Guest Post By Walter Dnes:

Image Credit and a special thanks to Josh
With GISS incorporating NOAA/NCEI “Pause-Buster” adjustments for their monthly anomalies as of June 2015 data, our friend Daft made another appearance. Also, I noticed that my temperature-tracking spreadsheet at home, and on Google Docs both needed to have their Y-axes extended, because the highest anomaly in the data (i.e., January 2007) was raised. This prodded me to check the progress of the GISS anomalies over time.
I only started downloading GISS data in 2008, plus I picked up a few older uploads back to 2005 from the “Wayback Machine”. This accounts for the limits on my comparisons. GISS data downloaded from here is given in hundredths of a Celsius degree; e.g. 15 ==> 0.15 C degree. This allows the numbers to be integers.
For those of you who wish to do their own analyses, the downloads are available in a zip file saved to WUWT here. The files are in 2 formats. The files named gissYYYYMM.txt (“YYYY” = year and “MM” = month) are in the original tabular download format, with 12 months of data per row. This is human-readable, but very difficult to import into a spreadsheet. For each such file, I’ve generated a file named gYYYYMM.txt, which is suitable for importing into a spreadsheet. The generated files contain date in decimal format, a comma, and the anomaly. As noted above, the anomaly is an integer equal to 100 times the actual anomaly. All files are in DOS/Windows format. Linux/Unix/BSD users, please run dos2unix on the files for use in a posix environment. Note that this data set uses the corrected data issued by GISS on July 19th. For details see the “News” section on GISS’s website where they acknowledge Nick Stokes for noticing a recent bug in the GISS data.
First, let’s look at the difference between GISS anomaly data from May 2015 and June 2015.

There were additional adjustments going back to 2005. Here is the graph of combined adjustments between August 2005 and June 2015.

As mentioned earlier, I had to extend the Y-axis in my graph, because the temperatures were adjusted upward. A quick analysis showed that the highest anomaly for almost every download (starting from 2007, obviously) was for the January 2007 anomaly. The only exception was the September 2012 download. It showed the March 2002 anomaly 1/100th of a Celsius degree higher than the January 2007 anomaly. The following graph shows the inexorable upward march of the March 2002 and January 2007 anomalies. Seven years ago in mid-2008, GISS told us that the January 2007 anomaly was +0.85. Today, they’re telling us that the January 2007 anomaly was +0.97. I wonder what they’ll be telling us seven years from now.

This encouraged me to look at the lowest anomalies for each download. From my earliest available download, August 2005, through May 2015 the lowest anomaly was always for the month of January 1893. But in the June 2015 download, the January 1893 anomaly jumped up +0.17 of a Celsius degree, giving up the lowest anomaly ranking to December 1916. Ten years ago, back in mid-2005, GISS was telling us that December 1916 was -0.56. Today they’re saying December 1916 was -0.77. Again, what will it be ten years from now?

No one believes that the land-based temps were measured with hundredth-degree precision and accuracy in the 1800s or the 1900s or even the 2000s. There is no value whatsoever in any pre-satellite dataset.
Which is one reason that I wish that somebody would resurrect and re-analyze the NEMS and SCAMS data from Nimbus E&F. That would back the data up to the early 1970s. Those instruments were precursors to the AMSU. Perhaps not as good as the AMSU, but a lot better than nothing at all. Especially true for sea surface coverage.
I think you miss the point. I’m less familiar with GISS as I concentrate more on HadCRUT4 (which makes its total error estimates available). HadCRUT4’s error estimates for the last few years — this is total estimated error from all sources — is around 0.1 C. Note that this is smaller than the adjustments in the GISS data, and is also on the close order of the difference between GISS LOTI and HadCRUT4:
http://www.woodfortrees.org/plot/hadcrut4gl/from:1983/to:2020/plot/gistemp/from:1983
I do not think this “error estimate” means what they think it means. It is supposed to be a 95% confidence (IIRC) in HadCRUT4, which means that one way of interpreting the graph above is that it is almost certain (according to HadCRUT4) that GISS LOTI is biased. And of course this is after all of the adjustments to HadCRUT over time, which have similarly been nearly unidirectional in their overall effect.
As I’ve pointed out on list any number of times, HadCRUT4 claims a total error estimate in 1850 only a bit over twice as large as their contemporary error estimate. This is absolutely absurd. When you add to this the fact that the overall adjustments over the years to both datasets already exceed their own claimed error, when you plot the summed adjustments over time against CO_2 concentration, there is really no possible statistical doubt that there is deliberate bias in the major temperature records. It is literally almost impossible to imagine that not only are almost all of the corrections to a good-faith temperature series going to have the effect of cooling the distant past and warming the present (How can they affect the present at all? Are they arguing that their contemporary data, gathered with extremely precise and reliable modern instrumentation, is so much in error that it can shift the result by as much as 1/3 their total 95% confidence interval claim in 1850?), and it is even less likely that the adjustments on a measurement that on an absolute scale is close to 300 degrees kelvin would be almost perfectly correlated with a linear trend when plotted in a scatter plot against CO2 level at the time of the measurement!
Any statistician who looks at this and knows a) the precision of the instrumentation; b) the magnitude of the absolute units being measured; c) the volume of contributing data will instantly recognize that this is impossible. You could Monte Carlo out simulated data sets from now until kingdom come and never get that kind of correlation over 165 years of data consisting of measurements on the scale of 288 K with acknowledged uncertainty in the collective average of 0.1 K and never, ever be able to resolve 0.1 corrections that somehow magically align themselves with CO_2 concentration where the total CO_2 concentration-linked total change in the data over this entire interval is around 0.8C, or 0.3% of the absolute number.
No matter how one slices, or dices, the input data itself or the “anomaly” computation or the kriging of results in 1865 to things like Antarctica, where no human had ever set foot, most of central Africa, etc etc the probability of a systematic correction in good faith data taken by tens of thousands of people in hundreds if not thousands of locations with all sorts of instrumentation of resolution no better than 0.1 K (and more likely 0.5 to 1 K) over 165 years that linearly correlates with CO_2 is, in a word, ZERO. You heard it here first, folks. This could never happen in any sort of world where the participants were not trying to make it happen, and the people taking the data were utterly unaware of the issue for almost all of that interval. The total variation of the averaged data itself produces a 165 year delta of 0.3% of the absolute temperature, the averaged data has an acknowledged error of at least 10% if not 30% of this value, but not only do they find the need to correct the data at the resolution of the known error but it is a smooth function of just one particular unknown that has a complicated nonlinear functional form when plotted against time and that happens to be the center of a major controversy and political battle?
If you can believe this, I have this bridge in New York city that I’m happy to sell you. You can make a fortune collectiging tolls all day long! And I’ll sell it to you for a song, just because I like you…
rgb
rgb, they all assume random measurement error and that the central limit theorem applies throughout. All error is assumed to converge to zero when the number of measurements is large. The assumption is completely unjustified.
I’ve been arguing this point for years, and have published on it, here (1 MB pdf) and here (1 MB pdf), with more to come. See also this, describing the analytical negligence that pervades consensus climate science.
When I’ve looked at the adjustments over time, I’m always amazed at how well they track the increase in CO2 levels. It’s as if there is a strong correlation between temperature increases and increased CO2 levels. Leastways, that is what the temperature data adjustments keep showing. Mass delusion has that ability to cloud one’s rational mind.
Pat,
This is a continuous battle. Folks just don’t accept that instrument accuracy specifications assume a rectangular distribution, not normal. There is no justification to the assumption that calibration variations within a specified accuracy range average to some central value, or even that multiple instruments will track with the same error profiles.
If temperature data are going to be “corrected” in the future, as we know they will, it means they cannot be relied on to be accurate today. And if they are not reliable today, what good are they? Any conclusions derived from the data can only be temporary, therefore they cannot be used for science. They can only be used for propaganda purposes like proclaiming: “The warmest year ever!”? A few years down the road, they’ll need to negate that proclamation by lowering past temperatures to make the present the “warmest ever!” It’s not science; it’s a political game of propaganda to its core.
http://www.wmo.int/pages/prog/www/IMOP/publications/CIMO-Guide/Ed2008Up2010/Part-I/WMO8_Ed2008_PartI_Ch2_Up2010_en.pdf
2.1.3.3 Response times of thermometers
For routine meteorological observations there is no advantage in using thermometers with a very small time-constant or lag coefficient, since the temperature of the air continually fluctuates up to one or two degrees within a few seconds. Thus, obtaining a representative reading with such a thermometer would require taking the mean of a number of readings, whereas a thermometer with a larger time-constant tends to smooth out the rapid fluctuations. Too long a time-constant, however, may result in errors when long-period changes of temperature occur. It is recommended that the time-constant, defined as the time required by the thermometer to register 63.2 per cent of a step change in air temperature, should be 20 s. The time-constant depends on the air-flow over the sensor.
http://www.researchgate.net/publication/44098340_Albedo_effect_on_radiative_errors_in_air_temperature_measurements
Reflected shortwave radiation and wind speed are routinely measured on many automatic weather stations and therefore available for the new scaling and air temperature correction.
