Dr. Roy Spencer proves what we have been saying for years, the USHCN (U.S. Historical Climatology Network) is a mess compounded by a bigger mess of adjustments.

==============================================================
USHCN Surface Temperatures, 1973-2012: Dramatic Warming Adjustments, Noisy Trends
Guest post by Dr. Roy Spencer PhD.
Since NOAA encourages the use the USHCN station network as the official U.S. climate record, I have analyzed the average [(Tmax+Tmin)/2] USHCN version 2 dataset in the same way I analyzed the CRUTem3 and International Surface Hourly (ISH) data.
The main conclusions are:
1) The linear warming trend during 1973-2012 is greatest in USHCN (+0.245 C/decade), followed by CRUTem3 (+0.198 C/decade), then my ISH population density adjusted temperatures (PDAT) as a distant third (+0.013 C/decade)
2) Virtually all of the USHCN warming since 1973 appears to be the result of adjustments NOAA has made to the data, mainly in the 1995-97 timeframe.
3) While there seems to be some residual Urban Heat Island (UHI) effect in the U.S. Midwest, and even some spurious cooling with population density in the Southwest, for all of the 1,200 USHCN stations together there is little correlation between station temperature trends and population density.
4) Despite homogeneity adjustments in the USHCN record to increase agreement between neighboring stations, USHCN trends are actually noisier than what I get using 4x per day ISH temperatures and a simple UHI correction.
The following plot shows 12-month trailing average anomalies for the three different datasets (USHCN, CRUTem3, and ISH PDAT)…note the large differences in computed linear warming trends (click on plots for high res versions):

The next plot shows the differences between my ISH PDAT dataset and the other 2 datasets. I would be interested to hear opinions from others who have analyzed these data which of the adjustments NOAA performs could have caused the large relative warming in the USHCN data during 1995-97:

From reading the USHCN Version 2 description here, it appears there are really only 2 adjustments made in the USHCN Version 2 data which can substantially impact temperature trends: 1) time of observation (TOB) adjustments, and 2) station change point adjustments based upon rather elaborate statistical intercomparisons between neighboring stations. The 2nd of these is supposed to identify and adjust for changes in instrumentation type, instrument relocation, and UHI effects in the data.
We also see in the above plot that the adjustments made in the CRUTem3 and USHCN datasets are quite different after about 1996, although they converge to about the same answer toward the end of the record.
UHI Effects in the USHCN Station Trends
Just as I did for the ISH PDAT data, I correlated USHCN station temperature trends with station location population density. For all ~1,200 stations together, we see little evidence of residual UHI effects:

The results change somewhat, though, when the U.S. is divided into 6 subregions:






Of the 6 subregions, the 2 with the strongest residual effects are 1) the North-Central U.S., with a tendency for higher population stations to warm the most, and 2) the Southwest U.S., with a rather strong cooling effect with increasing population density. As I have previously noted, this could be the effect of people planting vegetation in a region which is naturally arid. One would think this effect would have been picked up by the USHCN homogenization procedure, but apparently not.
Trend Agreement Between Station Pairs
This is where I got quite a surprise. Since the USHCN data have gone through homogeneity adjustments with comparisons to neighboring stations, I fully expected the USHCN trends from neighboring stations to agree better than station trends from my population-adjusted ISH data.
I compared all station pairs within 200 km of each other to get an estimate of their level of agreement in temperature trends. The following 2 plots show the geographic distribution of the ~280 stations in my ISH dataset, and the ~1200 stations in the USHCN dataset:


I took all station pairs within 200 km of each other in each of these datasets, and computed the average absolute difference in temperature trends for the 1973-2012 period across all pairs. The average station separation in the USHCN and ISH PDAT datasets were nearly identical: 133.2 km for the ISH dataset (643 pairs), and 132.4 km for the USHCN dataset (12,453 pairs).
But the ISH trend pairs had about 15% better agreement (avg. absolute trend difference of 0.143 C/decade) than did the USHCN trend pairs (avg. absolute trend difference of 0.167 C/decade).
Given the amount of work NOAA has put into the USHCN dataset to increase the agreement between neighboring stations, I don’t have an explanation for this result. I have to wonder whether their adjustment procedures added more spurious effects than they removed, at least as far as their impact on temperature trends goes.
