Mikhail Voloshin writes this detailed analysis of NOAA and GISTEMP climate data processing on his Facebook page:
Random Walk analysis of NOAA global temperature anomaly data
Summary
The global temperature record doesn’t demonstrate an upward trend. It doesn’t demonstrate a lack of upward trend either. Temperature readings today are about 0.75°C higher than they were when measurement began in 1880, but you can’t always slap a trendline onto a graph and declare, “See? It’s rising!” Often what you think is a pattern is actually just Brownian motion. When the global temperature record is tested against a hypothesis of random drift, the data fails to rule out the hypothesis. This doesn’t mean that there isn’t an upward trend, but it does mean that the global temperature record can be explained by simply assuming a random walk. The standard graph of temperatures over time, despite showing higher averages in recent decades than in earlier ones, doesn’t constitute a “smoking gun” for global warming, neither natural nor anthropogenic; merely drawing a straight line from beginning to end and declaring it a trend is a grossly naive and unscientific oversimplification, and shouldn’t be used as an argument in serious discussions of environmental policy.
Purpose
I find myself frequently citing and explaining my trend analysis of global mean temperature anomaly data from the National Oceanic and Atmospheric Administration. Sometimes I cite this analysis for people who are genuinely interested in understanding my findings. Usually though, I merely show it to debate opponents just to prove that, unlike them, I’ve actually looked at the numbers directly and have the know-how to understand them (and, of course, I welcome engagement with those who can say likewise). I write this paper to make these subjects accessible to laymen and non-experts.
First and foremost I’ll present a link to my math. I don’t claim that it’s elegant, but I do claim that it addresses a few specific questions about one specific set of data. The rest of this document is an explanation of what those questions are, and what results I found.
The Excel spreadsheet (.xlsx) : NCDC (NOAA) Temperature Anomaly vs. Markovian Null Hypothesis
I ran these numbers several years ago, and then repeated the run a few times since then. My study doesn’t address the quality of the underlying data, nor the “massaging” that the NOAA performs on its raw instrument records in order to produce a single numerical value every year representing the global mean temperature anomaly (more on that later). What my study does address is to ask, even given the NOAA’s own year-over-year numbers: Do those numbers actually represent an upward trend at all? To this end, I test the NOAA’s temperature records against a Random Walk Hypothesis, a principle used in technical analysis of stocks to determine whether or not a trend (either upwards or downwards) exists.
Background
In order to assert that the global temperature anomaly is rising, the raw temperature numbers must demonstrate an upward trend. This is more complicated than it seems. A simple glance at the NOAA mean temperature record since 1880 clearly shows that temperatures are nominally higher today than they were a century ago (I say “nominally” because the seldom-depicted error bars are enormous – again, more on that later). But there’s a difference between saying that something has risen versus saying that it is rising.
Imagine you’re in Vegas and you come to a roulette wheel whose last four spins were 3, 13, 17, and 22. Would you bet that the next spin is going to be around 28 or so? Most people would – and most people would lose their shirt as a result. That’s because there’s no underlying phenomenon driving an increasing output of the roulette wheel. The evident pattern in the numbers is purely illusory. What you’re seeing isn’t a “trend”, merely a coincidence.
Pareidolia
The human mind is exceptional at finding patterns – it is, in fact, our greatest evolutionary adaptation. But we have evolved very few safeguards against false positives. The human capacity for pattern recognition enables us to follow the tracks of fleeing prey, to determine the optimal time of the year in which to plant crops, and to derive the universal law of gravitation by observing celestial bodies. However, that same capacity also compels us to perceive images of the Virgin Mary on slices of burnt toast.
Every one of us, to one extent or another, suffers from pareidolia, the perception of patterns and correlations where none actually exist. It is from this tendency toward pareidolia that arise superstition, occultism, magical thinking, and even social ills such as racism. Of course, it’s also our correct perception of patterns and correlations in the world that enable us to discover natural laws, construct tools, develop technologies, advance medicine, and so forth. Clearly, a correctly perceived pattern is invaluable, but an incorrectly perceived one can be catastrophic.
Unfortunately, humans don’t have any innate way to know when our perceived patterns are right and when they’re wrong – obviously, if such a way existed, we would never be wrong!
It’s only been in the last 300 years or so, with the advent of the Age of Enlightenment, that we’ve developed practices such as the scientific method to help draw the line between true patterns and false ones, and it wasn’t even until the 20th century that Karl Popper’s principle of falsifiability was introduced as an integral component of the search for truth. The question, “Is the pattern I believe I see actually real?” is one that we’ve only begun asking very recently, and the vast majority of us – even scientists – still don’t find it easy. Entertaining the idea that you might be wrong is not something that comes naturally.
Inspiration from the finance industry
There is, in fact, an entire industry of people who literally put their fortunes on the line every day in an effort to differentiate illusory patterns from genuine ones. It’s the finance industry, and I happen to be a part of it, and I have some of their tools and techniques at my disposal. While these tools and techniques offer absolutely no insight whatsoever into the underlying physical properties of Earth’s climate system – thermodynamic feedback or cloud cover or convection or so on – they are exceptional at answering one simple question: Is there even a pattern here in the first place? Even before you get into all the computer models designed to figure out what’s causing the upward trend, you first have to establish that there is indeed an upward trend at all!
At issue is the question of predictive value – the question of whether observations of the past can help predict the future. Quantitative analysts in the finance industry, much more so than academic scientists, require their theories to exhibit predictive value.
Still Available: Climate Change the Facts, 2017
After all, when a scientist writes a paper that fails to correctly extrapolate future data, that scientist can merely write subsequent papers to explore why the previous hypotheses were wrong, ad infinitum. Indeed, as of this current writing, we see exactly this happening in climate science right now, as papers such as Emission budgets and pathways consistent with limiting warming to 1.5◦C and Causes of differences in model and satellite tropospheric warming rates try to explain why past climate models have predicted temperatures much higher than the ones actually measured in subsequent years.
(It’s worth noting that the latter paper, Causes of differences…, is co-authored by the prestigious activist climatologist Michael E. Mann, who developed the “Hockey Stick” historical temperature reconstruction made famous in Al Gore’s An Inconvenient Truth. It’s furthermore worth noting that, if you actually read the Causes paper, you’ll see that the analysis offered there is extremely similar to mine but in reverse. In effect, while I argue that natural fluctuation has caused temperatures to drift upward from a zero baseline (or at least that the data alone doesn’t rule out such a claim), they claim that natural fluctuation has caused temperatures to drift downward to mask at least part of what would otherwise be an already-cataclysmic anthropogenic global warming signal. I contend that we can’t rule out the possibility that our current temperatures are simply the result of natural back-to-back warm spells; they contend that current temperatures should be even higher, but are being held down by natural back-to-back cold spells. Our techniques are largely the same; and, counterintuitively, though the conclusions are mutually exclusive, the data fully supports both interpretations. Such is the nature of basing your argument on the evolution of systems of random variables – they could do the thing you predict, but they could also do a lot of other things, too. Random variability is a fickle mistress; and if you choose to dance with her, so too can your opponents.)
But when a hedge fund manager makes a prediction about the future movement of a stock or an index, and that manager is wrong, then the fund loses millions of dollars. I’ve personally witnessed this happen many times. It’s not a pretty picture.
As such, while both scientific academia and the finance industry are in the practice of drawing conclusions from numerical sequences, finance is much more strongly incentivized to ensure that those conclusions are actually correct. As in, true. As in, correspond to things that ultimately happen in the real world.
Climatology is not an experimental science. It’s slightly outside of our current technological capability to temporarily remove all clouds just to make sure we’re computing albedo correctly, or to keep all air in the atmosphere from moving for a while so that we can isolate convective effects from conductive and radiative ones. As such, in order to still be a scientific discipline at all (as opposed to merely an exercise in modern-day numerology), climatology must depend heavily on data processing techniques in order to provide the falsifiability that would otherwise be supplied by controlled experimental methodology. Climatology is not alone in being a non-experimental discipline; it shares this property with fields such as astrophysics and paleontology, for example. But these fields have succeeded largely on the merit of being extraordinarily good at making accurate specific predictions about subsequently gathered independent data – and you need to use analytic techniques to define exactly what is meant by the terms “accurate”, “specific”, and “independent” (or, for that matter, “data”). And, indeed, climatology has a much harder road to trek than both astrophysics (there are billions upon billions of observable stars, but only one observable Earth) and paleontology (a triceratops skeleton exists in the present day and is readily examinable by any researcher; the temperature of the North Atlantic in 1880, not so much). What’s even worse is that new data in climatology is slow to arrive, and is incredibly noisy and error-riddled when it’s acquired (again, more on “adjustments” below). What all of this means is that climate data needs to be handled with great tentativeness, and claims of the predictive value of resultant hypotheses need to be evaluated very thoroughly before being righteously asserted as “truth”.
Random walks
Now, when it comes to the Earth’s mean temperature, the simplest and most basic assumption, i.e. the null hypothesis, is the same as the null hypothesis for any other time series: that it behaves as a Markov process – specifically, a sub-type called a Martingale. What this means, quite simply, is that it has no “memory” outside of its immediate state – and that the single best predictor of any given year’s temperature is the temperature that came before it. That is, if the mean temperature in, say, 1980 was 14°C, then your best bet for the temperature in 1981 would be, likewise, 14°C. There will be some very small perturbation – sometimes the Earth radiates more energy than before, sometimes it receives more energy from the Sun due to solar activity, etc. – but overall you’d still bet on 14°C. Now, imagine that the perturbation was +0.05°C, so that 1981 turned out to be 14.05°C. What would be your bet for the temperature of 1982? Again, 14.05°C, plus/minus some small perturbation. Basically, whatever the temperature is in any given year, that’s what the temperature is likely to be the following year.
At this point, most people assume that, if the perturbations are unbiased, then this means that value of the Martingale stays near its initial value. If upward perturbations and downward perturbations occur at roughly the same frequency, then they figure that the upward ticks and downward ticks should generally cancel one another out over time, and that the overall value should never deviate far from its starting point.
In this regard, most people are wildly mistaken. While opposite perturbations do indeed cancel one another out, like-sided perturbations accumulate upon one another, causing the Martingale to potentially walk extremely far from its starting point. The long-term expected value of the process is indeed zero, but in practice it can deviate wildly based on pure Brownian motion.
To drive this point home, check out these sample runs of a randomly generated simulation of a temperature sequence, intended to mimic the NOAA’s annual temperature anomaly records since 1880. (In the spreadsheet, the code to generate these can be found under the tab “Random Walk sample run”.) All of these charts were created with the same simple technique: The anomaly starts at 0, and then every year a small random perturbation is added. The function that generates these perturbations is “fair”, i.e. it has no intrinsic positive or negative bias. Nonetheless, as you can see, perturbations can accumulate to cause the final value to be far from 0 indeed. By sheer coincidence, a chain of positive perturbations can arise that drive the value high, and then it tends to remain there; likewise by coincidence, alternating chains of positive and negative perturbations can arise, causing the cumulative value to swing wildly from positive to negative and back again. Mathematically, what this function is doing is taking the integral of a Gaussian random variable, and the results can often be highly unintuitive.

The key takeaway is that one cannot merely look at a graph of historical data, slap a trendline on it, and then assert that there’s some underlying force that’s propelling that trend. Stock traders have a very long history of doing exactly that and winding up penniless. Scientists who have to perform trend analysis, in particular climatologists, would be wise to learn from their mistakes.
Data
The National Oceanic and Atmospheric Administration (NOAA) is a scientific agency within the United States Department of Commerce. Within the NOAA is an organization called the National Centers for Environmental Information (NCEI), which hosts many publicly accessible archives of weather data of many different kinds. (At the time of my original analysis, this was part of a different sub-organization called the National Climatic Data Center (NCDC). The NCDC has been wrapped into the NCEI, but some of the web links still point to the NCDC). You can get extremely high-resolution data sets featuring time series collected from individual weather stations, satellites, ocean buoys, and so on – and I’ve worked with these data sets for analyses outside the scope of the ones I cover here.
But the NOAA summarizes it all into an annual year-over-year chart.

