Guest Post by Willis Eschenbach
Anthony Watts, Lucia Liljegren , and Michael Tobis have all done a good job blogging about Jeff Masters’ egregious math error. His error was that he claimed that a run of high US temperatures had only a chance of 1 in 1.6 million of being a natural occurrence. Here’s his claim:
U.S. heat over the past 13 months: a one in 1.6 million event
Each of the 13 months from June 2011 through June 2012 ranked among the warmest third of their historical distribution for the first time in the 1895 – present record. According to NCDC, the odds of this occurring randomly during any particular month are 1 in 1,594,323. Thus, we should only see one more 13-month period so warm between now and 124,652 AD–assuming the climate is staying the same as it did during the past 118 years. These are ridiculously long odds, and it is highly unlikely that the extremity of the heat during the past 13 months could have occurred without a warming climate.
All of the other commenters pointed out reasons why he was wrong … but they didn’t get to what is right.
Let me propose a different way of analyzing the situation … the old-fashioned way, by actually looking at the observations themselves. There are a couple of oddities to be found there. To analyze this, I calculated, for each year of the record, how many of the months from June to June inclusive were in the top third of the historical record. Figure 1 shows the histogram of that data, that is to say, it shows how many June-to-June periods had one month in the top third, two months in the top third, and so on.
 Figure 1. Histogram of the number of June-to-June months with temperatures in the top third (tercile) of the historical record, for each of the past 116 years. Red line shows the expected number if they have a Poisson distribution with lambda = 5.206, and N (number of 13-month intervals) = 116. The value of lambda has been fit to give the best results. Photo Source.
Figure 1. Histogram of the number of June-to-June months with temperatures in the top third (tercile) of the historical record, for each of the past 116 years. Red line shows the expected number if they have a Poisson distribution with lambda = 5.206, and N (number of 13-month intervals) = 116. The value of lambda has been fit to give the best results. Photo Source.
The first thing I noticed when I plotted the histogram is that it looked like a Poisson distribution. This is a very common distribution for data which represents discrete occurrences, as in this case. Poisson distributions cover things like how many people you’ll find in line in a bank at any given instant, for example. So I overlaid the data with a Poisson distribution, and I got a good match
Now, looking at that histogram, the finding of one period in which all thirteen were in the warmest third doesn’t seem so unusual. In fact, with the number of years that we are investigating, the Poisson distribution gives an expected value of 0.2 occurrences. In this case, we find one occurrence where all thirteen were in the warmest third, so that’s not unusual at all.
Once I did that analysis, though, I thought “Wait a minute. Why June to June? Why not August to August, or April to April?” I realized I wasn’t looking at the full universe from which we were selecting the 13-month periods. I needed to look at all of the 13 month periods, from January-to-January to December-to-December.
So I took a second look, and this time I looked at all of the possible contiguous 13-month periods in the historical data. Figure 2 shows a histogram of all of the results, along with the corresponding Poisson distribution.
 Figure 2. Histogram of the number of months with temperatures in the top third (tercile) of the historical record for all possible contiguous 13-month periods. Red line shows the expected number if they have a Poisson distribution with lambda = 5.213, and N (number of 13-month intervals) = 1374. Once again, the value of lambda has been fit to give the best results. Photo Source
Figure 2. Histogram of the number of months with temperatures in the top third (tercile) of the historical record for all possible contiguous 13-month periods. Red line shows the expected number if they have a Poisson distribution with lambda = 5.213, and N (number of 13-month intervals) = 1374. Once again, the value of lambda has been fit to give the best results. Photo Source
Note that the total number of periods is much larger (1374 instead of 116) because we are looking, not just at June-to-June, but at all possible 13-month periods. Note also that the fit to the theoretical Poisson distribution is better, with Figure 2 showing only about 2/3 of the RMS error of the first dataset.
The most interesting thing to me is that in both cases, I used an iterative fit (Excel solver) to calculate the value for lambda. And despite there being 12 times as much data in the second analysis, the values of the two lambdas agreed to two decimal places. I see this as strong confirmation that indeed we are looking at a Poisson distribution.
