{kind=link}
Guest Post by Willis Eschenbach
While investigating the question of cycles in climate datasets (Part 1, Part 2), I invented a method I called “sinusoidal periodicity”. What I did was to fit a sine wave of various periods to the data, and record the amplitude of the best fit. I figured it had been invented before, so I asked people what I was doing and what its name was. I also asked if there was a faster way to do it, as my method does a lot of optimization (fitting) and thus is slow. An alert reader, Michael Gordon, pointed out that I was doing a type Fast Fourier Transform (FFT) … and provided a link to Nick Stokes’ R code to verify that indeed, my results are identical to the periodogram of his Fast Fourier Transform. So, it turns out that what I’ve invented can be best described as the “Slow Fourier Transform”, since it does exactly what the FFT does, only much slower … which sounds like bad news.
My great thanks to Michael, however, because actually I’m stoked to find out that I’m doing a Fourier transform. First, I greatly enjoy coming up with new ideas on my own and then finding out people have thought of them before me. Some folks might see that as a loss, finding out that someone thought of my invention or innovation before I did. But to me, that just means that my self-education is on the right track, and I’m coming up with valuable stuff. And in this case it also means that my results are a recognized quantity, a periodogram of the data. This is good news because people already understand what it is I’m showing.
 Figure 1. Slow Fourier transform periodograms of four long-term surface air temperature datasets. Values are the peak-to-peak amplitude of the best-fit sine wave at each cycle length. The longest period shown in each panel is half the full length of the dataset. Top panel is Armagh Observatory in Ireland. The second panel is the Central England Temperature (CET), which is an average of three stations in central England. Third panel is the Berkeley Earth global temperature dataset. The fourth panel shows the HadCRUT4 global temperature dataset. Note that the units are in degrees C, and represent the peak-to-peak swings in temperature at each given cycle length. Data in color are significant after adjustment for autocorrelation at the 90% level. Significance is calculated after removing the monthly seasonal average variations.
Figure 1. Slow Fourier transform periodograms of four long-term surface air temperature datasets. Values are the peak-to-peak amplitude of the best-fit sine wave at each cycle length. The longest period shown in each panel is half the full length of the dataset. Top panel is Armagh Observatory in Ireland. The second panel is the Central England Temperature (CET), which is an average of three stations in central England. Third panel is the Berkeley Earth global temperature dataset. The fourth panel shows the HadCRUT4 global temperature dataset. Note that the units are in degrees C, and represent the peak-to-peak swings in temperature at each given cycle length. Data in color are significant after adjustment for autocorrelation at the 90% level. Significance is calculated after removing the monthly seasonal average variations.
I’m also overjoyed that my method gives identical results to its much speedier cousin, the Fast Fourier transform (FFT), because the Slow Fourier Transform (SFT) has a number of very significant advantages over the FFT. These advantages are particularly important in climate science.
The first big advantage is that the SFT is insensitive to gaps in the data. For example, the Brest tide data goes back to 1807, but there are some missing sections, e.g. from 1836-1846 and 1857-1860. As far as I know, the FFT cannot analyze the full length of the Brest data in one block, but that makes no difference to the SFT. It can utilize all of the data. As you can imagine, in climate science this is a very common issue, so this will allow people to greatly extend the usage of the Fourier transform.
The second big advantage is that the SFT can be used on an irregularly spaced time series. The FFT requires data that is uniformly spaced in time. But there’s a lot of valuable irregularly spaced climate data out there. The slow Fourier transform allows us to calculate the periodogram of the cycles in that irregular data, regardless of the timing of the observations. Even if all you have are observations scattered at various times throughout the year, with entire years missing and some years only having two observations while other years have two hundred observations … no matter. All that affects is the error of the results, it doesn’t prevent the calculation as it does with the FFT.
The third advantage is that the slow Fourier transform is explainable in layman’s terms. If you tell folks that you are transforming data from the time domain to the frequency domain, people’s eyes glaze over. But everyone understands the idea of e.g. a slow six-inch (150 mm) decade-long swing in the sea level, and that is what I am measuring directly and experimentally. Which me leads to …
… the fourth advantage, which is that the results are in the same units as the data. This means that a slow Fourier transform of tidal data gives answers in mm, and an SFT of temperature data (as in Figure 1) gives answers in °C. This allows for an intuitive understanding of the meaning of the results.