The raw data for the summary chart can be found here: https://www.ncdc.noaa.gov/cag/time-…
NCDC (NOAA) Temperature Anomaly vs. Markovian Null Hypothesis
There are a few things to understand about this chart, and the data that underlies it.
Measuring temperature anomaly, not absolute temperature
The first thing you may note is that the chart’s Y axis measures an “anomaly” rather than an absolute temperature. The chart does not depict a single specific value for the Earth’s temperature in any given year. Instead, it shows the temperature difference. But the difference from what, exactly? What actually was the Earth’s average temperature in any given year?
That’s actually not very easy to answer, nor is a specific number particularly meaningful. The issue is that different measurement techniques – satellites vs. ground stations vs. ocean buoys, etc. – offer such wildly different temperature profiles that globbing them all together is considered extremely poor scientific practice.
As a result, climatologists essentially don’t talk about the global temperature at all, but rather the global temperature anomaly. That is, while different measurement techniques tend to produce wildly different readings, the change in those readings tend to be more homogeneous and universal – at least, in theory.
The analogy most climatologists cite is this: Imagine you’re measuring an infant for a fever. You put thermometers in its mouth, in its armpit, and in its butt. The three thermometers report very different absolute numbers. But if the infant’s temperature does indeed rise, then all three thermometers will show an increase in whatever their numbers may be. Therefore, while the actual values of the thermometers may be meaningless, there is nonetheless a signal evident from each thermometer’s deviation from its own respective baseline.
As such, their annual mean global anomaly number for each year is calculated roughly as follows.
- For each station/buoy/etc., they break up its readings into time segments normalized to a year-over-year window, such as day of the year or month of the year, depending on how often its readings were collected; and then they’ll compute a mean for them. For example, for a station whose data was collected monthly, they will take that station’s readings for all Januaries that the station was in service, readings for all Februaries, etc.; and they’ll compute that station’s mean January temperature, mean February temperature, etc. They keep these “time segments” (in this case, months) separate in order to keep all numbers relatively close to one another for precision – otherwise, you’d be mixing warm summer temperatures with cold winter ones.
- For each station, for each time segment, they’ll rephrase that station’s records in terms of difference from the mean. For example, if a station’s all-time mean for all Januaries was 2°C, and its reading in specifically January of 1980 was 2.5°C, then they’ll rephrase the station’s January 1980 reading as +0.5°C . If some other station, let’s say in the Bahamas, has an all-time January mean of 20°C, and its reading on January 1980 was 20.5°C, then they’ll rephrase that station’s January 1980 reading as, likewise, +0.5°C. This relative difference isn’t the station’s temperature reading; this is the station’s “temperature anomaly”.
- Now that all stations (buoys, etc.) have been rephrased into “temperature anomalies” from their own individual year-normalized average readings, their position on the globe is taken into account and averaged into a year-normalized reading for a “gridbox”. That is, there may be many more stations in, say, Ohio, than in Mozambique. Because of this, if you were to merely average all stations together without taking their placement into account, you would risk over-representing the local conditions of Ohio and under-representing the local conditions of Mozambique. Therefore, they break up the globe into a grid. For each gridbox, for each time window, they average all of the temperature anomalies for all of the stations in that gridbox. Thus they compute an average anomaly for, say, Ohio January 1980, Ohio February 1980, Ohio March 1980, Mozambique January 1980, Mozambique February 1980, and so on. (The astute observer will note that this creates an additional problem: overcertainty in the record of Mozambique! After all, if Ohio is sampled with a hundred of weather stations but Mozambique is sampled with only a couple, then the Mozambique records are much more likely to depict local conditions at those stations rather than a true measurement of the regional climate.)
- For each time window (in this example, for each month), they average all of the globe’s gridboxes together to represent the global anomaly within that time window (i.e. that month).
- They average together the global anomaly of all the time windows (months) in a year to compute that year’s global temperature anomaly.
This homogenization process certainly strips a great deal of detail from the raw data. This loss of detail could be represented by offering error bars, but the NOAA’s error bars only represent a small handful of the sources of uncertainty (or more specifically, the over-representation of certainty) that arise from this process.
There’s a much greater source of uncertainty, too: the fact that, even before all this averaging starts to take place, the raw data from the individual instruments is subjected to “adjustment”.
Measurements are heavily “adjusted”
The NOAA compiles an enormous amount of data from many different sources in order to produce a single final number for every year. There are literally thousands of ground stations, many of which use different measuring technologies – some new ones might use digital thermometers, for example, while older ones might still use mercury. In the over 130 years that these stations have been in use, different protocols have been developed for what time of day to read them, how to select sites for them, and so on.
What’s worse is that many stations are missing months or years of data, due to disrepair or downtime during upgrades. The missing data for these stations is often filled in artificially through a process called “imputation”, which involves replacing the values of unmeasured months with a linear interpolation (or some related model) of the temperature before and after the missing window. This process treats the imputed data with the same level of certainty as data that represents actual measurements, but of course the imputed readings are purely fictitious – a “best guess” of what the station would have reported. Because this “best guess” is made by trying to keep the backfilled data consistent with an overall trendline, imputation risks the creation of a self-fulfilling prophecy: we use the assumption of a regression model to fill missing data with assumed values, and then we use those assumed values to validate the regression model. There are other imputation techniques, but they all amount to the same thing: pretending you’ve collected data that you didn’t actually collect.
By itself, imputation isn’t inherently bad science, but imputed data needs to be supplied with relatively enormous error bars to reflect its fundamentally fictitious nature.
For example, imagine a station measured a high of 20°C on a Monday, failed to get a reading on Tuesday due to a software bug, and then measured 22°C on Wednesday. (Assume that the thermometer itself is very precise, so that these measurements are both exact for all intents and purposes, i.e. +/-0°C). What can we fill in for the temperature on Tuesday? The “best guess” would seem to be 21°C, and indeed that’s a perfectly reasonable imputation value. But we didn’t actually measure this hypothetical 21°C. The station glitched that day. It could have still been 20°C. It could have already jumped to 22°C. It could have even gone down to 19°C or up to 23°C, and then swung relatively back to 22°C on Wednesday. We weren’t there, we don’t know. We can say with a great deal of certainty that the temperature on Tuesday probably wasn’t, say, 5°C, and likewise it probably wasn’t 40°C. But we can’t just put in a value of 21°C alongside the adjacent values of 20°C and 22°C and pretend that it’s just as reliable and factual as them. At best, we have to log the temperature with corresponding error bars, such as 21°C +/- 1°C. The appropriate size of these error bars is open to debate, but what’s certain is that they have to be much bigger than the error bars of actual collected instrument readings, possibly by several orders of magnitude.
So the question is: how do the climatologists that crunch these numbers, in fact, handle the error bars? Well, not to get into a lengthy digression on the topic, but suffice it to say that I’ve examined and experimented with their data processing code. Not from the NOAA/NCDC specifically, but from NASA’s Goddard Institute for Space Studies (GISS), which compiles a surface temperature analysis called GISTEMP that is then used by organizations such as the NOAA. Feel free to download the source code. Or browse it on Github. See for yourself. How do they handle error bars? Simple: they don’t.
And that’s just the land stations. The ocean buoys and satellites each have their own problems, with corresponding mitigation approaches.
All of these variations result in a very “dirty” raw data set. The NOAA stands by this data set on the grounds that it’s the best we have, and that the sheer size of the data set helps ensure that any problems with any individual station will come out in the wash.
Problems arise, however, when these backfilling and massaging techniques themselves introduce systemic bias into the data set, or when the data acquired through such techniques is mixed with original, unadulterated data (of which the official data set contains very little at this point).
For example, one “correction” applied to many older ground stations is to try to normalize their measurements to a common time of day. Before electronic record-keeping, daily station data would be logged by a human being physically trekking to the station every day, looking at the thermometer, and writing down the reading in a journal. However, there was no official standard for what time of day the researcher should do this, and clearly measurements taken in the mornings would be colder than measurements taken in mid-afternoon. As such, the NOAA applies a “correction” by taking early-morning measurements and increasing them by some amount to try to simulate what the station would have measured if it was checked in the afternoon. (An evaluation of the time of observation bias adjustment in the U.S.)
Likewise, ocean temperatures used to be measured by having ships lower a bucket into the ocean, draw that bucket aboard the ship, and stick a thermometer into the sea water. We now use buoys and satellites. According to the NOAA, the bucket process inadvertently introduced inordinately low temperatures – specifically, “…a cold bias of between 0.18 and 0.48C …[due to] the evaporative cooling of canvas and wooden buckets. The modeled bias was affected by variables such as the marine air temperature and both ship and wind speed.” (Bias Corrections for Historical Sea Surface Temperatures Based on Marine Air Temperatures) As such, to “compare apples to apples” – that is, to compare satellite and buoy readings with old ship-based readings – the NOAA “adjusts” the older measurements upward by some amount designed to offset this cooling effect, thereby giving us a number that represents not what the bucket thermometer actually said, but what the bucket thermometer hypothetically should have said if it wasn’t for those pesky “evaporative cooling” and “ship and wind speed” issues.
As a data analyst myself, my biggest problem with these adjustments is that they introduce enormous sources of systemic uncertainty. One cannot, in my opinion, go back into a historical data set and tweak the readings to reflect what you believe the instruments “should have” said at the time. The instruments didn’t say that; they said precisely what they said, and nothing more nor less. The issue is that you can’t perform an experimental validation of your “adjustment” without a time machine. You can concoct all sorts of smart-sounding reasons for why some data point or another should be increased or decreased just so, but how can you know you’re right? After all, what separates science from armchair speculation is the scientific method, and you can’t go back in time and perform the scientific method retroactively. In the case of those bucket-based ocean measurements, for example, how can the NOAA be certain that they increased the historical data enough? How can they be certain that they didn’t increase it too much? There’s no certain way to answer that question. In my opinion, the bucket readings and the buoy readings should be considered completely separate data sets, and not attempted to be merged with one another; that way, whatever systemic biases that affect the buckets remain consistent within the bucket data, and any possible heretofore-unknown systemic biases in the buoy set likewise remain with the buoys. This creates a much more fragmented temperature record that’s much harder to work with and contains enormous error bars – but that’s precisely the point. It’s better to represent your uncertainty truthfully than to pretend to know something you don’t. But I digress.
This adjustment process is not some deep dark secret (though I believe that, if more people knew about it, they’d be as skeptical about it as I am). The NOAA freely discusses these and other adjustments in their temperature monitoring FAQ. Naturally, these adjustments are the source of much criticism and debate. Some, like myself, are frustrated by the lack of error propagation and the failure to account for the inherent uncertainty that arises whenever one performs imputation or mixes heterogeneous data sources. Others are concerned that the adjustments themselves reflect the institutional academic incentives of the researchers – i.e. that climatologists tend to actively brainstorm and publish rationalizations for adjustments that will make older records colder and newer records warmer, while intuitively dismissing the possibility of the reverse (NOAA Adjustments Correlate Exactly To Their Confirmation Bias). And still others flat-out accuse climatologists of implementing these adjustments in bad faith (Doctored Data, Not U.S. Temperatures, Set a Record This Year and Exposed: How world leaders were duped into investing billions over manipulated global warming data).
If you’d like to know more about this adjustment process, check out this somewhat technical but spectacularly detailed write-up on the blog of Dr. Judith Curry. You might also appreciate this essay: Systematic Error in Climate Measurements: The surface air temperature record. A very good and less technical (but still very specific and detailed) writeup can also be found here: Explainer: How data adjustments affect global temperature records.
Finding sources of possible historic systemic bias and adjusting them is an ongoing task at the NOAA, as well as all other climate-monitoring organizations. And that brings me to the next important thing to bear in mind about the source data: the historical record changes over time.
The historical record changes over time
If you were to download the NOAA’s temperature readings in 2012, you would see different numbers than if you were to download them in 2015, or today.
For example, in 2012, the global temperature anomaly in 1880 was -0.16°C (per my spreadsheet). Today (September 2017), the global temperature in 1880 is -0.12°C. Apparently, 1880 was colder in 2012 than it is (was?) today.
On the face of it, it would appear that the NOAA employs The Doctor as a senior climatologist, and he’s bringing back temperature data from Earths from alternate timelines.

