Marcel Crok tips me via Twitter that a new analysis of ‘the pause’ by Dr. Ross McKittrick has given some new numbers for the different temperature datasets. It was published in the Open Journal of Statistics

NOTE: (added) Some people saw the green line in the figure above as a trend line. It is not. It is a comparison line to show the similarity of global temperatures 19 years apart in relation to McKittrick’s paper. It simply shows the “plateau” of temperatures has not changed much since then. To see more about the pause in trends, this essay will be informative.
The RSS satellite dataset says:

The paper:
McKitrick, R. (2014) HAC-Robust Measurement of the Duration of a Trendless Subsample in a Global Climate Time Series. Open Journal of Statistics, 4, 527-535. doi: 10.4236/ojs.2014.47050.
Abstract
The IPCC has drawn attention to an apparent leveling-off of globally-averaged temperatures over the past 15 years or so. Measuring the duration of the hiatus has implications for determining if the underlying trend has changed, and for evaluating climate models. Here, I propose a method for estimating the duration of the hiatus that is robust to unknown forms of heteroskedasticity and autocorrelation (HAC) in the temperature series and to cherry-picking of endpoints.
For the specific case of global average temperatures I also add the requirement of spatial consistency between hemispheres. The method makes use of the Vogelsang-Franses (2005) HAC-robust trend variance estimator which is valid as long as the underlying series is trend stationary, which is the case for the data used herein. Application of the method shows that there is now a trendless interval of 19 years duration at the end of the HadCRUT4 surface temperature series, and of 16 – 26 years in the lower troposphere. Use of a simple AR1 trend model suggests a shorter hiatus of 14 – 20 years but is likely unreliable.
…
The IPCC does not estimate the duration of the hiatus, but it is typically regarded as having extended for 15 to 20 years. While the HadCRUT4 record clearly shows numerous pauses and dips amid the overall upward trend, the ending hiatus is of particular note because climate models project continuing warming over the period. Since 1990, atmospheric carbon dioxide levels rose from 354 ppm to just under 400 ppm, a 13% increase. [1] reported that of the 114 model simulations over the 15-year interval 1998 to 2012, 111 predicted warming. [5] showed a similar mismatch in comparisons over a twenty year time scale, with most models predicting 0.2˚C – 0.4˚C/decade warming. Hence there is a need to address two questions: 1) how should the duration of the hiatus be measured? 2) Is it long enough to indicate a potential inconsistency between observations and models? This paper focuses solely on the first question.
…
Conclusion
I propose a robust definition for the length of the pause in the warming trend over the closing subsample of surface and lower tropospheric data sets. The length term MAX J is defined as the maximum duration J for which a valid (HAC-robust) trend confidence interval contains zero for every subsample beginning at J and ending at T −m where m is the shortest duration of interest. This definition was applied to surface and lower tropospheric temperature series, adding in the requirement that the southern and northern hemispheric data must yield an identical or larger value of MAX J . In the surface data we compute a hiatus length of 19 years, and in the lower tropospheric data we compute a hiatus length of 16 years in the UAH series and 26 years in the RSS series. MAX J estimates based on an AR1 estimator are lower but likely incorrect since higher-order autocorrelation exists in the data. Overall this analysis confirms the point raised in the IPCC report [1] regarding the existence of the hiatus and adds more precision to the understanding of its length.
Dr. McKittrick writes on his website: http://www.rossmckitrick.com/index.html
I make the duration out to be 19 years at the surface and 16-26 years in the lower troposphere depending on the data set used. R Code to generate the graphs, tables and results is here.
The full paper is here: http://dx.doi.org/10.4236/ojs.2014.47050
Perhaps eventually we will reach the conclusion that “the pause” extends to the 70s and “global warming” never existed to begin with.
It could be cooling at 0.1 degC per decade and the alarmists would still make claims of the ‘hottest year”, “hottest decade” and imminent thermageddon etc.
If I were to make any prediction it would be that Global warming will cease as soon as the funds to promote it are turned off.
Well put, OldEngland. Let us hope and pray that little ray of sanity comes quickly.
I would propose an alternate prediction…Global warming will cease to exist as soon as funding for an alternate crisis-du-jour is secured.
My guess is they will ramrod through a carbon tax and CO2 reductions, and when the temperature goes down into a little ice age, they will claim they were right.
Finding heteroskedasticity would mean the variability of the temperature data is non-constant when referenced over the time period evaluated.
John
The raw data isn’t available to the unblessed – including me and our author here. What actually seems to have happened, however, is that:
1- “satelite data” is a computational artifact created from orbital atmospheric observations and calibrated according to known surface, and near surface, measurements. Any systematic distortion in the calibration data will therefore produce comparable distortions in the computed satelite data.
