From the told ya so department, comes this recently presented paper at the European Geosciences Union meeting.
Authors Steirou and Koutsoyiannis, after taking homogenization errors into account find global warming over the past century was only about one-half [0.42°C] of that claimed by the IPCC [0.7-0.8°C].

Here’s the part I really like: of 67% of the weather stations examined, questionable adjustments were made to raw data that resulted in:
“increased positive trends, decreased negative trends, or changed negative trends to positive,” whereas “the expected proportions would be 1/2 (50%).”
And…
“homogenation practices used until today are mainly statistical, not well justified by experiments, and are rarely supported by metadata. It can be argued that they often lead to false results: natural features of hydroclimatic times series are regarded as errors and are adjusted.”
The paper abstract and my helpful visualization on homogenization of data follows:
Investigation of methods for hydroclimatic data homogenization
Steirou, E., and D. Koutsoyiannis, Investigation of methods for hydroclimatic data homogenization, European Geosciences Union General Assembly 2012, Geophysical Research Abstracts, Vol. 14, Vienna, 956-1, European Geosciences Union, 2012.
We investigate the methods used for the adjustment of inhomogeneities of temperature time series covering the last 100 years. Based on a systematic study of scientific literature, we classify and evaluate the observed inhomogeneities in historical and modern time series, as well as their adjustment methods. It turns out that these methods are mainly statistical, not well justified by experiments and are rarely supported by metadata. In many of the cases studied the proposed corrections are not even statistically significant.
From the global database GHCN-Monthly Version 2, we examine all stations containing both raw and adjusted data that satisfy certain criteria of continuity and distribution over the globe. In the United States of America, because of the large number of available stations, stations were chosen after a suitable sampling. In total we analyzed 181 stations globally. For these stations we calculated the differences between the adjusted and non-adjusted linear 100-year trends. It was found that in the two thirds of the cases, the homogenization procedure increased the positive or decreased the negative temperature trends.
One of the most common homogenization methods, ‘SNHT for single shifts’, was applied to synthetic time series with selected statistical characteristics, occasionally with offsets. The method was satisfactory when applied to independent data normally distributed, but not in data with long-term persistence.
The above results cast some doubts in the use of homogenization procedures and tend to indicate that the global temperature increase during the last century is between 0.4°C and 0.7°C, where these two values are the estimates derived from raw and adjusted data, respectively.
Conclusions
1. Homogenization is necessary to remove errors introduced in climatic time
series.
2. Homogenization practices used until today are mainly statistical, not well
justified by experiments and are rarely supported by metadata. It can be
argued that they often lead to false results: natural features of hydroclimatic
time series are regarded errors and are adjusted.
3. While homogenization is expected to increase or decrease the existing
multiyear trends in equal proportions, the fact is that in 2/3 of the cases the
trends increased after homogenization.
4. The above results cast some doubts in the use of homogenization procedures
and tend to indicate that the global temperature increase during the
last century is smaller than 0.7-0.8°C.
5. A new approach of the homogenization procedure is needed, based on
experiments, metadata and better comprehension of the stochastic
characteristics of hydroclimatic time series.
- Presentation at EGU meeting PPT as PDF (1071 KB)
- Abstract (35 KB)
h/t to “The Hockey Schtick” and Indur Goklany
UPDATE: The uncredited source of this on the Hockey Schtick was actually Marcel Crok’s blog here: Koutsoyiannis: temperature rise probably smaller than 0.8°C
Here’s a way to visualize the homogenization process. Think of it like measuring water pollution. Here’s a simple visual table of CRN station quality ratings and what they might look like as water pollution turbidity levels, rated as 1 to 5 from best to worst turbidity:





In homogenization the data is weighted against the nearby neighbors within a radius. And so a station might start out as a “1” data wise, might end up getting polluted with the data of nearby stations and end up as a new value, say weighted at “2.5”. Even single stations can affect many other stations in the GISS and NOAA data homogenization methods carried out on US surface temperature data here and here.

In the map above, applying a homogenization smoothing, weighting stations by distance nearby the stations with question marks, what would you imagine the values (of turbidity) of them would be? And, how close would these two values be for the east coast station in question and the west coast station in question? Each would be closer to a smoothed center average value based on the neighboring stations.
UPDATE: Steve McIntyre concurs in a new post, writing:
Finally, when reference information from nearby stations was used, artifacts at neighbor stations tend to cause adjustment errors: the “bad neighbor” problem. In this case, after adjustment, climate signals became more similar at nearby stations even when the average bias over the whole network was not reduced.
