‘Raw Data = “Crap” . . . But the 21st Century Alchemists can turn it into ‘Not Crap’?
A pile of Crap hosed down with Febreze ™ is still a pile of Crap that smells less crappy.
How can it be both ways?
Richard D
December 13, 2013 9:52 am
I love the term homogenized. Just like milk, they remove all the good stuff so whatever is left over will last forever.
………………………………….
Not really. It’s chemistry….homogenization makes a solution uniform throughout by transforming immiscible components to an emulsion – nothing is removed.
Slartibartfast
December 13, 2013 9:55 am
There is no such thing as raw data.
This is as asinine a statement as I have ever run across from a purported scientist.
Its raw data is a voltage.
Condradiction is a useful device if your objective is to muddy the waters rather than clarify.
My personal liking for having raw data at hand is that armed with raw data and how that raw data was processed, one can reproduce results. Then one can create different results as one pleases, using different hypotheses. But only if one has access to the raw data. Which either exists or doesn’t, depending on which Steve Mosher you’re talking to.
rgbatduke
December 13, 2013 10:07 am
There are no adjustments.
There is the raw data if you like crap.
There is qc data
There is breakpoint data.
Then there is the estimated field.
We dont adjust data. We identify breakpoints and slice.
Then we estimate a field.
Steven, a serious question. Estimating a field via e.g. kriging as a general rule cannot alter the mean, or perhaps should not alter the mean. To quote the wikipedia article: If the cloud of real values is plotted against the estimated values , the criterion for global unbias, intrinsic stationarity or wide sense stationarity of the field, implies that the mean of the estimations must be equal to mean of the real values.
The second criterion says that the mean of the squared deviations ( must be minimal, which means that when the cloud of estimated values versus the cloud real values is more disperse, the estimator is more imprecise.
Both of these are also intuitively obvious on the basis of information theory — you cannot generate information content out of thin air by means of an interpolation. Hence one cannot do better than a simple average over the data by kriging — unbias is a requirement of the method to avoid, well, bias. The second criterion is equally important — one cannot improve the precision of the estimate by kriging, because the “data” you add via the krige is not even conceptually iid samples, it is basically a model fit.
This is true even if you use Bayesian reasoning to try to include priors (and get a, well, biased estimation contingent on the priors. The priors themselves come with error estimates and so the biased estimated field variance should be strictly larger than the field variance of the data itself.
Finally, there are well-known systematic biases in the underlying data, the most prominent of which is the UHI, which can be thought of as the sampling bias introduced by the tendency of humans to (vastly, preferentially) systematically measure temperatures where they live instead of where they don’t live, plus the tendency of human/anthropogenic changes associated with building human habitat or converting forestland to farm field to introduce profound local warming (but only in the comparatively small area in which humans actually reside). Anthony has documented many, many such biases produced by poor local siting of weather stations now, and of course it is almost impossible to determine related biases from (say) the early 1900s or mid 1800’s. However, there is I think fairly reliable data that suggests that non-rural areas remain a degree or two warmer than the surrounding countryside (in a way that is even reasonably proportional to average population density) and yet contain the bulk of the thermometers that contribute to the field average.
So one would expect that to do the best possible job of estimating land surface temperatures from historical thermometric data, one has two options, one of which should always be undertaken, and the other of which might well be done several ways for comparison and plausibility, not necessarily as an improved claim.
The first is to do a straight up area-weighted average, accumulating large errors wherever the data is sparse (after eliminating e.g. nonphysical outliers, broken thermometers, alcoholic record keepers to the extent that you can detect them, etc). Nothing can provide you with the missing information in the sparse regions any better than the simple average — attempts that give a different answer are enormously risky (or comparatively easily doubtable, if you prefer) because you at the very least have to make it very clear indeed what the source is for the missing information content that you are generating. Maximum entropy, after all. Start with this baseline unbiased estimate based on the direct, naive use of the actual data as it is almost by definition the one that maximizes your use of the available information in the data itself.
Second, by all means correct for perceived biases in the sampling data itself — e.g the UHI. This is critical because while UHI warming is indeed anthropogenic, and while we can presume that it has occurred repeatedly throughout history when e.g. first growth forest has been cut down and replaced by agriculture, when 19,000 square miles of the US have been covered by asphalt roadways directly exposed to the sun instead of evaporative-cooling trees, where every alteration of the environment due to humans has some thermal effect, that isn’t relevant to the question of GHG-induced warming. To detect the latter, we could safely completely exclude all urban area records and concentrate only on areas that have a long-running continuous measurement of reliable temperatures and that are still “pristeen” as far as anthropogenic alterations of the environment are concerned. One needs to do this anyway, to be able to compare the warming of this subgroup to the warming of the complementary set — all of the sites that have experienced substantial, sustained urban growth (e.g. Los Angeles, New York, Mexico City). CO_2 could hardly be expected to act to preferentially warm proportional to population density unless it is related to local warming, not global warming. But one should be very wary of using corrections of this nature without very sound, well-separated evidence of bias and one should recognize that using them increases the expected error of the result because uncertainty in the correction always will increase the raw statistical uncertainty in the aggregated data itself.
Then publish the two side by side. Or the three, four, five side by side — there may be more than one correction one can justify, and one might well want to try permutations of the corrections, but one would always like to be able to see just what the corrections were and assess whether or not the resulting shift is plausible. It is precisely this that I’m having trouble with in the case of Cowtan and Way’s paper, where they explicitly state that they are not using unbiased kriging because they want to correct e.g. HADCRUT’s simple average data. Then one has to look very carefully at just where the difference they obtain comes from, and why it almost all appears post 2005 even as the satellite data they are mixing into the sparse, kriged surface data goes the other way. Angels fear to tread where kriging some field changes the baseline average, especially when looking at the data itself provides no obvious answer for why it produces the change it produces (and it MUST end up with a higher error estimate than the original unbiased average).
There are other things I’d worry about — one can learn a lot from jackknifing, for example, or (if you krige, especially if you krige to a different average) how well your methodology can take 1/2 the data, apply the method, and predict the missing other half. Training and trial methodology is useful for things other than just predictive modeling, and of course when you estimate a field you are doing predictive modeling, just not necessarily in time.
So I’m not sure what you mean when you say that you adjust breakpoints, slice, and estimate a field. And this isn’t an effort to suggest that your temperature estimate is bad, good, or in between. It truly is a request for information. It’s a lot more fun to talk about what you actually do and why than to engage in the usual round of ad hominem bashing that often occurs. Sure, if I were good, I’d get the poster and read or get the paper (if you send me a reference) and read it, but I’m lazy (and proctoring a final at the moment and then insanely busy for three days, so maybe I’m not really lazy) and I’m curious, so a slightly more illuminating nutshell would be appreciated.
rgb
Richard D says:
December 13, 2013 at 9:52 am
I love the term homogenized. Just like milk, they remove all the good stuff so whatever is left over will last forever.
………………………………….
Not really. It’s chemistry….homogenization makes a solution uniform throughout by transforming immiscible components to an emulsion – nothing is removed.
+++++++
The other thing that is done to milk (besides adding vitamin D3 it is pasteurized – heated so as to kill living things within it.
MarkB
December 13, 2013 10:15 am
Tilo says:
December 12, 2013 at 8:34 pm
. . .I’m still going with the satellite data as being the real deal on global temp.
Would this then give you heartburn?
I don’t want to get involved in the mud slinging contests, but I do have a pair of questions regarding the adjusted climate data that have always bugged me and for which I have never seen satisfactory answers (ones that, until I do see answers, force me to discard all temperature reconstructions based the surfacestation record).
The adjusted climate data from BEST, HadCRUT, and GISS all exhibit a markedly different trend from that seen in the raw data. I fully agree that the raw data is crap, and I agree that in principle it should be possible to use data from nearby stations to identify which portions of the raw data from individual stations are crap – averages over noisy data reduce noise, assuming that the noise is random and uncorrelated.