Finally, the sting in the end of the tale. With 1374 contiguous 13-month periods and a Poisson distribution, the number of periods with 13 winners that we would expect to find is 2.6 … so in fact, far from Jeff Masters claim that finding 13 in the top third is a one in a million chance, my results show finding only one case with all thirteen in the top third is actually below the number that we would expect given the size and the nature of the dataset …
w.
Data Source, NOAA US Temperatures, thanks to Lucia for the link.
Just as an FYI, I have tried all the above methods to predict the winner of a horse race, and have come to the realization, that 81% of the time my picks are wrong (maybe 90 %), so now I realize that I need to work on my stats, thanks 🙂
Where were you guys 30 years ago ?
u.k. (us) says:
July 11, 2012 at 10:01 pm
If you’ve come up with a system which allows you to say a given horse is 81%-90% unlikely to win, that could be considerably valuable. Pick races with two strong contenders, then eliminate one of them with your algorithm, and Bob’s your uncle.
KPR
Is the Poisson distirbution not a bit of misnomer here? Perhaps Willis can correct me if I’m wrong. You are assuming he is doing a Poisson experiment (perhaps it doesn’t matter to your point) – he doesn’t appear to be. He appears to have found a distribution with a positively skewed distribution and has tried to parameterise it with a Poisson model. I think for a blog that’s ok (I’ve seen worse in peer reviewed articles). Sure a pure statistical approach would be to carry out a normal score transformation, then you can carry out your analysis in “Gaussian space” and for each output back transform into your “data space”. But it is a blog and you’d probably have people switch off at that point.
Sorry KR…
Willis,
You say:
In fact, *for this dataset* the probability of having found one or more groups of 13 months in the top third is 100%. It has already happened. Exactly once. Of course the odds *for this dataset* are certainly not one in 1.6 million!! As several commenters have pointed out (with greater or lesser degrees of condescension), your analysis is tautologous.
Any distribution that fits the data well will give the same result. The better the distribution fits, the closer it will come to telling you what we already know: that *for this dataset* the expected frequency of groups of 13 months in the top third is excatly one in 116 (June to June) or one in 1374 if you sample all 13-month groups. Because that’s what the actual frequency in this dataset is.
The fact that the distribution looks a bit like a Poisson distribution is neither here nor there. It is very clearly NOT a Poisson distribution, because it can never have a value above 13. So the fact that it looks like a Poisson distribution tells you exactly nothing.
I think it is time to stop digging.
And as for those commenters who wrote such glowing assessments of Willis’s brilliant analysis, you should be ashamed of yourselves. You clearly aren’t skeptics!
As I was saying to Willis on another thread last week, a huge proportion of the comments on WUWT (and a fair number of the main posts) strongly suggest that the main form of argument being employed here is: I don’t want AGW to be true, so any argument that suggests it isn’t is fine for me, and I will uncritically accept it and laud it with praise.
I think the main point of Willis’s post was to show how stupid and ridiculous some of the statements made by climate scientists and mainstream commenters are. This is true. But Jeff Masters made a mistake and he publicly admits it. And according to analysis by people who really do understand statistics, he wasn’t actually that far off anyway. But I have seen very little that is quite as stupid and ridiculous as this “analysis” coupled with the somewhat pompous and dismissive attitude displayed in the author’s comments.
It’s sad to see that what’s happening on these pages exactly matches what Al Gore was complaining about in his famous “They pay pseudo-scientists…” monologue. No, I don’t think Mr. Eschenbach is paid by anyone for the “science” he’s presenting here but over time I’ve come to conclusion that what’s he presenting here is not science. It looks like science and it gives results likely everybody here wants to see but so far every single such result was mathematically unfounded and questionable at best.
I understand and share Mr. Eschenbach’s approach of ‘looking at and understanding the data’. But there is one more step he’s refusing to do – ask myself ‘okay, now after I got this result, let’s find out why is it wrong’, find all possible loopholes in the approach and prove that they don’t affect the result. Instead, he lets others to find out and when they do he steps up to defend his approach regardless how much evidence is against him.
