Summary of GHCN Adjustment-Model Effects on Temperature Data
Guest essay by John Goetz
As the debate over whether or not this year will be the hottest year ever burns on, it is worth revisiting a large part of the data used to make this determination: GHCN v3.
The charts in this post use the dataset downloaded at approximately 2:00 PM on 9/23/2015 from the GHCN FTP Site.
The monthly GHCN V3 temperature record that is used by GISS undergoes an adjustment process after quality-control checks are done. The adjustments that are done are described at a high-level here.
The adjustments are somewhat controversial, because they take presumably raw and accurate data, run it through one or more mathematical models, and produce an estimate of what the temperature might have been given a set of conditions. For example, the time of observation adjustment (TOB) takes a raw data point at, say 7 AM, and produces an estimate of what the temperature might have been at midnight. The skill of that model is nearly impossible to determine on a monthly basis, but it is unlikely to be consistently producing a result that is accurate to the 1/100th degree that is stored in the record.
A simple case in point. The Berlin-Tempel station (GHCN ID 61710384000) began reporting temperatures in January, 1701 and continues to report them today. Through December, 1705 it was the only station in the GHCN record reporting temperatures. Forty-eight of the sixty possible months during that time period reported an unflagged (passed quality-control checks) raw average temperature, and the remaining 12 months reported no temperature. Every one of those 48 months was estimated downward by the adjustment models exactly 0.14 C. In January, 1706 a second station was added to the network – De Bilt (GHCN ID 63306260000). For the next 37 years it reported a valid temperature every month and in most of those months it was the only GHCN station reporting a temperature. The temperature for each one of those months was estimated downward by exactly 0.03 C.
Is it possible that the models skillfully estimated the “correct” temperature at those two stations over the course of forty plus years using just two constants? Anything is possible, but it is highly unlikely.
How Much Raw Data is Available?
The following chart shows the amount of data that is available in the GHCN record for every month from January, 1700 to the present. The y-axis is the number of stations reporting data, so any point on the curve represents the number of measurements reported in the given month. In the chart, the green curve represents the number of raw, unflagged measurements and the purple curve represents the number of estimated measurements. The difference between the green and purple curves represents the number of raw measurements that are not changed by the adjustment models, meaning the difference between the estimated value and raw value is zero. The blue curve at the bottom represents the measurements where an unflagged raw value was discarded by the adjustment models and replaced with an invalid value (represented by -9999). The count of discarded raw data (blue curve) is not included in the total count represented by the green curve.

The second chart shows the same data as the first, but the start date is set to January 1, 1880. This is the start date for GISS analysis.

How Much of the Data is Modeled?
In the remainder of this post, “raw data” refers to data that passed the quality-control tests (unflagged). Flagged data is discarded by the models and replaced with an invalid value (-9999).
In the next chart the purple curve represents the percentage of measurements that are estimated (estimated / raw). The blue curve represents the percentage of discarded measurements relative to the raw measurements that were not discarded (discarded / raw). Prior to 1935, approximately 80% of the raw data was changed to an estimate, and from 1935 to 1990 there was a steady decline to about 40% of the data being estimated. In 1990 there was an upward spike to about 55%, followed by a steady decline to the present 30%. The blue curve at the bottom shows that approximately 7% to 8% of the raw data was discarded by the adjustment models, with the exception of a recent spike to 20%. (Yes, the two curves combine oddly enough to look like a silhouette of Homer Simpson on his back snoring.)

The next chart shows the estimate percentages broken out by rural and non-rural (suburban and urban) stations. For most of the record, non-rural stations were estimated more frequently than rural stations. However, over the past 18 years they have had temperatures estimated at approximately the same rate.

The fifth chart shows the average change to the raw value due to the models replacing it with an estimated value. There are two curves shown in the chart. The red curve is the average change when not including measurements where the estimated value was equal to the raw value. It is possible, however, that the adjustment models will produce an estimated value of zero. The blue curve considers this possibility and represents all measurements, including those with no difference between the raw and estimated values. The trend lines for both are shown in the plot, and it is interesting to note that the slopes for both are nearly identical.

What About the Discarded Data?
Recall that the first two charts showed the number of raw measurements that were removed by the adjustment models (blue curve on both charts). No flags were present in the estimated data to indicate why the raw data were removed. The purple curve in the following chart shows the anomaly of the removed data in degrees C * 100 (1951 – 1980 baseline period). There is a slight upward trend from 1880 through 1948, a large jump upward from 1949 through 1950, and a moderate downward trend from 1951 to present. The blue curve is the number of measurements that were discarded by the models. Caution should be used in over-analyzing this particular chart because no gridding was done in calculating the anomaly, and prior to 1892 only a handful of measurements are represented by that data.

Conclusion
Overall, from 1880 to the present, approximately 66% of the temperature data in the adjusted GHCN temperature data consists of estimated values produced by adjustment models, while 34% of the data are raw values retained from direct measurements. The rural split is 60% estimated, 40% retained. The non-rural split is 68% estimated, 32% retained. Total non-rural measurements outpace rural measurements by a factor of 3x.
The estimates produced by NOAA for the GHNC data introduce a warming trend of approximately a quarter degree C per century. Those estimates are produced at a slightly higher rate for non-rural stations than rural stations over most of the record. During the first 60 years of the record measurements were estimated at a rate of about 75%, with the rate gradually dropping to 40% in the early 1990s, followed by a brief spike in the rate before resuming the drop to its present level.
Approximately 7% of the raw data is discarded. If this data were included as-is in the final record it would likely introduce a warming component from 1880 to 1950, followed by a cooling component from 1951 to the present.
Epilogue
The amount of estimation and its effects change over time. This is due to the addition of newer data that lengthens time series used as input to the adjustment models. The following chart shows the percentage of measurements that are estimated (purple curves) and percentage of discarded measurements. The darker curves are generated from the data set as of 9/23/2015 (data is complete through 8/2015). The lighter curves are generated from the data set as of 6/27/2014 (data is complete through 5/2014). Clearly, fewer measurements were estimated in the current data set than in the past data set. However, more measurements from the early part of the record were discarded in the current data set.

A chart showing the average change to the raw data is not shown, because an overlay is virtually indistinguishable. However, the slope of the estimated data trend produced by the current data set is slightly greater than the past data set (0.0204 versus 0.0195). The reason that the slope of 0.0204 differs from the slope in the fifth chart above (blue curve) is that the comparison end month is May, 2014, whereas the chart above ends with August, 2015.
Note: the title was changed to better reflect the thrust of the article, the original title is now a sub headline. The guest essay line was also added shortly after publication, and a featured image added as the guest author did not provide these normal elements of publication at WUWT – Anthony
This is a wonderful report. Thanks much.
It would appear that this “data” set is darn near useless. It is mostly fudged up numbers that yield whatever “average” the minions need to produce for their paymasters.
And we should dismantle the industrialized west over this?
markstoval.
Why do you think the adjusted data set “is damn near useless”?
Why is the “data” set “darned near useless”?
Because 66% of the “data” is just plain made up. And the people making up the numbers have a job where showing CAGW is the objective. Biased, made up numbers used for political purposes is not a data set.
markstoval.
I won’t comment on your conspiracy theory because there is no point discussing a claim made with no evidence.
The data is not made up, it is derived by adjusting the “raw” values. The reason for the adjustments is sound.
Once data is adjusted, it is no longer “data”
No, it becomes an estimate of what the data might have been under certain assumptions.
“The data is not made up, it is derived by adjusting the “raw” values. The reason for the adjustments is sound.”
