Guest Post by Willis Eschenbach
One of the best parts of writing for the web is the outstanding advice and guidance I get from folks with lots of experience. I recently had the good fortune to have Robert Brown of Duke University recommend a study by Demetris Koutsoyiannis entitled The Hurst phenomenon and fractional Gaussian noise made easy. It is indeed “made easy”, I recommend it strongly. In addition, Leif Svalgaard recommended another much earlier study of a similar question (using very different terminology) in a section entitled “Random series, and series with conservation” of a book entitled “Geomagnetism“. See p.584, and Equation 91. While it is not “made hard”, it is not “made easy” either.
Between these two excellent references, I’ve come to a much better understanding of the Hurst phenomenon and of fractional gaussian noise. In addition, I think I’ve come up with a way to calculate the equivalent number of independent data points in an autocorrelated dataset.
So as I did in my last post on this subject, let me start with a question. Here is the recording of the Nile River levels made at the “Roda Nilometer” on the Nile River. It is one of the longest continuous climate-related records on the planet, extending from the year 622 to the year 1284, an unbroken stretch of 633 years. There’s a good description of the nilometer here, and the nilometer dataset is available here.
 Figure 1. The annual minimum river levels in Cairo, Egypt as measured by the nilometer on Roda Island.
Figure 1. The annual minimum river levels in Cairo, Egypt as measured by the nilometer on Roda Island.
So without further ado, here’s the question:
Is there a significant trend in the Nile River over that half-millennium plus from 622 to 1284?
Well, it sure looks like there is a trend. And a standard statistical analysis says it is definitely significant, viz:
Coefficients:
Estimate Std. Error t value P-value less than
(Intercept) 1.108e+03 6.672e+00 166.128 < 2e-16 ***
seq_along(nilometer) 1.197e-01 1.741e-02 6.876 1.42e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ' 1
Residual standard error: 85.8 on 661 degrees of freedom
Multiple R-squared: 0.06676, Adjusted R-squared: 0.06535
F-statistic: 47.29 on 1 and 661 DF, p-value: 1.423e-11
That says that the odds of finding such a trend by random chance are one in 142 TRILLION (p-value less than 1.42e-11).
Now, due to modern computer speeds, we don’t have to take the statisticians’ word for it. We can actually run the experiment ourselves. It’s called the “Monte Carlo” method. To use the Monte Carlo method, we generate say a thousand sets (instances) of 663 random numbers. Then we measure the trends in each of the thousand instances, and we see how the Nilometer trend compares to the trends in the pseudodata. Figure 2 shows the result:
 Figure 2. Histogram showing the distribution of the linear trends in 1000 instances of random normal pseudodata of length 633. The mean and standard deviation of the pseudodata have been set to the mean and standard deviation of the nilometer data.
Figure 2. Histogram showing the distribution of the linear trends in 1000 instances of random normal pseudodata of length 633. The mean and standard deviation of the pseudodata have been set to the mean and standard deviation of the nilometer data.
As you can see, our Monte Carlo simulation of the situation agrees completely with the statistical analysis—such a trend is extremely unlikely to have occurred by random chance.
So what’s wrong with this picture? Let me show you another picture to explain what’s wrong. Here are twenty of the one thousand instances of random normal pseudodata … with one of them replaced by the nilometer data. See if you can spot which one is nilometer data just by the shapes:
 Figure 3. Twenty random normal sets of pseudodata, with one of them replaced by the nilometer data.
Figure 3. Twenty random normal sets of pseudodata, with one of them replaced by the nilometer data.
If you said “Series 7 is nilometer data”, you win the Kewpie doll. It’s obvious that it is very different from the random normal datasets. As Koutsoyiannis explains in his paper, this is because the nilometer data exhibits what is called the “Hurst phenomenon”. It shows autocorrelation, where one data point is partially dependent on previous data points, on both long and short time scales. Koutsoyiannis shows that the nilometer dataset can be modeled as an example of what is called “fractional Gaussian noise”.
This means that instead of using random normal pseudodata, what I should have been using is random fractional Gaussian pseudodata. So I did that. Here is another comparison of the nilometer data, this time with 19 instances of fractional Gaussian pseudodata. Again, see if you can spot the nilometer data.
 Figure 4. Twenty random fractional Gaussian sets of pseudodata, with one of them replaced by the nilometer data.
Figure 4. Twenty random fractional Gaussian sets of pseudodata, with one of them replaced by the nilometer data.
Not so easy this time, is it, they all look quite similar … the answer is Series 20. And you can see how much more “trendy” this kind of data is.
Now, an internally correlated dataset like the nilometer data is characterized by something called the “Hurst Exponent”, which varies from 0.0 to 1.0. For perfectly random normal data the Hurst Exponent is 0.5. If the Hurst Exponent is larger than that, then the dataset is positively correlated with itself internally. If the Hurst Exponent is less than 0.5, then the dataset is negatively correlated with itself. The nilometer data, for example, has a Hurst Exponent of 0.85, indicating that the Hurst phenomenon is strong in this one …
So what do we find when we look at the trends of the fractional Gaussian pseudodata shown in Figure 4? Figure 5 shows an overlay of the random normal trend results from Figure 2, displayed on top of the fractional Gaussian trend results from the data exemplified in Figure 4.
