Guest analysis by Mark Fife
In today’s post I am going to go over how I went about creating a reconstruction of the history of temperature from the GHCN data sets using a variable number of stations reporting each year for the years of 1900 to 2011. Before I go into the details of that reconstruction, let me cover how I went about discarding some alternative methods.
I decided to create a test case for reconstruction methods by picking five random, complete station records. I then deleted a portion of one of those records. I mimicked actual record conditions within the GHCN data so my testing would be realistic. In different trials I deleted all but the last 20 years, all but the first 20 years or some number of years in the middle. I tried normalizing each station to its own average and averaging the anomalies. I tried averaging the four complete stations, then normalizing the fourth station by its average distance from the main average. In all cases when I plotted the reconstruction against the true average the errors were quite large.

The last option I tried was closer but still had unacceptable errors. In this option I constructed three averages: The four station average, the fifth station average, and the four stations averaged only for the same years as covered by the fifth station. I converted the fifth station to a set of anomalies to its own average and then translated that back to the main average using the four station sub-average as a translation factor.
From these trials I concluded you can’t compare averages taken at different times from different stations. The only valid comparisons you can make are from stations reporting at the same time. That of course limits you to just 490 stations for 1900 through 2011. The following explains how that limitation can be overcome.
If you convert a group of stations to anomalies from the station average what you are doing is converting them to an average of zero. If the stations in that group all cover the same years you are converting them to a grand average of zero for the years covered. The only questions then are how accurate the estimate of zero really is and how that relates to other periods of time.
I have found if you perform this exercise for a sufficient number of stations for a sufficient amount of time and construct an average percentage of stations based upon that distance from zero the resulting distribution, as an average of all stations for all years, is very nearly normal, with average equal to zero, and a standard deviation of one degree. See the charts below.


The following chart shows the cumulative percentages from the two most extreme years from 1900 to 2011. Those years are 1917 and 1921. Both are about 1.4° from the 1900 to 2011 average, one colder and one hotter. A 95% confidence interval from my distribution, rounded to significant digits, would be ± 2.0°. These years are within the realm of normal variation.

This of course does not mean there are no trends in the data. I believe the trends are obvious.
The following chart shows the details of how I approached reconstructing the data from disparate parts. I divided the time frame into smaller time segments of 1900-1924, 1925-1949, 1950-1974, 1975-199, and 2000-2011. I constructed five different charts, one for each time segment, using only stations reporting for the entire time segment. This came to 1302, 2837, 5046, 7305, and 7982 stations for the time segments in time order.
The next step was to estimate the grand average for 1900-2011 and an estimate for each time segment average using the set of 490 continuous stations. The individual time segment estimates are the point of the most error in estimation. The worst case is a 90% confidence interval of ± 0.5 for 2000-2011 and ± 0.3 for the remaining time intervals. The key factor is the number of years covered.
Note: This provides a quantifiable measure of how many years are necessary to determine a reasonable average temperature, namely the inverse of the square root of the number of years.
As stated above, normalizing the station data is just converting the station average to zero. With samples sizes as described above the statistical error here is minimal. The time segment average of the 490 stations is also an estimate of zero, all that remains is to subtract the average. The difference between the time segment average and the grand average of the 490 stations is an estimate of the difference between the time segment overall average, as defined by the large sample sizes above, and the grand average from 1900-2011. Therefore, the next step is to normalize the five sets of data and translate them onto the main data by the appropriate 490 station segment average.

The following chart shows the 490 station average in blue and the reconstructed average in orange for 1900 to 2011. The overall averages are the same, the primary difference is the reconstructed chart shows less variability. This is because the individual averages comprise far more stations for the reconstructed chart. Therefore, the extremes are minimalized. This is what you would expect to see. As stated above, the 90% confidence intervals are ± 0.3 from 1900-1999 and ± 0.5 from 2000-2011. Therefore, the exact anomalies from zero are subject to that level of uncertainty. However, the magnitude of the trends within the time segment intervals are subject to far lower levels of uncertainty.

The obvious criticism of this process I have gone through is I have done nothing more than force all the data to conform to the pattern of the original 490 stations. That of course is true, but I would contend the amount of forcing by method is minimal. It falls within the error factors I have listed above, certainly. However, the pattern does match the only long term stations available. You can only work within the limitations of the amount of existing data. The patterns of the individual time segments are also accurate within the limits I defined above. The worst case scenario, with 1302 stations, is a 90% confidence interval of ± 0.02. I will take that.
The final point here is explaining where the data comes from and why the 490 station average changes as it does.
The time frames cover different numbers of countries: 19 from 1900-1924, 39 from 1925-1949, 65 from 1950 to 1974, 126 from 1975 to 1999, and 123 from 2000 to 2011. The composition of countries obviously changed drastically. 1924-1949 saw countries like Argentina, Mexico, Puerto Rico, and Spain added to the list. 1950-1974 saw countries like Iran, Israel, Cuba, and Algeria added. 1975-199 saw the Bahamas, Barbados, Bermuda (UK), Botswana, Brazil, Chile, the Congo, and Costa Rica added. 2000-2011 saw Bahrain, Bolivia, Botswana, Colombia, Fiji, and Micronesia added.
