Guest post by Steven Goddard
In his recent article, NSIDC’s Dr. Meier answered Question #9 “Are the models capable of projecting climate changes for 100 years?” with a coin flipping example.
1. You are given the opportunity to bet on a coin flip. Heads you win a million dollars. Tails you die. You are assured that it is a completely fair and unbiased coin. Would you take the bet? I certainly wouldn’t, as much as it’d be nice to have a million dollars.2. You are given the opportunity to bet on 10000 coin flips. If heads comes up between 4000 and 6000 times, you win a million dollars. If heads comes up less than 4000 or more than 6000 times, you die. Again, you are assured that the coin is completely fair and unbiased. Would you take this bet? I think I would.
Dr. Meier is correct that his coin flip bet is safe. I ran 100,000 iterations of 10,000 simulated random coin flips, which created the frequency distribution seen below.

The chances of getting less than 4,000 or greater than 6,000 heads are essentially zero. However, this is not an appropriate analogy for GCMs. The coin flip analogy assumes that each iteration is independent of all others, which is not the case with climate.
[Note: Originally I used Microsoft’s random number generator, which isn’t the best, as you can see below. The above plot which I added within an hour after the first post was made uses the gnu rand() function which generates a much better looking Gaussian.]

Climate feedback is at the core of Hansen’s catastrophic global warming argument. Climate feedback is based on the idea that today’s weather is affected by yesterday’s weather, and this year’s climate is dependent on last year. For example, climate models (incorrectly) forecast that Arctic ice would decrease between 2007 and 2010. This would have caused a loss of albedo and led to more absorption of incoming short wave radiation – a critical calculation. Thus climate model runs in 2007 also incorrectly forecast the radiative energy balance in 2010. And that error cascaded into future year calculations. Same argument can be made for cloud cover, snow cover, ocean temperatures, etc. Each year and each day affects the next. If 2010 calculations are wrong, then 2011 and 2100 calculations will also be incorrect.
Because of feedback, climate models are necessarily iterative. NCAR needs a $500 million supercomputer to do very long iterative runs decades into the future. It isn’t reasonable to claim both independence (randomness) and dependence (feedback.) Climate model errors compound through successive iterations, rather than correct. How could they correct?
Speaking of Arctic ice cover and albedo, the sun is starting to get high in the sky in the Arctic, and ice extent is essentially unchanged from 30 years ago. How does this affect climate calculations?

GCMs are similar to weather models, with added parameters for factors which may change over time – like atmospheric composition, changes in sea surface temperatures, changes in ice cover, etc. We know that weather models are very accurate for about three days, and then quickly break down due to chaos. There is little reason to believe that climate models will do any better through successive iterations. The claim is that the errors average out over time and produce a regionally correct forecast, even if incorrect for a specific location.
A good example of how inaccurate climate forecasts are, is shown in the two images below. NOAA’s Climate Prediction Center issued a long range forecast for the past winter in February, 2009. Brown and orange represents above normal temperatures, and as you can see they got most of the US backwards.

