Guest post by Bob Tisdale
This post is a continuation of my post Tamino Once Again Misleads His Followers, which was cross posted at WattsUpWithThat here. There Tamino’s disciples and his other followers, one a post author at SkepticalScience, have generally been repeating their same tired arguments.
The debate is about my short-term, ARGO-era graph of NODC Ocean Heat Content (OHC) data versus the GISS climate model projection. This discussion is nothing new. It began in with Tamino’s unjustified May 9, 2011 post here about my simple graph. My May 13, 2011 reply to Tamino is here, and it was cross posted at WUWT on the same day here. Lucia Liljegren of The Blackboard added to the discussion here.
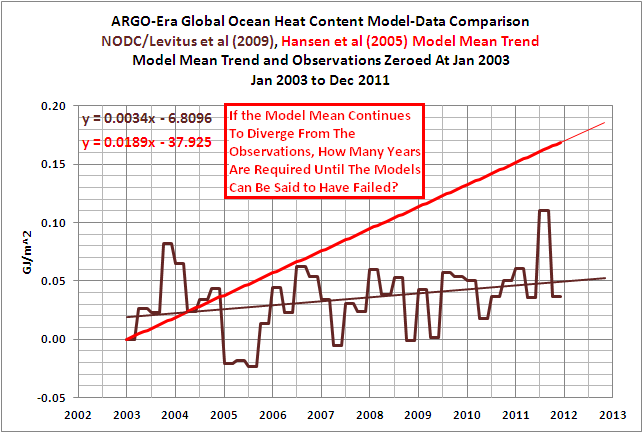
A graph that’s similar to the one Tamino and his disciples think is fake is shown in Figure 1. It’s similar but different, sort of a short-term OHC model-data comparison Modoki. We’ll get back to it.

Figure 1
First, let’s discuss…
…THE BLATANTLY OBVIOUS ERROR IN TAMINO’S RECENT FAILED CRITIQUE
Tamino’s recent failed critique is titled Fake Predictions for Fake Skeptics. Some people have noted that a fake climate skeptic would be an anthropogenic global warming proponent, but we’ll move on from the implications of that.
Tamino linked to the NODC Ocean Heat Content webpage as the source of his data. There, the NODC provides a spreadsheet of their global OHC data (here). Tamino presents a few preliminary graphs and observes:
Note that there’s a decided hot fluctuation in 2003. So we’ll “predict” the time span 2003 to the present, based on data from 1993 to 2003.
His next graph (my Figure 2) is identified only with the heading of “Ocean heat content 0-700m”. It includes a linear trend that Tamino claims is “based on data from 1993 to 2003”. The length of the trend line is assumedly based on the same period as data. But the period of his trend line does not include the “decided hot fluctuation in 2003.”

Figure 2 (Tamino’s 3rdgraph)
Tamino’s next graph, my Figure 3, includes an extension of his linear trend. In addition to the heading, the graph identifies the red trend line as “fit 1993-2003”, but his “fit 1993-2003” still does not include the “decided hot fluctuation in 2003.”

Figure 3 (Tamino’s 4rdgraph)
In the paragraph after that graph, Tamino states:
We can see that observations don’t follow the prediction exactly — of course! The main difference is that during 2003, the observations were hotter than the prediction. For that time span at least, the oceans had more heat than predicted.
He reinforces that the 2003 data is warmer, yet he and his disciples fail to observe that the 2003 data is not included in his “fit 1993-2003”.
The NODC clearly marks their quarterly data in the spreadsheet they provide here. The Global OHC value at 2002-12 is 6.368768 [*10^22 Joules], and the value at 2003-12 is clearly marked 11.6546 [*10^22 Joules]. But the data included in Tamino’s trend does not include the 4thquarter 2003 data at 11.6546 [*10^22 Joules].
If you’re having trouble seeing that, Figure 4 is similar to Tamino’s graph with the hash marks included. It shows the trend based on the period of 1993 to 2002.