… the radiative error is a strong function of the surface albedo …
The combination of incident solar radiation and low wind conditions leads to significant errors in air temperature measurements when using a sensor installed in a naturally ventilated radiation shield. These radiative errors tend to be particularly large over snow-covered surfaces (up to 10C).
Thermometry is not as simple as it looks. Anyone who claims he can measure air temperature to 0.1°C is kidding himself.
” Anyone who claims he can measure air temperature to 0.1°C is kidding himself.”
…
So, if you took an array of 10 calibrated thermometers that each could read to the nearest degree, and you took the average of 10 simultaneous readings all at the same time, and got 46.5 for the average, what is the actual air temperature?
Billy Liar
July 24, 2015 at 1:36 pm
“Thermometry is not as simple as it looks. Anyone who claims he can measure air temperature to 0.1°C is kidding himself.”
Or possibly trying to kid y o u at Paris.
Auto
Well, dim bulb Jackson since you asked with posting sufficient information. Some where between 44 and 45 degrees with error boundary of +/- 1.5 degrees.
If you are honest that is.
ATheoK
…
A swing and a miss.
…
Each individual reading has an error of +/- 0.5 degrees.
How the average error increases to +/- 1.5 degrees is ……uh……questionable.
…..
Technically, the standard error is the standard deviation divided by the square root of the number of observations, so the standard error is LESS than the standard deviation of the individual readings.
PS… ATheoK
…
46.5 +/- 1.5 is a range of 44 to 48 degrees, not “Some where between 44 and 45”
OOOPS
…
46.5 +/- 1.5 is between 45 and 48 degrees
Gary, you’re exactly right. Except apparently, none, not one, of the scientists who compile the surface air temperature understand that. It’s as though none of them have ever actually taken a measurement or struggled with an instrument.
Joel Jackson, typically reading accuracy is taken as 1/4 the smallest division. So, in your example, it would be ±0.25 C. That said, your analysis assumes random error. That’s the only sort that reduces as 1/sqrtN (N = number of measurements). The major source of error in the surface temperature record is systematic measurement error. See the last paragraph in Billy Liar‘s post. Uncontrolled environmental impacts dominate the uncertainty in the record. This problem is completely neglected in the literature.
Joel, you are also assuming that 10 instruments is an adequate number to accurately measure the air volume in question. What if we are talking about the Dallas stadium and 7 of the instruments are on the playing surface. 2 are in first 30 rows of seats and one is in the sky box.
Would you claim that these instruments, regardless of their accuracy would be capable of rendering a judgement regarding the average air temperature for all the air in that stadium?
Pat Frank
…
So according to your line of reasoning, by increasing the number of thermometers, you can in fact achieve 0.1 degree accuracy.
..
PS Mr. Frank, “uncontrolled environmental impacts ” is not at issue, the only thing discussed is measuring air temperature to within 0.1 degree.
…
MarkW
..
“measure the air volume in question. ”
…
This discussion is not about an air volume, it’s about measuring air at a single point. The strawman stadium example is not applicable to the discussion.
…
Mr. Buckingham
..
I agree with you. However, the point I was trying to make is that you can achieve 0.1 degree accuracy measurement by using enough thermometers that are only accurate to the nearest degree. In fact, by choosing the appropriate number, you could even get 0.01 accuracy.
Joel Jackson, you wrote, “So according to your line of reasoning, by increasing the number of thermometers, you can in fact achieve 0.1 degree accuracy.”
No. That’s your line of reasoning. In contrast to your view, and with systematic error, increasing the number of thermometers can increase the total error, or decrease it. Which error outcome occurs varies case-by-case. In either case, it’s impossible that ±0.1 C accuracy would ever be reached (see below).
You also wrote, ““uncontrolled environmental impacts ” is not at issue, the only thing discussed is measuring air temperature to within 0.1 degree.” (your bold)
The surface air temperature is at issue, and its accuracy. You proposed, “the standard error is the standard deviation divided by the square root of the number of observations,” which assumes that random error dominates the measurement. It does not. The surface air temperature measurement accuracy is dominated by systematic error, at whatever outdoor surface site you choose.
Your statement here, that “you can achieve 0.1 degree accuracy measurement by using enough thermometers that are only accurate to the nearest degree. In fact, by choosing the appropriate number, you could even get 0.01 accuracy.” is completely incorrect.
Accuracy is strictly limited by the resolution of the instrument. Not by the number of readings. A limit of instrumental resolution is not a statistical standard deviation. It is a characteristic of the capability of the instrument itself. Instrumental resolution can not decrease below its own lower limit.
At best, with only random errors that decrease by 1/sqrtN, your 1 C thermometer will never, ever, produce a temperature more accurate than ±0.25 C; the lower limit of resolution of your instrument. Not even with an infinite number of readings. It’s pretty clear you don’t understand measurement.
Joel,
Nope, you cannot increase the accuracy of a temperature reading beyond a single thermometer’s calibration accuracy using multiple identical thermometers. A thermometers calibrated accuracy is a rectangular +/- area of error. The calibration process guarantees only that error from true will reside somewhere inside that +/- range. It does not claim or guarantee that there will be variation between instruments or that averaging readings from multiple instruments will average to a truer central value than an individual instrument’s temperature reading. We are talking about real world instrumentation technology, not guessing the weight of a bullock at a rural county fair.
Averaging multiple readings of the same quantity can provide an improvement in accuracy if random noise variations are well understood and significantly larger than the rated accuracy of the measuring instrument. In that case, it may be possible to claim an accuracy better than each individual reading. Of course, that is only true if you do know your noise is actually normally distributed noise. However, regardless of how many readings are averaged, the accuracy can never be claimed better than the calibrated accuracy of the measuring instruments. Instrument calibration specs are not random noise.
Lets look at a reasonable example: We need to measure a metal bar of a length of about 10 cm to an accuracy of +/- 0.1 mm. We have in our hands a box full of grade school rulers calibrated with marks every 2 mm, +/- the width of the lines or so. These are good rulers and our kids are experienced at reading them. Now, by your method, 100 readings should get us +/- 0.2 mm accuracy and maybe 400 should get us our desired +/- 0.1 mm. I don’t know about you but I would not trust that method to produce the required accuracy but that is just like what you are saying about using thermometers.
Joel D. Jackson July 24, 2015 at 5:18 pm
You can not increase the accuracy of a measuring device of any kind beyond its error range. You could use a thousand identical thermometers each calibrated to +/- 1C accuracy. You will NEVER get an accurate result less than +/- 1C . Doesn’t matter what statistical flip floppery you use. You want +/- .1C, use a better thermometer.
Pat Frank:
You say
YES, but the problems are more fundamental than that!
There is no agreed definition of the ‘measured’ parameter.
Each team that ‘measures’ the parameter uses its own unique definition and changes the definition it uses most months.
And there is no possibility of a calibration standard for the ‘measurement’.
If you have not seen it then I commend you to read this item especially its Appendix B.
It reports that we considered mean global temperature (MGT) according to two interpretations of what it could be; viz.
(i) MGT is a physical parameter that – at least in principle – can be measured;
or
(ii) MGT is a ‘statistic’; i.e. an indicator derived from physical measurements.
These two understandings derive from alternative considerations of the nature of MGT.
And we determined that the obtained parameter is useless whichever of those two understandings is adopted.
If the MGT is assumed to be the mean temperature of the volume of air near the Earth’s surface over a period of time, then MGT is a physical parameter indicated by the thermometers (mostly) at weather stations that is calculated using the method of mixtures (assuming unity volume, specific heat, density etc). We determined that if MGT is considered as a physical parameter that is measured, then the data sets of MGT are functions of their construction. Attributing AGW – or anything else – to a change that is a function of the construction of MGT is inadmissable.
