By Andy May
Generally, it is agreed that the Earth’s top-of-atmosphere (TOA) energy budget balances to within the margin of error of the estimates (see Kiehl and Trenberth, 1997). The incoming energy, after subtracting reflected energy, is thought to be roughly 239 W/m2 which matches, within the margin of error, the outgoing energy of roughly 239 W/m2. Satellite data suggest TOA energy imbalances of up to 6.4 W/m2 (Trenberth, et al., 2008). However, Zhang, et al. (2004) suggest that the uncertainty in the TOA measurements is 5-10 W/m2 and the uncertainty in the surface radiation absorption and emission is larger, 10-15 W/m2. We examine some potential causes for these uncertainties.
To compute the magnitude of the greenhouse effect, the TOA incoming and outgoing radiation is usually compared to the Earth’s radiation emissions due to its overall average surface temperature of approximately 288K (14° to 15°C) according to the HADCRU version 4 1961-1990 baseline absolute temperature dataset. Using Planck’s function or the similar Stefan-Boltzmann law (see figure 1), the radiation emitted by the Earth can be calculated from its temperature (T), if we assume the Earth acts like a blackbody. Normally the radiation calculation is done assuming an emissivity (e) of 1, which means the Earth is a perfect blackbody that emits as much energy as it receives. The area used is one square meter, so the result is given in Watts/m2. Using these assumptions, the calculation results in the Earth emitting about 390 W/m2 (Kiehl and Trenberth, 1997) for a surface temperature of 288K.

Figure 1 and Equation 1 (source)
The greenhouse effect (GHE), when calculated this way, shows an imbalance of 390-239=151 W/m2. Kiehl and Trenberth, 1997 calculated a similar overall forcing of 155 W/m2 using the same procedure. This GHE calculation makes a lot of assumptions, not the least of which is assuming the Earth has an emissivity of 1 and is a blackbody. But, here we want to consider the problem of using a global average temperature (T) for the Earth, which is a rotating sphere, with only one-half of the sphere facing the Sun at any one time.
One specific problem is that the Earth is not at a uniform global temperature. If it averages 288K, then there will be places on the planet that are 288K and those spots will emit roughly 390 W/m2. But, much of the planet will be at a different temperature and will emit energy proportional to T4. The average of T taken to the fourth power is not the same as the average of T4. This is clear from basic high school algebra, so how much difference does this make?
To answer that we will turn to the Hadley Climate Research Unit (HADCRU) version 4 global temperature database. We will use their version 4 baseline 1961-1990 absolute temperature dataset and their 1850 to 2017 temperature anomaly dataset. The construction of the baseline and the anomaly datasets is described in Jones, et al. (2012). Since the temperature series anomalies are anomalies from each series’ 1961-1990 average, we should be able to use the series baseline temperature to convert the anomalies to actual temperatures. These are both 5° x 5° gridded datasets. Anomalies are computed for each station to avoid problems with elevation differences, etc. This is done before they are gridded. Thus, adding the baseline temperature to the anomaly does not restore the original measurements. To quote from the HADCRU web site:
“Stations on land are at different elevations, and different countries measure average monthly temperatures using different methods and formulae. To avoid biases that could result from these problems, monthly average temperatures are reduced to anomalies from the period with best coverage (1961-90). For stations to be used, an estimate of the base period average must be calculated. Because many stations do not have complete records for the 1961-90 period several methods have been developed to estimate 1961-90 averages from neighbouring records or using other sources of data (see more discussion on this and related points in Jones et al., 2012). Over the oceans, where observations are generally made from mobile platforms, it is impossible to assemble long series of actual temperatures for fixed points. However, it is possible to interpolate historical data to create spatially complete reference climatologies (averages for 1961-90) so that individual observations can be compared with a local normal for the given day of the year (more discussion in Kennedy et al., 2011).
It is possible to obtain an absolute temperature series for any area selected, using data from the absolute file, and then add this to a regional average of anomalies calculated from the gridded data. If for example a regional average is required, users should calculate a regional average time series in anomalies, then average the absolute file for the same region, and lastly add the average derived to each of the values in the time series. Do NOT add the absolute values to every grid box in each monthly field and then calculate large-scale averages.”
By the way, “NOT” is capitalized on the website, I did not change this. My plan was to add the grid 1961-1990 temperature to the grid anomaly and get an approximate actual temperature, but they say, “do NOT” do this. Why tell the reader he can add the absolute 1961-1990 baseline temperature average to averaged anomalies and then expressly tell him to not add the absolute temperature grid to an anomaly grid? Every anomaly series must be referenced to its own 1961-1990 average, why does it matter if we average the anomalies and the absolute baseline temperatures separately before adding? So, naturally, the first thing I did was add the absolute 1961-1990 grid to the anomaly grid for the entire Earth from 1880 to 2016, precisely what I was instructed “NOT” to do. The absolute temperature grid is fully populated and has no missing values. The year-by-year anomaly grids have many missing values and the same cells are not populated in all years, it turns out this is the problem that HADCRU are pointing to in this quote.
Figure 1 shows the 1880 to 2016 global average temperatures computed the way HADCRU recommends. I first averaged the anomalies for each year, weighted by the cosine of latitude because it is a 5° x 5° grid and the area of each grid cell decreases from the equator to the poles with the cosine of the latitude. Then I add the global average 1961-1990 temperature to the average anomaly. While the baseline temperature grid is fully populated with absolute temperatures, the yearly anomaly grids are not. Further the populated grid cells come and go from year to year. This process mixes a calculation from a fully populated grid with a calculation from a sparsely populated grid.

Figure 1, Average the anomalies and then add the average 1961-1990 global temperature
By doing it in the way they expressly advise us not to do, we obtain figure 2. In figure 2, I add the appropriate 1961-1990 absolute cell average temperature to each populated grid cell, in each year, to create a grid of absolute temperatures and then average that, ignoring null cells. In this process, the absolute temperature grid matches the anomaly grid.

Figure 2, Convert each grid cell to actual temperature, then average
The difference between figures 1 and 2 is most apparent prior to 1950. After 1950, the lower plot is a few tenths of a degree lower, but the trend is the same. With perfect data, the two plots should be the same. Each time series is converted to an anomaly using its own 1961-1990 data, multiple series in each grid cell are merged using straight averages. But, the data are not perfect. Grid cells are populated in some years and not in other years. Prior to 1950, northern hemisphere coverage never exceeds 40% and southern hemisphere coverage never exceeds 20%. Given the wide discrepancy between figures 1 and 2, it is not clear the data prior to 1950 are robust. Or, stated more clearly, the data prior to 1950 are not robust. It is also not clear why the period 1950 to 2016 is 0.2 to 0.3°C cooler in figure 2 than in figure 1, I’m still scratching my head over that one.
The HADCRU procedure for computing global temperatures
The procedure for computing the HADCRU version 4 grid cell temperatures is described on their web site as follows:
“This means that there are 100 realizations of each [grid cell] in order to sample the possible assumptions involved in the structure of the various components of the error (see discussion in Morice et al., 2012). All 100 realizations are available at the above Hadley Centre site, but we have selected here the ensemble median. For the gridded data, this is the ensemble median calculated separately for each grid box for each time step from the 100 members. For the hemispheric and global averages, this is again the median of the 100 realizations. The median of the gridded series will not produce the median of the hemispheric and global averages, but the differences will be small.”
Thus, the HADCRU version 4 global average temperature is not a true average. Instead it is the median value of 100 statistical realizations for each populated grid cell and both hemispheres. Every temperature measurement contains error and is uncertain. The 5° x 5° latitude and longitude grid created by HADCRU contains, for a 12 month calendar year, 31,104 grid cells. Most of these have no value, figure 3 shows the number of these cells that are null (have no value) by year from 1880 through 2016.

Figure 3: (Data source)
As you can see, most of the cells have no data, even in recent years. In figure 4 we can see the distribution of populated grid cells. The cells with adequate data are colored, those with insufficient data are left white. Coverage of the northern hemisphere approaches 50% from 1960-1990, coverage of the southern hemisphere never exceeds 25%.

Figure 4 (source: Jones, et al., 2012)
So, the data are sparse and most of the data is on land and in the northern hemisphere. Both poles have little data. So HADCRU has two problems, first how to deal with measurement uncertainty and second how to deal with the sparse and uneven distribution of the data. Measurement uncertainty is dealt with by requiring that each grid cell have a sufficient number of stations reporting over the year being considered. Since the baseline period for the temperature anomalies is 1961-1990, sufficient measurements over this period are required also. Generally, they require the stations to have at least 14 years of data between 1961 and 1990. Stations that fall outside five standard deviations of the grid mean are excluded.
The monthly grids are not contoured to fill in the missing grid values as one might expect. Once the median temperature is computed for each grid cell with sufficient data, the populated grid cells are cosine-weighted and averaged, see equation 9 in Morice, et al., 2012. The area varies as the cosine of the latitude, so this is used to weight the grids. The weighted grid values are summed for each hemisphere, averaging the hemispheres results in a global average temperature. Seasonal and yearly averages are derived from monthly grid values.
Most of the populated grid cells are on land because this is where we live, yet 71% of the surface of the Earth is covered by ocean. Currently, this is not a problem because we have satellite estimates of the sea-surface temperature and the atmosphere above the oceans. In addition, we have the ARGO buoy network that provides high quality ocean temperatures. Yet, historically it has been a problem because all measurements had to be taken from ships. The critical HADSST3 dataset used to estimate ocean temperatures is described by Morice, et al., 2012. A fuller explanation of the problems estimating ocean grid cell historical temperatures is found in Farmer, et al., 1989. The data used prior to 1979, are from ship engine intakes, drifting buoys, and bucket samples taken over the sides of ships. These sources are mobile and prone to error. The ocean mixed layer is, on average, 59 meters thick (JAMSTEC MILA GPV data). See more on the JAMSTEC ocean temperature data here. The mixed layer is the portion of the ocean that is mostly in equilibrium with the atmosphere. This layer has 22.7 times the heat capacity of the entire atmosphere and exerts considerable influence on atmospheric temperatures. It is also influenced by the cooler, deeper ocean waters and can influence them due to ocean upwelling and downwelling (see Wim Rost’s post here).
