°W to 170°W. The Niño 3.4 anomalies basically represent the average equatorial sea surface temperatures of an area stretching across the Pacific from about the dateline to the South American coast.
Then there is the Oceanic Nino Index (ONI). It uses the same area as the NINO34 Index, but the ONI uses a 3-month running mean of temperatures.
Finally, there is the Multivariate ENSO Index (MEI). (ENSO is “El Nino Southern Oscillation”). Unlike the others, it is calculated from five different variables—sea level pressure (SLP), sea surface temperature (SST), zonal and meridional components of the surface wind, and outgoing longwave radiation (OLR)) over the tropical Pacific basin (30°S-30°N and 100°E-70°W). Because it requires modern data, it can only be calculated post-1979.
To show what is happening with El Nino, I’ve used a LOWESS smooth of the various indices. A LOWESS smooth shows the general trend of a given phenomenon. Here, for example, is the MEI Index along with the LOWESS smooth, and a straight line showing the trend of the index.

Figure 4. Raw Multivariate ENSO Index, LOWESS smooth, and straight trend line. Positive values are El Nino conditions, and negative values are La Nina conditions.
And here is the LOWESS smooth and the trend of all four of the El Nino indices described above. I’ve “standardized” the indexes, meaning I’ve set them all to have a mean (average) value of zero and a standard deviation of one.

Figure 5. LOWESS smooths of four El Nino indices, along with their straight-line trends. El Nino conditions are more positive, La Nina conditions are more negative.
You can see the peaks representing the big El Ninos around 1997-98 and 2015-16. Recall that according to my thermoregulatory hypothesis, the Pacific should be trending towards a more La Nina condition which is more negative.
And all four indices, in varying amounts, show this exact outcome—in response to the slow gradual warming since 1980, we have more La Nina conditions cooling the planet.
Q.E.D.
Here on the Pacific Coast of northern California where I live, La Nina conditions generally are accompanied by a reduction in rainfall. The last two years have been dry. We’ll see what this year brings, but the good news is that two days ago we got a full inch of rain, and the forest around my house is smiling.

Not only that, but more rain is forecast for the weekend. What’s not to like?
My best wishes to everyone,
w.
OTHER NEWS: I’m still suspended from Twitter. Seems like they must be prioritizing releasing the big accounts from durance vile, at least that’s how I’d do it.
If anyone wanted to send a tweet to @elonmusk advocating for my release, you could reference my post entitled “An Open Letter To @elonmusk” in which I discuss the issues of free speech and so-called “hate speech” … or if not, you just might want to read the post. These are issues of great importance to everyone both on and off Twitter, particularly since the European claim that we should regulate the undefinable category called “hate speech” seems to be spreading to the US.
MY USUAL REQUEST: I can defend my own words and am happy to do so. I cannot defend your understanding of my words. Accordingly, please quote the exact words you are discussing, so we can all be clear on the subject of your comment.
“Over the entire 20th century, the temperature increased by about 0.2%.”
What’s the error bar with that?
Using Berkeley Earth data, the error is on the order of ± 0.06%. However, it’s unclear how much the Berkeley Earth data (or other global datasets) have been altered in the name of “homogeneity”.
w.
but how good is that data, really? I would think to be very accurate there would have had to be many thousands of thermometers all over the plant a century ago- and again now- I’m no statistician but I would think if that error bar is based on analyzing the data they have, it wouldn’t be proper statistics- isn’t much of the data based on using models to determine what might have been the data where no data was collected?
just wild talk from me here- I don’t claim to understand climate science at all- just asking questions as an uninformed citizen with no faith in climate science
The people in the field, including Berkeley Earth, assert that all temperature measurement error is random, Joseph.
Random error averages away, and Voila! the uncertainty bars are made tiny.
They are wrong. Most temperature measurement error is systematic, including for SSTs.
But they’ll never accept the reality. Were they to do so, they’d have nothing to say. There goes the career, the grants, the accolades, and the salary.
Berkeley is BS. They started by making a novel land temperature record, which was worth examination. After that they combined it with classical SST records and made a bastard mix which was worth nothing but propaganda value.
Muller should have stuck to the original aim to create a new index both sides accepted, instead of renegging on his engagement and publishing without reference to other parties like Watts and Curry who were on board with his project.
Muller ignores systematic measurement error in land surface air temperature measurements.
The land surface record isn’t better than ±0.5 C. It can’t say much at all about the magnitude or rate of warming since 1880.
You are being overly generous. The land surface record has an uncertainty much greater than +/- 0.5C. Since it is made up of daily mid-point values which have a +/- 0.7C uncertainty the total uncertainty has to be larger than that. Since there is no true value to be found when combining measurements of different things the uncertainty should be considered to grow without bound. Especially when combining temperature anomalies between the north and south hemispheres which have different variances (i.e. summer vs winter). You can always assume the uncertainties cancel (which is wrong) but you can’t just assume the variances of the components also cancel.
Correctamundo! Berkeley BS.
“The people in the field, including Berkeley Earth, assert that all temperature measurement error is random…”
That seems unlikely. Do you have a source?
Surely the whole point of the adjustments made to individual stations is because of that assumption that there are systematic errors?
See Brohan, et al., (2006) under 2.3.1.1. Measurement Error (ε_𝑜b). Measurement error is defined as random, diminishing by 1/sqrtN.
In the Berkeley group, Rohde et al., (2013), recognizes “statistical uncertainty,” and uncertainty due to spatial incompleteness.
Statistical uncertainty is the quality of the data and implicitly includes measurement error. This error is taken in several places to diminish with the number of measurements, e.g., typical of random error.
On page 11, Rohde, et al., associate their statistical uncertainty with “unbiased sources of random noise affecting the data.”
Systematic effects considered are such things as incomplete areal coverage, instrumental changes, and urban heat island effects.
There’s nothing about the significant systematic measurement errors due to irradiance or wind speed, revealed by every field calibration experiment. Berkeley doesn’t include it, nor does HadCRU, nor NASA GISS.
Treating random errors as random, doesn’t mean they are asserting that all measurement errors are random. The fact that they consider inhomogeneities, such as “instrumental changes” shows that they are not asserting all errors as random. If there were no systematic errors in observations, then changing the instrument would not cause a change in observations.
Measurement uncertainty is a combination of both systematic and random bias/error, u_total = u_systematic + u_random. The issue is that you cannot know what the value of each component is for field instruments. If you don’t know either component then there is no way to compensate or adjust for it. When you are combining uncertainty for different locations and different measuring devices you simply cannot assume that you get perfect cancellation of random error. Nor would that eliminate systematic bias. Yet that *IS* what is done in climate science. It’s why the standard deviation of sample means (derived from stated values only, not the measurement uncertainty intervals) is used as the uncertainty value of the calculated mean for a data set made up of single measurements of multiple things in climate science. The standard deviation of the sample means can be zero while the mean calculated from the samples can be significantly wrong!
Standard deviation of the sample means (often described by the misnomer “uncertainty of the mean”) has nothing to do with the standard deviation or variance of the population and the standard deviation or variance of the population has nothing to do with the uncertainty of the measurements themselves.
And climate science just goes on its merry way ignoring all actual measurement uncertainty. Even in the Berkeley Earth raw data they show the measurement uncertainty of some measurements pre-1900 as being in the tenths of a degree. Really? They will tell you that they are just using the resolution of the instrument as its uncertainty and that is “fixed” later in the process of using the data. Really? How many pre-1900 LIG thermometers do you really think had a resolution of +/- 0.1C? And how do they “fix” or “adjust” for this to come up with the uncertainty? My guess is that they use +/- 0.05C as the “uncertainty” (i.e. half of a resolution mark).
Any station change *should* result in a new station record, not in supposed “adjustments” to create an artificially long record. You simply cannot know the calibration drift over time for an instrument, Assuming the calibration offset today was the calibration offset for the past decade, as an example, is just so wrong I don’t have the words to describe it in polite company.
The point at issue is measurement error, not instrumental changes.
They’re assuming that measurement errors are random. The assumption is ubiquitous and wrong.
If you measure 100 different things with 100 different devices there simply isn’t any guarantee that you will even get offsetting positive and negative errors. They could all be positive or all be negative. You have no way of telling. That’s why you might get some cancellation and the use of root-sum-square addition can give a reasonable answer. But even with root-sum-square the uncertainty grows, it doesn’t cancel (because you square first).
You’re still failing to understand this simple concept after all these years. Still failing to understand that the uncertainty of an average is not the same as the uncertainty of a sum.
Why do you insist that an average that is wildly uncertain because of the uncertainty in the measurements can have its uncertainty defined by only the average of the stated values of the data elements while ignoring their uncertainty?
The standard deviation of the sample means can be zero while the calculated average from those sample means is huge.
As has been pointed out to you over and over and over – in the real world it doesn’t matter how precisely you calculate the average of the product of a production line. The standard deviation of the sample means can be zero. What matters is the accuracy of the that calculated mean! If the product is supposed to be 1 unit +/- .001 units then it doesn’t matter if the average of the samples comes out to 1 unit. What matters is how many are within that +/- .001 units. That tolerance specification determines the allowable uncertainty that the measurements can have.
Until you get out of your statistician box and understand that no one cares about the mean if it is a useless descriptive calculation derived from assumed 100% accurate stated values you’ll never understand. If you have a million measurements, all with an identical stated value of 1 unit then your standard deviation of the sample means, your “uncertainty of the average”, will be ZERO! 100% accuracy! But if each of those measurements have an uncertainty of +/- 1 unit then the accuracy of that “uncertainty of the average” is useless. The *actual* value of the mean will vary from somewhere between 0 and 1.4(sqrt n) – AND YOU WON’T KNOW FOR SURE WHERE IN THAT INTERVAL IT ACTUALLY IS! You simply won’t be able to lessen that uncertainty by “averaging”.
I keep telling you that it’s a damn good thing you’ve never been in a position to design something with real civil liability.
Usual word salad, that completely avoids answering the question. Why do you think it’s possible for measurement uncertainties to grow when taking an average? Why do you think the uncertainty of the average is the uncertainty of the sum?
You can’t seem to make sense of even the simplest of concepts.
Let me try again. You pull 10 square tables off the production line to sell to a customer. They each measure 2 units +/- 1 unit in width and length. (I’m using outrageous figures to demonstrate the concept). The mean of the stated values is 2units x 2units = 4 sq-units in area. If you pull samples from those ten tables you will get a mean of 4 sq-units from the stated values with a standard deviation of the mean of ZERO, i.e. 100% accuracy. Yet when the customer picks them up he could find that some of them have an area as low as 1 sq-unit and as large as 9 sq-units. The small tables would only be useful for plant stands and the large ones would be too big to fit in his diner booths. In other words some of the tables would be useless to him and he would refuse to pay for them.
The concept is that you *MUST* consider the uncertainty of each individual data element when describing the accuracy of the mean calculated from the stated values. You simply cannot ignore the uncertainties because they *DO* tell you about the accuracy of the mean, the average *will* have an uncertainty not described by standard deviation of the sample means. The standard deviation of the sample means, your “uncertainty of the mean”, is not a value useful in the real world where you have multiple measurands. The standard deviation of the sample means is *NOT* the same thing as the standard deviation of the data elements in the population.
Why you have such a hard time with this concept is beyond me. You just keep on, in every discussion, wanting to ignore the uncertainty of the data elements and the impact that uncertainty has on the average you calculate from the stated values of the data elements.
“Let me try again.”
Oh good, another meaningless example.
“You pull 10 square tables off the production line to sell to a customer. They each measure 2 units +/- 1 unit in width and length.”
So to be clear, each table you measure at exactly 2 by 2 units, despite the measurement uncertainty being ± 1 uni. That seems highly improbable.
“If you pull samples from those ten tables you will get a mean of 4 sq-units from the stated values with a standard deviation of the mean of ZERO, i.e. 100% accuracy.”
Again, highly improbable. And why take a sample? You”ve only got ten tables to start with. Even if your sample of less than ten all have identical sizes it would be risky to assume that wasn’t just coincidence, or that you are measuring with too coarse a resolution.
“Yet when the customer picks them up he could find that some of them have an area as low as 1 sq-unit and as large as 9 sq-units.”
Which is why you needed to state the uncertainty of the average. Each table is sold as being 4 ± 3 units^2, or whatever.
“The concept is that you *MUST* consider the uncertainty of each individual data element when describing the accuracy of the mean calculated from the stated values.”
Why do you want to know the mean size of the tables? That might make sense if you expect the tables to vary in size, but that doesn’t say much for your production methods.
“You simply cannot ignore the uncertainties because they *DO* tell you about the accuracy of the mean, the average *will* have an uncertainty not described by standard deviation of the sample means.”
Yes, if you come up with silly examples and try to do something silly with it you might come up with a silly answer. In this case you have a manufacturing process producing tables that randomly vary in size between 1 and 3 units, yet want to measure them with a device that seems to only be able to tell you the size to the nearest 2 units, and then for some reason want to sell them in units of 10 using an average based on a sub sample. You are doing something stupid and getting a stupid result.
This would be just the same if you measured a single table 10 times and took the average of those 10 measurements. You have a systematic error if you always get the result of 2 units regardless of the actual size.
But this is very different to what happens if you use a sensible measuring device, one that is capable of distinguishing between different sizes of things at a sensible resolution.
“The standard deviation of the sample means, your “uncertainty of the mean”, is not a value useful in the real world where you have multiple measurands.”
You still don;t understand that when taking an average, the average is the measurand.
“The standard deviation of the sample means is *NOT* the same thing as the standard deviation of the data elements in the population. ”
And again, I’ve no idea who you think, thinks the SEM is the standard deviation of a population.
“Why you have such a hard time with this concept is beyond me.”
It’s beyond you, because it’s one of your many strawmen. You keep trying to argue with your own imagination, in an attempt to avoid admitting your own misconceptions.
“You just keep on, in every discussion, wanting to ignore the uncertainty of the data elements and the impact that uncertainty has on the average you calculate from the stated values of the data elements.”
This entire discussion, which you jumped into, was about uncertainties in measurements. Nobody had mentioned uncertainties from sampling, and nobody has mentioned the standard error of the mean in relation to determining the uncertainty of global temperatures.
“Oh good, another meaningless example.”
Nope It’s right on point.
“So to be clear, each table you measure at exactly 2 by 2 units, despite the measurement uncertainty being ± 1 uni. That seems highly improbable.”
I’ll repeat what I said which you ignored: “I’m using outrageous figures to demonstrate the concept”.
“Again, highly improbable”
It doesn’t matter how improbable it is. It *still* describes the concept perfectly.
“And why take a sample?”
To prove to you the concept.
“Which is why you needed to state the uncertainty of the average.”
Which your preferred standard deviation of the sample means totally ignores when judging uncertainty of the mean.
“Why do you want to know the mean size of the tables? That might make sense if you expect the tables to vary in size, but that doesn’t say much for your production methods.”
What does the standard deviation of the sample means apply to? THE MEAN SIZE OF THE TABLES!
“Yes, if you come up with silly examples “
Again, this example perfectly shows what you stubbornly continue to ignore, propagating the uncertainty of the data elements onto the average!
“In this case you have a manufacturing process producing tables that randomly vary in size between 1 and 3 units, yet want to measure them with a device that seems to only be able to tell you the size to the nearest 2 units, and then for some reason want to sell them in units of 10 using an average based on a sub sample. You are doing something stupid and getting a stupid result.”
You aren’t addressing the issue. You are trying to ignore it by focusing on strawmen. It doesn’t matter to the concept what the resolution of the measuring device is.
“You are doing something stupid and getting a stupid result.”
Argument by Dismissal, an argumentative fallacy. Instead of addressing the concept that the accuracy of the mean has to come from propagating the uncertainty of the individual elements and not from the standard deviation of the sample means you just use an argumentative fallacy to avoid addressing the issue.
“You have a systematic error if you always get the result of 2 units regardless of the actual size.”
I didn’t say that *all* the tables had the maximum possible value. I said: “Yet when the customer picks them up he could find that some of them have an area as low as 1 sq-unit and as large as 9 sq-units.” (bolding mine)
You are back to making things up.
“You still don;t understand that when taking an average, the average is the measurand.”
The average is *NOT* the measurand. There is no guarantee that the average actually exists, at least in the real world. How do you measure something that doesn’t exist? The average is a statistical descriptor ONLY. It is *NOT* a measurand.
“And again, I’ve no idea who you think, thinks the SEM is the standard deviation of a population.”
Then of what use is the SEM?
“It’s beyond you, because it’s one of your many strawmen. You keep trying to argue with your own imagination, in an attempt to avoid admitting your own misconceptions.”
YOU are the one that keeps avoiding the concept, using argumentative fallacies in order to do so.
“This entire discussion, which you jumped into, was about uncertainties in measurements. Nobody had mentioned uncertainties from sampling, and nobody has mentioned the standard error of the mean in relation to determining the uncertainty of global temperatures.”
And you STILL don’t get it. This has nothing to do with uncertainties from sampling. It has to do with the uncertainty of the measurements!
Why do *YOU* keep on using the standard error of the mean when it comes to discussing the uncertainty of global temperature measurements when it is the uncertainty of the measurements that determines the accuracy of that global mean?
If you *actually* propagate the uncertainty of the temperature measurements onto the mean calculated from the stated values of those measurements it becomes obvious that the global mean is basically useless, even as an anomaly. The uncertainty becomes larger than the absolute and anomaly values.
“I’ll repeat what I said which you ignored: “I’m using outrageous figures to demonstrate the concept”.”
You misunderstood me. It wasn’t the size of the uncertainties I found improbably. It was the fact you were getting identical measurements for each table.
You really should explain what type of uncertainty you mean. Is the ±1 the result of random error, or is it systematic.
“It doesn’t matter how improbable it is. It *still* describes the concept perfectly.”
What concept? You just keep playing these games with hypothetical toy examples without explaining what you are trying to prove. If all you are saying is it’s possible to have a small SEM but a large inaccuracy – then you don’t need to create meaningless examples. It’s something I keep agreeing to.
“To prove to you the concept.”
Again, what concept? You start with a sample of 10 tables, then insist on taking a sub sample to estimate the average of the 10 tables. I’m sure you are groping towards a point that makes sense to you, but given how many times you demonstrate your lack of understanding, I have no intention of trying to guess what you are thinking.
“Which your preferred standard deviation of the sample means totally ignores when judging uncertainty of the mean.”
Why would I prefer it in this situation? You talking about a manufacturing process which I assume is intended to make identical copies of a table. Why would I expect there to be any significant deviation in the size? What’s the point of trying to find the average size of a table, especially when I’m using a ruler that adds much more uncertainty than the deviation?
“Again, this example perfectly shows what you stubbornly continue to ignore, propagating the uncertainty of the data elements onto the average!”
And the lies continue. I’ve been arguing with you throughout about how to propagate the uncertainty of the measurements onto the average. It’s what this whole nonsense has been about. I say that random uncertainties are propagated by dividing by root N, you say they are propagated by multiplying by root-N. How is this ignoring propagating the uncertainties.
All I’ve said is that in most normal cases measurement uncertainties is not that important, as they are going to be small compared with the uncertainties caused by the random sampling. This follows from the fact that you want your measuring tape to be able to accurately distinguish between the range of things you are measuring, hence the measurement uncertainties will be small compared with the deviation of the population.
All you are doing is coming up with an example where the deviation of the things being measure is small but the measurement uncertainties are large. In that case they will be more important, but this just illustrates a bad experimental design. Not a fundamental problem with statistics.
“You aren’t addressing the issue.”
If you want me to address the issue, you will have to explain what the issue is.
“You are trying to ignore it by focusing on strawmen. It doesn’t matter to the concept what the resolution of the measuring device is. ”
I’m trying to figure out what your point is. I’m trying to figure out how you can measure 10 tables of different sizes, with a measurement uncertainty of 1, yet get the same measurement for each. The only way I can see this is if you are saying the uncertainty comes form a low resolution measurement. Hence a table size 1 is rounded up to 2, and one of size 3 is rounded down to 2. If that isn’t what yopu are saying, the problem is with your explanation.