What’s actually happening is that the NOAA changes its adjustment practices over time. For example, in 2017 the NOAA updated the techniques that it uses for reconstructing historical sea temperature records (Extended Reconstructed Sea Surface Temperature (ERSST) v5), resulting in slight differences to the final yearly averages.
Again, from a personal perspective, what this tells me is that the certainty in the entire data set is grossly overstated. Put bluntly: if you’re going to tell me that a temperature reading gathered over a century ago needs to be changed by some amount in order to be “more accurate”, and then a few years later you come tell me that that same temperature reading actually needs to be changed by some different amount for the same reason, then I’m going to seriously question whether the word “accurate” means what you think it means. The first thing I’m going to ask is: When are you going to come tell me next what an even “more accurate” adjustment should be? I’m just going to take whatever you’re telling me now, assume your next value will be as different as your previous values have been, and in my own mind I’ll recognize the existence of error bars that are implicit from merely the fact that you can’t get your story straight. In the case of the NOAA’s global temperature anomaly for 1880, at one point they said it was -0.16°C, now they’re saying it’s -0.12°C, at various times they’ve said it’s various other things, and who the hell knows what value they’ll give it next. Maybe they’ll say it was actually -0.08°C; maybe they’ll say no wait, we were right the first time, it actually is -0.16°C after all. The point is, these repeated revisions make their numbers untrustworthy; you can’t take any historical value to the bank because you don’t know what it will be after their next revision.
And it’s not just historical data, either. It includes satellite records, which have recently experienced a spate of revisions based on new calculations that allege that their readings don’t properly account for orbital decay (A Satellite-Derived Lower-Tropospheric Atmospheric Temperature Dataset Using an Optimized Adjustment for Diurnal Effects). The latest such adjustment, as of this writing, has been generating particular attention due to the fact that the post-adjustment data set shows a 140% greater temperature increase since 1998. Climate alarmists consider this latest adjustment to be a powerful vindication of their stance; but, ironically, from a data quality standpoint this dramatically worsens the case for believing the processed instrument data. Again, put bluntly: If you’re going to tell me that the numbers you’ve been reporting have been off by 140% all along because of a glitch you only discovered today, then why should I believe the numbers you tell me now? What other currently unknown glitches exist in your instrumentation that you will only discover tomorrow, and how much will they demonstrate your current numbers are off by, and in what direction? In essence, every time an alarmist screams, “My God, it’s worse than we thought!”, what a data scientist hears is, “You just admitted that you didn’t know what you were doing before, and I’m going to infer that you probably still don’t.”
The point is, no matter what other error bars the NOAA might ascribe to the measurement, in addition to those error bars, each historical measurement also has a substantial extra degree of uncertainty that arises merely from the fact that the NOAA is reporting it. This doesn’t mean, of course, that the data is wrong per se; it just means that the data is much fuzzier/blurrier than it seems, and you have to squint much harder than you think in order to see a pattern in it.
Techniques and Results
The purpose of the kind of analysis I performed in this spreadsheet is to determine the likelihood of seeing the observed numerical sequence from an unbiased Markov process (i.e. a Martingale). More specifically, the question I ask, in various ways, is: Assuming that the temperature system can be represented as a Martingale, what is the probability that, if it’s started at the observed point in 1880, it would evolve to observations at least as extreme as what we observe today? That is, if the anomaly in 1880 was -0.16°C (which is what the NOAA records currently say it was), then what’s the probability that, purely by a random walk with no directional forcing whatsoever, the anomaly might end up at +0.57°C or beyond (which is what the NOAA records say it currently is)?
If the probability is low (traditionally <5%), then that means that the underlying assumptions are implausible — i.e. it would be a strong contradiction of the hypothesis that the system is unbiased. A high probability, on the other hand, does not rule out some bias, but it does indicate that the observations can be adequately explained without the assumption of an upward or downward trend or “forcing” of any kind.
If you’re technically minded and are following along on the spreadsheet, you’ll see that I perform a few analyses of the data, each chosen to be as general and agnostic as possible – that is, making as few assumptions as I possibly can about any properties about the underlying physical system.
For what it’s worth, a very similar analysis was performed in 2012 on behalf of British Parliamentarian Lord Bernard Donoughue. His work and mine were carried out independently of one another; I didn’t know about his question when I wrote my spreadsheet, and if he knew about my spreadsheet at the time of his question then I’d at least like a commemorative fountain pen.
Number of increases vs. number of decreases
In the first analysis, “+/- Bernoulli on NCDC”, I compare the number of year-over-year upward steps against the number of year-over-year downward steps. It’s that simple: Does the temperature of any given year likely to be higher or lower than the year before it?
The NOAA’s historical data, as covered by the spreadsheet, spans 132 years. 70 of those years were hotter than the previous one. 62 of them were colder.
What does that mean? Well, on the one hand, yes, there were more temperature increases than there were decreases. On the other hand, the increases barely outnumber the decreases.
So, what are the chances that we would see this kind of distribution of hotter/colder years if there wasn’t an inherent upward bias? I.e., could we see this kind of fluctuation purely by coincidence?
The question might be confusing to laymen. After all, if there was no upward bias, then we’d see the exact same number of upticking years as downticking ones, right?
Well, no. Imagine you flip ten pennies – fair, unbiased, normal pennies, each with 50/50 odds of heads or tails. Would you always expect to get exactly five heads and exactly five tails? Of course not. Sometimes you might get six heads and four tails. Sometimes you might get seven heads and three tails. Even getting all ten heads and no tails, though highly unlikely, is still possible.
So if you were to flip 132 pennies, what are the odds you’d get at least 70 heads (and the rest tails)? Or, for that matter, vice versa – 70 tails (and the rest heads)? That is, what are the chances that, with no inherent bias whatsoever, you’d get 8 more of one than the other?
The answer is 54%. You are in fact very likely to encounter a pattern like this from unbiased random fluctuation. Sometimes that random fluctuation moves your value higher, sometimes lower – but 54% of the time, a sequence of 132 random fluctuations will move you 8 or more steps away from your starting point.
Let’s phrase it another way: Imagine you play a little game with yourself. You start with a score of 0. Then you flip 132 pennies. For every heads, you add a point. For every tails, you subtract a point. What will your final score be? Well, if you play this game many times, you will see that 54% of the time your score is either >=8 or <= -8.
In the tradition of contemporary science journals, a metric called a “p-value” indicates the strength of an experiment’s results. In layman’s terms, the p-value of a result is the probability that the result could have been produced by the null hypothesis – which typically means unbiased natural random chance. For example, if you’re a biologist who’s feeding rats some experimental new foodstuff to see if it’s carcinogenic, and several of your rats do indeed develop cancer, then the p-value tells you how likely it would have been for at least that many rats in your study to develop cancer anyway with or without your foodstuff. An experiment’s p-values need to be small in order for a null hypothesis to be rejected; traditionally, p-values need to be less than 5% for journals to even consider publishing a paper. The example of the rats makes it clear why; because it’s not impossible for rats to just spontaneously develop cancer anyway, the odds of the observed cancer rates have to be so small (i.e. the cancer rates themselves have to be so high) that it would be functionally impossible (or at least extremely unlikely) for anything other than the foodstuff to have caused the cancer. At that point, the scientist must conclude that the foodstuff caused the cancer.
So in observing 70 upticks out of 132 years, must a scientist conclude that something is causing an unusual rate of upticks? Could those upticks be caused by, for lack of a clearer term, nothing?
Well, it turns out that there’s a 54% chance that those upticks are indeed caused by “nothing” (not literally nothing, of course, but merely by a very large and very noisy combination of forces that buffet the value hither and thither, with no preference of direction). One cannot conclusively state that there is anything driving upticks to be more frequent than downticks. Sometimes the temperature goes up, sometimes it goes down. And yes, it has gone up a little bit more often than it’s gone down. But it would be erroneous to assert that it clearly exhibits an upward trend.
Magnitude of rises vs. magnitude of drops
Given that the temperature seems to rise and to fall with roughly equal frequency, perhaps the rises are bigger than the falls? After all, even if the number of steps were equal or even if it was biased in favor of downward steps, if those steps are much smaller than the upward steps then it would be reasonable to assert that something is pushing the temperature upwards.
Specifically, such a pattern would be seen if there was a natural fluctuation overlaid atop a steadily increasing undercurrent – natural fluctuation would still make there be occasional upsteps and downsteps, but the undercurrent would make the downsteps smaller and the upsteps bigger.
This hypothetical undercurrent is what climatologists seek to clarify when they discuss a “signal”, to separate it from the natural fluctuation that data processing considers as “noise”.
As such, I performed a test to see whether or not downward fluctuations and upward fluctuations were “equivalent”. Technically, what this means is: Do they appear to come from the same distribution? Another way to think about it is: Could whatever process generated the upward movements also have generated the downward movements? If yes, then the upward and downward movements are essentially interchangeable; if not, then something is driving one and/or suppressing the other.
The test I performed is called Kolmogorov-Smirnov (K-S), which I selected specifically because it permits direct testing of two empirical distributions without making any assumptions at all about any underlying generative function or hypothetical source population. It involves taking two data sets, sorting their values from highest to lowest, and comparing the gap between them. A wide gap indicates that the values were probably drawn from different populations; a narrow gap indicates that they could have been drawn from the same population.
Listing the magnitudes of temperature rises against the magnitudes of temperature drops, sorted from highest to lowest, produces the following graph. (The “Decreases” looks dashed because there are fewer decreases than increases, requiring us to introduce gaps to make the spread equivalent. These gaps are strictly visualization artifacts; the K-S calculation is fully capable of handling empirical data series of different sizes.)

Visually, it’s clear that the Increases line and the Decreases line track very closely with one another, strongly suggesting that they were produced by the same process (or equivalent processes). If they weren’t, then this graph would show one curve offset from the other, or one curve flatter than the other, or one curve rising higher than the other, or in some other way introducing a gap between the two lines.
The K-S computation reveals a p-value of 0.591. That is, there’s a 59.1% chance that the null hypothesis is true, i.e. that the two data series were drawn from the same source population. This is nowhere close to the traditional value of 0.05 that’s usually required to reject the null hypothesis.
In short, it doesn’t appear that there’s any difference in the sizes of upward and downward steps in the year-over-year temperature anomaly data. There doesn’t appear to be any kind of “forcing” that drives upward steps to be bigger or downward steps to be smaller. If there is to be any kind of “signal”, it must be purely in the number of upward steps compared to downward ones – except, of course, we already ruled that out.
Wald-Wolfowitz Runs Test
The Wald-Wolfowitz “runs test” is widely considered a “standard” test for sequence randomness. It’s presented as a basic quantitative technique in the NIST Engineering Statistics Handbook.
The runs test is similar in nature to the “# Increases vs. # Decreases” test I performed and described above. Its operating principles depend on measuring the number of “runs” in the data set – that is, the number of times that a sequence changes direction. For example, if several years in a row exhibit upticks followed by a downtick, that series of years is considered a “run”. A random data set in which each element is drawn from a uniform distribution exhibits a very easy-to-predict number of runs of various lengths, and therefore a comparison of your actual observed number of runs against the expected number of runs offers a clue that your data set consists of such uniform random variables.
Running the year-over-year sequence of upticks vs. downticks through a Wald-Wolfowitz runs test produces a p-value of 0.586. I.e. there’s a 58.6% chance that a sequence of unbiased uniform random variable iterations (e.g. flips of a penny) would produce at least as many runs as the ones observed in the NOAA data set. Again, this is far above the traditional p-value threshold of 0.05, so the null hypothesis – that the temperature data is produced by an unbiased random process – cannot be rejected.
Autocorrelation tests (out of scope)
Traditionally, when evaluating a time series for evidence of a random walk, it’s customary to perform one or more tests that compare the data set to time-shifted versions of itself. These include the Box-Pierce Test and the related Ljung-Box Test, a Variance Ratio Test, and others. The primary use of these tests is to try to find cyclic patterns within a data set, such as a low-frequency rise and fall that is much larger than the individual steps.
