Marcel Crok tips me via Twitter that a new analysis of ‘the pause’ by Dr. Ross McKittrick has given some new numbers for the different temperature datasets. It was published in the Open Journal of Statistics

NOTE: (added) Some people saw the green line in the figure above as a trend line. It is not. It is a comparison line to show the similarity of global temperatures 19 years apart in relation to McKittrick’s paper. It simply shows the “plateau” of temperatures has not changed much since then. To see more about the pause in trends, this essay will be informative.
The RSS satellite dataset says:

The paper:
McKitrick, R. (2014) HAC-Robust Measurement of the Duration of a Trendless Subsample in a Global Climate Time Series. Open Journal of Statistics, 4, 527-535. doi: 10.4236/ojs.2014.47050.
Abstract
The IPCC has drawn attention to an apparent leveling-off of globally-averaged temperatures over the past 15 years or so. Measuring the duration of the hiatus has implications for determining if the underlying trend has changed, and for evaluating climate models. Here, I propose a method for estimating the duration of the hiatus that is robust to unknown forms of heteroskedasticity and autocorrelation (HAC) in the temperature series and to cherry-picking of endpoints.
For the specific case of global average temperatures I also add the requirement of spatial consistency between hemispheres. The method makes use of the Vogelsang-Franses (2005) HAC-robust trend variance estimator which is valid as long as the underlying series is trend stationary, which is the case for the data used herein. Application of the method shows that there is now a trendless interval of 19 years duration at the end of the HadCRUT4 surface temperature series, and of 16 – 26 years in the lower troposphere. Use of a simple AR1 trend model suggests a shorter hiatus of 14 – 20 years but is likely unreliable.
…
The IPCC does not estimate the duration of the hiatus, but it is typically regarded as having extended for 15 to 20 years. While the HadCRUT4 record clearly shows numerous pauses and dips amid the overall upward trend, the ending hiatus is of particular note because climate models project continuing warming over the period. Since 1990, atmospheric carbon dioxide levels rose from 354 ppm to just under 400 ppm, a 13% increase. [1] reported that of the 114 model simulations over the 15-year interval 1998 to 2012, 111 predicted warming. [5] showed a similar mismatch in comparisons over a twenty year time scale, with most models predicting 0.2˚C – 0.4˚C/decade warming. Hence there is a need to address two questions: 1) how should the duration of the hiatus be measured? 2) Is it long enough to indicate a potential inconsistency between observations and models? This paper focuses solely on the first question.
…
Conclusion
I propose a robust definition for the length of the pause in the warming trend over the closing subsample of surface and lower tropospheric data sets. The length term MAX J is defined as the maximum duration J for which a valid (HAC-robust) trend confidence interval contains zero for every subsample beginning at J and ending at T −m where m is the shortest duration of interest. This definition was applied to surface and lower tropospheric temperature series, adding in the requirement that the southern and northern hemispheric data must yield an identical or larger value of MAX J . In the surface data we compute a hiatus length of 19 years, and in the lower tropospheric data we compute a hiatus length of 16 years in the UAH series and 26 years in the RSS series. MAX J estimates based on an AR1 estimator are lower but likely incorrect since higher-order autocorrelation exists in the data. Overall this analysis confirms the point raised in the IPCC report [1] regarding the existence of the hiatus and adds more precision to the understanding of its length.
Dr. McKittrick writes on his website: http://www.rossmckitrick.com/index.html
I make the duration out to be 19 years at the surface and 16-26 years in the lower troposphere depending on the data set used. R Code to generate the graphs, tables and results is here.
The full paper is here: http://dx.doi.org/10.4236/ojs.2014.47050
It’s more instructive to use techniques such as exponentially-weighted moving average charts to determine the underlying behaviour of a time series.
http://en.wikipedia.org/wiki/EWMA_chart
Changing one input (lambda in the model) allows a time series of N points to be measured (lambda ~ 1/ N). Thus a 30 year moving average would have lambda = 0.0333, 10 year average would have 0.1 etc. Thus trends across different timescales are easily determined.
The method also gives the ability to construct alarm levels to determine when the trend has changed. This latter point could be of value for where we are with detecting the much anticipated increase in underlying temperatures.
nothing new to add except it hit the “mainstream media” http://blogs.news.com.au/heraldsun/andrewbolt/index.php/heraldsun/comments/no_warming_for_19_years
Now if only more would read and put away the cult status of this nonsense we’d be just fine…
There is a good video out there somewhere where Bob Carter shows that the trend is warming or cooling depending where you start. If you start in the holocene optimum the trend definitely shows cooling; if you start in the depths of the recent ice age (the one we are in) then wow are we warming; go back a few million years, and the trend is clearly down.
Nick Stokes says:
September 1, 2014 at 6:13 pm ““Ceteris Paribus these results are only 5% in danger of being wrong due to random error due to sample size limitations.”