My calculations
I started with the 1961-1990 baseline temperature data, called “Absolute” and found here. This is a series of monthly 5°x5° global temperature grids for the base period. Unlike the anomaly datasets, these grids are fully populated and contain no null values, how the Absolute dataset was populated is explained in Jones, et al., 2012. Figure 5 is a map of the average Absolute temperature grid.

Figure 5, Map of the “Absolute” data (data source: HADCRU)
My procedure is like the one used by HADCRU. I first read the Absolute grid, it populates an array dimensioned by 72 longitude 5° segments, 36 5° latitude segments, and 12 months or one year. Next, I break the HADCRUT4 global anomaly grid down year-by-year, average the populated cells, and then add the average Absolute 1961-1990 temperature to the average anomaly. The results are shown in figure 1. As discussed above, I also spent some time doing exactly what the HADCRU web site says I should “NOT” do, this result is shown in figure 2.
The HADCRU data go back to 1850, but there is very little global data before 1880 and much of it was taken in the open air. Louvered screens to protect the thermometers from direct sunlight were not in wide use until 1880, this adversely affects the quality of the early data. So, I only utilize the data from 1880 through 2016.
The surprising thing about the graph in figure 2 is that the temperatures from 1890 to 1950 are higher than any temperatures since then. Refer to figure 3 for the number of null values. There are 31,104 cells total, the maximum number that are populated is around 11,029 in 1969 or 35%. Figure 6, inverts figure 3 and shows the number of populated cells for each year.

Figure 6
Is the higher temperature from 1890 to 1950 in figure 2, due to the small number of populated cells? Is it due to the uneven distribution of populated cells? There is a sudden jump in the number of populated grid cells about 1950 that coincides with an anomalous temperature drop, what causes this? Is it due to an error I made in my calculations? If I did make an error (always possible) I have every confidence someone will find it and let me know. I’ve been over and over my R code and I think I did it correctly. I’ve read the appropriate papers and can find no explanation for these anomalies. All the data and the R code can be downloaded here. Experienced R users will have no problems, the zip file contains the code, all input datasets and a spreadsheet summary of the output.
Power and Temperature
The original reason for this study was to see what difference the computational sequence makes in computing the energy emissions from the Earth. That is, do we take the fourth power of an average temperature as done by Kiehl and Trenberth, 1997? Or, do we take each grid cell temperature to the fourth power and then average the Stefan-Boltzmann (SB) power from equation 1? The average of the 2016 HADCRU temperatures is 15.1°C. The SB energy emissions computed from this temperature (288K) are 391 W/m2 as commonly seen in the literature. If we compute the SB emissions from all the populated HADCRU grid cells in 2016 and average them, weighted by area, we get 379 W/m2. This is a small difference unless we compare it to the estimated difference that increasing CO2 might have. In the IPCC AR5 report, figure SPM.5 (page 14 of the report or you can see it here in the third figure) suggests that the total effect of man’s CO2 emissions since 1750 has been 2.29 W/m2, much less than the difference between the two calculations of the Earth’s emissions.
The comparison gets worse when we look at it over time. Figure 7 shows the computation of power emissions computed using a global average temperature or (Mean T)4. Figure 8 shows the calculation as done on each populated grid cell and then averaged or (Mean T4).

Figure 7

Figure 8
It seems likely that the differences from 1880 to 1950 are related to the number of populated cells and their distribution, but this is speculation at this point. One must wonder about the accuracy of this data. The comparison since 1950 is OK, except for the algebraic difference due to averaging temperature first or taking each temperature to the fourth power first and then averaging power. From 1950 to 2014, this difference averages 13 W/m2.
Discussion and Conclusions
I do not challenge the choice HADCRU made when they decided to create 100 statistical realizations of each grid cell and then choose the overall median value, weighted by cosine(latitude), as the average temperature for each hemisphere and then combine the hemispheres. This is a reasonable approach, but why is the result so different from a straightforward weighted average of the populated grid cells? To me, any complicated statistical output should line up with the simple statistical output, or the difference needs to be explained. The comparison between the two techniques over the period 1950 to 2016 is OK, although the HADCRU method results in a suspiciously higher temperature. I suspect the data from 1950 to 2016 is much more robust than the prior data. I would doubt any conclusions dependent upon the earlier data.
Their recommended calculation process is a bit troubling. They recommend averaging a sparse anomaly grid, then averaging a completely populated absolute temperature grid, and then sum the two averages. Then they explicitly instruct us not to select the same population of grid cells (anomaly and absolute), sum those, and average. Yet, the latter technique sums apples to apples.
Finally, it is very clear that using the SB equation to compute the Earth’s energy emissions with an estimated global average temperature is incorrect, this is how the emissions were computed in figure 7. When we compute the SB emissions from each HADCRU populated grid cell and then average the result, which basic algebra tells us is the correct way, we get the result in figure 8. Comparing the two suggests that there are significant problems with the data prior to 1950. Is this the number of null grid cells? Is it the areal distribution of populated grid cells? Is it a problem with estimated sea surface temperatures? Or perhaps some other set of problems? Hard to say, but it is difficult to have much confidence in the earlier data.
We are attempting to determine the effect of an increase in CO2. This results in an estimated “forcing” of about two W/m2. We also want to know if temperatures have increased one-degree C in the last 140 years. Is this data accurate enough to even resolve these effects? It is not clear to me that it is.
The R code and the data used to make the figures in this post can be downloaded here.
It looks like the surface records used by Hadley are so dodgy that trying to draw any conclusion from them is nearly futile. No wonder Tony Heller gets so exercised.
A genuine surface data set, raw or only justifiably and honestly adjusted, would like witch’s tits, with one at about 1926 to 1943 and the other at 1999 to 2016.
Witches’ tits? Wha…?
For goodness sake Andy, the dataset is called HadCRUT not HadCRU. At least get your title right !
“To answer that we will turn to the Hadley Climate Research Unit (HADCRU) version 4 global temperature database. ”
It’s worse than I thought !
The 100 realisations you refer are from the HadSST3 database ie SEA temps, nothing to do with land. The land air temps you seem to be using are called CRUTem4 , which despite being clearly labelled in the title of Jones’ graph you do not mange to get right.
There is no such place or institution. There is the UK Met Office Hadley Centre and the UEA Climate Reseach Unit.
The Hadley SST and the CRU land temps are mixed to provide a global gridded dataset of both land and sea, this is called HadCRUT ( hadSST + CruTem ) . There is no HADCRU, either as an insitution or as a dataset.
Please do you homework before writing an article.
Greg, You are picking nits to excess. The Hadley MET office and the East Anglia University climate research unit have been collaborating on this dataset for decades. And the collaborative organization has been abbreviated as HADCRU for nearly that long. And if you look at the length of my second sentence you will get a clue as to why that is. Either way, formal or not, HADCRU is the organization and HADCRUT is the dataset. I’ll stick with that. If you have an alternative, that is fewer than 12 words, I will consider using it for my next post on the subject. HADCRU is brief and well understood in this community.
False strawman argument. Invent a nit, then pick at it as if it has any import.
Hadley crud earns the respect it gets; i.e. none.
Greg, “the dataset is called HadCRUT.” The “T” stands for temperature. So saying HADCRUT temperature dataset is duplicating a word. Re-read what I have written, I think I was consistent in calling the organization “HADCRU” and the temperature dataset HADCRU temperature. Or I was referring to the organization, where the “T” is inappropriate. There is one place where I write HADCRUT and it is appropriate there. Normally I say HADCRU temperatures.
I’ve always loved that equation if only for the 4th power.
Funny aside … when I was in grad school the cliche du jour was “the rate of change [of everything] is accelerating constantly.”
I wrote a little note to the school newspaper pointing out that rate of change is the first derivative, and acceleration is the second derivative, yielding the third derivative, meaning that they were being constant jerks. No one got the joke.
I guess you had to be there.
(The third derivative is the impulse, or jerk, function.)
Max, I understand that this is well understood by teenage boys worldwide.
Indeed. Like climate science, it’s a tribute to man’s puny calculus.
I saw the light, thanks.
“One specific problem is that the Earth is not at a uniform global temperature.”
A greater problem is that Earth is not uniformly heated. The black-body temperature will be much higher when uniformly heated than when being directionally heated on one hemisphere.
An even greater problem is that comparing a SURFACE temperature average to a PLANETARY emission temperature average is like comparing a thin coating to a thick volume. Earth’s global average temperature happens close to the ground. Earth’s planetary emission temperature happens at an effective height of emission, which is, what?, eight kilometers above the ground. How can these two effective (average) surfaces even be compared to arrive at any greenhouse-effect magnitude at all?
The whole thing seems like a nonsense calculation, and dissecting nonsense merely results in smaller pieces of nonsense.
But I’ve said too much.
Nice analysis. More uncertainty monster.
Thanks Rud, take care during the hurricane. Yours looks much worse than ours.
Thanks, Andy. Just got the first rain squall with TS gusts. Quieted down now. Waves breaking over the reef maybe 8 feet. We are unlikely to lose power and water, unlike Wilma. Looks like we made the right call to shelter in place, thanks to CFANs 9/5 adjusted forecast published in Sun Sentinal 9/6.
Agreed, if you are above the maximum surge, sheltering in place is best. We are way above the surge (at 155 feet) and evacuated once, never again. Safer in the house than out in the parking lot called a freeway. If I were below the max surge (say below 20 feet or so) I would evacuate though.
“if we assume the Earth acts like a blackbody.”
