
Ross McKittrick writes via email:
A UK-based math buff and former investment analyst named Douglas Keenan has posted an intriguing comment on the internet. He takes the view that global temperature series are dominated by randomness and contain no trend, and that existing analyses supposedly showing a significant trend are wrong. He states:
There have been many claims of observational evidence for global-warming alarmism. I have argued that all such claims rely on invalid statistical analyses. Some people, though, have asserted that the analyses are valid. Those people assert, in particular, that they can determine, via statistical analysis, whether global temperatures are increasing more that would be reasonably expected by random natural variation. Those people do not present any counter to my argument, but they make their assertions anyway.
In response to that, I am sponsoring a contest: the prize is $100 000. In essence, the prize will be awarded to anyone who can demonstrate, via statistical analysis, that the increase in global temperatures is probably not due to random natural variation.
He would like such people to substantiate their claim to be able to identify trends. To this end he has posted a file of 1000 time series, some with trends and some without. And…
A prize of $100 000 (one hundred thousand U.S. dollars) will be awarded to the first person, or group of people, who correctly identifies at least 900 series: i.e. which series were generated by a trendless process and which were generated by a trending process.
You have until 30 November 2016 or until someone wins the contest. Each entry costs $10; this is being done to inhibit non-serious entries.
Good luck!
Details here: http://www.informath.org/Contest1000.htm
I’ve seen those graphs! Well, sort of. I track the MLB baseball season and the divisions look much like the above only they’re not nearly as random. For example:
http://wermenh.com/images/al_east_2015.png
Some are distinctly non-random:
http://wermenh.com/images/nl_cent_2015.png
See the season’s worth at http://wermenh.com/runnings_al_2015.html
Actually, there IS a certain amount of randomness in those baseball records. Check out
http://andrewgelman.com/2014/06/27/quantifying-luck-vs-skill-sports/#more-23235
The fraction of luck and skill can both be estimated based on a comparison of a random distribution and the actual distribution of wins and losses. For baseball the standard deviation of luck is about 0.039 for 162 games, the actual SD for luck is about 0.058.
Ric Werme, 11:15am, today.
The second “luck” should be “talent”:
All I care about is that lovely squiggle indicating the Blue Jays coming from last place, then shooting north of the damnyankees.
Unfortunately, nice graphs don’t help your team move a runner over from third base with nobody out 🙁
I don’t see the squiggle for the Royals, who actually won the World Series !
Does that mean that the graphs are pretty much random ?
🙂
You don’t see the Royals because you didn’t look at the full page. They’re in the AL central division:
http://wermenh.com/images/al_cent_2015.png
I also included the division leaders as skinny lines in my Wild Card graphs. For the AL:
http://wermenh.com/images/al_wild_2015.png
But if your team is the Yankees they have a higher than average likelihood of being above.500 and that I believe is independent of what Ric is calling talent, teams in Chicago are less likely to win independent of talent.
I think what you are noting is the talent of the management team in the front office. I may not like the Yankees, but they have some good noses for talent and DEEP POCKETS to pay for acquiring it. That is why they are more likely to have winning seasons…front office talent and money.
There is nothing in your “non random” series to suggest to me that they are actually non random. Do some research on fractal geometry.
Ric Werme, 11:15am, today.
Ooops! Wrong commenter — sorry AP.
And what is the connection of fractal geometry to randomness ??
Both of those sets of graphs look a bit contrived to me, which begs the question as to the algorithm that originated them.
My cause for concern is that all of the steps either up or down are taken at pretty much the exact same slope angles. So the walk wander is dependent only on the length of each segment.
I would think the outcome of a random walk would depend on the number of degrees of freedom. You say these are one dimensional.
I would think that truly random moves, would be represented in some fashion by a Gaussian distribution function.
From ancient times looking at white noise on an analog oscilloscope screen, it seems that the true RMS value of white noise is about 1/6th of what the eye perceives as the most probable guess for the peak to peak amplitude seen on the screen. In more recent times when looking at analog noise generated in analog MOS or CMOS circuits, it seems to be harder to judge what the peak to peak noise seems to be.
Just when you think you have it pegged, a much larger spike appears out of nowhere to confound you. After you look at CMOS analog noise for a long time, you eventually conclude that it isn’t truly white noise.
And you would be correct, it isn’t (most of the time).
MOS transistors produce a decidedly pink noise spectrum, which is due to the presence of a significant 1/f noise component.
1/f noise seems to have no lower bound to the spectrum, and the amplitude of noise spikes continues to grow at longer and longer time intervals.
Well I believe that the bottom end of the 1/f noise spectrum was actually the big bang itself.
1/f noise in MOS transistors is a fairly well understood physical phenomenon that relates to total gate area and the finite electronic charge. It dictates the use of PMOS over NMOS and the use of transistors with very large gate areas, compared to minimum geometries as found in logic gate circuitry.
I once designed a CMOS analog amplifier which had a 50 Hz 1/f noise corner frequency, along with a 1 MHz 3dB cutoff frequency.
For most MOS op amps, the 1/f corner is more likely to be 10 kHz.
I still have a partial wafer of chips, which were only 500 x 600 microns, and only had 3 pin connection pads. Signal input terminal was an on chip MOS photodiode, comprising most of the die area.
So I’m a bit leery of your walk graphs here; I would expect to see slope changes if it was physically random.
I seem to recall some random walk problem that involves walking across the gap between two parallel lines. Somehow a Pi or 1/ Pi comes in to it, but I’m damned if I can remember the details of that now.
I would suspect that Ross has that particular problem framed on the mantel above his living room fire place; maybe below the shot gun.
g
It is called Buffon’s needle. Probability is related to 1/Pi. Check out the various parameters.
Its called Buffon’s needle. Prob is related to 1/Pi. Its on wiki for all the gory details.
A random walk in a particular direction.
I think I am just going to take a random walk in a random park.
1/f noise seems to have no lower bound to the spectrum, and the amplitude of noise spikes continues to grow at longer and longer time intervals.
Also describes global temperature, which means our brief 135 year history tells us nothing about frequencies lower than 1/135…
I have a graph somewhere that tries to match the spectrum of GISS global temperature and estimates the spectrum below f = 1/135 using extrapolation in the frequency domain. (After all, anyone who says “the temperature is rising due to recent phenomena such as C02 is… well… extrapolating in the frequency domain).