The following shows a few of the major countries and how their contributions to the data have changed over the years.

There were obviously more changes, but I am making a point here.
Any attempt to homogenize and utilize all the data or even a significant portion of the data must contend with the addition of countries which are mainly in warmer climates than the US, Canada, and Europe. The only real connectivity to the past for countries and stations with no past histories is their relationship to long term records which cover the periods they are reporting. This is the uncertainty you are dealing with.
My contention is that determining the average global temperature is impossible with current data (or lack thereof) and current technology. Using an indeterminable number to foist new taxes, laws, and other prohibitions on the public is sheer lunacy.
I agree with this. It is good to study the local and regional changes.
Dr. S. Jeevananda Reddy
No, its deliberate criminal fraud.
Remember: All government is a self legalising protection racket. They only differ in the amount of extortion versus the amount of protection.
If you have time, do an internet search on “The death of democracy” for a listing of interesting, thoughtful essays that were written by some reasonably bright people.
“All government is a self legalising protection racket. They only differ in the amount of extortion versus the amount of protection.”
Thanks Leo… I needed that.
Can you calculate the enthalpy in the global atmosphere from the “global temperature”. If not, it is a worthless piece of information. I know the warmists will say it is relative, i.e. that steadily increasing temperatures still indicate rising enthalpy. But I ask, where is the physical proof?
I nominate you and Steve McIntyre to produce a credible alternative to GISS and HadCRU’s cooked books. Unfortunately, correcting CACA’s antiscientific charlatans doesn’t seem to be high on Trump’s list of concerns. Otherwise Gavin and Kevin would already have been packed off to inhospitable spots, or better yet, back to the benighted island sh!thole nations in training from which they came.
It seems Trump – having turned the US away from the global warming charade – has no reason at all to turn the rest of the world away from it. In other words, he is happy to allow other countries to lap up the global warming alarmism as that gives US companies a competitive edge.
In other words, it’s a dog’s breakfast.
Is the base data RAW, corrected for time of day, or “adjusted”? This doesn’t alter your point about how it is processed. I’m just curious which data set we are looking at. It would be interesting to produce your best averaged and processed data, and compare that with the “official” adjusted and homogenized data trends, for those longest records.
I am using the raw, unadjusted data. I have argued back and forth with a few people over the time of observation bias. That does not make sense to me. However, if there were such a bias, if it really is significant, and if it did in fact change in 1962 or whatever year they say that happened you would be able to detect the shift in the raw data at the station level. I have reviewed literally hundreds of individual stations. If it is there it is undetectable. Hence that can be ignored.
Tony Heller showed that the TOBS was not required.
I would say your reconstruction is accurate as any other reconstruction I’ve seen.
“Any attempt to homogenize and utilize all the data or even a significant portion of the data must contend with the addition of countries which are mainly in warmer climates than the US, Canada, and Europe”
I don’t see how you can take this further without doing some sort of area weighting. That is your problem here. With good area weighting, you would need less homogenization. It connects your numerical average to the actual land area you are trying to represent.
To get past the limit of stations having long continuous series, I use a least squares method, described here. BEST now does something similar.
The problem with area weighting is that you are assuming that your one station actually is representative of the entire area. The bigger the area, the greater then inherent and unacknowledged error.
“The problem with area weighting is that you are assuming that your one station actually is representative of the entire area”
That is actually the point of it. If you quote a regional average, you are assuming that something is representative of each area. What better than a local station? So you add each area multiplied by the best estimate of temperature there that you have. Spatial integration.
The practical point is to ensure that areas with lots of stations don’t dominate. Apart from being wrong, it is also prone to drift with time, as stations appear elsewhere.
Nick — in early 60s WMO brought out several reports like WMO (1966) on “Climate Change” written by eminent meteorologists from the meteorological departments around the world. They explained why they use 30 year as normal, why it is changed for next 30 years, etc and the average, etc. Here the objective is not make money but provide a guide to local conditions. Global warming is a concept by which groups are minting billions of dollars. Tell us Sir, what is going to happen with 1.5 to 4.5 oC range?
Dr. S. Jeevananda Reddy
In other words; there is no way the data can be adjusted to fit the task at hand, but since our salaries depend on us producing something, we’ll just pretend we know what we’re doing.
Weighting only works if there are numerous stations in each grid representing the region fairly.
What’s worse than only a local station? I would suggest no station is better than one station if it doesn’t represent the much larger area which can easily be the case.
If this same technique was applied for all grids, then global trends could be cherry picked what ever you wanted them to be. An area 1000 km squared with numerous stations using the very high concentrated areas have different trends to each other depending on how different weather patterns affected the regions.
