Nature Communications volume 10, Article number: 3870 (2019) | Download Citation
While the crisis of statistics has made it to the headlines, that of mathematical modelling hasn’t. Something can be learned comparing the two, and looking at other instances of production of numbers.Sociology of quantification and post-normal science can help.
While statistical and mathematical modelling share important features, they don’t seem to share the same sense of crisis. Statisticians appear mired in an academic and mediatic debate where even the concept of significance appears challenged, while more sedate tones prevail in the various communities of mathematical modelling. This is perhaps because, unlike statistics, mathematical modelling is not a discipline. It cannot discuss possible fixes in disciplinary fora under the supervision of recognised leaders. It cannot issue authoritative statements of concern from relevant institutions such as e.g., the American Statistical Association or the columns of Nature.
Additionally the practice of modelling is spread among different fields, each characterised by its own quality assurance procedures (see1 for references and discussion). Finally, being the coalface of research, statistics is often blamed for the larger reproducibility crisis affecting scientific production2.
Yet if statistics is coming to terms with methodological abuse and wicked incentives, it appears legitimate to ask if something of the sort might be happening in the multiverse of mathematical modelling. A recent work in this journal reviews common critiques of modelling practices, and suggests—for model validation, to complement a data-driven with a participatory-based approach, thus tackling the dichotomy of model representativeness—model usefulness3. We offer here a commentary which takes statistics as a point of departure and comparison.
For a start, modelling is less amenable than statistics to structured remedies. A statistical experiment in medicine or psychology can be pre-registered, to prevent changing the hypothesis after the results are known. The preregistration of a modelling exercise before the model is coded is unheard of, although without assessing model purpose one cannot judge its quality. For this reason, while a rhetorical or ritual use of methods is lamented in statistics2, it is perhaps even more frequent in modelling1. What is meant here by ritual is the going through the motions of a scientific process of quantification while in fact producing vacuous numbers1.
All model-knowing is conditional on assumptions4. Techniques for model sensitivity and uncertainty quantification can answer the question of what inference is conditional on what assumption, helping users to understand the true worth of a model. This understanding is identified in ref. 3 as a key ingredient of validation. Unfortunately, most modelling studies don’t bother with a sensitivity analysis—or perform a poor one5. A possible reason is that a proper appreciation of uncertainty may locate an output on the right side of Fig. 1, which is a reminder of the important trade-off between model complexity and model error. Equivalent formulations of Fig. 1 can be seen in many fields of modelling and data analysis, and if the recommendations of the present comment should be limited to one, it would be that a poster of Fig. 1 hangs in every office where modelling takes place.
Fig. 1
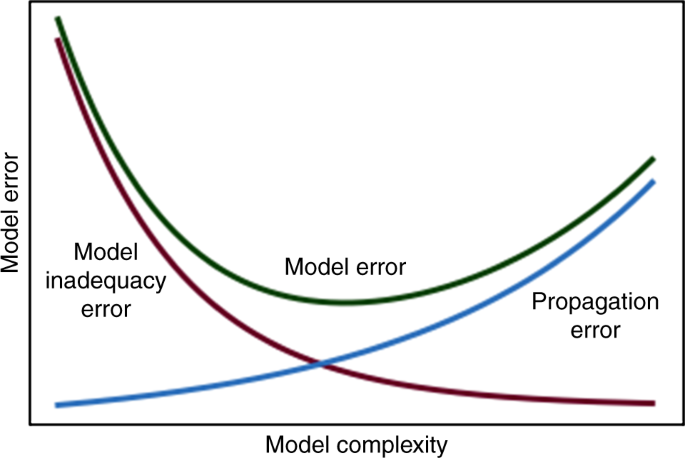
Model error as ideally resulting from the superposition of two curves: (i) model inadequacy error, due to using too simple a model for the problem at hand. This term goes down by making the model more complex; (ii) error propagation, which results from the uncertainty in the input variables propagating to the model output. This term grows with model complexity. Whenever the system being modelled in not elementary, overlooking important processes leaves us on the left-hand side of the plot, while modelling hubris can take us to the right-hand side
Sadly, I’m not smart enough to understand what, if anything, this means: “A recent work in this journal reviews common critiques of modelling practices, and suggests—for model validation, to complement a data-driven with a participatory-based approach, thus tackling the dichotomy of model representativeness—model usefulness.”3
Well said. Sadly the academic paper not well said.
Agreed. The over use of flowery language immediately suggested to me that the author has nothing of value to say and probably understands even less about the subject.
michael hart, et al.
Bear in mind that Saltelli was born in Rome. Can you write fluently in Italian?
So? Use a native English speaker copy editor. It should not be beyong the resources of Nature
They called it arm waving where I got my training.
Agreed, this sentence is completely unclear.
The paper itself, though, is quite simple and clear. The point its making will be familiar to anyone who has lived through the process of business case evaluation on some very large proposal involving big investments with possible future payoffs from new market developments.
An example was the auctions of radio frequencies during first the dot com bubble. All the mobile operators constructed enormously detailed spreadsheet models which attempted to assess how much it was worth paying for the different frequency groups. They were absolutely huge, full of the equivalent of ‘go-tos’, and because of this turned into black boxes.
As the paper suggests, the more detailed they got, the more specific the inputs they required, and the less clear it was how plausible the overall assumptions were as a set.
As an example, you could do a one page model in which revenue per customer and numbes of customers was an assumption. Then at least you could argue about whether this was plausible given what we presently observe about consumer behavior, you could argue about whether the necesary changes in society which would justify a given assumption would come about, and in doing so you would tease out the pros and cons and risks and uncertainties.
In the models as constructed, these assumptions were deeply buried and were themselves derived from lots of other detailed assumptions by complex calculations, so management found themselves, without intending to or realizing what had happened, arguing about the merits of the model. The question under discussion stopped being whether a given revenue per customer assumption was plausible and what in what sorts of futures it would happen, and became whether revenue per customer could plausibly be predicted from a whole heap of other micro assumptions.
In the end, under time pressure of an auction, management typically gave up, accepted the models, reassured themselves that so much detail must mean thoroughness and accuracy… and grossly overbid to an extent they never would have done if it had been a one pager which forced them to think for themselves about the key variables.
This was what the author describes as the increase in error propagation as a function of complexity. What management failed to grasp was that each detailed assumption had a margin of error, and the more of them you had to make, the greater the total uncertainty, since the error of each one propagated through the system.
Pat Frank made a similar point about the detailed climate models that policy makers are using to justify very large investments and huge public policy proposals. Its much harder with climate of course, because you cannot simply look at it and ask in the same way whether we really believe that in five years time this many people will be spending this much a month, or whether we really believe that network cost is going to fall at a given rate to given levels.
But you have the same underlying phenomenon, when you add detail you do not add certainty, nor do you add usefulness to the policy makers who have to decide. On the contrary, you give them a spurious feeling of confidence and you obscure the key driving variables which they ought to be thinking about.
I once quite early on in my practice saw this effect at first hand on a micro scale with a model I had constructed, and it served as a red flag to me. A group were trying to decide what to do with a service. To try to help them, I noted what they thought the drivers were and put them into a fairly simple spreadsheet. But, it did make assumptions which to them were black boxes, in the form of experience curves, the shape of which which you set by entering parameters.
To my surprise and dismay (I was very young then….) they did not engage with the curves and their drivers, which they couldn’t get their heads around at all, they just accepted the outputs given my preliminary assumptions as gospel. After all, they were generated by a computer!
It was a very valuable lesson. But of course, you had to be paying attention in order to hear what it was telling you. In most modelling processes there is no-one listening to this kind of thing. My impression is this applies to climate as much as to business modelling.
Very true, my experience was similar. When young, I built a model of a large mining investment, and then made it much larger by breaking down cost elements. My boss looked at it and hystcssud it was “spuriiously accurate”. Making lots of assumptions didn’t add anything whatsoever.
Since then I have always made my assumptions as explicit as possible, and after I had modellers working for me, insisted that the asumptions used are clearly stated upfront.
But still the majority of models I see are opaque.
“Make everything (models) as simple as possible … but no simpler” Albert Einstein. I make missiles and am a prolific user of detailed simulations. A spreadsheet calculation almost always gets you within 10% of the answers and the trends. If the complex simulation says otherwise … it is almost always wrong.
“After all, they were generated by a computer!” And, if they were created by a “scientist”, you have double certainty!!
