Elevated from a WUWT comment by Dr. Robert G. Brown, Duke University
Frank K. says: You are spot on with your assessment of ECIMs/GCMs. Unfortunately, those who believe in their ability to predict future climate really don’t want to talk about the differential equations, numerical methods or initial/boundary conditions which comprise these codes. That’s where the real problems are…
Well, let’s be careful how you state this. Those who believe in their ability to predict future climate who aren’t in the business don’t want to talk about all of this, and those who aren’t expert in predictive modeling and statistics in general in the business would prefer in many cases not to have a detailed discussion of the difficulty of properly validating a predictive model — a process which basically never ends as new data comes in.
However, most of the GCMs and ECIMs are well, and reasonably publicly, documented. It’s just that unless you have a Ph.D. in (say) physics, a knowledge of general mathematics and statistics and computer science and numerical computing that would suffice to earn you at least masters degree in each of those subjects if acquired in the context of an academic program, plus substantial subspecialization knowledge in the general fields of computational fluid dynamics and climate science, you don’t know enough to intelligently comment on the code itself. You can only comment on it as a black box, or comment on one tiny fragment of the code, or physics, or initialization, or methods, or the ode solvers, or the dynamical engines, or the averaging, or the spatiotemporal resolution, or…
Look, I actually have a Ph.D in theoretical physics. I’ve completed something like six graduate level math classes (mostly as an undergraduate, but a couple as a physics grad student). I’ve taught (and written a textbook on) graduate level electrodynamics, which is basically a thinly disguised course in elliptical and hyperbolic PDEs. I’ve written a book on large scale cluster computing that people still use when setting up compute clusters, and have several gigabytes worth of code in my personal subversion tree and cannot keep count of how many languages I either know well or have written at least one program in dating back to code written on paper tape. I’ve co-founded two companies on advanced predictive modelling on the basis of code I’ve written and a process for doing indirect Bayesian inference across privacy or other data boundaries that was for a long time patent pending before trying to defend a method patent grew too expensive and cumbersome to continue; the second company is still extant and making substantial progress towards perhaps one day making me rich. I’ve did advanced importance-sampling Monte Carlo simulation as my primary research for around 15 years before quitting that as well. I’ve learned a fair bit of climate science. I basically lack a detailed knowledge and experience of only computational fluid dynamics in the list above (and understand the concepts there pretty well, but that isn’t the same thing as direct experience) and I still have a hard time working through e.g. the CAM 3.1 documentation, and an even harder time working through the open source code, partly because the code is terribly organized and poorly internally documented to the point where just getting it to build correctly requires dedication and a week or two of effort.
Oh, and did I mention that I’m also an experienced systems/network programmer and administrator? So I actually understand the underlying tools REQUIRED for it to build pretty well…
If I have a hard time getting to where I can — for example — simply build an openly published code base and run it on a personal multicore system to watch the whole thing actually run through to a conclusion, let alone start to reorganize the code, replace underlying components such as its absurd lat/long gridding on the surface of a sphere with rescalable symmetric tesselations to make the code adaptive, isolate the various contributing physics subsystems so that they can be easily modified or replaced without affecting other parts of the computation, and so on, you can bet that there aren’t but a handful of people worldwide who are going to be able to do this and willing to do this without a paycheck and substantial support. How does one get the paycheck, the support, the access to supercomputing-scale resources to enable the process? By writing grants (and having enough time to do the work, in an environment capable of providing the required support in exchange for indirect cost money at fixed rates, with the implicit support of the department you work for) and getting grant money to do so.
And who controls who, of the tiny handful of people broadly enough competent in the list above to have a good chance of being able to manage the whole project on the basis of their own directly implemented knowledge and skills AND who has the time and indirect support etc, gets funded? Who reviews the grants?
Why, the very people you would be competing with, who all have a number of vested interests in there being an emergency, because without an emergency the US government might fund two or even three distinct efforts to write a functioning climate model, but they’d never fund forty or fifty such efforts. It is in nobody’s best interests in this group to admit outsiders — all of those groups have grad students they need to place, jobs they need to have materialize for the ones that won’t continue in research, and themselves depend on not antagonizing their friends and colleagues. As AR5 directly remarks — of the 36 or so named components of CMIP5, there aren’t anything LIKE 36 independent models — the models, data, methods, code are all variants of a mere handful of “memetic” code lines, split off on precisely the basis of grad student X starting his or her own version of the code they used in school as part of newly funded program at a new school or institution.
IMO, solving the problem the GCMs are trying to solve is a grand challenge problem in computer science. It isn’t at all surprising that the solutions so far don’t work very well. It would rather be surprising if they did. We don’t even have the data needed to intelligently initialize the models we have got, and those models almost certainly have a completely inadequate spatiotemporal resolution on an insanely stupid, non-rescalable gridding of a sphere. So the programs literally cannot be made to run at a finer resolution without basically rewriting the whole thing, and any such rewrite would only make the problem at the poles worse — quadrature on a spherical surface using a rectilinear lat/long grid is long known to be enormously difficult and to give rise to artifacts and nearly uncontrollable error estimates.