The point of station data is to show how the actual data points change over time, not how weighting or other means changes the data.
Weighting never works correctly in global temperatures because there were too few stations to use especially before the 1980’s, around the poles, Africa and in the southern hemisphere.
Actually, we had better station coverage before 1980…
https://m.youtube.com/watch?v=58mDaK9bH5o&feature=player_embedded&lang=en
Note that stations at highe latitudes and higher elevations were conveniently eliminated after about 1988.
I did generally mean less before this period which goes back the the 19th century, but the peak was around about a decade or so earlier. There was a significant reduction by 1991 of over 3000 stations. Reducing the amount of stations causes larger anomalies in the overall data.
It causes unforced errors. And eliminating higher latitude, higher altitude, and rural stations creates a warm bias in the data. Spreading that warm bias over enormous grids creates funding for more alarmism, and ammo for leftist agendas.
There are lots of theories on how to measure global temperatures in the best way.
But climate science always chooses the option which shows the most warming. As in the most artificial way of adjusting the results to accentuate the values.
I don’t think the climate has changed at all globally. Ask all billion farmers on the planet if any timing is different than their grandfathers used. They will answer it changed in decades past but it is now back to the same day of the season they grandfather used 100 years ago. Go ahead, ask any of them.
I hate it when Nick makes sense… 😉
Mr. Stokes makes sense but only if considerable research has been done to ensure that each station is truly representative of the area that it represents. Otherwise weighting only increases errors.
Nick, thanks for a most fascinating post and code. One question, I’m sure I’ll have more.
You describe taking stations and making a triangular mesh out of them. However, there is more than one triangular mesh possible. For example, consider a square. The triangle could connect top-left to bottom-right, or top-right to bottom-left. And in a complex series of stations, there could be literally dozens, perhaps hundreds of possible triangulations.
How do you resolve this ambiguity?
Appreciated,
w.
Willis,
The mesh I use is a convex hull. That is what you would get if the stations were just points in 3D space, and you placed a membrane very tightly over them. That is unique. The R function I use is convhulln in the geometry package.
There is an associated math property called Delaunay. For any set of nodes there is a unique mesh that has it, and for points lying on a sphere the convex hull has it. It means basically that the triangles are as compact as you can make them (not long and thin).
Willis,
Thanks. I didn’t quite answer your question about a square (or rectangle) – yes, you could draw the diagonal either way. That is a rather exceptional case, though, and actually doesn’t occur with the GHCN/ERSST set. A square lat/lon element isn’t a rectangle on the 3D sphere surface, unless it straddles the equator. I have a row of nodes on the equator, so that doesn’t arise.
The latest summary of all this, with links to the full code, is here.
Many thanks, Nick, that makes it quite clear. I’ll need to play with it a little, always more to learn.
Most interesting,
w.
All trends should be based on spot measurements comparing the spot with itself.
There should be no attempt to make a global or hemisphere construct.
There is no need for any area weighting. Simply compare say 450 stations with themselves individually, and then note how many of these stations show X deg cooling, Y deg cooling, Z deg cooling, no change, A deg warming, B deg warming, C deg warming.
That would tell us something of substance rather than the imaginary output of the highly processed thermometer set in current use.
Richard ….. I TOTALLY agree. I’ve said this all along! The term “global” is meaningless with regards to climate, and the advocates of global warming know it. But the global approach is useful in pushing forward a global agenda.
I’ve lived in the central US for the last 30 years, and there has been no meaningful change in the climate ….. NONE! The warming Arctic hasn’t effected us at all.
+1
However, be careful that the “number of station” is ALSO some sort of area weighting. For instance, big cities usually have several station basically sharing the same climate, while rural area may have a single station to cover a much greater area.
Wouldn’t it make more sense to just pick one station in any given area size you want to look at no matter how many there actually are and then compare your inferred temperature to the actual of all the stations you originally left out to determine that you can do what you say you can do?
Bob, you are correct if you are looking at anomalies and as has been claimed in previous columns that anomalies are good to up to 1200 km, and if the grid cells are less than 1200 km corner to corner then one high quality station per grid cell is all that is needed.
