Guest Post by Willis Eschenbach
The Argo floats are technical marvels. They float around below the surface of the ocean, about a kilometre down, for nine days. On the tenth day, they rise slowly to the surface, sampling the pressure, temperature, and salinity as they go. When they reach the surface, they radio home like ET, transmit the data from the instrumental profiles, and they drop back down into the eternal darkness for another nine days. The first Argo floats were put into the ocean in the year 2000. In 2007, the goal of 3,000 floats was achieved.
In “Krige the Argo Probe Data, Mr. Spock“, I discussed some issues with the Argo floats. Then in “Decimals of Precision” I discussed and strongly questioned the outrageous error claims made by the Argo researchers. They say that we can detect a temperature change with an error of 0.004°C per year in the top 1,800 metres of the ocean. I say no way, not yet.
In a comment on that thread, I posted a graphic showing the current distribution of the Argo floats, shown below as Figure 1.
 Figure 1. Distribution of Argo floats as of February 2012. SOURCE
Figure 1. Distribution of Argo floats as of February 2012. SOURCE
At that time I remarked on the distribution, saying:
However, I do see one place that they are not covering, and strangely, it is a crucial location—the intertropical convergence zone (ITCZ). Surface water around the ITCZ is heated. When it is heated it expands, which creates a gravitational trend downhill towards both poles. As the surface water is heated and moved polewards, it is replaced with deep oceanic water from below. So I’d say your suspicions are correct for at least that area.
In the Pacific, the ITCZ is generally found roughly ten degrees or so North of the Equator. You can see the blank area in Figure 1 just above the Equator. My speculation was that the blank area was not a random occurrence. So … I set out to take a look at where the Argo floats have sampled and where they haven’t sampled. I didn’t realize what I was getting into.
It’s a dang nuisance to get all the Argo files. They are available at the Global Argo Data Repository. The problem is that there have been over 8,000 individual Argo floats … and the rocket scientists at NOAA have decided to make the data available as one file per float, eight thousand individual files … grrr …
So I thought it might be of interest to describe how I went about getting the data. I haven’t gotten all of it, at the moment I’m somewhere between 5,000 and 6,000 files downloaded.
The first step in the process is to get the URL addresses of all of the files, which are shown on the web page at the link given above. To get the text of the URLs, remember that these are all listed in the “source” file that created that web page. Under the “View” menu (on the Mac, at least) you have a choice called “View Source”. This “source file” is a text file that contains the HTML information on how to make up the page, including all of the URLs of all the links on the page.
So … the first file listed on the web page is “IF000550”. I searched the source file for that, it’s at the start of the table. A similar search for “9018420”, the last file listed on the page, found me the end of the table.
I copied all of that information from the start to the end of the table from the “Source” document, and pasted it into a text processor. The end of an HTTP address is marked by the close code “”. I did a global search for that phrase, and replaced them all with a carriage return (“^p” in Microsoft Word). That left the text broken into short sentences suitable for pasting into Excel.
So I copied all of the resulting text, and pasted it into Excel. From there, it was easy to sort the lines. I wanted lines containing addresses that looked like
http://www.nodc.noaa.gov/argo/data/coriolis/7900073.tgz
These are the files with the actual float-by-float temperature profiles. I sorted them out, there were about 8,500 of them or so.
That gave me the list of all of the URLs of the files I was interested in. I saved those as a comma-delimited file, and opened it using the computer language “R”.
Using R, I was then able to automate the download process, having the computer download the files one after another. The one thing you need to do is leave gaps in your file requests. If you just request one file after another with no pause, you may get mistaken for a denial-of-service (DOS) attack on their server. So I put in a half second pause in after every five downloads. This adds about 12 minutes on 8,000+ downloads, not bad.
So that’s how I’m doing it. Once I get it all downloaded, I’ll put it together in some more reasonable format and stick it back out on the web, so people won’t have to go through that madness for the data.
