
Guest post by Pat Frank
The summary of results from version 5 of the Coupled Model Intercomparison Project (CMIP5) has come out. [1] CMIP5 is evaluating the state-of-the-art general circulation climate models (GCMs) that will be used in the IPCC’s forthcoming 5th Assessment Report (AR5) to project climate futures. The fidelity of these models will tell us what we may believe when climate futures are projected. This essay presents a small step in evaluating the CMIP5 GCMs, and the reliability of the IPCC conclusions based on them.
I also wanted to see how the new GCMs did compared to the CMIP3 models described in 2003. [2] The CMIP3 were used in IPCC AR4. Those models produced an estimated 10.1% error in cloudiness, which translated into an uncertainty in cloud feedback of (+/-)2.8 Watts/m^2. [3] That uncertainty is equivalent to (+/-)100% of the excess forcing due to all the GHGs humans have released into the atmosphere since 1900. Cloudiness uncertainty, all by itself, is as large as the entire effect the IPCC is trying to resolve.
If we’re to know how reliable model projections are, the energetic uncertainty, e.g., due to cloudiness error, must be propagated into GCM calculations of future climate. From there the uncertainty should appear as error bars that condition the projected future air temperature. However inclusion of true physical error bars never seems to happen.
Climate modelers invariably publish projections of temperature futures without any sort of physical uncertainty bars at all. Here is a very standard example, showing several GCM projections of future arctic surface air temperatures. There’s not an uncertainty bar among them.
{kind=link}
The IPCC does the same thing, brought to you here courtesy of an uncritical US EPA. The shaded regions in the IPCC SRES graphic refer to the numerical variability of individual GCM model runs. They have nothing to do with physical uncertainty or with the reliability of the projections.
{kind=link}
Figure S1 in Jiang, et al.’s Auxiliary Material [1] summarized how accurately the CMIP5 GCMs hindcasted global cloudiness. Here it is:

Here’s what Jiang, et al., say about their results, “Figure S1 shows the multi-year global, tropical, mid-latitude and high-latitude mean TCFs from CMIP3 and CMIP5 models, and from the MODIS and ISCCP observations. The differences between the MODIS and ISCCP are within 3%, while the spread among the models is as large as ~15%.” “TCF” is Total Cloud Fraction.
Including the CMIP3 model results with the new CMIP5 outputs conveniently allows a check for improvement over the last 9 years. It also allows a comparison of the official CMIP3 cloudiness error with the 10.1% average cloudiness error I estimated earlier from the outputs of equivalent GCMs.
First, here are Tables of the CMIP3 and CMIP5 cloud projections and their associated errors. Observed cloudiness was taken as the average of the ISCCP and Modis Aqua satellite measurements (the last two bar groupings in Jiang Figure S1), which was 67.7% cloud cover. GCM abbreviations follow the references below.
Table 1: CMIP3 GCM Global Fractional Cloudiness Predictions and Error
| Model Source | CMIP3 GCM | Global Average Cloudiness Fraction | Fractional Global Cloudiness Error |
| NCC | bcm2 | 67.7 | 0.00 |
| CCCMA | cgcm3.1 | 60.7 | -0.10 |
| CNRM | cm3 | 73.8 | 0.09 |
| CSIRO | mk3 | 65.8 | -0.03 |
| GFDL | cm2 | 66.3 | -0.02 |
| GISS | e-h | 57.9 | -0.14 |
| GISS | e-r | 59.8 | -0.12 |
| INM | cm3 | 67.3 | -0.01 |
| IPSL | cm4 | 62.6 | -0.08 |
| MIROC | miroc3.2 | 54.2 | -0.20 |
| NCAR | ccsm3 | 55.6 | -0.18 |
| UKMO | hadgem1 | 54.2 | -0.20 |
| Avg. 62.1 | R.M.S. Avg. ±12.1% |
Table 2: CMIP5 GCM Global Fractional Cloudiness Predictions and Error
| Model Source | CMIP5 GCM | Global Average Cloudiness Fraction | Fractional Global Cloudiness Error |
| NCC | noresm | 54.2 | -0.20 |
| CCCMA | canesm2 | 61.6 | -0.09 |
| CNRM | cm5 | 57.9 | -0.14 |
| CSIRO | mk3.6 | 69.1 | 0.02 |
| GFDL | cm3 | 71.9 | 0.06 |
| GISS | e2-h | 61.2 | -0.10 |
| GISS | e2-r | 61.6 | -0.09 |
| INM | cm4 | 64.0 | -0.06 |
| IPSL | cm5a | 57.9 | -0.14 |
| MIROC | miroc5 | 57.0 | -0.16 |
| NCAR | cam5 | 63.5 | -0.06 |
| UKMO | hadgem2-a | 54.2 | -0.20 |
| Avg. 61.2 | R.M.S. Avg. ±12.4% |
Looking at these results, some models improved between 2003 and 2012, some did not, and some apparently became less accurate. The error fractions are one-dimensional numbers that are condensed from errors in three-dimensions. The error fractions do not mean that some given GCM predicts a constant fraction of cloudiness above or below the observed cloudiness. GCM cloud predictions weave about the observed cloudiness in all three dimensions; here predicting more cloudiness, there less. [4, 5] The GCM fractional errors are the positive and negative cloudiness errors integrated over the entire globe, suppressed into single numbers. The total average error of all the GCMs is represented as the root-mean-square average of the individual GCM fractional errors.
CMIP5 cloud cover was averaged over 25 model years (1980-2004) while CMIP3 averages represent 20 model years (1980-1999). GCM average cloudiness was calculated from “monthly mean grid-box averages.” So a 20-year global average included 12×20 monthly global cloudiness realizations, reducing GCM random calculational error by at least 15x.
It’s safe to surmise, therefore, that the residual errors recorded in Tables 1 and 2 represent systematic GCM cloudiness error, similar to the cloudiness error found previously. The average GCM cloudiness systematic error has not diminished between 2003 and 2012. The CMIP3 models averaged 12.1% error, which is not significantly different from my estimate of 10.1% cloudiness error for GCMs of similar sophistication.
We can now proceed to propagate GCM cloudiness error into a global air temperature projection, to see how uncertainty grows over GCM projection time. GCMs typically calculate future climate in a step-wise fashion, month-by-month to year-by-year. In each step, the climate variables calculated in the previous time period are extrapolated into the next time period. Any errors residing in those calculated variables must propagate forward with them. When cloudiness is calculationally extrapolated from year-to-year in a climate projection, the 12.4 % average cloudiness error in CMIP5 GCMs represents an uncertainty of (+/-)3.4 Watts/m^2 in climate energy. [3] That (+/-)3.4 Watts/m^2 of energetic uncertainty must propagate forward in any calculation of future climate.
Climate models represent bounded systems. Bounded variables are constrained to remain within certain limits set by the physics of the system. However, systematic uncertainty is not bounded. In a step-wise calculation, any systematic error or uncertainty in input variables must propagate as (+/-)sqrt(sum(per-step error)^2) into output variables. Per-step uncertainty increments with each new step. This condition is summarized in the next Figure.

The left picture illustrates the way a GCM projects future climate in a step-wise fashion. [6] The white rectangles represent a climate propagated forward through a series of time steps. Each prior climate includes the variables that calculationally evolve into the climate of the next step. Errors in the prior conditions, uncertainties in parameterized quantities, and limitations of theory all produce errors in projected climates. The errors in each preceding step of the evolving climate calculation propagate into the following step.
This propagation produces the growth of error shown in the right side of the figure, illustrated with temperature. The initial conditions produce the first temperature. But errors in the calculation produce high- and low uncertainty bounds (e_T1, etc.) on the first projected temperature. The next calculational step produces its own errors, which add in and expand the high and low uncertainty bounds around the next temperature.
When the error is systematic, prior uncertainties do not diminish like random error. Instead, uncertainty propagates forward, producing a widening spread of uncertainty around time-stepped climate calculations. The wedge on the far right summarizes the way propagated systematic error increases as a step-wise calculation is projected across time.
When the uncertainty due to the growth of systematic error becomes larger than the physical bound, the calculated variable no longer has any physical meaning. In the Figure above, the projected temperature would become no more meaningful than a random guess.
With that in mind, the CMIP5 average error in global cloudiness feedback can be propagated into a time-wise temperature projection. This will show the average uncertainty in projected future air temperature due to the errors GCMs make in cloud feedback.
Here, then, is the CMIP5 12.4% average systematic cloudiness error propagated into everyone’s favorite global temperature projection: Jim Hansen’s famous doomsday Figure; the one he presented in his 1988 Congressional testimony. The error bars were calculated using the insight provided by my high-fidelity GCM temperature projection emulator, as previously described in detail (892 kB pdf download).
The GCM emulator showed that, within GCMs, global surface air temperature is merely a linear function of net GHG W/m^2. The uncertainty in calculated air temperature is then just a linear function of the uncertainty in W/m^2. The average GCM cloudiness error was propagated as:

“Air temperature” is the surface air temperature in Celsius. Air temperature increments annually with increasing GHG forcing. “Total forcing” is the forcing in W/m^2 produced by CO2, nitrous oxide, and methane in each of the “i” projection years. Forcing increments annually with the levels of GHGs. The equation is the standard propagation of systematic errors (very nice lecture notes here (197 kb pdf)). And now, the doomsday prediction:

The Figure is self-explanatory. Lines A, B, and C in part “a” are the projections of future temperature as Jim Hansen presented them in 1988. Part “b” shows the identical lines, but now with uncertainty bars propagated from the CMIP5 12.4 % average systematic global cloudiness error. The uncertainty increases with each annual step. It is here safely assumed that Jim Hansen’s 1988 GISS Model E was not up to CMIP5 standards. So, the uncertainties produced by CMIP5 model inaccuracies are a true minimum estimate of the uncertainty bars around Jim Hansen’s 1988 temperature projections.
The large uncertainty by year 2020, about (+/-)25 C, has compressed the three scenarios so that they all appear to nearly run along the baseline. The uncertainty of (+/-)25 C does not mean I’m suggesting that the model predicts air temperatures could warm or cool by 25 C between 1958 and 2020. Instead, the uncertainty represents the pixel size resolvable by a CMIP5 GCM.
Each year, the pixel gets larger, meaning the resolution of the GCM gets worse. After only a few years, the view of a GCM is so pixelated that nothing important can be resolved. That’s the meaning of the final (+/-25) C uncertainty bars. They mean that, at a distance of 62 years, the CMIP5 GCMs cannot resolve any air temperature change smaller than about 25 C (on average).
Under Jim Hansen’s forcing scenario, after one year the (+/-)3.4 Watts/m^2 cloudiness error already produces a single-step pixel size of (+/-)3.4 C. In short, CMIP5-level GCMs are completely unable to resolve any change in global surface air temperature that might occur at any time, due to the presence of human-produced carbon dioxide.
Likewise, Jim Hansen’s 1988 version of GISS Model E was unable predict anything about future climate. Neither can his 2012 version. The huge uncertainty bars makes his 1988 projections physically meaningless. Arguing about which of them tracks the global anomaly trend is like arguing about angels and heads of pins. Neither argument has any factual resolution.
Similar physical uncertainty bars should surround any GCM ensemble projection of global temperature. However, the likelihood of seeing them in the AR5 (or in any peer-reviewed climate journal) is vanishingly small.
Nevertheless, CMIP5 climate models are unable to predict global surface air temperature even one year in advance. Their projections have no particular physical meaning and are entirely unreliable.
Following on from the title of this piece: there will be no reason to believe any – repeat, any — CMIP5-level future climate projection in the AR5.
Climate projections that may appear in the IPCC AR5 will be completely vacant of physical credibility. Attribution studies focusing on CO2 will necessarily be meaningless. This failure is at the center of AGW Climate Promotions, Inc.
Anyone, in short, who claims that human-produced CO2 has caused the climate to warm since 1900 (or 1950, or 1976) is implicitly asserting the physical reliability of climate models. Anyone seriously asserting the physical reliability of climate models literally does not know what they are talking about. Recent pronouncements about human culpability should be seen in that light.
The verdict against the IPCC is identical: they do not know what they’re talking about.
Does anyone think that will stop them talking?
References:
1. Jiang, J.H., et al., Evaluation of cloud and water vapor simulations in CMIP5 climate models using NASA “A-Train” satellite observations. J. Geophys. Res., 2012. 117, D14105.
2. Covey, C., et al., An overview of results from the Coupled Model Intercomparison Project. Global Planet. Change, 2003. 37, 103-133.
3. Stephens, G.L., Cloud Feedbacks in the Climate System: A Critical Review. J. Climate, 2005. 18, 237-273.
4. AchutaRao, K., et al., Report UCRL-TR-202550. An Appraisal of Coupled Climate Model Simulations, D. Bader, Editor. 2004, Lawrence Livermore National Laboratory: Livermore.
5. Gates, W.L., et al., An Overview of the Results of the Atmospheric Model Intercomparison Project (AMIP I). Bull. Amer. Met. Soc., 1999. 80(1), 29-55.
6. Saitoh, T.S. and S. Wakashima, An efficient time-space numerical solver for global warming, in Energy Conversion Engineering Conference and Exhibit (IECEC) 35th Intersociety. 2000, IECEC: Las Vegas. p. 1026-1031.
Climate Model Abbreviations
BCC: Beijing Climate Center, China.
CCCMA: Canadian Centre for Climate Modeling and Analysis, Canada.
CNRM: Centre National de Recherches Météorologiques, France.
CSIRO: Commonwealth Scientific and Industrial Research Organization, Queensland Australia.
GFDL: Geophysical Fluid Dynamics Laboratory, USA.
GISS: Goddard Institute for Space Studies, USA.
INM: Institute for Numerical Mathematics, Russia.
IPSL: Institut Pierre Simon Laplace, France.
MIROC: U. Tokyo/Nat. Ins. Env. Std./Japan Agency for Marine-Earth Sci.&Tech., Japan.
NCAR: National Center for Atmospheric Research, USA.
NCC: Norwegian Climate Centre, Norway.
UKMO: Met Office Hadley Centre, UK.
Interesting but misguided. You were speaking about rounding errors when you should have been speaking of rounding accuracies. When viewed appropriately a lack of solid measurement and estimation allows certain knowledge of the instantaneous anthropogenic temperature anomaly induced on the wing of a bumble bee failing to fly in a computer simulation.
A suggestion as to how to get the models to more accurately reflect cloudiness changes.:
Measure the length of the lines of air mass mixing along the world’s frontal zones which appears to vary by thousands of miles when the jets become more meridional as comparted to zonal and / or shift equatorward as compared to taking a more poleward position.
I think that is the ‘canary in the coalmine’ as regards net changes in the global energy budget because it links directly to albedo and the amount of solar energy able to enter the oceans.