Figure 4
And Figure 5 gives you an idea what Tamino’s graph would look like if he had actually included 2003 data in his trend.

Figure 5
Animation 1 compares the two. (You may need to click on it to get the animation to work.)

Animation 1
How could Tamino and his disciples have missed such an obvious mistake? Some of you might even think it wasn’t a mistake on Tamino’s part, and that his disciples purposely overlooked that blatant error. I’m sure you’ll have a few comments about that.
HANSEN ET AL (2005) OFFSETS THE OHC DATA
A recent comment noted that the observations-based dataset in Hansen et al (2005) was not NODC OHC data, that it was the OHC data based on Willis et al (2004). I never stated that I was providing Willis et al (2004) data. My OHC update posts have always been about the NODC dataset.
My Figure 6 is Figure 2 from Hansen et al (2005). Note that the data starts at about zero watt-years/m^2 in 1993. And my Figure 7 is Figure 3 from Willis et al (2004). Note that the Willis et al data starts at -1 * 10^8 Joules/m^2 at 1993. Hansen et al converted the data, which is not in question since I’ve done the same thing, and Hansen et al have offset the data, which I have done also.

Figure 6
HHHHHHHHHHHHHHHHHHHHHH

Figure 7
Mysteriously, Hansen et al can shift the data without comment from Tamino, but when I do it, it’s interpreted by Tamino and his disciples, and by those from SkepticalScience, as a fake graph.
THE BEST WAY TO COMPARE THE MODELS TO THE OBSERVATIONS-BASED OHC DATA
Obviously, the best way to present the GISS Model-ER projection for Ocean Heat Content would be to use the actual GISS Model-ER data. The RealClimate annual model-data updates here and herepresent the Model-ER data. But the Model-ER OHC simulations are not available in an easy-to-use format like at the KNMI Climate Explorer. If it was available, all of this nonsense about my shifting data, my misrepresenting data, etc., would disappear. Why?
I have stated in comments at WUWT that I would use the ensemble mean of the Model-ER data and the NODC OHC observations for my future model-data comparisons. I’ve also stated I would use the base years of 1955-2010 to avoid the possibility of being accused of cherry-picking the base years.
Why? I presented this in a June 14, 2011post. And that post has been linked to all OHC updates since then.
Figure 8 is a graph from a 2008 presentation by Gavin Schmidt of GISS. It includes the OHC simulations of the Model-ER for the period of 1955 to 2010, which is the model data shown in the RealClimate model-data posts. It also includes the older version of the global NODC OHC data.

Figure 8
If we:
1. replicate the ensemble mean data of the GISS Model-ER,
2. replace the older NODC OHC data with the current version, and
3. use the base years of 1955-2010 so that no one can complain about cherry-picked base years,
Figure 9 would be a reasonable facsimile of the long-term comparison from 1955 to 2010. Notice where the ensemble mean of the GISS Model-ER intersects with the data near the ARGO era. Sure looks like 2003 to me. Figure 1 at the top of this post confirms how closely the GISS Model-ER would intersect with the NODC OHC data at 2003.

Figure 9
That graph in Figure 1 looks familiar, doesn’t it? It sure does look like the ARGO-era graphthat Tamino and his disciples dislike so much.
{kind=link}
MY OFFER
In my January 28, 2012 at 6:18 pmcomment at the WUWT cross post I wrote the following:
I offered in a comment above to use the base years of 1955-2011 for my short-term ARGO-era model-data comparison. That way there can be no claims that I’ve cherry picked the base years or shifted the data inappropriately. I do not have the capability to process the GISS Model-ER OHC hindcast and projection data from the CMIP3 archive. So I cannot create the ensemble member mean of the global data, on a monthly basis, for the period of 1955 to present. But some of you do have that capability. You could end the debate.
If you choose to do so, please make available online for all who wish to use it the Global GISS Model-ER hindcast/projection ensemble member data on a monthly basis from 1955 to present, or as far into the future as you decide.
