Note: This is a repost from Dr. Roy Spencer’s blog entry last Friday. I’ve done so because it needs the wide distribution that WUWT can offer. The one graph he has produced (see below) says it all. I suggest readers use their social media tools to share this far and wide. – Anthony
by Roy W. Spencer, Ph. D.
I’m seeing a lot of wrangling over the recent (15+ year) pause in global average warming…when did it start, is it a full pause, shouldn’t we be taking the longer view, etc.
These are all interesting exercises, but they miss the most important point: the climate models that governments base policy decisions on have failed miserably.
I’ve updated our comparison of 90 climate models versus observations for global average surface temperatures through 2013, and we still see that >95% of the models have over-forecast the warming trend since 1979, whether we use their own surface temperature dataset (HadCRUT4), or our satellite dataset of lower tropospheric temperatures (UAH):

Whether humans are the cause of 100% of the observed warming or not, the conclusion is that global warming isn’t as bad as was predicted. That should have major policy implications…assuming policy is still informed by facts more than emotions and political aspirations.
And if humans are the cause of only, say, 50% of the warming (e.g. our published paper), then there is even less reason to force expensive and prosperity-destroying energy policies down our throats.
I am growing weary of the variety of emotional, misleading, and policy-useless statements like “most warming since the 1950s is human caused” or “97% of climate scientists agree humans are contributing to warming”, neither of which leads to the conclusion we need to substantially increase energy prices and freeze and starve more poor people to death for the greater good.
Yet, that is the direction we are heading.
And even if the extra energy is being stored in the deep ocean (if you have faith in long-term measured warming trends of thousandths or hundredths of a degree), I say “great!”. Because that extra heat is in the form of a tiny temperature change spread throughout an unimaginably large heat sink, which can never have an appreciable effect on future surface climate.
If the deep ocean ends up averaging 4.1 deg. C, rather than 4.0 deg. C, it won’t really matter.
richardscourtney says:
February 10, 2014 at 12:30 pm
Friends:
“It seems sensible to copy two posts from the thread discussing the superb article by Roger A. Pielke Sr. It is here.
The first post I here quote was from Roger A. Pielke Sr. in reply to me and says
——————
Roger A. Pielke Sr. says:
February 8, 2014 at 2:40 pm
Hi Richard
Thank you for your follow up. We are in complete agreement, as you wrote, that
Hence, the models are excellent heuristic tools. And they should be used as such.”
The differences between hypotheses and heuristic tools is of great importance. Darwin’s claim that similarity of morphology indicates a common ancestor had to be down graded from a scientific truth to a heuristic tool. Because the vast majority of scientists are common sense realists, the distinction is doubly important. Computer models can serve as heuristic tools only.
Steven Mosher says:
February 10, 2014 at 1:01 pm
Totally agree with everything you wrote. But having written it, you cannot say that science supports your decision as policy maker. So, would you please inform the policy makers of your reasoning.
NotTheAussiePhilM:
Thankyou for telling us at February 10, 2014 at 1:07 pm
It is good to be informed that we are in the presence of a genius because, otherwise, some of us may not have noticed.
Thankyou for the information.
Richard
PLEASE QUIT implicitly validating their data sets as anything but trash!
The models are wrong DESPITE the fact that a false warming trend has been added onto the raw data via invalid adjustments and homogenizations. Even with this head start, they are wrong. There is hardly a thing right, in fact, in this field called “climate science.”
Please quit throwing them a bone by saying things like “And if humans are the cause of only, say, 50% of the warming …” They have tortured the data beyond use. We should start all over with the raw data, or with better experiments.
I have a book called `Oceans` at home, written in the 70`s, as the closing piece it wistfully talks of the future, where consideration is now being given to sink nuclear thermal power plants into the deep oceans to warm them from their inhospitable cold, to promote and sustain living organsims.
how times change
I also believe this is in essence, a Ponzi scheme meant to put into power and enrich a group of elite rich hippies who remembered their days of eating top ramen noodles, being dismissed by the media, and driving barely legal rickety vans, and who think themselves benevolent. When these hippies grew up and got jobs and owned/led major businesses and corporations, they suddenly became a not insignificant source of campaign cash that many politicians on both sides drooled after. So they were allowed to hold sway on who to tax next and who should win contracts built on subsidies and who got research grants. We get what we pay for. So in every country vote out any who did not fight tooth and toenail against this greed-without-work, anti-freedom mindset.