NOAA CPC’s long range forecast for winter 2009-2010
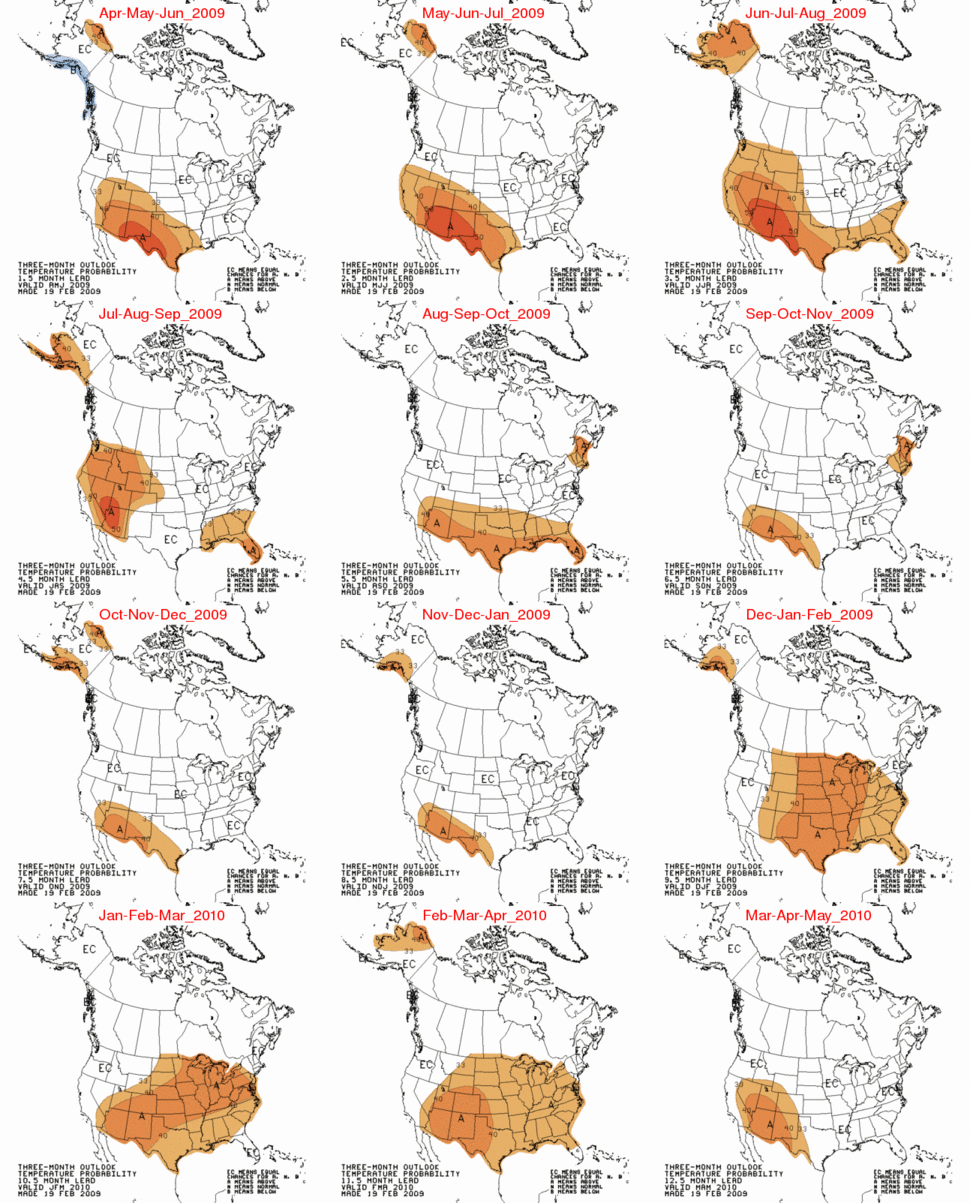{kind=link}

NOAA’s reported results for winter 2009-2010
The UK Met Office seasonal forecasts have also been notoriously poor, culminating in their forecast of a warm winter in 2009-2010.
The Met Office climate models forecast declining Antarctic sea ice, which is the opposite of what has been observed.


NSIDC’s observed increase in Antarctic sea ice
Conclusion : I don’t see much theoretical or empirical evidence that climate models produce meaningful information about the climate in 100 years.
However, Willis claims that such a projection is not possible because climate must be more complex than weather. How can a more complex situation be modeled more easily and accurately than a simpler situation? Let me answer that with a couple more questions:1. You are given the opportunity to bet on a coin flip. Heads you win a million dollars. Tails you die. You are assured that it is a completely fair and unbiased coin. Would you take the bet? I certainly wouldn’t, as much as it’d be nice to have a million dollars.2. You are given the opportunity to bet on 10000 coin flips. If heads comes up between 4000 and 6000 times, you win a million dollars. If heads comes up less than 4000 or more than 6000 times, you die. Again, you are assured that the coin is completely fair and unbiased. Would you take this bet? I think I would.
Discover more from Watts Up With That?
Subscribe to get the latest posts sent to your email.
Ric Werme (06:20:06) :
I thought some more about the issues of low order bits being flawed. Your suggestion of (random_number > (RAND_MAX/2)) would work for this case, but there are plenty of applications – like this one – which expect randomness in all bits. The distribution below would work with your algorithm, but is not random.