“And the lies continue. I’ve been arguing with you throughout about how to propagate the uncertainty of the measurements onto the average. It’s what this whole nonsense has been about. I say that random uncertainties are propagated by dividing by root N, you say they are propagated by multiplying by root-N. How is this ignoring propagating the uncertainties.”
Possolo disagrees. Taylor disagrees. Bevington disagrees. Nothing more really needs to be said.
If all uncertainties are equal then you get sqrt[ u1^2 + u2^2 + … + un^2] which reduces to sqrt[ (n)(u^2)] which then reduces to (u) sqrt(n). It’s the root-sum-square method of adding uncertainties. I’m not surprised you don’t recognize that.
“All I’ve said is that in most normal cases measurement uncertainties is not that important, as they are going to be small compared with the uncertainties caused by the random sampling. “
That’s a load of hoowie! You are now back to assuming you have a set of multiple measurements of the same thing using the same device where the random uncertainties cancel. In order to use the Um = s/sqrt(n) the measurements *must* be normally distributed in which case your sampling error should be vanishingly small as the sample size gets large. If you do *not* have a normal distribution of measurement values then you simply can’t use the s/sqrt(n) formula since the typical statistical descriptive calculations of mean and standard deviation are useless. You must use some other form of descriptive values such as the 5-number description of the data.
You just cannot get outside of that box you have placed yourself in where *EVERYTHING* must be a normal distribution with only random measurement errors. You keep claiming you are not inside that box but everything, EVERYTHING, you claim always winds up inside that box.
“ but this just illustrates a bad experimental design”
No, this illustrates the real world where you have single measurements of multiple things jammed together into a data set. *You*, from inside your box, want to always assume that’s going to give you a set of random error which cancels and a mean that is somehow a “true value”.
It just plain doesn’t work that way in the real world.
“Possolo disagrees. Taylor disagrees. Bevington disagrees. Nothing more really needs to be said. ”
Only because you can’t read basic equations. Nothing more needs to be said.
“I’m not surprised you don’t recognize that. ”
And once again you present the equation for the sum and claim it is for an average. If you believe that you must also believe Pat Frank is completely wrong.
“That’s a load of hoowie!”
[sarc] Argument by Dismissal, an argumentative fallacy. [/sarc]
“You are now back to assuming you have a set of multiple measurements of the same thing using the same device where the random uncertainties cancel.”
You still have not explained why you think errors will not cancel when you are measuring different things, but will when you are measuring the same thing.
“In order to use the Um = s/sqrt(n) the measurements *must* be normally distributed in which case your sampling error should be vanishingly small as the sample size gets large.”
“In order to use the Um = s/sqrt(n) the measurements *must* be normally distributed in which case your sampling error should be vanishingly small as the sample size gets large.”
Yet more lies about me. I keep on telling you that things do not have to be normally distributed and you keep claiming I say everything is normally distributed.
“It just plain doesn’t work that way in the real world.”
Tell that to everyone who uses sampling in the real world.
“And once again you present the equation for the sum and claim it is for an average. If you believe that you must also believe Pat Frank is completely wrong.”
You’ve been given the quotes from Taylor, Bevington, and Possolo that constants don’t add to uncertainty. It doesn’t matter if those constants are in the numerator or in the denominator. They don’t add to the uncertainty.
And nothing Pat Frank has done disagrees with that. The number of data elements in a data set is a constant, it’s derivative is zero. You are just making stuff up.
“You still have not explained why you think errors will not cancel when you are measuring different things, but will when you are measuring the same thing.”
In other words you STILL don’t understand what root-sum-square addition of uncertainties is for, do you?
Of course they do! That’s why mean and standard deviation are not good descriptors of skewed or multimodal distributions. It’s why other descriptors like the 5-number descriptors are used!
Oh, MALARKY! The standard deviation of the sample means is calculated from the stated values of the measurements and not from the measurement uncertainties.
Put down the bottle. You are going to be ashamed of yourself tomorrow.
“Yet more lies about me. I keep on telling you that things do not have to be normally distributed and you keep claiming I say everything is normally distributed.”
If the shoe fits then wear it! You keep on saying that things don’t have to be normally distributed but then you turn around and make assertions that require a normal distribution! You keep trying to justify ignoring measurement uncertainty so you can use the stated value of measurements to determine uncertainty – which requires a symmetric, random distribution of error whilde ignoring systematic bias.
Your denials are as meaningless as the average of a 2′ board and a 6′ board.
“You’ve been given the quotes from Taylor, Bevington, and Possolo that constants don’t add to uncertainty. ”
And I’ve explained so many times why that doesn’t mean what you think it means. Exact values do not add to the uncertainty but than do scale it.
Your problem is, I think, that you only keep trying to interpret everything anecdotally rather than actually look at the equations. You hear a phrase like “constants don add to uncertainty” and see that as a rule that you can always ignore constants. You can’t look at an equation such as
u(x)/x = u(y)/y
and figure out why that implies that if x is equal to y scaled by a constant, it must follow that u(x) is equal to u(y) scaled by the same constant. And you won’t even understand that when Taylor says that explicitly. It just goes against your long held believes, so you have to avoid seeing it.
“And nothing Pat Frank has done disagrees with that. The number of data elements in a data set is a constant, it’s derivative is zero. You are just making stuff up.”
Here’s the equation he uses, taken from Bevington. Note the divide by (N – 1). His equation amounts to saying you multiply the uncertainty by N – to get the uncertainty of the sum, and then divide by (N – 1) to get the uncertainty of the average. Of course as N is large this means the uncertainty of the average is just the same as any individual uncertainty. (All this based on the assumption that all uncertainties are systematic.)
More nonsense.
För once I agree. Complete nonsense that you can just assume that every instrument has the same systematic error.
And you still have zero clues about the fundamentals of measurement uncertainty. As you’ve told again and again, it is NOT error.
“Your problem is, I think, that you only keep trying to interpret everything anecdotally rather than actually look at the equations.”
I’ll try one more time.
You are the engineer-in-charge of determining the mass of a payload of small satellites on a rocket so the amount of fuel needed to reach insertion altitude can be determined.
Do you
Your answer will be most enlightening.
This in response to me suggesting you relied too much on anecdotes.
Of course I don’t take a sample. Why should I? There are only a small number of satellites, weigh them all.
You are dissembling. I didn’t tell you how many satellites there would be. If they are nothing more than RF transponders they can be *very* small – a UHF transponder can be as small as 1″ by 1″. You could fit a *lot* of them in the payload space.
Are you going to weigh them all or not?
Sigh. If you can weigh all the satellites then weigh all the satellites. If that’s impossible because you have so many satellites, then you have no option but to take a sample. That’s the point of sampling – you do it because it’s impossible or impractical to measure the entire population.
“You hear a phrase like “constants don add to uncertainty” and see that as a rule that you can always ignore constants. “
That is EXACTLY what Possolo says in the quote you have been provided.
“Note that π does not figure in this formula because it has no uncertainty, and that the “2” and the “1” that appear as multipliers on the right-hand side are the exponents of R and H in the formula for the volume.” (bolding mine, tpg)
You just keep on calling yourself the expert in all of this while ignoring what the *real* experts try to tell you. You are the quintessential narcissist who believes everyone is wrong except yourself.
“That is EXACTLY what Possolo says in the quote you have been provided. ”
And again, you prove my point. You misinterpret the words rather than think about the equation. I’ve explained to you why pi is still in that equation, how it means that the uncertainty of the volume will depend on the value of pi, but you just won’t see it.
“You just keep on calling yourself the expert in all of this”
I have never claimed to be an expert. Being able to read a formula and understand the logic behind it does not make me an expert.
“while ignoring what the *real* experts try to tell you.”
Yet in another thread you are accusing me of using an argument by authority.
I don’t think any of your sources are wrong. I think you are misunderstanding them. But at the same time I dopn;t assume that if an authority makes a claim, that that makes it certainly correct. If I see the maths doesn’t agree with the claim I go with the maths. People, even those who write text books, get things wrong, or write clumsy sentences. You need to learn to think for yourself rather than just assume everything they say is the biblical truth.
“ I’ve explained to you why pi is still in that equation,”
pi is *NOT* in that equation. It’s bee given to you over and over and over again!
[u(V)/V]^2 = (2 x u(R)/R)^2 + (1 x u(H)/H)^2
If pi had an uncertainty it would HAVE to show on the right side of the equation or the uncertainty value would be inaccurate! It doesn’t appear because pi has zero uncertainty.
[u(V)/V]^2 = (2 x u(R)/R)^2 + (1 x u(H)/H)^2
Which is
[u(V)/(πR^2H)]^2 = (2 x u(R)/R)^2 + (1 x u(H)/H)^2
As I keep trying to tell you, you can cancel out π on the right hand side, but it will end up on the left.
Apply this to the uncertainty of an average when you know the uncertainty of the sum, and avg = sum / N. Using the general formula you have
u(avg)^2 = 1/n^2 * u(sum)^2
Divide by the square of avg = sum / N and you get
[u(avg) / avg]^2 = [u(sum) / sum]^2
=> u(avg) / avg = u(sum) / sum
which should be obvious to anyone with a simple grasp of proportionality means that u(avg) = u(sum) / N.
You keep confusing the idea that there is no term for N on the RHS, with the idea that N is irrelevant to the uncertainty of the average.
“I didn’t say that *all* the tables had the maximum possible value. I said: “Yet when the customer picks them up he could find that some of them have an area as low as 1 sq-unit and as large as 9 sq-units.” (bolding mine)”
But you also say that all of the tables had the same measured size. Hence my confusion. You want the standard deviation of the measurements to be 0, despite the actual sizes all being different, and you also insist this isn’t caused by the resolution of the measurements. That’s why I say this is highly improbable.
“The average is *NOT* the measurand. There is no guarantee that the average actually exists, at least in the real world. How do you measure something that doesn’t exist? The average is a statistical descriptor ONLY. It is *NOT* a measurand. ”
As I said, you still don’t get it and there’s little point going over it again.
“Then of what use is the SEM?”
(Said in response to me pointing out that SEM and standard deviation of a population are not the same thing.)
Not sure if that question is worth an answer.
“Why do *YOU* keep on using the standard error of the mean when it comes to discussing the uncertainty of global temperature measurements when it is the uncertainty of the measurements that determines the accuracy of that global mean?”
Firstly, I don’t. I have never claimed anything about how the actual uncertainties of global average anomalies are calculated. The actual calculations include a number of different methods and sources of uncertainty, including measurement uncertainties.
Secondly, the reason I keep on about sampling uncertainties, is because they will in general be much larger than any measurement uncertainties.
“If you *actually* propagate the uncertainty of the temperature measurements onto the mean calculated from the stated values of those measurements it becomes obvious that the global mean is basically useless, even as an anomaly.”
Only because you don’t understand how to do it properly.
Irony overload level 6.
Another stupid claim, pulled out of an orifice, that allows you to just whitewash and ignore measurement uncertainty. And what is “sampling uncertainty” anyway?
Sampling uncertainty typically happens when you don’t have a normal distribution of data. This causes the standard deviation of the sample means to get quite large. But it also means you shouldn’t be using a mean as a statistical descriptor. Something like the 5-number descriptor would be more appropriate. it would be interesting to see someone do a 5-number statistical description of a temperature data base.
bellman just can’t get out of his own way.
He still can’t sort out the difference between random sampling of a fixed population and single measurements of a time-varying quantity. And if the distribution is non-normal (or even known!) it must be accounted for in the combined uncertainty.
He still doesn’t understand the difference between error and uncertainty, square one.
“But you also say that all of the tables had the same measured size. Hence my confusion.”
There should be no confusion. It was a teaching example. But you can only teach someone willing to learn. You are not. You want to remain inside your little box where all measurement data sets are made up of normally distributed measurement stated values and only random error exists which cancels itself out.
“As I said, you still don’t get it and there’s little point going over it again.”
You need to sit down for however long it takes you to write out 1000 times => “An average is a statistical descriptor, it is not a measurand.”
I hold NO hope you will ever do that. So you will never learn.
“Firstly, I don’t. I have never claimed anything about how the actual uncertainties of global average anomalies are calculated. “
Of course you have! You don’t even realize it!
“Secondly, the reason I keep on about sampling uncertainties, is because they will in general be much larger than any measurement uncertainties.”
If that is the case then you simply don’t have a normal distribution of measurements and you shouldn’t be using the mean and standard deviation as your statistical descriptors.
“Only because you don’t understand how to do it properly.”
Nothing you have said so far in this thread is correct. So how can you judge if what I am doing is correct or not?
“There should be no confusion. It was a teaching example. But you can only teach someone willing to learn. ”
Perhaps if you didn’t keep making up lies about me you would be a better teacher. I’ve explained why your example is confusing, and it has nothing to do with whether the errors are normally distributed.
“You need to sit down for however long it takes you to write out 1000 times”
I think that might be why you find this so difficult. Possibly your learning was by repetition rather than trying to think for yourself.
“An average is a statistical descriptor, it is not a measurand.”
If that’s so, then it can have no combined measurement uncertainty.
“Of course you have! You don’t even realize it! ”
Citation required.
“If that is the case then you simply don’t have a normal distribution of measurements and you shouldn’t be using the mean and standard deviation as your statistical descriptors.”
Do you ever read any of your text books. I’m sure they all point out what the mean and standard deviation is of many different distributions.
But my point is there would be no issue with instrument changes if there was no systematic error – hence they are not assuming all errors are random, let alone asserting they are.
And given that we are only interested in how temperatures are changing, systematic errors are irrelevant except when they change over time.
“But my point is there would be no issue with instrument changes if there was no systematic error – hence they are not assuming all errors are random, let alone asserting they are.”
And if pigs had wings they could fly!
They are assuming systematic error exists by ADJUSTING the record of measurements made by the instruments being replaced. The *actual* issue is those adjustments! How do they determine what the adjustments should be? Since the uncertainty includes both the systematic bias as well as random error how do you determine the size of each in order to account for them?
The answer is that if they have to make adjustments then they should start a new record instead. They don’t have a time machine. They can’t go back and figure out what the systematic bias was over time. No one can do that. Nor is systematic error amenable to statistical analysis.
“And given that we are only interested in how temperatures are changing, systematic errors are irrelevant except when they change over time.”
You have *NEVER* actually figured out uncertainty. Systematic bias *is* a time function in most cases and therefore is TOTALLY relevant to temperature changes determined from the measurements taken over time. An instrument 10 years old will most likely have more calibration drift than an instrument 2 years old! So the temperature change *will* be affected by the calibration drift (i.e. systematic bias).
“They are assuming systematic error exists by ADJUSTING the record of measurements made by the instruments being replaced.”
Thanks. That’s my point.
“Thanks. That’s my point.”
That point is irrelevant to measurement error.
All the record compilers assume measurement error is random. It’s not.
But you keep on missing the *whole* point. Since the uncertainty is a combination of *both* systematic bias and random error and neither is known as a time related function then how do you adjust for systematic bias over time?
What if the old instrument actually had a systematic bias of zero and the new one has a systematic bias greater than zero because of an installation error? Adjusting the old record based on the new values would *add* a systematic bias to all of the old data!
Again, systematic bias is not amenable to statistical treatment. You can’t determine the systematic bias from a statistical analysis of the data. A gradual change in the microclimate surrounding the area (e.g. deforestation, increasing UHI impact, etc) could easily be mistaken for a calibration drift. Statistical analysis simply couldn’t distinguish between a gradual change in the microclimate and calibration drift.
The systematic measurement errors do change over time, as they are caused by uncontrolled environmental variables.
Systematic errors due to changed instrumental response time and resolution are of a different order.
“hence they are not assuming all errors are random, let alone asserting they are.”
I never suggested they are “assuming all errors are random.”
I pointed out they assume all measurement errors are random. That assumption is repeatedly stated in their papers. There’s no dispute about it.
You’ll never convince bellman. He is absolutely convinced that the standard deviation of the sample means describes the accuracy of the mean. Thus you can ignore the uncertainties of the data elements and the standard deviation of the population. No amount of common sense or proof will shake his belief.
Correct, this has been demonstrated time and again. He’s not even right twice a day.
I understand, Tim. Trying to convince someone committed to a mistaken narrative is usually hopeless.
Generally, I post for the readers. I have a horror of leaving misleading pseudo-rationality uncorrected..
That’s the big reason for my continued posting on the subject.
Please stop lying about me, it’s getting really old.
“He is absolutely convinced that the standard deviation of the sample means describes the accuracy of the mean.”
Lie. I’ve told you repeatedly I do not believe that.
“Thus you can ignore the uncertainties of the data elements and the standard deviation of the population.”
Lie. And incoherent. I’ve spent the last few eternities trying to show you how measurement uncertainties affect the average, and how you can estimate the standard error of the mean from the standard deviation.
“No amount of common sense or proof will shake his belief.”
You could test that theory by demonstrating some proof or common sense.
You simply can’t have it both ways. You keep saying the standard deviation of the sample means is the accuracy of the mean calculated from those sample means.
If the standard deviation of the sample means is not the accuracy of the mean calculated from the sample means then it is absolutely meaningless in the real world of measurements.
Pick one and stick with it. Either the standard deviation of the sample means *is* a measure of the accuracy of the mean calculated from the sample means or it is *not*.
“ I’ve spent the last few eternities trying to show you how measurement uncertainties affect the average, and how you can estimate the standard error of the mean from the standard deviation.”
The standard deviation of the population is based solely on the stated values of the measurements. It does *NOT* encompass the accuracy of the mean unless you propagate the uncertainty of the individual elements onto that mean – which you never do.
You keep saying we are lying about what you say and then you turn around and prove that we are correct!
You can do all the statistical analysis you want and calculate all the statistical descriptive values you want and they are meaningless if they are based solely on the stated values of the individual measurements. Just like the standard deviation of the sample means, your “uncertainty of the mean”, is meaningless unless the uncertainty of the elements in the samples is propagated forward onto the calculated mean.
It’s why you always refuse to address the issue that the standard deviation of the sample means can be zero while the mean calculated from the sample means can be wildly inaccurate.
If you would just get that basic truth of measurement into your head you would stop talking about the standard deviation of the sample means being a measure of accuracy.
The standard deviation of the sample means is only useful in one, single situation – when all measurement uncertainty is random and symmetrically distributed around a true value. That means no skewness, no systematic bias, and no multimodal peaks. If your data set consists of single measurements of different things those restrictions are almost impossible to meet. That, in turn, means that the standard deviation of the sample means of that distribution will never be useful in describing the accuracy of the mean you calculate from the sample means.
You are just wasting everyone’s bandwidth with your stubbornly held belief that the standard deviation of the sample means is useful in the real world of temperature measurements where you have single measurements of multiple different things. Give it up!
Yet despite all his dancing around here, he still believes the milli-Kelvin uncertainties for GAT quoted by climastrologers are valid.
“Pick one and stick with it.”
I’ll do no such thing. This isn’t a binary choice. The Standard Error of the Mean is an important statistic, given an indication of the uncertainty of a sample, but subject to a number of assumptions. It may or may not indicate the accuracy, because that depends on how much bias there may be either in the sampling or the measurements.
“The Standard Error of the Mean is an important statistic, given an indication of the uncertainty of a sample, but subject to a number of assumptions. “
The standard deviation of the sample means is useless without knowing its accuracy and the standard deviation of the sample means tells you nothing, NOTHING, about the accuracy of the mean value you have calculated.
That should have been obvious if you had bothered to read and actually do some critical thinking about the example I just gave you. The example where the standard deviation of the sample means is 0, yet the uncertainty interval of that mean is more than double the value of the mean calculated from the stated values of the samples.
In fact, in the real world of measurements of different things the standard deviation of the sample means is useless except in certain, restrictive situations . The fact that you can’t accept that is literally beyond understanding. Temperature measurements meet NONE of the requirements for the standard deviation of the sample means to be useful.
Don’t think it goes unnoticed that you didn’t even see fit to address that issue. You didn’t address it because it would require you to admit that the standard deviation of the mean is useless for describing temperature measurements.