As a business man in the early days of computer spreadsheets we built several models (cash flow analysis) for every new endeavor or significant change in procedures.
The computer enabled us to make predictions based on a wide range of variables. I found that models using moderate and most likely assumptions were quite accurate in predictions for a year or two. Usually we extended them out to five years but in my experience they often varied so far from reality as to be practically useless by that time
They were useful for short terms because even those using worst case assumptions allowed us to build in a certain level of insurance or “what if” plans. We were also better able to recognize real world situations that could lead to disaster.
The point is that they were rather useless for long term prediction and needed constant adjustment to conform to real word developments.
The idea that we can use models to predict the climate in 100 to 200 years is ridiculous beyond belief. Their best use is to identify probabilities and possibilities in the short term to allow for some level of preparedness. Any inputs will be far too variable to allow for mitigation.
I hope this has been a little clearer than the sentence referred to above
model validation comes in many flavors;
Quantitative approaches tend to focus on validation against observed data
( model representativeness) Qualitative approaches ( sometimes used in decision
sciences) can tend to focus on usefulness and involve stakeholder participation.
on one hand you can have a model that is accurate but useless
on the other hand one that is useful ( for policy makers) but not very accurate.
An example of a accurate but useless model is a model that takes time T to compute
and answer that is required by the user at time T-x. accuarte but too late or complex
to give an answer when the customer needs it.
the suggestion is you need both approaches
the suggestion is you need both approaches
Reminds me of Segal’s Law: “A man with a watch knows what time it is. A man with two watches is never sure.”
Mosher
The goal should be to construct an accurate model. If it is accurate, then there is high confidence that the physics is correct. If the problem is speed, then ways can be found to increase the speed through coding optimization or specialized hardware. Another possibility is to degrade the accuracy, to increase the speed, in ways where it is known how the output is affected. A sensitivity analysis will show which parameters/variables have the least impact on accuracy and/or the greatest impact on speed with known degradation of accuracy. You then end up with your “not very accurate” model with controlled degradation. That is, it fails in what is often called a ‘soft’ manner rather than in an unpredictable, catastrophic way that requires artificial constraints. Pat Franks has shown that a ‘Black Box’ GCM can be emulated with much simpler model, which will run faster. But, first, one has to be able to demonstrate that the Black Box can be trusted, which is problematic.
With an alternative model developed independently that is “not very accurate,” it may not be known why it is inaccurate. So, unless it is a simple bug that can be located and fixed, the “not very accurate” model is less than useless. It may mislead policy makers, thus wasting money and imposing social changes that are not only useless, but counterproductive.
So, rather than developing both approaches independently, I think that the preferred method is to try to develop something that is shown to be fit for purpose, and if necessary, degrade the accuracy in a controlled manner.
Stokes’ remarks about testing for out-of-bounds values and then introducing a ‘fudge factor’ or resetting the output is too subjective and indicates that the models are not truly fit for purpose, even if they do run in a reasonable amount of time. If the outputs are ‘running off the rails,’ it is an indication of problems with the physics or the uncertainty of the measurements of the input variables. If it keeps running out of bounds in the same direction, that should be a clue that there is a systematic bias in the model.
“Dave Burton October 25, 2019 at 10:22 pm
Sadly, I’m not smart enough to understand what, if anything, this means”
Me neither
Reads like gobbledeegook.
The whole article does
My understanding is that one uses math modeling to state a testable implication of theory. Once that is done, we can use statistics to test the theory. Statistics is not a fashion statement but a procedure to test theory (testable math models of theory) against data. That’s the way I understand it anyway. See for example:
https://tambonthongchai.com/2019/09/04/correlation-analysis-co2-lags-temp/
a famous guy once said that if you can’t explain something simply then you don’t really understand it.
I remember a professor saying this to the class and I wanted to stand up and say what bull shit that was. I don’t think in my spoken language and speaking is a layer of translation (of thought) that often is quite difficult to match up on complex topics. I of course said nothing because I have a terrible stutter. I spent most of my life not talking due to that stutter. Which could have something to do with why my speech is not directly connected to my thought.
it is clear if you know modelling and READ THE CITATION
“model validation comes in many flavors;
Quantitative approaches tend to focus on validation against observed data
( model representativeness) Qualitative approaches ( sometimes used in decision
sciences) can tend to focus on usefulness and involve stakeholder participation.
on one hand you can have a model that is accurate but useless
on the other hand one that is useful ( for policy makers) but not very accurate.
An example of a accurate but useless model is a model that takes time T to compute
and answer that is required by the user at time T-x. accuarte but too late or complex
to give an answer when the customer needs it.
the suggestion is you need both approaches
“Me neither Reads like gobbledeegook.”
A lot of the message is embodied in figure 1. If your model is too primitive, it’ll probably be wrong because you left important stuff out. If the model is too complicated, it’ll probably be wrong because errors in your guesses about things that don’t really matter make your answers worse than they should/could be.
I don’t disagree although I think in many(probably most) cases the left hand curve should be steeper. Most stuff is driven by only a few major variables. Get them and their relationships right and you’ll probably get about the best result possible.
He means theory-driven models – like the greenhouse gas effect – can only be validated against data; otherwise they are useless. “validated against data” – means each model prediction must be observed in reality, under the same conditions (as the model).
This is published in Nature Communications where criticism of mathematical models and thought experiments such as the greenhouse gas effect is heresy. So he had to hide the meaning so as not to upset TPTB.
err NO.
the sentence has a citation. read the citation if the text is above your head
https://www.nature.com/articles/s41467-018-07811-9
I agree, it sounds like postmodern bafflegab.
Sometimes a picture is worth a thousand words. As far as I can tell, Fig. 1 nicely sums up the problem.
Healthcare modeling executive here, and what I think the author is getting at is the tendency for mathematicians to use all data they have access to if it has any correlation at all, without understanding what physical process the data represents (and thus having no theory of how it might matter).
As an example, a few years ago we built a model predicting billing error – the target was: is this claim over billed? In doing so one of the early version included a “CGUID” field….. which my data scientists didn’t realize was a claim globally unique identifier…. which we created during claim import from the insurance companies as a randomly assigned number. It just so happened that a random number generator matched up with over billing, and in such a way that it was mechanically impossible to actually be causally linked
Because my practice has (since a similar mistake early in my career) always been to include data engineers and context experts (doctors and nurses, in this case) we were able to weed that out early on.
What the author is getting at (I think) is that without the proper context for the data and the underlying process, a modeler is likely to include things (like random numbers) that can’t be causal, just because they’re not domain experts, so the best practice is to include people who can judge the usefulness of the model based on its underlying components.
Not being at atmospheric scientist, I’d guess that would include a lot of physicists, but others here would know.
I think it means that when your model doesnt match reality, you have to verbally abuse anyone who points this out, whilst waving flags
@Dave – try this: “A recent work in this journal reviews common critiques of modelling practices, and suggests—for model validation—to complement a data-driven with a participatory-based approach, thus tackling the dichotomy of model representativeness / model usefulness.”
The use of punctuation for clarity has not been taught for at least the last fifty years, in my experience. I was fortunate in that, in high school, I ran up against a Vassar graduate (a 1930s alumni, not one of the more recent ones) that believed even a male product of the public school system could be reformed.
(I’m also not adding “representativeness” to the spell checker. For once, it is right. That really should be “correctness.” But that is a somewhat smaller nit to pick.)
Remove this part and it suddenly makes perfect sense and is perhaps what the author is saying “common critiques of modelling practices, and suggests—for model validation, to complement a data-driven with a participatory-based approach, thus tackling the dichotomy of model representativeness—”
If the author’s ability to use math/statistics to enlighten a situation is as clear as his use of the English language, he might consider another line of work.
Glad you said that. I have no idea what she is talking about and I work in this field. A lot could be said about statistics and mathematical modelling, but she didn’t say it.
Correlation is not causation.
If the predictions don’t match observations, its wrong.
Very interesting. I’m looking forward to reading Nick Stokes’ remarks, should he make them. He always has something enlightening to add to the conversation.
I think the paper is waffly, and obviously itself quite unquantitative. It mainly seems to be a recommendation for sensitivity analysis, which is fine. But there is unsupported stuff like this:
“(ii) error propagation, which results from the uncertainty in the input variables propagating to the model output. This term grows with model complexity.”