Er, unbelievable. Here is presented, with pseudo-precise numerical content, the result of millions of dollars of computer code massaging, and, well, dick-all to do with the real world. Presented by an organization corrupt to the gneiss below its roots, and promoting a pre-concluded agenda.
This article, like many published in WUWT, conflates the idea that is referenced by the term “projection”
with the termwith the idea that is referenced by the word “prediction.” Actually, the two ideas differ and in ways that are logically important.Predictions state empirically falsifiable claims about the unobserved but observable outcomes of events. Projections do not. Being unfalsifiable, projections lie outside science.
Quick! Somebody tell the New York Times! Global warming called off! Stop the presses!
Oh wait. There’s no one listening. . .
/Mr Lynn
In my post of August 23, 2012 at 8:35 pm, please strike the phrase “with the term” and replace it with “with the idea.”
The amount of money wasted on this fools errand is astounding. It is a simple fact no amount of computer power of tweaking of the program will ever allow us to forecast, predict or project what going to happen in the future as to what going to happen with climate. It is a fact a chaotic system cannot be forecast any further out with any accuracy beyond a few days. Why anyone should pay attention to these expense toys is beyond me. Beyond that why is the tax payer being bilked for the tab on this idiocy
Another excellent post! Thanks again, Pat Frank.
Pat Frank,
Thank you for this fine post. It really got to me and is bookmarked.
I am somewhat of a late-comer to CAGW criticism – it took Climategate 1.0 to get my attention.
First technical question I had was “what do the thermometers actually say?” Stumbled onto something called surfacestations.org – promptly barfed just considering measurement uncertainty – and began marveling at just how radiant physics would work considering CO2 concentration contribution; practically instantaneously considering that earth atmosphere heat content is heavily dependent upon the hydrological cycle; hmmm…clouds…
Wouldn’t an insulating component of our atmosphere (Man-Made CO2) influence cloud formation, which in turn would influence heating as well as atmospheric heat content? In my mental picture/thought experiment it just makes sense that that process feedback is (highly) negative. No need to panic. But let’s get some better measurements; I mean really!
Clouds…
http://www.clouds-online.com/
High clouds, low clouds, wispy ones and rainy ones, storm clouds, white clouds set against brilliant blue skies, sun crowding grey sky clouds – all kinds of clouds.
My poetic point? Perhaps it isn’t just clouds as in quantitative but also clouds as in qualitative. Point here posted? Models don’t even come close to modeling these wispy, beautiful, billowing, dangerous at times, essential-to-our understanding of our atmosphere, things we call clouds. And the science is settled? What! Pure foolishness to claim that.
[Excerpt from the above article]
Climate projections that may appear in the IPCC AR5 will be completely vacant of physical credibility. Attribution studies focusing on CO2 will necessarily be meaningless. This failure is at the center of AGW Climate Promotions, Inc.
Anyone, in short, who claims that human-produced CO2 has caused the climate to warm since 1900 (or 1950, or 1976) is implicitly asserting the physical reliability of climate models. Anyone seriously asserting the physical reliability of climate models literally does not know what they are talking about.
Recent pronouncements about human culpability should be seen in that light.
The verdict against the IPCC is identical: they do not know what they’re talking about.
[end of excerpt]
Comparison to a recent excerpt from wattsup:
http://wattsupwiththat.com/2012/08/15/more-hype-on-greenlands-summer-melt/#comment-1058781
It should now be obvious that global warming alarmists and institutions like the IPCC have NO predictive track record – every one of their major scientific predictions has proven false, and their energy and economic recommendations have proven costly and counterproductive.
____________
Close enough.
Allan MacRae
It sounds as though you are under the misimpression that IPCC climate models make “predictions.” As the climatologist Kevin Trenberth emphatically stated in the blog of the journal Nature in 2007, they make only “projections.” Though predictions are falsifiable, projections are not. The models are not wrong but rather are not scientific.
They will adjust them after the fact as needed. Then show you how spot on their predictions were. No need for no stinkin’ physical uncertainty bars.
Physical uncertainty bars are for sissys! I used to have a license plate that read this in bold lettering on my pink bike with banana seat, sissy bars, and basket.
Terry Oldberg says that if “Predictions” are not falsifiable they cannot be regarded as science. They should not even be called predictions.
He is right. When Einstein predicted the deflection a light beam would suffer at grazing incidence to the sun he initially got the answer wrong by a factor of 2. Back then when “Science” still cared about “Integrity” his theory would have been discredited if he had failed to correct his error before Eddington published his observations. That was “Science”. CMIP3 and CMIP5 are “Non-Science” (aka “Nonsense”).
The statisticians here should have a field day deconstructing this one. If he wanted a worse error, he could have propagated it monthly instead of yearly. That would have been more impressive. How about daily? Can anyone figure out what he did wrong? Or, if the error is only 12% for a year, it must be tiny for a day to only grow to 12% for a year. Just needs some more thought.
The true responses seen here are lacking the basics.
Diurnal cloud cover, height, opacity to the wavelengths that matter and where they are during dayside and night-time throughout each and every day, is key.
A guess is always a guess and if you cannot differentiate between day (incoming solar attenuation) and night (OLR attenuation) you have not produced anything of meaningful value…
They are on the cutting edge of more government money.
(Most do not realize that as much as 60% of science grants go to the applicants, personally)
Not sure i agree with your comment about error bars. Error bars are measures of statistical uncertainty or variance. The output of climate models isn’t data, in the sense of measurements subject to statistical rules. Gavin Schmidt is clear about this.
What you are talking about is predictive accuracy. And I agree with Terry Oldberg. Until the climate modellers concede the model outputs are predictions, their outputs are just projections, and therefore not science.
I wish rather more people understood this.
Philip Bradley:
Thanks for engaging on the projections vs predictions issue. Before their models can make predictions, climatologists must define the underlying statistical population, for a prediction is an extrapolation to the outcome of an event in such a population. A predictive model makes claims about the relative frequencies of the various possible outcomes; these claims are checked by observing the relative frequencies in a sampling of observed events that is drawn for this purpose from the population. In modern climatology, though, there is no population and thus is no opportunity to make a check. This is why the research cannot truly be said to be “scientific.”
How do you calculate a 10.1% error in cloudiness with a model. And how do you know that error is correct; specially since as far as I ca tell, it isn’t even possible to measure global cloudiness with that kind of precision. It’s bad enough to claim they know the global temperature, given the poor sampling regimen, but the number of temperature recording sites must be orders of magnitude greater than the number of cloud measuring sites, specially for the 70 % that is ocean.
Sorry satellites don’t cut the mustard. A single satellite can’t return to a given point to take another sample in less than 84 minutes, and when the satellite does get back to the same place, it isn’t the same place; that’s about 22 degrees away. And clouds can appear out of nowhere, and then disappear in a few minutes. and how many satellites do we have that can simultaneously observe different poins on the surface.
Well I forgot, you can tell a temperature by boring one hole in one tree, so maybe you can get a cloudiness number from a single photograph.
Totally ridiculous to believe they can sample cloud cover of the whole globe in conformance to the Nyquist sampling criterion.
In this instance, what I mean by cloud cover is the total solar spectrum Joules per square metre at the surface under the cloud, divided by the Joules per square metre above the clouds (TSI x time)
Anthony, the link “(very nice lecture notes here (197 kb pdf))” doesn’t work, it has an extraneous slash at the end. The correct URL is http://www.phas.ubc.ca/~oser/p509/Lec_12.pdf
What an excellent article! Thanks to Pat Frank. Clouds are the elephant in the room of climate science. They come, they go and are the Venetian blinds of the earth. If you cannot model the clouds you cannot predict weather or climate.The IPCC is wasting both our money and their time.
Terry Oldberg says: August 23, 2012 at 8:35 pm
This article, like many published in WUWT, conflates the idea that is referenced by the term “projection” with the idea that is referenced by the word “prediction.” Actually, the two ideas differ and in ways that are logically important.
Predictions state empirically falsifiable claims about the unobserved but observable outcomes of events. Projections do not. Being unfalsifiable, projections lie outside science.
___________
Fair point Terry, but either way (prediction or projection). the ultimate conclusion is the same:
The climate models produce nonsense, and yet they are being used in attribution studies to falsely suggest that humanity is the primary cause of the global warming, and to the justify the squandering of trillions of dollars on worthless measures to fight this fictitious catastrophic humanmade global warming.
In summary the climate models are mere “projections” when one correctly points out their dismal predictive track record, but they are also portrayed as robust “predictions” when they serve the cause of global warming alarmism.
In fact, it is the warming alarmists themselves who have actively engaged in this duplicity.
Allan MacRae:
The authors of the IPCC’s periodic assessment reports have been repeatedly guilty of using the ambiguity of reference by terms to the associated ideas as a weapon in attempting to achieve political or financial ends that are favorable to them. Their technique is insert fallacies based on ambiguity of reference into their arguments. Using ambiguity of reference in this way, one can compose an argument that appears to be true when it is false or unproved. Confusion of “projection” with “prediction” serves this end. So does confusion of “evaluation” with “validation.” (Though IPCC climate models are not statistically “validated” they are “evaluated.”)
Ambiguity of reference by the word “science” plays a similar role. In the English vernacular, the word references the idea of “demonstrable knowledge” and the different idea of “the process that is operated by people calling themselves “scientists.” The IPCC’s “scientists” do not produce demonstrable knowledge but do call thermselves “scientists” and operate a process.
Climate “science” is not “demonstrable knowledge,” IPCC “projections” are not “predictions” and IPCC “evaluation” is not “validation” but the IPCC has led its dupes to believe the opposite. Through this technique, IPCC authors have duped the people of the world into parting with a great deal of money; currently, the IPCC is preparing them to part with even more.
Well it is obvious from this post that clouds are still not understood so how can any model produced work without this understanding? There are many other inputs to climate, many extraterrestrial, that are little understood and some we have yet to discover. If we knew all this, and had a computer big enough to handle the billions of bits of information fast enough, them a model might work.
My experience of cloud is that they have a cooling effect and negative feedback. Unfortunately belief in the GHG theory forces the opposite line of thought.
The CMIP5 models for the upcoming AR5 have gone from bad to worse at simulating global sea surface temperatures.
Here’s an excerpt from Chapter 5.5 of my upcoming book Who Turned on the Heat? The Unsuspected Global Warming Culprit, El Niño-Southern Oscillation:
We’ve seen that sea surface temperatures for a major portion (33%) of the global oceans have not warmed in 30 years. This contradicts the hypothesis of anthropogenic global warming. The models show the East Pacific Ocean should have warmed 0.42 to 0.45 deg C during the satellite era, but they haven’t warmed at all.
On the other hand, if we look at the global sea surface temperature record for the past 30 years, we can see that they have warmed. The IPCC’s climate models indicate sea surface temperatures globally should have warmed and they have. See Figure 5-5. Note, however, based on the linear trends the older climate models have overestimated the warming by 73% and the newer models used in the upcoming IPCC AR5 have overshot the mark by 94%. In simple words, the IPCC’s models have gone from terrible to worse-than-that. The recent models estimate a warming rate for the global oceans that’s almost twice the actual warming. In other words, the sea surface temperatures of the global oceans are not responding to the increase in manmade greenhouse gases as the climate models say they should have. Not a good sign for any projections of future climate the IPCC may make.
http://i45.tinypic.com/hs9bbr.jpg
We know it’s all about the money. Not Science.
http://www.bloomberg.com/news/2011-08-08/climatecare-buys-itself-out-from-jpmorgan-targets-u-n-offsets.html
JP Morgan also ran the Oil for Food Program and was involved in this:
http://dailybail.com/home/report-senior-atf-agent-in-charge-of-fast-n-furious-gun-runn.html
http://www.telegraph.co.uk/news/politics/tony-blair/8772418/Tony-Blair-visited-Libya-to-lobby-for-JP-Morgan.html
NOTE: Tony Blair was partners with Al Gore in the UK based Carbon Exchange.
Jim D says:
August 23, 2012 at 10:10 pm
The statisticians here should have a field day deconstructing this one. If he wanted a worse error, he could have propagated it monthly instead of yearly. That would have been more impressive. How about daily? Can anyone figure out what he did wrong? Or, if the error is only 12% for a year, it must be tiny for a day to only grow to 12% for a year. Just needs some more thought.
I am sure that ‘statisticians would have a field day’ but then there has to be understanding of what figures actually mean. A tiny variance in the cloud cover at the tropics will have a far larger effect than a similar variance in temperate or polar latitudes. A tiny variance during the day will have a different effect than a tiny variance during the night. High level cirrus has different effect than low level stratus. Convective clouds are an indication of heat being carried out of the atmosphere stratus are not. But statisticians would only deal in numbers not understanding the impact of the qualitative differences on the quantitative. Indeed by reducing the errors to just a single percentage vast amounts of information has been discarded. It would be interesting to know which cloud the models fail to ‘predict/project/extrapolate’ and where on the globe those models fail as that has a huge effect on the probability of a closer to reality result. But statisticians playing with averaged numbers will not have that information as it has been discarded. So yes it needs more thought – and less just playing with numbers.
Personally, I would like to see strict Validation of these models with repeated runs from different starting points with no change in parameterization between those runs. So starting at 1850, then at 1900, then at 1950, then at 2000 and compare their results to actual analyzed atmosphere (including actual cloud cover and type), maximum and minimum temperatures and humidities and sea temperatures perhaps resolved at one degree latitude and longitude. If a model fails to meet the ‘skill’ level required in its prediction then it should be discarded and further funding to that modeling group should cease. If the various research groups knew that they had a real meteorological skill/validation bar to cross that was sufficiently challenging or lose funding perhaps they would improve more than this article suggests they have.
Remember the results of these models are trumpeted throughout the world by the UN and used to kill major industries and keep 3rd world countries in fuel poverty – we aren’t talking about a simple post-doc project.
Thankyou for spelling this out.
I think that the problems with GCMs extend beyond those of albedo, or cloudiness. Albedo can be measured directly and continuously using geostationaty satellites – presumably the models have been “tuned” to hindcast the known data, but this says nothing about predictive capability.
In reading about the mechanics of GCMs a few months ago I found references to low pass filtering between integration time steps. Filtering is only valid when there is an a priori knowledge of “the signal” (eg a radio signal), however GCM “experiments” assume that the signal is produced by GHGs, therefore this is all that they can ever hope to detect, as all other mechanisms are filtered out.
Even worse, GCMs use pause/reset/restart techniqies in integration when physical laws are vioated (eg conservation of mass, momentum and energy), or boundary conditions are exceeded, in order to preserve “stability”. Such models can produce no useful information, by definition.