I then use that extrapolated spectrum to generate pink-like noise Monte Carlo runs and what do you know, the GISS temperature trend for the last 135 years is within the 95% confidence interval of the null hypothesis: i.e. the trend for the last 135 years is likely just noise, as at least 10% of the random pink-like noise runs exceed the GISS trend. This is the much adjusted GISS trend mind you…
Still not happy with the extrapolation, so I haven’t published yet. Most of the literature tries to generate a AR1 noise to generate a somewhat matching spectrum, but it’s not the same thing, they are just guessing the spectrum indirectly from the time domain instead of just using proper extrapolation in the frequency domain. Another case of the signal analysis folks and the stats folks not talking…
Of course I admit I’m extrapolating here. Unfortunately the warmists do not…
Peter
George E Smith, on randomness of the Big Bang: “Something that only happens once cannot be rated as to randomness.”
I am curious how you know the Big Bang happened only once.
“””””…..
Michael 2
November 19, 2015 at 7:18 am
George E Smith, on randomness of the Big Bang: “Something that only happens once cannot be rated as to randomness.”
I am curious how you know the Big Bang happened only once. …..”””””
Michael 2, my short term memory has gone to pot. Sometimes, I can’t even remember Albert Einstein’s name.
So refresh me. Just where did I say the big bang only happened once ?? But can I infer that you may have evidence of more than one ?
g
I have my own concept of what ” random ” means. Well that is what it means to me; it is not necessarily a definition that others would accept.
In my view, Any finite set of sequential finite real numbers, is random, if any subset contains no information that would enable one to deduce the value of the next number in the set (sequence), or even to determine the direction (up, down or sideways) from the last number of that sub set. That definition tolerates no limitation on the magnitude or sign of any number in the sequence; only that they be finite.
Now that has a problem in that if the numbers can have any finite value, then there can be an astronomical number of numbers between any two no matter how nearly equal.
Well you mathematicians know how to put that in kosher math form with epsilons and things. So if you like you can quantize the numbers and say that no number can be closer than 1 ppm to another number; or choose your own quantization.
My point being, the next jump could be a mm or a km, in either direction, or anything in that range.
Arguably, random noise is the highest information content data stream you can have, in that it is 100% information. Leave out any member of the set, and the remaining set gives NO information as to what the missing number was.
No I didn’t say the information was of any use. In fact most information is of no real use.
g >> G
So we have at least two wiki disciples. Dunno how I knew of Buffoons needle before wiki or the internet even existed (50 years before.)
Used to be you were supposed to actually remember what you learn in school. Or at least try my case.
g
I take a view that ‘randomness’ does not exist in nature (anywhere between higgs-boson to the totality of the Universe). No computer can be programmed to produce true ‘randomness’ (in my early days I used noise from a mu-metal shielded resistor). Randomness is product of the human thought.
Buffon’s needle is a clever statistical way to calculate Pi. Statistics itself was born out of gaming or gambling starting in the 17th(?), 18th(?) Century by a handful of math wizards.
g.e.s. said ” sequential finite real numbers, is random, if any subset contains no information that would enable one to deduce the value of the next number in the set (sequence)”
which is the information theoretical definition of maximum information entropy.
it can be hard to distinguish that from randomness, though- e.g., is the decimal notation for pi random?
and anyway, is not any sequence an infinitely improbable event in the universal set?
it happens that data compression is a way to measure randomness.
i think, in theory, if the data samples were compressed, the ones that compressed least must have been the most random to begin with.
In the random walk, at a set time interval (t) the walker goes a set distance (d) either in one direction or the other. So the plot will either go up or down, with the same slope every time, slope being d/t or -d/t.
Without knowing the date of the trade deadline, could you discern it from the graphs by statistically identifying inflection points?
I’m posting this as high on the thread as I can (I’ll post it below, too):
HOW TO ENTER THIS CONTEST:
Hurrah! #(:))
(I used his “contact me” info. on McKitrick’s website and e mailed him yesterday evening — and he answered me!)
“…whether global temperatures are increasing more that [sic, than] would be…”
The problems is that the raw data has not yet been properly cooked.
Once cooked it becomes flexible enough to show whatever you want it to show.
What? Are you a pastafarian?
A Pastafarian: One who believes His Noodly Appendage has been cooking the data.
Certainly it’s true that adjustments to the data are not random.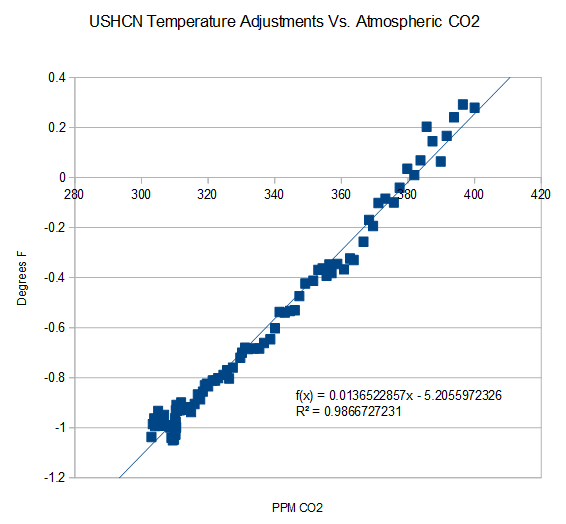 ?w=640
?w=640
Simple logical proof that the temperature data is not random:
Randomness is not a thing, it does not exist in the physical world and can not cause anything.
http://wmbriggs.com/post/16260/
Rather apparent randomness is a measure of lack of information about cause.
Therefore the temperature data is not random. The data takes the values it does for specific causes, even if we don’t know what the causes are, even if we are incapable of understanding the causes.
‘Randomness is not a thing, it does not exist in the physical world and can not cause anything.’
Who knows? And how did you define ‘can cause’ and ‘exist’ and ‘random’? Frankly there is no much more deeply confusing thing than the existence of randomness.
Roger that. It is stat math and therefore fiction.
g
“Frankly there is no much more deeply confusing thing than the existence of randomness.”
You are confused because you think randomness exists. Accept that it is just an illusion caused by the lack of information and there is no reason to be confused.
Sounds like new age mysticism where all things are relative and there is no such thing as evil.
I can easily think of many things that would be counted as random. That is; the outcome can not be predicted before hand.
You’ll need to provided some evidence of your claim that there is no such thing, rather than expecting us to accept your statement that it’s true.