The final and largest advantage, however, is that the SFT method allows the calculation of the actual statistical significance of the results for each individual cycle length. The SFT involves fitting a sine wave to some time data. Once the phase and amplitude are optimized (fit) to the best value, we can use a standard least squares linear model to determine the p-value of the relationship between that sine wave and the data. In other words, this is not a theoretical calculation of the significance of the result. It is the actual p-value of the actual sine wave vis-a-vis the actual data at that particular cycle length. As a result, it automatically adjusts for the fact that some of the data may be missing. Note that I have adjusted for autocorrelation using the method of Nychka. In Figure 1 above, results that are significant at the 90% threshold are shown in color. See the note at the end for further discussion regarding significance.
Finally, before moving on, let me emphasize that I doubt if I’m the first person to come up with this method. All I claim is that I came up with it independently. If anyone knows of an earlier reference to the technique, please let me know.
So with that as prologue, let’s take a look at Figure 1, which I repeat here for ease of reference.
There are some interesting things and curious oddities about these results. First, note that we have three spatial scales involved. Armagh is a single station. The CET is a three-station average taken to be representative of the country. And the Berkeley Earth and HadCRUT4 data are global averages. Despite that, however, the cyclical swings in all four cases are on the order of 0.3 to 0.4°C … I’m pretty sure I don’t understand why that might be. Although I must say, it does have a certain pleasing fractal quality to it. It’s curious, however, that the cycles in an individual station should have the same amplitude as cycles as the global average data … but we have to follow the facts wherever they many lead us.
The next thing that I noticed about this graphic was the close correlation between the Armagh and the CET records. While these two areas are physically not all that far apart, they are on different islands, and one is a three-station average. Despite that, they both show peaks at 3, 7.8, 8.2, 11, 13, 14, 21, 24, 28, 34, and 42 years. The valleys between the peaks are also correlated. At about 50 years, however, they begin to diverge. Possibly this is random fluctuations, although the CET dropping to zero at 65 years would seem to rule that out.
I do note, however, that neither the Armagh nor the CET show the reputed 60-year period. In fact, none of the datasets show significant cycles at 60 years … go figure. Two of the four show peaks at 55 years … but both of them have larger peaks, one at 75 and one at 85 years. The other two (Armagh and HadCRUT) show nothing around 60 years.
If anything, this data would argue for something like an 80-year cycle. However … lets not be hasty. There’s more to come.
Here’s the next oddity. As mentioned above, the Armagh and CET periodograms have neatly aligned peaks and valleys over much of their lengths. And the Berkeley Earth periodogram looks at first blush to be quite similar as well. But Figure 2 reveals the oddity:
 Figure 2. As in Figure 1 (without significance information). Black lines connect the peaks and valleys of the Berkeley Earth and CET periodograms. As above, the length of each periodogram is half the length of the dataset.
Figure 2. As in Figure 1 (without significance information). Black lines connect the peaks and valleys of the Berkeley Earth and CET periodograms. As above, the length of each periodogram is half the length of the dataset.
The peaks and valleys of CET and Armagh line up one right above the other. But that’s not true about CET and Berkeley Earth. They fan out. Again, I’m pretty sure I don’t know why. It may be a subtle effect of the Berkeley Earth processing algorithm, I don’t know.
However, despite that, I’m quite impressed by the similarity between the station, local area, and global periodograms. The HadCRUT dataset is clearly the odd man out.
Next, I looked at the differences between the first and second halves of the individual datasets. Figure 3 shows that result for the Armagh dataset. As a well-documented single-station record, presumably this is the cleanest and most internally consistent dataset of the four.
 Figure 3. The periodogram of the full Armagh dataset, as well as of the first and second halves of that dataset.
Figure 3. The periodogram of the full Armagh dataset, as well as of the first and second halves of that dataset.