 Figure 5. Two histograms. The blue histogram shows the distribution of the linear trends in 1000 instances of random fractional Gaussian pseudodata of length 633. The average Hurst Exponent of the pseudodata is 0.82 That blue histogram is overlaid with a histogram in red showing the distribution of the linear trends in 1000 instances of random normal pseudodata of length 633 as shown in Figure 2. The mean and standard deviation of the pseudodata have been set to the mean and standard deviation of the nilometer data.
Figure 5. Two histograms. The blue histogram shows the distribution of the linear trends in 1000 instances of random fractional Gaussian pseudodata of length 633. The average Hurst Exponent of the pseudodata is 0.82 That blue histogram is overlaid with a histogram in red showing the distribution of the linear trends in 1000 instances of random normal pseudodata of length 633 as shown in Figure 2. The mean and standard deviation of the pseudodata have been set to the mean and standard deviation of the nilometer data.
I must admit, I was quite surprised when I saw Figure 5. I was expecting a difference in the distribution of the trends of the two sets of pseudodata, but nothing like that … as you can see, while standard statistics says that the nilometer trend is highly unusual, in fact, it is not unusual at all. About 15% of the pseudodata instances have trends larger than that of the nilometer.
So we now have the answer to the question I posed above. I asked whether there was a significant rise in the Nile from the year 622 to the year 1284 (see Figure 1). Despite standard statistics saying most definitely yes, amazingly, the answer seems to be … most definitely we don’t know. The trend is not statistically significant. That amount of trend in a six-century-plus dataset is not enough to say that it is more than just a 663-year random fluctuation of the Nile. The problem is simple—these kinds of trends are common in fractional Gaussian data.
Now, one way to understand this apparent conundrum is that because the nilometer dataset is internally correlated on both the short and long term, it is as though there were fewer data points than the nominal 633. The important concept is that since the data points are NOT independent of each other, a large number of inter-dependent data points acts statistically like a smaller number of truly independent data points. This is the basis of the idea of the “effective n”, which is how such autocorrelation issues are often handled. In an autocorrelated dataset, the “effective n”, which is the number of effective independent data points, is always smaller than the true n, which is the count of the actual data.
But just how much smaller is the effective n than the actual n? Well, there we run into a problem. We have heuristic methods to estimate it, but they are just estimations based on experience, without theoretical underpinnings. I’ve often used the method of Nychka, which estimates the effective n from the lag-1 auto-correlation (Details below in Notes). The Nychka method estimates the effective n of the nilometer data as 182 effective independent data points … but is that correct? I think that now I can answer that question, but there will of course be a digression.
I learned two new and most interesting things from the two papers recommended to me by Drs. Brown and Svalgaard. The first was that we can estimate the number of effective independent data points from the rate at which the standard error of the mean decreases with increasing sample size. Here’s the relevant quote from the book recommended by Dr. Svalgaard:
 Figure 6. See the paper for derivation and details. The variable “m” is the standard deviation of the full dataset. The function “m(h)” is the standard deviation of the means of the full dataset taken h data points at a time.
Figure 6. See the paper for derivation and details. The variable “m” is the standard deviation of the full dataset. The function “m(h)” is the standard deviation of the means of the full dataset taken h data points at a time.
Now, you’ve got to translate the old-school terminology, but the math doesn’t change. This passage points to a method, albeit a very complex method, of relating what he calls the “degree of conservation” to the number of degrees of freedom, which he calls the “effective number of random ordinates”. I’d never thought of determining the effective n in the manner he describes.
This new way of looking at the calculation of neff was soon complemented by what I learned from the Koutsoyiannis paper recommended by Dr. Brown. I found out that there is an alternative formulation of the Hurst Exponent. Rather than relating the Hurst Exponent to the range divided by the standard deviation, he shows that the Hurst Exponent can be calculated as a function of the slope of the decline of the standard deviation with increasing n (the number of data points). Here is the novel part of the Koutsoyiannis paper for me:
 Figure 7. The left-hand side of the equation is the standard deviation of the means of all subsets of length “n”, that is to say, the standard error of the mean for that data. On the right side, sigma ( σ ), the standard deviation of the means, is divided by “n”, the number of data points, to the power of (1-H), where H is the Hurst Exponent. See the paper for derivation and details.
Figure 7. The left-hand side of the equation is the standard deviation of the means of all subsets of length “n”, that is to say, the standard error of the mean for that data. On the right side, sigma ( σ ), the standard deviation of the means, is divided by “n”, the number of data points, to the power of (1-H), where H is the Hurst Exponent. See the paper for derivation and details.