Hugs: So the location of individual helium atoms at any moment in a jar doesn’t meet your strict standards for randomness? I know gases aren’t strictly ideal but for engineers, PV=nRT works pretty well and even if they aren’t ideal and you have to correct for the volume taken up by the atoms, their location is still (close enough for any useful purpose) random. It certainly gave us the idea for the concept.
I have to agree on prinicple, but you are misunderstanding (or simply ignoring) the point.
While temperature is deterministic, the fluctuations of temperature are so great and of near-unknown origin that our only possible choice is to add significant random elements to any model. When there are significant random elements creating random walks over relatively short time periods, it is impossible to determine with accuracy what is due to the trend and what is due to chance.
Probably not the best explanation, and I have to agree that the phrasing is poor, but the point is important to make.
“When there are significant random elements”
There are no random elements, only elements we don’t fully understand, even in the computer models.
Computer random number generators are not random at all. They only appear random because you don’t know how they work.
All computer random number generators require a seed value. Usually the system clock time is used so that you have a different seed every time the process runs. However, if you repeatedly seed a random number generator with the same value you will get the same sequence of numbers every single time.
” Computer random number generators are not random at all.”
Historically this is true, thought I recently read about what is either a true random generator hardware or one that is for practical purposes.
That’s why I said “I agree on principle”. However, in practice, these things are random, and it doesn’t really matter what seed you use. As long as you vary it up by some independent function (most functions I know of use the clock as a seed), the lack of true randomness is immaterial.
” However, in practice, these things are random, and it doesn’t really matter what seed you use. As long as you vary it up by some independent function (most functions I know of use the clock as a seed), the lack of true randomness is immaterial.”
But if you do use the same seed, the sequence of values is the same.
Micro, at the risk of sounding like a bad joke, If you want to have random numbers, don’t use the same seed. While it could be useful to check for errors or the effect of changes in a calculation, typically you use some outside variable to seed your data. The best option I know of is your computer’s clock, since it will change continuously and you end up never using the same seed. I’m I’m not mistaken, that’s the default seeding method of most random number generators these days.
The question is whether you can show this not just believe it. Arguing over the precise meaning of “random” will probably enter the picture but if it *looks* random that’s good enough. How the universe itself suddenly came into existence may have been random, or not, but it cannot be shown to be one or the other.
Randomness implies repetition. Something that only happens once cannot be rated as to randomness.
g
The very first Viet Nam war draft lottery based on birth date, was declared to be non random, by some academic statistician.
With one test instance out a 366! possible draws, he was brazen enough to declare the result non random. Jan1, Jan2, Jan, 3, …..Dec 29, Dec 30, Dec 31 would have the exact same probability as the draw that actually occurred. The particular draw that happened will NEVER happen again, since the odds are so astronomical.
But it’s an absolute certainty that the statistician was an idiot.
g
PS Substitute 366 different icon picture labels for calendar dates to see that our calendar pattern is quite irrelevent to the issue.
As I recall, my number was 46.
The results of the draft lottery may be an example of Benford’s Law where the lower digits have a greater probability of occurring than the higher ones. There is a nice presentation at http://mathworld.wolfram.com/BenfordsLaw.html
Well Benford’s Law, which would seem to be nothing more than conjecture, gets hung up on irrelevancies, such as the decimal number system, which just happens to be a label system in the case of say a calendar year.
Replace the 366 dates with 366 picture icons, and Benford’s law disappears into a cocked hat.
So what would Benford’s law say about using Roman numerals in our calendar ??
And why do C and M have ANY significance to Romans, unless they already knew the decimal number system. In which case, why did they expunge zero in favor of just seven; excuse me that’s VII characters ??
I think I said before, that all of mathematics is fiction, and like other fiction, a whole lot of it is just crap.
g
Well in a calendar year, no month has more than 31 days. So no more than two days a month can start with a 3 and sometimes no days do.
If you number the days from Jan 1 to Dec 31; as in : 1, 2, 3, 4 ……
Precisely one day starts with the digit (1).
Seems like Benford also, was an idiot. Well I wonder what he knows about the Pyramid inch Code for the record of world history as chronicled in the main passage inscriptions in the great Pyramid of Giza. If he is a real expert, he would know where all of the arbitrary scale changes occur, in order to fit the chicken scratchings into a record of historical events.
g
I saw Benford’s law used on Clinton’s income tax returns. There are a very large number of millionaires between 1 and 1.99 million, fewer between 2 and 2.99 and fewer still in numbers higher than these. Naturally you are going to get a lot of ‘1s’ starting the number. Also true for the 6 figure brackets. Benford’s law has been used by forensic accountants to try to determine if books have been cooked. I guess one could learn how it works to confound the forensic guys! In my case, I’m in the smaller numbers side of things anyway.
“randomness is not a thing” ….. obviously you’ve never dated a twenty-something woman.
Or been married to a fifty-something woman….
I would think all decisions made by free will qualify as random events, but it is not clear to me that females are more random than males.
Dear Jim,
Thank you.
Janice
Or played craps.
Quantum mechanics begs to differ. Look up Bell inequalities.
Quantum mechanics can beg all they want, that doesn’t make them right. Just because we are incapable of determining the cause, does not mean that there isn’t a cause. Randomness is an illusion that we impose on ourselves through lack of information.
” Randomness is an illusion that we impose on ourselves through lack of information.”
On the QM analysis of location vs momentum, it is not a lack of information leading to uncertainty, it truly is uncertain. The explanation as best I know is the lack of reality, go read about the wheeler delayed choice experiment.
I think QM applies to ” probability ” not to ” randomness “.
g
MattS: Just because we are incapable of determining the cause, does not mean that there isn’t a cause.
True, but you make a stronger claim than that: There is a cause and the appearance of random variation results from incomplete knowledge.
Briggs may well be right in theory but wrong in practice. In an infinite universe there will always be hidden information which we perceive as randomness
A fan of the legendary Yogi Berra, I see – at least, as regards your first sentence :-). Your second, tho, nails the epistemic issue – a much simpler example than climate time series to think with being radioactive decay of a lump of uranium.
In theory, there is no difference between theory and practice. In practice, there is.
universe is not infinite
The key word there is perceive. It’s an illusion. Knowing that it’s an illusion, doesn’t get rid of the illusion, but you ability to understand the universe will increase once you understand that it is just an illusion. As long as you believe that the apparent randomness is real, you will draw wrong conclusions from your observations.
CBA, are you sure of that?