I will revise my recent OHC update and reuse that model data for future OHC updates. That way we don’t have to go through this every time I use that ARGO-era comparison graph as the initial graph in my OHC updates.
Fair enough?
Any takers?
CLOSING
I know the trend of the OHC data is not the model mean, but for those who are wondering what Tamino’s NODC OHC graph might have looked like if he had actually included the 1993 through 2003 data in his trend AND then compared it to the period of 2003 to 2011, refer to Figure 10.

Figure 10
And if he had lopped off the data before 2003, because it isn’t presented in the graph that he complains about so much, the result would look like Figure 11.

Figure 11
Utahn says:
I think the analogy should be a bit more complicated.
I did not provide an anaolgy. I gave an example. An example of an instance where the appropriate period of analysis was very short (instantaneous). You provide an example where the appropriate period of analysis is somewhat longer (a few hours to a day or so). We can easily provide another example – low grade fever indicative of a chronic infection – where the appropriate period of analysis could be several days to several weeks or even months.
That is my point. All of those periods are appropriate, for their intended purpose. You cannot a priori claim “cherry picking” based on the period alone. You need to compare it against the purpose to which the data are being put. WRT the validity of climate model predictions, periods of 10 to 15 years are clearly within the realm of consideration, and such periods that include the present are particularly relevant.
I think the reason people think “cherry-picking” is that if you look at the start point of Bob’ graph in context of more years of data, it’s clear that he starts at an anomalously high point.
Not true. And on top of that, irrelevant.
If you will look closely at Bob’s figure 10 above, you will see that the period for his recent era trendline starts first quarter 2003. That was, if anything, a low point – being below the trend line of the 1993-2003 data. Also, the data subsequent to 2003 are of similar magnitude to the 2003 data – hence the flatter trend over that period. So, Bob did not start his trend on the high point in 2003, and that point is not anomalous wrt the rest of the period.
And it would not matter if he had started on the high point. Appropriate and relevant analysis periods may start on high points, or low points, or points in between. The point chosen may be inappropriate, but that cannot be a priori determined from the relative magnitude of the point alone. The full context of the period and the purpose to which the data are being put must be considered. All too often, we see the ignorant name calling of “cherry picking” without consideration of those issues.
It may not be a deliberately picked cherry, but it still is an anomalously hight start point for a trend.
Nonsense. There is a clear break in trend around that point, and the period subsequent is long enough wrt the variability of the data and flat enough wrt the predicted trend to warrant consideration.
If you start the trend 6-12 months earlier the trend is quite different, even though just about the same percent of the data came from ARGO. Which is why, titillating as it might seem, Bob and your suggestions of being near model “falsification”, whatever that means, are off base.
Nonsense. Fifteen years of lower than predicted values, with an increasing disparity that results in a strongly divergent trend over the most recent 10 years, is significant. The only question before us is whether or not it is yet of sufficient significance to constitute a falsification of the models. It is certainly in the vicinity.
A further point that needs to be made regards “starting points”. In any trend analysis that includes the present, a perfectly valid and very useful question to ask is “For how long has the current trend been active.” That question is answered by extending the period of analysis back in time until the bounds by which you define the current trend are exceeded. The point reached is not the starting point, but rather the ending point, of that analysis. That point will most relevantly occur at a break in trend, and often at or near an extreme value. That it does so does not by itself render the trend invalid. Trends are not invalid. Only the use to which they are put can be invalid, and determining that requires consideration of much more than whether or not the trends starts, ends, or contains , a “high point”.
“Cherry picking” can be a valid complaint, but it is much overused – both by those that dont understand the concept as well as those that know better.
Peter says:
JJ, the problem with your logic is that is that it ignores things like measurement error that cause
noise or uncertainty in the data record.