This is a perfect example of why I pay little attention to purported cycles in the climate datasets. In the first half of the Armagh data, which covers a hundred years, there are strong cycles centered on 23 and 38 years, and almost no power at 28 years.
In the second half of the data, both the strong cycles disappear, as does the lack of power at 28 years. They are replaced by a pair of much smaller peaks at 21 and 29 years, with a minimum at 35 years … go figure.
And remember, the 24 and 38 year periods persisted for about four and about three full periods respectively in the 104-year half-datasets … they persisted for 100 years, and then disappeared. How can one say anything about long-term cycles in a system like that?
Of course, having seen that odd result, I had to look at the same analysis for the CET data. Figure 4 shows those periodograms.
 Figure 4. The periodogram of the full CET dataset, and the first and second halves of that dataset.
Figure 4. The periodogram of the full CET dataset, and the first and second halves of that dataset.
Again, this supports my contention that looking for regular cycles in climate data is a fools errand. Compare the first half of the CET data with the first half of the Armagh data. Both contain significant peaks at 23 and 38 years, with a pronounced v-shaped valley between.
Now look at the second half of each dataset. Each has four very small peaks, at 11, 13, 21, and 27 years, followed by a rising section to the end. The similarity in the cycles of both the full and half datasets from Armagh and the CET, which are two totally independent records, indicates that the cycles which are appearing and disappearing synchronously are real. They are not just random fluctuations in the aether. In that part of the planet, the green and lovely British Isles, in the 19th century there was a strong ~22 year cycle. A hundred years, that’s about five full periods at 22 years per cycle. You’d think after that amount of time you could depend on that … but nooo, in the next hundred years there’s no sign of the pesky 22-year period. It has sunk back into the depths of the fractal ocean without a trace …
One other two-hundred year dataset is shown in Figure 1. Here’s the same analysis using that data, from Berkeley Earth. I have trimmed it to the 1796-2002 common period of the CET and Armagh.
 Figure 5. The SFT periodogram of the full Berkeley Earth dataset, and the first and second halves of that dataset.
Figure 5. The SFT periodogram of the full Berkeley Earth dataset, and the first and second halves of that dataset.
Dang, would you look at that? That’s nothing but pretty. In the first half of the data, once again we see the same two peaks, this time at 24 and 36 years. And just like the CET, there is no sign of the 24-year peak in the second hundred years. It has vanished, just like in the individual datasets. In Figure 6 I summarize the first and second halves of the three datasets shown in Figs. 3-5, so you can see what I mean about the similarities in the timing of the peaks and valleys:
 Figure 6. SFT Periodograms of the first and second halves of the three 208-year datasets. Top row is Berkeley Earth, middle row is CET, and bottom row is Armagh Observatory.
Figure 6. SFT Periodograms of the first and second halves of the three 208-year datasets. Top row is Berkeley Earth, middle row is CET, and bottom row is Armagh Observatory.
So this is an even further confirmation of both the reality of the ~23-year cycle in the first half of the data … as well as the reality of the total disappearance of the ~23-year cycle in the last half of the data. The similarity of these three datasets is a bit of a shock to me, as they range from an individual station to a global average.
So that’s the story of the SFT, the slow Fourier transform. The conclusion is not hard to draw. Don’t bother trying to capture temperature cycles in the wild, those jokers have been taking lessons from the Cheshire Cat. You can watch a strong cycle go up and down for a hundred years. Then just when you think you’ve caught it and corralled it and identified it, and you have it all caged and fenced about with numbers and causes and explanation, you turn your back for a few seconds, and when you turn round again, it has faded out completely, and some other cycle has taken its place.
Despite that, I do believe that this tool, the slow Fourier transform, should provide me with many hours of entertainment …
My best wishes to all,
w.
As Usual, Gotta Say It: Please, if you disagree with me (and yes, unbelievably, that has actually happened in the past), I ask you to have the courtesy to quote the exact words that you disagree with. It lets us all understand just what you think is wrong.