2 – up to about 1991 the number of locations for which surface or near surface data expanded – slowly, and with priority given to areas important to aviation – but, after that, it shrank. That historic effect distorts the “data” because data for some areas are interpolated while others aren’t – and that mix changed over time so we have areas for which we have guesses followed by a decade or two of real data followed by guesses again – and, most of the time, no way to know which is which.
3 – up to about 2000 various players worked to lower recorded historic surface data (with consequent adjustments made to much of the public satelite record) while raising more current estimates. After about 1998 (mainly because of people like Anthony Watts) this became riskier, and so less of it was done. I believe (but do not know) that the effect is enough to account for “the pause”. If so, we may now have cooling, but did not have short term warming in the 1960-2000 period.
Basically, I imagine that Dr. McKitrick’s work, while valuable and interesting, is subject to the operation of an intervening variable: politics – and, if he wants to fix that, he’s going to have to work with the raw data and the matching sensor degradation data. Good luck!
Paul
I believe the “manipulation” continued into at least year 2000. Look at Hansen’s 1999 and 2000 temperature graphs for the US. (those two graphs should be on WUWT site somewhere). You will see significant changes in the 30’s, 40’s. 50’s & 60’s and lesser changes for the 90’s. Unless you have access to the raw data and can convincingly prove an error in processing, you should NEVER be allowed to “adjust” historical data, as Hansen did with little scientific or journalistic uproar. He should have been fired immediately! That may be the low point in recent climate science integrity. At least, I hope it is and that some sanity is finally creeping into the climate debates.
Bill
Judith Curry is also highlighting McKitrick’s paper in How long is the pause?
Also getting attention over at Dr. Judith Curry
http://judithcurry.com/2014/09/01/how-long-is-the-pause/#more-16779
JC comment: I find this paper to be very interesting. I can’t personally evaluate the methods, although I understand the importance of the heterskedacity an autocorrelation issues. The big issue with length of the pause is comparison with climate model predictions; I would like to see the climate model simulations analyzed in the same way. I would also like to see the HadCRUT4 results compared with Cowtan and Way and Berkeley Earth. I also seem to recall reading something about UAH and RSS coming closer together; from the perspective of the pause, it seems important to sort this out.
“I would like to see the climate model simulations analyzed in the same way.”
important point, apples etc.
Hiatus is bogus term. It implies a break from something constant. Temp rise , temp fall never was nor ever will be constant.
Good point, we too readily adopt the incorrect and suggestive language that mainstream climatologists constantly use to bias the mind of the reader.
I too have a problem with the terms “pause” and “hiatus”, let us not allow the alarmists to steer the conversation by using their biased language. “Plateau” is more suitable but maybe “peak” or “crest” would be even better because this layman suspects that by 2035 this period on the chart will obviously be the top of another gentle curve in transit from warming to cooling. In other words, business as usual.
Matt Bergin says:
Stopped is the correct alternative.
Correct. Global warming stopped many years ago.
Saying that global warming has “paused”, or that this is a “hiatus” is improper language. Because no one knows what will happen.
Global warming may resume at some future time. Or it might not. Or, global cooling may commence. No one knows. The Orwellian terms “pause” and “hiatus” are weasel words, used to allow those who made wrong predictions to gently climb down from the fact that the alarmist crowd never thought that global warming would ever stop — and for so many years.
No climate model predicted that global warming would stop, either. It is the most significant climate event of the last twenty years. The fact that no one saw it coming shows how little we know. Every alarmist prediction was that global warming would accelerate — until it didn’t. Then their predictions stopped.
Skeptics are on the right track: listen to what Planet Earth is telling us, then draw conclusions. If facts change, change with them. Compare that with the alarmist crowd, which arrives at it’s conclusions first, and then looks for corroborating facts. That is simply confirmation bias.
Agreed. The terminology of the global warmers carry implicit assumptions which cannot be sustained when examined closely.
The Princess is unhappy that you left out Summer, Winter, and Spring.
“Plateau” is a neutral alternative.
Stopped is the correct alternative.
I agree with “plateau” as the best descriptive term for the current situation.
After all the climate could warm again due to influences beyond (or possibly within?) our control…”Stopped” would imply that we KNOW the temperature is only going to go down or stay at this range – and you’d have to show me the data and models for that!
And “Pause” just means it is going take up rising again – and no one knows that for sure as far as I can tell.
The CO2 heating model just doesn’t work any more. The so-called missing heat going into the ocean is harmless as a 0.01 (or 0.1) degree raise in deep ocean temperature can’t warm up anything more than 0.01 (or 0.1) degrees unless you somehow factor in Maxwell’s Demon (breaking a law of thermodynamics in other words).
Post peak warming maybe?
The temperature range over the last 100 years remains unremarkable.
Plateau is applicable.
I agree. Wherever I post I use the term “flat lining” for that is what we’re seeing and it has the advantage of being value neutral.
So he uses a method that requires that the data be trend stationary to show that the trend is not statationary but is lower during the 19y ‘pause’.
