Friday’s post principally reported on the recent (February 8, 2022) article by O’Neill, et al., in Atmospheres, “Evaluation of the Homogenization Adjustments Applied to European Temperature Records in the Global Historical Climatology Network Dataset.” In the piece, O’Neill, et al., dramatically demonstrate that the NOAA/NCEI “homogenization” algorithm is wildly off the mark in its intended mission of identifying and correcting for supposed “discontinuities” or “breakpoints” in weather station location or instrumentation in order to provide a more accurate world temperature history. At the same time, although not mentioned in O’Neill, et al., the NOAA/NCEI algorithm is wildly successful in generating a world temperature history time series in the iconic hockey stick form to support the desired narrative of climate alarm.
What should be done? O’Neill, et al., for reasons that I completely cannot understand, buy into the idea that having a group of government-paid experts correct the temperature record with a “homogenization” algorithm was and is a good idea; therefore, we just need to tweak this effort a little to get it right. From O’Neill, et al.:
[W]e are definitely not criticizing the overall temperature homogenization project. We also stress that the efforts of Menne & Williams (2009) in developing the PHA . . . to try and correct for both undocumented and documented non-climatic biases were commendable. Long-term temperature records are well-known to be frequently contaminated by various non-climatic biases arising from station moves . . ., changes in instrumentation . . ., siting quality . . ., times of observation . . ., urbanization . . ., etc. Therefore, if we are interested in using these records to study regional, hemispheric or global temperature trends, it is important to accurately account for these biases.
Sorry, but no. This statement betrays hopeless naïveté about the processes by which government bureaucracies work. Or perhaps inserting this statement into the piece was the price of getting it published in a peer reviewed journal that, like all academic journals in the climate field today, will suppress any piece that overtly challenges “consensus” climate science.
Whichever of those two it is, the fact is that any collection of government bureaucrats, given the job to “adjust” temperature data, will “adjust” it in the way that best enhances the prospects for growth of the staff and budget of the bureaucracy. The chances that scientific integrity and accuracy might intrude into the process are essentially nil.
Is there any possibility that a future Republican administration with a healthy skepticism about the climate alarm movement could do anything about this?
For starters, note that President Trump, despite his climate skepticism and his focus on what he called “energy dominance,” never even drained a drop out of this particular corner of the swamp. It took Trump until September 2020 — just a few months before the end of his term — to finally appoint two climate skeptics, David Legates and Ryan Maue, to NOAA to look into what they were doing. Before they really got started, Trump was out and so were they.
Even if a new Republican President in 2025 got started on his first day, the idea that he could quickly — or even within four years — get an honestly “homogenized” temperature record out of NOAA/NCEI, is a fantasy. The existing bureaucracy would fight him at every turn, and claim that all efforts were “anti-science.” Those bureaucrats mostly have civil service protection and cannot be fired. And there don’t even exist enough climate skeptics with the requisite expertise to re-do the homogenization algorithm in an honest way.
But here are some things that can be done:
- Do an audit of the existing “homogenization” efforts. Come out with a report that points to five or ten or twenty obvious flaws in the current algorithm. There are at least that many. The O’Neill, et al., work gives a good starting point. Also, there are many stations with good records of long-term cooling that have been “homogenized” into long-term warming. Put the “homogenizers” on the hot seat to attempt to explain how that has happened.
- After the report comes out, announce that the government has lost confidence in the people who have been doing this work. If they can’t be fired, transfer them to some other function. Don’t let the people stay together as a team. Transfer some to one place, and some to another, preferably in different cities that are distant from each other.
- Also after the report comes out, announce that the U.S. government is no longer relying on this temperature series for policymaking purposes. It’s just too inaccurate. Take down the website in its current form, and all promotion of the series as something providing scary information about “hottest month ever” and the like. Leave only a link to hard data in raw form useful only to “experts” with infinite time on their hands.
- Stop reporting the results of the USHCN/GHCN temperature series to the hundredth of a degree C. The idea that this series — much of which historically comes from thermometers that only record to the nearest full degree — is accurate to one-hundredth of a degree is completely absurd. The reporting to an accuracy of a hundredth of a degree is what gives NOAA the ability to claim that a given month was the “hottest ever” when it says temperature went from an anomaly of 1.03 deg to 1.04 deg. I suggest reporting only to an accuracy of 0.5 of a degree. That way, the series would have the same temperature anomaly for months or years on end.
- Put error bars around whatever figures are reported. Appoint a task force to come up with appropriate width of the error bars. There should be some kind of sophisticated statistical model to generate this, but I would think that error bars of +/- 0.5 deg C are eminently justifiable. Again, that would make it impossible to claim that a given month is the “hottest ever,” unless there has been some sort of really significant jump.
HadCRUt takes it further. Precision to 1/1000th of a degree.
To 6 or 7 decimal places for monthly “data”.
And Colorado University’s Sea Level Research Group tells us that acceleration of sea level rise is 0.098 mm/yr². Besides it being phony, why didn’t they round it up to 0.1 mm/yr².
Climate science comes up short on the various aspects of numerate competence, understanding the concept of the number of significant places is only one.
Perhaps they thought 98 was a standard acceleration to use for everything on earth
works for gravity, why not SLR?
Increased rainfall accelerates sea level rise. Falling rain accelerates at 0.0981hm/sec2 (hectometers/second/second).
There you have it, they just rounded down to 3 decimals.
More rain is result of more evaporation before, reducing sealevel.
May be they measure sea level just before and after rainfall, take the difference, and ‘hey presto’ they get + SLR acceleration. Measure it just after one rain fall and just before the next next one there will be – SLR. Hence, there is a natural oscillation in SLR. Statistics is just decorative ‘numerical origami’ of science or even more so of the quasi- and pseudo- science.
Well, then, it’s no wonder that the news lately has been so full of reports of flooding around the world. 🙂
Would that be true if, say, the rainfall acceleration was in reality 0.0979 hm/sec2 instead of the reported 0.0981 hm/sec2?
Inquiring minds want to know.
They wanted to publish an even better number that 97% of “climate scientists” would agree with.
…. and if they rounded it up to 0.1, people might think they were faking it.
97% is so 2020
2021 was 99%.
The current 2022 consensus
is 105%
The notion that an acceleration derived from a line fit over a period of 30 years is ridiculous in its own right. The 2 significant figures might be justified on a statistical basis, but is their data splice?
BTW, the acronym for the “University of Colorado” is CU. This leads to people then mistakenly referring to it as Colorado University.
Other universities follow this convention, e.g. the University of Oklahoma is OU. But the University of Michigan is UM of U of M.
“CU” is what they put on the football helmets.
The Denver campus isn’t called “CU Denver”, but rather UCD.
Yes. Sometime University of Colorado at Boulder is abbreviated as UCB.
Not to be confused with the University of California, Berkeley.
And in other news, Denver will finally get above freezing on Saturday. Someone needs to adjust the numbers from this week upward PDQ.
Stating something like temp or SLR to 3 decimal places shows the drones are really, really hard at work and doing very precise cyphering.
With the level of acceleration stated, then one could expect 6″ of SL rise around 2050 and just over 2 feet of rise by 2100. However, going backwards using their quadratic equation, indicates a bottoming of SL around 1975 and a fall of about a foot from 1900 to 1975.
Obviously, the fit does not describe past reality. Of course, they aren’t overtly making the claim that it does, but back to Steve’s point, it would seem that the two significant figures that they report is perhaps wrong or deceptive.
I think they should explain their motives around the descriptive statistics that they use and perhaps how it should be interpreted. That would give us more information at least.
It is known as “over-fitting.”
“why don’t they round up …?”
well, perhaps because then folks like you will proclaim “they ROUNDED UP!”
also, this is an acceleration, not a rate/velocity. If a rate is significant at 0.1 mm/yr, then acceleration would be significant at 0.01 mm/yr2
The error in this whole line of thought (the article, not your quibble) is that Classical Statistics is known to be more misleading to the public – and to many Statisticians – than necessary. Classical Statistics was invented to suggest possible causal models from small [O(10)] data sets with no time component (see R.M. Fischer, et al). The proper way to assess temporal-causal hypotheses is with Bayesian methods (as is done by Attribution Science). There are no ‘statistics’ in Bayesian analysis. Rather, Bayesian models are judged based on the odds that the model explains the data, not if some shape parameter is ‘significantly’ greater than zero.
because three decimal places is more “scientific” sounding.
The data files say the 95% CI is ±0.05 [1]. Where are seeing an uncertainty of 1/1000th of a degree?
The resolution limit of an MMTS sensor is ±0.1 C, under lab conditions. https://doi.org/10.1175/1520-0426(2001)018<1470:SPORIS>2.0.CO;2
A 1σ CI of ±0.025 C is four times smaller than the lower limit of instrumental resolution.
Data magicked from thin air. More proof, if we needed it, that climate science is ever so special.
PF said: “Data magicked from thin air. More proof, if we needed it, that climate science is ever so special.”
It’s not magic. It’s how the propagation of uncertainty plays out when you follow it through all of the steps of the process.
I will say that I did a Type A evaluation of the HadCRUT, GISTEMP, BEST, and ERA uncertainty a few months back and I got a 1σ CI of ±0.038 C which is a bit higher than what each are claiming via their respective Type B evaluations. But I don’t think anyone is going to cry foul with a difference that small. Either way I think everyone will agree that 0.025 or 0.038 is significantly different than 0.001.
Assuming you did the calculations properly, then the temps should only be reported to be significant to the hundredths position, and the CI should be reported as ±0.04 deg C, at best.
I don’t disagree. Just know that if they did that someone will inevitably say the datasets are not being transparent and hiding the digits. On Dr. Spencer’s blog I would frequently discuss the trend to 2 decimal places and get accused of fraudulently making the trend look higher than it was since it was actually getting rounded up to +0.14 C/decade instead of the lower +0.135 C/decade value. Over here I provide 3 and sometimes 4 digits and then I’m accused of displaying too many digits and even accused doing the linear regression calculation wrong. It’s basically a no-win situation. Anyway, the other nice thing about having the extra digits is that you can do calculations with less rounding error and you can see how often past months are changing. For example, if you only used the 2 digit UAH TLT file you might not notice changes in past month values like you can plainly see with the 3 digit file. That’s the other thing. UAH TLT reports to 3 digits even though their own assessed uncertainty is ±0.2 C yet few people care to indict of Dr. Spencer and Dr. Christy of the same sf rule violations they indict others of. My point is this…someone is always going to “nuh-uh” the reporting of digits either way. And in the end reporting more digits does not harm especially when the uncertainty is explicitly provided.
The accepted practice is if a number is anticipated to be used in subsequent calculations, is to place a ‘guard digit’ in brackets to the right of the significant digits. To play is safe show both: +0.14 C/decade (+0.13[5] C/decade).
I don’t disagree. In fact, I have reported values both with and without the guard clause and I still see people getting bent out shape on here. In one blog post I got fed up with it all and said I’d just post all of the IEEE 754 digits that Excel provides and let the WUWT audience figure out how to display the value. I had one guy respond insinuating that IEEE 754 was either stupid and/or an unfortunate invention that allows scientists to report a precision that isn’t justified. I had another guy tell me that if I didn’t use sf rules strictly then the entire result including the calculation is wrong. If this all sounds absurd it’s because it is absurd. Clyde, I hear what you’re saying. I’m just saying it doesn’t matter. I significant percentage of the blog posts I participate in descend into distracting conversations about how I or someone report a figure even if the sf rules are applied strictly and correctly.
Unfortunately, that seems to be the way it is. While I’m a dyed in the wool skeptic, I have my detractors on both sides. I think that part of the problem is that the alarmists have pulled so many shenanigans with respect to measurements that some skeptics have come to dislike any and all alarmists, and look for something to criticize.
Clyde, I think if you and I sat down for a coffee we’d likely get along fine and probably even agree on a lot of topics related the climate. I get tired of the alarmist of claptrap like the erroneous and evidentiary unsupported claims from Al Gore and the likes too. I’m completely open to the idea that the uncertainty on global average temperatures is higher than the reported ±0.05’ish C figures. But claims that it is on the order of 1 C or higher is not consistent with the evidence. Even claims that it is 0.5 C does not fit the evidence.
Quit whining. The resolution of most temps in the 21st century is only to 1/10th of a degree. That’s 1 decimal place. The floating point calculations for 1 decimal place in a computer have little to with determining Significant Digits. I can do those calculations to one decimal place on my old Pickett slide rule.
For the United States it is actually about 0.3 C. The reason is because temperatures where recorded in Fahrenheit to the nearest integer. F to C has a 5/9 scaling so ±0.5 F is about ±0.3 C. And that’s only the reporting uncertainty. There would be a instrumental and human read uncertainty to factor in as well.
Are you able to read with comprehension?
I think so. JG said “The resolution of most temps in the 21st century is only to 1/10th of a degree.” which is only true for stations that reported in C. For stations that report in F like those in the United States it is actually 3/10th of a degree because of the scaling factor between F and C. Do you disagree?
Kool! Caught a double-down-vote.
“UAH TLT reports to 3 digits even though their own assessed uncertainty is ±0.2 C yet few people care to indict of Dr. Spencer and Dr. Christy of the same sf rule violations they indict others of.”
It’s ±0.3 C, actually. I discussed that a bit with Roy Spencer when we met long ago in Chicago. He shrugged me off.
My interest is focused on the surface air temps because those are the data that are being abused in the name of AGW.
The past global average temperature trends have no value in predicting the future temperature. Check the data in the past 120 years. Therefore, the number of decimal places is irrelevant. You probably have never noticed, because you are not very bright, that predictions of future global average temperature rise rates are unrelated to measurements of the past global average temperature.
Two wrongs don’t make a right. Don’t use someone else’s practice to justify what you do.
UAH may have the resolution to discern more precise radiance values, and from that more precise temps. I don’t know the answer to that. Yet the expanded uncertainty may also be pretty large when clouds, drift, etc. are used to develop the uncertainty. Your
What it should tell you is that trends of less than 0.3 are irresolute. You simply can’t discern what a real value is when inside the uncertainty window.
Here is one of your problems.
CM said: “Here is one of your problems.”
Do you think 0.025 or 0.038 are the same as 0.001?
No, I think all three are optimistic bollocks.
Do you think anyone else thinks 0.025 or 0.038 are the same as 0.001?
I think you completely missed the point.
If no one things 0.025 or 0.038 are the same thing as 0.001 then why is it problem if I think everyone would agree that they are different? Why do we continue to have mindless distracting discussions of things that really don’t matter?
0.025, 0.038, and 0.001 all have a measurement resolution of 1/1000th.
That is 25 thousandths, 38 thousandths, and 1 thousandth.
You show you ignorance by asking the question. A mechanic or machinist can tell you what these measurements mean.
A simple example is a brake rotor. The run out shouldn’t exceed 0.002 inches. Can you average measurements from a number of different rotors using a ruler that reads out to the nearest inch (an integer) to get what the uncertainty actually is?
Here is a link discussing engine main bearing clearances. Think you can do them with a ruler to the nearest 1/16th of an inch?
https://www.bracketracer.com/engine/mains/mains.htm
That is what you are doing with temps and anomalies. You are “calculating” digits of resolution that don’t exist.
Digits in a measurement (resolution) provide a certain amount of information and only that amount. You can not add information to that measurement through mathematical calculations of any kind. Pretending that you can create additional information out of thin air via calculations is naivete at its finest.
Just curious – what was N in your uncertainty analysis? What factors were included in your uncertainty budget? Even the simplest MU evaluation must include at least three factors.
N was 3096. It was a purely type A evaluation so no specific factors were considered. It was just an analysis using 3096 comparisons of the monthly global average surface temperature between 1979 and 2021. Type B is the one where you combine specific factors like 1, 2, and 3 you mentioned above plus a bunch of others like spatial and temporal sampling, grid infilling, etc. Individually Morice et al. 2020 describe the procedure for HadCRUT, Lenssen et al. 2019 for GISTEMP, and Rhode et al. 2013 for BEST. It is interesting that each uses wildly different methods for computing the global average surface temperature and wildly different methods for assessing uncertainty and yet the results are consistent with each.
From your response I infer that your data set had a standard deviation of 2.11 which you divided by the square foot of 3096 to arrive at 0.038. What you have calculated is not the uncertainty it is the standard error of the mean. Thus the 95% confidence limit of the mean of your data set is +/- 0.076. To arrive at the uncertainty of your mean you must add (in quadrature) all the other factors that increase the uncertainty. These factors are not subject to the square root of N reduction. And once you arrive at the correct estimate of the actual uncertainty multiply it by 2 to get the 95% confidence level.
I never took the square root of 3096 in this particular case. What I did was compared 3096 measurements. The difference in measurements fell into a normal distribution with a standard deviation of 0.053. And sqrt(0.053^2/2) = 0.038. Notice that the uncertainty of the difference of two different measurements each with 0.038 standard uncertainty combine via root sum square or sqrt(0.038^2 + 0.038^2) = 0.053. It is important to understand that 0.053 is the standard uncertainty of the difference of two measurements while 0.038 is the standard uncertainty of a single measurement.
There is another type A method where you can take the standard deviation of the values in the grid mesh and divide by the number of cells in the grid mesh. I have used that method before. In fact, I just did it for the UAH TLT Jan. 2022 grid which has 9504 cells The standard deviation was about 13 which yields a type A evaluation of 13/sqrt(9504) = 0.13 C. Interestingly the Christy et al. 2003 type B evaluation was 0.10 C.
“N” should not be the number of samples. It should be the sample size. You may have 3096 samples but. “N” is probably 12, the number of months in a year.
“N” is only the number of measurements when you are measuring the same thing multiple times with the same device.
You must distinguish between the two types of uncertainty: accuracy and precision. There is a big difference on how you handle them. Uncertainty due to precision errors can be reduced using mathematical processes such as averaging multiple readings; not so with accuracy. When you mix measurements from instruments that have different accuracy ratings and non-identical precision error models, determining the true uncertainty gets very complicated. As far as I can tell, none of the creators of those temperature sets has undertaken that kind of analysis. Personally, I discount everything to the right of the decimal point in the final results. Daily values seem believable at +/- 0.5, for what that’s worth.
As bwx has been told many times, there is no way to use averaging of multiple measurements of a time series to reduce random uncertainty—after value is measured once it is gone forever.
I’ve never claimed that averaging measurements reduces the uncertainty of the individual measurements themselves. That’s your strawman. You own it. Don’t expect me to defend it.
What I have said is that the uncertainty of an average is less than the uncertainty of the individual measurements that went into it. That is something completely different. And my statement here is backed by literally every statistics reference out there including the one you prefer.
Keep on fooling yourself, see if I care.
Temperature is a time-series, see if you can figure out what this means.
bdgwx- Sorry, your claim only applies to repeated measurements of the same artifact with the same instrument by the same person. To illustrate, when precision studies are done on a particular measurement process two results are reported. Repeatability which is a measure of variance when the same person using the same instrument measures the same artifact. Reproducibility evaluates the variance when a different person using a different instrument measures the same artifact. Repeatability is virtually always better than reproducibility for obvious reasons. Further, the results of these studies are commonly used to evaluate measurement uncertainty along with other factors I mentioned previously.
Rick C said: “bdgwx- Sorry, your claim only applies to repeated measurements of the same artifact with the same instrument by the same person.”
I’ve never seen any such requirement. In fact, it’s the exact opposite. In the GUM their examples frequently use a combining function that not only accepts uncertainties of measurements of different artifacts but uncertainties of measurements using different instruments that measure completely different kinds of things with completely different units combined in arbitrarily complex output functions.
Rick C said: “Repeatability which is a measure of variance when the same person using the same instrument measures the same artifact. Reproducibility evaluates the variance when a different person using a different instrument measures the same artifact.”
R&R is a different topic.
No! The mean (average) has an SEM which is the interval within which the mean may lay. It has nothing to do with the precision of the mean.
If you are finding the mean of a number of integer measurements, you may find that the SEM is very small. That very close to the actual mean of a POPULATION. Yet the average can have no more digits of resolution than the measurements themselves.
bwx never listens !
There are virtually no measurements (raw data) in the global average temperature compilation.
There are “adjusted” numbers and infilled numbers.
The adjusted numbers are personal opinions of what the raw measurements would have been if measured correctly in the first place.
These adjusted numbers are no longer real data.
The infilled numbers were never real data.
There is no way to verify whether the adjustments created a more accurate picture of reality, or whether the infilled numbers were in the vicinity of reality.
Ads a result, it is impossible to calculate a margin of error for such adjusted and infilled numbers.
The number of decimal places is not very relevant.
Exactly! What they do with data turns science into religion.
FWIW, I would put the uncertainty on individual temperature observations at closer to 1 C prior to WWII. I think 0.5 C is pretty reasonable for automated stations. One exception might be USCRN which I believe is reported to be around 0.3 C.
You know nothing about real metrology, your estimates are worthless.
That’s not what Berkeley thinks!
Here’s just one of their records:
462373 1 1929.625 22.500 0.0500 -99 -99
See the 0.0500 value? That’s the uncertainty they assign to a measurement taken in 1929! Huh?
Berkeley seems to use the precision instead of the actual uncertainty. .05C is 0.1F. How many thermometers in 1929 had a resolution of 0.1F?
Here’s what Berkeley says about their Breakpoint Corrected data set:
“4) “Breakpoint Corrected”: Same as “Quality Controlled” except a post-processing homogenization step has been applied to correct for apparent biasing events affecting the long-term mean or local seasonality. During the Berkeley Earth averaging process we compare each station to other stations in its local neighborhood which allows us to identify discontinuities and other inhomogeneities in the time series for individual weather stations. The averaging process is then designed to automatically compensate for various biases that may appear to be present. After the average field is constructed, it is possible to create a set of estimated bias corrections that suggest what the weather station might have reported had apparent biasing events not occurred. This data set is recommended for users who want fully quality controlled and homogenized station temperature data. This data set is created as an output of our averaging process, and is not used as an input.” (bolding mine, tpg)
In other words it’s all guess work. As I’ve pointed out multiple times you cannot average stations more than 50 miles away and the actual distance may be less than that depending on elevation, terrain, humidity, etc. How many groupings of stations has Berkeley used that are outside this restriction?
And this isn’t all:
“5*) “Non-seasonal”: Same as “Single-valued” except that each series has been adjusted by removing seasonal fluctuations. This is done by fitting the data to an annual cycle, subtracting the result, and then readding the annual mean. This preserves the spatial variations in annual mean.” (bolding mine, tpg)
Tell me again how the temperatures are not “adjusted” using guesses?
TG said: “See the 0.0500 value? That’s the uncertainty they assign to a measurement taken in 1929! Huh?”
What does the data say about that value? Would mind posting the text verbatim so that the WUWT audience can see for themselves?
If you don’t then I will. I just want to give you the opportunity to post it out of respect.
How magnanimous of you.
Seeing as you don’t seem interested in posting what Berkeley Earth actually said I guess I’ll do it myself.
More spamming.
Translation from bzx-ese:
“WHAAAA! NOTICE ME! PLEEEZE!”
“What does the data say about that value?”
“For raw data, uncertainty values usually reflect only the precision at which the measurement was reported.”
And the measurement precision in 1929 was 0.05C?
I’m not surprised you didn’t see fit to address that!
TG said: “And the measurement precision in 1929 was 0.05C?”
That looks correct to me. I discuss this in more detail down below.
Then why is the uncertainty in 2000 greater than the uncertainty in 1929? Only a climate scientist could come up with this!
Please pontificate on the accuracy and precision of the infilled tempetature data.
Accuracy greater than instrumental resolution is impossible.
ha ha
Maybe in real science,
but not in the magical world of “climate change” !
PF said: “Accuracy greater than instrumental resolution is impossible.”
I never said it was.
“I never said it was.”
Yes you did. Right here.
Ah…but I’m evaluating the combined uncertainty of a function that computes the AVERAGE of its inputs in that post. I’m not saying the uncertainty of the inputs themselves are lowered when fed into that function. I’m also not saying that you can reduce the uncertainty of individual measurements. All you can expect is a lower uncertainty on the AVERAGE relative to the uncertainty of the individual measurements that went into it. I have capitalized, bolden, and underlined the word AVERAGE so that there can be no mistake what I, Taylor, the GUM, NIST, your own source Bevington, and other of the other texts dealing with propagation of uncertainty say.