In the NOAA data set, the Pacific Decadal Oscillation (PDO), which drives El Nino/La Nina events, exhibits such a cyclical pattern; and indeed, most of what we currently know about the PDO is data that we gleaned empirically from performing autocorrelation tests on time-series analysis. Likewise, the roughly 11-year solar cycle is likely to show a sustained pattern of rising and falling temperatures that has been shown to correlate well with year-over-year temperature anomaly data.
However, by definition, these cyclical patterns are ones that reset at the end of every cycle. Identifying such patterns isn’t a useful exercise for the task of determining whether or not there exists an overarching directional trend within a data set. The temperature data may rise and fall in 11-year crests with the solar cycle and in 30-year crests with the PDO; but if each iteration of the PDO were a little bit warmer than the last, then we would use different tests than autocorrelation to reveal that – such as the tests we’ve performed above.
Nor are autocorrelation tests useful in discovering cycles whose duration is longer than the total duration of the data set itself. A cycle needs to repeat at least once during the observation period in order to be identifiable as a cycle at all, so autocorrelation tests on data gathered since 1880 cannot tell us, for example, whether or not we’re in the upswing period of some hypothetical 500-year-long oscillation.
For these reasons, I’ve left autocorrelation tests out of the scope of this analysis.
Overdoing it
We have a joke in the world of quantitative analytics: If you torture the data for long enough, it will eventually confess to anything you require.
I could fill this paper with a dozen more tests for randomness, and eventually I will find one that rejects the null hypothesis at a p-value level of 0.05. However, the reason for that is itself pure chance. Remember, the (informal) definition of “p-value” is the probability that “randomness” (or more technically, factors outside of the controlled parameters) caused your observed results, and it’s traditional to reject the possibility of mere “randomness” when the observed results have less than a 5% chance of being explained by randomness alone. The caveat is that, with every experiment you run or with every analysis you perform, you roll that die again – and eventually that d20 will roll a 1.
XKCD has a great illustration of such an event in action.
This phenomenon is called the Look-Elsewhere Effect. It’s also known as the Multivariate Effect, the Texas Sharpshooter Effect, and others. In data mining operations, we call it “data dredging”, and we try hard to avoid it (those of us with scruples and professional integrity, at least).
I only mention it here because I don’t believe any data science discussion targeted at laymen is complete without it. Bringing awareness of the Look-Elsewhere Effect is a bit of a personal crusade of mine. I’ve seen the Look-Elsewhere Effect wreak havoc in academia and finance alike – whether it’s in the form of technical traders trying to simultaneously buy/sell on 20 different mutually exclusive trading strategies, or epidemiologists claiming that power lines cause childhood leukemia after testing 800 different possible ailments, or a neuroscience researcher observing the effects of photographs of human faces on the brain activity of a dead salmon.
Anyway, my point is: There comes a point at which data mining becomes data dredging, a point at which further tests actually muddy your results and make them less convincing. This seems like a good place to stop before that happens.
Conclusions and Discussion
The simplest assumption one can make about any physical system, no matter how complex, is that its state in the next moment in time will be roughly the same as its state at the present one. While this is obviously not always true, the burden of proof lies with whoever claims that the system shouldn’t remain static, that there exists some force that will compel it to some state other than the one in which it’s currently found. That burden can be met by employing proof by contradiction, by demonstrating that the system evolves in a manner that would be so unlikely in a static scenario that the static scenario simply cannot be true.
The annual global temperature anomaly data provided by the NOAA consists of many layers of complexities, of which the actual global temperature anomaly, i.e. the underlying physical phenomenon being measured, is merely the beginning. The instrumentation itself, the processing of instrument records, the merging of heterogeneous instrument sets, and the collation of those records into a single annual value is fraught with byzantine methodologies that introduce uncertainties (if not outright biases) at multiple systemic levels.
Through all of this complexity, therefore, the safest and most uncontroversial assumption is that of single-timestep autocorrelation: whatever value this whole process produced for any given year, it should produce approximately the same value the following year. When this assumption is extended for many years (over 130 in the NOAA data set), it produces a pattern called a “random walk”, which can amble aimlessly away from its starting point without any force explicitly “pushing” it in one direction or another.
This assumption is qualitatively different from the assumption used by climatologists in the formulation of the very term “temperature anomaly”. Their assumption is that there exists some ideal desired “normal” value that their instruments should be measuring (a “zero anomaly” state). Whatever value they measured one year, they believe that the following year’s value should be closer to this “normal” value. When that isn’t the case, they hold that there must be some external “unnatural” force that’s driving those values away from their desired “normal” state, and this force is anthropogenic global warming.
Essentially, this is the difference between assuming that the underlying physical system behaves like a soccer ball in a valley (where it naturally lies at the center, and if you kick it in any direction, its natural tendency is to roll back to the center) versus like a soccer ball in a flat open field (where it naturally lies wherever it last got kicked, and if you kick it in any direction, it will land at some new spot and remain there as its starting point for whatever next kick might come along).
Few climatologists, indeed few physical scientists of any kind, would deny that the steady-state assumption is always at least tentatively valid; i.e. that a physical system’s state at time t, absent any other knowledge, is best predicted by its state at time t-1 – and, indeed, recent discussions of the Earth storing thermal energy in its oceans is consistent with the idea that the Earth’s temperature in any given year is typically going to be whatever it was the year before plus/minus some small variation. But likewise, few data analysts would deny that there must be some physically enforced boundaries on the terrestrial thermal system – if Earth’s temperature truly was an unrestrained random walk, then at some point in the last few billion years a series of same-direction steps would have coincidentally arisen that would have either incinerated the planet or frozen it to such a chill that it would have snowed oxygen. These two positions aren’t mutually exclusive; essentially, it’s possible for the Earth’s thermal system to function as a random walk within a certain range, but for the boundaries of that range to be rigidly enforced. Conceptually, this could be visualized as a flat soccer field at the bottom of a valley; the ball will generally land where you kick it, but you can’t kick it completely out of the field. However, this transmutes the discussion into hypotheses about just how wide this field is, how steep the walls are, etc.; and, unfortunately, this discussion is almost entirely speculation. Certainly the answers to such conjectures do not lie in the 130-year-old instrument temperature data set; and if it did, then the data needs to unambiguously reflect that.
The point of this discussion, therefore, is to emphasize that, when it comes to temperature anomaly data, Occam’s Razor suggests that the year-over-year time series is a random walk. The burden of proof is on those claiming that there is a trend to the time series, that the “walk” isn’t random. This burden can be met by showing that the data exhibits statistical properties that would be extremely unlikely for a purely random data set.
Verdict: Proof of non-randomness not found
The analysis in this paper shows that the data does not exhibit telltale markers of non-randomness. We’ve applied several techniques that would show non-randomness – techniques borrowed from the finance industry, a world extremely well-versed in the finding of true patterns in time-series data; and each technique failed to rule out the null hypothesis. One does not need to introduce the assumption of an upward forcing function in order to explain the evolution of temperatures in the post-industrial period. The data is consistent with the assertion that the temperature has evolved in the last 130 years due to nothing more than purely random sloshing.
What this means is that it is naive to merely look at the 130-year annual temperature anomaly graph and conclude that it represents a rising trend. Analytically speaking, it doesn’t clearly show anything more prominent than the path of a proverbial drunkard stumbling between the bar and his home.
A logical prerequisite to any discussion about whether or not humans are causing climate change is the establishment of an actual upward signal at all. Despite the impression one might get through visual pareidolia, the data does not exhibit such a signal, rendering all logically dependent discussions ungrounded from reality and suitable only for abstract conjecture.
Random variability is a fickle mistress
But I do need to add this caveat: The data doesn’t disprove a trend either.
The purpose of this analysis is merely to establish that it is well within reason to believe that the 130-year global temperature anomaly record is the result of a random walk, rather than a forced physical phenomenon; i.e. that a random walk can produce the temperature record as we’ve observed it. But some kind of systemic forcing, be it anthropogenic or natural, can produce this record as well.
- The data is consistent with a random walk that has wobbled its way upward through pure coincidence.
- The data is also consistent with natural forcings.
- The data is also consistent with a combination of natural and man-made forcings.
In fact, per the Causes of differences… paper cited above, the data is even consistent with a very large anthropogenic signal that looks smaller than it should because it is being masked by a random walk that has wobbled its way downward!
All of these proposed physical processes and combinations thereof can produce temperature histories that match what we’ve observed from the instrument record. Yes, some of these proposed processes are more plausible than others; some involve making more underlying assumptions than others, some involve more articles of faith than others. The decision of which process best represents reality then moves away from which one could have created this data, and into topics of model plausibilities and Bayesian prior probabilities.
What one cannot do, though, is hold the data aloft as though it is a divine truth etched into tablets by an almighty being (as if it hasn’t been gathered and processed by dirty, filthy humans), and declare that it supports your model. Data doesn’t “support” any model. Data can invalidate a model, but just because you’ve produced a model that’s consistent with the data doesn’t mean that there aren’t an infinite number of competing models that are also consistent with that same data.

So if you’ve ever, in the course of a heated argument, thrown graphs in someone’s face believing that the visuals speak for themselves and that the data is on your side, know this: You’re wrong. The data isn’t on your side. The data is never on your side. At best, the data might simply be not against your side. But data by itself isn’t on anyone’s side. At best, you maybe aren’t the data’s enemy. But never believe that the data is your friend. Data has no friends.
That’s why it and I get along.
“Random” means what exactly? (UPDATE 2017-10-02)
After this essay had begun circulating, I realized that I had spent inordinate pages talking about randomness without really explaining what exactly that term means on a technical level. Most people, I think, see “randomness” as a force unto itself – some fundamental property of Nature that wiggles coins as they flip in flight, or reaches its finger into coffee to guide wisps of freshly mixed cream. The truth is that neither climatologists nor quantitative analysts believe in any such supernatural powers (or at least, if we do, such belief doesn’t factor into our math).
“Random” is simply a term we use to describe a large combination of “unknown unknowns”. “Random” is a summary of all the forces we have not measured, cannot measure, or don’t even know we’re supposed to measure – and all the ways that those things affect the phenomenon we’re measuring. Coin flips are “random” not because they are tweaked by a capricious god, but because we don’t have access to precise readings of a coin’s mass and angular momentum. (Interestingly enough, it is possible to get such readings from a roulette wheel, and a team of physics students at UC Santa Cruz in the 1970s managed to beat Vegas casinos by building a rudimentary portable computer to perform the calculations in real time.) Stock movements are “random” not because any physical force is buffeting them about, but because we cannot collectively model the psychologies of all of an instrument’s traders. (We actually can in certain conditions, which is why folks like me have a job at all.)
In short, “random” just refers to the aggregate effects of all the things we cannot make predictions about.
So when I talk about temperature records exhibiting a “random walk”, I don’t mean that the atmosphere of our planet is being trotted on a leash by Loki and yanked about by his whim-driven hand. What I mean is that the only thing we can take for granted about the temperature is that, wherever it is now, it’s likely to remain there next year; all other assumptions are tentative and must yet be proven. Only by rejecting the premise that we cannot predict the evolution of the temperature system, can we prove that we can predict the evolution of the temperature system. It seems like a braindead tautological statement, but actually doing it is trickier than it seems.
This point is particularly important to bear in mind in the Discussion section below, in which I talk about boundaries on the random walk. In the purest mathematical sense, a random walk is unbounded – and that’s obviously an absurd simplification of the real world. If the Earth’s thermal system was purely “random” in the sense that there was actually some omnipotent force moving it upward or downward every year, then in the last billion years we’d have occasionally grown hotter than Sol while on other occasions fallen far below absolute zero.
Obviously, therefore, comparison of the temperature record to a random walk does not literally mean that some magic supernatural entity has been physically applying Gaussian thermal steps to the planet’s atmosphere. What it means is simply to ask, within the time period that we’ve been collecting data and within the range that we’ve observed results, can we make reliable predictions? That is, predictions more reliable than uncorrelated, unconnected phenomena.
Can we outperform predictions made by tea leaves? Or chicken bones? Or tarot cards? Or coin flips? Or predictions that we would make anyway by simply throwing up our hands and saying, “We don’t really know what the heck is going on!” Well… Can we?
Eye candy for the next month or so. LOVE IT!