The UK Met Office’s climate models lose fidelity after just a few days of simulated elapsed time, and produce results that are shown to be hopeless after a few days of reality. To believe that these models can produce any sensible data AT ALL with simulated elapsed times of decades is laughable to anybody with the meanest knowledge of mathematics and physics.
While I agree with Terry Oldberg on the predictions vs projections thing, either way the modellers have zero stake in accuracy. A bookmaker taking bets on future climate would be much more likely to get it right, because being wrong costs real dollars.
So all we need to know the real answer is a reliable independently verifiable measure of climate and real climate gambling.
So who is up to running the Great Climate Casino – place your bets now.
Thanks, Pat. I like to see someone who takes the trouble to be specific about what they are NOT saying when explaining their work. It helps crystallize genuine understanding and is the mark of an honest educator.
Regarding “The verdict against the IPCC is identical: they do not know what they’re talking about. Does anyone think that will stop them talking?”: This is where the so called “Precautionary Principle” is often invoked, essentially as an argument from ignorance.
More honestly put, the precautionary principle usually amounts to no more than: “I don’t know what the answer is, but I do know that I can frighten you into doing what I say.”
Well, I for one, am not frightened by climate models [only by some of the people that use them].
I read this and thought that Willis had it all covered, still does. His hypothesis should be the touchstone for every serious research program in climate. He’s not alone, but his explanations are the clearest of all of them.
http://www.stuff.co.nz/science/7400061/Global-warming-science-tackled
Next up, lets talk about how well we understand the relationship between cosmic rays and cloud formation 🙂
wiki Freeman Dyson to see what he says about GCM’s.
From my lay viewpoint I’d say that GCM’s are astounding intellectual achievements, but they seem to be pushed beyond their capabilities and misused to promote political agendas. Sort of like quantum chromodynamics being used to select the next US President.
In fairness to the GCM’s, please remember that all parameter values are not equally probable. Any particular electron could be here in this room with me or it could be orbiting the planet Zog, but the wave function might say that the second case has negligible probability. I use this technique to build fairly robust economic models.
In order to understand GHG forcing better I’ve been reading up on atmospherics. One of the key variables is naturally the bond albedo. Google Earth’s albedo and you’ll get values ranging from 0,28 to 0,31. Ditto for Mars and the spread is 0,16 to 0,25!! This makes quite a big difference and I’d suggest that they spend more time nailing it down before any climate modelers ask us to trust their projections.
Thank you, Pat.
I wondered lonely as a cloud
Why no one else said this aloud.
Ian W says: August 24, 2012 at 3:40 am
Quite so. One gains an impression that modellers reject runs that give large errors by their criteria, while refusing to use time-honoured criteria.
Philip Bradley says:
August 23, 2012 at 11:22 pm
“What you are talking about is predictive accuracy. And I agree with Terry Oldberg. Until the climate modellers concede the model outputs are predictions, their outputs are just projections, and therefore not science.
I wish rather more people understood this.”
Unfortunately the average voter, and politician for that matter, does not understand the difference. I believe this lack of understanding is being used by modelers to advance the gravy train of monetary grants while allowing them to have an escape clause when they are eventually proven wrong.
george e smith says:
August 23, 2012 at 11:43 pm
“How do you calculate a 10.1% error in cloudiness with a model. And how do you know that error is correct; ”
Yes, what are the error bars associated with the error bars?
Sorry teach but my eyes glazed over long before “version 5 of the Coupled Model Intercomparison Project “.
I must learn to pay attention in class
I must learn to pay attention in class
I must..
Nice article Pat Frank.
Water Vapour and Clouds are the make or break factors in the theory. If these factors are not the positive feedback assumed in the theory, then then entire proposition falls apart. In fact, if they are just 50% of the positive feedback assumed, the theory still falls apart because there is not enough feedbacks on the feedbacks to get anywhere near to 3.0C per CO2 doubling.
Clouds are a major uncertainty (they could be positive or negative) but the biggest assumed feedback is Water Vapour. Water vapour is supposed to be +6.0% already and +22% by 2100.
So far, it is Zero. The IPCC AR5 Water Vapour forecast versus actual observations to date. The climate models are way off already.
http://s8.postimage.org/epbk2gtlh/ENSO_TCWVIPCC_July12.png
And here is all the climate model forecasts over time going back to Hansen and the first IPCC forecast versus actual temperature observations to date.
http://s17.postimage.org/jobns27n3/IPCC_Forecasts_Obs_July2012.png
Terry Oldberg
We all can agree on 2 areas
1.] Climate models make projections and not predictions.
2.] The IPCC approach is not scientific as there is no way to have a statistically and empirically validated control and trial population for testing any hypothesis.
Nobody disagrees with both of these points. Can you please now stop posting these same points over and over in every thread for years?
Venter:
While you claim that “nobody disagrees with both of these points” the evidence is sadly to the contrary. As of this moment, professional climatologists have yet to identify the statistical population that underlies the claims of their climate models yet they claim to be “scientists” pursuing “science.” In AR4, IPCC authors present “evaluations” of models that are designed to convince the statistically naive that statistical validation is taking place when it is not. Here in WUWT, article after article presents a new model plus a scientifically meaningless IPCC-style “evaluation” of this model. Bloggers routinely weigh in on the issue of whether a given “evaluation” falsifies the model or does not falsify it when an “evaluation” does neither. Skeptics such as Lord Monckton appeal to IPCC-style “evaluations” in presenting logically flawed arguments for the exaggeration of the magnitude of the equilibrium climate sensitivity by the IPCC.
The truth is that climate models are currently insusceptible to being either falsified or validated by the evidence. They will remain in this state until: a) the IPCC identifies the statistical population and b) models are constructed for the purpose of predicting the outcomes of the events in this population. Very few WUWT bloggers exhibit an understanding of this state of affairs. The editors of WUWT do not exhibit an understanding of it in selecting articles for publication. Aside from you and me and a few others, amateur climatologists and professionals are alike in acting as though they don’t have a clue to how scientific research is actually performed.
A great Aussie saying I came across a minute ago, pertinent to this debate: “The hamster’s dead, but the wheel’s still turning.”
Sadly, although I’ve done very similar analyses of the doomsday curves from Hansen et. al. that presume different forcing/feedback scenarios, I do have to take issue with the methodology used to forward propagate the errors. The GCMs are numerical simulations — they are at heart systems of parametric coupled nonlinear differential equations. The solutions they generate are not, nor are they expected to be, normal. Hence simple forward propagation of errors on the basis of an essentially multivariate normal assumption (e.g. the one underlying Pearson’s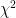 ) is almost certainly egregiously incorrect for precisely the reasons warned about in the Oser lecture — the system is more, or at least differently, constrained than the simple linear addition of Gaussian errors would suggest.
) is almost certainly egregiously incorrect for precisely the reasons warned about in the Oser lecture — the system is more, or at least differently, constrained than the simple linear addition of Gaussian errors would suggest.
With a complex system of this sort, the “right” thing to do (and the thing that is in fact done, in many of the GCMs) is to concede that one has no bloody idea how the DISTRIBUTION of final states will vary given a DISTRIBUTION of input parameters around the best-guess inputs, and hence use Monte Carlo to generate a simulated distribution of final states using input that are in turn selected from the presumed distributions of input parameters. Ensemble models do this all the time to predict hurricane trajectories, for example — they run the hurricane model a few dozen or hundred times and form a shotgun-blast future locus of possible hurricane trajectories to determine the most probable range of values.
To put it in more physical terms, because there are feedbacks in the system that can be negative or positive, the variations in cloudiness are almost certainly not Gaussian, they are very probably strongly correlated with other variables in the GCMs. Their uncertainty in part derives from uncertainty in the surface temperatures, the SSTs, the presence or absence of ENSO positive, and far more. Some of these “uncertainties” — feedbacks — amplify error/variation, but most of them do the opposite or the climate would be unstable, far more unstable than it is observed to be. In other words, while the butterfly effect works on weather state, it tends to be suppressed for climate; the climate doesn’t seem enormously unstable toward hothouse Earth or snowball Earth even on a geological time scale, and the things that cause instability on this scale do not appear to be any of the parameters included in the GCMs anyway because we don’t really know what they are or how they work.
However, the basic message of this is sound enough — there should be error estimates on the “projections” of GCMs — at the very least a Monte Carlo of the spread of outcomes given noise on the parameters.
rgb
pat says:
August 23, 2012 at 10:52 pm
They are on the cutting edge of more government money.
(Most do not realize that as much as 60% of science grants go to the applicants, personally)
_______________________
Actually even the scientists are complaining. The grant money generally gets wasted in bureaucratic red tape they are saying.
The comments are the really interesting part of the article.
I would rather see a lottery system. This would hopefully do away with the entrenched old boy system that keeps innovative ideas from being considered.
This commenter expresses how I feel about the situation.
An honest lottery system would have allowed “Denier” Scientists a bit more of a fair shake and perhaps would have kept the IPCC – CO2 mania more under control.
Retired senior NASA atmospheric scientist, Dr. John S. Theon, the former supervisor of James Hansen, has now publicly declared himself a skeptic and declared that Hansen “embarrassed NASA”. He violated NASA’s official agency position on climate forecasting (“we did not know enough to forecast climate change or mankind’s effect on it”). Hansen thus embarrassed NASA by coming out with his claims of global warming in 1988 in his testimony before Congress. [January 15, 2009]
Theon declared: “Climate models are useless”.
See: James Hansen’s Former NASA Supervisor Declares Himself a Skeptic – Says Hansen ‘Embarrassed NASA’, ‘Was Never Muzzled’, & Models ‘Useless’ (Watts Up With That?, January 27, 2009) http://wattsupwiththat.com/2009/01/27/james-hansens-former-nasa-supervisor-declares-himself-a-skeptic-says-hansen-embarrassed-nasa-was-never-muzzled/
It is difficult to believe that energy poverty is being imposed on Earth to prevent very flawed predictions from becoming true.
This article again shows how useless GCMs are. Thanks, Pat!
This is easily fixed. Add three conditions under each CO2 scenario: El Nino, La Nina, and neutral (we know what the jet stream and clouds kinda do under each condition). Run several trials with the dials turned up to different settings for El Nino, turned up for different settings for La Nina, and several runs between the margins for neutral, and then average for each CO2 scenario. Wonder if one of the models does this already?
And just for giggles, get rid of the CO2 fudge factor and run that under the three ENSO conditions (so you will have three conditions with, and three conditions without CO2 FF). Just to compare. Include accuracy bars of course.
SO WHAT if you have determined that GCM projections are worthless!!!!
Us warmers can take solace knowing we STILL can cling to the universally proven, physiologically compatible, unprecedented, data substantiated, untainted, statistically validated, global encompassing, court approved, and PEER reviewed tree ring data showing MASSIVE specie extinction by 2030.
/sarc
Robert Brown – thanks for that comment.
Sorry satellites don’t cut the mustard. A single satellite can’t return to a given point to take another sample in less than 84 minutes, and when the satellite does get back to the same place, it isn’t the same place; that’s about 22 degrees away. And clouds can appear out of nowhere, and then disappear in a few minutes. and how many satellites do we have that can simultaneously observe different poins on the surface.
http://en.wikipedia.org/wiki/List_of_Earth_observation_satellites
Actually, satellites do cut the mustard, they even cut it quite finely. Geostationary satellites in particular can easily resolve and correct for geometry of almost the whole globe, and the one place they are weak is tightly sampled by polar orbit satellites. They are the one source of reliable global data.
rgb
How about a little skepticism from Anthony Watts before posting such things? On what possible grounds do the error bars grow with time in the way shown, and how on earth do the mean A,B,C, projections collapse into one another. Neither makes any sense to me.

REPLY: Well I’m sure Pat can answer, but from my view a as forecaster, forecasts grow more uncertain the further they are in the future, just as temperature and paleo data grow more uncertain back in time. We all know that a weather forecast for two weeks ahead is far less certain than one for two days ahead. Conversely, unless properly recorded/measured, the past is less certain than the present.
For example due to errors in siting/exposure (like on the north side of buildings) we know the temperatures measured in 1850 -vs- 1950 have wider error bars. See the recent BEST graph to see what I mean:
If you think error bars should get smaller into the future for a forecast, I have a big chunk of ice I can sell you in
a warmingAntarctica. – AnthonyThere is a new paper by Troy Masters of UCLA which indicates that the Cloud Feedback has been negative from 2000 to 2010 using all satellite and temperature data sources. There is much uncertainty based on the dataset and timeframes used but generally the Feedback is negative. [The paper doesn’t really say that but that is what the data shows – it got quite a going-over by Andrew Dessler who had recommended rejection and other referees had recommended it be less certain about the negative cloud feedback – so to get it published, vagueness is always required if you are going against the theory/gospel].
http://www.earth-syst-dynam.net/3/97/2012/esd-3-97-2012.pdf
There is a supplemental to the paper which contains all the data (and more) which would be immensely helpful to those who are looking at this issue in more depth (zip file so I won’t link to it).
Don’t know if the link will work, but Oregon and many other states use this method for agricultural forecasting. Why? State after state has determined that analogue model forecasting outperforms climatological (IE dynamical) model methods. Farmers get testy when the forecast results in wilted or frozen crops and dead or worthless animals. That state agricultural departments are ignoring CO2/climate change models is telling.
cms.oregon.gov/oda/nrd/docs/forecast_method.ppt
Why waste time on climate models? Miskolczi has shown that water vapor feedback is negative while these bozos have it positive. Furthermore, their cloudiness error is huge. It has been suggested that cloudiness actually has a negative feedback and no one has been able to dispute that. According to Miskolczi’s work with NOAA weather balloon data the infrared absorbance of the entire atmosphere remained constant for 61 years while carbon dioxide at the same time increased by 21.6 percent. This is a substantial addition of carbon dioxide but it had no effect whatsoever on the absorption of IR by the atmosphere. And no absorption means no greenhouse effect, case closed. You might ask of course, how is it possible for carbon dioxide to not absorb IR and thereby violate the laws of physics. This of course is not what is happening. According to Miskolczi theory the existence of a stable climate requires that the IR optical thickness of the atmosphere should remain constant at a value of about 1.86. If deviations occur the feedbacks among the greenhouse gases present will restore it to that value. For practical purposes it boils down to carbon dioxide and water vapor. Carbon dioxide is not adjustable but water vapor has an infinite source in the oceans and can vary. If more carbon dioxide is added to the atmosphere the amount of water vapor changes to compensate for its absorption and the result is that the optical thickness does not change. This means that water vapor feedback is negative, the exact opposite of what IPCC says and what these models incorporate. If you believe in positive water vapor feedback the amount of water vapor in the atmosphere should increase in step with the increase in carbon dioxide as determined by Mauna Loa observatory. Satellites just don’t see it. And Miskolczi has shown that the infrared optical thickness of the atmosphere has remained constant for the period of observation recorded by NOAA weather balloon database that goes back to 1948. He used seven subsets of the NOAA database covering this time period and reported to the EGU meeting in Vienna last year that the observed value of the optical thickness in all cases approached 1.87 within three significant figures. This is a purely empirical observation, not dependent upon any theory, and override any calculations from theory that do not agree with them. It specifically overrides all those GCM-s like CMIP5 that this article is boosting.