It just isn’t necessarily true. A lot of complexity is created by a need to better constrain the output. That also reduces error propagation. A recent example was where a physics-free model was used to estimate error propagation in GCMs. An uncertainty region was then quoted which a more complex model would have unequivocally rejected due to conservation principles.
Where is the author’s sensitivity analysis of his Fig 1?
its model of modelling is rather simplistic
Like all statistical models
But it is rather instructive.
State of the climate AO models from the climate modellers themselves claim their work is as complex as any today running on Supercomputers. (Hubris some yes, but with so many DoFs and time steps and grid cells… probably)
Q: So what does Figure 1 say about Propagation error(s) as complexity increases?
A: Asymptotic.
Conclusion: Output to 80 years forward for GSMT to +/- 1 K… utterly useless. Actually worse than useless since they then are tuned to get what the modellers expect. Misleading junk.
The entire Climate modelling field is pure pseudoscience trying to model GMST under any GHG scenario to 2050. ..2100 etc…
And folks trying to defend that only identify themselves as defenders of junk.
Why do you defend junk climate model science Mosh? Is it the money? The paycheck?
Far from simplistic, it is very general, therefore applicable to all models.
In response to Nick’s comment above, the paper isn’t so much looking for something as limited as a sensitivity analysis, although it does mention this issue. More, it is looking for some integrity to be built into models, eg by documenting the objectives and success criteria (my words, not the author’s) in at the start.
Steven and Nick: I think the article is intended to be broad brush not detailed. Detail would probably take many volumes. For example observe that Figure 1 is certainly domain specific. Some problems will skew far to the left — you only need to evaluate a few variables to get a useful result and more variables just add useless precision or maybe even introduce errors. On the other hand, some problems will skew far to the right. You need to know a lot of stuff to get a useful result. I think the Figure is merely intended to convey a sense of what the authors are talking about..
Nick, I think the underlying point is quite a serious one. Its that as the assumptions become more numerous and more detailed, the uncertainty does not necessarily reduce. Though it does become less visible.
And therefore, if you are a general manager looking to use the thing, you feel more confident because its so detailed, when actually you should be feeling less because you can’t any longer rely on or debate your intuitions about the key large variables driving the business case.
Someone who has been in a business for years, making mistakes and getting things right about consumer behavior, will have an ability to argue his way through assumptions about that. Bury this as an output of a twenty deep spreadsheet model of great detail, half of which is written in VB by non-programmers, and he will find himself unconvinced, baffled, unable to argue, and finally going along with something he knows in his heart to be nonsense.
Seen it happen.
Good comment.
Michel: “and he will find himself unconvinced, baffled, unable to argue, and finally going along with something he knows in his heart to be nonsense.
Indeed. If you ever come across a copy of C Northcote Parkinson — “Parkinson’s Law ” read his description of “Parkinson’s Law of Triviality” https://en.wikipedia.org/wiki/Law_of_triviality There’s a description of a Committee meeting where a contract to build a nuclear reactor is settled in two and a half minutes because it’s one member’s pet project and the only other member who understands anything about it thinks his objections will not be understood. The other agenda items — money for a bicycle shed and funding for refreshments are debated endlessly.
Parkinson’s Law is a VERY funny book.
“A lot of complexity is created by a need to better constrain the output. That also reduces error propagation.”
Adding complexity can reduce the spread in the model results (aka precision). This does not automatically reduce the gap between reality and the model results (aka accuracy or trueness).
That is why a propagated calibration error using an emulator can be much larger than the spread in an ensemble. In that case it is a hint the complex model has some aspect of the system wrong (or missing). It also hints the added complexity probably was not needed.
“In that case it is a hint the complex model has some aspect of the system wrong”
You made a simpler model which ignored various things, and disagreed with the complex model. That doesn’t suggest the complex model is wrong. It suggests you ignored things you shouldn’t have ignored.
+10!
Kind of like how a simplified model of natural gas infrastructure could lead one to thinking that rural areas actually have natural gas piped to their homes or where spatial distribution averaging can mislead policy makers into thinking Alice can go down that hole and can show up 100 miles away with a smile on her face.
https://wattsupwiththat.com/2014/01/07/canceled-carbon-footprint-savings/
And the complex UN IPCC climate models give us a tropical tropospheric “hot spot.”
(Sorry for late reaction. RL got in the way.)
You can’t assume a complex model is always better than a simple model. It is always possible some of the added parts are wrong in some way. That could vary from a simple programming error up to errors in the underlying theory.
As a general rule: the results of a simple model are optimistic compared to a complex model because the simple model leaves out certain aspects (constraints). Of course you need some expertise to judge what is optimistic in the relevant context.
Pat Franks results using an emulator for one aspect only, already shows a much wider range of uncertainty than the complex models. That makes me scratch my head. IMHO it should be analysed in detail how that difference arises before the complex models can be declared ‘fit for purpose’.
Nick, “You made a simpler model which ignored various things, and disagreed with the complex model. That doesn’t suggest the complex model is wrong. It suggests you ignored things you shouldn’t have ignored.”
Rather, the simpler model began with the same assumptions driving the complex models and gave results in agreement with the complex models.
It then used a resolution lower limit of the complex models — one ignored by the modelers, — to show that the complex models produced spuriously constrained results.
Nick is still trying to defend the CGMs by implying their inputs have no uncertainty and their outputs have no uncertainty. The CGMs come out they way they do because of all the uncertain inputs and all the uncertain assumptions used in the models. They don’t blow up because of all the fudge factors used to keep them from blowing up.
Your thesis shows that just ONE uncertainty is enough to show the output of the CGMs are not reliable. And Nick still can’t accept that.
So using a greater number of uncertain assumptions doesn’t create greater uncertainty? Oh because you artificially constrain the outputs by “knowing” the answers. Right, that works.
Talk about fooling yourself.
If you know the range the outputs can fall in in the real world, then that’s your answer. The additional complexity in the model is adding nothing whatsoever. I can forecast next quarter’s GDP growth with a vastly complex model of all the things that make up GDP growth, or I can say it will be between minus 0.2% and plus 0 2%. The latter will be just as accurate and much, much quicker.
Nick Stokes <== You didn't disappoint!
What was the example of the "physics-free model"? I'm really curious about that one.
Over the years, I've done both modeling and model evaluation, mostly in flight dynamics of space launch vehicles, reentry vehicles, and spacecraft, but also in propulsion and gas dynamics. The number of factors impacting model accuracy is far, far larger than people realize.
The first computer I ever used with a keyboard and a screen was a PDP-11 that my major professor had bought on our program back in 1979. It was a 16 bit machine with 32 k memory, and two 8-inch 512 k floppy drives. It came with a Fortran compiler that used, IIRC, the Fortran 66 standard. In my gas dynamics class, we had a problem involving both Rayleigh and Fanno line flows in one situation. We were supposed to use the Purdue computing center CDC machine to solve it, but I used the PDP because it was in the lab where I spent my life. On top of that, I realized that the problem could be solved analytically, and exactly. That was half of the solution I provided. The other half was the output of a numerical integration on the PDP-11, using fourth-order Runge Kutta (which was actually to whole point of the homework assignment). This was a time-dependent problem, no less. I was astonished to see that the numerical solution quickly diverged from the analytical solution. I went back into my source code and set all of the flow variables to double precision. The results diverged a little more slowly, but ultimately blew up.
Appending time-step controls and "error correction" delayed the blow-up a little, but never matched the analytical solution (which, btw, I was able to prove). I never did run the code on the computing center's CDC 6500 computer, which featured Minnesota FORTRAN (and I think had a 32 bit architecture) – I suspect the results would have been much better. But still, a 16 bit computer running double precision Fortran should have been better, IMHO.
Looking back, I have to wonder how much coding error had to do with my results. No one ever did IV&V, and despite my best efforts at iteratively debugging the code, I could never have guaranteed that it was 100% correct. Climate models are vastly more complex than my little 1-D unsteady compressible code was, but I'll be willing to bet that they have never been through IV&V. The number of errors that can be introduced just by normal coding goofs is enough to make an honest programmer lose a lot of sleep.
When I was at DARPA, I spent a lot of time with the software people who had a program going with Microsoft (and others, whom I can’t recall), to establish a framework for mathematically proving that a) software source code performed only the tasks (and no others) specified for it, and b) that compiled code retained that its integrity. If DARPA doesn’t screw it up, it should become a standard for the software industry. And it will undoubtedly reduce the number of errors in big models, without having to submit them to the much more subjective process of IV&V.