Of course, this study ignores the fact that NOAA’s data has been corrupted by adjustments that lower 1938 and warm the present. Our recent warm period only got to about the temperature of 1953 when we were already cooling.
No such study should be done with patently false data. To pretend to prove anything regarding false data, proving it neutral, is meaningless, as it is still altered data and not true.
It doesn’t ignore it at all. It discusses it at great length.
In an attempt to be the first to comment you didn’t read the actual post.
Totally agree.
To the other commenters who are taking higley7 to task. Yes it is mentioned several times BUT it is WRONG in that he notes that earlier temp records were adjusted UPWARD when fact they were adjusted DOWNWARD. I fear that his REASON got the better of him because who IN THEIR RIGHT MIND would consider adjustments DOWNWARD.
The take-away is that IT DOESN’T MATTER. Regardless of the data futzing, real or imagined, you still can’t find statistical significance to unambiguously support an upward trend.
Agreed, Pamela!
Exactly the phrasing I had in mind, “I Love it!”
Though I did encounter an error trying to open his spreadsheet with my version of Excel:
What I did download looked quite interesting, though I am certainly not a believer in NOAA’s anomaly science, or lack of.
Mikhail Voloshin does write an excellent summation regarding many of NOAA’s foibles and fantasies regarding temperatures and dodgy mathematics. Absolutely destroying NOAA’s claims for confidence levels.
Very well done Mikhail!
What is frightening is that Mikhail does not review every NOAA method for data torture and abuse.
No wonder the climate team and miscreants so desperately want to avoid dealing with the null hypothesis!
But, unless I’m mistaken, Alarmists claim a human signal not from 1880, but from perhaps 1950. Should we be adding a test to see if the pre-1950 data as compared to post-1950 data whether randomness still can’t be ruled out?
This article is a superb example of what made America great. An independent web site founded by an individual (thanks Anthony) publishing the even-handed highly skilled analysis of a data expert who seems to be of Russian heritage. Wonderful.
It would be useful if the summary could be a bit more detailed as many people, particulary the young, might not read the full article.
I would be interested to hear more about how balloon and satellite temperature measurements compared with the adjusted surface temperature records and what adjustments are made to satellite and balloon measurements.
According to the NOAA web site the last 9 hottest years have a combined temperature rise of 0.33 degrees or an average of 37/1,000 degrees C rise in temperature for each hottest year. Reports in the MSM almost never mention how little the temperature increased to create these hottest years and there is never a mention of any error range.
Well done, extremely readable for such a long and scholarly document. I look forward to reading more from this author.
Absolutely convincing, and beyond reproach in the math and argument. A landmark.
No smoking gune for sure but a smoking bong or pipe is perhaps close to the mark. A bit of weed, some hash, a bit of ice, crack… man what a brew this CAGW scam is. Everything an off their scientific tits narcissist could dream about…
I gotcher “smokin gun”
Higley7’s words are: “corrupted by adjustments that lower 1938 and warm the present. Our recent warm period only got to about the temperature of 1953 when we were already cooling.”
Dennis Dunton’s claim is a false strawman argument with implied ad hominem.
Higley7 correctly states that NOAA lowered temperatures in 1938 but have been adjusting present temperatures upward.
Can you send a copy of this to Dr. Brian Cox please. I would like to mine some comedy gold from his reply.
Too difficult for him to understand.
” Likewise, the roughly 11-year solar cycle is likely to show a sustained pattern of rising and falling temperatures”
Oceans’ thermal capacity is smoothing the sunspot cycle variability to an extent that is not readily extracted from global temperature data.
Solar activity went a bit up in September. Sunspot cycle 24 numbers in the old money (Wolf SSN) rose from 19 to 26 points while the new Svalgaard’s reconstructed number is at 43.6
Composite graph is here
SC24 is nearing what might be the start of a prolong minimum (possible late start of SC25 too) but a ‘dead cat bounce’ from these levels could not be excluded.
Even with all the cooking that the numbers have been subjected to, they still can’t be differentiated from a random walk.
I’m trying to decide if that’s more funny, or more pathetic.
…I’m going with crooked
Actually it proves that the climate experts are ignorant of proper data handling for if they had been knowledgeable they would have fudged it more convincingly. Ironic that Dr.Mann has now started to do so.
Expect further (entirely plausible “we found an error” ) adjustments now that they have read this article.
By jove the reverend has it.
As Jones the idiot said. He didn’t understand basic Excel
‘The NOAA stands by this data set on the grounds that it’s the best we have’
Climate ‘science ‘ is full of such ‘better than nothing ‘ style of data , proxies are used because there is no measured data to be hand , and often that which is measured is ‘iffy ‘ quality and may have little historic value and vast areas of both land and sea have no coverage. To make up for all these issues you have ‘models ‘ ,the best part of which is you throw enough garbage in , often enough to get any result you ‘need’
On on this quicksand they have managed to build a castle of ‘settled science ‘, which is frankly amazing.
a bit like the researcher “discovering” some of the argo bouys were running cold, yet not discovering a similar amount were running warm.
Actually NOAA see the use of “best available data” (BAD) as a statutory mandate from Congress. Seriously! However, they think nothing of excluding data points and sets, most especially if they didn’t control them from the start. That can mean someone in NOAA’s predecessor agency they didn’t like and certainly anyone outside NOAA.
What conclusions can you draw from a similar examination of the longer monthly anomaly series?
My question about the “allege that their readings don’t properly account for orbital decay” was, how were they calibrating the satellites? They go over known temperatures enough to be able to calibrate the data no?
Thousands of weather balloons are used: (WIKI)
“The balloons are launched from hundreds of locations around the world twice a day every day of the year. The launches occur simultaneously worldwide! This gives meteorologists a snapshot of the earth’s three-dimensional atmospheric conditions.”
But how could it go years without adjustment and then they determine that because it was a degree and half off from the other satellites that the data must be bad? How are they calibrating the satellite temperatures that his might occur? Are the other two to be trusted?
I mean 0.15 degrees different.
As i recall, GSS was last calibrated with a model. Go figure.
There are two ways that “orbital decay” can be “not accounted for properly.” One is that, due to warming of the very thin upper reaches of atmosphere that affect satellites in Low Earth Orbit, the satellites experience increased drag and drop more quickly in altitude than the planners anticipated. Consequently the satellite observes a deeper, warmer chunk of atmosphere sooner than anticipated by the model. If you have a handle on the temperature of outer reaches of the atmosphere, you can predict the rate of orbital decay and code a factor into the reading to adjust for the change. The other possibility is that due to atmospheric cooling, due – for example – to a less active sun, the outer atmosphere shrinks. It reduces orbital decay rates and the satellite may actually remain at an unanticipated altitude beyond expectations. That can result in unexpectedly cool readings as the model over-corrects for altitude loss that didn’t happen. This latter has in fact been an issue with systems like GPS and GLONAS in the last 10 years, requiring attention to satellite almanacs to maintain precision. So, adjusting for overly cool readings might be necessary. This seems to be what NASA and friends are actually dealing with by warming the record, but have they explained the rationale anywhere, other than the vague indication of “orbital decay?” If so, that would mean not just the out atmophere but the the troposhere as well have cooled, not warmed and possibly the adjustment was overdone.
over the top excellent article Mikhail….Anthony thank you for posting it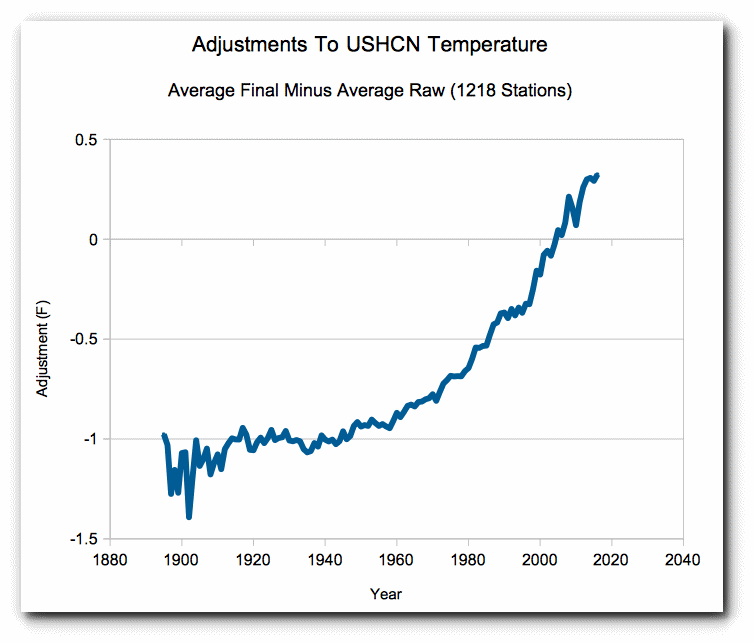
…Mikhail’s graph and this one look strangly familiar….
Even more eye opening:
HI Bart and all,
Here is why I prefer UAH to other temperature data:
.
http://www.woodfortrees.org/plot/gistemp/plot/hadcrut3vgl/plot/uah6
Best, Allan
Hmmm, so if NOAA stopped doing their adjustments, we’d see falling CO2 levels? Whew, that’s a relief! /sarc
I love it how the temperatures are often quoted to the HUNDREDTH of a degree. e.g. The temperature anomaly in 1880 was -0.16 C .
I will therefore tell you my modification to the classic “dick” joke, probably appropriate considering how many dicks there are in Climate Science.
“Mine’s 12.067″ but I don’t use it as a precision linear measuring instrument”
Centimetres or inches?
There is a ” , but if you cannot see it I guess you have made your point anyway.
The problem is that the inches mark resembles the close quote mark in many fonts.
On the internet, unless you specify it in the html, the font that you post in may not be the font that people are reading in.
Until you pointed it out, I was assuming that you had unmatched quotation marks.
Interesting analysis. One thing fairly well established in the very fuzzy field of psychology and research is the need for “blind” procedures in research design. Having people knowing which subject is in which group, or “knowing” how the test is supposed to come out, fairly reliably produces a bias.
How to correct for this effect in this field would be something of a bear. Automated data analysis would probably just move the bias to the programmers, and make it even harder to find.
These changes and the hype that goes with them always remind me of the New Sudso best ever clean washing powder adverts. I often wonder if these adverts and NOAA press releases are written by the same people.
These changes to the temperatures made on a regular basis remind me of virtually every car ad that starts with this phrase: “introducing the all-new”. Can you imagine how much it would cost to create an all new car every year?
You can double your wonderment by subjecting the “new improved” information to Mad Magazine style use of that new information to unravel what the “old unimproved” information was really telling you
Here’s what comes into my mind when I read “new and improved”:
New and Unproved.
Very informative. I shall bookmark this and re-read it many times. Thank you.
Hansen included a test of this in his ’88 paper, see Fig 1, he ran the model for 100 yrs with constant input. Showed a period of growth and a period of decline, max value about +0.2ºC, min value about -0.2ºC, std dev 0.11ºC.
Let’s phrase it another way: Imagine you play a little game with yourself. You start with a score of 0. Then you flip 132 pennies. For every heads, you add a point. For every tails, you subtract a point. What will your final score be? Well, if you play this game many times, you will see that 54% of the time your score is either >=8 or <= -8.
So in observing 70 upticks out of 132 years, must a scientist conclude that something is causing an unusual rate of upticks? Could those upticks be caused by, for lack of a clearer term, nothing?
Well, it turns out that there’s a 54% chance that those upticks are indeed caused by “nothing” (not literally nothing, of course, but merely by a very large and very noisy combination of forces that buffet the value hither and thither, with no preference of direction).
Actually there’s a 27% chance that there will be 8 or more ‘upticks’.
I am guessing that the red team, (and if Judith is not a member, her too) would love to have this in journal-ready form. Bottom line, do whatever it takes to get this published in a peer-reviewed journal. When we went shopping for my research, we added a well-respected researcher to the author list, who substantially improved the write-up and data analysis (though I did the research and most of the CO-ANOVA crunching with Statview). It also led to getting a Master’s degreed Research Audiologist into a national peer-reviewed journal. What you have here is a gold mine.