The above link is a powerpoint so you have to cut and paste into your browser in order to see the slides that form the basis of the following regularly updated forecast. For Oregon in the next three months we could be seeing some cold and some warm temperatures, and slightly damp conditions, followed by warmer and dryer conditions, followed by cold and variably damp/dry conditions. Put in extra wood for the winter. I think it will be colder than usual this winter and the drought may continue. It’s a good thing I put in a new well a few years back on the ranch. Under these conditions, the ranch used to run out of water in the 50’s. Our well was only 25 feet deep and depended on shallow ground water coming out of the mountains. It now goes 300 plus feet down into an aquifer. There are places here with wells that go 900 plus ft down.
http://cms.oregon.gov/ODA/NRD/docs/pdf/dlongrange.pdf?ga=t
Very good general points. In researching the climate chapter of forthcoming Arts of Truth, dug into cloud trends from ICOADS and ISCCP versus what is modeled in CMIP3. Observationally, TCF has increased slightly since 1965 (baseline chosen per NASA to include ‘primarily’ AGW). There has been no statistically significant change in the proportions of low, medium, or high altitude clouds at editorial or mid latitudes. (High latitudes were under sampled prior to satellites, the trends are less certain.) ISCCP also has optical depth unchanging.
By contrast, 12 of 13 GCMs examined have TCF decreasing. All CMIP3 GCMs have clouds as a net positive feedback (cooling effect diminishes with tmperature increase). On average, low cloudiness is underestimated by 25% and medium altitude cloudiness variable by up to 50%. They also underestimate precipitation, which suggests they underestimate optical depth and negative feedback from it by a factor of up to four. Each of these findings is from peer reviewed literature post AR4. It will be interesting to see how much of this makes it into AR5 consideration. Probably very little.
All references, plus data charts and more details, are in the book.
For those arguing semantically whether the models are intended to provide predictions or projections, consider the somewhat archaic definition of a “projector” from dictionary.com.
“a person who forms projects or plans; schemer”
john says:
August 24, 2012 at 3:29 am
JP Morgan also ran the Oil for Food Program.
___________________________
Maurice Strong of the UN Earth Summits fame was implicated in the “oil for food” scandal so we are really talking about a rather small number of people involved in all these scams. A bit of poking around the internet turns up another player.
So who is BNP bank? “….Europe’s leading provider of banking and financial services, has four domestic retail banking markets in Europe, namely in Belgium, France, Italy and Luxembourg.”
SInce when did banks get voted overseers of the human race?
The President of BNP Paribas is Michel Pébereau a very powerful man it would seem. So I guess that does make him out “better”
A specialist in Science Fiction??? So now we know how they are coming up with all this stuff!
When you read this Annual Report, remember commodities future trading is linked to the food riots in 2008 and derivative products are linked to the economic crash and Forclosuregate in the USA.
Do not forget ENRON was neck deep in the Cap ‘n Trade Scam. From the National Review no less Al Gore’s Inconvenient Enron
And Pat Frank, thanks for bring us up to date on the latest iteration of the climate models.
As far as I am concerned they are way way ahead of themselves. They have not even identified all the various possible parameters yet. Sort of like a blind man building a model of an elephant who hasn’t gotten past investigating the tail and thinks it looks like a snake.
Robert Brown says:
August 24, 2012 at 6:58 am
“However, the basic message of this is sound enough — there should be error estimates on the “projections” of GCMs — at the very least a Monte Carlo of the spread of outcomes given noise on the parameters.”
I want to add a word or two for emphasis. There must be some standards that can be applied to models. Maybe the Monte Carlo is sufficient for now. However, the more important problem that you see is the following:
“…the things that cause instability on this scale do not appear to be any of the parameters included in the GCMs anyway because we don’t really know what they are or how they work.”
I agree fully. The fundamental problem is a lack of understanding of the physical facts.
Yet some very accomplished scientists who have turned to modeling seem to believe that if the model is complicated enough then it must contain a physical theory and that physical theory must comprehend the facts. I think that this kind of mystical reasoning is worthy to be named a fallacy. I propose that it be called the Congressman Akin fallacy because it parallels his reasoning to the conclusion that the female anatomy can distinguish among various kinds of sexual assault. .
Terry Oldberg,
I think you are beating the prediction vs projections drum to death. I really don’t care if the IPCC et al calls what they put out as predictions, projections, forecasts, or tea leaves. The point is that what they said in the past was going to happen didn’t, and what they say now is going to happen probably won’t. In the court of public opinion the semantics of prediction vs projection are immaterial, the only thing the matters is “did they get it right or wrong”. They got it wrong. Repeatedly. Beat that drum. Loudly and repeatedly.
“I think you are beating the prediction vs projections drum to death”
Seconded, and such petty nitpicking misses the point entirely – what the climate models are trying to do, in the way that they are trying to do it, is mathematically impossible.
“””…..rgbatduke says:
August 24, 2012 at 8:08 am
Sorry satellites don’t cut the mustard……”””””
Well I do get your point Professor Bob, but just what is it that satellites, either geo-stationary
or mobile, are measuring ?
Common sense tells me that any satellite is receiving some species of electro-magnetic radiation, that is proceeding upward/outward from the earth (above the clouds)
Absolutely none of that radiation can have any effect on the earth or its climate or weather.
What we would like to know is what the sum total of all species of EM radiation proceeding downward / earthward underneath the clouds is; and of course where it is, so we can predict its fate.
If the satellite network imitates an integrating sphere, then the problem is solved as regards total planet emission, and subtracting from TSI we have total planet absorption. But just exactly where all that energy went or is, would seem to be still largely unknown. If not, then I will withdraw my objection.
davidmhoffer says:
Terry Oldberg,
I think you are beating the prediction vs projections drum to death.
Don’t blame Terry. It is the chicken-feces pseudoscientists of the IPCC that are constantly equivocating on those terms. Terry is just pointing that out. It is relevant to this discussion, as every time someone brings up a point such as Pat’s, the snotty reply from on-high at Team headquarters is generaly some version of “those aren’t predictions, those are projections.”
Terry gives us the appropriate response – “Then they aren’t science, so go cluck yourself.”
Pardon the fowl language.
Regarding the “assumption” in GCMs that water feedback (clouds) is “positive”; which the general chatter suggests is the case. Well I’ve never looked at a GCM; don’t have a terrafloppy computer to run one on.
Why the hell is ANYONE constructing ANY model of ANYTHING, making any assumption, a priori about the consequence of some circuit connections.
If you assemble some physics model representing real physical phenomena, that can be described by some well established mathematical equations; you do not presume that this or that “feedback” or “forcing” or “driver” or “power source”or “whatever” is this or that polarity.
You simply wire up the components of the system to replicate the real connections of the actual real physical world system, and then run it.
The system model itself will decide whether some connection is positive or negative; NOT you !
In the case of some system connection that DOES actually form a positive feedback loop, well the system can overshoot, or even oscillate, or operate with increased “gain”, depending on the parameters, but the running system model will decide if such and such is a positive feedback or not, or even if it is a feedback.
If some modeller has to be told just what some piece of the kit is, and where it assembles to in the finished model, then they clearly shouldn’t be building models.
I suggest they buy themselves a Mr Potato Head, and go sit in a corner and play with it.
If they put pieces upside down or in the wrong holes, at least they won’t be dooming millions of people to poverty.
JJ
Don’t blame Terry. It is the chicken-feces pseudoscientists of the IPCC that are constantly equivocating on those terms. Terry is just pointing that out.
>>>>>>>>>>>>>>>>>>>>>>>>>>
The average person in the street doesn’t understand the point being made, nor do they care.
Me: The IPCC made multiple predictions about climate change that have not come true and are demonstrably false.
Cimate Scientists: Well those were projections, not predictions…..
Me: Fine. The IPCC made multiple projections about climate change that have not come true and are demonstrably false.
Get it? It is a nuance that has no value to discuss further.
Gail, I really appreciate your comment and it helped more then you think.
I have been looking into this for quite awhile and…
http://www.eco-business.com/news/upc-renewables-eyes-two-more-wind-projects/
Robert Austin says:
August 24, 2012 at 9:24 am
For those arguing semantically whether the models are intended to provide predictions or projections,
It’s not a semantic distinction.
You can reduce science (the scientific process) to 3 elements, all of which are necessary for an activity to be called science. The first of these elements is deriving (quantified) predictions,
The reason the modellers steadfastly maintain the model outputs aren’t predictions is because predictions can be compared to observations (measurements) and the source of the predictions (the models) falsified.
Which is why I say the climate models aren’t science.
BTW, the way to make the climate models scientific is to progressively break them apart identifying the source of errors (prediction-observation discrepancies).
The reason this isn’t done, is the modellers know as well as I do that it will be a very long time before the components produce sufficiently accurate predictions for the models to be reassembled.
Terry Oldberg says: August 24, 2012 at 8:22 am
Allan MacRae
It sounds as though you are under the misimpression that IPCC climate models make “predictions.” As the climatologist Kevin Trenberth emphatically stated in the blog of the journal Nature in 2007, they make only “projections.” Though predictions are falsifiable, projections are not. The models are not wrong but rather are not scientific.
_________
Actually, I think I understand your points quite well Terry, although I’m not sure I would rely on Trenberth for enlightenment on this subject.
The warming alarmists represented their models as providing credible predictions when they wanted to support their Cause to “fight global warming” and more recently have had to recognize that their models have no predictive skill.
Hence the semantic games of “prediction” versus “projection”, but it is all just CAGW-BS.
In conclusion:
The climate models produce nonsense, and yet our society continues to squander trillions of dollars of scarce global resources, based on this nonsense.
All,
People don’t read reports, they just look at the pictures. Here’s the picture from AR4 WG1
http://www.ipcc.ch/publications_and_data/ar4/wg1/en/figure-10-26.html
I really don’t care if you call the different scenarios predictions, projections, forecasts, estimates, WAG’s, tea leaf readings or tarot cards, reality is that we’re seeing more CO2 emissions and less temperature change and all these pictures are WRONG.
By debating predictions versus projection we’re just playing the perception management game by their rules. Play it by our rules. Here folks is what they said would happen, it isn’t happening, they’ve over estimated CO2’s effects and their models are useless as shown by comparing the results to what they said was going to happen.
davidmhoffer:
In seeking to disambiguate the terms in which a debate is conducted, one’s purpose is not to manage perceptions but rather to ensure that a false or unproved conclusion will not appear to be true. If a policy of disambiguation is applied to the terms “prediction” and “projection” with a “prediction” defined as an extrapolation from an observed condition to the unobserved but observable outcome of a statistical event and a “projection” defined as it is in the field of ensemble forecasting then a conclusion of high importance emerges in conjunction with the absense in IPCC climatology of identification of the statistical population underlying the IPCC climate models. This is that the projections which are made by these models are not falsifiable. Predictions are falsifiable but they are not made by these models. Do you not agree, then, that a policy of disambiguation should be followed by debaters in this particular thread?
Pat Frank says
Climate modelers invariably publish projections of temperature futures without any sort of physical uncertainty bars at all. Here is a very standard example, showing several GCM projections of future arctic surface air temperatures. There’s not an uncertainty bar among them.
———
That is a completely clueless thing to claim.
The models are calculations not physical measurements. You are supposed to infer their uncertainties differently, by:
1. studying the spread of the different simulations
2. comparing the simulations with actual measurements
The next calculational step produces its own errors, which add in and expand the high and low uncertainty bounds around the next temperature.
———-
Utter nonsense. Whether this happens depends on the character of the numerical simulations involved.
Terry Oldberg,
Do you not agree, then, that a policy of disambiguation should be followed by debaters in this particular thread?
>>>>>>>>>>>>>>>>>
Do you understand that the vast majority of the population understands completely what I said and hasn’t got a clue what you said?
davidmhoffer:
As I have used the term “statistical population” it is a set of events and not, as you seem to have assumed, a set of humans. Each such event can be described by a pair of states. One such state is a condition on a model’s independent variables and is conventionally called a “condition.” The other state is a condition on the same model’s dependent variables and is conventionally called an “outcome.” A “prediction” is an extrapolation from the observed condition of an event to the unobserved but observable outcome of the same event.
Suppose, for example, that the condition is “cloudy” and the outcome is “rain in the next 24 hours.” Given that “cloudy” was observed, an example of a prediction is “rain in the next 24 hours.”
This discussion needs clarification.
How about this:
When a global warming alarmist makes a “prediction” that proves false, he calls it a “projection”.
I note that global warming alarmists make an awful lot of projections these days, and no predictions.
This observation is entirely consistent with my “Law of Warmist BS”
http://wattsupwiththat.com/2012/02/28/the-gleick-tragedy/#more-57881
“You can save yourselves a lot of time, and generally be correct, by simply assuming that EVERY SCARY PREDICTION the global warming alarmists express is FALSE.”
This Law had stood the test of time, and has yet to be falsified.
NEW SCIENTIFIC REVELATION – “Axiom 1 of the Law of Warmist BS”
“Global warming alarmists don’t make predictions anymore – they just make projections.”
🙂
I knew a guy. A real card. He used to go to the track with a kit. It was a box with a handle on the top. He’d go sit down at a table in the clubhouse and with great ceremony put on eye shades, open up his racing form, and then reach in to his kit box and pull out a spinner card.
Look!
8 predictions, Zero projections!
http://wattsupwiththat.com/2012/07/25/lindzen-at-sandia-national-labs-climate-models-are-flawed/#comment-1046529
Sallie Baliunas, Tim Patterson and I published an article in the PEGG in 2002:
Here is what we predicted a decade ago:
Our eight-point Summary* includes a number of predictions that have all materialized in those countries in Western Europe that have adopted the full measure of global warming mania. My country, Canada, was foolish enough to sign the Kyoto Protocol, but then wise enough to ignore it.
Summary*
Full article at
http://www.apegga.org/Members/Publications/peggs/WEB11_02/kyoto_pt.htm
Kyoto has many fatal flaws, any one of which should cause this treaty to be scrapped.
1. Climate science does not support the theory of catastrophic human-made global warming – the alleged warming crisis does not exist.
2. Kyoto focuses primarily on reducing CO2, a relatively harmless gas, and does nothing to control real air pollution like NOx, SO2, and particulates, or serious pollutants in water and soil.