But until the people doing “statistics” on the output of the GCMs come to their senses and stop treating each GCM as if it is an independent and identically distributed sample drawn from a distribution of perfectly written GCM codes plus unknown but unbiased internal errors — which is precisely what AR5 does, as is explicitly acknowledged in section 9.2 in precisely two paragraphs hidden neatly in the middle that more or less add up to “all of the `confidence’ given the estimates listed at the beginning of chapter 9 is basically human opinion bullshit, not something that can be backed up by any sort of axiomatically correct statistical analysis” — the public will be safely protected from any “dangerous” knowledge of the ongoing failure of the GCMs to actually predict or hindcast anything at all particularly accurately outside of the reference interval.
Roy Spencer says:
May 7, 2014 at 7:51 am
Dr. Spencer, from reading ‘Alex Hamilton’s words, they seemed a lot like D. C. – I think you know who that is . . . !
I exchanged a few emails with mathematician Chris Essex recently who claimed (I hope I’m translating this correctly) that climate models are doomed to failure because you can’t use finite difference approximations in long-time scale integrations without destroying the underlying physics. Mass and energy don’t get conserved. Then they try to fix the problem with energy “flux adjustments”, which is just a band aid covering up the problem. , and use interpolated T’s on an inadequate grid de facto assuming unbiased noise around the interpolation, one will strictly underestimate the transport.
, and use interpolated T’s on an inadequate grid de facto assuming unbiased noise around the interpolation, one will strictly underestimate the transport.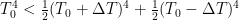 for any
for any  .
.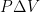 (work) evaluate
(work) evaluate  and try to infer work from this plus a knowledge of the cell temperature, plus a knowledge of the cell’s heat capacity plus fond hopes concerning the rates of phase transitions occurring inside the cell. Yet without this, the model cannot work because ultimately this is the source of convective forces and the cause of things like the wind and global mass-energy transport. Not to worry, this is what the Navier-Stokes equation is all about:
and try to infer work from this plus a knowledge of the cell temperature, plus a knowledge of the cell’s heat capacity plus fond hopes concerning the rates of phase transitions occurring inside the cell. Yet without this, the model cannot work because ultimately this is the source of convective forces and the cause of things like the wind and global mass-energy transport. Not to worry, this is what the Navier-Stokes equation is all about:

 this does not work. Or rather, it works, but enormously inefficiently and with nearly uncontrollable error estimates. By the time one has a grid that integrates the equator accurately, one has a grid that enormously oversamples the poles. Using a differential adaptive routine can help, but it still doesn’t account for the non-rectangular nature of the cells at the poles and hence one’s error estimates there are still sketchy.
this does not work. Or rather, it works, but enormously inefficiently and with nearly uncontrollable error estimates. By the time one has a grid that integrates the equator accurately, one has a grid that enormously oversamples the poles. Using a differential adaptive routine can help, but it still doesn’t account for the non-rectangular nature of the cells at the poles and hence one’s error estimates there are still sketchy.
We spent many months trying to run the ARPS cloud resolving models in climate mode, and it has precisely these problems.
I’ve spent a fair bit of time solving open stochastic differential equations (or, arguably, integrodifferential equations) — things like coupled Langevin equations — back when I did around five or six years of work on a microscopic statistical simulation of quantum optics, as well as LOTS of work numerically solving systems of coupled (de facto partial) differential equations (the system detailed in my Ph.D. dissertation on an exact single-electron band theory). Even before one hits the level of stiff equations — quantum bound states — where tiny errors are magnified due to the fact that numerically, eigensolutions are always numerically unstable past the classical turning point, problems with drift and normalization and accumulation of error are commonplace in all of these sorts of systems. And yes, one of the consequences of drift is that conservation laws aren’t satisfied by the numerical solution.
A common solution for closed systems is to renormalize per time step (or N time steps) to ensure that the solution is projected back to the conserved subspace instead of being allowed to drift away. This prevents the accumulation of error and ensures that the local dynamics remains MOSTLY on the tangent bundle of the conserved hypersurface/subspace, if you like, with only small/second order deviation that is immediately projected away. This is, however, computationally expensive, and it isn’t the way e.g. stiff systems are solved (they use special backwards ODE solvers).
For open systems doing mass/energy transport, however, there is a real problem — energy ISN’T conserved locally ANYWHERE, and most cells can both gain or lose energy directly out of the whole system. In the case of climate models, in some sense this is “the point” — sunlight can and does warm the entire column from the TOA to the lower bound surface of light transport in the model, outgoing radiation can and does cool the entire column from the TOA to the lower bound surface of light transport for the model, AND each cell can exchange energy not only with nearest neighbors but with neighbors as far away as light can travel from the cell boundaries and remain inside the system laterally and vertically combined. That is, radiation from a ground level atmospheric cell can exchange energy with a cell two levels up (assuming that the model has multiple vertical slabs) and at least one cell over PAST any nearest-neighbor, same level cell. One can model this as a nearest-neighbor interaction/exchange system, but it’s not, and in physics systems with long range interactions often have startlingly different behavior from systems that only have short range interactions. Radiation is a long range coupling and direct source and sink for energy.