I’ve been doing some analyses in climate data myself and I know it’s HARD. There are many ways how to process the data and by careful selection you can always find a way to get the conclusion you want to see. The real science is not in the conclusion – it is the art of using the right approach. And sure enough, the position “I’m right because you have not convinced me that I’m wrong” is not scientific at all.
What we know is that the mean of the data is 5.2. But all that means is that p is not 1/3 as you claim, it’s some larger number, to wit, 5.2/13. It doesn’t mean that we are not looking a Poisson distribution. It just means that your estimate of p is incorrect.
Why? Because the earth is warming, obviously, so the chances of being in the warmest third are greater than if it were stationary. But again, that doesn’t mean the distribution is not Poisson. It just means that your estimate of “p” is wrong.
So, you’ve proved that in a warming world there is a reasonably high likelihood of getting a hot streak of 13 consecutive months in the top tercile, while that would be extremely unlikely if the world were not warming. Congratulations, that was precisely what Jeff Masters was setting out to show in the first place!
I have no idea what you mean by an “estimate of p”. p is not estimated, it is specified in the problem definition. The probability of being in the top 1/3rd is 1 in 3. Period. The fact that retrofitting a Poisson curve to the data gives you the wrong p is conclusive proof that the data are not derived from a Poisson process. I’m mystified that this seems to be so difficult to grasp.
pjie2
As I said to KR, in the purist sense he should’ve normal score transformed the distribution into Gaussian space, interrogate the data there and then back transfrom the outputs. But phew, that would make for an incredibly boring post. It’s just a blog, lighten up. Your point is probably correct, but then he isn’t running a Poisson experiment just waht looks like an attempt to parameterise his distribution. I think for “here’s something that might be of interest” stuff, it isn’t too bad – you’ll see a lot worse in peer reviewed literature.
cd_uk says “you’ll see a lot worse in peer reviewed literature”.
I challenge you to find a single example of peer reviewed literature in any non-vanity journal that includes an analysis that is as bad (on so many levels) as this is. This is cargo cult science at its finest.
It would appear that most commenters on WUWT really have no critical faculties at all. The thought process seems to go: Willis seems like a good bloke and he writes lots of sciency-looking stuff that always comes to the conclusions I want to hear, so everything he writes must be great, and anyone pointing out the glaring flaws in his circular argument should “lighten up”.
Well, the limiting case is to truncate the data to 13 months for a probability of 1. Also 1 for all 13 years in the middle and lower thirds. So the nature of the distribution changes over time even if the trend is flat. My head started to hurt so I dropped back to simple N of M analysis. , which is the mean lifetime of a snowball in hell. Now make
, which is the mean lifetime of a snowball in hell. Now make  , so that the jump to the top third is a once sided
, so that the jump to the top third is a once sided 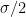 . Now our Bernoulli trial probability is around 1/3 (finally) and we get approximately
. Now our Bernoulli trial probability is around 1/3 (finally) and we get approximately 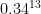 and we are as good as the Masters etc prediction — for this point at the boundary of the bottom third.
and we are as good as the Masters etc prediction — for this point at the boundary of the bottom third. larger, we increase this (for this point) until we reach the limit for
larger, we increase this (for this point) until we reach the limit for 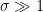 of
of  — now a true coin flip Bernoulli trial and still a sucker bet (for this point).
— now a true coin flip Bernoulli trial and still a sucker bet (for this point). guarantees that it will be a thirteen month run. In fact, you have to make
guarantees that it will be a thirteen month run. In fact, you have to make  quite large to have a good chance of making the thirteen trial run back to the second third. However, it is indeed a lot easier to fall back (given a large
quite large to have a good chance of making the thirteen trial run back to the second third. However, it is indeed a lot easier to fall back (given a large  than it was to move forward, because to move forward you had to win thirteen flips in a row, to lose and fall back you only have to lose one time in thirteen tries.
than it was to move forward, because to move forward you had to win thirteen flips in a row, to lose and fall back you only have to lose one time in thirteen tries.
