Guest post by Steven Goddard
In his recent article, NSIDC’s Dr. Meier answered Question #9 “Are the models capable of projecting climate changes for 100 years?” with a coin flipping example.
1. You are given the opportunity to bet on a coin flip. Heads you win a million dollars. Tails you die. You are assured that it is a completely fair and unbiased coin. Would you take the bet? I certainly wouldn’t, as much as it’d be nice to have a million dollars.2. You are given the opportunity to bet on 10000 coin flips. If heads comes up between 4000 and 6000 times, you win a million dollars. If heads comes up less than 4000 or more than 6000 times, you die. Again, you are assured that the coin is completely fair and unbiased. Would you take this bet? I think I would.
Dr. Meier is correct that his coin flip bet is safe. I ran 100,000 iterations of 10,000 simulated random coin flips, which created the frequency distribution seen below.

The chances of getting less than 4,000 or greater than 6,000 heads are essentially zero. However, this is not an appropriate analogy for GCMs. The coin flip analogy assumes that each iteration is independent of all others, which is not the case with climate.
[Note: Originally I used Microsoft’s random number generator, which isn’t the best, as you can see below. The above plot which I added within an hour after the first post was made uses the gnu rand() function which generates a much better looking Gaussian.]

Climate feedback is at the core of Hansen’s catastrophic global warming argument. Climate feedback is based on the idea that today’s weather is affected by yesterday’s weather, and this year’s climate is dependent on last year. For example, climate models (incorrectly) forecast that Arctic ice would decrease between 2007 and 2010. This would have caused a loss of albedo and led to more absorption of incoming short wave radiation – a critical calculation. Thus climate model runs in 2007 also incorrectly forecast the radiative energy balance in 2010. And that error cascaded into future year calculations. Same argument can be made for cloud cover, snow cover, ocean temperatures, etc. Each year and each day affects the next. If 2010 calculations are wrong, then 2011 and 2100 calculations will also be incorrect.
Because of feedback, climate models are necessarily iterative. NCAR needs a $500 million supercomputer to do very long iterative runs decades into the future. It isn’t reasonable to claim both independence (randomness) and dependence (feedback.) Climate model errors compound through successive iterations, rather than correct. How could they correct?
Speaking of Arctic ice cover and albedo, the sun is starting to get high in the sky in the Arctic, and ice extent is essentially unchanged from 30 years ago. How does this affect climate calculations?

GCMs are similar to weather models, with added parameters for factors which may change over time – like atmospheric composition, changes in sea surface temperatures, changes in ice cover, etc. We know that weather models are very accurate for about three days, and then quickly break down due to chaos. There is little reason to believe that climate models will do any better through successive iterations. The claim is that the errors average out over time and produce a regionally correct forecast, even if incorrect for a specific location.
A good example of how inaccurate climate forecasts are, is shown in the two images below. NOAA’s Climate Prediction Center issued a long range forecast for the past winter in February, 2009. Brown and orange represents above normal temperatures, and as you can see they got most of the US backwards.