There are sound reasons to try many different hypothetical approaches. Every month there are new reasons and new ways to adjust/correct/massage the data. There is no solid evidence beyond those speculative “reasons” that the adjustments are valid.
Put another way, there were sound reasons in humanities past to believe the earth was flat.
You betcha it’s ‘sound’. It’s also ‘fit for purpose’, and the purpose is to prop up a predetermined conclusion. Not making the raw data available makes things pretty obvious, don’t you think? I wonder if Gruber learned from The Team.
Yep once adjusted the data becomes conjecture.
As conjecture it is no longer scientific evidence. It is interpretive opinion.
@ur momisugly Svante Callendar
“I won’t comment on your conspiracy theory because there is no point discussing a claim made with no evidence.”
I mentioned no conspiracy. You just made that up so that you could knock down a strawman. In other words, you are a liar.
John Mentions the Berlin Tempel station. In looking at early temperature and weather observations, this book is invaluable.
https://books.google.co.uk/books?id=O6jAo4m4L_gC&pg=PA10&lpg=PA10&dq=mannheim+palatine+thermometers&source=bl&ots=MrQt0bcAUN&sig=KJeS24aO5RAaSNgkEJ_5KYW6z1g&hl=en&sa=X&ved=0CDMQ6AEwA2oVChMI6Ya4kd6RyAIVQQ4aCh0–gDf#v=onepage&q=mannheim%20palatine%20thermometers&f=false
Readers might especially enjoy the chapter commencing page 8 ‘the emergence of organised meteorology.’
There were a number of attempts to set up organised networks from 1717 to 1727 covering Germany and London and other places
From 1724 the Royal society organised observations in Britain, North America, India and elsewhere. This noted a rapidly growing period of warmth from the deep cold of the LIA in 1695 (best seen in CET) which in Britain culminated in the 1730’s becoming the warmest decade until the 1990’s. A fact noted by Phil Jones who observed in his 2006 paper that natural variability had been greater than he had hitherto realised when examining the juxtaposition of the cold 1690’s the warm 1730’s and the catastrophic cold of 1741.
Then as now, there is little evidence of any conspiracy theory, which would have to be on a massive scale to be effective. There is however a lack of appreciation of natural variability and data that is not always robust is used.
tonyb
IF you ‘adjust data’ from a test of an engineered product you are engaging in a criminal act. Ask the ex CEO of Volkswagen. The same applies to mining, petrochemical exploration or clinical trials.
Only in the field of climate science is adjusting the data allowed. This is an egregious insult to the thousands of men and women, largely unpaid volunteers, who spent their lives collecting this information in the days before automated instruments. At school (in the 60’s) had a science teacher who took the readings several times a day from the station in the grounds regardless of weather or how he felt. That this data so carefully observed can just be tossed aside in favour of a set of adjusted values is a disgrace.
Note that when the CRU at the University of East Anglia were requested to provide the unadjusted values recorded over decades they claimed to have lost it. They also refused to provide the code used for the adjustments. What we now have is next to useless and is utterly untrustworthy.
You do not have to believe me, they actually admit it on their web site.
http://www.cru.uea.ac.uk/cru/data/availability/
“Since the 1980s, we have merged the data we have received into existing series or begun new ones, so it is impossible to say if all stations within a particular country or if all of an individual record should be freely available. Data storage availability in the 1980s meant that we were not able to keep the multiple sources for some sites, only the station series after adjustment for homogeneity issues. We, therefore, do not hold the original raw data but only the value-added (i.e. quality controlled and homogenized) data.”
So records that could be stored up to 1980 suddenly became impossible to archive eh !
Can you imagine the reaction if the British Library decided to throw away all its books printed before the 1980’s on the grounds that it was inconvenient to keep them and that they had ‘improved’ texts available !
Welcome to the wonderful world of ‘Climate Science’ where we are expected to spend billions of pounds and trash our economy on the basis of conclusions reached from data that has been discarded.
Not even George Orwell thought of that one.
@rah
Surely the question is why NOAA aren’t held to account?
Unless you can present and defend your “adjustment” methodology, then it is just made up.
To date, the so called scientists refuse to do that.
My first reason for thinking so is that …. overall, from 1880 to the present, ….. 100% of all Interglacial Global Warming temperature increases have been “high-jacked” by the proponents of CO2 causing Anthropogenic Global Warming.
It is impossible for said proponents to determine the difference between Interglacial caused temperature increases and Anthropogenic caused temperature increases …. thus they claim all said increases as being anthropogenic to benefit themselves and justify their “junk science” claims.
>> The reason for the adjustments is sound.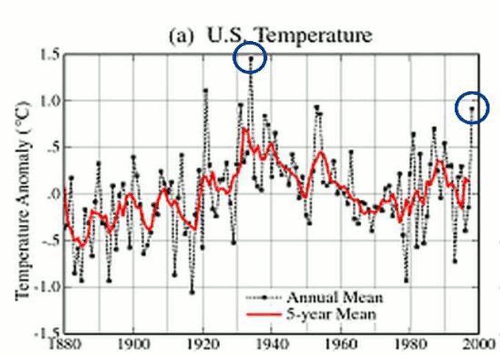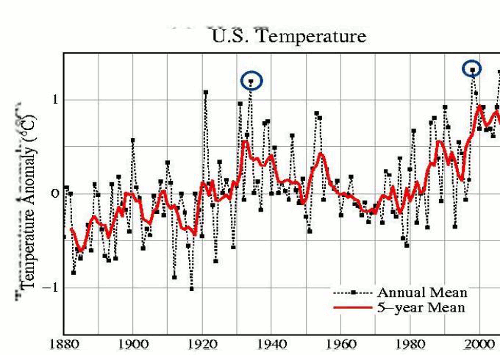
The reason for the adjustments is political manipulation.
It is simply not possible to have an honest and valid adjustment system, that consistently makes the past cooler and the present warmer. This obvious bias is not an ‘adjustment’, it is data manipulation for economic or political gain.
Check the following ‘before and after’ graph, from Steven Goddard’s site:
Seriously?
You want to remake the world economy based on guesses?
This is not data, it’s literally guesses.
As an attempt to recreate temperatures it’s fine, but to make any kind of claim of accuracy is laughable.
Confirmation bias is a thing, M Stoval is making the assumption that bias has favored adjustments which tell a warming story. Based on the vast amount of evidence for warming bias, I would say he attributing correctly. Surface records cannot be taken seriously, I propose we decide on an appropriate instrument and sitting regs and we form our own reporting network which will no doubt falsify the existing.
If it was down on paper ,say in the form of a newspaper, then at least you would be able to use it in the bottom of a parrot’s cage, or your kitty litter box.
But if it is only in electronic form, you can’t even do that.
What possible earthly use is ANY set of numbers, which don’t actually reflect anything that anybody ever observed or measured anywhere at any time, because nothing like it ever happened anywhere to be observed.
g
Svante, It is not a conspiracy at work but the normal research funding process. Here is how it works.
With respect to bias, NASA/NOAA funding priorities could not be more biased. To anyone who has worked for any length of time based on winning competitive grants or contracts from Federal agencies, it is no mystery why so much climate research comes to alarmist conclusions no matter what the data actually says. The key to winning a grant or contract is to propose work that 1) you have demonstrated capability to do and 2) addresses what the sponsor wants. Gauging what the sponsor wants and targeting those wants is perhaps the most important determinant of your proposal. Thankfully I have long been involved in this in another area, but just for fun I thought I would look at the NOAA Broad Area Announcement (BAA). BAA’s are a typical request for research or development proposals from Federal Agencies.