No, 13 months means a probability of zero that all of them are in the top third of 13 months. Also, it is by no means 1 for years in the upper third, because we’re looking at months, not years. Even a warm year can (and “usually” does) have a cold, or at least a normal, month). Under most circumstances, but in particular under the circumstance of non-trended data with gaussian fluctuations of some assumed width around some assumed mean, the probability of encountering one is zero until one hits month 39 (so one CAN have 13 in a row) and then monotonically increases with the size of the sample (but is very small initially and grows slowly).
If the data is trended everything is very different. Suppose the trend is perfectly linear with slope 0.01, which is a decent enough approximation to the 100 year actual data. Suppose that the noise on the data is — ah, we discover a key parameter — is the noise gaussian? Is it skewed? What’s its kurtosis? And above all, what is its width? Let’s say the noise is pure gaussian, width 0.1. In that case the probability of finding a hit in the first half of the data is essentially zero. In year 33 for example, the data mean for each month is exactly at the lower third boundary. You then draw 13 marbles from the gaussian hat. Each marble has to add 0.33 to barely make it to the top third. That is 3 sigma, so you are basically looking at rolling a 0.001 uniform deviate 13 times in a row in a Bernoulli trial. Your odds of winning the lotter or the Earth being struck by a civilization-ending asteroid are higher. Now suppose sigma is 0.33. Now it is a 1 sigma jump to the top third. This is good — your chances of making it are up to a whopping
Note that as we make
Now consider the top point. It is there sitting at the top of the top third. Now small
Now consider the latest 13 month run as a datum. Suppose you reach into the hat and pull out a thirteen month rabbit. Forget all modeling, it’s a real rabbit, sitting there looking at you. What does it teach you?
Well, one thing it does is it tells you something important about sigma and/or autocorrelation, or it tells you something about the data itself. What it does not do is tell you anything about the trend itself — it only tells you something about the trend compared to sigma!.
Either it is a random rabbit, p happens, bad/good luck pip pip, or else — and I’m just throwing this out there — it tells you something about the underlying temperature trend.
For example, suppose that the real temperature trend were just 0.066 per year, but I was nefarious and adjusted data (or failed to correctly account for instrumentation) so that my reported trend were much higher, and strongly biased at the end so that it was highest at the end. In that case the trend might well overrun sigma so that it becomes a lot more likely that the rabbit is pulled! Observing the rabbit is thus indicative of a problem with the data.
There is a lovely example in The Black Swan, where Taleb describes two people who are asked almost exactly this question. Moe (or whatever, book not handy) the taxi driver is asked what the chances are of flipping heads on a coin, given the information that the last 100 flips here heads. Dr. Smartaass (again, wrong name, but you get the idea) who is a Real Scientist is asked exactly the same question. Dr. S replies “Fifty percent, because the coin has no memory”. Moe says “It’s a mugs game. The coin has two heads, because there is no friggin’ way you can flip 100 heads in a row on a two sided coin.”
Bayes, Jaynes, Shannon, Cox all agree with Moe, not Dr. S! It’s a mug’s game. What one should conclude from the observation of 13 months in a row given precisely the presented analysis is that the temperature series used to compute it is seriously biased!
We will now return to your regular presentation.
rgb
I made an interesting discovery.
According to my latest calculations, on the development of the speed of warming and cooling,
– looking at it on what energy we get from the sun -, ie. the maximum temperatures,
(which nobody who is anybody in climate science is plotting)
I get that global warming started somewhere in 1945 and global cooling started in 1995.
That is a cycle of 50 years.
Does that ring a bell somewhere?
There is very likely an ozone connection.
http://www.letterdash.com/henryp/global-cooling-is-here
Willis Eschenbach – The question Masters was investigating was how likely the 13 months in a row of top 1/3 temperatures was absent a trend? And to do that he (and Tamino, and Lucia) looked at the variance and behavior of the monthly data and estimated how likely the observations are give that behavior.