In the statistics of normally distributed data, the standard error of the mean (SEM) is sigma (the standard deviation of the data) divided by the square root of N, the number of data points. However, as Koutsoyiannis shows, this is a specific example of a more general rule. Rather than varying as a function of 1 over the square root of n (n^0.5), the SEM varies as 1 over n^(1-H), where H is the Hurst exponent. For a normal dataset, H = 0.5, so the equation reduces to the usual form.
SO … combining what I learned from the two papers, I realized that I could use the Koutsoyiannis equation shown just above to estimate the effective n. You see, all we have to do is relate the SEM shown above, 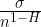

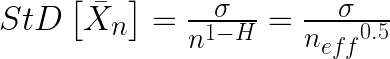
where the left-hand term is the standard error of the mean, and the two right-hand expressions are different equivalent ways of calculating that same standard error of the mean.
By inverting the fractions, canceling out the sigmas, and squaring both sides we get
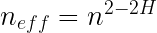
Egads, what a lovely result! Equation 1 calculates the number of effective independent data points using only n, the number of datapoints in the dataset, and H, the Hurst Exponent.
As you can imagine, I was quite interested in this discovery. However, I soon ran into the next oddity. You may recall from above that using the method of Nychka for estimating the effective n, we got an effective n (neff) of 182 independent data points in the nilometer data. But the Hurst Exponent for the nilometer data is 0.85. Using Equation 1, this gives us an effective n of 663^(2-2* 0.85) equals seven measly independent data points. And for the fractional Gaussian pseudodata, with an average Hurst Exponent of 0.82, this gives only about eleven independent data points.
So which one is right—the Nychka estimate of 182 effective independent datapoints, or the much smaller value of 11 calculated with Equation 1? Fortunately, we can use the Monte Carlo method again. Instead of using 663 random normal data points stretching from the year 622 to 1284, we can use a smaller number like 182 datapoints, or even a much smaller number like 11 datapoints covering the same time period. Here are those results:
 Figure 8. Four histograms. The solid blue filled histogram shows the distribution of the linear trends in 1000 instances of random fractional gaussian pseudodata of length 633. The average Hurst Exponent of the pseudodata is 0.82 That blue histogram is overlaid with a histogram in red showing the distribution of the linear trends in 1000 instances of random normal pseudodata of length 633. These two are exactly as shown in Figure 2. In addition, the histograms of the trends of 1000 instances of random normal pseudodata of length n=182 and n=11 are shown in blue and black. Mean and standard deviation of the pseudodata has been set to the mean and standard deviation of the nilometer data.
Figure 8. Four histograms. The solid blue filled histogram shows the distribution of the linear trends in 1000 instances of random fractional gaussian pseudodata of length 633. The average Hurst Exponent of the pseudodata is 0.82 That blue histogram is overlaid with a histogram in red showing the distribution of the linear trends in 1000 instances of random normal pseudodata of length 633. These two are exactly as shown in Figure 2. In addition, the histograms of the trends of 1000 instances of random normal pseudodata of length n=182 and n=11 are shown in blue and black. Mean and standard deviation of the pseudodata has been set to the mean and standard deviation of the nilometer data.
I see this as a strong confirmation of this method of calculating the number of equivalent independent data points. The distribution of the trends with 11 points of random normal pseudodata is very similar to the distribution of the trends with 663 points of fractional Gaussian pseudodata with a Hurst Exponent of 0.82, exactly as Equation 1 predicts.
However, this all raises some unsettling questions. The main issue is that the nilometer data is by no means the only dataset out there that exhibits the Hurst Phenomena. As Koutsoyiannis observes:
The Hurst or scaling behaviour has been found to be omnipresent in several long time series from hydrological, geophysical, technological and socio-economic processes. Thus, it seems that in real world processes this behaviour is the rule rather than the exception. The omnipresence can be explained based either on dynamical systems with changing parameters (Koutsoyiannis, 2005b) or on the principle of maximum entropy applied to stochastic processes at all time scales simultaneously (Koutsoyiannis, 2005a).
As one example among many, the HadCRUT4 global average surface temperature data has an even higher Hurst Exponent than the nilometer data, at 0.94. This makes sense because the global temperature data is heavily averaged over both space and time. As a consequence the Hurst Exponent is high. And with such a high Hurst Exponent, despite there being 1,977 months of data in the dataset, the relationship shown above indicates that the effective n is tiny—there are only the equivalent of about four independent datapoints in the whole of the HadCRUT4 global average temperature dataset. Four.
SO … does this mean that we have been chasing a chimera? Are the trends that we have believed to be so significant simply the typical meanderings of high Hurst Exponent systems? Or have I made some foolish mistake?
I’m up for any suggestions on this one …
Best regards to all, it’s ten to one in the morning, full moon is tomorrow, I’m going outside for some moon viewing …
w.
