IT’S WORSE THAN WE THOUGHT~ctm
Public Release: 31-Jul-2017
From Eurekalert
University of Colorado at Boulder
Even if humans could instantly turn off all our emissions of greenhouse gases, the Earth would continue to heat up about two more degrees Fahrenheit by the turn of the century, according to a sophisticated new analysis published in Nature Climate Change. And if current emissions continue for 15 years, odds are good that the planet will see nearly three degrees (1.5 C) of warming by then.
“This ‘committed warming’ is critical to understand because it can tell us and policy makers how long we have, at current emission rates, before the planet will warm to certain thresholds,” said co-author Robert Pincus, a scientist with CIRES at the University of Colorado Boulder and NOAA’s Physical Sciences Division. “The window of opportunity on a 1.5-degree [C] target is closing.”
During United Nations meetings in Paris last year, 195 countries including the United States signed an agreement to keep global temperature rise less than 3.5 degrees F (2 C) above pre-industrial levels, and pursue efforts that would limit it further, to less than 3 degrees Fahrenheit (1.5 C) by 2100.
The new assessment by Pincus and lead author Thorsten Mauritsen, from the Max Planck Institute for Meteorology is unique in that it does not rely on computer model simulations, but rather on observations of the climate system to calculate Earth’s climate commitment. Their work accounts for the capacity of oceans to absorb carbon, detailed data on the planet’s energy imbalance, the climate-relevant behavior of fine particles in the atmosphere, and other factors.
Among Pincus’ and Mauritsen’s findings:
- Even if all fossil fuel emissions stopped in 2017, warming by 2100 is very likely to reach about 2.3 F (range: 1.6-4.1) or 1.3 degrees C (range: 0.9-2.3).
- Oceans could reduce that figure a bit. Carbon naturally captured and stored in the deep ocean could cut committed warming by 0.4 degrees F (0.2 C).
- There is some risk that warming this century cannot be kept to 1.5 degrees C beyond pre-industrial temperatures. In fact, there is a 13 percent chance we are already committed to 1.5-C warming by 2100.
“Our estimates are based on things that have already happened, things we can observe, and they point to the part of future warming that is already committed to by past emissions,” said Mauritsen. “Future carbon dioxide emissions will then add extra warming on top of that commitment.”
###
The research was funded by the Max-Planck-Gesellschaft, the U.S. Department of Energy and the National Science Foundation.
Disclaimer: AAAS and EurekAlert! are not responsible for the accuracy of news releases posted to EurekAlert! by contributing institutions or for the use of any information through the EurekAlert system.
Then why are global temperatures decreasing in 2017? And why is NASA now predicting a Solar Minimum? And why were there Winter storms in July in the Northern Hemisphere?
I suspect with the Sun putting out less energy the Earth will cool several degrees through 2030.
I suspect? Is that your argument? Any data that supports that suspicion? Australia’s temperatures are not cooling it is on course for the hottest year on record, again!
As I type this, my fingers are freezing off, yet again on a cold Canberra day. You can’t make stupid global warming claims on a day like this. Come back in the summer, when people may be more inclined to believe wild-arsed claims like that.
Doesn’t look like it according to GISS
112 stations to measure the whole of Australia? 68,500 square kilometers for each device, most located at an airfield of airport.
well it sure beats assurances based on models that do not support the assurances, let alone agree with the actual data Steve….
Wow! Next time the IPCC delivers a report on global warming they should ask Hivemind how cold his hands are? So if you put some gloves on and your hands are warm then climate change is happening? You do know the difference between weather and climate don’t you? I will point to the gathering of data by the Bureau of Meteorology, Australia in 2017 is heading towards record temperatures.
And does your BOM claim include the admission by BOM that have misrecorded minimum temperatures by artificially limiting the minimum that can be recorded? And I never knew Australia was the entire globe?
Wikipedia, which is well known for its warmist stance, cites the hottest temp recorded as 50.7 °C (123.3 °F) at Oodnadatta, South Australia on 2 January 1960, and perhaps more significantly cites (as a world record), the most consecutive days above 37.8 °C (100 °F): 160 days; Marble Bar, Western Australia from 31 October 1923 to 7 April 1924
If you want to know what a warm year was, you need to go back to 1924.
PS. As we all know BOM data is very suspect, and one should be extremely cautious with anything they put out. You would be well advised not to be taken in by mere propaganda.
And then of course there is BoM. Using the tracker data for mean and maximum show 2016 was not really hot.
http://www.bom.gov.au/climate/change/#tabs=Tracker&tracker=timeseries&tQ=graph%3Dtmax%26area%3Daus%26season%3D0112%26ave_yr%3D0
I don’t know if that will work.- or
http://www.bom.gov.au/climate/change/#tabs=Tracker&tracker=timeseries
So Steve, are you actually denying that the earth has cooled noticeably in 2017?
As to David’s comments, why don’t you get equally upset about all the weasel words in the various AGW forecasts?
Don’t be obtuse, Steve. David cited three indicators:
decreasing global temperatures in 2017
NASA predicting a Solar Minimum, and
winter storms in Northern Hemisphere summer
It has become a ritual to media to present what the international media reports relating global warming or climate change using suo-motto global warming and its impact on all types of sundry issues. All those articles presented in this web also appeared in Indian media.
The Prime Minister of India attributed global warming for the floods in northern parts of India. While south is in deficit in rainfall. On this I sent the following:
Open Letter to the Prime Minister of India:
The Current Floods in northern India are part of Natural Climate only”
Dr. S. Jeevananda Reddy
Hyderabad, 31st July 2017
Respected Prime Minister,
Sir, this is with reference to your statement – mann ki baat, 30th July 2017 — attributing present floods in northern parts of India are due to global warming.
This is not correct. They are part of natural climate of the respective regions. Unfortunately, Sir, you have been given wrong advice by mediocre groups of advisors – this is true with majority of the advices under mann ki baat.
