From Molecular Brain, Biomedical Central
Molecular Brain volume 13, Article number: 24 (2020) Cite this article
Abstract
A reproducibility crisis is a situation where many scientific studies cannot be reproduced. Inappropriate practices of science, such as HARKing, p-hacking, and selective reporting of positive results, have been suggested as causes of irreproducibility. In this editorial, I propose that a lack of raw data or data fabrication is another possible cause of irreproducibility.
As an Editor-in-Chief of Molecular Brain, I have handled 180 manuscripts since early 2017 and have made 41 editorial decisions categorized as “Revise before review,” requesting that the authors provide raw data. Surprisingly, among those 41 manuscripts, 21 were withdrawn without providing raw data, indicating that requiring raw data drove away more than half of the manuscripts. I rejected 19 out of the remaining 20 manuscripts because of insufficient raw data. Thus, more than 97% of the 41 manuscripts did not present the raw data supporting their results when requested by an editor, suggesting a possibility that the raw data did not exist from the beginning, at least in some portions of these cases.
Considering that any scientific study should be based on raw data, and that data storage space should no longer be a challenge, journals, in principle, should try to have their authors publicize raw data in a public database or journal site upon the publication of the paper to increase reproducibility of the published results and to increase public trust in science.
Introduction
The reproducibility or replicability crisis is a serious issue in which many scientific studies are difficult to reproduce or replicate. It is reported that, in the field of cancer research, only about 20–25% [1] or 11% [2] of published studies could be validated or reproduced, and that only about 36% were reproduced in the field of psychology [3]. Inappropriate practices of science, such as HARKing (Hypothesizing After the Results are Known) [4], p-hacking [5], selective reporting of positive results and poor research design [6,7,8], have been proposed to be a cause of such irreproducibility. Here, I argue that a lack of raw data is another serious possible cause of irreproducibility, by showing the results of analyses on the manuscripts that I have handled over the last 2 years for Molecular Brain. The analysis shows that many researchers did not provide the raw data, suggesting that raw data may not exist in some cases and that the lack of data may constitute a non-negligible part of the causes of the reproducibility crisis [9]. In this editorial, I argue that making raw data openly available is not only important for reuse and data mining but also for simply confirming that the results presented in the paper are truly based on actual data. With such concept, the data sharing policy of Molecular Brain has been changed and I introduce this update.
Raw data rarely comes out
As Editor-in-Chief of the journal, I have handled 180 manuscripts since early 2017 to September 2019 and have made 41 editorial decisions categorized as ‘Revise before review’, with comments asking the authors to provide raw data (Fig. 1; See Additional file 2: Table S1 for details).
Fig. 1

Flowchart of the manuscripts handled by Tsuyoshi Miyakawa in Molecular Brain from December 2017 to September 2019
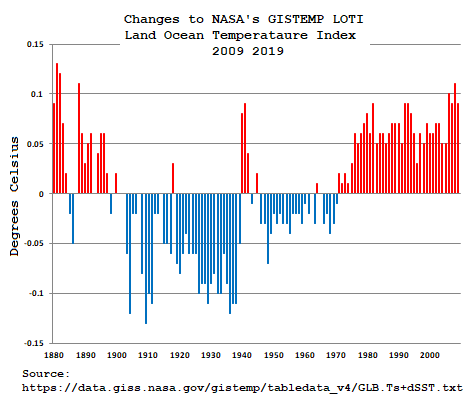
Some climate data gets changed on a regular basis. So, I keep files on sea level and GISTEMP
Tide gauges don’t get changed, but the satellite record does, although Colorado University’s Sea Level Research Group hasn’t published any data for over two years now.
But GISTEMP does regular monthly updates, and data are regularly altered:
Number of Changes to GISSTEMP’s LOTI for 2019:
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
843 370 481 633 1359 566 281 400 674 284 284 341
Number of Changes to GISSTEMP’s LOTI for 2020:
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
319
Over time those changes do make a difference:
and
What has that to do with lying or the intent of the article? Jack whyte.
Ferd III … 11:43 am
What has that to do with lying or the intent of the article? Jack whyte.
In the first paragraph:
In this editorial, I propose that a lack of raw data or data fabrication is another possible cause of irreproducibility.
Is GISTEMP fabricating data?
From my file of quotes, tag lines and smart remarks:
That climate science routinely alters historical data is a matter of fact.
Why Climate science routinely makes those changes is a matter of opinion.
It means there is no longer a concern about group organized lying.
What we now have is institutional lying. Where lying is part of people’s job.
This is not a few bad apples. This is the rot that happens when there is no thinking, honest press on the side of the country. This is what happens when a party becomes corrupt and the only thing that matters is wining the next election.
The difference is the motivation for the lying.
In the case of systematically (lower past data and raise recent data to create a hockey stick, exactly like the Hockey stick scandal) altering temperature data (GISS) or altering ocean level (same scam), it is institutional support for a political position. i.e. It is people on staff in the institution who follow political direction.
The people that are lying to push the dead theory CAGW believe they are on the side of good. They are of course Zombies who also believe in the green scam fairy tale.