MJPenny
Anomalies are garbage from one station up to 1200 km and these links below shows why.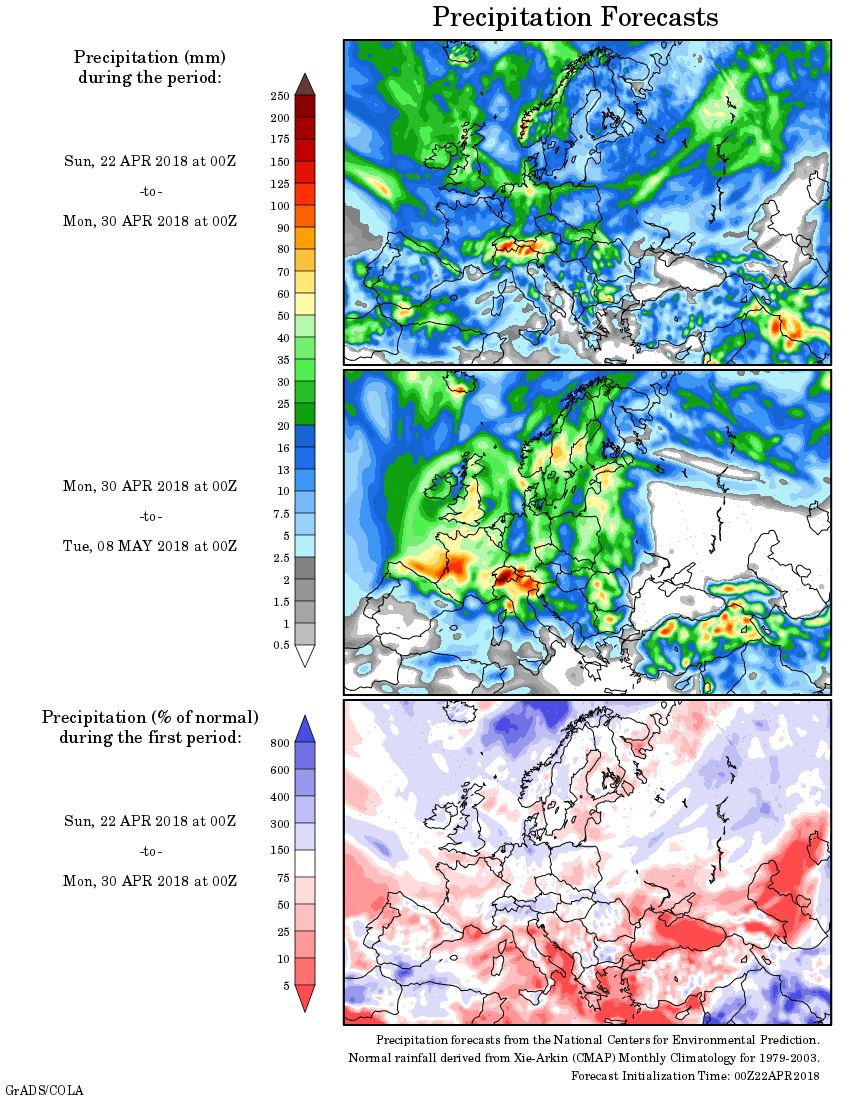
Clear skies, cloud and precipitation hugely affects temperatures and they vary widely under this range.
Weather patterns affect areas just hundreds of miles away and immediate coasts greatly, depending where they are on the wet or dry side and/or on the cool/cold or warm/hot side.
Area weighting, i.e. spatial statistics, makes no sense what so ever in constructing an average temperature in this situation. You are literally trying to wag the dog. The first thing to do is exactly what I have done, you must look at how the data is distributed. You construct an overall model. That is what I have done.You then, as a natural extension of that process, assess how well the model works for individual stations. I have done that. They conform within the specified variation. The other clue you have is the fact I went from 490 to over 7900 stations and from 36 countries to 126 and the data distribution did not change. the only change effected by varying the countries and locations was to change the absolute temperature average.The objective here is to accurately describe the average trends. By that criteria an area weighted average fails.
There are only two reasons to even engage in area weighting or spatial statistics. One would be if there is evidence of significant differences in trends based upon different areas. There is none. Even if there were, the weighted average would be less than optimal in terms of providing information. If the trend did in fact vary depending upon temperate zone, would it not be more accurate to trend each temperate zone? Why would you not want to do so?
The only other possible reason I see to do so would be as a part of determining the energy balance of the Earth over time. That would betray a complete lack of understanding as to what this is actually being done here. Number one, this is just a trend analysis. There is very little information about what the average temperature for a given year in Bolivia is, for example. However, we can estimate how much temperatures changed for a given time frame to within a 90% confidence interval. That is the only point of this exercise at all.
The other factor is each station average is only an average between daily highs and lows. It is assumed to place upper and lower bounds upon what happened in between. It is at best only a rough estimate for the amount of energy radiation actually generated at a site location for a 24 hour period.
Plus, the temperature recorded at a station is not an average temperature of the site. That is a serious misconception. It is literally the momentary temperature of a temperature reactive element inside a vented box of air. That is it. The actual temperature of the site surface is a different temperature, the air temperature will also vary based upon height and location within the site. The station is nothing more than a proxy for the site location. It doesn’t reflect the actual radiating temperature of the site, it is just assumed it correlates very highly to the site trends.
And what areas do you weight? Grassland versus forest? Shore versus inland? Those above 300m and those below?
Without knowing what affects temperature over the long term – you cannot weight the stations so as to better represent these various long-term trends. And if you don’t now what long term trends exist and what is causing them – then you have no basis to assume one form of weighting is any better than any other.
In spite of what Nick says, weighting does not help. Areas near the poles and places like central Africa wound up with inflated temperatures. It was just shown here on WUWT and by Tony Heller.