MattS: I think rgbatduke & others had something to say about randomness and models.
CBA If it is not then what else is?
Hey! You just invalidated Quantum Theory!
What you are indulging is a confusion of category. Randomness (note the “ness”) is not an entity, it is a quality or behavior of entities. Both entities and their behavior occur in the physical world.
A very good positive example of the presence of randomness (aside from casting dice and tossing coins), is the kinetic theory of gases, elaborated by James Clerk Maxwell and Ludwig Boltzmann. It leads directly to the gas laws we observe in practice, down to fine detail. Here’s the point: if the gas laws were not based on randomness, we would observe the discrepancy at large scale. Which we haven’t. (There are very small discrepancies at high gas densities, but these amount to violations of the assumptions constraining the randomness, where the volume for the moving molecule becomes less available, and the molecules themselves begin to exert collective forces on each other. These are handled by corrections based on the physical phenomenology.)
Radioactive decay is another example of a random process, typified by very large numbers of events. Very close correspondence to randomness.
Statistical mechanics is a very-well-established branch of physics. Statistical processes represent the highest state of entropy, thus typify thermodynamic equilibrium. There is a widespread misconception that information persists eternally, but the reality is that information can be destroyed completely. Among other things, this is why the dead remain dead (zombies and vampires to the contrary).
Here’s a problem for your point of view: There is no structured process that can generate a random process. The theory of random processes predicts this. There are many “random number” generators, but they generate only pseudo-random numbers.
“Here’s a problem for your point of view: There is no structured process that can generate a random process. The theory of random processes predicts this. There are many “random number” generators, but they generate only pseudo-random numbers.”
Even physical dice and coin flips are only pseudo-random. If you train yourself to flip the coin in a very consistent way, you can significantly bias the outcome.
This is no problem for my point of view at all. My point of view is that random does not exist in the real world. Random is an illusion that results from lack of information about cause.
” Randomness (note the “ness”) is not an entity, it is a quality or behavior of entities. ”
No, it is not. Randomness is not a quality or a behavior of entities, it is a measure of the lack of information about the qualities and behaviors of the entities.
Isn’t the calculation of Pi an example of a structured process that creates a perfectly random sequence, so random in fact that no pattern can be discovered in it?
@ur momisugly Scott Bennett
Pi = – (sqrt(-1)). Ln(-1) Exactly.
So what is unstructured about that ??
@ur momisugly george e. smith
Thank you for making my point (I think that is what you were doing?)
Anyway, you’re the lucky winner of a chunk of pie. Enjoy:
Whoops! Help Admins! I didn’t mean to throw that Pi! Can you add some line returns please! Sorry 😉
[Reply: series truncated. ~mod.]
Dear MattS:
1) You completely duck the example of statistical gas physics, which is a predictive theory based on the premise that the collisions of gas molecules are entirely random. It matches reality. If reality were otherwise, the theory wouldn’t match. You might want to open a book and learn about it, because your comments indicate you know nothing about it.
2) You also duck the example of radioactivity. Given that you don’t seem to have much information on these subjects, does that make your understanding “random”? Just askin’….
3) Coins are not symmetrical. If I gave you a coin without face or tail, and the sides could only be determined by a Geiger counter and the fact that one side was radioactive, I think you would have a hard time biasing the outcome (if you were denied use of the Geiger counter). You wouldn’t even know the income. (And, yes, there is a tiny probability that the coin will land on its edge, but that results from the deviation between the premises of the theory and the reality of implementation. If it is beveled to a sharp edge, this exception will be removed.)
4) Your “point of view” evidently is based on whatever you have pulled out of your pocket, because it does not conform to the understanding of probability and randomness obtained from either statistical mechanics or information theory…from which we have obtained nuclear energy and advanced communication techniques.
5) Pi is not a random number. It can be calculated from the Bailey-Borwein-Plouffe formula, which suggests an underlying periodicity. (It is an “irrational” number, but not like some of the exchanges among WUWT participants.) But, more importantly, it is inappropriate to consider it “random” because the concept does not apply. Pi is not a member of a population of events, entities, or observations. Single instances of anything are not “random,” because randomness is only relative to the rest of an observed population.
It’s all very well to exchange japes. Someone once told me that debates are like tennis games: you play to the level of your opponent. The problem here (as maybe anywhere) is that the self-inflated opinionists have no humility when trying to converse with those who know the subject. That elicits a bad response, if the informed party takes umbrage at the lack of respect and returns service. I hope I have shown that (a) I don’t respect your understanding, (b) I have politely shown you strong counterexamples, and (c) I have no intention of further debate with someone who isn’t interested in learning actual information.
@ur momisugly Scott Bennett
The digits of pi are not random.
James: “The digits of pi are not random.”
The sequence of the digits of pi passes all known tests for randomity, as do all other transcendental numbers such as phi and e.
So Michael J Dunne, how do you propose to make a perfectly symmetrical coin with only one face being radioactive..
You know of some special isotope that comes in two identical forms but one of them is radioactive and the other isn’t ??
Wunnerful !
You could make the coin out of single crystal GaAs (can’t recall which orientation), but one face will have exposed Gallium atoms, and the other face will have exposed arsenic atoms.
Not perfectly symmetrical, but close enough.
You may argue that no sample point in the temperature series is due to random cause and I can see where that makes perfect sense. However, I think you’re missing Keenan’s point. He’s essentially saying falsify the null hypothesis, which holds that any temperature trend observed is by chance (natural variations), using a model that can reliably do so. The 1000 datasets are intended to validate the model’s skill and show that the model’s falsification of the null hypothesis is not by chance within the model itself.
Chance is not a cause of natural variations. Nor is it a cause of anything that happens in the model. Nothing does or can happen by chance. Chance, probability, like randomness is a measure of the lack of information, nothing more.
You’re still seeing the term “Chance” as describing an underlying process. Chance, as defined by statistics, does not do so. Chance refers to the probability of an interaction between an independent variable and a dependent variable. The chance (read probability) of a model not exhibiting an acceptable goodness of fit such that it can be in error in finding significance when there is none (Type 1 error) or not finding it when it exists (Type II error) is very real. To create a statistical word picture, what is the “chance” of you winning a million dollars on your first pull of a slot machine in Las Vegas?