However, that final clause is the kicker here. The adjustment process – whatever it may be – significantly alters the trend of the raw data. This suggests, prima facie, that whatever noise or bias is present in the raw data is either not random or not uncorrelated. Otherwise, one should expect up adjustments to roughyl cancel down adjustments and the overall trend to be substantially unchanged. This is not what is happening.
Therefore, there is something that is biasing the raw data in a systematic way. This leads me to my questions: first, what is biasing the raw data in a systematic way which would justify alteration of the trend? And second, given that the noise in the raw data is systematically biased, what justification is there for assuming that averaging, kriging, slicing, or any combination of those will correcly identify and rectify it?
Regarding the first, the obvious answer is that the urban heat island effect is contributes a systematic bias; however, it biases the raw data in the wrong direction – it should lead to an adjusted trend that is cooler. not warmer, than the raw data in recent times. Thus, there must be an additional source of bias – and one that is stronger than the known bias of the UHI. What is it?
Regarding the second, if the raw data is systematically biased, then it seems wrong to assume that using data from nearby stations will help to remove that bias, because it is no longer clear that it is more likely that a collection of such stations will have better data than any given single station.
” Thus, there must be an additional source of bias – and one that is stronger than the known bias of the UHI. What is it?”
This is pulling on a thread that has been bugging me–in an interest way, not bad way. Locales with UHI tend to be in well-sampled’ urban areas. Because these areas are preferentially sampled they are over-represented in the overall sample population. (This is entirely separate from the UHI.) It would seem that detailed care is needed to sift thru and ‘sort’ the numbers in these areas where both effects are potentially skewing estimation of a global average.
Kriging does intrinsically accommodate clustering to a degree but even that depends on the parametrized variogram/correlation function. Unfortunately clustering can also have a direct effect on the variogram making coming up with a good model (variogram) more difficult. I still think that BEST is headed down a good road but from a geostatistical perspective it is just in initial stages…there have to be a lot of priorities in something of this scope.
BTW a very entertaining and manageable learning exercise is to pick a set of data, e.g., US COOP [warts and all] and explore it with geostatistics [geoR, gstat, gslib, etc.]. Note: I have been using COOP because I am interested in a data set for a region that is small enough (~1200] to be relatively easy to manipulate, but covers a region large enough to have distinct physiographic regions. From the POV of a look into the window, it has been a fortuitous choice. Additional gravy is the promise of more information regarding station data quality, but that is just something still down the road–if at all.
rgbatduke
December 13, 2013 10:29 am
bias due to experimenter expectation effect is independent of honesty or sincerity. In fact, honesty and sincerity can make the problem worse, because you are more likely to suspect errors in the work of a dishonest or insincere person. However, even the most honest and sincere among us still have bias. We all do, and it is the in-built bias that blinds us to error that match our bias. Thus the failing of peer review to catch errors when the author and reviewers share the same bias.
Amazingly welle said once again, sir. Bravo!
As Feynman said, the person we have to be the most careful not to fool is ourself. Then we can be just ordinarily honest with other folks.
I teach introductory physics (in fact, that’s what I’m doing right at this moment, sort of, proctoring a final). I am pretty good at it. Give me a kiddy-physics problem and I’m hell on wheels. I lecture cold — no notes, I just walk in and do it. After all, I wrote the book I’m using.
However, teaching like this one quickly learns several things. For example, you can’t find your own errors in anything you write. Not just physics — if you miswrite a sentence, the human brain reads what you meant to say, not what you said, when you try to reread your own work. Never have I worked harder than when I tried to proofread my own novel — it took 20 or so passes, with long times in between for me to forget what I actually wrote (and there are probably still errors in the text). Second, you can’t find your own conceptual errors in anything you write or do. I teach with other, very talented, physics people. Every now and then one of them points out where I’ve been teaching something incorrectly (often for decades). Or where I use nonstandard notation. Every now and then I do the same for them — we all have those “holes” and again, we cannot pull the mote out of our own eye, for that we need help.
Third, my students find errors in what I do. I lecture live. I make algebra mistakes. I bribe the students with chocolate for every error they catch me making at the board, and make an average of 1-2 per lecture. Lots of times they are trivial algebra errors (which I’m as prone to as anybody else) — or I’ll literally SAY one thing (one half of my brain) and WRITE a different thing (a different half of my brain). With luck I catch my own errors — I’m constantly checking units and while I don’t remember the exact results or answers for everything I derive or solve for at the board, I can often recognize a problem and do so with my eyes while I’m talking about the next things. No candy for you! when I catch my own errors.
This is for easy stuff — Newton’s laws, elementary E&M. It isn’t just “bias” — the most honest of us make honest errors, even in the case of stuff we know extraordinarily well. We are also mistaken in places that our knowledge is as good as we think it is. We just don’t know where those places are. To find them, we often need help.
The desire to prove a point is an entirely natural human tendency. It is also one of the great mind-traps, perhaps even the world-class mind trap. Jaynes calls it the http://en.wikipedia.org/wiki/Mind_projection_fallacy
… the tendency to believe that the way one sees the world is the way the world really is. Once infected, one “Insensibly one begins to twist facts to suit theories, instead of theories to suit facts” as Sherlock Holmes put it long before Jaynes put a Bayesian cast on the logic of science.
Three words every scientist should make a part of their commonly used repertoire: “I’m not sure.”
rgb
rgbatduke
December 13, 2013 10:34 am
There is a very big difference between someone you disagree with and someone trying to sell you snake oil. Confusing the two makes you look bad. The BEST project is very trasparent, if they are selling snake oil then they are at least advertising it as such. In the many years I have been following climate science I have found many people who do not appear to be honest and sincere in their opinions. Mosh isn’t one of them (and not even close for that matter). Prove him wrong or thank him for the work that he does.
Also well said, and I agree. Besides, you can tell he isn’t a “real” climate scientist from the photo above. He isn’t bald, and has no beard.
I, on the other hand, just might be… Gads!
rgb
rgbatduke
December 13, 2013 10:53 am
1. I wanted jones data and code so that I could do a better job.
2. My goal was to use all the data and show every step.
3. Next I wanted to use methods suggested by skeptics
A. Slicing rather than adjusting.
B. Kriging rather than averaging
This is better, but I’m still confused. Kriging and averaging “should” give the same result if the kriging is done correctly, because that is a constraint on doing it correctly, is it not? The only kriging does is give you a comparatively high(er) estimate for infilled regions that are strictly consistent because they lead to the same average and hence didn’t invent information where there was none in the data.
Or maybe I just don’t understand this.
Also, how do you “slice” a time dependent increase in general urban population correlated to a general temperature increase distinct from and added to the non-rural temperature variations? The answer, of course, is into lots of tiny slices, a.k.a. a continuous adjustment. I appreciate your not treating a moved station or a station that changed measurement methods or stations that had a road built right in front of them in a six month stretch as different stations, but that doesn’t allow for the fact that some of these “slices” are discrete and monotonically produce more warming, some of the changes are occult and indistinguishable from a sudden but real warming or cooling, and the fact that in many locations, it isn’t just the road, it is the road, the factory down the road, the farm across the road (where there used to be trees), and the small village that springs up along the road to staff the new factory, with small changes happening every year that introduce a local bias into the data that is anthropogenic local warming, to be sure, but not GHG-linked AGW.
rgb
I teach introductory physics (in fact, that’s what I’m doing right at this moment, sort of, proctoring a final). I am pretty good at it. Give me a kiddy-physics problem and I’m hell on wheels. I lecture cold — no notes, I just walk in and do it. After all, I wrote the book I’m using.
++++++++
Love it! Sounds like you enjoy thinking on your feet!
