Guest Post by Willis Eschenbach
Since we’ve been discussing smoothing in datasets, I thought I’d repost something that Steve McIntyre had graciously allowed me to post on his amazing blog ClimateAudit back in 2008.
—————————————————————————————–
Data Smoothing and Spurious Correlation
Allan Macrae has posted an interesting study at ICECAP. In the study he argues that the changes in temperature (tropospheric and surface) precede the changes in atmospheric CO2 by nine months. Thus, he says, CO2 cannot be the source of the changes in temperature, because it follows those changes.
Being a curious and generally disbelieving sort of fellow, I thought I’d take a look to see if his claims were true. I got the three datasets (CO2, tropospheric, and surface temperatures), and I have posted them up here. These show the actual data, not the month-to-month changes.
In the Macrae study, he used smoothed datasets (12 month average) of the month-to-month change in temperature (∆T) and CO2 (∆CO2) to establish the lag between the change in CO2 and temperature . Accordingly, I did the same. [My initial graph of the raw and smoothed data is shown above as Figure 1, I repeat it here with the original caption.]

Figure 1. Cross-correlations of raw and 12-month smoothed UAH MSU Lower Tropospheric Temperature change (∆T) and Mauna Loa CO2 change (∆CO2). Smoothing is done with a Gaussian average, with a “Full Width to Half Maximum” (FWHM) width of 12 months (brown line). Red line is correlation of raw unsmoothed data (referred to as a “0 month average”). Black circle shows peak correlation.
At first glance, this seemed to confirm his study. The smoothed datasets do indeed have a strong correlation of about 0.6 with a lag of nine months (indicated by the black circle). However, I didn’t like the looks of the averaged data. The cycle looked artificial. And more to the point, I didn’t see anything resembling a correlation at a lag of nine months in the unsmoothed data.
Normally, if there is indeed a correlation that involves a lag, the unsmoothed data will show that correlation, although it will usually be stronger when it is smoothed. In addition, there will be a correlation on either side of the peak which is somewhat smaller than at the peak. So if there is a peak at say 9 months in the unsmoothed data, there will be positive (but smaller) correlations at 8 and 10 months. However, in this case, with the unsmoothed data there is a negative correlation for 7, 8, and 9 months lag.
Now Steve McIntyre has posted somewhere about how averaging can actually create spurious correlations (although my google-fu was not strong enough to find it). I suspected that the correlation between these datasets was spurious, so I decided to look at different smoothing lengths. These look like this:

Figure 2. Cross-correlations of raw and smoothed UAH MSU Lower Tropospheric Temperature change (∆T) and Mauna Loa CO2 change (∆CO2). Smoothing is done with a Gaussian average, with a “Full Width to Half Maximum” (FWHM) width as given in the legend. Black circles shows peak correlation for various smoothing widths. As above, a “0 month” average shows the lagged correlations of the raw data itself.
Note what happens as the smoothing filter width is increased. What start out as separate tiny peaks at about 3-5 and 11-14 months end up being combined into a single large peak at around nine months. Note also how the lag of the peak correlation changes as the smoothing window is widened. It starts with a lag of about 4 months (purple and blue 2 month and 6 month smoothing lines). As the smoothing window increases, the lag increases as well, all the way up to 17 months for the 48 month smoothing. Which one is correct, if any?
To investigate what happens with random noise, I constructed a pair of series with similar autoregressions, and I looked at the lagged correlations. The original dataset is positively autocorrelated (sometimes called “red” noise). In general, the change (∆T or ∆CO2) in a positively autocorrelated dataset is negatively autocorrelated (sometimes called “blue noise”). Since the data under investigation is blue, I used blue random noise with the same negative autocorrelation for my test of random data. However, the exact choice is immaterial to the smoothing issue.
This was my first result using random data:

Figure 3. Cross-correlations of raw and smoothed random (blue noise) datasets. Smoothing is done with a Gaussian average, with a “Full Width to Half Maximum” (FWHM) width as given in the legend. Black circles show peak correlations for various smoothings.
Note that as the smoothing window increases in width, we see the same kind of changes we saw in the temperature/CO2 comparison. There appears to be a correlation between the smoothed random series, with a lag of about 7 months. In addition, as the smoothing window widens, the maximum point is pushed over, until it occurs at a lag which does not show any correlation in the raw data.