“What was the example of the “physics-free model”? I’m really curious about that one.”
He is referring to this one :
https://wattsupwiththat.com/2019/10/15/why-roy-spencers-criticism-is-wrong/
On one of those threads related to Nic Lewis’ paper, Nick referenced GFDL, which according to NOAA’s own website, “…as long as the (atmospheric) layer thickness is positive, the model retains stability…”
As far as I can tell, your discovery was similar to that of Edward Norton Lorenz. He was modeling weather and also discovered that the climate is chaotic.
Michael,
I used a CDC 6600 at Adelaide Uni. It was the same as the 6500, but more powerful. This was a supercomputer in its day, processing 10 million instructions per second. It had 60 bit words, with 18-bit address registers. 17 bits were actually used, which means that it could have 131,000 words of memory.
It was a wonderful architecture, very reminiscent of the RISC architecture that came later. Of course, these days you have more powerful computers running your car.
Purdue’s last big computer purchase (that I’m aware of) was a Cyber 205, which had an “astounding” 4 million words of memory (64 bit words, so 32 megabytes), and could perform 800 million floating point operations per second. I was working at TRW Ballistic Missiles Division at the time, and started an IR&D project to produce a computer model to predict the side forces on nozzles during ICBM staging events (produced by shocks reflected by the lower stage forward dome travelling that tilted as they propagated back upstream). It was a 3-D unsteady problem, but the total time involved was only around two hundred milliseconds.
I subcontracted the effort to my former Purdue fluid mechanics professor, Joe Hoffman. He was one of the pioneers in CFD, and was fairly confident that the problem would be tractable given the enormous power of the Cyber 205.
It wasn’t. Even using a Sandia Labs SALE 3-D code, the problem was simply beyond the capability of the Purdue mainframe.
I’m typing this on an HP laptop that has 8 gigabytes of RAM, a terabyte hard drive, and benchmarks at about a gigaflop with compiled FORTRAN. It also cost $500 at Costco. Back in the Cyber 205 days, RAM was $1 per kilobyte, so just the memory of my machine, if it could be had at all, would have cost $8 million.
I wouldn’t attempt to write a staging side force model on it. The problem is too hard, still.
Back then, Michael, who predicted an analogue to your (inferior, IMO) HP laptop? Now, predict the exact climate and world-wide economy 80 years hence.
Michael S. Kelly LS, BSA Ret.
You asked, “What was the example of the “physics-free model”?” It was a snide ad hominem aimed at Pat Franks.
I seriously doubt that you had a coding error.
You ran into the two irreducible problems with numerical integration; truncation errors and trajectory errors. From the story you obviously understand both problems; converting to double precision numbers reduces truncation errors and time step controls (shorter step sizes where rate of change of the slope is high) help with trajectory errors. Both of these approaches help limit the problem, but cannot eliminate the problem.
Yours is an excellent cautionary tale for anyone doing numerical simulations. If a numerical simulation is run long enough truncation and trajectory errors will render the simulation meaningless. It would be interesting to know if the GCM modelers have attempted to estimate the point at which the accumulation of these errors render the GCM results useless, or if they’ve even thought about this.
“A lot of complexity is created by sneed to restrain the output”
I have seen similar things from Nick in the past, and it always gives me pause. To me this means the models don’t give a logical output so the modelers go back in and create a restraint on whatever process drives the model out balance. This what be subject action that ultimately would lead any model to show the desired result not the scientific result, humans either subconsciously or consciously always correct things to support their own beliefs, it only the strongest willed people that can be purely objective. How many of believe that the modelers are objective? There whole lives a dedicated to this one subject. 150 years scientist would move from one idea to the next as each one would pass or fail so objective test, you read story after story of this scientist or that inventor who tried this and it failed and tried that and it failed and they went bankrupt three times but then by luck or pluck they finally hit or something. Today they work for university’s or think tanks who pay for a politically useful outcomes, the less proveble the idea the better.
Bob boder
Stokes’ defense of extant GCMs reminds me of a situation where the autopilot of an autonomous car has to be overridden periodically by the passenger to avoid a crash. Once it is back on the road, it chugs along fine until the next ‘curve’ takes it off the road. God forbid that the passenger should decide to take a nap or read a book. If the AI isn’t reliable in all situations, then it should be analyzed to find out why it isn’t, and fixed.
Relying on overrides to get performance within an envelope of acceptability strongly suggests that the GCMs are not fit for purpose.
And the modelers admit they adjust (tune) various UN IPCC model parameters until they get an ECS that “seems about right.”
Nick. –> “It just isn’t necessarily true. A lot of complexity is created by a need to better constrain the output. ”
The earth’s weather has constrained itself for eons without artificial constraints (at least as far as we know).
Your admission that artificial constraints are used is a tacit admission that the GCM’s are incomplete and/or have errors. Either way THERE ARE UNCERTAINTIES INVOLVED. The constraints you mention do not alter the uncertainties involved, they only hide them.
Jim Gorman
+1
“Your admission that artificial constraints”
The constraints are not artificial. They are the effect of physical laws. Specifically conservation of mass, energy and momentum.
If you have a curve fitting model like Pat Frank’s, it has no such requirement, and can claim that initial error can lead to a wide range of outputs. But a proper model will return only those outputs which satisfy conservation of energy. Solutions which satisfy conservation laws are not greatly perturbed by initial error. Their value is determined by balancing fluxes etc as time progresses.
While we are on this topic, I would like to interject an observation. It has been established that changes in the initial conditions of global circulation models (GCM) of only 1 trillionth of a degree C will result in completely different results over a long integration period. In one online discussion of this a reader (in essence) asked this question: Will two different computers running the same GCM with the same initial conditions produce the same results?
As I recall, Dr. Spencer ultimately responded that yes, of course they would. The questioner then probed deeper and asked if the same computer running a GCM with the same initial conditions would always produce the same results run-to-run. Again Dr. Spencer (if I recall correctly) responded that yes, of course it would, because a computer is a deterministic system, and will always function the same way.
That’s not true. Digital computers have a degree of randomness in their operation, often summarized in bit error rates. A variety of phenomena can result in a single bit of memory to toggle to a value other than the “correct” one. Computers have a panoply of defenses against these in terms of error correction codes. Some are completely bullet-proof, but like any portion of a code, they add overhead. GCMs have so many operations that bullet-proof error correction codes would consume more CPU time than the fluid mechanics calculations themselves. If only one bit error occurred, even in the least significant bit, it could propagate into an entirely different solution from a prior run having all of the same software and identical initial conditions.
That’s a big problem, in my humble opinion.
Nick –> You are the one that used the term”constraints”. That means you are not allowing a solution to go to completion if it volates some law. That means you don’t have a proper interaction somewhere.
Maybe you aren’t using the right term to describe interactions. Constrain does mean artificially limiting a solution to certain values.
Nick writes
And what about the curve fitting models that look physics-ish but just aren’t with respect to cloud implementations in GCMs?
“The constraints are not artificial. They are the effect of physical laws. Specifically conservation of mass, energy and momentum.”
If your models were physically correct to begin with they wouldn’t need “constraints” to keep them from blowing up.
Many years ago I was provided with a model of a complex process that involved 6 measured inputs and required solving 5 simultaneous equations for 5 unknowns. After seeing some rather questionable outputs I dug into the source code and found that it included constraints that essentially set and unknown variable solution that came out to a negative number to 0. This avoided calculation of unphysical intermediate results. But it turned out that the real reason for the negative results was an error in the assumption that some of the measured inputs in the model equation were constants when in reality they were variable. By not figuring this out, the modelers simply introduced a substantial bias into the calculations. I removed the constraints, reran the model and the result was very acceptable agreement to experimental validation data. It was shown that the negative values were compensated for by errors on the high side elsewhere so that the integrated end result was accurate.
Of course the issue would probably not have been discovered if we had not had an independent experimental method to compare model results to.
“due to conservation principles.”
Once again mistaking error for uncertainty. Some people never learn.
Nick writes
I’m not quite sure about which physics-free model you’re talking about but are you suggesting that models (GCMs) cant be created that obey the conservation of energy and yet produce wildly different results based on their assumptions and implementations of climatic processes?