“All you can expect is a lower uncertainty on the AVERAGE relative to the uncertainty of the individual measurements that went into it.”
Not true. Not when the uncertainty is from instrumental resolution. That never, ever, diminishes no matter the number of measurements.
And the subject under discussion has been instrumental resolution, right from the start. Not averaging measurements with only random error.
Your supposed ±0.025 C uncertainty is 1/4th the MMTS resolution. Claiming to know historical air temperature to ±0.025 C is impossible. It’s magicking data out of thin air.
Even the new aspirated sensor of the USHCN claim ±0.03 C field resolution.
PF said: “Not when the uncertainty is from instrumental resolution. That never, ever, diminishes no matter the number of measurements.”
We’re going to work through this together.
Take a temperature reported to the nearest integer of X. Considering only the reporting uncertainty the true value could be between X – 0.5 and X +0.5. If X is a random variable then that means the probability of true > X is 50% and true < X is 50%.
Now consider two values X and Y. The probability of both X and Y being lower than true is 25%. Given 3 values X, Y, and Z the probability of all 3 being lower than true is 12.5%.
The reason is this is the way it is because the uncertainty is uniform. And when you average values of this nature the positive and negative errors tend to cancel thus reducing the uncertainty of the average.
Don’t take my word for it. Prove this out for yourself with a monte carlo simulation. Or you can use the NIST uncertainty calculator which do both the monte carlo simulation and the partial derivative procedure for you.
BTW…bonus points…what is the standard deviation of a uniform distribution with a lower bound of A and an upper bound of B? What is it for integer values like the temperature reports? Hint…there is a well known formula for it.
Aren’t you the special one.
You continue equating instrumental resolution to measurement uncertainty. It’s not.
A resolution limit is the perturbation level below which the instrument is no longer sensitive to the observable. The data do not exist.
PF said: “You continue equating instrumental resolution to measurement uncertainty. It’s not.”
No I’m not. And I agree that they are different things. You have to combine them via Bevington 3.14 or the well known root sum square formula.
This doesn’t change the fact that reporting measurements to the nearest integer results in a reporting uncertainty that is uniform from -0.5 to +0.5 of the reported value. This too must be combined with all of the other sources of uncertainty via Bevington 3.14 or the well known root sum square formula.
So YOU do it and quit yammering about Pat Frank’s paper.
Obviously it represents a threat to your worldview.
I do it because combining different uncertainty sources is appropriate. What I wouldn’t do is take two estimates of the same uncertainty source and combine them. That’s one of my concerns with Frank 2010. It combines the Folland and Hubbard uncertainties but does so only under the suspect assumption that they are different. We can’t tell from Folland’s publication either way if it is different or not because he was so terse about it. I’m willing to accept that they are different but no one can or is motivated to show me the evidence that they are.
Quite obviously you’ve never had to use a manufacturer’s spec sheet inside a real UA.
Quit lecturing intelligent people on subjects for which you have no knowledge.
“It combines the Folland and Hubbard uncertainties but does so only under the suspect assumption that they are different.‘
They are demonstrably different. The ±0.2 C is Folland’s judgment call. It is it a guesstimated mean of error not known to be stationary, not known to be random, and of unknown distribution. The ±0.2 C must then and necessarily condition every measurement as a constant in uncertainty.
The H&L uncertainty is an empirically determined field calibration error.
Their difference could not be more apparent or more stark.
Brohan, et al., 2006 provide a further explanation of Folland’s ±0.2 C guesstimate: “The random error in a single thermometer reading is about 0.2 C (1 σ) [Folland et al., 2001]; the monthly average will be based on at least two readings a day throughout the month, giving 60 or more values contributing to the mean. So the error in the monthly average will be at most 0.2/[sqrt(60)] = 0.03 C and this will be uncorrelated with the value for any other station or the value for any other month.”
The centrally important phrase is “in a single thermometer reading” The 0.2 C error is a read error — the visual LiG thermometer parallax error of the station agent.
Folland and Brohan each assume the mean magnitude of historical parallax read error is 0.2 C and further assume it is of random distribution. All that without any possibility of validating either assumption.
The ±0.2 C error is therefore a judgment call, exactly as described in my paper. Not known to be random, and having no known distribution.
The ±0.2 C read error must then enter every estimate of temperature measurement uncertainty as a constant.
In 2011, WUWT hosted a repost about thermometer metrology, Mark Cooper original post here, that discussed the errors that accrue to meteorological thermometers, including discussion of parallax read errors. It’s not all random and 1/sqrtN roses.
Mark Cooper’s final meteorological LiG uncertainty of ±1.3 C is about 3x the MMTS calibration lower limit of uncertainty from systematic error.
As Willis Eschenbach pointed out in an extended comment, read errors tend to cluster around the most probable error, rather than around zero.
PF said: “Brohan, et al., 2006 provide a further explanation of Folland’s ±0.2 C guesstimate”
Now we’re getting somewhere!
Brohen said: “So the error in the monthly average will be at most 0.2/[sqrt(60)] = 0.03 C and this will be uncorrelated with the value for any other station or the value for any other month.”
Didn’t this catch your eye?
Brohen used σ / sqrt(N).
You used sqrt[N*σ/(N-1)].
BTW…we know that the 0.2 figure is a standard uncertainty because 1) it is described as being “standard” and 2) it is used in a formula that only accepts a standard deviation. We also know that it is random and uncorrelated. The uncorrelated bit is important because it proves that Bevington 3.14 or the shortcut 4.12 which is derived from 3.14 are the appropriate formulas for the propagation of uncertainty in this case.
PF said: “Mark Cooper’s final meteorological LiG uncertainty of ±1.3 C is about 3x the MMTS calibration lower limit of uncertainty from systematic error.”
That seems reasonable. I’ve been telling people on here the LiG uncertainty is higher than the oft cited 0.5’ish C value I’ve seen thrown around.
PF said: “As Willis Eschenbach pointed out in an extended comment, read errors tend to cluster around the most probable error, rather than around zero.”
Why would that not cancel out with the anomaly subtraction. I mean, if it truly clusters around a specific value then that specific value will be equally represented in both components of the anomaly subtraction. Mathematically this is..
ΔT = (Tb + E) – (T + E) = (Tb – T) + (E – E) = Tb – T
…which as you can see the error E gets removed by the subtraction.
Subtracting a baseline does NOT cancel uncertainty, it INCREASES IT!
Dont you know that the CALCULATED baseline is a CONSTANT and has no uncertainty? /sarc
Silly me!
CM said: “Subtracting a baseline does NOT cancel uncertainty, it INCREASES IT!”
Strawman. I never said subtracting the baseline cancels uncertainty. What I’m saying is that systematic error as described by Willis cancels when subtracting the baseline.
So “systematic error” is not uncertainty on the planet you inhabit?
No wonder you are so confused.
What makes you think the systematic error cancels?
You *add* uncertainties whether you are adding or subtracting.
a = present measurement
b = baseline average
anomaly = a – b
The uncertainty of a + b and a – b is the same!
The total uncertainty is the sum of the uncertainties in “a” and in “b”. So the total uncertainty in the anomaly (a-b) is ẟa + ẟb. Or, if you like sqrt[ ẟa^2 + ẟb^2 ].
The uncertainties do *NOT* cancel!
“We also know that it is random and uncorrelated.”
How do you know it is random? If it is a *stated* value then it can’t be random.
What do you think it is correlated with? Itself?
“then that specific value will be equally represented in both components of the anomaly subtraction.”
we: “cluster around the most probable error”
Why do you think a “cluster” will be equally represented in both components? It’s the old Taylor rule that only random error cancels. A cluster doesn’t represent either a random error or constant error.
“You have to combine them via Bevington 3.14 or the well known root sum square formula.”
You just refuted your own program of (specious) fault-finding.
“uniform from -0.5 to +0.5 of the reported value.”
Systematic error is not a uniform distribution.
PF said: “Systematic error is not a uniform distribution.”
I didn’t say it was. I also never called the uncertainty that occurs as a result of reporting temperatures to the nearest integer as systematic error.
And you STILL refuse to acknowledge what is clearly stated upfront in Pat Frank’s paper, that it is a LOWER LIMIT. Do you understand that this implies a more rigorous value is likely to be considerably higher?
“Take a temperature reported to the nearest integer of X. Considering only the reporting uncertainty the true value could be between X – 0.5 and X +0.5. If X is a random variable then that means the probability of true > X is 50% and true < X is 50%.”
Nope. Uncertainty has no probability distribution. All you know that it is somewhere in the interval. You simply don’t know if X is a random variable or not.
“Now consider two values X and Y. The probability of both X and Y being lower than true is 25%. Given 3 values X, Y, and Z the probability of all 3 being lower than true is 12.5%.”
Again, uncertainty is not a random variable. And if X and Y are measurements of different things, e.g. temperature at location X and location Y, you simply don’t know that there is anything random about the measurements.
If there is any systematic error in either one then all of the measurements may be on one side of the true value or on the other side. You have no way of knowing.
“The reason is this is the way it is because the uncertainty is uniform.”
Again, uncertainty has no probability distribution, not even uniform. If there is any systematic error at all, and there is almost *always* some systematic error in any physical measurement, then you simply have no idea where in the uncertainty interval the true value might lie.
I don’t need to do any simulation. I’ve run machine tools. I know from experience that because of wear on the cutting tool that error in the outputs can all lie on one side of the “true value”. That’s one reason for re-calibrating the machine on a regular basis against a standard gauge block.
It is like measuring all the rod journals in an engine and averaging them to find what single value of oversize bearings to order. I mean the average is more accurate and precise than any of the individual measurements, right?
The sensor uncertainty is only PART of the uncertainty of the measurement station.
Still spewing your standard bullshite.
This is really just the same as your manufactured data.
“Ah…but I’m evaluating the combined uncertainty of a function that computes the AVERAGE of its inputs in that post. I’m not saying the uncertainty of the inputs themselves are lowered when fed into that function.”
Of what use is the average of the uncertainties? What if each element has a different uncertainty? You’ll get the same overall uncertainty using the u_1 + u_2 + … + u_n as you’ll get with N * u_avg.
” I’m also not saying that you can reduce the uncertainty of individual measurements.”
Then of what use is the average of the uncertainties? What can you do with it?
“All you can expect is a lower uncertainty on the AVERAGE relative to the uncertainty of the individual measurements that went into it.”
In other words, mathematical masturbation!
TG said: “Of what use is the average of the uncertainties?”
I have no idea. I never said anything about the average of the uncertainties. What I said is that it is the uncertainty of a function that computes the average. That is a completely different thing with completely different math.
TG said: “What if each element has a different uncertainty?”
Then you have to use the partial differential method described by Bevington 3.14, Taylor 3.47, or GUM 10.
TG said: “Then of what use is the average of the uncertainties?”
I still have no idea. And I still never said anything about the average of the uncertainties.
“I have no idea. I never said anything about the average of the uncertainties.’
What in Pete’s name do you think you were calculating?
“What I said is that it is the uncertainty of a function that computes the average”
So a function that computes the average uncertainty is not calculating the average uncertainty?
“Then you have to use the partial differential method described by Bevington 3.14, Taylor 3.47, or GUM 10.”
And as I showed you that just winds up with the root-sum-square of the individual uncertainties, not with the average uncertainty.
“Ah…but I’m evaluating the combined uncertainty of a function that computes the AVERAGE of its inputs in that post.”
In other words you are running away from your own assertion!
The function that computes the average of the inputs is
q_avg = (x_1 + x_2 + x_3 + …. + x_n)/n
And the average uncertainty is
ẟq/q_avg = ẟx_total/x_total ->
ẟq = (x_total/n)(ẟx_total/x_total) = ẟx_total/n
What is ẟx_total/n except the average uncertainty?
You’ve converted individual uncertainties in the data set to an average so that the ẟx_total = (ẟx_total/n) * n
The average uncertainty is merely mental masturbation. It tells you nothing that you don’t already know. It is *certainly* not the total uncertainty nor is it equal to the stadard deviation of the mean calculated from sample means.
You still don’t understand the GUM or uncertainty textbooks. The equations you are using are based on either multiple measurements of the same measurand with the same device OR that there is a functional relationship between multiple measurements that make up a total measurement like a volume or the total height of a staircase with multiple risers.
Independent measurements of different measurands (different microclimates) with different devices have no functional relationship. Using an statistical parameter like a mean is not a substitute for a functional relationship.
You can not use an SEM as descriptor of measurement uncertainty. It is only a descriptor of the precision of the mean in a distribution of unrelated stand alone measurements. It also is calculated from an assumption where the data points are assumed to be 100% accurate and with a precision way beyond the resolution of the measuring devices. If Significant Digit rules were properly used, anomalies would have no more resolution/precision than the recorded temperatures they are derived from.
How many times have you and so many others gone around and around about uncertainty and error with bdgwx, Jim?
And he just keeps repeating the same mistake over and yet over again. It’s hard to believe bdgwx’ repetitive insistence on wrongness is due to a supernaturally refractive ignorance.
A variation upon Higher Superstition comes to mind. Perhaps Higher Trollness. Über alles dedication to a subjectivist narrative.
A very good question; bellman is almost a carbon copy in this respect.
Pat, if I’m wrong then all of the texts on propagation of uncertainty are wrong including those provided by Taylor, the GUM, NIST, and even your own source Bevington. It would also mean a large portion of the knowledge science has obtained over the centuries is wrong. Is this really the claim you are wanting to make?
You’re insistently misapplying their work, bdgwx.
Jim and Tim Gorman know that, Carlo, Monte knows that, Richard Greene knows that, Rick C knows that, I know that, Paul Penrose knows that. And others unnamed.
We’ve all explained the problem ad nauseam. You insist on making the same wrong claims ad nauseam + 1.
Ad nauseam + 1 seems to be your only goal.
Pat Frank – rightly – cites, Carlo, Monte, Richard Greene, Rick C, and “others unnamed”.
bdgwx – also rightly – cites “all of the texts on propagation of uncertainty”.
Oooh, tough choice….
Another voice from the idiocy squad—blob.
bdgwx wrongly cites the texts, bob.
Either you’re as ignorant as he is, or you’re just being opportunistically disingenuous.
A False Appeal to Authority is still an argumentative fallacy. When you don’t understand the difference between the standard deviation of a mean and the total uncertainty of a dataset then trying to say that the authorities quoted agree with you makes no sense.
Do *YOU* understand the difference between the two? Have *YOU* ever built a beam to span a foundation by using only the standard deviation of the mean to figure the length of the beam you’ve put together?
These folks have never used real physical measuring devices to try and obtain the best measurement possible. They have never said to themselves, is the instrument I am using in good repair. With a micrometer, has someone dropped it and bent the frame, is the anvil the correct one, do i need to get a new $1000 one with better resolution? I suspect they have never had to take the width of a saw blade into account or the wobble in a miter saw blade when doing finish carpentry on crown molding when doing carpentry.
As a result, they are dealing with numbers, which to a mathematician, can be manipulated to a never ending extent.
“It’s not magic. It’s how the propagation of uncertainty plays out when you follow it through all of the steps of the process.”
Very amusing, bdgwx. There are no data to be had below the instrumental resolution limit.
Even assuming that all measurement error was iid random and averaged away (pretty much never true), the ultimate uncertainty attached to the measurement would be the instrumental resolution limit.
Uncertainty never is, and never can be, less than instrumental resolution.
PF said: “Uncertainty never is, and never can be, less than instrumental resolution.”
But…the uncertainty of the average of several measurements can be less than the resolution of the instrument used to provide those measurements and is less than the total uncertainty of the individual measurements.
That is a fact. Your own source (Bevington) says that the uncertainty of a function that computes the average is σ_avg = σ/sqrt(N) when σ is the same for all uncertainties that are being propagated into the average. And this is consistent with all of the other texts on propagation of uncertainty like Taylor and the GUM and which you can confirm with the NIST uncertainty calculator.
“But…the uncertainty of the average of several measurements can be less than the resolution of the instrument used to provide those measurements and is less than the total uncertainty of the individual measurements.”
Even Dr. Frank, a man with undeniably strong pockets of intelligence, has amygdal overamp and retreats into hysterical blindness when confronted with this truth. Dan Kahan redux, in his discussion of “ideologically motivated cognition as a form of information processing that promotes individuals’ interests in forming and maintaining beliefs that signify their loyalty to important affinity groups.”
http://journal.sjdm.org/13/13313/jdm13313.pdf
blob to the rescue with a fine blob word salad!
Well done blob!
Bull Snot.
Let’s use the brake rotor test. Brake rotors with a runout of 0.002″ should be replaced. Would you trust a mechanic who pulls out his trusty 1 foot tape measure with 1/16″ markings, measures yours, then measures 25 rotors from the junk pile, and gives you an answer that need/don’t need repairs?
That is what you are saying. “… the uncertainty of the average of several measurements can be less than the resolution of the instrument …”
You obviously have no idea about the concept you trying to discuss.
Maybe if you try harder….
Idiot.
Try addressing the point!
I even put it in bold.
“… the uncertainty of the average of several measurements can be less than the resolution of the instrument …”
bob — “But…blah…”
No it can’t. bdgwx is wrong and so are you.
Lil-Mike expressed it most succinctly: “you can’t justify a precision greater than the granularity of your equipment.”
You and bdgwx claim detail is available within a single pixel. It’s not. You’re wrong.
“But…the uncertainty of the average of several measurements can be less than the resolution of the instrument used to provide those measurements…”
No, it can’t.
And you’re misapplying Bevington. Again. Ad nauseam.
PF said: “No, it can’t.
And you’re misapplying Bevington. Again. Ad nauseam.”
Oh yes it can. And that is exactly what Bevington says. Skip to example 4.1 if you don’t want to derive the formula on your own. However, I highly advise starting with the generalized propagation equation 3.14. Define your function x = f(y_1, y_2, …, y_3) = (1/N)Σ[y_i, 1, N] and follow the partial differential procedure for equation 3.14. You will see that the uncertainty of the average is less than the uncertainty of the individual inputs into the function computing the average.
Don’t take my word for it. Actually do it yourself. If you want I’ll work through it with you.
“ If you want I’ll work through it with you.“
Ordinarily, I would accuse you of condescension. But I’ll bet you a coke that Dr. Frank won’t take this golden opportunity to prove you wrong. Rather, the usual prevarications that, so far have resulted in him preaching to the ever reducing acolytion here.
The Rule of Raylan still applies:
Look into a mirror, blob.
The low quality of your comments make it often difficult to respond to you with civility, bob. But this time you’ve been stupidly scurrilous.
bdgwx has misread or misunderstood 4.1 in Bevington. And you’re so foolish as to disparage from ignorance. No surprise there.
“Skip to example 4.1 if you don’t want to derive the formula on your own.”
Example 4.1 does not deal with instrumental resolution at all. The uncertainties in that example are given by Bevington eqn. 4.13, which is just the variance of the mean measurement.
Bevington doesn’t deal with instrumental resolution at all. The closest he gets is instrumental uncertainties— finite precision — which isn’t the same thing as below the detection limit.
Your understanding is incorrect, bdgwx.
“Bevington doesn’t deal with instrumental resolution at all. The closest he gets is instrumental uncertainties— finite precision — which isn’t the same thing as below the detection limit.”
““- Angela de Marco: God, you people work just like the mob! There’s no difference.
– Regional Director Franklin: Oh, there’s a big difference, Mrs. de Marco. The mob is run by murdering, thieving, lying, cheating psychopaths. We work for the President of the United States of America.””
You’re insane, blob.
HTH
PF said: “Example 4.1 does not deal with instrumental resolution at all.”
Add it in using the procedure defined in section 3.2 and see if changes the fundamental conclusion that the uncertainty of an average is less than the total uncertainty of the individual measurements that went into it.
PF said: “Bevington doesn’t deal with instrumental resolution at all.”
First, he tells you have to propagate all uncertainty in section 3.2.
Second, if you disagree then why are you using him as a source?
Worst case for your view, in my view, is that the instrumental resolution introduces stair steps into the overall uncertainty envelope. So, there would be no change in the method of evaluation of their propagation.
And FYI. folks w.r.t. Dr. Franks unexamined (by him) head fake about errors in accuracy, they are either correlated, or not. If they’re correlated, thereby introducing systemic accuracy error, then that has been spotted and accounted for already. If they are uncorrelated, then the normal evaluation of propagation still applies.
blob hath spake, the world is shaken.
“head fake about errors in accuracy,”
Taken from published field calibration experiments.
Yet another fake head comment from you, bob. Completely impervious to reality.
“that has been spotted and accounted for already”
Where?
“Where”
Judicious use of the rule of Hitchens:
“What can be asserted without evidence can be dismissed without evidence.”
Your explicit assertion is that there are systemic, unremediated accuracy errors in old temp data. Errors large enough to change the temp trends under discussion. But you repeatedly fail to present any.
I am merely dismissing what has been asserted without evidence.
Another hypocrite.
So you believe that the uncertainty of temp measurements in 1929 is 0.05 but in 2000 it is 0.1?
What evidence do you need to just know intuitively that something is wrong with this?
RUOK? If so, then you might want to address this post to whoever you think believes that. Directionally, the 2000 uncertainty is less than 1/3 that of 1929.
“Your explicit assertion is that there are systemic, unremediated accuracy errors in old temp data.”
““What can be asserted without evidence can be dismissed without evidence.”
You wanted evidence? I just gave it to you. Of course you just used the argumentative fallacy of Argument by Dismissal to avoid addressing the issue. There are systemic errors in the data and they are un-remediated.
“I am merely dismissing what has been asserted without evidence.”
You now have the evidence. My guess is that you will *still* dismiss Pat’s assertion!
Dismissing for lack of proof of a claim is not “Argument By Dismissal”. “Argument By Dismissal” is dismissal of a claim because it is “absurd”. I did not claim that about Dr. Franks claim. Rather, I dismissed it because he offered no proof and because it is part and parcel of his Dan Kahan “flight” mindset.
“You now have the evidence.”
To quote Dr. Frank, “where”?
Argument by Dismissal: an idea is rejected without saying why. Dismissals usually have overtones. For example, “If you don’t like it, leave the country” implies that your cause is hopeless, or that you are unpatriotic, or that your ideas are foreign , or maybe all three. “If you don’t like it, live in a Communist country” adds an emotive element.
Poisoning the Well: discrediting the sources used by your opponent. This is a variation of Ad Hominem
““What can be asserted without evidence can be dismissed without evidence.”
This is Argument by Dismissal. You provided no evidence as to why you dismissed the argument.
Pat *did* provide you the evidence. You just used the argumentative fallacy of Poisoning the Well by saying his evidence was not evidence.
You are GREAT at using argumentative fallacies.
TG said: “So you believe that the uncertainty of temp measurements in 1929 is 0.05 but in 2000 it is 0.1?”
The reporting uncertainty for an F reading from station 63 in 1929 with 30 days of observations is (0.5 * 5/9) / sqrt(30) = 0.05.
The reporting uncertainty for a C reading from station 993313 in 2000 with 24 days of observations is 0.5 / sqrt(24) = 0.1.
I’m not seeing what the issue is.
Very simple, you are an incompetent fool who doesn’t know what he doesn’t know.
I showed how this root-N garbage is illogical and nonphysical, and you pull out a ridiculous fable about “correlation”.
Got any more rabbits in your hat?
Where did you get 30 measurements? The record I posted for 1929 shows the number of observations as 99 – i.e. unknown!
And you are *STILL* trying to say average uncertainty is the same as total uncertainty! If these are monthly averages of temperatures then the uncertainty is the TOTAL uncertainty, not the average uncertainty of each individual temperature reading.
You are, once again, trying to divide by n when it is not justified.
As both Bevington and Taylor show:
(σ_total)^2 = (σ_u1)^2 + (σ_u2)^2 + … + (σ_30)^2
It is NOT
(σ_total)^2 = [(σ_u1)^2 + (σ_u2)^2 + … + (σ_u30)^2] / 30
Why do you keep dividing the total uncertainty by the number of data elements in order to get something you consider to be the uncertainty? It is *NOT* the uncertainty!