In any case, I have downloaded the coordinates of all of the temperature profiles ever done by any Argo float. Remember that I started out on this hegira to see if my eye were good, and if there was a sampling inconsistency in the Pacific just above the equator.
Figure 2 shows how many samples have ever been taken everywhere in the global ocean. There have been a total of about 890,000 Argo temperature profiles taken to date. Sounds like a lot … but the ocean is a huge place. I began by counting the number of observations per gridcell on a 1° x 1° grid basis. I then standardized them by area as the number of temperature profiles taken per 10,000 square km. I picked this size for a couple of reasons. First, it’s close the area of a 1° x 1° gridcell at 40° North. This reduces distortion of the counts. And second, it’s a square which is a hundred kilometres (about sixty miles) on a side, so it can be easily visualized. It is a huge expanse of ocean.
 Figure 2. Number of temperature profiles ever taken by Argo floats in various areas of the ocean. Percentages in the second row refer to the percentage of the total ocean area having that number of temperature profiles. Percentages in the third row refer to the percentage of the ocean area from 60°N to 60°S having that number of temperature profiles. Click on image for larger version.
Figure 2. Number of temperature profiles ever taken by Argo floats in various areas of the ocean. Percentages in the second row refer to the percentage of the total ocean area having that number of temperature profiles. Percentages in the third row refer to the percentage of the ocean area from 60°N to 60°S having that number of temperature profiles. Click on image for larger version.
So … what are we looking at in Figure 2? We are seeing which areas of the ocean are better sampled, and which are more poorly sampled.
The red areas are those parts of the ocean which have never been sampled at all by Argo floats. In some cases, such as the area around Indonesia, or the east side of the bottom half of South America, it is because the ocean is shallow there. Up north it’s because of ice. And down south? It seems the currents don’t carry the floats down that far. This makes sense because the cold surface waters are sinking around Antarctica and flowing north in that region, carrying the submerged floats with them away from Antarctica.
In other areas, such as off the westernmost point of South America and the area on the western side of South Africa, the cause for the lack of samples seems to be the local upwelling in the areas. Presumably, since the water is radiating outwards at depth as well as at the surface, the floats are moved away from that area.
The areas in orange, another 10% of the global ocean, have only ever been sampled from just once to eight times. So a quarter of the ocean has either never been sampled, or has been sampled less than eight times per 10,000 sq. km, since the beginning of the Argo program in 2000.
In other words, a quarter of the global ocean has been sampled less than once a year per 10,000 sq. km. by Argo floats … yet they claim an error of only a few thousandths of a degree in the global average.
To get around part of this problem, sometimes the Argo data is used solely from 60° north of the Equator to 60° south. This eliminates some of the problem, but there is still 8% of that ocean area from 60°N/S that has never been sampled at all. How can they possibly claim to know the temperature of that huge volume of ocean to within ± 0.004°C, when 8% of it has never been sampled at all, much less adequately sampled? Another 8% of the ocean 60°N/S is sampled on the order of once a year … again, nowhere near adequate for the claimed accuracy.
What else can we see? There are areas which are way oversampled compared to the rest (cyan color, more than 96 measurements/10,000 sq km), places where it is clear that the floats tend to “get stuck”. These include the ocean around Japan, parts of the Mediterranean, the Bay of Biscay off France, the south tip of Greenland, the northern Indian Ocean, and the Gulf of Alaska. It appears that the Argo floats get trapped in these bays, corners, and dead ends. Presumably the wind is driving them onshore when they are at the surface, and they move offshore when they are at depth. This keeps them in the same area, leading to the large number of samples.
Finally, the hunch that started me on this quixotic quest is confirmed. There is indeed a band which is only infrequently sampled just above the Equator in the Pacific. There have been many more samples taken just above and below that band. The infrequently sampled area is also the area where the El Nino upwelling occurs. I hardly take this as a coincidence.