The consequence of this is that enforcing energy conservation per se is impossible. All one can do is try to solve a system of cell dynamics that is conservative at the differential level, basically implementing the First Law per cell — the energy crossing the borders of the cell has to balance the change in internal energy of the cell plus the work done by the cell. Errors in the integration of those ODE/PDEs cannot be corrected, they simply accumulate. To the extent that the system has negative feedbacks or dynamical processes that limit growth, this doesn’t mean that the energy will diverge, only that the trajectory of the system will rapidly, irreversibly and uncorrectably diverge from the true trajectory. If the negative feedbacks are not correctly implemented, of course, the system can diverge — the addition of a series of randomly drawn -1, +1 numbers diverges like the square root of the number of steps (a so-called “drunkard’s walk”). In the climate system the issue isn’t so much a divergence as the possibility of bias in the errors. Even if you have some sort of damping/global conservation principle forcing you back to zero, if the selection of +/- 1 steps is NOT random but (say) biased 2 +1’s for ever -1, you will not be driven back to the correct equilibrium energy content. This sort of thing can easily happen in numerical code as a simple artifact of things like rounding rules or truncation rules — setting an integer from a floating point number and then using the integer as if it were the float.
It can also happen as an artifact of the method used to extrapolate when solving differential equations or finite difference equations, or because of using interpolation on an inadequate grid while trying to solve dynamics with significant short term variation. Interpolation basically cuts off extremes, but in a nonlinear model the contribution of the excluded extremes will not be symmetric in the deviation specifically when the deviation is normally distributed around the interpolation. As a trivial, but highly relevant example, if one has a transport process that (say) is proportional to
In fact, if one creates a field that has a fixed mean and a purely normal distribution around the mean, and use the mean temperature as an estimate of the (say, radiative) transport, one will strictly underestimate the actual transport because the places where the temperature is warmer than the mean lose energy (relative to the mean) faster than the places where the temperature is cooler, do, relative to the mean temperature. If you like:
Mass transport is even harder to deal with. Well, not really, but it is more expensive to deal with. In the Earth system, one can probably assume that total mass of atmosphere plus ocean plus land (including the highly variable humidity/water/ice distribution that can swing all three ways) is constant. Yes, there is a small exchange across the “boundary” from thermal outgassing and infalling meteor and other matter but it is a very, very small (net) number compared to the total mass in question and probably is irrelevant on less than geological time (in geological time that is not clear!) But GCMs don’t work over geological time so we can assume that the Earth’s mass is basically conserved.
Back a few paragraphs, you’ll note that one has to implement the first law per cell in the model. This is nontrivial, because cells not only receive energy transport across their boundaries in the form of radiation and conduction at the boundary “surfaces”, but they can receive mass across those boundaries and the mass itself carries energy. Worse, the energy carried by the mass isn’t a simple matter of multiplying its temperature by some specific heat and the mass itself; in the case of pesky old water it also carries latent heat, heat that shows up or disappears from the cell relative to its temperature as water in the cell changes phase. Finally, each cell can do work.
This last thing is a real problem. It is left as an exercise to see that a cell model with fixed boundaries cannot directly/internally compute work, because work is a force through a distance and fixed boundaries do not move. If a cell expands into its neighbors it clearly does work (and all things being equal, cools) but “expanding into neighbors” means that the neighbors get smaller and cell boundaries move. One cannot compute the work done at any single boundary from mass transport alone, because no work is done by the uniform motion of mass through a set of cells — a constant wind, as it were. One cannot compute work done by any SIMPLE rule. One has to basically look at net flux of mass into/out of a constant volume cell and instead of evaluating
http://en.wikipedia.org/wiki/Navier%E2%80%93Stokes_equations
In fact, the NS equations do even better. They account for the fact that there the motion of the transport is accompanied by the moral equivalent of friction — drag forces that exert shear stress across the fluid, a.k.a. viscosity. They account for the fact that the motion occurs in a gravitational field, so that downward transport of parcels is accompanied by the gain of total energy while upward transport costs total energy (the kind of thing that gives rise to lapse rates). They can be modified to account for “pseudoforces” that appear in a rotating frame, e.g. Coriolis forces, so that mass transported south is deflected spinward (East) in the northern hemisphere, mass transported upwards is deflected antispinward (West) in both hemispheres, by “forces” that depend in detail on where you are on the globe and in which direction you are moving. However, when solving the system (as this article notes) a statement of mass conservation is necessary, for example the continuity equation:
Recall, though, that the continuity equation in climate science is not so simple. The ocean evaporates. Rain falls. Ice melts. Water itself also transports itself nontrivially around the globe according to a separate, coupled NS equation with its own substantial complexity. Not only does this mean mass transport is difficult to enforce as a constraint, it means that one has to account for enormous, nonlinear variations in cell transport dynamics according to the state of a substantial fraction of the mass in any given cell. Where by “substantial” I don’t mean that it is ever a particularly large fraction — most of the dry atmosphere is nitrogen and oxygen and argon — but water averages 0.25% of the atmosphere and locally can be as much as 5%!