3. Kyoto wastes enormous resources that are urgently needed to solve real environmental and social problems that exist today. For example, the money spent on Kyoto in one year would provide clean drinking water and sanitation for all the people of the developing world in perpetuity.
4. Kyoto will destroy hundreds of thousands of jobs and damage the Canadian economy – the U.S., Canada’s biggest trading partner, will not ratify Kyoto, and developing countries are exempt.
5. Kyoto will actually hurt the global environment – it will cause energy-intensive industries to move to exempted developing countries that do not control even the worst forms of pollution.
6. Kyoto’s CO2 credit trading scheme punishes the most energy efficient countries and rewards the most wasteful. Due to the strange rules of Kyoto, Canada will pay the former Soviet Union billions of dollars per year for CO2 credits.
7. Kyoto will be ineffective – even assuming the overstated pro-Kyoto science is correct, Kyoto will reduce projected warming insignificantly, and it would take as many as 40 such treaties to stop alleged global warming.
8. The ultimate agenda of pro-Kyoto advocates is to eliminate fossil fuels, but this would result in a catastrophic shortfall in global energy supply – the wasteful, inefficient energy solutions proposed by Kyoto advocates simply cannot replace fossil fuels.
[end of excerpt]
______
P.S.:
In a separate article in the Calgary Herald, also published in 2002, I (we) predicted imminent global cooling, starting by 2020 to 2030. This prediction is still looking good, since there has been no net global warming for about a decade, and solar activity has crashed. If this cooling proves to be severe, humanity will be woefully unprepared and starvation could result. This possibility (probability) concerns me.
P.P.S.
If I’m wrong about my global cooling prediction, I’ll just call it a projection, and get a job with the IPCC. 🙂
Allan MacRae says:
“I note that global warming alarmists make an awful lot of projections these days, and no predictions…
“Axiom 1 of the Law of Warmist BS…
“Global warming alarmists don’t make predictions anymore – they just make projections.”
•••
Exactly right. Every ‘prediction’ has been debunked and falsified. When their feet are held to the fire of the scientific method, their conjecture fails. It is based on pseudo-science; pure anti-science.
If I am wrong, all it would take to deconstruct the skeptical position would be to provide scientific evidence showing a clear connection between human CO2 emissions and global warming.
But there is no such evidence. None. They are winging it.
Thanks Smokey – valid comments – but I thought you were in the penalty box.
I guess you got off with a minor for roughing.
Mann gets a double-major and game misconduct for high-sticking.
Allan,
Only in the penalty box for roughing Perlwitz. But that was on a different thread. BTW, here is another ‘wheel’ to go with the article. ☺
Terry Oldberg;
As I have used the term “statistical population” it is a set of events and not, as you seem to have assumed, a set of humans.
>>>>>>>>>>>>>>>>>>>>
I made no such assumption and you have completely missed the point of my comment.
davidmhoffer:
If you were to more fully explain what the point of your comment was, perhaps I could address it.
Robert Brown, August 24, 2012 at 6:58 am said”
“…..the climate doesn’t seem enormously unstable toward hothouse Earth or snowball Earth even on a geological time scale,…….”
The climate has been varying for billions of years without triggering any “tipping points”, extreme or irreversible changes such as those described in Jimmy Hansen’s “Fairy Tales”; those tales are less related to reality than the ones written by Hans Christian Andersen.
The planet experienced “Ice Ages” when CO2 concentrations were >7,000 ppm. Thus one should take any model that “predicts” temperature rises of 1.4 to 5.8 Kelvin by 2100 based on a rise in CO2 concentration to 650-970 parts per million (AR4) with a pinch of salt. Far from recognising the absurdity of the AR4 “Predictions”, AR5 seems to be heading further into cloud cuckoo land. Thankfully physicists like “rgb” are helping us separate “Science” from “Politics”.
Thanks everyone for your interest and comments. Regrets for the delay in replying . . . it was a long day at work.
But forthwith:
Maus, GCM cloudiness error is an accuracy error, not a rounding error. By “viewed appropriately” I suppose you mean fancy can take flight when there are no measurement constraints. In that arena we can find philosophy, religion, and, all too often, politics.
Stephen maybe a letter to GISS or NCAR?
Mike B the K, the GCM temperature projection emulator noted above will produce a GCM-equivalent GHG temperature projection for approximately zero cost.
Terry, the CMIP5 GCMs were tested against physical measurements. The modelers have made a predictive representation, validating an error analysis. But I agree with you that GCMs are unfalsifiable and do not make predictions in the scientific sense.
Mr. Lynn, thanks for giving me the opportunity to make an important point. Nothing I’ve posted says that human-caused climate warming is not happening. The point of the essay is that the analysis shows climate models are unable to resolve anything at the few W/m^2 level of GHG forcing.
Science is not about what’s happening; nor is it about “the universe.” It’s about what we know about what we’ve observed. We’ve observed the climate has warmed. But climate models are completely unable to tell us why that’s happened.
We’ve also observed that there’s nothing whatever unusual about any weather extremes, about the rate or the duration of the recent warming, or about any weather trends. In other words, there is no scientific or empirical support for any discrete alarm. But, again, that doesn’t mean the recent warming isn’t due to the extra GHGs. We plain don’t know.
Mark given serious advances in physics, climate models may eventually be able to tell us how climates behave, even if they can’t predict exactly how our particular climate will behave in detail. It’s worth pursuing climate science. It’s just that so many climate scientists have abandoned integrity for a righteous and sentimentalized advocacy. Think baby, bathwater.
Thanks, Theo. 🙂
Terry Oldberg says:
August 24, 2012 at 9:15 pm
davidmhoffer:
If you were to more fully explain what the point of your comment was, perhaps I could address it.
>>>>>>>>>>>>>>>>>>>>>
OK, I’ll take one more crack at it.
You’re position is completely correct. Now ask yourself, of what value is it to be correct if nobody understands you? How many people can you persuade that the IPCC reports are garbage if they cannot understand your explanation?
I’m in the persuasion business. Someone asks me what I do for a living and I say that I architect and implement large scale, highly resilient, data management infrastructures. The vast majority of people look at me like I just grew an extra head. So I tell them I sell really big computers like the kind governments and really big companies use. Both descriptions are accurate, but one almost everyone thinks is gibberish and the other almost everyone understands. Which answer I give depends on the technical background of the person I am talking to.
In the climate debate, trying to accurately differentiate between predictions and projections for most people, is gibberish. Pointing out that the IPCC reports said certain things were going to happen by now, and they haven’t, is accurate, and people understand it. Let the IPCC’s advocates respond to explain that they used projections not predictions, and most people will just tune out.
So, you want to be technically accurate but tuned out by almost everyone? Or do you want to persuade the majority of people that the IPCC science is bunk? If the latter, then choose your arguments wisely and couch them in terms that the average reader can understand.
davidmhoffer:
Thanks for the clarification. Your question of how to explain this to the masses so they understand it and take action to throw out the corrupt or incompetent “scientists” is a good one. I don’t know the answer. If you have any ideas, I’d like to hear them.
I have a background in the planning and management of scientific studies. With this background, I know that if a purportedly scientific study lacks a statistical population then this study is not scientific, for claims made by the models that are a product of this study are insusceptible to being falsified by the evidence. Rather than being scientific, the methodology is dogmatic. Adoption of a dogmatic methodology ensures a failure to learn and consequential waste of the money that is invested in the research. However, a dogmatic methdology disguised as a scientific methodology is ideal for the purpose of duping people into false beliefs.
Four years ago, out of idle curiosity I began to poke around in climatology. Within half an hour, Web searches had produced enough evidence for me to be pretty sure that the methodology of the research was not scientific; I also found that the IPCC was representing the research to be scientific. In the report of AR4, I was unable to find reference to the statistical population. Also, an IPCC reviewer named Vincent Gray reported that he had informed the IPCC that its models were insusceptible to statistical validation; the IPCC had responded by obfuscating the issue using the strategy of ambiguous reference by terms in the language of its assessment reports. Elements of this strategy included: a) using “prediction” and “projection” as synonyms b) using “evaluation” and “validation” as synonyms and c) exploiting ambiguity of reference by the word “science” in which the word references the idea of “demonstrable knowledge” and “the process that is operated by people calling themselves ‘scientists’.” Subsequently, I did a more thorough investigation and published my findings under the peer review of Judith Curry ( http://judithcurry.com/2011/02/15/the-principles-of-reasoning-part-iii-logic-and-climatology/ ).
I’ve seen this situation before. Twenty-seven years ago, after accepting the lead role in an area of engineering research, I discovered that past research in this area defined no statistical population. To remedy the situation would require modification of an industrial process but to do so would require admission of past error on the part of high level mucky mucks. When I attempted to remedy the error, I experienced unanimous opposition from the mucky mucks. Today, twenty-seven years later, this error remains in place where it threatens the lives of people who travel on aircraft or work in nuclear power plants. Many of the mucky mucks went on to even higher levels of glory. My family and I suffered years of hardship from my temerity in taking on the mucky mucks.
Hans Christian Anderson’s story “The Emperor’s New Clothes” provides a metaphor for situations such as this. As the emperor marches naked through the village, his ministers profess to see him clothed in the nonexistent golden cloth for which he has paid swindlers but a child, being free from the pretensions of the adults, crys out “the emperor has no clothes!” Apparently unaffected by this disclosure, the king continues to march gloriously along in his nonexistent golden clothes.
gregole, you’re right about clouds. They are a huge unknown. GHGs increase the energy content in the atmosphere, which may well influence density and types of clouds. But climate science isn’t advanced enough to know how.
As it’s turned out, the oceans are another huge unknown. Carl Wunsch has noted that ocean models don’t converge, meaning they give no unique solution. But he’s said modelers ignore that because the results “look reasonable.” Those non-converged ocean models enter into GCM climate predictions and are part of the reason they’re so inaccurate. CW has also noted that the thermohaline model is fine for cocktail party conversation, but doesn’t describe ocean dynamics.
So, there’s a lot to do, but all that’s really hard work. Instead of hard work, many climate scientists have gotten lazy, preferring to play video games and issue portentous statements.
Jim D, the GCM model outputs were annual average cloudiness. The errors are error in average annual cloudiness. Why isn’t it correct, therefore, to calculate the uncertainty over annual time-steps?
AlaskaHound, everything is in terms of annual averages: averaged over 365 days, 365 nights. Average excess energy, average feedback error.
Philip Bradley, as long as they’re comparing their model outputs to physical measurements, it’s valid to calculate and propagate an error.
george e smith, if you look at the SI to my Skeptic article, here (892 kb pdf), you’ll find that the 10.1% error was derived by integrating GCM hindcasted vs observed global average cloudiness. I.e., it’s an empirical error estimate.
Global average cloudiness turns out to be fairly constant from year-to-year. Total cloud cover has been available since about 1983 with the GMS series satellite. Here’s an overview of the US part of the International Satellite Cloud Climatology Project (ISCCP).
Allan MacRae, right on! And as long as they’re publishing comparisons between GCM hindcasts and target observations, it’s worth calculating the errors and propagating the uncertainties to drive home the point that GCMs are unreliable and their predictive robusticity is mere politics.
Ian W, “Personally, I would like to see strict Validation of these models …” Good luck getting that program started. 🙂
Robert Brown, please recall that the analysis is concerned with GCMs rather than with climate. Clearly GCMs are complex beasts, as you say, “systems of parametric coupled nonlinear differential equations”
However, with respect to GHG-induced air temperature, GCM outputs are no more than linear extrapolations of GHG forcing. That is made clear by the very good emulation of GCM air temperature projections using an equation with only one degree of freedom — increasing GHG forcing. All the internal complexity of a GCM is somehow lost in air temperature projections. Their output is linear. That being true, one has an empirical justification to forward propagate GCM temperature error using the same linear function that successfully emulated the GCM forward projection of air temperature itself.
Wonderful comments Pat- very informative.
Regarding hindcasting of models, you may have seen this exchange with Douglas Hoyt on aerosols. I would be interested in your opinion. I continue to correspond from time to time with Douglas, and would be pleased to invite him onto this thread if you so requested.
http://wattsupwiththat.com/2012/04/28/tisdale-a-closer-look-at-crutem4-since-1975/#comment-970931
markx says:April 29, 2012 at 9:56 am
ferd berple says: April 28, 2012 at 12:09 pm
Climate scientists complain when someone outside of climate science talks about climate science, but ignore the fact that climate science is no qualification to build reliable computer models.
Markx: IMHO, this one of the most important observations made within these pages.
___________
Allan:
Agree – when you build a mathematical model, you first try to verify it. One method is to determine how well it models the past (“hindcasting”).
The history of climate model hindcasting has been one of blatant fraud. Fabricated aerosol data has been the key “fudge factor”.
Here is another earlier post on this subject, dating from mid-2009.
It is remarkable that this obvious global warming fraud has lasted this long, with supporting aerosol data literally “made up from thin air”.
Using real measured aerosol data that dates to the 1880’s, the phony global warming crisis “disappears in a puff of smoke”.
Regards, Allan
http://wattsupwiththat.com/2009/06/27/new-paper-global-dimming-and-brightening-a-review/#comment-151040
Allan MacRae (03:23:07) 28/06/2009 [excerpt]
FABRICATION OF AEROSOL DATA USED FOR CLIMATE MODELS:
Douglas Hoyt:
The pyrheliometric ratioing technique is very insensitive to any changes in calibration of the instruments and very sensitive to aerosol changes.
Here are three papers using the technique:
Hoyt, D. V. and C. Frohlich, 1983. Atmospheric transmission at Davos, Switzerland, 1909-1979. Climatic Change, 5, 61-72.
Hoyt, D. V., C. P. Turner, and R. D. Evans, 1980. Trends in atmospheric transmission at three locations in the United States from 1940 to 1977. Mon. Wea. Rev., 108, 1430-1439.
Hoyt, D. V., 1979. Pyrheliometric and circumsolar sky radiation measurements by the Smithsonian Astrophysical Observatory from 1923 to 1954. Tellus, 31, 217-229.
In none of these studies were any long-term trends found in aerosols, although volcanic events show up quite clearly. There are other studies from Belgium, Ireland, and Hawaii that reach the same conclusions. It is significant that Davos shows no trend whereas the IPCC models show it in the area where the greatest changes in aerosols were occurring.
There are earlier aerosol studies by Hand and Marvin in Monthly Weather Review going back to the 1880s and these studies also show no trends.
___________________________
Allan:
Repeating: “In none of these studies were any long-term trends found in aerosols, although volcanic events show up quite clearly.”