“It may or may not indicate the accuracy, because that depends on how much bias there may be either in the sampling or the measurements.”
If you don’t know the systematic bias then how is it possible for you to assume there is none? Do you know the systematic bias in the temperature measuring device at your nearest airport? Does anyone? If you don’t know then how can you possibly know that the standard deviation of the sample means have anything to do with the accuracy of the mean you calculate from the samples?
The ONLY way you can measure the uncertainty of the mean is by propagating the uncertainty of the individual measurements onto that average value. And it doesn’t matter if you sample the population or calculate the average for the entire population. You *have* to propagate the uncertainty of the individual elements in both cases.
“It’s why you always refuse to address the issue that the standard deviation of the sample means can be zero while the mean calculated from the sample means can be wildly inaccurate. ”
As far as I can remember this is the first time you’ve raised that, and I discussed it in you nonsense about tables with huge uncertainties. I really don’t know what your obsession with it is now. The only way the SEM can be zero is if all values in the sample are identical or if you have a sample of infinite size. In either case the mean could still be “wildly inaccurate”, either because you took wildly inaccurate measurements, or because you had a wildly bad sampling technique. The later is generally more normal.
I really don’t know what point you think this proves.
“As far as I can remember this is the first time you’ve raised that”
I have raised this in every single discussion we’ve ever had.
It doesn’t matter if the uncertainty is large or not. It is the concept that matters. You *must* propagate the uncertainty of the individual elements onto the mean. It’s not conceptually any different than adding variances when combining independent random variables.
Every stated value of measurement has uncertainty. Anything that is calculated solely from the stated values ignores the uncertainty that goes with those values.
If you only have two measurements, say 2 units +/- 0.1 unit the average will be 2 units with a standard deviation of zero. Yet those measurements could both be as small as 1.9 units and as large as 2.1 units. That implies that the mean could actually be 1.9 units or 2.1 units. That uncertainty of the elements *has* to be propagated onto the average you calculate.
It doesn’t matter if you have only two elements or a million elements. The accuracy of the mean *IS* dependent on the uncertainty of the individual elements. You can deny that all you want but it is the truth of the real world.
“I have raised this in every single discussion we’ve ever had.”
You’ve raised the issue of a standard error of zero in every discussion? Could you provide some evidence for this. My memory is far from perfect, but it’s such a dumb argument I’m sure I ‘d have remembered it on a few occasions.
“It doesn’t matter if the uncertainty is large or not. It is the concept that matters.”
In that case, why bring up a SEM of zero at all?
“You *must* propagate the uncertainty of the individual elements onto the mean.”
I don;t have to do anything. All you are doing is arguing by assertion. I’ve explained many times why it usually isn’t necessary.
“It’s not conceptually any different than adding variances when combining independent random variables. ”
Which is presumably why you keep getting that wrong as well. I’ll repeat with no expectation you’ll accept it, that if you are averaging random variables you have to divide them by the square of N, not just add them.
“If you only have two measurements, say 2 units +/- 0.1 unit the average will be 2 units with a standard deviation of zero.”
You can keep rep;eating this same argument all you want. It still won’t make it meaningful for the general case. Again all you are doing is showing what happens when the measurement uncertainty is greater than the standard deviation. In this case infinitely greater.
If your sample is only 2 and they are both the same there is very little you can tell from the sample. If you have a larger sample and get exactly the same value each time, then either it’s likely the population is the same or your measurements do not have sufficient resolution to detect the small changes across the population. In that case you really need to use a better measuring device.
“The accuracy of the mean *IS* dependent on the uncertainty of the individual elements. You can deny that all you want but it is the truth of the real world. ”
I’m not denying it, I’m agreeing with you. I’m just pointing out why it’s a flawed example.
You can apply exactly the same logic to measuring the same thing repeatedly with the same measuring device. If you get 2 units each time, but you know your device only has a resolution of 0.1 units, you can still only know the true value is between 1.9 and 2.1.
“You’ve raised the issue of a standard error of zero in every discussion? Could you provide some evidence for this. My memory is far from perfect, but it’s such a dumb argument I’m sure I ‘d have remembered it on a few occasions.”
You are a troll. I’m not dancing on the end of your puppet strings.
“In that case, why bring up a SEM of zero at all?”
because it’s part of the whole concept that the standard deviation of the sample means has nothing to do with the accuracy of the mean you have calculated. I’m not surprised that you don’t remember the posts with graphs that I’ve given you showing the difference between precision and accuracy. The standard deviation of the sample means is a measure of how precisely you have calculated the mean, a standard deviation of the sample mean that is zero implies you have very precisely calculated the mean. It does *NOT* mean that the value you come up with is accurate at all!
“I don;t have to do anything. All you are doing is arguing by assertion. I’ve explained many times why it usually isn’t necessary.”
No, you’ve explained why it isn’t necessary in that little box you live in where all uncertainty is random and symmetric around a true value. Therefore all measurement uncertainty cancels and you can use just the stated values for your statistical descriptors.
“Which is presumably why you keep getting that wrong as well. I’ll repeat with no expectation you’ll accept it, that if you are averaging random variables you have to divide them by the square of N, not just add them.”
I didn’t say anything about averaging random variables. I said when you add them together!
The average uncertainty (variance) is *NOT* the uncertainty (variance) of the average. The average uncertainty (variance) is just a way to spread an equal amount of uncertainty over all the data elements so when you do the sum you get the same sum as when you add the individual uncertainties which can vary from element to element.
Once again you are out in left field!
“You can keep rep;eating this same argument all you want. It still won’t make it meaningful for the general case.”
Unfreakingbelievable! If the general case can’t handle two simple measurements or the example I gave then something is wrong with the concept you are trying to apply. The general case is *EXACTLY* like both examples I’ve given you. Your only rebuttal is to dismiss them because you can’t fit them into your world view!
“If your sample is only 2 and they are both the same there is very little you can tell from the sample.”
Once again, MALARKY! Most teaching methods start with simple examples and expand into larger examples. You are basically saying that doesn’t work for you. That’s *YOUR* problem, it isn’t a problem with the examples.
“In that case you really need to use a better measuring device.”
Another deflection. This doesn’t have *anything* to do with propagating uncertainty. You just can’t let go of the assumption that all uncertainty cancels.
“I’m not denying it, I’m agreeing with you. I’m just pointing out why it’s a flawed example.”
Neither example is flawed. Only your understanding of uncertainty is flawed. Thinking that you can determine the accuracy of a mean using only the stated value parts of a set of measurements is flawed – totally and utterly flawed.
“You can apply exactly the same logic to measuring the same thing repeatedly with the same measuring device. If you get 2 units each time, but you know your device only has a resolution of 0.1 units, you can still only know the true value is between 1.9 and 2.1.”
And now we are back to discussing resolution versus uncertainty. They are related but they are *NOT* the same thing. Resolution doesn’t define uncertainty. But uncertainty encompasses resolution.
You just can’t get *anything* right, can you?
“You are a troll. I’m not dancing on the end of your puppet strings.”
As I suspected, it was another lie.
“No, you’ve explained why it isn’t necessary in that little box you live in where all uncertainty is random and symmetric around a true value. Therefore all measurement uncertainty cancels and you can use just the stated values for your statistical descriptors.”
I keep telling you that if there are systematic errors in your measurements they will not cancel, and that therefore the mean will not be completely accurate. But your own biases won’t let you see what I say.
“I didn’t say anything about averaging random variables. I said when you add them together!”
But we are discussing averaging. What’s the point of telling me what happens to random variables when you add them.
“The average uncertainty (variance) is *NOT* the uncertainty (variance) of the average.”
And I keep telling you that’s correct. The variance of the average is the sum of the variances divided by the square of the sample size, or if you prefer the average variance divided by sample size.
“Once again, MALARKY! Most teaching methods start with simple examples and expand into larger examples.”
So if the SEM for a sample of two identical values is meaningless, it must also meaningless for all other sample sizes?
“And now we are back to discussing resolution versus uncertainty.”
You are the one claiming you can measure 10 tables of different sizes each with a large uncertainty and get exactly the same measurement each time. You still won;t explain how that is possible, but reject the idea it has anything to do with the measurement resolution. Your example is worthless if you won’t explain exactly what you are trying to do.
“The standard deviation of the sample means is only useful in one, single situation – when all measurement uncertainty is random and symmetrically distributed around a true value.”
You keep ignoring the issue of bias in the sampling, which is generally going to be much more of an issue. But yes, if there is a systematic bias in the measurements that will make the mean less accurate, but it does not mean it is completely useless.
“That means no skewness, no systematic bias, and no multimodal peaks.”
Skewness or multimodel peaks are not normally the issue, assuming a large enough sample. Systematic bias is the problem, but how much of a problem depends on how big the bias.
“If your data set consists of single measurements of different things those restrictions are almost impossible to meet.”
You keep asserting that, and I keep saying it’s wrong. Systematic bias is more likely if you are measuring the same thing with the same instrument. If you have a sample of different things measured with different instruments, then even if each instrument has it’s own systematic bias, if each instrument bias is different it will no longer be so systematic.
“That, in turn, means that the standard deviation of the sample means of that distribution will never be useful in describing the accuracy of the mean you calculate from the sample means.”
And you keep making the best the enemy of the good. Nothing is perfect, but that doesn’t mean it can’t be useful. Your argument amount to saying you should never measure anything because you can never be sure there isn’t some bias.
This is just pure Bull Pucky, an assertion you make without any justification, and which underscores your abject ignorance about metrology and uncertainty in general.
Can you believe it? He keeps claiming he understands uncertainty better than anyone, even Taylor/Bevington/Possolo and then turns around and makes a statement like this. Unfreakingbelievable.
Keep on lying.
I do not claim I understand it better than any of your authorities, just that I understand them better than you.
So, can you explain to a layman like myself why it’s impossible for there to be less bias when using different instruments than when using the same instrument?
You might like to reference Taylor’s example where he specifically says it will be a good idea to measure something using different instruments and different observers in order to reduce bias.
“So, can you explain to a layman like myself why it’s impossible for there to be less bias when using different instruments than when using the same instrument?”
I don’t think you even understand what you are asking!
If you are using different instruments then I presume you are measuring different things. When you are measuring different things the uncertainties add. The uncertainty for each instrument is U_systematic + U_random. Therefore the systematic bias of each instrument adds to the total.
That’s not true when you are using the same instrument to measure the same thing. Any systematic bias is constant, it doesn’t add to the uncertainty each time you take a measurement. In essence you wind up with a random distribution around an offset. If the random uncertainties cancel then you are left with an offset bias to the true value.
Once again, when you are measuring multiple things you must consider each single measurement as an independent, random variable with a variance, i.e. an uncertainty. When you combine those into a data set then the variances (uncertainties) add.
When you are making multiple measurements of the same thing you are generating a single random variable with a a single variance. The measurements are not truly independent because they are measuring the same thing. Each measurement process may be independent since it doesn’t depend on the prior or future measurements but the measurand is *not* independent. When you are measuring multiple things the measurand is independent as well as the measuring process itself.
“You might like to reference Taylor’s example where he specifically says it will be a good idea to measure something using different instruments and different observers in order to reduce bias.”
This allows “fliers”, if you will, to be identified but it doesn’t really “reduce” bias, it allows you to identify it. If you have six different instruments and six different observers and take six individual measurements using the six different instruments and six different observers then if one of the measurements is way off from the others then you have either an instrument problem or an observer problem and that measurement can be legitimately ignored as a “flier”.
See Taylor’s Chapter 6 for an introductory discussion of rejecting data.
It’s why I have at least two of everything. If I am measuring a critical resistor to go in a circuit I’ll measure it with two ohmmeters. I’ve caught several instances where I forgot to zero the meter before using it. That’s human operator error but it causes just as much systematic bias as an un-calibrated meter.
Bottom line? You are back to cherry-picking without actually understanding what it is hoping you can find something that sticks to the wall. Fail once again.
“If you are using different instruments then I presume you are measuring different things.”
A bad assumption. The logic works as well if you are measuring the same thing. You will have the same systematic error every time you measure it with the same instrument.
“When you are measuring different things the uncertainties add.”
They don’t if you are taking average. And it doesn’t matter how many times you assert it does.
“The uncertainty for each instrument is U_systematic + U_random. Therefore the systematic bias of each instrument adds to the total. ”
You were meant to be explaining why systematic errors are a problem when using different instruments. But you “logic” applies just as much here to random as it does to systematic uncertainties.
“Each measurement process may be independent since it doesn’t depend on the prior or future measurements but the measurand is *not* independent.”
You keep getting confused about what needs to be independent here. It’s the independence of the uncertainty not of the measurement that is relevant.
“When you are measuring multiple things the measurand is independent as well as the measuring process itself.”
And again, when considering just measurement uncertainty, it’s the independence of the uncertainty not of the individual measurements that matters.
I think you keep confusing yourself over this. On one hand you only want to talk about the measurement uncertainty, but then you raise the idea that the individual measurements are different as an issue.
“This allows “fliers”, if you will, to be identified but it doesn’t really “reduce” bias, it allows you to identify it.”
That’s not what Taylor is doing in his example (4.5).
“If I am measuring a critical resistor to go in a circuit I’ll measure it with two ohmmeters.”
Which was what I suggested months ago when I was told it would be absurd to measure something twice with two different instruments, as it would only increase uncertainty.
“Bottom line? You are back to cherry-picking without actually understanding what it is hoping you can find something that sticks to the wall. Fail once again.”
Do you have to end every comment with a long list of cliches.
“A bad assumption. The logic works as well if you are measuring the same thing. You will have the same systematic error every time you measure it with the same instrument.”
Your math inadequacy is showing again.
If you are measuring the same thing you wind up with the true value, the “mean”, being offset. The normal curve you will generate will simply be shifted over above the offset.
That is *NOT* the case if you are measuring different things.
“They don’t if you are taking average. And it doesn’t matter how many times you assert it does.”
you have yet to give me a real world example where the average of different things means anything in the real world. Even in the satellite example you avoided saying you would calculate an average from a sample in order to calculate the total payload! Nor did you bother to lay out what you would tell the fuel engineers the possible payload would be along with an uncertainty factor.
You are beating a dead horse just like a troll does.
“You were meant to be explaining why systematic errors are a problem when using different instruments. But you “logic” applies just as much here to random as it does to systematic uncertainties.”
Which just further shows you have no idea what you are speaking of. Did you not bother to read about why I use two instruments when measuring critical components?
“You keep getting confused about what needs to be independent here. It’s the independence of the uncertainty not of the measurement that is relevant.”
More malarky! The reason you can calculate a true value when measuring the same thing is because the measurements are all associated with the same thing. You can *NOT* calculate a true value when you are measuring different things because there *IS NO* true value. The uncertainty goes with the measurement when you are measuring different things.
“I think you keep confusing yourself over this. On one hand you only want to talk about the measurement uncertainty, but then you raise the idea that the individual measurements are different as an issue.”
OMG! Different things *are* different things. Of course the measurements will be different!
“To allow for irregularities in the sides, we make our measurements at several different positions, and to allow for small defects in the instrument, we use several different calipers (if available).”
And what do you think using different calipers provides? Does it somehow cancels out random error or systematic bias? A *defect* is a systematic bias. If two different instruments give different answers then you need to determine why. You will notice that further on in the example he does *NOT* differentiate which instrument provided what measurements. Why do you suppose that is?
“Which was what I suggested months ago when I was told it would be absurd to measure something twice with two different instruments, as it would only increase uncertainty.”
You were *NEVER* told that. It’s why machinists will use a gauge block to check check an instrument, it’s essentially the same thing as using two different instruments and comparing them. It would be like using a 0.5% calibration resistor before measuring a critical component – it would give the same indication of a calibration error like forgetting to zero the meter.
It’s useless to try and teach you. I’m done.
“you have yet to give me a real world example where the average of different things means anything in the real world.”
Moving goal posts again. The question was about how uncertainties propagate when taking an average, not about the usefulness. But I’ve given plenty of examples, you just keep rejecting them. An obvious example of a real world average of “different things” is the average global temperature anomaly, which is constantly being used even on this website.
“Even in the satellite example you avoided saying you would calculate an average from a sample in order to calculate the total payload!”
I didn’t avoid saying it, I explicitly told you I wouldn’t do that.
“You can *NOT* calculate a true value when you are measuring different things because there *IS NO* true value.”
How many more times does it need to be explained that when taking an average the “true” value you are interested in is the average.
“And what do you think using different calipers provides?”
It reduces the danger of systematic error. If you use just one instrument and it has a systematic bias then all your readings will have the same bias, and the mean will have that bias. If you use different instruments for each reading then there’s at least the possibility that each will have a different bias.
“Does it somehow cancels out random error or systematic bias?”
It won’t random errors because they are going to cancel in any case. But it might help cancel out systematic errors.
“If two different instruments give different answers then you need to determine why.”
But measurement uncertainty means you will always get different results. And as you keep saying you can’t tell how much is due random verses systematic error.
“You will notice that further on in the example he does *NOT* differentiate which instrument provided what measurements. Why do you suppose that is?”
Because he’s not trying to find which instruments are most faulty. The purpose it to reduce the risk of systematic errors. It’s error correction not error detection.
Here’s the thread I was referring to
https://wattsupwiththat.com/2021/12/02/the-new-pause-lengthens-by-a-hefty-three-months/#comment-3402872
And further down the thread:
https://wattsupwiththat.com/2021/12/02/the-new-pause-lengthens-by-a-hefty-three-months/#comment-3404955
“But yes, if there is a systematic bias in the measurements that will make the mean less accurate, but it does not mean it is completely useless.”
The mean is only useful if it describes something in the real world. If it doesn’t exist in the real world then it is useless. I can’t use the average value of a set of 2″x4″ boards that vary from 2′ long to 10′ long to build a stud wall for a new room. The average of those boards may not even physically exist let alone be the most commonly found value in the pile.
“Skewness or multimodel peaks are not normally the issue, assuming a large enough sample. Systematic bias is the problem, but how much of a problem depends on how big the bias.”
Of course they are the problem! What do you get when you combine annual temperature measurements from the southern hemisphere with those from the northern hemisphere? What do you get when you combine summer temps with winter temps, each of which have a different variance? Anomalies won’t help when the variances are different.
Systematic bias *is* a problem but it is *NOT* amenable to statistical analysis. You can’t eliminate it through average or homogenization. The possibility of systematic bias has to be included in the total uncertainty of each measurement and then the total uncertainty of each measurement has to be propagated to any anything calculated from them.
“You keep asserting that, and I keep saying it’s wrong. Systematic bias is more likely if you are measuring the same thing with the same instrument.”
Total and utter BS. When you are taking single measurements of different things you have the *same* chance of systematic bias in each individual measurement as you would have in multiple measurements of the same thing. Do you *ever* stop and think about what you are saying?
“If you have a sample of different things measured with different instruments, then even if each instrument has it’s own systematic bias, if each instrument bias is different it will no longer be so systematic.”
Systematic bias remains systematic bias. It doesn’t matter if instrument_1 has a relative uncertainty of 1% and instrument_2 has a relative uncertainty of 0.5%. The systematic component of each measurement made by each instrument remains a systematic uncertainty which gets propagated into the total uncertainty of the data set.
You are just showing your continued lack of understanding of uncertainty. You are in a deep, deep hole. Stop digging.
“And you keep making the best the enemy of the good. Nothing is perfect, but that doesn’t mean it can’t be useful. Your argument amount to saying you should never measure anything because you can never be sure there isn’t some bias.”
If I can’t use it in the real world then it is useless. It’s like a shovel head with no handle, a hammer handle with no head, a punch with a bent shaft, a broken stapler, a flat tire, etc.
And I’ve never even implied that you should never measure anything. What you *must* do is understand the uncertainty that goes with the measurements and propagate that uncertainty properly instead of just ignoring it – which is your approach. Right down to arguing that the stated values of a measurement define the uncertainty of the mean more than does the uncertainty of the measurements themselves, so you can just ignore the measurement uncertainties in all cases.