“Your explicit assertion is that there are systemic, unremediated accuracy errors in old temp data. Errors large enough to change the temp trends under discussion. But you repeatedly fail to present any.”
The MMTS sensor is more accurate than any historical meteorological LiG thermometer in a Stevenson screen. Of that, there is no dispute.
Hubbard and Lin 2002, for example showed that the PRT in a Stevenson screen produced far more error than the equivalent PRT in an MMTS shelter. That greater error was due greater susceptibility to the effects of irradiance and wind speed.
Between about 1880 and 1980 most meteorological air temperatures globally were measured with LiG thermometers housed in a Stevenson screen. After 1980, they were gradually replaced with MMTS sensors.
Therefore, the lower limit of MMTS systematic field measurement calibration error will necessarily be less than the lower limit of error of a historical LiG thermometer in a Stevenson screen.
That makes the MMTS lower limit globally and historically relevant.
That’s definitive evidence, bob. You can stop dismissing it now.
I never claimed that there were no systemic errors. Just that they have been – yes – adjusted, based on our knowledge of them. And it has also been obvious for some time that those “adjustments”, while valid, have nada relevance to the trends now under discussion.
Folks, the common path of these subthreads:
Please point out any false statements in this link.
https://www.carbonbrief.org/explainer-how-data-adjustments-affect-global-temperature-records
The fact that the “adjustments” continually change over time (as has been well-documented by others) reveals the claim that they are known is false.
And if, as you claim, they have no effect on the Holy Trends, why bother with them?
“I never claimed that there were no systemic errors.”
Evasive. You claimed I “repeatedly fail to present any.” And were insulting in doing so.
And yet, the paper does present direct evidence and cites the H&L calibration experiment.
The MMTS calibration error is a valid global lower limit. All these things were and are available for investigation by any competent investigator. (inference alert)
“Just that they have been – yes – adjusted, based on our knowledge of them.”
Systematic errors due to solar irradiance and wind speed are both deterministic and variable in time and space.
The past systematic measurement errors that arose from these uncontrolled environmental variables cannot be known.
The reason is because the magnitudes and signs of unrecorded past measurement errors are forever lost.
Errors unknown in sign or magnitude cannot be adjusted away. Ever.
Knowing this is not rocket science.
Your link doesn’t have one word about irradiance or wind speed sensor measurement errors. It is oblivious to the greatest source of systematic error in air temperature measurements.
And for good reason. To recognize the existence of these errors is to toss out any climatological significance of the purported trend.
And with loss of significance goes loss of climatological employment income. Which likely explains the widespread professional reticence to operate with professional integrity.
Your whole link is beyond false, bob. It’s misleading, it’s a lie by omission, and it’s a monument to incompetence. It’s a scientific farce.
“To recognize the existence of these errors is to toss out any climatological significance of the purported trend.”
180 out. To recognize these errors and to correct them in a timely manner increases the significance of those trends. But it’s all moot anyhow. Whether you use “adjusted” or raw data, the concerning trends are still there and are still statistically/physically undeniable. It’s why, when Nick Stokes and others commits truth, and asks you all to compare them, you deflect big time.
I believe you know that as well, since, even with your inflated uncertainties, you still get statistically/physically durable trends. Which is why, in your 2010 paper you just threw up your hands and declared victory instead of actually evaluating those trends. with your concomitant uncertainties.
AGAIN, Dan Kahan, redux….
“To recognize these errors and to correct them in a timely manner increases the significance of those trends.”
More blather. As noted, the systematic measurement errors corrupting past temperature records cannot be “corrected.”
“Whether you use “adjusted” or raw data, the concerning trends are still there and are still statistically/physically undeniable.”
So says bob about a net 0.8 C trend with a lower limit 95% physical uncertainty of ±1 C. Ever so statistically/physically great thinking. No doubt about that. (is an irony alert necessary here?)
“It’s why, when Nick Stokes and others commits truth, and asks you all to compare them, you deflect big time.”
You’ve obviously never been present at any of those debates. In this one, for example, Nick and I debated his claim that thermometers have perfect accuracy and infinite precision.
I even went to Nick’s site to debate him there. He deleted my comment.
With your continued side-stepping of the impossibility of raising past measurement errors from the dead, you’re not a guy to accuse others of deflection.
“even with your inflated uncertainties, …”
Pejorative dismissal. The empirical field calibration uncertainties are analytical and entirely defensible.
“… you still get statistically/physically durable trends.”
No you don’t. Evident just by inspection.
The graphic below is the 2010 Figure, but with a 2σ lower limit uncertainty bound stemming from the MMTS field calibration.
Where is your, “statistically/physically durable trend,” bob?
Try squinting. Maybe that will help.
my guess is that bob won’t even understand what the graph shows!
“Where is your, “statistically/physically durable trend,” bob?”
As the nerds told Al in “Married With Children”, when they were lording their riches over him at their HS reunion, “You should’a done your homework, Al”.
https://wattsupwiththat.com/2022/01/14/2021-tied-for-6th-warmest-year-in-continued-trend-nasa-analysis-shows/#comment-3436608
ROFL! The NASA trend doesn’t properly evaluate uncertainty! At best they use the resolution of the measurement device as the uncertainty, at worst they just ignore the uncertainty!
A little expansion:
All easily replicable to non Rorschachian evaluators with a few minutes to spare….
Free clue, blob: the standard practice in climastrology of “evaluating and comparing trends” is not an uncertainty analysis.
“The standard trend errors agree to with a few pptt,” because the inconvenient published field calibration experiments have been self-servingly ignored.
Your work is right up to the standards of consensus climatology, bob — namely ignore field calibrations, assume all the measurement errors are small and random, and all the means are perfectly accurate.
Hopeless.
Your prior comment completely missed the boat, bob. The 1980 through 2005 air temperature measurements increasingly relied on MMTS sensors.
The lower limit of uncertainty is based exclusively on field calibrations of MMTS sensors.
That makes the MMTS lower limit of uncertainty exactly applicable to the 1980-2010 temperature record.
And applicable to the prior record as well, which relied upon LiG thermometers in Stevenson screens that are less accurate than the MMTS.
Your supposed “statistically/physically durable trend” is submerged beneath the uncertainty bounds.
These are obvious analytical points. And are game, set, and match, against your position.
“Your supposed “statistically/physically durable trend” is submerged beneath the uncertainty bounds.”
I already demonstrated that they are not. They are accurately evaluated by me. I think you missed the part about how I used your uncertainties. And true to form, you’re just deflecting into more hand waving instead of actually evaluating the trends, with your uncertainties. Bone throw – you’re obviously capable of doing so, but, for whatever reason, would rather not.
Folks, more Dan Kahan avoidance, or just garden variety wanna be rightism? You be the judge….
Who are these “folks” you have a need to appeal to?
“I already demonstrated that they are not.”
You merely demonstrated the common self-serving neglect of sensor calibration error.
“I used your uncertainties” Actually, Folland’s assigned uncertainty combined with the MMTS calibration error in H&L
If you’d used those, as you claim, you’d have produced my result. Because the derived uncertainty can’t average away.
“Folks, more Dan Kahan avoidance...” Projection. A personal failure common among demagogues.
It is why records should be stopped and a new one started when a break occurs. One can not know what the microclimate was so any “correction” is pure guesswork. If the belief is that the record is not fit for purpose, discard it. To claim that one can use statistics to correct a record when you do not have access to the phenomena to remeasure it is a false confidence in statistics.
Agreed, Jim. AGW pseudoscience lives and breathes on false precision.
Even MMTS measurement devices have uncertainty because of the tolerance of the electronic components used, e.g. 1% resistors. The more 1% components you have from the same production batch the higher the uncertainty will grow since not all random effects will cancel.
Don’t forget “the greatest enemy of the electrical engineer” (as I still remember a professor saying) — temperature. All those little components have temperature coefficients, which are never specified as plus-% or minus-%, but rather plus/minus-%. Meaning you don’t even know the directions that component values change, and it is impossible to claim they cancel as “random”..
It is all uncertainty.
You’re dead-on right, Tim.
Lin & Hubbard discuss electronic sensor errors in detail, in their (2004) Sensor and Electronic Biases/Errors in Air Temperature Measurements in Common Weather Station Networks,
doi: 10.1175/1520-0426(2004)021<1025:SAEEIA>2.0.CO;2.
From their abstract, “For the temperature sensor in the U.S. Climate Reference Networks (USCRN), the [RMS] error was found to be 0.2° to 0.33°C over the range −25° to 50°C. The results presented here are applicable when data from these sensors are applied to climate studies and should be considered in determining air temperature data continuity and climate data adjustment models.”
The final sentence further obliterates all of b.o.b.’s fondest misrepresentations.
“Just that they have been – yes – adjusted, based on our knowledge of them. And it has also been obvious for some time that those “adjustments”, while valid, have nada relevance to the trends now under discussion.”
Hubbard and Liu in 2006 demonstrated that regional adjustments introduce bias.
“Thus, the constant Quayle surface temperature adjustment factors are not applicable for extreme temperature bias adjustments”
This may be an inconvenient truth for you but it is the truth nonetheless. Microclimate conditions vary widely from station to station. That doesn’t make their readings any less accurate. What it means is that trying to force them into a perceived “more accurate” reading is nothing more than adding a subjective bias into the temperature record.
This is what uncertainty is meant to address. You simply cannot reduce uncertainty in the temperature record by adding a subjective bias into the record. You have to *objectively* evaluate the uncertainty and take it for what it is!
“But we hate the know, proven methods of “adjusting” for any systemic errors.”
You can’t adjust for systemic errors if you don’t know what they are. And you simply don’t know on a station-by-station basis what the systemic error is in 1929. All you can do is make a judgement on what the uncertainty is for those stations and then propagate that uncertainty throughout your data set.
“We hand wave and pronounce the resulting trends statistically indurable without doing the work to actually find out.”
Statistics simply can’t tell you what you don’t know and can never know. Pretending you can is nothing more than adding subjective bias into the data record.
“… the uncertainty of an average is less than the total uncertainty of the individual measurements that went into it.”
Nothing to do with instrumental resolution or with deterministic non-iid systematic error.
“Second, if you disagree then why are you using him as a source?”
Because my paper is about systematic measurement error. Not about instrumental resolution.
Bevington is entirely appropriate for assessing that error.
I don’t disagree with Bevington at al. Acknowledging that he doesn’t deal with instrumental resolution isn’t disagreement.
PF: “Bevington is entirely appropriate for assessing that error.”
Then why not use the procedure defined in Bevington section 3.2 exactly the way it is written. Why use the formula sqrt[N * σ / (N-1)] which is inconsistent with the procedure or any other method in Bevington for propagating uncertainty?
BTW…I still have no idea where you got your equation 9. It doesn’t show up anywhere in Bevington that I can see.
10 GOTO 10
You are your own worst enemy!
sqrt[N * σ / (N-1)] is nothing more than the root-sum-square of the individual uncertainties. It is *NOT* the standard deviation of the mean.
In fact N/(N-1) is GREATER THAN 1. So multiplying σ by a value greater than 1 makes it larger!
And exactly what do you think the sqrt( σ) gives you? You wind up with the sqrt of the sqrt of the variance. Huh?
TG said: “sqrt[N * σ / (N-1)] is nothing more than the root-sum-square of the individual uncertainties. “
First…typo. My bad. That should have been sqrt[N * σ^2 / (N-1)].
But, no that’s not even the root-sum-square formula. The RSS formula when the individual uncertainties are the same is sqrt[N * σ^2].
So what? N/(N-1) is *still* greater than 1!!
The uncertainty is going to grow whether you have σ or σ^2.
Thus you do *NOT* decrease average or total uncertainty with more observation!
Paper eqn 9 is Bevington eqn 1.9 with (x_i – x_bar)² = (σ_bar)’² because Folland’s measurement uncertainty is a constant across every instance.
Recognize that (x_i – x_bar)² is the variance of each measurement about a mean. So is Folland’s (σ_bar)’² as purported.
Bevington eqn 3.13 reduces to eqn 1.9 with two combined uncertainties and with the correlation term excluded because the uncertainty is a constant guesstimate.
Total sidebar. If you want “boot heel values” in St. Charles, vote for Bob Onder for your executive. I know nada about you or your pol views, but I’m guessing that you don’t want a Hawley clone (not) running the show.
Do the right thing, and I’m willing to consider any carbon based life form you recommend who is willing to primary Cori Bush. Her reply to my letter to her on the 45q give aways championed by David Middleton was depressingly anodyne…
“But…the uncertainty of the average of several measurements can be less than the resolution of the instrument used to provide those measurements and is less than the total uncertainty of the individual measurements.”
Malarky! Like Dr. Frank said not *all* random error will cancel, even when you are measuring the same thing with the same instrument.
When you divide the σ by sqrt(N) you are determining the AVERAGE UNCERTAINTY VALUE FOR EACH ELEMENT IN THE DATASET. That is *NOT* the same thing as the total uncertainty obtained when the measurements are combined into a total.
If you average 20 +/- 0.2 and 40 +/- 0.4 then the average uncertainty becomes +/- 0.3. But that is *NOT* the total uncertainty of the combined measurements. That total uncertainty is +/- 0.6. You can get that by adding 0.2 and 0.4 = 0.6 or by multiplying the average uncertainty by two -> 2 * 0.3 = 0.6.
Assume those are two boards you are putting together to form a beam to span a foundation. The uncertainty of the total length is *NOT* +/- 0.3. It is +/- 0.6. If you put enough boards together you might do a root-sum-square instead of direct addition but the overall uncertainty *will* still GROW, just at a slower rate!
As for Bevington, his equation 4.12 is the same thing you can’t seem to understand from Taylor. The standard error of the mean is how precisely you have calculated the estimate of the mean It is *NOT* the same thing as the total uncertainty propagated from combining all of the data elements.
If you have a pile of 2’x4′ boards in your backyard you can pull some out of the pile (your sample) and use them to estimate the average length of all of the boards. The more samples you pull the more precisely you can calculate the average length of the boards, i.e. the smaller the standard deviation of the calculated mean. BUT! When you are combining some of the boards to build a beam spanning a distance you cannot use that standard deviation of the mean to determine your uncertainty in what the final length of the beam will be. The uncertainty of the final length is the *sum* of the uncertainties for the boards. It is *not* the uncertainty of the mean!
TG said: “When you divide the σ by sqrt(N) you are determining the AVERAGE UNCERTAINTY VALUE FOR EACH ELEMENT IN THE DATASET.”
Bevington derives that formula from the general propagation of error formula 3.14.
TG said: “As for Bevington, his equation 4.12 is the same thing you can’t seem to understand from Taylor.”
Bevington 3.14 and Taylor 3.47 are the exact same partial differential method. Bevington 4.12 can be derived from either Bevington 3.14, Taylor 3.47, or GUM 10. All statistics texts agree that when you run a bunch of measurements through a function that computes the average the shortcut formula is σ_avg = σ / sqrt(N). You can also derive this shortcut formula via Taylor 3.18 which you said was your preferred method. The reason you don’t get σ_avg = σ / sqrt(N) when you do it is because you keep arithmetic mistakes.
Maybe you can do me a favor. Use Taylor 3.18 (your preferred method) and convince Pat Frank that the propagation of uncertainty through an averaging function is σ_avg = σ / sqrt(N). Just make sure you do the arithmetic correctly this time.
Hypocrite! When confronted with applying your fav formulas to the temperature sampling problem, you run away under the cover of some vague claims about “correlation” that supposedly invalidate your fav formulas.
“Bevington derives that formula from the general propagation of error formula 3.14.”
So what? It is *still* the average value of all the uncertainties!
“Bevington 3.14 and Taylor 3.47 are the exact same partial differential method.”
And you don’t understand either one of them!
(σ_x)^2 =(σ_u)^ 2 ) (ẟx/ẟu)^2 + (σ_v)^2) (ẟx/ẟv)^2 + …..
In this case u and v represent two different measurements.
If these measurements are linear in nature then (ẟx/ẟu) and (ẟx/ẟv) will equal 1. (e.g. x = u + v)
Then (σ_x)^2 = (σ_u)^ 2 + (σ_v)^2)
The standard root-sum-square version of adding uncertainties.
Do it for multiple measurements, u,v,w,y,z,….
you’ll still get
(σ_x)^2 = (σ_u)^ 2 + (σ_v)^2) + (σ_w)^2 + (σ_y)^2 + (σ_z)^2
Still root-sum-square for the total uncertainty — NOT THE STANDARD DEVIATION OF THE MEAN and NOT THE AVERAGE UNCERTAINTY OF EACH INDIVIDUAL ELEMENT!
σ_avg = σ / sqrt(N) gives you the AVERAGE uncertainty per data element. It does *NOT* give you total uncertainty for the entire data set. It’s nothing more than mental masturbation.
If you already know all the uncertainty values, which you must know if you are going to calculate their average, then you’ve already pretty much calculated the final uncertainty! Either use the direct sum or take its square root, your choice.
Excellent! Getting tiresome having to explain physical measurements to statisticians who have no experience in making physical measurements.
I’ve recently done all the finish carpentry in the house. You think all walls have 90° corners, ha. All walls are vertical, ha. Trying to miter the cuts with minimal gaps makes you understand uncertainty.
But if you know the *average* value of all the ceiling-to-floor heights then shouldn’t all the heights be equal to the average? If you know the average value of the uncertainty of all your ceiling-to-floor heights then shouldn’t the average of all those heights be the uncertainty in all your measurements? You should be able to cut all the trim boards to the same length and have them all fit, right?
Ha, bwaaa, ha, ha!
TG said: “If these measurements are linear in nature then (ẟx/ẟu) and (ẟx/ẟv) will equal 1. (e.g. x = u + v)”
And if x = (u + v) / 2 then then (ẟx/ẟu) and (ẟx/ẟv) will be 1/2.
Remember x = u + v is the sum while x = (u + v) / 2 is the average. I really don’t mean for this to be condescending but since you have conflated the two before it is important for me to point this out again.
Liar. Can someone that makes up fake data be trusted?
I simply don’t know how to get this through to you. The average uncertainty is merely an artificial way to equally distribute the total uncertainty across all the data elements making up the data set.
If you have just two data points, one with 0.4 uncertainty and one with 0.6 uncertainty then the average uncertainty is 0.5.
0.5 * 2 = 1.0. The exact same thing as 0.4 + 0.6 = 1.0
The total uncertainty in both cases is 1.0. All you have done is mask the variance of the uncertainty by making each element have the same uncertainty value.. Mathematical masturbation. The average uncertainty is useless when it masks the characteristics of the population such as variance.
Let’s say you are the engineer designing the big o-ring on the space shuttle keeping the fuel and oxidizer separated. You have several technicians dispatched to different places around the country to measure the thickness of the various o-rings and get the uncertainty data set
0.2, 0.3, 0.6, 0.7, 0.8
The average uncertainty is 0.45.
You run to your boss and say the average uncertainty of these o-rings is 0.45, well within safety requirements.
One day your boss calls you in, says you’re fired, and armed guards escort you off the premise.
Do you have even an inkling as to what happened?
TG said: “I simply don’t know how to get this through to you. “
The best way to convince me is demonstrate that Bevington, Taylor, GUM, NIST, monte carlo simulations, decades of texts and experiments concerning propagation of uncertainty are all wrong.
I’ve demonstrated what Bevington shows. Taylor is no different.
See the attached photo of Bevington. There is no division by “n” anywhere in the equation.
Again, the “average” uncertainty merely spreads the total uncertainty across all data elements making the variance of the uncertainty zero.
The GUM is exactly the same. The GUM has the same equation that Bevington and Taylor has. Nor are there any decades of texts and experiments that prove any differently.
What there *IS* is just you misunderstanding basic physical metrology. Statistical masturbation that changes the basic characteristics of the underlying data is either due to ignorance or fraud, take you pick as to which applies to you.
Idiot.
Please give bdgwx the respect he deserves in the future !
Call him “Mister Idiot”
Noted.
Anyone who has taken a science course
knows three decimal places or more is real science.
Anything less is baloney.
What’s really sad is how many “scientists” there are that don’t realize you were being sarcastic.
But here are some things that can be done:
__________________________________
I realize the the scope of this particular edition of “The Greatest Scientific Fraud Of All Time — Part XXX” only covers the temperature recording but there’s a lot more than just that. Trump pulling out of the Paris Agreement was a very good step in the right direction.
How ’bout cancelling subsidies and funding for the wind mills and solar panels – Forcing NPR and PBS to do a 180 on the climate nonsense.
Resurrect Harry and Louise who did the series on Hillary’s health care plan dissect the climate charade bit by bit; polar bears, hurricanes, tornadoes, floods, fires, heat waves, glaciers, sea ice, ice caps, sea level rise, methane, ocean pH, scientific corruption — feel free to add to the list.
Your suggestions are akin to asking that some non-believer outsiders be brought in audit, analyze, and reformulate the Pope’s decreess to better … whatever. Chances are nil.
They could ask James Hansen why he said 1934 was the hottest year, and now he says it is not? Was Hansen lying then, or now? (Hint: Now).
“ How ’bout cancelling subsidies and funding for the wind mills and solar panels – Forcing NPR and PBS to do a 180 on the climate nonsense. ”
For all the good that Trump did this is one area he let us all down on. But sadly it is very difficult to get rid of subsidies. 😣
great list and here is one more. stop diluting gasoline with ethanol.
I would like to require all gas pumps to show, based on a standard vehicle MPG EPA estimate, a listing for MPG of each octane value with and without ethanol.
Then require the pump to provide $ per mile for the fuels provided, you know, like the feds require stores to show $ per oz. lb. etc. for foodstuffs.
The same for diesel and biodiesel. ALL diesel MAY have up to 5% biodiesel, but require the individual pumps to list the actual volume of biodiesel in the mix.
I usually buy my diesel at Costco, but this last go round I filled up at a Smith’s. I “seemed” to get a higher MPG from the Smith’s fuel over a 250 mile drive. Hard to base anything on this since it is winter. With the politics of Costco management, I would assume their fuel has the most “good stuff” possible. I KNOW that I get MUCH WORSE mileage with biodiesel #5 than standard D #2. I will never put that crap in my truck again. The winter after I mistakenly put #5 in my truck I had to remove the fuel filter and clean the gunk out and add cold weather additive to the fuel to get the truck running right. I have not had that problem since, and it is around 0 f now where I am. So 2 winters no problem, 1 winter after biodiesel, problem.
Longer chain hydrocarbon molecules inherently contain more energy. Adding shorter chain ethanol reduces the average energy content of the fuel and hence gas mileage. But, I suspect the difference with available grades might be less than the effect of ambient temperature, especially in the Winter.
There’s a serious risk that uninvolved people might think that the ONLY scientific fraud is the manipulation of the temperatures, when the simple fact is that the whole of climate science is the real fraud, and the temperature manipulation is, by comparison, a tiny fringe issue. Yes, it’s massively important and probably one of the worst scientific frauds in its own right, but it is a mere minnow (bacterium?) beside the whole of climate science.
I remember a previous occasion when WUWT got excited about this “worst scientific fraud”. GWPF was really going to do something about it. The Telegraph was onto it to. They announced:
“An international team of eminent climatologists, physicists and statisticians has been assembled under the chairmanship of Professor Terence Kealey, the former vice-chancellor of the University of Buckingham. Questions have been raised about the reliability of the surface temperature data and the extent to which apparent warming trends may be artefacts of adjustments made after the data are collected.”
Of course, nothing ever happened.
That fraud lasted 37 years…while ‘nothing ever happened’ …
That fraud lasted 20 years while ‘nothing ever happened‘
Note the typical Marxist use of cancel culture to stifle the opposition…
So that was a pretty long time while the accepted scientific answer’ was in fact wrong.
And nothing ever happened.
Models are only as good as their assumptions, and the assumption that the only parameters that were significant were the molten core and radiative cooling provided and answer that was out by 4.4 billion years, or almost 87%…
Maybe Nick, history is doomed to repeat itself for those who do not learn it, and maybe the reason why ‘nothing ever happened’ was that people were paid handsomely not to report it.
We all know that the whole IPCC/ClimateChange hypothesis hinges on one particular assumption, namely that all late 20th century climate variation whose ’cause’ cannot be otherwise established by simple linear models, is down to the increase in anthropogenic CO2, and if the radiation equations don’t match the rather steeper rise from 1980 to 2000, then positive feedback must be happening.