The NOAA BAA (and others) can be found at the grants.gov site via a search
http://www.grants.gov/web/grants/search-grants.html?keywords=noaa
and then clicking on the link to NOAA-NFA-NFAPO-2014-2003949
The BAA spells out what NOAA wants by stating the given assumptions up front:
“Projected future climate-related changes include increased global temperatures, melting sea ice and glaciers, rising sea levels, increased frequency of extreme precipitation events, acidification of the oceans, modifications of growing seasons, changes in storm frequency and intensity, air quality, alterations in species’ ranges and migration patterns, earlier snowmelt, increased drought, and altered river flow volumes. Impacts from these changes are regionally diverse, and affect numerous sectors related to water, energy, transportation, forestry, tourism, fisheries, agriculture, and human health. A changing climate will alter the distribution of water resources and exacerbate human impacts on fisheries and marine ecosystems, which will result in such problems as overfishing, habitat destruction, pollution, changes in species distributions, and excess nutrients in coastal waters. Increased sea levels are expected to amplify the effects of other coastal hazards as ecosystem changes increase invasions of non-native species and decrease biodiversity. The direct impact of climate change on commerce, transportation, and the economy is evidenced by retreating sea ice in the Arctic, which allows the northward expansion of commercial fisheries and provides increased access for oil and gas development, commerce, and tourism.”
If one plans to put in a proposal, it better toe this line. No wonder so much research aims to identify alarming consequences of AGW, and does it no matter what.
However, that given, it is very difficult to communicate the reality of research funding to those without direct personal experience within its workings. For my part, I have over 30 years experience as a principal investigator doing research (not in climate science) and several terms serving as a government official responsible for research portfolios. It is difficult to convey the tremendously arcane, mundane, and irritating legal and bureaucratic overhead associated with the process. But it is the case that those who manage the funds and award successful proposals do so with significant guidance from the agency heads and the office of the president, if the political mojo is flowing that way. Remember Gina Mccarthy’s famous statement that “there better not be any deniers here” when she took over the EPA. The rank and file program managers and researchers are not evil or malevolent, simply trying to do their jobs under the constraints they are given.
Those who claim conspiracy and have in mind the closed room setting of global agendas have no concept of how the government administers research. A conspiracy in that sense is impossible given the way the bureaucracies operate. However, program managers quickly learn the priorities of the agency within which they work and learn to operate within them.
All too true. Sad but true. But there is also a conspiracy, as amply demonstrated by the Climategate emails, but already well known among real climatologists.
FAH,
This is among the most sensible things I’ve seen written here on WUWT. I’ve noticed a lot of conspiracy theory type thinking creeping in and frankly it does nothing to advance the sceptic view. An an organization organization or institution can be corrupt without any conspiracy – it is a complex web of incentives, ideologies and human psychological biases. Human behaviour is a complex system just like climate, most certainly much more complex.
Whenever VolksWagen (VW) hampers with measured results, they are charged and fined, and the CEO has to resign. Whenever the ‘climate specialists’ (NOAA) hamper with measured results, it’s just another day in the office…
@ur momisugly FAH
I think your comment should be expanded upon and sent in for a post to this site. It is important for lay people to understand the funding issues are and how the need to get funding drives the “consensus” since the feds are funding “science” research. Please consider doing a full post on the issue.
So VW should not be held accountable?
Seems institutions become “institutionalized”
I agree I would like to hear more knowledgeable info about how the grant funding bureaucracy operates, without deliberate conspiracy, to nevertheless bias climate research. One of the main sticking points in arguing the skeptical position is that people don’t believe scientists would deliberately be biased or mislead. They don’t understand how it is a symptom of the system.
I’ve noticed a lot of conspiracy theory type thinking creeping in and frankly it does nothing to advance the sceptic view. An an organization organization or institution can be corrupt without any conspiracy – it is a complex web of incentives, ideologies and human psychological biases.
_______________________________________________
Which is exactly how conspiracies are organised and run. Conspiracies start with high level influence, and then others jump on the bandwagon because they find it advantageous, or they find the results of not joining the bandwagon highly disadvantageous.
Ralph
It’s not a conspiracy theory but a conspiracy fact, as evinced by the conspirators own words in the Climategate emails and testimony of scientists presumed to be in on the conspiracy by the conspirators. You can debate the conspirators’ motives, but the fact of the conspiracy is not in doubt.
A succinct and brilliant summation. Thank you.
Even if the raw numbers were accurate to 0.001th of a degree, the idea that you could take those numbers and calculate the daily average to a few hundredths of a degree is ludicrous.
Then add in the fact that the records from 100 years ago were only recorded to the nearest degree C, through in the many other well documented problems with the data and you get a result that makes ludicrous look good.
Exactly. Chart average global temperature between the daily min and max anywhere in the world, and you have a stubbornly flat line. It is only by claiming “post adjustment” an unachievable precision that any “trend” appears. To say we can measure .2 global temp delta between 1920 and 1984 for example is beyond absurd.
It is like recording the thermostat settings in 1000 homes and claiming the average ambient in door temperature of every household in the world has risen by .6 degrees.
Liars lying out of their liar holes………….
I think this is an important approach to exposing this science for what it really is.
Which is anti-scientific politics.
An agenda cloaked in a lab coat.
The white-frocked priesthood of High Druids.
Are you now being nit picky too ??
g
In light of the modern common core math where getting the right answer is not important but the method of seeking it is.
I thought it would be axiomatic that if you do employ the proper method you do get the correct answer, which is surely the ONLY test of the correctness of the method.
Make that getting the correct answer.
g
It is not surprising the “adjusted” data set contains adjustment. My guess is the number of adjustments will increase over time.
So what is the issue exactly?
Personally, I do not see any issue with it. All temperature measurements are estimates, even the “raw” ones.
They should not be thought of as ‘estimates’ but more as ‘models’. You change your model assumptions and you change your model trends.
willnitschke.
Hence the need for the adjustments to remove non-climatic changes. I doubt if any of the measurement stations has remained the same for the entire age of the data set. I do recall reading somewhere (can’t remember the reference) that a measurement station is expected to change in some way once every 10 years or so.
“I do recall reading somewhere (can’t remember the reference) that a measurement station is expected to change in some way once every 10 years or so.”
Mann! just imagine the error bar height with those assumptions/errr estimates, but then they are never shown, how convenient.
Only if your adjustments plausibly improve the data, rather than make it conform to assumptions on what the temperature should have been. There is a world of difference here. When your adjustments end up creating a certain trend that didn’t previously exist, you’ve build a model, not plausibly “improved” the data. If you find yourself in that situation, it’s more scientifically rational to remove your assumptions and let the data speak for itself. Errors will tend towards averaging out over time.
Why do all the adjustments introduce a warming bias, even those supposedly intended to adjust for the UHI effect?
Except of course for adjustments to data from before the 1940s, where the bias is always toward cooling.
Lady G,
Good question. But I don’t think
harrytwinotter“Svante Callendar” will answer.Lady Gaiagaia.
“Why do all the adjustments introduce a warming bias, even those supposedly intended to adjust for the UHI effect?”
Do they? Do you have evidence for that?
dbstealey.
Back in your box, rover.
I wonder sometimes about blogs that use attack dogs to disrupt discussions.
Svante Callendar,
Yes, I do. Anyone who has studied the adjustments comes to that unavoidable conclusion.
The so-called “surface record” is science fiction with a political objective. Just compare the older record as NCAR had it in the late 1970s with what it now purports to be. Compare the ’80s and ’90s as they happened with where they are now. It’s glaringly obvious.
Nor are the continuous “adjustments” in any way justified on the basis of science. Only politically.