I note that your issue is with the term, “randomness.” That is also a term used in statistics but likewise, it does not refer to physical processes. It has a very different meaning and application – randomization of a study, random selection of samples, etc…
“You’re still seeing the term “Chance” as describing an underlying process. Chance, as defined by statistics, does not do so. Chance refers to the probability of an interaction between an independent variable and a dependent variable.”
Exactly. And yet you are the one saying things can happen “by chance”. For anything, even a model result to happen “by chance” chance must be an underlying process with causative power, but it isn’t so stop saying things happen J”by chance”.
Read “The Commonplace Thesis.” Then you’ll understand better why the use is in context to probability of outcome and not to describe the underlying process whether it is understood or not. The mathematician, Futuyama, I think best states how we use the term:
In this case, Futuyma refers to chance, as it is commonly used in my work, to refer to single-case objective probability. My use of the term is correct in the context it is used. There is no need for me to stop using it.
What if the causes are random, or chaotic?
For example, a single coin toss could in theory be modelled using physics, but in practice, minute changes in all the variables lead to an unpredictable outcome.
Actually, your coin toss example proves my point. Those minute changes are impossible to fully know, but they are all causative in very specific ways. The unpredictability, the apparent randomness is the result of lack of information about the precise conditions, not an inherent property of the system.
Matt S: AP’s first point, what if the causes are random or chaotic is still in play. His choice of a coin flip may not have been a good one. In any case, I trust you accept that use of the concept is of very practical.
MattS:
At the philosphical level your post makes a lot of sense. (Einstein said: “As I have said so many times, God doesn’t play dice with the world.”)
Contrary to that point of view, though, I wonder if you still maintain the “non-existence” of randomness at the quantum level of nature?
“Contrary to that point of view, though, I wonder if you still maintain the “non-existence” of randomness at the quantum level of nature?”
Yes. Just because we don’t, and by all indications, can’t ever have enough information to predict outcomes at the quantum level, does not mean that outcomes at the quantum level don’t have specific causes.
MattS
Interesting. Would it be correct to say, then, that you believe that physics is (always – at some level) deterministic? And, if so, doesn’t this lead to or imply that there is no such thing as “free will”?
Not disagreeing with you, but wondering at the implications if reality (whatever that is) is truly deterministic.
Well Heisenberg would insist that you cannot even know the state of anything, enough to determine what it will change to next.
So how could anything in Physics be deterministic ??
g
And that’s a good thing.
Because the macro scale (not named after me) effect is purely (well in particular cases) statistical, and at least in the constraints of the particular system maintains determinism.
“Interesting. Would it be correct to say, then, that you believe that physics is (always – at some level) deterministic? And, if so, doesn’t this lead to or imply that there is no such thing as “free will”?”
Technically yes, but at the lowest levels, it is so complex that only an omniscient being could comprehend it.
It only implies no such thing as free will if intellect is strictly physical, which it isn’t.
So – randomness does not exist, it is just a measure of lack of information. Really? If randomness did exist, how could you distinguish it from lack of information? I’m not exactly saying you’re wrong, just that your assertion looks rather difficult to prove. Maybe you could try the approach that ‘existence of randomness’ is a null theory because it can never be applied, but I suspect that even that isn’t as easy as it might look (eg. error bars can represent randomness).
“error bars can represent randomness”
No, error bars always represent uncertainty about the true value.
That statement relies on the assumption that randomness doesn’t exist.
MattS wrote, “Rather apparent randomness is a measure of lack of information about cause.”
The ratio of information we have (what we know) to information we don’t have (what we don’t know) is so large as to be indistinguishable from zero.
Okay, then replace “randomness” with “apparent randomness.” But the fact remains that we lack information about the cause of increases in global temperatures. If we knew the cause (or causes), we could likely predict future global temperatures. The fact that we can’t means we don’t know much about the causes. CO2 may be one of the causes, but it is certainly not the only cause or even the main cause. Until we know what all the causes of global temperature changes are, they might as well be viewed as random because you can’t tell the difference.
” CO2 may be one of the causes, but it is certainly not the only cause or even the main cause. Until we know what all the causes of global temperature changes are, they might as well be viewed as random because you can’t tell the difference.”
Sure we can, if was Co2, it would on average cool off more at night than it warmed the prior day.
Louis: However, with nearly all the energy reaching the earth being from the sun, what we have is a range of temperatures around the TSI value of temperature, impeded by aerosols of varying opacity and enhanced by a period of retention (slowing down of exit from the earth). The TSI itself would be related to the variations of the sun itself. For example, we aren’t going to reach either 300C or absolute zero given the position and TSI of the sun. Now a bombardment by huge bolides could heat us up plenty, but we would eventually return the centralized range based on TSI. The idea of Thermageddon imagined by the nut fringe (Al Gore, etc.) just ain’t going to happen. I believe temperature in particular is not random. The “walk” would have to be restrained between the swing values – perhaps the glacial and interglacial values in the long run record, and smaller ones in the shorter periods under consideration.
This is from warming of the surface, not a low down from Co2 in the atm. Water vapor in the atm has a slight short term delay, as it cools at night rel humidity goes up, and at high humidity water condensing out of the atm or changes in the optical transmittance of IR to space slows the cooling rate.
But cooling is almost immediate as the length of day starts to drop.
We know that part of the cause of temperature series is adjustments to the data.
Randomness is not a thing? Quantum mechanics is irreducibly random (via complex numbers, not nice probabilities, which is why it’s so weird), and it’s the most accurate model of reality we have. Chaitin has argued at length for what looks uncommonly like randomness in the whole numbers. His basic definition of randomness is that a number or a sequence is ‘random’ if you cannot compress it. I would dearly love to believe in “hidden variables” underlying QM but the evidence seems to be against.
To put it another way, if we can’t tell the difference between some measurements and a data set generated by a random model (like 1/f noise), then those measurements might as well *be* random as far as we are concerned. The issue after all is not whether God knows some cause and can discern some trend but whether a trend *we* think we can see is “really” there in some practically important sense.
I think one of the most important lessons of the twentieth century is that we are very good at seeing patterns that are not really there and then by seeking to confirm them instead of refute them we are very good at locking in false beliefs.
That’s why (a) this is a really neat challenge (can you reliably tell a real pattern from an illusion when we *know* which is the case, because if you can’t, you have no right to claim the pattern you see in the climate data is real) and (b) I doubt very much whether this challenge will get any serious takers, because people naturally don’t *want* to refute their beliefs but to confirm them. Why would any warmist put their ideas to this test? They “KNOW” they’re right, and those of them with the knowledge to make an attempt would find it less risky to get their next USD 100,000 from some concerned government.