UPDATE: Demetris Koutsoyiannis was kind enough to comment below. In particular, he said that my analysis was correct. He also pointed out in a most gracious manner that he was the original describer of the relationship between H and effective N, back in 2007. My thanks to him.
Demetris Koutsoyiannis July 1, 2015 at 2:04 pm
Willis, thank you very much for the excellent post and your reference to my work. I confirm your result on the effective sample size — see also equation (6) in
http://www.itia.ntua.gr/en/docinfo/781/
As You Might Have Heard: If you disagree with someone, please have the courtesy to quote the exact words you disagree with so we can all understand just exactly what you are objecting to.
The Data Notes Say:
### Nile river minima
###
## Yearly minimal water levels of the Nile river for the years 622
## to 1281, measured at the Roda gauge near Cairo (Tousson, 1925,
## p. 366-385). The data are listed in chronological sequence by row.
## The original Nile river data supplied by Beran only contained only
## 500 observations (622 to 1121). However, the book claimed to have
## 660 observations (622 to 1281). I added the remaining observations
## from the book, by hand, and still came up short with only 653
## observations (622 to 1264).
### — now have 663 observations : years 622–1284 (as in orig. source)
The Method Of Nychka: He calculates the effective n as follows:

where “r” is the lag-1 autocorrelation.
It’s ten after one in the morning here. Alas, I can’t do much moon viewing – the monsoon has set in, and it’s just a big bright spot in the clouds.
Truly fascinating – I will be following these papers up myself. This looks like an excellent approach to auto-correlated data (and for determining when you are actually dealing with it, rather than a normal set).
You can also do it easily as follows:
Calculate Rt as the difference between observations X(t) – X(t-1). That is, create a new series of differences at lag 1. Use this Rt series in your Monte Carlo simulations: randomly shuffle it 10,000 times. Create 10,000 new series of X. Calculate the trends of the 10,000 new series. If the original series trend is more extreme than 95% of the generated series, then bingo, it’s significant (and you can tell how significant by the proportion of random series are more extreme).
The key point is to use the differences between observations, not the observations themselves. Caveats may apply.
I think I may have to leave my own caveat there ‘cos I think the series generated will all have the same slope. It’s been a long year since I did this and it was for a different purpose. (To separate random walks from bounded series, etc). I guess it holds but only for subsections of the data. Sorry ’bout that. Anyway I’ll now sit down with pencil and paper and work out a simple Monte Carlo way… if there is a way…
Final gasp:
I can’t see an easy way to do it as I was so boldly claiming above. If you randomize the differences you don’t always get the same slope, but you do always get the same start and end value, which is not so hot. (‘cos the sum of differences is always the same no matter how you reorder them). It keeps the same persistence, but also the slope you want to test. If you randomize the observations themselves, you get a range of slopes centred on 0, but you lose the persistence.
Any answers on a postcard welcome…
Someone well known in WUWT circles has written about the Hurst phenomenon in global mean temperature time series: Michael Mann.
http://www.meteo.psu.edu/holocene/public_html/shared/articles/MannClimaticChangeSpringboard11.pdf
Willing to have a go at that paper?
Mann writes in his paper
And according to the neff formula, the total number of effective climate data points we have is
(1999-850)x12 ^ (2 – 2 x 0.870) = ~12
12 climate data points since before the MWP. Ouch.
and
(1999-1850)x12 ^ (2-2 x 0.903) = ~4
So Mann agrees with you Willis. We have 4 climate data points in the modern era. Nice.
And so to bed.
4 points – thats hilarious. All those billions of dollars, for a trend based on Neff of 4.
It would be funnier if there was nothing better the money could have been spend on, eh Mr. Worrall?
Is there a non-paywalled source of Koutsoyiannis?
Yes: Here it is: https://www.itia.ntua.gr/getfile/511/1/documents/2002HSJHurst.pdf. I think the head post links to the wrong Koutsoyiannis paper.
There is also one here
http://www.tandfonline.com/doi/pdf/10.1080/02626660209492961
Thank you Willis.
Does the method of calculating the number of effective data points say anything about where they are, in particular?
Do they correspond in any way to the decades to centuries-long fluctuations in the Nile data?
If I look at the Nile data graph from across the room, I can discern several trends up and down. Maybe seven of them, maybe eleven, depending on where I stand.
Thank you again, very interesting and thought provoking as always.
BTW, Ten of five here, and I have to wake up in an hour for work 🙂
Thanks Willis, you found an excellent way to explain this relatively complicated topic.
We have had a Climate Dialogue about Long Term Persistence, in which Koutsoyiannis participated, together with Armin Bunde and Rasmus Benestad. It’s fascinating to see how mainstream climate scientists (in this case Benestad) are a bit well let’s say hesitant to accept the huge consequences of taking into account Hurst parameters close to 1 🙂
See http://www.climatedialogue.org/long-term-persistence-and-trend-significance/
Marcel
Thanks for that link, Marcel. It is a most fascinating interchange, with much to learn. I’m sorry I didn’t know about it at the time.