Alternatively:
If the thermometers (mostly) at weather stations are each considered to indicate the air temperature at each measurement site and time, then MGT is a statistic that is computed as being an average of the total number of thermometer indications. But if MGT is considered to be a statistic then it can be computed in several ways to provide a variety of results, each of different use to climatologists. (In such a way, the MGT is similar in nature to a Retail Price Index, which is a statistic that can be computed in different ways to provide a variety of results, each of which has proved useful to economists.) If MGT is considered to be a statistic of this type, then MGT is a form of average. In which case, the word ‘mean’ in ‘mean global temperature’ is a misnomer, because although there are many types of average, a set of measurements can only have one mean. Importantly, if MGT is considered to be an indicative statistic then the differences between the values and trends of the data sets from different teams indicate that the teams are monitoring different climate effects. But if the teams are each monitoring different climate effects then each should provide a unique title for their data set that is indicative of what is being monitored. Also, each team should state explicitly what its data set of MGT purports to be monitoring.
Richard
Gary Wesscom said : “Joel, Nope, you cannot increase the accuracy of a temperature reading beyond a single thermometer’s calibration accuracy using multiple identical thermometers.”
Yes, you can: http://www.ni.com/white-paper/3488/en/
Richard Courtney, thank-you for the link and the very salient analysis. As I take your assessment, there can be only one GMT, presuming the existence of a valid global mean. As the various compilations vary in places by more than their own 2σ’s then all but at most one contain spurious trends. Most likely is that they all do.
I enjoyed your discussion regarding masking using GCMs as well. It seems you’re quite right — a GCM masking exercise that reproduces statistical trends that are known to be spurious cannot itself be a valid indicator of any sort of anthropogenic fingerprint.
Chris, your link shows only that random error can be averaged away with multiple measurements. We all know that. It says nothing about increasing accuracy past the limit of resolution of the instrument.
The method of multiple repeat measurements described in your link will, at very best, reduce random error down to the resolution of the instrument. In a 1 C graduated thermometer, the limit of resolution is ±0.25 C. This is the limit that will be asymptotically approached by multiple measurements, when the error is strictly random. Strictly random means stationary with a mean of zero, and no systematic error.
Bottom line: measurements cannot be more accurate than the instrumental resolution.
When systematic error is present, the limit of instrumental resolution will never be attained, no matter how many times the measurement is repeated.
Pat Frank says: “Bottom line: measurements cannot be more accurate than the instrumental resolution.”
…
https://www2.southeastern.edu/Academics/Faculty/rallain/plab193/labinfo/Error_Analysis/08_Multiple_Measurements.html
…
Pat, no, it says very specifically that the use of multiple instruments can improve accuracy. From the link I posted: “Averaging multiple samples to arrive at single measurement (and error) is a good way to improve the accuracy of your measurements. The premise of averaging is that noise and measurement errors are random, and therefore, by the Central Limit Theorem, the error will have a normal (Gaussian) distribution. By averaging multiple points, you arrive at a Gaussian distribution. You can then calculate a mean that is statistically close to the actual value.”
Note the words “improve the accuracy”, and then later in the same section: “Therefore, the more points that are taken in the average, the smaller the standard deviation from the average. In other words, the more points averaged, the more accurately you know the actual value.”
Joel D Jackson,
You utterly missed the point. Read this slowly and try to comprehend. According to the WMO:
… the temperature of the air continually fluctuates up to one or two degrees within a few seconds …
so, what is the temperature?
Auto
July 24, 2015 at 2:48 pm
Or possibly trying to kid y o u at Paris.
They’ve been trying to kid me for years. I haven’t swallowed it.
Billy LIar says: “You utterly missed the point.”
…
I don’t think so.
…
The temperature is the average of the 10 readings.
Take a second average of the 10 readings a minute later, then rinse and repeat.
Strawmen will come clean with enough cycles of washing and rinsing.
Joel D Jackson,
You’ve now convinced me you don’t understand measurement at all.
Billy LIar, you might get that impression since you apparently don’t understand how sampling affects standard error with a given standard deviation.
..
http://ww2.tnstate.edu/ganter/BIO311-Ch6-Eq1.gif
…
“s” is the standard deviation of the instrument in question
“n” is the number of observations
Chris,
Picking out one lead in sentence in a rather trivial write up on signal averaging does not do you very well. Read section 3 of that document. It describes when averaging will not achieve desired accuracy improvement. The main concept is that only normally distributed noise can be reduced by averaging. Instrument calibration variations inside a specified accuracy tolerance range cannot be assumed to be normally distributed. Normal distribution of calibration offsets from true may be a convenient assumption but it is false. You will never find engineering design calculations based upon anything but the total possible error range of an instrument measurement and many times a safety margin is added as well.
It bugs us instrumentation types when folks try to tell us our instruments are more accurate than what we adjust them to be using traceable standards. Having done many instrument calibrations myself, including thermometers and electronic weather monitoring gear, I can assure you random error around true not a likely outcome. Each instrument type and manufacturing run has its own quirks and calibration offset.
Gary Wesocom, you say: “Normal distribution of calibration offsets from true may be a convenient assumption but it is false.”
…
If they are not normally distributed, what distribution do they follow?
PS…..Gary Wescom
…
I do hope you are not confusing the distribution of the sampling with the distribution of the instrument error. They are two different things. The standard deviation for the instrument is fixed, and not at all “distributed” but the sampling error is normally distributed.
Joel,
The distribution error profile is rectangular. Probability of error values from true is equal across the full calibration tolerance range. Stated more graphically, there is no hump in the middle of the error profile for the instrument.
As for you second statement: “I do hope you are not confusing the distribution of the sampling with the distribution of the instrument error. They are two different things. The standard deviation for the instrument is fixed, and not at all “distributed” but the sampling error is normally distributed.” That is kind of nonsensical from an instrumentation perspective. “Standard deviation for the instrument” is not a standard deviation, it is a rectangular block of values to which all other deviations must be added. Noisy observed values from an instrument may have a normal distribution that may be reduced by averaging. That noise may be from actual instantaneous process values or maybe eyeball observation angle variations for thermometers. You are still left with the potential error of the measuring instrument which may be anywhere within its stated calibration accuracy. That instrument error is unknown and fixed within that range. It will not be reduced by averaging. likewise, assuming instrument error withing state calibration range(s) across a large number of independent instruments is also unknown and fixed – and not reducible by averaging.
Gary Wescom says: ” “Standard deviation for the instrument” is not a standard deviation, it is a rectangular block of values to which all other deviations must be added.”
Obviously you don’t know what “standard deviation” means. It is a value that is calculated from that “rectangular block of values. ”
…
Here is the formula for standard deviation.
..
http://4.bp.blogspot.com/-ClgskLBxLjQ/Ut-smPagORI/AAAAAAAAA4k/q_u7caTUj-0/s1600/stdev_s.gif
…
Now that applies to your “instrument error”
…
The sampling error is a different thing entirely. The error in measuring the mean of the sample is reduced by increasing the number of observations (samples). By using that technique, you can get a more accurate measure of the sample mean.
…
Here’s an example.
..
Suppose you had an eight foot stick, and it had markings on it at 4ft, 5ft, 6ft, and 7 ft.
…
Now if you use that stick to measure 10,000 adult American males to the nearest foot. You then calculate the average of the 10,000 readings, you will get roughly 58333 as the sum of all the measurements. When you divide that by 10,000 you get 5.83.
…
So with a stick that measures to the nearest foot, you have reached an accuracy of 0.01 feet. This follows the formula for “standard error” (see http://wattsupwiththat.com/2015/07/24/impact-of-pause-buster-adjustment-on-giss-monthly-data/#comment-1993149 ) where the sqrt(10,000) is 100.
Joel,
Who marked the stick? How accurate are the marks? Could they actually be 5.1, 5.9, and 6.95 feet marks? You have not stated. Whatever you calculate by averaging will not remove error in the original markings. It does not matter how many sticks or how many readings you take, you must allow for the error in the marking of the sticks. Assuming the error in the marking will be randomly distributed is invalid. After all, all the sticks could have been marked by the same person making the same error each time.
Instrument error is not reduced by averaging. What you have described in instrumentation terms is increasing the PRECISION of a reading. Precision and accuracy are different concepts. In this case, you have described a very precise but not necessary an accurate measurement. You have neglected the calibration error of the sticks. You cannot claim perfect calibration in the real world.
Gary Wescom….
..
All of your concerns about instrument error are incorporated into the variable “s” in the following formula:
.
http://wattsupwiththat.com/2015/07/24/impact-of-pause-buster-adjustment-on-giss-monthly-data/#comment-1993149
….
The ” the error in the marking of the sticks” is incorporated into the “s” in the above formula. If as you claim that the error for your instruments is “rectangular” then the standard deviation for a uniform distribution applies. It is [(b-a)**2 ]/12.
….
Now…I am 100% in agreement with you when you say: “Instrument error is not reduced by averaging.” But sampling error is reduced by increasing the number of observations. Again, I will repeat, sampling error, and instrument error are two different things. Reducing sampling error is a way to get more accurate measurements of the population mean than the instrument is capable of measuring.