Larry Ledwick: ‘A quick calibrated eyeball evaluation of that mess of spaghetti seems to me that only about 5 or 6 are even in the running for reasonable approximations of reality’.
No, we need an integral judgement. If you take a multiple choice exam and you answer 95% of the items incorrectly, what would you achieve with the five percent you answered correctly? The judgement is that you failed miserably, like Spencer concluded, and the five percent is only correct by chance. The climate scientists are in the mourning phase of negotiating about a few correct models, missing heat hiding in the deep ocean, and a temperature development which is only a pause, as their hoped future will show. They may get some help from family and friends but this is not our task.
richardscourtney! LMAO!
While somewhat off-topic, it is also indicative:
Prior to the SuperBowl on 02 February 2014, I read that some wags used the “Madden NFL” game to run a series of simulations (ensemble, anyone?) to ‘predict’ the winner of SuperBowl 48.
Dozens of simulations, and the “consensus” of the simulations was Denver, most often by 3 or 3.5 points (yes, I know, there is no ‘half-point’ in football). I checked the odds just before kickoff, and sure enough, the odds-makers had Denver winning by at least three points.
Highly instructive. One cannot “model” a stochastic system (unless a plethora of assumptions are made … … … )
Obviously, things were going just great in the 80’s and 90’s as they got the global temperature right…………for the wrong reasons.
One issue with climate models. The testing period to validate or invalidate it takes years but what is inexcusable, relates to the fact that climate scientists and model builders were convinced they had it right from the beginning.
So right, that when it become obvious the models had it wrong/were too warm, rather than make appropriate adjustments to the sensitivity and feedback equations, they instead came up with creative explanations to justify why the models really are right…………..but something else that was unexpected is temporarily interfering.
This strategy might have worked quite effectively if it was a laboratory experiment and time expired for the testing period several years ago. However, time continues to elapse here in the real world and time continues to harshly judge the increasing disparity between observations and models.
The modelers, climate scientists and politicians can’t shut down the experiment with statements like “the science is settled” or “the debate is over” because they can’t stop time from ticking on and with time, comes fresh empirical data.
This data is the only way to judge all theories and science to see if they can stand up to the test.
Global climate models appear to be a catastrophic failure and those justifying them as evidence to make critical decisions regarding governmental policies only look more more foolish and dishonest with time.
I’ve been hammering exactly the same point on two of yesterday’s and the day before’s threads. Roy’s figure doesn’t do it justice. If one compares to figure 9.8a of the IPCC AR5, one notes that the leftmost part of his graph includes part of the training data, the “reference period” from 1961 to 1990 used to initialize and pretend to validate the CMIP5 models. That is, the models and HADCRUT4 are virtually constrained to come together in 1990, not the starting point in Roy’s graph (which looks like a redrawn variation of AR5’s infamous figure 1.4 from the SPM.
I’ve been reading over chapter 9 of AR5 in some detail, as it deals with the statistical basis for claims of validation and accuracy of model predictions. It is interesting to note that in sections 9.2.2.2 and 9.2.2.3, AR5 openly acknowledges that the Multimodel Ensemble (MME) mean is, well, dubious at best, utterly meaningless at worst. To quote (again) from section 9.2.2.3:
…collections such as the CMIP5 MME cannot be considered a random sample of independent models. This complexity creates challenges for how best to make quantitative inferences of future climate…
To put it bluntly, it doesn’t “create challenges”. The correct statement is that there is no possible basis in the theory of statistical analysis for assigning a meaning to the MME mean! Specific problems that they mention in section 9.2.2 with this mean include:
a) The models in this “ensemble” (it isn’t an ensemble in any sense that is meaningful in statistics, so we must presume that they really intended the term “collection” or “group”) are not independent. This means that even if the model results were in some defensible sense samples drawn from a statistical distribution “of models” the variance and mean cannot be quantitatively analyzed using e.g. the central limit theorem and the error function. Any assignment of “confidence” on the basis of MME mean results is pure voodoo with no defensible basis in statistics.