After making the first graph of the effect of smoothing width on random blue noise, I noticed that the curves were still rising on the right. So I graphed the correlations out to 60 months. This is the result:

Figure 4. Rescaling of Figure 3, showing the effect of lags out to 60 months.
Note how, once again, the smoothing (even for as short a period as six months, green line) converts a non-descript region (say lag +30 to +60, right part of the graph) into a high correlation region, by the lumping together of individual peaks. Remember, this was just random blue noise, none of these are represent real lagged relationships despite the high correlation.
My general conclusion from all of this is to avoid looking for lagged correlations in smoothed datasets, they’ll lie to you. I was surprised by the creation of apparent, but totally spurious, lagged correlations when the data is smoothed.
And for the $64,000 question … is the correlation found in the Macrae study valid, or spurious? I truly don’t know, although I strongly suspect that it is spurious. But how can we tell?
My best to everyone,
w.
Try wayback machine: http://web.archive.org/web/20041230090904/http://www.john-daly.com/
Try the internet archive: http://web.archive.org/web/20041230090904/http://www.john-daly.com/
Correlation is not
causationcorrelation. Thanks, WillisThis has some similarities to an essay I wrote a few years ago when the first BEST results were made public. I was concerned by the large correlation coefficients between temperatures at large station separations, the graph is in the following.
It started off with a bit of geostatistics, a sub-discipline that I think needs more examination for context in climate work. It deals a lot with lagged data and correlations.
For simplicity, I started with a single station and then lagged various blocks of Temperature data from daily to monthly to annual, separating Tmax from Tmin, showing that at this station (Melbourne BoM Central) they had different behaviour.
A four-part series was intended, but the first part (here) drifted off because there was too much noise in the data.
I’d really appreciate some feedback as I know Willis would also, because as you take these concepts further they end up interacting with procedures like gridding, interpolating, contouring, map making etc. I think that we have a current case in Australia where maps showing Australia temperature as a whole have some bad looks about them and some headlines that might not be supportable.
I will have to learn R program. I started with machine language in 1969.
http://www.geoffstuff.com/GHS%20on%20chasing%20R%2c%20extended.pdf
Willis – I always enjoy your contributions. Particular thanks this time for noting the exemplar of McIntyre to thoroughness and the gentlemanly art of polite disagreement.
Both of you have the gift of droll wit, pointed irony, and damnation with faint praise.
From my geological perspective, I can only say that “Because the world has not gone to ruin in the past, it is highly unlikely to do so in the future. Any belief to the contrary is an arrogance of human influence.”
This post leaves me with more questions than answers & my gut says something is wrong with the calculations here , although not enough information is provided to tear this apart.
“Since the data under investigation is blue”. Is it really ? Did you look at the power spectrum & did it have increasing power density with increasing frequency? Very few signals in nature have this characteristic. This would surprise me, but since the original data sets & their associated power spectra aren’t present, I really can’t say if this is right or not (this is critical to the rest of the thoughts below). So, I would love to see a plot of the original raw data & it’s power spectra if you could add those to this post – that would certainly help clarify things. Next, is this the character of both the CO2 signal & the temp signal vs time ( That would be even more surprising !! ).
All that being said, if the data has a blue characteristic to it, a gausian filter will hammer the data. Remember that a gausian filter is basically a high cut / low pass filter . If the data is blue, then most of the energy is in the higher frequencies , so if we run a gausian filter over the data, we will remove most of the energy from the data (and that’s likely where the signal is – the rest may be just noise). So, again, looking at the original datasets, filtered & unfiltered would be instructive & useful. If the data is blue, the filtered data is going to look like a very lazy & very flat signal compared to the unfiltered signal – is that in fact the case ? As described , it should be – since most of the energy (amplitude) was in the higher frequencies – which you filtered out – so the remaining signal has very little amplitude of all & may only be the noise component of the dataset.