[Incidentally, insofar as the Shapiro-Wilk test goes, monthly anomalies standardized by their SD (which is reasonable considering that the top 1/3 check is on a monthly basis) do follow the normal distribution. See http://tamino.wordpress.com/2012/07/11/thirteen/%5D
The question you asked (and answered) is how much do the observations look like the observations? You fit a Poisson distribution – you might as well have fit a skewed Gaussian, a spline curve, or a Nth order polynomial; each would be in that case descriptions of the observations. And, oddly enough, the observations match that description at 1:1, +/- your smoothing of those observations. You have no expectations in your evaluation, and hence nothing to compare the observations or their probability to.
You’ve put the observations in a mirror – and they look just like that reflection. You haven’t compared them to any expectations, or you would notice the antenna and extra limbs, and perhaps find them a bit unlikely…
—
As said by multiple posters here and elsewhere – the 13 month period of high temperatures is extremely unlikely without a climate trend. With the warming trend, it goes from a 5-6 sigma event to a 2-3 sigma. And that is the point that Masters was making.
pjie2 says:
In fact, your analysis is even weaker than I thought, since all you’ve shown is that Poisson is the wrong model, i.e. that hot months “clump” together more than would be expected by random chance. That could be for several different reasons, most notably (1) if there is a trend over time, or (2) if there is autocorrelation between successive months. Note that those are independent – you could have a non-stationary dataset without autocorrelation, or a data set with autocorrelation but no net trend.
One example of a dataset with autocorrelation but no net trend is data derived from a cyclic process. High values clump near the peaks, low values near the valleys, and middle values near the nodes. Many alternatives to the IPCC climate narrative of catastrophic, monotonic, anthropogenic ‘global warming’ propose that surface temps operate on a 60ish year cycle. Those alternatives also tend to include a modest net warming trend, explained as representing non-catastrophic, moslty natural warming – such as that from LIA recovery.
One could calculate the odds of seeing 13 consecutive upper third months given those assumptions, when sampled near one of the cyclic peaks. Masters did not do that, because the odds would be nowhere near as low as what you get when assuming an absolutely invariate climate as he did. Masters performed the correct analysis, but used a strawnam model that doesn’t represent actual skeptic positions. He then compounds the offense by making a false dichotomy (if it isnt no change in climate whatsoever then it must be ‘global warming’ doom and gloom) and other egregious propaganda driven errors (like conflating ‘warm’ with ‘warming’). Amatuer statisticians are too busy perseverating over minor errors in practice to call Masters on the big lies.
Masters compares the observations to the wrong stochastic model, and cliams he’s found something. Willis compares the observations to themselves, and claims he’s refuted Masters. Flailing about in a dark room, two men will periodically bump their heads together.
Not at all Nigel
As I said I would’ve done things differently, but it is a blog; it isn’t being used to inform decision makers, and he hasn’t stated that he’s a statistician. I don’t think he’s right but then as I’ve stated many times above doing any type of statistical analysis such as this on a time series without determining whether its first and second order stationary is a waste of time (in both pro and anti camps). But it is just a blog post where at least he’s making an attempt to approach the issue “casually” without dismissing things out-of-hand.
I think everyone seems to be getting a bit hot under the collar. Make your criticism, suggest a better way and move on.
JJ excellent post!
Coming at it from a slightly different angle. It is summer, close to the summer solstice (June 20th) given the observed change in the Jet Streams over the past couple of years, blocking highs with consecutive high temperatures are to be expected.
This article also states:
In other words given a low zonal index, that is a loopy jet stream, the chances of having a blocking high with several days of hot dry weather (here in NC humidity was often below 50%) is to be expected. Also to be expected is the cool rainy weather in the UK.
Of interest is this statement from Astronomy Online: The Tropopause can shift position due to seasonal changes, and marks the location of the Jet Streams – rivers of high winds energized by UV radiation.
And is echoed here:
Sounds a little like Stephen Wilde doesn’t it?