Seems to have lost something in translation. 😕
He is not showing that the data are stationary. He takes a trendless or stationary data set and assesses the duration of the interval that can be said to be robustly stationary as per the HAC test.
Eyeballing the HADCRUT4 curve we can perceive a very clear warming trend up to about 2007, followed by a very clear cooling trend. Is our non-trend simply a reflection of the temp. cycle rolling over the top?
talking of a “pause” is wrong
there is no pause
in nature, it is either warming or cooling
we are now cooling
http://blogs.24.com/henryp/files/2013/02/henryspooltableNEWc.pdf
Reblogged this on Canadian Climate Guy and commented:
This can’t simply be explain away as “heat hiding in the oceans”. Although the alarmists will use any “explanation” to keep the hype going.
Its an ‘averaged’ pause as clearly the temperatures have moved both ways during the period so ‘pause’ is perhaps not a worthwhile matrix. . Eyeballing it I would say the first 10 years of the 19 year graph is rather variable whilst the second 9 year period is much more constant and would surely merit the term ‘plateau’
tonyb
Someone please correct me if I am wrong, but I believe the first graph, which did NOT come from Dr. McKitrick’s paper is highly misleading. The line is NOT flat since 1995. In fact the line is only flat since 2001. And Dr. McKitrick never said it was flat. My understanding of what Dr. McKitrick said is that at the 95% level of confidence, we cannot be sure there is any statistically significant warming since 1995. I would redraw it as shown below to indicate the possibility of 0 from 1995. (By the way, Nick Stokes’ site says that for Hadcrut4: Since December 1996: CI from -0.026 to 1.139.) So there is a slight difference of about 2 years between Nick and Ross.
http://www.woodfortrees.org/plot/hadcrut4gl/from:1995/plot/hadcrut4gl/from:1995/trend/plot/hadcrut4gl/from:1995/trend/detrend:0.184/plot/hadcrut4gl/from:1995/trend/detrend:-0.184/plot/hadcrut4gl/from:2001.05/trend
Werner
You say
Thankyou, yes, that is my understanding, too.
However, that is also my definition of “no discernible global warming at 95% confidence” which I have repeatedly put to you on WUWT and, therefore, your and my “understanding of what Dr. McKitrick said” may be distorted by knowledge of my definition.
Richard
Thank you!
The exact quote from the paper is:
“Throughout this paper we use α = 0.025 and hence a
95% confidence interval.”
I assume we both agree that this means that there is a 2.5% chance that there is cooling since 1995 according to Hadcrut4.
Yes, we do agree “this means that there is a 2.5% chance that there is cooling since 1995 according to Hadcrut4″.
And I add that it also means that there is a 2.5% chance that there is warming since 1995 according to Hadcrut4”.
In both cases, the trend cannot be discerned as being different from zero.
Richard
And I add that it also means that there is a 2.5% chance that there is warming since 1995 according to Hadcrut4″.
I do not agree with this. I believe there is a 97.5% chance that there is warming since 1995. The flat line is from 2001, which I interpret to mean that there is a 50% chance it is warming and a 50% chance it is cooling since 2001. So the chances of warming since 1995 would be greater than 50%.
richardscourtney September 1, 2014 at 2:12 pm
Yes, we do agree “this means that there is a 2.5% chance that there is cooling since 1995 according to Hadcrut4.
And I add that it also means that there is a 2.5% chance that there is warming since 1995 according to Hadcrut4.”
And so there’s a 95% chance of, well, what exactly?
Discernible has nothing to do with statistically significant. A hot day in summer is likely not statistically significant. But it’s discernibly hot.
The slope over this period was, says WFT, 0.94°C/cen. SS says that there is a 2.5% chance that if the weather could be rerun with random effects, you might get cooling. It doesn’t say cooling and warming are equally likely.
I agree with Werner. I made that plot in WFT, added the trend, and got
this.
Raw data gave the trend as 0.009409 C/yr, or 0.94 C/century.
Maybe that’s not statistically different from 0. But it isn’t statistically different from 1 °C/cen, or maybe even 2. You could equally well say each of those was the trend.
Nick Stokes says:
“September 1, 2014 at 4:08 pm richardscourtney September 1, 2014 at 2:12 pm
Yes, we do agree “this means that there is a 2.5% chance that there is cooling since 1995 according to Hadcrut4.
And I add that it also means that there is a 2.5% chance that there is warming since 1995 according to Hadcrut4.”
And so there’s a 95% chance of, well, what exactly?
Discernible has nothing to do with statistically significant. A hot day in summer is likely not statistically significant. But it’s discernibly hot.
The slope over this period was, says WFT, 0.94°C/cen. SS says that there is a 2.5% chance that if the weather could be rerun with random effects, you might get cooling. It doesn’t say cooling and warming are equally likely.”