Which is isn’t.
70% is covered by a substance that is highly wavelength variable.
How very true! Plus shortwave radiation can penetrate the ocean to a depth of 200 meters +. How long will it take for that energy, turned into long wave IR, to emerge from the ocean depths? To paraphrase James Carville – It’s the oceans stupid!
“It’s the oceans stupid!”
And the sun ! 🙂
In addition, some of that heat gets stuck in subsurface currents that can dive under a colder top surface. Most people think that heat will always rise to the top and not get caught and held below a colder surface. Have you checked out the ocean currents that wind their way below another surface current? Remember, density is the overall factor in water sinking below the surface. But density is not determined solely by temperature. It can also be determined by salinity and wind. Therefore, warmer water can still sink below colder water if its salinity makes it denser, or wind piles up colder water on top of warmer water. It is this non-temperature related process that I believe makes for long term and uber-long term changes in ocean heat, that when combined with Milankovitch Cycles and continental positions, trigger stadial and possibly even ice age glacial periods on the surface of our planet.
Pamela Gray, agreed. Both Javier and Wim Rost have discussed this and they have more to come along these lines.
We had a lot of discussions along these lines a couple of weeks ago, when George (CO2ISNOTEVIL) introduced his model.
Oceans are certainly the main capacitor of thermal energy on our planet. But their temperature stratification on climatic time scales is quite permanent. While, indeed, very slight density differences may arise due to great differences in salinity, leading to snail’s-pace sinking of warm waters into slightly cooler layers, such inversions are quite rare and relatively minor. Upwelling of strongly cooler water by seasonal winds that drive the warm surface layer offshore is confined to coastal regions While clearly having an appreciable effect on local climate, the effect of these factors upon the variations of global heat content is minimal.
AndyG55,
Actually, water has very high emissivity in the IR, but deviates considerably from being a Blackbody at the shorter wavelengths, particularly if there are suspended materials. Geologic materials are highly variable in their absorption spectra and dispersion with wavelength. All the more reason to calculate separate emissivities and temperatures for the oceans and land, and to do a weighted average for the two (ignoring clouds and vegetation for the moment).
Something that doesn’t get talked about is that even on the sunlit side of the Earth, IR energy is being emitted. It is similar to what gets emitted on the dark side, over the oceans. However, because the rocks and sand get so much hotter than water, the energy emitted is greater for a unit area on land, AND the peak emission is shifted to a shorter wavelength. I haven’t done the calculations, but it might well be outside the peak absorption for water and CO2.
The real world is so much more complicated than climatology theory that I don’t think that a single average temperature or emissivity (or reflectivity, approximately the complement of emissivity) is adequate for a good understanding of what is happening!
This is a fine expose of what I have long called the “anomaly shuffle” that goes into the manufacture of “global” temperature indices from a data base that is temporally incomplete and heterogeneously sparse in spatial coverage. The opportunities to materially alter the final result via seemingly innocuous procedural choices are numerous.
To circumvent any such legerdemain, the cursory procedure I adopted was to use only nearly intact, century-long, thoroughly vetted, largely non-urban station records in compiling a straightforward estimate of the global average temperature. To avoid geographic bias, a large minimum spatial separation was required between stations, and short gaps in any record were adaptively filled by referencing a highly coherent neighboring record.
The proprietary global estimate for 1902-2005 (when GHCN v. 3 adjustments began to distort reality grossly) is enlightening. The relatively trendless anomalies obtained referencing the 1902-2000 average indeed resemble Sixto’s “witch’s tits” much more than any of the published indices. In fact, cross-spectrum analysis with those indices reveals insignificant coherence at multi-decadal periods, but strong coherence throughout the higher frequencies. This indicates that, despite their verisimilitude in wiggle-matching, the much-trumpeted indices cannot be trusted to represent the actual trends or multi-decadal behavior of temperature variations throughout the globe.
” GHCN v. 3 adjustments began to distort reality grossly”
They don’t. But if it bothers you, why not use GHCN V3 unadjusted?
Besides raw station data from small towns, there are numerous pristine project sites scattered over the globe at which my professional clients have made careful temperature measurements for decades. They provide ample evidence that “unadjusted” GHCN v.3 data indeed distort reality grossly.
Move some warm water from the tropics to some other place on the globe below the Arctic circle. The temperature changes linearly and all the linear operations like averaging and using anomalies works fine. Now move the same water to the Arctic. Some more ice melts and the temperature stays the same. Because of this non-linearity, the use of averages and anomalies is no longer valid.
It’s like an ice cube in a cold drink, until the ice cube is completely melted, the temperature remains relatively constant in spite of continuous energy input from the surrounding warmer air.
Temperatures are easy to measure which is why they are used in climate science. It’s the same as noticing where the planets and stars are and using them to determine our fates using astrological science.
I have a problem with “Stations that fall outside five standard deviations of the grid mean are excluded.“. When climate models were run with a trillionth of a degree difference in initial temperatures, and with all other parameters and settings unchanged, some regions varied in the model results by more than 5 deg C. That’s five trillion times the original variation. The modellers thought this was OK – that it simply illustrated how variable Earth’s climate could be. [I think they were nuts on several counts, but that’s what they said. https://www2.ucar.edu/atmosnews/perspective/123108/40-earths-ncars-large-ensemble-reveals-staggering-climate-variability%5D. Well, if that’s their reaction to that particular shenanigan, why should anyone reject an actual measured temperature just because it is different to the others? Isn’t that what temperatures do? For example, if you discarded any rainfall measurement outside 5 standard deviations, wouldn’t you discard Hurricane Camille and maybe Harvey, and probably all of the California dustbowl too? Surely all measurements must be accepted and worked with, unless there is clear direct evidence that the instrument or its reader was inaccurate..
PS. When they discard those stations, doesn’t that alter the standard deviation so that more stations should then be discarded – etc, etc.
PPS. Andy – You have made a valiant effort to interpret the instrumental temperature record, but I think that all you have achieved is yet another clear demonstration that the instrumental temperature record is quite simply unfit for any climate purpose. [I tried it a year or two back with the same result.].
Of course it is unfit for for purpose if you are doing energy budget calculations since you can not average temperatures of different materials. HadCRUFT4 is a land+sea “average”.
If you want a simple metric to bullshit the general population and trick them into adopting your political agenda, it is fit for purpose.
Those doing this are well aware of both points.
Mike Jonas and Greg, I agree with you. It is unfortunate, but once you start pulling a single thread from the clothing called “CAGW” you find yourself naked in no time. Nothing survives a close inspection.
Mike, Sounds like Chaos to me. I’d be grateful if you’d look at my post about Kiel Trenberth below and pass comment. I have read many of your previous post and we are on a similar page.
“Well, if that’s their reaction to that particular shenanigan, why should anyone reject an actual measured temperature just because it is different to the others?”
The NCAR note has nothing to do with measurement. It is an issue of the way that GCM’s evolve with little dependence on initial conditions. And it reflects the way the planet’s weather and local climates could have turned out differently. HADCRUT etc is about measuring how they did turn out.
“Surely all measurements must be accepted and worked with”
Yes, and they are. The issue in global averaging is always estimating the temperature in local regions from site data. Sometimes it is inconsistent, and you have to use what seems most reliable.
Hi Nick – There seems to be a bit of a contradiction in your comment. “Yes, and they are” says you use all measurements, but then “you have to use what seems most reliable” says you don’t use all measurements.
“says you don’t use all measurements”
It’s usually a matter of weighting. Normally nearest measurement points get the highest weight in estimating temperature of a region. But that might be varied if there are reliability doubts.
From the Kiel Trenberth diagram above let (a) esAT^4=396*A where A is surface area of earth and T is global average temperature and 396 is radiation from the surface using Boltzmann. After removing all atmosphere and taking account of 23 W/M^2 reflected energy the earth’s temperature T0 would obey (b) esAT0^4 =(341-23)*A where 341 is incoming radiation.
Current global Average temperature is 15 deg C = 288 deg K so substituting in (a)
esA(288^4) = 396*A. Then taking (b) esA(T0^4)=318*A.
Dividing (a) by (b) (288^4)/(T0^4)=396/318
ie T0=( (288^4)*318/396)^(1/4)= 272.63
Therefore the atmosphere etc increases the global temperature by 288-272.63 = 15.37 deg K
But if CO2 drives the temperature increase then
B*Ln(400) = 15.37 where B is the constant relating CO2 to temperature increase and doubling CO2 to 800 ppm means that the temperature increase will rise by B*Ln(800)= Trise ie Ln (800)/ln(400)= Trise/15.37 ie Trise = 17.15 ie doubling CO2 increases global average temperature by 17.15- 15.37 = 1.78 deg C
So should we ever manage to double the CO2 level to 800 ppm then global average temperature will rise from 288 deg K to 289.78 deg K. 1.78 deg C
This does not frighten me. Is there an error in my maths here?
Son of Mulder, Quite clever, thanks! I have no idea if it is correct, but it is amusing and fun to read.
Thanks Andy, I’d like it to be challenged scientifically. It’s a simple observation and often the Achilles Heal of sophisticated arguments which try to support a challenged hypothesis is that holes get dug that can be used to invalidate the basis. I have no idea if the Kiel Trenberth diagram is correct but it certainly seems to be consistent with Luke warming.
Net absorbed = 0.9 +/- 17.
But that would be the case in each scenario so just subtract 0. 9 or 17 from each equation (a) and (b) and would make only a very minor change to the 1.78 deg C.
I wonder if the flat earth model can be trusted to the accuracy of 0.26% (0.9 W/m2 out of 341 W/m2). There are minor neglected things like day and night, summer and winter, or ocean, jungle, and desert.
@son of mulder
It is late at night and I have had something to drink, so I may be overlooking something obvious. I apologize if I have done.