And finally we have NASA on the sun:
As the solar wind and the sun’s magnetic field weaken the amount of cosmic rays striking the earth increase. However the current theory is cosmic rays DESTROY the ozone not create it, but not all agree.
New theory predicts the largest ozone hole over Antarctica will occur this month – cosmic rays at fault
Whether or not it is cosmic rays causing an increase in ozone or the “less puffed up” atmosphere, a negative PDO or something else, the pattern of the Jet Stream has changed from a high zonal index to a low zonal index. Even a lowly farmer would notice the winds are no longer steady out of the west in NC but from all points of the compass including from the east and this has been going on for a couple of years now. Therefore the possibility of blocking highs with record breaking consecutive temperatures is not 1 in a million but an expected occurrence.
Data has been fit to a Poisson Distribution. How do we know that the sampling period is long enough to have fully encountered ever singe possible even that could occur at the tails? One of the posters above notes that if you look at a 5 year non-ElNino/LaNina period of time in the east Pacific that once an El Nino occurs it will appear to be a one-in-a million chance.
There is simply no way to determine if what we are seeing is a Black Swan that could have occurred in an unchanging climate. Thu,s just because you can fit the data to a Poisson curve (sorta) doesn’t mean that this is the proper model because we don’t have a long enough period of time to determine what the tails of the distribution should actually look like.
– Looks like some good work and analysis here. A few hot months are to be expected. I’d only add that a Kolmogorov-Smirnov test could be useful to see how well the Poisson distribution is fitting the data. (e.g. http://mathworld.wolfram.com/Kolmogorov-SmirnovTest.html)
rgbatduke says:
That’s an autocorrelation problem again. El Nino is a short-term trend, and the distribution of warm months isn’t random. Remove the autocorrelation, though, and you can get a real estimate of the probability of a streak.
But yeah, once you add a long-term trend, or even just multidecadal variability that hasn’t yet been properly sampled in the historical series, then this all goes to pot. Which is what we have in the US.
Excellent post, btw. I agree almost completely. I do keep encountering people (in this case, I wouldn’t call them “skeptics”, since they’re not looking rationally at data) who deny that the US has warmed. Sure, if we were looking at a patch of space around Bolivia or the Indian Ocean, I’d agree that we’d be cherry-picking.. but for some reason, some people on both sides seem to be fixated on the US temperatures. /shrug. The only reason why, I could imagine, is that US temperatures will drive US opinions.. but is that a good thing to encourage? Probably not.
Still, a “yes, the US has warmed, and no, it doesn’t matter except in a global context” might be more effective at educating people.
Nigel Harris says:
July 12, 2012 at 1:53 am
“As several commenters have pointed out (with greater or lesser degrees of condescension), your analysis is tautologous. “
That’s not quite right either, though. IF these data fit the requirements for the particular distribution, it would be quite possible to estimate a non-trivial probability for an event which had not been observed, and the mean frequency of such events in any case.
JJ says:
July 12, 2012 at 6:42 am
IME, your posts are always perspicuous and perspicacious.
rgbatduke says:
July 12, 2012 at 6:04 am
“Well, the limiting case is to truncate the data to 13 months for a probability of 1. Also 1 for all 13 years in the middle and lower thirds. So the nature of the distribution changes over time even if the trend is flat. My head started to hurt so I dropped back to simple N of M analysis.”
No, 13 months means a probability of zero that all of them are in the top third of 13 months.
Actually after 13 months the probability is meaningless, every month is simultaneously the highest and lowest for that month! You’d have to have at least 39 months for the statistic to have any real meaning.
pjie2 says:
July 12, 2012 at 2:48 am
If that was what Jeff Masters was trying to show, then he’s a fool … why not just look at the temperature record? But he was NOT trying to show that the climate was warming. I can prove that by looking at what he said. He’s changed the post now, but he quotes from the old post:
In other words, no, he is not using that to say the earth is warming. He is claiming that in a warming climate (which he describes as “the climate is staying the same as it did during the past 118 years”) we should only see one more 13-month period between now and 124,652 AD. Note that well. His forecast does not set out to prove it is warming as you claim. His forecast specifies that the assumption is that it is warming, and his odds assume that it will continue to do so.