This will severely affect the country in terms of agriculture and floods and flood management, reservoirs water managements, etc. In fact I submitted a detailed letter on this to you, Sir, dated 14th January 2016 titled “Is Global Warming a Reality?” for your kind perusal and appropriate actions in this regard. To meet the political greed, (1) we are destroying coastal zones and this in turn affecting millions of people and millions of acres of fertile lands with the tidal fury; and (2) polluting coastlines by dumping both solid and liquid wastes.
The present day hype on the Global Warming and Paris Agreement on Climate change are political in nature to share one billion US dollars Green Fund per year for five years only. So far the so-called Global warming component of global temperature anomaly is around 0.15 oC only, which is insignificant to influence Indian rainfall or for that matter the general circulation patterns that influence the India weather. Let me explain this with Gujarat met sub-divisions rainfall data [1871 to 1990].
Gujarat Met Sub-division [21]:
The mean annual rainfall is 907 mm with a coefficient of variation [CV] – presents the nature of year to year variation — of 31%. The same during the Southwest Monsoon (SWM) [June to September] period is 863 mm and 31%. During the 120 year period the highest rainfall recorded was 1578 mm in 1878 and the lowest was 211 mm in 1899 – annual rainfall during 1899 was only 222 mm –. This met sub-division received > 1000 mm of rainfall in 42 years and 600 mm in 12 years and 500 mm in 8 years and < 100 mm in 18 years.
You can see the contrasting rainfall [from June to October] in 1917 and 1899:
1917 – J-155, J-298, A-357, S-353, O-224 mm
1899 – J-171, J-013, A-010, S-017, O-001 mm
Saurashtra & Kutch [S&K] Met Sub-division [22]:
Gujarat Met Sub-division receives better rainfall pattern while Saurashtra & Kutch Met Sub-division receives highly variable rainfall pattern.
The annual mean rainfall of S&K is 467 mm with CV of 43%. The same during the SWM is 432 mm and 45%. This clearly shows major part of rainfall occurs in SWM only. The highest rainfall in 1878 was 1080 mm and in 1959 it was 1072 mm. The lowest rainfall in 1889 was 82 mm and in 1987 it was 63 mm.
The mean and CV for July are 189 mm and 68%. The highest rainfall in 1894 was 603 mm and in 1959 it was 672 mm. The lowest rainfall in 1889 was 3 mm and in 1949 it was 13 mm.
The mean and CV for August are 111 mm and 86%. The highest rainfall in 1900 was 472 mm and in 1953 it was 434 mm. The lowest rainfall in 1877 was 6 mm and in 1966 it was 5 mm.
Even if we look at West and East Rajashan met sub-divisions [17 & 18] rainfall, they present high variations similar to Gujarat and S&K met sub-divisions: Mean & CVs are 294 mm & 37% and 694 mm & 25%. In both the cases most of the annual rainfall occurs in Southwest Monsoon period which are 256 & 636 mm.
Other issues:
Sir, here one important point is that the rainfall occurs in rhythmic pattern. Unless these are not characterized through the analysis of long term rainfall data series, the citizens will suffer in all respects and politicians gain. The current floods are not new to these regions. The governments failed in implementing appropriate disaster management practices, as this is against political culture.
Unfortunately it has become ritualistic to attribute everything to global warming. It is a bad science.
Sir, it is the right time to have qualified advisors, at least by the next mann ki baat telecast.
Sir, if central government follows the footsteps of the state governments, people of India suffer. To clarify this, a simple example is, the two Telugu states bribing the opposition elected representatives from other parties – who won against the very same party – to get more MLCs and MPs to Rajya Sabha through them. Now BJP ruled states are following the same and central government is encouraging them [directly/indirectly]. The Rajya Sabha nominations show phenomenal growth in the assets of the people fighting for getting a birth in RS. Such people, will they serve the nation or for that matter people to achieve the goals enunciated, Sir in your mann ki baat programmes except wasting of public time!!!
With kind regards
Dr. S. Jeevananda Reddy
Formerly Chief Technical Advisor – WMO/UN & Expert – FAO/UN
Fellow, Andhra Pradesh/Telangana Akademy of Sciences
Convenor, Forum for a Sustainable Environment
Hyderabad, Telangana, India
jeevanandareddy@yahoo.com
https://www.climatecouncil.org.au/2016-hottest-year-report One bloke below comments about a particular area in Australia as being really hot for a number of days, so therefore it must be the hottest year on record was the conclusion. Really? And then sites Wikipedia as his source of information. This is at the end of his comment …… “PS. As we all know BOM data is very suspect, and one should be extremely cautious with anything they.put out. You would be well advised not to be taken in by mere propaganda”. What this buffoon didn’t realise is that Wikipedia got their information from the BOM. I rest my case!
That would be great if you had a case! You don’t even have a clue!
Steve
I note that you did not wish to respond directly to me with evidence refuting the point that I made.
Wikipedia is well known as a warmist site. It is a gatekeepers kept site. If one tries to edit articles to give a more balanced view, anything which runs against AGW is promptly deleted.
But it was not just a few days. It was a sustained period of 160 days. That is right ONE HUNDRED AND SIXTY DAYS>That is the best part of half a year, It is more than the whole of the summer.
How many consecutive days were above 100defF in 2016, how many in 2015, how many in 2014.
I would be extremely surprised if there were 60 consecutive days, ie., nothing like 1924 when there were 160 consecutive days above 100degF.
As regards my postscript, after my comment, you will note that there are now 2 recent articles on BOM, BOM is a complete disgrace, and has been for a long time. Anything they produce should be taken with a pinch of salt.
Two points==>The models used to relate CO2 to temperature have run too hot in the past, so the estimate is highly dubious. And, so what? We are probably not as warm yet as the Medieval Warm, and very likely not as warm as the Roman Warm, which were decidedly not climatic disasters.
Sorry, that’s bollocks.
Observations do NOT “point to” anything. Certainly not anything that may occur in 100 years time. Humans are what “points to” something and it’s called extrapolation. Extrapolating 100y hence on the basic of time limited and highly uncertain “observations” is totally unscientific and would be laughed out of court in any hard science.