Nonsense. To the contrary, a comprehensive analysis dedicated to identifying measurment error will seek out obvious discontinuities in the data and breaks in the trend, such as occur in the OHC data ca 2003. They are often indicative of a problem with the data. Given that this discontinuity and trend break is coincident with the changeover to the entirely different instrumentation and methodology of the ARGO-data-based OHC estimates, one of the first things I would question is whether or not there is an error in the homogenization of that hybrid dataset. If there is, it needs to be fixed before those data are put to any use. If there is not, then the discontinuity and break in trend are real, and the length of the period over which they operate and their recent behaviour render them worthy of consideration.
And because there is noise in the data you need to look at a long term record before you can draw conclusions about the rate of change.
You say “long term record” as if that has a singular meaning, and no doubt you equate that singular meaning with whatever period it takes to achieve your predetermined result. Nonsense.
To properly analyze trend data, one need not look at a “long term record”. One need only look at a long enough term record. “Long enough” is determined by the purpose of the analysis and the magnitude of the variability of the data vs the size of the change or trend in the data. Ten to fifteen years of large and increasing divergence is long enough to support asking questions regarding the validity of these model predictions vs these data. It is in the vicinity of long enough to invalidate those models against these data and the purpose for which these predictions are being used, though you will note that neither Bob nor I have yet drawn that conclusion.
That is why you need a multi-decade record of data before you can draw conclusions about the rate of change.
Nonsense. There is no set period necessary for drawing conclusions about the rate of change, “multi-decadal” or otherwise. The necessary period is determined by the measured
rate of change and the variability of the measurements. I trust that if the global average surface temperature began rising 1 degree C per year for the next five years, you would not calmly demand another twenty five years or so of monitoring before coming to the conclusion that the rate of change had increased.
ClimateForAll says:
January 31, 2012 at 3:53 pm
“Hi Everyone!
If Open Mind allowed for comments to discuss/debate articles from that site, WUWT probably wouldn’t have to publish an article to provide a dissenting view.
But there it is.
Open Mind and other Pro-CAGW sites just don’t allow for intelligent discourse and proper debating.
So be it.
The thing that gets me is, is that WUWT allows for such types of discussions(mind you civil), giving rise to dissenting Con-CAGW views, yet these posters defend websites that censor.
Period.
……….
You want us to respect your opinion, demand open discourse from you trusted friends at Real Climate and Open Mind and the like.
But until then, you are but a tool of the worst sort.”
Very well said ClimateForAll!
Ockham says: “Please help me out here and correct me if I’m wrong. The data splice occurs in 2003. Tamino built his trend without using 2003 data. Had he used 2003, he would have had to combine older data plus the first year of ARGO data to calculate his trend. That doesn’t seem legitimate.”
The NODC Ocean Heat Content dataset includes data from a number of different sampling devices. One of them is ARGO. There is no specific date when XBTs were stopped and ARGO floats started. XBT’s were still being used in 2010, but the number of ARGO measurments now dwarfs those by XBTs.And the spatial coverage of the global oceans is much, much better. Then there are the TAO project buoys in the tropical Pacific, which were deployed starting in the 1990s.. They are still in use.
Regards
Nick Stokes says: “Not in Gavin’s presentation…”
That’s understood. My discussion of the GISS preference for Model-ER simulation data related to why I would use it in a model-data comparison—because Hansen and Gavin use it.
You continued, “The error is in the inference, which was that the model was wrong because the extrapolation didn’t look good. All you can deduce is that the post-2003 OHC went in a different direction. That no more invalidates the pre-2003 model results than it invalidates the pre-2003 data. And that’s all that were used here.”
If the GISS OHC model simulations were available in an easy-to-use format, I would use it. Since they’re not, I have to rely on the extrapolation just as Gavin does in his annual model-data updates at RealClimate.
JJ:”I did not provide an anaolgy. I gave an example. An example of an instance where the appropriate period of analysis was very short (instantaneous)…All of those periods are appropriate, for their intended purpose. You cannot a priori claim ‘cherry picking’ based on the period alone. ”
Thanks for the clarification. I would say that a graph showing 7-8 years, starting at an unusually high datapoint, is not appropriate for the intended purpose (as shown always in red letters), of wondering about model falsification.