___________________________
Here is an email just received from Douglas Hoyt [my comments in square brackets]:
It [aerosol numbers used in climate models] comes from the modelling work of Charlson where total aerosol optical depth is modeled as being proportional to industrial activity.
[For example, the 1992 paper in Science by Charlson, Hansen et al]
http://www.sciencemag.org/cgi/content/abstract/255/5043/423
or [the 2000 letter report to James Baker from Hansen and Ramaswamy]
http://74.125.95.132/search?q=cache:DjVCJ3s0PeYJ:www-nacip.ucsd.edu/Ltr-Baker.pdf+%22aerosol+optical+depth%22+time+dependence&cd=4&hl=en&ct=clnk&gl=us
where it says [para 2 of covering letter] “aerosols are not measured with an accuracy that allows determination of even the sign of annual or decadal trends of aerosol climate forcing.”
Let’s turn the question on its head and ask to see the raw measurements of atmospheric transmission that support Charlson.
Hint: There aren’t any, as the statement from the workshop above confirms.
__________________________
IN SUMMARY
There are actual measurements by Hoyt and others that show NO trends in atmospheric aerosols, but volcanic events are clearly evident.
So Charlson, Hansen et al ignored these inconvenient aerosol measurements and “cooked up” (fabricated) aerosol data that forced their climate models to better conform to the global cooling that was observed pre~1975.
Voila! Their models could hindcast (model the past) better using this fabricated aerosol data, and therefore must predict the future with accuracy. (NOT)
That is the evidence of fabrication of the aerosol data used in climate models that (falsely) predict catastrophic humanmade global warming.
And we are going to spend trillions and cripple our Western economies based on this fabrication of false data, this model cooking, this nonsense?
*************************************************
LazyTeenager says:
That is a completely clueless thing to claim.
No, it isn’t. Pat is correct.
The models are calculations not physical measurements. You are supposed to infer their uncertainties differently, by:
1. studying the spread of the different simulations
2. comparing the simulations with actual measurements
You left out:
3. By running sensitivity analyses, in which the uncertainty of the input data and the assumptions of the model are propagated thru the model in a way that determines the range and probability distribution of the model results that may arise from those factors. The spread of the results of such sensitivity analyses is one component of the error bars that should be presented on model prodictions. You would need to do this for each of the scenario runs in 1)
Such analyses are almost never performed, when performed are almost never published, and when published are almost never publicized. The cumulitive effect is indistinguishable from never.
http://www.scribd.com/doc/14434852/Terrestrial-Sources-of-Carbon-and-Earthquake-OutGassing-Thomas-Gold
They also noted that at the epicenter of the earthquake of May 14, 1970, an intensive release into the atmosphere of H2,CO2 and He was observed for a period of 40 days.Thus the observations in southern Dagestan give strong support to the view that there are deep and presumably abiogenic sources of hydrocarbons in the crust; that faults and earthquakes play a role in the escape of gases from great depths; and that gas emissions over regions of hundreds of km can all be affected by a single event. The authors suggest indeed that lithospheric outgassing of carbon through faults may be a major factor in the supply of surface carbon .
Anthony, in your reply you rightly point out that weather forecast errors grow with time, but this is completely different. I’m in no way saying the uncertainties shouldn’t grow with time, but the critical issue is *how* they grow. In any case my main question was about the collapse of the A,B, C scenarios onto one another, which makes no sense I can figure out. Frank doesn’t seem to have answered either question.
As for Antarctica — don’t worry, I’m not likely to buy anything you are selling!
Eric Steig;
In any case my main question was about the collapse of the A,B, C scenarios onto one another, which makes no sense I can figure out.
>>>>>>>>>>>>>>>>
What collapse? figure b is scaled so that the error range can be depicted in comparison to the scenarios themselves.
Terry Oldberg;
I sympathize with your predicament because I’ve been in the same situation more than once. Speaking Truth to Power is a risky business, and as you learned yourself, doing so is what gave rise to that oft repeated phrase “don’t shoot the messenger”. My advice to you is to craft the message to the audience. If you are one on one with someone who has the background in stats to understand the issues, by all means. If you are talking to a wider audience, “they said X would happen and it didn’t” is more effective and not innacurate.
P.S. to Pat:
I am not convinced that CO2 has ANY significant impact on gloabl temperature.
In 2008, I published that dCO2/dt varied ~contemporaneously with average global temperature, and atmospheric CO2 concentration lagged temperature by ~9 months. This CO2-lags-temperature observation is consistent with longer lag times observed (on longer cycles) in the ice core data.
I concluded in 2008 that temperature drives CO2, not the reverse. This conclusion is opposite to the conventional “wisdom” of BOTH sides of the rancorous global warming (CAGW) debate. I now predict that within ten years, temperature-drives-CO2 will be the newly accepted scientific premise of the climate science community.
Full article at :
http://icecap.us/index.php/go/joes-blog/carbon_dioxide_in_not_the_primary_cause_of_global_warming_the_future_can_no/
My paper was published two years before Murry Salby presented the same conclusion, with more supporting evidence, at:
______
Finally, I conclude that the entire global warming crisis has been a huge waste of scarce global resources (see prediction #3 above) that could have been used to solve real environmental and social problems that exist today, such as providing clean drinking water and sanitation systems in the third world.
In the ~25 years that the world has obsessed with alleged dangerous humanmade global warming, over 50 million children below the age of 5 have died from drinking contaminated water. That is more people (of all ages and from all sides) than were killed in World War 2. That is the “nominal” cost of the misguided obsession with global warming mania. And that reality also concerns me.
Regarding error bars, predictions need error bars. However, projections don’t have them.
By the way, in my initial response I neglected to thank Anthony for posting my essay. Forthwith the repair: thank-you Anthony! You’re a real sanity-saver!
Think of it – how would we all air our dismay, quantitative or otherwise, about what’s going on without Anthony and his like giving us public digital space? Without them, one is faced with either frustration-induced insanity or, in despair, abandoning the contest entirely — focusing down to protect one’s mental health.
So, thank-you Anthony. You’re doing more for personal sanity than any group of psychologists, ever.
And now . . . 🙂
Eric Steig, error bars grow when uncertainties are propagated into subsequently calculated properties.
When those calculated properties, e.g., climate variables, are projected forward by further calculations, the prior uncertainties are also propagated forward.
The standard method for propagated uncertainties in any serial calculation is sqrt{sum-over_i [(uncertainty)^2]_i]}, where “i” is each calculational step. See Bevington and Robinson “Data Reduction and Error Analysis for the Physical Sciences,” Chapter 3, Error Analysis, and especially pp. 39ff.
Hanson’s three lines don’t really collapse into one another. They’re as far apart in the “b” side as they are in the “a” side. The reason they look so close is that the ordinate of the plot in “b” has become ~40x wider than in “a” to accommodate the uncertainty bars.
Anthony is correct. Forecasts get more uncertain into the future, just as hindcasts get more uncertain into the past. Tree-ring paleotemperatures have no uncertainty at all, of course, because they’re not temperatures.
But now that you’re here, I’d like to ask you a temperate question: are you aware of the temperature-sensor measurement error analysis of H. Huwald, et al. (2009) “Albedo effect on radiative errors in air temperature measurements Water Resources Res. 45, W08431? They used sonic anemometers to measure the albedo-induced systematic error in an unaspirated R.M. Young probe mounted in a glacial snow field in the Swiss Alps, across two winters.
The measurement errors they found are non-normal and long-tailed to the high T side. The errors lower the resolution of any measurement data set to about (+/-)0.5 C. How did you discount the analogous systematic error that should have been in the measurement data sets you used for your Antarctic temperature reconstruction?
Their photographs, by the way, also showed wind-encrusted snow blocking the louvers of the RM Young shield. The consequent blockade of air-flow is another source of systematic error; one also relevant to Antarctica.
Bill Illis, thanks for the link to Troy Master’s paper on cloud feedback. Once again, it seems, the science proves to be unsettled. Sorry to say, it’s no surprise that Andrew Dessler “went to town” on it (in the Phil Jones sense).
Here is the zip-file supplement. FWIW, I downloaded the zip and scanned that copy with up-to-date Norton antivirus. It verified as virus-free.
Arno Arrak thanks for the description of Ferenc Miskolczi’s results. He’s come up with an interesting theory and I wish him a lot of luck. On the other hand, my essay wasn’t “boosting” the CMIP5 GCMs. It offers an error analysis.
Rud Istvan, as you know my analysis is very basic and incomplete. It looks only for an average lower limit of uncertainty.
A more thorough-going uncertainty analysis pertaining to clouds would compare GCM-projected and observed clouds at altitude and latitude globally, use data and theory to translate the differences into cloud feedback energy error, and use that in turn to construct an uncertainty estimate that reflected cloud error more specifically.
Maybe you’ll be in a position to give that a try, assuming all that data is actually in hand.
davidmhoffer, the IPCC also call their climate projections, “story lines,” which is an especially apt description. But you’re right, whatever they call them, the IPCC presents them as predictions. Predictions that they term “highly likely.” They are disingenuous to the max, and you’re also right that the intent is entirely polemical; meant to influence legislators and the public who are generally untrained in science.
george e smith, the if you can’t build it you don’t know it engineering approach to climate science! 🙂 Your point is well-taken, but after all no one can build a physical model of Earth. So, computer models are a necessity (as they are in all of science and engineering these days). Your implicit point is completely right that, given the large unknowns, much more modesty is required than is shown by climate modelers of the IPCC-stripe.
Philip Bradley, you put your finger right on a nub problem of the field, IMO.
davidmhoffer, you’re exactly right. GCM projections are offered as predictions, and they have turned out to not correspond to observations. That is a prima facie case of falsification.
It’s true, too, that the projections are not true predictions. They’re more like naive existential statements — the moon is made of green cheese. Such statements can be falsified by examination, but neither the statement nor the falsification constitute doing science.
As you know, all the supposed uncertainty limits on the AR4 WG1 SRES picture you linked merely show statistical model variability, given various inputs. They’re derived from numerical variances, not from physical errors or uncertainties. The lack of physically real uncertainties makes those projections physically meaningless. It can’t be that no one among the modelers or in the IPCC is unaware of that.
Terry Oldberg, in science a prediction is not, “an extrapolation from an observed condition to the unobserved but observable outcome of a statistical event.” Rather, it’s a deduction from falsifiable theory of an experimental or observational outcome. In terms of prediction, statistics has some scientific validity if it is applied in the necessitating context of a theory, such as in the distribution of photons in a double-slit experiment of QM. But direct statistical extrapolation of an observation is induction, which is a-scientific.
On the other hand, as you pointed out, projections are not predictions unless — following Steve McIntyre’s observation about climate and weather — they are. 🙂
LazyTeenager, the head post is about physically real uncertainties, not about numerical variances which are obtained by “studying the spread of the different simulations.” Strictly numerical variances have zip to do with physical uncertainty. Your number 1 objection is irrelevant.
Your number 2, “comparing the simulations with actual measurements,” is exactly what I did. You have no complaint here.
And you forgot number 3: Physical uncertainty estimates derived by propagating errors and (parameter) uncertainties through the model. I’ve never seen such a study published.
LazyTeenager next post: not correct. Serial calculations of physical quantities require serially propagated physical errors.
Allan MacRae, thanks. 🙂 I missed the aerosol thread, but seem to recall reading about Doug Hoyt’s aerosol work previously; maybe on the website he used to maintain.
Doug is very welcome to comment here; he’s always been a rational voice. In any case, everyone is welcome to comment here.
JJ, I should have just linked to your comment when replying to LazyTeenager. 🙂
Eric Steig, I’ve now replied to both of your questions. Also note davidmhoffer’s explanation. He’s exactly right.
If a “critical issue” is “*how*” physical uncertainties grow in a climate projection, why has no one published on that, ever, anywhere, any time?
Note my response to Robert Brown, in which it’s pointed out that GCMs merely linearly propagate GHG forcing, demonstrated here. That makes error propagation very straight-forward.
Allan MacRae, regarding CO2, I tend to agree in that there certainly has been no evidence of any influence on temperature.
In May 2010, JeffID was kind enough to post study I did on 20th century climate sensitivity. It had turned out there was a cosine component in global temperatures that had appeared when the land surface air temperatures were subtracted from the global surface air temperatures (Figure 1 here). The periodic temperature dependence represented by the cosine function was present in the SSTs, which imposed the thermal signal globally.
The entire air temperature anomaly trend since 1880 can be fit with that cosine (period 60 years) plus a positive-slope straight line. That line represents the warming trend. Looking in detail at the straight line component, a small increase in slope can be found for 1951-2010 relative to 1880-1950. Assigning the positive difference to GHG produced an estimate of climate sensitivity = 0.34 C/doubling of CO2, or 0.1 C/W-m^-2 of extra forcing. Not much to worry about.
Your comments are exactly on target regarding the huge waste of money and the terrible immorality of global warming environmentalist extremism. The waste of resources and the enriching of PR groups and eNGO lawyerly fat cats at the expense of amelioration of real problems, with the willfull collusion of scientific societies, will be remembered as the most widespread and systematic betrayal of ethics, ever.
Pat Frank:
Thank you for for sharing your views on the important issues that you have raised with respect to my various remarks. My response follows.
It sounds as though you have concluded from my use of the term “statistical event” that my remarks pertain only to statistical models. This conclusion is mistaken. My remarks pertain to models that are purely mechanistic, to models that are purely statistical and to models that mix the statistical and mechanistic approaches to building models. The three types of model have in common that they rely upon the existence of observed statistical events for the statistical testing of them. The statistical and hybrid approaches rely upon the existence of observed events for the additional purpose of building the associated models.
As I define the terms, a “condition” is a condition on the Cartesian product space of a model’s independent variables and is a proper subset of the tuples in this space. A meteorological example of a “condition” is “cloudy.”
An “outcome” is a condition on the Cartesian product space of a model’s dependent variables and is a proper subset of the tuples in this space. A meteorological example of an “outcome” is “rain in the next 24 hours.”
A condition and an outcome describe a statistical event. For example, “cloudy, rain in the next 24 hours” describes an event. A “prediction” is an extrapolation from a condition to an outcome. For example, it is an extrapolation from the condition “cloudy” to the outcome “rain in the next 24 hours.” At the time a prediction is made, the condition has been observed; the outcome has not been observed but is observable.
The complete set of events that are referenced by a study is a kind of statistical population. Each of the possible outcomes of an event has a relative frequency. In testing a model, one compares the predicted to the measured relative frequencies. If there is not a match, the model is falsified.
The links between the deductive logic, the inductive logic and science can be uncovered with the help of information theory. The English word “science” makes ambiguous reference to the associated ideas. One of these ideas is “demonstrable knowledge.” It is convenient to label this idea by “scientia,” the Latin word for “demonstrable knowledge.”