But they went looking for that years ago, and ‘nothing ever happened’
The alternative hypothesis that, like Lord Kelvin’s age of the Earth estimate, something else was going on they didn’t know anything about, was entirely dismissed from any consideration.
Why?
Cui Bono, Nick Stokes, Cui Bono?
“We all know that the whole IPCC/ClimateChange hypothesis hinges on one particular assumption, namely that all late 20th century climate variation whose ’cause’ cannot be otherwise established by simple linear models, is down to the increase in anthropogenic CO2, and if the radiation equations don’t match the rather steeper rise from 1980 to 2000, then positive feedback must be happening.”
Leo, the notion that something must be so because we can’t think of anything else should be like a red rag to a bull for anyone with the least amount of scientific curiosity. I have a piece on the TCW Defending Freedom blog which suggests a warming mechanism which is anthropogenic, would have begun to make a major difference from the early 20th century, explains Tom Wigley’s blip and shows how the mechanism is currently causing anomalies in temperatures around the world.
Briefly: some areas are warming very much faster than climate science can explain — for example, certain lakes and seas are warming at two to three times the global average. There are ways to stop those from continuing to heat up, but for TCW I’ve approached it from the opposite direction, looking for ways that we could warm the world if a cooling trend resumed and got out of hand, then pointing out that we are already carrying out those warming measures inadvertently.
Look at
http://www.youtube.com/watch?v=J0FRqrI__D0
wwwdotconservativewomandotcodotukslashcold-comfortslash
Briefly, oil/surfactant/lipid smoothing of water surfaces warms by lowering albedo and reducing low level stratus — other reasons like reduced evaporation etc. Lipid increases because we are dumping nutrients into the water from sewage and agricultural run-off. The latter also feeds in the dissolved silica that diatoms, a very efficient lipid producer, need.
Do you still have my email? it’s the same.
JF
Unlike most of climate science this is testable. Lord Rayleigh and Benjamin Franklin are on my side.
Excellent.
When I was a pup, we were taught that there were scientific frauds and fallacies in other places and in the past. The implication was that we were so much wiser, and it couldn’t happen here.
But it was happening here. Ancel Keys’ focus on dietary fat as the cause of an epidemic of heart disease, and his suppression of science pointing to sugar as the true villain, probably killed millions of people.
Cui bono? Evidence points to the sugar industry.
Then we have the statement, by a former editor of the British Medical Journal that it’s …
link
I’m guessing that the pandemic has resulted in enough fraudulent research to sink a battleship.
So, when it comes to fraudulent science, there’s nothing special about us.
When you have something like climate science, which is highly politicized, the temptation to cook up results will be yielded to by many scientists. So, overwhelmingly, we have to assume fraud.
Excellent!
And the physicist referenced here…
“But a supposedly definite ruling against such an old Earth came from a physicist who calculated how long it would take an originally molten planet to cool.”
…was no other than Lord Kelvin – the classic ‘appeal to authority’, and now the primary ‘go to’ tactic of alarmists of all stripes (climate, public health, etc.).
The lesson seems to be that when politicians, or even scientists with unassailable credentials, get involved, real science loses out. That is sort of the opposite of ad hominem attacks, or ‘Defenders of the Faith’ insisting that only ‘real’ climatologists publishing in pay-walled journals have anything to say worth listening to.
Science + politics = politics
It’s climate science things like truth and accuracy are not important as long as everything supports emission control it gets the nod. The fact emission control is never going to happen adds to the humour of the field.
“Nothing ever happened”
Nice deflection.
I suppose you should pat yourself on the back for nothing happening.
Nothing has happened YET.
Truth is the daughter of time.
A lot of numbers in the average temperature statistic are wild guesses.
Infilled numbers that can never be verified.
Still true today.
But especially true before 1920.
It is called distraction. Illusionists do it all the time.
You comment is baloney.
There is real climate science
It involves data
The study of the present and past climates
The always wrong wild guess predictions
of the future climate are not science
They are data free.
There are no data for the future.
Just unproven theories
and wild guess speculation.
But that IS NOT SCIENCE.
I wonder if insisting that all original measurements be included inside the error bars would work? That way if the adjustments get really out of hand, you’d get an embarrassingly large error bar. The estimated error of the original measurement should also be included, of course
Adjustments are not usually made because measurements were in error. They are made because something changed which was not a reflection of temperature change in the region.
A classic case is that of Cape Town, frequently bandied about here. There was a very long record at the former Royal Observatory, in town by the sea. But in 1961, the government decreed that the new airport would be used for official CT temperatures, and GHCN followed suit. But the Observatory continued to report as a GHCN station.
The situation is shown in this graph (from here).
The red curve is the GHCN V3 unadjusted, the green is adjusted. There is a big deviation in 1961. But up to that year, the red is readings from the Observatory, and that continued as the blue curve. So you can see that the airport really is consistently cooler, as measured. The change in 1961 did not come from a climate change, but from an administrative change.
The GHCN adjusted corrected for this by extending back, allowing for this 1.5°C difference in observed temperature. The convention with adjustment is that you take the current situation as given, and make any adjustments backwards. But as you can see the adjusted tracks the continuous Observatory record, but 1.5°C cooler. Either is a valid representative of the region, which is what is really wanted. Anomalies sort out the difference.
I understand the rationale, nevertheless when you see an adjustment vs raw series which looks like a hockey stick it naturally raises suspicions about whether the adjustment process is flawed in some way.
https://wattsupwiththat.com/2020/11/03/recent-ushcn-final-v-raw-temperature-differences/
I think including the raw temperatures inside the scope of the error bars seems a rational way of resolving the situation.
Another post that doesn’t seem to realise that USHCN was replaced (by ClimDiv) eight years ago. These averages were not calculated by NOAA.
In the old USHCN, the main difference between raw and final was TOBS, based on actual records of time of observation. ClimDiv does it differently, but probably with similar results. Time of observation matters; it is known to have changed, and you have to adjust for that.
Why is there no hockey stick with sea measurements 🤔
You don’t have to adjust for it. You could just work with what you have and acknowledge that the data have limitations. How are temperatures handled that are in immediate proximity, but on opposite sides of a time zone boundary? How are temperatures handled that are on opposite sides of a time zone? Are all readings converted to solar time? How is the situation of a cold front passing through a region between readings handled when the stations used for homogenization aren’t impacted by the cold front? Are such transient events just ignored in correcting what seems to be bad data?
At the end of the 19th century the difference is much more than 1.5C. So, the past has been made cooler. How come?
Outside of the US. Europe and the east coast of Australia,
there were few land weather stations pre-1900
Ocean surface measurements were even worse.
Little data from the Southern Hemisphere
Not useful temperature numbers for science until the use of
satellite data in 1979, with only 5% infilling required
over both poles.
Or we could just accept that we don’t have a continuous record and stop trying to knit discontinuous data sets together.
We did have a continuous record, at the Observatory.
Yes. The nail went in with one swing!
That is actually a very very funny graph, I cracked up at it and it is very instructive of the problem with doing that junk and why in real sciences you can’t do that shit.
So Nick what caused the warming between what looks like 1850 and 1950 well before the hockey stick takeoff off CAGW 🙂
I will give you a much much more likely answer .. the land use around the site is changing heavily over the years. That is the problem with altering historic data you have absolutely no idea what is going on and you are making adjustments based on guesses but hey it’s the norm for Climate Science tm.
Why the warming rate from 1900 to 1940 is the same rate as from late 1970s to present is a question that has been asked many times and needs answering. No-one has yet offerred a rigorous explanation, just waffle. I might even soften my stance on AGW by CO2 if a proper answer is forthcoming but in following this for 20 years nothing remotely resembling a physical explanation has been put forward.
Nick: I get what you said. But why have the pre-1900 readings been adjusted downwards?
From rough scaling on your graph, the raw numbers from about 1900 to 1961 are all adjusted downwards by about 1.1°, to correct for the 1961 discontinuity. Fine. But the downward adjustment increases progressively going back from 1900 to about 1858, when it’s a whopping 2.0° down.
It looks like a bad example to use as a demonstration of how rigorous and objective the adjustments have been.
You brought up the Cape Town record. Do you know something about 19th century Cape Town that would have led to introducing a 0.22°/decade warming trend that wasn’t in the original record?
The cynic in me says that was just helping to cool the pre-industrial past on order to further dramatize anthropogenic warming. But, if you do know something definitive, please share it with us.
“Do you know something about 19th century Cape Town…”
No. But the fact that I don’t know it and you don’t doesn’t mean that the adjustment isn’t justified.
In fact a lot of adjustments at about that time came from the introduction of Stevenson screens, which cut out spurious radiant warming.
What are the uncertainties of these “adjustments”?
Very true, and I only raise questions rather than make accusations.
I don’t think the introduction of a Stevenson screen at Cape Town was something phased in over 40 years – it would have surely led to a visible discontinuity in the series. So there’s probably some other reason, that should be documented somewhere, and if it’s not, that would be a bit suspicious in itself. After all, I’m pre-disposed to be suspicious about anything coming from the climate orthodoxy; there’s too much politics and too much money involved.
Nick, your comments at WUWT are unfailingly polite, literate and usually accompanied by some evidence. I hope to see you here more often in the future.
He has the patience of a saint, and the ethics of a sophist.
If an original measurement is not correct, then it is in error. If it is a random error, such as from transcription of field notes, then it probably should be dealt with in the same manner as extreme outliers — delete it. If it is a systematic error, which is repeated numerous times, and is easy to miss, then it probably should be incorporated into the formal uncertainty assessment for the entire data series.
A good test is whether the adjusted numbers show a very different shape or slope from the raw data. That should be a red flag that the data are of poor quality.
The character of the government bureaucrats INVOLVED tells you whether or not you should trust their data. YOU SHOULD NOT TRUST SURFACE TEMPERATURE DATA !
I would rather have poor quality data — even just order of magnitude — than no data at all. The issue is that those using the data should acknowledge the true uncertainty of the raw data and not pretend that their largely subjective manipulations actually improve the accuracy or precision of the raw empirical measurements.
A total dingbat comment.
If the measurements are not in error,
then there is no need for adjustments.
It would be an error to change the location
of a specific weather station without
a period of time to see if the old location
and new location were both
registering the same temperatures.
If the new station location fails to replicate
measurements at the old station location,
it will be creating an error in the global
average temperature dataset.
That error should be corrected.
Although there should have been
a very good reason to move the
weather station to begin with.
The first question is whether the new location
will provide more accurate measurements
than the old location. If not, why the move?
“That error should be corrected.”
Exactly. And that is just what they are doing.
In the Cape Town example, there is no dispute about the accuracy of measurement at the respective stations, nor about their suitability as representative of the region. What is not representative is the drop of 1.5°C in going from one to the other in 1961. That is an artefact of an administrative decision, and needs to be corrected.
As to “why the move”, historically temperatures were not measured for the needs of climate science. Choices were made for other reasons. In this case, the airport station was likely to be more reliably maintained (and it was). That doesn’t change the fact that it was a cooler location.
All temperature stations measure the microclimate surrounding it. Microclimates can change up for many different reasons. A windbreak a half mile away may grow higher and lower the prevailing wind speed. Grass underneath can change. On and on. The criteria is if the data is usable as is or not. If it is unfit, discard it.
The rationale of needing LONG DATA RECORDS is anathema to well known and followed scientific methods. It leads one to do things like made up “corrections”.
With measurement uncertainty of 0.5C or more for each station how do you determine which one is right? The old station or the new station? You are assuming that the old station has to be the one that is incorrect. On what basis do you justify that assumption?
Measurement stations, even new ones, are affected by the ground cover below the station. If the new station is over gravel/concrete it will read differently than an old one sited over bermuda grass. Which one is giving the “correct” reading?
Thermometers measure the microclimate surrounding it, nothing more and nothing less. If a station is moved, then it has a new microclimate. Comparing it to the old station at the original station tells you nothing. There can be all kinds of things that change the temperature even within mere feet of the old station.
If a station is moved, the old record should be terminated and a new data record started.
What a load. This is what Anthony is looking for in another thread.
Why was the station reduced for the whole preceding time of existence. In real science the record would have been stopped and an entirely new one started. Replacing DATA with MADE UP information is simply not done in science. You can’t justify doing so.
Would the FAA let Boing replace recorded data with calculated “corrections”? Would the EPA allow previous recorded data to be replaced with calculated “corrections”? Could Pfizer tell the FDA that they want to replace previous data with calculated “corrections”? The answer is a big NO. Any “correction” would also need to be NEW MEASUREMENTS and would replace the old in its entirety. That is a far cry from replacing data with MADE up “corrections”.
As per above even the original data has some issues because it is warming heavily pre 1950. There is clearly a lot going on at the site and yes it needs to be tossed out or at least make some real investigations as to what was happening.
About all you can see is why the CAGW faithful want to keep the site in because it is going the right way even if likely for very wrong reasons.
Admiral Worrall, I like your many articles here. You and WE are the kings of WUWT.
There are original raw measurements, and also wild guesses called infilling
How can one estimate error bars on infilled numbers that can never be verified?
And the rest of the numbers in the global average are “adjusted” numbers,
not raw data. Adjustments are personal opinions on what the raw measurements
would have been if measured correctly in the first place.
How can one state margins of error for adjusted and infilled numbers?
Anyone one who changes data should be fired or lose their job. You can’t “fix” data, it is what it is. If you guess does not align with the data the guess is wrong not the data.
Measurement of temperature in a given place at a given point and time is just that, what you can get out of that only applies to that place and the time the measurement was made. It is not a reflection of the next station or the world, it is a reflection of what happening at that place in a given time period.
The though you can come up with the “world temperature” is insanity now if you can explain why some are going up and other are going down and make a guess as to why that happen you best explain why some are going up while other are going down. Adjusting those going down to up is fraud.
I also don’t give a whit that the adjustment are approved and well understood and peer reviewed. That was also true with the mafias’ books.
In 2009, they did “fix” the data, the original, raw data. They made it better, but they didn’t tell anyone that they fixed it, and they left the raw (pure, unadulterated data) label on it, so that any scientist looking for global warming would see that, by golly, it’s right there in the raw data.
The poster child was Olney, Illinois.
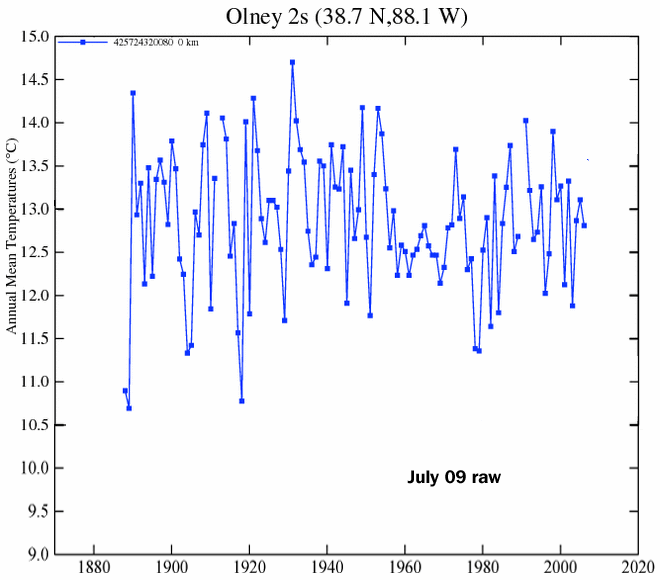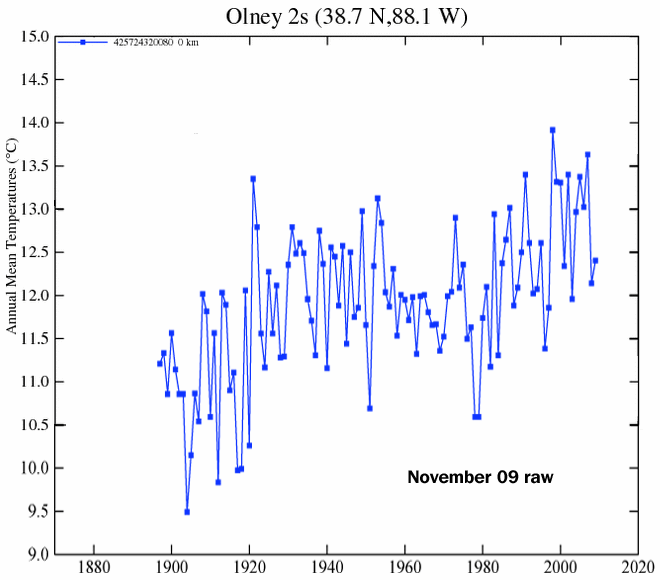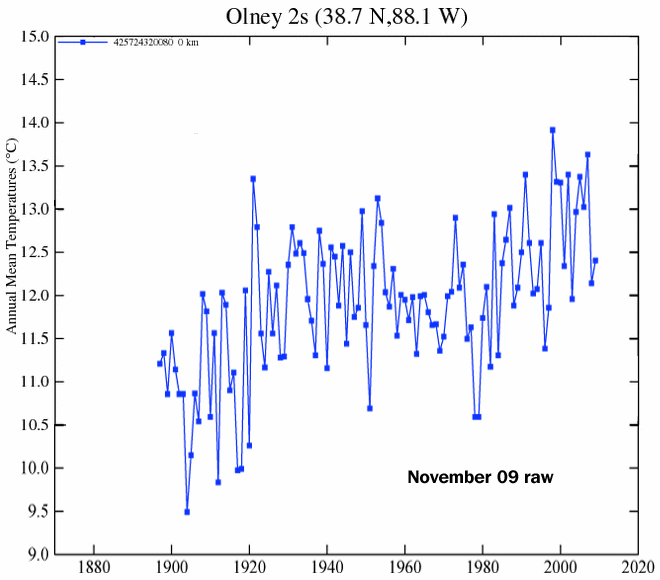
I blinked every station in Illinois, Iowa, and Wisconsin.
https://www.rockyhigh66.org/stuff/USHCN_revisions.htm
Blinking awesome!
Are you sure your November 09 raw images are correct? I’m asking because I looked at several of the stations on that website including Olney that you posted here and I’m seeing raw data that is consistent with the July 09 raw images when using the station data provided by GISTEMP here.
Don’t you have data you should be busy corrupting rather than spending time on WUWT?
The charts were absolutely correct at the time I posted the blinks in 2009, when they went internationally viral before viral was an internet word. I had 130,000 downloads when I finally took the counter off the pages.
With their fraud exposed, they went through and calmed down the obviously egregious alterations, and re-labeled everything as USHCN version 2. So you won’t get the same charts today that I discovered in 2009.
The currently downloadable “raw” data are still not the original numbers. The only way to get that is to download the original B-91 forms that the observers filled out when they read the thermometers.
Old B-91 scans are downloadable here:
https://www.ncdc.noaa.gov/IPS/coop/coop.html
Many are unreadable. Of course.
E.M. Smith’s web site helped spread the word in 2010. The similar French and Scandinavian web site pages aren’t online anymore.
https://chiefio.wordpress.com/2010/01/15/ushcn-vs-ushcn-version-2-more-induced-warmth/
Thanks for the response. I wonder what happened in November of 2009 then and why we don’t see it today?
Something to note is that by ‘correcting’ the data, rationalized as improving it, the standard deviation has increased significantly because of the trend introduced. That means that the uncertainty for the entire data set has increased.
The “world temperature” is a joke from the beginning. At any point in time the average temp in Kansas may be 80F = 27C and in South America it may be 20F = -7C.
The average of the two averages is 50F. Does that average of averages tell you *anything* about the climate in Kansas and South America? It certainly doesn’t tell me squat.
The global average temperature is no different. Does a change in the GAT happen because of Tmax changes, Tmin changes, or a combination? You simply cannot tell. If the change is because of Tmin going up is that somehow a bad thing? If it’s not a bad thing then why is so much money being spent on it and quality of life being degraded so badly.
How about just throw the whole record in the trash bin? Temperature isn’t a measure of the heat content of an atmosphere that includes water vapor. Enthalpy is.
Enthalpy is a measure of the heat content of atmospheric air plus water vapor. It’s the temperature plus the “latent heat” that is associated with water vapor. It takes energy to evaporate water, and energy is released when water vapor condenses. Enthalpy accounts for that energy. Its units are BTUs per pound of dry air and associated water vapor (or kJ/kg).
The enthalpy (total heat content) of air at 115 °F with 5% relative humidity, is the same as air at 70 °F and 80% relative humidity, but the difference in temperature is 45 °F. Temperature has nothing to do with the heat content of Earth’s atmosphere.
A global average temperature is a metric without meaning.
Burbank, California, 20 September 2021 at 4:53 PM, 87 °F, 45 °F dew point = total heat content of 28.2 BTU/lb.
Burbank, California, 12 February 2022 at 1:53 PM, 87 °F, 8 °F dew point = total heat content of 22.3 BTU/lb.
The temperature is the same, in the same location, but the total heat content is 25% greater in September, because there is more moisture in the air.
Or consider this fact, during an El Niño, warm water that was stored in the Pacific warm pool sloshes back across the Pacific, causing the atmosphere to warm. But that heat is just on its way from the warm pool to deep space. It passes through the atmosphere, causing warming, but the plant is actually cooling.
A global average temperature is a metric without meaning.
Yup..
A warming atmosphere is a cooling Earth. Entropy and The Entire Universe is absolutely screaming that fact – why does nobody hear it?
And while they’re sorting that AND getting a handle on it AND because it is supposedly all about the surface of the Earth, let’s include the energy contained inside the top 1 metre of soil/dirt ##
To get a true reflection of Earth’s actual average temperature (and energy content) use the most sensitive and accurate thermometer there ever could be.
It’s Gas Thermometer.
Such things work on First Principles and are what scientists of centuries ago could and did use to read temperatures down to 0.001 Celsius. Repeatable and accurate.
It’s called The Stratosphere
Modern Science including the Sputniks tell us it is cooling. Apparently – but is it actually? Because the insane theory of the GHGE says that heat is trapped in the Troposphere – hence the Stratosphere must be cooling.
Is that another ‘adjustment’
## My pet rave since forever and why I have a temperature data-logger buried 50cm deep in my garden, directly 2 metres below an identical logger
They do not follow any sort of identical trajectory over any and all 24 hour periods nor over and periods of 365 days
“Temperature isn’t a measure of the heat content of an atmosphere that includes water vapor. Enthalpy is.”
Ditto. Well said, and well illustrated. It’s a point I’ve made more than once in these pages, only to be rebuffed almost every time.
The rebuffs make no sense. People cite their favorite TOA radiation imbalance number, then do all sorts of calculations to demonstrate the effect on atmospheric temperature. But a radiation balance is a difference between energy in and energy out, so a change in the total energy on Earth is the thing we are talking about. When it comes to the atmosphere, that is enthalpy – nothing more nor less. And the water vapor content at the points of measurement have an enormous influence on the enthalpy.
Song et al. 2022 provide the equivalent potential temperature (theta-e) data. Since 1980 the dry-bulb temperature has increased about 0.75 C while theta-e increased about 1.3 C.
The unanswered question is just what does CO2 add the enthalpy at that point in the atmosphere. We can easily calculate what H2O does to the enthalpy. Do you ever wonder why no scientist has worked out how CO2 adds heat to the atmosphere and how much? Maybe it is too small to measure when compared to water vapor?
“Stop reporting the results of the USHCN/GHCN temperature series to the hundredth of a degree C.”
People who cite USHCN are those who get their knowledge of temperature measurement from Tony Heller. In the real world, USHCN was replaced by ClimDiv eight years ago. The authors of this MDPI paper also seem to be unaware of the change. They must be getting their updates from Heller.
I would have thought that with this galaxy of talent, they might have done what I have never seen a “sceptic” do, which is to calculate the global average with and without adjustments, to see what is the real effect of homogenisation.I regularly calculate the average using unadjusted data, but I check with adjusted data too. I described the result of one comparison here.