Whether they are using complex GCMs or some other extrapolation technique does not change the fact that it is invalid extrapolation , way outside the data sample, Their attempt to pretend that this is “observations pointing to ” is completely false and a blatant misrepresentation of what they are doing.
“The window of opportunity on a 1.5-degree [C] target is closing.”
The basic salesman’s trick again: create urgency, close the sale.
Observations point to a very low sensitivity, as water vapor provides nearly equal negative feedback at night.
Yep, time is running out, so call within the next fifteen minutes to secure your future survival.
Only $ 19,999.99 will help accelerate research to save your butt. Don’t delay. Only fifty investment opportunities remain open. … In the USA, just call 1-900-CO2-DOOM. That’s 1-900-CO2-DOOM.
Would that be urgent enough?
micro,
Night? What’s that? You mean we have to figure that there’s day AND night stuff going on? We can’t just blur it all into some average something or other?
Bullshitometric concordance:
could 3
would 2
“odds are good ” = may 1
“very likely” = may 1
“There is some risk that” = may 1
“there is a 13 percent chance” = may 1
“they point to” = may 1
10 mystical references = 10 dimensional fantasy
They seem to be confused as to what a computer model is. I simply cannot see that they are doing anything actually different. Take numbers, do something to them.
“The window of opportunity on a 1.5 degree C target is closing”
If we’re having trouble coming up with the money they’ll give us some more time!
And certainly not as warm as the Holocene optimum.
The theory states that each incremental unit of carbon dioxide has less impact than the one that went before, and it takes a doubling (250 ppm to 500 ppm, 500 ppm to 1,000 ppm) to create 1.6 degrees of warming. Ergo, HOW could the warming be “baked in the cake” if we continue to release carbon dioxide at the roughly same RATE? Don’t we have to continually be doubling the release of carbon dioxide to maintain the same rate of warming?
And you’re right – the models have been running consistently hotter than reality. This is because the models greatly overestimate one thing – climate sensitivity, which appears to be very low.
Let me take a stab here – assume we release carbon dioxide at a constant rate. And that climate sensitivity is nearly zero. What we would see in the temperature record is some rapid warming, ten slowing in, then an extended pause – since it takes longer and longer to double atmospheric concentrations. Is it just me, or isn’t this exactly the pattern we are seeing?
Tenn, the broken CAGW THEORY is that feedbacks above the direct ghg affect will amplify the warming over time.
So let me get this clear. They are all wrong, all the scientific institutions around the planet are all making stuff up all at the same time and with all the same made up conclusions. Every institution in every country in the world are in on the scam? Really? Who is telling all of these countries to make up the data? Australia is heading towards the hottest year on record again! Of course its all fake news!
“Steve August 1, 2017 at 4:31 pm
Australia is heading towards the hottest year on record again!”
No it’s not.
Steve,
I would suggest that you study the history of Eugenics. Perhaps a visit to the Holocaust Museum would enlighten you on how “every institution in every country in the world” were “in on the scam”. Maybe then you will see that what appears to be only possible with a grand conspiracy is in reality the result of human herd mentality.
Patrick, “Australia is heading towards the hottest year on record again!”
No it’s not.”
That depends on BoM.
“lee August 1, 2017 at 10:15 pm”
Yes, certainly does depend on BoM fiddling with numbers.
Pretty much yes, Steve.
As my Phd academic brother in law says “we are not independent experts, we are public sector employees and we produce what the government tells us”.
Scientists have egos, bank balances and families just like everyone else.
You need to step back and see ‘climate change’ in broader political and economic context, and ask yourself:
Cui Bono?
And then it becomes clear that for some very powerful elites who are loosely affiliated, Climate change is a massively convenient lie.
At least in the short term.
Now I don’t know whether your income and career depends on ‘climate change, the narrative’ as a paid astroturfer, or whether you are just a ‘useful idiot’.
Human society is changing rapidly. Today’s elite may not be tomorrows elite. That is the real story.
The climate? Not so much. It really is about the same as it was 60 years ago, plus minus natural variation.
What controls what people buy, how they vote, and how they act, in all facets of life?
Their perceptions as to what is real and what is not.
The perception of a jihadist on a self righteous moral crusade, is not the same perception as an engineer designing a computer chip, nor yet a gun toting libertarian from the flyover states.
Controlling perception is the tool of corporate marketing, political marketing, and mass religious entities. And their chief agents are the MSM and their hirelings, Hollywood et al. And of course churches and mosques.
You really dont think they are going to let environmentalism have an independent existence, when the whole green movement could be (and was) bought for a few million dollars?
Climate change was never really science. It was always from that start a political and commercial emotional narrative, a story based on fear and guilt that would appeal to a certain class of person who would otherwise have been a pain in the ass.
It uses standard propaganda faux logic and reasoning. The assertion ‘man is making the world dangerously warmer’ is not supported by the evidence. So evidence is created using ‘models’.
When faced with two competing narratives, neither of which can be proved to be true, and both of which seem plausible, most lay people will pick something in between. So in climate change most people think its getting a bit warmer due to human activity and it might be a bit dangerous.
But game theory and straight logic shows that if one protagonist is shameless and conscience free and does not care about truth, only about outcome, this human tendency becomes very dangerous,
If one side deploying huge amounts of money is able to make, unopposed, seriously outrageous claims, then the centre of gravity of public consensus will be moved a long way from ‘fact based’ understanding.
I dont know why you are a protagonist for this lie Steve. That’s between you and your conscience, if you have one. I dont know if its your bank balance, or your ego that benefits.
But I will leave you with a final thought. Momma Nature don’t dig propaganda. Nature is as Nature does. The precautionary principle applied correctly says that in the absence of certain knowledge we should do nothing, so lets stop spending trillions of dollars on stuff that doesn’t even work as advertised, and start saving it up for stuff we might actually need for a real crisis we haven’t even thought of yet.
Like mass migration as populations exceed Malthusian limits in local contexts, or asteroids that hit, or Yellowstone park erupting…and where our high priests sacrificing on the altar of Climate Change are found utterly and completely wanting, because they have dealt with nothing but propaganda for so long they have zero competence in dealing with the Real World™.