Nick wrote
“It just isn’t necessarily true. A lot of complexity is created by a need to better constrain the output. That also reduces error propagation.”
Error propagation is a process not a thing or a result. The statement above is like comparing apples to eating.
Uncertainties about inputs do not get “reduced”. What you describe as “better constrained” is a limit placed on the output, not a reduction is the propagation of error, or uncertainty if you wish to call it that.
I think you should restate that paragraph more clearly. Uncertainty propagated never reduces. It is an attribute of the answer, even if the answer has been judged impossible and therefore discardable.
The need for additional climate model constraints to limit the impossible answers otherwise generated are not “reducing uncertainty” they are needed because of the inadequacy of the model to represent anything real. The highly uncertain answers are a feature, not a bug.
A climate model “constrained” to show only 6 degrees of global warming for a doubling of CO2 is constrained because left to its own devices and uncertainties it might produce (would?) temperatures of +80 or -80 C per doubling.
Modelers should not get away with claiming their generated outputs are more certain because they have edited out the ridiculous numbers their basic theories and calculations would otherwise produce.
This is not a subtle point. The invalid claim that propagated uncertainties can be reduced by deleting (constraining) the model outputs is rife in the climate science community. It is mathematical BS. Uncertainties don’t propagate to lower uncertainties. If they did, we would not have to make instruments with greater accuracy and precision. But we do (have to).
Climate modelers should embrace the disciplines of science, not just the budgets.
“Uncertainties don’t propagate to lower uncertainties. If they did, we would not have to make instruments with greater accuracy and precision. But we do (have to).”
+1
Nick does not understand the difference between accuracy and precision, therefor he is incapable of understanding the point you are making.
“While the crisis of statistics has made it to the headlines”
Really? No headlines cited. Has anyone seen any?
Plenty. You haven’t?
The statistical crises (plural) exist almost exclusively in the Social Sciences — economics, sociology, and psychology. Much of that is the questionable reported p-values with no reproducibility.
https://www.theguardian.com/politics/2017/jan/19/crisis-of-statistics-big-data-democracy
But then there is that Mann-ian Hockey Stick tortured statistics episode from 15 yrs ago.
There are issues right throughout science – where ever formulaic statistics alone are used to imply causation from correlation. This certainly happens in climate science too.
It’s not only social sciences. Medical science has more than its share of unreproducable studies. Most of them have statistics as their basis.
It’s also in fisheries and ecological models, which are even more complicated because they depend on the climate, natural events too often ignored. One, after a lifetime on the subject, mostly on cold temperate species, concluded that “…science of recruitment does not exist.” What he was saying is that there needed to be so many more assumptions actually measured and that costs. Big problem is matching different life stages.
Cushing, D. H. 1996. Towards a science of recruitment in fish populations. Excellence in Ecology. Inter-Research 7. 175pp.
Tons of papers were published on p-values, for example, where do you live, under a rock?
One of the first was this one: https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.0020124 but many have followed.
“Tons of papers were published on p-values”
The man said headlines! p-values are the same as they always were. They don’t tell you everything, they don’t tell you nothing.
John Ioannidis’ paper is a good place to start for the ‘crisis of statistics (and other things) in medicine.
https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.0020124
It’s not only in medicine. The flaws are general, although some sciences are more affected than others.
Psychology fails badly, for example: https://www.nature.com/news/over-half-of-psychology-studies-fail-reproducibility-test-1.18248
It’s the crisis of bad statistics in science making so much published science today non-replicable, leading to a scientific replication crisis. Statistics, itself is OK; no crisis there. You can read about the statistics community doing something about this by reading what they say. The problem is scientists, educated to a rudimentary level in statistics, using invalid formulaic methods to write nonsense articles = cargo-cult statistics.
Andrew Gelman | Cargo-cult Statistics
Stokes
You are splitting hairs. Inasmuch as Saltelli is Italian, English is probably a second language for him. You might cut him some slack for trying to use English idioms to convey the importance of what is commonly recognized as a significant problem in research. Just because the NY Times hasn’t spread it across its banner doesn’t mean it isn’t important.
“While the crisis of statistics has made it to the headlines”
Really? No headlines cited. Has anyone seen any?
Sure. Here’s one: “On Average, Statisticians Becoming More Mean.”
A key point here:
Statistics usually deals with actual data. With Observations. With Recorded results of physical experiments.
Mathematical model outputs are not data. They are outputs based on what the programmers coded and the input. Nothing more. That is not data of a measure of the real world. Which is one reason why applying model ensemble “means” to climate models (simulations) outputs is an absurd exercise in junk science.
Mathematical models are simulations. Simulations that can have Superman flying around the world with the energy of thought at the Speed of Light to send time backwards and also stopping speeding trains by standing in front of them.
Simulations not grounded in observations are the coders’ fantasy.
I always tell myself …
A model is a small imitation of the real thing.
A model is a symbolic device built to simulate and predict aspects of behavior of a system.
I think that this is a very important call for sanity and independent evaluation according to logical criteria in the whole field of mathematical modelling.
But, because it’s sensible and long overdue, and because there is now extensive reliance on poor practice to generate fame and funding, I fear it will be ignored….
It’s a simple answer.
Statistics cannot be used to model. There is no clearer way to say it.
– You cannot put statistically produced data into a mathematic model and get a correct answer.
– You cannot precisely represent any state or system with statistics.
– You cannot predict past or future with statistics.
– You cannot predict NOW with statistics.
Any claim of “statistical modeling” is fraud from the get-go because applying statistics to anything not only produces unreal numbers, it places egregious errors into the data immediately.
Statistics is a method of analyzing mathematical systems to find their nomic architecture and is ALWAYS inferior to calculus. If you cannot perform calculus on a data set then you don’t have the data set accurately enough to perform any calculations or evaluations.
Statistics, by its very nature, includes ALL the wrong answers from the start. Both in inclusion AND exclusion. It is a method of producing a more readily readable and precisely WRONG representation of an otherwise apparently chaotic system without accounting for ANY of the variables or constants in the data from the real system. It cannot be used to “model” anything and its output is 103% hearsay.
Einstein put it simply , but not too simply – “God does not play dice”.
Now look at Quantum Mechanics, ala Bohr.
But dice always behave like dice, and quite predictably in the long run.
Computer programmers and mathematicians will tell you that the mean value for 100 rolls of a six-sided dice is 3.5. It doesn’t matter if the probability of ever rolling a 3.5 from a six-sided dice is precisely zero. Try and roll a 3.5 at a Las Vegas crap table!
When Prjindigo says statistics includes all the wrong answers he was absolutely correct. No amount of quantum mechanics can ever get a 3.5 roll from a six-sided dice.
“It doesn’t matter if the probability of ever rolling a 3.5 from a six-sided dice is precisely zero. “
Precisely.
Nick,
“Precisely.”
It only shows how divorced from reality you are. I’m still waiting for your answer to the warden.
Next you’ll be telling me that in countries with an average of 1.8 children they don’t tend to have more children than in countries with an average of 1.6 children “because a person can’t have 1.8 children”. That’s not how averages work.
Say someone offered you a bet: 100 rolls of the dice and look at the total. If it’s over 380 you win, if it’s under you lose.
You wouldn’t take such a bet, because you know the mean result is 350. You would not argue that because 3.8 is not a result that the game was fair. Whereas if offered a win on a total of 320, you would be all over it.
That mean of “3.5” from a dice roll does have a meaning. And you know it.
Clyde,
If I tell you the average length of a pile of girders in my lot is 20 feet would you trust that average to tell you if you could span a gap of 20 feet with a girder picked at random?
If I tell you the average temperature here went up can you tell me from the average why it went up?
While your example is a good one showing where the mean might be useful to know, I’ve never played a crap game based on the total of 100 throws. So knowing the mean of 3.5 is still not useful to me.
The real problem is that you are mistaken. You are assuming that each number comes up the same number of times in 100 rolls. There is no guarantee that this will occur. Every time you roll the die each number has the same probability of coming up. I recently saw a study that talked about how many coin tosses it would take to erase 7 heads in a row. If I remember correctly it was a very large number, like 5000 tosses. I don’t believe a mere 100 rolls is enough to guarantee that all numbers come up exactly the same number of times.
So, it becomes a game of chance with just 100 rolls. Your guess is as good as mine as to whether the total is over/under 380. Notice the word guess. That is what uncertainty means.