It says that if the results were from a process with random error, and you could rerun the process, there is a 5% (or whatever) chance that the trend might be negative. That doesn’t mean a 5% chance that it would be positive. It means a 95% chance.
The actual trend reported by WFT for HADCRUT 4 since 1995 was 0.94°C/century.””
You, and many many others who post on this site, are over interpreting what can be gleaned from confidence intervals. It says that if the results were from a process with potential random error, which they are, and you could rerun the process, there is a 5% (or whatever) chance that the results might be DIFFERENT from what you got the first time. The largest mistake folks tend to make, though, is to forget all the other types of error that can enter into these calculations other than sample size error, as I mentioned in my previous post. The probability theory upon which confidence intervals are based says nothing about these other potential errors. That is why the Ceteris Paribus, and the Ceteris is hardly ever Paribus.
I tried to reply in line, but the “reply” buttons on the thread seem to have disappeared. Oh well.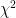 or some other measure (all of which make certain assumptions about the generating process, e.g. normal excursion around the trend, zero autocorrelation, that are probably categorically false for GASTA, a probability that in a proper Bayesian analysis you would have to account for as a prior of the error computation and be prepared to correct on the basis of a posterior analysis to the extent that future data necessitates.
or some other measure (all of which make certain assumptions about the generating process, e.g. normal excursion around the trend, zero autocorrelation, that are probably categorically false for GASTA, a probability that in a proper Bayesian analysis you would have to account for as a prior of the error computation and be prepared to correct on the basis of a posterior analysis to the extent that future data necessitates.
This statement is simply incorrect. All trends within the error estimate are not equally probable. The correct statement is: “If the data being fit are independent and identically distributed random samples (sets) drawn from a temporal distribution that in fact has a linear trend, the best fit is the most likely in the specific sense that a large number of fits to sets of data would produce a distribution of trends peaked on the true trend. Consequently, given a fit to a single sample — the actual data — it is the one most likely to be correct, given the data so far.”
Further, given only the data in the sample, one can at least estimate the probability that the true trend is within any given excursion of the sample trend by considering the spread in the data and e.g. Pearson’s
To make it really simple: If one rolls two dice, one can state with 95% confidence that the total number that turns up will be between 3 and 11. That does not make all of these numbers equal. In fact, the most probable number is 7 (3 + 4,2 + 5, 1 + 6, all times 2 for 6/36 = 1/6 probability as opposed to e.g. 1 + 1 only one way for 1/36 for snake eyes), and any good backgammon player knows that it is better to leave yourself at risk to a roll of ten than a roll of seven. A p-value of 0.05 simply means that there is at least a 5% chance of getting the observed data if the null hypothesis is true, not that one is 95% certain that the null hypothesis is true.
It’s not really time for a full lesson in statistics (although it would be so very useful if many of the participants in the discussion would look into taking one, buying a book or two, Cartoon Guide to Statistics, whatever) but there are a number of statistical measures that are relevant to the discussion. For example, one can compute the probability of the data given a zero trend. That is, in fact, the p-value droid you are looking for. What is being asserted above is — at best — that there is a 5% chance that the data actually has a zero trend. Not that it is 95% probable that it has a zero trend. I mean, jeeze. What is being stated is that one cannot rule out a zero trend to the data at 95% confidence for an interval umpty years long in at least some of the equally umpty non-independent model-extrapolated sparse data based estimates of GASTA.
As I said, it’s Nick is Dead Right day. The top article presents a result that is as sketchy as Monckton’s occasional cherrypicking forays in the same direction and yes, sure, as the IPCC’s nonsense in the opposite direction. Having access to a good stats package such as R or SAS is no substitute for common sense.
Look, you’ve motivated me to go searching for Briggs’ so very beautifully written analysis of this sort of thing:
Visit: http://wmbriggs.com/blog/?p=3266
Please. Note that he says exactly what I say above, only better, more poetically, and with a sardonic cast that I wish I could fully capture. I can merely quote:
This, by the way, is the one thing Nick still is getting (a bit) wrong. It’s not that when we fit a linear trend to a collection of dots — especially a collection of dots that represent “the global temperature” according to an arcane and opaque data-based model — that future data reprocessed by this same model might not continue the linear trend. Of course it might.
It’s that when we look into the past (far enough) at the very same data — urr, I means “the output of the very same data-based model”, it never has done so.
I’ve got to keep searching. Briggs made this same point with a lovely graphic on another occasion where he actually showed the fallacy of worshipping the linear trend and pre-trending that you can, after performing such a fit, ignore the actual data (reality) completely, in the future as much as the unfit past.
rgb
Why don’t scientists ask the most basic of every question about nature-where is the experimental data that proves the Hypotheses of the greenhouse gas effect?