See if Judith or any of the other ones currently publishing in climate science want to play. Seriously. Publish. Or publish it with just you. You have the credibility and then some.
i will second that pamela. also essential reading for anyone without a science background with even a mild interest in the debate.
Also seconded. A summary in 4 or 5 paragraphs for those less technically minded would be good. something starting like:
“Given a set of temperature data which contains 2 supposed signals, natural and human produced, the natural moving up and down somewhat randomly and the human one supposed to be an increasing trend the task is to “extract” the steadily increasing bit from the overall up/down fluctuations…..”
If the start pont is 1880, then that isn’t very long after the end of the Little Ice Age. In general, with
some notable fits an starts (Little Ice Age), the planet has been warming since the last Ice Age, hasn’t it? The sea level rises per century were truly large for a long period of time – as I recall often over 100 feet per century.
…first they convince you the LIA ended in 1850
When I teach a class on random walks the test we adopt is to plot the (displacement)^2 from the origin, for a random walk this will be linear, for deterministic motion it will be more like quadratic. Applying that test to this dataset shows that it is deterministic, not a random walk.
You are doing it wrong, and so is everybody you teach.
Phoenix44 October 1, 2017 at 11:38 am
You are doing it wrong, and so is everybody you teach.
Really. Care to explain?
Phil. October 1, 2017 at 12:08 pm
Phoenix44 October 1, 2017 at 11:38 am
“You are doing it wrong, and so is everybody you teach”.
Really. Care to explain?
I guess Phoenix isn’t going to back up his assertion.
Einstein in his random walk model for Brownian motion derived the following relationship for the mean square displacement: MSD=2Dt
So as I said random walk gives a linear plot vs time, this NOAA data does not.
Phil, you are indeed doing it wrong. First of all, the expected displacement of a random walk after N steps is not D^2, as shown here:
https://math.stackexchange.com/questions/904520/why-is-the-expected-average-displacement-of-a-random-walk-of-n-steps-not-sqrt
Second, even if it was, you don’t reject a null hypothesis with a p-value of 50%. You reject it at 5%. At the very best, you’re teaching your students to reject the null hypothesis when it reaches a point of “slightly less likely than not”. That’s deeply wrong; you’re literally teaching them to commit Type 1 errors. Not good.
omedalus October 1, 2017 at 7:16 pm
Phil, you are indeed doing it wrong. First of all, the expected displacement of a random walk after N steps is not D^2, as shown here:
https://math.stackexchange.com/questions/904520/why-is-the-expected-average-displacement-of-a-random-walk-of-n-steps-not-sqrt
Indeed the average displacement of a random walk is zero, as I said the average squared displacement is proportional to N, the number of steps.
Second, even if it was, you don’t reject a null hypothesis with a p-value of 50%. You reject it at 5%. At the very best, you’re teaching your students to reject the null hypothesis when it reaches a point of “slightly less likely than not”. That’s deeply wrong; you’re literally teaching them to commit Type 1 errors. Not good.
I didn’t say this so I don’t know where you got it from.
If you plot MSD for a random walk it’s a straight line, if it’s deterministic motion it’s a quadratic, plot the NOAA data and from 1960 onwards ti’s strongly quadratic.
It’s easy to do in Excel, upload the data as linked to above, subtract 1880 from the date, add 0.2 to deltaT and square it.
@Phil;
Since the data set goes back to 1880, why exactly do you think it appropriate to truncate it at 1960? Cherry pick, much?
D. J. Hawkins October 2, 2017 at 4:35 pm
@Phil;
Since the data set goes back to 1880, why exactly do you think it appropriate to truncate it at 1960? Cherry pick, much?
I didn’t ‘truncate’ it, I analyzed the whole set, it doesn’t have the characteristic of random walks and from 1960 onwards it shows a clear quadratic behavior.
IMO the real climate system is not totally random over minimal 30-year intervals or greater. However the bogus, so-called “surface data sets”, despite their deterministic “adjustments”, do qualify as random walks. For instance, they resemble the highest of these eight random walk trends:
https://upload.wikimedia.org/wikipedia/commons/d/da/Random_Walk_example.svg?download
“Example of eight random walks in one dimension starting at 0. The plot shows the current position on the line (vertical axis) versus the time steps (horizontal axis).”
Note that, as would be expected, four trend higher than the start point and four lower, although one not by much at the end of the time run.
Will try again:
William Briggs has a post on random walks using the Arcsine rule here:
http://wmbriggs.com/post/257/
He gives an “R” program you can download and run for yourself.
Most of the in actuality random walks ‘look” significant to my prejudiced eye.
In order for the series to be significant, the number of “up” or “down” anomalies would have to exceed 78 at which point the 95% confidence limit would be exceeded. In other words, merely 7 more up years and 7 less down years out of 132 would have done the trick. Close, but no cigar for the warmistas.
Excellent article –
I’d suggest tagging the all data by date and measurement type and running a k-mean cluster analysis. If it still breaks up into groups that reflect individual sub population defined by measurement type then the assumption must be made that combining them into one is a no no. Alternatively the other conclusion is that there are more data adjustments to come. Perhaps that is the only prediction that can be made on the temperature data sets with any accuracy.
Consider yourself sufficiently cynical. 🙂
Excellent post. Kolomogorov-Smirnov brought back fond memories. I wrote a Fortran program to read the daily S&P 500 prices for a couple of years, apply KS, to show stock price changes are log normal not normal (fat tailed). Prof John Lindner of HBS had done the analytic math, and he wanted an observational validation. Directly relevant to CAPM (capital asset pricing models) using a company’s beta.
Beautifully written, it captures the reader, is simple to understand and does not fudge the conclusions. I enjoyed the whole piece.
No – I did NOT!
Micky “the Master” Mann tried to blackmail me to do that by kidnapping K-9. But he lost against the sonic srewdriver.
I hear K-9 took a particular interest in one tree.
Yes indeed. I think it was a lonely bristle cone.
The fact that K-9 took an interest in that tree might explain why it experienced accelerated growth in recent years.
Besides the cheap attack at my integrity – a real great post – I love it!
It really demonstrates nicely why not data need adjustments but error bars.
Every now and then one of these articles pops up saying that you can use a Brownian motion or random walk as your physical model. That supposes that a great range of things can happen by chance, and so you can’t prove that what actually did happen was not by chance. It’s basically saying that we just can’t make sense of the world.
But we can, and do. This article is explicitly inspired by the analysis that might be applied to financial instruments, like stocks. But there is a very fundamental difference between that and a physical property like temperature. Stocks can, and all too often do, just crash. The time series takes them into oblivion. They can also bubble. But there is one big piece of evidence about temperature that is not taken into account by this analysis. It has been around for many millions of years, and the seas have not boiled, and the atmosphere hasn’t liquefied.
With a random walk, that wouldn’t be true. It can go anywhere, and will. It has no boundaries. That is just not the behaviour that we observe. And it is not the behaviour that physics reasons about. Real temperature is subject to conservation laws. There is a finite energy influx, and a mandatory radiation to space. None of those fit within a random walk.
The post doesn’t claim that Brownian Motion IS a valid or let aone “the true and ony” physical model. It demonstrates that the uncertanty and range of NOAA data even compares with what you get if you’d accept random walk as null hypothesis. Big difference!
Coin flipping was a method of explanation of a random, constrained walk.
That does not mean that the author thinks climate is a random walk.
What this illustration explains is that GISS data cannot be described as other than a random walk, so all theories of ‘climate change’ remain on the table.
So the AGW theory is just one of these.
As is ‘business as usual.’
As is a combination of both.
‘The point of this discussion, therefore, is to emphasize that, when it comes to temperature anomaly data, Occam’s Razor suggests that the year-over-year time series is a random walk. The burden of proof is on those claiming that there is a trend to the time series, that the “walk” isn’t random. This burden can be met by showing that the data exhibits statistical properties that would be extremely unlikely for a purely random data set.’
Funny how, even when arguing against solid mathematical analysis, the Climate Fascist argument STILL boils down to “It’s not a cat, so it must be a dog.” LMAO
NS,
You said, “But there is one big piece of evidence about temperature that is not taken into account by this analysis. It has been around for many millions of years, and the seas have not boiled, and the atmosphere hasn’t liquefied.” Mikhail is not arguing that all temperature changes on Earth have been random. He is, instead, arguing that the changes in the last 132 years, out of 4.5 billion (not “millions”!) years, cannot be distinguished unequivocally from a random walk. That is, the null hypothesis cannot be rejected. The Law of Large Numbers predicts that a sequence will converge on the theoretical value with a very large number of readings, but that doesn’t prevent individual short runs from deviating significantly from the theoretical number.
There is nothing in his analysis that precludes the possibility of negative feedback loops correcting any random walk deviation and bringing it back to regress about the long-term mean. Indeed, he specifically avoided trying to attribute changes to physical processes.
You also said, “It’s basically saying that we just can’t make sense of the world.” Sometimes we can’t! Philosophy and theology may grapple with the question of why there is evil in the world and whether there is such a thing as “karma.” When (good) scientists find that a physical process or system doesn’t behave in a manner that is comprehensible, they try to discover why. Einstein died trying to come up with a grand, unified theory. There are many following in his footsteps. We still don’t have an answer. It is only alarmist climatologists that claim to know everything, and are deaf to criticism.
“He is, instead, arguing that the changes in the last 132 years, out of 4.5 billion (not “millions”!) years, cannot be distinguished unequivocally from a random walk. That is, the null hypothesis cannot be rejected.”
It’s an improper null hypothesis. The requitrement of a null hypothesis is that it is plausible, involves nothing new, and would explain the data. A random walk cannot explain the data, because of its unboundedness. A random walk that operates only over the last 132 years, but not at other times, itself introduces novelty and requires explanation, so isn’t a valid null hypothesis.
Simplicity itself. First order AR model with very long time horizon relative to the interval of interest. Indistinguishable from a random walk over 132 years.
“First order AR model with very long time horizon”
And it’s subject to the same objection. You can dream up statistical processes in which the present rise is to be expected, as a random event. But then, in that model, very much larger changes must also happen at considerable frequency, by the same statistical rules. And that just isn’t observed. You may point to glacial cycles, but no-one seriously thinks they are the expression of a statistical process. And anyway, random walk and related models would wander far beyond glaciation variations.
The proper answer is: “We do not know what is the root cause of the five observed 1000 year long cycles in the earth’s climate, nor do we know the cause of the dozens of shorter 65-70 year cycles superimposed on the 1000 year long cycle. We know these cycles exist, we do not know their cause. ”
Like the cities, sailors and ship captains who knew the tides were associated with the moon long before Newton “discovered” the Law of Gravity, and long after we knew the tides varied by depth of the bays, length of the rivers, and width of the inlets worldwide, we can “use” the results without “knowing” the physics, chemistry, or meteorology. And climatology.
But today’s “catastrophes-in-the-making” astrology-by-CO2 is propaganda. For the governments, by the governments, with the governments, using the governments to control the people.
“But then, in that model, very much larger changes must also happen at considerable frequency, by the same statistical rules.”
Not at all. I can create an ARMA model that will look like a random walk over just about any timeframe you want, but which is ultimately statistically bounded to not much more than your observations indicate.
NS,
You are adding requirements to the definition of a null hypothesis that are not generally accepted.
A null hypothesis is accepted commonly to be “… a general statement or default position that there is no relationship between two measured phenomena, or no association among groups.”
[ https://en.wikipedia.org/wiki/Null_hypothesis ]
While a null hypothesis MIGH be rejected because it can be demonstrated to be impossible, that doesn’t apply in this case. There is no strict requirement that a random walk is always effective. It may well be overpowered by exogenous forces at times. One has to consider the increments in the random walk (noise) compared to the influences of an external signal. It is also possible that a run for short periods of time (I.e. much less than 4.5×10^9 years) may be unchanging. Most importantly, there appear to be feedback loops that prevent “unbounded” behavior, while still allowing random walks within a region of ‘permissible’ ranges.
The claim in the article was that a random walk cannot be rejected as a reasonable and probable explanation for observed temperature changes over the last 132 years based on commonly used statistical tests, therefore, it is as reasonable an explanation of the recent temperature record as the claim that there is some sort of ‘trend’ resulting from forcing. You are characterizing the effect of the random walk as being the totality of effects. You are being disingenuous!