This is not negligible in any sense of the word when integrating a long, long time series!
So just as was the case when considering energy, one has to consider mass transport across cell boundaries and the forces that drive this transport, where one is not tracking parcels of mass as they move around and interact with other parcels of mass, but rather tracking what enters and leaves fixed volume, fixed location cells. One is better off because one only has to worry about nearest neighbor cells. One is far worse off in that one has to worry not only about dry air, but about the fact that in any given timestep, an entirely non-negligible fraction of the fluid mass in a cell can “appear” or “disappear” as water in the cell changes state, and worse, does so in perfect consonance with the appearance and disappearance of energy in the cell as measured by things like the “temperature” of the atmosphere in the cell.
Maintaining normalization in circumstances like this in a purely numerical computation is enormously difficult. One could in principle do it by integrating the total mass of the system in each timestep and using the result to renormalize it to a constant value, but this is safe to do only if the system is sufficiently detailed that it can be considered closed. That is, the solution has to track in detail the water in inland lakes, the water locked up as ice and snow, the water that evaporates from the surface of the ocean, the total water content of the ocean (cell by cell, all the way to whatever layer you want to consider an “unchanging boundary”. Otherwise errors in your treatment of water as a contribution of total cell mass will bleed over into errors in the total dry atmospheric mass, and the system will drift slowly away into the nonphysical regime as the integration proceeds.
Finally, one has the same issues one had with energy and granularity, only worse. Considerably worse on a lat/long grid on a sphere. At the poles, one can literally step from one cell to the next — in fact at the north pole itself one can put one’s foot down and have it be in dozens of cells at once. Dynamics based on approximately rectilinear cells at the equator, where cells are hundreds of kilometers across and one might be forgiven for neglecting non-nearest neighbor cell coupling are totally wrong at the poles where a fire in one call can heat somebody’s hands when they are standing four cells away. Mass transport dynamics is also skewed — a tiny storm that would be literally invisible at the equator in the middle of a cell might span many cells at the poles, just as “Antarctica” stretches all the way across a rectangular map with linear latitude and longitude, apparently contributing a 12th or so of the total area of the globe in spite of it being only a modest sized continent that is far less than 1/12 of the land area only, where land area is only 30% of the globe in the first place. Siberia, Canada, Greenland are all similarly distorted into appearing comparatively huge. One can of course compensate — in a sense — for this distortion by multiplying by a suitable trig factor in the integrals (the Jacobean) but this doesn’t correct the dynamical algorithms themselves!
This I do have direct experience with. In my band theory problem, I had to perform projective integrals over the surfaces of spheres. Ordinarily, a 2D integral with controllable error would be simple — just use two 1D adaptive quadratures, or without too much effort, write a 2D rectilinear adaptive quadrature routine to use directly. But on a sphere, using a gridding of the spherical polar angles
Finally, note well my use of the word adaptive. Even when solving simple problems with ordinary quadrature (let alone trying to solve a nonlinear, chaotic, partial differential equation that cannot even be proven to have general solutions) one cannot just say “hey, I’m going to use a fixed grid/step size of x, I’m sure that will be all right”. Errors grow at a rate that directly depends on x. Whether or not the error growth rate for any given problem can be neglected can only rarely be known a priori, and in this problem any such assertion of a priori knowledge would truly be absurd. That is why even ordinary, boring numerical integration routines with controllable error specification do things like:
* Pick a grid size. Do the integral.
* Divide the grid size by some number, say two. Do the integral again, comparing the answers. (Some methods will do the integral a third time, or will avoid factors of two as being too likely to produce a spurious/accidentally accepted result that is still badly wrong.)
* If the two answers agree within the requested tolerance, accept the second (probably more accurate) one.
* If not, throw away the first answer, replace the first by the second, divide the grid size by two again, and repeat until the two answers do agree within the accepted tolerance.
Again, there are more subtle/efficient variants of this — sometimes adapting only over part of the range where the function itself is rapidly varying (e.g. applying the sort of process observed above directly to the subdivisions until they separately converge). All adaptive quadrature routines can, however, be fooled by just the right function into giving precisely the wrong answer, for example a harmonic function with zero integral will give a nonzero result of the initial gridding is some large, even integer multiple of the period as even 2 or three divisions by 2 will of course give you the same nonzero value and the routine will converge without discovering the short period variation.