I think the best interpretation is that there is a 95% confidence interval that these results are not due simply to sample size error. That says nothing about equipment error, human error, changing environmental conditions other than the temperature that is being measured that could affect the measurements. etc. and says nothing about the probability of it getting warmer or colder. Ceteris Paribus these results are only 5% in danger of being wrong due to random error due to sample size limitations.
“Ceteris Paribus these results are only 5% in danger of being wrong due to random error due to sample size limitations.”
It says that if the results were from a process with random error, and you could rerun the process, there is a 5% (or whatever) chance that the trend might be negative. That doesn’t mean a 5% chance that it would be positive. It means a 95% chance.
The actual trend reported by WFT for HADCRUT 4 since 1995 was 0.94°C/century.
Werner Brozek, Nick Stokes and Jim G
Thankyou for your comments. I write this single response not as insult to anybody bit for clarity at this point in the silly nested system.
It is important to remember that we are discussing abstract statistical constructs: both trends and “trendless” are abstract concepts which the data are calculated to demonstrate or to not demonstrate.
Mick Stokes illustrates the nature of my point when he writes to dispute it by saying
This is his plot http://www.moyhu.org.s3.amazonaws.com/pics/mci1995.png
Clearly, Nick’s plot is not what Werner calls “flat”.
Nick’s plot has a trend, and Nick’s regression indicates a slope of 0.94 C/century.
And Nick’s actual disagreement with me is specifically stated when he writes
This is really a dispute with Ross McKitrick and perhaps the ‘Open Journal of Statistics’ which published his paper titled “Measurement of the Duration of a Trendless Subsample in a Global Climate Time Series” that we are discussing.
The dispute is about the meaning of “trendless” in the paper.
In the discussed analysis a trend is the linear least-squares fit calculated to have inherent errors of the data sample which are estimated to be at 95% confidence: i.e. there is only a 1 in 20 chance that the trend will be outside the error range and, therefore, all trend values within that range have equal probability of being ‘true’.
I say of the discussed type of analysis
1.
A trend statistically differs from zero at 95% confidence when its linear regression slope has 95% confidence limits that do not include zero trend.
2.
A trend is not discernibly different from zero when its linear regression slope has 95% confidence that includes zero trend.
In case 2 the trend has a value of zero (because all trends within the error estimate are equally probable) and, therefore, the data set is said to be “trendless”.
Of course, being “trendless” is a statistical construct: the data certainly did vary so it rose and fell throughout the time period.
And Nick does not not state the range of 95% confidence he determined so he may be right when he asserts “Maybe that’s not statistically different from 0. But it isn’t statistically different from 1 °C/cen, or maybe even 2. You could equally well say each of those was the trend.”
But so what?
At issue is to determine if the data can be discerned as being different (at 95% confidence) from zero – i.e. the test is for “trendless” – and it is not relevant whether the data can be discerned as being different from 2°C/cen.
Nick stresses that
And I stress that this is completely irrelevant because it ignores the confidence limits and, thus, ignores that the data is “trendless”.
Hence, we come to the probability that the parameter represented by the data has a trend outside the range indicated by the estimated 95% probability. Of course, that probability is 5% (i.e. 1 in 20). My error was to agree Werner’s value of 2.5% because I was more concerned to point out that the difference from zero could be warming or cooling; mea culpa.
And I agree with JimG that this analysis pertains to the data and not the validity of the data.
Richard
Thank you for your reply Richard.
I just want to say that I agree with Nick about the 0.94/century. The only thing I would add is that the error bars according to my limited understanding would be +/- 0.94/century. So we can conclude with 95% confidence that the real slope varies from 0/century to 1.88/century.
However I feel that I am in over my head to discuss any specifics about “trend” and “trendless”, etc. Perhaps Nick can take this further with you.
Richard,
“And I stress that this is completely irrelevant because it ignores the confidence limits and, thus, ignores that the data is “trendless”.”
The confidence limits are not limits on the observed trend. There will be some, determined mainly by measurement error. The trend observed actually was 0.94, within these narrow limits.
The CI’s referred to here are those of an underlying trend, as might be inferred from some statistical model. They represent the spread of trends you might observe if the climate could be re-run. Not uncertainty about the trend that actually happened.
Nick Stokes
Thankyou for your view, but I don’t understand it.
Your reply to me by says in total
What do you think “trendless” means?
If you don’t say what you think “trendless” is then your comments do not relate to the paper under discussion.
I made a clear distinction between
(a) the “underlying trend” which is “inferred from” the “statistical model” of a linear trend
and
(b) the 95% confidence limits (CLs) of the trend observed according to that model.
Of course the CLs concern the “statistical model”: they are calculated from it!
And I remind that I wrote
Your reply seems to have forgotten that important fact.
Richard
richardscourtney September 2, 2014 at 2:37 am
“Nick Stokes
What do you think “trendless” means?”