In addition, Steve McIntyre showed the problems with it in Antarctica several years ago.
Data massaging, pretty much a sour pickle these days. I am sure it’s legit but c’mon, really
I miss raw data, minus homogenizing, weighting, etc. Somehow this all seems nebulous and intentially vague. Probably it is. All this massaging, churning, etc to produce a number that has little relationship to local climates and those are the only ones that matter. So much better if we stayed with local and dropped the global thing. Maybe then we could actually do something to truly benefit humans.
+1
I did not follow the worst case: “1302 stations, is a 90% confidence interval of ± 0.02” How the heck do you add non-continuous temperature data sets in and get an error margin of +/- 0.02?
I did not think temperature sensing devices in the early 1900’s could do any better than +/- 1 degree F, especially when you have humans of differing heights eyeballing the data at differing times (let’s just say I am skeptical they always recorded the data exactly on time).
The contributions from different stations in varying countries over time just makes the data set even more difficult to decode. I say stay with the original 490 stations for these kind of research – inclusion of the other data just increases doubt and bias.
And would you not need to look in the data for obvious errors, and changes of equipment? Or is all this already accounted for in the data? If so, then the data is already possibly biased by people’s beliefs in what and how much to account for. (like UHI effect)
I guess I am confused about what you are trying to demonstrate.
Still, interesting work – thanks.
FIrst off, what he has done is take real, complete data and then randomly remove some of the data. He then tries to use the remaining data to reconstruct the missing data.
His reconstructions differ from the real data by 0.02C.
Mr. Fife, If I’ve misunderstood your method, I apologize.
It’s interesting, but the accuracy is remarkable. I have maps of temperatures 2 miles apart that vary dramatically. I can’t see how “estimating” ever gives an accurate answer unless of course you beat and churn it and weight it and …….it’s unrecognizable. I just can’t see this whole thing as legit.
I did like the posting though. It helps me see what is being done.
That was just a trial to test different methods. The actual trial error between 5 stations ranged up to half a degree or more.
The ± 0.02° 90% confidence interval is in estimating the actual average based upon a sample size of 1302 stations. That provides an estimate for the error in a trend analysis within the time segment being looked at.
The point of this exercise is to analyze trends. The actual starting and ending points within a time segment have a vertical error margin of ± 0.3° for a 25 year time segment relative to the actual 112 year average. The individual year averages have a ± 0.02° margin of error to the actual 25 year average. Hence the error margin for a trend line over a 25 year time segment would be ± 0.04°.
I hope that clarifies things.
Mark F: Thank you for clarifying.
Mark Fife –> What Robert has tried to say is that you’re dealing with arithmetic when you claim an error margin of such a small value. This has been discussed many times here. Basically you are saying your arithmetic is showing an excellent correlation. Great. However, because the errors of the readings were originally, lets say, +/- 1 degree as Robert points out, error propagation requires you to also include this in your statement of how accurate your temperature range is. So basically anyone using your data must assume the temperatures can range from +/- 1.02 degrees.
In essence, assume all the data you are using could be one degree higher or one degree lower. Your trend may be the same (+/- 0.02), but it will be applied to vastly different temperatures. A chart needs to show both so when people read your data chart, they will see the possible temperature ranges due to inaccuracy of readings.
The assumption is the data is the data. You are only able to speak according to the data. The objective here is not to post calibrate the gages or study gage repeatability and reproducability. When you are assessing capability for the feature of a part in manufacturing you do not incorporate a gage R & R study into the part capability study. That is nonsense. No serious Quality Engineer would consider doing such a thing.
What you do is you assess the part capability, meaning the statistics of the production process. If you have conducted a gage R&R study so that measurement variability is known you can incorporate that into the study results if necessary. The standard in industry is if the total variation due to measurement variability is less than 10% of the product specification you discount it. If it is more then yes, you add that to the process variability.
If it is more than 10% of the tolerance it is understood gage variability is a major source of process variability. You understand what I am saying? If my process has a true inherent variability of ± 0.010 at a 90% confidence interval and if the gage has an equal variation of ± .010 at a 90% confidence interval the measured then the expected value for a 90% confidence interval of the process as measured would be ± 0.014. When reporting the results of this you would say the process measured at ± .014 at a 90% confidence with a ± 0.010 gage variability.
When you state a physical number like a temperature, the next most important step is to quote its uncertainty or error estimate.
There are two broad camps when it comes to errors. One camp (including me) says that all known sources of error should be included in the estimate of error. If, by observation, global T data sets show that a site change commonly needs a homogenisation adjustment of +/- z degrees, then that figure should find its place in the error analysis. The other camp (that seems populated mainly by climate researchers) tends to use a stats approach, doing things like fitting a linear regression through a time series of data points and then quoting the Excel RMS number from the graph as an estimate, or worse, THE estimate of error.