Do you know, Steve, what scares me most? You do. People like you, who are either bought up by propagandists, and don’t care whether you talk the truth or not, or are stupid enough to believe what propagandists tell you.
You and your ilk are fighting a public relations war to keep powerful and greedy people in powerful and lucrative positions.
The rest of us here are definitely worried, not about the lies you propagate, but about the fact that the successful propagation of lies is bad, not just for the plebs whose perceptions you are in the business of controlling but also for you, and the elites you support.
You are messing with forces you do not understand. In a dangerous way. The society you live in depends on the mindset of at least a small subset of humanity, charged with the construction and maintenance of its infrastructure, knowing what is real and what is not. An environmental jihadist may net you the political power you crave, may sell the green products you have designed, but he wont be able to fault find a broken internet. Or grow crops. Or construct a nuclear reactor.
What have you ever done to create support or maintain the world that created supports and maintains YOU?
Instead you would seem to be working for it’s destruction, in a typically Marxist act of stupidity in the mistaken assumption that if today’s society and civilisation is destroyed, a better one will naturally arise,.
A nice narrative., It didn’t work in Russia. It didn’t work in Cuba. It didn’t work in Zimbabwe. It isn’t working in Venezuela, and it only worked in China when they stopped destroying and started building anyway .
Steve. Wake up, smell the coffee. Are you the psychological equivalent of a neighbourhood drug dealer selling addictive narratives to people who need something to believe in? Or will you join the people who wake up to the fact the world is a lot different from the cosy propaganda stories we have all been fed. People are not naturally nice, they are naturally vicious aggressive grabbers and takers, and nice guys are the ones getting shafted. Man is not in control of anything but other men’s minds. Nature is. And what is in your mind is not the same as what is outside it. And the greater the difference the more danger you are in.
And that in fact, today, the environmental movement is part of what they always warned you about. And you are just a useful tool.
Take the red pill Steve.
Leo, well said.
So again they are all in on it? https://climate.nasa.gov/scientific-consensus/ these guys are all in on it, all of them. If that’s the case, who is co-coordinating this? Not one of the respondents linked to any science at all. All I got was an attack. Stick to the science, provide links, not personal opinions or abuse, please!
Because that’s never happened in science before? Except all the time. Particularly when all the money flows to a single viewpoint, science is inevitably dominated by Groupthink, and it can take decades to change course. Look at Keys fat hypothesis for CVD for example. And the claimed increases are so small relative to the raw data, that it is easy to convince your self the adjustments are correct. Scientists are human, and like all of us are prone to self-delusion. That is why scepticism is the default scientific approach.
“So let me get this clear. They are all wrong, all the scientific institutions around the planet are all making stuff up all at the same time and with all the same made up conclusions.”
Yes, Steve, that is pretty accurate. The only reason why you think that is outrageous is that you are apparently unaware of the history of science. The history of science is not a constant flow of increasing understanding of nature. It is often stagnant and then lurches from one wrong paradigm to one that is usually, but not always, better than the one it replaces. But scientists aren’t ‘making stuff up’ willy nilly. They are making stuff up to fit the current paradigm. Every observation is filtered through the paradigm. Every calculation is governed by the paradigm. Every conclusion is put into the context of the paradigm.
This is currently happening in climate and in cancer. The evidence is overwhelming that CO2 is not a major driver of global temperature. The evidence is overwhelming that cancer is not a gene problem, but a cell metabolism problem. Despite this evidence, all major institutions continue to operate exclusively in the faulty paradigms, and demonize anyone who tries to point out why they are incorrect. In both cases, there is a huge amount of money driving the faulty paradigm, and almost no money to be made in the better paradigm. The cancer paradigm will likely shift in the next 5 to 10 years, because thousands of people are needlessly dying every day under the current, pharmaceutical controlled paradigm. That is a huge incentive to adopt the metabolic approach which is showing amazing success. The climate paradigm may take longer, because people are not directly dying from carbon mitigation schemes, although the indirect deaths are becoming more noticeable.
For some reason, Steve wants us to be impressed that the politicians who run these organizations are making decisions based on politics.
Leo Smith
August 2, 2017 at 12:13 am
Wow, very well said Leo Smith!
Steve:
We are in a grand fight in the halls here. Two sides attempting to point at the obvious thing they see in the data. It is blatantly obvious isn’t it?
Except it isn’t really two sides, it is many.
There are folks who see the consequence of the pronouncements pointing at changes in policy.
There are folks who see the irrational in the data presentation.
There are folks who see big [something] involved in the process.
There are folks who think science is absolute.
There are folks who think science application.
There are folks who think atomization of a problem will help solve it.
The list goes on.
If any one of us attempts to keep all of these groups in mind as we write comments on a blog, we will sound like a chaotic imbecile. If we target just one, we can easily be perceived from a wrong point of view. Life sucks.
I learned yesterday that one of my idols of the skeptical world (as in James Randi and Dowsing), believed that he could Prove something scientifically. I assumed that he understood that that was impossible. The best we ever do is fail to disprove.
That sucks.
To summarize. Yes, THEY ARE ALL WRONG!. We are all wrong. That is the nature of the problem. Every morning we wake up and continue to try and minimize how wrong we are. We do not maximize how right we are. The difference is really really hard to point at. There are people reading this nodding their heads and saying “Exactly”, there are others who think I am playing semantic games.
Communication always fails. The miracle is how often the failures result in successful outcomes.
Well, let me first say you ask a good question. Which deserves a good answer.
1) Climate science and climate change as a subject is exceedingly complex. We can agree on that right? The general public doesn’t get it. Politicians don’t understand it. Certainly the news is clueless. One of the problems is it is cross disciplinary – people who understand the geologic record don’t know meteorology. Those that understand meteorology may not understand statistics, or physics, or the sun…all in all it gets very, very complicated. Modeling the climate is probably one of the most difficult things human beings have ever tried to do. Harder than the moon landing.
2) I think this all started with genuine, heartfelt, concern. Imperfect studies and models reveled that we might have a problem. I’m not faulting the initial studies and models – they did the best they could do with what they had.