Well, it’s Ross’s word. He doesn’t define it explicitly, but his result, to which it seems to refer, is:
” The length term J MAX is defined as the maximum duration J for which a valid (HAC-robust) trend confidence interval contains zero for every subsample beginning at J and ending atT – m where m is the shortest duration of interest.”
That’s what he means. YMMV.
I think he could have saved a lot of time by just looking up my trend-viewer with the “Lower CI trend” box ticked. Then you find the areas he is looking for neatly marked with a brown curve.
Nick Stokes
Your reply does not reduce my bemusement but adds to it.
As you now agree, “trendless” is the term used in the paper so is what we are discussing.
I stated my understanding from the paper when I agreed with Werner when he wrote
And I expanded on that when I wrote
But you say
Turning to your link I don’t see a “brown curve” but I do see a red trend line with value zero and no confidence limits which stretches over the period 1990 to present. Obviously, that line is not what McKitrick is discussing because his trend is for the period to present from 1995 (n.b. not 1990 as your line suggests).
Also, if Ross does mean your trend line then what do you think he means when he says
“trend confidence interval contains zero for every subsample beginning at J and ending atT”?
What is the “trend confidence” and how does it contain “zero for every subsample”?
My understanding states the meaning of those terms; i.e. as I have repeatedly said,
“A trend is not discernibly different from zero when its linear regression slope has 95% confidence that includes zero trend.
In case 2 the trend has a value of zero (because all trends within the error estimate are equally probable) and, therefore, the data set is said to be “trendless”. ”
So, I thought I understood what Ross wrote, I still think I understand it, and I cannot equate your comments with it. I hope this explains my bemusement.
Richard
Nick
Sorry, I see that your Link was to RSS which explains the 1990 value.
However, this does not alter my puzzlement.
Richard
Today is “I agree with Nick Stokes” day. Personally I am highly cynical about the processes used to determine “the length” of “the pause”, just as I’m cynical about the efforts on the other side to extrapolate “the trend” of a single cherry-picked 15-20 year interval from the late 20 century. The venerable theory of statistics takes a regular beating from all sides in these discussions.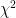 . The fit displayed treats all of the data as being infinitely precise. If one decorates the early data with huge error bars, those data have much less impact on the overall linear fit as one can drop
. The fit displayed treats all of the data as being infinitely precise. If one decorates the early data with huge error bars, those data have much less impact on the overall linear fit as one can drop 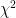 by fitting the later, more precise data at the expense of the earlier data. In addition, nobody sane thinks that this curve can be extrapolated indefinitely into the future any more than my early growth curve can. There are almost certainly numerous negative feedbacks that prevent the Earth’s climate system from running away on the hot side, or it would have already run away without CO_2 forcing. Note well that by this standard, it is possible that James Hansen is not sane, as he seems to stand alone extrapolating some sort of linear trend all the way to boiling oceans.
by fitting the later, more precise data at the expense of the earlier data. In addition, nobody sane thinks that this curve can be extrapolated indefinitely into the future any more than my early growth curve can. There are almost certainly numerous negative feedbacks that prevent the Earth’s climate system from running away on the hot side, or it would have already run away without CO_2 forcing. Note well that by this standard, it is possible that James Hansen is not sane, as he seems to stand alone extrapolating some sort of linear trend all the way to boiling oceans.
I am reminded of an article William Briggs wrote some years ago on the obsession people have with “trends” (it might have been in the context of climate science, but maybe not I can’t remember). To succinctly summarize his conclusions — don’t spend all of your mental energy (or computational energy) fitting linear trends to nonlinear data as if it means something. It does not. If it did, we’d all make fortunes on the stock market, three nice days in a row would guarantee a fourth one, I’d currently be at least 6 meters tall (extrapolating a linear approximation to my growth rate from the first 20 years). Instead, just look at the data. The data is what it is. You don’t need a “trend” to see what the data does. And no trend you fit, to any interval, cherrypicked or not, has the slightest a priori predictive value and asserting that it does is a complex logical fallacy that has impoverished as many people as it has ever enriched.
If one examines HADCRUT4 — all of it — it is pretty clear that fitting linear trends to the data is a global waste of time:
http://www.woodfortrees.org/plot/hadcrut4gl/from:1800/to:2015/plot/hadcrut4gl/from:1800/to:2015/trend
The linear trend of 0.05 C/decade sucks as a predictor of the curve. It is off by 0.2 to 0.3 C for easily half of the displayed (error bar free, sigh) interval. In addition to the fact that this linear trend is not a best fit to the data because the “right” way to generate the best linear fit to the data is to use the error bars to minimize e.g.
It would be ever so useful for people who want to play the linear trend game to look at the entire climate record over all available time scales, not any cherrypicked interval with some presumed or assumed linearized structure. The climate, as expressed any way one likes, is not ever a linearly extrapolable system — or rather, in the past it never has been. I would also commend Koutsoyiannis lovely paper in which he introduces Hurst-Kolmogorov statistics of weather/climate-like phenomena (in his case, he was studying hydrology — drought/flood clustering in the long term record). In the introduction, he illustrates the essential fallacy of fitting polynomial series or “special” functions like exponentials, quadratics, sines, straight lines to data series like those that occur in weather or climate and asserting that the results have some extrapolable virtue.