” That’s why (a) this is a really neat challenge (can you reliably tell a real pattern from an illusion when we *know* which is the case, because if you can’t, you have no right to claim the pattern you see in the climate data is real) and (b) I doubt very much whether this challenge will get any serious takers, because people naturally don’t *want* to refute their beliefs but to confirm them. ”
For a, I didn’t look at his data, but I presume it’s not daily min max data, if it was I think I could detect a trend, the problem with the published data is they’re all doing the same wrong thing.
For b, BEST is doing something like this, but their made up data is based on the same wrong idea they use to generate the trends that are wrong, and even if they use a clean room process, they use the faithful, which is why the trends are wrong in the first place.
MattS: Rather apparent randomness is a measure of lack of information about cause.
That is intrinsically untestable, and therefore should not be believed or relied upon. To test it you would have to do every experiment twice, once with perfect information about cause, and once with lack of information without cause; and the result would have to be that apparent random variation only occurred with imperfect information. What is known empirically is that random variation has occurred in every experiment, so the most likely induction is that the next experiments will have random variation.
” That is intrinsically untestable, and therefore should not be believed or relied upon. To test it you would have to do every experiment twice, once with perfect information about cause, and once with lack of information without cause; and the result would have to be that apparent random variation only occurred with imperfect information. What is known empirically is that random variation has occurred in every experiment, so the most likely induction is that the next experiments will have random variation.”
QM is the most tested theory of modern science, and has never been disproven. I would suggest you spend some time studying it. QM uncertainty is not a measurement problem.
Sorry mathewrmarler, I mash your replay and the quoted statement all together, I’d delete the post if I could.
“What is known empirically is that random variation has occurred in every experiment”
No, this is not known empirically. What is known empirically that every experiment has had variation in observations due to unknown causes. You call this random, but just because you don’t understand what causes the variation does not mean that it doesn’t have a cause or that the cause is some how “random”
Matts,
While I appreciate your arguments (as I see them) for an ultimately causal universe, I disagree with your insistence that this renders randomness nonexistent, because the word does not actually imply non-causality, as far as I can tell;
Merriam Webster ~ Definition of RANDOM
: a haphazard course
— at random
: without definite aim, direction, rule, or method <subjects chosen at random
Earlier you wrote;
"Even physical dice and coin flips are only pseudo-random. If you train yourself to flip the coin in a very consistent way, you can significantly bias the outcome."
Then that would not be truly random, but it seems to me the very same person could flip the coin in a way that lacked such an intent aspect, and it would be random.
microw6500: QM is the most tested theory of modern science, and has never been disproven. I would suggest you spend some time studying it. QM uncertainty is not a measurement problem.
That is a good comment. I was not the one who suggested that QM was a “measurement problem”. MattS suggested that apparent randomness was a result of “lack of information”. In QM randomness is treated as a given, and the attempt to distinguish “empirical” randomness (or “epistemological” randomness) from “metaphysical” randomness was abandoned as fruitless (Pauli called it “mere metaphysics”). My assertion is that the assertion by MattS is intrinsically untestable; the one thing we know with more confidence than anything else (except maybe the famous “the sun will rise tomorrow”) is that random variation will always be present. It has been observed more times than the rising of the sun. Random variation is the variation that is non-reproducible and non-predictable — it occurs everywhere, such as in the calibration of measurement instruments; and measuring the effects of the Higgs Boson.
Yes, sorry, mashed post-atoes.
So, MattS, I strongly disagree that QM is a lack of information problem (as mentioned in a number of posts, again read about Wheelers delayed choice experiment, while not about Quantum Uncertainty, but without a lot of gymnastics is hard to argue that fundamentally reality isn’t real at all.
But I’m far more likely to agree with you about Earths surface temperature.
Which does give some hope about models, granted not the models they have, but the models that might be possible. They have a digital timing analyzer for electronic systems that basically doesn’t require patterns, something logic simulators do require. But such an analyzer does require a complete understanding of the exact operation of the system under test, which they don’t have or even begin to understand.
MattS: variation in observations due to unknown causes.
That is the very assertion that I claim is untestable. I did not assert that it is false, but that it is untestable. The presence of random variation (variation that is not predictable and not reproducible) is attested in every attempt to repeat previous experiments, such as confirming the calibration curves of measurement instruments. Whether it is all due to lack of information about causes is untestable.
Quantum electrodynamics…..
Therefore the temperature data is not random. The data takes the values it does for specific causes, even if we don’t know what the causes are, even if we are incapable of understanding the causes.
When there are insufficient number of known variables, the process is easily modeled by a pseudo-random process where the result matches the interpolated spectrum of the observed data. Generally statisticians try to use an AR1 model to do this though I argue there are better methods.
The more you find out about the system, the less that works. Let me know when you can model down to 1km in the global climate models… sometime in the next 200 years or so I think.
Until then, the random model generates a valid null hypothesis. Which trend the temperature isn’t exceeding, therefore, the null hypothesis, that the last 135 years of temperature trend is merely random variation, hasn’t been falsified.
BTW this process of Monte Carlo simulation with random data whose spectrum matches the underlying signal is very common in signal analysis and statistics. Lots of papers out there. For example follow all the references for this one:
http://journals.ametsoc.org/doi/pdf/10.1175/1520-0477%281998%29079%3C0061%3AAPGTWA%3E2.0.CO%3B2
Peter
Peter: And you can even integrate with Monte Carlo for difficult complex functions.
Yes, the individual temperatures are not random and all have physical cause to vary over time and space but the SUM of of those temperatures will tend towards a random gaussian distribution.(Central limit theorem) Annual Global temperature is not a temperature measurement: it is a humungous average of over a million individual actual measurements. Average = SUM/n
No, not actually, Have you tried running a histogram or an FFT on the data?
A Gaussian distribution has a certain spectrum of noise. At the very least, there’s strong autocorrelation across 2-3 months, (extremely obvious in the data) and there are numerous other long and short term correlation mechanisms at work, both known and unknown. The global temperature record doesn’t match a Gaussian spectrum.