CONCLUSIONS
• The sampling of the oceans is by no means as uniform as I had expected. Part of the ocean is undersampled, sometimes badly so, compared to other areas. Half of the global ocean has been sampled less than 20 times per 10,000 sq. km, and 14% has never been sampled by Argo floats at all.
• Even when we look at just the area from 60°N/S, half the ocean has been sampled less than 24 times per 10,000 sq. km, and 8% is unsampled.
• The area of the El Nino phenomenon is a critical area for the regulation of planetary heat loss. Oceanic heat content in this area can change quite rapidly. However, parts of it are woefully undersampled.
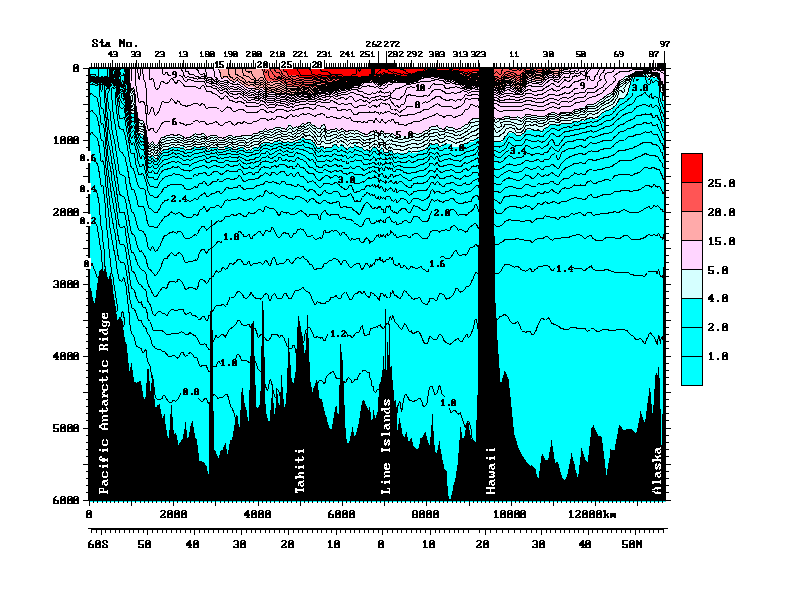
• Finally, the older Argo floats sample either down to 1,000 metres, and intermittently go to 1,500 metres depth. The newer ones go down to 1800 metres. Which is quite deep, about a mile down. But the estimates of oceanic heat storage include the whole ocean. Figure 3 shows a pair of transects from Antarctica (on the left) to Hawaii, and then Hawaii to Alaska on the right, to give some sense of scale.
![]() Figure 3 (Figure 10 from cited source.) North/South Pacific transect at 150°W. ORIGINAL CAPTION: Vertical section of potential temperature (°C) along 150°W from data collected in 1991-1993 as part of the World Ocean Circulation Experiment. Data north of Hawaii were collected in 1984 (Talley et al., 1991). Potential temperature is the temperature a parcel of water would have if moved to the sea surface with no change in heat content, and is lower than measured temperature since temperature increases when water is compressed due to the high pressure in the ocean. Source and Image
Figure 3 (Figure 10 from cited source.) North/South Pacific transect at 150°W. ORIGINAL CAPTION: Vertical section of potential temperature (°C) along 150°W from data collected in 1991-1993 as part of the World Ocean Circulation Experiment. Data north of Hawaii were collected in 1984 (Talley et al., 1991). Potential temperature is the temperature a parcel of water would have if moved to the sea surface with no change in heat content, and is lower than measured temperature since temperature increases when water is compressed due to the high pressure in the ocean. Source and Image
{kind=link}
The Argo floats operate mostly in the warmer area up top of Figure 3, above the lower thermocline (light blue). Average depth in this entire transect is much deeper than that, about 5,000 metres. So the Argo floats are measuring less than a quarter of the water in this part of the Pacific basin. Makes the whole question of oceanic heat content kinda iffy.