One of many such studies finding consistent warming bias for recent decades:
http://hockeyschtick.blogspot.com/2015/05/new-paper-finds-large-warming-bias-in.html
Svante Callendar: “I wonder sometimes about blogs that use attack dogs to disrupt discussions”.
dbstealey is not an attack dog. Those are only found on warmist blogs.
(Sorry Anthony)
michael
Not to mention the subject of this post as an example of warming bias.
Lady Gaiagaia.
“Yes, I do. Anyone who has studied the adjustments comes to that unavoidable conclusion.”
Please explain.
Also, that paper from Schtick does not say anything about a warming bias from station measurement which is what the GHCN-M is. Are you sure you have read the actual paper?
Yes, that and many more.
To see the bias, just look at “Steven Goddard’s” comparison of previous records of the early 20th century warming with the ongoing “adjustments”. Look at how NCAR saw the post-war cooling in 1975 and how it sees it now.
The warming bias is incontrovertible fact and a criminal conspiracy.
Svante Callendar
I wonder about people who use false names that are a play on deceased scientists. I like to think we’ve moved on since then.
Here is the NOAA graph of the adjustments. It slopes strongly up from about 1920-1990:
http://cdiac.ornl.gov/epubs/ndp/ushcn/ts.ushcn_anom25_diffs_urb-raw_pg.gif
“I wonder sometimes about blogs that use attack dogs to disrupt discussions”
And I wonder about climate attack dogs sent to disrupt discussion, as you very obviously are.
“Svante Callendar” says:
Back in your box, rover. I wonder sometimes about blogs that use attack dogs to disrupt discussions.
On another thread (June 4, 2015 at 8:29 pm) “harrytwinotter” wrote:
dbstealey,
Back in your box. Don’t you ever tire of the “attack dog” role?
There are other “harrytwinotter” comments that use the same “back in your box”, “attack dog” comments.
What say you, “Svante”?
Looking at Jim’s graph, anyone care to explain why there is a systematic trend of correction to hotter values required?
What is the physical explanation for this effect in the adjustments?
If everybody just reported what their equipment recorded, and in addition recorded accurately whenever the equipment of other parameters change, then anybody who wanted to make use of the information; including the information that the equipment or other conditions had changed, then all such things could be taken into account by those who use the data for whatever purpose.
Reporting anything other than the equipment readings; plus information on that equipment or other conditions of the experiment; is just blatant fraud in my book, and I would fire anybody who did that.
“Mr. Mac” the father of McDonald Aircraft used to say: ” We seldom fire anybody for making a mistake; but we invariably fire anybody who tries to cover up a mistake. ”
A philosophy to live by; sometimes called ” being nit picky. ”
g
The issue is overstating the results.
We have continually evolving adjustments producing unstable data-sets somehow leading to the unsupported assumption that the data-sets are becoming more accurate. It is foolish. Recursively re-estimating raw data does not lead to more accurate data. It simply cannot. It is a fallacy.
A fuzzy picture that is artificially sharpened does not produce more detail. There is never more detail than the original – claiming more detail and more accuracy is overstating the results, it is simply creating new detail that never existed.
Overstating results and making stuff up is pathological in climate science.
Yeah, why not just invent numbers totally and ditch any attempt at mirroring reality?
Excellent, Brother John. (He’s a fellow station-surveyor, and anyone who has surveyed a station is my brother.)
TOBS is a valid adjustment (though I have no idea whether NOAA’s method is correct) so you must either use TOBS data for those — or drop ’em (I go for option b.) MMTS is a valid adjustment, though it is clear that NOAA is doing that wrong. It must include a “CRS adjustment” (sharply reducing CRS trend, esp. Tmax) as well, but it does not.
Then we need to adjust for . . . microsite! That can only be done correctly and reliably for stations whose microsite is known. That is a whopping 60% downward adjustment to Tmean trend (or else just drop the badly sited stations for the same effect).
This does not affect sea temp trends, of course, except where station radii overlaps ocean (350 km for Bad Haddy and 1200 km for Wicked uncle GISS).
Thanks Evan. I agree that TOB has a measurable effect and must be accounted for. But, when we “adjust” we turn the data into an estimate. The typical adjustment is applied every month for multiple years, and one can see from recent CRN data or Wunderground stations that TOB bias is no where near a constant.
I know that some will argue over time the estimate averages out. But I have two problems with that argument.
One is that it might or might not average out. We simply have no independent way to validate a TOB estimate for much of the record.
Two is that we hear every month that the past month ranked n on a scale of hottest months ever. Claiming a particular month is nth hottest does not leave a lot of room for “averaging out” multiple estimates. Such a declaration assumes certainty. And using estimated data produced by mathematical models requires us to give up some degree of certainty.
“we turn the data into an estimate”
It was an estimate anyway. That is the issue with TOBS. When you combine daily max and min temps to form a monthly average, you assume that those maxes and mins were recorded on consecutive, distinct, days. They may not have been, and that creates a bias, with warm afternoons or cool mornings double counted (depending on TOB).
There is nothing special about the assumption made in “raw” data. It’s just based on not having any reason to think the min/man days aren’t consecutive. Now we do, and we can figure how often it would have happened.
I will add that I take a fundamental approach different than BEST’s. They adjust. I drop.
I have sympathy for BEST. I can drop. They can’t: I am looking at USHCN over a 30-year period; they are doing the entire GHCN. I can get (arguably) enough spots in my grids even when I drop 78% of initial sample. I got the data-rich CONUS. But BEST has Outer Mongolia.
Thing is, that dropping is a check-sum on adjusting. If you include only “pristine” stations, then you can look at a thinner but far more real signal, and you can see cleraly what the adjustments are up to and whether they are correct.
In short, I deduce. BEST induces (they have no choice). But I think we have found the two factors unaccounted for in the GHCN adjustment procedures: Microsite and CRS issues. Furthermore, there is a “systematic” error in their dataset, and that makes a travesty of homogenization.
Evan, didn’t you forget the “UHI” joke of an adjustment, that bears no relationship to the amount of UHI everyone knows exists as they are told about it during every weather forecast?
The question is not whether UHI causes increased temperatures (offset). That is non-controversial for all sides. The question is how much it affects trends. Our findings are ambivalent. Gridded urban data shows more warming than non-gridded, but the well sited urban stations are very few, and the non-gridded, well sited urban trend is actually a bit lower than non-urban stations.
What is essential and decisive is not UHI. It is Microsite. Heat sink Effect — HSE. Well sited urban stations warm far slower than poorly sited urban stations. Same applies to non-urban.
Conclusion: HSE is the new UHI. You heard it here first. Microsite is where you will find your disparity, but not so much for mesosite (UHI).
Computers are wonderful tools for recording and cataloging and recalling data.
But they are also dangerous tool for changing data and other things.
The internet?
In the past if one wanted to change something previously recorded, in say, an encyclopedia or almanac, they’d have to go round up all the and burn what they didn’t want known.
With the internet, a few keystrokes makes that much easier. (Think Wikipedia.)
I have to admit here is a certain beauty to it all: modeled temperature data for climate models. Never have to worry about reality. What could be sweeter for a climatologist?
“Overall, from 1880 to the present, approximately 66% of the temperature data in the adjusted GHCN temperature data consists of estimated values produced by adjustment models,”
Well, yes. The adjusted set is … adjusted. I can’t see the point of this count. Once an adjustment is made, all the previous values are moved, since present is the reference. So it doesn’t calculate individual identified adjustments, just the propagating effects.
With US data, any change in time of obs will change all previous data. Elsewhere, any station move etc will, if identified, produce the same propagating effect. It is hardly implausible that more than 66% of stations have moved, or had an equipment change, over their time. In fact, the MMTS change alone would have caused a very large amount of past data to be adjusted.