Central Limit Theorem applies to INDEPENDENT measurements. In a time series, temperatures are not independent Heck, over SPACE they are not independent. This destroys a pile of assumptions being used by Berkeley Earth, GISS, HadCrut, et al in their attempts to homogenize spotty temperature records. My wild guestimate from some back of the envelope Monte Carlo simulations is that their error bars are 2.5x bigger than they say they are based on spatial autocorrelation alone. I haven’t had a chance to look into problems with finding breaks and stitching things together (see my post elsewhere in on this page), that’ll likely just add to the errorbars. (I’d have to run their entire code set with a newer stitching algorithm, I don’t have the resources to do that right now).
The CLT is likely the most abused assumption in modern scientific literature.
Peter
Reading your post Peter, made me think of something that keeps nibbling around the edges, measured daily temps are a sine wave plus noise (weather), globally with a average peak to peak range of ~18F, and a period of 24 hours, you’ve lost all the useful info by the time you have a monthly average, and this daily signal is on top of a 12 month period sine wave, with a peak to peak signal of ~80 – 90F.
Peter
I am the author of the bizarrely labelled Checker 22 comment. My brevity is at fault in leaving the impression that CLT is being naively applied. I do understand that it applies to independent measurements and I was also referring to annual global temperature anomaly index calculations, not monthly or shorter periods.
I will try and restate because I am interested in understanding the problems with this approach.
An annual global index calculation involves averaging over 1 million individual temperature measurements (2x365x(say) 2000 stations). There are many many local correlations in time and space in that population but likewise there are subsets that are effectively independent. At some stage in the build up to the annual index, we will be averaging September averages in Peking with January averages in London. At this stage we are averaging effectively independent sub-averages and could reasonable expect CLT to have an impact.
If over a million individual measurements was actually the equivalent to just (arbitrarily)100 independent measurements, which I think is overly pessimistic, the averaging process will still dramatically improve the signal (correlated component) to noise (uncorrelated component ) ratio. Those components of the signal which correlate year to year will survive the averaging process intact. Those components which are effectively independent will turn into a Gaussian mush whose variance will reduce as (i/root(n) where n is the number of effectively independent measurements. It is alleged that the AGW signal is global and effectively immediate and so is the ultimate example of a component of the signal whose S/N ratio would be be improved by a factor of 10 (if n were 100) (linear).
So, in this case I believe the usual (almost trivial) starting point of time series analysis that the calculated index (global annual temperature anomaly) = signal + noise, the noise being (in the limit) Gaussian and the signal being whatever it is.
And yes I have seen FFTs and histograms and spectral analysis but of course only ever of the composite (signal plus + noise) and I am the first to agree that the composite is not Gaussian. But that was my point: the composite is not easily separable into its components (which is why we are writing here in the first place) for very low S/N ratios.
Even after the massive average crunching for the annual index which will have improved the signal to noise ratio, the standard deviation of the year on year variation is still of the order of 0.5 degree whilst the real or imaginary “trends” being calculated over various periods vary around 0.01 to 0.02 degree year on year. A “trend” which is embedded in noise whose year-on-year 1 standard deviation is (say) 30 times bigger than the year-on-year trend, is not really detectable without a lot more independent inputs.
Jonathan
I’ve had a long standing offer of $2250 ( 1k x the ratio of Venus’s surface temperature to its orbital gray body temperature ) ( and being on my own penny ) for anyone who can provide the physical equations in SI units , and experimental demonstration of the asserted spectral , ie , electromagnetic , phenomenon . If they can do that , then we are both rich and our energy problems are over .
Of course , HockeySchtick has shown that the temperature differential is a necessary function of the difference in gravitational energy from top to bottom of atmospheres .
BTW : I will be presenting my 4th.CoSy linguistic environment melding Ken Iverson’s APL with Charles Moore’s Forth at the Silicon Valley FIG “Forth Day” Hangout at Stanford the Saturday . Check my http://CoSy.com for details and to download a free and open down to the x86 system if you have a mind for it .
It’s probably not totally random; it is more likely chaotic.
I hope the rules don’t permit the kind of “homogenization” that has been done to the data being used because they are definitely rehung on an upward trending adjustment series. Having said that, a simple formula for determining the frequency of record temperatures over a given period where the changes are random, is to assume the first year’s average temperature is a record and then calculate Ln (N) where “N” is the number of years in the record (say N=100). This is based on a random distribution of a series of numbers from one to one hundred. Starting from the first entry, you count the next higher temperature in the series and then the next and so on. It seems to be reasonable for snowfall and flood records I’ve looked into.
Ln(100)= 4.6 (say 4 to give some freedom to using the first as a record). Ln(200)= 5.3, (say 5 increasing records. Ln(500)=~6, Ln(1000)= ~7
Dr. Douglas Keenan is the one who alerted the university to the (‘alleged’) Wei Chyung Wang climate fraud. It was reported there, but I’ve not heard about it since. Here is his detailed accusation in .pdf form.
As Nelson said: “I see no [trend]”
http://www.dailymail.co.uk/sciencetech/article-2936797/Global-warming-slowdown-NOT-climate-model-errors-Natural-variations-weather-explain-pause-says-study.html
The check’s in the post 🙂
I predict that while there will not be a winner,
there will be many losers of $10 US.
It’s like the farmer who is selling a horse for $100…this fellow buys the horse, gives the farmer the $100 and tells him that he will pick up the horse in the morning. The next day he shows up to collect the horse. The farmer tells him he can’t do that as the horse died during the night. No worries says the buyer, just give me back my $100. The farmer tells him he can’t since he has spent the money. Ok…says the buyer I will just take the dead horse. The dead horse is loaded up and off goes the buyer. Two weeks later the farmer is in town and he spots the buyer walking down the street. “What happened with the horse”, asks the farmer. “Everything went well and I made $300”, said the buyer. “What…how was that possible ?” asks the farmer. “I raffled off the horse.. sold tickets for $10 apiece”, said the buyer. “What did the winner say when he found out that he had won a dead horse”, asked the farmer. “He did not complain to much since I gave him back his $10″……..
LOL + 1
I’m reminded of a prior article on the arcsine by William Briggs.
Download R, and run Briggs’ program to generate your OWN random climate forecasts
http://wmbriggs.com/post/257/
It’s an intriguing idea. This type of approach was used to discredit some of Mickey Mann’s work, feeding white noise into his statistical processes and having it spit out a hockey stick.
In this case, they produce white noise reflecting the expected amount of variability of the global temperature, using a trendless model. Then they either add or don’t add another random trend of >1 degree or <-1 degree over the 135 data points of each time series.