When I give presentations I use words sparingly on screen. Rather I use images that set up for an open ended, though framed, discussion. After all, I need to read the class/audience so that I can figure out how to deliver the messages through interactive engagement.
When I coach race car drivers, I do not follow a script. I set up the controls, and then figure out what they need to go faster safely. As long as they act without hesitation when I deliver one of three commands (gas, brake or easy) and they agree to let me keep a hand on the steering wheel, then I am in control of the situation. I need to get bumper stickers that read, “my student can kick your student’s *ss”
Richard D
December 13, 2013 11:05 am
No candy for you!
++++++++++++++++++++++++++++++++++
Bummer. And a bit stingy, professor 🙂 ………..I had a chemistry professor who would give a point added to exams for errors we found in the text. I was seriously interested in reading the text.
rgbatduke says:
December 13, 2013 at 10:53 am
&
Richard D says:
December 13, 2013 at 11:05 am
…………….
I educated was at a university where certain lectures were compulsory regardless of courses selected. Pointing out at errors in the theory presented would seriously jeopardised once further academic advance, even expulsion was realistic possibility. Fortunately, that is no further case.
Janice Moore
December 13, 2013 12:20 pm
A Story with a Moral
(and, yes, I believe it is a true story — you need not to get the point, though, I think…)
Once there were three wealthy Persian kings who were brilliant astronomers. They knew the diamond spangled night sky like they knew the sparkle in their childrens’ eyes when their little ones ran to greet them upon their entering the family living quarters each evening. Year after year, they watched the heavens, just for the love of knowledge (a.k.a. “science”). Then, one night, they saw it. They would talk about this night for the rest of their lives, “… and remember the night we saw The Star?” And, then, once again, with the youngest grandchildren eagerly listening and the older grandchildren smiling while rolling their eyes, they would excitedly tell the story… .
First King: BAM! There it was, out of nowhere. I couldn’t believe my eyes. It was an enigma, an anomalous phenomenon
Second King: Yes, yes, but we knew from it’s position that it meant that a new king had been born and that he was great.
Third King: AND, we figured out that he was Jewish.
2K: And we knew our minds’ calm sea would be tossing until we had seen him. No matter how long it took.
Grandchild 1: So… you called for your finest camels and packed up and —
Grandchild 2: — you didn’t forget the gold, frankincense, and myrrh because he was a king and because he was also something more than a king and you didn’t know what the myrrh was for.
Grandchild 1 (glaring at being interrupted, but quickly gets over it)
2K: That’s right (smiling), you know the story as well as we do. We just all three had this idea that myrrh was something to take along. So, we did.
1K: And we hoped it didn’t mean that one of us would die on the journey and would need to be embalmed with it. We just took it along not knowing why, just that it seemed important. Remember, children, never throw out what you believe may be significant even if you have no idea what it could be used for and even if you don’t like the implication of what that use might turn out to be.
3K: Also, do not assume you know why it is significant. Wait until you have strong evidence before coming to a conclusion.
Grandchild 1: (eyes shining) Tell us about that crazy old Herod. And how you were mixed up and …
3K: (rolling eyes and grimacing) Herod, ugh. Well, when we finally reached Jerusalem nearly two years after we left, we went straight to Herod — who else would know where the new king would be?
Grandchild 1: But, he DIDN’T KNOW.
1K: No, he didn’t know. And we didn’t know what he would do. (everyone is silent, faces downcast, remembering Herod’s brutal murder of all the babies 2 years old and under in Bethlehem because of what the 3 kings had told him).
2K: Well, that old snake’s eyes narrowed when we told him we were looking for the new king of the Jews. He got all oily and smiled a lot and asked us a lot of questions. His advisors were the real brains of the administration; they were scholars and knew that Bethlehem was the place we should look.
Grandchild 2: (jumping up and doing a fine imitation of Herod) And he gyrated and he rolled his googly eyes and …. (all the grandchildren jump up and go crazy acting like Herod) … and THEN he threw himself DOWN ON THE FLOOR AND THREW A TANTRUM and… (all the children follow suit, collapsing in a giggling pile)
2K: (chuckling) Okay, okay, it was sort of like that, heh, heh. Anyway, we headed for Bethlehem. We took measurements all along the way. Sure enough, the star was directly over that little town. We checked and double-checked. We re-calibrated our instruments on known constellations. We really thought we were way off course and wondered if we had come all this way for nothing. You just can’t imagine how we felt, standing there outside that shabby town. We were so sure… .
3K: Our data was correct. We had made, without even realizing it, an unwarranted assumption. We assumed that all kings were found in palaces, among wealth and fine things. We were wrong. But, we were determined to follow the data wherever it led us, so, we were perplexed, but we were still on the road to truth, for we trusted the data more than we trusted our own minds.
1K: And, we found what we were actually searching for, not what we thought we were searching for.
Grandchild 2: A little boy in a wee house without even a carpet on the floor…
Grandchild 1: (soberly) … or even one servant. Not even a cook. Just Mary and Joseph who were very nice people but not what you had expected at all… .
************************
Keep following that star of observations, O Science Giants of WUWT — you and not the guys at BEST are on the road to truth. They, poor souls, are wandering in the wilderness.
@Bill Illis:
I looked at the Ottawa (Canada) station data from BEST, and compared it to the Environment Canada record. The BEST graph looks like the usual ho(c)key stick: http://berkeleyearth.lbl.gov/locations/45.81N-75.00W
It shows, eyeballing it, about 1.5 degrees C of warming in the last 75 years. (!) They don’t show the raw data they started with. But EC has some: http://climate.weather.gc.ca/climateData/monthlydata_e.html?timeframe=3&Prov=ONT&StationID=4337&mlyRange=1938-01-01|2011-06-01&Year=1970&Month=01&Day=01
From there it is possible to download monthly average temperatures since 1938, and calculate running 12-month means, which I did, and plotted the result here: http://imgur.com/bSLOZrQ
I don’t know where BEST got data for Ottawa prior to 1938, because according to Environment Canada, there isn’t any. They just made it up? But there definitely isn’t a hockey stick here. It may be a bit warmer in the last few years than it was prior to the 1998 El Nino, but I don’t see any influence other than that small step. The most recent 12-month average I plotted is cooler than it was in the 1940s, for instance. Prior to 1998 it is basically completely flat.
I suppose Steve M. will have some kind of explanation for this that involves breakpoints and slicing. As others have said, this just doesn’t pass the smell test…
Janice Moore says:
December 13, 2013 at 12:20 pm Keep following that star of observations. O Science Giants of WUWT….
Yes, observations, observations… , but the giants of WUWT tell you that results of the observation are pseudo-science and nonsense (see link ). Well, agree one Earth year is 365.25 and not 364 days; 178 & 222 may not mean much, but together they make 400 days, not a place to elaborate.
Janice, doing science for fun is a serious business.
mwgrant
December 13, 2013 2:51 pm
One area in which BEST will likey need to improve/change is how how spatial correlation changes over time. A single parameterized correlation function over time and space is just too crude beyond initial calculations. Keeping in mind that the final product is an estimated temperature/anomaly field at time landmarks of interest things like station location/layout changes while remaining important will take on a different perspective–more isolated in time.
Also as long as kriging is employed and as long as anomalies are used some one probably needs to work out/check/search nitty-gritty details, e.g., invariance of the correlation function/variogram to the selection of a reference range used for calculating anomalies. The local mean temperature of a range changes with translation in space, and in an evolving system this suggests that employment of different reference ranges can lead to different anomaly spatial distributions for a given year. Said another way, each anomaly calculation is local and each location evolve differently. Maybe it shakes out. Still a ways to go…nothing wrong with that.