I showed the result as a graph of trend to present, calculated either way. The x-axis year is the starting point of the period, so recent years give silly results. The purple line used adjusted GHCN data, the blue unadjusted. The difference to trend is small, and has cooling effect for trends since about 1970. Here is the graph:
I see BTW that there is an indication of the seriousness of MDPI peer review. The paper was submitted 13 Jan, accepted 6 Feb.
Thanks Nick. And welcome back.
Ooh that annoying Tony Heller, doesn’t he just get under your skin, Nick?
So your graph prooves the corrrection introduces an acceleration on the temperatures. The trends are lowered before 1970 and increased after. Since this occures on the trends it implies an acceleration on the temperatures.
This is a very missleading graph
One problem with trends is that they are, to use an English colloquialism, “tricky buggers”. They very often do “unexpected” things.
An alternative to “trend from start / to end” graphs is “sliding window” versions, which have a set of fixed-length trends plotted instead.
The standard integration time for “climate” is 30 years, but in AR6 (section 1.4.1, page 1-54) they state :
“In AR6, 20-year reference periods are considered long enough to show future changes in many variables when averaging over ensemble members of multiple models, and short enough to enable the time dependence of changes to be shown throughout the 21st century.”
Extending “N-year reference period anomaly offset calculations” to “N-year trend calculations” I plotted the 20-year (trailing) trends for various IPCC “projections” and the main instrumental GMST records (see graph below).
NB : For the RCP (CMIP5 / AR5) model runs, the common “Historical Data” inputs went to 2005, with individual “pathway” inputs used from 2006.
For the SSP (CMIP6 / AR6) model runs, the “Historical Data” was updated and extended to 2014, individual “pathways” only split off from 2015 onwards.
Note how the NCEI and GISS datasets deviated from the other (relatively ?) “tightly grouped” instrumental datasets for the set of 20-year periods from (roughly) 1890-1910 to 1955-1975. These differences would have been masked using your “trend to present” methodology.
Note also how badly the (trailing) trends of the model reconstructions for the section of the “Historical” period from 1935 to 1965 compare to those of the instrumental datasets, as well as during the most recent (since 2000) part of the “Modern Warming” period.
“These differences would have been masked using your “trend to present” methodology.”
Well, I was focussed on the difference between adjusted and unadjusted, and people normally criticise adjustment in terms of its effect on trend to present.
But hey, I can do 20 year trends too. Here are my program TempLS using adjusted and unadjusted data, compared with Had5, GISS and NOAA (NCEI). I haven’t done the HAD relatives, so now HAD looks like the outlier. Otherwise it looks like yours
It’s a bit crowded, so I plotted the same data in terms of difference from TempLS (unadjusted):
Now it’s clear that the difference due to adjustment is less than the difference between different indices.
Yes, my post is slightly “off topic”.
Probably due to associative memory, I saw “Trends” and “°C per century” and thought “Hey ! Didn’t I do something along those lines a month or so ago ?”.
I compared :
1) GISS (NASA)
2) NCEI (NOAA)
3 + 4) The “old” HadCRUT4 and its “kriged” version (Cowtan & Way)
5 + 6) The “new” HadCRUT5, in both “Infilled” and “Non-infilled” versions
7 + 8) Both version of the BEST reconstruction (“Air” and “Water”)
9 to 12) The 4 main CMIP5 (RCP) “ensemble means”
13 to 16) 4 of the 5 main CMIP6 (SSP) “ensemble means”
I noted that among the (8) “instrumental / measurement” datasets “GISS + NCEI” were similar, but differed from the other “group” of six options.
You only compared GISS, NCEI and “Had5” (which version ???). Given the similarity between GISS and NCEI it is not surprising that you ended up with “now HAD looks like the outlier”.
From your “A guide to the global temperature program TempLS” [ now using GHCN V4 ] webpage :
It is not surprising that your “TempLS program” has results closer to my “GISS + NCEI pair” than “the group of 6 others”.
Looking at your graph, if you squint a bit it looks like “TempLS (unadjusted) – TempLS (adjusted)” (the smooth purple line) and “TempLS (unadjusted) – GISS” (the jagged lime-green line) are very similar from 1920 to 1970 or so …
I can’t visualise the result in my head (especially post 2005-ish), please could you add “NOAAlo – GISSlo” to your (second) graph ?
Here is another graph showing differences from GISS. NOAA-GISS is the greenish curve.
The Had5 is the infilled version. I think infilling was always the right thing to do, so I think the other version is just to save face for a while, and will disappear.
Infilling has to be the right thing to do. Otherwise anyone who takes the spatial average of 85% of the grid cells and treats it as if it covered 100% then they are implicitly “infilling” the remaining 15% of the cells with the average of the 85% whether they realized it or not. At least with HadCRUTv5’s kriging-like method they are doing the infilling using a local weighted strategy instead of just assuming the empty cells follow the average of the entire globe.
Dry-labbing is unethical scientific fraud, something you apparently excel at.
No they are not implicitly “infilling” anything. They are simply showing what the measured part of the globe is. If 85% of the globe is doing something, do you think the rest of the globe is off doing its own thing with vastly different trends?
Your preoccupation with “Global” blinds your thinking. You are a mathematician first and a physical scientist second. A global average is a worthless message for how mitigation should accomplished. Most of the tropics aren’t supposed to see much change in temps regardless, only the poleward locations. Do you think they care about “global” temp increases?
First, thank you for being so patient and responding so quickly to my “knee-jerk” reactions to your posts.
NB : In compiling the data for this post I noticed the “uptick” in the “TempLS (adjusted) – TempLS (unadjusted)” and “TempLS (adjusted) – GISSlo” lines for the last 2 years (2020 and 2021) in your “… difference from …” graphs.
Is that a “glitch” or an actual “bug” (/ “feature”) ???
– – – – –
The attached graph is a subset of possible deltas from my spreadsheet.
NB : The following “Notes” are more “stream of consciousness” than anything else. Some readers may find them more confusing than if I had simply posted my graph without writing anything else (?) …
Notes
– The heavy red and green lines, “HC5 (Infilled) – GISS” and “NCEI – GISS”, are the equivalent lines in your third graph.
– Continuous lines are the differences between “variants of the same type”, especially “HadCRUT5, Infilled vs. Non-infilled” and “BEST, Air vs. Water”.
NB : “HadCRUT4 – HadCRUT5 (Non-infilled)” is also included in this subset.
– Teal (light-blue) lines are “HadCRUT4 – X” options
– Orange lines (apart from the heavy-red “HadCRUT5 – GISS” one !) are “HadCRUT5 (Infilled) – X” options
– Dashed lines are “X – BEST (Air)” options
– Dotted lines are “X – GISS” options
– Dash + 2 dots lines are “X – NCEI” options
– HadCRUT4 (the subset of teal lines …) does indeed seem to now be an “outlier” …
– The other (non-HC4) deltas are all in the range +/- 0.6 (°C / century). While that is indeed “more than” the +/- 0.1 of the “Adjusted – Unadjusted” range it could be argued that it’s still “of the same order of magnitude” …
Mark,
Thanks for the note about the uptick. I’ll check that carefully; those were years when for various reasons I wasn’t as attentive as in other years. I’m currently working on a blog post comparing results for GHCN V4 adjusted; so far I have only posted about V3. V4 is looking similar. Some light might be shed on this uptick along the way.
Incidentally I post a csv file of monthly data back to 1850 (or where available) each month. The latest one is here
https://s3-us-west-1.amazonaws.com/www.moyhu.org/2022/02/month.csv
The file includes the majors, including satellite, but also the variants of TempLS. You can get earlier months by varying the date in the url, although recent months are missing (more housework to do). They are useful for checking changes to old data.
NB : I’m now moving this thread to my “check once or twice in the next week, rather than every day, then drop it” set of bookmarks.
This will probably be my last post here.
Thanks for that.
Although my “analysis” is much less sophisticated than yours it’s always good to get “more grist for the mill”.
Just checking (using the SUMXMY2() function to do a quick “sum of squares of differences” series of calculations) I noted that the closest alternative to all of your “TempLS*” options (the last 10 columns in your CSV file) is “RSS TLT V4”.
Although the grid is “designed to match that of GISS”, I systematically get “GISSlo” having the third best match (with “RSS-TTT4” in second place).
You’re going to be looking at the details of TempLS anyway, but I’m not sure whether having the idea of “it ends up being closest to RSS LT than anything else” will count as “useful” or “a distraction” …
Thanks, Mark. Interesting about RSS. Did you adjust the sum squares for the different lengths of overlapping record?
I did a study a while ago comparing indices
https://moyhu.blogspot.com/2015/10/how-well-do-temperature-indices-agree.html
It was V3 GHCN, V3 RSS etc. I found that the satellite indices were not very close.
No !
It came to me in “a blinding flash” about 6 hours after I hit the “Post Comment” button (when I was looking at a completely different subject).
One of those (all too frequent recently) “so enormous I completely missed it” mistakes.
Very much “second pass / needs more verification” results, but I’m seeing the same thing.
For me (at least) it is definitely worth filing away this “temporary / scratch-pad” spreadsheet for future reference …
What if it is not possible to have a global average temperature?
The title of our paper is “Evaluation of the Homogenization Adjustments Applied to
European Temperature Records in the Global Historical
Climatology Network Dataset“. For the record, I am aware of ClimDiv, and I would expect that our other authors are also aware of it, but I do not intend to waste anyone’s time confirming that. ClimDev is not from the relevant continent in this context, as I am sure Nick is aware. USHCN is indeed mentioned in our paper, being relevant to any discussion of GHCN and PHA.
His quotation is from this blog, not from our paper. If by “updates” he means GHCN temperature data, the source used was NOAA. I have no wish to get involved in any differences he may have with Tony Heller.
Perhaps Nick would be better occupied actually reading the paper itself and submitting any relevant comments he may have here, and at MDPI (the paper is open access, comments are welcome).
Posted too hastily without adding a link to the post for comments at my own blog and without proper attention to wording and punctuation of the final paragraph. It should read:
“submitting any relevant comments he may have here and at https://oneillp.wordpress.com/2022/02/23/comments-on-oneill-et-al-2022/(At MDPI the paper https://www.mdpi.com/2073-4433/13/2/285 is open access). Comments are welcome.”
” USHCN is indeed mentioned in our paper”
It’s a bit more than that. The paper says, for example, that:
“Since Version 2, the GHCN includes a separately processed dataset for the contiguous United States (i.e., all states except Alaska and Hawai’i) called the United States Historical Climatology Network (USHCN) [20,21].”
and that just isn’t true. It was so in V3, but V4 has over 10000 US stations, mot of which were never in USHCN, and which don’t get special processing.
I have read the paper. I think that makes me unique on this thread, including the lead author, Francis Menton. The paper is a gripe about
“However, only 19% of the breakpoints (18% for Version 3) were associated with a documented event within 1 year, and 67% (69% for Version 3) were not associated with any documented event.”
This is in reference to Europe, choosing particularly Ukraine as an example. But the whole reason for having PHA is that metadata in much of the world is unsatisfactory. The best indicator of an event requiring adjustment is the temperature record itself.
No error bars, Nitpick Nick?
What percentage of the numbers
used in the global average are infilled guesses?
Tell us now, or shut up.
If you don’t know the answer to that question,
you are not educated on the data you so often
pontificate about.
“What percentage of the numbers used in the global average are infilled guesses?”
100%
“If you don’t know the answer to that question you are not educated on the data”
I know the data very well. I have written my own program, TempLS, to calculate global average anomaly, and every month, I am the first to post the previous month’s temperature.
All the temperature measures we have are from a finite number of small enclosures. Everything else is obtained by interpolation (infilling). This is also common usage. When you say it was 80°F in Biloxi, you are quoting a measurement taken in an enclosure somewhere – you probably don’t know where. The notion that it is representative of Biloxi is an extrapolation.
This situation is universal in science. We can only measure at a finite number of points and the rest is inferred by interpolation (infilling). How do you know about the steel in a beam? Test samples. Ore content in a mine? Samples and interpolation. Etc.
Testing samples from the same beam is a far different thing than infilling temperature data from different measurement stations. Infilling temperature data includes the assumption that temperatures are correlated sufficiently that one point is indicative of another point. Since the temperature profiles at two stations are sin(t) and sin(t + a) their correlation factor is cos(a). That’s equivalent to about 50 miles if there are no other factors. Other factors can lower that distance significantly, things like elevation, humidity, and terrain (e.g. intervening water). This makes infilling temperature data a losing proposition.
“Testing samples from the same beam is a far different thing”
No it isn’t. You infer the properties of the whole beam from measurements at a few sample locations. That is similar interpolation. Virtually all we know about the physical world is interpolated from samples.
Only in climastrology is this kind of abuse of data tolerated.
You really don’t know about the real world do you?
Read this for testing steel pipelines. Testing of pipes and pipeline components — CEPS a.s. (ceps-as.cz)
Read this about testing I-beams for strength. https://www.ideals.illinois.edu/bitstream/handle/2142/4126/engineeringexperv00000i00068.pdf?sequence=3
You really need to take some physical science engineering courses.
So I looked at your first link, and what do I see?
“Fatigue tests are carried out either on test vessels during their hydrostatic pressure tests or on CT samples to detect fracture-mechanical properties of pipeline steel.“
Either way you are inferring properties of the pipeline from samples.
Do you have any experience in quality control? You miss the whole point. These are COMPREHENSIVE tests on products going to building sites. Yes, samples are pulled from the production line, but there are detailed calculations on how many samples must be examined in order to provide the quality that is needed. They are real physical measurements.
What you are suggesting is using a sample of one from a quantity which has different suppliers and then assuming that all the rest have similar characteristics.
We used to test concrete for highways. One truck from each supplier had to be tested from each batch of concrete. I don’t remember a single batch ever having a varying hardness. I suspect that beams made from a single pour are the same too. That is a far cry from using temps from different thermometers (akin to a number of different batches of concrete) to determine what to put into a given area.
You just won’t admit that temperature trends at different thermometers can vary over short distances.
In fact, you argue that they don’t. You and others here make the case that homogenization doesn’t change the overall trends shown by raw data. If that is the case, then all the time and effort to homogenize is simply wasted and for what purpose?
“but there are detailed calculations on how many samples must be examined in order to provide the quality that is needed”
Yes. And there are detailed calculations on how the quality (measured as uncertainty) of the sample density of surface temperature measurements.
“all the time and effort to homogenize is simply wasted and for what purpose?”
You don’t know that it is wasted until you have done it. Just as you tested all those concrete trucks unnecessarily, as you said. It turns out to be unnecessary, but you don’t know until you have done it.
You admit to being one of these dry-labbing liars, making up fake phony numbers and calling it “data”.
But the beam represents samples of the same thing. Temperature samples are *NOT* from the same thing.
I’m not surprised you failed to address the correlation. Samples from the same beam have a high correlation. Air samples from Los Angeles are *NOT* correlated with air samples from Kansas City.
In fact, air samples from Topeka, KS are not correlated with air samples from Kansas City. If you take samples from both at 2PM CST the temperatures will fall at different points on the daily temperature profile. The correlation factor will be less than 0.8.
“Samples from the same beam have a high correlation. “
So there is no difference in principle. The only question is whether the homogeneity is good enough.
And of course you miss the main point here. Anomalies do have good homogeneity. Enough that you can interpolate over the distances between measuring points in GHCN V4.
Fraud and lies.
Oh my freakin lord!
Multiple measurements from the same thing is *NOT* the same thing as multiple measurements from different things!
There *IS* a difference in principle!
Multiple measurements of the same thing give you an expected value for the next measurement of the same thing, within the limits of uncertainty.
Multiple measurements of different things do *NOT* give you an expected value for the next different thing being measured, not even within the limits of uncertainty!
Anomalies can *NOT* just be assumed to have good homogeneity. Since the process of calculating the anomaly hides the variance and range of the underlying data you simply can’t tell of there is homogeneity or not!
In addition, if q = a – b then the total uncertainty of a – b is
ẟanomaly = ẟa + ẟb.
The uncertainty adds when you calculate an anomaly. So how does that help you determine homogeenity?
TG said: “In addition, if q = a – b then the total uncertainty of a – b is
ẟanomaly = ẟa + ẟb.”
Nope. Your own source Taylor 3.16 says it is ẟanomaly = sqrt(ẟa^2 + ẟb^2).
Wow! So you are using root-sum-square instead of direct addition!
RSS applies when you can assume there is partial cancellation of random error in the presence of systematic error. With just two values, exactly how much cancellation can you expect?
The direct addition is the upper bound and the RSS is the lower bound on the uncertainty.
Tell me how much cancellation of uncertainty you expect to get from two independent measurements of different things.
I spent 20 yrs collecting data on a daily basis for the UK Met Office. The data I collected was sent in to a regional office where it rounded up. 0.5mm of rainfall became 1mm, for example. Any missing data was infilled using data collected elsewhere. All collected data was also adjusted for human error, location and instrument calibration.
As long as data was collected within an hour (either side) of 9am (10am in the summer), it was deemed acceptable.
Now, all stations are digitalized, relying on hourly reports sent via the monitoring equipment directly to computers…..a much better system. I don’t trust the Met Office one little bit.
“I don’t trust the Met Office one little bit.”
I don’t trust any of the data mannipulators.
I trust the unmodified (raw), regional surface temperature charts, which show CO2 is not a factor in the Earth’s temperatures. The reason to trust the regional surface temperature charts is because the data was recorded by people who did not have a human-caused climate change agenda, all they were doing was recording the temperatures.
And isn’t it funny: The regional surface temperature charts show it was just as warm in the recent past as it is today which means CO2 is a minor player, but the computer-generated Hockey Stick charts produced by the alarmists show a completely different picture with temperatures getting hotter and hotter and hotter.
The alarmists have a political agenda and use their computers to lie to the world about the Earth’s atmosphere.
We should stop using these liars product. We have a perfectly good substitute: the unmodified, unbiased, regional surface temperature data.
If we did that, then we wouldn’t have to listen to the alarmists and activists tell us about how all that data needs to be mannipulated before it is useful. Useful to them, is what they really mean. Not useful to the truth.
Here is a regional surface temperature chart (U.S. Hansen 1999) next to a bogus, bastardized instrument-era Hockey Stick chart. Notice how different the temperature profiles are. One shows a benign temperature profile and the other shows a “hotter and hotter and hotter” profile.
All the regional surface temperature charts resemble the U.S. chart. None of them resemble the “hotter and hotter” Hockey Stick chart. One of those chart is not telling the truth
And then there is this:
http://notrickszone.com/2017/06/16/almost-300-graphs-undermine-claims-of-unprecedented-global-scale-modern-warmth/#sthash.neDvp33z.hWRS8nJ5.dpbs
I want to see Nick try to debunk all those charts.
Now I know for a fact you know the history of GISTEMP and the problems with these these graphs because you asked a couple of days ago and I responded. Would you mind sharing the details with the WUWT audience here?
Don’t whine.
Where do you find the unmodified data? Looking at Berkeley Earth data from 1750-1850 gives what one would expect, wide swings in warming and cooling while HADCRUT has no such swings and appears grossly tampered and unusable. (Note no extreme warming of the 30’s) So without a reliable temp foundation, everything done in relation to it is false. The modern temp records actually follow urbanization and population growth quite well (Willis). This appears intentional to conclude the solution is population control which would result from the elimination of fossil fuel energy IMHO.
Berkeley Earth is a good one-stop shop for all of the data. You can download it here.
Berkeley Earth claims to have data from 1750-1850 ??
If it is true that Berkeley claims to know a global average temperature
before 1900, the organization is a FRAUD.
There were very few land weather stations pre-1900
especially in the Southern Hemisphere.
Sea surface measurements were worse,
with buckets and thermometers used almost
entirely in Northern Hemisphere shipping lanes.
If you think Berkeley is a good one stop shop,
then you are a fool.
Oh that’s nothing. People claim to know the global average temperature hundreds of millions of years ago.
Anyway I say Berkeley Earth is a good one-stop shop because all of the data is listed on a single page, can be downloaded quickly and provided in easy to read plain text files. You don’t have to get the data from them. You can go to the providers individually, but that’s a lot of work.
While this ranks very close to number one, covid and the murdering vaccines are clearly the number one fraud of all time
Covid is not a fraud.
Cases, hospitalizations and deaths are exaggerated.
The vaccines are very dangerous, but not “murdering”
You are a dingbat.
From the article: “For starters, note that President Trump, despite his climate skepticism and his focus on what he called “energy dominance,” never even drained a drop out of this particular corner of the swamp. It took Trump until September 2020 — just a few months before the end of his term — to finally appoint two climate skeptics, David Legates and Ryan Maue, to NOAA to look into what they were doing. Before they really got started, Trump was out and so were they.”
Trump had a lot on his plate other than climate change, like two impeachments and constant attacks from the Democrats using the federal government as their weapon, and the RINO’s who are too stupid to know what’s best for them or the country.
Exactly right.
The RINO’s are not stupid. They’ve thrown in their lot with the Dems in a quest for their share of globalist money and power. It’s why the RINO’s in the state legislatures of the swing states are blocking action on dealing with the massive vote fraud that happened in their states.
“The RINO’s are not stupid. They’ve thrown in their lot with the Dems in a quest for their share of globalist money and power.”
Being greedy doesn’t make one intelligent, necessarily.
Trump’s results were pitiful
Worst president in history,
until Jumpin Joe Biden showed up.
Trump fought the Deep State
and China trade, and lost both.
I give him credit for trying.
After four years, CO2 was still a “pollutant”
I will never forgive Trump for that.
I voted for Trump in 2020 because
I knew Biden would be worse.
Biden was even worse than I thought
in his first year, and Biden is heading for
worse than worse than I thought in his
second year. He did provide us with some
entertainment by picking a completely
unqualified total dingbat as vice president —
Kamela, the Queen of cackling and word salads !
From the article: “And there don’t even exist enough climate skeptics with the requisite expertise to re-do the homogenization algorithm in an honest way.”
We don’t need a “global temperature” for anything. The regional temperature data is sufficient to our task. The regional temperature data tell us we have nothing to worry about with regard to CO2
There’s no “global temperature” anyway. When it’s cold in the northern hemisphere, it’s warm in the southern hemisphere, so how do you get a global temperature out of that? You don’t, you get an “average”. of the hot and cold. That average doesn’t tell me how hot or cold I feel. it doesn’t tell me anythng useful.
All temperature and precipitation summaries should be applied to characterize the Köppen climate zones, and NOT a global average. It would be most instructive to see if the different climate zones are exhibiting changes, and if so, which ones and in what direction. Most of the potential information is lost in trying to reduce all the measurements to one number.
Well said!!
I suspect the results of such a study would greatly disappoint the Alarmists.
Look here:
https://www.nature.com/articles/s41598-018-25212-2
A study done by ag scientists, not climate scientists. Their conclusions do not support the AGW claims that earth will become a cinder.
Tim, thank you for the link. It was an interesting read.
It’s not just temperature data. Homogenization is also done to balloon humidity data. To make sure that that model predictions agree with alternative reality. Soon, it will all be clown world data. Why would anyone need to homogenize balloon data too (apart from straight-jacketing it into ‘validating‘ climate models)?
Balloons are an even bigger problem than surface observations. Not only are they subject to the same station move, instrument changes, and other observing factor issues, but they also drift away from the station. The drift profiles differ depending on a lot of factors including the type and prevailing winds. AFAIK no traditional dataset handles the drift problem. However, I believe reanalysis like ERA5 handles this since the observations are tagged with GPS coordinates and a timestamp and so can be assimilated by the more advanced 4D-VAR technique. Anyway, for those interested here is a really cool site that tracks the balloons in realtime.
Great link, that SondeHub! Thanks for posting!
How does a drifting balloon differ functionally from a cold front passing the station during the time the balloon is aloft? The drifting balloon implicitly assumes that the atmosphere is laterally homogeneous, at least within layers of the same altitude. If they aren’t, then the balloons tell us about how the measured parameters vary laterally.
Balloons drift all of the time regardless of frontal passage. Unless the winds are zero they never actually measure the vertical profile of the temperature above the station. And the higher up the balloon travels the further it tends to drift. During periods of light wind and when the surface is superadiabatic they tend to follow the thermals upward at least until the temperature inversion is reached. This is a difficult problem to solve. The only way I’ve heard of doing it prior to GPS tracking is to use a global circulation model to estimate the drift trajectories and the bias that drift may introduce not unlike how HYSPLIT works. The problem is the same that RSS encountered for their diurnal adjustment prior to v4. You’re using a GCM as part of the observational strategy which is usually frowned upon when used for climatic purposes.