Prjingo,
Thanks, that is a really interesting comment, to me, as I am coming to the opposite conclusion 🙂
I do not disagree at all with your point1 and I guess your point 2 is probably not incorrect. Points 3 and 4 might be correct if by ‘predict’, it is implicit that you mean ‘precisely predict’ .
However I would suggest that the frustration that comes when modelling real world data comes from failing to relax the rules of physics .
I am not sure if this thought experiment works for you (I hope so):
Imagine we are doing a hookes law (or vaguely f=ma) experiment, we have a spring balance and a container/bucket with volumetric measurements down the side, we put varying amounts soil into the bucket and measure the springs extension.
We get a pretty noisey scatter around a regression line, we also have good information on the acceleration due to gravity the modulus of the spring and average bulk density of the soil.
Do we go with our OLS regression line to predict the extension of the spring from a given volume of soil or do we go with a physics-derived prediction of the spring extension ?
I would suggest that the OLS fit is the way to go. Importantly this has an intercept term despite our spring balance not being pre-tensioned. The fit will have a slope that is less than the physics will suggest due to the random error in estimating the mass of material in the bucket.
We could also derive a real world equation that goes along the lines of F=0.7*ma +c which would be beat any pure physics derived estimate.
OK we might be able to recover the underlying physics by an error in variables regression model.
But (and I think that this might the important point) the close-to-the-pure-physics model one produces from this regression cannot be used for prediction purposes … it needs to be de-rated and an intercept term added back in.
If the correct EIV model was RMA then one would multiply the slope (which should agree with the pure physics) by the OLS derived correlation coefficient.
Essentially: All (necessarily incomplete) physics-based predictions need to be derated by their statistical correlation with reality.
Depending on assumptions, you are likely each correct.
Before we had computers we tended to base our thinking about the future on what had happened in the past.
In matters of warfare the generals used war gaming. Now this can be complicated by many factures, one of the more recent was a Japanese war game in 1940 about what could happen if two big fleets met in the Pacific.
In this particular game the USA won, sinking more ships than the Japanese. So national pride came into play and the sunken ships were refloated and the Japanese won, a case of wishful thinking.
The battle of Midway was won by the Americans, but what is seldom mentioned was by just how close it was to being a Japanese victory,.
A USA submarine was detected by their main fleet and a Japanese destroyer was sent to deal with it. The chase which proved negative caused the destroyer to be some distance from the flied.
But right now along came a number of US dive bombers. Now up till then the Japanese were winning having shot down the numerous planes. The dive bombers were lost and were close to running low on fuel and thinking of returning to their carriers.
But they spotted the wake of the destroyer who at high speed was returning to its fleet. The dive bombers followed and found the Japanese all ready for a take off against the US carriers, all of their fighters was at low altitude having just dealt with the US torpedo planes.
The dive bombers dived and the rest is history.
Put that into a computer and the Japanese would have probably won, as they almost did. The uncertain factor was just plain Luck. Good for the USA, but bad for the Japanese.
In the real world if the USA had lost, the remaining US carriers would have returned to Pearl and the war would have continued as a Island hopping exercise, Midway would been lost after a big fight, and as with Wake would have been recaptured later on.
The USA manufacturing output was so far ahead of the Japanese that long term the USA would still have won, but it would have taken a bit longer.
In climate modelling there is far too much uncertainty involved. Nature in the real world is far too complicated for even the next generation of computers to be able to model with any accuracy .
So instead of what are just guesses , they should be using known facts plus maybe some modelling., on what has happened in the past. We have up to 3000 years of written observations , so use them.
MJE VK5ELL
“In matters of warfare the generals used war gaming.”
In the early days of computing, the Defence Advanced Research Projects Agency (DARPA) did a lot of research into the practical use of computers in warfare. In one project, a new model of advanced computer was programmed with all the information about previous battles that could be found. The general in charge of the project had the computer programmed about one battle and asked the computer if they should attack or retreat. The computer promptly responded “Yes”. The general was understandably incensed at this and asked “Yes, what?” The computer responded “Yes, sir!”
“In the real world if the USA had lost, the remaining US carriers would have returned to Pearl and the war would have continued as a Island hopping exercise…”
The Japanese plans for the war recognised that they would not beat the US in a war of attrition, but they expected to score early victories against an enemy which was not prepared, then they would consolidate their position and make peace from a position of strength.
So, if the USA had lost the initial round, we would expect the war to continue by the Japanese blockading the West Coast, exerting pressure on US interests in the Pacific, and offering peace negotiations which recognised the new Japanese position in Asia.
Perhaps rather similar to Hitler in 1940, when he was in control of the European mainland and offering peace negotiations to Britain which would recognise his position there. In each case the aim of the Axis powers was not to invade and completely destroy their enemies, but rather to alter the power balance so that they would become expanding empires while the existing local powers would reduce in size and become unimportant….
Never heard of US War Plan Red ?
https://en.wikipedia.org/wiki/War_Plan_Red
a strategy in case of an attack by Japan working for the British Empire.
Put that into your gaming engines.
Due to such luck, we are here. My father could easily have died in that war, for example, and more basically one sperm cell succeeds at a time.
Andrea Saltelli,
Yours is a most important message, but one that I fear will be ignored by many who need to act on it.
With some models we used in mineral exploration – a classic one being the derivation of properties of a discrete magnetic body at depth derived from surface magnetrometry – the models kept on being used and improved because they delivered useful results. They would not have survived if their best effort was to produce a credible outcome each run. Validation is so important. Geoff S
“In climate modeling there is far too much uncertainty involved. Nature in the real world is far too complicated for even the next generation of computers to be able to model with any accuracy .”
Yes, and there is even more uncertainty in our knowledge of climate processes. If we don’t know of/how a process works in the climate system we can’t model it. It’s even worse when we model a process that we thinks does X when in fact it does Y in the real world. That takes Propagation of Error to a whole different dimension.
There are some seriously stupid comments above. There’s actually no difference whatever between statistical and mathematical modelling other than in the heads of academics who want to make some ridiculous intellectual argument. As usual it’s all smoke and mirrors.
The simple fact of the matter is that whenever you use measured data you’re inevitably introducing errors. This is a 100% fact of scientific life. The whole point of the statistical analysis is to provide a level of confidence around the findings it produces; and this should not be confused with ‘statistical confidence’, which has a specific meaning in statistical terms. Such errors don’t just include the instruments used to measure the data but also the context in which the measurements are being made, such as the siting of a meteorological station at an airport or in an urban area, for instance. Common sense will tell anyone that this is highly likely to introduce major errors. Anyone except climate scientists, apparently.
The problem across many scientific disciplines is that the scientists themselves don’t understand the statistical analyses they’re using to “interpret” their results. Nowhere is this more apparent than in climate modelling. What so-called climate “scientists” never do is reveal the true confidence in which predictions from their models are being made. This, in itself, puts a massive hole in the centre of any grounds they might have for claiming they’re following the scientific method.
Another problem is that modelling what has happened can be remarkably easy whereas predicting what will happen is incredibly difficult. It hardly needs Einstein to understand why.
This is the real nub of the problem with climate science isn’t the claims they make but the certainty with which they’re making them. No matter how good any mathematical models might be, in the real world there are so many unknown unknowns that any predictions being made are never going to be remotely close to the certainty with which climate scientists claim; and I can say that with 100% certainty. The irony is lost on these people.
Look at the real confidence with which any predictions about man-made effects should be being made and you very quickly come to the conclusion that the likelihood of them being real is actually very remote. Yes, the world is warming and the climate is changing but the likelihood of this being mainly down to man is extremely low indeed. That is the real value of statistics.
How does the common disclaimer go? Past performance is not a guarantee of future results!
This isn’t exactly true. Statistics analyzes past data in order to infer what may happen in the future or to assist in deducing why something happened in the past. Models only purpose is to predict what will happen in the future. Predicting the past is meaningless. Matching the past may be useful in validating the model but that isn’t the reason for designing a model.
Using statistical parameters to predict the future is fraught with error. A simple example is trying to determine what the next throw of a dice may be using past data with a mean and standard deviation.
Jim Gorman
At issue in extrapolation are the unstated assumptions: All things being equal, and assuming no significant changes in the conditions leading to the statistical summary.