In information theoretic terms the “scientia” is the mutual information between a pair of state-spaces. One of these state-spaces contains the states that I have called “conditions.” The other state-space contains the states that I have called “outcomes.” The “scientia” is the information that one has about the outcome given the condition. Conversely, it is the information that one has about the condition given the outcome.
It can be shown that the inductive logic differs from the deductive logic in the respect information for a deductive conclusion is missing for the former branch of logic but not the latter. Thermodynamics and quantum mechanics are examples of models for which information about the outcome, given the condition, is missing; both are regarded as “scientific.” Thus, it is inaccurate to claim that a model built under the inductive logic is “a-scientific.” A model is properly described as “scientific” if and only if it conveys “scientia” to its users.
Finally, I’d like to address your contention that the climate has a “climate sensitivity ” (CS). This contention references a pair of state-spaces. One contains all of the possibilities for the change in the equilibrium temperature at Earth’s surface. The other contains all of the possibilities for the change in the logarithm of the atmospheric CO2 concentration. The mutual information between the two state-spaces is not defined, for the equilibrium temperature is not an observable. Thus, the change in the logarithm of the CO2 concentration provides no information about the change in the equilibrium temperature. It provides no “scientia.”
Allan, thanks for the link to the video. Murray Salby ‘s work on the source of atmospheric CO2 looks very important. Has he published it anywhere? I didn’t find anything using Google Scholar, and there’s nothing in his on-line publication list.
Thanks for your comments Pat,
Perhaps not coincidentally, prior to my January 2008 icecap.us paper, my best estimate of “climate sensitivity ” to a doubling of atmospheric CO2 was 0.3C, versus your 0.34C.
Close enough, I guess. 🙂
P.S.
My immediate concern, which I apologize for carping about yet again, is the use of 40% of the huge USA corn crop for gasoline additives. Due to the drought this season, corn now costs over US$8 per bushel – and corn is a staple for many poor people in the Americas.
This situation is simply wrong – it is a monstrous ethical and humanitarian failing, and our leaders in the USA and Canada should have the courage and integrity to end the fuel ethanol mandate immediately.
Pat Frank says: August 26, 2012 at 6:48 pm
Re your question Pat:
I read that Murry Salby was writing a book on this subject.
Since 2008, there has been considerable discussion on climateaudit.org , wattsup and elsewhere on this subject, particularly between Richard S Courtney and Ferdinand Engelbeen. Ferdinand holds to the “mass balance argument” regarding the role of humanmade CO2 emissions in the increase in atmospheric CO2, whereas Richard (and I) say this argument is not necessarily correct.
I also recall someone admonishing me that the C13/C12 ratio disproved my hypo – I recall it took me about twenty minutes of serious investigation to dismiss that notion. Then someone said the C14/C12 ratio would disprove it – and frankly I could not be bothered to check, since I was a bit annoyed at the time by the C13/C12 nonsense. Hope Murry Salby is checking C14/C12.
Here is a more recent (2012) presentation to the Sydney Institute by Salby – it takes a while to load:
http://podcast.thesydneyinstitute.com.au/podcasts/2012/THE_SYDNEY_INSTITUTE_24_JUL_MURRY_SALBY.mp3
I think there are a few people who may have a pretty good grasp of this situation – perhaps Jan Veizer and close colleagues.
Best, Allan
@ Pat Frank
“””””…..george e smith, the if you can’t build it you don’t know it engineering approach to climate science! 🙂 Your point is well-taken, but after all no one can build a physical model of Earth. So, computer models are a necessity (as they are in all of science and engineering these days). Your implicit point is completely right that, given the large unknowns, much more modesty is required than is shown by climate modelers of the IPCC-stripe. …..”””””
Don’t have a problem per se Pat, with computer models; I use them constantly for 10 or more hours every day. So my clients can go from my modelled projections; excuse me “predictions”, to a manufactured finished product, with hard tooling; and I have never had one not perform as predicted. The difference is the computer “models” I use ARE built around the applicable Physical laws, and actually, in a hierarchy of complexity and rigor. For example, you don’t need Einstein general relativity, or special, to learn how to drive a car in a fuel economical way. Newton’s laws will suffice..
So I don’t have to build physical models, since the available mathematics, describes the observed Physics, to well beyond the precision needs of my clients’ product needs.
But I put in math representations of the physical objects I plan for my customer to use, placed where I want him to place them, and then run it. I don’t make any prior judgement, as to how they will interract; the computer will show me that. If I don’t like the result, then Ichange something.
Of course it helps to be thoroughly grounded in the theory, so that I can make the changes in an intelligent way, and expect the behavior to be perturbed by about the right amount.
If astronomers can model stars from birth to death, I don’t see why earth’s clouds can’t be modelled so they behave as observed, without having to decide first whether they go into the model as a positive feedback, or negative, or ANY feedback at all. Put them in so they obey known physical laws; not homogenizedanomalies.
george e smith says: August 26, 2012 at 11:18 pm
Hello George,
If I may interject: Your models are apparently built with integrity, whereas the climate models are not.
The climate models have been an exercise in pseudo-scientific fraud, in my opinion.
For example, the climate models falsely assume a sensitivity of climate to a doubling of CO2 that is about an order of magnitude too high (3C versus 0.3C). The modelers then justify this false high sensitivity by assuming false manufactured aerosol data that force-fits the hindcasting of the global cooling that occurred from ~1940 to ~1975. This is perhaps better explained in the 2009 post below.
As for the modeling of clouds, I’m not sure we understand the physics of clouds well enough to model them, even at a first-order approximation of their complexity.
Finally, this entire post assumes that atmospheric CO2 drives temperature. I came to the conclusion in 2008 that temperature drives CO2. I was not the first to reach this conclusion. The following quotation is from “Celestial Climate Driver: A Perspective from Four Billion Years of the Carbon Cycle” (Jan Veizer, Geoscience Canada, Volume 32 Number 1 March 2005):
“Again, while CO2 may act as an amplifying greenhouse gas, the actual atmospheric CO2 concentrations are controlled in the first instance by the climate, that is by the sun-driven water cycle, and not the other way around.”
__________________
http://wattsupwiththat.com/2009/06/27/new-paper-global-dimming-and-brightening-a-review/#comments
Leif Svalgaard (13:21:18) :
Allan M R MacRae (12:54:27) :
“There are actual measurements by Hoyt and others that show NO trends in atmospheric aerosols, but volcanic events are clearly evident.”
But increased atmospheric CO2 is NOT a significant driver of global warming – that much is obvious by now.
Leif: But what has that to do with aerosols?
**************************
Leif, I did say:
“The sensitivity of global temperature to increased atmospheric CO2 is so small as to be inconsequential – much less than 1 degree C for a doubling of atmospheric CO2. CO2 feedbacks are negative, not positive. Climate model hindcasting fails unless false aerosol data is used to “cook” the model.”
Connecting the dots, to answer your question:
The fabricated aerosol data allows climate model hindcasting to appear credible while assuming a false high sensitivity of global temperature to atmospheric CO2.
The false high sensitivity is then used to forecast catastrophic humanmade global warming (the results of the “cooked” climate models).
What happens if the fabricated (phony) aerosol data is not used?
No phony aerosol data -> no false-credible model hindcasting -> no artificially high climate sensitivity to CO2 -> no model forecasting of catastrophic humanmade global warming.
Regards, Allan
Allan, thanks for the further information and the updated video. I’d sure like to see him write a paper on the subject. If his thesis proved out, it would completely undercut the entire paradigm of blame.
He’s also the first researcher I’ve seen mentioning the recent IBUKI satellite results.
george e smith, honestly I don’t have any trouble with computer models either, George. From the sound of it, you’re developing and using well-verified engineering models.
Engineers have to pay close attention to detail developing such models, mapping out their response to high accuracy within the required specifications (boundary conditions). They have to be sure that the models give physically accurate predictions, validated by performance. I have nothing but respect for that business.
One of my brothers is a double-E, and uses engineering models to develop signal-processing ICs that go into microwave devices. Large amounts of money, not to say safety, depend on those working as advertised.
I use models in research, too, and am aways sweating uncertainties. Climate modelers seem to have lost perspective, treating their models as physically complete and accurate, so that nothing more is needed than to map out the response phase-space. In that supposition they’re being naive (or incompetent) to an astonishing degree.
Several years ago, Jerry Browning discussed climate models extensively over at Climate Audit. He described how small errors grow exponentially, making predictions impossible. He also discussed the modelers suppressing sub-grid turbulence by imposing a hyperviscous atmosphere, noting that a “molasses atmosphere” necessitated unphysical parameterizations. The whole climate model business is extremely shaky and it’s beyond knowing how that is so thoroughly unremarked in the profession or the journals.
Terry Oldberg, thanks for the interesting conversation. My comment started from your definition of “prediction” as being the extrapolation of an observation, i.e., your ““prediction” defined as an extrapolation from an observed condition to the unobserved…” That sounds just like inductive inference to me, which is non-scientific. If you had meant prediction to be an, ‘extrapolation from an observed condition to the unobserved by means of deduction from (a scientifically valid) theory,’ I’d have no problem.
As it is, I don’t really know what you mean by “model.”Your description seems to mean an ad hoc mathematical system that reproduces known past behavior? Such models can’t make predictions. On the other hand statistical models can derive probabilities of future behavior, but only based upon the assumption that the future is like the past.
Such models are useful, but they don’t really follow the scientific method. Regarding statistical models, you wrote that, “If there is not a match [between observed and predicted outcomes], the model is falsified.” But whats really falsified in that case is the assumption of regularity. The statistical model itself has not been falsified. One merely needs to adjust the model coefficients to the statistics of the new conditions. In science, the model itself would be falsified if observations contradicted the predictions.
You wrote that, “Thermodynamics and quantum mechanics are examples of models for which information about the outcome, given the condition, is missing …” I presume you mean Statistical Thermodynamics, as that completes the analogy with QM.
But in any case, both theories are completely deterministic in that their states evolve in a completely deterministic way, and their predicted outcomes are also completely determined by theory. In QM, the observable of an individual scattering event can not be predicted, but Heisenberg’s uncertainty statement makes that inability a function of theory, not of information. That is, information cannot be said to be missing when the theory itself specifies that information cannot exist. Beyond the quantum horizon, “information” has no meaning and so supposing it is “missing” is to make a category mistake. One cannot say something is missing when it cannot in principle be present.
In chemical physics, the trajectories of individual atoms can be predicted, e.g., in a Penning trap, and also see, but then, of course, Statistical Thermodynamics no longer apply.
You’re right that I was careless in describing a “climate sensitivity.” The term is common parlance in climate science, and I did use it in the conventionally off-hand manner. Many people have noted that the climate is always out of equilibrium. It would better be called a dissipative system in the far-from-equilibrium sense of Prigogine; one that can transition between many quasi-stable states.
I meant the concept only in terms of a perturbation of a magnitude to cause a response in the local state energy content without causing a state transition. You were right to call me on it.
In other news, Eric Steig has not answered my question about how he discounted systematic temperature sensor measurement error in his study of Antarctic temperature trends.
Pat Frank:
Thank you for the stimulating response. In my definition of the term, a “model” is a procedure for making inferences. As logic contains the principles for discrimination of correct from incorrect inferences, by this definition of the term one ties the idea that is referenced by the term “model” to logic. To do so is to set ones self up for discovery of logical errors in the methodology of an inquiry. To do so is also to set one’s self up for specification of a methodology for a scientific inquiry that is logically flawless. I found the latter feature quite useful in a period in which I earned my living through the design and management of scientific inquiries.
The scope of the deductive logic is generally inadequate for the task, but a generalization of it proves adequate. The generalization replaces the rule that every proposition has a truth value by the rule that every proposition has a probability. This generalization produces the “probabilistic logic.” In this logic, it is easy to show that every inference has a unique measure. The measure of an inference is the missing information in it for a deductive conclusion, the so called “entropy.” This finding arms the searcher for methodological error with the machinery of information theory.
In the philosophical literature, the realm lying outside the deductive logic is called the “inductive logic.” It follows from the existence and uniqueness of the entropy as the measure of an inference that the inductive logic differs from the deductive logic in the respect that the entropy of an inference is non-nil. In thermodynamics, the entropies of the inferences are generally non-nil and thus the logic of thermodynamics is generally inductive.
A caveat applies to what I have just said. The idea of a “probability” implies that every set bearing a probability is crisply defined but as it turns out the crispness of these sets is antithetical to the existence of a quantitative independent variable such as the global average temperature at Earth’s surface. This shortcoming may be overcome through a generalization that incorporates Zadeh’s fuzzy set theory. Zadeh’s theory preserves the idea of entropy while generalizing the idea of probability such that the generalized probability is defined on fuzzy sets.
Using these ideas, I’ve initiated a search for errors in the methodology of the IPCC’s inquiry into global warming. This search has uncovered errors that are fatal to the IPCC’s pretensions to having conducted a scientific investigation. The presence of these errors is, however, obscured by the ambiguity of reference to the associated ideas by terms in the language of climatology. The ambiguity of reference yields negation of Aristotle’s law of non-contradiction. Using the negated law as a false but apparently true premise to a variety of arguments, authors of IPCC assessment reports make arguments whose conclusions seem to the general public to be true but whose conclusions are actually false or unproved. Among the stratagems used by IPCC authors in achieving this end is to conflate the idea that is referenced by the term “projection” with the idea that is referenced by the term “prediction” by using the two terms as synonyms.
I’ve just discovered that four days ago, Michael Tobis called me “tedious” and a purveyor of “falsehoods” in a post that also linked me with pseudoscience, confusionism, and garbage. Apart from that, he offered no actual critique of my cloudiness error analysis.
I’ve invited MT to dispute me here (we’ll see whether the invitation survives moderation), where neither of us will be censored. So far, I’ve had two experiences debating Micheal on blogs he controlled. Neither experience encourages confidence that freedom will prevail on his Planet 3.0
Terry Oldberg, logic has an invaluable part to play in the validity of scientific inferences, it’s true.
Every theory in science must be internally self-consistent in the logical sense as you mean it. Typically, logical self-consistency is achieved by coding the theory in mathematics. A basic conflict is revealed by this within Physics, which is that QM is expressed in discrete mathematics whereas Relativistic Mechanics requires continuum mathematics. The choice of mathematical expression is not arbitrary, of course, nor axiomatic, but rather imposed by the results of experiment. That observational foundation frees the conflict from Philosophy.
The freedom of Science from Philosophy leads me to the source of a need to part ways a bit from your analysis. The various logics you describe are all useful; most especially when assessing polemics. Polemical views are always based in some assumed view, and philosophical analysis is probably the best way to reveal that. Hence your success examining the rhetorical flourishes of the IPCC.