Which bring us to the next point – a proper cross-correlation of signals pre-conditions the signal by dividing through by the mean, but the mean has now been completely changed by the filtering. Just because you are getting a strong cross-correlation peak with the filtered data doesn’t mean anything now – as again, if the data is blue, you have basically removed the majority of the energy from the signal – all it is saying is that there is some sort of correlation in the low frequencies, which supposedly don’t have much energy in them to start with – it could just be showing you some non-random noise in the datasets .
Again, the way this is all presented, it leaves me with a whole lot more questions than answers. A re-post showing all the intermediate steps, with datasets vs time, associated power spectra, filtered data sets & spectra & ultimately the cross-correlations, both filtered & unfiltered would be a lot more instructive & would help answer your question :
” … is the correlation found in the Macrae study valid, or spurious? ”
I don’t think you even need to do the random data set if you can set forth the above plots – it should be pretty obvious whether it is valid or not & exactly what the physical meaning of the cross-correlations are (both filtered & unfiltered).
BTW, thanks for the tip on R – I will be looking into that!
Willis,
About a week ago I noticed John Daly’s site was suspended. I inquired at Jo Nova’s site and she said it had been down for about a week already at that time. John’s wife passed away last year. So it may be down permanently. Jo inquired of someone in the area who is trying to get more information, but she hadn’t heard back. I’m with you, it would be a shame to have John’s site gone permanently, but John passed in 2004 and eventually all good things come to an end.
“Since then I’ve learned… several dialects of Basic including… Assembly Language…”
I truly hope there was an editing problem here. Actually, probably should say “… and several others including Basic… Assembly Language…”
[Thanks, clarified I think. -w.]
Who let John Daly become suspended?
nice.
for those wanting to learn R. get Rstudio.
subscribe to the R list.
Domain Name: JOHN-DALY.COM
Registrar: DNC HOLDINGS, INC.
Whois Server: whois.directnic.com
Referral URL: http://www.directnic.com
Name Server: DNS1.HRNOC.NET
Name Server: DNS2.HRNOC.NET
Status: clientDeleteProhibited
Status: clientTransferProhibited
Status: clientUpdateProhibited
Updated Date: 18-jul-2009
Creation Date: 06-apr-2001
Expiration Date: 06-apr-2014
>>> Last update of whois database: Sun, 31 Mar 2013 04:07:23 UTC <<<
NOTICE: The expiration date displayed in this record is the date the
registrar's sponsorship of the domain name registration in the registry is
currently set to expire. This date does not necessarily reflect the expiration
date of the domain name registrant's agreement with the sponsoring
registrar. Users may consult the sponsoring registrar's Whois database to
view the registrar's reported date of expiration for this registration.
TERMS OF USE: You are not authorized to access or query our Whois
database through the use of electronic processes that are high-volume and
automated except as reasonably necessary to register domain names or
modify existing registrations; the Data in VeriSign Global Registry
Services' ("VeriSign") Whois database is provided by VeriSign for
information purposes only, and to assist persons in obtaining information
about or related to a domain name registration record. VeriSign does not
guarantee its accuracy. By submitting a Whois query, you agree to abide
by the following terms of use: You agree that you may use this Data only
for lawful purposes and that under no circumstances will you use this Data
to: (1) allow, enable, or otherwise support the transmission of mass
unsolicited, commercial advertising or solicitations via e-mail, telephone,
or facsimile; or (2) enable high volume, automated, electronic processes
that apply to VeriSign (or its computer systems). The compilation,
repackaging, dissemination or other use of this Data is expressly
prohibited without the prior written consent of VeriSign. You agree not to
use electronic processes that are automated and high-volume to access or
query the Whois database except as reasonably necessary to register
domain names or modify existing registrations. VeriSign reserves the right
to restrict your access to the Whois database in its sole discretion to ensure
operational stability. VeriSign may restrict or terminate your access to the
Whois database for failure to abide by these terms of use. VeriSign
reserves the right to modify these terms at any time.
The Registry database contains ONLY .COM, .NET, .EDU domains and
Registrars.Registration and WHOIS Service provided by Directnic.com
DNC Holdings, Inc. provides the data in the directNIC.com Registrar WHOIS
database for informational purposes only. The information may only be
used to assist in obtaining information about a domain name's registration
record. The use of this data for any other purpose without prior written
consent by DNC Holdings, Inc. is expressly forbidden.