Statistical Significance: As I stated above, I used a 90% level of significance in coloring the significant data. This was for a simple reason. If I use a 95% significance threshold, almost none of the cycles are statistically significant. However, as the above graphs show, the agreement not only between the three independent datasets but between the individual halves of the datasets is strong evidence that we are dealing with real cycles … well, real disappearing cycles, but when they are present they are undoubtedly real. As a result, I reduced the significance threshold to 90% to indicate at least a relative level of statistical significance. Since I maintained that same threshold throughout, it allows us to make distinctions of relative significance based on a uniform metric.
Alternatively, you could argue for the higher 95% significance threshold, and say that this shows that there are almost no significant cycles in the temperature data … I’m easy with either one.
Data and Code: All the data and code used to do the analysis and make these graphics is in a 1.5 Mb zipped folder called “Slow Fourier Transform“. If you change your R directory to that folder it should all work. The file “sea level cycles.R” is the main file. It contains piles of code for this and the last two posts on tidal cycles. The section on temperature (this post) starts at about line 450. Some code on this planet is user-friendly. This code is user-aggressive. Things are not necessarily in order. It’s not designed to be run top to bottom. Persevere, I’ll answer questions.
Alex says “to Thinking Scientist:
I thought you could use any number, not just a prime one. The series of numbers you referred to are not prime”
You may be correct about any number, but I thought it was only primes. As for the numbers, I didn’t refer to the numbers, they were from the linked quote. They are all powers of the prime 2. An fft can be efficiently solved for any prime, the genius of the fftw code from MIT is that it decomposes the dimensions of the problem into prime factors. It also works in 2D or 3D. If you give it datasets for which the number of samples in each coordinate are already powers of primes, it is astonishingly fast.
The most effiecient appear to be powers of 3, 5 and 7. It can perform fft up to prime factors of 13 as I recall.
Willis Eschenbach: “I’d love to [directly compute the Fourier integral], but I don’t see how to do what you propose. Perhaps you could explain in a bit more detail.”
I’m not positive, but he may have meant something along this line:
DFTtrunc = function(x){
# x is the raw data whose first and last values are not missing
# This function computes half the DFT and omits the DC term
N = length(x);
K = floor(N / 2); # Frequency-bin count; only half a full DFT
X = complex(K); # Receives the DFT
dt = 2 * pi / N;
t = (0:(N-1)) * dt;
# Starting k at 0 eliminates the DC term:
for(k in 1:K) X[k] = sum(x * exp(1i * k * t), na.rm = TRUE) / length(x[-is.na(x)]);
list(mag = abs(X), phase = Arg(X)) ; # Magnitude and phase
}
I haven’t actually run the code above, but the point, as I mentioned in my previous comment, is that correlation (which Fourier Transformation does) is equivalent to error minimization, and you may thereby skip a lot of computer cycles.
An FFT is possible for any NON-prime (called “composite”) length. For example, there are FFTs for length 64 (2^6), for 100 (2*2*5*5), for 99 (3*3*11) but not for 97 or 101. In a language such as Matlab, you ask for an FFT of any length. If the number is prime (e.g., 101) Mallab apparently does the DFT.
The FFT and the DFT or a sequence should be identical to many many decimal places. The FFT is just a fast algorithm for calculating the DFT (a formula). In terms of numerical results, the two terms are largely used interchangeably.
To see the difference in computation time, one can measure flops for different length for an amusing plot such as:
http://electronotes.netfirms.com/AN387.pdf
Here you see an N^2 curve for the prime numbers and what I found to be 3.3 N Log2 N for the powers of 2. Lengths that are neither prime nor powers of 2 are in between. The most composite are faster. For lengths that have only two factors (e.g., 3 and a prime factor) we see a corresponding quadratic trend.
You need to window your finite time series. Note that the Fourier transform function goes from negative infinity to positive infinity. You don’t have that much data. Mathematically, the DFT treats a finite series as infinitely repeating the same series. This means for example if you start with a temperature of 10deGc and end with a temperature of 12deGC you end up with a step function of 2deGC in your infinite time series, which ends up as a sinx/x noise in the frequency domain. It looks to me like I could draw a sinx/x kind of envelope around your data in some cases, so I’d be worried about that.