Solving differential equations has exactly this problem, only — you guessed it — worse. The accurate knowledge of the integral to be done for each step depends on the accuracy of the integral done in the step before. Or, in many methods, the steps before. Even if the error in that step was well within a very small tolerance, integrating over many steps can — drunkard’s walk fashion — cause the cumulated error to grow, even grow rapidly, outside of the requested tolerance for the ODE solution. If there is any sort of bias in the cumulated error, it can grow much faster than the square root of the number of steps, and even if the differential equations themselves have intrinsic analytic conservation laws built in, the numerical solution will not.
Certain differential systems can still be fairly reliably integrated over quite long time periods with controllable errors by a good, adaptive code. These systems are called (generically) “non-stiff” systems, because they have an internal stability such that the solutions one jumps around between due to small uncontrollable errors in the integration tend to move together so that even as you drift away you drift away slowly, and can usually make the step size small enough to make that drift “slow enough” to achieve a given probable tolerance or absolute error requirement.
Others — yes, the ones that are called “stiff” — cannot. These are systems where neighboring trajectories rapidly (usually exponentially or faster) diverge from one another, even when started with very small perturbations in their initial conditions. In these systems, simply using different integration routines from precisely the same initial condition, or changing a single least-significant digit in the initialization will, over time, lead to completely different solutions.
Guess which kind of system the climate is. Not just the climate, but even comparatively simple systems described by the Navier-Stokes equation. One doesn’t even usually describe such systems as being merely stiff, as the methods that will work adequately to integrate stiff systems with a simple exponential divergence will generally not work for them. We call these systems chaotic, and deterministic chaos was discovered in the context of weather prediction. Not only do neighboring solutions diverge, they diverge in ways described by a set of Lyapunov exponents:
http://en.wikipedia.org/wiki/Lyapunov_exponent
Note well that the Maximal Lyapunov Exponent (MLE) is considered to be a direct measure of the predictability of any given chaotic system (where the “phase space compactness” requirement mentioned in the first paragraph is precisely the requirement that e.g. mass-energy be conserved by the dynamics (allowing for the ins and outs of energy in the energy-open system). The differential equations of quantum eigensolutions aren’t chaotic as they diverge “badly” and produce non-normalizable solutions (violating the axioms of quantum theory, which is why only eigensolutions that are normalizable are allowed), they are merely stiff. I’m not certain, but I’m guessing the the MLE for climate dynamics is such that system stability extends only out to pretty much the limits of weather prediction, decades away from any sort of ability to predict climate.
Without an adaptive solution, one literally cannot validate any given solution to the system for a given, a priori determined spatiotemporal gridding. One cannot even say if the solution one obtains is like the actual solution. All one can do is solve the differential system lots of times and hope that the result is e.g. normally distributed with respect to the actual solution, or that the actual solution has some reasonable probability of being “like” one of the solutions obtained. One cannot even estimate that probability, because one cannot verify that the distribution of solutions obtained is stationary as one further subdivides the gridding or improves or merely alters the algorithm used to solve the differential system.
The really sad thing is that we know that there are numerous small scale weather phenomena that easily fit inside of an equatorial cell in any of the current gridding schemes and that we know will have a large, local effect on the cell’s dynamics. For example, thunderstorms. Tornadoes. Mere rainfall. Winds. The weather system is not homogeneous on a scale of 3 degree lat/long blocks.
What this in turn means is that we know that the cell dynamics are fundamentally wrong. If we put a thunderstorm in a cell, it is too big that has one, it is too big. If we don’t put a thunderstorm into a cell that has one, we miss a rapidly varying mass fraction, latent heat exchange, variation of albedo, transport of bulk matter all over the place vertically and horizontally carrying variations in energy density with it. There isn’t the slightest reason to believe that dynamics carried out with thunderstorms that are always a hundred kilometers across or more will in any way have a long term integral that matches the integral of a system with thunderstorms that can be as small as one kilometer across (not a crazy estimate for the lateral size of a summer thunderhead), or that either extreme of assigning thunderstormness plus some interpolatory scheme for “mean effect of a cell thunderstorm” will integrate out to the right result either.
So here’s the conclusion of the rather long article above. In my opinion — which one is obviously free to reject or criticize as you see fit — using a lat/long grid in climate science, as appears to be pretty much universally done, is a critical mistake, one that is preventing a proper, rescalable, dynamically adaptive climate model from being built. There are unbiased, rescalable tessellations of the sphere — triangular ones, or my personal favorite/suggestion, the icosahedral tessellation. There are probably tessellations still undiscovered that can even be rescaled N-fold for some N and still preserve projective cell boundaries (some variation of a triangular tesselation, for example). These tessellations do not treat the poles any different from the equator, and one can (sigh) still use lat/long coordinates to locate the centers, corners and sides of the tessera. Yes, it is a pain in the ass to write a stable, rescalable quadrature routine over the tessera, but one only has to do it once, and that’s the thing federal grant money should be used for — to fund eminently practical applied computationa mathematics to facilitate the accurate, rescalable solution to many problems that involve quadrature on hyperspherical surfaces (which is a nontrivial problem, as I’ve worked on it and written (well, stolen and adapted) an algorithm/routine for it myself. It happens all the time in physics not just NS equations on the globe in climate science.