“The mean is only useful if it describes something in the real world. If it doesn’t exist in the real world then it is useless.”
Absolute nonsense.
“I can’t use the average value of a set of 2″x4″ boards that vary from 2′ long to 10′ long to build a stud wall for a new room.”
You need to get out of your woodworking box.
No time to plough through the rest of your diatribe tonight.
What stuck me more was the claim of 30% swings. 30% 0f 300K is about 90 deg C. Where is that happening?
Thanks, CG, good catch. It should have said 30°C, not 30%. Fixed.
w.
Most monthly maximum and minimum temperatures at a land site have a spread of less than 9 K, or 3% of absolute temperature, so 0.2% should be significant. But that is for a site with a good record and zero development around it. Large areas of land have a single station with a poor or short record, while well populated areas have considerable changes around and to the station.
Thanks, Robert. The average annual range of land temperatures from winter to summer is 30°C (CERES data). But despite swinging that far, they come back to the same point. Clearly, that’s NOT because of thermal inertia.
w.
The measured temperature changes fit reasonably well with the way the solar EMR is changing.
Most warming is occurring in the Northern Hemisphere.
Northern ocean temperature is increasing fastest in July, which aligns with higher land temperature reducing the water cycle.
Northern Land temperatures north of 40N show very rapid increase in January temperature. That can only occur with increased advection resulting in more snowfall.
Antarctica and the Southern Ocean are cooling as the solar EMR reduces there.
Calling it “global warming” is not accurate. On average the globe is warming but it has happened in the same circumstance 4 times in the past 500kyr as interglacials terminated.
Sure the temperatures are fiddled to produce steadier trends but the trends likely reflect reality.
The NOAA/Reynolds interpolated SST is a very good set. The July ocean temperature north of 20N is increasing at 2.9C per century according to NOAA/Reynolds. The average solar EMR over this region of ocean was at a minimum in J0000. It has increased by 2W/m^2 since then. The oceans have enormous thermal inertia. Centuries to thousands of years to get heat from the surface into the deep oceans. Near land locked waterways like the Mediterranean respond faster. Shallow enclosed water bodies respond even faster the the changing EMR intensity.
The January temperature for land north of 40N is increasing at 3.7C per century.
Extending these temperature these trends, the snowfall over all land north of 40N will increase 60% by 2250. And that is just 2200 years into a northern ocean warming cycle that will run another 8000 years.
The climate always changes and the modern interglacial is terminating due to the northern hemisphere warming up..
Over the entire 20th century, the temperature increased by about 0.2%.
—–
~288 °K x 0.2% = ~0.6 °K, (or °C since said temperature is a delta.)
Is ~0.6 °C what you are claiming?
Something on that order, depending on which dataset you use.
w.
uh huh- you mean “the science is settled” in 2 different realities? 🙂
Willis great post,
I have two questions:
What is your best estimate on where the global temp. will be in Feb. or March after the La Niña?
Does this imply that we are now facing a cooling world?
Unknown. Unlike most people, I’m reluctant to predict the future until I understand the past … and that’s a ways away.
w.
WE, nice analysis. Hadn’t thought about ENSO that way before now. Makes sense. ‘More’ El Niño could be deeper, longer, or more frequent, or all three to some degree. This third consecutive winter of La Niña for sure means a very cold EU winter based on past patterns.
Something else important yet not in any climate model, same as Lindzen’s adaptive infrared iris—related to your Tstorm hypothesis—with Tstorm affected tropical cirrus as his main thermoregulatory mechanism (bigger Tstorms => less anvil detrained water vapor =>less cirrus => more cooling). When Mauritsen and Stephens added an adaptive iris to their climate model, it reduced ECS significantly. Judith and I wrote back to back posts on this back in 2015 when their paper first appeared.
Rud, for sure there is a marked difference between weather during El Niño or La Niña conditions, here in west-central Argentina. During the El Niño phase there are many large thunderstorms, and damaging hail (one such storm punched tennis ball sized holes through our roof tiles) in the summer, whereas during La Niña there is less overall rain and the thunderstorms are less aggressive, with only occasional small hail. The wine grape growers prefer El Niño, with more retained heat at night and mor rain, willing to risk the hail damage (and if they like it…we like it).
So far Euopean+British autumn/winter has been incredibly MILD. But the claim that La Nina means cooling of erroneous. It is the phase where MORE solar energy is entering the system. After three years we may be seeing the effects of this.
Carts and horses.
To affect the balance between La Niña and El Niño it is necessary to alter the proportion of solar energy able to enter the oceans. Less favours La Niña and more favours El Niño.
To do that it is necessary to alter global cloudiness.
To change global cloudiness involves changing the waviness of jet stream tracks and to do that it is necessary to change the gradient of tropopause height between equator and poles.
That in turn requires a solar effect on the ozone production process in the stratosphere because ozone warms surrounding air by directly absorbing incoming solar energy and a warmer stratosphere pushes the tropopause downwards.
So, to change that gradient the sun has to have a different effect on ozone above the equator compared to the effect above the poles and that appears to be what happens.
It is some time ago that I suggested that a change in the balance between El Niño and La Niña would be a consequence of the change in solar activity.
That would appear to be coming to pass.
After a period of La Niña dominance the rise in atmospheric CO2 should stop and if it continues a fall should begin.
Our CO2 emissions are irrelevant to atmospheric CO2 content because CO2 is heavier than air and is quickly absorbed by nearby vegetation.
It is the oceanic absorption/ emission process that is changed by solar variability and the ice cores do not appear to capture that shorter term large scale natural variability in atmospheric CO2.
Henry’s Law is not strictly applicable because the surface waters are constantly being exchanged with colder deeper waters to keep the momentum going. Henry’s Law applies to a static scenario.
Stephen
I agree that GB somehow works with the ozone production TOA and that this changes weather patterns. CO2 is not a factor but we had an extraordinary situation that GB is delayed or diminished by extra heat coming from earth itself.
Would you agree with me on that?
https://breadonthewater.co.za/2022/08/02/global-warming-how-and-where/
Henry, I understand that you are desperate to hijack this discussion into talking about your own theory.
Pass.
w.
“warmer stratosphere pushes the tropopause downwards”
Why wouldn’t a warmer stratosphere merely expand freely out towards space?
Because in the stratosphere the lapse rate is negative, it gets warmer with increasing height, so upward expansion is suppressed by the warmer air above, Instead, the tropopause is forced down.
https://www.researchgate.net/publication/267928023_Effect_of_tropospheric_and_stratospheric_temperatures_on_tropopause_height#:~:text=Decrease%20in%20stratospheric%20temperature%20increases%20the%20tropopause%20height%2C,impact%20is%20more%20evident%20over%20ocean%20than%20land.
Here’s what your paper says, Stephen: “As the [stratospheric temperature] decreases and [tropospheric temperature] increases, [tropospheric height] increases, whereas [stratospheric temperature] increases and [tropospheric temperature] decreases, [tropospheric height] decreases.“
That relation doesn’t seem very radical. Their analysis is statistical, which does not establish causality.
Their R²’s are heavily influenced by the high point scatter of their data. Inspection of their figures, reveals the tropospheric data to have more scatter than the stratospheric. This vitiates the strength of their causal inference.
“…temperature stability is due to the thermoregulatory effect of a variety of different emergent phenomena. These include tropical cumulus cloud fields, thermally driven thunderstorms, dust devils, cyclones, and most relevant to this post … the El Nino phenomenon.”
_____________________________________
And how well does the IPCC and the rest of Climate Science do in terms of predicting/projecting future El Niño and La Niña events? Probably says a lot about the probability of the “Existential Crisis of Our Time” actually being true.
Willis writes, “The El Nino phenomenon is a curious beast. When the Pacific Ocean gets hot off of the coast of Peru, this is called an ‘El Nino’ condition.”
This is an antiquated definition. Not all El Nino events as currently defined have a noticeable impact on the NINO1+2 region, which includes the Pacific waters off Peru.
figure-12.png (641×1627) (wordpress.com)
The sea surface temperature anomalies of the NINO3.4 region (5S-5N, !70W-120W), which is along the east-central part of the equatorial Pacific is now commonly used to define El Nino, ENSO neutral or La Nina conditions, along with the Southern Oscillation index.
Willis continues, “It generates extensive winds. These winds blow the warm equatorial surface waters to the west, cooling the ocean surface.”
This is blatantly incorrect. During an El Nino, the Pacific Trade Winds in the Eastern Tropical Pacific slow, because the temperature difference reduces between the Eastern and Western tropical Pacific. DUH!. This is well-documented with the NOAA PMEL TAO buoys.
The transition from El Niño to ENSO-neutral starts after the El Niño has reached its seasonal peak, usually in December. When tropical Pacific sea surface temperatures have cooled sufficiently, the westerlies subside and the trade winds return and strengthen toward normal. IF (big if) the trade winds increase in strength beyond their normal, this will cause additional cool water to be upwelled along the eastern equatorial Pacific, to create La Nina conditions. Again, this is all well documented with TAO buoy data. Further, not all El Nino events have a trailing La Nina event, and not all La Nina events are preceded by an El Nino.
No reason for anyone to read the rest of your post, Willis, if it has these obvious errors early on.
Regards,
Bob
Bob Tisdale December 3, 2022 11:08 am
Bob, I am giving a simplified description. Yes, there are a lot of modern variations of El Nino, “El Nino Modoki”, El Nino Neutral … so what?
Seriously, so what if there is an “El Nino Modoki”??? My goal is a functional definition of El Nino, not an exhaustive list of all the possible variations.
Yes, you are 100% correct, during the El Nino, trade winds slow. But then, as a result of the El Nino, the winds increase, and we get a La Nina. DUH! Again, I’m not sure why you are nitpicking this.
I’m describing a sequence of events. The result of the El Nino, what happens next, is increasing winds leading to La Nina conditions. I’m sorry you have misunderstood that, as other people seem to have been able to grasp the concept quite easily.
What we have are not “obvious errors”. What we have is obvious nitpicking, and I have no clue why you are doing it. You’re destroying the respect I’ve always had for you with this unpleasant focus on trivialities. Why?
How about you concentrate on actually trying to grasp the essence of what I’m saying, and until you are able to do that, you might want to sit this one out.
w.
Willis’s reply to my comment includes first an incomplete quote from my comment, then, “Yes, you are 100% correct, during the El Nino, trade winds slow. But then, as a result of the El Nino, the winds increase, and we get a La Nina. DUH! Again, I’m not sure why you are nitpicking this.”
I explained why this was wrong in the next paragraph in my comment, the one you obviously overlooked in your reply. There I wrote (underlined this time so you won’t miss it): The transition from El Niño to ENSO-neutral starts after the El Niño has reached its seasonal peak, usually in December. When tropical Pacific sea surface temperatures have cooled sufficiently, the westerlies subside and the trade winds return and strengthen toward normal. IF (big if) the trade winds increase in strength beyond their normal, this will cause additional cool water to be upwelled along the eastern equatorial Pacific, to create La Nina conditions. Again, this is all well documented with TAO buoy data. Further, not all El Nino events have a trailing La Nina event, and not all La Nina events are preceded by an El Nino.
Why did I comment? It is definitely not nitpicking. With what you’ve written as a simple “sequence of events” in your post and with your reply to my earlier comment you have shown a very limited understanding of ENSO basics…to the point that you’re misinforming your readers. WUWT is where we fight misinformation, not create it.
Regards,
Bob
PS: For you. Willis, and your readers: About ten years ago, I wrote a very detailed and well-documented description of ENSO, in a 550+page book in PDF form called Who Turned on the Heat?, which I later made available for free
https://bobtisdale.files.wordpress.com/2016/05/v2-tisdale-who-turned-on-the-heat-free-edition.pdf
It was first introduced here by Anthony.
Bob, I repeat: SO WHAT?
Yes, your detailed description is more accurate than mine. And if my goal had been to provide a detailed description, it would have looked much like yours.
I said that the El Nino “generates extensive winds.” You claim this is a grevious error, and instead you say the winds come up after the El Nino has subsided … SO WHAT? What difference does your description make?
As you insist on not understanding, providing a detailed description of the Nino/Nina alteration was NOT my goal. And as a result, your trivial nitpicking is meaningless.
Look, I’m glad you wrote a 550 page book on the El Nino.
SO WHAT?
w.
Bob, I’ve added an update to the head post, with a link to your book for those who find my description too simple.
Now, can we get back to the actual subject of this post, which is NOT the 10,000 details of the El Nino effect?
Thanks,
w.
Thanks for including a link to my book, Willis. But I notice that you’ve left in the misleading paragraph, continuing to illustrate for all that your understanding of ENSO basics is poor. Why do you insist on misleading readers here at WUWT? The category of your post is El Nino Basics, yet you’ve shown no understanding of those basics.
Good-bye, Willis. You’re wasting my time with your circular arguments.
Bob, I purposely left that part unchanged so you wouldn’t accuse me of changing the head post in such a way that your objections couldn’t be referenced to the head post.
Teach me to be a good guy … so I’ve now gone ahead and altered the head post to make it clearer.
w.
PS—This isn’t an airport. No need to announce your departure.
Didn’t you get in a tizzy with someone else (Jim Steele?), insisting that you were NOT implying causation but just a temporal order of events ?!
CG, I call it a “chain of effects”, where one effect results in the next effect resulting in the next effect and on down the line.
So no, I’m not implying causation.
Any other nits you want to pick?
w.
I cannot believe I am reading this. So “results in” is NOT “causation”.
Yes, I have another “nit” to pick: Can you define what a woman is ???
I have always appreciated your sound , down to earth approach and your insights. Whenever I recognised one of your graphics in header, I’d think : great, a post from Eschenbach, this should be interesting.
However, your astounding lack of integrity here blows me out. Like Jim Steele, I will never take you seriously again. Very sad.
climategrog December 7, 2022 8:53 am
Groggy, suppose someone gets a virus. The virus results in damage to the liver, which results in hormonal imbalance, which results in damage to the autonomic nervous system, which results in the man’s death.
Did the damage to the liver cause the man’s death, or did the hormonal imbalance cause the man’s death, or did the autonomic nervous system damage cause the man’s death, or did the virus cause the man’s death?
It seems you missed my Sufi story above, viz:
And since I’m neither a fool nor a child, this is why in climate I generally refer to “a chain of effects” rather than “cause and effect”.
This is particularly true with circular chains of effects, like:
What is the “cause” of that circular chain of effects? The sun? The temperature? The cumulus? The cumulonimbus?
As to my “lack of integrity”, I have no clue what you are referring to because you’re too damn lazy or too arrogant to quote whatever it is you are whining about.
As to Jim Steele, that lowlife individual falsely and nastily accused me of being a liar without the slightest scrap of a reason to do so. If he’d had the balls to apologize like a decent human being when I objected, I’d have gladly forgiven him and moved on, but instead, he just doubled down on his ugly accusations.
I won’t stand for any man calling me a liar. I’ve made lots of mistakes in my life, I’ve been wrong many times. But I don’t fabricate and lie. I tell the truth as best I know it, and I’ll call out any man who falsely claims otherwise.
Don’t like it? Don’t care. I’m an honest man. Get used to it.
w.
climategrog December 7, 2022 8:53 am
Groggy, suppose someone gets a virus. The virus results in damage to the liver, which results in hormonal imbalance, which results in damage to the autonomic nervous system, which results in the man’s death.
Did the damage to the liver cause the man’s death, or did the hormonal imbalance cause the man’s death, or did the autonomic nervous system damage cause the man’s death, or did the virus cause the man’s death?
It seems you missed my Sufi story above, viz:
And since I’m neither a fool nor a child, this is why in climate I generally refer to “a chain of effects” rather than “cause and effect”.
This is particularly true with circular chains of effects, like:
What is the “cause” of that circular chain of effects? The sun? The temperature? The cumulus? The cumulonimbus?
As to my “lack of integrity”, I have no clue what you are referring to because you’re too damn lazy or too arrogant to quote whatever it is you are whining about.
As to Jim Steele, that lowlife individual falsely and nastily accused me of being a liar without the slightest scrap of a reason to do so. If he’d had the balls to apologize like a decent human being when I objected, I’d have gladly forgiven him and moved on, but instead, he just doubled down on his ugly accusations.
I won’t stand for any man calling me a liar. I’ve made lots of mistakes in my life, I’ve been wrong many times. But I don’t fabricate and lie. I tell the truth as best I know it, and I’ll call out any man who falsely claims otherwise.
Don’t like it? Don’t care. I’m an honest man. Get used to it.
w.
You accused Jim of repeated “refusing” to answer your requests after you arbitrarily assumed he was “following the discussion” and deliberately ignoring you rather than he has better things to do all day. I guess that did not get you off to a good start.
Saying “results in” IS stating a causal link. That is not obfuscated by trying to wrap it all in a dozen other supposed “results in” claims and then argue about which came first , the chicken or the egg.
Tip: when in a hole stop digging.
It could be that the way it was worded wasn’t clear. Going back to the ultimate cause of the ENSO cycle, my question/guess is this: the strengthening of off-shore trade winds near S. America (Peru, specifically) creates enhanced upwelling. This brings colder water from below to the surface, and therefore lower tropical SSTs are associated with La Niña. But it’s the stronger trade winds that come first. My question: what ultimately causes the stronger trades? Or the shift from negative to positive SOI? Solar activity?
Solar variability is at least one cause:
https://www.sciencedaily.com/releases/2019/03/190328150946.htm
I would also lean to solar activity. All other explanations seem to be circular arguments or are just insufficient, like “a pool of cool water appears near the equator that magically affects the Northern Hemisphere jet stream”…
johnesm, please forget the NINO1+2 region off the coast of Peru in a discussion of ENSO. The primary action takes place above and below the surface of the equatorial Pacific. With that in mind, I’ll rewrite your question as What causes the initial extra cool sea surface temperatures along the eastern equatorial Pacific that causes the trade winds to increase in strength?
Answer: An upwelling Kelvin wave that traveled from the western equatorial Pacific to the east along the Pacific Equatorial Undercurrent (a.k.a. the Cromwell Current), which draws the thermocline and its cool waters toward the surface. See the NOAA discussion here…
Oceanic Kelvin waves: The next polar vortex* | NOAA Climate.gov
…which I linked to in a number of posts here at WUWT…back when I was a regular contributor (i.e. author of blog posts), which were cross-posted from my blog here:
https://bobtisdale.wordpress.com/
Regards,
Bob
johnesm, please also see the discussion of ENSO in my WUWT post here:
Does The Climate-Science Industry Purposely Ignore A Simple Aspect of Strong El Niño Events That Causes Long-Term Global Warming? – Watts Up With That?
Regards,
Bob
A more refined question: I live in the Western US, and the influence of ENSO here is strong and (to me) obvious. I’m trying to understand how Kelvin Waves and conditions in the tropical Pacific can have such an impact on the Northern Hemisphere to such an extent. I can understand that significant hemispheric changes as described by the SOI can play a role in that, but Kelvin Waves and equatorial sea surface temperatures? I don’t see the connection. I can see how SOI shifts can lead to Los Niños etc., but I don’t see how a Kelvin Wave can do that. Thanks.
johnesm, downwelling Kelvin waves transport huge amounts of warm water (“downwelling Kelvin waves” because they push down on the thermocline) eastward from the West Pacific Warm Pool along equator. If they travel far enough to the east and if there are enough of them, an El Nino will form as that warm water is upwelled to the surface.
For an explanation for the many interrelationships among variables, see Billy Kessler’s answers to FAQs about El Ninos:
Occasionally-asked-questions (washington.edu)
And a NOAA discussion for how El Ninos affect US weather patterns:
What are El Nino and La Nina? (noaa.gov)
Both webpages are kind of old and provide overviews.
Regards,
Bob
PS: johnesm, I provided lots of illustrations in the following WUWT post that discusses the ENSO ocean-atmosphere interrelationships:
An Illustrated Introduction to the Basic Processes that Drive El Niño and La Niña Events – Watts Up With That?