…..
If you use my “stick example” to measure a person’s height, you will have a very large error. If you use my “stick example” to measure 10,000 people, you will find that the average of 5 foot 10 inches will be the result.
Joel Jackson, your linked reference assumes random error. How many times must I reiterate that my point concerns systematic error? The analysis at that link is entirely irrelevant. Systematic error is not stationary and almost certainly does not have a mean of zero. It does not diminish as 1/sqrtN.
Read the first paper linked in my initial post. It’s a free download. It explains the whole thing.
Your claim will not be correct no matter how many times you repeat it.
Chris, notice the comment within your own quote: “The premise of averaging is that noise and measurement errors are random … etc.”
Systematic error is not random. There is no apriori reason at all to suppose that systematic error approaches a Gaussian distribution at large N.
Systematic error violates the premise of your argument. The central limit theorem does not apply. Systematic error is never stationary and can never be assumed to have a mean of zero. Systematic error does not diminish as 1/sqrtN.
And finally, even if error is known to be overall random — the only time the central limit theorem can be legitimately applied — the limits of instrumental resolution can never be exceeded. Instrumental resolution is the asymptotic accuracy limit that is approached at large N when error is random. Even with the random condition satisfied, not even an infinite number of repeated measurements will bring measurement accuracy below instrumental resolution.
Gary, you’re talking to refractory ignorance. Joel has no idea what you’re talking about. Even worse, he has no idea what he’s talking about.
That said, you’re clearly an astute guy, with extensive experience in temperature sensor performance. You are highly qualified to write up an analysis of instrumental error in the global air temperature record. I’d really encourage you to do it.
My paper on uncertainty in air temperatures references the work of Hubbard and Lim. Look at their 2002 paper on real time error filtering. It provides the field calibration of a number of sensor configurations, and gives a good view of errors produced by the various shields used for land based temperature sensors over the late 19th and all of the 20th century.
The paper gives my email address. I can send you the Hubbard and Lin paper if you like. Their paper is one of very few that actually investigates the accuracy of the measurements going into the global record. The neglect of error is astonishing for data asserted to rationalize trillion dollar economic reforms.
I see why your paper didn’t pass peer review.
…
On page 976: “Although they may have an identical instrumental noise
structure, they are experimentally independent measurements of physically different
observables, each measured separate”
…
Really? How can one temperature measurement be “physically different” from another temperature measurement?
…
You’re kidding right?
…
Now I see why people accuse E & E of low standards of peer review.
..
Roger Pielke Jr said: “If I had a time machine I’d go back and submit our paper elsewhere.”
Jackson
How can two, three, four, five or fifty-five thousands temperature measurements NOT be physically different and temporally and technically different from those previous and those next in sequence? NO two, three, or fifty-five temperature measurements can be in the same place at the same time measuring the same mass of air at the same place. If nothing else, the air that heated the first thermometer up to “ambient temperature” has now changed energy and now hits the second thermometer at a different initial temperature.
Pat Frank….I’m sorry, I should have also included this link when referencing the E & E journal
..
http://www.realclimate.org/docs/thacker/skeptics.pdf
Joel Jackson wrote, “Reducing sampling error is a way to get more accurate measurements of the population mean than the instrument is capable of measuring.”
Insist on that and you’d fail any freshman first semester physical science or engineering lab course.
Here is a very short explanation of the difference between random and systematic error from an early physics course at Columbia University. It vacates your position.
An important addition to their explanation is that when systematic error arises from uncontrolled experimental or environmental variables, it is not a constant shift. Data are shifted up or down depending on which uncontrolled variable happens to dominate during any given measurement. One never knows the sign or magnitude.
The only way to get a grasp on systematic error is to carry out careful calibrations against a standard under the same conditions as one will use in the experiment, and record the errors. The magnitude of error is averaged and then reported with every experimental measurement.
This is standard practice in all the physical sciences, and I’d expect across engineering as well (Gary Wescom can correct me here). The only area of science where I’ve found it consistently missing is in consensus climate science (CCS); which lack puts CCS outside the pale of authentic physical science.
Joel Jackson, so you don’t understand the physical difference between a measured Tmin and Tmax? So, you don’t understand the physical difference between day and night?
And then you presume to criticize my paper? Fools rush in . . .
That paper didn’t fail peer review, by the way. It passed peer review at the AMS Journal of Applied Meteorology and Climatology.
After passing review, the editor came back and rejected the paper anyway on the grounds that the careful 2002 field calibration experiments of Hubbard and Lin, involving multiple sensors and many thousands of measurements taken across several months, had no greater significance than for those sensors at that site. He would not allow any rejoinder, thereby directly violating the ethics of peer review.
By that opinion, the editor merely revealed his incompetence.
On the other hand, one of the reviewers at E&E found an mistake missed by all the reviewers, the chief editor, and two associate editors at JAMC. So which journal in fact displayed the superior “standards of peer review,” do you suppose?
Joel Jackson, your Thacker essay is scientifically vacuous. Like pretty much everything you’ve posted in this thread.
Pat Frank/Gary Wescom, you say that systematic errors negate the premise that using multiple instruments in one location can achieve accuracy better than that of an individual instrument. Say I take 10 temperature loggers, all the same mfr and model, and place them within 1m of each other, under identical shade cover. According to the link you posted, systematic error is “Systematic errors are errors associated with a flaw in the equipment or in the design of the experiment.’
For my specific environment, what are the systematic errors that can/will occur?
RACookPE1978
…
It’s really simple. Measuring a temperature is measuring a temperature. Measuring the mass of something is not measuring its temperate.
…
Got it?
Pat Frank
…
Here’s another pretty ridiculous claime in your supposed “paper”
..
page 972:
…
“However, a further source of uncertainty now emerges from the condition .
The mean temperature, , will have an additional uncertainty, ±s, reflecting the fact that the τi
magnitudes are inherently different. T ”
….
You are saying here that the standard deviation of the instrument varies with respect to the measured value. That is bogus.
Chris, Pat Frank’s entire introduction of “systemic error” is a red herring.
Chris, you asked “For my specific environment, what are the systematic errors that can/will occur?”
“Will occur,” we can’t really know without doing the actual experiment.
Can occur is speculative. Are the instruments staggered so that one doesn’t block the airflow of another? Is the shade good enough to prevent low-angle insolation? Are some insolated, but not others? What is the ground albedo like? Is there any thermal reflection up to some of your instruments, but not others?
If any of these environmental impacts are present, then some or all of your array of instruments may well display systematic errors that vary with placement. Those errors do not average away.
The primary environmental impacts are these — shield warming from insolation, insufficient air flow, and upward thermal reflection from local surface albedo. In the winter, shields can also get snow encrusted, blocking or restricting airflow and possibly adding a cold-bias. Reflection from snow albedo is known to put a warm error into winter temperature readings.
Much of these environmental impacts are ameliorated when the field temperature sensor is aspirated. You didn’t mention aspiration as part of your set-up. If the shields in your array are naturally ventilated, then there may be times when the airflow is insufficient to exchange in the outside air. The sensors will then produce systematic errors no matter that they are otherwise calibrated and functioning properly.
The USCRN sensors are aspirated, and should provide air temperatures to ±0.05 C – ±0.1 C accuracy. So long as they are in good repair.
Likewise, if there is zero systematic error from environmental impacts, and all error is random, then the averaged measurement from your array will approach the limit of instrumental resolution.
Keep in mind, too, that true fluctuations in air temperature across the array would mean that your instruments will measure different temperatures, even when the measurements are accurate and simultaneous. The averaged temperature will then have a ±(state-uncertainty), different from error.
Joel Jackson, you wrote regarding page 972, “You are saying here that the standard deviation of the instrument varies with respect to the measured value. That is bogus.
No. The statement on p. 972 says ±s, the state uncertainty, varies with the scatter of specific (and accurate) temperatures entering the average. It’s a very basic idea, and you’ve managed to completely misunderstand it.
You’ve now quoted from the paper twice to the same effect. Congratulations on being consistently wrong, Joel.
Joel Jackson, my introduction of systematic error is based upon very careful peer-reviewed published calibration experiments (some of them referenced in my paper) demonstrating beyond any rational doubt that systematic error contaminates even the air temperature measurements of sensors that are both calibrated and in good repair.
Beyond any rational doubt, Joel. You now have a decision to make.
“varies with the scatter of specific (and accurate) temperatures”
…
English is pretty plain. If it varies with temperature, you really need a better thermometer…..one where the scatter of the measurement is not dependent on what you are measuring. You know, that nasty thing call “variance”
…
Too funny
PS Pat Frank.