NOAA CPC’s long range forecast for winter 2009-2010
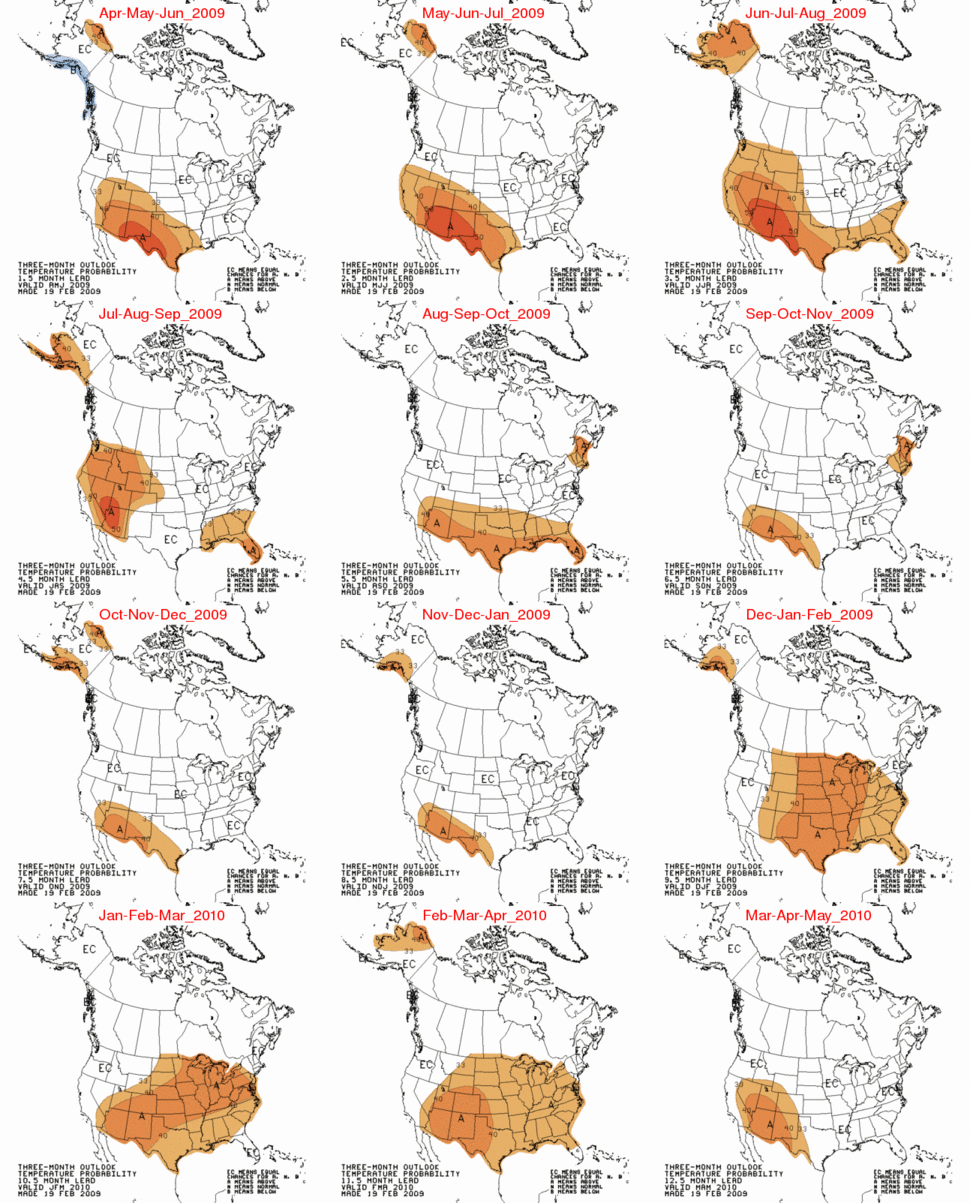{kind=link}

NOAA’s reported results for winter 2009-2010
The UK Met Office seasonal forecasts have also been notoriously poor, culminating in their forecast of a warm winter in 2009-2010.
The Met Office climate models forecast declining Antarctic sea ice, which is the opposite of what has been observed.