SOP for inventing any new time of signal analysis is to put various standard signals in and see that you get out what you would expect. For example, pink noise, red noise, white noise, sine wave of various frequencies phase shifted various amounts, triangle wave. There are tons of texts that show you what the output should ideally look like for ideal signals.
Another point – in general you need about 4 periods to get any interesting data on the low frequency side. You have about 206 years of data, which means any signal slower than 50 years is going to be pretty fuzzy. (yes in theory you could do this with 2 cycles, but with noisy data it’s much harder). Think of this as Nyquist limit on its head. It’s not much discussed unfortunately, all the texts talk about Nyquist on the high frequency side, but it applies on the low frequency side as well.
In the end, the big problem with CAGW is – there simply isn’t enough data to support any conclusions in either direction. We just have to wait for the data.
Joe Born says:
May 4, 2014 at 12:24 pm
Joe, as always good to hear from you. Actually, I found a faster method, which may have been what he meant. This is to use a linear model fitting sine and cosine terms of the form
value = a sin(w t) + b cos(w t)
where w is 1/period, t is time, and a and b are the variables to be fitted.
I use a linear model lm() to give me the values for a and b. The amplitude I’m looking for is the range of the fitted curve. No optimization.
Regards,
w.
Peter Sable says:
May 4, 2014 at 12:51 pm
Thanks, Peter. I agree completely. My rule of thumb is nothing longer than a third of the dataset. That’s the reason for the yellow lines up above, a danger zone. I probably should put the yellow line at a quarter of the dataset length as you propose, and a red line at a third of the length.
And yes, I discuss this a lot. Folks keep trying to squeeze 60-year cycles out of 7-year datasets and the like … can’t be done.
Actually, we’re getting to the point where that is less of an issue, although it will always be an issue in the field. Things like the satellite measurements of temperature and ice coverage are in their fourth decade or so. And the Argo buoys have greatly increased our understanding of the ocean.
However, for understanding the long-term effects, you are 100% correct, we need centuries of data.
In addition, even when we have a number of repetitions to confirm our results, say five cycles of the ~22-year signal in the early halves of the three datasets, that satisfies the statistical requirements … but the son of a gun disappears in the later halves of the datasets. Go figure.
w.
http://mathworld.wolfram.com/DiscreteFourierTransform.html
Explore
rgb says: “I pointed out that what is called “pressure broadening” produces a Lorentzian line shape in radiation physics because collisions randomly interrupt the phase of the emitted wave, effectively doing the same thing but with many possible data intervals smeared out over a range.”
Thanks, I missed that one last time around. I knew it was a Lorentzian profile but it’s interesting to see that explanation of why.
Do you know anything about correcting for instrument defects by deconvolution, by any chance?
Sorry, by “instruments” I meant diffraction spectrometers. In particular I’m trying to wring a bit more resolution out of an ‘echelle’ spectrometer.
@Willis Eschenbach
Considering a square wave: In your example, this would be insensitive. I think the “spectra” you have shown are interesting because, using an FFT you would get the the well known series (assuming the series is symmetric about zero) of
cos(wt)+cos(3wt)+ cos(5wt)……
Your example shows this but, as expected the higher frequencies are degraded in the decimated version. If you were to use a shorter period or a higher frequency, this effect would be more pronounced. In other words, it sort of works for your example but you cannot assume that this is always true.
What is striking, however, is that there are marked side-lobes at the fundamental frequency/period, at about 20% of the peak amplitude. These should definitely not be present and are an artefact of the processing, which in the regularly sampled data should be, according to your thesis, exact. The shape is of the form sinc(w) which suggests that there is an artifactual windowing problem.
As regards quadrature: This is reasonably straight forward provided the sampling decimation is not too severe. In principle, one interpolates the signal between samples and evaluates
integral[A(x).f(x)]dx between xn and xn+1, where A(x) is a harmonic and f(x) is the signal. There are a number of schemes for doing this but they all have problems. Any data with discontinuities (by which I mean the derivatives are discontinuous) may cause problems, although these are handled exactly in the regularly spaced DFT.. See Froberg(1970) Introduction to Numerical analysis, chapter 10.