…
If you insist that the scatter depends on the temperature measured by the instrument, then I congratulate you on making the biggest logical flaw in your entire “paper.” You will have assumed the systematic error you are trying to prove exists. They call that “begging the question.”
When you list the “systemic errors” not one of them is in the instrument themselves but in the environment.
..
Now, I’m going to thank you for making the following statement, “if there is zero systematic error from environmental impacts, and all error is random, then the averaged measurement from your array will approach the limit of instrumental resolution.”
…
That is wrong.
..
Very wrong.
…
The standard error is inversely proportional to the sqrt of the number of obs, so that by increasing the number of obs, you can exceed the limit (the “s” in the SE equation) of the instrument. The standard error is the instrument’s standard deviation divided by the sqrt of N.
Pat Frank says, ” In a 1 C graduated thermometer, the limit of resolution is ±0.25 C. ”
…
Nope
..
“The resolution of an instrument is the smallest value that is shown on the display. Thus an instrument that has a 0.1°C Resolution means that it will read to the nearest 0.1°C (Perhaps 46.6°C) whereas a 1°C Resolution instrument will only read to the nearest 1°C (i.e. 47°C). ”
…
Reference: http://thermometer.co.uk/content/41-thermometer-resolution-accuracy-and-tolerance-guide
In reality Mr. Pat Frank, if your thermometer is marked in one degree increments, the resolution is +/- 0.5 degrees, not +/- 0.25 as you stated.
So, Joel Jackson, you’re apparently unable to understand clear analytical English. So, rather than make an effort, you resolve your confusion by supposing a simplistic falsehood. And then you complain about it.
The measurement scatter (your bold) comes from varying air temperatures.
So, in your own words, you’re upset that, “If [the measured temperature] varies with temperature, you really need a better thermometer.”
Incredible.
My paper is clear. For the benefit of our few readers, here’s how the section that excites you starts: “Now suppose the conditions of Case 1 are changed so that the N true temperature magnitudes, τ_i , vary inherently but the noise variance remains stationary and of constant average intensity. Thus, τ_i ≠ τ_j ≠ τ_k ≠ … ≠ τ_n, while σ_i = σ_j = σ_k = … = σ_n.”
A little further down is the part where your lexical disability came on display, “However, a further source of uncertainty now emerges from the condition τ_i ≠ τ_j. The mean temperature, T_bar, will have an additional uncertainty, ±s, reflecting the fact that the τ_i magnitudes are inherently different.”
Got that? “Inherently different.” I’ll explain what that means, because analytic notation is apparently difficult for you.
It means the measured temperatures are all different. Because, well, the temperature of the air changed from time to time. But the measurement noise structure remained the same random.
Thiiiinnnkkk about what that means, Joel. Different temperatures … same error. Diiiifffferent temperatures … saaaame error.
Let’s continue.
The average temperature is T = (τ_1 + τ_2 + … +τ_n)/N.
The empirical scatter of each different temperature around the average temperature is (T-τ_i) = s_i.
The total empirical state uncertainty, ±s, is from the variance of the mean scatter of all the temperatures around their average, with one degree of freedom lost, ±s = sqrt{[Σ_i=1,n(T-τ_i)]/(N-1)} = sqrt{[Σ_i=1,n(s_i)]/(N-1)}.
±s is just a measure of how any given set of true temperatures scatter around their average. ±s necessarily changes when the magnitudes of the measured temperatures change.
That simple meaning is what has escaped you, Joel.
I’ll simplify it further for you: scatter varies with the data.
Figure it out.
Joel Jackson, if you truly believe that, “scatter depends on the temperature measured by the instrument” (your gloss), has identical meaning with, scatter depends on “the inherently different temperature magnitudes about the mean” (what’s in the paper), then I suggest you consult a neurologist about lexical aphasia or perhaps take a beginner’s course in scientific logic.
You’re not just in left field, Joel. You’re not in the stadium.
“n I suggest you consult a neurologist about lexical aphasia or perhaps take a beginner’s course in scientific logic.”
…
I’ll make a deal with you……I’ll do so after you take a freshman college course in basic statistics. The standard deviation of a uniform distribution is determined by the range of values, not by the specific values of the random variable.
Pat Frank posted regarding reading a thermometer to the “nearest degree” : “Joel Jackson, typically reading accuracy is taken as 1/4 the smallest division. So, in your example, it would be ±0.25 C. ”
…
Reference: http://wattsupwiththat.com/2015/07/24/impact-of-pause-buster-adjustment-on-giss-monthly-data/#comment-1992693
……
Now Pat Frank writes: “If the scale is marked in 1c steps (which is very common), then you probably cannot extrapolate between the scale markers.
This means that this particular thermometer’s resolution is1c, which is normally stated as plus or minus 0.5c (+/- 0.5c)”
..
Reference: http://wattsupwiththat.com/2011/01/22/the-metrology-of-thermometers/
…
This is a perfect example of a phenomena called “cognitive dissonance” and Mr. Frank needs to make up his mind on this matter.
Pat, earlier you said that it was not possible to achieve accuracy better than that of one instrument by using multiple instruments due to systematic error. Then, in your most recent comment to me, you stated “Likewise, if there is zero systematic error from environmental impacts, and all error is random, then the averaged measurement from your array will approach the limit of instrumental resolution.”
You initially said that multiple instruments could not achieve accuracy below that of 1 instrument due to systematic errors. Now you are saying that in a carefully designed deployment, with systematic errors reduced to 0, you cannot get accuracy better than that of one instrument, because????
You say the instruments will have a rectangular accuracy distribution rather than Gaussian. While I don’t see how that is possible, let’s go with your distribution. Each instrument has an accuracy of +/-1 .1C. Therefore, out of 10 deployed loggers, when the actual temp is 20C, some will read 19.9, some 20.0, some 20.1. The only way the averaged number will be 19.9 (or 20.1) is if all 10 instruments read .1 low, or all read .1 high. That is statistically highly, highly unlikely. By averaging the 10, you will get a result closer to 20C – closer than if you used just 1 logger. Using multiple instruments to measure temperatures at 1 location will give a more accurate result.
Joel Jackson, You wrote, “When you list the “systemic errors” not one of them is in the instrument themselves but in the environment.” (your bold)
Incorrect thinking, Joel. The errors are in the measurements.
The complete system is the instrument plus its environment. The two are inseparable. The measurement is the observable is all you get.
Any temperature “T,” is, observed T = [true T + error]; T_o = (T_t + e). “e” has both instrumental and environmental components.
But e and T_t are inseparable and convolved inside T_o.
The error “e” is an organic part of T_o. It’s inside T_o, you don’t know how big it is, you can’t separate it out, and it doesn’t go away merely because it was imposed by the environment.
One can put a good accurate thermometer outside in a naturally ventilated screen, and the resuting measured temperatures will be ridden with environmentally-imposed systematic error. This is an empirical fact of published calibration experiments. Systematic error is not random. It does not diminish as 1/sqrtN. Your argument is wrong.
You wrote, “Now, I’m going to thank you for making the following statement, “if there is zero systematic error from environmental impacts, and all error is random, then the averaged measurement from your array will approach the limit of instrumental resolution.” (your bold)
…
That is wrong.
..
Very wrong.”
Clearly, the concept of instrumental resolution is too arcane for you, Joel. So, I’ll try arguments from authority.
From “The Joint Committee for Guides in Metrology (JCGM/WG1) 2008 Guide to the expression of uncertainty in measurement. F.2.2.1 The resolution of a digital indication
“One source of uncertainty of a digital instrument is the resolution of its indicating device. For example, even if the repeated indications were all identical, the uncertainty of the measurement attributable to repeatability would not be zero, for there is a range of input signals to the instrument spanning a known interval that would give the same indication. If the resolution of the indicating device is δx, the value of the stimulus that produces a given indication X can lie with equal probability anywhere in the interval X − δx/ 2 to X + δx/ 2. The stimulus is thus described by a rectangular probability distribution of width δx…” (my bold)
Got that, Joel? The lower limit of any instrument is the instrumental resolution. And, as Gary Wescom pointed out, instrumental resolution is a box (“rectangular”) distribution. It remains constant and present no matter the number of repeated measurements.
The JCGM discussion concerns the resolution limit for digital instruments, but applies equally to analogue instruments (such as a mercury thermometer).
From Bevington and Robinson, “Data Reduction and Error Analysis for the Physical Sciences
“Section 3.1 Instrumental and Statistical Uncertainties
“Instrumental Uncertainties
“Instrumental uncertainties are generally determined by examining the instruments and considering the measuring procedure to estimate the reliability of the measurements. In general, one should attempt to make readings to a fraction of the smallest division on the instrument. For example, with a good mercury thermometer, it is often easy to estimate the level of the mercury to a least count of one-half of the smallest scale division and possibly even to one-fifth of a division. The measurement is generally quoted to plus or minus one-half of the least count [i.e., ±1/4 or ±1/10 degree, respectively — P] and represents an estimate of the standard deviation of a single measurement.