Regards,
Bob
Good to see you are still around on this Bob. I think your insights in this all those years ago were significant. However please stop talking of “upwelling Kelvin waves”, that’s an oxymoron. Kelvin waves are a SURFACE phenomenon. By definition there can be no such thing as an “upwelling Kelvin wave”.
“DUH!”
Unjustifiably insulting, Bob. It’s unworthy in both directions.
Agreed, it’s pretty stupid language which has no place in science. DUH!
“No reason for anyone to read the rest of your post, Willis, if it has these obvious errors early on.”
No reason to be this aggressive Bob. I wanted to ask some questions on this page, but I’m not going to jump into a conflict. I don’t care who is right or wrong. Your aggression was unwarranted – your concerns could have been expressed in a much better manner.
Over and out.
HERE IS MY QUESTION FOR ANYONE WHO WANTS TO SUGGEST A CREDIBLE HYPOTHESIS:
Prize for the best answer is a brand-new Harrier Jump Jet.*
Regards, Allan
*Pepsi Promise
BACKGROUND:
Source:
CO2, GLOBAL WARMING, CLIMATE AND ENERGY – Watts Up With That?
by Allan MacRae, June 15, 2019
7a. Why does the lag of atmospheric CO2 changes after temperature changes equal ~9 months?
In a perfect sine wave, the integral lags its derivative by pi/2, or 1/4 cycle.
There should therefore be approximately a (4 times 9 months = 36 months) 3 year average period in the data.
The Nino34 data shows a 3.1 year average period (Fig.7a in Excel spreadsheet and Table 7a).
Global Lower Troposphere Temperature data shows a 3.1 year average period (Fig.7b and Table 7a).
Mauna Loa Atmospheric CO2 data shows a 3.1 year average period (Fig.7c and Table 7a).
The climate data are not perfect sine waves and the data are natural and chaotic.
Nevertheless, it appears that an approximate 3.1 year average period is present in all three datasets, as hypothesized.
The cycles are in phase with the lag of CO2 after Nino34 SST.
…
7b. Statistical analyses support the existence of an average ~3.1 year period in the data for Nino34 SST, UAH LT temperature and atmospheric CO2, averaging ~3.6 years before year 2003.5 and ~2.5 years after 2003.5, as depicted in Figs. 7e to 7j (Excel spreadsheet) and Table 7b.
QUESTION:
WHY does the Period in the data for NIno34 SST (AND UAH LT temperature AND atmospheric CO2) average ~3.6 years before year 2003.5 and ~2.5 years after 2003.5?
What caused this change?
Is it significant?
Answer: because it is dCO2 which is in phase with SST. There is no reason to look at the temporal lag because that will only be constant for constant frequency.
Neither variable is really cycle so there are many “periods” and different lags. That is why the temporal lag is not constant , as you last qu points out.
Looking at dCO2 covers all frequencies, if that is the underlying physical relationship.
Can you deliver the Harriers to Europe ?
I discussed all that in this paper.
CO2, GLOBAL WARMING, CLIMATE AND ENERGY – Watts Up With That?
by Allan MacRae, June 15, 2019
I shall ponder your answer, but I don’t think it addresses my question.
Thank you for your response, but NO jet yet.
The graph you published is from my 2008 paper and associated plots:
In the modern data record: dCO2/dt vs UAH LT Temperature (MacRae, January 2008)
https://www.woodfortrees.org/plot/esrl-co2/from:1979/mean:12/derivative/plot/uah6/from:1979/scale:0.18/offset:0.17
dCO2/dt vs Hadcrut SST3 Global Sea Surface Temperature Anomaly
https://www.woodfortrees.org/plot/esrl-co2/from:1979/mean:12/derivative/plot/hadsst3gl/from:1979/scale:0.6/offset:0.1
dCO2/dt vs Hadcrut SST3 Global Sea Surface Temperature Anomaly, Detrended
https://www.woodfortrees.org/plot/esrl-co2/from:1979/mean:12/derivative/plot/hadsst3gl/from:1979/scale:0.6/offset:0.1/detrend:0.25
I’ve understood that relationship for many years.
You wrote: “dCO2 covers all frequencies, if that is the underlying physical relationship.”
You definitely did NOT answer my question.
First, you’ve got the sequence backwards. dCO2/dt changes ~contemporaneously with temperature changes, but its integral CO2 changes do NOT lead, they lag in time.
The sequence is, from the above 2019 paper:
6. The sequence is Nino34 Area SST warms, seawater evaporates, Tropical atmospheric humidity increases, Tropical atmospheric temperature warms, Global atmospheric temperature warms, atmospheric CO2 increases (Figs.6a and 6b).
Other factors such as fossil fuel combustion, deforestation, etc. may also cause significant increases in atmospheric CO2. However, global temperature drives CO2 much more than CO2 drives temperature.
Fig.6a – Nino34 Area SST warms, seawater evaporates, Tropical atmospheric humidity (offset) increases, Tropical atmospheric temperature warms… ?resize=628%2C280&ssl=1
?resize=628%2C280&ssl=1
Fig.6b …and UAH LT Tropics Atmospheric Temperature leads UAH LT Global Atmospheric Temperature, which leads changes in Atmospheric CO2.
BTW, the above sequence is an absolute disproof of the phony CAGW hypothesis – the future (CO2 change) cannot cause the past (Atmospheric Temperature change).
Repeating, my Question is:
WHY does the Period in the data for NIno34 SST (AND UAH LT temperature AND atmospheric CO2) average ~3.6 years before year 2003.5 and ~2.5 years after 2003.5?
What caused this change?
Is it significant?
BTW, we call that multi-year oscillation the ENSO (but you knew that):
El Niño-Southern Oscillation, or ENSO
is a climate pattern that occurs across the tropical Pacific Ocean on average every five years, but over a period which varies from three to seven years, and is therefore, widely and significantly, known as “quasi-periodic.” ENSO is best-known for its association with floods, droughts and other weather disturbances in many regions of the world, which vary with each event. Developing countries dependent upon agriculture and fishing, particularly those bordering the Pacific Ocean, are the most affected.
Thanks for you replies Allen. Sorry I’ve not been back in a day or two.
Obviously untrue. I plotted that graph myself from source data using gnuplot. If you take the time to look it uses ICOADS SST, which is NOT present at wtf.org
I totally agree, that is not the point I was addressing. The lag is a strong indication of direction of causality, but that was not your question.
Looking at your spread sheet with figs 7a,b,c I’m sorry that is not a “statistical analysis”. Counting bumps like that to determine “period” is not statistics ! You count the 1993/4 bump but not the 2016/17 bump, neither of which are credible. Your actual spectral analysis in 7g show a fairly clear peak at 3.6y.
I would respectfully say that talking of periods in looking at successive bumps is pretty unscientific and there is not much sense in looking for an explanation.
Nino3.4 is probably too localised to be the best SST to compare to MLO CO2, which is reconned to be a well mixed sample of a much wider region.
Also a longer lowpass filter of 6y still shows in phase relationship of dCO2 and SST, which is interesting.
https://climategrog.wordpress.com/ddtco2_sst_72mlanc/
BTW, 12mo difference is a horrible filter if you look at its frequency response. I would suggest a classic gaussian or triple running mean of the monthly difference to gain that sort filtering.
https://climategrog.wordpress.com/12m_notch/
If you are into weighted means (convolution) as an implementation of filtering, difference of gaussian is a nice way to do a “smoothed” version of the rate of change.
https://climategrog.wordpress.com/2016/09/18/diff-of-gaussian-filter/

Your response is argumentative and obtuse. What I wrote Is that I published essentially the same observation in 2008.
I learned later that Kuo et al had made that observation in Nature in 1990 and Humlum et al published it again in 2013.
Also, we not only “counted the peaks”, we also did a statistical analysis in my cited 2019 paper and got the same answer.
So you are not trying to discuss the question, you are just being a smartass and you are wasting everyone’s time.
Does anyone know why the ENSO period changes so significantly and what drives that change?
I had a failed medical procedure yesterday that was needlessly incompetent that left me with considerable pain and moderate loss of the use of my left arm, so I am in a rank mood.
Accordingly I have no patience and may have responded a bit sharply. I still so not like your response since I knew all this 15 years ago.
Allan, climategrog,
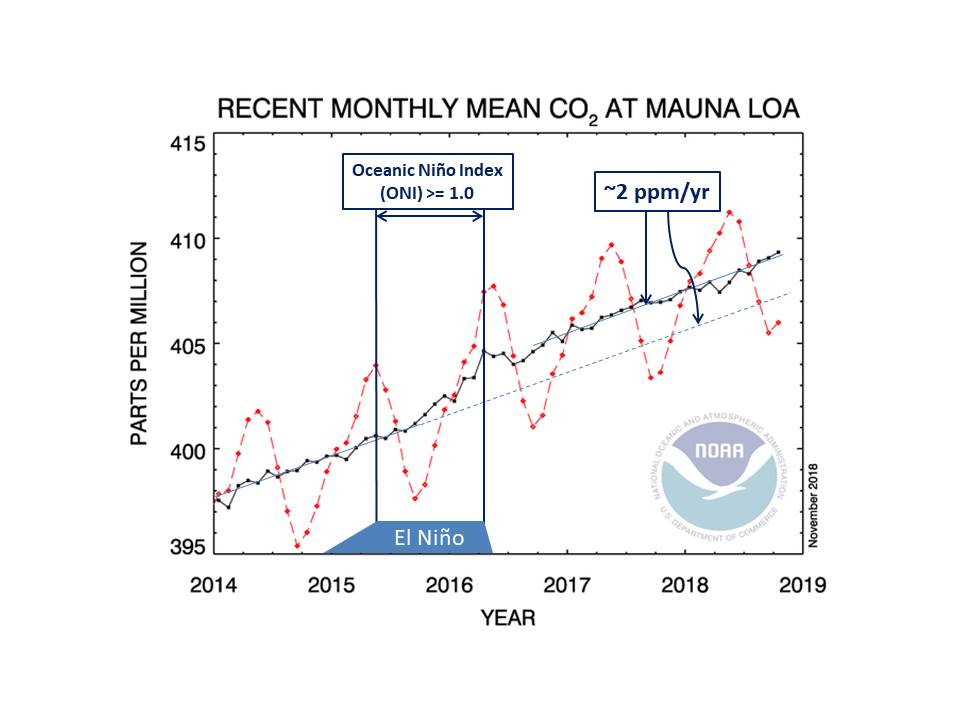
I think we all agree that there is a link between strong ENSO events, both positive and negative, and changes in atmospheric CO2 growth rate. The correlation ‘problem’ arises from the distinction between monthly temperature anomaly values (absolute) and the rate of change of atmospheric CO2 (a derivative). Attempts to deal with this distinction, especially the methods (averages/filtering) used to ‘remove’ the seasonal cycle from monthly CO2 values published for Mauna Loa are, in my opinion, masking the true relationship. While the monthly temperature data (anomalies, hence with the seasonal cycle largely removed) clearly show cyclicity, the following plot indicates that such cyclicity may not exist in the monthly CO2 data once the seasonal CO2 cycle is removed.
The basis for this conclusion is illustrated by the following plot.
The plot is as published by NOAA to which I have added a schematic indication of the timing and duration of the 2015-2016 El Niña as reflected by the Oceanic Niño Index (ONI) and indications of approximate CO2 growth rates before and after the obvious increase in rate (about double the longer term trend) due to the El Niño. The extent of the 2015-2016 El Niño extends from late 2014 through to spring 2016 (ONI above 0.5), peaking at an ONI value of 2.6 in late 2015. I have just highlighted the period when it is continuously above 1.0 for simplicity. The black line reflects the monthly mean values of atmospheric CO2 after correction by NOAA for the average seasonal cycle (moving average of 7 adjacent seasonal cycles centered on the month to be corrected). The increased rate of growth starts 3 to 4 months after ONI reaches 1.0, but then appears to stay roughly the same (above 4 ppm/year) through to just after the end of the El Nino event, after which it returns to the background rate of circa 2 ppm/year. There is no suggestion of cyclicity in the gradient, just a shift from 2ppm/yr to 4 pppm/yr for the duration of the El Nino event and then back to 2 ppm/yr (all estimates here are, of course, approximate).
Note that this character of a rapid change in atmospheric CO2 growth rate is not unique to the 2015-2016 El Niño. It is just that it is followed by only a very weak La Niña, unlike the 1997-1998 El Niño which was followed by two years of strong La Niña events. Nevertheless, the rapid onset of increased CO2 growth rate as well as the lack of any cyclicity in gradient is still clearly visible as shown here:
https://www.woodfortrees.org/plot/esrl-co2/from:1995/to:2001
Note: the wft data for CO2 is the NOAA version after removal of the seasonal cycle.
There is one further observation that must be considered in any interpretation. As soon as the CO2 growth rate increases, the 13C/12C ratio of the incremental CO2 also changes virtually instantaneously (decreases), indicating a material change in net source(s) of CO2. I have some plots showing this if anyone is interested.
In summary, as a non-expert I am reluctant to provide any specific hypothesis but, since strong ENSO events are clearly linked to changes in rate of atmospheric CO2 growth rate, I suggest that there may be an intermediate ENSO-driven change in a temperature contrast (or pressure contrast or some other contrast) that is leading to the change in both the growth rate and the net isotopic character of the additional atmospheric CO2.
Thanks Allen. Food for thought. If you are interested in changes to the annual cycle you may find this interesting. I got a good fit using 12mo 6mo cycles + linear rise. I like raw data not NOAAs wand waving “corrections”.
https://climategrog.wordpress.com/co2_daily_2009_fit/
the 13C/12C ratio would be interesting if you are still following this.
Also I looked at derivative relationship throughout the 1998 El Nino.
https://climategrog.wordpress.com/co2_sst_regression_nino98
climategrog,
I assume that your comment was addressed mainly to me rather than Allan. First, I always start with the raw data, which is why I do not like to see it smoothed unnecessarily. I prefer the correction applied by NOAA to remove the seasonal cycle for two primary reasons: Scripps CO2 program, whose data I mostly use, apply a similar technique and get similar results (I show the Scripps version of the 1997-1998 El Niño below, which can be compared to the NOAA version for which I showed the wft plot previously); and, the same characteristics show up in the corrected data from other observatories, including data from the South Pole, which are barely influenced by any seasonal cycle and hence the correction is very minor there.
You are probably familiar with the nomenclature used to report the 13C/12C ratio in atmospheric CO2, i.e. δ13C, but in case there any readers left here who are not familiar I will provide a very brief explanation. Put simply, the δ13C of a CO2 sample is the difference between the measured 13C/12C ratio and the 13C/12C ratio of a fixed standard, expressed in per mil terms. Thus, a negative δ13C means that the sample has a lower 13C/12C ratio than the standard. The units of ‘per mil’ mean per thousand, so exactly the same as if expressed as a percentage (per hundred) but multiplied by 10. So, for example, a δ13C of -13 per mil means that the sample has a 13C/12C ratio that is 1.3% lower than the 13C/12C ratio of the standard.
This is very neat mathematically, because it can be treated just like the ratio provided any equations are consistent in its application and is widely used in the literature in this way. Also, since 13C and 12C are stable isotopes both must (individually) be consistent with mass balance principles. The other important point is to be aware of the average net δ13C content of incremental CO2 for the entire period of direct measurements is -13 per mil, and even going back to 1750 but that, as they say, is another story. The reason for specifying it as ‘net’ is that it makes no assumptions about sources or sinks, it is simply the resultant blend in the CO2 that is being added to the atmosphere. The reason for specifying it as ‘average’ is that it is not constant (as I will show below) over periods of a year of two, but is constant when averaged over longer periods.
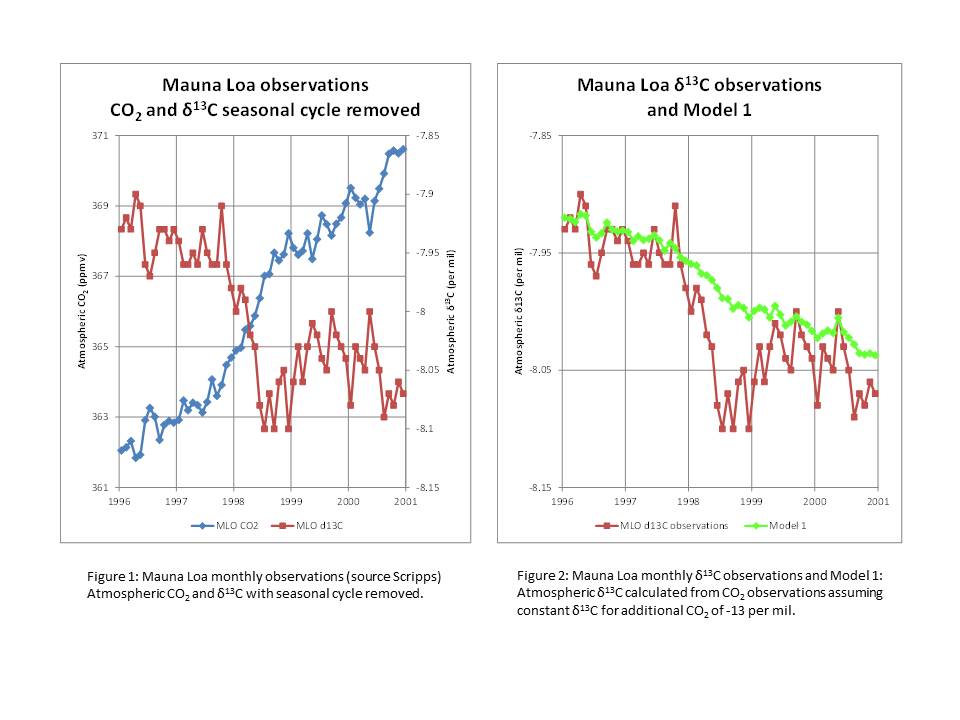
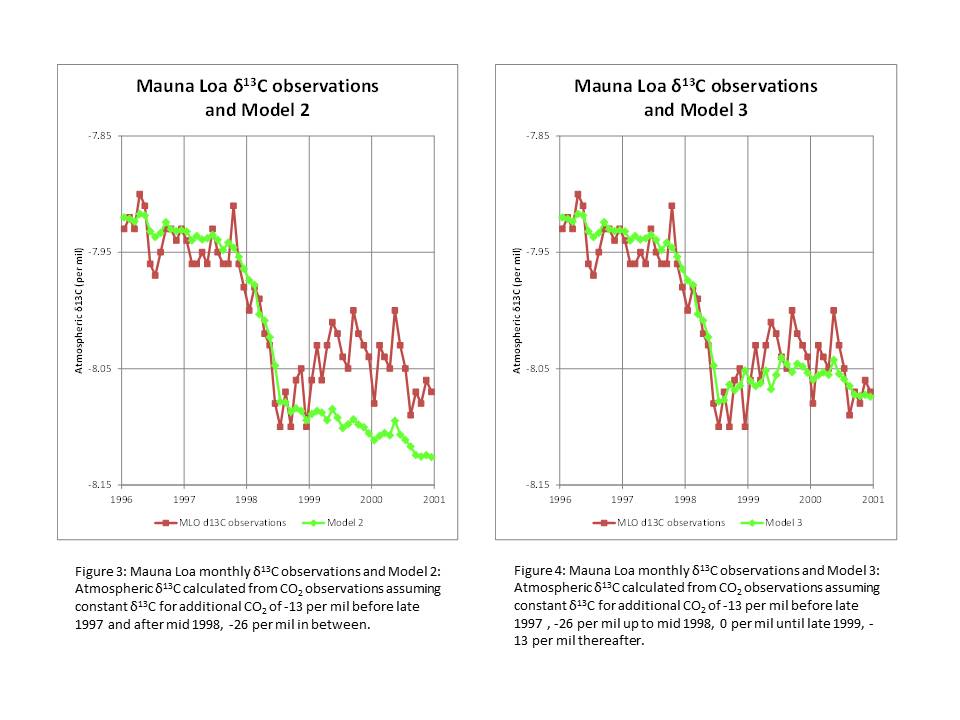
I prepared a very simple to model to evaluate the evidence for changing δ13C associated with changes in rate of growth of CO2. The model is based on mass balance considerations whereby if we know CO2 levels at two different times and also their δ13C values, we can easily determine the net δ13C of the incremental CO2. The numbers used in the model for δ13C are not meant to be definitive, but they do need to be directionally correct to explain the observations.