You say:
When I realized how small the actual number of effective independent data points is in high-Hurst datasets, I had the same thought. I thought, mainstream climate scientists are not going to be willing to truly grasp this nettle … despite the fact that I was able to use the Monte Carlo analysis to verify the accuracy of the neff of 11 in the dataset in the head post.
All the best to you,
w.
Thanks, Willis, for an intriguing conundrum (and thanks, Marcel, for doing Climate Dialogue). I have a suggestion that might help to resolve the issue (or might just demonstrate that when it comes to statistics I’m totally ignorant). Suggestion : take a highly correlated data series where there are both known genuine trends and “random” variation, for example temperatures at one location throughout one day, or daily maximum temperatures at one location over a year, and see how your new method perceives it.
…extending from the year 622 to the year 1284, an unbroken stretch of 633 years. …
Er… 1284 – 622 = 662, not 633. Minor transposition error – your reference gives a correct 662.
In fact, that Nilometer has several gaps in its record – there has been a Nilometer on that spot since around 715, but there were earlier ones (presumably stretching back to some 3000BC?). Shame we haven’t got all the data…
Er…No.
Which year don’t you include, 662 or 1284. Include them both and it’s a span of 633 years.
Were does 662 come from? The OP says <i<"from the year 622 to the year 1284, an unbroken stretch of 633 years"
There is no ‘662’ mentioned at all…
OK, that’s a misprint, but I think you’ve worked it out now.
The basic assumption underlying the error estimates in regression techniques is that that the deviations from whatever relationship you fit are: a) uncorrelated, that is the next deviation does not depend on the foregoing one, and b) they are (in this case) Gaussian distributed.
One glance at the plot shows that both conditions are not satisfaied.Hence any “error” estimate on the fitted parameters are meaningless. In fact, it is obvious from the graph that there is no long term trend.
Meeting these assumptions bothers me with most climate data, too. Here, as well, Willis has revealed the persistent memory within these sets. I’m not sure we’re entitled to make any inferences at all with these data, although I appreciate the temptation. That leaves only making observations/descriptions of data and attempting to find words to make “real world” sense of the observations.
The post-normal whackos will say that this is another failure of classical scientific methods and instead these data clearly show we need to collect a bunch of taxes and damn the river.
http://geography.about.com/od/specificplacesofinterest/a/nile.htm
ah they did 🙂
michael
Yes, basic statistics always starts with the assumption that data samples are representative of the population.
Global surface temperature data certainly do not represent the globe. A few individual surface stations do have good data for their microclimate, eg some rural stations. Such data show zero warming.
The statement “no long term trend” is not the same as saying that the slope of the trend line is insignificantly different from zero. This gets into hypothesis testing, and assumptions about the underlying nature of what is being meaured. My observation of the same chart is that the trend line is irrelevant to the data. Or, the first year of data are insignificantly different from the last year. Or, etc, etc.
That’s my take as well. There appears to be a lot of signals other than Gaussian noise in the data. My experience from fitting data is that if increasing “N” doesn’t cause a decrease in the residual, then there is some sort of signal lurking in the original that the fitting routine is not fitting for.
First thing I would do is to do a Fourier transform of some sort to see if any spikes show up.
This is also why ignoring the PDO and AMO an really bite when trying to determine ECS.
Willis,
“Or have I made some foolish mistake?”
If your analysis of HadCRUT4 indicates there is no significant trend then, regrettably, I think the answer to your question is yes.
Certainly, the HadCRUT data has been doctored and “adjusted” to within an inch of its life, like all the other surface series, in order to get the desired warming trend.
But the data, as it stands, clearly shows a significant trend. There must be something wrong with your analysis – but as a non-statistician, I’ve no idea what.
In the first set of random examples, the real data does stand out: there’s less vertical random deviation. I find it slightly suspicious that you have to switch to another kind of random data to get the desired result.
Also, the Nile data corresponds nicely to the climate of the time. It shows falling levels as the world descended into the colder climate of the Dark Ages and then rising and peaking spot-on on the Medieval Warm Period. In general, drought is less likely in a warmer climate because warmer air can carry far more moisture.
You do have to be very careful about complex statistical analysis – the Internet is full of such warnings, and advice that analysis must be tempered by using the Mark One Eyeball as a sanity check. Your analysis on the South American river solar correlation was an excellent example of this: the scientists had used advanced statistics to arrive at a conclusion that was almost certainly completely wrong.
I’m sorry, but both the Nile data and HadCRUT both show clear trends. Reminds me of that old saying about lies, damned lies and statistics….
Chris
Yes but do those apparent trends mean anything?
Excellent question and it takes more than statistics to answer – we frequently found statistical significance with very small measured differences (pretty well controlled biology studies) that held no behavioral significance.
@chris, Of course we see trends in these data. Any gambler in Vegas on a “streak” sees a trend. The question of statistical significance is: Can what we see be explained by random chance? Or is there a “system” at work?