b) The models in this ensemble do not all contribute the same number of “perturbed parameter” runs from the per model perturbed parameter ensemble (PPE) of outcomes when tiny changes are made to initial conditions and model parameters. These results do constitute a defensible statistical sampling of outcomes — for that one model, per model — to the extent that a valid statistical method for doing a Monte Carlo sampling of the phase space of possible initial conditions is used. The PPE simultaneously tells one how robust the model results are and what the statistical spread of results around the PPE mean is, which in turn can be used in an ordinary hypothesis test to gauge the probability of observing the actual climate given the null hypothesis “this is a perfect model”. Still, when one model only generates 10 PPE runs and another generates 160 and the two PPE means are given equal weight in the meaningless MME super-mean, this is simply a statistical absurdity. One is expected to have 4 times the variance of the other and even the crudest of chi-square methodology would discount the lesser model’s statistical relevance in the final number.
c) Finally, 2.2.3 openly acknowledges that mere model performance is ignored in the construction of the MME mean. That is, the IPCC is perfectly happy to average in obviously failed models that are run far too hot as long as it keeps the MME mean equally high, even though I literally cannot imagine any sort of statistical analysis were such a practice could be justifiable.
This decision is not arbitrary. One has (or should have) direct access to the PPE data, and can directly compare per model the degree to which the actual predictions of the model with perturbed parameters overlaps the observed temperature and interpret this as the probability of the natural occurrence of the observed temperatures if the model were a perfect model and all variation is due to imperfect specification of model parameters and initial conditions. That is, one can perform a perfectly classic hypothesis test using the PPE data, per model to clearly reject failed models (p-values less than 0.05, to call into question model with low p-values (given an “ensemble” of model results, Bonferroni corrections mean that rejection should occur for substantially higher p-values given all of the chances to get an acceptable one and the known/expected overlap in the various model lineages), and to include at most the models that have a reasonable p-value in any sort of collective analysis.
These are the errors they acknowledge. Ones they make no mention of include the fact that all of the models are effectively validated against the reference period, and that the MME mean utterly fails to describe the entire thermal history of the last 155 years in HADCRUT4 as it stands!
This is perfectly obvious from a glance at figure 9.8a in AR5. The black line (actual HADCRUT4 measured/computed surface temperature) lies above the red line MME mean) a grand total of perhaps 25 years out of 155, including the training set! If one just estimates the p-value for this assuming a roughly 5 year autocorrelation time and random discursion in both cases from some sort of shared mean behavior with equal probability of being too high or two low, the p-value for the overall curve is order of 0.0001 or less. Less because there are two clearly visible stretches — from 1900 to 1940 and from 2000 to the present — where the MME mean is always greater than the actual temperature.
The stretch from 1900 to 1940 is especially damning, since in the 20th century the warming visible in HADCRUT4 in 1900 through 1950 exactly matches the warming observed from 1950 through 2000, so much so that only experts sufficiently familiar with HADCRUT4 to be able to pick up specific features such as the 1997-1998 Super ENSO spike at the right of the latter record would ever be able to differentiate them. The MME mean completely smooths over this entire 50 year stretch, effectively demonstrating that it is incapable of correctly describing the actual natural, non-forced warming that occurred over this period!
Even before one looks at the CMIP5 models one at a time, and fails to validate most of them one at a time for a variety of reasons (not just failure to get the global mean surface temperature anywhere near correct, but for failure to get weather patterns, rainfall, drought, tropospheric warming, temperature autocorrelation and variance, and much more right as well) nobody could possibly look at 9.8a in AR5 and then assert a prediction, projection, or prophecy of future climate state of the Earth based on the MME mean with any confidence at all!
If one eliminates the obviously failed models from CMIP5 from playing any role whatsoever in forecasting future warming (because there is no defensible basis for using failed models to make forecasts, is there?), if one takes the not-failed yet models and weights their contribution to mean and variance of the collective model average on the surviving residual models, if one accounts for the fact that the surviving models are all clearly still consistently biased on the warm side and underestimate the role of natural variability when hindcasting the bulk of the 20th century outside of the training/reference interval, there would be little need to add a Box 9.2 to AR5 — basically a set of apologia for “the hiatus”, what they are calling “the pause” because ordinary people know what a pause is but are a bit fuzzy on the meaning of hiatus and neither one is particularly honest as an explicit description of “a period of zero temperature increase from 1997 to the present”.
Although the remaining models would still very likely be wrong, the observed temperature trend wouldn’t be too unlikely given the models and hence it cannot yet be said that the models are probably wrong.