The lies in big pharma are all about making money.
Steve, pauses in updating always seem to herald another revision of data to increase alarm. They are always associated with mortal critiques of these aspects by sceptics.
SLR (they did this before when they added in a glacial rebound of the ocean floor). This is a sea volume issue. The correction means our sea ‘level’ surface is somewhere above the real level into the atmosphere, presumably rising still further until rebound stops. I’m betting that ‘acceleration’ is going to be added. The critique: if the globe is warming in a frenzy, why is sealevel only rising linearly for over a century.
The The Karlization of the two decade Pause or Hiatus in global temperatures. The Pause had caused an epidemic of “Climate Blues” that ended the careers of a number of climate scientists. Sceptics were on this in spades and the team was in a stir. They had to do something.
Note, with warming still lackluster , the NSIDC is a month behind in ice extent. Look at Antarctica. The extent began to increase rapidly and would appear to have crossed the 30yr average back into ice increasing mode if updated. Critique: they have been yammering about the shrinking glaciers and dangerous sea level rise – can’t have increasing ice extent!
BMO in Australia used to update the ENSO graph every Monday without fail. Now we have month old data.
This is a raw data crisis that puts the medical one here in the shade. As you say the changes are continuous. Mark Steyn famously said at a Senate hearing on climate: how are we supposed to have confidence in what the temperature will be in 2100 when we don’t know what the temperature WILL be in 1950!!
Gary Pearse February 23, 2020 at 12:04 pm
Thanks for that. Maybe CSLRG* is waiting for Mörner to kick off – he has a 1938 DOB.
*Colorado Sea Level Research Group pronounced SEE slurg.
My year, too!
It’s the University of Colorado, not Colorado University, a common mistake that is made because they abbreviate it CU.
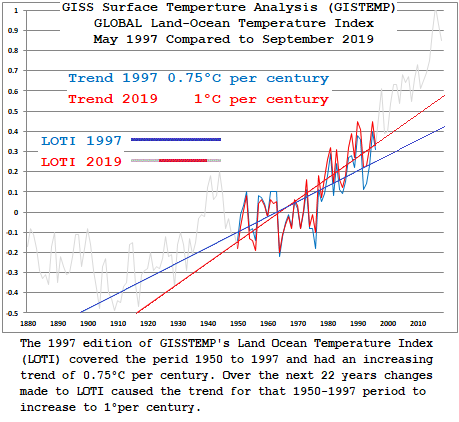
“Over time those changes do make a difference:


and
1. The difference between 1997 and current LOTI are due to several changes made in the following
A) in 1997 GISS, used GHCN V2 adjusted, and USHCN adjusted for the USA
B) in 1977 GISS did not have any adjustment for UHI
C) in 2020 GISS has moved on to using GHCN version 4, ADJUSTED DATA
This added over 20000 new stations to the data
D) in 2020 GISS has added and upgraded its criteria for calling a station urban
E) in 2020 GISS used a UHI correction method which decreases the trend slightly
2. Month to Month GISS data for stations will change for the following reasons.
A) GISS takes data from NCDC. They ingest ADJUSTED DATA from NCDC. The
ADJUSTED data from NCDC is for 27,000 stations. As new data is recovered, a small percentage of
data will change. if 1% of NCDC data changes you will see 270 changes in GISS.
B) GISS method uses a reference station method. This will also cause slight changes over time.
So lets understand the flow of data FIRST. Its published code so there is NO EXCUSE for not knowing this.
NCDC takes raw data for 27000 stations and they create an adjusted dataset. GHCN-ADJ
GISS Ingests this dataset– they ingest ADJUSTED DATA– and does TWO THINGS
A) they stitch together reference stations ( to get long stations)
B) the adjust stations (cooling many) by applying a UHI correction algorithm
if you compare the data giss ingests with its output you can see that GISS adjustments (UHI)
COOL the NCDC data on average. its a tiny cooling less than .1C
Now UPSTREAM of GISS, when NCDC takes raw data and creates ADJ data they do so by comparing all the stations with
their neighbors. So a change in 1 station out of 27000 will potentially cascade into minor changes
in all the neighbors. These changes are then picked up by GISS. there is nothing GISS can do about
it. GISS imports NCDC Adjusted data. This is in the code. you can audit this. you wont.
Thus, A change in 1 station in NCDC will also cascade into changes in the Reference station algorithm
and the UHI algorithm.
Upstream changes
So, what causes a change in NCDC data?. NCDC has raw data on 27000 stations. It’s millions
of data points. They get this data from NWS, national weather services, and from ITSI.
Historical data is constantly being scrutinzed and cleaned. For QC problems, for provenance problems.
Missing data is routinely found as NWS do data rescue. For example, in Oct 2019 the NWS may
only have data for 30 years for a given site. Then they discover in Dec 2019, undigitized data for that station. So they change the data that they send to NCDC. They ADD data to the database.
There are MILLIONS AND MILLIONS of records on paper that are being added to the old historical
records. More old raw data gets added every year. Before NCDC had 7000 station, now they have 27000. In addition, some stations disappear from the
raw files!.