Anyhow, that’s my first look at the question of the float distribution. I have some other projects in mind once I get the data downloaded. I’ve been downloading while the Super Bowl has been on, I’m up to 6,000 files downloaded, only 2,500 or so to go … but tomorrow is Monday, it’s back to my day job in construction pounding nails, that slows the science down. I just want to find someone to pay me for my research. Where are Exxon and the Koch Brothers when I need them?
My best to everyone,
w.
PS: I was quite happy with my map. It’s the first one I’ve done of a 1° x 1° grid. I found that to get it to print properly, I could use one dot per 1° x 1° gridcell. But to make it work, I had to size the dot by the cosine of the latitude. Took me a while to figure out how to do that in “R”, I’m kind of an R klutz, I only learned it a few years ago. But I made it work.
My experience of the ITCZ is that it is a line of violently convecting cumulonimbus clouds which contain enough energy to build way above the tropopause. These clouds were not to be flown into and the clear air turbulence even outside these clouds was severe enough to try to climb through which we tried once and at 620,000ft we gave up with clouds building way above us.
The route met report we submitted was not believed. It was 1966 and our aircraft a Vulcan2 flying over the Indian Ocean.
Fantastic work.
What is more obvious than the lack of sampling around the equator is the blue line above it. it is almost as if someone had drawn the line!
Ah, Willis, the magic a shell script can work! I’m downloading all 8000 now, shouldn’t take long. Drop me an email and I’ll get you a .zip of them all.
As always, your tenacity is a wonder to behold.
Wonderfull work. Congratulations.
Excellent piece of research.
One would think that the curators would have a better handle on the appropriate degree of precision.
“An error of 0.004°C per year” ? For what it’s worth, I relate the following. Conclusions, if any, I leave for others to draw.
At one time as part of some research, I needed to control the temperature of a few liters of water in a laboratory to +/-0.001. After much experimentation I found that the only way of doing this was to use a powerful circulation pump (albeit adding heat to the system) together with a cold source plus a hot source that provided heat proportionate to the difference between he actual temperature and the required temperature. This finally worked! In a large volume of water ( > 10 liters or so), thermal currents arose irrespective of stirring and a) made it impossible to achieve the required temperature and b) undermined the significance of the recorded temperature for one had to ask “For which volume of water is this ‘result’ applicable?”
Thanks for your great post as well as great effort, Willis.
So, a measurement of about 3/4 of the area and about 1/4 of the depth, roughly 3/16 of the volume and then not well sampled.
However approximate this is, it’s a huge improvement on pre Argo data
Viva the sceptics!
620,000ft
I think you might be wrong by a factor of 10
Nice work Willis. Its good to get a properly considered perspective on OHC measurements. And in the light of this, imagine how bad the data from the XBT days was!
at 620,000ft we gave up with clouds building way above us.
The route met report we submitted was not believed.
———————————————————————-
I find it very hard to believe as well. 620,000 ft is about 190KM up – into the lower end of Low Earth Orbit and half way to the ISS. I’ve never heard of either aircraft or clouds extending into the mesosphere, let alone 100KM above it in the thermosphere
Did you perhaps mean 62.000ft?
Excellent report, Willis! Most illuminating. What relation do the placements of the floats as they report data have with their original placement in the ocean? Put another way, can anyone tell how far the float has moved–and in what directions–since it was installed? And why not anchor the silly things to the ocean bottom to keep them from moving away (joke)?
Nice article Willis, very informative and lots of potential for further analysis.
Wilils, there is a Firefox (Chrome and Safari too) extension known as “DownloadThemAll!” (https://addons.mozilla.org/en-US/firefox/addon/downthemall/) that works wonderfully. Set the directory to put the files in, add the txt and tgz file filters, configure the download threads (I choose 3) and limit the bandwidth (I chose 700 KiB/s. Presto. It’s running at between 10 to 112 KiB/s actually. It’s taken just a few minutes to get 1251 of the 16854 files so far. No fuss no muss.