And I must admit that those adjustments constituting virtually all of the warming signal in the last 40 years is disconcerting. When “global warming” only shows up after the data are adjusted, one can understand why so many people are suspicious of the adjustments.
Nick Stokes says: April 14, 2012 at 2:33 am
Richard S Courtney says: April 14, 2012 at 2:06 am
“Really? You know that? How?”
Greenhouse effect. Putting CO2 in the air impedes outgoing IR. Heat accumulates, temperature rises. Flux balance then restored (until more CO2 accumulates).
Past evidence wouldn’t precisely support your claim. In the early 18th century England (before industrialisation) increase of the CO2 was negligible, and yet if we compare two 50 year temperature records for now and then we get
http://www.vukcevic.talktalk.net/CET1690-1960.htm
great deal of similarity except that the CET than rose faster than now.
You may dismiss this as a local event, but it can be seen that the current CET well correlates to both the Northern hemisphere’s and the global temperatures.
Local natural event then, the CO2 now.
Not so. The same natural event appear to be responsible for the rise then and now, at least as the CET is concerned, And it is all to do with the North Atlantic-Arctic warm/cold currents balance
http://www.vukcevic.talktalk.net/CGNh.htm
And what is the natural force changing that balance?
Not easy to prove, it looks like something to do with the solar activity, but not at a degree that the classic sunspot count would suggest
http://www.vukcevic.talktalk.net/SSN-NAP.htm
Data? Yes, all available.
Published? No, there is no interest, but the ‘climate’ is changing, as ever.
I saw this graph on a dutch website
http://www.klimaatfraude.info/images/sverdrup.gif
from
http://www.klimaatfraude.info/oceaanopwarming-of-zeespiegelstijging-door-co2-is-niet-mogelijk_193094.html
“The solar radiation penetrates the ocean to 100 metres at visible wavelengths but to much shallower depth as wavelength increases. Back radiation in the far infra-red from the Greenhouse Effect occurs at wavelengths centred around 10 micrometres and CANNOT penetrate the ocean beyond the surface ‘skin’.”
If the oceans warm the Earth but CO2 cannot warm the oceans and we know that the last years we had no warming in the oceans
http://www.klimaatfraude.info/flitspost/images/2011-05-30_021050.jpg
Warming must be mainly an artifact of adjustments.
Urederra says: April 14, 2012 at 3:05 am
“No sir, Goodridge already proved that CO2 has no effect on temperatures by demonstating that rural stations do not show any warming over the last 100 years despite of global CO2 increase.”
He didn’t prove that at all. He showed in 1996 that some rural counties in California showed little increase. He gave no statistics of the effect of this small sample.
In fact globally there is very little difference between the trends of rural and urban stations.
Why adjust at all? The data set is large enough, and encompasses an enourmous number of natural variables – should not these measurement variables just be averaged in with the rest. Either drop down to a micro-climate level and record the datum properly OR smash it all together and establish an error bound “average”.
Once you start adjusting, where do you stop?
Neville. says:
April 13, 2012 at 4:41 pm
If this really is so simple then why can’t you expose this nonsense as soon as possible? Also if the US station adjustments are so prone to error then what about the rest of the planet?…..
________________________________
The same type of problems are being seen elsewhere. This is highlighting just a few.
New Zealand
href=”http://wattsupwiththat.com/2010/08/16/new-zealands-niwa-sued-over-climate-data-adjustments/”>New Zealand’s NIWA sued over climate data adjustments
The Goat ate my homework: NIWA’s confession that it lost the Schedule of Adjustments (SOA) for the official New Zealand temperature record is the latest event in a long-running scandal…
AUSTRALIA
http://notalotofpeopleknowthat.wordpress.com/2012/03/15/an-adjustment-like-alice/
Australian temperature records shoddy, inaccurate, unreliable. Surprise!
RUSSIA
IEA: Hadley Center “probably tampered with Russian climate data
On Dec 15, 2009, it was reported that the Moscow-based Institute of Economic Analysis (IEA) issued a report “claiming that the Hadley Center for Climate Change based at the headquarters of the British Meteorological Office in Exeter (Devon, England) had probably tampered with Russian-climate data.”
CHINA
There is also the question of how good the data is during the time of Red China’s “Purges” where up to 80 millions were killed. (While reading that link, it pays to remind ourselves that this is the same country our leaders are handing over world economic leadership to using CAGW and the World Trade Agreement.)