That was really my point. Balloon data always has to deal with sampling with a non-vertical, or non-parallel transect of the air column, caused by different factors. Therefore, what is obtained is measurements along the surface of hypothetical cones of different interior angles.
“Those bureaucrats mostly have civil service protection and cannot be fired.”
Oh, there are ways— like, moving them out to some very undesirable location.
I might have asked this before. Has anybody analysed the data ignoring the actual temperatures and making no adjustments to say, it’s getting warmer, it’s not getting warmer.
Yes, the data has been analyzed without correcting for time-of-observation changes, shelter/instrument changes, station moves, bucket/engine/buoy differences, etc. Without these corrections it appears (in error) that the planet warmed more than it actually did over the period of the instrumental temperature record.
As far as doing it without actual temperature records, yes, that is actually possible with reanalysis. They do it occasionally as part of data denial experiments to test data assimilation techniques for global circulation models. I’m not aware of it ever being done with reanalysis products used for climatic purposes though.
I’m psychic, predicted this post.
If what you said is true, how do you explain the alterations in the temperature series of the US which cool the past and warm the present? (See Mike MacMillan’s post above at 2.24 am).
These publications do a far better job explaining the biases and corrections than I ever could.
Vose 2003: 10.1029/2003GL018111
Hubbard 2006: 10.1029/2006GL027069
Menne 2009: 10.1175/2008JCLI2263.1
Still fraud, albeit well-disguised by a “sciencey” veneer. Try again.
Your first article is by Thomas Karl, of Karlization fame.
Why is changing the time of observation, changing the shelter/instrument of station, and/or addressing these two points of bias fraudulent?
Do you use a time machine to retrieve these values of “bias” from each and every station?
Yes, you can determine the bias for each and every station. No, it does not require a time machine.
NFW. Only in climastrology is this garbage acceptable.
How do you determine the bias? By comparing to other stations? How distant are those other stations? How accurate are those other stations?
And, yes, it *would* require having a time machine. Otherwise your corrections are nothing more than biased guesses!
TG said: “How do you determine the bias? By comparing to other stations? How distant are those other stations? How accurate are those other stations?”
I’m going to give you the same answer I gave you last time. Read Menne 2009. It tells you how the bias is determined. It tells which comparisons are made. It tells you how the comparisons are selected. It tells you the efficacy of the procedure. And if you download the station meta data you’ll find the lat/lon coordinates that are used for determining distance.
Fraud.
I have read Menne. And I’ll give you the same answer I did the last time. Menne did *not* take into consideration the correlation of the stations based on all the factors such as distance, elevation, humidity, terrain, etc.
He did just as most climate scientists do – ignore the real physical world.
Because, unless you can compare parallel measurements of the same temperatures on the same days on the two instruments you know absolutely nothing.
Have you ever heard of calibration curves? People like myself who work in Chemistry use them all the time.
Because the people doing it CAN NOT BE TRUSTED.
You don’t have to trust them. You can download the data and do your own changepoint analysis and bias corrections.
How do you know what caused the changepoint? Are the temps before or after the changepoint more accurate? If you don’t know that then how do you determine the correction? A biased guess?
TG said: “How do you know what caused the changepoint?”
For stations with well kept meta records you cross reference to that. For stations that don’t have well kept meta records or if those records are nonexistent you may be able to determine the cause of a changepoint only after a thorough investigation.
TG said: “Are the temps before or after the changepoint more accurate?”
More accurate. That is the point of making the change.
HAHAHAHAHAHAHAH
Liar.
Really? You think someone logs it in when the grass below the station gets mowed? Or when a mud dauber builds a nest in the air inlet? And exactly who is going to go out and do a physical investigation? Does someone from Berkeley get dispatched to El Paso, TX to check out a station installation when they see something resembling a breakpoint?
“More accurate”
ROFL!! In other words you are making an unjustified assumption! How do you *know* the accuracy of the new station? All kinds of error can be introduced during transit! I think you mean you *hope* the new station is more accurate than the old one. More bias!
You *truly* have never lived in the real world!
How do you know what impacts the time of observation and/or changing the shelter/instrument caused?
Was the older measurement device more accurate than the new one? How do you address the differences if you don’t know which one is more accurate?
TG said: “How do you know what impacts the time of observation and/or changing the shelter/instrument caused?”
Vose 2003 and Hubbard 2006.
TG said: “Was the older measurement device more accurate than the new one?”
That’s not the issue. The issue is with the step changes that TOB shifts and shelter/instrument changes cause.
TG said: “How do you address the differences if you don’t know which one is more accurate?”
The issue isn’t with accuracy. The issue is the step change. You can address the step change by either 1) adjusting the older portion of the timeseries 2) adjusting the newer portion of the timeseries 3) adjusting both to a common reference or 4) split the timeseries and treat them as separate stations like what BEST does.
You people are really out to lunch.
“Vose 2003 and Hubbard 2006.”
Hubbard’s study said you need to determine corrections on a station-by-station basis. And he based his corrections on using a newly calibrated station when compared to an existing one. You can’t use other distant stations to determine corrections.
Your reference doesn’t say what you think it does.
“That’s not the issue. The issue is with the step changes that TOB shifts and shelter/instrument changes cause.”
Why are you worried about TOB? Again, if the station in Hays, KS and the station in St. Louis, MO both take their readings at 3PM CST in the afternoon the readings will be different because of the distance between them if not for other reasons. Their correlation will be poor! How do you correct for this? Does it really matter if the station in St. Louis changes the TOB from 3PM to noon? The temps will still not be correlated.
TOB only mattered when you were taking two readings per day. How many stations do that today? It’s the *profile* that determines the climate, not the temperature at a specific time of day.
“The issue isn’t with accuracy. The issue is the step change. You can address the step change by either 1) adjusting the older portion of the timeseries 2) adjusting the newer portion of the timeseries 3) adjusting both to a common reference or 4) split the timeseries and treat them as separate stations like what BEST does.”
Once again, 1-3 are p*ss poor ways of trying to maintain a long record. How can you apply a correction determined in 1995 to a temperature reading in 1935? You don’t even know what the environment at the station was at the time. The microclimate could be entirely different in 1935 and the correction applied might totally misrepresent the microclimate at that time. Even in a rural environment farmers may have changed from planting wheat in the fields surrounding the station to planting corn or soybeans. Because of the differing evapotranspiration rates of the crops the temperature readings will vary as well!
Creating new stations is the *ONLY* way to do it and meet physical measurement standards. But this also means that you *must* do some kind of weighting if you are going to apply short current records and short past records together, especially if there are more recent short records because of there being more stations. Yet I don’t read anywhere in Berkeley documentation where they do that!
“But…But…But…But! Made up fake phony data is better than no data!”—bwdx
I thought that the problem was that there was an extended hiatus in warming, and Thomas Karl (2014?) ‘corrected’ (increased!) the Argos buoy temps to agree with the warmer, ship engine-room intake temperatures to show that warming was still happening.
Karl didn’t make the adjustments. He just updated NOAAGlobalTemp to use ERSSTv4. The adjustments for the bucket/engine/buoy observations are applied within ERSST. Haung et al. 2015 document the changes.
BTW…here is what the upgrade to ERSSTv4 did (a) and the net effect of all adjustments (b).
from your link:
“For example, heat loss estimates have been made for SST measurements from buckets that occur during the time between the hauling of buckets from the ocean surface and the reading of thermometers (Folland and Parker 1995).” (bolding mine, tpg)
“tudies have shown that the parametric uncertainty is an important component of the total uncertainty as demonstrated in the latest Hadley Centre dataset, HadSST3 (Kennedy et al. 2011). These have been estimated in this new ERSST.v4 in the accompanying Part II paper (Liu et al. 2015, hereafter Part II).”(bolding mine, tpg)
Estimate after estimate after estimates. Estimates are guesses. Guesses are *always* biased.
Let me make sure I’m understanding your argument here. Are you saying that the primary criticism you have with Haung et al. 2015 is not with their methods or even their results, but with the words they use to communicate those ideas?
My recollection is that the adjustment between Argo buoys and engine room intakes was about 0.12 deg C (in the wrong direction) to address the apparent hiatus in warming. I don’t see that addressed in your illustrations. I would expect it to be quite evident since Karl claimed that it dispelled the claim of a hiatus.
Tim Gorman remarks about estimates. Were there rigorous calibration experiments done to correct the pre-1940 bucket temperatures? It is interesting the corrections appear fairly uniform, which would not be expected for bucket temperatures in the Antarctic versus in the tropics.
CS said: “My recollection is that the adjustment between Argo buoys and engine room intakes was about 0.12 deg C”
The average adjustment was 0.12 C. Buoys record lower than engines. So to fix the inhomogeneity you can either adjust the engine measurements down or the buoy measurements up. Haung et al. chose to adjust the buoy measurements up. This choice was made because it allowed Haung et al. to make targeted adjustments. The 0.12 C figure is only the average of the targeted adjustments. If they had chosen to adjust the engine measurements down then they would have applied a constant 0.12 C adjustment to decades worth of engine measurements.
One thing that I’ve noticed is confusing people is the sign convention adopted by Karl and Haung. Karl did buoy minus engine (buoy-engine) whereas Haung did engine minus buoy (engine-buoy). The knee jerk reaction from the blogosphere is that Karl fraudulently adjusted in the wrong direction which is absurd because 1) he didn’t do the adjusting and 2) the difference was only in the sign convention.
CS said: “I don’t see that addressed in your illustrations.”
Look closely. The black line is slightly higher than the red line in the top graph especially beginning after the 1970’s.
CS said: “I would expect it to be quite evident since Karl claimed that it dispelled the claim of a hiatus.”
Take a look at figure 1. It shows the change in the linear regression trend from 1998 to 2012 between the two version of NOAAGlobalTemp. The period 1998-2012 is used because that is what is referred to as the last 15 years in IPCC AR5. You’ll notice that the trend increased enough to bring the lower bound above 0 for that period. Note that this in no way eliminates the “hiatus” as it is defined for other periods like 1998-2010.
The issue is very analogous to what Hubbard found with one-size-fits all corrections to temperature measurement stations. The factors are just too numerous to create any kind of accurate one-size-fits-all. Speed of the ship when the measurement was taken determines the depth the bucket reached, the length of the rope determines how quickly the bucket reaches the deck as does the deck height above the sea. the speed of the observer in taking the measurement, where is the water intake, what environment does the piping from the intake go through, what is the wave height when the measurement is taken, is the ship heavily loaded or lightly loaded (affects water intake height and heat output from the engine). I’m sure there are some factors I’ve left out.
You can *always* assume an average value for all of the factors and create a one-size-fits-all correction but doing so introduces more uncertainty than you started with! Assumptions like this are guesses and guesses create bias. Since most of these factors change with each measurement it’s probably not even possible to come with a ship-by-ship correction factor!
It’s always getting warmer or colder.
Warmer since the late 1600s
At least +2 degrees C.
And that was very good news.
Next trend will be cooler I suppose.
“The future climate will be warmer,
unless it is colder” — I predicted that in 1997.
The best climate prediction OF ALL TIME !
I was hoping at least for a Nobel Prize
participation trophy.
I’m as ordinary a man as there is and the idea global policy is being determined on data that is so unusable it has to be statistically juggled is plain bonkers. Go with a solid sample like USCRN built for purpose, professional and doesn’t require fiddling with. The virtually flat line trend might irk cult warmster but at least it’s honest ….. for now. Ouch!!
USCRN confirms that the USHCN FLs.52j file with PHA applied is closer to the truth than the raw file [1].
How are infllled numbers truth?
A spatial average should not require any grid cell infilling since there are plenty of observations to fill the grid mesh especially during the USCRN and USHCN overlap period at least for any reasonably sized grid.
That is an impressive name, Fitzgerald, but you are WRONG.
Global policy is NOT based on climate history.
It is based on predictions of FUTURE global warming
that will allegedly be 2x to 3x faster than the actual warming
since the 1970s. And constant warming too.
And completely ignoring the global
cooling from 1940 to 1975,
since “”adjusted” to a flat trend.
Predictions are NOT just an extrapolation of recent trends.
So even if the historical temperature data were perfectly accurate,
we’d still be getting wild guess predictions of much faster future warming.
Predictions, of course, are not reality.
Where there’s smoke, there’s fire. Officially sanctioned “climate science” is rife with fraud and fraudsters only looking out for themselves and their cohorts.
Here is the source code for the pairwise homogenization algorithm used to correct the biases caused by station moves, time-of-observation changes, shelter/instrument changes, etc. Would you mind pointing out which section of the code contains the fraud?
More spam.
Drivel. See my comment above concerning calibration.
It is my understanding that most of the historical thermometers were max/min thermometers, and no one actually knew what times the extremes were reached. How does one ‘correct’ such data?
(I’m not going to try to wade through the source code of some computer language I am probably not fluent in.)
CS said: “How does one ‘correct’ such data?”
Vose 2003 provided a procedure using hourly data to determine when a carry-over or drift of a Tmax or Tmin observation occurred and determine the magnitude of the effect. Honestly the procedure is so intuitive and easy that most people would be able to figure out how to do it with only a few minutes of thought even with no knowledge of the Vose publication or others like it.
The Vose method isn’t used in practice though since hourly data is not available to most datasets. Instead the more general pairwise homogenization algorithm can detect the changepoint when the TOB switched from PM to AM plus a lot of other reasons for the changepoint.
So, a tutorial in dry-labbing?
My understanding is that most of the recent historical temps were obtained with Max/Min thermometers. The only time there should be an issue of which day was recorded was the day the change occurred. After the procedure was changed, everything should be OK.
The issue with max/min thermometers is that you only know the max or min between the time of the observation and the last reset. You don’t actually know which day the max and min occurred.
For example, if you take the observation at 6 pm and reset the thermometer and the temperature at 6 pm on day D is higher than at any point on day D+1 then day D+1 gets erroneously assigned the Tmax of D as well. What happens is that a higher Tmax values get carried over to the next day or drifted into a different month if the carry-over occurred on the last day of a month.
Effectively what is happening is that Tmax averages are biased high. This isn’t a huge problem as long as the TOB doesn’t change because of the anomaly analysis since the anomaly baseline will be biased high about the same amount as the anomaly value itself.
The problem is when you change the TOB from PM to AM in which case the opposite problem of Tmin’s getting carried-over and drifted starts to occur such that Tmin averages are biased low. It’s a double wammy. Tmax averages lose the high bias and Tmin averages gain a low bias. This creates a step change in the station timeseries with the early period being high and the later period being low.
The TOB changes from PM to AM started after WWII. Because they don’t all occur at once, but over a period of decades (and still technically ongoing) this creates a persistent low bias in the warming trend that has nothing to do with the accuracy of the instruments. I think most of the stations in the United States have completed the change. Globally I’m sure a lot of changes are still occurring.
The reports I send from my weather station to the NWS and CWOP contain the 24 hour max and min temperatures, not the daily max and min. It happens a lot that the max temp for D+1 is less than the 24 hour max. How does the NWS and CWOP handle this?
I have no idea what is happening with your weather station reports. Are you apart of the COOP program or is this a PWS?
I report to the CWOP not the COOP. It is a PWS.
They don’t do much with CWOP except look at it occasionally for nowcasting.
And (max+min)/2 is not an average, it is the median.
That is a good point. Though it is important to note that ERA provides hourly grids processed at 10’ish minute time steps and it’s warming trend is indistinguishable from GISTEMP, BEST, and HadCRUT which use the (Tmax+Tmin)/2 method.
I suspect that should read, “… it’s warming trend is indistinguishable from GISTEMP, most of the time.”
Perhaps. ERA begins in 1979. From 1979 to 2021 the GISTEMP trend is +0.189 ± 0.005 C/decade and ERA is +0.191 ± 0.005 C/decade. Within the margins of the linear regression standard uncertainty (0.005) these two trends are indistinguishable for the whole overlap period. And before anyone misrepresents what I’ve said I’m not saying ± 0.005 quantifies all of the uncertainty here. It is only the raw output from Excel’s LINEST function. And full disclosure…Excel uses IEEE 754 so LINEST actually provides 15 decimal places on all outputs. I have no intention of hiding information by using sf rules here. So for those of you who are triggered by how I report these figures would you mind holding your grievances just this once so that CS and I can discuss the essence of the figures and not get distracted with the mindless claptrap of yet another significant figures discussion?
Probably more properly called the “mid-range” value with only two samples. A typical median is obtained from multiple samples.
But numerically identical.
At one point I vainly tried to demonstrate to he and bellman an absurdity with their ideas about measurements. Suppose you have a temp. sensor, with ±0.5°C uncertainty specs, and want 1-minute data. Instead of sampling once every minute, you decide to sample once per second and calculate the average.
According to them, the uncertainty of this average number is ±0.5 / sqrt(60) = ±0.06°C! Cool, huh? Just by taking a whole bunch of points the uncertainty goes down.
But wait, it gets better—you can sample once per microsecond and get 60*10^6 points. Then your uncertainty drops to 64 uK! Great plan, huh?
They absolutely refused to acknowledge that having U go to zero as N goes to infinity is not physically possible. They have no comprehension about the implications of sampling from a time-series, and think they can blindly apply canned equations for which they have no understanding and get reasonable results.
That they also think it is possible to create data that does not exist and get reasonable results should be no surprise.
And as Bellman and I have said numerous times those samples are almost certainly going to be correlated. But we can’t even start discussing that nuance because you refuse to accept the procedure for the propagation of uncertainty of the ideal uncorrelated case even from your own preferred source.
Your ignorance is not my problem, jack.
And this stupid “correlation” line is hypocritical sophistry—plug it into YOUR formulae.
What in Pete’s name does correlation have to do with this?
Once again, you are trying to say the standard error of the mean is the total uncertainty of the dataset. If the 60 samples per minute had *ONLY* random error then you could possibly make the assumption that the random error cancels and the standard deviation of the mean is the total uncertainty. But with temperature measurement stations that just isn’t possible. If there is a systematic error in the station anywhere then the errors won’t cancel. This could be from component drifting in an electronic sensor, it could be from tolerance in the components, it could even be from detritus on the sensor from an insect infestation.
You simply cannot substitute standard deviation of the mean for measurement uncertainty in most physical field measurements.
TG said: “What in Pete’s name does correlation have to do with this?”
Measurements taken at microsecond intervals are very likely to have correlated errors.
This claim is nothing but bloviation based on hot air and a need to cover your butt for the huge hole in your goofy ideas..
“Measurements taken at microsecond intervals are very likely to have correlated errors.”
How many temperature stations read out every microsecond? How many sensors have a response time of microseconds. It’s quite likely that the recorded temperatures are correlated solely due to the response time of the measuring station. That doesn’t make the errors correlated as you move along the time line. Even the newest thermistors have non-linear responses plus hysteresis effects plus thermal inertia impacts. The electronics reading the thermistors also have limits on response time.
Readings taken within those response times are not correlated because the temperatures are correlated but because the stations are unable to respond quickly enough. If you move the measuring interval out to one per second then there is a probability that the temperature readings may be uncorrelated because of environmental effects (clouds, rain, etc).
I would agree that there should be some correlation because of the movement of the sun along a sine curve. But you have to be sure to not try and move that correlation out too many digits because the correlation in the short term may not be there.
There is an old joke that the former US analog television standard, NTSC, was an acronym for “Never Twice the Same Color.”
Even measuring every microsecond, one is not measuring the same temperature a million times. One is measuring a million different temperatures once. They may be very close to each other, but they are different temperatures.
There is an aphorism that you only get one chance to make a first good impression. Similarly, you only get one chance to make a good temperature measurement.
Very well said!
Your comments here !
Lets start with this function
“subroutine minbic(iopt, xseg, yseg, end1, end2, qcrit, qstat, * qmin, qoff, rmuq, slpq, sseq, inqtype, iqtype, mkfinq, ifail)”
Prove to me that you are entiled to use any of that on the data?
Interestingly some of the comments in the code reference are aware of the issue yet they seem to do nothing about it or check it.
I love
BIC = -2 * LL + log(N) * k
what could possibly go wrong 🙂
It’s easy to waffle bullshit but lets see if you understand what is really going on.
minbic is the function that selects the minimum BIC model where BIC is the Bayesian Information Criterion and uses a technique developed by Schwarz 1978. Menne 2009 documents this in section 3c. I’m not sure where you are seeing -2*LL+log(N)*K. Is that where the fraud happens?
So if you know the background you should know the possible problems.
So prove that it’s a valid to use the analysis on the data because they sure as hell don’t (yet strangely they aware of the issues in the comments). In science outside the stupidity of climate science it’s called the look elsewhere effect and you are demanded to do it.
There is a great example with the graph above from Nick Stokes above any actual scientist seeing that graph would want some site background because there is obviously a lot going on. Nick like the climate scientists thinks it’s just okay to process that crap like normal.
My issue with most climate scientists are they are refugees from other fields and don’t even do the basics right.
There are a lot of potential problems with this method. It’s not perfect. No method will ever be perfect.
Anyway, Menne 2009, Hausfather 2016, and others have assessed the efficacy of PHA and all concluded that it is better than doing nothing.
If PHA still offends you then why not consider other datasets like BEST or ERA which do not adjust station timeseries via PHA?
BTW…where do you see -2*LL+log(N)*K? I mean it fits the form of the Schwarz scoring function so I’m not suggesting you made it up. But I’m not seeing it in the source code. I even looked at the bayes subroutine where the Schwarz scoring function is implemented and I’m not seeing that exact formula either written verbatim or inferred as a composite of a series of Fortran statements. Maybe I’m just missing it?
Anyway, back to the main question…where’s the fraud?
Just like I told to blob, look in the mirror.
So you have at least conceded it’s not perfect, I would argue the claim of what it shows with that much room for error is full science retard or as we like to say politely “not even wrong”.
So we are down to the question of is it fraud or just really really bad science with the refugee from other fields just not knowing any better?
I would like to err to the latter but the problem is they are at least aware of some of the problem. So it would appear their activism got infront of their scientific good sense and that probably does lead into the murky area of fraud.
There’s no need for me to concede it isn’t perfect. If you’ve tracked my posts on here I’ve been telling everyone there is no aspect of climate science or any science at all for that matter that is perfect. Science in general will never be perfect…ever.
There is a big difference between being fraudulent and being wrong.
There is also a big difference between providing something useful and providing nothing at all.
Not really. Climastrologists are both.
Something useful like a hammer when you are trying to “drive” screws.
“ and all concluded that it is better than doing nothing”
And they also refuse to admit to the uncertainty associated with what they are doing let alone publicize it. A fraud on the public.
Why should they do this? They want to fool people. They know their data is invalid. Why would they want to correct it?
They want to correct it because station moves, time-of-observation changes, shelter/instrument changes, etc. introduce unwanted biases.
I suppose they just keep the biases they do want then.
For scientists all biases are unwanted. For contrarians it seems like the biases are desired since any and all attempts to remove them are met with the criticism not of the method used but because it was even attempted in the first place.
Bias is a powerful thing. It would appear from your perspective there are scientists and then there are contrarians. the bias runs deep.
Just to be clear here…the biases I’m talking about are specific to the temperature record. They are things caused by time-of-observation changes, shelter/instrument changes, different measurement practices (bucket, engine, buoy), etc. I also didn’t intend to create a dichotomy between scientists in general and contrarians in general.
Admiration of statistical complexity is a common trap. But, as any good scientist knows, no amount of complexity will reduce uncertainty – most particularly of a sparsely sampled past. If the publishers of said data are good scientists they know this and they have successfully baited the trap. Or, they have somehow managed to fool themselves (not uncommon) and their successors. Adjust to your heart’s content; the most compelling arguments here are about false representation of uncertainty and, thus, the strength of conclusions drawn from past trends.
Government bureaucrat scientists predict what they are paid to predict — a coming climate crisis. The junk science is a result of starting with the conclusion.
Show me any study of the biases when repeatedly changing sea surface measurement methodologies and instyruments over the past 140 years, or shut up.