How? well the NWS do historical reviews. they may find that two stations have the
identical data even though they are miles apart. After investigating they determine that 1 of the stations is just a copy of the other. So they eliminate the duplicate. Then they update NCDC and NCDC
removes the station.
In short NCDC has a dataset of historical raw data that CAN change slightly month to month.
A station gets 7 months of data added. Another station gets deleted as a duplicate. A NWS
adds 3 new stations based on their historical studies. These small changes all mean 1 thing.
When the adjustment code runs it considers All the neighbors of a station. When you change
1 station that can cause minor changes in dozens or hundreds of its neighbors. OR NOT.
The algorithm always works with all the data to find the best answer for the data it is given.
In a nutshell.
A) the historical raw record is constantly be improved UPSTREAM of NCDC.
1. station months are added
2. station months are deleted
3. entire new stations ( rescued old data from paper) are added.
4. Duplicate stations are deleted
B) NCDC takes the improved historical raw data and does the following.
1. its own internal QC
2. Calculates a new adjusted dataset based on the latest historical raw.
C) GISS takes NCDC adjusted data ( which changes month to month in minor ways and
1. combines stations in a reference station algorithm
2. Adjusts urban stations, cooling them.
All of the input datasets and code for doing this is online
Mr. Modhet:
Start with the assumption that all the temperature adjustments are logical and reasonable, the bigger problem is:
Considering that temperature records, both present and past, are still undergoing significant revisions, how can you formulate policy based on a temperature record which is constantly admitted to as being wrong and in need of adjustments?
This very situation screams that policy should be based on current conditions – the results brought on by current weather – rather than hypothetical situations based upon temperature data known to be flawed. This is particularly true considering any change that has occurred in temperature in the last twenty years has been very small. Any future adjustments to the temperature records over the last three decades will be greatly magnified when extrapolated out for the next hundred years.
So is it reasonable to base policy on flawed temperature data? If you argue that it is not flawed, i.e.,there will be no more adjustments, or it is not sufficiently flawed as to preclude its use, please tell us what evidence you base that on.
I am sorry, fingers slipped on the key board, Mr. Mosher.
Steven Mosher February 23, 2020 at 9:32 pm
1. The difference between 1997 and current LOTI are due to several changes made in the following
Blah … blah … blah … blah … blah … blah … blah … blah … blah … blah
And it nearly always follows a pattern on lowering the earlier temperatures and bumping up the recent. Why don’t you pull my leg again?
I have a file of tag lines, quotes and smart remarks, one of them says:
If the Climate Change headline says,
“Worse than previously thought”
Historical data is being re-written.
This monotonously goes on over and over and over again. The pigs in George Orwell’s “Animal Farm” illustrated this process perfectly.
Just recently I emailed NOAA to ask why the Climate at a Glance data for TMax May-October had dramatically changed from a negative trend to a positive trend. I got a nice email back that said:
…our Climate Monitoring section who produces these graphics. They mention that there was a data source change within that era. That’s what is behind the differences. It was initially unadjusted Global Summary of the Month data and now it’s their in house “NorthAm ” database, which is adjusted for inhomogeneities. In addition, with their February release, they removed all estimated data, which explains the data gaps in the timeseries.
I had happened to save the Tmax May-Oct graph for Los Angeles. I also have one for Cincinnati that shows the same bullshit. Too bad that’s all I have. I expect that most cities around the U.S. have had their historic temperature time series re-written in the same fashion. And we peasants are supposed to sit still for it.
Meanwhile Senator Sanders wants to spend Trillions to solve “The Climate Crisis” and cities in California and Massachusetts have already banned hook-ups to natural gas in new residential construction.
I’m guessing you are smugly satisfied with your position on all of this.
“Some climate data gets changed on a regular basis. So, I keep files on sea level and GISTEMP”
really, then you should have no trouble.
A) sharing the actual data you downloaded.
B) sharing the test you did to insure that you downloaded it correctly
C) proving that you downloaded it when you said you did.
you see verification of data integrity is harder than you think.
Psst Blockchain solves all of this as does content addressable data.
https://youtu.be/BA2rHlbB5i0?t=292
Psst, maybe you could get the climate gatekeepers to do all the things you expect of us.
” sharing the test you did to insure that you downloaded it correctly”
1. It is spelled ‘ensure’ not ‘insure’, oh uneducated one.
2. That is in the TCP/IP protocol. In the public domain. You may fail to download data, but unless a human agency is involved, you wont download CORRUPT data.
By which I can now deduce the following facts about you.
1. You are only a smartass, not smart.
2. You are inventing things that look superficially relevant but to someone who actually knows their field are in fact arrant blatherskite, of the first order.
You may fool your climate change gopikas, but you don’t fool smart people.
“2. That is in the TCP/IP protocol. In the public domain. You may fail to download data, but unless a human agency is involved, you wont download CORRUPT data.
Oh my. well there are things you dont know.