Given that you (correctly) take account of the solar that is reflected from the surface without being absorbed by the surface (23 W/M^2), please explain why you are not also taking account of the fact that some of the incoming solar (said to be 79 W/M^2) is either reflected by clouds and the atmosphere such that it never reaches the surface to be absorbed?
In short doesn’t the K&T energy budget cartoon suggest that the effective incoming solar is not 341 W/M^2, but rather only 262 W/M^2 (ie., 341 W/M^2 – 79 W/M^2)?
Richard, My take on it is that I could have assumed that the 79W could have been reflected by the surface in the same proportion as the 23 vs 161. That would mean 23×79/161=11 extra reflected so would reduce 341 by 11+23=34. I don’t think that will make much difference to my conclusion.
Thank you Son of Mulder.
I guess that that is indeed a possibility, and without accurate and proper measurement, we do not know. It could have a material impact as your calculation suggests.
I find the K&T energy budget cartoon so far removed from planet Earth that it irritates me. I fail to understand why anyone would view the planet as if it was a uniform ball fully immersed in a warm soup which is radiating energy uniformly across all of the entire surface area of the ball on a 24/7 52 week of the year basis. Since it is so divorced from reality, why would anyone expect it to be informative?
It does not represent the geometry of our planet with axial tilt, nor the rotational implications of the spinning globe with amongst other things packages of solar being received in bursts, nor does it reflect the fact that albedo is not a constant, nor that for approximately 70% of the surface of globe (the oceans) solar is not absorbed at the surface, but instead is absorbed at depth with the absorbed solar irradiance being distributed in 3 dimensions throughout the oceans. i could go on. It beggars belief that a ,i.science could have such a cartoon forming a central plank.
Richard,
“I fail to understand why anyone would view the planet as if it was a uniform ball fully immersed in a warm soup which is radiating energy uniformly across all of the entire surface area of the ball on a 24/7 52 week of the year basis.”
And no-one does. It is a budget. Energy is conserved, so you can track it. Averaged over the surface, and over a year, surface emissions add up to 396 W/m2. No-one claims that that is the rate everywhere and at all times. What you can do is track where that energy came from and where it goes. It would probably be clearer if done in global total Joules/year, but reducing it to J/s/m2 makes the numbers manageable. 161 W/m2 came from sunlight. That doesn’t mean the sun was shining everywhere 24/7. It’s just the total, on the same basis. And the various totals have to add up. That is why budgetting makes sense.
And it is why mulderson’s calculations can’t work. I think there are other problems, but you can’t equate an average temperature with an average flux by S-B. The relation is an integral in time and space, and a T^4 relation won’t be preserved under that.
Nick Stokes said “and it is why mulderson’s calculations can’t work”
But they can, but maybe not in the way you envisage. If the planet I applied my calculations to was a planet, not rotating, not with a sun in the conventional sense but surrounded by a heat source, spherically uniform and delivering the energy flux as in the Trenberth diagram along with all the other energy budgets in the diagram then my calculations would be reasonable and not require the integral in space and time that you suggest because of symmetry.
Now consider a slightly more complex planet obeying the same energy budget but where one half it has a temperature of (T+x)/2 and the other half with temperature (T-x)/2 then it’s total surface radiation would be esA((((T+x)/2)^4)+((T-x)/2)^4))) ie global average temperature = T and the value of x for which outgoing radiation is minimum is when x=0. A bit of differentiation will show that. So the warmest such planet is when x=0 because it needs a higher temperature to radiate its insolation.
In my original calculation I suggest that the planet I described was the warmest of the family of planets with average temperature T and the same energy budget. That’s an infinite number of planets of which earth is one.
So in the calculation of planetary temperature I showed the maximum such planet. Again doubling CO2 it would be the warmest such planet from that family. I think it follows that the difference between the temperature at 400 ppm and 800 ppm would also be the greatest.
Hence what I have shown is the maximum example of sensitivity. Planet earth will be less than my example. Ie sensitivity will be less than 2 because surface temperature is not uniform.
Now you may argue that clouds, water vapour etc mean my argument is fallacious as once clouds are introduced then some insolation is reflected but CO2 and water vapour combined produce extra back radiation.
But when min/max analysis are done usually the simple, symmetric model is either the min or the max. Here I say it’s the max. Any comments?
Thanks Nick for your further comments.
Whilst it is good to simplify, one must be careful not to over simplify. Therein lies the problem with the K&T energy budget cartoon. Whilst I am well aware of energy conservation, the cartoon is simply not representative of this planet, and this becomes significant when one is looking for an imbalance of only a few watts.
As I noted, for some 70% of the surface of the planet energy is not received at the surface, but rather at depth, and then that energy is sequestered to further depth not reappearing in our life time, or may be not for thousands of years, perhaps even not for millions of years. The 3 dimensional oceanic currents are important and energy not simply gets sequestered to depth (for lengthy periods) but also gets trapped under ice, or goes to melt ice etc. It is only by chance that we see the surface temperature that we see today. If we were to go back in time, say to the Holocene Optimum, we would see a significantly different temperature not because more energy was received from the sun, or less energy was being radiated, but rather because the way energy is distributed and resurfaces over time. The planet is never in equilibrium, not on short time scales nor medium time scales. Because the planet is not in equilibrium, one cannot get a balanced budget.
In a living world there are so many processes not even represented in the cartoon. That cartoon is so devoid from reality that it is no surprise that an imbalance of a few watts may be seen.
Personally I suspect the reason why so many scientists make absurd pronouncements regarding the loss of Arctic sea ice is that they have got into the mindset of viewing the planet as a flat Earth, as depicted in the K&T cartoon. They are overlooking the geometry of the planet, and how energy is actually received. The axial tilt of the planet, and the resultant impact upon how energy is received at the pole, acts akin to a negative feedback making the loss of Arctic sea ice difficult.
In my post at son of mulder September 10, 2017 at 2:56 pm
I meant T+x and T-x not (T+x)/2 and (T-x)/2 but my argument is unaffected.
But water vapor is the most abundant GHG at 1%-3% versus CO2 @ur momisugly 0.04%. So CO2 is a fractional player in the GHE. And the positive feedback the GCM modelers use to get their scare alarmist scare stories to get to 3 deg to 6 deg C doesn’t exist because of the convective precipitable nature of water in the atmosphere.
My money is on a 2xCO2 ECS of < 1 deg C.
Note that in the Trenberth diagram above, posted by SoM, the surface reflectance is 14%, very similar to Mars! With the Mars only having mafic and ultramafic rocks (which are typically dark) and the Earth having abundant Sialic rocks (which are typically light), quartz rich beaches and desert sands, ice and snow, and vegetation that is nominally in the range of about 8% to 18% (average~13%). I have previously argued that the specular reflectance alone from water ( https://wattsupwiththat.com/2016/09/12/why-albedo-is-the-wrong-measure-of-reflectivity-for-modeling-climate/ ) may be as high as 18% on average. It seems to me that the surface reflectance is too low!
son of mulder – That’s an ingenious approach, but I think it’s very difficult to regard the results as reliable. That’s because you are working with small differences between large numbers – a small error in the large numbers results in a large error in the small differences.
1. I’m not sure your “(341-23)” is correct. Shouldn’t it be 341*(161-23)/161 = 292? ie, wouldn’t the proportion reflected be the same, not the amount reflected? Your 15.37 then becomes 21.12, and your 1.78 becomes 2.45. But …
2. “if CO2 drives the temperature increase” is surely not a realistic assumption. If I have understood your calcs correctly, the “temperature increase” we are talking about is the difference between with- and without-atmosphere. But the atmosphere also contains water vapour, and water vapour would be responsible for a large part of the “temperature increase”. So the “2.45” now has to be reduced by quite a large factor. I think it would end up a very long way below your “1.78”. ie, CO2 would be a much smaller factor.
I would prefer to see the calcs done on a gridded planet rather than on global averages, because of the ^4’s, but it might not affect the result much. No matter how you cut it, CO2 is not going to end up having a large effect. There’s also the fact that Earth’s is a non-linear system, so (a) your calcs are purely theoretical, and (b) no-one can know what effect a doubling of CO2 would have in the real world – it would depend on conditions at the time.
I’m soon off to the Russian wilderness for a week, so may be offline for a while.
Thanks Mike, I’ll see you half way. See my response to Richard Verney above. If I reduce the without cloud absorbed by 11 I get 2.0 instead of 1.78. Have a good holiday, if that’s what your doing.
Mike, Thinking about your comment concerning “small differences between large numbers” the only division my calculations use is between large numbers and certainly large denominators of a similar magnitude to their numerator so there isn’t a risk of blowing up a calculation because of a small difference error. I think your comment about the assumption that CO2 drives being unrealistic is likely correct but I think that would mean that the sensitivity to CO2 would be less than I calculate because unforced water vapour is doing some of the warming. I’m not worried about grid cells because I’ve used global numbers to calculate a clearly defined measure of global temperature based on Boltzman being calibrated to the actual global average temperature defined from thermometers.
son of mulder September 9, 2017 at 1:39 pm: “But if CO2 drives the temperature increase then (…) doubling CO2 increases global average temperature by 17.15- 15.37 = 1.78 deg C”
WR: Am I right that “doubling CO2 increases global average temperature by 17.15- 15.37 = 1.78 deg C” ” but only if ‘all other things remain the same’?
Important, because when temperatures rise, important ‘other things’ will not remain the same. Like evaporation, clouds etc..
I think your numbers seem correct, but noticed a couple comments that aren’t accurate.
1) water vapor is the bigger issue when it comes to energizing and heating the atmosphere. Co2 accounts for approx 24% if I remember correct. The reason for such focus on co2 levels is because it is the controllable expense, if you will. Water vapor is going to be dictated by conditions, but co2 is being increased by man made processes. This leads me to point 2….