The point is that two thirds of the data that are consumed by organizations giving us a global temperature (such as GISS) are actually estimates of what the actual temperature might have been. Almost all of the public who hear pronouncements that a particular month was the nth hottest on record believe someone smart was able to stick a thermometer in the dirt and measure it directly. What is less understood is that the thermometer measurements have “flaws” and are therefore sent through mathematical models to bring them “into line”. But the models are not perfect, so we end up largely with estimates.
The organizations who estimate the global temperature do so on the basis of estimates of the temperatures of regions. Not of thermometers. Thermometer readings are part of the evidence. And if the basis for relating those readings to the region has changed, then of course they should change their estimation procedure.
As I said, I thought the MMTS adjustments alone would have changed at least 50% of readings. So what should they do? Pretend the change made no difference? Climate didn’t change because they brought in MMTS.
You, personally, are already aware that the organizations are working with estimates. Most people are not aware that organizations such as NOAA are unable to use raw data for a variety of reasons and must instead estimate temperatures. They are further unaware that this introduces uncertainty.
The public is fed information that is stamped with the label of authoritative certainty, and to believe otherwise is to deny that authority. I think it is important that the public understands that even the underlying data is still debatable.
“The public is fed information that is stamped with the label of authoritative certainty”
The public expects that people who actually know what they are doing will give the best estimate they can of global temperature. And they do. That involves detecting and correcting inhomogeneities.
The public is expecting surety, because they are told the debate is over. They are expecting certainty, but we are not dealing with certainty.
Nick Stokes. BOM has adjusted Carnarvon. The raw data says long term cooling, the homogenised data says long term warming. That seems to imply a failing station. With a budget of >$340m, why not replace the station? Or put in a temporary one and adjust for any step-change? The step -change is a constant .
There is little point in debating with Nick Stokes. He states complete nonsense with a high degree of chutzpah hoping that he can steam roll over logic.Global temperature adjustment is the only field in science that takes the arrow of time and works it backwards. It’s idiocy to the nth degree, but to Nick Stokes it’s all fine so long as it gives him the results he wants.
“The raw data says long term cooling, the homogenised data says long term warming”
It’s frustrating when people rattle off this stuff with no links or backing.
Here is the GHCN Carnarvon adjusted and unadjusted. Both rising at the same rate, in fact in GHCN the adjustment is nil. The unadjusted will be the same as the BoM data.
Nick Stokes September 24, 2015 at 6:34 pm
“The public is fed information that is stamped with the label of authoritative certainty”
The public expects that people who actually know what they are doing will give the best estimate they can of global temperature. And they do. That involves detecting and correcting inhomogeneities.
——————————————
How does the public know that these people know what they are doing?
Is your statement true for all publics; American, Lithuanian, Syrian?
Is the intuition of the public always so infallible?
Does the term ‘public’ include deviant members, who do not conform?
If so, what percentage of the public can be non-conforming without impacting the reliability of their good sense?
Are you a politician?
@ur momisugly Nick Stokes
You say …”climate didn’t change”
>>>>>>>>>>>>>>>>>>>>>>>>>>
Indeed, well said.
“The public expects that people who actually know what they are doing will give the best estimate they can of global temperature.”
???????????????????????????????
I’ve seen the estimates…………………………..ROFL
John Goetz.
The objective of the adjustment process is to improve the accuracy of the measurements. So not doing that would be a disservice to the public.
You talk as if “actual” measurements are somehow a better representation of the temperature. This is an unfounded assumption on your part.
I think the unfounded assumption is that the adjustment process improves the accuracy of the measurements. Once a measurement is adjusted it is no longer a measurement. It is now an estimate. Now we are arguing about the accuracy of the estimate.
“The objective of the adjustment process is to improve the accuracy of the measurements.”
The strawman is to assume that adjustments always make the data better, when they might well make the adjustments worse. If your adjustments, say, reverse the trend found in the original data, that is a red flag that something has gone wrong with your alterations to the data. Adjustments are fine in theory, until too many red flags start waving. Then you are doing a great disservice to the public.
Nick Stokes, I haven’t figured out how to post an image. But look at this please.
http://kenskingdom.files.wordpress.com/2014/07/carnarvon-tmin.jpg?w=450&h=256
I’ll agree the modern data seems to accord pretty well with the raw data.
@ur momisugly lee and Nick Stokes. https://kenskingdom.wordpress.com/2014/07/16/the-australian-temperature-record-revisited-part-4-outliers/
@Nick Stokes
The graph for unadjusted data is “quality controlled” . What happens in the “quality control” process?
@ur momisugly Svante.. try adjusting your measurements in a physics class to make your experiment work… see how long it will take before you are in the dean’s office. That’s the most ridiculous statement I’ve ever read. Well, except for adjusting the original data then throwing the original date away in a landfill. What scientist in their right mind would do such a thing? The only reason I can think of is to commit fraud.
I could just as easily adjust the data to indicate a cooling world. In fact, it probably is. Let’s say the theory of AGW is correct. Then if the temperature is suppose to be what the IPCC says it is suppose to be and it isn’t, the concern should be that even with the massive amount of co2 that has been released since 1998, without that, the temperatures would already be dangerously cold…… so which is it? Is it getting colder or warmer? You’re going to be hard pressed to make a case for absolute warmer.
Even with the adjustments, which in my view enhance global warming, the temperatures have fallen below the lowest projection of the models. Care to elaborate?
The net effect of adjustments is to greatly and spuriously inflate the trends of land surface stations, Nick. I have walked the walk. That’s just the way it is.
This does not address the effects of Bad Haddy and Wicked Uncle GISS and their recent SST adjustments, which have come under heavy criticism and refutation.
“But look at this please.”
It’s very hard to work things out when they are so poorly referenced. Carnarvon’s climate data is here. Those look like minimum temperatures, though I can’t see that mentioned anywhere on kenskingdom.
OK, so why would minimum temps be so adjusted. Well, here is the ACORN station catalogue. The site was at the PO, by the sea until 1950. Then it moved to not sure where, then to its present location about 2km inland in 1974. Now Carnarvon is in a dry area, so 2km inland makes a big difference to minimum temperatures.
Nick Stokes, apart from a step-change in the record, why the other adjustments?
“why the other adjustments”
What other adjustments? Please specify.
Are we supposed to believe that the methods used to make adjustments for things like “time of obs” are an exact science? They can never be more than rough estimates. So the more temperature data that has to be adjusted, the greater the margin of error becomes. When a new hottest-day ever occurs by 1 one-hundredth of a degree, it is laughable. With adjustments to 66% of the data, there’s no way the average temperature can be anywhere near that accurate.
“Are we supposed to believe that the methods used to make adjustments for things like “time of obs” are an exact science?”
Time of observation is entirely quantitative. The effects on the min/max average are clear-cut. And the changes of observation times are documented.
But what counts is the statistical effect of the changes, because they are used for averaging. There it is important to remove bias. Unbiased noise is greatly reduced by averaging.
Phrases such as “clear cut” and “documented” are weasel words, used when you cannot say they have been demonstrated as correct.
Coincidence?
KTM.
“Coincidence?”
Who knows? Steve Goddard’s stuff is so bad it is usually impossible to figure out what he is talking about.
Hilarious!
Sad, but true.
What a scam.
Costing the world trillion in treasure and million in lives.
Criminal mass murderers.
“Who knows? Steve Goddard’s stuff is so bad it is usually impossible to figure out what he is talking about.”
Then you need help with your reading comprehension. The Goddard site is written so that even an 8th grader could follow. Yet you complain it is too hard for you.