Nick Stokes says:
April 14, 2012 at 1:12 am
Andrew says: April 13, 2012 at 11:34 pm
“but do I take it this figure represents the “consensus” estimate of global climate sensitivity?”
None of these figures relate to anything global at all. They are about ConUS.
_________________________
Exactly.
You don’t realize it, but you just gave your whole game away.
Since almost all (and quite possibly all) of the “Global Warming” touted in datasets is from ConUS adjusted datasets.
The cooler the southern hemisphere and other locales- the more adjustments to the ConUS records.
Geoff Sherrington says: April 14, 2012 at 12:46 am
“Nick, when the BOM send data to NOAA or Met Office or whomever, do they currently send Tmax and Tmin as read from Min-max thermometers read once a day, or as calculated from many readings per day?”
Geoff, here’s a typical BOM monthly summary. You’ll see that they list the max and min for each day. This is based on their daily summary in which they list the Max and Min and exact time observed. They give an average Max and min in their monthly table, and I believe those are the numbers that go into the CLIMAT form.
As to splicing, that is part of the larger issue of matching MMTB readings to the earlier thermometer readings.
Nick Stokes says:
April 14, 2012 at 2:33 am
“Greenhouse effect. Putting CO2 in the air impedes outgoing IR. Heat accumulates, temperature rises. Flux balance then restored (until more CO2 accumulates).”
I thought the it was the postitive feedback of a warmer atmosphere holding more water vapor that was the major factor of global warming. Are you now not including this feedback or did you just forget to mention it?
Sean says:
April 13, 2012 at 5:53 pm
In other words, instead of admitting up front that they really do not have useful data on which to draw the kind of conclusions that they are making, due to the poor and inconsistent experimental method used to gather this data, climatology is just making things up and lying. My only conclusion is that field of climatology is currently not a science any more than alchemy is a science.
_____________________________________
BINGO!
Especially when much of the early data was to the nearest whole degree, or as one commenter noted intentionally rounded up to give pilots an added safety margin. How the heck anyone can get a trend of “0.161 C/decade” using a sample size of n=1 from that type of data is beyond me.
When we did statistics we separated out the different cavities on each mold for each molding machine as different sets of data that should not be mixed. These alchemists lump data from different days and different locations together using their magic wand called “anomalies” and some how create accuracy and precision where there was none before.
Tom in Florida says: April 14, 2012 at 5:49 am
” thought the it was the postitive feedback of a warmer atmosphere holding more water vapor that was the major factor of global warming. Are you now not including this feedback or did you just forget to mention it?”
Yes, water vapor feedback amplifies the temperature increase due to any forcing.
I have carried out the same analysis for individual states (see the series at Bit Tooth Energy which gives the result by state, listed on the RHS of the blog and comparing time of observation corrected data against final adjusted values and GISS temperatures for each state). Given that the population changes with time one has to be careful as to which intervals one compares with current population. Given also that the larger population centers tend to lie in the lower elevations and that temperature is sensitive both to elevation and latitude, it is really a 3-factor dependence. But the correlation runs at an r^2 of around 0.14 when a log function is used for population (which is the correlation that most often has been cited in the past) and running a five-year ave temp against current populations, in many states.
There is an interesting temperature drop of around 4 degF that happened in about 1950 in the North East states, that they have only just recovered from, and it had an interesting effect on the habits of the Black capped Chickadee.
RoHa says:
April 13, 2012 at 7:12 pm
In case you have forgetten, I’d like to remind you that we’re doomed.
____________________________________
You are correct but it is doom via greedy politicians and the Regulating Class and not doom via climate.
TheInqjirer says:
April 14, 2012 at 12:13 am
…..If Dr Spencer is claiming that climate scientists have “fudged the data” he should be having a field day in the journals deconstructing the hypothesis…..
_________________________
Dr Spencer tried. The journal’s Editor-in-Chief’s resigned because he published Dr Spencer’s paper: http://www.drroyspencer.com/2011/09/editor-in-chief-of-remote-sensing-resigns-from-fallout-over-our-paper/
Without reading the replies yet, I predict this will anger the warmers alot.
.013C/decade just doesn’t cut it for proper alarmism.