2) the doubling of co2 (or climate sensitivity) is based off pre industrial co2 levels, not levels of today. Pre industrial was 280, or maybe 260. Either way, we are mostly there on our way to a doubled co2 value. This leads to my next point…
3) the concern with agw the 1.8, it’s the side effects of the 1.8. It’s the concern that a slight raising of ocean heat could lead to smaller or shorter seasoned ice caps, which have a very high reflectivity value, over 90%. It’s the concern that increased temps could lead to increased moisture in the air. Water vapor traps heat as a function of the square of the mass, not linearly like co2. A little water vapor will have a much larger effect than its equal co2 counter part.
I think you would be hard pressed to find any scientist who will disagree that a doubling of co2 from pre industrial times will lead to a permanent increase of 1.8C. Where disagreement arises is how long will that shift take to fully set in and the impact of other systems on future climate because of the tipping of the scales, so to speak, associated with that initial doubling.
“The 5° x 5° latitude and longitude grid created by HADCRU contains 31,104 grid cells.”
Something odd here. A 5×5 grid has 2592 cells. 31104 is 2592*12. I assume it is the product of cells and months in the year.
Nick Stokes, yes. Each year contains 31,104 grid cells. I see the confusion, I’ll change the phrasing a bit to make it more clear. I did every calculation on a whole calendar year to avoid seasonal problems.
OK, Nick, it is fixed. Thanks.
“Why tell the reader he can add the absolute 1961-1990 baseline temperature average to averaged anomalies and then expressly tell him to not add the absolute temperature grid to an anomaly grid?”
This is an old chectnut. GISS and NOAA also emphatically tell you NOT to do this. There is a reason which you should figure out. Averaging the anomalies is NOT the same as averaging the temperatures and then subtracting the global average. And that is the reason why your Fig 2 is all wrong.
A monthly average is a sampled estimate of a global average. And the sample changes from month to nonth, depending on which cells have data. Now there is a well-known statistical science of sampling. The issue is inhomogeneity. You may have a populatiuon in which some parts are expected to measure differently than others. Think of polling and rural/urban etc. So you have to worry about whether you have the right proportions of each before averaging.
Temperatures are very inhomogeneous, and you can’t choose your sample freely. What you can do is modify the homogeneity, but subtracting from each mean its expected value. This is the anomaly. It now doesn’t matter nearly so much that the sample varies.
The practicality of this is that, over time, the nature of the cells in your sample changes. Fig 2 suggests that in modern times there are more cold cells measured (eg Antarctica). That brings down the average, even though the world isn’t getting cooler.
I have quantified the hogogeneity issue here, and in many earlier places. The neglect of consistency of samples is one frequent source of error in Steven Goddard graphs, as I describe here. A test for this is to repeat the same graphing exercise as in Fig 2, but instead of using monthly data, use the long term averages for each cell, but still include only the cells which report in each month. There is no time-varying climate information, but I think you’ll see the same pattern as in Fig 2. It isn’t telling you about the climate; it’s telling you about what is in your sample.
Nick Stokes, I agree with your analysis and it was what I concluded also. Figure 2 is incorrect for the reasons you give. I said that in the post, but perhaps not clearly enough. The question is, is figure 1 correct from 1880-1950? The difference between figures 1 and 2 is very large over that period. Then there is that annoying .2 to .3 degree fairly consistent difference between figures 1 and 2 after 1950, what is that all about? I’m happy to call both plots from 1880 to 1950 very uncertain. From 1950 to the present we have better data and better locations, but the two different, but mathematically identical techniques are 0.2 to 0.3 degrees different and it isn’t random? Why? This raises a red flag.
Andy,
“The question is, is figure 1 correct from 1880-1950?”
It seems to be just a conventional anomaly average, with a number (about 14) added. So the shape is right. The doubt is about that number 14. GISS says, DON’T, but if you really must, use an average from models. NOAA says DON’T, but when some idiot lapses, they use a number (about 14) from a paper by Jones. It doesn’t really matter – it’s just an issue of sliding labels up and down on the y axis.
As to why the difference, well, Fig 2 is meaningless anyway. But I see that you are averaging by latitude band, rather than globally. This makes a small difference. HADCRUT averages by hemisphere, and that makes a difference too. In fact, I showed here that latitude band averaging achieves much of the benefit of Cowtan and Way kriging. The issue is that whenever you average spatially, you assign implicitly the average value to missing cells. Assigning a latitude average is better than global.
“but mathematically identical techniques “
No, they aren’t. And one is wrong. Actually, the reason why Fig 2 is not so bad post-1950 is that there were fewer changes in the population of filled cells. It isn’t right, just more stable.
Nick Stokes: “It doesn’t really matter – it’s just an issue of sliding labels up and down on the y axis.”
Precisely my point! If you use the average of the fully populated 1961-1990 grid and add it to a sparsely populated 1890 anomaly grid average all you do is show the anomaly with a different Y axis. It’s BS. The only meaningful graph is figure 2 and it is BS for the reasons in my post and in your comment. Basically we know nothing about the temperature of 1890 at all. I’m not even convinced we know anything about global temperatures in 1950.
‘“but mathematically identical techniques “
No, they aren’t.’
OK, they aren’t if one of the grids is sparsely populated. But, if one of the grids is sparsely populated, the more correct way is the way figure 2 was done. That is using the average 1961-1990 grids added to the same 1890 (or whatever year) grids. Apples and Apples. Otherwise, following the HADCRU instructions, we are just arbitrarily moving the Y axis up and down as you have said and I have said. Figure 1 is BS from a mathematical point of view. Figure 2 says something, but it is wrong because the underlying data is meaningless.
The value of figure 2 and figure 8 is they show the whole HADCRU exercise is meaningless from a temperature and power perspective. The anomaly trend may have some meaning directionally, but I doubt it is accurate enough to make any difference, except perhaps from 1950 to today – and even then there are problems.
(A-a)+(B-b) = (A+B) – (a+b).
I’m not being facetious, its just that I think that this is more important than the mean T^4 coming out exactly as wanted.
Nick Stokes re latitude band averaging with the oblate spheroid earth. Granted it (lba) gets the sun energy input right but would the possible land height differences (distance from the centre of the earth) influence the temperature averaging as you go around the band?
” would the possible land height differences (distance from the centre of the earth) influence the temperature averaging”
Not if you are using anomalies. The main inhomogeneity in a latitude band is between sea and land. But as to how you do averaging, again, the key issue is that if you leave cells without data unfilled, they are treated as if they had the average value for that operation. So lat band is better than just global, but you can do better still. Unknown cells should be infilled, implicitly or explicitly, with the best estimate. That isn’t “making up data”; unsampled locations are universal in spatial averaging. It’s just doing the best you can with what you have.
Good one, Dorothy.
Layer upon layer of faulty science, erroneous physics and distorted maths piled upon one another are not worth debating for ALL the conclusions will be wrong. Surely we all agree that the assumption the Earth is a black body radiator with an emissivity of 1 is complete and utter BS? It’s something you can experimentally test with a shovel, a bucket and some basic school type lab equipment anyway. If you start with this kind of crap everything that follows is only fit for the dustbin.
The nature of the T4 relationship means that radiated power is going to be spectacularly non-linear over even short geographical distances. Thus an under-sampled grid has a high probability of producing very bad results because the data-infilling approaches are simply not capable of reproducing the fine temperature detail.
I am not sure, but this may be the point you are making?
Michael Hart, Yes, that was the main point originally. Once I got started with the HADCRUT4 dataset though I found a lot more to write about. As you can see in the map in my post temperatures vary dramatically around the globe and since emitted energy varies with the fourth power of temperature, there is a huge problem trying to estimate global emissions.
MH,
And I think that any time interpolation (and especially extrapolation) is used to infill an under-sampled grid, the error bars should be expanded!
Andy I have been advocating T^4 as the correct metric to average and trend for years (to mostly deaf ears) so VERY glad to see someone take a crack at it. One of the problems is finding the base temperature data to work from in the first place, it never occurred to me to reverse engineer it from the anomaly data like you did, that was rather clever! That said, a couple of comments:
1. I don’t know that doing it on a grid cell/month basis gets you to where you need to be. You’re essentially starting with T that has been averaged across multiple weather stations and over time, so you’re “smearing” the average of T into the base calculation of the average of T^4. I think to do this you’d need to go back to the raw temperature data and start from there. Of course to do THAT you need access to a LOT of data plus the compute horsepower to crunch it all and EVEN THEN all the problems with adjustments, variations in station location/technology/TOBS and lack of data in so many places at so many different times makes the end result just as suspect as what you get from HADCRU. Still would be interested to see it though to find out how the result differs from HADCRU.
2. Heat likes to move from the places that it is to the places that it isn’t. Equatorial regions absorb more heat than the radiate for example, but the excess gets pumped by air and water currents to the poles. Convection carries heat from hot surface to colder upper reaches of atmosphere, and so on. Given that the majority of the lack of coverage weather station wise is in the cold upper latitudes and high altitudes, averaging T^4 may be missing some very important data.
3. Given the above, have you considered doing a T^4 average based strictly on satellite data? Much shorter record of course, but reasonably consistent coverage across most of the globe, and I for one would be very interested in how they compare.
4. In your article, you note about a 13 w/m2 change since 1950. My observation is that there seems to be a step change in the late 50’s that is quite large, and likely related to the data problems you discuss prior to that. So I’d tend to go with discarding anything pre 1960, which yields a change of more like 7 w/ms (perhaps less if you consider that your graph seems to end in the 2016 super El Nino)
Very glad to see this kind of discussion, would like to see more like it, thanks!
I do not understand how the anomaly is calculated, nor precisely what it represents and in particular whether it carries any statistical significance. Perhaps Nick Stokes or Andy will enlighten me.
In my opinion to have a meaningful time series anomaly, one must always compare the same sample set with the very same sample set, in order to see how the average temperature of that sample set has varied over time. As soon as one alters the constitution of the sample set, no meaningful comparison can be made.