Some people like Pat Frank frame this difference of method in terms like accuracy and precision, or errors of type 1 and type 2. (Reference is often made by researchers like Pat to the prime authority on error analysis, the Paris based BIPM).
Mark Fife above withholds a period of data from a time series and then tries to infill it with data from surrounding sites. His error is then derived by comparing the original with the infill. This is a valid approach, but when the error is presented for discussion, it needs to be put into the context of whether it is an “accuracy” or “precision” type of error estimate, because the two types can be rather independent. One would expect, for example, that the error result would be different if raw and homogenised data were used as start points, then the error compared. This is because in each case, there is a difference in the ceteris paribus assumptions of what was held constant or accounted for in each case.
Fundamentally, it comes back to simple observations like how much error is involved in reading a thermometer, how much observers differ, how much the screen housings differ, whether the thermometer can be traced to a primary source of calibration etc etc. These simple processes can lead to quite large accuracy type errors, but modern wisdom seems to be to keep quiet about them as if they are mental relatives locked in the attic that families do not speak about.
I have tried to get overall error estimates from Australia’s BOM, but I continue to await an answer from them, maybe because I phrased the question poorly. It is a fundamental topic, one that used to be second nature in the older days of science. The overall error estimate is quite important because, among other properties, it is a fast filter for assessment of the quality of a publication about measured data. Times seem to have changed. The technique of application of an ensemble average and its error to a group of computer climate simulations in the style of the CMIP comparisons leaves traditionalists simply aghast.
So, Mark Fife, might you please be a little more explanatory of what your findings on errors are re your essay above, particularly what sources of error were included, what was excluded and what was assumed to be held constant (or without error) for the purposes of your estimation. Thank you Geoff.
+ 1
I tried to point out the same, but you beat me to it and did a better job.
+10
This is an interesting question. I will try to answer as best I can. The first thing I would like to address is the idea concerning errors of precision versus errors of accuracy. What exactly would an error of precision be? Perhaps we are not working from the same definitions for these concepts. I will explain by an example.
If I am measuring the length of a steel gage block I can use a number of different types of instruments. I can use a caliper or a micrometer. If you look at the dial of a caliper it is graduate by .001″. The micrometer may also be graduate to by .001″. In both cases, the precision of the instrument is the same. They both read to the nearest .001″. You would assume the accuracy would be ± one graduation, or ± 0.001″. That is not the case because of the physical design of the instrument and how it works. The micrometer, if properly calibrated, is accurate to within ± 0.001″, the caliper is not. Accuracy for a caliper would be ± 0.002 or higher.
Accuracy is always the difference between what is and what is measured. Precision is literally the limit of how finely a measurement can be made.
Now a word about variation. There appears to be a misconception concerning variation and how that affects measurement results. People here seem to think you add measurement variability to the results. That is incorrect. The measured results contain all variation from all sources. Variations affect the measured results.
In manufacturing the practice is to perform a gage R & R study. That study quantifies the amount of instrument variability and the amount of operator induced variability. the resulting variability from both is then calculated. It is not a simple addition, it is a square root of the sum of the squares function.
When that is known, the standard is a gage and operator variability is acceptable if it does not exceed 10% of the tolerance for what you are measuring. It can be discounted. You do not add it to what you are measuring. In large sample inspection measurement variability typically cancels out because there are usually as many plus as minus errors.
There are many instances where measurements are biased. A bias is by definition not variability. It is a consistent error. Improper calibration is one. Hanging a thermometer too high so that you consistently read the temperature as being too low is another.
Gage bias is certainly something you could correct for after the fact. But that would take finding an existing bias for every gage and every operator, quantifying that bias, and determining when the bias was in place and when it was not.
So, to sum this up the factors involved are bias and variability. A bias, if determined and consistent, can be adjusted. Variability is already inherently included.
I hope that clears things up.
Mark, thank you.
There are many terminological issues in this topic. I have to read your comment more deeply to match it up with my observations. Geoff.
Worth a read:
https://www.atmos-chem-phys.net/18/5147/2018/acp-18-5147-2018.pdf
Global average sfc T anomalies indicative of anomalies in outgoing energy is not well supported over the historical temperature record in model ensemble or more recent satellite observations.
The lack of a direct relationship between sfc T and radiation balance suggests that it may be profitable to investigate alternative formulations. Parameterizing the response in terms of 500 hPa tropical temperature is superior in many ways.
I am doing similar work with New Zealand’s record. Here, the most influential factor in regional variation is elevation. One has to try to have a good cross section and maintain it when bringing in stations to cover certain 30 yr periods throughout the entire history. Its a bit hit-and-miss. It easy to skew things either way through selection based on elevation. Obviously, latitude also has an influence. A mix and match record ain’t that robust. Sadly we had a number of stations with a century + near-complete record that were closed down in the 90’s. Crazy. What were they thinking?
The people responsible for the closings down are still around. It should be possible to ask them. National (Bolger then Shipley) were in power throughout the 90s, so I imagine the present government would be delighted to blame them for something, especially as our current PM is a Believer in AGW.