“science” is now in the process of whitewashing cupidity as unfortunate but unintentional statisitical process errors; understandable mistakes by well-meaning and honorable people. We’re moving from ‘hide the decline’ to ‘rehab mine”.
Seems like there are paper(s) ascribing about 40-50% of the original increase value to natural variation. Now is that 50% of the total – what ever that might be – or is that about 0.4 deg C ? If it’s the 0.4 deg C, then aren’t we just about out of warming? Thermostat controls work by allowing small variations it the controlled variable to set the values of the control variables. Because of this and because of the fact that there should be some temperature rise caused by co2 concentration, there should be something left over in the way of an increased temperature. Otherwise, we are headed in the wrong direction and in for the truly serious consequences of cooling.
1. Homogenization is necessary to remove errors introduced in climatic time
series.
No it isn’t. Nor does it.
William Briggs on the topic.
http://wmbriggs.com/blog/?p=1459
If I understand the IPCC website correctly, this paper is in time to be considered in AR5. Someone needs to make sure it is submitted to the IPCC. They can easily ignore it, of course, as they have ignored everything that doesn’t fit the pre-written Summary for Policymakers, but at least it needs to be put in front of them.
Cut-Off Dates for literature to be considered for AR5
Updated 17 January 2012
Working Group I – 31 July 2012 Papers submitted – 15 March 2013 Papers accepted
Working Group II – 31 January 2013 Papers submitted – 31 August 2013 Papers accepted
Working Group III – 31 January 2013 Papers submitted – 3 October 2013 Papers accepted
http://www.ipcc.ch/pdf/ar5/ar5-cut-off-dates.pdf
Isn’t 30% of the past century’s warming ascribed to solar effects? Seems like there isn’t much CO2 induced warming at all given that we are now better than halfway to a doubling in CO2 and the logarithmic nature of the CO2 effect means that the majority of the warming associated with CO2 increase has already occurred.
Makes me feel all warm and fuzzy. Recall that I recently pointed out that one perfectly reasonable interpretation of the recent “run” of 13 months in the top 1/3 of all months in the record, warming trend or not, is that the data is biased! That is, a very small p-value argues against the null hypothesis of unbiased data. That is all the more the case the more unlikely the result is made, so the more “unusual” it is — especially in the absence of anything otherwise unusual about the weather or climate — the more the p-value can be interpreted as evidence that something in your description of the data is horribly wrong. . This is the probability of getting the result from unbiased corrections. Even if there have been only 4 corrections (all net warming) it is 1/16. It’s like flipping a coin and getting 4, or 8, heads in a row.
. This is the probability of getting the result from unbiased corrections. Even if there have been only 4 corrections (all net warming) it is 1/16. It’s like flipping a coin and getting 4, or 8, heads in a row. or 3000/4 = 750. The square root of 750 is roughly 27. The observation is 500 over the mean with n = 3000. 500/27 = 18, give or take. This is an 18 sigma event — probability a number close enough to zero I’d get bored typing the leading zeros before reaching the first nonzero digit.
or 3000/4 = 750. The square root of 750 is roughly 27. The observation is 500 over the mean with n = 3000. 500/27 = 18, give or take. This is an 18 sigma event — probability a number close enough to zero I’d get bored typing the leading zeros before reaching the first nonzero digit. ,
, 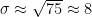 ,
,  ,
, 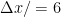 . The probability of a six sigma event is still — wait for it — zero. I wouldn’t get bored, exactly, writing the zeros, but the result is still in the not-a-snowball’s-chance-in-hell-it’s-unbiased range.
. The probability of a six sigma event is still — wait for it — zero. I wouldn’t get bored, exactly, writing the zeros, but the result is still in the not-a-snowball’s-chance-in-hell-it’s-unbiased range.
At that time I thought about the temperature series and almost did a similar meta-analysis (but was too lazy to run down the data) on a different thing — GISS and Hadley have, IIRC, made a number of adjustments over the years to the algorithm (secret sauce) that “cooks” the raw thermometric data into their temperature series. I fully admit to having little but anecdotal recollection of a few of them, mostly from reading about them on WUWT. Anthony has duly noted that somehow, they always seem to warm the present and cool the past, on average.
Let’s say there have been 8 of those adjustments, and all of them warmed the present and cooled the past to the point where they quantitatively increased the rate of warming over the entire dataset but especially the modern era. There is no good reason to think that the thermometers used back in the 30’s were systematically biased towards cold temperature — the default assumption is (as always with statistics) that the error in thermometric readings from the past with the exception of cases that are clearly absurd or defective series (the one kept by the alcoholic postmaster of Back-of-the-Woods, Idaho, for example, back in the 1890s) is unbiased and indeed, probably normal on the true reading. In particular, it is as likely to be a positive error as a negative one, so the best thing to do is not adjust it at all.