Have there EVER been any studies comparing each methodology used in the same location, at the same time
Of course not.
Given that oceans are 70% of the surface, it is possible that changes in measurements methodologies (and locations) account for a large portion of the warming claimed for oceans. I guess we’ll never know?
RG said: “Show me any study of the biases when repeatedly changing sea surface measurement methodologies and instyruments over the past 140 years, or shut up.”
Haung et al. 2015.
RG said: “Have there EVER been any studies comparing each methodology used in the same location, at the same time”
Yes. See above.
RG said: “Given that oceans are 70% of the surface, it is possible that changes in measurements methodologies (and locations) account for a large portion of the warming claimed for oceans. I guess we’ll never know?”
We do know. See above.
Your ouija board techniques for creating data where none exist.
Define “contrarian”.
CM said: “Define “contrarian”.”
I person that holds a position significantly inconsistent with or contrary to the abundance of evidence.
So metrology is now a legislative process?
CM said: “So metrology is now a legislative process?”
I didn’t say or even remotely imply anything of the sort.
Of course you did.
I think you have me confused with someone else or you are posting in the wrong subthread or even blog post. Either way I have no idea where metrology being a legislative process came from. I do know it has nothing to do with Matthew Sykes’ post though.
It’s safe to say that if a large proportion of the effect purported to be discovered is reliant on adjustments and corrections to raw data the idea rests on thin ice. Mass acceptance on such a basis is highly unusual in the history of science.
If by effect you mean the global temperature trend then the net effect of adjustments don’t matter a whole lot especially after WWII when the warming trend became most acute.
The ludicrously low uncertainty reported is the final straw for many who object to the consensus, it is a red-flag of dishonest science. You must understand the dilemma.
Interesting. I thought ±0.05 C for an average was ludicrously high. I mean that is an uncertainty on the order of only about 1 part in 5000. That’s not even noteworthy in the annuals of 19th century science and here we are in the 21st century.
I’m afraid we’re not operating in the same framework of logic and reason if you believe ±0.05 C is ludicrously high. The argument of “1 part in 5000” is telling, it shows you are lost in number theory and you have lost touch with physical meaning on the subject.
Today we can measure the triple point of water to within better than 1 part in 500,000. And some of the type A and type B evaluations are close to 1 part in 10,000,000. Even Cavendish’s experiment in the 1700’s had a sensitivity at least 1 part in 10,000. So 1 part in 5000 does not impress me. BTW…branching out to other types of measurements I think the current record holder is LIGO which can measure the rippling of the space-time fabric to within about 1 part in 1,000,000,000,000,000,000,000. Given all of that I think it is rather disappointing that we only measure the global average to 1 part in 5000.
The motivation to claim miniscule uncertainty on estimates of historical temperature series is obvious. This is a very common temptation in many sciences to provide support for one’s claim. It is a well known issue. Scientists have a duty to be honest with the data and to communicate clearly. At this point your arguments are quite bizarre. I thought for a moment that you have a scientific background but what you are engaging in is not scientific discourse. Looping and endless arguments are regressive and I do not take kindly to such games.
JCM: “ I thought for a moment that you have a scientific background but what you are engaging in is not scientific discourse.”
Let me make this really scientific for you then. I challenge Pat Frank’s assessement of uncertainty of σ = 0.46 because of these 3 main issues.
1) He treats the Folland 2001 uncertainty of 0.2 and the Hubbard uncertainty of 0.25 as two separate types of uncertainty that must be combined. The problem is that Folland is incredibly terse on details so I question how he could possibly know they are different.
2) He uses the formula sqrt(N*σ^2/(N-1)) for the propagation of uncertainty into annual and 30yr averages. The problem is that this isn’t how you propagate uncertainty through an average. It isn’t even consistent with his own reference from Bevington 2003.
3) He only estimates the uncertainty for individual temperature anomalies. There is no attempt whatsoever to propagate this uncertainty through the gridding, infilling, and spatial averaging steps. As best I can tell he doesn’t even attempt to assess the uncertainty of the global average temperature yet advertises his 0.46 figure as being that.
You said scientists have a duty to be honest. I’ll you ask for your opinion here. Is Pat Frank being honest? What about others players like Rhode et al. 2013, Lenssen et al. 2019, or Morice et al. 2020? Why or why not?
Frank has been in this thread so I suggest you ask directly. If you are not satisfied with Frank’s responses then you may need to reassess your own bias and why you doubt the responses provided.
All anyone can do is define the minimum level of uncertainty and it only goes up from there. Statistics offers some clues for that.
One then has the option to impose their judgement about a realistic uncertainty envelope. The sources of uncertainty are boundless in earth science observables. Anything from wildlife counts to air temperature. Not least when the measurand is a fleeting target in time and space. Global surface temperature estimates are in no way related to stationary measures such as gravity potential constant or the triple point of water. Your examples were perplexing and somewhat disturbing. Straightforward empiricism just simply doesn’t work outside of pure physics.
Many have provided ample examples of geospatial (under)sampling and bias at various points in time. Realistically, most of the unknowns are unknowable. Scientists must employ judgement based on their expertise and experience. The job of the scientist is certainly not to wow us by minimizing their uncertainty, but that seems to be the game these days. It’s a race to the bottom.
We can easily check if uncertainty is being honored by comparing an older generation of a dataset vs one based on newer techniques. If the midrange of estimates at any point of time is outside the total uncertainty envelope of a previous generation then the uncertainty reporting has failed and it has been glazed over.
Good luck to you,
JCM
JCM said: “If you are not satisfied with Frank’s responses then you may need to reassess your own bias and why you doubt the responses provided.”
So no matter what Pat Frank holds the monopoly on truth while me, Rhode et al., Lenssen et. al, Morice et al., and the rest of the world are automatically wrong? With that worldview I’ll never be able to convince you of anything.
JCM said: “All anyone can do is define the minimum level of uncertainty and it only goes up from there.”
That is patently false. Pat Frank’s own source (Bevington equation 3.13) says the uncertainty of an average is bounded by σ/sqrt(N) on the low end when the inputs are uncorrelated (covariance cancels) and σ on the high end when the inputs are correlated (covariance is perfect) where σ is the standard uncertainty of the individual inputs.
JCM said: “We can easily check if uncertainty is being honored by comparing an older generation of a dataset vs one based on newer techniques. If the midrange of estimates at any point of time is outside the total uncertainty envelope of a previous generation then the uncertainty reporting has failed and it has been glazed over.”
You’re probably going to need to clarify this statement. It sounds like you’re saying new and better measurements cannot provide anymore certainty on a measurand than older and worse measurements. Nobody would seriously make that claim so I’m obviously not understanding what you are trying to say here.
This is the understatement of the millennium.
“That is patently false. Pat Frank’s own source (Bevington equation 3.13) says the uncertainty of an average is bounded by σ/sqrt(N) on the low end when the inputs are uncorrelated (covariance cancels) and σ on the high end when the inputs are correlated (covariance is perfect) where σ is the standard uncertainty of the individual inputs.”
You *STILL* have not figured this out!
The uncertainty of an *average* is not the total uncertainty of the combined elements. I give you again the two boards, on being 20 +/- .02 and the other being 40 +/- 0.4.
The uncertainty of the mean is *NOT* the uncertainty you get when you lay the boards end to end.
An average uncertainty only gives you a consistent value to use with every member of the data set. The uncertainty of each individual element is *NOT*, however, the uncertainty of the combination of the element!
TG said: “The uncertainty of the mean is *NOT* the uncertainty you get when you lay the boards end to end.”
Agreed.
For 20 +/- .02 and 40 +/- 0.4 with no correlation.
Bevington 3.13 says u_avg = 0.2
Bevington 3.13 says u_sum = 0.4
Taylor 3.47 says the same thing.
GUM 10 says the same thing
NIST says the same thing.
Bevington 3.13
x = u + v
(σ_x)^2 = (σ_u)^2 (ẟx/ẟu)^2 + (σ_u)^2 (ẟx/ẟv)^2
Since ẟx/ẟu and ẟx/ẟv = 1 the calculation becomes
(σ_x)^2 = (σ_u)^2 + (σ_u)^2
the common root-sum-square equation
(σ_x) = sqrt[ (σ_u)^2 + (σ_u)^2 ] =
sqrt[.02^2 + .4^2] = sqrt[ .0004 + .16 ] = .4
.4/2 = .2 (average uncertainty)
So the total uncertainty is 0.4. What do you need to know the AVERAGE uncertainty for? Total uncertainty 0.2 * 2 = 0.4!j The same value you already knew!
Taylor does the same thing!
You already knew the total uncertainty! So why are you concerned with the *AVERAGE* uncertainty?
All you are doing is mathematic masturbation.
You are *NOT* proving that total uncertainty can be reduced with more observations! And it is the TOTAL uncertainty that is of interest, not the average uncertainty!
TG said: “Since ẟx/ẟu and ẟx/ẟv = 1 the calculation becomes”
For a function that computes an average ẟx/ẟv = 1/N.
TG said: “So why are you concerned with the *AVERAGE* uncertainty?”
I’m not. I don’t care about the average of the uncertainties. I care about the uncertainty of the average.
average of the uncertainties is Σ[σ_i, 1, N] / N
uncertainty of the average is sqrt(Σ[(1/N)^2*σ_i^2, 1, N])
“For a function that computes an average ẟx/ẟv = 1/N.”
All that does is give you the average uncertainty for ONE ELEMENT. We’ve been down this path before.
If you have five data elements with uncertainties ẟu = 0.2, ẟv = 0.4, ẟw = 0.6, ẟy = 0.8, and ẟz = 1.0 then the average uncertainty is 3/5 = 0.6, exactly as you would expect it to be. 5 * 0.6 = 3. The same value as 0.2 + 0.4 + 0.6 + 0.8 + 1.0!
And, as both Bevington and Taylor show
(ẟtotal)^2 = ẟu^2 + ẟv^2 + ẟw^2 + ẟy^2 + ẟz^2
They do *not* show total uncertainty to be
(ẟtotal)^2 = [ ẟu^2 + ẟv^2 + ẟw^2 + ẟy^2 + ẟz^2 ] / 5
You simply cannot reduce the overall, total uncertainty by dividing by n. As I said before, if you already know the individual uncertainties so you can calculate their sum then finding the average uncertainty for each element is nothing more than mental masturbation.
If those data elements are actually sample means with the uncertainty from the individual elements propagated into the uncertainty of those means then their variance becomes
[(.6-.2)^2 + (.6-.4) + 0 + (.8-.6)^2 + (1.0-.6)^2 ] / 5 =
[(.4)^2 + (.2)^2 + 0 + (.2)^2) + (.4)^2] / 5 =
[.16 + .04 + 0 + .04 + .16} /5 =
(.4)/5 = .08
and the standard deviation of the sample means is sqrt(.08) = .28
That’s a measure of how precisely you have calculated the sample mean. It is *NOT* the uncertainty of the precisely calculated sample mean
The total uncertainty associated with that mean is still somewhere between 3 and sqrt(3) = 1.7.
This is why the standard deviation of the sample means is not the same thing as the uncertainty of the mean.
bdgwx said: “For a function that computes an average ẟx/ẟv = 1/N.”
TG said: “All that does is give you the average uncertainty for ONE ELEMENT.”
Nope. What that gives you is the partial derivate of the output function x wrt to input v. Literally…ẟx/ẟv = 1/N. It is neither an average nor an uncertainty.
You are *still* finding the uncertainty of one element, the mean.
You can run but you can’t hide.
You could cause the space shuttle to blow up at launch using your uncertainty of the mean to describe the total variance of the entire uncertainty data set.
1) Wrong
2) Wrong
3) “Representative” is clearly a foreign concept.
4) attempted slander.
And 5 — bdgwx here attempted to project his ignorance as another’s failing.
Pat,
1) Then show us using a source (preferably from Folland) other than your own paper what that 0.2 “standard error” means.
2) Then show us what equation from Bevington you are using and demonstrate that it is appropriate for the propagation of uncertainty through a function that outputs an average.
3) How does the uncertainty of individual station anomalies represent the uncertainty of a global average considering that they have to propagate through the gridding, infilling, and spatial averaging steps.
4) I’ve slandered no one. I’ve never used an ad-hominem on your or anyone on WUWT. I have never made personal attacks on anyone. I have no problems with you personally. In fact, if you and I sat down for coffee I think we’d get along just fine. My concern here is solely with the method (or absence of) that have been present in the paper you are listed as author on. And for the record you can take comfort in the fact that you can insinuate that I’m ignorant all you want and I’ll never return the sentiment in kind.
Your severely swollen hat size is an ad-hom.
1) My paper quotes Folland (2001) exactly. You can reference it or Folland, et al., to equal benefit. But you knew that already didn’t you.
My paper also points out that Folland’s estimate is not cited, as you again know. It is indistinguishable from an assigned number. The discussion of that point is both detailed and sound. You can’t exclude it by fiat.
2) My usages are referenced and correct.
3) Instrumental field calibrations are representative of uncertainties in instrumental field measurements.
4.1) Yes, you did. Right here. You questoned my honesty. Slander by invited inference.
4.2) Your posts repeatedly indicate no knowledge of instrumental resolution. How is that to be judged, if not of ignorance?
PF said: “ It is indistinguishable from an assigned number.”
Standard deviations are not assigned numbers. They come from taking the square root of Bevington 1.9 of a sample.
PF said: “My usages are referenced and correct.”
No they aren’t. They aren’t consistent with the propagation of error through an averaging function as specified by Bevington 4.14 and or through the general partial differential method specified by Bevington 3.14 or the example 4.1.
PF said: “Instrumental field calibrations are representative of uncertainties in instrumental field measurements.”
That’s not the issue. The issue is that they aren’t representative of the uncertainty in a global average temperature.
PF said: “Yes, you did.”
No, I didn’t. I’m asking JCM to evaluate the honesty of all parties including Rhode et al., Lenssen et al., and Morice et al. in play because he made a big deal of honesty. You are only 1 among 28 people I mentioned who are authors of publications I cited. There are dozens more that I didn’t cite, but don’t want to exclude either. I’ll pose the question to you as well. Are the other 27 people being honest or they committing fraud like what many of the WUWT audience thinks?
PF said: “Your posts repeatedly indicate no knowledge of instrumental resolution. How is that to be judged, if not of ignorance?”
You can judge it however you like. You can question my intelligence all you want or call me as many names as you want. I’ll even defend your right to do so without ever returning the sentiment to you. I’ve said this before and I’ll say it again. I think you’re fine person. I think you’re brilliant. And I also think we’d get along just fine if we met in person. But the thing about math and science is that it doesn’t care about the intelligence or labels of people. It works the same way for everyone.
Irony alert.
No amount of math or neat number tricks will give anyone any reasonable sense of global average temperature reliability from 90 years ago. I don’t care how many think they can. I don’t care how sophisticated the tricks might appear, I don’t care who is carrying out the tricks, their titles, or their institutions. The honest scientist can do all the number tricks they like; then in the end admit it’s all hogwash and move on. The perceived scientific fraud is the inability to accept there are limits to knowledge about an under-sampled past. You will not find fraud in any code or equations. The fraud starts before all that – it is in the very epistemology of the endeavor.
There is much more to science than applying algorithms and code. It requires a deep appreciation of epistemology and ethics. It requires judgement and hard decisions. The masses will trust the published conclusions at face value and with that a responsibility of the analyst to seek truth rather than a desired outcome. Sometimes the truth is that something is unknown or deeply uncertain. Scientists who depart from their responsibilities must be called out and held accountable.
Absolutely correct JCM, on all accounts. Hopefully these people will open their minds a little and heed these words.
I agree.
You’re probably going to be shocked or maybe annoyed, I don’t know, when I tell you that not only are people measuring the global average temperature from 90 years ago, but hundreds of thousands and even millions of years ago. They are also doing for it planets other than Earth some of which aren’t even in our own solar system. Are they providing perfect measurements? Nope and they never will. But they are providing useful measurements with reasonable margins of error. If your bar for acceptance is perfection then you’re going to be dissatisfied with all disciplines of science in general the least of which is climate science.
You mean like tree-ring thermometers, bzx?
The hollow rebuttals, misdirection, and mischaracterization of remarks only damages your cause. The agenda is self evident – and it is evidently not truth seeking. The need to prove your beliefs and the defensive tactics you employ signify a deep insecurity. People are not as obtuse as you might believe. People recognize a phony from a mile away and you are not doing your idols any favors.
Truth is what I seek. I believe that the best approximation of the truth is that coming from the consilience and abundance of evidence. I believe that addressing biases and errors in scientific data is the ethical and right thing to do. I believe that imperfect data is better than no data at all.
Those are my genuine beliefs whether or you or anyone else accepts it or not. I realize that a lot of people (especially those that [hold a position significantly inconsistent with or contrary to the abundance of evidence]) think I’m obtuse, phony, ignorant, idiotic, a piece of ****, and countless other labels I’ve been given on here and other forums some of which I actually find funny.
I’m going to tell you the same thing I tell everyone else. You can use whatever ad-hominem or label you want. You can question my honesty, integrity, motivations, etc. And I will defend you’re right to do so even though I’ll never return any negative sentiment in kind. Just know that math and science doesn’t care about any of it. It works the same way for everyone.
I do humbly ask that after all of that is said and done that we at least return back to the topic of biases like those caused by time-of-observation changes, station moves, shelter/instrument changes, bucket/engine/buoy differences, etc.
Your manufactured evidence will persuade no one with an iota of integrity. The remarks I have provided could not be more clear. In one ear and out the other I suppose. The holier than thou virtuous victimhood is noted.
So what would convince you that pairwise homogenization is useful and does not embody the “the greatest scientific fraud of all time”? What would convince that time-of-observation changes, station moves, shelter/instrument changes, etc. should be addressed? How do you delineate between “manufactured” evidence and evidence you would accept?
As you’ve been told many many times, using imaginary fudge factors CANNOT increase a state of knowledge.
You can’t adjust away uncertainty.
If you are insistent on having a long term data set in support of your cause then the issues you identified can be dealt with by increasing the uncertainty envelope on a homogenized timeseries.
That is the only reason to require all this homogenization, corrections, adjustments. It is to generate evidence in support a preconceived claim.
The usual way to handle historical discontinuous data in time and space that doesn’t show much of any trend is to conclude that evidence is lacking to make sweeping conclusions.
I’ve already shown you how pair-wise homogenization ignores all the correlation factors that must be accounted for and the fact that they admit that the pair-wise homogenization is only a guess.
Since this isn’t made apparent to the readers of the studies they are committing a fraud on the public by implying more accuracy than is justified.
No, you make demands of people that they hoe to your hedgerows.
This is UNethical and fraudulent, as the Contrarian article plainly states.
You DO NOT KNOW these numbers, using such jived-up imaginged adjustments can only INCREASE uncertainty.
Just take a station move. How do we know the microclimate at the new location shouldn’t give a different reading? Should *all* microclimates give the same reading? Should the microclimate in Denver give the same reading as the microclimate on Pikes Peak?
Take the shelter changes. How do we know that the new shelter is more accurate? Does anyone do an onsite calibration when it is placed? How do they do that calibration outside a lab environment?
“You DO NOT KNOW these numbers”
Yep. All you can do is GUESS at them. Guesses are biased.
You mean the imaginary fake phony made-up infilled extrapolated fraudulent “data” evidence?
“I tell you that not only are people measuring the global average temperature from 90 years ago, but hundreds of thousands and even millions of years ago.”
Really? And exactly how are they doing this? Ice core data is only useful where there has been ice for millions of years ago. And I can’t find *any* reconstruction that gives any kind of an uncertainty measurement other than “it was colder then” or “it was warmer then”.
Most of them don’t even do that. They use so-called anomalies based upon “differences” in what they are using. Those anomalies don’t show what baseline was over the time period. There is just no way to judge within what, 10 or 20 degrees of what the real temperature was. Consequently the reconstructed “anomaly” is bridged on to current calculated one’s.
Paleo temperature people use statistics to scale their proxies into the temperature record, Tim. There’s no physics involved. The temperature numbers are physically meaningless.
“Standard deviations are not assigned numbers.”
Folland’s guesstimate is not a standard deviation. It’s an assigned constant value uncertainty. You’ve read his paper. You know that. You’re misapplying terms.
“No they aren’t.”
Yes, they are. You’ve been misapplying Bevington every time you’ve remarked on it.
[Instrumental field calibrations are] not the issue.
Yes they are.
“The issue is that they aren’t representative of the uncertainty in a global average temperature.”
The MMTS calibration error in fact comprises a global lower limit of uncertainty, because the MMTS is the most accurate meteorological temperature sensor used from the 19th century right through to 2000.
This point is indisputable and is the entire focus of my paper, which you apparently continue to miss.
“You are only 1 among 28 people I mentioned …” You uniquely specified my first name and last. That you approve of the others’s output and disapprove of mine is known to all here. The invited inference is obvious. So let’s stop with after-the-fact demurrals.
“the other 27 people” seem to know nothing of systematic air temperature measurement error or of instrumental resolution. Diagnose that as you like.
Thanks for your reassurances.
Unless you (or anyone) can demonstrate that they are not different, because we are dealing with uncertainty, I think that the appropriate think to do is assume that they are different and deal with them as such.
Only in a lab, you very silly person; NFW in the middle of the Indian Ocean.
And with extremely well controlled environmental conditions. Which, if you are to repeat, you must also control is a similar fashion.
This has nothing to do with measuring temperatures in the field over a long (years) period of time.
Nor with the bogus made-up additive fudge factors that “reduce error”.
In other words, someone who doesn’t accept the current paradigm.
DING DING DING
wrong as usual, bdwax
Contrarian is merely a person who does not agree with the majority opinion. The majority opinion often has nothing to do with evidence.
The majority opinion of the future climate is evidence free — there is no evidence or data for the future. You comments are tedious and usually wrong.
I’m just telling how I use the word “contrarian”. If you want me to use another word that means “A person that holds a position significantly inconsistent with or contrary to the abundance of evidence.” I’m fine with it.
You are being cynical. The point is, the events you mention corrupt the continuity of the time-series. However, assuming that it is a good faith attempt to salvage the data, and increased its accuracy, it is almost impossible to prove that the underlying assumptions for the corrections have actually improved the data set, and to what degree. Besides the possibility of introducing a whole new set of errors, there is the potential for mischief when the analyst believes that the end justifies any means, which is not unknown in science.
as opposed to wanted biases ???
It might be a poor choice of words on my part. I don’t know. But sadly, yes. There are many (in this very blog post actually) that would prefer to keep the time-of-observation bias, shelter/instrument change bias, bucket/engine/buoy biases, etc. I and most others would prefer to have them addressed. Any bias is unwanted IMHO.
And you (likely dishonestly) refuse to consider that changing old data (what you euphemistically call “addressing biases”) is unethical.
That’s right. I refuse to accept that addressing biases is unethical. In fact, it is the exact opposite. Drawing conclusions from data you know is contaminated with errors or biases without addressing them is at best unethical. And if you didn’t disclose that you knew about the problems it could rise to fraud.
Thus you are fraudulent as well as unethical.
Would you fly in an airplane that was deemed airworthy after having past test flight “corrected” because someone see something that MIGHT be a bias? Or, would you want new data gathered to use in the airworthiness application?
Same thing. How many trillions of dollars and how many people will be in energy poverty because you and others think fixing what “LOOKS” like bias is the correct thing to do.
What is wrong with declaring the data unfit for use and discarding it?
You have yet to even address this issue and why it isn’t the superior thing to do.
And he never will, instead he’ll just insist you go off and read some paper/author he pushing.
“Drawing conclusions from data you know is contaminated with errors or biases without addressing them is at best unethical.”
You address them with the uncertainty intervals associated with each data element. You don’t create new data based on the assumption that you *know* what the error or bias is by guessing at it!
Many want raw data, Infilled data, and adjusted data
all clearly identified, and available for audit.
I could not care less, because I do not trust the
government bureaucrats who compile the data.
HaaaaaHaaaa! They do it so they can maintain “long” time records over the whole time of the station. It is done because “short” records distort the trends. And they are right about that.
However, does the FAA let Boeing change/correct their past data? Nope! How about the EPA with concentration studies? Nope. How about nuclear power plants? Do they get to go back and “correct” radiation readings?