Without understanding the physics behind interrelated variables, the safest extrapolator is a linear regression, assuming that the data appear to be linear. Polynomial regressions are infamous for shooting off into the wild blue yonder beyond actual data. Yet, a 2nd-order polynomial is sometimes the best fit based on both the R^2 value and the physics.
The real problem is when a model produces a highly non-linear output and the only way of reproducing it is with curve fitting of a high-order polynomial. All bets are off in extrapolating the output! The best approach is to be sure that the model is fit for purpose and use it instead of a curve fitted to it. There is little evidence that the extant GCMs are fit for purpose. The only thing they all have in common it the sign of the slope for future projections.
“There’s actually no difference whatever between statistical and mathematical modelling other than in the heads of academics who want to make some ridiculous intellectual argument. As usual it’s all smoke and mirrors.”
err no.
Simple example: for statistical modelling of sea level rise, one might say.
Model the sea level rise “according to” the data. which would mean fitting a statistical model
to past data and extrapolating. mathematical modelling ( also called physics modelling) would
not fit a model to the data. it would start with the physics of water expansion and temperature
and predict based on that. If your math model is good it also explains past data.
Statistical modelling: start with the data fit functions to the data. the function
is your “data generating” function. it may not make physical sense. it may just work.
Math modelling: start with known physics, IF you get it right it will beat the stats model on past data
and give you a EXPLANATION of why the past was the way it was and what to expect in the future.
jesus, even a stupid english major like me was taught this on the job in the first year.
SM, “mathematical modelling ( also called physics modelling) …”
Then call it physical modeling, not mathematical modeling.
MarkWe is correct. Statistics is a branch of mathematics. Statistical modeling is a branch of mathematical modeling. OLS is mathematical modeling.
Physical modeling is causal. Steve M. got that part right.
But to call physical modeling mathematical modeling is an abuse of language, because it obscures the absolutely fundamental difference between physics and math.
The fact that climate modelers rely exclusively on statistical criteria of judgment (precision, yes; accuracy, no) is a dead give-away that climate modeling is currently not a branch of physics.
Pat
I wasn’t aware that climate modelers paid any attention to precision. 🙂
MarkWe: “The simple fact of the matter is that whenever you use measured data you’re inevitably introducing errors.”
I think that you’ve just trashed the entire discipline of Statistical Mechanics.
I actually agree with most of your points, but I think that there are real differences between statistical and mathematical modelling. Statistical methods can tell you a lot about some situation even though you have not the slightest idea how the mechanics actually work. That’s pretty much how nineteenth century physicists got from knowing little more about thermodynamics than you average caveman to the threshold of Relativity and Quantum Mechanics in just 100 years.
You must be careful about terms and their actual usage. Statistics uses measured past data to make INFERENCES as to what might happen in the future. What you get is a range of possibilities with uncertainty.
Physics/math is used to DEDUCE what will happen in the future. What you get is a prediction with errors and uncertainty.
Can statistics be used to refine physics/math? Certainly.
I think WUWT has struck a nerve – this looks like a response to Pat Frank’s
Propagation of Error and the Reliability of Global Air Temperature Projections
which I now see goes back to 2015 here, and 6 years of publication blocking.
97% of statistics are made up.
What about the other 13 percent?
The included figure and it’s discussion is, well, deficient. Wrong model error doesn’t necessarily increase with model simplification. Example: Newtonian mechanics is a workhorse of engineering and science. To add the complexity to make mechanics absolutely correct, special relativity let’s say, does zero to reduce this source of error except in special circumstances. Now, one can leave out or over simplify important factors in a mechanical model such as including frictional losses as proportional to speed when many are more complex, but this simplification is usually done for mathematical convenience to help build intuition about some phenomenon. The figure is not too useful when divorced from context. What is the ultimate purpose of a model is an important consideration when evaluating its utility.
One way to think about oversimplification is to ponder whether a model which is meant to explain the consequences of some physical factor, considers a complete set of all factors having potentially the same effect.
Numbers are scary and their everywhere.
I don’t understand the distinction between “statistical modelling” and “mathematical modelling.” Models all try to do the same thing — capture a meaningful and useful reflection of reality. Statistics is just a mathematical way to deal with inputs and outputs that are probability distributions.
Steve,
I agree the definitions seem to be imprecise. In the end all models are mathematical. At the risk of mucking up the waters here’s how an engineer looks at models.
Models fall into two broad categories: Empirical and First Principles.
Empirical models are derived from analyzing data and determining relationships between (assumed) independent inputs and (assumed) outputs using some form of linear or non-linear regression, principle components, or neural network methodology. If correlation is shown (not causation) it is assumed there is a relationship between the input(s) and output(s). I believe this is what they are calling statistical models.
First Principle models use known physical relationships in the models (e.g. F = ma). I believe this is what they are calling mathematical models.
Models can also mix empirical and first principle methodologies because, after all, it’s just equations and the solution engine doesn’t know or care where the equations came from.
People care very much about the distinction between empirical and first principle models because first principles equations are very well proven and can be trusted to give reliable results (within the range of applicability). Empirical models are not well proven; in fact it is much easier to make a bad empirical model than it is to make a good empirical model (as someone who has made many bad empirical models, but enough good ones to continue to get paid). The process control community over the years has built a wealth of knowledge on how to develop empirical models for control and how to evaluate whether an empirical model is good enough for control. Hint: it requires much more than just looking at the statistics.
I strongly suspect the GCM’s use a mix of first principles and empirically derived equations. If true this allows supporters and skeptics of GCM’s to talk past each other. Supporters point out that first principles equations are used (as I would expect); skeptics point out the use of parameter tuning to match historical data (prima facie evidence of the use of empirical approaches requiring the use of statistics to “prove” a relationship). Having built and used empirical, first principles, and mixed models my bias is towards the skeptics. There are just too many ways to screw up an empirical model starting with inadequate data (and to my mark one eyeball the available data appears to be grossly inadequate). The fact that some of the equations are first principles doesn’t mean the empirical parts are somehow made better.
That said just because I suspect the GCM’s are not fit for purpose doesn’t mean that they aren’t. Pat Frank is digging at something very important; understanding the limits of the models. I would love to participate in a cold eyes review of one of the GCM’s and on the list of things to do would be to explore how pushing the parameters to the extremes of the published ranges affects the model outputs. How hot does the GCM get when all the parameters that drive heat up are maximized and parameters that drive heat down are minimized and vice versa. (Running ensembles of models with presumably similar parameterization does nothing to outline the possible range of outputs). [P.S. I love breaking software!]
detengineer
You said, “The fact that some of the equations are first principles doesn’t mean the empirical parts are somehow made better.” How true! If one were to write a simple computer model that worked perfectly, and then added a random number generator to the calculations, the output would be corrupted. If parameterizations or measurements are wrong, they then behave like the random number generator. Although, I suspect that the introduced error for GCMs is a positive additive or multiplicative error, based on models lack of agreement with measured temperatures.
I think that the modeling community would do themselves a service if they sought advice from a team of interdisciplinary peers to question assumptions and procedures.
I’ve always had a talent for breaking software. Back when I was doing a lot of coding, particularly Computer Assisted Instruction software, I would rigorously test keyboard inputs for reasonableness and not allow the user to continue to the next input variable if they input unreasonable values.
Re climate modelling, GCMs, CMIP processes, the concept of accountability seems under-emphasised.
A rough question illustrates. Why should any more funding be directed to this work? When public funds are used, the public expects that there is a commensurate benefit. What has been the benefit to date? What, if any, is the continuing benefit? Are significant breakthroughs possible if funding continues?
Part of the answers concerns those handing out the funds. Do they know the true values of the current work and the expected values of future work? If not, is there any reason to continue with funding?
Parts of the answers to these questions relate to uncertainty and verification and thus relate to the Andrea Santelli paper.
My hypothesis is that the dispensers of these public monies know very little about these matters. The dispensers might include high-level scientists and mathematicians, but I doubt that such people have the time or professional interest to acquaint themselves with factors that really matter like the ways that models have been validated, what their true uncertainties are, what breakthroughs are seen as likely, even possible – even impossible if the science is settled. Those who approve climate model funding should have criteria and those criteria have to include uncertainty. How can they be given accurate uncertainty figures when modellers do not produce them?
It is a truism that the funding rationale has become dominantly political. The results of climate modelling to date are showing little quality and because of natural fundamentals (at least) there is little chance of improvement. The cloud argument persists. The scientists themselves are not so great at volunteering reasons for the lack of performance, such as why modelled climate sensitivity to greenhouse gases has been stuck in a broad, rather useless range for 40 years; and why projected future temperatures are so different to measured ones as time goes by.