Shall I count the times users have downloaded data, then
read it in with a program only to screw up their data ingest?
so the first thing I ask guys to do is send me a hash of the data they downloaded
( to make sure they got the right file)
Then I ask them to send me the data AS USED by their program.
Things you can screw up.
Download old data
Click on the wrong link
wget() the wrong file
corrupt/misread the file you downloaded properly when you ingest it
into your program.
Seems like you have not worked much with data
And no doubt Mr Mosher, you can explain why the Australian BoM temperature records for Darwin during the 1930s are 3 to 5C above those recorded at the time.
“And no doubt Mr Mosher, you can explain why the Australian BoM temperature records for Darwin during the 1930s are 3 to 5C above those recorded at the time.”
Nope I don’t use BOM adjusted data.
But I do know this having studied and run adjustment code.
Start with 1000 stations.
Now, randomly through some spot noise at it, or some broadband noise, or
even randomly throw a few shifts into the data series.
Next
Run your algorithm on the corrupt data and see what it does.
1. Does it correct all the errors? Nope
2. Does it adjust the data in the correct direction. Yes.
3. are there peculiar cases where out of 1000 stations, it will create 1 or 2 that are
outliers? OF COURSE its a statistical approach to data correction.
Last.
Go back and improve your code and reperform your testing with random data.
My preferred solution is just to hold out australia, When you throw out all Australian
data the global average doesnt change and trolls have a fit.
“Start with 1000 stations.”
That’s the problem. Each station is a distinct entity. The temperature at that station is an intensive property of THAT station. Averaging that with OTHER stations is meaningless. I’m sure you know this, but can’t seem to get away from it.
Steven Mosher February 23, 2020 at 9:39 pm
…you should have no trouble.
A) sharing the actual data you downloaded.
B) sharing the test you did to insure that you downloaded it correctly
C) proving that you downloaded it when you said you did.
You’re calling me a liar aren’t you?
Colorado Sea Level Research Group 2004 Release 1.2
GISTEMP Land Ocean Temperature Index June 2006
The GISTEMP LOTI link from my Feb 27 – 6:03 post above should have said June 2002 not 2006
It is also possible that the raw data is proprietary. My kid’s Masters thesis spent as much time being reviewed by the corporate legal team as the university’s science team. Everyone attending her defense meeting had to sign NDAs.
What nonsense. So hiding, fabricating, lying is now science? Lower education.
Yeah Dawg, but corporations are protecting real data of commercial and competitive value. This article is about non-existent raw data, insufficent and made up raw data, Harking, p- hacking, etc.
Maybe I wasn’t clear. I can see many instances where “the data isn’t available” is actually “the data isn’t available for release.” I just wanted to point out the difference between the data being available and the data being embargoed.
I also know there are lots of examples where, as the author suggests, the data do not support the publication.
You are correct.
No! That’s beyond insulting. No “hiding”, no “insulting,” no “lying.” Commercially funded research isn’t as you describe it. You need to apologize.
Then screw them. No raw data, no publish. No ‘peer’ (pal) review, no public credit etc and no status or funding reward for the authors or their organisation. Treat the work as unverified assertion or declare it de facto fake. The issue here is the public credibilty of evidence in the same way that evidence in a court case must actually be presented for examination andcross examination. It is an essence of a robust evaluation system.
You let your employee use your experimental labs and fields, even a multi-million dollar harvester to advance the field of seed science and then you can be the one to let all you’ve learned loose for free. Until then learn to live with the… ahem… “hybrid” science we got.
What the hell is proprietary about government run and funded metorological or equivalent organisation generated data?
What the hell is proprietary about weather-cliumate-temperature data?
This stuff is not like some invented product that implicitly has proprietary rights associated with it. Even if it was, seeking it to be accepted by government as a basis for public policy means it should be open to scrutiny.
Still the same response from me, screw them. If they want public regognition and to influence public policy then they put it all out in the open.
Then should they be publishing at all? If you give people a screen to hide behind, it will be greatly abused by others.
Researchers signing an NDA on their research data should be told upfront that that precludes the publication of their results, at least until such time they are released from their NDA.
“such as HARKing (Hypothesizing After the Results are Known”
How does this differ from hypothesizing after the unexpected results of a test? Isn’t the reproducibility crisis really due to HACKing (Hypothesizing After the Conclusions are Known)?
CO2isnotevil: It is actually the same thing. To legitimately test a hypothesis you first make a prediction based on the hypothesis then design and conduct an experiment to see if the prediction is correct. If it’s not, you can form a new hypothesis that fits the result, but you can’t claim the result supports the hypothesis. You must make a new prediction and perform a new test. Unfortunately, a great deal of recent science has involved HARKing without being called out as invalid -much of it in climate science.
Rick,
Of course testing must continue, but more importantly, reproducibility requires making the relevant information available to expect and enable others to develop and perform their own tests. The problem with climate science isn’t that testing doesn’t continue so that failed hypotheses can be called out, but that tests performed by others aren’t accepted when they call out an incorrect hypothesis.