Figure 1 shows the observations (seasonal cycle removed) for Mauna Loa for the El Niño of 1997-1998 and subsequent La Niña. The increased rate of growth in atmospheric CO2 is clearly evident, starting in late 1997 and finishing around mid-1998. Atmospheric δ13C shows a rapid drop in late 1997 through to mid-1998, which is synchronous with the CO2 rate changes.
Figure 2 shows the same δ13C data in red, while the green data is calculated from the CO2 data shown on Figure 1 by assuming that the CO2 trend reflects a constant net δ13C content of -13 per mil for the incremental CO2. While it shows an increase in the rate of decline of atmospheric δ13C as expected, the drop is nowhere close to the observed change.
The basis for Figures 3 and 4 are stated on the figures. In Figure 4, the model δ13C was changed to -26 per mil from late 1997 to mid-1998 during El Niño and then to 0 per mil until late 1999.
So, it would appear that higher CO2 growth rates broadly correspond to a lower net δ13C content (more negative) of CO2 than the average of -13 per mil, while lower CO2 growth rates associated with La Niña events (and Pinatubo as well) coincide with a higher net δ13C content of CO2 than average, generally closer to the then current atmospheric δ13C level and possible even higher on occasion.
Apologies Jim. I misread who it was from and by the time I noticed the edit window was shut.
All these “climatology” methods have horrible residues and monthly noise. Climate “scientists” have no idea of how to process physical data. Most of their ideas seem cobbled from economists, another group who are masters of failed predictions.
The up step after 1998 just goes to show there is an important “out gassing” element to rising atm CO2.
Absolutely no problem, easily done.
Oh well I just posted a lengthy reply and now it’s disappeared ! Here’s the links without the chat.

https://climategrog.wordpress.com/co2_sst_regression_nino98/
https://climategrog.wordpress.com/co2_daily_2009_fit/

Ja. Ja.
It is the 87 year Gleissberg. With the sun, we are now 1935. But the earth also gives more heat. Drought time on the higher latitude is probably not over yet.
And winter is coming.
Obviously. It is due to more CO2 and extra heat = water vapor from earth that the drought time is not as bad as it was during the dust bowl drought.
Nein. Nein. Folks who claim there is a “Gleissberg Cycle” can’t even decide how long it is. Read my posts “The Tip of the Gleissberg and The Effect of Gleissberg’s “Secular Smoothing”.
w.
Dear Willis.
Average is important here. Click on that word here,
https://breadonthewater.co.za/2022/11/20/the-lord-of-the-weather/
The evidence that I predicted on the drought at the higher latitude and heavy rain around the equator is IMHO quite impressive.
Pass. You want to push your theory. How about you do that on your own thread. This thread is not about your claims about geothermal heat. It’s about the response of El Nino/La Nina to increasing temperatures.
w.
Willis
I am sorry that indeed many people here climb on their own little horse when you do a post. But, as someone already asked, I also wonder: how does the heat travel to the arctic, especially where the Chuckchi sea is warming at a rate of 0.7K per decade, the highest that I have seen it, anywhere. How do you explain the values I reported in Table 1:
https://breadonthewater.co.za/2022/08/02/global-warming-how-and-where/
Anyone?
ENSO is not “El Nino Southern Ocean”. It is El Niño Southern Oscillation. The Southern Oscillation is the difference in air pressure between Tahiti and Darwin, which you mention.
Also, you confuse cause with effect. SST off South America doesn’t cause the trade winds to change. Trade wind strength determines whether El Niño, La Niña, La Nada or something in between (such as Modoki states) occurs. This is why ENSO is called a coupled oceanic-atmospheric phenomenon.
The trades typically blow from east to west, piling up sun-warmed surface waters in the western tropical Pacific. In El Niño conditions, the trades weaken, allowing warm water to slosh eastward into the central or even western Pacific. In super Los Niños, they can even reverse, as happened at peak Super El Niño in February 2016.
Since then, the world has cooled for almost seven years, despite steadily increasing plant food in the air.
John Tillman December 3, 2022 11:17 am
Thanks, John, moving too fast. Corrected.
This is why I ask people to QUOTE MY EXACT WORDS. I’m quite certain that I never used the terms “cause” or “effect” in my post. In fact, I’m quite cautious about ascribing cause in climate, as it is rarely clear. Instead, I describe what I call a “chain of effects”.
Here are a couple of Sufi storis about that.
STORY THE FIRST
One fine, philosophical morning, a scholar asked Nasruddin, “What is Fate?”
“An endless succession of intertwined events, each influencing the other,” was the Mulla’s answer.
“Well, personally, I believe in cause and effect,” sniffed the scholar.
“Very well,” said Nasruddin, pointing to a procession in the street. “See that? That man is being taken to be hanged. Is that because someone gave him a silver coin that let him buy the knife with which he killed his victim; or is it because someone saw him do it; or because nobody stopped him?
Only a fool or a child looks for cause and effect in the same story”
STORY THE SECOND
Nasrudin was walking along an alleyway when a man fell from a roof and landed on his neck. The man was unhurt; the Mullah was taken to hospital.
Some disciples went to visit him. ‘What wisdom do you see in this happening, Mullah?’ ‘Avoid any belief in the inevitability of cause and effect! He falls off the roof – but my neck is broken! Shun reliance upon theoretical questions such as: “If a man falls off a roof, will his neck be broken?”’
Regards,
w.
You said that “El Nino…generates extensive winds.”
“The El Nino phenomenon is a curious beast. When the Pacific Ocean gets hot off of the coast of Peru, this is called an “El Nino” condition. It generates extensive winds.”
Thanks, John. I am describing a sequence of events. One event follows another, viz:
• The El Nino builds up.
• This is followed by an increase in the strength of the trade winds.
• This is followed by the trade winds pushing the warm surface water westward.
• This is followed by a return to the neutral conditions.
• This is followed by a buildup of El Nino conditions.
• This is followed by …
Lather, rinse, repeat.
Perhaps you can ascribe cause and effect in that circular chain of events. Me, I’m nowhere near that optimistic.
Regards,
w.
That’s not the sequence. First El Nino “builds up” because of weakening trade winds. What do you suppose causes El Nino conditions in the first place?
It’s an oscillation, controlled by changes in air pressure. The proximate cause is strength of trade winds. At least one ultimate cause is changes in solar radiation, affecting air pressure, hence wind strength.
https://www.ncei.noaa.gov/access/monitoring/enso/technical-discussion
John Tillman December 3, 2022 12:17 pm
Clearly, you’re not reading what I said. I’m not ascribing causes. I’m describing a circular chain of effects.
YOU are the one insisting that you have some insight that allows you to ascribe causes to a circular sequence of repeating events.
Me, I don’t even try to do that.
w.
I’m adding to your sequence. What happens before El Nino “builds up” is that the trade winds weaken. That event also happens to be what causes El Nino’s “build up”.
This fact has been known for a long time. Why do you deny it?
http://ww2010.atmos.uiuc.edu/(Gh)/guides/mtr/eln/elyr.rxml#:~:text=The%20air%2Dsea%20interaction%20that,and%20the%20trade%20winds%20weaken.
Just because you find an observation of nature mysterious doesn’t mean the observation isn’t valid. Weakened trade winds allow Los Ninos to “build up”. No mystery there.
What primarily causes trade winds to weaken is however subject to debate.
So after claiming that you know the cause in the circle of Nino/Nina/Neutral, you now say you don’t know the cause?
Pass. I can’t deal with that level of disconnect.
w.
I do know the proximate cause of El Niño conditions, as does anyone who has ever studied the phenomenon.
I also ascribe to the common conclusion that solar variability causes the trades to strengthen and weaken. But I can’t rule out other factors.
There is a mutual reinforcement ( positive feedback ) effect. The dogma says ENSO “causes itself” because they do not have the mental capacity to work out the triggering event.
In non linear coupled systems with +ve f/b a small input can trigger a large effect. This is like the emergent phenomena Willis is so fond of.
Willis: you say:
In your head post, you use the words:
Which does sound like you are saying the El Niño causes (“generates”) the winds.
Thereby giving fodder to pickers of nits.
I’m not taking sides here – it’s just about semantics and there are no real sides to take.
But I am impressed by the way you have used public-domain data to come up with a new angle on how climate manages to stay within limits. Keep up the good work, sir.
Willis.
John Tillman asked a very good question “What do you suppose causes the (warm) El Nino conditions in the first place?
It is obvious that you do not have a clue, just saying that it is a circular turn of events..
Since 1900, there have been 35 El Ninos. 28/35
started before Oct; 15/35 began before July, so it is obviously not a year-end seasonal effect.
So WHAT does cause them.?
The answer is that EVERY El Nino since 1880 has been caused by a reduction in the amount of dimming SO2 aerosols in the atmosphere, either volcanic induced, or from global “Clean Air” efforts to reduce Industrial SO2 aerosol. pollution.
The cleaner the air the warmer it will get, until the next VEI4 or larger volcanic eruption injects more SO2 aerosols into the stratosphere. .
Burl, almost no matter what I write about, you jump in to promote your theory about SO2.
Pass.
w.
Willis:
It is more than a theory. It explains every nuance of Earth’s climate.
I cannot understand why, you as a searching scientist simply dismiss it out-of-hand
Burl, I didn’t “dismiss it out of hand”. Not my style. I went and got the SO2 data, examined it in the light of your theory, and found nothing of substance.
Regards,
w.
That clearly implies causation not just a sequence of events. A little humility and honesty goes a long way.
[Snipped.]
That was nothing but an ugly personal attack. Discuss the science or go away.
w.
Climategrog said
I changed it to make it clear a while ago. You’re invited to kiss my humility.
w.
So you rewrote it to “clarify” LOL.
With communications skills like that you should be working for the Biden WH. Kiss your own “humility” if you can find it.
“There, because the air is dryer than in the moist tropics, more of the radiated heat from the warm water can escape to space.”
Sounds a lot like Lindzen’s “Iris effect” on how tropical thunderstorms dry out the upper atmosphere which then leads to more IR escaping to space. FWIW, I’m not accusing you of plagiarizing Lindzen, but coming up with a similar idea independently. As an example, I came up with a signal processing scheme for a project, and the realized that the scheme was a reinvention of orthogonal frequency division modulation.
Thanks, Erik. The Iris Effect is not involved with the dryness of the air.
“In 2001, Prof. Richard Lindzen and colleagues published his “iris hypothesis” (Lindzen et al., 2001). The hypothesis has two parts: First, in a warmer climate, enhanced precipitation efficiency will lead to less cloud being detrained into the troposphere from convection. Second, with less cloud cover, more infrared radiation can escape to space, thereby creating a strong climate-stabilizing negative cloud feedback that prevents significant warming from increasing greenhouse gases.”
So no, this has absolutely zero to do with the Iris Effect.
w.
Willis,
I was under the impression, perhaps mistaken, that the increased IR transparency of dry air was part of the “Iris effect”.
I’m convinced that thunderstorms (and rainfall in general) are part of the earth’s thermoregulatory mechasnism as a lot of heat gets transferred in the process. Would be fun to see a detailed analysis of where the heat goes.
What would have happened to the ENSO effect When the Panama Gap was open and the Atlantic could flow into the Pacific?
Or did the closing of the gap trigger the ENSO effects?
No clue.
w.
That’s proper answer, if you don’t know you don’t know. Not enough people in all walks of life say “I don’t know” when they don’t know.
Data and modeling show lessened ENSO variability in the Pliocene, as would be expected.
https://www.nature.com/articles/s41561-022-00999-y
NOAA alters ENSO indices based on a 5 year moving average. This makes it appear that La Nina events are getting stronger and El Nino events weaker. You may be simply graphing their changes.
In addition, we have ENSO data back to 1950. What happens when you go all the way back. Some might call 1980 a cherry pick.
Finally, what happens when you remove the current triple-dip La Nina? Linear trends are often more affected by end points. Does the analysis still hold?
Richard, do you have a link to your claim about the “5-year moving average”? I strongly doubt that that is true about the SOI, for example. From NOAA:
Nothing there about a “5-year moving average”. And given the good agreement of the SOI with the three others, any “adjustment” to them seems unlikely.
As to “cherry picking”, you can stuff that ugly accusation up your fundamental orifice. I started when I did because that is the start of the MEI. So I couldn’t go back further than that.
And as to “cherry picking” again, you seem to want to cherry-pick the endpoint … funny how that works.
w.
All I did was provide you with facts. That you chose to respond in such an ugly manner is counter productive.
I have no opinion on your view here. Just showing where you could improve the strength of the claims.
As to the 1980 start date, there is data going back further. You certainly could have looked at one of the data sets to see if the trend continued back in time. That would cut off potential accusations. If it didn’t support your result, then you would have more work to do.
As for the endpoint, I was again pointing out a potential problem that could affect your analysis. Your objection makes no sense. This is what I would expect from someone trying to support a predetermined result.
Richard, sorry I missed your comment earlier about the 1980 start date. In a comment on this thread I asked Willis about that start year and further wrote, 1980 is a curious start year for your analysis, considering that the 1982/83 super El Nino follows shortly thereafter. One might think you cherrypicked the start year of 1980 to support your hypothesis. If you started the graphs in 1970, the trends will flatten, because of the dominance of La Ninas during that decade.
Surprise, surprise, I used the word cherrypicked too.
And to Willis, so the MEI starts in 1979. As you like to write, SO WHAT. Exclude the MEI and start your graphs in 1970, so that they in include the La Nina dominant period of the early 1970s.
Regards,
Bob
Further to Willis. It is well known that there are multidecadal variations in El Nino/La Nina dominance. (See Figure 4-85 in my book Who Turned on the Heat linked above.) What happens to your hypothesis when El Ninos dominate again in the future?
Regards,
Bob
For those following this part of the thread, Willis and I continued our discussion way later on the thread. Here:
https://wattsupwiththat.com/2022/12/03/how-the-el-nino-is-changing/#comment-3645840
Regards,
Bob
Getting pissy does not strengthen your argument, it makes you look weak and threatened. I think the 5 year claim is spurious too. You should have stopped there.
Willis, this site explains SOI https://www.longpaddock.qld.gov.au/soi/ and this site has posters which give a record of the SOI and IP. At the right side of the posters there is an explanation of the effects of El Nino and La Nina in relation to SOI https://www.longpaddock.qld.gov.au/rainfall-poster/
I live on the Sunshine Coast in South East Queensland and have a 130year record of rainfall from official sites near my home until closed and added to by my own daily measurements. I have been recording daily SOI figures from the longpaddock site since 2015 to find patterns in connection with SOI and possibly the tidal heights at Darwin. For example in Jan 2022 (this year) the SOI was 2.61 well below the +10 value for excess rain and the rainfall was 150mm well below the long term average of 240mm. In May 2022 the SOI was18.64 (above the +10 value) and the rainfall 624mm well above the long term average of 150mm and there was bad flooding.
From my records I do not believe there have been 3 La Ninas rather one extended one. nor do I think the rainfall this year is special particularly in the summer months. Record rainfalls occurred in summer of 1893 and 1898 when rainfall over 3000mm in Feb and March (respectively) with record falls for the year of close to 4m.
RichardM, are you referring to NOAA’s ONI index. There NOAA uses a 30-year average, updated every 5 years:
Climate Prediction Center – ONI (noaa.gov)
Regards,
Bob
Correct, Bob. Here’s another link to help explain.
https://origin.cpc.ncep.noaa.gov/products/analysis_monitoring/ensostuff/ONI_change.shtml
Since I only use the ONI, I have never looked into the other data sets.
The last 5 year reset for the Nino34 undertaken by BoM was actually down. That was deflating for these CO2 demonisers and was given zero press coverage as far as I can find.
You are misunderstanding what is being done. It’s like the “temperature anomalies”. They give anomalies relative to a long term mean. The base period for that mean is updated periodically. That adds an offset to the whole record , it does not change form of the graph or affect its slope.
If you look at the 30 year average for 2021 when I believe it was last updated, it is lower than the previous 30 year average in 2016. Not every month down but on average down. It was the first time the 30 year average was lower for a long time.
Richard M is absolutely correct and it is not the same as the treatment of temperature anomalies where the updated base period is used for the whole record. A couple of quotes from the link provided by Richard follow:
“So, ONI values during 1950-1955 will be based on the 1936-1965 base period, ONI values during 1956-1960 will be based on the 1941-1970 base period, and so on and so forth.”
“For example, for the set of years between 2001–2005, the ONI values (and El Niño and La Niña episodes) will permanently be calculated as the departure from the 1986–2015 base period.”
The effect of this procedure is to remove longer term trends. I recalculated ONI (from 1950 to 2020) based on a single base period of 1971-2000) and it shows a long term increase in ONI of 0.08C/decade. Using the values as published, there is zero change.
Richard M
<blockquote>Finally, what happens when you remove the current triple-dip La Nina? Linear trends are often more affected by end points. Does the analysis still hold?</blockquote>
Is it currently a triple-dip La Nina?
Double Dip La Nina Persists At The End Of September 2022and up to date.
See http://www.gujaratweather.com/wordpress/?page_id=26987
All I know is that no matter whichever mathematical equation one chooses to express climate, I cannot control the climate. You cannot control the climate. And most certainly Joe Biden nor the EU can control the climate.
The $595 billion investment in green in 2020, the $755 billion spent in 2021, the $920 billion spent in 2022… equals an end result of “Global CO2 concentrations set a new record of 417.2 parts per million (ppm), up 2.5ppm from 2021 levels”. -CarbonBrief. Or so they say.
I don’t dispute their math, just their failure to achieve anything after spending $2.270 trillion USD.
Back in the day, not only would I not be given successive $billions after failing with the first $600 billion. I would have been sacked certainly by the third monumental loss of $920 billion USD with nothing to show for it. Most definitely not encouraged to spend ever more billions come 2023.
So, if we agree with the proposition that we don’t control the climate, the question is, when do we put the nonsense aside and stop the suffering we’ve caused worldwide in its name, and let go of the anti-humanistic attacks on our industrial society?
Because I’ll tell you, the end game driven by these anti-human ideologues, is a dismal hell of universal suffering for anyone not wealthy enough to be an exploiter of the massive underclass that will develop out of this hell they view as utopian.
True. But I suspect the answer is that those funds weren’t spent in an attempt to control the climate, but rather in an attempt to control the narrative, and thus the electorate. Who could doubt that in that sense, the expenditure has been wildly effective? Things, however, may change rapidly if too many people freeze to death in Europe this winter. Or not – damned if I understand which direction the general public will stampede these days.
Philip CM:
You are WRONG.
We ARE controlling our Climate!
Atmospheric SO2 aerosols are the Control Knob for Earth’s Climate, and by reducing them, we are increasing the intensity of the Sun’s rays striking the Earth’s surface, causing it to warm up.
Biden’s “Green New Deal”, banning the burning of fossil fuels and their attendant SO2 aerosol emissions, WILL cause temperatures to rise, not fall, as is his intent…
“So … if we accept my hypothesis that the El Nino/La Nina alteration is an emergent phenomenon that acts to cool the planet, an obvious question arises—if the earth is gradually warming, will the Pacific shift towards more El Nino conditions, more La Nina conditions, or remain unchanged?”
The only significant warming in the last 20 years was from El Nino conditions.
La Nina acted to cool the planet during the Holocene Thermal Optimum, and through the Medieval Warm Period La Nina conditions were more common.
El Nino conditions usually increase during centennial solar minima, and a teleconnection linkage from El Nino episodes through the North Atlantic Oscillation drives major warm pulses to the AMO, with a 7 month lag.
Ulric Lyons:
“Through the Medieval Warm Period La Ninas were more common’
No, La Ninas are COOLING episodes and were extremely rare, or non-existent, during the MWP
How could you make such a comment?