I completely agree with your point that the IPCC tendentiously conflates/distinguishes prediction and/from projection, whenever it suits their fancy. This, their tendency, is mentioned in passing in my Skeptic article.
I also agree that deployment of logic can be very useful in determining the validity and coherence of a scientific project.
With regard to the inadequacy of deductive logic, I believe that most scientists would agree with you. The fact that any theory is incomplete and therefore unable to yield completely specified predictions is well-known. This lack always leaves open the possibility of ad hoc adjustments to avoid falsification.
The persistent availability of ad hoc adjustments strictly removes what you called the “unique measure” of the probability of the expectation value of a theory (the calculated outcome or prediction). Employment of Ockham’s Razor gains its utility here.
When discussing science, it’s necessary to be very careful with the use of terms. Physical “entropy” is the the number of states among which a system may distribute itself. Typically the greatest entropy includes large numbers of degenerate (equipotential) states. But you have used “entropy” in the Shannon sense. I consider that use an illicit absconding of the term, based merely on the equivalent mathematical structure of physical entropy and Shannon’s information loss.
Consider this pair of statements (H/T Bill Wattenberg): “Time flies like an arrow. Fruit flies like a banana.” Equivalent syntax, orthogonal meanings. Such are physical and Shannon entropies.
If I understand your distinction of inductive and deductive logic, your statement is that an inductive inference is “non-nil,” meaning that every inductive inference has a unique measure, which in your terminology seems to also be a unique probability measure.
As I see it, the uniqueness of your probability measure derives entirely from the axiomatic basis from which your inductive inference proceeds. If that’s true, then the non-missing information in your inference stems from the fact that the necessary quantity of information has been assumed. That is, like mathematics, your certainty of consequence — your measure of probabilistic uniqueness — comes from the fact that your conclusions are contained in your assumptions. The logic is thoroughly and completely rigorous, but ultimately nothing is new even if it may be surprising.
Science, however, is anaxiomatic in the sense that no assumptions are invariantly held as true. Science derives its theories irrationally, i.e., despite insufficient information, even though they are required to be expressed logically and coherently, and then tests them using observations. Discoveries of science can therefore, and uniquely, be both new and surprising.
The “missing information,” due to the lack of grounding axioms and leading to theory invention and to deductive logic, is a strength of science. It allows knowledge to progress in the face of ignorance.
Thermodynamics, prior to the Statistical Thermodynamics that grew out of Atomic Theory, was almost strictly an observational science. The Carnot Cycle was derived inductively, for example, and formed the basis for 19th century thermodynamics. That makes its inferences probabilistic in the sense you perhaps mean.
But virtually all of classical thermodynamics can now be derived from Newtonian Physics, Statistical Thermodynamics, and Maxwell’s Theory.
That is, classical thermodynamics is now a deductive inference, even though Statistical Thermodynamics can make what you call non-nil inferences, i.e., unique probabilistic statements.
At the end, I’m not saying your analysis is wrong; only that it is in some cases incomplete with respect to the methodological structure of science.
As an interesting convergence, one might see your “ambiguity of reference yield[ing] negation of Aristotle’s law of non-contradiction” with reference to the IPCC, also in the consistent lack of physical error analysis in the IPCC’s representations of future climate. The representations are presented as physics, but the consistent lack of physical uncertainty bounds makes them physically meaningless. I.e., they appear to be self-contradictory in the Aristotelian sense you describe. My analysis is a first-step attempt to resolve the contradiction.
By the way, Chris Essex & co published a paper showing that global average temperature is not a physical quantity at all, and has no sure physical meaning. You may enjoy it: C. Essex, R. McKitrick, and B. Andresen (2007) Does a Global Temperature Exist?” J. Non-Equilibrium Thermodynamics 32, 1–27 Here’s the abstract page. The usual AGW suspects derided it, but the thermodynamic idea is sound, namely that temperature is a physical observable and not a statistic.
I’d like to offer two points in clarification and three examples. First point of clarification: in logic, there is not a distinction to be made between the physical and Shannon entropies; they are simply different applications of the same concept.
Second point in clarification: the entropy is the unique measure of an inference in the deductive as well as the inductive branches of logic. In the deductive branch, the value of the entropy is nil while in the inductive branch it is not-nil.
First example: Cardano’s theory of fair gambling devices offers a mathematically simple application of the inductive logic. Under the principle of entropy maximization, the entropy of the various ways in which the outcome can occur is maximized, under constraints expressing the available information. In Cardano’s theory there are no constraints. Maximization of the entropy without constraints assigns equal numerical values to the various ways. For example, it assigns 1/6 to each of the 6 ways in which an outcome can occur in the throw of a die.
Second example: Thermodynamics results from an application that is similar but that adds a constraint. The ways in which an outcome can occur are the “microstates” and the constraint is energy conservation. Maximization of the entropy under this constraint (the second law of thermodynamics) assigns equal numerical values to the probabilities of the microstates that satisfy energy conservation, the so-called “accessible microstates.”
Third example: In other applications it is logical to minimize the conditional entropy of one type of inference and to maximize the entropy of a different type of inference. This approach yields, for example, Shannon’s mathematical theory of communication.
Terry, I accept your examples. My only point is that logic is not science, although science uses logic as a critically important tool.
The observational foundations of science means that Shannon entropy is not physical entropy. It’s very central to realize that equivalence in mathematical structures does not equal equivalence of meaning.
In your post of 27 august, you wrote that, “It sounds as though you have concluded from my use of the term “statistical event” that my remarks pertain only to statistical models. This conclusion is mistaken. My remarks pertain to models that are purely mechanistic, to models that are purely statistical and to models that mix the statistical and mechanistic approaches to building models.”
And also that, “A condition and an outcome describe a statistical event. … The complete set of events that are referenced by a study is a kind of statistical population.”
I believe these comments are central to your approach, and would like to express the point of view of a scientist. The point will not contradict your views, but does move science to its proper place outside of them.
That is, the statistical analysis of scientific outcomes is posterior to the construction of the theory and the measurement of the data. The final decision about application of statistics, and the determination of what form the statistics should take, comes after the anticipations of theory and after evaluation of the form taken by the data.
The emergent values of data, in particular, are independent of prior expectations. It is for this reason that science is not, and can not be, axiomatic.
Therefore, whereas “a condition and outcome [can] describe a statistical event,” under the methodology of science, they need not. That is, statistics is not inherently necessitated by science, nor is science a branch of statistics.
The array of outcomes — observables — following an experiment are predicted by a theory that describes the partitioning of energy states, with consequent and dependent material transformations. These, as described by theory, may produce an ensemble of outcomes that is statistically analyzable. However, the condition of able to be analyzed by statistics follows from the content of theory and and the structure of the observation, rather than from any a priori necessity stemming strictly from statistics or logic.
That is, statistics and logic themselves do not determine the structure of science, no matter that they have turned out to be useful in analyzing the structure of science following its emergence.
Therefore, the success of your approach as regards science, starting as it does from logic and a statistical formalism, depends for its power on the pre-existent and independent presence of statistical elements in the theory and results of science. As there are many pre-existent elements in physical theory that have been found to follow a statistical order, from subatomic theory all the way up through Biology, your approach from logic and statistics will have success.
However, it must be kept in mind that the success of your approach to science follows after, and is dependent upon, the pre-presence of statistical elements throughout science. These statistical elements in science arose because they were demanded by the structure of the ensemble of observations.
There is no prior necessity that observations should have taken that structure nor any prior necessity that science should have followed certain logical or statistical rules.Terry, I accept your examples. My only point is that logic is not science, although science uses logic as a critically important tool.
The observational foundations of science means that Shannon entropy is not physical entropy. It’s very central to realize that equivalence in mathematical structures does not equal equivalence of meaning.
Pat Frank:
Thanks for sharing your views.
A point of commonality between the “physical entropy” and the “Shannon entropy” is that both are the unique measure of an inference. Logic contains the rules that discriminate correct from incorrect inferences. Thus, from a logical perspective, there is not a difference between the physical and the Shannon entropy.
Pat Frank:
While one can draw a distinction between the “physical entropy” and the “Shannon entropy,” there is not a difference between the two concepts. In both cases, the concept that is referenced by the term is the missing information about the unobserved state per event.
You’ve raised the issue of the relationship between logic and science. Ambiguity of the English word “science” muddies the waters in attempts at addressing this issue. To clarify these waters, I’ll substitute the Latin word “scientia” for “science.” “Scientia” means “demonstrable knowledge.”
In information theoretic terms, the “scientia” is the information per event that is provided by the model about the unobserved but observable state, given the observed state. The entropy is the information per event that is NOT provided by the model about the unobserved but observable state of an event given the observed state. The entropy and the scientia are related in this intimate way.
Logic is related to entropy and thus to scientia by the facts that: a) its entropy is the unique measure of an inference and b) logic contains the principles that discriminate correct from incorrect inferences. In a 49 year old advance, these principles were discovered: In a set of inferences that are candidates for being made by a model, the correct inference is the one that minimizes or (dependent upon the type of inference) maximizes the entropy.
Academia has not yet caught up with this advance. A consequence is for most model builders to discriminate correct from incorrect inferences in the old fashioned way through the use of heuristics. A result from widespread use of heuristics is for most of the models that we use today to be riddled with logical errors. One has only to poke around in these models a bit to find the errors.
Moderator, the last sentence of my prior post was somehow followed again by the first four sentences (two small paragraphs). If you could please remove them, and this post too, thanks very much.
As of this writing, Michael Tobis has not responded to my invitation to refute the head-post analysis, given that he had called the analysis misleading and me tedious.
Nor has Eric Steig responded to my request that he illuminate how he had apparently discounted 100% of the systematic temperature sensor error in his Antarctic work.
Terry Oldberg
You wrote, “In information theoretic terms, … the entropy is the information per event that is NOT provided by the model about the unobserved but observable state of an event given the observed state.
That’s fine, Terry, but entropy is not “missing information” in physical theoretic terms. It’s about the dispersal of particles, including photons, among available microscopic energy states.
It’s clear that the equivalence of the mathematics makes seductive the redefinition of physical entropy in terms of information. After all, we humans think of knowledge in terms of accurate descriptions of discrete events, and entropy is defined probabilistically.
But the probabilistic description doesn’t mean information is missing. The probability distribution is the information. No other information is possible, therefore no information is missing.
You’re clearly wedded to the information theoretic account of things, as I am to the physical theoretic account of things. Your adherence to information theoretic axiomatics requires that you describe entropy as missing information. But axiomatic conclusions are necessarily self-referential, for reasons noted above.
Physical theory is not axiomatic, in the sense that the reliance on observation means that the system is not closed. Science is not self-referential for that reason.
For all the power of your logic, its application to science is happenstantial. Physical science has developed in a way, such that information theory has an accidental congruence with the structure of science. That accident has conferred an analytical power.
But I believe it’s a mistake to push the analogy too far, to the point of redefining the meaning of physical concepts so that they are extruded into an information theoretic mold. Doing so only sows confusion. Logic is not related to physical entropy. In no physical theory does logic enter as a calculational term.
Pat Frank:
Thank you for taking the time to respond. I have to point out that when you claim that “the probability distribution is the information,” your claim is inconsistent with the information theoretic definition of “information.” When the “information” and the “missing information” are properly defined, a logic emerges from these definitions. One of many applications of this logic is the second law of thermodynamics. As the physicist Edwin Jaynes realized in his 1957 paper “Information theory and statistical mechanics,” the second law can be regarded as an application of the generally applicable principle called “entropy maximization.” Though it was first discovered in empirical data, entropy maximization can be mathematically derived from its roots in measure theory and probability theory
In their own words: “climate models trump data” ( the big lie )
“The data doesn’t matter. We’re not basing our recommendations on the data. We’re basing them on the climate models.”
– Prof. Chris Folland,
Hadley Centre for Climate Prediction and Research
“The models are convenient fictions that provide something very useful.”
– Dr David Frame,
climate modeler, Oxford University
* Source: http://www.green-agenda.com
Terry Oldberg, you wrote that, “when you claim that “the probability distribution is the information,” your claim is inconsistent with the information theoretic definition of “information.””
But my claim is not inconsistent with the definition of information within science. And science, after all, provides the full context of any discussion concerning the meaning of predictions and projections made by climate scientists.
As we all know, meaning (information) in science arises from the inter-relation of falsifiable theory and replicable result, where “result” is the objective outcome of an experiment or an observation. Information in science does not come from properly defined logical premises, alone.
I don’t doubt you’re right that information theoretical logic produces a result that looks exactly like the second law of thermodynamics. But consider: in the absence of referential objective data that information theoretic outcome is no more than philosophy.
As you noted, the second law “was first discovered in empirical data.” The second law remains irremediably embedded in empirical data. Any mathematical derivation of the second law takes its meaning in science from the inter-relation of the derived expression and the relevant empirical data. Either part alone — derived expression or empirical data — are physically meaningless. Only the outcome of the relational interplay has meaning in science.
As a theory of science, the second law remains open to refutation and falsification by experiment. As a deductive conclusion within an axiomatic Information Theory, the analogical second law expression remains forever true, regardless of experiment. This distinction — open to falsification vs. forever true — completely demarcates Thermodynamics from Information Theory, and completely distinguishes the meaning of the second law in science from the same expression in information theory.
Whatever meaning the derived second law expression has within information theory, within science that meaning is conditional upon the feedback from empirical outcomes and the explanatory coherence of the second law within the greater context of relevant physical theory.
Any part of the information theoretic meaning of the second law equation that does not map exactly onto physical meaning is irrelevant to science. With respect to science, at best, any extra-scientific information theoretic meaning might constitute a scientific hypothesis that must wait upon an empirical test for its validity.
As “information” is not a physical observable, and/or has no observable consequences, “information” makes no appearance in the equations of Thermodynamics, has no physical meaning, and can make no contribution to Thermodynamic explanations. That doesn’t mean people will not be seduced by the power of analogy to suppose a congruence.
One may find that non-scientific information theoretic meanings are useful in assessing the logic and coherence of proposed scientific or engineering programs. That utility, however, does not validate any claim that the meanings of information theory can be directly imported unchanged into science itself. Nor can that utility support a claim that meaning in science is conditioned upon information theory.
I appreciate the power and coherence of your thinking, Terry. But the grounding of physical meaning in observation forever frees science from axiomatic systems.
This sentence, “But consider: in the absence of referential objective data that information theoretic outcome is no more than philosophy.” should have finished this way:
‘But consider: in the absence of referential objective data that information theoretic outcome is no more than philosophy, and its force is limited to evaluating the logic of syllogisms.’
Also, the non-axiomatic, observational basis of science frees it from any constraint implied by Godel’s incompleteness theorem.