“The Goddard site is written so that even an 8th grader could follow.”
Sure, but that doen’t make it much better.
Goddard’s graphs are funny, or scary, but their value as science is nil before somebody reproduces them. And Goddard is somewhat pompously not explaining what he does, rather he just tells how everybody are included in the big conspiracy. Not convincing.
While I like Goddards excerpts from old newspapers, I don’t like his Excel ‘science’.
They are overstating the accuracy and certainty of the temperature data-sets.
Somehow the science is settled does not jive with we are still working on it. We really do not know what the temperatures actually were, we only know what they are adjusted to based on assumptions and latest best hypothesis/guesses.
Now assumptions are only required when you do not know. They may be reasonable assumptions but they are still based on lack of knowledge. So who is going to tell the public about the level of assumptions and the fact we do not know enough and may never know enough to be certain of past temperature to hundredths of a degree. Who is going to tell the public the data-sets in essence are unproven hypothetical models of the temperature record.
Or is this one of those “They can’t handle the truth!” moments. Just tell them climate change leads the world to climate annihilation and leave it at that.
Nick writes “With US data, any change in time of obs will change all previous data.”
Where is the adjustment due to changes in thermometer response times?
And so it is just coincidence with: I) Obama going ecoloon in trying to hobble the U.S. economy by imposing new illegal environmental rules through the EPA, and ii) the potentially disastrous meeting of Paris-ites later this year, that GISS suddenly embarked on yet another unjustified set of temperature adjustments to make the past cooler and the present warmer?
Was this an executive order, or just climate bureaucrats trying to preserve their comfortable lifestyles?
Anyhow, that embarrassing Pause was eliminated by what can only be described as the dodgiest of statistical methodology, so bad that it might have even made the great Mann himself blush.
So you think the reported temperature series is not somehow anchored to the actual measured temperature but to some adjusted value.. That must be so if an adjustment to a reading changes all previous reported temperatures. And if that is so then any present error propagates into nearly the entire ‘data’ set making the whole thing useless.
That ain’t science or even engineering.
There are six separate steps in the adjustment procedure, which end up showing a consistent increase in adjustment over time (bigger negative adjustments the further back in time it goes). It’s actually hard to believe that there isn’t some little routine in their programs that introduces a date factor. Otherwise, an outside observer with experience in dealing with slightly messy data from other fields of endeavour might expect that the adjustment vs time plot would be randomly spiky with no consistent trend.
Which is a polite way of saying – it looks like the data are fudged to enhance the warming story,
Heaven forfend!
No, I have crawled through their code and there is nothing nefarious like that.
However, from much of what I have been able to decipher, their algorithms produce estimates that reinforce what are perceived to be long-term trends. In my opinion this is a flawed approach and only serves up confirmation bias. I see no reason to believe that the temperatures of 1887 behaved like the temperatures of 2013, for example. I would be able to better accept a model that adjusted temperatures by looking forward and backward by 10 years than forward by 130 years.
“A chart showing the average change to the raw data is not shown, because an overlay is virtually indistinguishable. ”
So a whole article on “virtually indistinguishable”. Good one.
I guess you did not understand the article. I was referring to the changes in the estimated data between 5/2014 and 8/2015 as being virtually indistinguishable. But that was not the point of the article, only a side note.
But your money graph shows little difference either.
You will have to let me know which one is the money graph.
This is much to do about nothing.
From Judith Curry’ website:
“On balance the effect of adjustments is inconsequential.”
http://judithcurry.com/2015/02/09/berkeley-earth-raw-versus-adjusted-temperature-data/
From Berkeley Earth
“Having worked with many of the scientists in question, I can say with certainty that there is no grand conspiracy to artificially warm the earth; rather, scientists are doing their best to interpret large datasets with numerous biases such as station moves, instrument changes, time of observation changes, urban heat island biases, and other so-called inhomogenities that have occurred over the last 150 years.”
To educate yourself go to:
http://berkeleyearth.org/understanding-adjustments-temperature-data/
Luke,
B.E.S.T. is not credible. They only show what they want the public to see:
My complaints about BEST are 1.) that they do not account for microsite when they pairwise. They should pairwise with only Class 1\2 stations. That would reduce the trends by 50%, and, 2.) They do not address the defective CRS stations — they should not be increasing MMTS trends, they should be (hugely) reducing CRS trends.
Point 2 will have a decisive effect on the entire pre-MMTS record.
That is not true. The GHCN adjustment models introduce a warming bias of approximately 0.25 C per century.
Your source?
Luke, my source is the GHCN unadjusted and adjusted data sets, as spelled out in this post. Did you skip over the post and jump directly to the comments?
John Goetz.
I would like to know how you derive that 0.25C per century figure as well.
He just told you how he derived it… (facepalm)
willnitschke.
If you think you how the figure was derived, please share with us then.
“my source is the GHCN unadjusted and adjusted data sets”
You can download both sets of data and subtract the differences between them if you don’t trust the claim.
Svante Callendar September 24, 2015 at 9:50 pm
willnitschke.
If you think you how the figure was derived, please share with us then.
John Goetz September 24, 2015 at 6:20 pm
Luke, my source is the GHCN unadjusted and adjusted data sets, as spelled out in this post. Did you skip over the post and jump directly to the comments?
Talk less read more.
michael
It’s not complicated. Go to the 5th chart which represents Estimate – Raw. There are two trend lines, one for each of the curves. Visually you can see the approximate 0.25 C per century trend. Or, you can look at the two equations I included and use the slopes ( x is the number of months ). Take the curve with the smallest slope, and use 1200 months per century (that is a measurement, not an estimate):
.0205 * 1200 / 100 = 0.246 C
I divided by 100 because the monthly data upon which the trend is express is in degrees C * 100, as is shown on the y-axis label.
I don’t think ‘bias’ is the right word here. They introduce some warming to the trend, but knowing where the biases are, is the hot potato. Adjustments are supposed to fix biases.
Jims graph posted above at 2.40 am on September 25 shows the graph of adjustments with time, as actually shown by NOAA.
The question is – what is the physical explanation for a systematic trend in the adjustments? Why will no-one answer that question?
McIntyre shows a +0.46C/century adjustment to USHCN trends to 2006 (+0.14 to +0.60) over the raw data, using the USHCN1 dataset.
The question is – what is the physical explanation for a systematic trend in the adjustments? Why will no-one answer that question?
Outliers, TOBS-bias, MMTS adjustment, station moves. Then (groan), homogenization.
MMTS is handled ass-backwards from how it should be. Outliers, TOBS-bias and moves are valid concerns, but I have no idea if HCN addresses them correctly. But failure to adjust the trends sharply downward for microsite is a fiasco, and the H-word makes it even worse than the straight average.
Raw data is bad. It warms too quickly. The raw trend must be adjusted (DOWN) for HSE, or else all stations with non-compliant microsite must be dropped.
In other new snake oil salesman tell us how affective snake oil is in application.
And reminds us what is stopping these same people telling the public about the poor quality of the data that needs so many ‘adjustments’ , could it be that would be a hard sell after you spent so long telling the same people how it is all ‘settled science ‘ ?
No ‘grand conspiracy’ true , but a lot of self serving interest in an area which will lose a great deal if ‘the cause ‘ falls .
That’s like saying nothing. If they don’t know then why is the rhetoric and the tone so certain that if we don’t stop right now nothing but disaster? Why are people saying that they need to invoke the Rico act to shut critics of AGW up? I wouldn’t have thought there was collusion 20 years ago, and the people who were saying so I thought were a little off, well, AGW has convinced me that I think there is collusion too. Are you aware of how many published contradictions have been made every time a valid point has been raised? Most of 2006 was spent arguing about co2 and isotopes, how long co2 stayed in the atmosphere. Now it seems that most of the certainty about co2 on the part of CAGW was little than guesses, and wrong ones to support their cause.