For example, the nominal sensitivity factor of 0.8C per W/m^2 results in a 4.4 W/m^2 increase in the average surface emissions for each W/m^2 of forcing. Given the 240 W/m^2 of total forcing from the Sun and that all Joules are the same, the nominal sensitivity predicts that if each W/m^2 resulted in 4.4 W/m^2 of surface emissions, the surface would be emitting over 1000 W/m^2 corresponding to an average temperature close to the boiling point of water. Clearly it’s not, thus this failed prediction falsifies the nominal ECS.
From the article: “I argue that making raw data openly available is not only important for reuse and data mining but also for simply confirming that the results presented in the paper are truly based on actual data.”
This needs to be applied to NASA Climate and NOAA’s data manipulation of the raw temperature data. Congress should pass a law requiring this. Or the president should issue an Executive Order requiring this.
“This needs to be applied to NASA Climate and NOAA’s data manipulation of the raw temperature data. Congress should pass a law requiring this. Or the president should issue an Executive Order requiring this.”
Both NASA and NOAA supply the raw data and the code used to adjust it.
next time Monkton posts ask him for his data and code and watch him squirm
Like Lonnie Thompson? Like Mann? Like Santer?
Yep Monkton is exactly like them. Thanks for pointing it out
The difference is, Monckton isn’t dictating world-wide policy.
Surely you can post your verified letters to editors and world leaders, that climate research is seriously lacking for the reasons you stated.
Monckton isn’t trying to take food out your mouth, gas out of your car, heat out of your house (in winter), the car out of your garage, the airplane out of your vacation, the joy out of your life.
You are! You need to prove it. Not him.
Psst. I’m not doing any of those things OR suggesting them.
I support expanding nuclear power and volunteer my time free of charge to advance nuclear
what the hell do you do to advance nuclear?
Nice try at changing the topic
Nuclear, the faux umbrage of the scared environmentalist. Nuclear is dead, you will never convince people who are scared of their own breath to place a nuclear facility in their backyard. This is so obvious as to almost be axiomatic.
If you are a true supporter of nuclear then you’d be honest in addressing the gaps, hell whole canyons, in theory, data, models, reports, conclusions of CO2 induced panic.
CO2 panic kills nuclear faster than it kills coal.
Much of the data that I’ve used to falsify a high ECS originated from GISS (ISCCP)!
For example this, which shows how the relationship between the surface temperature and the planets emissions is nearly indistinguishable from a gray body whose emissivity is 0.62 (the green line), moreover; the effective emissivity is unexpectedly constant from pole to pole!
http://www.palisad.com/co2/tp/fig1.png
And this, which shows that the incremental surface emissions sensitivity is only 1 W/m^2 of incremental emissions per W/m^2 of forcing (the magenta line) (< 0.2C per W/m^2) and once more is constant from pole to pole!
http://www.palisad.com/co2/tp/fig2.png
And finally this, which shows how clouds are the free variable that adapts as required in order to maintain the unexpected constant effective emissivity from pole to pole.
http://www.palisad.com/co2/sens/se/ca.png
Isn’t the presentation of an idea as fact, unsupported by verifiable data nothing more or less than a lie? And if that liar, be that scientist, researcher or whatever, gains in any way (In getting a grant, recognition or advancement) from that lie, are they not committing fraud?
But then in a culture with such fluid moral standards, such niceties are irrelevant.
Reproduce this experimental evidence that there is no “extra” BB LWIR upwelling from the surface, no “extra” energy for GHG/s to “trap,” therefore no man caused global warming or climate change.
https://www.linkedin.com/posts/nicholas-schroeder-55934820_climatechange-climate-science-activity-6611673792517337088-VTCm
Progressives and their ilk don’t believe in evidence – just feelings and emotions….
I think they genuinely don’t believe in or understand reality. Fantasists, that’s why they’re leftys.
The root cause it seems to me is academic science culture. There is no moral downside to publishing rubbish based on shoddy work. You get a reprimand only if it’s outright fraud. Added to this is the peer review process that appears utterly bankrupt. I think the data exists in these, but examination of it would contradict the papers conclusion.
True.
There’s an oversupply off PhDs chasing too few tenure track jobs.
What’s the alternative to a tenure track job? Teaching part time for a pittance and no benefits. What a waste of an education. You’d be much better off as a plumber.
How do you get a tenure track job? You publish. How do you get published? You first need a research grant. You spend half your life writing grant applications. Once the work is done, the gatekeeper is the editor of a journal.
What is an editor looking for? An editor wants interesting/novel results but they can’t upset any apple carts.
So, you produce interesting results, no matter what. There’s no penalty for being wrong. The only penalty is if you are caught fabricating data or if you plagiarize someone else’s work.
Universities want professors who publish amazing stuff in high impact journals. Winning a Nobel Prize helps a lot. Just ask Donna Strickland. It feels like the most important thing for university administrators is prestige. If a candidate does not increase the prestige of the institution, then that candidate is discarded. (University administrators are scum and have multiplied beyond all reason, but that’s a topic for a different rant.)
So, desperation creates the replication crisis. Folks do whatever they have to do. The situation is bad enough that the general public has become aware of it. Politicians will ask, “Why are we wasting oodles of money on bogus results?” The scientific community will trot out its usual rationalizations. They are getting harder to believe.