Given a solid, trivially rescalable grid, many questions concerning the climate models could directly be addressed, at some considerable expense in computer time. For example, the routine could simply be asked to adaptively rescale until the model converged to some fairly demanding tolerance over as long a time series as possible, and then the features it produces could be compared to real weather features to see if it is getting the dynamics right with the many per-cell approximations being made. Many of those approximations can probably be eliminated, as they exist only because cells right now are absurdly large compared to nearly all known local weather features and only manage large scale, broad transport processes while accumulating errors with an unknown bias in each and every cell due to the approximation of everything else. The MLE of the models could be computed, and used to determine the probable predictivity of the model on various time scales. The dynamically adaptive distributions of final trajectories could be computed and compared to see if even this is converging. And finally, one wouldn’t ever again have to completely rewrite a climate model to make it higher resolution. One would simply have to alter a single parameter in the program input to set the scale size of the cell, and a single parameter to set the scale size of the time step, with a third parameter used to control whether or not to let the program itself determine if these initial settings are adequate or need to be globally or locally subdivided to resolve key dynamics.
I’m guessing that predictivity will still suck, because hey, the climate is chaotic and highly nonlinear. But at least such a program might be able to answer metaquestions like “just how chaotic and nonlinear is that, anyway, when one can freely increase resolution or run the model to some sort of adaptive convergence”. Even if solving the model to some reasonable tolerance proved to be impossibly expensive — as I strongly suspect is the case — we would actually know this and would know not to take climate models claiming to predict fifty years out seriously. Hey, there are problems Man was Not Meant to Solve (so far), like building a starship within the bounds of the current knowledge of the laws of physics, solving NP complete problems in P time (oh, wait, that could actually be what this problem is), building a direct recursion relation capable of systematically sieving out out all of the primes, generating a truly random number using an algorithm, and who knows, maybe long term climate modelling.
rgb
As Robin put it, “They [GCMs] justify government action to remake social rules without any kind of vote, notice, or citizen consent. It makes us the governed in a despot’s dream utopia that will not end well.”
Sadly, that, boys and girls, is the really important take-away. The back-and-forth about science is a Punch and Judy show distraction, like the games politicians play. We tend to believe they are real, important, meaningful. They are not; they are only shadows we are watching. Real world reality is taking place behind us, where we aren’t looking. …..Lady in Red
Again. it goes to show what a colossal waste of time, energy, money and manpower the whole CAGW scam has been – and continues to be.
The climate system is chaotic. Only a complete imbecile would try to model it. Surely?
Nick Stokes says:
May 7, 2014 at 8:04 am
OK. You can derive the acoustic wave equation this way, but this really has nothing to do with “dynamic pressure” directly. Please be more careful with your wording in the future.
As for the Courant number restriction, it depends on your wave speeds. If your equations exclude/filter sound waves, then the convective velocity becomes the characteristic velocity for stability (Courant # = V*dt/dx <= 1). However, stability for non-linear systems is never guaranteed, and particularly for COUPLED non-linear systems. Which is why I commented above that the whole stability issue goes way beyond a simplistic Von Neumann stability analysis.
Man Bearpig: You need NO engineers, just a sh*t load of mechanics.
Stephen Rasey: “You make it sound that if you are not some post-doc octopus, you are not worthy to make comments on the GCM code. Quite the contrary, only a post-doc octopus may be capable of writing such a model, but normal one-fisted experts ought to be able to point out flaws in any part of the process.”
I heartily agree. If Geordi Laforge tells me that because the Enterprise has 27 flux capacitors in its cargo deck and 33 flux capacitors in its WT shack there are no more than 50 flux capacitors total on the starship, I am entitled to question his conclusion even though I’m not a warp-drive engineer and in fact wouldn’t know a flux capacitor from a toaster.
But Dr. Brown’s main point is well taken: the system is so arranged that almost no one who doesn’t have a vested interest in perpetuating the system has the wherewithal to inventory the cargo deck and WT shack and thereby scrutinize raw data the high priesthood doesn’t deign to divulge.
Too many mistakes in this post to correct
If you want to build a GCM. use this one or get somebody who is competent to help you.
http://mitgcm.org
there is a support list and plenty of people to help you.
resolution? play with this:
http://oceans.mit.edu/featured-stories/mitgcm
Interesting approach to gridding
http://mitgcm.org/projects/cubedsphere/
REPLY: So Mr. Mosher, please show us the climate model that YOU designed.
I thought so. – Anthony
Dr Brown & Others,
Do we know how much of this FORTRAN code (that makes up the models) that is devoted to unit-tests? From a software quality perspective, there ought to be substantial amounts of unit-tests for a code base of, say, a million lines of code. Also, out of curiosity, where can one
download these code bases?