“That was, if anything, a low point – being below the trend line of the 1993-2003 data. ”
It is only looks like its below the trend line because Bob didnt continue the trend, but skipped a quarter! That’ one of the complaints. If you look at the data that doesn’t start at 2003(as in fig 3), you can see that it was indeed anomalous relative to what had preceded it.
“Trends are not invalid. Only the use to which they are put can be invalid, and determining that requires consideration of much more than whether or not the trends starts, ends, or contains , a ‘high point’.” Agreed, and a 7 year trend, starting at an anomalously high point, is invalid for suggesting falsification of a long term model.
Utahn says:
Thanks for the clarification. I would say that a graph showing 7-8 years, starting at an unusually high datapoint, is not appropriate for the intended purpose (as shown always in red letters), of wondering about model falsification.
As explained above, it is not an unusuallly high point relative to the subsequent data. There is an apparent break in trend. It is not too soon to begin asking about that, given the size of the divergence with model predictions and the significant break in slope with same. See Fig 9.
It is only looks like its below the trend line because Bob didnt continue the trend, but skipped a quarter! That’ one of the complaints.
In Fig 10, the trend is continuous. Q1 2003 is below that line. This is also true of Fig 3 above, which is Tamino’s.
If you look at the data that doesn’t start at 2003(as in fig 3), you can see that it was indeed anomalous relative to what had preceded it.
But not anomalous relative to what has followed it…
JJ: “As explained above, it is not an unusuallly high point relative to the subsequent data.”
That’s what you’d expect if global warming is occurring. Kind of like temps after the strong El Niño Influence on 1998 not falling back down as low as before.
If you look at the residuals of the smoothed curve on Tamino’s post, it’s clear 2003 was anomalous compared to before and after…
“In Fig 10, the trend is continuous. Q1 2003 is below that line. This is also true of Fig 3 above, which is Tamino’s.”
You might want to look at that again.
Actually I don’t have as much of a problem with Fig 10, using a trend that ends in a date, then starting from that date to predict forward is not out of line. Though having the end point of your trend calculation occur at an anomalously high point in the data is slightly setting up your trend to fail, of course.
Utahn says:
JJ: “As explained above, it is not an unusuallly high point relative to the subsequent data.”
That’s what you’d expect if global warming is occurring. Kind of like temps after the strong El Niño Influence on 1998 not falling back down as low as before.
It is also “what you’d expect” if global warming has peaked and flattened prior to the onset of global cooling. That’s the problem with those “consistent with” pseudo-arguments – they are indeterminate.
BTW, surface temps after the 1998 El Nino did fall back down as low as before. The step up occurrred when temps did not fall back down as low after the 94-95 El Nino. That provided the elevated base from which the 1998 El Nino operated.
“In Fig 10, the trend is continuous. Q1 2003 is below that line. This is also true of Fig 3 above, which is Tamino’s.”
You might want to look at that again.
You are correct. Q1/2003 is slightly above the trend line. It remains that this point is not anomalous.
Actually I don’t have as much of a problem with Fig 10, using a trend that ends in a date, then starting from that date to predict forward is not out of line. Though having the end point of your trend calculation occur at an anomalously high point in the data is slightly setting up your trend to fail, of course.
The choice of endpoint for that trend calculation is inconsequential wrt the import of analysis. The trend from Q1/1993 – Q4/2003 is ~ seven times the trend from Q1/2003 – Q4/2011. Remove the “anomalous high point” (it isnt) from the early trend, and it is still ~ six times the recent trend. The break in trend is obvious. This is “what you’d expect” if global warming has peaked and flattened prior to the onset of global cooling. A peaked and declining 3rd order polynomial fits the data from 1993 -2011 better than the linear trend over the same period. That isnt an argument, just an observation wrt curve fitting that is as relevant to this discussion as you believe curve fitting to be.