Very common sort of thing in exploration seismic processing, where countless variations of what you have described are used for interpolation and noise suppression. One such variation is known as the anti-leakage Fourier transform.
Willis, I enjoyed seeing your work and description,. I often think that “multiple independent invention” of new concepts is common in science, as there may be thousands of scientists coming to similar analysis & conclusions at the same time, but only one, the “first past the publishing post”, gets the credit when that is a very artificial criteria, but one that : [is at least verifiable, can have a big influence on careers and status, often ignores subtleties and important advantages of the “also ran” analysis]. One of very many historical examples, if I remember correctly, is the derivation of Force = 1/2 * mass * acceleration by an Italian contemporary (and fan of) Isaac Newton, whose later formula did not of course have the 1/2 factor. Re-inventing the wheel IS an important process as well – we need at least some people to pursue independent tinking, as this helps highlight failures and weaknesses in the mainstream consensus scientific religions.
It would be nice to see the same results if you were to tackle wavelet and Hilbert transforms (as per rgbatduke’s interesting comments of May 4, 2014 at 9:50 am). I am lost with the latter, but it has become a line of pursuit by at least one scientist, Walter Freeman, for the “meso-scale” analysis of brain signals (EEG, between the microscale neuron assembly scale and the “macro-scale” level of brain regions or whole brian analysis) – this is an interesting practical aaplication of a technique that apparently is linear in a sense. Of particular interest are analysis for “discontinuities” including non-stationary transitions.
Willis Eschenbach: “Actually, I found a faster method, which may have been what he meant. This is to use a linear model fitting sine and cosine terms of the form. . . .”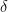 of x.” Or “There’s less than a 5% chance that the outcome we’ve observed would result if the situation we’ve assumed for the sake of argument really prevailed.” But I can’t map either of those meanings to this context. Can you or someone else here explain that usage?
of x.” Or “There’s less than a 5% chance that the outcome we’ve observed would result if the situation we’ve assumed for the sake of argument really prevailed.” But I can’t map either of those meanings to this context. Can you or someone else here explain that usage?
Yes, that’s faster as a practical matter for the R user. Since you probably used “lm” rather than “nlm,” though, it probably actually does use essentially the correlation approach internally that I’ve suggested, but (at least if I had optimized the operation order) I’m guessing that from the computer’s point of view “lm” requires the extra step of solving two linear equations simultaneously; “lm” wouldn’t know initially that the two model functions are orthogonal and thereby finesse around that step.
By the way, for those of us who are allergic to statistics, I wonder if you could explain what you mean by “significance” in “used a 90% level of significance in coloring the significant data.” I’m guessing that you’re comparing something to, say, 1.65 standard deviations of the untrended data, but I don’t know what that something is.
Specifically, my statistics-bereft view of “significance” is that it means, “If the process works in such and such a fashion, (i.e. if a certain model applies), then (e.g.) 95% of the time its outcome will be within
I make my living largely off the FFT. One can represent any shape at all with it. But the technique is NOT predictive. One can’t use it to predict the future. I support what you do with climate skepticism but I am a big skeptic of using Fourier transforms to predict the future. Discrete FT’s are repetitive, periodic and repeat their shapes exactly over time.
Glenn Morton says:
May 4, 2014 at 4:06 pm
Couldn’t agree more, Glenn.
w.
Does Willis give money to Watts?
Watts up is the greatest Skeptic site ever. Except for the Willis stuff.
People come to this site. And it’s brilliant! But Willis posts. And it’s stupid!
Why does Watt post Willis stuff?
RS says:
May 4, 2014 at 2:34 pm
Thanks, RS. I don’t assume that it is always true. It’s hard for me to assume much, as I am I was just taking a look at the square wave at your suggestion, because you seemed to assume that the problem of missing data would be bad there … however, I didn’t find that to be the case. Even a lot of missing data didn’t change the shape of the resulting periodogram.