I note that looking at the Weather Underground map for the city I live in, I see differences on the order of 1C within the space of a km. The north facing and south facing side of a hill may have the same latitude and elevation, but they won’t have the same temperature.
Michael, I’d love to learn more. Can you contact me through my blog:
http://scottishsceptic.co.uk/c0ntact/
The important take away from Mr. Fife’s (And Steve Goddard’s, despite Watts’ nebulous issues with him) analyses, is that the closer towards “high quality” one gets with respect to data, the more “global” warming seems to be in reality an artifact of the large, complex, fragmented, short duration, UHI infected, geographically biased data sets. And of course in the case of the contiguous US adjustments and fake NOAA data, for which the justifications are irreducibly complex.
Honorable mention to E.M. Smith, Paul Homewood, and all the others who, with zero funding, dissect the temperature records.
I think Tony Heller’s data is often conclusive ipso facto.
Its interesting but a 90% confidence level is far too low to be meaningful. Even that junkiest of sciences, epidemiology, uses 95%.
What are the differences at 95%? Presumably much higher?
“From these trials I concluded you can’t compare averages taken at different times from different stations”
Bad conclusion driven by inferior spatial temporal methods.
WOW steve you are soooo informative and convincing!
Mosher wades in with another ignorant comment.
For how do you know that the best way to normalise data is spatially? What about by habitat type, or by distance from the ocean or height.
Without having a long term model of how natural variation occurs – you cannot have a model of how to weight the stations. …. and it doesn’t help if you keep insisting there is no long term natural variation.
Scottish Sceptic April 20, 2018 at 7:29 am
Mosh is many things. Ignorant is not among them. Go to his website, you’ll see how much he knows.
However, his drive-by comments drive me nuts. Somewhere underneath, there is an informed, reasonable objection to the statement about the comparison of averages … but it’s anybody’s guess just what that objection might be.
Sigh …
w.
Its simple willis.
The problem is that people are stuck in the paradigm of estimating (averaging) temperature in one location or one time period from temperature in a different location or time period.
The key is to do something entirely different, in fact you yourself found this out..
the fundamental insight comes from RomanM.
I’m amazed people forget one of the climateaudit stars.
Not in mood to explain, pearls, swine and all that. You have much more patience for sun nuts than I have for folks who ignore decades of stats of spatial/temporal data.
And now for a cool thing… folks are collecting and digitizing more old data from new locations where we didnt have data before..
any way..
enjoy
Steven Mosher April 22, 2018 at 3:51 am
Thanks for the clarification, Steve.
I believe that Mosh is referring to the idea of the temperature field. In this procedure, you first get rid of the components of the temperature that are due to elevation and latitude. This leaves you with a much simpler problem. See my post called “The Temperature Field” for more about the idea.
Regards to all, and thanks, Mosh, for the further explanation.
w.
Roman M simply pointed to long-established least-squares statistical methods in estimating the mean of a uniform population from a large aggregate of presumably unbiased samples spanning different time intervals and locations. Being a statistician, rather than an experienced geophysical analyst, he tacitly assumed many properties that simply are not manifest in station data, such as month-to month uniformity of variance about the local mean. Once he discovered this misconception, he cautioned about the difficulties of finding actual “breaks” in monthly data series,
Nevertheless, the ambitious academics at BEST, no more aware of the vagaries of actual in situ data, seized upon this methodology, in conjunction with a theoretically simplistic “break-detection” algorithm, to produce grossly idealized, ill-specified regional “temperature fields.” Despite the fact they often bear little resemblance to the spatial features of actual climatic regimes, which can undergo sharp changes over short distances that have nothing to do with latitude or elevation, they use those fictional fields to adjudicate the validity of station data, adjusting it at will to fit their preconceptions. A more egregious example of academic hubris in circular reasoning is difficult to find.
As if it is possible to determine a meaningful global average temperature. It is a fool’s errand, and skeptics need not apply.
Mark Fife did BETTER than BEST.
the entire history of the global average temperature:
Willis Eschenbach asked about methods for estimating average temperatures. I see that Clive Best has worked on this on his blog. http://clivebest.com/blog/. Using triangles for the whole globe.
Another great piece of work by Mark. What I find so informative is the complete contrast between his methodical approach and thoroughly logical conclusion and the total cock up and clear massaging of data we see daily from alarmists.
Has the world warmed yes. Has it warmed “abnormally” … No, there is not one shred of evidence the temperature is doing anything other than behaving normally.
What is also striking is the contrast between this and the massaged data. Clearly if you assess global temperature using an average of the available sensors that have been affected by global temperature for longest, we see almost no trend. So, how do the alarmists obtain their massive warming trend? The answer must be that like the hockeystick where one tree created most of their uptrick, here a very few sensors must bve massively over-influencing the long term trend.
When this nonsense will stop?
THERE IS NO WAY TO DO WHAT YOU INTEND TO DO.