They do not.
So while Nick is completely correct in complaining that the top article in some sense misrepresents the length of the pause by determining (however correctly) the longest interval where linear-trend neutrality cannot be rejected at 95% confidence (or 97.5% confidence or whatever), and while he is entirely correct in pointing out that over the interval cited the linear trend is roughly 1 C/century, not flat, as the “most probable” linear trend fit to the data subject to the assumptions that the data are infinitely or uniformly precise, that there are no biased errors in the data, and that the underlying processes don’t have meaningful nonlinear components on any commensurate time scale (all of which and more would confound the linear fit) the only thing one can say — again, either way — is so, what?
Tomorrow (for a suitable definition of tomorrow), the temperature could do “anything”. It could leap up faster than it has ever leapt. It could plummet. It could flatten. It could descend a bit or rise a bit. The “trend” could go from being linear to being absolutely anything, and the new trend could completely change shortly after that. The linear trend is almost certainly not extrapolable indefinitely. It is rather UNlikely to properly represent the long term behavior of the temperature series — it would be an unlikely but fortuitous chance if it does, as if one looks back at the temperature series the temperature has never been describable by a linear trend for longer than 20-30 years anywhere in the thermometric record, and we are already close to that. And no, that record doesn’t justify the assumption that when the linear trend stops being linear it will go up, or down.
The data is the data. Global temperature has obviously levelled out over the last 10 to 20 years compared to the previous 15 to 20. The rise in the previous 15 to 20 began from a long interval from maybe 1940 to 1945 to the late 70s early 80s over which the temperature was really pretty linear and nearly flat. This sort of qualitative description of the data is just stating what one can see. It implies nothing of the future. I think Briggs would agree — why bother with statistical numerology as if it has some predictive force?
rgb
rgbatduke
You say
That is all true but completely without merit in this discussion because IPCC et al. do consider linear trends.
You are saying that the procedures of so-called climate science are erroneous, misleading and pointless. I agree. Indeed, I have been saying that for decades. But it ignores the reality that those procedures were adopted, were accepted and are being acted upon.
The paper by McKittrick accepts those procedures and shows that the same assumptions which induced the scare (i.e. there was a linear trend of global warming) now indicate little need for concern (i.e. there is a longer linear trend of no global warming).
As the Paris conference approaches alarmists are moving goal posts. They are proclaiming that global warming continues because heat is going into the oceans. And – as Nick Stokes is demonstrating – some are saying that linear trends at 95% confidence are no longer of interest.
Global warming as ‘investigated’ by the IPCC is an increase to global average surface temperature anomally (GASTA) and is assessed e.g. by the IPCC as being indicated as linear trends with 95% confidence.
Global warming has stopped. The assertions of global warming were wrong because they were based on false definitions and procedures. Those false definitions and procedures now indicate that global warming has stopped. Alarmists need to be held to their false definitions and procedures until they admit that definitions and procedures indicate global warming has stopped.
Richard
richardscourtney September 2, 2014 at 5:38 am
“Turning to your link I don’t see a “brown curve” but I do see a red trend line with value zero and no confidence limits which stretches over the period 1990 to present. Obviously, that line is not what McKitrick is discussing because his trend is for the period to present from 1995”
Sorry, it was the colourful triangle that I wanted to draw attention to – I didn’t try to get the dates right on the associated plots. The triangle there shows by shading not trend but lower CI, and the zero level is marked with brown. So Ross’ definition is basically the largest brown-free region you can find.
“In case 2 the trend has a value of zero (because all trends within the error estimate are equally probable) and, therefore, the data set is said to be “trendless”.”
The trend is just a weighted sum of specific data; for this particular case, it’s value is 0.94 °C/century, +- some measurement error.
You can then argue about what it means. Does it work for the future (RGB says no)? Would it apply if we could rerun the climate for those years? Resample? That is what the CI’s stated here relate to. We’d get a distribution (of trends) with a mean. The most likely value of the mean is 0.94, but based on this one sample, it’s just possible that the mean could be less than zero (or >1.88). In my view, that’s a very poor basis for saying the trend is zero (or trendless).
Of course, we’re not really able to resample the recent climate. The relevance is to a future in which one postulates (contra RGB) that the conditions that created that trend will persist, and so the future will in effect be another sample.
Two thoughts. This is using the ‘enhanced’ temperature trace of the warmists. The period of the ‘hiatus’ will increase two years each year with declining temperatures. Ten more years and the short anthropo global warming era will have been erased entirely. So the hiatus won’t be 30 years fifteen years from now, but more like 60 years.