Justification for future funding must surely involve estimates (and a form of proof) of how useful this modelling has been for the past several decades, plus words about the benefit:cost analysis of continued funding. As I noted above, some valuable models of my acquaintance in another field have survived because they produced useful results, in this case useful in the sense that $$$ gained from their use far exceed the cost of their development and verification against real data. Can climate modellers by now claim that beneficial funds can be handed out to the public as a result of their work?
In closing, I ask what benefits climate modelling can claim, in return for the substantial costs of several supercomputers, many decades of research time, costly seminars, large exercises like CMIPs that in the cold hard light of day are little more than optimistic rearrangements of artificial numbers, numbers that are hard to relate to the physical world without bias and great uncertainty – and seldom are.
Would the funds have been better spent on people going to developing counties to build new fossil fuelled power stations? That effort has a simple justification by benefit:cost analysis, though World Bank policy cannot see it.
No, Virginia, there is not a Santa Claus. Geoff S
We still lack a clear unequivocal comment by climate modelers attached to models that states their calculation of both the model predictions error and uncertainty.
Nick Stokes has kindly pointed to “KNMI gives a collection of runs, including ensemble runs, here. ” (http://climexp.knmi.nl/selectfield_cmip5.cgi?id=someone@somewhere) ; but the statement by the modelers as to error and uncertainty remains lacking.
Conservations of energies, (noting the time dependent fluxes between reservoirs remains significantly imprecise or ‘uncertain’), may ‘close the loop’ for the iterative process of GCM modeling – or it may not –
Hindcasting analysis might make amenable a verification of claimed error and uncertainty (from a particular model)
“Constraints” applied to calculations in order to “maintain conservation of energies” is an implicit admission that something is wrong in the model. As far as we know, there isn’t an external force that reaches into the earth’s atmosphere to maintain conservation of energy. Therefore, one must assume that natural forces interact to maintain it. The logical conclusion is that the models are missing processes or have incorrect programming in the order of their interactions.
Most folks indicate that clouds are a problem. I suspect that topography has a strong affect also. Mountains, hills, trees, grassy plains, lakes, ponds, and now windmills, etc. can also have profound affects on winds and weather fronts. These all affect energy flows in the atmosphere. I also expect they are going to be terribly difficult to program properly.
Jim
I may be wrong about this, but I suspect that the process of homogenization pretends that microclimates don’t exist.
Try explaining to a believer/the BBC why models are not provable science… but its good this reality is published in Nature without having a debate along the the lines of “Do you believe in models?”..
Perhaps the key points were best made in separate parts by Richard Feynman on proof:
https://www.youtube.com/watch?v=EYPapE-3FRw
and Freeman Dyson on the use of models, which help understanding but don’t prove anything.
https://www.youtube.com/watch?v=TtNB-oNyvXs
Models may use proven theories to help form new theories concerning relationships of cause and effect, that can then be tested absolutely by observation, but prove nothing without that essential independent observational validation.
Hiding your data and calculations, based on some observations, massively modified by statistical adjustment to bear no relations to the original proxy observations, as Michael Mann did and continues to do, is the direct opposite of provable science and denies any right to claim proof or knowledge, because the crucial possibility to independently test the conclusions independently is denied. Why would you do that, if its decent, honest, truthful – and hence repeatable?
Mann’s/Climate “scientists” approach is fundamentally similar in its approach and conclusions to that of the MMR extremist and fraud, Andrew Wakefield. Another self styled expert falsifying data to “prove” his beliefs for reward, and so impose them regressively on others by scaring people, and even forcing numpty politicains into legislating for their unprovable beliefs. Feynmans pseudo science, writ large. Now the political belief comes before the science.
Invent a belief, then fund a uNiversity to fix the science to “prove” it, that must be believed, put into law as the only true remedy., often to cure a non problem with an undeliverable solution. Climate science is no better in a tool for fraud, perhaps worse, than economics or sociology, neither of which are sciences, just the study of possible correlations that no one can prove using observation, with or without laws. When created for profit and power by a consensual group, these are no better than forms of religious belief, certainly not provable science.
Proof can only come from evidence that repeatably confirms the predictions of the theories used in models for all observers. “If the theory doesn’t match observation, its wrong. Doesn’t matter who said it, what his name is, which University he works for, etc…”
But climate modellers don’t expect to be subject to this absolute and final test, precisely because they don’t have any clear theories, or even understanding of the climate systems they claim to understand. in particular clouds and the lithosphere. Primarily “climate science” was created to add credibility to the UN IPCC’s presumption that energy use produced “Climate change”, caused primarily by CO2 that causes global warming through GHE, energy use essential to keeping developed economies developed, and hence a key way to control them by imposition of laws governing energy.
But, the observations are very different to the models, the heat does not appear as predicted, so they are wrong.
In particular, the theory they included as regards the ACTUAL effect of CO2 on GHE is disproved.
This is obviously because they were paid by the UN, and governments with agendas, to prove a problem, rather than find a cause.
Yet the scientific and popular media prefer to promote what is proven wrong, because that’s where the money is, in supporting a consensus that drives $Billions in easy carbon taxes and subsidies for renewable energy that can’t ever replace fossil energy at the level required to remain developed, in most countries. This is now a dangerous religion for developed countries, pointlessly threatening the very basis of their prosperity,.
In my broader view, the use of statistical correlation and computer models as the basis for newly created pseudo sciences has made it possible to create new academic industries in Universities, in particular as hiding place for the less able refugees from reality children of middle classes in America, who can claim expertise in subjects they can’t prove but become “experts” in, like nutrition or Coral Reefs. Most based on bad, presumptive and ultimately unprovable science, thus creating lifetime careers in pointless subjects where self appointed experts agree on a consensus that cannot and has not been tested in hard science fact, because it never can be, does not include all the variables, just chosen scapegoats the supposed effects are attributed to, while their conclusions are presented as if they were facts to policy makers.
Richard Feynman expressed this so typically well, as regards vague theories and the pseudo sciences they support, especially his throwaway last key line in the clips. “They’re scaring people”. If only he was around now to call out the climate modelling racket…..or the vegan nonsense, an attack on the developed farming methods that solved famines and made modern life safe, and have no real provable effect on the climate, done as is normal and prudent..
https://www.youtube.com/watch?v=hz2SENYI1rE
https://www.youtube.com/watch?v=tWr39Q9vBgo
This corruption of real science goes far wider than just climate, but other pseudo sciences have far less damaging effects on developed economies in terms of the $Billions pa wasted on faux remedies for non problems, profiting only law makers and their conies..
This corruption of science to expand pointless University careers at public expense, and fuel the mad but profitable views of extremists and force them onto others, is scientifically and academically wrong, financially fraudulent, actually deceitful, and dangerous for the rest of us who pay for it, and depend on the scientific advice given to law makers to be both provable and proven. Ever less likely in the new academic industries for profit of the 21st Century.
“Models built to prove your theory NOW. Great prices, nothing we can’t prove! Roll up, roll up.”
Dave Burton October 25, 2019 at 10:22 pm
Sadly, [ ] “A recent work in this journal reviews common critiques of modelling practices, and suggests—for model validation, to complement a data-driven with a participatory-based approach, thus tackling the dichotomy of model representativeness—model usefulness.”
____________________________________
Try this:
A recent work featured in this journal looks at known critiques of model applications
and recommends for model evaluation:
– to complete pure data processing
– with a application-, usage-based approach.
And so to distinguish between
– representativeness; and
– usefulness of the model applied / used.
( note: the graphic depiction shows an alleged increase in usefulness when actual representativeness drops )
Dave Burton October 25, 2019 at 10:22 pm
Sadly, [ ] “A recent work in this journal reviews common critiques of modelling practices, and suggests—for model validation, to complement a data-driven with a participatory-based approach, thus tackling the dichotomy of model representativeness—model usefulness.”
____________________________________
Try this:
A recent work featured in this journal looks at known critiques of model applications
and recommends for model evaluation:
– to complete pure data processing
– with a application-, usage-based approach.
And so to distinguish between
– representativeness; and
– usefulness of the model applied / used.
( note: the graphic depiction shows an alleged increase in usefulness when actual representativeness drops / and vice-versa )