As one knows the sample set throughout the entire time series is constantly changing, such that the sample set used to obtain temperature data in the period 1880 to 1890, is not the same sample set as that used to obtain temperature data for the period 1890 to 1900, which in turn is different to the sample set used for the period 1900 to 1910 which in turn is different to the sample set used for the period 1910 to 1920, which in turn is different to the sample set used for the period 1920 to 1930, which in turn is different to the sample set used for the period 1930 to 1940 etc.etc. I see this constantly changing sample set to potentially render the time series anomaly data set worthless, since at no time during the temporal period is one compare like with like. such that one never knows whether there has been any change on a like for like basis, still less the extent of change
So we are told that the anomaly is from the period 1961 to 1990. Accordingly, when assessing say the 1880 anomaly does one identify the stations that reported data in 1880 say 406 stations (being 400 in the NH and 6 in the SH), then ascertain the average temperature of those 406 stations, and then check the period 1961 to 1990 to ascertain how may of those 406 stations were still reporting data during the period 1961 to 1990, then find the average for those extant stations during the period 1961 to 1990, and then take the difference between that average (ie., the 1961 to 1990 extant average) and the average figure for the 406 stations reporting temperatures in 1880?
If that is not what is being done then the resultant time series anomaly set is statistically meaningless since one cannot say whether the temperatures ascertained say in 1920 are higher or lower than 1961 to 1990.
WHOOPS
Slight error to the end of the fourth paragraph. Should have read:
“As soon as one alters the constitution of the sample set, no meaningful comparison can be made.”
No, that’s the whole idea of sampling. You can form a good estimate of the population mean, and as such can be compared. We do it all the time. The classic example is political polling. Every sample is different, but each is an estimate of the whole population. It isn’t perfect, but it isn’t meaningless. A more perfect example is estimating half-life for radiation. Clearly you are never resampling the same atoms. But because in this case we believe we have perfect homogeneity, that doesn’t matter.
“So we are told that the anomaly is from the period 1961 to 1990.”
The anomaly base is from 1961 to 1990. That is just one number for any site, subtracted from the values at all times. The idea is just to put cold and hot places on much the same basis, and it isn’t critical which expected value you use, except for one thing. If you just subtracted the average for each station over all time, then there would be a drift in those averages due to climate. Stations that reported for a while 100 years ago and stopped would have a cooler average than if they could have been measured more recently. So some of the trend which actually reflects a change in climate gets transferred to a trend in averages, and thus removed from the anomalies. I described here the practical effect of this.
Nick
i much appreciate your response, but I do not consider your comments to allay my concerns that there is not the problem that I raise. let me make my point a little clearer.
Personally, I would not wish to make any comparison with political opinion polling, which polling is riddled with errors and is never reliable. The science of polling since Brexit and President Trump has taken a hit and has a tarnished reputation, and only exit polls provide insight, within reasonable margins of errors.
One issue is sampling. Only the delusional would claim the globe to be well sampled. it is not well sampled today, and even less well sampled on a historical basis. Approx 70% of the globe is ocean and prior to ARGO there was no effective sampling of the oceans, and I do not consider ARGO to have enough floats to properly sample the oceans (there are many shallow seas not sampled at all). I am very very familiar with ocean temps, since I have spent approximately 30 years reviewing ship’s data, and I know well the limitations of such data. Phil Jones in his 1980 paper commented upon the lack of sampling in the SH, and in the Climategate emails he went as far as saying that SH temps are largely made up. Factually he was correct on that comment, since the SH is so sparsely sampled and so little historic data exists. Incidentally, Hansen, in his 1981 paper, noted the comments of Phil Jones with respect to the limitations of SH data, and Hansen did not join issue.
We know that in the 1980s everyone accepted that SH sampling was too sparse, not well spatially covered, lacked historical depth and was therefore unreliable. In my opinion it is extremely poor science to even to attempt to make a global data set (other than on the basis of the satellite data), and instead it should be accepted that there is only a reasonable quantity of data for the NH, and any data set should be limited to NH only. Of course, that does not stop SH regions, such as Australia, making their own regional data set, but it should not be extended to a hemisphere wide data set.
But isn’t that exactly what you are trying to find, namely whether the temperatures have drifted up or down over time?
As I see it, it is quite simple and no undue error results on a comparative basis, but one must properly record the limitation and hence error bounds that come with the size of the sample set being used each year. Thus:
http://www.conceptdraw.com/How-To-Guide/picture/2-circle-venn-diagram.png
A represents all stations that reported during the period 1961 to 1990 and it is these stations that go to form the base reference, and B represents the historical year, it is the date on the X axis on the time series. B will vary in size each year, such that B will be different in size in 1940 than it was in 1880 or 1920 etc. The importance is the common area in the overlap of both data sets and it is this which is used to assess the anomaly..
Now to calculate the relevant anomaly, one does the following: Say in 1880 there were 406 stations that reported data for the year 1880 (they are represented by B), and of those 406 stations 225 were reporting data during the entire period 1961 to 1990 (they are the overlap between A and B), and it is these that form the Both area in the Venn diagram. One averages the temperature at those 225 stations for the base period 1961 to 1990, and then one averages the temperatures that those 225 stations reported in 1880. One then notes the difference of the average of the 225 stations for 1880 from the average of those 225 stations during the base period. that is the anomaly.
One does exactly the same for 1881. This time there are 208 stations reporting data in 1881, but during the period 1961 to 1991, only 225 were still continuously reporting data, and one does the same averaging process.
One does exactly the same for each year through to 2016. It may well be that in 1940 there were say 6000 stations reporting data, but of these 6000, only 2900 reported data continuously through the base period of 1961 to1990 So one averages the temperatures of those 2900 stations during the base period 1961 to 1990 and one averages the temperatures from those 2900 stations as recorded in 1940 and then one notes the difference between these two averages to form the 1940 anomaly.
In this manner one is always making a like for like comparison during the entirety of the time series, but the number of stations being used to form the anomaly will continually be varying. Sometimes it will be relatively few, sometimes it will be many. This should be noted on the series. The series should contain a note for each year detailing the number of stations used to form that year’s anomaly figure and a map showing the location of each of those stations.
In that manner, one has something of substance. One can say that the temperature at the stations in 1880 are different to the temperature at those same stations during the period 1961 to 1990. Presently, due to the way the anomaly data set is constructed, we cannot say anything of significant because we do not know how the temperatures at the 1880 stations has varied over time, if those temperatures have varied at all. All we are doing is looking at the changes of sampling sets, not whether temperatures have or have not truly changed.
Richard,
“The science of polling since Brexit and President Trump”
In fact, the polls were reasonable on Brexit – they predicted a very close result, and it was. On Trump, they were predicting how people would actually vote (not the EC), and got it pretty right. But the main point is that, by estimating with different samples, they do get a meaningful result. Pols take notice of them, whatever they say.
“I do not consider ARGO to have enough floats to properly sample the oceans”
The main source in recent decades has been drifter buoys, which are much better for purpose than ARGO. They don’t have a depth limitation, and they measure surface continuously.
“he went as far as saying that SH temps are largely made up. Factually he was correct on that comment”
Often said here, but just untrue. He didn’t say that at all. As to 1980 comments, they referred to data available at that time, which was indeed sparse. I worked on a project in 1980 using Australian data. It had only just been digitised; I was probably the first to use it. When I started work on it, it seemed I would have to wade through the hand-written log books. People forget how it was in pre-internet days. 1200 baud etc. For me to get that just-digitised data, BoM had to put it on a 20-inch “floppy” disc for a PDP-11 and send it by courier. That was possible because I was in Melbourne, where the data was held. It would have taken a long time for that data to be available to someone overseas.
As to your Venn diagram, the limitation of reporting in 1961-90 is exaggerated. The main thing in getting an anomaly is to have some base to subtract. There is a problem of drift, which CRUTEM (land) deals with rather rigidly by requiring data in that period. Other groups estimate where necessary, using other methods to counter that drift. That is perfectly OK. BEST and I use a logically consistent least squares approach, which doesn’t specify any period at all (although it is later normalised). In fact, the comment of Jones that you misquote actually referred to this process of estimating normals (in part of the Southern Ocean, not SH generally), not data. He is probably responsible for the unnecessarily rigid approach of CRUTEM; he may not understand the issue.
“So one averages the temperatures of those 2900 stations during the base period 1961 to 1990 and one averages the temperatures from those 2900 stations as recorded in 1940 and then one notes the difference between these two averages to form the 1940 anomaly.”
No. I say it over and over. This is not how it is done. You always form the anomalies first, for each site, before averaging anything. There is a partial exception if the base itself has to be estimated, but CRUTEM doesn’t even allow that.
Thanks Nick
i don’t want to get side tracked on opinion polling. Let us just beg to differ on that.
I agree that on a literal basis, what he said is often exaggerated, but not really the thrust of the point he is making. South of 40deg South for practical purposes there is simply a deficiency of historic data to make any assessments of past temperatures, or to assess normals from which to create an anomaly.
Australia, of course, is one of the few places in the Southern Hemisphere with some historic data, but BOM disregards the pre 1900 data because it is inconveniently warm pre 1900.
It is true that there is some doubt as to the extent of the use of Stevenson screens prior to 1900, but then again, it is clear that some sites were using Stevenson screens (there are even old photographs confirming this) and yet even data from these sites is disregarded.
The SH is simply a mess, and for practical purposes reliable historic data is so sparse and the spatial coverage so uneven, that all SH data should be disregarded. We should only look at the NH, and this is no problem to a theory which rests upon CO2 being a well mixed gas.
This is essentially a numbers game, and it is paramount to use only good quality data when examining numbers. One should not start with a pile of cr@p, and then seek to adjust it in the vain hope that something useful can be extracted. It cannot. One should work with the cream and throw out everything that is of dubious quality.