By submitting a WHOIS query, you agree to all the terms and limitations
herein and that you will use this data only for lawful purposes. You also
agree that under no circumstances will you use this data to:
(a) allow, enable, or otherwise support the transmission by email,
telephone, or facsimile of mass, unsolicited, commercial advertising or
solicitations, including, but not limited to, spam, to entities other than
the data recipient's own existing customers;
(b) enable high volume, automated, electronic processes that send queries
or data to the systems of any Registry Operator or ICANN-accredited
registrar or
(c) enable any automated or robotic processes to collect or compile data
for any purpose, including data mining.
DNC Holdings makes this information available "as is", and provides no guarantee
or warranty as to its accuracy.
Registrant:
Jerry Brennan
5 Craigmoor Terrace
Danbury, CT 06810
US
203 743 7899
Domain Name: JOHN-DALY.COM
Administrative Contact:
Brennan, Jerry brennan@john-daly.com
5 Craigmoor Terrace
Danbury, CT 06810
US
203 743 7899
Technical Contact:
Brennan, Jerry brennan@john-daly.com
5 Craigmoor Terrace
Danbury, CT 06810
US
203 743 7899
Record last updated 03-20-2004 08:22:50 PM
Record expires on 04-06-2014
Record created on 04-06-2001
Domain servers in listed order:
DNS1.HRNOC.NET 216.120.225.19
DNS2.HRNOC.NET 216.120.238.254
The compilation, repackaging, dissemination, or other use of this WHOIS
data is expressly prohibited without the prior written consent of
DNC Holdings, Inc.
DNC Holdings reserves the right to terminate your access to its WHOIS
database in its sole discretion, including without limitation, for
excessive querying of the database or for failure to otherwise abide by
this policy.
DNC Holdings reserves the right to modify these terms at any time.
NOTE: THE WHOIS DATABASE IS A CONTACT DATABASE ONLY.
LACK OF A DOMAIN RECORD DOES NOT SIGNIFY DOMAIN AVAILABILITY.
” Fortran, LISP/LOGO, C, C++, several dialects of Basic including Visual Basic, Pascal, Hypertalk, Datacom, Assembly Language, VectorScript, and a couple of the Mathematica languages. ”
But no LabView; that, my friend, (LV) represents a paradigm shift …
BTW, for those interested Mathics (*1) a Mathematica look-alike “is a free, general-purpose computer algebra system featuring Mathematica-compatible syntax and functions”
Mathics also offers an online calc engine, then there is Wolfram Alpha (*2), a “computational knowledge or answer engine developed by Wolfram Research”
*1 – http://www.mathics.org/
*2 – http://www.wolframalpha.com/
.
Thanks, Willis. Most instructive.
And thanks for the “R” plug. I’ll add:
An Introduction to Statistics – R Tutorial: http://www.r-tutor.com/
The Blackboard » Learning R: http://rankexploits.com/musings/category/statistics/learning-r/
I believe William Briggs, professional statistician, counsels against smoothing data. Here is the link to his blog on this subject. http://wmbriggs.com/blog/?p=195
I have an idea why the smoothed data shows a correlation and a lag, and
the unsmoothed does not.
There are annual cycles in global temperature and in CO2 level. The
annual cycle in global temperature comes from the northern hemisphere
having more land and less water than the southern hemisphere, and so
the northern hemisphere has greater seasonal variation in temperature.
Global troposphere temperature probably peaks in August, when the
northern hemisphere as a whole (land and sea, including temporarily
ice-covered sea) is hottest. Or a little after northern hemisphere land
temperature or maybe surface temperature peaks – the surface warms the
troposphere, so the troposphere lags the surface – or at least lags land.
Also, seasons on northern hemisphere extratropical land affects that
land’s production and capture of CO2. CO2 tends to peak in May, just
before northern hemisphere vegetation gets busiest at converting CO2
to biomass.
As for lack of correlation in the unsmoothed data: I suspect the
unsmoothed data has its variations mainly short-term noisy or noise-like
ones that the smoothing removes. I suspect that a spectrum analysis of
the temperature and CO2 datasets will show most of the “AC content”
being at frequencies high enough for the smoothing to largely remove.