Nick Stokes: Yes, ambient water vapor is a positive feedback, but if the vapor instead assumes the form of low cloud cover, then it’s a negative feedback.
Gail: Actually, you can get more precise readings from crude data — by “oversampling”. If you take hundreds of readings that are accurate to within a degree C and average them, you wind up with an accuracy finer than a degree C.
The problem occurs, however, when NOAA claims the readings are accurate to within a degree C, and it transpires that they are not. #B^j
013C/decade just doesn’t cut it for proper alarmism.
McIntyre’s USHCN1 raw data figures average out to 0.14C per century, while the adjusted come out to 0.59. He worked this out around 2007. (USHCN2-adjusted is a good chunk higher.)
When you grid the raw data to 5-degree boxes, however, it comes out to 0.25C. That’s still less than half the adjusted rate, but it is a bit warmer than the ungridded average.
(I’ve been up to my eyeballs in these stats for the last four years.)
OK, that screwed up again. Rats. For some reason the wordpress interface is actually getting worse than it was three or four months ago. km$latex^2$. This works out to
km$latex^2$. This works out to 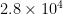 square km per station in the first case, and
square km per station in the first case, and  square km per station in the second. Taking the square root and multiplying by 2 in both cases leads to a crude estimate of the (root mean) average distance between stations of 330 km and 160 km, respectively. This makes sense — there are four times as many stations in the second set so the distance between stations is half as great.
square km per station in the second. Taking the square root and multiplying by 2 in both cases leads to a crude estimate of the (root mean) average distance between stations of 330 km and 160 km, respectively. This makes sense — there are four times as many stations in the second set so the distance between stations is half as great.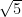 shorter mean distance between the stations in the denser set instead of identical means.
shorter mean distance between the stations in the denser set instead of identical means.
I will quickly summarize my partial post in case it went through instead of away. I’m having trouble with the final two figures and conclusion that average neighboring station distances are the same for the two datasets. The reason is that the continental US has an area of
What this means is that a lot more stations in the second set have neighbors within 200 km, simply because the average distance between stations is less than this cutoff and most stations indeed have multiple neighbors within the cutoff. This is reflected in the numbers — on average every station in the first set has four neighbors within the cutoff (two pairs), while every station in the second set has twenty neighbors inside the cutoff (ten pairs).
And here’s the rub. This means that one packs 20 stations into a circle of radius 200 km and ends up with the same mean distance between them that you end up with packing 4 into the same circle. This is at least a bit odd. I do realize that the stations are hardly randomly distributed (far from it) and that in all likelihood they were selected with a minimum distance criterion, so that they are spatially antibunched on the short end of the length scale, while on the other hand humans live in a highly bunched environment along artery roads an in or near urban centers, so that they are bunched on the long end of the length scale, but one would still expect something like a
I think that this means that one cannot fairly compare the two spatial autocorrelation “corrections” (where I actually think that trying to compute such a correction is such a horrendous abuse of statistics as to beggar the imagination, by the way — I can see why one has to apply some corrections to site data if it is known that the data is recorded differently between sites, although this correction comes at the expense of increasing the error bars on the final result (that never seem to get plotted, why is that one wonders) but one is never justified in trying to “correct” one site’s temperature on the basis of temperature measurements from neighboring sites.
Once one has the best guess for a site’s max/min/mean temperature, there is only one reasonable way to transform that data into a continentally averaged temperature and that is to perform a numerical integral of the temperature field over the area. There is no possible justification for smoothing the data on any length scale before doing this integral — the whole point of doing the integral is that it is the only unbiased way of doing the smoothing, given that one has no theoretical basis for cutting off any interpolating polynomial representation at some spatial length that is longer than the distance between sites.
I sometimes wonder if anybody who works in climate science has actually taken a course in numerical methods and learned about numerical quadrature and the problems attendant thereupon (or ODE solution methods, or if they actually understand statistics, or…)
What is really needed in this field is a double blind experiment. After all, an unbiased observer, performing a double blind analysis of the data, would not know what is being computed and would not know what direction “up” and “down” were for the variable. They would simply be given a pile of data presumably sampled from a wide range of sites around the US and asked to turn it into an average and trend. It might represent average exam scores of students in high school, it might represent a normalized estimate of the prevalence of drug abuse, it might represent average wind speed, it might represent average income per household (all on suitably obfuscated scales). Note that some of these might have the same kinds of problems that temperature has (only bigger) — the exam itself might have changed over the time studied, or high school students might be getting more intelligent (Flynn effect), or high school exam scores could be confounded by prevalence of drug abuse. However, “correcting” for these things using some sort of prior knowledge is dangerous because one of the things one might wish to do is infer the effect of an exam change, Flynn, drugs from the result, so “correcting” for them a priori simply makes the result useless, a self-fulfilling or obscuring prophecy.