16383, 16382, 16383, 16382, 16384, 16385, 16384, 16385
If a RNG can’t be counted on to generate randomness in even/odd (bit 0) distribution, that definitely is not a good thing.
Joe (08:04:00) :
Integer division on any microprocessor is a very slow operation, typically taking between 15 and 80 clock cycles. Logical & takes one clock cycle.
Thus, the algorithm you suggest is much slower than what I am using. One billion iterations is too slow already.
I’ll stick with gnu in this case, thanks.
“Steve Goddard (09:24:57) :
Joe (08:04:00) :
Integer division on any microprocessor is a very slow operation, typically taking between 15 and 80 clock cycles.”
CPU architectures that contain a barrel shifter – amongst them the Core 2 [Duo] – can do very quick multiplications, and divisions are somewhat accelerated, though often not as much as multiplications.
Here’s an interesting table, contrasting the Pentium IV (no barrel shifter) with the Core 2 Duo:
http://www.behardware.com/articles/623-5/intel-core-2-duo-test.html
“Wren (22:12:28) :
[…]
So about 10 years or so into that 1890-2009 projection, skeptics would have been saying DickH your temperature projection sucks. ”
Oho, i made Wren use invectives… Running out of arguments so fast?
Steve,
No generator gives good randomness in all the bits of its state.
You are using the C language, where the entire state is exposed by the standard library random function. The legacy of the C language is such that things cannot be changed for the better with the standard library function, which is why there are so many alternative functions described both on the internet and in reference material.
The industry standard (used by State Gaming Comissions and so forth) for random number generation is the Multiply-With-Carry methodology using a large number of generators. it is far more heavyweight than you will find in a standard library:
http://en.wikipedia.org/wiki/Multiply-with-carry
As far as integer division. Yes, its slow. But I didn’t suggest integer division. You cannot get a result 0 <= x < 1.0 with integer division. I suggested floating point work there.
In any case, RAND_MAX is most often of the form (2^n-1) where n is the number of bits of state that the generator keeps.
This means that you could use fixed point methods and shifting, instead of a division operation. The methodology I gave was only an illustration of what needs to be done in order to use rand() safely. There is also the option of multiplying by a floating point constant instead of dividing (all constant divisions can be converted into constant multiplications.)
There are plenty of examples of proper usage in C on the internet, such as:
http://members.cox.net/srice1/random/crandom.html
No I do not work for Microsoft. The fact is that the weakness of LCG's is common knowledge among many software developers. Like I had said, you can refer to Knuth – The Art of Computer Programming. This is the bible for most serious developers. Other references on the subject will cite this reference.
For example, wikipedia:
http://en.wikipedia.org/wiki/Pseudorandom_number_generator
http://en.wikipedia.org/wiki/Linear_congruential_generator
Both cites Knuth, the second even mentions the problem you are experiencing.
As far as Microsofts documentation. Its probably bad. My experience with MSDN is that its gotten worse every year since the late 90's. I would not be surprised if they only gave the minimum information necessary in order to generate a single random number.
Now, in your use case I do not think that the slowness of division is an issue. There is a much more alarming performance concern, and that is that you are branching down two different code paths randomly. The branch prediction logic in a processor simply cannot cope with random branching, and the worst case for the predictor would in fact be a 50/50 split. I suggest that performance is already severely degraded because of the pipeline dumps that random branching creates, and avoiding that would be first priority if performance is a concern.
An inner loop body something like:
int coin = (int) (rand() * (1.0 / (RAND_MAX + 1)));
number_of_ones += coin;
The properties of this are such that the multiplication is by a constant (1.0, RAND_MAX, and 1 are all constants, so will be converted into a single coefficient with optimizations turned on at compile time,) but you do incurr both an integer to float and a float to integer conversion (pretty fast on modern processors, actually)
No branching is required, because coin is either 0 or 1
The only issue is that (RAND_MAX + 1) must be a power-of-two in order to give an absolute long term balance of 0.5 heads and 0.5 tails because of the way floating point approximates fractional non-powers-of-two. After doing a bit of searching, I couldn't find a single standard library implementation where RAND_MAX was not a 2^n-1, so you should be safe regardless of where you port (the power of two makes sense, after all)
(other) rw (12:50:45)
This may be so, but it then appears that many of the modellers are guilty of the same misunderstanding. How else to explain the claims of an ice-free Artic in 2008 or by 2015, etc., as well as the UK Met persistent seasonal forecasts, which I believe are based on their models?