…
“If it is possible to make repeated measurements [pay attention here, Joel] then an estimate of the standard deviation can be calculated from the spread of these measurements as discussed in Chapter 1 (Ch. 1 introduces inter alia random errors — P]. The resulting estimate of the standard deviation corresponds to the expected uncertainty in a single measurement. In principle, this internal method of determining the uncertainty should agree with that obtained by the external method of considering the equipment and the experiment itself, and in fact, any significant discrepancy between the two suggests a problem, such as a misunderstanding of some aspect of the experimental procedure.” (original emphasis)
Let’s condense that last.
external uncertainty: ±1/4 of the smallest readable division. This is instrumental resolution.
internal uncertainty: ±σ of the repeated measurements. This is experimental error, taken as random.
Bevington and Robinson tell us that in a correctly done experiment with repeated measurements and random error, internal uncertainty = external uncertainty, and external uncertainty = instrumental resolution.
So, there it is. When errors are random, repeated measurements reduce the uncertainty to the level of instrumental resolution. And no further.
If that’s not enough for you, try consulting the pragmatic discussion in Agilent Technologies’ “Fundamentals of UV-visible Spectroscopy” (2.3 MB pdf; free download). Read the section “Key instrumental parameters, p. 44ff, and especially the discussion of instrumental spectral band width vs natural band width. It’s made very clear that instrumental resolution is the lower limit of accuracy of any measurement.
Here’s the money quote: “ Resolution is closely related to instrumental spectral bandwidth (SBW). The SBW is defined as the width, at half the maximum intensity, of the band of light leaving the monochromator (see Figure 30). The accuracy of any measured absorbance depends on the ratio of the SBW to the natural bandwidth (NBW) of the absorbing substance. The NBW is the width of the sample absorption band at half the absorption maximum (see Figure 31).”
And below that: “If an instrument with an SBW of 2 nm is used to measure samples with an NBW narrower than 20 nm (for example, benzene), an error in absolute absorbance measurements will result. This error increases as the NBW decreases (see Figure 32).”
“nm” is nanometers, the wavelength unit of visible and ultraviolet light. Agilent is saying that the resolution of their instrument is 2 nm. If the natural band width of the material is less than 10x the 2 nm instrumental spectral band width, the accuracy of the measurement becomes seriously compromised.
Again: the instrumental spectral bandwidth of Agilent’s UV-visible spectrophotometer is 2 nm. This 2 nm is the lower limit of resolution of the instrument.
Any given wavelength measured from a spectrum obtained using that instrument can be any place within that 2 nm. Any quoted wavelength obtained using that spectrophotometer must be quoted to no better accuracy than ±1 nm; i.e., ±1/2 the instrumental resolution.
And that’s the way of it. Any instrument has a limit of resolution. The same analytical logic applies to all of them. There are no magic thermometers. No number of measurments will ever produce a result more accurate than the resolution lower limit of the instrument.
You should have gotten it by now, Joel. Any intelligent person will have done.
Joel Jackson, quotes, “Now Pat Frank writes: “If the scale is marked in 1c steps (which is very common), then you probably cannot extrapolate between the scale markers.
This means that this particular thermometer’s resolution is1c, which is normally stated as plus or minus 0.5c (+/- 0.5c)”” (original bold)
..
And assigns it to me at: “Reference: http://wattsupwiththat.com/2011/01/22/the-metrology-of-thermometers/
But those quotes never appear under my name.
They appear in the metrology head-post essay.
That essay is, “A guest re-post by Mark of Mark’s View“. Those quotes are Mark’s. Not mine.
Faulty reading yet again, Joel.
You then wrote, “This is a perfect example of a phenomena called “cognitive dissonance” and Mr. Frank needs to make up his mind on this matter.”
A phenomenon, singular, not “a phenomena.” “Phenomena” is the plural. Fairly common mistake, though.
In any case, your attribution is merely your carelessness on view again and yet another indicator that you have recurrent trouble parsing written English.
Joel Jackson, “The standard deviation of a uniform distribution is determined by the range of values, not by the specific values of the random variable.”
The conversation is not about random error, Joel. It’s about systematic error.
I’ve made that point over and over and yet over again.
Here, and here and here and here, for example. Need I go on?
Here, here. And it continues past that.
Is that simple point really so impenetrable for you, Joel? Is it an inability to understand, or is systematic error something you consciously refuse to countenance?
Chris, thanks for the considerate conversation.
First, see the post that includes the discussion from the JCGM Guide. It discusses rectangular uncertainty.
Essentially, if the limit of instrumental resolution is ‘X±a,’ then one doesn’t know where within ‘±a’ the true value of ‘X’ lays because the instrument gives the same reading ‘X’ everywhere within ‘±a’ of the (invisible) true value. I.e., the uncertainty is constant ±a about the measured value, not a Gaussian. It never diminshes with averaging.
Regarding the average of multiple thermometers. Let’s suppose that error is only random (no systematic errors). Let’s also suppose the instrumental resolution is ±r = ±0.1 C. We average “N” measurements. Let all N measurements give identical values, “t” over mesurements i = 1 –> n (no state-uncertainty).
So, the average temperature is T = Σ_i=1,n(t_i)/N = t.
The average uncertainty in T is the root-mean-square of all the certainties in all the individual measurements going into the average.
So, ±σ = sqrt{[Σ_i=1,n(±r_i)^2]/N}. All the ±r_i = ±0.1 C. So, the average uncertainty works out to sqrt[N x ±0.1^2/N] = ±0.1 C.
And the average of the measured temperatures is T±0.1 C; the same uncertainty as for the measurement of a single instrument.
Now let’s go on to your example. The measurements are not identical, but rather vary randomly at ±0.1 C. You average 10 such measurements. The root mean squared uncertainty is σ = ±sqrt[Σ_i=1,10(0.1 C)^2/10] = ±0.1 C. We can apply this equation confidently because we know for a fact that the errors are random.
But since we know for a fact that the errors are random, σ diminishes as 1/sqrtN. For ten measurements, the final uncertainty in the average is ±0.1 C/sqrt10 = ±0.1 C/3.3 = ±0.03 C.
When one averages up all the individual temperature measurements, one may not get exactly 20 C, even though you specified 20 C as the “true” temperature in your example.
In real life, of course, we don’t know the true temperature. We only know what we’ve measured. So, even if the true temperature is 20.00 C (which one wouldn’t know), and the measurement average is 19.9 C, the uncertainty from the random error in 10 measurements would still be ±0.03 C, because we do know the size of the instrumental error and we do know it’s random.
But notice that the uncertainty due to instrumental resolution is unchanged.
Some people will separate the resolution and measurement uncertainties and report the final average as T±0.1±0.03 C. Others will make the Pythagorean sum of all the errors. In our case that’s sqrt[(0.1)^2 + (0.03)^2] = T±0.104 C. The uncertainty is totally dominated by the instrumental resolution, and here one really needn’t report the uncertainty from random error.
One gets an identical final uncertainty whether averaging 10 (ideally) identical instruments taking one measurement, or one (ideally) perfectly functioning instrument taking 10 measurements.
“The conversation is not about random error,”
…
Your introduction of “systemic error” is a red herring as I have posted above.
..
http://wattsupwiththat.com/2015/07/24/impact-of-pause-buster-adjustment-on-giss-monthly-data/#comment-1993873
…
Repeating a red herring over and over is pointless. The fact is that in case 1 of your “paper” you admit to the fact that increasing the number of obs will reduce the noise.
..
The second case of your “paper” claims that you cannot reduce the scatter (sigma) of the measurements by increasing the number of obs. That may be true, but in the case of changing temperatures over an interval, it’s not the standard deviation that you want to eliminate. It’s the standard error. The instrument error has little effect on the delta between the population mean and the sample mean, in fact it is fixed, and your “paper” confuses the instrument error with the sampling error. That is why your “paper” is bogus.
…
Let me take you down memory lane to show you why your “case 2” is bogus.
…
On a given interval, the REAL temperature is a continuous function on that interval. Continuous because between any two temperature measurements, you can insert another, and for any given instant of time, there is only one temperature. So if you remember your first class in calculus, you’ll remember that you can integrate a continuous function on an interval. Why is ithis important? Because if that continuous function is a representation of temperature on that time interval, you can calculate the average temperature on that interval by dividing the area under the curve by the length of the interval.