The divergence between the trend in observations and the model prediction trend is more interesting. The model has been predicting higher than actual temps for the last 15 years, and the disparity is increasing – over the last 8-9 years, the disparity is increasing at a rate that approximates the models predicted rate of increase.
These are significant issues, and cannot be glossed over by quibbles over intercepts and endpoints.
“Remove the “anomalous high point” (it isnt) from the early trend, and it is still ~ six times the recent trend. ”
How about removing the anomalous high point from the earlier trend(it is) and starting the second trend from the same point, rather than skipping a quarter?
Looking at short term trend is great, and I think wondering what variation is caused by underlying CO2 or natural or manmade variability is great too, but model falsification, it ain’t.
JJ, forgot to mention, curve fitting, as you suggest, I don’t find relevant, but looking at residuals to find anomalous data (not in error, just anomalous for whatever reason), I think is highly relevant.
Utahn says:
“Remove the “anomalous high point” (it isnt) from the early trend, and it is still ~ six times the recent trend. ”
How about removing the anomalous high point from the earlier trend(it is) and starting the second trend from the same point, rather than skipping a quarter?
I didn’t skip a quarter. Endpoint choice is simply not a significant factor here. The break in trend is 6X or 7X. It doesn’t matter which. A break of 3X would be noteworthy.
Looking at short term trend is great, and I think wondering what variation is caused by underlying CO2 or natural or manmade variability is great too, but model falsification, it ain’t.
“Natural or manmade variability” is such a weasel term. In this context, it should be referred to as “unmodeled parameters”. And sufficient magnitude of those results in a useless model. Fifteen years of increasingly greater over prediction suggests something isn’t be accounted for properly.
JJ, forgot to mention, curve fitting, as you suggest, I don’t find relevant, but looking at residuals to find anomalous data (not in error, just anomalous for whatever reason), I think is highly relevant.
So do it. Which points are “anomalous”? Q4/2003? Q1/2004? Q1-Q3/2001? Q2/1996?
Q4/2003 is a break point for trend. That is also highly relevant.
Utahn says: “It is only looks like its below the trend line because Bob didnt continue the trend, but skipped a quarter! That’ one of the complaints.”
That’s news to me, Utahn. Please identify what quarter you claim I missed and in what graph.
Bob I did have a goof, the figure I was thinking JJ was referring to was fig 1 of your last post, “part 1.”. In that figure I thought a quarter was skipped because Hansens trend ends at fourth-quarter 2002 whereas your trend begins at first-quarter 2003.
For the figure 10 above JJ was actually referring to my only complaint is that the initial trend ended it anomalously high data point q4 2003.
JJ: “Endpoint choice is simply not a significant factor here”.
If not, then why are figure 4 and 5 so different above? Figure 4’s trend ends at a non-anomalous datapoint, figure 5 ends at a hot anomaly.
For the residuals, why not look at Tamino’s post where they are shown? (I am a “disciple”, had to try)
Sorry for the mixup Bob and JJ, most of this is on the bus and phone.
It also appears that in one regard I have not been misled by Tamino, but did misunderstand both his critique and your response, thereby misleading myself. I see in reading Hansen et al that they didn’t end in last quarter 2002, so I retract my poorly founded accusation that a datapoint was “skipped”. Very, very sorry, probably need more time to read all posts. Bad disciple, bad!
My only complaint remains the choice of endpoint/startpoint, and the shifting of the intercept of the trend from years past to an anomalously high startpoint for such a short trend (in Fig 1 from Part 1). Which was actually Tamino’s actual complaint, not the one I made up in my head…
Utahn says:
JJ: “Endpoint choice is simply not a significant factor here”.
If not, then why are figure 4 and 5 so different above? Figure 4′s trend ends at a non-anomalous datapoint, figure 5 ends at a hot anomaly.
Because both of those trends, though they are a somewaht different from each other, are very different from the trend of the more recent data. – and that is the difference that was the subject of Bob’s initial post. It doesn’t matter much which point in the vicinity of the break you use, the period before and the period after are substantially different in trend.