I don’t recall stating that my sampling would be “exact”. To the contrary, I said:
So I’m not unaware that there are limitations, and that different kinds of problems with the data will have different effects on the results. No surprise, my method is subject to the usual constraints and caveats that any mathematical method has, user discretion is advised, void where prohibited or taxed, do not insert square peg into round hole … that’s true of mathematical procedure from addition on up.
.
But it works very well for my purposes, in that I can determine where the most powerful cycles are in a dataset with gaps in it. I have been investigating purported cycles in the various climate datasets, many of which have gaps in them, and for that it is a very useful tool.
My thanks for all your assistance and comments, much appreciated,
w.
Blue Sky,
Willis posts lots of interesting stuff. Some just can’t appreciate it I guess.
@Joe Kirklin Born
Your comment about statistics of cycles is well taken.
If the noise is gaussian (or nearly so) the power spectrum is a chi squared distribution and the power in each harmonic is chi-squared with two degrees of freedom, i.e.: a negative exponential distribution. Knowing the total power in the signal allows one to calculate whether a particular harmonic is “significantly” above the noise.
Lokking at WE’s plot of the spectrum or periodogram of a square wave above in response to my comments about an irregularly sampled square wave, there are obvious artefacts with side-lobes around the fundamental which are comparable in magnitude to the 3rd harmonic. I guess that any simple statistical test on the basis of power distribution would regard these as significant harmonics.
Looking more closely at these plots, there is a problem because the higher harmonics do not have the same amplitude, which they should for a square wave. This may be because the test function is not even and this is basically a cosine transform. If phase is calculated, then the results strike me as wrong.
Also, there should be no no leakage in the spectrum for a simple case such as this. It looks as though the spectrum has been convolved with a sinc(w) function, which in the normal way of looking at spectra, would imply a window in the time domain.
I don;’t know what the explanation of this is, but there seems to be something seriously wrong with the computation. I would suggest that this methodology needs to be thoroughly tested on cases where there known solutions.
Blue Sky (!) Perhaps choose a more appropriate screen name to accompany your vitriolic comment. Or withdraw the comment. Or use your real name.
RS says: May 4, 2014 at 5:11 pm
“Looking more closely at these plots, there is a problem because the higher harmonics do not have the same amplitude, which they should for a square wave.”
No, there should be odd harmonics diminishing as 1/n, and that looks right.
Blue Sky says:
May 4, 2014 at 4:24 pm
###
If more people took the same approach as Willis in getting from zero knowledge to working understanding, we would not be in the mess we are in right now. One can learn a lot from the methodology he employs. He shows us all that anyone with the will, the guts and the curiosity to push oneself in the pursuit of knowledge, can understand anything.
ThinkingScientist “Its not new or original and its very inefficient.”
But it is easy to understand. Not everyone is a mathematician. I am not. I can struggle with calculus but since this problem is to be solved numerically anyway, which by its nature is discrete/finite, it isn’t an exact representation of the integral anyway.
RS: “why not perform the calculation using simple quadrature, i.e.: direct integration of Fourier integral?.”
Because I don’t know how to do that? Naturally if the data were itself continuous — not sampled into data points but *continuous*, and expressable as a function, then you could use math functions directly and the output would be a transformed continuous function.
But that’s not how computers work. The data is finite and sampled at discrete, sometimes irregular intervals. Calculus just isn’t going to work for *implementation* but is a good way to express the problem IF your readers understand the math (I probably won’t without a lot more work than I’m likely to have time to invest).
GlynnMhor “If a cycle has a period of 50 years one time, then 65 years, then 60 years, it will not appear in the frequency spectrum as a strong peak.”
Agreed — BUT if the cycles are not sinusoidal a complex family of sine and cosine periods will be found that, when reconstituted, reproduce the observation. As a diagnostic tool, this result is evidence only of complexity of the input data although it has been argued that with enough patience you can analyse these peaks and discern the period modulating signal that might itself not be apparent or visible in the data.
As others have pointed out, many of these phenomenon exist in audio and radio engineering.