…
So…now, remember how they first showed you how to find the area under the curve? They did it with a number of equal width histograms fitted under the curve. They then showed you that by increasing the number of histograms (decreasing their width) you’d get a better and better approximation of the area under the curve. As the width approached zero, the limit of the x*f(x) equaled the exact area under the curve.
…
When you use the sample mean to estimate the population mean the same thing happens. The “number of observations” is equivalent to the number of histograms you use to calculate the area. So as the number of obs increases, the sample mean’s limiting value is the population mean.
…
PRESTO…..your case number two variance is irrelevant to measuring the population mean by sampling.
…
I didn’t even bother to read about case number 3 because of the flaw in your logic in case number two. Why continue when your analysis is not representative of reality?
In an attempt to put a cap on this subject for non-instrumentation types, I give a concrete example:
Let’s look at the Min/Max Liquid-In-Glass thermometers used in climate monitoring stations until recently. The modern version of these devices covers -50 to +130 degrees Fahrenheit or -45 to +55 degrees Celsius, depending upon which model you buy. Their temperature graduations are 1 degree Fahrenheit or 0.5 degree Celsius. Accuracy is quoted as +/-0.2 degree Celsius which is +/-0.36 degree Fahrenheit.
What is the accuracy of temperature observations made with these thermometers? First, we must look at the resolution specification. In the USA, Fahrenheit thermometers were traditionally used. Long practice has shown that experienced observers can reliably read thermometers like those described here to one fourth of the graduations. In this case, it would be to +/-0.25 degrees Fahrenheit. We could then state that the recorded observation value will be within +/-0.25 degrees of what ever the thermometer actually reads. But then remember that the manufacturer says the thermometer itself cannot be assumed to be more accurate than +/-0.36 degrees Fahrenheit. That is to say that no matter how many different trained observers were to make that specific observation with any single thermometer, exactly the same temperature would be recorded by each (though it might get a bit crowded with all those eyeballs trying to look at the same time.) Averaging those observations would, of course, produce a different number. We can count on all of their observations to be +/-0.61 degrees of the true temperature.
That +/-0.61 degrees in the above example, of course, is +/-0.36 +/-0.25 degrees as these values are fixed, not random, so they cannot be taken in quadrature. Stated another way, the meniscus at the top of the mercury or alcohol fluid in the thermometer could be off from true by +0.36 degrees Fahrenheit and still be within calibration. Our trained observers could, in turn, read that value +0.25 degrees above that and still meet our expectations for proper technique. The value he would record could then be +0.36 plus +0.25 degrees or 0.61 degrees above true. The same, of course would be true for -0.36 and -0.25 for a total of -0.61 degrees.
Keep in mind too that the +/-0.36 degree Fahrenheit thermometer accuracy value gives no assurance or even likelihood that given a large number of them the errors will average close to true. There may, and often will be a similar error profile for all of the thermometers in a given manufacturing run. Observations with these thermometers will average to some non-true value that may well be 0.36 degrees above or below true.
Our thermometer observational accuracy is correctly stated at +/-0.61 degrees Fahrenheit. That accuracy cannot be improved by averaging since given the same instrument and precisely same air temperature, exactly the same observed value would be recorded. But that is not the whole story by a long way.
There are many things in the real world that can cause thermometer observations to vary from what we would define as true air temperature. Many of them are random over relatively short periods so can generally be safely removed by averaging multiple observations. Some things that effect our temperature observations produce long term variations (bias) from true values. There are techniques for dealing with these short and long term error (bias) sources. However, none of those techniques can retroactively remove our +/-0.61 degree potential thermometer accuracy/human observer error. The best those techniques can do is allow us to approach the +/-0.61 accuracy level.
Joel Jackson, your “red-herring” assertion is bald and unsupported by any analysis. It’s worthless.
Case 1 in my paper directly assesses, “constant temperature and stationary random noise.”
For those still reading, my paper explores the consequences of error in three increasingly complicated cases. Case 1 is the simplest: repetitive sampling of the same temperature magnitude with stationary (random) instrumental error. The conclusion of Case 1 that random error diminishes as 1/sqrtN is a rigorous outcome of its assumptions, and is not an “admission.”
In paper Case 2, the measured temperatures are not constant, but the instrumental error is constant (stationary). This has got Joel excited. He evidently doesn’t understand the distinction made in Case 2 between measurement error and the variance produced by multiple measurements of truly different temperature magnitudes about their mean.
As has been usual all along, Joel, you give no evidence of working through an analysis. Instead, you invariably assert some shallow conclusion and then criticize that. Jumping to a conclusion is easier than doing the work. I don’t think you do it cynically. It seems more likely you just haven’t a clue. Just FYI, Joel, Case 2 doesn’t consider sampling error at all. Neither do Case 3 or Case 3a.
Your reading of my paper is faulty (just as has been your reading of my posts), your conclusion is wrong, your discussion is irrelevant, and you plain don’t know what you’re talking about.
Look at this, for example. You wrote, “The instrument error has little effect on the delta between the population mean and the sample mean,….”
When instrumental error is significant and systematic, Joel, one hasn’t any idea where the true population mean is. Further, systematic error ensures that the sample mean is diverged by some unknown amount from the population mean. That means one’s ignorance of your “delta” is empirically total. Therefore, there’s no point in discussing it at all. But that simple understanding has escaped you.
Systematic error, in any case, violates your assumption of a normal distribution. That alone vitiates your entire discussion.
Your argument completely misses the point, both of the paper and of the discussion. It’s irrelevant. Your arguments have always been irrelevant. If the past is any indication of the future, they’ll always be irrelevant.
But I don’t want to interfere with your enjoyment. So, rave on, Joel.
A very clear and pertinent example of the limits of resolution, Gary, following exactly along the JCGM discussion. But one can predict it’ll make no impression. 🙂
For the nth time, you bring up the red herring of “systemic error”
…
Pat Frank says “In paper Case 2, the measured temperatures are not constant,”
..
Better re-read my post regarding measuring temperatures in a given time interval. It just so happens to be directly applicable to environmental measurement of temperatures……the ones your paper attempts to address.
You write: “The mean temperature, , will have an additional uncertainty, ±s, reflecting the fact
that the τi magnitudes are inherently different. The result is a scatter of the inherently
different temperature magnitudes about the mean”
…
This “additional uncertainty” is nothing more than sampling error, which can be dealt with easily by increasing the obs.
…
I now understand why this “paper” was published by E&E……the managing editor was impressed with your gobbledygook.
Joel Jackson, my entire paper is about systematic measurement error, of which you clearly understand nothing.
The ±s is not “sampling error but represents true state variability, of which you also clearly understand nothing.
Your continued insistence is an object example of Russell’s adage that the ignorant are full of certainty.
“What will it be 10 years from now?”
It depends on how far the global temps fall… at least THAT much.
The adjustments are bigger than the error bars…. Should that bother me less than it does?
Unless the adjustments are extremely well documented such as site changes… Yes. For data in the 19th century, I would fail you in high school statistics if it didn’t.
Their algorithm is as follows:
1) Inflate current temperatures.
2) As time proceeds, if this inflation is no longer sufficient to show a significant trend, then depress what was inflated in the past.
3) Repeat from step 1.
But programmer, IIRC Mosher told us it was okay since there were just as many dots bellow 0 as above 0. So nothing really changed.
Some time in the future they will have to adjust today’s temps. back down again. My question therefore is, by having to make adjustments, does this not indicate that they didn’t get it (the measurements) right to begin with? So where does all the confidence in the established settled science come from? If there is a tendency to get things wrong now, with all the modern, high tech facilities we have today, and all the benefit of experience we have, then how certain can we be that we are comparing the present with the past? The hiatus is approaching nineteen years, during which time we have seen many technological advancements. If these adjustments mean they have been wrong for such a short period of time, then for a mere mortal like me, it looks like the ”experts” are getting lost in the statistical world that probably has no significance to the real world.
Eamon.
I was thinking the other day of why we have to spend to much money on science that was settled over a decade ago according to Al Gore. Then it hit me, we are dealing with ‘the religion of upslope’. Imagine a straight horizontal line running across a sheet of paper. Normal people look at the line and quickly notice it is horizontal, but when you are from ‘the religion of upslope’, you need lots and lots of money to explain to everyone why that line is not horizontal but is sloping up. So you receive millions in grant money and adjust the data on the left down and on the right up and prove the line was sloping up the whole time. Or you receive millions in grant money to discover why we are being fooled into believing it is a horizontal line. Well duh, the viewers right eye is slightly lower than their left eye causing them to think the line is horizontal. It takes a lot of money to manipulate straight lines into upslopes.