Fortunately, for climate science, there are a number of them that potentially exist. I offer one of them up for consideration:
Suppose one takes all of the station data and inverts it with respect to its (station) mean, and then passes all of the data through the same “correction” process. Note that this is a pure symmetry operation; if one is looking for a temperature anomaly inverting with respect to the station means had better produce a perfectly symmetric downward trend in temperatures!
That is, if one has the UHI effect and all other corrections right, then an inversion of the data must lead to a perfectly symmetric inversion of the trend. This seems like an absolutely trivial test that can be performed with almost no additional programming effort to any of the algorithms used to transform temperature data into anomaly. If inversion of the data is not symmetric, the algorithm is biased. It is as simple as that. Symmetry is a necessary condition of an unbiased algorithm.
There are several other ways to effectively “double blind” temperature analysis. For example, give the data to a professional statistician but lie about what it represents. Tell them that it is data representing the average count of golliwogs per square hectare, that you suspect that it is biased by golliwogs being kept in urban zoos so that those numbers may be up a bit and you want to correct for that in the spatial average as you really want only the wild golliwog count, and that some of your golliwog counters did a better job than others (but you aren’t sure who is who). Let them take it away, crank up SAS or R and come back in six weeks with a Grand Average Golliwog Population of the US curve. I’ll bet that given exactly the same data their curve would look nothing like any of the “official” temperature curves.
I would be very, very interested in how CRU or GISS would respond to a demonstration that their algorithms do not possess inversion symmetry, if it were to be clearly demonstrated that this is the case. Personally, I think that would be the end of the game. How is it possible to argue that they should not possess this symmetry? If there isn’t every bit as much cooling apparent from inverted data as there is warming now, how exactly could we observe cooling in the future? Inversion symmetry must be an absolute constraint of any average temperature estimate, a sign that a UHI correction (or any other corrections applied) are plausible.
rgb
Mr. Watts, Taking into consideration the early comments of Richard S Courtney, and further considering the numerous qualified contributors to this site and your universal coverage and appeal, might I suggest that you add a section to this site for ‘peer reviewed climatology papers’ that are ‘impossible to get published anywhere else’. You have a much broader base and readership than the official journals and a h.ll of a lot more credibility. You could start with Richard S. Courtney’s paper. I can feel the frisson going through the ‘Team’ part of the ranks of climatologists, and cheers going up from the other part.
Robertvdl says:
April 14, 2012 at 4:46 am
///////////////////////////////////////////////
I wish that I could understand the Dutch site. It is probably very interesting.
As I see matters there is a considerable problem with DWLWIR and the oceans which has not been fully nor properly thought through. .
First, as you note, due to its wave length, DWLWIR is fully absorbed within the first 10 microns of the ocean. However, of more significance, 20% of all DWLWIR is absorbed within 1 micron and 60% within 4 microns. If DWLWIR has the intensity suggested by the K & T energy diagram. it would mean that from an optical physics persepctive there would be so much energy being absorbed in the first couple of microns that it would lead to rampant evaporation. There is a problem here since if there was such eavporation, the energy would not enter the ocean but would end up in the atmosphere (as a consequence of the evaporation and latent heat change). We are not seeing rampant evaporation and this therefore suggests that DWLWIR is not of the order of magnitude claimed, or lacks sensible energy, or is merely nothing more than a signal incapable of performing sensible work, or that much of the DWLWIR is either blocked from reaching the ocean, or is simply reflected by the ocean.
Second, water is essentially an LWIR block (this follows from the fact that LWIR is fully absorbed within 10 microns and 60% of all LWIR within 4 microns). If there is a very thin veil of sea swept mist/spume/spray of just a couple of microns thickness, lying immediately above the oceans, then this very thin veil would be sufficient to effectively block DWLWIR from penetrating the oceans below. For much of the time over much of the oceans there will inevitably be such a thin veil of wind swept mist/spray/spume.