In this case the probability that any sort of data correction will produce net warming — even of a little tiny bit — should be fifty-fifty. This is the null hypothesis in hypothesis testing theory: If the corrections are unbiased, they have an even chance of resulting in net warming.
Next one computes the probability of getting 8 warmings in a row, given the null hypothesis:
In actual hypothesis testing, most people provisionally reject the null hypothesis at some cutoff. Frequently the cutoff used is 0.05, although I personally think this is absurdly high — one in twenty chances happen all the time (well, one in twenty times, but that’s not that infrequently). 4 in a thousand chances not so often — I’d definitely provisionally reject the null hypothesis and investigate further upon 8 heads in the first 8 flips of a supposedly unbiased coin — that coin would have to behave very randomly (after careful scrutiny to make sure it didn’t have two heads or a magnet built into it) in future trials or betting that it is unbiased is a mug’s game.
TFA above has extended the idea to the actual microcorrections in the data itself, where of course it is far more powerful. Suppose we have 3000 coin flips and 2/3 of them (2000) turn out to be heads. The null hypothesis is that the coin is unbiased, heads/tails are equally likely p = 0.5. The distribution of outcomes in this case is the venerable binomial distribution, and I don’t have to do the actual computation to know the result (because I do random number generator testing and this one is easy). The p-value — probability of getting the result given the null hypothesis is zero. The variance is
Now, I have no idea whether or not there are 3000 weather stations in their sample above, but suppose there are only 300.
Visibly, there look like there could easily be 300 dots in the map above, and frankly, who would trust a coin to be unbiased if only 100 flips produced 2/3 heads? One is finally down to only a 3 sigma event, sorta like 8 heads in a row in 8 flips, p-value of well under 1 in a 100. I don’t know Steirou, but Koutsoyiannis is, I predict, going to be the worst nightmare of the keepers of the data, quite possibly eclipsing even Steven McIntyre. The guy is brilliant, and the paper sounds like it is going to be absolutely devastating. It will be very interesting to be a fly on the proverbial wall and watch the adjusters of the data formally try to explain why the p-value for their adjustments isn’t really zero, but is rather something in the range 0.05-1.00, something not entirely unreasonable. Did our drunken postmaster weathermen in the 1920s all hang their thermometers upside down and hence introduce a gravity-based bias in their measurements? Silly them. Is the modern UHI adjustment systematically positive? I never realized that cities and airports produces so much cooling that we have to adjust their temperatures up.
Or, more likely, it is simply something that Anthony has pointed out many times. The modern UHI adjustments are systematically too low and this is biasing the trends substantially. One could even interpret the results of TFA is being fairly solid proof that this is the case.
rgb
Interesting observation happening in NE Oregon. The noon temps have been warm to hot, but less than an hour later have dropped like a stone. Why? Thunderstorms. And we have at least two weeks of them. So was the whole day hot? Yes according to noon temps on old sensors. No according to sensors that average the temps together.
Which leads me to another issue. Those record temps are nonsensical. A moment at 107 degrees now may be compared to who knows how many hours at 107 degrees back then or visa versa and be called equal. Really? How was the peak temp measured way back when, compared to the peak temps of today? Are we comparing two different types of records? If so, why would we be calling the record temps this year “new records” that take the place of the old records set years and decades ago?
If I remember correctly, some of the alarmists were saying that solar forcing could only account for about one third of the warming seen this century. If one third is solar, and one half is an artifact, then what’s left for the anthropogenic component? This was assuming that there was zero internal forcing from ocean currents. What’s the latest estimate from the alarmists for the solar component?
Here is ushcn USA only adjustments in a blink chart…
http://stevengoddard.wordpress.com/2012/07/16/how-ushcn-hides-the-decline-in-us-temperatures/
Mann made GW for certain.
The data doesn’t need homogenization. If one location is hotter or colder than a neighbouring location, that’s weather. Raw data is the only data that’s worth anything. Once you bend the data out of shape, it becomes worthless.
Isn’t it about time that the homogenizers are pasteurized?
From the post:
“Authors Steirou and Koutsoyiannis, after taking homogenization errors into account find global warming over the past century was only about one-half [0.42°C] of that claimed by the IPCC [0.7-0.8°C].”
So the net effect of CO2 is most likely some small fraction of 0.42 degrees C. I interpret this to mean that the coal trains of death, aren’t.