3) This possible problem, once identified, was seized on by environmentalists and politicians alike. Environmentalists always think humans are despoiling the environment. Leftists, being anti-capitalist, saw this as a vindication of their beliefs. Politicians saw the best thing of all – a never ending crises that only they could manage.
4) Bad news on climate and bad research was trumpeted, and richly rewarded. Doubting studies (and there have been many) were discounted and attacked. Everyone was claimed to be in the pocket of big coal, big oil, big something or other. At the same time, there were many well meaning people, people who believe that they are genuinely saving the world. That if we don’t gin up a climate panic, we are all going to die.
This goes to the question of whether, if you could go back in time, would you kill Hitler? It sounds silly, I know, but would you? How about when he was a baby? Would you kill his parents to prevent his birth? It is a moral question – what level of evil would you perpetrate to save the world? Would you change a few numbers here or there? Tweak a model to show greater warming? Knowing, if you don’t, people might not be scared enough to take the drastic action necessary to save the world? That you could be the person that killed the planet? How about attacking skeptical voices? Or maybe just snubbing them? Now add to that, you get social pats on the back, money for research, all sorts of things for doing it? You get told you are a planet saving hero.
Imagine another scenario. You own a very powerful telescope. The only one in the world. And you see an asteroid that might strike the Earth in 100 years. Say it has a 10% chance of hitting us. You think, wow, this is definitely something we should prevent from happening. But you worry – it is going to be expensive to divert the asteroid, and it is only a 10% chance of a hit. Would you be willing to tweak the data, maybe just a little, to show it being a 20%, or even 50% chance? Especially if you weren’t entirely sure of your 10% calculation? Err on the side of caution? So you tweak your data a bit to show a higher probability. And that is what you report.
5) So we have a LOT of people who don’t know what they are talking about attacking skeptics for political social reasons. We have a lot of scientists pressured (socially, financially, morally, etc.) to put a thumb on the scale. Many of them don’t know the whole picture – just their little slice of it.
Now, I write this as a believer in global warming – I just think, based on the real observed response of the environment to carbon dioxide emissions to date, that the problem is enormously overstated and overblown. It is a minor problem we are likely to solve at little or no cost (just look at the carbon dioxide emissions in the U.S. over the last 15 years), and certainly without having to resort to drastic social and economic changes. Yet, as a scientist, I dare not express this belief publically and openly.
Why? And why do I know many scientists who feel the same way I do? And is that good for the science of climate change?
“So let me get this clear. They are all wrong, all the scientific institutions around the planet are all making stuff up all at the same time and with all the same made up conclusions.”
It doesn’t take everyone. All you need is a few well placed people to alter a data set here and there that everybody else uses as the basis of their research, and the fix gets baked in to everything else.
Watch this …
[youtube https://www.youtube.com/watch?v=wgKQIfPr9to&w=560&h=315%5D
… and then come back and comment on whether or not you think that ANY scientists are making stuff up. That will be the first step down a better path for you.
Pal Review. ‘Nuff said.
@ThomasEdwardson you can’t find something if you never look. Or if you do look you do not see anything.
https://micro6500blog.wordpress.com/2016/12/01/observational-evidence-for-a-nonlinear-night-time-cooling-mechanism/
@ThomasEdwardson you can’t find something if you never look. Or if you do look you do not see anything.
https://micro6500blog.wordpress.com/2016/12/01/observational-evidence-for-a-nonlinear-night-time-cooling-mechanism/
“sophisticated” means that previous analysis was not?
“There is some risk that warming this century cannot be kept to 1.5 degrees C beyond pre-industrial temperatures. In fact, there is a 13 percent chance we are already committed to 1.5-C warming by 2100.”
Who wants to live in their pre industrial world where people were freezing, people were reading by candlelight, and food production was insufficient? For an alleged 13% chance?
The elites and climate manipulators should go for it themselves and leave us peons alone.
I just can’t get my head around why people are so worried about what will happen to mankind when they themselves are long gone. Are they REALLY REALLY worried about that? Do they lie awake nights? Are they that unselfish and altruistic? Really? What about the suffering of their fellow humans in the here and now? That suffering is real. It is not computer generated. It is REAL! Look at the plight of innocent Syrian women and children fleeing their war torn country? If they are REALLY concerned about mankind, I suggest they put the models away and work on relieving the misery of these innocents and the many millions like them around the world. Let 2100 take care of itself.
Nicely put. . .but theoretical compassion doesn’t work in real time Trebla! Real compassion is too hard for scaremongers . .
Actually sort of yes, a little but mostly because who wants to admit they aren’t?
That’s how the Left works in terms of virtue signalling.
“Do you mean that as long as your life is great, you dont care what happens to the world after you are dead?”
Who has the courage to answer
“Yup” ?
Which is why the mass hypocrisy exists. Paying lip service to state education but sending your kids to private schools. etc.
Ah, but then they are not saving the world. The Messiah Complex drives far too much of our science and politics.
Phil Jones says critical 2-degree C limit was ‘plucked out of thin air’
True. By PIK’s Joachim Schellnhuber. He was giddy with the admission. NoTricksZone amongst others covered his presser on it.
POOMA, more likely.
Yeah, basing all this on a 2C figure, that was chosen for no reason that anyone has ever explained.
Cities are up to 20 degrees hotter than the surrounding countryside and birds , bees, flowers and trees seem to thrive in this hotter micro-climate.
“hereby dense cities have been empirically found to be up to twenty degrees Fahrenheit warmer than their surrounding hinterlands’
http://www.yalescientific.org/2013/05/five-things-you-didnt-know-about-cities/
Nature does just fine when it’s warm.
Personal opinion? Any science behind your claim?
“Personal opinion? Any science behind your claim?”
Have a look at say biodiversity as you from pole to tropic. Tell us what you see.
Just look out your window Steve. The evidence is there, if you will pull your head out of your models long enough to see it.