And the short term (few months or less) noise items and “noise-
resembling signals” in one dataset are unlikely to have much all-same-
lag correlation with each other, if any at all.
I thought that’s a pretty old rule: never analyze smoothed data. When you average over data points, you are causing correlation between each point and the
data points, you are causing correlation between each point and the 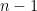 others it was averaged with.
others it was averaged with.
Steven Mosher says:
March 30, 2013 at 9:11 pm
Thanks, Mosh. Since I’d not heard of either one, let me add the links:
Rstudio I just took a look at that, very, very impressive. I’m migrating, at least I think so …
R list
I wasn’t clear which list you referred to, as the cite says there are four of them.
Regards, appreciated,
w.
I think that the breadth of features and ease of use of R can make it *too* simple for modelers and data analysts to achieve glib results from methods which they have not adequately analyzed.
The technology should perhaps be harder and more conducive to requiring careful thought about what is being done at each step.
Something like Haskell, which is a pure functional language and therefore very unforgiving of sloppy work, would be my preference.
_Jim says:
March 30, 2013 at 9:14 pm
True ‘dat … I played with it a little, never could afford the modules. I did like the paradigm, though. That kind of visual building-block programming was used as well in a database whose name now escapes me.
w.
Readers might want to follow with these:
“Do not smooth times series, you hockey puck!”
3 in a series by William M. Briggs
Number I:
http://wmbriggs.com/blog/?p=195
Number II:
http://wmbriggs.com/blog/?p=86
Number III:
http://wmbriggs.com/blog/?p=735
I just realized something else: Looking at smoothings of more than a year,
the correlation time increases with smoothing time. I suspect the reason here
is that for longer term smoothing, annual cycles are smoothed out.
When smoothing is Gaussian with FWHM of 9-12 months, CO2 lag is
seasonal. With longer term smoothing, the lag could increase due to the
smoothing causing the correlation to concentrate more on longer term
correlations, such as with more lag when the (non-constant) positive
feedbacks are greater.
Something else I noticed: The correlation curves for smoothing by 2 to 24
months appear to me to have a fair amount of symmetry about zero both
horizontally and vertically. I would expect seasonal variations to have a pair
of correlation peaks, one leading and one lagging, 1 year apart – showing
1-year periodicity, rather than symmetry about the origin (zero-zero point).
Or, am I missing something? Perhaps, temperature anomalies lasting a
few months to a year have an effect on production and decomposition of
biomass, causing biomass short-term-accumulated-decomposition to lag
upward temperature anomalies by almost a year.
Something else I noted: Figure 4 shows positive correlation running high
in longer correlation periods, when the two correlated datasets are random
samples of “blue noise”. Is not “blue noise” something biased to higher
frequency spectral content? If random samples repeat positive correlation
towards longer of periods of correlation, then I question the correlation
method. Does the correlation method intrinsically have a bias to indicate
positive correlation – even (and especially) if for long lag periods and higher
frequency noise spectral content? Since Fig. 4 shows mostly positive
correlation over all of the frequencies being considered, I would suspect the
smoothing method to have a bias to show positive correlation, especially at
frequencies among the lower frequency ones being considered.
By any chance, does the smoothing method use RMS calculations for
smoothing when calculations of averages instead of RMS could be what
shows a type of random noise to be random?
An interesting read on smoothing data:
http://wmbriggs.com/blog/?p=195
Slightly OT, but after reading this post I checked John Daly’s Wikipedia entry. What a shambles.
He gets less than this week’s reality TV nobody, and looking at the history of amendments, his entry has been a battleground for years even though he died in 2004.
I suppose that it’s a backhanded compliment (the Supreme Censor Connolly has been involved), but it’s just another reminder that Wiki is really useful for checking episode guides for your favourite TV show, but utterly unreliable when it comes to anything that is contested.
Just saw this:
http://www.dailymail.co.uk/news/article-2301757/Governments-climate-watchdog-launches-astonishing-attack-Mail-Sunday–revealing-global-warming-science-wrong.html
“The empire strikes back”?????
Shameless commercial plug – do read my little essay about 4 posts down from the top, because it raises similar outcomes but without smoothing. It simply uses averaging, as in making days into weeks. And the process constructs artefacts from numbers. And people make the mistakes daily.