@willis, Another issue that should be considered is whether the underlying process randomness is Gaussian. You might consider running you Monte Carlo using non-normal pseudo random number generators. I have also found that people regularly under estimate the number of MC iterations required to achieve a converged result. The simple trick of computing the relevant statistic over each half of the sample set and increasing the sample size until they are in acceptable agreement is often helpful.
Yes, they exhibit clear trends. But the question is whether those trends are “significant.”
If my end-of-month checking-account balance falls for three successive months, that’s a clear trend. But that trend is not strong evidence that over the long term (as evidenced by, say, my last sixty years of checking-account balances) my checking-account balance’s month-to-month change is more likely to be negative than to be positive: the trend is clear, but it’s not “significant.”
Mr. Eschenbach is saying that the same may be true of the temperature trends.
Analysis of autocorrelated data is always fraught. The “normal” statistical methods all fail without drastic correction for autocorrelation. This was pounded home in laboratory methods coursework in the 80’s. There were many tests we had to perform on the datasets before we could even begin serious statistical work, and the professor was diabolical in giving data to analyze that would fail odd tests but would give totally bogus but great looking results to the wrong analysis if you skipped prequalification.
I haven’t seen any courses like that since I have been back in academia. Maybe that is part of the problem in climate science – except most of the practitioners went to school back when I did or a decade before.
But the data, as it stands, clearly shows a significant trend.
====================
nope. the data shows a trend. under the assumption that the data is normally distributed (that temperature acts like a coin toss), then the trend is significant.
however, what the Hurst exponent tells us is that HadCRUT4 data does not behave like a coin toss. And as such, the statistical tests for significance that rely on the normal distribution need to account for this.
In particular, “n”, the sample size. We all understand that a sample of 1 is not going to be very reliable. We think that a sample size of 1 million will be significant. that we can trust the result.
However, what Willis’s result above tells us is that as H goes to 1, the effective sample size of 1 million samples also goes to 1. Which is an amazing result. H-1 tells us that 1 million samples is no more reliable than 1 sample.
Thanks Ferd, for a such a concise summary of the background to (yet another) fascinating article from Willis. Your comment lit the lamp of understanding as far as I am concerned.
ferd berple: “However, what Willis’s result above tells us is that as H goes to 1, the effective sample size of 1 million samples also goes to 1. Which is an amazing result. H-1 tells us that 1 million samples is no more reliable than 1 sample.”
Excellent observation. Is that plausible? I think not. So I suspect that the method of estimating H fails as H goes to 1.
I guess I will have to go an create a bunch of artificial data sets for which I know the answer, and see what I get.
Chris, you really need to reread Willis’ article with emphasis on methods and methodology. The Mk 1 eyeball is ideal for understanding Willis choice, if you actually follow his text.
All Willis is saying is that when a system has a lag time that is comparable to or greater than the time spacing of the data points, neighboring data points are not independent. That is simply common sense. Willis is just going into the math. Consider AMO/PDO as just two examples of *known* long-timelength effects. Any measurement they effect must be recognized as one in which the point-to-point data are correlated. Suppose you have a variable that spends years in a “low” state, then an event happens that sends it to a “high” state, but the measurements are autocorrelated such that the measured value stays “high” for many years. The first points are lower than the last ones, but that does not make a trend.
There are a multitude of timescales for just thermal inertia, to take only one example: air warms and cools quickly, the ground not so much. I live in an old, stone building, and the thermal lag seems to be a few days for the building itself to warm up or cool down during periods of extremely hot/cold weather. If the walls are warm to the touch at noon, they will still be warm at midnight and warm again tomorrow. I can tell that even without a PhD in Climate Science.
“There are a multitude of timescales”
This is where I thought he was going but he didn’t.
Once upon a time, when the earth was still young and warm, auto-corelations were frequently used. They were helpful in quickly showing the underlying timescales in the data, kind of like neff but not really. With the time scales somewhat estimated people would then take a stab at fitting various functions around the data with asymptotic expansions or wavelet analysis, etc., i.e. make up a function and see if it could be wrapped around the data in some fashion. Everyone had their favorites. With the advent of digital signal processing and the Cooley Tukey algorithm, the Fourier series kind of won out over the others.
Would anyone like to run the Central England Temperature data set as a nice test of a long time series for U.K. temperatures?
Yes, I did this statistical test some years ago – just for my own edification. The result was unambiguous: the Hurst exponent, H, was significantly different from 0.5.
Looks like the issue here is how one defines ‘trend’ and the time scales applied.
The Nile clearly varies with latitudinal shifting of climate zones.
This is a neat description of statistical techniques but is rather akin to arguing how many angels can fit on a pin.
We need to know why the climate zones shift in the first place and the most likely reason is changes in the level of solar activity.