“Dr. Pincus’s work focuses on the interaction of clouds and radiation. His interests include the representation of clouds in global models, the evaluation of those clouds using observations, the use of observations to develop process-level understanding, and the coupling between radiation and dynamics in models at all scales. ”
https://experts.colorado.edu/display/fisid_121596
I suspect that Dr Pincus has just indulged in an extravagant piece of circular logic. He supposedly focuses on the “interaction of clouds and radiation” and does his evaluation using observations. He would surely have observed the ~4.5% decrease in cloud cover over the period 1985-2009 (assuming he doesn’t have access to cloud data not available to everyone else). He would have attributed that change to radiation (ie. he would have assumed that radiation caused it) and then used that assumed interaction to determine that future radiation would cause future cloud cover decrease. ie, he concluded that we would get exactly what he had assumed. A commenter above used a rather negative word to describe Dr Pincus’ work. IMHO it was justified.
“warming already baked in”
This is an excellent description of climate science itself. To bad we can’t Chop it. This is not a dessert.
Andrew
Crimatology is a half-baked science.
only 13% is baked in – so is 87% is baked out?
A 13% chance does not mean it is “baked in.” I would like to invite these authors to join me in a game of chance where they have a 13% chance of doubling their money and I have an 87% chance of pocketing their bet. If they think 13% means their chances of winning are “baked in,” then they shouldn’t hesitate to accept my odds, right?
13% that is the 2 pick odds on Keno. Keno is a very popular game in Las Vegas, so odd are with what I can see about the IQ of you average “climate scientist” they might actually take you up on your bet.
If we could just hang on for another 100 years, who knows what new climate control technologies we’ll have! Unless we’re too impoverished from trying to control the climate before we’re ready to be flexible and innovative.
Among the many things they don’t get, any solution developed 10 or 50 or 100 years from now will be better than any solution developed today. Force a solution before it’s ready and it will be more expensive, more cumbersome, and less effective.
Forcing a solution before you understand the system you are attempting to control is a recipe for unmitigated disaster.
We have no idea what we are doing so how can we event think we know what should be done to get a desired result?
Except that they dont actually care about the solution.
the solution is not a solution to ‘climate change’. That’s massive misdirection. Its a solution to constructing a profitable business and virtue signalling your way to political power.
The Lie is so Big that you haven’t quite caught on yet.
The higher probability thing to predict is that demographic change in Europe to a more fatalistic society will put a stop to anything that remains of the wifty-poofty science of the clime and more than a 13% chance a stop to science altogether, even honorable stuff, a 100% chance Mona Lisa, history, real science and and innumerable other things gone…plague and nouveau classical ruins for future archeologists. I’m usually such a cheery guy.
Gabby Pierce:
Your post at 3:08 pm contains one sentence with about 195 words
and another sentence with 6 words.
Please make up your mind.
And what does wifty-poofty mean?
Not that there’s anything wrong with that.
There appears to be two other uses of this derogatory expression on the internet. An onomatopoeic explanation for “wifty-poofty” science could be: Science based on a whiff of this idea and a whiff of that belief — and POOF! — before you know it you have a full-blown meme, ready to scare the gullible into funding a solution to the non-problem.
Let me guess – they’re assuming a hundred years of warming because the CO2 we already have in the atmosphere will stay in the atmosphere, no matter what. Even though it left the atmosphere BEFORE, due to being absorbed by plants…
That’s one of the “I saw you hide that card” things about AGW: they make dire assumptions because, well, reasons. They assume that, even though they know CO2 only has a five to seven year lifetime in the atmosphere, that any CO2 absorbed by plants will almost immediately be re-released because “the plants will die.” And turn into vapor, apparently.
90% of the CO2 has been locked up in limestone by shelled sea creatures. They never rest.
This is what happens to CO2 if we stop emitting today (a few years out of date now but accurate none-the-less). Almost certainly not the way they calculated it but then climate scientists have never understood this issue and they are just bad with math all the time anyway.
Said same thing differently in my comment below. Just the logic, not the math.
Just a heads up on more data adjustments to come?
Exactly!
Are their crystal ball gazings based on their mysterious upward adjustments?
We in Australia are continually exposing these upward adjustments but the government continues to run shotgun for our beureu of meteorology. By refusing to initiate an independent audit into its fraudulent practices of raw data manipulation.
While introducing government policy to “fight” the mythical global warming based on that very same fraudulent data.
That very same beureu of meteorology has just announced, with much fanfare, the “hottest July” in over a hundred years in Australia. Which was headline news from print to digital media and plastered across our tv screens right around the country.
What wasn’t reported is at the link.
http://joannenova.com.au/2017/08/scandal-australian-bureau-of-meteorology-caught-erasing-cold-temperatures/
don’t interrupt me, I’m a changing the spark plugs in my all electric car
Dr. James Hansen, arguably the inventor of CAGW has dialled back the alarmism. link Clearly, some folks didn’t get the memo.
There is wide agreement that the transient climate sensitivity is not what they used to think it was. They have postulated that equilibrium climate sensitivity is greater but we’ll be in the next glaciation before that kicks in. 😉 link
Maybe that’s what all the adjustments are for.
If the media reports that a tree has fallen in the forest, based solely on computer models rather than observations, did it actually happen? If climate scientists adjust global temperatures to 2 degrees of warming based on computer models rather than observations, are we still doomed?
“Committed warming inferred from observations”
http://www.nature.com/nclimate/journal/vaop/ncurrent/full/nclimate3357.html?foxtrotcallback=true
Their climate sensitivity looks reasonable…
http://www.nature.com/nclimate/journal/vaop/ncurrent/carousel/nclimate3357-f1.jpg
Nice graphs. Any data points there?
It is a competent study and, being based on an observations and a very simple model rather than complex climate models, it is much more realistic than many.
However, the claim in the University of Colorado press release that “Even if humans could instantly turn off all our emissions of greenhouse gases, the Earth would continue to heat up about two more degrees Fahrenheit by the turn of the century” seems to be wrong. The paper’s 1.1 K (= 2 degrees Fahrenheit) figure is for warming from pre-industrial levels, not from recent levels. The turn of century projection is for only about 0.3 K (just over half a degree Fahrenheit) more warming than the 0.8 K that has already occurred (based on the 2005-2015 average). I have advised the authors of this mistake. (The news release at the Max Planck Institute, where Thorsten Mauritsen is based, does not make this incorrect statement.)