Third, the K & T energy diagram shows solar irradiance being reflected from the surface. This is predominantly from the oceans reflecting solar rays at low angles of incidence. Why does the diagram not show any reflection of DWLWIR? Since GHGs radiate in all directions, it follows that some DWLWIR must be bombarding the oceans at a low angle of incidence? Why is this not reflectsd? Can DWLWIR not be reflected? Can the oceans not reflect DWLWIR? Not sufficient consideration has been given to the reflection of DWLWIR.
Fourth. at the very top micron level of the ocean, the energy flow is upward. The top micron layer is colder than the 4 to 8 micron layer. It follows from this and from the first two points that it would appear that there is no effective mechanism whereby DWLWIR could warm the bulk ocean. It would appear that given that the energy flow is upwards, heat cannot run against it and thus any energy absorbed in the first few microns could not find its way downwards into the bulk ocean and thereby cannot heat the bulk ocean.
The upshot of the above is that ocean heat is almost certainly driven simply by solar irradiance and an increase in ocean heat is a factor of an increase in solar energy, possibly (I would say probably) due to a reduction in cloudiness.
Anyone who thinks a minus 0.05 degree C adjustment for UHI is adequate need only consider the previous post concerning peak temperatures at airports. Recall as well that even in the early 1950s commercial jets were uncommon.
evanmjones says:
April 14, 2012 at 6:22 am
“When you grid the raw data to 5-degree boxes, however, it comes out to 0.25C. That’s still less than half the adjusted rate, but it is a bit warmer than the ungridded average.
(I’ve been up to my eyeballs in these stats for the last four years.)”
Less than half a degree? My work here is done.
rgbatduke: I am no scientist but boy does your “inversion symmetry test” sound like a good idea. Thanks for a great comment…
vanmjones says:
April 14, 2012 at 6:22 am
Gail: Actually, you can get more precise readings from crude data — by “oversampling”. If you take hundreds of readings that are accurate to within a degree C and average them, you wind up with an accuracy finer than a degree C….
________________________________
I am well aware of that. If I take a sample and mix well, divide into ten samples and do my chemical analysis on each of the ten samples I can come up with a better estimate of the true value. (BTDT) However that is not applicable here because as I said the sample size is ONE.
You are not doing several readings with calibrated thermometers at the same time at the same place. Instead you are doing a bunch of number juggling but the sample size is STILL ONE, therefore the estimate of the true value of the temperature for that specific location at that specific time has the error bars for a sample size of one. You can not get better accuracy or precision into that specific record by comparing it to the reading from the next town over any more than I could by combining the measurements of a widget from the machine next to the first machine. Heck by combining widgets from several cavities in just one machine I would INCREASE the error not decrease it.
We know darn well the Atlantic Ocean modifies the temperatures along the Eastern Seaboard such that you can see it.
Raw 1856 to current Atlantic Multidecadal Oscillation
href=”http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=425723080040&data_set=1&num_neighbors=1″>Norfolk City VA
Elisabeth City NC
Wilmington NC
The same holds true for the West Coast and the Pacific. The location of the jets determine the location of the Polar Express, Arctic air that gets sucked down over the USA. Therefore you can not just group a bunch of temperature data together to get a larger sample size.
TheInqjirer says:
April 14, 2012 at 12:13 am
“One of the claims against AGW scientists is that they have apparently started with a preposition (AGW) and massaged the data to fit….”
You got it totally wrong. Did you read the article? Did you try to think logically?
The skeptics observe the adjustments, realize these are almost all done in one direction. They realize the adjustments are bigger then the signal, adjustments becoming the signal itself. The new graphs go outside the error bars of the previous graphs, they are not compatible.
And then due to this do skeptics ask themselves if the “AGW scientists” did not massage the data to get the results they wanted knowingly or not.
Your post is pure smoke screen to distract from discussion.
More good work Dr. Spencer, thank you!
rgbatduke says:
April 14, 2012 at 6:47 am
OK, that screwed up again. Rats. For some reason the wordpress interface is actually getting worse than it was three or four months ago.
____________________________
Boy you can say that again! I get to see about two lines at a time. It is a real pain when trying to edit and I do not have the computing power to have a word program working well when WUWT is open.