These all require declaring the old data unfit for purpose and new measurements are done. Too bad. Time has passed and as of the present time, we have no way to go back and obtain new temp measurements. That doesn’t mean the data shouldn’t still be declared unfit for purpose though. It just means discard it and move on.
And yet the planet continues to warm, sea levels continue to rise, and atmospheric CO2 levels continue to climb.
And Barry continues to expose his lack of knowledge.
… and, if true, the world becomes a little more hospitable.
Isn’t it odd that nobody actually notices any difference?
Sea level up for 20.000 years
Temperature up for 20,000 years
CO2 level up for 20,000 years
100% natural for AT LEAST 19,900 of those 20,000 years
I love how they declare that they are fixing undocumented biases in the data.
If they are undocumented, how do you know that there are biases in the data?
Clearly, they believe if the data doesn’t match the models, there must be problems with the data, even if they can’t figure out what those problems are.
MarkW said: “I love how they declare that they are fixing undocumented biases in the data.”
Some of the changepoints are documented.
MarkW said: “If they are undocumented, how do you know that there are biases in the data?”
Changepoint or breakpoint analysis. Here is how NOAA does it. Here is how Berkeley Earth does it. Note that although BEST does the breakpoint analysis they don’t adjust the timeseries to homogenize like what NOAA does when gridding the data. Instead they use the “scalpel” method where they split the timeseries and treat them as separate stations. For convenience they still provide a breakpoint analyzed timeseries for those interested in that product.
MarkW said: “Clearly, they believe if the data doesn’t match the models, there must be problems with the data, even if they can’t figure out what those problems are.”
If it is clear then it should be really easy to point out where in the source code it takes model data as an input. Would you mind pointing it out for us?
Still whining?
Explain why the scientific method of declaring the data unfit and discarding it is never considered! We are waiting.
Published physically valid uncertainty bounds on the global air temperature record here, here, and here.
The left graphic shows uncertainties as published by the field mavens.
The right graphic shows uncertainties reflecting the impact of non-normal systematic sensor measurement error.
These are 1σ bounds. At the 95% confidence interval, the rate or magnitude of the global rise in surface air temperature since 1850 is unknowable.
Pat, I’d like to continue our conversation from earlier. Below is my understanding of the calculation used to get that 0.46 figure. Please correct my understanding where needed.
(1a) 0.2 from Folland 2001 described as “standard error”
(1b) sqrt(N * 0.2^2 / (N-1)) = 0.200
(1c) sqrt(0.200^2 + 0.200^2) = 0.283
(2a) 0.254 from Hubbard 2002 described as “gaussian”
(2b) sqrt(N * 0.254^2 / (N-1)) = 0.254
(2c) sqrt(0.254^2 + 0.254^2) = 0.359
(3) sqrt(0 283^2 + 0 359^2) = 0.46
Folland is pretty terse on details. There is no indication that I see which suggests it is a different form of uncertainty from that provided by Hubbard. So why are you combining the 0.2 and 0.254 values provided by Folland and Hubbard?
The use of sqrt(N * σ / (N-1)) appears to be inconsistent with the procedure defined in the GUM. Why did you use this equation and not the formal procedure (like GUM equation 10) for combining uncertainty here?
Where are you propagating the uncertainty through 1) the gridding step, 2) grid infilling step, and 3) grid averaging step?
I discussed Folland’s 0.2 C in detail, and explained why it cannot be assumed to average away.
Figure 4 in H&L provides the profile of each average systematic measurement error in their shield calibration experiment. None of them are Gaussian.
Average uncertainty is the RMS of the components of error. (N-1) is used in the denominator when the average is empirical, because a degree of freedom is lost from the data set.
All of this is discussed in my paper. Why are you (repeatedly) asking questions when you should already have the answers? You have my paper. Read it.
PF said: “I discussed Folland’s 0.2 C in detail, and explained why it cannot be assumed to average away.”
It looks like you declare the 0.2 C as fitting into case 3b without justification. The Folland 2001 publication is so terse on details I’m not sure we say either way what it is referring to. The only thing we know is that it was described as “standard error” so I think it is say to assume that it is a standard deviation. But that’s about all we can say about it from what I’m seeing. Now if you have more information not provided in Folland 2001 I’d certainly be happy to hear about it.
PF said: “Figure 4 in H&L provides the profile of each average systematic measurement error in their shield calibration experiment. None of them are Gaussian.”
I don’t disagree. But if I understood your method correctly you calculated the 0.254 from a gaussian fit of the data. When I say “gaussian” I’m referring to your publication.
PF said: “Average uncertainty is the RMS of the components of error.”
That’s not consistent with the text of Bevington section 5.
PF said: “(N-1) is used in the denominator when the average is empirical, because a degree of freedom is lost from the data set.”
This part I’m okay with. It’s the application of RMS to the propagation of uncertainty through a function that produces an average that is not consistent with what I’m seeing in Taylor, Bevington, and the GUM.
PF said: “All of this is discussed in my paper.”
There is no mention of the propagation through gridding, infilling, and averaging of the grid that I can see. In fact, I don’t see any discussion of a grid mesh at all.
“without justification.”
Justified. You argue the paper as though you haven’t read the section you’re questioning.
The ±0.254 C is the estimated SD from the fit to the MMTS daily average error provided in H&L Figure 2c. The fit reproduced the MMTS SD in H&L Table 1.
“That’s not consistent with the text of Bevington section 5.”
It follows 3.2ff in Bevington, which is the correct section.
The paper is a representative lower limit of systematic error each sensor at each station. Lower limit is the key concept.
A lower limit is a valid estimate of the minimum of systematic error for every sensor. Hence the choice of MMTS for evaluation.
The lower limit of error in the global average land surface temperature is just the RMS of all the lower limits of error.
PF said: “It follows 3.2ff in Bevington, which is the correct section.”
I don’t see a 3.2ff in Bevington. I do see section 3.2 which is definitely relevant. It happens to agree with the texts by Taylor and the GUM. In fact Bevington presents the partial derivative method which is exactly the same as in Taylor and the GUM. The Bevington notation of equation 3.14 is as follows.
σ_x^2 = σ_u^2*(∂x/∂u)^2 + σ_v^2*(∂x/∂v)^2 + …
where x = f(u, v, …) and u, v, … are inputs to the function.
So when x = f(v_1, v_2, …, v_i) = (1/N)Σ[v_i, 1, N] then ∂x/∂v_i = (1/N) for all v_i. Simplifying from there we have σ_x^2 = σ_v^2 / N and so σ_x = σ_v / sqrt(N).
The rest of section 3 and section 5 follows from 3.14. In fact, you can use 3.14 to derive many of the other equations appearing in those sections.
Your equation 9 is not consistent with Bevington section 3 or 5.
PF said: “The paper is a representative lower limit of systematic error each sensor at each station. Lower limit is the key concept.”
You didn’t propagate the uncertainty through the gridding, infilling, and averaging steps. You didn’t even attempt to find the lower limit of the global average temperature. All you did was find the lower limit of a single station anomaly and even that is suspect because you combined Folland and Hubbard which I’m not convinced is valid.
PF said: “The lower limit of error in the global average land surface temperature is just the RMS of all the lower limits of error.”
Bevington section 3 and 5 say the lower limit on the uncertainty of an average is σ_avg = σ_i / sqrt(N). When we apply this to a grid mesh it is σ_Tavg = σ_Tcell / sqrt(N) where Tcell is the temperature of a grid cell and N is the number of grid cells.
“Your equation 9 is not consistent with Bevington section 3 or 5.”
It’s consistent with Bevington eqn. 1.9.
Section 3.2ff discuss propagation of errors.
Bevington Chapter 5 is not relevant to any of the work in “Uncertainty …”
You continue to falsely impose the statistics of random error onto a treatment of systematic error. You’re wrong.
You were wrong the first time you did that, you’ve been wrong every time you’ve done it since, and you’ll be wrong every time you do that in the future.
Just to be clear here I am looking at Data Reduction and Error Analysis by Bevington & Robinson 3rd Edition published by McGraw-Hill in 2003.
PF said: “It’s consistent with Bevington eqn. 1.9.”
That’s the well known formula for variance. Your equation 3.9 is consistent with it only in the sense that it is presumed that the square of your per measurement noise symbol is itself a variance of which I have no challenge. I really do think σ^2 = 0.2^2 and σ^2 = 0.254^2 are true variances. But equation 3.9 itself does not follow from Bevington 1.9. How could it? The well known variance formula does not combine variances (or standard deviations). All it does is calculate a single variance from a single sample..
PF said: “Section 3.2ff discuss propagation of errors.”
Section 3.2 discusses propagation of errors. I have no idea what you are referring to when you say “section 3.2ff“.
I can’t see that your equation 3.9 is consistent with anything mentioned in Bevington 3.2.
PF said: “You continue to falsely impose the statistics of random error onto a treatment of systematic error.”
No, I’m not. And it wouldn’t matter if I were, because my criticism of your work is not related to the distinction between random and systematic error. My criticism here is with your use of equation 3.9 which is not consistent with the Bevington section 3.2 or any other section.
PF said: “You were wrong the first time you did that, you’ve been wrong every time you’ve done it since, and you’ll be wrong every time you do that in the future.”
If I’m wrong (it happens a lot) then just tell me 1) where it is made clear that Folland 2001 is different than Hubbard 2002 and 2) where you got your equation 3.9 and 3) where you propagated the station anomaly uncertainty into the gridding, grid infilling, and grid averaging steps. If you can’t or won’t do that then I have no choice but to dismiss your claim that the global average temperature uncertainty is σ = 0.46 C. It’s nothing personal.
There is no equation 3.9 in my paper.
Equation 9 combines the uncertainties of N measurements into the mean uncertainty, with the loss of one degree of freedom. There’s no mystery in that.
And if you can’t understand it, then I suggest you retire until you do.
The paper discussed Folland’s assigned uncertainty in detail. It’s a constant value with no distribution. I treated it as such.
It’s all there and readily accessible. Your continued confusion is very peculiar.
PF said: “There is no equation 3.9 in my paper.”
Yep. My apologies. I meant equation 9.
PF said: “Equation 9 combines the uncertainties of N measurements into the mean uncertainty, with the loss of one degree of freedom. There’s no mystery in that.”
If that is your intent then the result is inconsistent with Bevington. Why not use the procedure defined in section 3? If you want we can work through this together.
PF said: “The paper discussed Folland’s assigned uncertainty in detail. It’s a constant value with no distribution.”
Folland described it as “standard error”. That means 0.2 is the standard deviation. How can you have a standard deviation without a sample and associated distribution?
PF said: “It’s all there and readily accessible. Your continued confusion is very peculiar.”
Just to be clear here. Even though I think you’ve used Folland inappropriately and made a math mistake my primary criticism is the absence of the propagation through the gridding, infilling, and spatial averaging steps. If that is all there then would you mind telling me which page I can find it on?
Pat has already given you way more attention than you deserve.
“If that is your intent then the result is inconsistent with Bevington. Why not use the procedure defined in section 3?”
Because in that instance Bevington eqn 1.9 is correct.
“Folland described it as “standard error”. … etc.”
Folland can describe it as he likes. The evidence from the paper is that it’s an assigned number.
“Even though I think you’ve used Folland inappropriately and made a math mistake …”
Without evidence or cogent argument.
“my primary criticism is the absence of the propagation through the gridding, infilling, and spatial averaging steps.”
A “representative” lower limit of instrumental calibration error is applicable to every historical air temperature sensor in the world. There’s no point to gridding.
Infilling is creation of fake data that is not independent. It should never be done. Ever.
Spatial averaging will only increase the uncertainty. My paper derived a representative lower limit.
PF said: “Because in that instance Bevington eqn 1.9 is correct.”
Bevington 1.9 is the formula for variance. It is not the formula for the propagation of uncertainty through an average or even the propagation of uncertainty at all.
Bevington 4.14 is the propagation of uncertainty through a function that computes the average. Bevington derives 4.14 from 3.13 starting on pg. 53.
Why not just look at example 4.1?
PF said: “The evidence from the paper is that it’s an assigned number.”
Where? And why does that matter?
PF said: “Without evidence or cogent argument.”
Here is the evidence.
Bevington partial differential method 3.14.
Bevington equation 4.14 derived from 3.13 & 3.14 pg. 54
The Guide to the Expression of Uncertainty in Measurement partial differential method equation 10 pg. 19.
Taylor partial differential method 3.47 pg. 75.
NIST uncertainty machine
PF said: “A “representative” lower limit of instrumental calibration error is applicable to every historical air temperature sensor in the world. There’s no point to gridding.”
All datasets that compute a global average temperature grid the data. You cannot determine a spatial average without a grid.
PF said: “Spatial averaging will only increase the uncertainty.”
Your own source says this statement is patently false. Follow the procedure outlined in Bevington section 3.2 starting pg. 39. Define a function that computes the spatial average and then run it through equation 3.14.
“Bevington 1.9 is the formula for variance. It is not the formula for the propagation of uncertainty through an average …”
In Bevington, immediately above eqn. 1.9: “The standard deviation is the root mean square of the deviations, and is associated with the second moment of the data about the mean. The corresponding expression for the variance s² of the sample population is given by [eqn. 1.9]”
Bevington 1.9 is the equation for the variance in a mean. That’s exactly how it was used.
“Bevington 4.14 is the propagation of uncertainty…”
Bevington eqn. 4.14 is the 1/sqrtN reduction in random measurement errors about a mean. It has nothing to do with the systematic errors discussed in the 2010 paper.
You’ve apparently confused my 2019, which in fact propagated calibration error through an iterative calculation (eqn. 3.13), with my 2010, which throughout combined uncertainties in quadrature, accounting for the loss of a DOF as neccessary.
It is inappropriate to apply Bevington eqns. 4.11-4.14 to the 2010 work because the combined uncertainties are neither equal nor the result of random error.
You’re the self-described expert on all things math and uncertainty, YOU do the work.
I’m no expert. I’m just an amateur with happens to have a passion for the topic. And there is no need for me to do something that has already been done by dozens of scientists far better than I ever could and by those far smarter than I’ll ever be.
When exposed, you immediately drop the condescending persona and jump into the humble persona.
This act is fooling no one (except yourself, perhaps).
The Keepers of the Holy Trends do not like to see realistic uncertainty limits because doing so exposes the statistical insignificance of their “rises”, which must be defended at all costs.
Right on CM. Insufficient accuracy, too.
First my background. I am a retired test engineer with over 40 years making precision measurements. I usually had to push passed accuracy limits. This included calibration the WSR-88 weather radar.
Some people will explain their background
before making a comment on climate science
I see the your background,
but where is your comment?
Forget about getting a job as a government
bureaucrat scientist who measures things !
You probably know too much !
All the usual suspects should show up presently to deny that temperature data is routinely altered.
It is impossible to make good decisions based on bad data.
And just as bad to live with the consequences.
Decisions are not made on historical climate data.
If they were, the prediction for the next 47 years
would be more mild, pleasant, harmless
global warming, as we had in the past 47 years.
Decisions are made on PREDICTIONS of FUTURE,
constant. rapid, dangerous global warming, much faster
and more consistent, than any past global warming.
From the above article’s quoted excerpt of the O’Neill, et.al., publication in the journal Atmospheres:
If a scientifically-accurate correction for urban heat island (UHI) effect was applied across the globally-obtained data sets, there would be a progressive DECREASE on the yearly averages reported for global warming, not the INCREASE that is asserted to result from the NOAA/NCEI “homogenization” algorithm.
It is that simple . . . to quote a passage from the Bible:
“Why do you reason because . . . Do you not yet perceive nor understand? . . . Having eyes, do you not see? . . .”— Mark 8:17-18, Bible, NKJV
I wrote an article on UHI adjustments by NASA-GISS a few years ago
Their adjustment was tiny
They claimed UHI caused about +0.05 degrees C. warming per century.
Other government agencies decided UHI was too small to adjust for.
The NASA GISS UHI adjustments were bogus, as you might expect.
UHI should usually cause extra warming at any land weather station
where there was economic growth in the vicinity. That can mean
formerly rural stations where there has been lots of growth
in the vicinity.
So almost all of the adjustments should be to reduce warming
at many station where there was such economic growth.
But NASA-GISS apparently wanted a tiny UHI adjustment,
just enough to say they did a UHI adjustment.
How did they do that?
For stations they claimed had a UHI warming trend over time,
they claimed almost as many OTHER weather stations
had UHI cooling trend over time ??? The resulting net total
UHI adjustment was tiny — insignificant.
That was NASA-GISS science fraud, in my opinion.
But since the planet is 70% oceans and 30% land,
even an honest UHI adjustments could not be very large.
“But since the planet is 70% oceans and 30% land,
even an honest UHI adjustments could not be very large.”
Uhhh, excuse me, but what percentage of the stations reporting surface air temperature data over Earth’s total area are located on land compared to those located on the world’s oceans?
And isn’t it true that interpolating temperatures over the intervening distances between land-based and sea/ocean-based measuring stations necessarily requires use of many UHI-contaminated station data obtained from costal land stations?
In other words, the 70%-30% areal split that you refer to does NOT properly reflect the true areal impact of land-based air temperature measurements, nor the true extent of UHI-contamination of global temperature measurements.
And, is the average accuracy of a sea-based surface air temperature measurement equal to that of land based measurement? . . . I think not.
Did not mean to post yet. 1. There is no legitimate way to correct a historical measurement unless you have duplicate measuring equipment recording at the same time. Even then the question remains, which one is correct? 2. I can think of dozens of ways measurement errors could cause a higher indicated temperature, and exactly none that could cause a lower indicated temperature. 3. Your suggestion to change the reported precision to 0.5 degrees, while completely justified, will have the side effect of now the warmest day (month, year) will be 0.5dg instead of 0.01dg warmer. I would suggest a 1 or 2 term polynomial fit curve graph instead. 4. EVERYTHING should have error bars. I would love to see error bars and a calibration certificate for : tree rings, ice cores, historical ocean pH, and hot air coming out of various AGW sites. 5. Between calibration problems, training, and sparsity of measurements I think to farther back in time the bigger the error bars.
What I find remarkable is that Nick Stokes and his ilk arrogantly think they know more about the temperatures a century ago or more than the people who actually performed the measurements.
Absolutely correct—the dishonestly is a stinking pit of fraud and unethical behavior, whether they see it or not.
“Nick Stokes” and “think” should never be use in the same sentence !
regarding your points 2,4, and 5, how would you put together an R&R study on these? I have seen very few posts that actually quantify the suitability of the measurement system for the task it is used for ( I believe the only one was a blog post on satellite sea level measurement).
RB said: “I can think of dozens of ways measurement errors could cause a higher indicated temperature, and exactly none that could cause a lower indicated temperature.”
Wouldn’t double counting Tmin observations result in a lower indicated temperature?
Wouldn’t switching from LiG/CRS to MMTS with the radiation shield result in a lower indicated temperature?
Wouldn’t relocating a station to a higher elevation result in a lower indicated temperature?
Wouldn’t switching from engine intake measurements to buoy measurements result in a lower indicated temperature?
Wouldn’t relocating a station from an urban site to a rural cite result in a lower indicated temperature?
And you truly believe you can know these numbers?
Yes. But that’s not a requirement to know that these factors would result in a lower indicated temperature. I’m just trying to help Richard think of things that would cause a lower indicated temperature. That’s all.
Then you are a liar, to others as well as yourself.
Yes, but that shows the level of fraud and sophistry in the system. Karl chose to align the data from the expensive, built-for-purpose Argos buoys to agree with the poorly calibrated, heat-soaked, coarse resolution, boiler intake temperatures (read by untrained and poorly motivated sailors). No one in the climatology community called him out on that! With that kind of behavior, should you or anyone be surprised that skeptics don’t trust adjustments made for what are largely unknowable errors in the historical record?
That wasn’t Karl. It was Haung et al. I happen to agree with Haung here. When you are homogenizing two timeseries you have two choices. You can shift one up or shift the other down. If you shift the engine measurements down you have to apply a constant shift at each and every space and time step since there are not enough colocated buoy measurements to asses the specific shift value applicable for that time and space. On the other hand, if you shift the buoy measurements up you can apply the time and space specific shift since there are sufficient colocated buoy and engine measurements need for the shift.
Homogenization of temperatures = data tampering.
Homogenization of temperatures = FRAUD.
He will never acknowledge the truth here, has too much invested.
No, I was referring to Karl et al. (2015)
https://www.science.org/doi/abs/10.1126/science.aaa5632
That seems to more of a convenience or rationalization when one has every reason to expect that the made-for-purpose Argo buoys are more accurate and precise. That is, the Argo buoy temperatures are degraded to the quality of the obviously inferior engine-room readings. That seems like a waste of tax-payer money if the default standard is going to be engine-room standards.
I know you were referring to Karl et al. 2015. Karl still didn’t make the adjustments. Haung et al. 2015 did.
It just depends on whether you want to the same adjustment applied to decades worth of data or specific adjustments applied to years worth of data. Not only the later less invasive, but it is going to be more appropriate shifts are determined on a per time period and per grid cell basis.
You’re insane if you think this data creation stuff is rational.
But, less accurate. An ‘invasive’ procedure on poor quality data, with larger uncertainty, probably distorts reality less than a similarly invasive procedure on high quality data. Big bucks spent to achieve state-of-the-art technology is wasted if it isn’t given the priority it deserves!
The Argo floats may be more precise but their calculated uncertainty is still 0.6C for the overall float.
TG said: “The Argo floats may be more precise but their calculated uncertainty is still 0.6C for the overall float.”
Where do you see that?
Go search for it. It took me a while to find it. That was two years ago. It wouldn’t surprise me that it has been deleted.
It went into calculations of uncertainty for salinity, for water inlet blockage (e.g. from a barnicle), from sensor drift, etc. The uncertainty is *NOT* the resolution of the sensor element!
Tim, I believe you’re thinking of this, Hadfield, et al., (2007) “On the accuracy of North Atlantic temperature and heat storage fields from Argo.”
From the abstract: “A hydrographic section across 36°N is used to assess uncertainty in Argo-based estimates of the temperature field. The root-mean-square (RMS) difference in the Argo-based temperature field relative to the section measurements is about 0.6°C. The RMS difference is smaller, less than 0.4°C, in the eastern basin and larger, up to 2.0°C, toward the western boundary.”
An RMS difference of 0.6 C is, of course, a measurement uncertainty of ±0.6 C. Such a large calibration uncertainty almost certainly reflects a systematic measurement error probably from variable impacts of the marine environment.
The CTD and SBE35 thermometers Hadfield et al., used to calibrate the Argo floats are described on p. 68ff in Cunningham, 2005 and are very accurate.
Thanks, Pat. Of course you are on top of things!
Or, you can simply discard the data as not fit for purpose like every other scientific endeavor does.
To assume the old is WRONG is just that, an ASSumption. As stated in other comments, that ASSumption implicitly includes the fact that the people responsible for reading and maintaining the thermometers weren’t very good at their job.
Each instrument has a different microclimate it is measuring. They both can be entirely accurate in their measurements. That should be the default position unless PROVEN otherwise. If the difference in measurements is a concern, then end the original station data set and start a new one.
This preoccupation with maintaining a “long” record is misplaced. Errors and trends are being derived from information that has no basis in real, physical measurements. Changes ARE NOT new data, never were and never will be.
“Wouldn’t relocating a station to a higher elevation result in a lower indicated temperature?”
Moving a station would result in a new microclimate being measured. That is not a reason to adjust prior information without proof that it was wrong.
In any case, the existing record should be stopped and a new one started when a physical move takes place. Trying to adjust previous data is introducing unknown accuracy errors into the temperature record. The only reason I have ever seen is to maintain a “long record, and that is not sufficient justification.
Again, this is a change in the microclimate being measured. It is not a justification for changing what should be considered accurate data unless you have direct evidence that something was wrong. Stop the existing record and create a new one.
Error bars are a rarity in climatology.
Hey I just found your comment after that brief introduction, and it’s a good one !
In the 1800s most surface grids had to have wild guessed (infilled)
numbers because of such sparse coverage. There is still far too much
infilling today. I don’t see how anyone can claim to know margins or error
when there are so many made up numbers. Your expert comments
would be welcome.