Clyde,
“A null hypothesis is accepted commonly to be “… a general statement or default position that there is no relationship between two measured phenomena, or no association among groups.””
That’s a bit too null. It has to be enough that you can calculate the probability of the outcome under the NH. This article proposes that instead of the normal stationary NH, one should use a martingale. That isn’t just asserting no relation; it’s asserting a particular structure. So the question is, why?
Bartemis,
“I can create an ARMA model that will look like a random walk over just about any timeframe you want, but which is ultimately statistically bounded to not much more than your observations indicate.”
I’ll believe it when I see it.
Bartemis October 1, 2017 at 12:58 pm
Simplicity itself. First order AR model with very long time horizon relative to the interval of interest. Indistinguishable from a random walk over 132 years.
Ok run it 50 times starting at 0,0 then take the mean of all 50 trajectories then plot the mean vs time if it’s a random walk it will have a mean of zero. Then take the mean square of the trajectories, to be indistinguishable from a random walk it will give a straight line. Let us know how that works out.
Guys, this is silly. It’s a trivial problem. You just set the autoregressive time constant to a bit longer than your data record.
“…then take the mean of all 50 trajectories then plot the mean vs time if it’s a random walk it will have a mean of zero. “
One cannot “take the mean”, one can only estimate it. And, that estimate is, itself, a random variable. It is very unlikely to be precisely zero. In fact, the probability is vanishingly small, thought not completely zero when using quantized number representations in a computer.
“Then take the mean square of the trajectories, to be indistinguishable from a random walk it will give a straight line.”
This, again, can only be estimated, and is unlikely to produce a completely straight line, or even a moderately straight line. However, it will produce very nearly as straight a line as you can get from an actual random walk.
I’m beginning to wonder if you guys know anything about stochastic processes at all.
Bartemis October 2, 2017 at 5:00 pm
Apparently you don’t know much about random walks. I don’t see what the difficulty is about calculating the mean of 50 numbers.
The first 3mins of this video shows 4000 random walks.
You cannot calculate the mean. You can calculate the average, which is an estimate of the mean, but you cannot calculate the mean. As you can readily see, you never get precisely zero.
Bart, you bragged that you could “create an ARMA model that will look like a random walk over just about any timeframe you want”. So I said OK so why don’t you do so and perform the appropriate test to demonstrate that. Instead of doing so all we get from you is sophistry about means!
Bartemis October 3, 2017 at 4:47 am
You cannot calculate the mean. You can calculate the average, which is an estimate of the mean, but you cannot calculate the mean. As you can readily see, you never get precisely zero.
I told you how to do it. It’s easy.
I do not deal in sophistry. This is an important point – the parameters of a statistical model cannot be known in truth, they can only be estimated. It is a cornerstone of statistical analysis. We derive confidence intervals based on the statistics of our estimates. If you don’t know it, if e.g. you regularly confuse means and averages, then you immediately betray a lack of sophistication in the arena.
I get charged with sophistry a lot also when I inform people they are mixing up necessary and sufficient conditions for a given conclusion. Untutored people typically jump from the former to the latter, without realizing they have committed an egregious fallacy.
Way too many people think science is all about saying stuff that sounds sciency, and that they are somehow immune to misconceptions such as often encountered in the past because they have iphones and stuff. They really do not understand science at all, but I am regularly lectured by such ingenues that it is I who lack awareness.
My earlier reply appears to have disappeared so I’ll try again.
Bartemis October 3, 2017 at 11:48 am
I told you how to do it. It’s easy.
No, you bragged that you could do it, so I suggested you do so and create 50 trajectories and could test whether they were random walks. All that followed from you was bluster about the difference between means and averages. From which I conclude that you’re unable to back up your claim.
Sorry Nick, that’s not true. The flipping of coins demonstrates random walks quite nicely, but the probability of it being unbounded in any one direction becomes vanishingly small in relatively few flips. Likewise, financial markets are also bounded by zero on the bottom and a diminishing probability of increasing value on the top.
Certainly the Earth’s atmosphere is bounded by the physics of water, the Earth’s rotation and distance from a relatively stable sun, the makeup of the atmosphere and so on, but there is a level field inside those bounds were atmospheric temperatures can and do meander. Certainly they do not meander by chance, but through an extremely complex interaction of forces and variables that are not, by any means, quantified and understood. The ‘Pause’ is more than enough evidence to this fact.
Mikhail Voloshin is not arguing that atmospheric temperature is the product of random chance, only that it cannot be distinguished from something generated by random chance. In other words, it is not statistically possible to identify any one thing as the cause of the observations, because the observations are not distinguishable from what might occur from a random walk. This includes CO2.
Your boundary argument is irrelevant. Anywhere inside given boundaries, a random walk can occur.
“The flipping of coins demonstrates random walks quite nicely”
The flipping of coins is a stationary process. A random walk, as the author explains, is necessarily unbounded. You can add bounding conditions, but then you have to explain them.
“Anywhere inside given boundaries, a random walk can occur.”
But the boundaries are not given. If they existed, that would be a whole other story.
Nick, you either did not read the entire write up, or missed several points. He clearly stated that there could be boundaries but within these boundaries the random walk variation could occur. This is a basic chaotic problem (4th power radiation, non-linear NS, air and ocean transport and storage and release, etc).
Leonard,
“He clearly stated that there could be boundaries”
No, I’ve dealt with that in several comments. Yes, you can assume boundaries. But where are they? and what happens there? That is why it fails as a null hypothesis. It just means that there is a whole lot more to explain. Before you know it, you’re up to your armpits in epicycles.
“Certainly the Earth’s atmosphere is bounded by the physics of water, the Earth’s rotation and distance from a relatively stable sun, the makeup of the atmosphere and so on, but there is a level field inside those bounds were atmospheric temperatures can and do meander. Certainly they do not meander by chance, but through an extremely complex interaction of forces and variables that are not, by any means, quantified and understood.”
The lack of understanding is the problem!
Trends are funny things. Meaningful trends can be extracted from three samples: e.g. ‘Don’t light three cigarettes from the same match,’ or ”Once is happenstance, twice — coincidence, but three times …’
Much longer trends, with an inadequate understanding of the underlying systems, can reasonably be viewed as a meaningless sequence of unrelated facts. (The last quoted sentence spells it out, beautifully.) This is the prime reason why ALL of the ‘spaghettified’ climate models are inherently worthless — even if, by some freak of chance, one of them happens to accurately predict an observed trend. If one doesn’t understand the system, then there is no way to be sure that a hitherto accurate model will continue to be accurate.
Also, given the unknown influences of forces from outside our immediate solar neighbourhood (cosmic rays, etc.), it is appropriate to consider the Earth as an UNbounded system. So, we have a poorly understood, unbounded, significantly chaotic system. Under the circumstances, adaptation would seem to be far more rational than the delusional presumptuousness of anthropogenic climate modification.
No, it is not a random walk, not when the “adjustments” correlate so well to the desired outcome. These are not random.
And NOT when there has been known and INTENTIONAL adjustment to the data, especially the wiping away of the 1940 temperatures. These are not random,
You don’t seem to have read the piece.
If a random walk can simulate the data, then the data can be a random walk.It is that simple.
+1
Nick: “look a squirrel”
Nick,
Here you go again, adding something to the article and no one else brought up,don’t you ever get tired of making Red Herring comments?
When are you going to explain to Tony why you wrote that dishonest comment about the two charts in the other thread?
His latest in exposing your B.S.
Nick Stokes : Busted Part 3
“Nick Stoke’s final idiotic claim takes us right to the heart of this scam.
The first GISS plot is not the usual land/ocean data; it’s a little used Met Stations only
This was the GISS web page in 2005. Top plot was “Global Temperature (meteorological stations.) No ocean temperatures.”
https://realclimatescience.com/2017/09/nick-stokes-busted-part-3/
Why write the way you do,Nicky?
Well, that’s for sure a red herring. What is the connection here?
But if you insist, try finding the GISS Met stations only data in the rather extensive WUWT global temperature page. Or even in the GISS 2005 annual temperature report.
“try finding the GISS Met stations only data”
..you don’t need to “find” it…..it’s all they got
“what James said……”
You are pathetic,Nick since the link I provided answered your questions. The very chart you whine about is right there on the GISS webpage. Tony showed both 2001 and 2005 webpages in his post with links to them.
Here is the 2005 webpage of the charts in it:
Stop being this dumb.
The great Nick, couldn’t find the data for the 2005 chart,which was given to him in Tony’s link I provided:
https://web.archive.org/web/20051019133758/http://data.giss.nasa.gov/gistemp/graphs/Fig_A.txt
“Global Surface Air Temperature Anomaly (C) (Base: 1951-1980)”
ALL the data from 1880-2004, in the link Tony provided that you didn’t bother looking.
Nick writes,
“But if you insist, try finding the GISS Met stations only data in the rather extensive WUWT global temperature page. Or even in the GISS 2005 annual temperature report.”
The answer was in the link you never visited. You appear dumber every time you do this……
Sunset,
You seem to have a lot of trouble following simple arguments. I didn’t say I couldn’t find the GISS met stations only data. In fact, it’s one of the ones I monitor every month , as GISS Ts. And it is one of the ones I show in the interactive comparison of indices with Hansen’s 1988 projections. I argue that it is specially appropriate for that, because it is the index he used in his original comparison, and represents what he was projecting. That tends to get howled down, because it actually follows a bit on the high side of scenario B, currently touching A.
What I am saying here is that the index is little used, not that it is hard to find if you really try. For that I note that since 2005, and somewhat before, GISS has based its annual reports entirely on Land/Ocean (with SST). The Ts (Met stations only) index is not mentioned. And I noted that it isn’t shown in the WUWT collection.
That’s why I think it is dishonest to wave these plots about as evidence of GISS “data torture”, without explanaton of what it is. You obviously and persistently fail to distinguish between that and the well-known GISS Land/Ocean index, and I suspect most of Tony Heller’s audience doesn’t care about the difference either. If you want to complain about GISS adjustments, you should show the effect on the GISS plot that people actually use.
And for this thread, it’s still a red herring.
Nick writes,
“You seem to have a lot of trouble following simple arguments. I didn’t say I couldn’t find the GISS met stations only data.”
You say I have trouble following you,when you can’t even notice i GAVE you the data for THAT chart!
You earlier wrote,
“But if you insist, try finding the GISS Met stations only data in the rather extensive WUWT global temperature page. Or even in the GISS 2005 annual temperature report.”
Here is the data I linked to,for the SECOND time……
https://web.archive.org/web/20051019133758/http://data.giss.nasa.gov/gistemp/graphs/Fig_A.txt
You seem to be ignoring links,I posted because they keep answering your comments.
Try reading better.
“Try reading better.”
You can’t even read what you quote. I said
“But if you insist, try finding the GISS Met stations only data in the rather extensive WUWT global temperature page. Or even in the GISS 2005 annual temperature report.”
and what you link to is not that. You have linked to a file with text data on the internet. I can find that data with no trouble. My point is that you will not find it in the places where temperature information is udsally sought. That includes what GISS includes in its reports, or what WUWT lists for its readers. It is not what readers understand as GISS global temperature. Its use here is a misrepresentation.
Mr Stokes, you clearly didn’t read to the end of the article. The author explained the issue you describe by a series of soccer field analogies. You are describing the analogy of the flat soccer field within which a random walk happens , bounded by steep walls of a valley.
Why do you always automatically try to rubbish good work just because it ‘tests’ your religious beliefs? You are not demonstrating the sort of logical, scientific mind you would have us believe you possess.
obviously Nick didn’t read the link Tommy posted either…..he’s just shooting from the hip
…..he’s just shooting from the hip…
Wouldn’t that be shouting from the hip?
Grandson of Navier-Stokes,
You argue with something the author did not say. He did not say, ” The average temperature of the Earth is a random walk.”
He said, “The 132-year NOAA record of the average temperature of the Earth cannot be STATISTICALLY distinguished from a random walk.”
“Climate Science” howls about Hottest Year Ever in an attempt to prove that we must adopt an austere lifestyle. They actually do this because they hate any and all mining operations, no other reason I can detect.