The calculated future warming includes the effects of not only ceasing to emit greenhouse gases but also ceasing to emit aerosol precursors. The resulting reduction in cooling aerosols accounts for much of the 0.3 K projected future warming.
Thanks for pointing this out Nic. Doesn’t this paper accept the notion that all the warming since the industrial revolution (.8C) is from fossil fuels to make their projection of future warming? If so this seems to me to be a poorly founded assumption. In light of the new papers demonstrating no correlation between emissions and temp and even no correlation between emissions rates and growth of CO2 in the atmosphere and the new one showing back radiation almost completely controlled by H2O I think that assumption is on very shaky supports.
Yes it does. And that per AR4 WG1 figure SPM.4 is clearly an erroneous assumption. See my recent guest post here, ‘Why Models run Hot’ for details.
DMA, Yes, this paper assumes that almost all warming since preindustrial times is from human causes, mainly greenhouse gas emissions. I’m not sure what papers you refer to that challenge that. I think that it is a good working assumption, albeit that it might turn out that natural influences account for more than a minor part of the warming to date.
In fact, the correlation over the instrumental period (~1850 to date) between the estimated radiative forcing generated by greenhouse gases and other human influences on the climate (eg, via aerosols) is pretty high, particularly if the effects of sporadic explosive volcanism and of multidecadal variability in (north) Atlantic surface temperatures are allowed for. When doing so, I obtain a correlation of over 0.9. But the regression slope (the amount of warming per unit forcing) is substantially (~30%) lower than in most of the global climate models used by the IPCC.
I also find, using a simple but scientifically reasonable model, that carbon dioxide atmospheric concentration, and hence the radiative forcing it exerts, can be expected to grow somewhat more slowly with cumulative emissions than the complex climate models used by the IPCC assume.
Nic
The H2O vapor paper is just out-Lightfoot 2017, The correlation papers may be only online so far but are Wallace 2016 and 2017and are discussed at “http://www.carlineconomics.com/archives/3533”
Is there any reason to assume that all the warming since the last Ice Age (13,000 years ago, sea levels 130 m lower) has not been man-made?
DMA, you say “The H2O vapor paper is just out-Lightfoot 2017”
I can’t find any paper matching that author and year in Google Scholar. What is the title, and/or the name of the journal?
nic, the correlation is only high is you take the temperature at the start of the CO2 run up and compare it to the temperature today.
On the other hand, we have 100 years of warmup coming out of the LIA, with little to no increase in CO2 levels. Add to that, over the last 70 years temperatures have gone up, gone down, and stayed the same, all while CO2 was increasing monotonically.
The correlation is weak, very weak.
The globally averaged temp change between 1850 to 1950 is about the same as the globally averaged temp change between 1950 – present, but almost all the “excess” CO2 has been released since 1950. Hypothesis: There is a background warming trend (unrelated to CO2) since preindustrial, and then the rate of warming increased noticeably around 1950 as the CO2 concentration in the atmosphere went up relatively fast. Assuming the background trend is still ongoing, then one would have to hypothesise that not all the observed warming since 1950 has been driven by CO2 alone.
Thanks nicle, while you’re at it ask then exactly when the LIA ended
Easiest ‘precise’ date is 1814, the year of the last Thames ice fair.
By 1814 the CET had four out of five coldest winters on the record, but an outlier occurred 150 years later. Five outstanding cold winters in the CET records are
1. 1684
2. 1740
3. 1963
4. 1795 & 1814 (equal)
in 1963 Thames partially froze.
http://i.dailymail.co.uk/i/pix/2013/01/17/article-2264031-16FED33F000005DC-848_634x355.jpg
by 1963 the huge increase in the London’s population and industrial activity kept river temperature higher. During 19th and 20th centuries large parts of the Thames river banks were reclaimed, embankments were built to hight of 6-7 meters, resulting in a much faster river flow.
p.s. the 22 storey high building on the South Bank, on the other side of the Waterloo bridge from the Faraday and Marconi houses, where I spent most of my working life, was build in 1971 behind 6m high wall, now an embankment; its ‘floating’ concrete platform is balanced by four huge hydraulic jacks.
<b.You forgot to mention the winter of 2010/11. As per Wikipedia:
Incidentally the winter of 2009/10 was also a very cold winter. It was said to be a 1 in 30 event, and the winter of 2010/11 that followed was said to be a 1 in 100 event. Both were due to a blocking high which brought clear skies and the high Arctic jet stream further south. At low levels there was all but no wind, and wind energy for about 30 days averaged less than 8% nameplate capacity. Many days it was net drawing energy from the grid.
The UK would have faced disaster had it been highly dependent upon wind energy for its energy in these conditions which as I say extended for about 1 month in almost record cold temperatures.,
the above quoted years are for average of the three winter months, Dec-Jan-Feb.
I want to illustrate one of the really relevant findings of Mauritsen et.al and cite their fig.1:
http://i.imgur.com/KnfPGfU.jpg
From observations they confirm a TCR of 1.32 and an ECS of about 1.8 which is very near to the estmates of Lewis/Curry and some posts in the past here and elsewhere.