Wooops, that should have been:
int coin = (int) (rand() * (2.0 / (RAND_MAX + 1)));
number_of_ones += coin;
That will teach me not to double check things before posting.
Arn Riewe 07:54:58:
Thanks for the offer of the services of Punxsutawney Phil, but if he’s been forecasting since 1887 he’s a very old groundhog by now, so he might not stand the journey! Anyway, we’ve got plenty of seaweed.
Wren said:
“And the 2000-2009 decade was warmer than the 1990-1999 decade despite that 1998 El Nino, wasn’t it? Warmer still will be the 2010-2019 decade.”
———-
Indeed it will be (unless we get a series of big Pinatubo type volcanoes). Trends are what AGW models are all about– not specific events or exact timing. Ocean heat content already does indeed have a many decades of warming “baked into the system”. Depsite the protests of many on this site, the oceans have absorbed 80-90% of the heat from AGW, and this heat must eventually be released.
I actually think the Met Office was a bit bold in predicting that 2010 would be the warmest year on record, as it would be more prudent to say one of the next three to five years, but I don’t disagree that it is likely 2010 will be, but these kinds of specific predictions have less to do with climate science than with long range weather prediction. Just as I think that we’ll see a new record low summer arctic sea ice sometime in the next 3 to 5 years. So it’s just better just to say the next ten years will be warmer than the last ten and leave it at that…
netdr: “The assertion is frequently made that it is easier to correctly model 100 years of climate than it is to model 10 years. The assertion is that errors would cancel out ! For this to be true each event must be totally random and independent of all previous events which is NOT TRUE OF CLIMATE EVENTS !
This is nonsense. A model is like an algebra test with 10 questions where the answer to #1 is the input to question #2 and the answer to question 2 is the input to question 3 and so on.”
Netdr, for me the main evidence that global warming is absolute twaddle, is the frequency curve that indicates a form of noise “with memory”. I don’t need to know why the current events are being affected by historic events, or why today’s climate is not independent from last decades. Nor do I have to know what causes the climate to change, all I need to know is the normal signature of the climate, and I can tell you it has “memory” and that the signature is still perfectly consistent with normal variation in the climate.
I have a confession to make here.
I think I may be responsible for this discussion about coin flipping.
“A New and effective climate model”
“Politicians cost lives (14:49:22) :
I fail to even see the point in this exercise. This so called model, if indeed it qualifies as such, is based on far too many unfounded suppositions.
The only thing we need be concerned with, is whether or not CO2 causes the atmosphere to warm?
The answer of course is NO it does not.
What else do we need to know?
Climate Models will never be able to predict the unpredictable. It is impossible to consistently predict the flip of a coin even with a million super computers, yet there is only two possible variables involved,
1. Which side the coin is on when you flip it.
2. How hard you flip the coin.
and only two possible outcomes.
Heads or tails!
It’s just climate change for Christ’s sake. We’ve only had our entire evolutionary existence to get used to it.
As a species we should always be prepared for the onset of cooling or warming. That way we can stop wasting billions in taxpayers money on pseudo science and get on with more important things.”
If so, then I think that I should clarify what I meant with regards to super computers predicting coin tosses.
I was of course making the point that a million super computers would not be able to consistently predict the flip of a coin by a human hand.
I assumed that would be clear enough by the two variables 1 and 2, which were meant to illustrate that even just two natural and unpredictable variables make such a system impossible to accurately predict, even for the worlds most powerful computers.
The point being that no computer can accurately predict the outcome of a coin toss if it doesn’t even know which way up the coin was before hand, let alone exactly how hard the coin was actually flipped.
Anymore than a computer can know that for example:
1. convective parameterisation is a pitiful representation of real convection
or that
2. in order to frame CO2 as a “greenhouse gas”, it was necessary to spend almost 150 years developing the fallacy that Oxygen and Nitrogen are “practically transparent to radiant heat”.