Bill Illis
December 13, 2013 2:52 pm
Steve says:
December 13, 2013 at 1:19 pm
—————
At EC, there is a station called Ottawa which goes (monthly) from 1872 to 1935 (lots of missing months) and one called Ottawa CDA that goes (monthly) from 1889 to 2006 (with almost no missing months). Ottawa airport from 1938 to today.
Should be able to put a long record together from that.
@Steven Mosher: You wrote “And uah doesnt measure temparature. Its raw data is a voltage. This gets turned into a temperature by applying a physics model. That model is also the same model that says co2 warms the planet. I bet you thought uah was data. Its not. Its adjusted modelled outputs. Go read the theory behind satellite data.”
+++++++++++
Not so fast. I thought about what you wrote and it was intellectually dishonest. First – what is temperature but a measured value? I digress. Let me address the physics, which is where I have a real problem with your statement. The physical model used to determine temperature using platinum is known and repeatable. So repeatable in fact, that platinum is the “gold” standard for electronic temperature sensing devices. There is no physical model that (honestly) “says CO2 warms the planet” that is repeatable! It’s not the same, but you feel it advances the argument.
Your statement is yet another attempt at obfuscation, in my opinion. I am not going to tell you to “read the theory about” anything because I already know that you know I am right.
I do feel a little bit bad about harping on you, since for you to come clean and advance our understanding of your knowledge would be career suicide for you. We both know that. I am only a man seeking truth, and will selfishly continue on my journey. So I apologize ahead of time for my modus operandi.
Steven Mosher says:
December 12, 2013 at 10:53 pm
I want to thank folks for the kind comments about climategate.
1. I wanted jones data and code so that I could do a better job.
2. My goal was to use all the data and show every step.
3. Next I wanted to use methods suggested by skeptics
A. Slicing rather than adjusting.
B. Kriging rather than averaging
Berkeley did everything I asked and skeptics asked. So I volunteered over a year of free time to help.
Bottomline. I wont say no to anybody with a better idea of how to estimate the historical climate field. But whoever has a better idea has to put in the time and live with the answer their approach produces. I dont have time for critics who wont work. I learned from steve mcintyre and anthony. If you want to criticize you better be willing to work. Sometimes for free..sometimes for years.
+++++++++++
There’s so much wrong here.
Regarding “3. Next I wanted to use methods suggested by skeptics”
When did skeptics say the stations with poor siting should be subjectively sliced and added to mix so their warming could fit the narrative?
Neither BEST nor you have ever honestly addressed why “if only urban areas show warming, while rural areas don’t, that you could slice (in?) the poorly sited urban stations to make their “crap” value warm the entire temperature record.
Don’t have much time before I need to run for dinner, but a few things in this thread caught my eye:
Stephen Rasey: the march of the thermometers meme was so 2010. Berkeley uses ~40,000 stations, and 2012 has more station date than any prior year (it increases pretty monotonically. GHCN-M version 3 (which NCDC/NASA now use) also has much more station data post-1992 than the prior version 2.
rgbatduke: The Berkeley method does a few things. First it uses pair-wise comparisons of nearby stations to identify localized step-changes in difference series that are specific to one station but not seen in surrounding stations. These are assumed to be localized biases (e.g. station moves, instrument changes, time of observation changes). We cut the station record at these breakpoints, and treat the record after these cuts as a different station.
Second, all resulting station records are combined into regional estimates using a kriging approach for spatial interpolation. Fragmentary records are in a region aligned using a least-squares method to avoid discarding short series.
Third, we use a jackknife approach to estimate uncertainty both for each grid cell and over larger areas (e.g. global land).
You can find full details on the methodology here: http://www.scitechnol.com/2327-4581/2327-4581-1-103.pdf
And additional details here: http://www.scitechnol.com/2327-4581/2327-4581-1-103a.pdf
Tom J: Be nice. Also, I think I might have accidentally grabbed my fiancee’s blue dress shirt that looks exactly the same as mine (but is a small rather than a medium), but so it goes. :-p
To others: We will try and get a version of the poster online soon, as the image Anthony posted is hard to decipher. In short, its a downscaled U.S. version of the Berkeley dataset at 25 kilometer resolution from 1850 to present using ~20,000 stations.
@Steven Mosher says:
December 12, 2013 at 10:09 pm
C02.
Like skeptics Lindzen, Christy, Spencer, and Anthony I know that adding C02 to an atmosphere will warm a planet not cool it.
Below the tropopause, CO2 does nothing. The radiative bands are fully closed and “always” have been. (as far as human existence is concerned)
The tropopause is dominated by convection precisely because of this radiative closure. That is WHY there is a troposphere…
Above the tropopause, IR active gasses cause increased radiation of heat. That is, CO2 net radiates more heat off the planet.
There’s a fair argument that more CO2 simply causes more net radiation to space from above the tropopause.
(Not saying I’m convinced by that argument; but it’s an interesting case…)
See this graph / image: http://www.atmosphere.mpg.de/media/archive/1460.jpg
from this paper: http://www.atmosphere.mpg.de/enid/20c.html
discussed here: http://chiefio.wordpress.com/2012/12/12/tropopause-rules/
The caption reads:
3. Stratospheric cooling rates: The picture shows how water, cabon dioxide and ozone contribute to longwave cooling in the stratosphere. Colours from blue through red, yellow and to green show increasing cooling, grey areas show warming of the stratosphere. The tropopause is shown as dotted line (the troposphere below and the stratosphere above). For CO2 it is obvious that there is no cooling in the troposphere, but a strong cooling effect in the stratosphere. Ozone, on the other hand, cools the upper stratosphere but warms the lower stratosphere. Figure from: Clough and Iacono, JGR, 1995; adapted from the SPARC Website. Please click to enlarge! (60 K)
Notice the large ‘diamond’ of cooling reds / yellows in the stratosphere. Caused by CO2. (so labeled in the graph).
I think this matters.
E.M.Smith
Editor
December 13, 2013 7:27 pm
Steven Mosher says:
December 12, 2013 at 10:22 pm
EM smith also does not understand the process.
Oh, please Mosh. You know darned well I “understand the process”. I was making a general comment about how climate data food products behave with respect to discontinuities (the spice and dice) and not fingering you. So you give me a personal slam? Sheesh. Starting to get a bit sensitive aren’t you?
The problems arise as soon as you start to average and blend different things and think that gives more accuracy. It doesn’t. It can remove random error, but not systematic error. Temperature measurement is dominated by systematic error, not random. So you take an error prone intrinsic (or intensive) property and average it. It simply can not be done and have any meaning. (Since most data sets start with an average of high / low or an average over a month, from the outset the math is meaningless) http://chiefio.wordpress.com/2011/07/01/intrinsic-extrinsic-intensive-extensive/
Now you want me to believe that you have overcome the fundamental nature of physical properties and have a magic sauce that fixes it. No, not going to happen. I’m sticking with fundamental properties of the universe, thank you. So I don’t really care if you use Kriging or Averaging or how you manufacture your “field”. At the outset the fundamental philosophy of the process is broken. There simply can not be a “global average temperature” so it can not rise nor fall. For that you want to claim I don’t understand your “process”? When from the very foundation it is a fools errand of fundamental impossibility? Just who is not understanding what can and can not be done with intrinsic properties? Hmmm?
Look, you guys made a good effort. Put a lot of time in. Likely did some good code and some nice experience was gained. In the end, the product is useless simply because the fundamental philosophy of the math is broken. No more nor less useless than any other system that uses averages of temperatures or does similar things with intrinsic properties, but still, just as pointless.
Sorry to be the one to break it to you, but that’s how the reality just is.
Now go back and look at individual instruments and their trends. Not any adjusted, fixed, averaged, or otherwise molested composite. Some go up, some go down. Most of the world simply is not warming. What is warming is often over tarmac at airports and in urban areas. It’s not the climate that changed, it’s the instruments and locations. Intrinsic properties are like that…


‘Raw Data = “Crap” . . . But the 21st Century Alchemists can turn it into ‘Not Crap’?