HTTrack can get all files on a web page into a local Directory. It is open source at http://www.httrack.com
Thanks
JK
Rubbish altimeters in them there Vulcan2s John.
Anyway Willis, thank you for a very good article – how do you find the time to do all this – and write lots of articles as well? – I am impressed.
Keith Gordon
Very interesting article as usual from Willis, and what a huge amount of work he has put in to further our understanding, we are indebted to him, It does point out the difficulties in measuring global ocean heat content. I will enjoy reading this several times. But this quote from the article particularly jumped out at me.
“Potential temperature is the temperature a parcel of water would have if moved to the sea surface with no change in heat content, and is lower than measured temperature since temperature increases when water is compressed due to the high pressure in the ocean”.
Can anyone explain if that pressure heat relationship happens in the ocean why could it not in the atmosphere. I am just genuinely interested in hearing the views of our contributors on this matter. Hope it’s not off topic!
Keith Gordon
“The Argo floats are technical marvels. They float around below the surface of the ocean, about a kilometre down, for nine days. On the tenth day, they rise slowly to the surface, sampling the pressure, temperature, and salinity as they go. When they reach the surface, they radio home like ET, transmit the data from the instrumental profiles, and they drop back down into the eternal darkness for another nine days. The first Argo floats were put into the ocean in the year 2000. In 2007, the goal of 3,000 floats was achieved.”
What a wonderful scientific project! Methinks, this is money well-spent, a job well-done.
This is how humanity tries to make sense of the natural world, kids: observe everywhere high and low, get data, accumulate data, and see if you can locate any pattern in the data. These are the first steps in any scientific investigation.
Question: There seems to be a proliferation of ARGO floats on the Eastern Coast of Japan. Is that because of the intense seismic in the area?
and
How are these floats kept so spread out in the swirling currents of the oceans? I take it there is now a permanent crew of technicians on boats who go around picking up these floats and re-locating them thousands of miles away after a health check-up, re-charge and repair.
Hi Willis, I share you concerns about the ARGO floats, especially I think the precision claim (“to detect a temperature change with an error of 0.004°C per year in the top 1,800 metres of the ocean”) seems ludicrous to me.
Just two thoughts:
1. In the shallow areas there is no deep ocean. If the ocean depth is less than 1.800 meters, there is nothing to sample. (It is the same as not measuring the ocean temperature at a land location.) You should not use a map of the oceans surface, but a map that shows the parts of the ocean that are deeper than 1.800 meters.
2. If the density of coverage does not change over time, then the ARGO floats could yield a useful number – albeit still with the question whether the uncertainty is low enough to make useful conclusions. Bill Briggs posts about problem with “Prediction of Models” comes to my mind.
(R seems like a useful tool, I should really learn it too.)
Is it possible that the lack of data from the ITCZ is because the upwelling means the buoys are pushed out of that area?
Might be 20,000 feet , I think 62,000 feet is beyond the Vulcan ceiling.
Tom and pwl;
“What? why use a crane and wrecking ball, or a jackhammer, when I got this here perfectly good 16-lb sledge? ”
Heh.
Someday maybe the mathemagical AI at Wolfram Alpha will respond to a natural language request, “Send me all the Argo data files in a spreadsheet.” Then tell Eureqa Mk IV, “Find out what all this means.”
😀
WOW !!!
8000 files. One at a time !!!
Interesting post, Willis. I am looking forward to the next installment in this series!
What you talking bout Willis?
As a Brit, I’m somewhat puzzled that all of the water around the British Isles (North Sea, Channel, Irish Sea) are Argo-free zones. Does the ‘shallow waters’ exception apply to ANY area within the continental shelf? Fantastic work – the degree of diligence required is astonishing.