I think that the problem is we have politicians that are akin to Pharaohs arguing that the Nile is following a clear statistically significant rising trend in floods since those pyramids were built so is planning a pyramid tax, but the statistics are being incorrectly applied due to their not taking note of the Hurst phenomenon. As with today’s politicians they are completely disinterested in what the reasons are for the Nile floods and will call you a Nile Flood d*nier should you question their ‘statistical trend’ and thus their reasons for filling their coffers.
I remember reading some time ago that El Niño gave less Blue Nile flood and silt (originate in Ethiopia). The white Nile originate in either Rwanda or Burundi. So the Nile is actually 2 rivers originating from 2 different places in Africa. Probably also affected by PDO? https://en.m.wikipedia.org/wiki/Nile
If anyone wants to play around, there’s a real time random generator with autocorrelation (or 1/f noise) at uburns.com
Why muck around with all the calculations?
If you want to work out the effective N, why not simply do a fourier transform, look at the spectrum and work out how much it is depleted from normal white noise?
In effect if you’ve only got 70% of the bandwidth, then information theory says you only have 70% of the information = statistical variation.
To find the white noise floor you need to know the variance of the noise component. How would you determine this in a dataset with significant autocorrelation? In other words, if we’re able to seperate the noise from the signal, we’d be done and the FT would be superfluous.
I am reminded of a random walk plot
https://en.wikipedia.org/wiki/Random_walk
Thank you very much for this post; to me it was one of your more interesting.
But I am embarrassed to confess that, despite intending to for some years, I have not allocated the time to master this derivation, and I won’t today, either. Nonetheless, this post and the references it cites have gone into the folder where I keep the materials (including a Nychka paper I think I also got from you) that I’ll use to learn about n_eff if a long enough time slot opens before I pass beyond this vale of tears.
If it’s convenient, the code that went into generating Fig. 8 would be a welcome addition to those materials. (I’m not yet smart enough about Hurst exponents to generate the synthetic data.)
Dear Willis,
I have a reasonable doubt. How do you know what the Hurst Exponent is for the nilometer data? I have no idea, but I assume that it is something that you calculate by looking at the data itself, and not something based on any previous understanding of the underlying physics of the phenomenom. Please correct me if I am wrong.
In case that I am correct, and you calculate the Hurst Exponent by looking at the data, then the Hurst Exponent is useful to DESCRIBE the data, but is not useful in any way to calculate the likelihood of having data like that. The only way to calculate such likelihood is based on the understanding of the underlying physics.
Let’s say that I have a six-sided dice and I roll ten times, getting 1,1,2,2,3,3,4,5,6,6 for a fantastic upward trend. The likelihood of getting such a result is extremely poor, because the distribution is indeed normal (rolling dices). But if you are going to calculate the Hurst Exponent by looking at the data and not at the underlying physics, you are going to get a high Hurst Exponent, because the data indeed looks like it is very autocorrelated. And if you then run a Monte Carlo analysis with random variables with the same Hurst Exponent, The Monte Carlo analysis will tell you that, well, it was not so unusual.
I hope that you understand my point. If you compare something rare with other things that you force to be equally rare, the rare result will not look rare anymore.
Best regards.
estimating Hurst Exponent – (with reference to Nile data)
http://www.analytics-magazine.org/july-august-2012/624-the-hurst-exponent-predictability-of-time-series
Thanks a lot for that. As can be seen in your link, the Hurst Exponent is calculated from the data. Therefore it is good for describing the data, and probably also good for modeling possible behaviour in the future based on past behaviour (the original intention), but it tells you nothing about how rare the past behaviour was. Nothing at all. It can’t.
When using it to model the future, it will do a good job only if the past behaviour was not rare in itself for any reasons, be it due to changes of the underlying physics or “luck”. So, the more normal and less influenced by luck your past data is, the better job the Hurst Exponent will do at characterising future behaviour.
The Hurst Exponent is ASSUMING that the variations experienced in the past characterise the normal behaviour of the variable being studied. And this may be a correct assumption… or not. The longer the time series, the more likely it will be a safe assumption. But it will still tell you nothing about how rare the past behaviour was. It can’t be used for that, because it already assumes that the past was normal. It assumes so in order to use the information to predict the future. So if you take your data and compare it to other random data with the same Hurst Exponent, of course it will not look rare. You have made them all behave in the same way. This doesn’t mean that your data wasn’t rare by itself.
Exercise: run 1000 times random series of pure white noise with 128 data points. Calculate the trend for each of them. Take the one series with the greatest trend (either positive or negative). We know it is a rare individual, it is 1 among 1000. But let’s imagine that we didn’t, and we wanted to find out whether it was rare or not. Let’s do Willis’ exercise: calculate its Hurst Exponent. It should not be any surprise that it departs somewhat from 0,5. Now we compare it with another 1000 series of Random Fractlonal Gaussian Pseudodata with the same Hurst Exponent, instead of white noise. We calculate the trends of those series. Surprise! The trend of our initial dataset doesn’t look rare at all when compared with the trends of the other Random Fractlonal Gaussian Pseudodata series. Following Willis exercise, we would conclude that our data was not rare at all. And we would be wrong.