Walt’s coin toss analogy to climate may not be that bad. “If the models are coorect then we would be faced with remediation costs for ngatives and bonuses for positives- good crop yields etc. If the models are wrong and we set about to cool off the climate, we die (some of us would survive in prehistoric conditions in the tropics) . Also, let us note that the coin toss model is infinitely superior to climate models. Going along with them is far less certain than a coin toss. What would be the safest bet with them – bet on them to be wrong.
I’ve said this before but the output of GCMs unless internally constrained in some way will be a random walk.
I’ve done this with the output of solid state accelerometers. There is a small amount of output noise which when integrated (added up) to get velocity is a random walk. The errors don’t average out to zero even when the thing is sitting on the bench. All inertial navigation systems display this behaviour and after a certain time when the error exceeds the users desired accuracy they must be re-initialised with data derived from some absolute source.
Dr Meier has a severe misunderstanding of the problem if he compares this to multiple coin tosses. A better (but still dodgy) coin toss analogy is assign a value of +1 to a heads and -1 to a tails and ADD each result to the total so far. Plot the result. Do it multiple times and see the differences in the graphs.
Anyone care to simulate this on a PC and post the results here?
No matter how costly the computer, GI-GO. Climatologists are bad guessers on how things work, so, the projections are wrong. This is not flipping coins here, with a 50/50 chance of being right. If you are wrong at the start of a program it just gets more wrong as it projects into the future. The earth self corrects, look at the record. The models show runaway heating. Therefor the models are wrong, Wrong, WRONG!
Start over, build new models. And use over 60 years of information. Basing projections on 30 years, or less, of data is lazy and stupid. Use data that is real, and not adjusted to fit preconceptions. Then the computer projections may be some resembalance of future reality.
I occurred to me as I headed out for the day that my suggestion of doing “if (random_number > (RAND_MAX/2))” is really just checking the high order bit and does not count as “If you had looked at all the bits.” However, as you found, using high order bits is better than using low order bits.
Don Knuth wrote “By far the most successful random number generators known today” (Copyright 1969, hey I paid $18.50 for this book desipte it having a tear in the cloth spine) are special cases of the following scheme….
X[next] = (aX + c) mod m
This is called a linear congruential sequence.”
Assuming that rand () is an LCM, then m is RAND_MAX+1. That seems to be a power of 2 on most systems, easy to compute.
“c” is almost always odd, otherwise if “a” is even, then we add a zero bit on each call, or if X is seeded with an even number, the low bit will always be zero. If “c” is odd, then the last bit would alternate between 0 and 1. Pretty useless, but better than converging on zero for all bits.
I forget what Knuth says about that in the 160 pages he wrote, and I won’t dig it down. Some systems I’ve seen shift out the low 8-16 bits. The introduction of real randomness like Leif’s posts is not mentioned at all. Hey, you were lucky to have a time-of-day clock. One of the bootstrap operations was to enter the date and time on most systems of that era.
——-
Steve, see http://home.comcast.net/~ewerme/wuwt/ for some notes on using <pre> or <code>. Oops, not there. I’ll add it. Look at http://wattsupwiththat.com/resources/ and search for 15:11.
You’re being done in by blank lines terminating the <pre> Let me experiment with a couple things:
Using <code>, next line is has .
line with text and two spaces between words.
Hmm, I guess I need the fourth case. Perhaps all you need is to use <pre> for code, and use <code> for, well, I don’t know what it’s good for.
Using <code>, next line is blank.line with text and two spaces between words.
Joe (10:36:23) :
Seems to me that a random number generator should be able to generate a decent distribution of even/odd numbers, which is what I am using for heads/tails.
gnu can, and there really isn’t a good excuse for Microsoft not to.
I don’t buy the idea that somehow climate models magically correct themselves over time. That sounds like religion, not science.
Steven Goddard’s example is not demonstrating that it can be easier to model a compex system than a simple system. To model the system of 10,000 coin flips, he would have to tell us in which order each and every one of the coin flips comes up heads and tails. All he is doing is creating such a wide margin of error, that the result has almost certianly to fall within the bandwith of error. His example, is little more than saying that there is a 50% chance that tomorrow will be at least as warm if not warmer than today. Create a wide enough error margin and you will always be able to predict results within that error margin.
If you want to look at the modelling test to see how the system behaves, it is much easier to model the reults of one flip. Forget, the landing on the edge, your computer model will get the right answer approximately 50% of the ime. Now model the order of 10,000 flips and I bet you that the model will never get the running order correct.