This is a point that I often make. if temperatures begin to fall over the next 5 or so years, there will be a rapid increase in the duration of the ‘pause’/’plateau’
Obviously no one knows what the future will bring, but I think that many people overlook the significance of even modest cooling over the next 5 to 7 years.
What we are seeing is the confirmation that the earths total energy balance is stable and constant. The energy flux through the system though, is subject to cycles that give the appearance of temporary warming or cooling, depending on where and when measurements are taken.
For those non-statisticians, like me, encountering a chewey new word and having not the slightest idea what it means, Wiki provides a definition: “In statistics, a collection of random variables is heteroscedastic if there are sub-populations that have different variabilities from others.” (Notice the c/k exchange as in “skeptic/sceptic.” How appropriate.
chesmil, I just looked it up on Skeptical Science’s glossary. They say it means the unassailable right of any author at SKS to stretch the truth on any subject 😉
“Application of the method shows that there is now a trendless interval of 19 years duration at the end of the HadCRUT4 surface temperature series,”
I am surprised McKitrick uses the word “trendless” when he means the trend is horizontal (as opposed to an upward or a downward trend). There is nothing “trendless” about a 0 deg. trend.
True.
One thing that is often overlooked when discussing the ‘pause’/”plateau’ and claims, by warmists, that this has happened in the past, is that if CO2 leads to ever more DWLWIR and ever increasing energy imbalance, it is more difficult to have a ‘pause’/’plateau’ with atmospheric levels of CO2 at the 380 to 400ppm mark, than it is to have a ‘pause’/’plateau’ when the CO2 levels are say 310 to 330ppm. .
Yes my partner often argues with me as to whether “vanilla” ice cream is actually a flavour.
The use of the word pause or hiatus (implying the temperature is going to rise again) is just as indefensible as the word peak, the latter implying that the temperature is going to drop. All these words make assumptions about the future.
Shouldn’t climate modelers slowly start to consider the starting Grand Solar Minimum, one wonders. At least the younger ones who won’t be able to rely on the Global Warming scare for the rest of their careers.
Anyone also noticed the ‘pause’ in dinosaur activity? I am sure that they will resume soon.
1 Sept 2014 22:47 GMT.
Unfortunately Ross Mckitrick has chosen to use the HadCRUT4 temperature data set for his analysis. Since the metadata for this says that it has a known cooling trend then his analysis is pretty worthless. Perhaps that is why his paper was not published in a reputable climate journal – the editors would have known this, but possibly the statistics journal editors do not.
Further, it has been shown that if you control for the state of ENSO (the El Nino Southern Oscillation) by plotting separate trends for negative, neutral and positive values of the Nino 3.4 index (used as a single standard variable to define the ENSO state) then you see only the expected positive trends. This strongly implies that the pause is an artifact of the ESNO state, each with a trend of around 0.16 degrees C / decade. See http://www.skepticalscience.com/john-nielsen-gammon-commentson-on-continued-global-warming.html.
Peter
You can always produce more warning by referencing data sets (such as GISS) that have well known (although not acknowledged by the authors) warming trends. You can also produce more warming by adjusting out parts of the climate system that are colder, such as by making ENSO related adjustments. But the question being asked here is this: Has the atmosphere warmed in 19 years? The answer is no. Coming up with explanations for why it hasn’t warmed, which is what you’re doing, is an entirely separate question.
From Peter on September 1, 2014 at 3:45 pm who managed to timestamp his comment two minutes into the future:
http://www.metoffice.gov.uk/news/releases/archive/2012/hadcrut-updates (bold added)
The UK Met Office does not say there is a known cooling trend. Instead they say the overall warming signal since 1900 has not changed.
You have failed to show where in the metadata this cooling trend is stated, and you have referenced SkepSci, a known unreliable site run by number-buggers who deliberately spread deceptive mis-truths.
Thus your comment is pretty worthless.
it appears to have escaped peters attention the anthropogenic part of agw was supposed to overwhelm all natural variation thus creating an ever warming trend . unfortunately for peter and his friends at sks ,it did not ,thus no amount of mathturbation by the sks team will convince anyone the earth will be catastrophically warming any time soon.
I would have thought that heteroskedasticity is an alternative lifestyle toward which we should adopt a tone of quiet and respectful reverence…
🙂
Jamie Irons
With record SSTs occurring right now, one would expect air temps to rise in the near future. What will happen to the “flat” trend line then? I suppose you can always shift the start date out to 1998 flatten it out again.
So. A new way to talk about natural variation. Peter says it’s an artifact. Given than ENSO is a driver I wonder Peter if you would also say your warming trend is an artifact? In the past an artifact was regarded as a false reading that negates a null hypothesis, in this case a natural phenomenon. In other words, a type 1 error. A false positive. This is the most egregious error due to it leading us down the primrose path for no good reason. No scientist I know of would consider any part of ENSO to be an artifact of a temperature trend. There are a few scientists popping up here and there that are beginning to question whether or not the notion of anthropogenic warming, on a global scale, is an artifact of bias. So Peter, if you want to be taken seriously, watch your vocabulary. You did yourself no good service by calling an ENSO-driven temperature trace an artifact.