The approach we are adopting to the assessment of temperature and changes thereto is fundamentally flawed.
We can never say what has happened to the globe over time, but we can say what has happened at various sites over time. If we want to know whether there has been any warming since say the 1940s, the only way that that can be properly determined is to retrofit all stations used in 1940 with the same type of LIG thermometer used by each station in question, and today make observations at each station with the same practice and procedures as used at those stations in the 1940s. Then historic RAW data for the 1940 can be compared directly with RAW data obtained today with no adjustments, and we would then have to consider the impact of environmental changes which may have impacted upon the station between 1940 and today and set out an error bound for such changes. That would tell us what changes had taken place at those sites. To the extent that those sites give good spatial coverage, we may infer that they are representative of changes on a hemispherical basis, or a continent basis, or a latitude basis etc.
Richard Verney, “I see this constantly changing sample set to potentially render the time series anomaly data set worthless, since at no time during the temporal period is one compare like with like. such that one never knows whether there has been any change on a like for like basis, still less the extent of change”
In my opinion, this is the crux of the problem. Every series must have sufficient data in the years it is used and in the period 1961-1990. That way the anomalies can be computed. There are very few that meet that criteria prior to 1950 apparently. So we are stuck averaging a fully populated grid (1961-1990) and then adding it to a sparse grid that may only have 20% of the cells populated. Then we add the apples to the oranges and get sewage. Nick Stokes may have a different view, but if figure 2 is bad due to sparse data, figure 1 is also bad due to sparse data. Perhaps I improved it slightly by averaging by latitude band, but I still don’t think the reconstruction is any good prior to 1950 in either figure. And, I have some doubts about the post-1950 reconstructions.
“Every series must have sufficient data in the years it is used and in the period 1961-1990. That way the anomalies can be computed.”
It does in HADCRUT’s method. I use a least squares method which doesn’t require any specific period; BEST now uses this too. GISS and NOAA use various methods to get a base value for sites that don’t have enough data in the fixed period.
“if figure 2 is bad due to sparse data, figure 1 is also bad due to sparse data.”
No. The issue is the varying sample set (cells) coupled with inhomogeneity (which makes variation matter). Anomalies used in fig 1 radically redice inhomogeneity.
Ridiculous. How can it? The data simply doesn’t exist. No statistical method is ever going to change that fact.
We will never know the global temperature in 1850, and certainly not to a precision to a tenth or hundredth of degree Celsius. The idea that we can is completely absurd. Anyone suggesting this is not practicing science; they are practicing propaganda.
In the Climategate emails, Phil Jones admitted that the Southern Hemisphere data was largely made up. You have to be a Koo Aid drinker or on the take to believe any of this.
“Phil Jones admitted that the Southern Hemisphere data was largely made up. “
He did not, and it wasn’t.
As is well known, data abundance diminishes as you go back it time. That doesn’t mean we know nothing.
Nick,
Well, he did admit that SST “data” were made up so that they’d comport better with the artificially heated land data.
And of course Arctic “data” are entirely fictitious.
Nick Stokes: “No. The issue is the varying sample set (cells) coupled with inhomogeneity (which makes variation matter). Anomalies used in fig 1 radically reduce inhomogeneity.”
I will grant that working with anomalies reduces inhomogeneity, that is the point and it is valid. But, to compute radiation emissions we need an accurate temperature for every point on Earth. Anomalies do not improve accuracy. They do remove differences due to elevation, they make everything look smoother and nicer, but the resulting temperature is a fiction.
Andy
“But, to compute radiation emissions we need an accurate temperature for every point on Earth.”
At every point that can emit. High troposphere is the main one there, and there aren’t any thermometers there. And you need to know the emissivity – not trivial, especially with varying water vapor. You just can’t do it that way, and imperfections in surface data are a negligible part of the reason. And T^4 isn’t a sensible part of the story. It just doesn’t apply.
We can beg to differ on the substance of what he was saying, but we all ought to be able to accept that it is SH temperatures are largely made up simply because there is so little sampling on a historic basis.
Phil Jones
Now South of 60 deg, there is all but no data since this is substantially Antarctica where there is next to no data, especially on a historic basis (say prior to 1940). viz: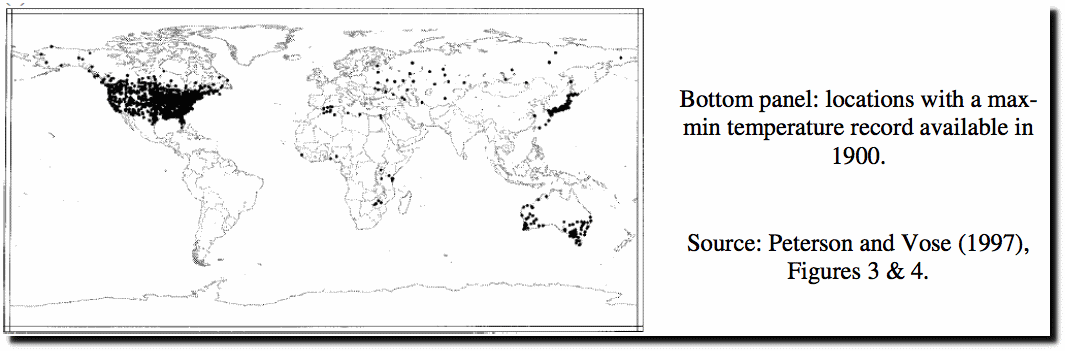

http://www.hashemifamily.com/Kevan/Climate/Stations.gif
And:
Let us not pretend that we have sufficient data when clearly we do not.
Richard,
Yes, this is the quote that people stretch way beyond the truth:
“For much of the SH between 40 and 60S the normals are mostly made up as there is very little ship data there.”
It isn’t SH as a whole, but more importantly, he’s talking about normals. The issue he’s addressing is that there is good modern data with drifters, but not much earlier data in that region to estimate a 1961-1990 normal. That doesn’t reduce the validity of modern data; it just means a bit more work to estimate normals (for anomaly) in a way that doesn’t create trend artefacts. That can be done properly, although Phil may not understand the process properly. CRUTEM is his thing.
If a lengthy series of anomalies is to maintain a consistent meaning, then EACH of the constituent data series indeed MUST reference a common datum level: their respective average during the SAME sufficiently long basis-period. Moreover, unless very highly coherent neighboring stations are available, the detection of climate change requires the set of constituent stations to remain FIXED throughout the entire series. Otherwise, strong differences not only in average levels, but also in strength of multi-decadal and longer variations even within a region, render the anomalies uncertain in their significance.
While the least-squares model proposed some years ago by Roman M accounts for the strongly differing average values from station to station by introducing fixed monthly offsets relative to the (unknown) regional average, it fails to account for patent changes in those offsets due to factors, natural or anthropogenic (UHI), acting over longer stretches of time. Roman M come to realize that severe shortcoming some years later. Sadly that realization never seems to have enlightened BEST (or Nick Stokes), who continue to pretend that this elaborate “logic” makes the maintenance of the above specified constraints unnecessary.
I strongly suspect that the stark differences noted by Andy May between pre- and post-1950 global anomalies are a direct consequence of ignoring these fundamental imperatives. Along with massive post-WWII urbanization came the introduction of stations at newly constructed airports throughout the globe. By turning a blind eye to the biases introduced into this highly non-uniform, increasingly-more-corrupted data base, “global anomaly” indices continue to be manufactured to conform to the AGW narrative.
Andy,
The differences in Figs 7 and 8 are just an amplification of the differences between 1 and 2. The spatial intrgral of T^4 is not the fourth power of the average of T. That’s just elementary linear operator stuff. But there is also the effect of inhomogeneity. You have over time a varying mix of hot and cold places, and T^4 amplifies this. Averaging absolute T is wrong, and averaging T^4 us wronger.
But the whole focus on T^4 is misplaced. Emission to space is mainly not from surface, but from GHG’s high in the atmosphere. That is why the amount emitted is what you would expect from a 255K black body (T^4). Much of the IR from a surface at T^4 is balanced by back radiation from near atmosphere, at a temperature not so different from T. Net IR radiation from the surface carries significant power, but the net flux isn’t simply dependent on T^4.
Another way of saying this – the SB law is for radiation from a surface at uniform temperature, with emissivity uniform over frequency. Otherwise the total isn’t T^4. You’ve given a nod to the non-uniform temperature, but emissivity is also an issue. If you loo at an outgoing spectrum, it shows a high flux intensity in the atmospheric window, corresponding to about surface temperature, but elsewhere the flux is lower, corresponding to about 230K ( near tropopause, and of course also varying with latitude). This doesn’t integrate over frequency to any kind of T^4.
Nick, We agree on all of your points. But, I was not addressing emissions to space. I was focused on the 390-391 W/m2 emitted by the surface. This is the other portion of the particular greenhouse effect definition I was addressing, as stated in the post. I compared the error in the 390 with the proposed CO2 greenhouse effect of ~2 W/m2.
Good work Andy and good point well made. The emission should be computed by grid and then summed. The global average temperature is a concept not a temperature.
Thank you for this post.
I must admit I can’t get my head around this. It takes energy for evaporation, massive amounts of it to lift tons of water up into the atmosphere. That energy is spent and will never be radiated back into space. So there will always be an energy imbalance of in going and outgoing energy radiation. How could there not be?
I think that analyzing T^4 and temperature might be important for another reason. Willis posted on this previously where reducing temperature variation and maintaining energy will always result in increased average tempurature. Given that most of the temperature increases have occurred in the coldest places and at night (essentially reducing variability) will have automatically increased average tempuratures. Might be worthwhile to see how much of the current tempurature increase is because of this.
A good question is how much variation in mean (T4) there is from a change in the distribution of temps with the same mean T. Most likely small but is it insignificant?
A small side track. I hate the hand waving explanation that the Earth is warmer than the Moon because it has an atmosphere. Just the oceans is enough to explain the difference.