What about missing data:
If you simply remove the missing data and abut the next series of points, the step discontinuity will cause ringing (as several readers have identified) but viewed as a process what happens is the abrupt change in phase causes failure to cancel noise at nearly all wavelengths and a small loss of amplitude of discovered peaks, depending on how many good cycles were found compared to the gap. You still get your period detection with slightly smaller amplitude because some of that amplitude has been diverted to “sidebands” in the spectrum.
A family of regularly-spaced sidebands reveals a step discontinuity and the spacing will itself be an artifact of the size of the discontinuity. It is essentially identical to radio “phase modulation” because the missing data causes a phase shift, or modulation, which creates sidebands.
One solution to the problem is to pad the gap with zeros — don’t interpolate (IMO) — such that when the data resumes it is still in phase. If your data is daily and you skip 30 days, insert 30 zeros. What will happen is these zeros will then multiply by your testing sine wave and will neither add to, nor subtract from, the energy of the particular wavelength you are testing at that moment. You’ll still get discontinuity harmonics and a bit less noise cancellation but at least you won’t get a phase shift and sidebands.
Highly discontinuous data shouldn’t use the row number as the divisor for the sine generating function. Rather, you should map the row number to a time function, and then insert that time function into your sine generating function. It will work fine and give good results.
The idea can be expressed by imagining RANDOM sampling of a sine wave while keeping track of the time each sample was made. When analyzed, you use the time stamps as the multiplier of where you are on the cycle:
For each data point with timestamp and value: Sum ( sin(datapoint_timestamp/slicesize) * datapoint_value )
The “slicesize” is incremented on each pass and determines the wavelength of the sine wave (the period being sought).
Do this all in floating point for great flexibility and precision. The SFT we’ve been looking at is basically the same but presumes a regular timestamp increment. If it isn’t regular then it ought to be specified.
With a long enough integration time (many samples), white noise should cancel completely in any DFT/FFT. But since all real-world samplings start and end, these endpoints introduce a period and artifacts.
I very much like the fact the Willis doesn’t always “know” what some of those who were formally trained may “think they know”. Every once in a blue moon, what they think they know isn’t true. Takes a considerable pair to head off into the academic deep grass without the standard-issue map those who inhabit that grass carry in their breast pockets. Great fun to watch!
Few people had commented on issues related to windowing of the data. I think it would be important to point out that Fourier transform of any kind is not necessarily appropriate method for analysis of climate data, at least not without applying carefully chosen window.
The issue here is that Fourier transform assumes that data that is being transformed is periodic and infinitely repeats itself – for example, if you use 200 years of global temperatures, the previous 200 years are exact copy of it and following 200 years are exact copy of it, and so on ad infinitum.
This assumptions is of course wrong – as we all know, climate is always changing so it does not repeat itself, no matter what interval it is.
To illustrate the problems that could be expected from such an assumption, consider Fourier Transform of simple sinusoidal. It should be a single spectral line in frequency domain. But depending which data set is used for transform, results could be very surprising. When doing FT of whole period (or any number of whole periods) of that sinusoidal, the result is correct, a single spectral line of that frequency. But try to imagine what would happen if you take, for example, 1.5 periods of such sin wave and append it to the end of another 1.5 periods. This would not look like original sinusoidal at all. This is, however, what FT assumes is being transformed, and output of FT would be the spectrum of such curve, not the simple sinusoidal that was used.
This problem is well known in DFT processing, and it is dealt with by applying window function, which tapers endpoints of data set to 0 in a specific fashion, that depends on particular window function.
What is interesting about SFT is that it could be made immune to this problem, given proper selection of optimization function and proper constraints on the way it finds its solution. In case of my example of 1.5 period of sin wave, optimization algorithm would probably find proper single sinusoidal rather then set of different frequencies and phases.
I can also see how it can be much more robust dealing with missing data.
So, subject of more serious verification, I’d say this method should be much more appropriate than FFT for analysis of climate data.
FYI, In general, similar methods are pretty common in noise cancelation algorithms where noise is non-random.
I, for example, used it to find appropriate amplitude and phase of 60Hz noise source in very weak signal (similar to EEG and EKG noise cancellation).
Best