A pile of Crap hosed down with Febreze ™ is still a pile of Crap that smells less crappy.
How can it be both ways?
I love the term homogenized. Just like milk, they remove all the good stuff so whatever is left over will last forever.
………………………………….
Not really. It’s chemistry….homogenization makes a solution uniform throughout by transforming immiscible components to an emulsion – nothing is removed.
This is as asinine a statement as I have ever run across from a purported scientist.
Condradiction is a useful device if your objective is to muddy the waters rather than clarify.
My personal liking for having raw data at hand is that armed with raw data and how that raw data was processed, one can reproduce results. Then one can create different results as one pleases, using different hypotheses. But only if one has access to the raw data. Which either exists or doesn’t, depending on which Steve Mosher you’re talking to.
There are no adjustments.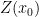 is plotted against the estimated values
is plotted against the estimated values  , the criterion for global unbias, intrinsic stationarity or wide sense stationarity of the field, implies that the mean of the estimations must be equal to mean of the real values.
, the criterion for global unbias, intrinsic stationarity or wide sense stationarity of the field, implies that the mean of the estimations must be equal to mean of the real values. must be minimal, which means that when the cloud of estimated values versus the cloud real values is more disperse, the estimator is more imprecise.
must be minimal, which means that when the cloud of estimated values versus the cloud real values is more disperse, the estimator is more imprecise.
There is the raw data if you like crap.
There is qc data
There is breakpoint data.
Then there is the estimated field.
We dont adjust data. We identify breakpoints and slice.
Then we estimate a field.
Steven, a serious question. Estimating a field via e.g. kriging as a general rule cannot alter the mean, or perhaps should not alter the mean. To quote the wikipedia article:
If the cloud of real values
The second criterion says that the mean of the squared deviations (
Both of these are also intuitively obvious on the basis of information theory — you cannot generate information content out of thin air by means of an interpolation. Hence one cannot do better than a simple average over the data by kriging — unbias is a requirement of the method to avoid, well, bias. The second criterion is equally important — one cannot improve the precision of the estimate by kriging, because the “data” you add via the krige is not even conceptually iid samples, it is basically a model fit.
This is true even if you use Bayesian reasoning to try to include priors (and get a, well, biased estimation contingent on the priors. The priors themselves come with error estimates and so the biased estimated field variance should be strictly larger than the field variance of the data itself.
Finally, there are well-known systematic biases in the underlying data, the most prominent of which is the UHI, which can be thought of as the sampling bias introduced by the tendency of humans to (vastly, preferentially) systematically measure temperatures where they live instead of where they don’t live, plus the tendency of human/anthropogenic changes associated with building human habitat or converting forestland to farm field to introduce profound local warming (but only in the comparatively small area in which humans actually reside). Anthony has documented many, many such biases produced by poor local siting of weather stations now, and of course it is almost impossible to determine related biases from (say) the early 1900s or mid 1800’s. However, there is I think fairly reliable data that suggests that non-rural areas remain a degree or two warmer than the surrounding countryside (in a way that is even reasonably proportional to average population density) and yet contain the bulk of the thermometers that contribute to the field average.
So one would expect that to do the best possible job of estimating land surface temperatures from historical thermometric data, one has two options, one of which should always be undertaken, and the other of which might well be done several ways for comparison and plausibility, not necessarily as an improved claim.
The first is to do a straight up area-weighted average, accumulating large errors wherever the data is sparse (after eliminating e.g. nonphysical outliers, broken thermometers, alcoholic record keepers to the extent that you can detect them, etc). Nothing can provide you with the missing information in the sparse regions any better than the simple average — attempts that give a different answer are enormously risky (or comparatively easily doubtable, if you prefer) because you at the very least have to make it very clear indeed what the source is for the missing information content that you are generating. Maximum entropy, after all. Start with this baseline unbiased estimate based on the direct, naive use of the actual data as it is almost by definition the one that maximizes your use of the available information in the data itself.
Second, by all means correct for perceived biases in the sampling data itself — e.g the UHI. This is critical because while UHI warming is indeed anthropogenic, and while we can presume that it has occurred repeatedly throughout history when e.g. first growth forest has been cut down and replaced by agriculture, when 19,000 square miles of the US have been covered by asphalt roadways directly exposed to the sun instead of evaporative-cooling trees, where every alteration of the environment due to humans has some thermal effect, that isn’t relevant to the question of GHG-induced warming. To detect the latter, we could safely completely exclude all urban area records and concentrate only on areas that have a long-running continuous measurement of reliable temperatures and that are still “pristeen” as far as anthropogenic alterations of the environment are concerned. One needs to do this anyway, to be able to compare the warming of this subgroup to the warming of the complementary set — all of the sites that have experienced substantial, sustained urban growth (e.g. Los Angeles, New York, Mexico City). CO_2 could hardly be expected to act to preferentially warm proportional to population density unless it is related to local warming, not global warming. But one should be very wary of using corrections of this nature without very sound, well-separated evidence of bias and one should recognize that using them increases the expected error of the result because uncertainty in the correction always will increase the raw statistical uncertainty in the aggregated data itself.
Then publish the two side by side. Or the three, four, five side by side — there may be more than one correction one can justify, and one might well want to try permutations of the corrections, but one would always like to be able to see just what the corrections were and assess whether or not the resulting shift is plausible. It is precisely this that I’m having trouble with in the case of Cowtan and Way’s paper, where they explicitly state that they are not using unbiased kriging because they want to correct e.g. HADCRUT’s simple average data. Then one has to look very carefully at just where the difference they obtain comes from, and why it almost all appears post 2005 even as the satellite data they are mixing into the sparse, kriged surface data goes the other way. Angels fear to tread where kriging some field changes the baseline average, especially when looking at the data itself provides no obvious answer for why it produces the change it produces (and it MUST end up with a higher error estimate than the original unbiased average).
There are other things I’d worry about — one can learn a lot from jackknifing, for example, or (if you krige, especially if you krige to a different average) how well your methodology can take 1/2 the data, apply the method, and predict the missing other half. Training and trial methodology is useful for things other than just predictive modeling, and of course when you estimate a field you are doing predictive modeling, just not necessarily in time.
So I’m not sure what you mean when you say that you adjust breakpoints, slice, and estimate a field. And this isn’t an effort to suggest that your temperature estimate is bad, good, or in between. It truly is a request for information. It’s a lot more fun to talk about what you actually do and why than to engage in the usual round of ad hominem bashing that often occurs. Sure, if I were good, I’d get the poster and read or get the paper (if you send me a reference) and read it, but I’m lazy (and proctoring a final at the moment and then insanely busy for three days, so maybe I’m not really lazy) and I’m curious, so a slightly more illuminating nutshell would be appreciated.
rgb
Richard D says:
December 13, 2013 at 9:52 am
I love the term homogenized. Just like milk, they remove all the good stuff so whatever is left over will last forever.
………………………………….
Not really. It’s chemistry….homogenization makes a solution uniform throughout by transforming immiscible components to an emulsion – nothing is removed.
+++++++
The other thing that is done to milk (besides adding vitamin D3 it is pasteurized – heated so as to kill living things within it.
Tilo says:
December 12, 2013 at 8:34 pm
. . .I’m still going with the satellite data as being the real deal on global temp.
Would this then give you heartburn?
Raw data is the king.
This is what the NASA got from a set of the ‘adjusted’ geomagnetic data
http://www.nasa.gov/images/content/525284main_earth20110309b-full.jpg
and this is what I got from the same set of the raw data
http://www.vukcevic.talktalk.net/SSN-LOD.htm
I don’t want to get involved in the mud slinging contests, but I do have a pair of questions regarding the adjusted climate data that have always bugged me and for which I have never seen satisfactory answers (ones that, until I do see answers, force me to discard all temperature reconstructions based the surfacestation record).