You cannot create information, destroy entropy, violate second law. There is no way you can figure out missing data out of existing data. So, either existing data, however incomplete and fragmentary, does have all the data you need, and reconstruction is useless. Or it doesn’t have it, and your reconstruction is literally “made up”; and useless, too.
Besides, you are doomed by Arrow’s impossibility theorem: there is no “good” way to aggregate individual data into a global data. Such aggregation can be done, of course, but the result is all about weighting, whether explicit or implicit. You’ll get the result implied by the method you choose, and, obviously, you will adopt a method which fit you bias.
As I said above, I so miss raw data and simple graphs and spreadsheets.
I agree with the Scottish Skeptic and paqyfelyc above. I live about 1 mile from
the closest official weather station on the leeward shore of a relatively narrow lake,
In winter, the temperature on my back porch is 1-3 F warmer than the official reading,
depending upon the wind. In the summer, the reading is 1-3 F cooler than the official
reading. It is very rare that the thermometers agree,
In my opinion, any change of the official reading is opinion and is bad data and cannot
be used.
My wife managed clinical research projects before we retired. She would not allow any
data considered to be suspect to be used in any way and she cannot that climate
science does.
Absolutely! My wife has two thermometers with external sensors. The sensors are less than a foot apart in a location which receives no direct sunlight. The one location is consistently a few degrees warmer, even if she switches sensors and thermometers. The only difference I see is one is closer to being centered on a bush. It may be it blocks the wind just a bit more there, or whatever humidity it generates affects the one and not so much the other.
Which, if you want to be really consistent about things, a temperature measurement alone is less than useful. It should be considered within the context of absolute humidity, pressure reading and movement direction, wind speed and direction, location surface, location surface temperature, and location soil water content. So many factor to consider!
And please consider any criticisms of my effort would apply in spades to what anyone else is doing. It is, I think, a more rational, practical approach. In any event, I didn’t just throw it out there and say it was correct enough to detect a 1.5° in temperature as absolute truth. By my own statements the overall trend error at a 90% uncertainty level would be ± 1.1° or a potential error of 2.2°. My only claim to real accuracy was in the 25 year trends. I am really amazed no one noticed that. I put that information in there as plain as day.
Actually I am not THAT amazed.
Whoops, even I messed up. That is ± 0.3° times 4 plus ± 0.5, or ± 1.7°. Oh well. The point is no one noticed that.
wrong
So you believe 2nd law can be violated and information created out of nothing. Makes sense with your other beliefs.
paqyfelyc April 23, 2018 at 4:17 am
Say what? Steven Mosher said nothing of the sort. He merely said “wrong”. Although he is almost always cryptic, which drives me nuts, in this case he appears to be responding this statement:
“Official readings” are changed all the time, for very good reasons. Suppose, for example, we have a series of readings of some variable that are:
4.6, 4.2, 4.8, 4.5, 4.6, 45, 4.7, 4.3
Obviously, what has happened is a transcription error, where “4.5” has been written down as “45” because someone left out the decimal point. As part of the normal process called “Data Quality Control”, I would have no problem putting the decimal point back in.
Steve McIntyre pointed out a famous one a while back. In the middle of a bunch of Celsius temperature readings where a week’s worth looked like
17 19 14 18 22 19 23
there was a week that looked like
62, 67, 58, 65, 71, 67, 73
Obviously, someone had forgotten to convert readings that were originally taken in Fahrenheit to Celsius for the official record. Again, I’d have no problem fixing the error by making the conversion.
So no, Steven’s not talking about violations of the 2nd law. He is talking about fixable errors in measurements. These errors can be from faulty instruments, changes in time of observation, improper unit conversion, or human frailties of a variety of types. They do not necessarily require that we throw out the data. That is a simplistic view of real-world data collection.
Regards,
w.
When I really think about it, “global warming” has no meaning.
Average temperature tells us about as much (about energy) as average stock price tells us about profits. There’s so much more to it.
Consequently, all the statistical manipulations in the world, designed to achieve internal certainty of the calculating process, are STILL missing detailed information, and the only thing the certainty is describing is the mathematical manipulating process that creates the new numbers from the raw data.
An anomaly is a statistical concept, right? — a mathematical concept dealing with the numbers at hand plugged into the calculation methodology. The calculation methodology can be pristine, but if it uses numbers that have limited realistic meaning, then the calculation itself has limited realistic meaning.
I’m sure somebody can say it better than me, but that was my feeble attempt.
GIGO.
I had to look it up. I knew the saying — I just didn’t recognize its abbreviation:
GIGO = Garbage In Garbage Out
The garbage might be more compacted and neater looking, but it’s still garbage … garbage that’s been processed into a different shape without improving its fundamental constitution.
Scientists have been creating global temperature time series using a wide variety of different approaches since the 1880s. See http://ipcc.ch/publications_and_data/ar4/wg1/en/ch1s1-3-2.html for details on their various approaches.