For the residuals, why not look at Tamino’s post where they are shown? (I am a “disciple”, had to try)
Looking at those, it is clear that 2003 is by no means anomalous (not that it would matter a hill of beans if it were, see above). Several of those observations deviate more from the 1993-2002 trend Tamino used than does 2003. And, as Bob illustrates in fig 4 & 5, had Tamino used the 2003 data to compute his trend as his text and labeling stated he had, some of those other points would have deviated more from the trend, whereas 2003 would have deviated less. Causes one to question if that was the intention.
The really interesting and relevant issue, of course, is the deviation of the model predictions from the observations. From Fig 9 above, that deviation starts about 15 years ago as a divergence in the slope of the trend that would itself result in a bust over a fairly short period of time, with the model predicting higher heat than actually occured. That divergence steepened 8-9 years ago, and currently approximates the slope of the trend in the model predictions. That is significant.
Note that the model results also reliably under predict OHCs prior to that point. Under prediction in the past, plus over prediction in the present, equals a greatly exaggerrated warming trend in the model. No wonder some folks are trying soooo hard to distract from Bob’s point, with pissant complaints over irrelevant intercepts and misleading graphs that dont present what they cliam to, let alone what they should.
JJ: “Because both of those trends, though they are a somewaht different from each other, are very different from the trend of the more recent data. – and that is the difference that was the subject of Bob’s initial post. It doesn’t matter much which point in the vicinity of the break you use, the period before and the period after are substantially different in trend.”
If it didn’t matter, then using figure 4 (that is, the long-term trend extrapolated from the trend ending in q4 2002), and starting the short term “divergence-assessing” trend from q4 2002 onward would be just fine and should show about the same divergence problem, right?
I’d have no problem with that graph, it’s only one datapoint earlier than the starting point Bob uses for his “divergence-assessing” short term trend that started q1 2003. Why don’t we just ask Bob to show us that graph, and I’ll shut up about it…
Perhaps given my earlier errors, Bob doesn’t feel inclined to waste time on this, which is completely understandable, but how about it Bob?
Utahn says:
JJ: “Because both of those trends, though they are a somewaht different from each other, are very different from the trend of the more recent data. – and that is the difference that was the subject of Bob’s initial post. It doesn’t matter much which point in the vicinity of the break you use, the period before and the period after are substantially different in trend.”
If it didn’t matter, then using figure 4 (that is, the long-term trend extrapolated from the trend ending in q4 2002), and starting the short term “divergence-assessing” trend from q4 2002 onward would be just fine and should show about the same divergence problem, right?
Yes. Even including that low point (Q4 2002) in both trends (not standard practice) demonstrates a significant break in trend before and after.
I’d have no problem with that graph, it’s only one datapoint earlier than the starting point Bob uses for his “divergence-assessing” short term trend that started q1 2003. Why don’t we just ask Bob to show us that graph, and I’ll shut up about it…
Why would Bob waste any more time than he already has on these irrelevant rabbit trails?
Bob’s point was the divergence between model predictions and actual observations. Bob’s point was not the break in trend that occurs in the observations ca 2003. Tamino raised that as a distraction. In his misleading post, he refused to include data relevant to Bob’s point, the the divergence between model predictions and actual observations, because he did not want anyone to notice the divergence between model predictions and actual observations that Bob was pointing out.
You are doing the same, and with a persistance that indicates intention.
JJ: “Yes. Even including that low point (Q4 2002) in both trends (not standard practice) demonstrates a significant break in trend before and after.”
It’s interesting, looking at Figure 4, you think Q4 2002, which occurs where the line changes color, is a low point, and that Q4 2003, the big mountain next door, is not anomalous?
“Tamino raised that as a distraction.”
If any trend line, modeled or not, is drawn so that it starts or stops at an anomalous datapoint, that’s also a distraction, a distraction from reality. I guess my “intention” is to make that point.