If they can use statistical analysis to discern the "anthropogenic signal" in the real-world temperature series, they should be able to do the same for these 1000 model runs.
This is yet another clear example of how "global warming science" isn't science at all. Real scientists talk to each other using math and statistics. When you ask them to demonstrate the robustness of their math and statistics, they fail.
Maybe I'm wrong and they'll correctly identify 90% of the time series for what they are and claim the prize. My guess is they never do and most won't bother to even try because they know their statistics are bogus.
And randomness is the mother of all superstition.
The number of hackers trying to decode Answers.txt will probably exceed the number of people trying to solve the problem.
Quite reasonably so. Looks easier than trying to figure out what ‘trendless statistical models’ were used and what is meant with ‘trend averaged 1°C/century’.
10,001 entrants are all that are needed.
Unless I am going blind as well as senile in my old age, I can not see a place to send an entry and $10.
Details here: http://www.informath.org/Contest1000.htm
I don’t see an entry form. I have downloaded the data.
Dear Moderator — summoning you to help out Walt D. (just above) and others who want to enter… . There is no entry form at the informath.org link.
Thanks!
And THANK YOU FOR ALL YOU DO FOR TRUTH IN SCIENCE!
Janice
Hey, Walt! Here ya go! #(:))
HOW TO ENTER THIS CONTEST:
Hurrah! #(:))
(I used his “contact me” info. on McKitrick’s website and e mailed him yesterday evening — and he answered me!!)
Apologies Walt.
I just cited the link and had no idea it didn’t work. Link was at end of the article.
D
Doug Keenan is the challenging sort of guy this science needs, but he can be a pretty tiresome room-mate, I’d imagine.
“The file Series1000.txt contains 1000 time series. Each series has length 135 (about the same as that of the most commonly studied series of global temperatures). The series were generated via trendless statistical models fit for global temperatures. Some series then had a trend added to them. Each trend averaged 1°C/century—which is greater than the trend claimed for global temperatures. Some trends were positive; others were negative.”
Each trend AVERAGED 1 deg/century (+ or -). A lot of those trends (90%?) could be pretty close to zero, or at least within the noise.
Can’t see this thing going very far.
“A lot of those trends (90%?) could be pretty close to zero, or at least within the noise.”
By Jove, I think he’s got it.
Each trend averaged 1°C/century. If a series had a trend added to it, the trend was ±1°C/century, when averaged across the series. The trend was not necessarily deterministic-constant throughout the whole series though: it might vary decade by decade, or in some other way.
Dear Douglas J. Keenan,
(asking on behalf of Walt D. (2:31pm, today))
There is no entry-form, just data, apparently (on the informath.org link in article).
Thank you for adding that info. to the post (I hope!).
Excellent post, too, by the way!
Janice
“The series were generated via trendless statistical models fit for global temperatures. Some series then had a trend added to them. Each trend averaged 1°C/century—which is greater than the trend claimed for global temperatures. Some trends were positive; others were negative.”
No reasonable statistician will fall into this trap.
“No reasonable statistician…”
Ah so, the No True Statistician fallacy!
HIlarious!
w.
I’m always struck by the fact that Ken Rice – aka: attp, who posts such negative comments and had a lot to say about this at Bishop Hill, never seems to comment here at WUWT. As he’s from Edinburgh, one could offer a good Scottish word: ‘Frit’.
Or possibly banned?
ATTP has long been banned here.
well, its conceptually an easy problem to solve.
You discard all the data that has a downward slope as time increases and you keep ONLY that data that has an upward slope over time.
Then, with the remaining data, you perform your least squares analysis – which, of course will have a correlation coefficient near one – and voila, there you have it.
True, you have to provide a reason to discard any data you do not like and , once again, the reason is very simple; it was discarded because it contradicted the answer you wanted to obtain.
But, you may be criticized for providing this stupid reason, and the response to this is straightforward; you would say to the “denier;”
“You Stupid moron, the science is settled. 97% of ALL scientists agree that climate change is real and, by the way, how much are you being paid by Exxon?”
Very simple, really.
A truly wonderful idea. Bravo! Time to read A random walk down Wall Street again
“There have been many claims of observational evidence for global-warming alarmism.”
Well yes, any demonstration or opinion piece arguing for lesser use of fossil fuels because of risks associated with climate change is observational evidence of that.
“I have argued that all such claims rely on invalid statistical analyses.”
Has anyone done a statistical analysis on the occurance of global-warming alarmism? Is there a reference somewhere?
“Some people, though, have asserted that the analyses are valid. Those people assert, in particular, that they can determine, via statistical analysis, whether global temperatures are increasing more that would be reasonably expected by random natural variation. Those people do not present any counter to my argument, but they make their assertions anyway.”
(Now seriously) Do the people you disagree with think that your statistical model is physically plausible?
I’ve been saying for a couple years, surface stations, when you compare daily rising temp to the following nights falling temp, show no trend in rising temps, and has a slight Falling trend, but is smaller than the uncertainty of the measurements.
Yes, you have, and very well, Mike Crow. This post by Mike Crow (and the comments below, too) is worth revisiting:
http://wattsupwiththat.com/2013/05/17/an-analysis-of-night-time-cooling-based-on-ncdc-station-record-data/
Keep up your valiant efforts for truth in science, O “Army of One” {eyesonu — on above comment thread} !
#(:))
” Keep up your valiant efforts for truth in science, O “Army of One” {eyesonu — on above comment thread} !”
My name is legion, we are one!
Thank you.
I have added to the original collection of data.
It’s not a paper, but a collection that could someday become one.
https://micro6500blog.wordpress.com/
Mike Crow,
My pleasure.
Thank you for sharing all that data, so carefully collected, so scrupulously recorded.
After reading through your work, I found this statement by you quite moving:
What I’ve done with surface station data, a modest weather station, and an IR thermometer the last 5-6 years.
What you have done… .
With admiration,
Janice
cooling the past, warming the present….using a algorithm that adjusts the past every time you enter a new set of temperatures etc….is not random
And here is just one of many WUWT posts (and comment threads) which backs up what Latitude said (at 2:15pm today):
Werner Brozek here:
http://wattsupwiththat.com/2015/08/14/problematic-adjustments-and-divergences-now-includes-june-data/
by Werner Brozek and R. G. Brown (ed. by Just the Facts)
Statisticians can prove anything they want.
What is more important is to identify the effects, beneficial or otherwise,on us of whatever temperature changes occur, whether statistically significant or not