I wish I had the time to do the exercise myself.
Nylo has a very made strong point “Following Willis exercise, we would conclude that our data was not rare at all. And we would be wrong.”
But I think he misses the fact that outside of the industrialized “CO2” period, the earth’s climate didn’t have an H of 0.5 at all like his white noise did. So what is a good value of H to use?
I second this notion, particularly the final statement
“If you compare something rare with other things that you force to be equally rare, the rare result will not look rare anymore.”
Terrific point, Nylo. I might add that the usual statistical formulas for error estimates require an unknown quantity: the standard deviation of the population. Estimates of that quantity from the sampled data are typically quite poor, unless one has a very large number of data points. So I wonder how reliable is H, and therefore effective n, estimated from the data.
Hi Willis,
Interesting post. I think there may be a problem with the contribution of a real underlying trend to the value for the Hurst exponent. If you detrended the Nile data and then calculated the Hurst exponent, you might get more effective data points.
Separating ‘causal’ long term variation from autocorrelation driven long term variation is no simple task. I suspect you could look at the variability of absolute values of slopes for different series lengths of real Nile data and synthetic autocorrelated data and see differences in the ‘distribution of slopes’ for different series lengths.
I hate linear trend lines drawn on non-linear data. Climate scientists and other social scientists are particularly enamoured of them.
The secular trend could simply be slow subsidence on the island.
It’s all relative, dependent on the reference frame assumed as constant.
I doubt they had differential GPS surveyors back then to know which is the case. 😉
Interesting stuff, but my intuition is that something has gone wrong here. The Nile data visually does have a clear trend and that trend looks significant.
I wonder, if you took a timeseries consisting of the integers 1 through 1000 and applied the same methods to it, what would N(eff) for that be?
Nigel Harris July 1, 2015 at 5:38 am
Interesting stuff, but my intuition is that something has gone wrong here. The Nile data visually does have a clear trend and that trend looks significant.
Isn’t the comment “something has gone wrong here. The Nile data visual does have a clear trend…” equivalent to not accepting the climate data because it doesn’t agree with the theory. There may be many reasons to question the accuracy of this post, but because it doesn’t agree with a “visually clear trend” is not one of them.
We’ll have to disagree on that.
However, I’m pretty sure something is wrong here.
The equation N[eff] = n^(2-2H) implies that for H between 0 and 0.5 (negative autocorrelation) the effective n would be larger than n, which is clearly impossible.
for H between 0 and 0.5 (negative autocorrelation) the effective n would be larger than n, which is clearly impossible.
Wouldn’t such a case be indicative of a very well behaved time series where intermediate points between sampled points are highly predictable? When a time series function is known exactly, doesn’t the Neff approach infinity?
I’m glad you wrote this, as I can’t explain it in proper terms, but this is exactly what I was thinking.
And the 2n relates to the 2 samples required to perfectly sample a periodic function, think nyquist sampling.
Well perfectly isn’t right, but the minimal required to reproduce the waveform.
The original reference restricted the solution to H >= 0.5; however since values of H < 0.5 imply negative correlation, I suspect but can not prove that simply replacing 2-2H with 1-abs(2H-1) that the equation would cover the full range of H correctly.
Yes, a negative autocorrelation DOES mean that the effective n is greater than n.
Nigel Harris writes “the effective n would be larger than n, which is clearly impossible.”
I dont think so. The way I see it, 2 “data” points describe a line and neff is 2. 3 “data” points can lie on a line but neff is still 2…
4 data point, that sounds right to me, I need to figure out how to do this on the difference dataset I’ve created with no infilling and no homogenization.
I know the bi-annual trend is strong, as it should be (also highly auto-correlated), and the annual max temp has almost no trend, not sure about min temps.
But I’m still calculating solar forcing for each station for each day, in the second week of running, but I’ve redone it a couple times, and it’s now doing about 8,000 records/minute, it’s finished 54 million out of ~130 million.
But to answer your fundamental question, yes as I’ve said for a few years now, all of the published temp series are junk, and the trend is a result of the process, and they’re all about the same because they all do the same basic process.And my difference process is different, and it gives a very different set of answers (it’s more than one answer).
Max temps do not have an upward trend, what they do have is a different profile, ie the amount of time during the year we’re at the average max temp has changed, but this trend looks like it’s a curve that peaked ~2000.
Willis I always find your postings stimulating and provocative. Thank You.
Thanks. As Joe Born says above, good statistics lesson — Steve McIntyre–like.
Have you made some foolish mistake? Probably not, but we will need to run a Hurst Exponent system test on our data of foolish mistakes to be sure.
On a more serious note, I am dubious of all conclusions about statistics that try to comprehend data from a system where physical function properties of that system are not understood. It’s like analysing the stock market graphs. Easy to do in hindsight. Apply whatever equation you like to it, it still won’t help you predict the future any better. Trends are only trends until they are trends no longer.