And I promise, the adjusted for statistical sanity CMIP5 MME mean, extrapolated, would drop climate sensitivity by 2100 like a rock, to well under 2 C and possibly to as low as 1 C.
Where is the honesty in all of this? Is not the entire point to educate the poor policy makers in the limits in the statistical confidence of model projections? How can one possibly publish chapter 9, openly acknowledge in one single numbered paragraph that the MME mean is a meaningless quantity that nobody knows how to transform into confidence intervals because it is known to be corrupted by multiple errors that they do not bother to try to accommodate, and then make all sorts of bold statements of high confidence in the SPM?
High confidence based on what, exactly? Somebody’s “expert opinion”? A bogus average of failed models that artificially raise climate sensitivity by as much as 2 C over any sort of sane bound consistent with their own observational data? Or the political needs of the moment, which most definitely do not include acknowledging that they’ve been instrumental in the most colossal scientific blunder in recorded history, one that cost enough money to have ended world poverty three times over, to have treated billions of the world’s poorest people for easily preventable diseases, to have built a system of universal education — I mean, what can one do with a few trillion dollars and the peacetime energies of an entire global civilization, when CAGW is no longer a serious concern?
We may, possibly, soon find out.
Instead of being so negative about the climate models why not focus your attention on changing the observational record to close the gap? [/sarc]
Steven Mosher says:
February 10, 2014 at 1:01 pm
” …Blog commenters do not get tell policy makers what information assists them. …”
—-l
That seems to be the preise attitude which resulted in the CAGW meme. Perhaps if policy makers paid more attention to blogs, they would be able to make better decisions?
Another post based on faulty “managed” temperature databases…
FTFA:
Where are the bodies of those killed by human-caused climate change again? Where is this “history” we should be learning from?
Inasmuch as lowly “blog commenters” are voters they most certainly get to tell policy makers what the government’s policy should be. Or at least they should, in a democracy.
Jack says:
February 10, 2014 at 12:34 pm
…1978 was chosen as the starting point because it was when the world is going to freeze scare started. Those were among many other faults with the graph. Point is that anyone that believes in the graphs the models produce is being well and truly suckered.
Not at all. The “new ice age” scare began in the late ’60s and early ’70s. Winkless and Browning, for instance, published “Climate and the Affairs of Men” in 1975, which looked for a new ice age of at least the same magnitude as the LIA. Their ability to forecast events proved to be just about as sound as the “team’s”, i.e. not sound at all.
A fairly severe drought in the early to mid-1970s interrupted that kind of thinking in the western US. In fact, in California the state initiated a study of “paleo” rainfall evidence. The study concluded that under the worst cases supported by the available evidence – 200 years of lower than “normal” rain and snowfall in the Sierra – California would not receive enough rainfall to support the population of the time. No number of dams or reservoirs will impound water that does not fall. Similar results continue to be published, e.g.: http://www.academia.edu/3634903/New_Evidence_for_Extreme_and_Persistent_Terminal_Medieval_Drought_in_Californias_Sierra_Nevada
Yep, spot on.
First rule of climate ‘science ‘ when the models and reality differ in value , its reality which is wrong . takes cares of this issue.
Stop thinking science and start thinking religion and you will see how this works in practice.
eyesonu says:
February 10, 2014 at 12:33 pm
To expand further on Larry Ledwick’s comment above. How about attaching the names of the so-called “climate scientists” to their individual model plots with a comparison of the observed data.
———————————————————————
That is a great thought. They could then ‘proudly’ show the quality of their work for all to marvel at.
Let’s say you have 100 mathematical models that purport to determine 2 + 2.
These models produce results that vary from 35 to 45, and when averaged, they average out to about 40.
Then some gaggle of “experts” concludes that 2+2= 40.
Conceptually, this sort of “analysis” is performed by climate “scientists.”
By the way, please tell me, what is it about today’s climate that the planet earth has not experienced over the 250,000 years prior to, say , 1850 (prior to the industrial revolution) ?
Check out the comments of Maurice Strong ; he spilled the beans long ago regarding the true purpose of the AGW / CO2 scam.
95% of climate models agree that they totally missed predicting real temperatures and are unfit for their intended purpose. A large portion of them never even at their lowest projected temperature limit even touch real world measured temperatures. for
for 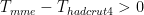 to those of
to those of  for
for  . K-S tests determine whether it is plausible that these two curves could be samples of some sort of the same underlying process. Obviously, if they were the total integral of the two should be close to zero. There are other methods one might use to compare them, but they are all going to give the same general result. No, the CMIP5 MME mean is not a good representation of HADCRUT4.