You have several comments on here, all repeating the same error, contradicting something the author simply did NOT say, why do you bother…
“He did not say, ” The average temperature of the Earth is a random walk.””
I didn’t say that he did. It helps to actually quote what people say. What he did say is:
“Now, when it comes to the Earth’s mean temperature, the simplest and most basic assumption, i.e. the null hypothesis, is the same as the null hypothesis for any other time series: that it behaves as a Markov process – specifically, a sub-type called a Martingale. “
And what I say is, no, you can’t make that assumption. It is inconsistent with Earth’s history, as he acknowledges. Temperature hasn’t wandered without bounds. It just fails as a null hypothesis at a basic level. So he has to adorn it with fancies that it sometimes is and sometimes isn’t (so why does it change, and what is it when it isn’t?). Or that there are some barriers where it stops being a random walk (So where are they, and how does it behave there?). The hypothesis either doesn’t explain, or it isn’t null, which means it leaves a whole lot else to explain.
Besides inventing brand new red herrings Nick, you just busted your own strawman.
You just verified that the null hypothesis stands and has not been accounted for or disproven.
Your ineffectual hand waving does not cause null hypothesis or hypotheses, if you prefer, to evaporate just because you don’t like the method or message.
• Disprove the mathematics involved! Which means you have to prove decades of financial testing of those methods are wrong.
• Disprove all of the error bounds NOAA, MetO and BOM overlook!
• Disprove all of the data mishandlings NOAA, MetO and BOM forcibly use to abuse their data.
Stokes-as-he-ever-was,
You make an analogy between 132 years of thermometer records with 4.5 billion years of no thermometer records, FAIL
“It’s basically saying that we just can’t make sense of the world.”
No it’s not. It’s saying that the NOAA data set in question is probably telling us nothing about the real global temperature trend. You are trying to make the same argument as Niel Degrasse Tyson when he said people trust science to predict solar eclipses, so they should trust science to predict the future climate. Earth-moon orbital mechanics is a much better defined problem, where the moon’s orbit around the earth is known with great precision. There is little randomness involved, so we can easily make sense of it. Global temperatures have a lot of apparent randomness, and the available data record is short and corrupt. Therefore we can make no sense of it!
Another “Nick Stokes” bogus strawman logical fallacy. Fake through and through.
Try reading the article, Nick; not inventing fake sentences and then pretending the author of the article wrote them.
Nick, I think the author just said what you said when he said “The decision of which process best represents reality then moves away from which one could have created this data, and into topics of model plausibilities and Bayesian prior probabilities”
HAS,
Well, yes. But my point is that a random walk fails on model plausibility. Temperatures clearly haven’t varied without bound. And the notion that we are just going through a period of random walk when normally it isn’t is also not plausible.
What is quite plausible is that the instrumental period is, if that’s all you’ve got. You only can claim its bounded by peaking outside the dataset.
Now you might argue the utility of that pov, but it might be a very good approximation when working at that scale and resolution. We regularly use different models to describe phenomena that differ in this way (think quantum and Newtonian mechanics). If any period of a couple of centuries at a daily resolution behaves this way then that is pretty useful for thinking about what might happen over the next 50 years.
HAS
“What is quite plausible is that the instrumental period is, if that’s all you’ve got. “
It isn’t all we’ve got. We’re sure that the seas haven’t boiled in the last billion years, and that is inconsistent with a random walk.
“We regularly use different models to describe phenomena that differ in this way (think quantum and Newtonian mechanics).”
We use them on different scales. But we don’t assume that Newtonian mechanics was true up until 1900 and then the universe changed to quantum mechanics. That’s the analogy here.
Nick, it may be academic but it is informative to consider what the data – at the resolution in question – tells us if this is all you have. It is useful precisely because there is this unique period in time when we have it at this resolution.
However I think you are missing the point, for short periods at high resolution the assumption of unboundedness may be good enough. We don’t put aside Newtonian mechanics because strange things are going on at the edge of the universe. If we had instrumental data for the first couple of centuries of the last millennium and were interested in studying things on that time scale we may well apply avsimpler unbounded model to the problem.
Models in the end are judged on their utility, and for the purposes of short run high resolution study boundedness may not matter (and I think this post is suggesting just that).
Whether there is a better model for this particular application therefore may well come down to Occam’s razor.
PS Perhaps to make it crystal clear with a direct analogy, we don’t not use Newtonian mechanics because the speed of light seems be a limiting factor.
HAS
“However I think you are missing the point, for short periods at high resolution the assumption of unboundedness may be good enough. “
Or bad enough, which seems to be the aim here. We have data which makes good sense with a conventional stationary model with imposed secular variations, but then someone dreams up a model with more uncertainty, so that the observed features could be “explained” as random.
But as I said elsewhere, the problem is that if you assume a model where the current marked rise is merely a random occurrence likely to occur frequently, then even larger, and very much larger, changes are also likely to occur over a few million years. And that just hasn’t happened. So then you have to add an assumption that there is something special about the period for which we have observations, so that the model you want tio apply now would not have applied in the past.
But why would you assume that?
You can have convergence, without having infinite impulses?
Nick, so you now agree that there can be utility in modelling the global temperature for short periods of time at high resolutions that don’t take account of aspects of the wider domain that are not discernible within the domain being modeled.
With the speed of light and Newtownian mechanics, if you start going very fast or operating on large scales it might be useful to included it, but we generally agree we don’t need to bother. In the same way it might just not be useful to accommodate bounds in a temperature model for this narrow purpose.
The question for you is when does the assumptions of a stationary model with imposed secular variations become more useful, noting that this isn’t able to be discerned from the domain in question?
Note this is a contingent question, not handed down from the gods as you are suggesting.
HAS,
“The question for you is when does the assumptions of a stationary model with imposed secular variations become more useful”
But you are not looking for useful. You are looking for useless. A null hypothesis sufficiently general that it can’t be rejected. You could adopt the null hypothesis “Could be anything”. That’s very hard to reject. But it’s inconsistent with what we know of the world.
This really relates to statistical power. Adopting random walk is minimising the power. That is not useful, and is the opposite of what true scientists try to do.
The author covered this:
“The decision of which process best represents reality then moves away from which one could have created this data, and into topics of model plausibilities and Bayesian prior probabilities.”
Plausibility has to be evaluated in terms of everything we know about temperature. The basic structure of a stat inferential test is: OK, our bright idea will explain the results, but there is an alternative, plausible explanation (NH) which could also possibly (5% say) explain them. Or not. Plausibility is the key.
To be clear: ‘Random walk’ in itself is not enough. One would specify the kind of randomness.
So if someone just says ‘random walk’ he may mean Brownian motion (random walk with red noise) or a Gaussian random walk (white noise) or it may mean a random walk using a kind of randomness coming from some unspecified/unknown distribution. The latter may very well be the case here.
Because he (Mikhail Voloshin) uses non-parametric statistics it doesn’t matter whether we know the distribution of the ‘randomness’ or not.
Random walks commonly are constrained (bounded) in which case the number of steps is bounded to a certain maximum, there is a ‘random walk length’. And there is a maximum to the expected excursion from the starting point.
In many processes the random walk is actually bounded, sometimes just one sided. For example stock prices are bounded on the downside to 0.
Many processes can’t be pure random walks because that could indeed imply unbounded growth.
See e.g.:
Stationary Processes That Look like Random Walks: The Bounded Random Walk Process in Discrete and Continuous Time [2002, João Nicolau]
And see also:
Random walk lengths of about 30 years in global climate [2011, Bye et al.]
Sure, but the post was based on an analysis of a brief finite range of years. Your critique is misdirected.
I found this to be a very informative and very well-written article. I have to admit, at first I could only marvel at how well Gates McFadden could simulate being knocked out by a faux slap. Then I started thinking: “What does this have to do with anything?”
Since the temperature record was never a legitimate argument for a man-made global warming crisis, due to the natural warming of the early 20th Century equalling the warming of the late 20th Century, this article doesn’t really add anything to the skeptical argument.
The following section from the article probably stokes the the crisis paradigm in the minds of any doom-and-gloomers who read that far:
“In fact, per the Causes of differences… paper cited above, the data is even consistent with a very large anthropogenic signal that looks smaller than it should because it is being masked by a random walk that has wobbled its way downward!”
The climate crisis paradigm has not been foisted on politicians and the public based on robust science and statistical analysis. Those things simply don’t exist for the warmests. They never have. The crisis has always been sold with emotional arguments and the irrational Precautionary Principle. If a crisis could happen (no matter how little the evidence supports it), shouldn’t we put an end to our CO2 emissions immediately? Of course, the answer is and very emphatic ‘NO!’, for very rational and sound reasons, but the warmests can’t hear those reasons. They are in an emotional state of fear!
http://www.michaelcrichton.com/state-of-fear/
“The whole aim of practical politics is to keep the populace alarmed (and hence clamorous to be led to safety) by an endless series of hobgoblins, most of them imaginary.” H. L Mencken
However, the take-away from the article – and one thing that an otherwise excellent article missed stating EXPLICITLY – is that the wise analyst, whether they are a stockbroker or a politician, does NOT</b lay any money down when there is no way to tell whether there is a trend there, or not.
What this analysis shows is that, even making the thoroughly invalid assumption that the currently accepted “data” for the last 132 years is accurate and unbiased in any way, it tells us nothing about the trend. The world temperature could be warming. The world temperature could be cooling. The world temperature could be static. No way to tell. Don’t mortgage the house to lay a bet; you are all too likely to end up huddled over a vent on the cold, cold street. The call by “warmists” to invest just about all of the GGDP – Gross Global Domestic Product – on the bet that the world is warming is the same as mortgaging everybody’s entire belongings, as well as their lives. Which is completely unacceptable.
Now, with a longer data set, we can show fully justified and mathematically defensible trends (as semi-regular cycles). That data set tells us that we will be drastically cooling in the relatively near future, as in a return of the massive glaciations. However, the error bars on that data set are such that we cannot say just when. “Coolists” are largely honest with their predictions; e.g., “Sometime in the next 10,000 years, Manhattan will once again be under a mile of ice.” So, of course, they don’t get much attention from the press (quite rightly, by the way…) Then again, “coolists” are not calling for a massive, economy distorting investment in fusion power plants and solar mirror arrays in space to hold off the glaciers. Many of us do call for reasonable investment in those things – but for near-term benefits, not the anticipated glaciation. We also have no problems with reasonable investments in improving solar cell efficiency, better batteries, and so on. Also for the near-term benefits, not to prevent the anticipated melting of the ice caps. (“Reasonable,” to me = “somewhere north of $100 million, but well south of $10 billion, per year.)
By the way an honest reading of the cycles says that the ice caps will melt away in the future – sometime in the range of 100,000 to 250,000 years from now.
Should be “by menacing it with” and endless series of hobgoblins. A favorite quote of mine since it describes AGW precisley.
AN endless series (typo)
Mikhail,
I think that this is a very-well written post, and it raises some extremely important points!
You said, “A logical prerequisite to any discussion about whether or not humans are causing climate change is the establishment of an actual upward signal at all.” Should the Red/Blue Team exercise come to pass, I think that this should be the first topic of discussion: “Are we seeing a rise in temperature that can be attributed unequivocally to anthropogenic forcings, or is it just an illusion?” I think that you have just raised the bar significantly for those who are alarmed by recent temperature changes.
First bullet point on the agenda should be “Are we seeing a real trend in temperature.” Period, dot. As shown by Mikhail – we cannot say that we are seeing a real trend in temperature. Meeting adjourned, where should we go for lunch?
Don’t mind where, as long as its filling and warming.
Exactly. Who gets to decide “normal”? Would we be happy with the temperatures of the LIA and were they “normal”, if a recovery from then is considered “abnormal”, or even “unprecedented”. Anomaly base years can be changed to produce very different results and Phil Jones didn’t want the 1960-91 base changed until he had retired, because so many stations disappeared. I believe the public at large know nothing of “anomalies” and think they are being being presented with real temperatures running out of control.
Temperature readings today are about 0.75°C higher than they were when measurement began in 1880,
That would put them where they were in about the mid 1920’s.