The Hypotheses was proposed in 1824 by a credible scientist but in the 190 years since then much has been learned in science including quantum physics which is all about atoms and molecules absorbing EMR. Why do people believe “climatologists” who are temperature historians at best , lacking a knowledge of “hard science” physics, quantum physics. and chemistry and the most important factors that control weather on this planet, incoming energy from the sun and the water cycle. I learned about the water cycle in my 8th grade general science class 60 years ago, water absorbs sun light heats and evaporates cooling the surface. Water vapor cools in the upper atmosphere when the temperature is below the dew point. Clouds form, blocking some of the sun light cooling the ground below causing turbulence and other effect.
This is a simple version of what causes weather.
Definition: Climate is an average pattern of thousands of weather event end to end for one location. There are thousands of different “climates” in the world
Adding 50 or a 100 years of weather days to an average pattern made up of hundreds of thousand data point will have little or no effect on the average pattern.
There are experiments that prove that the greenhouse gas effect does not exist. Science is never settled.
Mann-made global warming is a four letter dirty word-Hoax,
Ahh, I found it. In fact, it was the very next article in my Google return.
So here’s an assignment for everybody, and I do mean everybody, participating in this discussion. Read this:
How To Cheat, Or Fool Yourself, With Time Series: Climate Example
This isn’t as succinct or sardonic as the previous article, but it does present an actual graph of a temperature series before showing how a person with any preconceptions at all can — with only the best of intentions and using the finest of statistical software — talk themselves into believing, presenting, defending, absolute nonsense using nothing but a “properly” fit linear trend.
Some really, really useful quotes:
(Emphasis his!)
Note well: 5 to 10 times too sure of ourselves. I would say that even this is generally optimistic — it depends on there only being comparatively normal excursions to data that is actually (at least somewhat) linear trended by some underlying process, plus a medium sized boatload of other assumptions about the parameters that need to be integrated out that permit them to be integrated out within even these limits. Taleb’s “Black Swan” — also worth reading — is basically a statistical poem devoted to non-normal processes that generate time series and the horrors that befall those that take “normal” too seriously. It isn’t just that we are 5 to 10 times too sure of ourselves. Our result could actually work to extrapolate the series for 95% of the time — until it didn’t — but the failure could be truly catastrophic if we are at risk on the bet. (Taleb is a market analyst and his “Black Swan events” are market crashes that bankrupt people who believe even in complex non-linear timeseries trends/ extrapolatory fits obtained with the most sophisticated software from the most impeccable data.)
And here is a quote that should be graven on the corners of the eye as a warner to him who would be warned:
(Emphasis his, again!)
Sheer poetry. There is only one legitimate reason to fit a linear trend to a time series. That is to see if the trend is extrapolable, that is, to propose it as a predictive model. The only point of a predictive model is to predict, and one can — fairly legitimately — build estimators of how well they predict future data, not the data used to build the model no matter how it was selected and used and use their performance in this worthy goal to judge the fitness of the model for that purpose. Clever and honest model builders will of course try to do a good job of this and use part of the data to build a model, part to test the model they’ve built, but Briggs is lamenting the fact that apparently climate models are not being honestly built or presented and that the model results are not being honestly compared to future data with an eye to rejecting failed models. Briggs is dead on right, 2 1/2 years ago, even before the travesty that is Chapter 9 of AR5 was published and studiously ignored even within the rest of AR5.
If all you are doing is wondering if the data has gone up, down, or danced a jig on the foredeck of the ship of fools (as opposed to trying to build a predictive model that eventually might or might not prove to have predictive skill, just look at it. Drawing imaginary lines through it will not alter the data by a tittle, and in the end they have no more axiomatically supported (objective, reliable) meaning than the face of Jesus we “see” in burned toast or in a swirl of tree-bark, if we squint a bit and don’t look too hard.
And I would humbly add the following to Briggs’ lament. Why would one trust any statistical model even if it can skillfully predict new data today? Tomorrow it could fail, even fail catastrophically.
Here we really, truly, can learn something very important by looking at all of the timeseries data, not just HADCRUT4, HADCRUT5 (the one where they eventually adjust the current temperature anomaly up another half a degree without actually altering the underlying data — again), BEST, WORST, and the paleoclimatological proxy derived timescales over the geological past. That is that no linear trend actually fits the climate timeseries over geological time. Let me see if I can get wordpress to do a truly big font for this:
Climate Is A Non-Stationary Process!
I mean, duh!
rgb
Oops, sorry mod, failed to correctly close the anchor of the provided link. So the entire comment is not a link to Briggs’ article. This isn’t a completely bad thing — maybe it will tempt somebody to actually click the link and read the article — but it is ugly. Maybe fix the anchor for me? Sorry sorry?
rgb
[The link works, let us leave it as-is for now. .mod]