-Thorsten
Um, Nick, explain this then: http://en.wikipedia.org/wiki/Blast_wave. Are you really going to tell me that a pressure wave cannot be propagated faster than a sound wave? What do you think lightning does in a thunderstorm then? Can a numerical weather model do thunderstorms without tricks?
In England the guy who fixes something is called an engineer.
The underlying question behind the problem is “how long are we willing for a parking meter to be out of service and what percent of the time are we willing for that to happen.” It’s very similar to the problem of “how many telephone lines do we need between city A and city B?” The parking meter problem is complicated by the fact that we can’t just use the average driving time.
It is very easy to come up with a “simple reality check” and that often works … as long as you’re willing to be out by an order of magnitude in your calculations.
The whole point of Dr. Robert G. Brown’s post is that “it’s complicated folks”. GCMs have been over-sold. The pathetic thing is that the ‘folks in charge’ should know better. Chaos theory is a result of climate modelling. Judith Curry has a wonderful post based on the opinion of Edward Lorenz, climate modeller and the father of chaos theory. Using different reasoning, he corroborates Dr. Brown.
The really pathetic thing here is that Kevin E. Trenberth was a doctoral student of Lorenz. He, of all people, should know better. The problem is so wicked, evil, and complicated that nobody should pretend to have any confidence in GCMs.
@Steven Ramey, unless it has changed from my student days, Type I errors could also be called false positives or Type A errors. Type II errors could also be called false negatives or Type B errors.
“have several gigabytes worth of code in my personal subversion tree”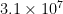 seconds/year and typing a letter (byte) of code per second I would have to write code for 31 years to write a single gigabyte, and I’m not quite 2×31 years old.
seconds/year and typing a letter (byte) of code per second I would have to write code for 31 years to write a single gigabyte, and I’m not quite 2×31 years old.
I hope it’s not several gigabytes of your code only or else you are a really bad programmer (which often is the case since everybody who’s taken some kind of university course consider themselves fit for computer programmning).
Rest assured, my man. Even though I type like the wind itself and really do write a lot of code, there are only
I, like any sane programmer, liberally steal other people’s (open source, legal) code and at every opportunity clone my own code rather than retype it. Also, not all of that is (honestly) code, but the ephemera of code — makefiles, comments, documentation, probably in some cases leftover object files. Then again, subversion saves differences and isn’t linearly efficient — the size of a program in subversion includes the sizes of all of the diff-able variations of the code I’ve checked in as well as the size of the code tree itself.
Still, I really do have a shit-pile of code that I have written myself all the way back to entire boxes of fortran on punch cards to do e.g. the complete resolution of angular momentum coupling of nuclear targets and incident particles in nuclear scattering theory back in 1977-1978, where I had to write my OWN code to generate 3j, 6j, 9j symbols as well as a huge pile of nested loops summing over angular momentum indices and phases. And I never throw anything away — that’s why God created version control systems as a means of versioned archival storage, to permit the reuse and resurrection of old code.
I still regret the code I’ve lost. For example, back in the early 80s I wrote a Mastermind emulator in APL on an IBM 5100. For a couple of decades, I had the QIC tape with the program on it in my office, but the 5100 was a brief flash in the pan and — although I think I’ve rewritten Mastermind three times so far, in APL, in BASICA for the IBM PC, and in C for the IBM PC — I could never get the code off of the tape and so it is lost in the mists of the past (ditto, actually, the BASICA and C versions, sigh).
rgb
Yes I see.
<>
Robert Brown:
Thank you for this most instructive follow-up, from which I’ve learned in far more detail what is meant by adaptive convergence. And if I may myself go back and diverge slightly …
Yep, formation of our moon through a major planetary collision would I guess play havoc with the conservation assumptions here. And that reminds me of another mind-bending piece this week – by Matt Ridley in The Times two days ago:
That’s paywall protected so I guess I shouldn’t quote more. But well worth a read, if one gets the chance, and a reflection how much our moon has made possible the miracle of climate allowing the evolution of intelligent life. Gaia couldn’t go the distance but Goldilocks has.
Nope. That’s too hard.
There are some very clever people here.
Missing link:
Judith Curry’s post on Lorenz is here:
link
Here is the link as a url: http://judithcurry.com/2013/10/13/words-of-wisdom-from-ed-lorenz/ (just in case)
Dr. Brown is too modest. In addition to the “climatist qualifications” boxes he justifiably checks off, he is a superb writer and presumably can check other relevant boxes regarding team-building and project management. Most of all, he has the perspective to see things as they are and the courage to speak about them.
The spectrum of large-scale science projects, as many of us know too well, can range from “unacceptable nonsense” at one end, through “acceptable nonsense”, “plausibly insightful”, all the way to the other end of the spectrum where we may find “robust, repeatable , tested body of knowledge”. Dr. Brown convincingly positions climate models, and by inference much of the other “global warming” work, clearly at the “unacceptable nonsense” end of the spectrum. Not even the redoubtable Dr. Stokes can nick or pick apart much of Dr. Brown’s narrative (though some may be amused by his attempts.)