NSIDC’s observed increase in Antarctic sea ice
Conclusion : I don’t see much theoretical or empirical evidence that climate models produce meaningful information about the climate in 100 years.
However, Willis claims that such a projection is not possible because climate must be more complex than weather. How can a more complex situation be modeled more easily and accurately than a simpler situation? Let me answer that with a couple more questions:1. You are given the opportunity to bet on a coin flip. Heads you win a million dollars. Tails you die. You are assured that it is a completely fair and unbiased coin. Would you take the bet? I certainly wouldn’t, as much as it’d be nice to have a million dollars.2. You are given the opportunity to bet on 10000 coin flips. If heads comes up between 4000 and 6000 times, you win a million dollars. If heads comes up less than 4000 or more than 6000 times, you die. Again, you are assured that the coin is completely fair and unbiased. Would you take this bet? I think I would.
Discover more from Watts Up With That?
Subscribe to get the latest posts sent to your email.
Steve,
I am sorry that you just dont get it.
First, there is no integer division in either of the algorithms I gave. Really. None-at-all.
The first algorithm implies a *floating point* division, but that can be avoided when implementing it, while the second is actual code and multiplies by a constant expression (thus, a constant single VALUE, with no divisions at all)
Secondly, you should *measure* performance instead of making claims.
Integer division vs flushing the pipeline .. your thinking was valid a decade or two ago, but not any longer. Its not so simple these days.
You are only looking at instruction latency, but not instruction throughput. A pipeline flush destroys insruction throughput. Not only does it waste the previous efforts of speculative execution by the execution units, the execution units must further wait for the pipeline to fill back up before doing anything. Thats at least 14 cycles on a Core2, and 20 cycles on P4’s, and more than 20 on P4E’s.
To quote Agner Fog:
http://www.agner.org/optimize/
(from the Optimizing C++ document)
——-
“There is an important distinction between the latency and the throughput of an execution unit. For example, it may take three clock cycles to do a floating point addition on a modern CPU. But it is possible to start a new floating point addition every clock cycle. This means that if each addition depends on the result of the preceding addition then you will have only one addition every three clock cycles. But if all the additions are independent then you can have one addition every clock cycle.
The highest performance that can possibly be obtained in a computationally intensive program is achieved when none of the time-consumers mentioned in the above sections are dominating and there are no long dependency chains. In this case, the performance is limited by the throughput of the execution units rather than by the latency or by memory access”
——
(from the microarchitecture document)
“The Core 2 microarchitecture allegedly has a pipeline of only fourteen stages in order to reduce power consumption, speculative execution and branch misprediction penalty. However, my measurements indicate that the pipeline is approximately two stages longer in the Core2 than in PM. This estimate is based on the fact that the branch misprediction penalty is measured to at least 15, which is 2 clock cycles more than on PM.”
——
In short: If you are worried about latency, then you arent optimizing correctly. Instruction latency is an issue that can be made moot in practice, by maximizing for instruction throughput when optimizing. Pipeline flushes prevent ALL instruction throughput for many cycles, and EVEN waste previous cycles of work performed by the CPU.
I really don’t care what you believe. I’ve said my peace. If you are really concerned about performance than you’ve got a lot to learn. You are focused on instruction latency when thats just about the least important thing to be concerned about these days: Instruction Throughput and maintaining Cache Coherence are the #1 performance concerns on modern processors.
Well, i don’t see much differnce between the last two graphs.
Jason,
One graph is going up, and the other graph is going down. Is that different?
Steve,
Well, yeah, but between 2000 and 2010 they are basically the same, and that’s the only part they are together. At least, so far 😉 I don’t find it very useful to compare a trend obtained with past data to a trend that only takes place in the future in that model.
I have to agree with Joe. He is absolutely correct, in every way.
The way he suggest to use rand() is how you should be using it.
Multiplication by reciprocal (whenever possible) is what you do in signal processing to avoid division. (knowledge of this particular trick is how I distinguish a embedded DSP person vs wannabe during job interview)
Pentiums can do floating point math very efficiently, so you save very little by avoiding it. Pipeline flashing would be major reason for performance degradations here, by an order of magnitude at least.
If you worried about performance you should look into random number generators that are much more efficient than microsoft’s supplied, you’d get much better bang for the buck that way. I had a need for a good random number generator that I could use with Matlab and with my own C program a few years back. I found one that was much better then rand() in performance and quality of pseudo-random sequence, available in source code. It has been a while, but I could dig it up if you interested.
Wow!
My mentioning the possibility of poor implementation of the MS Rand() function rather than Rand() being defective certainly generated a healthy exchange of views. Interesting stuff about instruction costs and cache flushing.
My take-away. MS Rand() has not been demonstrated to be worse than the Gnu one. It just operates differently than was assumed. Relying on the low bit state while using an unfamiliar generator is not wise.