. K-S tests determine whether it is plausible that these two curves could be samples of some sort of the same underlying process. Obviously, if they were the total integral of the two should be close to zero. There are other methods one might use to compare them, but they are all going to give the same general result. No, the CMIP5 MME mean is not a good representation of HADCRUT4.
Larry, it is worse even than that. In Box 9.2 in AR5, I quote:
However, an analysis of the full suite of CMIP5 historical simulations (augmented for the period 2006–2012 by RCP4.5 simulations, Section 9.3.2) reveals that 111 out of 114 realizations show a GMST trend over 1998–2012 that is higher than the entire HadCRUT4 trend ensemble…
That is, it is 97.4% of CMIP5 simulation and they know it but did not moderate the confidence of their projections or alter their presentation of figure 1.4 in the SPM in any way except to hide this fact from policy makers, who of course are most unlikely to read, or correctly interpret, paragraph 9.2.2.3 or figure 9.8a.
Oh, and the 97.4% is as of 2012 and does not include the last two years of a continued lack of warming. I suspect that we are out there at 99% at this point. As I said, a proper analysis of figure 9.8a already would produce a p-value for the null hypothesis “The MME mean is a meaningful predictive quantity” of practically zero, under no reasonable circumstances higher than 0.01 and IMO (without doing a full, detailed computation) more likely to be around 0.00001 to 0.000001 once one does the integrals for some sort of Kolmogorov-Smirnov test with some reasonable assumption of autocorrelation and unbiased excursion from a correctly represented mean.
Mentally compare the time integrals of
Interestingly, the EMIC simulations (figure 9.8b) in AR5 do much better from 1961 to 2005. They still are not convincing as predictors of the future, however, because across the entire span they run too cool across the critical stretch of 20th century warming from 1920 to 1940 where the temperature change most closely mirrors the reference period. They are certainly a lot more convincing than CMIP5, however, perhaps because some of the EMIC models do actually run cooler than observation even as some run warmer. It would be interesting to compare the systematics of this — from a glance a 9.8b it appears that they manage this magic trick by mixing many models that are far too flat and were too warm in the past that crossover to too cool in the present, with models that were too cool in the past and crossover in the reference period to models that are too warm in the present. All of them are too smooth and fail to reproduce the excursions of the actual thermal record qualitatively or quantatively, have terrible autocorrelation times (they all appear to be heavily smoothed over decadal intervals where the actual climate has substantial variations — zigs and zags up and down — over segments of rough 5 years, suggesting that the EMIC fail to capture the local climate dynamics that hold the climate to a semi-stable centroid while also failing to correctly locate the centroid in almost all cases. I cannot tell from the figure if there exist models between the two crossover extremes that are close to “just right” — not too hot, not too cold — but if there are, obviously they should be given the greatest weight in any future projection of the climate.
rgb
[GMST is Global Mean Surface (or Sea) temperature? Earlier, you used GAST. Mod]
Would someone mind please explaining what the black data line represents?
Mod, sorry, failed to correctly close a boldface tag again. Please help. I didn’t mean to shout/emphasize the entire latter half of the previous comment.
[But at which point? All should be emphasized! 8<) Mod]
EVERY honest observer, with an open mind, will become curious and start looking for mechanisms to explain the unexpected observations. EVERY self-proclaimed climate scientist MUST close his mind and assume that the observations must be wrong. ALL politicians, bureaucrats and their laity who need “climate scientists” for their agendas and their religious dogmas WILL start cherry picking the observations that support their preconceptions and dismissing the observations that challenge their preconceptions. Published and propagandized “Climate Science” as it is today IS scientific fraud and IS the intellectual equivalent of sticking your fingers in your ears and saying: “La la la”.
Phil Jones once admitted in a Climategate email that he wants the world to burn, to vindicate his ego.
http://www.ecowho.com/foia.php?file=1120593115.txt
As you know, I’m not political. If anything, I would like to see the climate change happen, so the science could be proved right, regardless of the consequences. This isn’t being political, it is being selfish.
Prioritising one’s ego above unimaginable pain and suffering on a global scale – draw your own conclusions.