Complex systems must instrinsically be more complex to model especislly when you do not know all the components within the system still less how the behave and interact.
An example such as Syeve Goddard’s does not assist the debate.
Just a quick note about doing things like (rand() modulo 1) .. or modulo anything small for that matter. Like the even/odd approach above …
The random number generators can have very short cycles in any given bit, or subset of bits so its unwise to take a bit to use as your ‘coin’ toss result. You will get better results by checking the value is above or below the mid point of the range of the random number generator.
I discovered this a great many years ago as a student helping verify new adaptive compression algorithms (LZF). We needed random input to give to the new super duper compression algorithms that my professor was designing (random sequence don’t compress of course). So I used rand()%1 to generate random bit strings .. well his compression tool promptly compressed the megs of what I thought were random bits in to a neat 1024 length bit string and a replication factor .. my prof thought he had screwed up the algorithm but I ran an FFT on the output of rand()%1 and sure enough there were distinct cycles (peaks) in the different bit positions. If I remember correctly each bit exhibited a 1024 or so cycle with differing phases.
Anyway the point being that its the entire N-bit number that is pseudo random with the claimed properties. Any given bit or subset of bits will not be so well behaved and will possibly have short cycles. Its the combination of all those non overlapping cycles in each bit that give the desired behavior to the full N-bit number.
Ric Werme (17:24:05) :
The introduction of real randomness like Leif’s posts is not mentioned at all.
Knuth is a mathematician, so physical entropy items were beneath his radar back then. I still like my own definition of a [real] random number, namely a number I can compute, but that you cannot.
Joe (10:36:23) :
The branch misprediction in the code is much less expensive than an integer divide. Both taken and not taken paths are in the first level cache – so you are looking at a few cycles, 50% of the time, to flush the front end of the pipe.
Integer divide costs 15-80 clocks, 100% of the time.
Steve, you are following a red herring in my opinion.
We can all agree upon its possible to make a gaussian distribution in a computer.
That isnt the point.
The point is ; A GCM is different. Its not giving a gaussian distribution of result.
So what is the objective here? Surely it must be to understand how the climate scientist is handling this?
What is their approach? What do they believe will work? After all, back in 2001, IPCC concluded GCM’s couldnt predict climate. Do the IPCC believe they can now, in 2010? Why?
kwik (23:02:40) :
After reading your comment, I’m wondering if you read the article.
R. Gates (14:48:12) :
“Except 2010 follows on the [heels] of the warmest decade on instrument record, and so is part of an ongoing trend. You see, I have no problem with the leveling of the growth in temperatures in 2003-2008 timeframe as I can accept that the solar minimum would do this…”
Depends on your definiton of ‘instrument’. The problem with your point R Gates is that 2003-2008 was not really a time of ‘solar minimum’. That is a 5 year stretch of a 13 year cycle. It reads as if there as a solar minimum in the middle of 2003-2008 so the temperatures being ‘high’ somehow must be explained by the CO2, not something solar-rooted.
I frequently find CO2 proponents mis-stating the main solar influence as TSI, though it is actually cloudiness. I find the meme, ‘It was hot 2003-2008 and the sun’s activity was at a minimum so it can’t be solar, it must be CO2 forcing,’ mischievous. Surely it is well known by now that there is a delay between solar activity and atmospheric temperature of about 4 years? Cooling from solar inactivity should follow on for at least 4 years after the drop in the AA Index. Lo and behold it does.
I find the reluctance by CO2 proponents to properly discuss all solar and galactic impacts on terrestrial climate as strange as the refusal by some solar proponents to discuss barycentric tidal influences on the sun, as if the sun lives in glorious isolation from its planets. It is patently obvious this is not the case, hence the far greater accuracy of the Farmer’s Alamanc, compared with the MET Office.
Next year’s main weather everts are being calculated right now by the barycentric Almanac staff. Farmers don’t care about CO2 or an isolated sun, they care about the weather so they take an inclusive view.
Remember 5 feet of snow in Washington this year? “Major US storm 18-22 Feb 2010”. Farmer’s Almanac, written in Feb 2009. Not bad work if you can do it.