This is absolute, positively unfalsifiable, irrefutable proof that G.I.G.O exists …..
…Also known as the ” Garbage In, Garbage Out ” paradox !!!!
Garbage In, Gospel Out.
The most depressing part of all this is rounding up or down all these figures to a hundredth or even a tenth of a degree and pretending that the results are meaningful in any way. They are estimates and should be treated as such. If you were doing this in a financial system and told your boss that this is the estimated cost of doing something to such a finite number you would be laughed out of the room.
I have to agree that I find an adjustment of 0.03C applied to every month’s worth of data for decades a bit laughable.
John Goetz.
“I have to agree that I find an adjustment of 0.03C applied to every month’s worth of data for decades a bit laughable.”
Why do you say that?
If that is result from the algorithm, then to just ignore it would be irresponsible.
I did not ignore it. I just laughed at it.
Svante Callendar
“If that is result from the algorithm, then to just ignore it would be irresponsible.”
Indeed. To ignore such a laughable adjustment would indeed be irresponsible. Your faith in the magical algorithm is remarkable.
As an engineer I estimated stuff all the time, including the cost of a project. Often 30% wasn’t that big of deal. (Being as it’s software, 1.5x-2x is all too common on schedules…)
The rise since 1880 is 0.8degC. The adjustment is 0.25degC. I’m perfectly fine with calling the rise 0.65degC if you want. It’s still going up. That’s why the lukewarmer hypothesis is likely the most correct – That’s what the evidence is showing so far. A bit of warming that’s not that alarming, whether there’s adjustments or not.
The adjustments are 30%. The models are 100% to 200% off adjusted and unadjusted values. I’d worry far more about the models. Crying foul over the adjustments is almost nitpicking.
Peter
You call yourself an engineer and can’t even subtract 0.25 from 0.80.
The earth is coming out of the LIA, of course it has been getting warmer.
The adjusted data is used to create Headline news, the hottest ever month, year or decade it has nothing to do with Science.
You are forgetting the uncertainty of the results, too. Take a look, for instance, at the error bars for 1900.
http://data.giss.nasa.gov/gistemp/updates_v3/ersst4vs3b/
http://data.giss.nasa.gov/gistemp/updates_v3/ersst4vs3b/v3b+v4_lrg.png
Ha. I just noticed the new values (right graph) for 1882 and 1900 are outside the old CI (left graph). So, the old CI was wrong. How do we know the new CI isn’t also wrong?
Some may say this is inconsequential nitpicking. But the big-brained experts claim to measure temperature differences from year to year with accuracy to hundredths of a degree. So, these small things matter, too.
The adjustments are 30%. The models are 100% to 200% off adjusted and unadjusted values. I’d worry far more about the models. Crying foul over the adjustments is almost nitpicking.
No it ain’t — because the trends need to be sharply adjusted downward (owing to the Heat Sink Effect from poor Microsite). It is off by ~60% from HSE alone. And then there is the fatally flawed CRS stationset to consider. “A thoid — skimmed right off the top.” (I know Bela. He didn’t offer you beans.)
Oh, it’s fine to have the calcs below the MoE — provided you include the MoE, of course. (Otherwise, it’s false precision.)
Never mind the estimates … what about the language ?
There is no way a mean of between 14 and 15 C can
be described as ‘hot’ …. anyway, I am now beginning to
find climate scientists insufferable, strutting about suffused
with self-importance … they may know something about
climate, but it is clear that they know nothing about the
collection, analysis, and interpretation of survey data, which
is critical.
“they know nothing about the collection, analysis, and interpretation of survey data, which is critical.”
Really? Please enlighten us all by publishing your critique of their analyses in a peer-reviewed scientific journal.
Peer review is a bad joke. In “climate (anti-)science” there is only pal review, as shown by the Climategate emails.
“they know nothing about the collection, analysis, and interpretation of survey data, which is critical.”
Really? Please enlighten us all by publishing your critique of their analyses in a peer-reviewed scientific journal.
I think Rex should; but having first Establishing a fee you should pay, knowledge isn’t cheap you know.
michael
I was wrong to describe the land-based matrix of temperature
stations as a ‘survey’ … it is a dog’s breakfast. Climate scientists
serm to make the same mistake some of my fellows in the survey
analysis field, in which I’ve been involved for 45 years: they assume
that the ‘survey error’ is the same as the statistical error. Ah, no.
That temperature range can be described as HOT by the same process that characterizes a change in ocean pH from 8.60 to 8.58 as “THE OCEAN IS GETTING MORE ACIDIC!!” By that line of thinking, if i cut down the number of my adulterous affairs from 20 women to 19, I am being more faithful to my wife. Yay for me.
…and the other 34% is automatically retroactively adjusted every time they put in a new set of numbers
That makes the whole 100% f a k e
Surely there must be some thermometers that are highly accurate. Have they ever tested their adjustment algorithms against accurate thermometers to see how far off they are? For example, have they collected hourly temperatures for a year or so and then fed them into adjustment algorithms to see how close they are in their estimates? If they collected hourly data and then simulated a change in time of observation, they could see how well the adjustments compared to the actual temperature readings they collected for the new time. It would be an interesting experiment and would give some idea of how far off the estimates can be. I’m sure they must have already run some tests on their algorithms, but have they made the results public?
The ARGO thermometers are extremely accurate (+/- 0.001degC). Of course they adjusted the heck out of them, instead of adjusting the bucket measurements like they should have…
If you look at Fluke Instruments website you can find calibrators that are accurate to +/- 0.001degC.
Example: http://us.flukecal.com/products/temperature-calibration/calibration-baths/standard-calibration-baths/7008-7040-7037-7012-70?quicktabs_product_details=2
We’ll have to wait 50 years or so to get a decent trend out of the Argo data though.
Peter
The Argo thermometers supposedly have great precision. Whether they are accurate is anybody’s guess.
Yes. For example: http://judithcurry.com/2015/02/22/understanding-time-of-observation-bias/
There are also a number of side-by-side MMTS/CRS experiments. See this post for links and additional analysis: http://rankexploits.com/musings/2010/a-cooling-bias-due-to-mmts/
When you assume station operators don’t know how to use min/max thermometers while ignoring acres of asphalt appearing around your stations you’re going to give yourself credibility problems.
The net adjustments are obviously wrong. NCDC has been reporting near-average Great Lakes temperatures concomitant with record Great Lakes ice coverage. The raw data do not have this disagreement with reality (I saw the ice, I stood on the ice, it was not computer-generated). There is additional corroboration from snow cover, numbers of 100 degrees days reported, etc.
The data quality is way too low for this kind of analysis to be useful anyway, you really can’t even know the average annual temperature of the Earth to within a degree or you wouldn’t have these gigantic adjustments to past data even since 2000 or 1983. You guys should just average your crappy data (the actual measurements, such as they are), report the result, and apologize for the smell rather than mashing it into pleasing shapes, putting frills on it, and calling it civit at a huge markup.
Coincidence?
It was very cold yesterday where I was, so I went to my phone app and checked the current temperature and then the temperatures of some neighbouring suburbs and I found variations of 1-3C. It struck me how utterly idiotic it was for these ‘temperature modelers’ to be smearing their thermometers readings over great plots of land. These people really seem to be fools.
Will,
Not fools but shameless birds feathering their nests.
It’s obviously not a coincidence.
But nor is it proof of deliberate corruption of the data.
There’s a reason that real science uses double-blind trials.