That was what I objected to. You and KR and other folks say that he was using his calculation to show the climate was warming. But he specifically made the claim that he was talking about the odds in a warming climate, not that he was using those odds to show that the climate was warming.
Now, what I have done is that show that the odds, not in your claimed theoretical world but in the current warming climate that he himself specified, or as he said “assuming the climate is staying the same as it did during the past 118 years”, that those odds were nothing like what he claimed. If we assume (as he did) the climate continues as it was in the last 118 years, then my result gives the correct odds for it happening.
So no, Masters was NOT setting out to prove the climate was warming, that’s totally contradicted by his own words. He was claiming that in the current, warming climate, the odds were greatly against 13 being in the warmest third. They are not, it’s about a 50/50 bet.
w.
Mods, any idea where my response to this post is?
KR says:
July 12, 2012 at 6:31 am
Willis Eschenbach – The question Masters was investigating was how likely the 13 months in a row of top 1/3 temperatures was absent a trend? And to do that he (and Tamino, and Lucia) looked at the variance and behavior of the monthly data and estimated how likely the observations are give that behavior.
As said by multiple posters here and elsewhere – the 13 month period of high temperatures is extremely unlikely without a climate trend. With the warming trend, it goes from a 5-6 sigma event to a 2-3 sigma. And that is the point that Masters was making.
And I agree (although what the sigma is depends, as noted, on parameters of the model estimation process and their best interpretation is that the data fails the null hypothesis of unbiased data, BTW, precisely because it is a 2-3 sigma event, infinitely more so as a 5-6 sigma event).
A secondary, but absolutely fascinating possibility is that the natural variance of the weather was strongly suppressed in the US for that period by an equally natural process. This reduces the probability of the event to “completely irrelevant” as it is a consequence of complicated chaotic non-Markovian dynamics with no predictive value whatsoever (it is a “black swan”).
As noted above, as a demonstration of warming trend it is a big “so what” point. One can visit:
http://commons.wikimedia.org/wiki/File:Holocene_Temperature_Variations.png
on up (any of the figures linked therein) and the mere thermometric data shows the roughly 0.01 C/year trend over the last 100-150 years. And anybody too stupid or paranoid to believe the mere thermometric data isn’t going to understand, or believe, Masters’ argument.
Don’t get me wrong — I’m a long time WU subscriber, and generally I like Masters’ blog, especially when he waxes on about tropical storms (something of his specialty and the main reason I subscribed originally, as I’m sitting here looking out my window in the direction of Cuba across the Atlantic and tropical storms sometimes roll right up to the back door of the house I’m living in). But comparing apples to oranges to prove that bananas attract flies? Not good. Overtly bad if it is done to fool those too ignorant to be able to understand the inanity of the argument that bananas attract flies. Where the bananas bit isn’t to establish that there is a warming trend, it is to establish that there is an anthropogenic warming trend that will lead to catastrophe if we fail to spend lots of money in certain specific ways.
rgb
Willis Eschenbach says:
July 12, 2012 at 10:33 am
That was what I objected to. You and KR and other folks say that he was using his calculation to show the climate was warming. But he specifically made the claim that he was talking about the odds in a warming climate, not that he was using those odds to show that the climate was warming.
Now, what I have done is that show that the odds, not in your claimed theoretical world but in the current warming climate that he himself specified, or as he said “assuming the climate is staying the same as it did during the past 118 years”, that those odds were nothing like what he claimed. If we assume (as he did) the climate is as it was in the last 118 years, then my result gives the correct odds for it happening.
No it doesn’t because as pointed out before your assumption that it is the result of a Poisson process is wrong because you can’t use a Poisson process when there is a trend. Not only that but your own results show that it’s inappropriate because the mean for the statistic is defined to be 4.33 not the arbitrary fitted 5.2 that you found. So even if it were a Poisson process you don’t get the right odds because you use the wrong data.