The adjusted climate data from BEST, HadCRUT, and GISS all exhibit a markedly different trend from that seen in the raw data. I fully agree that the raw data is crap, and I agree that in principle it should be possible to use data from nearby stations to identify which portions of the raw data from individual stations are crap – averages over noisy data reduce noise, assuming that the noise is random and uncorrelated.
However, that final clause is the kicker here. The adjustment process – whatever it may be – significantly alters the trend of the raw data. This suggests, prima facie, that whatever noise or bias is present in the raw data is either not random or not uncorrelated. Otherwise, one should expect up adjustments to roughyl cancel down adjustments and the overall trend to be substantially unchanged. This is not what is happening.
Therefore, there is something that is biasing the raw data in a systematic way. This leads me to my questions: first, what is biasing the raw data in a systematic way which would justify alteration of the trend? And second, given that the noise in the raw data is systematically biased, what justification is there for assuming that averaging, kriging, slicing, or any combination of those will correcly identify and rectify it?
Regarding the first, the obvious answer is that the urban heat island effect is contributes a systematic bias; however, it biases the raw data in the wrong direction – it should lead to an adjusted trend that is cooler. not warmer, than the raw data in recent times. Thus, there must be an additional source of bias – and one that is stronger than the known bias of the UHI. What is it?
Regarding the second, if the raw data is systematically biased, then it seems wrong to assume that using data from nearby stations will help to remove that bias, because it is no longer clear that it is more likely that a collection of such stations will have better data than any given single station.
” Thus, there must be an additional source of bias – and one that is stronger than the known bias of the UHI. What is it?”
This is pulling on a thread that has been bugging me–in an interest way, not bad way. Locales with UHI tend to be in well-sampled’ urban areas. Because these areas are preferentially sampled they are over-represented in the overall sample population. (This is entirely separate from the UHI.) It would seem that detailed care is needed to sift thru and ‘sort’ the numbers in these areas where both effects are potentially skewing estimation of a global average.
Kriging does intrinsically accommodate clustering to a degree but even that depends on the parametrized variogram/correlation function. Unfortunately clustering can also have a direct effect on the variogram making coming up with a good model (variogram) more difficult. I still think that BEST is headed down a good road but from a geostatistical perspective it is just in initial stages…there have to be a lot of priorities in something of this scope.
BTW a very entertaining and manageable learning exercise is to pick a set of data, e.g., US COOP [warts and all] and explore it with geostatistics [geoR, gstat, gslib, etc.]. Note: I have been using COOP because I am interested in a data set for a region that is small enough (~1200] to be relatively easy to manipulate, but covers a region large enough to have distinct physiographic regions. From the POV of a look into the window, it has been a fortuitous choice. Additional gravy is the promise of more information regarding station data quality, but that is just something still down the road–if at all.
bias due to experimenter expectation effect is independent of honesty or sincerity. In fact, honesty and sincerity can make the problem worse, because you are more likely to suspect errors in the work of a dishonest or insincere person. However, even the most honest and sincere among us still have bias. We all do, and it is the in-built bias that blinds us to error that match our bias. Thus the failing of peer review to catch errors when the author and reviewers share the same bias.
Amazingly welle said once again, sir. Bravo!
As Feynman said, the person we have to be the most careful not to fool is ourself. Then we can be just ordinarily honest with other folks.
I teach introductory physics (in fact, that’s what I’m doing right at this moment, sort of, proctoring a final). I am pretty good at it. Give me a kiddy-physics problem and I’m hell on wheels. I lecture cold — no notes, I just walk in and do it. After all, I wrote the book I’m using.
However, teaching like this one quickly learns several things. For example, you can’t find your own errors in anything you write. Not just physics — if you miswrite a sentence, the human brain reads what you meant to say, not what you said, when you try to reread your own work. Never have I worked harder than when I tried to proofread my own novel — it took 20 or so passes, with long times in between for me to forget what I actually wrote (and there are probably still errors in the text). Second, you can’t find your own conceptual errors in anything you write or do. I teach with other, very talented, physics people. Every now and then one of them points out where I’ve been teaching something incorrectly (often for decades). Or where I use nonstandard notation. Every now and then I do the same for them — we all have those “holes” and again, we cannot pull the mote out of our own eye, for that we need help.
Third, my students find errors in what I do. I lecture live. I make algebra mistakes. I bribe the students with chocolate for every error they catch me making at the board, and make an average of 1-2 per lecture. Lots of times they are trivial algebra errors (which I’m as prone to as anybody else) — or I’ll literally SAY one thing (one half of my brain) and WRITE a different thing (a different half of my brain). With luck I catch my own errors — I’m constantly checking units and while I don’t remember the exact results or answers for everything I derive or solve for at the board, I can often recognize a problem and do so with my eyes while I’m talking about the next things. No candy for you! when I catch my own errors.
This is for easy stuff — Newton’s laws, elementary E&M. It isn’t just “bias” — the most honest of us make honest errors, even in the case of stuff we know extraordinarily well. We are also mistaken in places that our knowledge is as good as we think it is. We just don’t know where those places are. To find them, we often need help.
The desire to prove a point is an entirely natural human tendency. It is also one of the great mind-traps, perhaps even the world-class mind trap. Jaynes calls it the
http://en.wikipedia.org/wiki/Mind_projection_fallacy
… the tendency to believe that the way one sees the world is the way the world really is. Once infected, one “Insensibly one begins to twist facts to suit theories, instead of theories to suit facts” as Sherlock Holmes put it long before Jaynes put a Bayesian cast on the logic of science.
Three words every scientist should make a part of their commonly used repertoire: “I’m not sure.”
rgb
There is a very big difference between someone you disagree with and someone trying to sell you snake oil. Confusing the two makes you look bad. The BEST project is very trasparent, if they are selling snake oil then they are at least advertising it as such. In the many years I have been following climate science I have found many people who do not appear to be honest and sincere in their opinions. Mosh isn’t one of them (and not even close for that matter). Prove him wrong or thank him for the work that he does.
Also well said, and I agree. Besides, you can tell he isn’t a “real” climate scientist from the photo above. He isn’t bald, and has no beard.
I, on the other hand, just might be… Gads!
rgb
1. I wanted jones data and code so that I could do a better job.
2. My goal was to use all the data and show every step.
3. Next I wanted to use methods suggested by skeptics
A. Slicing rather than adjusting.
B. Kriging rather than averaging
This is better, but I’m still confused. Kriging and averaging “should” give the same result if the kriging is done correctly, because that is a constraint on doing it correctly, is it not? The only kriging does is give you a comparatively high(er) estimate for infilled regions that are strictly consistent because they lead to the same average and hence didn’t invent information where there was none in the data.
Or maybe I just don’t understand this.
Also, how do you “slice” a time dependent increase in general urban population correlated to a general temperature increase distinct from and added to the non-rural temperature variations? The answer, of course, is into lots of tiny slices, a.k.a. a continuous adjustment. I appreciate your not treating a moved station or a station that changed measurement methods or stations that had a road built right in front of them in a six month stretch as different stations, but that doesn’t allow for the fact that some of these “slices” are discrete and monotonically produce more warming, some of the changes are occult and indistinguishable from a sudden but real warming or cooling, and the fact that in many locations, it isn’t just the road, it is the road, the factory down the road, the farm across the road (where there used to be trees), and the small village that springs up along the road to staff the new factory, with small changes happening every year that introduce a local bias into the data that is anthropogenic local warming, to be sure, but not GHG-linked AGW.
rgb
I teach introductory physics (in fact, that’s what I’m doing right at this moment, sort of, proctoring a final). I am pretty good at it. Give me a kiddy-physics problem and I’m hell on wheels. I lecture cold — no notes, I just walk in and do it. After all, I wrote the book I’m using.