Thanks, a great post. However, I always felt that El Nino and La Nina were artificial constructs. For example, “we have several indices that measure the state of the Pacific Ocean regarding El Nino” – is it the same thing as measuring El Nino? Can we measure La Nina?
Yes. El Niño is warmer than average water off South America or in the equatorial central Pacific. La Niña is cooler than usual SST there.
The mean difference is about 0.9 C. Doesn’t sound like much, but it’s detectable, as is the effect on fish and weather.
“If it were true, the global average temperature would go up and down like a yo-yo on steroids.”
Unless λ = 0 🙂
Cheers, Willis.
Oh, very good, Pat. Always good to hear from you.
w.
It is indistinguishable from zero. There are two ways adding CO2 could alter the energy balance. One is enough to measurably change the mass of the atmosphere. The other is to alter the albedo of snow and/or temperature of solidification/melting.
There is not enough to alter the mass and there is no mechanism that I know of where it alters the properties of water solidification and melting of snow or sea ice.
But the average solar EMR over oceans north of 20N has increased 2W/m^2 since J0000. That is having a significant, easily observable impaction on climate as it has 4 times in the last 500kyr.
“Indistinguishable from zero” is about right, Rick.
The whole air temperature trend since 1880 can be explained as a sum of a 60-year oscillation, and the rising phase of a ~240 year oscillation found in a European spleothem.
See Lüdecke, et al., (2013) Multi-periodic climate dynamics: spectral analysis of long-term instrumental and proxy temperature records. Clim Past. 9(1), 447-452. doi: 10.5194/cp-9-447-2013.
Mentioning it got me ejected from LinkedIn, discussed here at WUWT.
But the point is that the entire temperature record since 1880 can be very reasonably explained by natural variation. without reference to CO2 at all. Its effect is, indeed, indistinguishable from zero.
I disagree with this. The temperature changes are far more nuanced and ocean time constants are much longer than most appreciate.
Antarctica and Southern Ocean is cooling. Nino34 region has cooled very slightly. Northern winters have warmed dramatically. Greenland up from about -35C to -25C in 70 years – a huge temperature increase per attached.
Northern ocean surface warming is much higher in August than the global annual average.
Greenland will have 100% permanent ice cover by 2070.

These trends will continue until the ice accumulates on land like it did last time there was “global warming”. There are problems with the term “global warming” because the warming is far from global but the upward temperature trend in the NH will continue for a long time. The SH on average will turn down in a few hundred years. The Southern Ocean has enormous thermal inertia and very slow response to changes in solar intensity. The northern ocean surface temperature response to the changing solar intensity is much faster than the SH oceans because the high proportion of land essentially shuts down advection from the oceans during the summer months so the NH oceans retain more heat.
“I disagree with this.”
And yet, there it is.
It is not a matter of just fitting the global trend. You need to explain why different parts of the globe are cooling; different parts have no trend; other regions have some monthly trends exceeding other monthly trends..
If you cannot do that then you are not doing anything better than CO2 being the control known.
The precession cycle is the dominant driver of Earth’s climate. Its period of 23kyr is the first distinctive peak in the frequency analysis of the sea level reconstruction.
I’m not claiming the plot shows causality, Rick. Only that known oscillations provide an alternative for the recent air temperature record.
Lüdecke, et al., provide a power spectrum of their own. It covers a 1400 year period, which is much shorter than your 23kY time frame, and shows short periods that would not be resolved in a power spectrum analysis focusing on sea level.
I am claiming causality. The observed trends can be explained by precession and the changing solar EMR.
It is the dominant factor in reconstructions of recent geological times and also the dominant factor now in the observed trends.
There is no doubt that there are short term influences in solar variation that are observable. These cause temporary changes in the weather patters but they are not driving climate trends.
The idea that surface imbalance can impact on deep oceans in a matter of decades is ridiculous. The deep oceans have enormous thermal time constants that take centuries to show impact of surface imbalance.
It appears to me, Rick, that we’re not discussing the same thing.
You’re clearly focused on climate change over geological time.
My point concerns relatively short-term oscillations, with empirically-derived periods of half-century to a few centuries.
This means that there is a new equilibrium temperature after a persistent change in the energy budget. That implies an overall negative feedback is stabilising the system and the new higher temperature balances the change in forcing.
This unspoken recognition of the fundamental stability of the climate system which is due to the Planck feedback. The estimations of values of climate “sensitivity” is simply small perturbations either side of the Planck. ie is the earth slightly more of slightly less sensitive than it would be with just Planck f/b.
When climatologists claim that “net feedbacks” are positive , they are claiming they slightly reduce the Planck f/b. The true net f/b is ALWAYS negative o/w the entire system would be unstable. ie net feedbacks are positive ….. except for the over-riding NEGATIVE f/b we prefer to ignore to make it all sound more scary.
For us in Australia the IOD is at least as relevant as ENSO. Should not any discussion on El Nino also include the whole Indian Ocean given the effect extends there a shown in Figures 2 and 3.
Is that the IOD that is visible in the Indian Ocean in the charts above?
This is muddled thinking and indicates misunderstanding of the process. 30C warm pools form the most powerful convective towers. The 30C pools draw mid level moisture from cooler regions while the upper level air diverges to the cooler regions.
The phase switch in ENSO is likely due to changes in surface salinity. High saline water has lower heat of vaporisation than lower saline water. Persistent warm pools will eventually become less saline and the energy required to liberate water goes up compared with regions that are currently cooler net evaporation zones.
Warm pools always have net precipitation so they have lower salinity. And warm pools are not static they move east and west and north and south. There is a tendency for them to crowd the western Pacific because land is able to generate more powerful towers as the surface warms faster with sunlight. The region just to the east of PNG is the only location in the oceans that has an annual average above 30C.
Willis, what stops the El Nino warm waters splitting North and South when they hit the Americas, as they do on my side of the pond in South Australia (where Summer is only now waking up after a very cold winter/Autumn)?
Thanks for your continuing educational efforts
It’s the geometry of where they hit. Equatorial trade winds blowing across the Atlantic hit the northern sloped part of the South American continent, where they are all directed north to form the Gulf Stream.
w.
It is NOT the geometry of the coast line, it is the Coreolis driven circulation of the main ocean gyres. CW in NH, CCW in SH. The Gulf steam runs up the east coast because that is the direction the N. Atlantic currents turn.
The warm waters do spread along the American coasts, but more south than north of the equator, since they mostly move east in the low latitudes of the SH.
Willis, I stopped reading at the point of your description saying, “The La Nina wind cool the equatorial Pacific, and thus the planet” When said that way, it can be misleading.
It is more accurate to state that winds of La Nina cause strong upwelling of cooler waters in the tropical eastern Pacific which thus cools the global Average Air Temperature. But it also causes conditions that increase solar heating in the eastern Pacific and that heat then gets transported and stored at depth in the western Pacific. Thus La Nina warms the planet if we consider the whole system and not just air temperature.
Similarly, the transport of stored heat back to the eastern Pacific and closer to the surface during El Ninos allows that stored heat to ventilate and thus cools the earth’s climate system despite causing the average air temperature to increase.
Thanks, Jim. All I can tell you is that on averge for the two years following the largest Nino/Nina alterations (Nino followed by Nina ~12 months later, measured from the lowest part of the Nina), the global surface air temperature is lowered.
In addition, you haven’t included the poleward movement of the warm equatorial waters, which increases the radiative heat loss.
Also, although La Nina “causes conditions that increase solar heating in the eastern Pacific”, it also causes conditions that decrease solar heating in the western Pacific. Where is that in your analysis?
So … should I have “stopped reading” when you didn’t include those issues? Nope. I continue to read so I can understand the whole of your argument. It’s only polite.
w.
Yes, I did not include the increased poleward movement of heat. But that doesnt fully account for the increased heat storage at depth as well as contributions to the so-called conveyor belt.
And yes that poleward heat will ventilate and cool more rapidly outside the tropics but it is that ventilating heat that raises the global average air temperature. ONce criticism is that such analyses must make the distinction between a warming air temperature, ocean heat accumulation and the earth’s entire climate system.
Furthermore, additional heat being transported into the Arctic has melted sea ice that allows more stored heat in the Arctic’s Atlantic layer to ventilate. So, while La Nina cools the eastern Pacific, it indirectly allows increased ocean heating, and resulting changes in ocean circulation allow that heat to ventilate raising air temperatures. My criticism for this article is that it makes a blanket assertion that La Nina’s cool the earth’s climate system, when the opposite is true.
Jim, you say:
Say what? If the heat is ventilated at the equator, more of it remains in the atmosphere. But if it is moved poleward, more of it escapes to space and less warms the atmosphere.
Net effect is that the atmosphere is cooler. And you’ve already admitted that La Nina cools the atmosphere. Yes, some fraction of the equatorial surface heat is taken downwards into the deeper ocean … and? We don’t live underwater, we live in the atmosphere, so I’m not clear why this is an issue.
w.
“Say What?” you say! I’m finding your defensive reactions quite baffling and disappointing.
Please look at any La Nina illustration that demonstrates heat accumulation at depth as provided here.
It is well established that outside the tropics temperatures are warmer than solar radiation at each latitude would provide. That additional warmth is due to the transport of heat out of the tropics via ocean and atmospheric circulation and ventilates. That ventilation alway happens to some degree, but is modulated by ENSO, AMO, AMOC, etc.
Simultaneously with increased ocean heat storage, La Ninas ALSO increase poleward heat transport. That transport doesnt mean La NIna is NOT increasing ocean heatig This is evidenced by looking at the Pacific Decadal Oscillation that exhibits a more La Nina-like ocean with a cooling in the tropical eastern Pacific but a warming in the north central Pacific.
During a La NIna, trade winds/Walker circulation are always amplified which increases the westward flow of heated waters, those warmer waters flow north, south and into the Indian Ocean. That increase feeds warmer waters that then leak into the southern Atlantic via the Agulhas Leakage and feed the AMOC.
Wherever this heat gets ventilated air temperatures warm. Thus the global average air temperature trend continues to rise ,DESPITE the short term drop after EL Nino ventilates stored heat, because a preponderance of La Nina-like conditions have existed since the 1850s.
I would predict the oceans will soon exhibit a cooling trend as La Nina-like conditions DECREEASE as the PDO goes positive and the trade winds relax with decreased solar irradiance.
Jim Steele December 3, 2022 4:43 pm
Ok, apologies, my bad. But in your haste to correctly bust me for being defensive, you failed to reply to my statement.
You claimed the opposite. Not understanding why.
w.
What isn’t clear with “Simultaneously with increased ocean heat storage, La Ninas ALSO increase poleward heat transport. That transport doesn’t mean La Nina is NOT increasing ocean heating”
Jim, you say:
“… a preponderance of La Nina-like conditions have existed since the 1850s.”
For that we have to use the SOI (inverted, of course, to match the other indices where positive values are Ninos). It’s the only index that goes back that far.
The trend of the SOI Jan 1955 – Apr 2022 is very slightly positive (0.0012 index units per year ± 0.0014 units), so not statistically significant.
Not seeing the “preponderance”.
Regards, and sorry for any unintended offense.
w.
“La Nina-like” conditions refers to the cold eastern-warm western Pacific that increases upwelling. Currently La Nina gets defined narrowly when temperatures exceed .5C lower than average in the Nino 3.4 region that covers between 5 N&S latitude and 120 & 170W longitude. Such temperature change during the LIA are not totally reliable.
As a measure of upwelling in the eastern Pacific, I prefer the well established marine biological response to upwelling that can be examined in the historical sediment records as reported by Chavez (2011) showing upwelling greatly increased since the LIA
Could you PLEASE start providing links to your graphics and “studies”? It took me half an hour to track down your last graphic about the surface flux, and I’m not going on another snipe hunt.
Thanks.
w.
Marine Primary Production in Relation to Climate Variability and Change Chavez (2011)
Thank you sir!
w.
Learn about Hadley cells
Jim Steele:
“…it makes a blanket assertion that La Ninas cool the earth”s climate system, when the opposite is true”
What NONSENSE!
La Ninas COOL the earth’s climate system, being caused by increased levels of dimming SO2 aerosols in the atmosphere, primarily from volcanic eruptions.
The following warming is caused by the eventual settling out of the volcanic aerosol pollution, typically within 12-14 months, allowing the sun’s rays to strike the Earth’s surface with greater intensity, usually resulting in an El Nino.
As such, El Ninos do not cause warming temperatures, the whole Earth is being warmed, along with the Pacific ENSO area.
What nonsense you say? Hmmm. You always make such insulting assertions wherever it contradicts and challenges your obsession with your idea that SO2 controls the earth’s temperature and El Ninos.
As you wrote in your article “The Cause and Timings of El Nino Events”
from your abstract: “It has been discovered that the cause of an El Nino event is the removal of dimming Sulfur Dioxide (SO2) aerosols from the atmosphere. For the modern era,(1850-present), the SO2 removal episodes are coincident with business recessions, or Clean Air Act reductions.”
It makes absolutely no sense that recessions or the Clean Air Act caused El Ninos when ENSO activity has been recorded for the last 7000 years. What year was the Clean Air Act?
Jim Steele:
I said “for the modern era (1850-present)”.
During recessions, the climate temporarily warmed up by about 0.2 Deg. C. because there were fewer SO2 aerosols in the atmosphere due to idled industrial activity.
And “Clean Air” efforts were were instituted specifically to reduce industrial SO2 .emissions because of Acid Rain and Heath concerns.
You say that it makes no sense for recessions or the Clean Air Act to cause El Ninos, yet they DID.
This is the abstract from my paper “A Graphical Explanation of Climate Change”
“A “WoodforTrees.org” interactive plot of average anomalous global temperatures for the years 1850-present shows complete correlation between American business recessions and temporary temperature increases. The increases were caused by decreases in the amount of industrial Sulfur Dioxide (SO2) aerosols in the atmosphere during periods of reduced industrial activity.
Additional temporary temperature increases due to El Ninos after ~1980 , caused by global “Clean Air” reductions in atmospheric SO2 levels, are also shown”
The entire paper can be viewed on Google Scholar
All earlier El Ninos, then, would have occurred for the same reason–a reduction in the amount of SO2 aerosols in the atmosphere,during an absence of volcanism and their attendant SO2 aerosol emissions. .
FYI, After posting my criticism of the misleading overview, I went back to read the whole post because we share the same concerns.
I also made this point. La Nina is when the heat content of the system is recharged. The lower mean global surface temperature is misleading. Similarly most neophytes think El Nino causes warming because of temporary increase in mean surface temps but it is the phase of heat loss from the climate system.
Since Willis has often published about the stabilising, corrective effects of tropical thunderstorms, I’m surprised he fell into this mistake.
Cooler surface temps means less thunderstorms and more heat into the tropical Pacific.
Also consider that most researchers suggest the Little Ice Age was characterized by the Pacific in an El Nino-like state. That explains the cooling of the oceans. Since 1850, the Pacific has been more frequently in a La Nina-like which explains why the Indo-Pacific Warm Pool has been steadily increasing. The increased upwelling driven by La Nina-like conditions is further supported by the increased productivity since 1850 that is driven by La Nina-like upwelling. So again, when considering earth’s entire climate system, La NIna’s warm the earth and El Ninos cool it.
Jim Steele December 3, 2022 3:05 pm
Thanks, Jim. That’s one explanation.
My explanation would be that the El Nino is an emergent phenomenon, such that in warmer times we get more Ninas that tend to cool the planet, and that in colder times we get more Ninos that tend to warm the ocean.
By your logic, since there are more tropical thunderstorms in the afternoon when the ocean is warmer than in the morning when it’s cooler, and since where tropical thunderstorms form the ocean in general is warmer, therefore tropical thunderstorms must be warming the ocean …
I take the opposite position—that like Ninas, afternoon tropical thunderstorms are an emergent phenomenon that form in response to warming ocean temperatures, and cool the ocean …
As I’ve said before, assigning cause and effect in climate is difficult.
w.
PS—It’s not clear what you are calling “Nina-like conditions” leading to “increased productivity” since 1850. Productivity of what? How was productivity measured in say 1863?
Willis what are you talking about????
I never mentioned thunderstorms at all! So how can you attribute to me your claim “By your logic, since there are more tropical thunderstorms in the fabricated afternoon when the ocean is warmer than in the morning when it’s cooler, and since where tropical thunderstorms form the ocean in general is warmer, therefore tropical thunderstorms must be warming the ocean …” Such fabrication is beneath you!
My position is ocean warming is caused by La Nina-like conditions because clearer skies, induced by cool upwelling in the eastern tropical oceans, allow greater solar heating . Clear skies dont usually produce thunderstorms heatin
Never claimed you said it. I said that your logic is that Ninos drive ocean temperature. I say that there is another explanation, which is that ocean temperatures drive Ninos.
I was merely pointing out that your logic (emergent phenomena drive sea temperatures) doesn’t apply to e.g. thunderstorms, so you might want to consider that it might not apply to Ninos as well.
w.
Im losing respect. Yes you never said that I said it explicitly. You simply said “By your logic”, and that you were “merely pointing out that my logic” that I never espoused. That is dishonest fabrication.
Agreed. Willis is a stickler for “quote my words” which is a very sound idea. He should apply it himself.
I’ve always appreciated Willis’ ideas on the effect of tropical thunderstorms providing a mechanism for a negative feedback which stabilises tropical SST. However this article and his response to counter arguments here is very disappointing. It’s odd that he should be so far off. The defensive attitude in replies do not help.
And yes ENSO is an emerging phenomenon, but it has been emerging since 7000 years ago as the Holocene cooled and the ITCZ migrated southwar.
Link? Source? You keep claiming “studies show” and presenting graphics without links or substantiation of any kind.
Also, I said that ENSO is an emergent phenomenon, not an emerging phenomenon—very different things.
w.
A simple request for a link would do without trying to beesmirch me with “you keep claiming”
The Holocene trend in ENSO activity has been well established, so I assumed you were familiar. Not sure which paper the graph was extracted from but if memory serves it was most likely Mid-Holocene El Nino–Southern Oscillation (ENSO) attenuation revealed by individual foraminifera in eastern tropical Pacific sediments Koutavas(2006). If not a similar graph can be found in Variability of El Nino/Southern Oscillation activity at millennial timescales during the Holocene epoch by Moy 2002, or Shrinkage of East Asia Winter Monsoon Associated With Increased ENSO Events Since the Mid-Holocene Wu(2019)
Jim Steele December 3, 2022 8:01 pm
Jim, that was my THIRD request for a link. I was not “besmirching” you, I was exasperated with asking not once, not twice, but three times.
Next, I note that in this case, you cannot even give me a link for your graphic. And no, I’m not going to root through a bunch of possibilities for you. Do your own homework and cite your own graphs. Not my job.
w.
I didnt realize what an arrogant ignorant anal sphincter you can be. You foolishly think I saw and ignored your request???
Well for now on I will. You will need to find out how wrong you are all by yourself
Jim, I’m not the one posting uncited, unreferenced graphics, making claims about uncited, unreferenced “studies”, and when questioned about it, asking someone else to find the citation.
That would be you.
As to whether you saw and ignored my requests that you put your citations where your mouth is, what else was I supposed to think? You’ve been treating me like I was ignorant garbage since you entered the discussion.
I made the three requests three hours ago. I foolishly assumed you were following the conversation. It appears you weren’t. How was I expected to know that?
And to your credit you did provide one link … so I was surprised and frustrated when you continued to make uncited, unreferenced claims.
Look, Jim, I had and still have great respect for you and your undoubted knowledge. But your style of attempting to impart that knowledge sucks. I’m not some six-year-old who you can impress with some graphic that you cannot even provide a link for.
And when you can’t even find a link for your own damn graphic, I certainly didn’t expect you to just blow it off by saying you “assumed I was familiar” with the subject of the graphic … and then follow up that arrogance by assuming I’d do your homework for you and track down the source of your purported evidence. That’s the very definition of adding insult to injury.
I assumed you’d man up, say “sorry, I should have cited the graphic”, and then proceeded to do so.