Research perversions are spreading. The situation is getting worse. The solutions may be unpalatable.
The thing is, 0.00097% of scientific papers produce things so useful that it makes up for the gigantic waste of talent and treasure that otherwise typifies science these days. The trick is thus to avoid throwing the baby out with the bath water.
On the other hand, “Trust me, I’m a scientist” is just so darn … Grrrr!
If you have a PhD, you could always try getting a job in the ‘Real World’ ( I can hear the screams from here)….. Mind you, depends if that is a real PhD in a real subject…
Just have to add a caveat to that. You can have a real PhD in a real subject and struggle to get a real job. Happened to my PhD brother in law after he was laid off from his real job working for a real corporation. Turns out there wasn’t a real lot of opportunities for his degree at the time he was laid off. Sometimes it’s really about timing.
On the plus side, he didn’t lower himself to the level of trying to get on as a professor at a university.
“ You get a reprimand only if it’s outright fraud.“. I don’t think that’s quite correct. Groups have been set up with the specific purpose of approving outright fraud (Penn State’s whitewashing of Michael Mann’s hockey-stick fraud for example). I think a more accurate statement would be that you get a reprimand if you don’t follow the ruling paradigm.
I see there’s no longer a downside to committing fraud:
https://areomagazine.com/2020/02/20/how-universities-cover-up-scientific-fraud/
“…As Ivan Oransky notes in Gaming the Metrics, “the most common outcome for those who commit fraud is: a long career.”
“.. If universities open an investigation, they must notify relevant federal agencies and share their later findings, but if they decide not to investigate, the case closes. Closing cases without full investigations is an effective way to prevent government involvement and to avoid having to return fraudulently obtained taxpayer money, because federal agencies rarely reopen closed cases. Often, they do not find out about them at all.
Universities can make a lot of money from sham science. They lose money from catching fraudsters. ”
“,,,,His research showed that fraud is widespread in science, that universities aren’t sympathetic to whistleblowers and that those who report fraudsters can expect only one thing: “no matter what happens, apart from a miracle, nothing will happen…”
Administrations really only care that grant money is being brought in, the overhead from which will be used to pay salaries and bonuses for administrators.
To: Mike MCHenry
The root problem here is the RTP process of universities (retention, tenure, promotion) where “the number of publications in the previous year” is an important consideration. This creates the publish or perish situation and that in turn creates various anomalies in research including the explosion of pay to pay to publish journals. This mess can be cleaned up somewhat with a minor change to RTP. Change “number of publications in peer review journals” to “evaluation of scholarly activity” that would include for example serving as peer reviewer, conference presentations, authoring books or chapters in books, and creative activity not only as inventions but new teaching and student evaluation methods and so on and so forth. The RTP process needs to change.
If the federal government required full disclosure as condition of research grants that would also clean up the mess. We can see a sample reaction from both academia and the journals with the US EPA request for the same
If the raw data cannot be provided, the publication should be rejected. PERIOD. This idea that one can publish a scientifically valid research paper using data no one else can see is wrong-headed. Science is based on peer review, and it should start with the data. If the data cannot be validated, nothing based on it can be accepted as valid. The best you could do at that point is publish a hypothesis, not a theory or finding.
Changing raw data is perfectly acceptable as long as the original is always preserved and all changes are explained and processes used published. This allows someone to go back and validate the changes (or reject them as invalid changes). Hiding original data is equivalent to lying and then saying “trust me” to others seeking it. No such research should be trusted outright.
RofT – What you state seems so obvious. Why do professionals not assume the information they provide should not be similar to what they provide to 1) their university professor, or 2) their employer? Without high pedigree data, the paper is useless – especially if it presents a conclusion. (Might be useful if you’re looking for a grant – as long as no conclusion is given.)
“f the raw data cannot be provided, the publication should be rejected. PERIOD.”
yes. This should also be the rule on blog articles
Well there goes ‘skeptical science’ then 🙂
WUWT too!
except for willis he is the only guy who posts his data when he blogs.
Just about everyone who posts graphs in their head posts cites the source. That’s where the data is. You know this too, but are trying to deflect.
Every published study and every blog article should be withdrawn and retracted every three years if it uses a published database of temperatures or sea level or ice extent that are routinely changed.
The only way to get them republished is to revise them with the newest data.
This is the only way to create the pressure to once and for all decide what and how temperature databases should be managed. It will not stop scientists from revising raw data for their own purposes but they will need to catalog the changes and the reasons for doing so in each study, paper, or post.
Several commenters have questioned whether HARKing (hypothesizing after results known) is actually acceptable in some circumstances. I would say YES when the results of some other hypothesis-trial-experiment are far, far different from anything hypothesized a-priori. You know, like “Testing whether sulfur, copper and tellurium alloys present high-function conductors”, only to find that one particular alloy is a frikkin’ superconductor at outrageously warm temperatures!