I won’t shut up about it until someone shows me that Q4 2002 stop and start graph or just admits that 2003 is an outlier and shouldn’t be used to make claims about “model falsification”, whatever that means (all models wrong, some useful yadayada). No one has to waste time on humoring me here, but if they did, I’d shut up, which might be a plus!
I’ve just permanently banned a blogger for troll-like behavior at my blog. My guess is he’ll show up here and complain.
Utahn says:
February 5, 2012 at 1:12 pm
JJ: “Yes. Even including that low point (Q4 2002) in both trends (not standard practice) demonstrates a significant break in trend before and after.”
It’s interesting, looking at Figure 4, you think Q4 2002, which occurs where the line changes color, is a low point, and that Q4 2003, the big mountain next door, is not anomalous?
Yes, Q4 2002 is a low point, relative to both of the trends referenced. And yet including that low point in both trends – as you suggested be done – still results in a significant break in trend. And yes, Q4 2003 is not anomalous. See above.
If any trend line, modeled or not, is drawn so that it starts or stops at an anomalous datapoint, that’s also a distraction, a distraction from reality.
That is simply not true.
I guess my “intention” is to make that point.
Your “point” is irrelevant to what Bob was posting about. Bob’s point was the divergence between model predictions and actual observations. Bob’s point was not the break in trend that occurs in the observations ca 2003. You perseverate on that as a distraction from what Bob was talking about: the divergence of the model predictions from the observations.
I won’t shut up ..
The first step is admitting the problem. Do proceed.
… about it until someone shows me that Q4 2002 stop and start graph …
Make it yourself. The exercise would be good for you.
… or just admits that 2003 is an outlier …
It isn’t even anomalous, let alone an outlier.
The only reason that you make such assinine claims, is because you think (incorrectly, btw) that calling names at Q4-2003 supports your preconceived outcome of Tamino’s trumped up dispute over the break in the trend of the observations. If you actually bothered to consider the topic of Bob’s post – the divergence of the model predictions from the observations – then you would rapidly drop the notion that 2003 is “anomalous”, as those few “anomalous” points ca 2003 are the only ones in the last fifteeen years that come close to the model prediction. Everthing else is low, and getting lower all the time.
… and shouldn’t be used to make claims about “model falsification”, …
There have been no claims made about model falsification. There has been a question asked, and that question is predicated on the divergence of the model predictions from the observations. None of that has anything to do with what you are talking about, which is the break in trend within the observations. This has been pointed out to you more than enough times.
Why don’t you spend a little time considering the divergence of the model predictions from the observations? If doing so doesn’t shut you up altogether, perhaps it will at least rekindle your love for the OHC data from 2003.
JJ: “Yes, Q4 2002 is a low point, relative to both of the trends referenced. And yet including that low point in both trends – as you suggested be done – still results in a significant break in trend. And yes, Q4 2003 is not anomalous.”
Really, a significant break in trend? Statistically signficant or “because I want it to be” significant? Well, I did take a look with my crude XL skills. And using Q4 2002 as a stop and restart point shows what looks like a slight decrease in trend compared to the 1993-Q42002 trend, but nothing like the claimed 14X trend difference that shows up using *less than one year* later. Apologies that I haven’t got the skillz to make a pretty picture to insert. So to me, that 2003 mountain still looks pretty relevant,and starting or zeroing a trend line there seems misleading. Also playing around it looks like you can even make negative trends over short time series, and also markedly positive trends worse than GISS would predict.
I guess it still seems to me like we’re going down the up-escalator (http://www.skepticalscience.com/graphics.php?g=47) , and that start and stop points really do matter for short term estimations of *model or observational* trends.
I think I’ll let you have the last word JJ and actually shut up about it after all, having admitted my problem, and now dealing with it. Thanks for the discussion!
You refuse to acknowledge to topic of the discussion, you quote lies from the likes of Cook, and you add your own (14x?) to the mix. Clearly, there is no purpose in discussing anything with you, apart from demonstrating the desperate and dishonest behaviour of warmist groupies. That mission well accomplished, I’m signing off.