The link to the (correct) PR from the Max Planck Institute Hamburg : https://www.mpimet.mpg.de/en/communication/news/single-news/news/aus-beobachtungsdaten-abgeleitet-einfluss-frueherer-emissionen-auf-zukuenftige-temperatur/
I also add the HadCRUT4 temp data in support of my comment. (Couldn’t figure out how to edit the original, so leaving a new comment).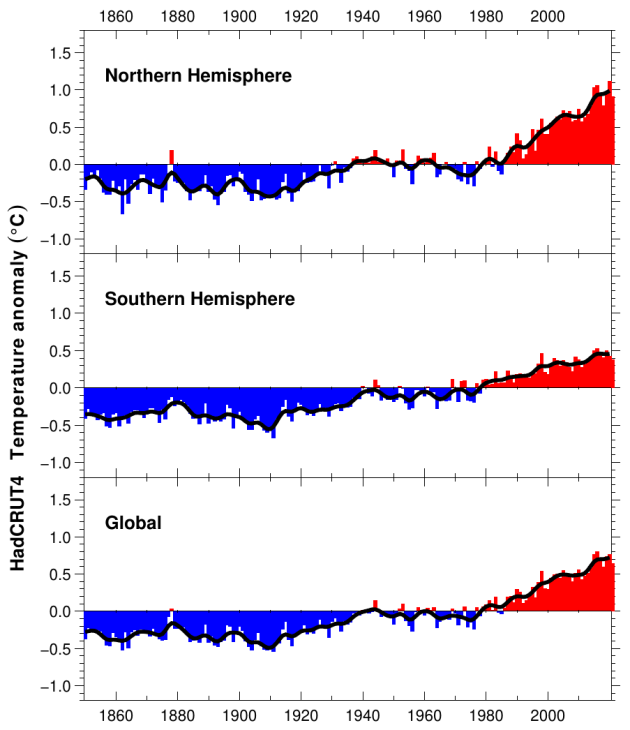
So perhaps UC is adding some alarmism to keep #resistance alive!
Ummmm. Two degrees of warming……..
Baked-in or half-baked-in?
I only have three issues with climate predictions:
1) the historical data is insufficient and unreliable (really, how well do we know temperatures from the south pacific before satellites? Why is it constantly necessary to update the temperature of the past?)
2) the models are overly complicated (“with four parameters I can fit an elephant, with five I can make him wiggle his trunk” Separately they require positive feedback loops which are actually quite rare in nature)
3) even if the earth warms I cannot see how it is a problem (Most of the warming is expected to occur in polar regions and oceans. If frozen wastelands and the oceans deserts warm who cares? Kind of like if Mars warms)
South Pacific? How well do we know the temperature of any of the oceans, not to mention Africa, South America, the arctic and antarctic regions, And most of Asia.
So if I am not getting this wrong, these guys are contemplating a 13% chance that there may just be a chance to argue up to some point against the hiatus by the end of the century….. :),
regardless of the actual anthropogenic emissions scenarios……
a 13% chance that the hiatus may at last end by 2100..:)
Amazing…..
some thing is wrong there, definitely….:)
cheers
LOL…yep
Yogi Berra explained this long ago, making predictions is hard especially about the future.
Yogi also said:
“I really didn’t say everything I said.”
I loved him as a kid when I was a NY Yankees fan.
Today Yogi is my favorite philosopher.
“We’re lost, but we’re making good time.”
is my favorite Yogi remark when driving with the wife, and lost,
right after she tells me to stop and ask for directions.
To repeat Nic Lewis and add an observation inferred from the SI (paper itself is paywalled):
The abstract rise is from the 1850-1899 base, not from present. No alarm –already half way there–, as the three modeled ECS were ~1.8 to ~2.4. Lewis and Curry 2014 place observational energy budget ECS at ~1.65, and Lewis 2015 using Schmidts revised aerosol is ~1..5. A real climb down from Trenberth’s ‘baked in the cake’ alarmist estimates with heat hiding in oceans.
A probable further flawed assumtion. It appears from SI figure 1 that the efold time for CO2 sinks is too high (slow), perhaps based on known faulty Bern 2. The correct halflife of atmospheric CO2 is about 40-42 years, and the correct efold time is ~ 55 years IIRC. Willis had a 2015 post calculating this concerning the Salby confusion between molecular residence time (<14 years based on C14 bombspike) and halflife/efold net concentration times. Figure one should not continue rising after ~ 2060 as the CO2 forcing is more than halved if emissions cease in 2015.
ristvan
August 1, 2017 at 1:45 pm
Yes true the paper is paywalled, but let me try to show you my understanding of the abstract..
The assessment is about the degree of warming range already subject or allowed in accordance with climate equilibrium as per earth’s energy imbalance…..regardless of anthropogenic CO2 emissions…..
It means, the assessment of what is permissible according to the climate equilibrium as per warming allowance……. based mostly in the analyses of the observation of the actual change hapened and still happening in climate…..
In regard and relation for the preindustrial the value is at 1.5K, and as per present is 1.3K, 0.2 less….
And when considering some other conditions that drops even further to ~1.1K, which more or less already there.
So from these angle there is no any further warming up, and considering also that the main long climatic trend is a cooling one, as the time progresses that value is subject to further drop…….
That is why the risk of a higher than the Paris accord figure only at 13%……
So 13% warming versus 87% no warming (where cooling included too withing the 87%)….
I could be wrong with this yes, but I can not see any other way that the abstract will make any other sense…
As per the abstract I do not think climate equilibrium means ECS or any connection to it, as far as I can tell,
cheers
The SI clearly refers to ECS. So it did enter the calculations, alneit not noted in the abstract as you correctly note.
ristvan
August 1, 2017 at 2:55 pm
From the abstract….
” the Earth’s climate is not equilibrated with anthropogenic forcing.”
Simply translating: ” the Earth’s climate is not equilibrated with RF”,
where “anthropogenic” used as a means of a “tracer” for the assessment that relies in the IPCC figures.
Meaning that the assessed warming commited to is not caused by the RF, therefor no any AGW up to now and no any in the future, all due to natural functioning of the Earth’s system……..according to that abstract, as far as I can tell.
ECS is an anthropogenic metric artifact,….
I hope you at list get my point, regardless if it is correct or not……time will tell
cheers
Note that, although the paper is paywalled, Thorsten Mauritsen has very helpfully made the Python scripts, and data used and resulting figures available on his home page: https://www.mpimet.mpg.de/en/staff/thorsten-mauritsen/
All if these kinds of future climate scenarios are based on the TCRE (transient climate response to cumulative emissions), a flawed device.
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3000932
Whenever I see somebody’s product described as “sophisticated”, my first reaction is “Did they tell you that?”