++++++++
Love it! Sounds like you enjoy thinking on your feet!
When I give presentations I use words sparingly on screen. Rather I use images that set up for an open ended, though framed, discussion. After all, I need to read the class/audience so that I can figure out how to deliver the messages through interactive engagement.
When I coach race car drivers, I do not follow a script. I set up the controls, and then figure out what they need to go faster safely. As long as they act without hesitation when I deliver one of three commands (gas, brake or easy) and they agree to let me keep a hand on the steering wheel, then I am in control of the situation. I need to get bumper stickers that read, “my student can kick your student’s *ss”
No candy for you!
++++++++++++++++++++++++++++++++++
Bummer. And a bit stingy, professor 🙂 ………..I had a chemistry professor who would give a point added to exams for errors we found in the text. I was seriously interested in reading the text.
rgbatduke says:
December 13, 2013 at 10:53 am
&
Richard D says:
December 13, 2013 at 11:05 am
…………….
I educated was at a university where certain lectures were compulsory regardless of courses selected. Pointing out at errors in the theory presented would seriously jeopardised once further academic advance, even expulsion was realistic possibility. Fortunately, that is no further case.
A Story with a Moral
(and, yes, I believe it is a true story — you need not to get the point, though, I think…)
Once there were three wealthy Persian kings who were brilliant astronomers. They knew the diamond spangled night sky like they knew the sparkle in their childrens’ eyes when their little ones ran to greet them upon their entering the family living quarters each evening. Year after year, they watched the heavens, just for the love of knowledge (a.k.a. “science”). Then, one night, they saw it. They would talk about this night for the rest of their lives, “… and remember the night we saw The Star?” And, then, once again, with the youngest grandchildren eagerly listening and the older grandchildren smiling while rolling their eyes, they would excitedly tell the story… .
First King: BAM! There it was, out of nowhere. I couldn’t believe my eyes. It was an enigma, an anomalous phenomenon
Second King: Yes, yes, but we knew from it’s position that it meant that a new king had been born and that he was great.
Third King: AND, we figured out that he was Jewish.
2K: And we knew our minds’ calm sea would be tossing until we had seen him. No matter how long it took.
Grandchild 1: So… you called for your finest camels and packed up and —
Grandchild 2: — you didn’t forget the gold, frankincense, and myrrh because he was a king and because he was also something more than a king and you didn’t know what the myrrh was for.
Grandchild 1 (glaring at being interrupted, but quickly gets over it)
2K: That’s right (smiling), you know the story as well as we do. We just all three had this idea that myrrh was something to take along. So, we did.
1K: And we hoped it didn’t mean that one of us would die on the journey and would need to be embalmed with it. We just took it along not knowing why, just that it seemed important. Remember, children, never throw out what you believe may be significant even if you have no idea what it could be used for and even if you don’t like the implication of what that use might turn out to be.
3K: Also, do not assume you know why it is significant. Wait until you have strong evidence before coming to a conclusion.
Grandchild 1: (eyes shining) Tell us about that crazy old Herod. And how you were mixed up and …
3K: (rolling eyes and grimacing) Herod, ugh. Well, when we finally reached Jerusalem nearly two years after we left, we went straight to Herod — who else would know where the new king would be?
Grandchild 1: But, he DIDN’T KNOW.
1K: No, he didn’t know. And we didn’t know what he would do. (everyone is silent, faces downcast, remembering Herod’s brutal murder of all the babies 2 years old and under in Bethlehem because of what the 3 kings had told him).
2K: Well, that old snake’s eyes narrowed when we told him we were looking for the new king of the Jews. He got all oily and smiled a lot and asked us a lot of questions. His advisors were the real brains of the administration; they were scholars and knew that Bethlehem was the place we should look.
Grandchild 2: (jumping up and doing a fine imitation of Herod) And he gyrated and he rolled his googly eyes and …. (all the grandchildren jump up and go crazy acting like Herod) … and THEN he threw himself DOWN ON THE FLOOR AND THREW A TANTRUM and… (all the children follow suit, collapsing in a giggling pile)
2K: (chuckling) Okay, okay, it was sort of like that, heh, heh. Anyway, we headed for Bethlehem. We took measurements all along the way. Sure enough, the star was directly over that little town. We checked and double-checked. We re-calibrated our instruments on known constellations. We really thought we were way off course and wondered if we had come all this way for nothing. You just can’t imagine how we felt, standing there outside that shabby town. We were so sure… .
3K: Our data was correct. We had made, without even realizing it, an unwarranted assumption. We assumed that all kings were found in palaces, among wealth and fine things. We were wrong. But, we were determined to follow the data wherever it led us, so, we were perplexed, but we were still on the road to truth, for we trusted the data more than we trusted our own minds.
1K: And, we found what we were actually searching for, not what we thought we were searching for.
Grandchild 2: A little boy in a wee house without even a carpet on the floor…
Grandchild 1: (soberly) … or even one servant. Not even a cook. Just Mary and Joseph who were very nice people but not what you had expected at all… .
************************
Keep following that star of observations, O Science Giants of WUWT — you and not the guys at BEST are on the road to truth. They, poor souls, are wandering in the wilderness.
@Bill Illis:
I looked at the Ottawa (Canada) station data from BEST, and compared it to the Environment Canada record. The BEST graph looks like the usual ho(c)key stick:
http://berkeleyearth.lbl.gov/locations/45.81N-75.00W
It shows, eyeballing it, about 1.5 degrees C of warming in the last 75 years. (!) They don’t show the raw data they started with. But EC has some:
http://climate.weather.gc.ca/climateData/monthlydata_e.html?timeframe=3&Prov=ONT&StationID=4337&mlyRange=1938-01-01|2011-06-01&Year=1970&Month=01&Day=01
From there it is possible to download monthly average temperatures since 1938, and calculate running 12-month means, which I did, and plotted the result here:
http://imgur.com/bSLOZrQ
I don’t know where BEST got data for Ottawa prior to 1938, because according to Environment Canada, there isn’t any. They just made it up? But there definitely isn’t a hockey stick here. It may be a bit warmer in the last few years than it was prior to the 1998 El Nino, but I don’t see any influence other than that small step. The most recent 12-month average I plotted is cooler than it was in the 1940s, for instance. Prior to 1998 it is basically completely flat.
I suppose Steve M. will have some kind of explanation for this that involves breakpoints and slicing. As others have said, this just doesn’t pass the smell test…
Janice Moore says:
December 13, 2013 at 12:20 pm
Keep following that star of observations. O Science Giants of WUWT….
Yes, observations, observations… , but the giants of WUWT tell you that results of the observation are pseudo-science and nonsense (see link ). Well, agree one Earth year is 365.25 and not 364 days; 178 & 222 may not mean much, but together they make 400 days, not a place to elaborate.
Janice, doing science for fun is a serious business.
One area in which BEST will likey need to improve/change is how how spatial correlation changes over time. A single parameterized correlation function over time and space is just too crude beyond initial calculations. Keeping in mind that the final product is an estimated temperature/anomaly field at time landmarks of interest things like station location/layout changes while remaining important will take on a different perspective–more isolated in time.
Also as long as kriging is employed and as long as anomalies are used some one probably needs to work out/check/search nitty-gritty details, e.g., invariance of the correlation function/variogram to the selection of a reference range used for calculating anomalies. The local mean temperature of a range changes with translation in space, and in an evolving system this suggests that employment of different reference ranges can lead to different anomaly spatial distributions for a given year. Said another way, each anomaly calculation is local and each location evolve differently. Maybe it shakes out. Still a ways to go…nothing wrong with that.
Steve says:
December 13, 2013 at 1:19 pm
—————
At EC, there is a station called Ottawa which goes (monthly) from 1872 to 1935 (lots of missing months) and one called Ottawa CDA that goes (monthly) from 1889 to 2006 (with almost no missing months). Ottawa airport from 1938 to today.