Two hypothetical worlds based on the temperature ranges seen on the Moon and Earth. The Moon at night cools from about 120 K to 90 K at the equator and warms to an average of about 340 K and max of 390 K during the day, so my hypothetical moon has 4 night and 4 day zones of equal size with temperatures of 90, 100, 110, 120, 310, 330, 350 and 370 K for a mean T of 222 K. My hypothetical Earth like world of just ocean has 273, 275, 280, 285…305K for a mean of 288. Both have the same mean (T4).
Only an illustration of how the spread of heat around the globe by oceans makes a huge difference.
That and the Kiel Trenberth diagram above [son of mulder at 1:39 pm]. Must be wrong. 99% of the enthalpy the atmosphere ocean system is in the oceans, The water is not heated by the air passing over it. It must be heated by the sun. Pictures of the Earth clearly show the Oceans as dark, and the atmosphere as transparent. The solar radiation falls on the ocean and warms it. The air is warmed by the Ocean, even at night.
Last week I asked the question of what would be the temperature of the atmosphere of a planet that is just like earth except that the atmosphere consists solely of Argon. My hypothesis is that it would be the same as earth.
It may well be the case that it is the fact that the planet is rotating receiving bursts of energy say twice a day, and has has a huge reservoir of specific heat content (the oceans) and an atmosphere which has thermal inertia that is the reason why the planet is warm.
Personally, I consider that it is probably a question of the specific heat capacity of the atmosphere. There is not such a substantial difference between the specific heat capacity of Argon, Nitrogen, Oxygen and Carbon Dioxide and the resultant thermal lag that these gases give to the atmosphere.
That said, I consider water vapour to be extremely important, not because of its radiative properties but because of the way in which it carries and redistributes energy throughout the atmosphere and the latent energy associated with phase changes.
Mars is not cold because it lacks so called GHGs such as CO2. The Martian atmosphere contains an order of magnitude more CO2 molecules than does Earth’s atmosphere. On a molecular basis it contains more molecules of so called GHGs.
The reason Mars is cold is because the atmosphere is not dense and lacks thermal inertia. Quite simply there is not enough volume of atmosphere to create the necessary lag. NASA acknowledges this when it accepts that Mars is cold due to the lack of density/pressure of its atmosphere, and that geo engineering requires the increase in mass of its atmosphere.
“The reason Mars is cold is because the atmosphere is not dense”
The reason Mars is cold is that it gets about 43% of earth’s solar flux intensity.
Thanks Nick.
It is generally accepted that there is no measurable GHE on Mars. The reason given is that the atmosphere is not dense. Not that it does not contain enough so called GHGs. It is the lack of thermal inerta in the atmosphere that is the problem.
So when I talk about Mars being cold, I mean that it has no measurable radiative GHE, not that 20 deg C or 0 deg C or – 30 degC is cold.
In actual practice, Mars although quite a lot further away from the sun, because its atmosphere does not have clouds, and is not dense, results in a lot of solar irradiance reaching the planetary surface. If I recall correctly, the solar irradiance at the equatorial region of Mars is about 65% of that seen on planet Earth at the equatorial region.
I think the thermal inertia that Richard has mentioned is the Specific Heat of the substance. The Specific heat of liquid H2O is taken to be 4.2. I note that the specific heat of N2 and O2 are higher than that of CO2.
The specific heat for constant pressure and constant volume processes (kJ/(kg K)) (approximate values at 68°F (20°C) and 14.7 psia (1 atm)).
CP CV
Air 1.01 0.718
Ar 0.520 0.312
CO2 0.844 0.655
N2 1.04 0.743
O2 0.919 0.659
H2O* 1.93 1.46
*for steam @120-600°F
http://www.engineeringtoolbox.com/specific-heat-capacity-gases-d_159.html
It’s all about the oceans that store 1,000 times more heat per degree than than the atmosphere, and control the climate and the atmosphere that in turn controls the weather, not vice versa. Obs. Atmosphere heating the oceans? Not really. Everything to do with environmentalist beliefs and its statistical science is the reverse of science reality and method. Topsy turvy eco worriers., heads in the clouds or up their computers when they should be underwater, where the controlling energy is stored. Irma didn’t get generated by the atmosphere, it’s simply an effect of the oceans. A few mms of global ocean rise is wholy insignificant in a 20 foot upwelling by the Oceanic Dyson, that the ocean created, etc.
However the integrated energy from the Sun impinging on the Oceans is truly massive, I make it 4×10^24 Joules pa, and varying the c. 50% absorption by the atmosphere before it impinges on the oceans by 1% is a very significant effect. If it was all aborbed that’s enough to cause an interglacial maintained over 1,000 years, given the obvious fact that the Oceans must gain 7X10^25 Joules to deliver a complete 12 degree K interglacial (nb: Milankovitch extremes are not said to be likely to produce a positive energy imbalance on the system, taken over a year).
BTW Having been ambivalent about the effect of CO2, and more interested in the actual fraud on the engineering fact of renewable energy susbsidies that make CO2 emissions expensively worse by law on most heterogeneous grids, I now don’t believe CO2 can have anything of significance to do with the effect of the atmosphere on the dominant feedback processes in the global heat exchange systems, BTW.
Nothing adds up on scrutiny, and plants are more than capable of maintaining CO2 at <0.2%, as they have for the last 1 Bilion years through all kinds of serious climate shit , starting on a wet 95% CO2 atmosphere. And as plants are demonstrating again now. Modellers, who I no longer recognise as fellow scientists as they have taken the environmentalist shilling to promote a belief by distortion as a physical law, are no better than latter day priests of a fraudulent get rich quick religion. Modellers statistics are not physcal science, they are a classic example of Feynman's pseudo Science/Cargo Cult science, prove nothing except forced correlation in fact. More tellingly, they denied the pwerful effect of dynamic p[lant regulation of CO2 and simply claimed plants would be are overwhelmed by an extra 100ppm in 400ppm we produce – in the face of the planetary story of the atmosphere that proves the opposite. J'accuse!
Who says they will be overwhelmed? Piltdown Mann et al? Where is the proof? I don't think so. Show me.
When modellers paid by public sector organised crime and its enrgy lobbyists start making such assertions that you MUST believe or else, then we have a serious cult in science, fuelled by morally bankrupt scientists more interested in money and the peer group esteem than skeptical scientific principles, It's like Religion met organised crime – if there ever was a difference.
True scientists not compromised by the organised crime of climate change garnts and snake oi remedies need to stick to the one true deterministic physics, and denounce the false prophets of climate change by CO2. Pseudo science modelling isn't real science. Change happens VERY S L O W L Y over lifteimes. It probably isn't to do with CO2, the sky is not falling, the next ice age is coming, the oceans will dissappear over the edges of continetal shelves back into their basins. Happened 5 times in the last Million years, regaular as clockwork. The people should be told, somehow…… that turned into a tec rant on real science, but I shared the key facts. If only people would do the big mass and energy balances and avoid the statistical fictions – but that wouldn't support the renewable enrgy subsidy protection rackets, would it? CEng, CPhys, MBA
CORRECTION: Heat reaching Oceans is 2×10^24 Joules per annum, not 4………….. Doh!
(340W/m^2 average solar radiation X 3.62m^2 ocean area X 31.54X10^6 seconds pa X 48% absorbed by atmosphere and reflected by clouds, atmosphere and surface). Failed physics 101. Still several grades above cliamate modellers, it seems.
Perhaps im missing the point here ,but didn’t Nick say that ‘Mars is colder because it gets about 43%of earths solar flux ‘ implying that it is not due to its lack of atmosphere,so is it illogical to conclude that earth is warmer because it gets more solar irradiance ,& is not due to it’s atmosphere ?
Brian,
Where do you get that 48% of irradiance from the sun reflected by clouds and absorbed by the atmosphere? Only a very small sliver will be absorbed in the way in given that there isn’t much that falls into the absorption bands of the atmosphere. That would leave cloud cover to make up the majority of that 48% which to me seems way too high.
From the the accepted calculations based on more studies than you cpuld possibly imagine that NASA produces amongst others. Not sure where you get your science from? 23% absorbed by atmosphere and 23% reflected by clouds and atmosphere, 7% reflected from surface.
Wouldn’t the right way to determine the Earth’s emissions be to park spectrographs at the Lagrange points and focus them on the Earth?
Or is observation too much like cheating?
Experiments that apply proven deteministic physics in actual repeatable experiments requiring scientific proof rather than forced correlation consistent with the beliefs of the Climate Clergy are a heresy against the FIrst Church of Climate Science, punishable by de-funding and placing on the list of climate deniers.
Great idea but….you think NASA would ever launch a satellite that they know would destroy their carefully constructed belief systems with obvious and basic scientific facts? Surely not? And don’t call me Shirley.
Shirley: I apologize for leaving out the /sarc tag.
Shirley,
You’d think they would have done that. So weird that they haven’t….
https://ceres.larc.nasa.gov/order_data.php
/sarc
No idea what this comment means, sorry. Please ask a question or make a statement that has a subject I can repsond to.
.
Brian,
Just trying to clarify that satellites are in place that measure incoming and outgoing flux. We do have measured observations.
Is the differing surface area of each set of grids properly accounted for? 5° by 5° at the equator is a lot bigger than near the poles.
Using a rough estimate of -40C to +40C as earth’s temperature variation at different locations, would be about a +/- 14% variation in Kelvin from average temperature. 0.86^4 ~ 0.55 and 1.14^4 ~ 1.69 This is a variation of about 3 to 1 in radiated energy. Any averaging of temperature before calculating the radiant energy would give an erroneous number for radiant energy. How much error would depend on the actual temperature distribution.
Mods
i have tried to post a comment a couple of times but it/they has simply disappeared. The comment is entirely innocuous so I cannot see why it should disappear.
Please will you look out for it and post it.
many thanks