Now about those GCMs ……
The two citations are plainly wrong.The abstract is not a ”new peer reviewed paper recently presented at the European Geosciences Union meeting.” It is an conference abstract by E. Steirou and D. Koutsoyiannis, which was presented at the session convened (organized) by Koutsoyiannis himself.
http://meetingorganizer.copernicus.org/EGU2012/oral_programme/9221
Conference abstracts are not peer reviewed, you cannot review an abstract of 260 words. At EGU all abstracts, which are halfway about geoscience are accepted. Their purpose is to select, which people get a talk and which ones get a poster presentation.
REPLY: I was of the impression that it was “in press” but I’ve change the wording to reflect that. Hopefully we’ll know more soon. – Anthony
Skeptikal says:
July 17, 2012 at 6:24 am
The data doesn’t need homogenization. If one location is hotter or colder than a neighbouring location, that’s weather. Raw data is the only data that’s worth anything. Once you bend the data out of shape, it becomes worthless.
You’re wrong. The data does need some kind homogenization to correct for inaccurate or poorly situated instruments. We also need it to be able to summarize the weather over larger regions to make predictions and comparisons.
Here’s an example of how you yourself can use homogenization to help guarantee the next thermometer you buy will be more accurate.
Go to a place that sells cheap thermometers (Walmart etc). Normally there will be 5 or 10 instruments on display of various brands. You will immediate notice that they are all predicting different temperatures. Maybe some will read in the mid or low 70’s, some in the high 70’s. There will always be a maverick or two with readings way of into the impossible range.
Which thermometer, if any, should you buy?
Well, it is likely that there are several instsruments in the bunch reporting fairly accurately. Best way to find the most accurate thermometer is to whip out your pocket calculator, add up all the temps and divide by the number of thermometers. (Throw away any obviously bogus readings first, such as a thermometer reading zero.) The resulting average value is most likely to be closest to the “real” temperature.
That is how homogenization works, on a small scale.
Something that troubles me about the USHCN v2 homogenization process is that it apparently assumes a linear relationship between station temperatures. That is OK when dealing with measurement errors but not, in my opinion, when creating the influence of each station’s temperature in the areal product.
Considering that heat flows from hot to cold, it would seem to me that a more representative temperature relationship between a hotter station and a colder one would be a function of the square of the distance between the stations. The quantity of heat represented by the difference between the two station temperatures disburses radially from the hot station and the temperature of the surface layer air would drop in proportion to the diffusion of the differential heat. For instance, the temperature difference at a point half way between the hot station and the cold station would be 1/4 the two station difference. With the current process, the temperature difference half way would be 1/2 the two station difference.
If vertical mixing is also considered, the influence of the hot station on the path to the cold station would be even more quickly diminished. My opinion is that the current homogenization process tends to give too much weight to the hot stations on surrounding areas. The process appears to be manufacturing additional heat where none exists which then is misinterpreted as global warming due to CO2.
But maybe I am missing something in my understanding of the homogenization process.
This is why the NCDC and BEST like using the Homogenization process.
They know what the end-result does – it increases the trend. Its not like they didn’t test it out in a number of ways before implementing it.
So they write a paper about the new process and provide a justification that it is reducing errors and station move problems. But what they are really doing is introducing even more error – and one might describe it as done on purpose.
The Steirou and Koutsoyiannis paper is about GHCN Version 2. The NCDC has already moved on to using GHCN-M Version 3.1 which just inflates the record even further.
And then someone needs to straighten out the TOBS adjustment process as well. The trend for this adjustment keeps rising and rising and rising, even 5 year old records. The TOBS issue was known about 300 years ago. Why are they still adjusting 10 year old and 5 year old records for this? Because it increases the trend again.
Misspelling! Homogenization not homgenization
Anthony Watts cited the two major errors of the abstract:
“increased positive trends, decreased negative trends, or changed negative trends to positive,” whereas “the expected proportions would be 1/2 (50%).”
You would not expect proportions to be 1/2, inhomogeneities can be have a bias, e.g. when an entire network changes from North wall measurements (19 century) to a fully close double-louvre Stevenson screen or from a screen that is open to the North or bottom (Wild/Pagoda) type-screen to a Stevenson screen, or from a Stevenson screen to an automatic weather stations as currently happens to save labor. The UHI produces a bias in the series, thus if you remove the UHI the homogenization adjustments would have a bias. There was a move from stations in cities to typically cooler airports that produces a bias and again this would make that you do not expect that the proportions are 1/2. Etc. See e.g. the papers by Böhm et al. (2001) Menne et al., 2010; Brunetti et al., 2006; Begert et al., 2005.