Unwittingly, the “scientists” can bias the output because they know what it should be.
I see this as proof of shoddy work providing shoddy outputs form which shoddy policy decisions are made. But no-one wants to be rubbish.
They just are.
This is what I found when I dug deep enough, everything I found had some reference to model results indicating why their little piece of the puzzle fit the bigger picture.
There are also a number of side-by-side MMTS/CRS experiments.
You said it; I didn’t.
And rather than adjust the seriously inaccurate CRS units to match the MMTS units, they do it the other way ’round. yeah, I have no trouble with applying any conversion offsets. I do that according to Menne (2009) estimates. But Menne now does a 15-year pairwise spread (Ooo, ick, and other comments) and then distorts the far more accurate MMTS record to match in with the inaccurate CRS record. Forget the engineers. That’s even enough to make a wargame designer’s heart rebel.
http://wattsupwiththat.com/2015/06/14/despite-attempts-to-erase-it-globally-the-pause-still-exists-in-pristine-us-surface-temperature-data/
The USCRN was designed to collect accurate data from pristine sites, so that the measurements would not require any adjustments. Since it went into operation, zero warming has been measured.
Maybe at some point they’ll start adjusting USCRN to account for the air intake temperatures of aircraft flying nearby, as they did to ARGO?
KTM.
The US is not the world. Plus they have not been collecting the data long enough.
“Svante Callendar” says:
…they have not been collecting the data long enough.
And they will never collect data long enough. Because the data refutes the ‘dangerous man-made global warming’ narrative.
“This evidence suggests that much of the reported U.S. warming in the last 100+ years could be spurious, assuming that thermometer measurements made around 1880-1900 were largely free of spurious warming effects. This is a serious issue that NOAA needs to address in an open and transparent manner.”
http://www.drroyspencer.com/2012/08/spurious-warmth-in-noaas-ushcn-from-comparison-to-uscrn/
The USCRN was designed to collect accurate data from pristine sites
“Pristine” my left ass. (But, yeah, that’s the claim.)
“Louis Hunt September 24, 2015 at 6:38 pm
Surely there must be some thermometers that are highly accurate. Have they ever tested their adjustment algorithms against accurate thermometers to see how far off they are?”
There is probably sufficient data available from the US Climate Reference Network stations to run through the adjustment algorithms as a validation test. I doubt the results of that test would improve anyone’s confidence in the accuracy of the algorithms.
There is probably sufficient data available from the US Climate Reference Network stations to run through the adjustment algorithms as a validation test.
Yes, CRN is so beautiful it makes a man weep. I’ve surveyed ~a dozen, and they are so Class 1 it hurts. Consistent equipment. Triple-redundant sensors. No TOBS issue. To be served raw. Sublime. Climate sushi. But it’s still just a child, and its lifetime is over a near-zero trend span. So there’s only so much we can garner.
Surely there must be some thermometers that are highly accurate. Have they ever tested their adjustment algorithms against accurate thermometers to see how far off they are?
Why, yes. That is the meat and drink of Anthony’s siting project. It is, in fact, the basis of all my comments.
Within the USHCN, ~22% are “valid” (from 1979 to 2008): Well sited (vitally important), not moved, no significant TOBS bias or moves. (Urban stations are fine — provided always that they are well sited.)
There is, however, the CRS problem to consider. ALL of those stations are in need of trend adjustment. A cooling adjustment. A big one. A CRS unit carries its own heat sink on its back no matter how well it is sited.
In medical research bias was found to affect results approximately 100% of the time. There is no doubt that these people are biased in which case there can be no doubt their results are incorrect. This has been proven over and over again. It does not matter how honest or how hard the scientists try to avoid bias.
Using poorly maintained, non-calibrated, poorly sited devices is bad enough. But, trying to guess at the real signal by those who truly believe it must show more warming is clearly going to show more warming than actually occurred.
Reblogged this on Public Secrets and commented:
And yet we should take drastic and extreme economy and liberty-killing measures… based on guesswork. Right.
If it were halfway decent guesswork, I wouldn’t mind so much.
The reality is that propagandists like Obama don’t give a damn about science.
Scientists are deluding themselves that this climate change controversy is about climate science and climate data. It is not. It is all about politics, and the once in lifetime opportunity for the United Nations, once and for all, to crush democracy and capitalism, and impose the ambitious, arrogant and unscrupulous ideology of environmentalism.
If people think I’m talking “pie-in-the-sky” stuff, consider who the United Nations has now put in charge of Human Rights – Saudi Arabia, which is currently planning on crucifying a Shia muslim who dared speak out against the government. How many people would have thought that possible?
Obama is driving the UN’s agenda for the ‘New World Order” in which the facade of democracy will still exist but in reality, governments will be enforcing the UN’s agenda … a UN made up of unelected people imposing their view of the world on everyone else.
If we had wanted that, we could easily have left Hitler to take over the world. Back then, we had Sir Winston Churchill, thank God. Who do we have today?
It’s worse than it looks, this is monthly data, in NCDC’S global summary of days data set slightly more than half (72 million records out of ~125 million) are part of a station that took nearly a full year (greater than 360 samples per year) of data that year.
But, while you can’t monitor global temperature, you can measure a reasonably good rate of change at those individual locations and determine what happened at those locations, since 1940 it’s either 0.0F + / – 0.1F, or if you carry a few more decimal points, it cools slightly more at night than it warmed the previous day.
It’s no longer appropriate to refer to published temperature records as “data,” they are now “models.”
Someone notify the AP Style Guide!
“(Yes, the two curves combine oddly enough to look like a silhouette of Homer Simpson on his back snoring.)”
DOH!!!!
The Homer Simpson Constant… Don’t you love it so…
This explains why land-based temp data are so inaccurate and spurious and why ONLY satellite/radiosonde/un-tampered ARGO data global temp data should be used in climate science.
The pro-CAGW Homer Simpson Constant fudge factors of land-based temp data, and now the Karl2015 ARGO ocean temp data fudge factor are the ONLY things keeping the CAGW hypothesis on life support…
Satellite data show there hasn’t been a global warming trend for almost TWO decades, despite 30% of ALL manmade CO2 emissions since 1750 being made over JUST over the last 20 years:
http://www.woodfortrees.org/plot/rss/from:1996.6/plot/rss/from:1996.6/trend/plot/esrl-co2/from:1996.6/normalise/trend/plot/esrl-co2/from:1996.6/normalise
And there are such HUGE discrepancies (2+ standard deviations) between CAGW model projections vs. reality, that the CAGW hypothesis is already a disconfirmed hypothesis under the rules of the Scientific Method….
CAGW will go down as one of the biggest and most expensive scandals in human history…
CAGW is despicable.
+100… very well said.
There is no CAGW. But some AGW, I think. We are in a negative PDO now. Should be cooling, but is essentially flat. (That’s the measurable extent of AGW, such as it is. Not so much, but not nothing, either.)
If a general circulation model with 75,000 surface cells is seeded with data from 6,000 reporting stations, it is understandable that one would have to get creative with the meagre measurements available.
Not to mention the many vertical layers and the 30 minute time increments.
The GHCN V3 “data” are useless at best and fraud as most probable.
“The monthly GHCN V3 temperature record that is used by GISS undergoes an adjustment process after quality-control checks are done. The adjustments that are done are described at a high-level here.”
Some questions:
– is the GHCN-M data set used by GISS?
– the description link given is for the USHCN. Is this description relevant to GHCN-M?
Some people have no problem doing the usual song and dance about how adjustments are necessary/proper/irrelevant. But when you drill down to the adjustments being applied to individual stations, the hand-waving falls apart and the hand-wringing begins.