Should be able to put a long record together from that.
@Steven Mosher: You wrote “And uah doesnt measure temparature. Its raw data is a voltage. This gets turned into a temperature by applying a physics model. That model is also the same model that says co2 warms the planet. I bet you thought uah was data. Its not. Its adjusted modelled outputs. Go read the theory behind satellite data.”
+++++++++++
Not so fast. I thought about what you wrote and it was intellectually dishonest. First – what is temperature but a measured value? I digress. Let me address the physics, which is where I have a real problem with your statement. The physical model used to determine temperature using platinum is known and repeatable. So repeatable in fact, that platinum is the “gold” standard for electronic temperature sensing devices. There is no physical model that (honestly) “says CO2 warms the planet” that is repeatable! It’s not the same, but you feel it advances the argument.
Your statement is yet another attempt at obfuscation, in my opinion. I am not going to tell you to “read the theory about” anything because I already know that you know I am right.
I do feel a little bit bad about harping on you, since for you to come clean and advance our understanding of your knowledge would be career suicide for you. We both know that. I am only a man seeking truth, and will selfishly continue on my journey. So I apologize ahead of time for my modus operandi.
Steven Mosher says:
December 12, 2013 at 10:53 pm
I want to thank folks for the kind comments about climategate.
1. I wanted jones data and code so that I could do a better job.
2. My goal was to use all the data and show every step.
3. Next I wanted to use methods suggested by skeptics
A. Slicing rather than adjusting.
B. Kriging rather than averaging
Berkeley did everything I asked and skeptics asked. So I volunteered over a year of free time to help.
Bottomline. I wont say no to anybody with a better idea of how to estimate the historical climate field. But whoever has a better idea has to put in the time and live with the answer their approach produces. I dont have time for critics who wont work. I learned from steve mcintyre and anthony. If you want to criticize you better be willing to work. Sometimes for free..sometimes for years.
+++++++++++
There’s so much wrong here.
Regarding “3. Next I wanted to use methods suggested by skeptics”
When did skeptics say the stations with poor siting should be subjectively sliced and added to mix so their warming could fit the narrative?
Neither BEST nor you have ever honestly addressed why “if only urban areas show warming, while rural areas don’t, that you could slice (in?) the poorly sited urban stations to make their “crap” value warm the entire temperature record.
Don’t have much time before I need to run for dinner, but a few things in this thread caught my eye:
Stephen Rasey: the march of the thermometers meme was so 2010. Berkeley uses ~40,000 stations, and 2012 has more station date than any prior year (it increases pretty monotonically. GHCN-M version 3 (which NCDC/NASA now use) also has much more station data post-1992 than the prior version 2.
rgbatduke: The Berkeley method does a few things. First it uses pair-wise comparisons of nearby stations to identify localized step-changes in difference series that are specific to one station but not seen in surrounding stations. These are assumed to be localized biases (e.g. station moves, instrument changes, time of observation changes). We cut the station record at these breakpoints, and treat the record after these cuts as a different station.
Second, all resulting station records are combined into regional estimates using a kriging approach for spatial interpolation. Fragmentary records are in a region aligned using a least-squares method to avoid discarding short series.
Third, we use a jackknife approach to estimate uncertainty both for each grid cell and over larger areas (e.g. global land).
You can find full details on the methodology here: http://www.scitechnol.com/2327-4581/2327-4581-1-103.pdf
And additional details here: http://www.scitechnol.com/2327-4581/2327-4581-1-103a.pdf
Tom J: Be nice. Also, I think I might have accidentally grabbed my fiancee’s blue dress shirt that looks exactly the same as mine (but is a small rather than a medium), but so it goes. :-p
To others: We will try and get a version of the poster online soon, as the image Anthony posted is hard to decipher. In short, its a downscaled U.S. version of the Berkeley dataset at 25 kilometer resolution from 1850 to present using ~20,000 stations.
Folks can find a full high-resolution version of our poster here: https://www.dropbox.com/s/lzivyl2dd7bfl2s/AGU%202013%20Poster%20ZH.pdf
@Steven Mosher says:
December 12, 2013 at 10:09 pm
C02.
Like skeptics Lindzen, Christy, Spencer, and Anthony I know that adding C02 to an atmosphere will warm a planet not cool it.
Below the tropopause, CO2 does nothing. The radiative bands are fully closed and “always” have been. (as far as human existence is concerned)
The tropopause is dominated by convection precisely because of this radiative closure. That is WHY there is a troposphere…
Above the tropopause, IR active gasses cause increased radiation of heat. That is, CO2 net radiates more heat off the planet.
There’s a fair argument that more CO2 simply causes more net radiation to space from above the tropopause.
(Not saying I’m convinced by that argument; but it’s an interesting case…)
See this graph / image: http://www.atmosphere.mpg.de/media/archive/1460.jpg
from this paper: http://www.atmosphere.mpg.de/enid/20c.html
discussed here: http://chiefio.wordpress.com/2012/12/12/tropopause-rules/
The caption reads:
3. Stratospheric cooling rates: The picture shows how water, cabon dioxide and ozone contribute to longwave cooling in the stratosphere. Colours from blue through red, yellow and to green show increasing cooling, grey areas show warming of the stratosphere. The tropopause is shown as dotted line (the troposphere below and the stratosphere above). For CO2 it is obvious that there is no cooling in the troposphere, but a strong cooling effect in the stratosphere. Ozone, on the other hand, cools the upper stratosphere but warms the lower stratosphere. Figure from: Clough and Iacono, JGR, 1995; adapted from the SPARC Website. Please click to enlarge! (60 K)
Notice the large ‘diamond’ of cooling reds / yellows in the stratosphere. Caused by CO2. (so labeled in the graph).
I think this matters.
Steven Mosher says:
December 12, 2013 at 10:22 pm
EM smith also does not understand the process.
Oh, please Mosh. You know darned well I “understand the process”. I was making a general comment about how climate data food products behave with respect to discontinuities (the spice and dice) and not fingering you. So you give me a personal slam? Sheesh. Starting to get a bit sensitive aren’t you?
The problems arise as soon as you start to average and blend different things and think that gives more accuracy. It doesn’t. It can remove random error, but not systematic error. Temperature measurement is dominated by systematic error, not random. So you take an error prone intrinsic (or intensive) property and average it. It simply can not be done and have any meaning. (Since most data sets start with an average of high / low or an average over a month, from the outset the math is meaningless)
http://chiefio.wordpress.com/2011/07/01/intrinsic-extrinsic-intensive-extensive/
Now you want me to believe that you have overcome the fundamental nature of physical properties and have a magic sauce that fixes it. No, not going to happen. I’m sticking with fundamental properties of the universe, thank you. So I don’t really care if you use Kriging or Averaging or how you manufacture your “field”. At the outset the fundamental philosophy of the process is broken. There simply can not be a “global average temperature” so it can not rise nor fall. For that you want to claim I don’t understand your “process”? When from the very foundation it is a fools errand of fundamental impossibility? Just who is not understanding what can and can not be done with intrinsic properties? Hmmm?
Look, you guys made a good effort. Put a lot of time in. Likely did some good code and some nice experience was gained. In the end, the product is useless simply because the fundamental philosophy of the math is broken. No more nor less useless than any other system that uses averages of temperatures or does similar things with intrinsic properties, but still, just as pointless.
Sorry to be the one to break it to you, but that’s how the reality just is.
Now go back and look at individual instruments and their trends. Not any adjusted, fixed, averaged, or otherwise molested composite. Some go up, some go down. Most of the world simply is not warming. What is warming is often over tarmac at airports and in urban areas. It’s not the climate that changed, it’s the instruments and locations. Intrinsic properties are like that…