Also the change from roof precipitation measurements to near ground precipitation measurements cause a bias (Auer et al., 2005).
Anthony Watts citation:
“homogenation practices used until today are mainly statistical, not well justified by experiments, and are rarely supported by metadata. It can be argued that they often lead to false results: natural features of hydroclimatic times series are regarded as errors and are adjusted.”
Personally I just finished a study with a blind numerical experiment, which justified statistical homogenization and clearly showed that homogenization improves the quality of climate data (Venema et al., 2012). http://www.clim-past.net/8/89/2012/cp-8-89-2012.html
Many simpler validation studies have been published before.
Recently the methods were also validated using meta data in the Swiss; see:
http://www.agu.org/pubs/crossref/pip/2012JD017729.shtml
The size of the biased inhomogeneities is also in accordance with experiments with parallel measurements. It is almost funny that Koutsoyiannis complains about the use of statistics in homogenization, he does a lot of statistics in his own work. I guess he just did not read the abstract of this student (at least E. Steirou affiliation is the same as the one of Koutsoyiannis, but Steirou is not mentioned in the list of scientists).
http://itia.ntua.gr/en/pppp/
Even if one attributes all (yes, 100%, LOL) of that 0.42 degrees Celsius trend to CO2 increase that would put sensitivity to 2XCO2 between 1 and 2 degrees Celsius.
Assuming:
dF = 5.35ln(CO2f/CO2i)
dT=S(dF)
Using values @ur momisugly the century endpoints:
dF = 5.35ln(375/300)=1.19
S=0.42/1.19×3.7=1.3
And allowing for some lag in the system(s) by using a CO2 from several years prior to 2000:
dF = 5.35ln(360/300)=0.97
S=0.42/0.97×3.7=1.6
More evidence that the 3-5 degree Celsius sensitivity to 2XCO2 claim is exaggerated.
Yeah – and having weather stations at airports, nicely located next to taxiways to benefit from nice warm jetwash, doesn’t help the accuracy of raw data either…
I suppose the question I have is what algorithm did they use for “homogenisation” and do they use it on
1) “suspect” stations only
2) all stations using the original neighbouring station data.
I guess case 1 otherwise the effect would be a spatial smoothing as in case 2 (again assuming on the routine: sounds like simple IDW mean). Case 2 wouldn’t have a bias unless there were more anomalously high temperature stations than low temperature ones. But then this would give you the suspected spatial average anyway.
Anyways, this seems like bad stats especially if they didn’t do a QC plot (interpolated vs actual) to see how the “high fideility” stations fair when their values are interpolated from other nearby – high fideility stations – using the same/similar algortihm. If they didn’t do this then the adjustments are all BS based on just a load of assumptions.
Pamela Gray says:
July 17, 2012 at 6:18 am
Interesting observation happening in NE Oregon. The noon temps have been warm to hot, but less than an hour later have dropped like a stone. Why? Thunderstorms. And we have at least two weeks of them. So was the whole day hot? Yes according to noon temps on old sensors. No according to sensors that average the temps together.
Which leads me to another issue. Those record temps are nonsensical. A moment at 107 degrees now may be compared to who knows how many hours at 107 degrees back then or visa versa and be called equal. Really? How was the peak temp measured way back when, compared to the peak temps of today? Are we comparing two different types of records? If so, why would we be calling the record temps this year “new records” that take the place of the old records set years and decades ago?
This has always bothered the hell out of me. We really need the integral of the curve for the day, and the RH% to tell if there is heating or cooling.
Re: Victor Venema says:
July 17, 2012 at 6:45 am
“The two citations are plainly wrong.The abstract is not a ”new peer reviewed paper recently presented at the European Geosciences Union meeting.” It is an conference abstract by E. Steirou and D. Koutsoyiannis, which was presented at the session convened (organized) by Koutsoyiannis himself.”
What about it Anthony? I’d already blown this one out to everyone I knew calling it “peer reviewed and presented at….”
Massage the data until it tells you what you want it to tell. That’s how science is done by the Climate Liars/Alarmists.
Why would anyone be surprised the data is corrupt. Global warming has never been about climate science. It’s about imposing a fascist political agenda by frightening people into thinking the world is coming to an end.
I don’t know why we keep debating the Climate Liars. They won’t change their minds because it’s never been about the facts; facts don’t matter to these people. They’ll continue to believe what they believe despite reality.
The people we should be reaching out to are the masses who still think that global warming is real. Once they realize global warming is a hoax, Gore, Hansen and their compadres in crime will become irrelevant – and hopefully prosecuted for fraud. These endless debates with people who have no ethical or moral standards are a waste of time.