And now your response is to say you’ll ignore me in the future? This is supposed to be some kind of threat, that I won’t be faced with your uncited graphics, your requests that I do your job and find the citations for any and all of your uncited claims, and your condescension from on high?
Seriously? That’s your threat?
Jim, I won’t be happy to see you go. But I can’t say your participation here has burnished your reputation. Yes, I still am impressed with your knowledge.
But so far, you’ve called me “baffling” and “disappointing”. In response, I apologized for whatever offence I’d caused … and apologized not once but twice.
Then you accused me of “fabrication”, meaning lying, which is the lowest of accusations. I take pride in being an honest man, and I don’t “fabricate” anything. You followed that up by accusing me of “dishonest fabrication”.
I follow the Captain’s Code, the code of my great-grandfather. Among the parts of his code was the following:
Since it’s no longer 1870, I haven’t shot anyone, but I’ve done my utmost in my life to live up to that part of the Captain’s Code, particularly in my science. So you accusing me of lying puts you among the lowest of the low.
You went on to say I was “besmirching” you because I had to ask for the third time to provide links. I foolishly assumed that once I’d brought it up, in succeeding comments you’d provide evidence for your claims. That’s why I said
I said that because that is exactly what you kept doing.
In response to me pointing out what you were undeniably doing, continuing to put forth unreferenced claims and graphics, you called me an “arrogant ignorant anal sphincter”.
Charming.
And now you pretend that you have the high moral ground here, and you’re stomping off in high dudgeon?
Really?
After twice accusing me of lying, persisting in making uncited claims, asking me in a most unpleasant manner to look up the source of your own damn graphic, and calling me ugly childish names, your claim is that I’m the bad guy?
That dog won’t hunt. I’m sorry for whatever it is that has you in such an unpleasant mood, and if it was something I said, you have my sincere apologies.
But I’m not the bad guy here, and I won’t be called a liar by any man.
Sadly,
w.
Neither has yours. When Jim Steele says you are mistaken you probably are.
Grog, Jim got all defensive when I had the temerity to start my response to him with “Say what?”. For which I apologized.
Twice.
I may indeed be wrong, and Jim is indeed a brilliant scientist. And when he says I’m mistaken, I very well may be.
But then lots of folks said the same about me and Michael Mann’s work, and me and Phil Jones’s work, and me and all the brilliant scientists claiming that Darwin was wrong and sea level would drown coral atolls. So at this point … I listen to smart folks like Jim, but I don’t assume he’s right.
The problem was, he seemed to take my disagreement as me being dishonest. He proceeded to call me a liar twice, tried to get me to find the source for his graphic as though I was his graduate student or something, and called me an asshole.
Meanwhile, all I did was ask him three times to cite his claims.
So I have no issues with my reputation in this. Not one. And I won’t let any man call me a liar. So sue me.,
w.
What is going on with you Willis!?!?!? You will probably edit my reply exposing your personal attacks as well, but here goes.
You write, “The problem was, he(me) seemed to take my disagreement as me being dishonest. He proceeded to call me a liar twice, tried to get me to find the source for his graphic as though I was his graduate student or something, and called me an asshole.”
Yes indeed I pointed out how YOU fabricated some whacko logic about thunderstorms that you then attributed it to me that I never said or implied. It’s there for everyone to see. So I called that a dishonest fabrication. If you think that makes you a liar, so be it. Instead of “manning up” as you suggested for me, you played a word game and tried to turn your dishonest fabrication against me by claiming that I am mistreating you? SAY WHAT???
Then you play Sensitive Sally writing, “As to whether you saw and ignored my requests that you put your citations where your mouth is, what else was I supposed to think? You’ve been treating me like I was ignorant garbage since you entered the discussion.”
Say What???? I started treating you like garbage from my first entry??? You are delusional!
Here is my first entry, and again, I’ll repeat you are again dishonestly fabricating everything I have said when you denigrate me as treating you like “ignorant garbage.” And later you launch more vile personal attacks against me with, “your style of attempting to impart that knowledge sucks.”
In my first entry I wrote, “Willis, I stopped reading at the point of your description saying, “The La Nina wind cool the equatorial Pacific, and thus the planet” When said that way, it can be misleading.
It is more accurate to state that winds of La Nina cause strong upwelling of cooler waters in the tropical eastern Pacific which thus cools the global Average Air Temperature. But it also causes conditions that increase solar heating in the eastern Pacific and that heat then gets transported and stored at depth in the western Pacific. Thus La Nina warms the planet if we consider the whole system and not just air temperature.”
Then later again you dishonestly fabricate my intent writing that I “tried to get me (you) to find the source for his (my) graphic as though I was his graduate student.” Say What????
The upwelling and productivity graph was listed as Chavez (2011). The La Nina graph simply illustrated how warmer waters get stored in the western Pacific, something I know you understand without a link, so no need for a link. When I checked back into the thread , I found you were arrogantly demanding I immediately provide you with links to my graphs and implying I am pushing unvetted information. Why do you suggest I might be lying?
For the Holocene increases on ENSO Activity I gave you 3 possible citations all with very similar graphs, not having adequately labeled that specific graph in my files. Even though the first reference was indeed the correct one, you accuse me of trying to treat you as a graduate student. Say What????
But apparently you didnt seem to really want that link writing, but just looking for more veiled personal attacks saying, “I’m not going to root through a bunch of possibilities for you. Do your own homework and cite your own graphs. Not my job.”
So I appropriately replied “I didnt realize what an arrogant ignorant anal sphincter you can be. “ (BTW technically that is not the asshole, so I never called you that. But you got my meaning and I am “man enough” to stand by it as you request!)
You wrote, “I made the three requests three hours ago. I foolishly assumed you were following the conversation. It appears you weren’t. How was I expected to know that?”
Of course you didn’t know why I didnt immediately reply to your demands. But even a 6th grader could guess I just might have many other things happening in my life other than following every thread 24/7 and dropping everything just to immediately reply to Sir Willis. Patience would have been thee better road to take, but you chose to personally attack me.
All this huffing and puffing about defending your honor, seems driven by the simple fact that several people challenged your theory. But you seem to be following your Captain’s code.
“If a man calls you a liar, shoot him.
If a man can honestly call you a liar, shoot yourself.
And Indeed all can see that your false fabrications are just you shooting yourself in the foot.
Hard pass.
I won’t have anything to do with some charming individual like you who calls me a liar. I can’t shoot you, but I sure as hell won’t have anything to do with you. I’m an honest man, and I don’t “fabricate” a damn thing. Perhaps you’re thinking of yourself or your friends, but me, I don’t do that.
Go argue with yourself. Not interested in the slightest. It’s now clear to me that to my disappointment and surprise, you come under the First Rule Of Pig Wrestling, viz:
“Never wrestle with a pig. You just get dirty and the pig enjoys it.”
Sadly,
w.
LOL You can continue to insult me to divert the problem, but your dishonest fabrications, for all to see, reveal what you are capable of , no matter how hard you try to deny it.
Rave on, Jim, it’s actually kind of amusing.
w.
Jim, El Niño is how the planet cools by increasing atmospheric (even stratospheric) energy transport at the expense of oceanic energy transport.
Analyzing the relationship between El Niño and Bond events that Moy et al. 2001 mention, it is easy to see that El Niño activity increases when the planet is cooling and decreases once it is very cold and the rate of cooling decreases.
That’s why it gives the impression that Bond events leave a negative imprint in the ENSO record, and El Niño activity increased during the rundown to the LIA and decreased during the LIA.
Willis focuses his analysis on surface temperature so he misses the energy changes in the whole climate system.
To change climate normally it is required to change the energy balance at the top of the atmosphere (exceptions are few, like the 8.2-kyr event or DO events), and the equation at the start of the post (∆T = λ ∆F) is a way of expressing it.
Lastly, by far the greatest heat flux into the oceans happen where La Nina-like conditions (both in the Pacific and Atlantic) where upwelling is the greatest promote greater solar heating, as most studies examining ocean heat flux have determined. In the illustration, positive values represent more heat entering the ocean than leaving, while negative values represent net cooling.
I think you are confusing what Willis is saying. You are talking about stored energy while Willis is talking about the atmosphere.
Also during the ice ages, it is more about the inability of heat to move poleward that causes “el nino” like conditions. The tropics where most certainly every bit as warm as they are today, but because of Willis’s theory no warmer.
But that is exactly my point real bob!
Willis refers to the average air temperature and I am arguing that the global air temperature is it not the correct measure of the entire earth system’s energy balance.
Thanks, Jim. The “entire earth system energy balance” is not what the current kerfluffle is about. It’s about the increase in the surface air temperature, which people claim is a “crisis”. So yes, I’m discussing global surface air temperature.
For example, much is made of the “earth’s energy imbalance” warming the ocean. But over the last 67 years, the top 700 meters of the ocean have warmed by 0.3°C. And were it not for scientists doing very careful measurements, nobody would even know that happened. Why? We don’t live under the ocean.
So yes, I am talking about global air temperature.
w.
And that’s my criticism. The global air temperature should not be equated to the earth’s energy imbalance!” People are fooled into thinking there is a climate crisis be incorrectly focusing on global air temperature and not understanding the dynamics driving it.The temporary atmospheric warming caused by an El Nino should be reported as a “cooling of the earth’s climate system” as ventilating heat just temporarily warms the atmosphere. It should be reported that La Nina retains energy and affects the energy imbalance by increasing the earth’s energy storage but the ocean warming has been falsely attributed to CO2 caused retention.
I would say more people are fooled into thinking there was ever an energy balance on earth. Northern oceans north of 20N have been getting higher solar intensity since J0000. Now up 2W/m2 since it reversed to warming and another 15W/m^2 to go before it reverses again in 8000 years.
I have seen ridiculous statements that if you start climate models with any starting conditions at 1850, they will arrive at accurate state now. As if there was no climate change before 1850.
Earth is very close to peak melt. Greenland is gaining land ice extent and elevation. Iceland is gaining ice extent and elevation. The larger land masses still have retreating permafrost but snow fall is increasing.
Snowfall on land north of 40N will increase 60% over present level by 2250.
Willis is correct that all the believers bother about is average air temperature increasing.
January temperature on land north of 40N is increasing at 3.7C per century. Way above the global avcerage and is why snow is ramping up.
Surface temperature for oceans north of 20N are increasing at 2.9C per century in August. That shows how rapidly the heat is rising in the Northern oceans that feed the winter advection to land, driving the increasing snowfall.
The modern interglacial will come to a rapid end as it did in similar circumstances four times over the last 500k years.
Jim Steele:
You say “the temporary atmospheric warming caused by an El Nino…”
This does not happen.
Since ALL El Ninos are caused by decreased SO2 aerosol emissions into the atmosphere, the whole Earth is simultaneously being warmed,NOT just the ENSO region
Once again, thanks. Could you provide links to a few of the other studies that disagree with the “most studies”?
After some trouble I found the source of your graphic. I got the underlying reanalysis “data’, and have duplicated the graphic.
The graphic does say that where the La Nina occurs off of Peru the ocean is absorbing extra energy. The part you didn’t highlight is that it also says that where the La Nina pushes the warm water along the east coasts of the continents, the ocean is absorbing less energy … it’s unclear what the net of the two is.
Regards,
w.
This is due to the rise of low clouds in the cool air in the southeast Pacific.
True … and the net of them is essentially zero. In part this is because while heat flux is high in the La Nina areas, it’s low where the La Nina pushes the heat, along the coasts of Asia, North America, and Australia. Push one up, and you push the other down.
w.
Sure over many years it’s close to zero but a small net difference could lead to warming or cooling on decadal or centennial scales. The blue areas you point out are the last cycle of ocean heat dissipating, the red La Nina area is recharging OHC for the next cycle. The La Nina conditions are causing an increase in the solar energy input into the oceans.
The balance of the two is what produces “trends” and it is not really zero.
This is what Bob Tisdale pointed out something like 15y back.
There are a whole raft of different thermal responses.
One thing for sure is that it is very difficult to warm deep ocean from surface imbalance.
And another certainty is that earth’s climate has never been and never will be in thermal equilibrium. To think that the climate did not change until humans started burning fossil fuels is so silly it is way beyond ridiculous.
If climate models were useful they would have identified the current warming as the termination of the modern interglacial in similar circumstances as occurred 4 times in the past 500kyr; almost identical to the termination of the interglacial 399k years ago.
I have two serious issues here. First, this sequence of events appears wrong to me. When warm water reaches the west coast of South American during an El Nino it proceeds toward higher latitudes north and south. When I lived on the Washington coast during the 1998 el nino it was many months later for the warm surface water to reach us. It came from the south and brought all sorts of anomalous fish along with it.
Second, there is no way a person can discuss this event without bringing very long wavelength ocean waves into the picture. This is an event involving internal waves.
Finally, the analysis should begin with the source of energy, which is a long period of solar input into the warm pool of the southwest Pacific, and converging air flow. When trade winds lessen the resulting thickened pool of warm water is no longer stable and breaks out as a internal wave eastward.
Effect of Super El Niño 1997-98 in CA and the PNW:
https://www.nps.gov/articles/1997-1998-el-nino-1998-1999-la-nina.htm
Willis: “—in response to the slow gradual warming since 1980, we have more La Nina conditions cooling the planet.
Q.E.D.”
In what way is La Nina supposed to be cooling the planet? The colder surface waters means less thunderstorms : the emergent phenomina which take heat from the oceans and up to the tropopause. La Nina is rather the input phase of the cycle, with clearer skies, where solar energy in INPUT into the tropical Pacific. El Nino, when the hotter waters of the WPWP spread out across the tropics, causes more thunderstorms and is the phase when the ocean heat content it tranported to the atmosphere, on its way to space. That is the cooling phase in terms of energy budget.
IIRC, that was Bob Tisdale’s contribution. That this “cycle” is the input and output phases of heat entering and leaving the system and it is the frequency and duration which allows heat energy to accumulate or escape from the planetary system. That was quite insightful for someone with little scientific training.
Many people with a trivial understanding of the process see El Nino as causing “global heating” because it leads to a temporary increase in mean surface temperature but this just by a spreading out of the warmer waters of the WPWP, spreading out does not represent a change in OHC in itself. Ultimately it does lead to a COOLING since OHC is transfered to the atmosphere.
Maybe you could explain in what way you consider that La Nina is cooling the planet.
I think it’s the atmosphere not the entire system that is being discussed here
In the 80s and 90s there were two major eruptions which caused several years of reduced solar input to the lower climate system. The positive El Nino conditions represent deeper OHC flushing heat out to ocean surface and into the atmosphere to compensate ( negative feedback control ).
Since the strong El Nino of 1998, there have been no large atmospheric disruptions and the generally more La Nina conditions have been recharging the OHC energy store of the planet.
YHGTBSM!
VEI 4 & 5 eruptions since 2011. I’ve experienced quite a few of these myself.
VEI 5:
https://en.wikipedia.org/wiki/Hunga_Tonga%E2%80%93Hunga_Ha%CA%BBapai
https://en.wikipedia.org/wiki/Puyehue-Cord%C3%B3n_Caulle
VEI 4
https://en.wikipedia.org/wiki/Semeru
https://en.wikipedia.org/wiki/Fukutoku-Okanoba
https://en.wikipedia.org/wiki/La_Soufri%C3%A8re_(volcano)
https://en.wikipedia.org/wiki/Taal_Volcano
https://en.wikipedia.org/wiki/Ulawun
https://en.wikipedia.org/wiki/Raikoke
https://en.wikipedia.org/wiki/Volc%C3%A1n_Wolf
https://en.wikipedia.org/wiki/Calbuco_(volcano)
https://en.wikipedia.org/wiki/Manam_Motu
https://en.wikipedia.org/wiki/Kelud
https://en.wikipedia.org/wiki/Mount_Sinabung
https://en.wikipedia.org/wiki/Nabro_Volcano
Thanks John. I was watching a documentary about Hunga Tonga a couple of weeks back. I intend to go and look at its effect on TLS and opacity ( AOD ) to see how it compares to Mt P.
I don’t think any of the others are comparable.
It was titanic. Its scale was not initially appreciated as semi-submerged.
John Tillman:
The Smithsonian rated it as a VEI5. However, it injected only 0.2 Megatons of SO2 aerosols into the stratosphere, compared to ~20 Megatons for Pinatubo, so its global climatic effect will be no more than that of a VEI4 eruption.
(Have you noted any red sunsets recently, as I and my brothers 400 miles away have? They are due to Tonga’s SO2 aerosols settling out of the atmosphere).
I have had a quick look previously and any direct link to global atmospheric temperatures was not obvious, unlike the El Chichón (1982) and Pinatubo (1991) eruptions, but we probably need more data. In any event, the fact that it was submerged could effect the temperature outcome. I have a graph showing the relationship between UAH global temperatures and ONI together with the two major eruptions, but I need to tidy it up first (add labels). Should be able post it later today.
Sorry, run out of time for today. Will add timing for Hunga Tonga–Hunga Haʻapai eruption (Dec 2021-Jan 2022) and post tomorrow. I also want to look more closely at Allan MacRae’s latest comment first.
OK, here are two plots that may be of interest. The first one simply shows the timing of the three major eruptions under discussion. The cooling of UAH global atmospheric temperature anomalies coinciding with El Chichón (1982) and Pinatubo (1991) eruptions is clearly evident. Based on the current data, I do not see the same response (as yet) from the Hunga Tonga–Hunga Haʻapai eruption (Dec 2021-Jan 2022), not least because the drop in global temperatures occurring just before the eruption fits nicely with a La Niña event. Indeed, the comparison between ONI and UAH shown in the second plot highlights where UAH deviates from ONI, i.e. it illustrates where UAH global temperature anomalies are not primarily related to ENSO events (which is quite rarely).
(For directly comparative purposes with ONI, the UAH data have been de-trended, averaged over three months and the delay of about 4 months between them removed.)
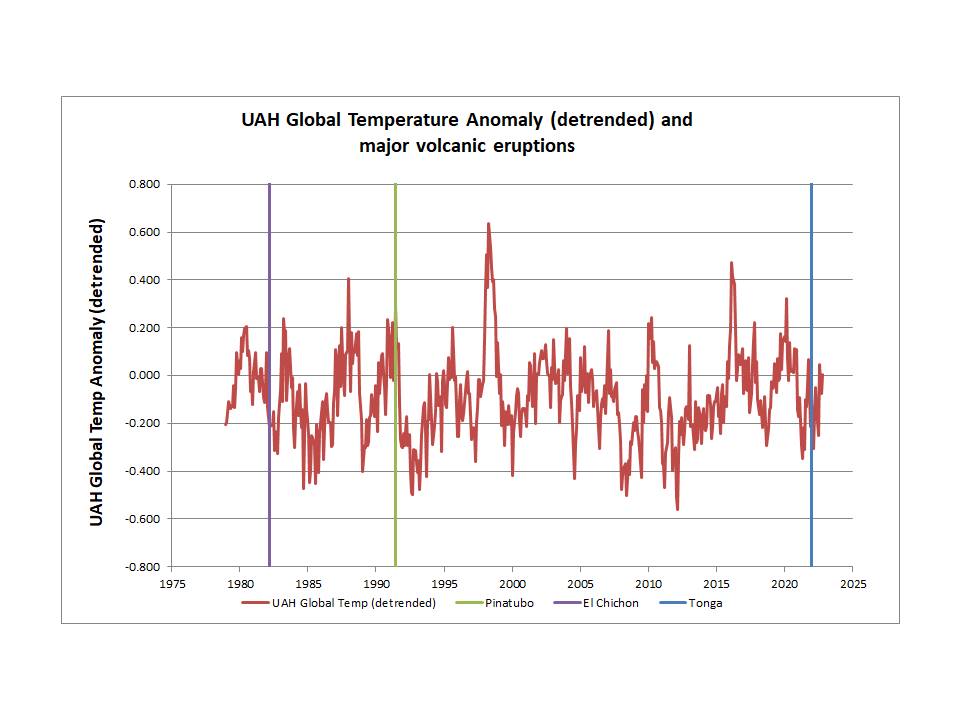
It must be Climate Change (TM).