That particular example is real. It was how the whole class of superconducting tertiary cuprate compounds was accidentally discovered. Needless to say, subsequent hypotheses were … substantially along the lines to support the newly-known superconduction evidence.
Still, in the broader sense, HARKing can-and-usually-is deeply disingenuous: it is used to fluff up the reputation of an experimental and/or theoretical researcher as having unusually good hypotheses and ideas. Especially when the subject matter is fairly mundane, or at least not much of a stretch from where mainstream lines of research are already headed.
The truth is dark: the vast (98% or more!) number of researchers are “in it for the sheepskin”, using their awards and papers to land lucritive jobs, so that their careers “take off” financially. To pay back the educational costs, live a better life, and all that. I hate to say it, but of the hundreds of PhD’s and PostDocs I’ve met, precious few are really in it “for the research”. Most, to land the pay-grade whale, then nurse medium-stint jobs along in serial-flipping fashion, for a lifetime of remarkably well paid work.
AND there is NOTHING WRONG with that, in a way. Seriously!
But we shouldn’t expect that there isn’t a whole lot of subtle feather-bed fluffing going on, par course.
Know what I mean?
⋅-=≡ GoatGuy ✓ ≡=-⋅
“Several commenters have questioned whether HARKing (hypothesizing after results known) is actually acceptable in some circumstances. ”
it could be seen as part of what we called EDA.
https://en.wikipedia.org/wiki/Exploratory_data_analysis
After spending 40-some years in what is now called Neuroscience, I find this attitude of this ex-journal editor insulting. One of the problems I fought throughout was journal editors who did not even send papers out for review if they were counter to the current popular ‘theory’. I and all of my colleagues were sh1t scared of students, technicians and clinical collaborators ‘making data prettier’.
The problems that have been noted in the scientific literature are partly because very complicated procedures get changed in ways that sometimes make them better and the results change; journal editors put pressure to shorten papers leading to inadequate methods sections; BOTH editors and reviewers want the results to support their perspective; there are some bad hats who are really bad; there are others who think one swallow makes a summer and want to dine out on it; some have so much invested in an hypothesis that changing would be a disaster putting a large lab out of work – this is a problem with how funding works; questionaires get the language wrong and get the wrong answer. I could give examples of each of these.
An important principle of doing experimental science is that ideas are cheap; proving them is hard work; if one hypothesis doesn’t work out, there will be another along in a while – I sat on some data that I could not explain for years until it fit into a framework, other experiments worked out as expected.
Barbara McClintock (jumping genes or transposons) was able to work for years in obscurity, much denigrated for her ‘crazy’ ideas: nearly 40 years later she won a Nobel. As far a climate science is concerned, the time frame for her work to be recognised as valid makes me pessimistic that I will live to see the CAGW die the death I think it will.
FranBC, thank you for your 40 years in Neuroscience and your comments about principles. I started University as a Nuclear Physics major, but quickly realized that the majority of sciences had an unhealthy inclusion of “politics”. This led me to switch to geology, and especially mining exploration geology. This type of science is very direct: study the data, maybe develop a theory, gain more data relevant to refining the theory, present a drill recommendation for your target theory, and watch as the drill bites into the target zone, then wait for the assays. Try to imagine the verification of your theory several times a year. Try to imagine being switched to “cutting bait” when your drill targets find mystery rocks and no gold, either yellow or black. Kudos to those medical scientists that are motivated by wanting to help their fellow man and press on with research no matter how difficult, but for me I am glad I switched to hands-on science. Relevant to the CAGW nonsense, try to imagine the thrill of finding a kitchen midden a hundred feet above current sea level!
Ron,
Likewise, mineral exploration.
In that field when I worked in it, there was a requirement to submit all relevant data to the State or Territory government (in Australia) as a condition of keeping legal hold on a licence or lease.
It was second nature to spend long hours getting the data in order so there was no doubt a third party could read and understand it easily.
So, this business of not letting your data go public for fear someone would want to find something wrong with it was quite alien.
This example provides years of long-established data release practices, so that newbies like climate researchers have no case to say that it would not work.
Geoff S
Lack of raw data? Why not call it what it is – faking research.
In climate (so called) science, the disconnect is between what the data actually says and what the authors states are the inclusions. Suffice it to say, the conclusions are always “due to climate change”. As such, you may have data that shows a decrease in Arctic Ice Extent or volume, so you do have raw data. However, in the discussion and conclusions, it is always stated as being due to man made climate change, even though there is no data illustrating that the decrease in ice has anything to do with climate change. Their go to is a predetermined result …. of course, as the temperature rises ice melts, … duh …. but to make the claim that the temp rose due to mans CO2 is just purely an unproven theory that is politically acceptable.
Very well spotted!!
I was also surprised to see almost all papers there were conclusions using the term climate change. In the whole study, there was no connection to climate change but in the end, all conclusion will lead to climate change. Probably then it is easier to get published and to help receive more citations. Top scientists are involved in such a malice practice!
Why people are not raising voices on these issues.
Also, Trump International Golf Links, Trump’s property in Ireland needed to be protected from “climate change” (which is probably just oceans being oceans).