What the public relations geniuses have managed to do over the past thirty years is to reposition climate science, in the minds of the public and the press, from the unacceptable side of the spectrum to the robust side. Meanwhile the science itself has made no such journey and is arguably not far along the road.
One can understand how awkward this is for honest scientists. As Dr. Brown points out, only a very small number of individuals actually can grasp the full structure and disciplines involved in building these climate models. But, just as one needn’t be a playwright in order to be a competent drama critic, it isn’t necessary to be able to check all the quantum physics, statistics, thermodynamics and other boxes in order to have a pretty good idea of what is actually going on. Are there really so many senior scientific professionals unwilling to spill the beans and admit to the wobbly underpinnings of their “climate science”?
@ur momisugly Stephen Ramey, please excuse my misspelling your name. Sorry. Mea culpa, mea maxima culpa.
I feel sure that if co2 caused any additional warming then Chilbolton facilities would be able to show the definitive proof.
http://www.stfc.ac.uk/Chilbolton/facilities/24807.aspx
Here is what they have to say about climate models
“Formation of precipitation in boundary-layer clouds is critical to understanding their microphysical and dynamical evolution, and the impact such clouds have on the earth’s radiation balance
and hydrological cycle. Climate models have so far been unable to realistically simulate this “warm-rain” process”
http://www.nerc.ac.uk/research/sites/facilities/list/ar_cfarr.pdf
ah i should add the end of the piece,
……..Applying the new scheme based on the CFARR
data dramatically improved the agreement with observations in these regions, solving a long-standing model error.
“Given a solid, trivially rescalable grid, many questions concerning the climate models could directly be addressed, at some considerable expense in computer time. For example, the routine could simply be asked to adaptively rescale until the model converged to some fairly demanding tolerance over as long a time series as possible, and then the features it produces could be compared to real weather features to see if it is getting the dynamics right with the many per-cell approximations being made.”
Nailed it. Comparison between models and “real weather features” is the heart and soul of working with models. It rests on knowledge that is inherently practical and empirical. Imagination is required. Please note that it is not possible to do this kind of work until an organization has one or more “experts” who can provide his/her practical and empirical knowledge and who can make judgments about the future that will be severely criticized. Models cannot substitute for empirical science that does not exist.
Brent Walker says: May 7, 2014 at 4:01 am “I started programming almost 50 years ago initially using plug board machines…”
IBM 407 accounting machine. What a beast (over a ton if I remember right).
First I learned to program it and then I became a repairman of such things and I am still amazed by its engineeering. Too bad Charles Babbage didn’t live to see it.
It had hundreds of timing cams and thousands of wire-contact relays and if I remember right a 3/4 horsepower induction motor to drive it. The master timing wheel was calibrated to 1/4 of a degree and so were most of its hundreds of cams.
Weather forecasting was a big consumer of early computers. I am amazed that anyone can forecast the weather 3 days from now with about 50 percent confidence.
I’m watching the Chris Essex video above now, and it is interesting to see that (so far) we are saying exactly the same things. I mean, it’s scary. One by one, he is laying out the points I made the the post just above on the grid. Except (so far) the tessellation problem. I’m waiting for it.
I do have to say, though, that he is much funnier.
I strongly urge people who have a hard time understanding what I’m saying about the numerical complexity of the problem and the absurdity of the claims of predictivity to watch this video, especially Nick Stokes (who I am perfectly happy to agree with, but not today). Or rather, perhaps I DO agree with him today. Yes, GCMs are basically weather prediction programs repurposed to climate prediction, based on fake physics (Chris Essex’s words, but I don’t disagree) that works well enough to predict weather some moderately short distance out and implemented on an absurd grid that arose because some graduate student in the extremely remote past had never heard of tessellation but had heard of spherical polar coordinates or latitude and longitude and use them as “rectangular” grid coordinates in the very first implementation of a weather prediction problem. Everything since then is mere code inheritance. As Chris (and I) point out, however, that gives us absolutely no good reason to believe that they will work for long term climate prediction in a nonlinear complex system whose climate dynamics is known to be strongly governed by what amount to structured, self-organized, named, macroscopic enormously nonlinear quasi-particle dynamics. ENSO. The PDO. Hadley cells. THE NAO. Monsoon. We don’t even really know the sign of the changes in macroscopic climate descriptors likely to be consequential on an increase in atmospheric CO_2 forcing. All we have is fond hopes, belief that the fake physics on an absurd grid at a ludicrous resolution will integrate 50 years into the future in some meaningful way, a hope that the climate models themselves do not support as one examines the full envelope of their integrated solutions.
rgb
John Whitman says:
May 7, 2014 at 7:37 am
I see no other position they can take except they warmed the models for the precautionary principle. They aren’t doing science.
The question is, is what they did lying?
————————————————-
I’m all for the precautionary principle. Can we please defund them before they destroy the economy that our children and our grandchildren will inherit?