As for the paper, I see it as dancing around the more serious question, admiring the problem instead. It’s a pause! A long one! Now get over it and start working on why it’s a pause already!!!!!!
So who do you all think will be the alarmist turncoat that will answer question number 2 posited by McKitrick,, and in what century? And do you think he or she will have to leave the country to avoid arrest for spilling the dirty little (Shshsh, it’s Gaia wut dunnit) secret?
The Pause is only a pause if the observed warming was not merely an artifact of the estimation methods.
The super-El Nino of 1998 confuses the issue, which is why any analysis looks back to at least 1994, 20 years back. To go back further requires statistical modeling such as presented by Dr McKittrick.
It’s worth contemplating Dr McKittrick’s full paper via the link provided in this blog. Dr McKittrick’s Figure 1 shows Hadcrut4 surface data back to 1850. We can see the shift to warming from 1910 to about 1940, 30 years. Then cooling for about 30 years to 1970 or so. Then warming for 30 years to around 2000. (Dates eyeballed).
In my opinion, what Hadcrut4 is measuring is the warming and cooling effects of multi-decadal oceanic oscillations. This view is consistent with the view that the Earth’s radiation budget is roughly in balance.There has been little if any net warming or cooling of the oceans. I base this view on my interpretation of papers by NASA scientists.
I offer as evidence four papers, two by James Hansen and others and two by Norman Loeb and others, papers by mostly NASA authors.
Reference Loeb et a. (2009): Toward Optimal Closure of the Earth’s Top-of-Atmosphere Radiation Budget based on satellite observations. J.of Climate, AMS, V.22, p.748.
The authors summarized the combined effect of all errors found. When estimates of solar irradiance, SW and LW TOA fluxes are combined, taking account of +0.85+/-0.15 Wm-2 heat storage by the oceans (Hansen’s 2005 estimate), the possible range of TOA flux becomes Minus 2.1 to Plus 6.7 Wm-2,
Based on well-established physical theory, the instruments tell us that net radiative flux is either positive or negative. The Earth is either radiating more energy than it receives or less energy than it receives.
URL:
http://www.nsstc.uah.edu/~naeger/references/journals/Sundar_Journal_Papers/2008_JC_Loeb.pdf
In 2011 Hansen et al corrected their 2005 figure to give +0.58+/-0.15 Wm-2.
References Hansen et al (2005, 2011): Earth’s Energy Imbalance: Confirmation and Implications (Science 3 June, Vol. 1434 308, 2005)
URL: http://www.earthjustice.org/sites/default/files/black-carbon/hansen-et-al-2005-earths-energy-imbalance.pdf
URL: Earth’s energy imbalance and implications, Atmos. Chem. Phys., 11, 13421-13449, 2011) URL: http://www.atmos-chem-phys.net/11/13421/2011/acp-11-13421-2011.pdf
Reference Loeb et al, (2012): Observed changes in top-of-the-atmosphere radiation and upper-ocean heating consistent within uncertainty. Nature Geoscience VOL 5 February 2012.
URL: http://www.met.reading.ac.uk/~sgs02rpa/PAPERS/Loeb12NG.pdf
According to Loeb et al, net radiation flux is close to zero and fluctuates above and below zero.
According to Hansen et al.,the net heat entering the oceans (0.58 Wm-2) was close to one-sixth of one percent (0.17%) of incoming solar radiation (340 Wm-2). Not zero but close enough to zero to be offset by interannual variations in the net radiative flux. And close enough to zero to be overwhelmed by variations in sea surface temperatures caused by multi-decadal oscillatons.
Further, estimates of net radiative flux and estimates of net heat entering the oceans are either equal to or exceed the errors in calibration of the instruments or errors in estimating average values of the parameters used in the calculations.
Example from Loeb (2009): The error in estimate of radiative flux introduced by assuming the Earth is a sphere and not a spheroid is greater than and opposite to Hansen’s (2011) estimate of heat entering the oceans.
My conclusion from these four papers is that the errors in measuring the radiation budget combined with inter-annual variations in the budget allow for the possibility that the net heat entering the oceans is nearly zero and in some years may be negative.
As a consequence, climate sensitivity to CO2 is probably closer to one degree Celsius than to 2 degrees Celsius. So little is known about negative feedback from clouds that it is still impossible to say what is happening now, what has been happening during the last 90 years, and what will happen in the next 85 years.
Probably, what Hadcrut4 has been measuring is the warming and cooling effects of multi-decadal oceanic oscillations, only loosely related to the effect of greenhouse gases in increasing the opacity of the atmosphere to long wave radiation.