Which “proved” that Donald Trump “accepted” “science” when dealing with his properties.
Irreproducibility of results is an old issue in journal publication as seen in this journal started by israeli pranksters.
The Best of the Journal of Irreproducible Results https://www.amazon.com/dp/0894805959/ref=cm_sw_r_cp_apa_i_tHUuEb983TVZA
As noted in this wuwt post, it has gotten a lot worse in recent times for two reasons. 1. The booming pay to publish business. And 2. Activism driven research, as seen here.
https://tambonthongchai.com/2018/05/06/consensus-science/
“Goodhart’s law (named after the British economist who may have been the first to announce it) states that when a feature of the economy is picked as an indicator of the economy, then it inexorably ceases to function as that indicator because people start to game it. ”
The moment a bureaucrat uses a statistic it starts to be corrupted and becomes useless.
There is no fix.
Papers need to meet rigorous standards of open data and methods. Job for the Editor. Get rid of the peer review and hire English majors* to make sure the grammar is correct and the paper is comprehensible. Peer review should be of the published paper. A comment section with fully disclosed names and institutions should suffice. (*Of course other languages for journals using them.)
I think they over-egg the pudding slightly wrt cancer research trials. Many of these trials would be expected to fail because they are attempting more than to just replicate earlier preliminary findings in a field fraught with technical difficulties and failure. People don’t actually try to do that very often because… why would they? Try getting funding for it.
However, reference #2 probably makes the best point:
Great to see 97% in a far, far more credible context.
A huge problem here is the woeful lack of statistical knowledge and understanding among all of those involved in the peer review process. This is a massive issue and it’s getting to the point where every peer review should have to include a specialist statistician.
Those providing the funding for scientific research usually have preferred results in mind. In Climate Science the Government funding decision makers ALWAYS have specific results in mind.
Nutrition Science shows us clearly that just about any result you want can be bought. That’s what we see in Climate Science where almost all funding decisions are made by Activist Leftists in Government and in Academia. It’s a really tough choice for Government/Academia funded researchers…hop onto the Climate Crisis Gravy Train and your pockets will overfloweth and all the favorable press imaginable will be yours…Else find or report the wrong results and you can forget any further funding and forget about ever getting published again…or rehired/promoted when your contract is up…you science denier.
The vast majority of researchers are in Government or Academia BECAUSE they are Leftist Activists. They are right at home with their leftist fellow travelers in the natural HOME of all Leftists…which is in all the TAXPAYER FUNDED Institutions (or in the press). It’s All Leftist Activism all the time in the unelected Deep State (and in the press).
I imagine we see lots of spurious statistical results. The results can have high confidence but because so many studies are carried out, just by chance some will show high confidence results but in reality is is just an artifact of chance. This is why studies need to be reproducible.
Scissor February 23, 2020 at 2:57 pm
It’s the University of Colorado, not Colorado University, a common mistake that is made because they abbreviate it CU.
Nobody above wrote CU except you. Besides that, the banner at their website
http://sealevel.colorado.edu/
says:
“CU Sea Level Research Group”
If raw data will not be made available because of commercial interests, then why publish? Patent is supposed to protect the inventor or discoverer commercial interest. If the discovery could not be patented such as basic scientific principle such as Newton’s laws of motion, scientists disclosed the result as soon as possible to claim they are the first one as there are others who would most likely be on the same path of discovery. If the discovery is of great commercial interests to the enterprise and they would like the world to know about it but feels the patent law or other safeguards to the discoverer rights are insufficient for the moment, they should not submit it as a scientific paper but rather pay for an advertisement. Is it not time for scientific journals to have paid advertisement sections for those discoveries where the raw data is not available and remove the paywall so other researchers and in general the public will have access to the scientific paper and the raw data to verify or reproduce the results? The paid ads could make any claim subject to advertisement laws and ethics– but we know it is a paid advertisement rather than a “scientific paper” with questionable scientific value.
> If raw data will not be made available because of commercial interests, then why publish?
Because Edison. Come on. “We can make wheat ripen to peak on a specific day.” Is that not science worthy news? What do you want here? To make corporations shut down R&D in bio/organics like they did in engineering in the 70s/80s because reveals hurt them?
read the whole text.
Here’s a joke.
I will write to the author and ask him for his raw data.
His raw data is all the papers as submitted and his requests for raw data.
Yes getting the data is important. Even for blog posts.
Will everyone who posts a graph here supply the data?
Here’s another joke. You won’t do it.
he was kind enough to supply the entire list of papers, not their content because of
copyright restrictions.
So your joke got deflated. You’ll post an apology, right?
Didn’t think so.
How raw does raw data have to be? Is a data base raw or are photocopied pages from a notebook raw enough, or does it have to be the notebook itself? A data base, or the original download from a data logger? I don’t understand, if somebody wants to fake data, surely enough has been written on the characteristics of faked data that reasonably legitimate looking data sets can be spontaneously generated by any moderately intelligent fraudster. It seems to me that once the fundamental ethic of being true to the data has been betrayed, then no amount of policing can put that genie back in the bottle.