Jared, I have always been curious as to how corrupt people seem to be able to easily find other like minded corrupt people to help them.
Money, prestige.
They draw the corrupt like moths to a flame.
Once it became known that the only research that would be funded was global warming research, it did not take long to destroy the credibility of science.
Once it became known that only pro global warming papers would be published, it did not take long to destroy the credibility of scientists.
Once it became known that people who turned to the dark side would be given awards and prize money and be given prestige through those and media, it did not take long for people to line up to get theirs.
People in all social dynamics tend to surround themselves with like-minded people. Look on any college campus and you will find people dividing themselves up by personality type and labeling themselves with Greek letters so everyone else knows it. In that light, it’s not at all difficult to believe that people like – oh, say James Hanson to name just one (who happens to be the one squawking the loudest over the last few days), would spend his entire tenure at NASA stocking the place with like-minded disciples – that’s why nothing changes when a guy like Hanson leaves his post – because he’s replaced with Gavin Schmidt – or Lisa Jackson at the EPA replaced with Gina McCarthy.
They’ve got themselves in a hole
And they need to stop digging,
The data recordings
They need to stop rigging,
A return to honest science
Is urgently needed,
But are they too radicalised
For that call to be heeded?
http://rhymeafterrhyme.net/i-wish-i-believed-in-global-warming/
Regardless of recent adjustments in ocean data as they apply to surface (land and ocean together) data sets, it has yet to be shown that global ocean warming is a recent change. Oceans have been warming on a centennial scale. To take adjusted data to Paris to prove AGW cannot be supported.
http://flux.ocean.washington.edu/2014_ocean510/roemmich.challenger.pdf
How much warming trend do adjustments add by themselves?
I wrote a matlab (octave) program to calculate this. ?dl=0
?dl=0
Over the entire record length, comparing 2005 to 2015 (and stopping the data in 2005), the trend change was 0.01 degC/decade.
The data (copied), and source code is at:
https://www.dropbox.com/sh/qi9h70otb2p9j9h/AABPE2Uf-s8xe8iGGr1BhQULa?dl=0
I haven’t yet calculated the trend change since 1950, when CAGW was supposed to start. (is that the right year?)
Peter
I had done the same thing with the earlier data set, comparing the 2010 data to 2015. The increase in the slope was from 0.0057 to 0.0062 degrees K per month (nearly 10%):
https://dl.dropboxusercontent.com/u/75831381/NOAA%20alterations–Dnes%20data.pdf
The increase in the slope was from 0.0057 to 0.0062 degrees K per month (nearly 10%):
Careful, as the file is read by default (at least in matlab/octave), the X axis units are in YEARS, the month appears as decimal. I got confused by that initially…
So if the X axis is indeed years this means you are seeing a difference of .0005/year, or 0.005/decade. Which is half of mine (0.01/decade). I can’t explain the factor of 1/2. I’m using the formula theta = (pinv(X’*X))*X’*y, which is the standard normal equation for doing a linear least squares fit. Where’s your source code so I can replicate?
These alterations to recent data are only the tip of the iceberg.
For more, readers here might want to start with these two posts on Tony Heller’s blog site:
https://stevengoddard.wordpress.com/alterations-to-climate-data/
https://stevengoddard.wordpress.com/data-tampering-at-ushcngiss/
Sorry–that slope change between 2010 and 2015 was from 0.0057 to 0.0062 K per year, not per month.
Using the new data from 2005 to June 2015, the slope increase is from 0.0049 to 0.0059 (nearly 20%). So the pause-buster change about doubled the global warming–not bad for a few months work.
https://dl.dropboxusercontent.com/u/75831381/GISS%20adjustments%20June%2005%20June%2015.pdf
Just for fun here are two trends, since 1950 and since 1975. (.03 and .08 difference respectively) ?dl=0
?dl=0 ?dl=0
?dl=0
I’m having a hard time finding a definitive reference for “when does anthropogenic warming start”… I see 1915, 1950, 1975… take your cherry pick!.
Peter
Sorry–that slope change between 2010 and 2015 was from 0.0057 to 0.0062 K per year, not per month.
Using the new data from 2005 to June 2015, the slope increase is from 0.0049 to 0.0059 (nearly 20%).
Right, your initial stab was with 2010. That’s the discrepancy, I was comparing 2005. Whooops.
Your 2005 and 2015 numbers agree with mine except that I found .0059775 rounds to 0.0060 (degC per year). You probably didn’t round correctly when you posted.. I’ll call it Reproduced!
This exercise right here is a great example of why even simple analysis needs to be reproduced, just like experiments need to reproduced. To do that, you need source code and properly annotated data, and perhaps 25 years of seeing 10s of thousands of software bugs to be properly skeptical of software…
Peter
Peter wrote: “… and perhaps 25 years of seeing 10s of thousands of software bugs to be properly skeptical of software…”
Good point. Entirely too many people still think that if it comes out of a computer it must be so. Bugs can be insidious and evil. I have even heard some say that software bugs are intelligently evil. Perhaps self-aware even. 🙂
Perhaps self-aware even. 🙂
We call the really bad ones “Heisenbugs”. They are sneaky, they hide when you are looking for them.
Peter
This reminds me of the time I got into yet another futile argument with a warmist. When I pointed out the models in the 1990s have been falsified, they pointed out “but the new ones are better. They have 600k lines of code”.
I’d bust out laughing if so much money wasn’t being wasted…
Peter
@ur momisugly Lance ” I had done the same thing with the earlier data set, comparing the 2010 data to 2015. The increase in the slope was from 0.0057 to 0.0062 degrees K per month (nearly 10%)”
I followed the conversation between you and Peter and I tell you the temp differences have made me break out in a real sweat!
I finally got a contour plot of all known GISS releases over time. I forgot how much I hate dealing with multi-dimensional matrices in matlab… The code should be able to handle all future releases or new discoveries of old releases with no changes needed. ?dl=0
?dl=0
Clearly something interesting happened in to the trend in a 2006 release and in a 2013 release, as well as the recent 2015 release. That’s about what this graph is useful for – visualizing when significant changes were made that affect the overall trend. Suggestions for a more useful graph welcome. I probably should just write a function that finds the biggest deltas in trends and plots only those trends on a 2D chart…
source code same as in this thread.
Peter
Here’s the plot I really wanted. ?dl=0
?dl=0
Looks like in 2006 they made a significant change, released no changes till 2012, inadvertently released a big change in early 2012 and backed it out, then committed to that change mid-2012, then made another significant change in 2015.
Okay I’m done spamming for now. I can now chart overall trend changes on any new release and compare to old releases. If you dig up any other old releases please let me know.
I can probably start tracking 1995-2014 changes by release with a small mod to the code…
Peter
GAH, off by 10 in the Y axis. Dropbox updated, but have to resnapshot for wordpress. Sorry about the spam. ?dl=0
?dl=0
Peter
The “pause” is simply the discrepancy between what was forecast and what actually happened. Now unless I’m very much mistaken, what they forecast was that the temperature datasets available when they made the forecast would rise WITH A HIGH DEGREE OF CONFIDENCE … bla bla bla.
What they didn’t say was that … some imaginary as yet to be defined dataset that we make up on the spot will warm by ….
That’s the whole point about the pause. The fact the pause occurred cannot be changed retrospectively. It occurred in the datasets that were predicted to rise and GISS can huff and puff and frankly do whatever they want to do, but they cannot change the fact the pause is real.
And just to remind GISS — it was sceptics like me who identified the pause and so as original discovers it is us who define what it means not GISS, NOAA or any other climate charlatans trying to redefine the pause trying to wind their inane arguments!
“What they didn’t say was that … some imaginary as yet to be defined dataset that we make up on the spot will warm by ….”
I love that point. Datasets made up on the spot to fit their needs. Yes indeed.
In science “adjusting” the data is lying. This is organized lying, Not Science. No useful conclusions can be based on their constructed data. pg
Yup. Cal it what it is.
One can say in in ten words, or in hundreds to thousand of words including graphs and charts.
But it amounts to the same thing.
Organized lying.
For a specific purpose and with a specific goal.
And with large financial gain to be had, based on being very convincing.
Lots of people say that skeptics should not use words like fraud, or hoax, or scam.
But when one considers the above, and then looks up what words describe such behavior, well…
I’d actually use the word ‘cheating’. But, yeah – what he said.
Another consequence of their latest adjustments are that the period of statistically significant warming greatly decreased from May to June. In May, it was from November 2000, or 14 years and 7 months which is pretty close to NOAA’s 15 years. But now, it is from August 2003 or only 11 years and 11 months.
To paraphrase that apocryphal comment from the Vietnam War We, ‘had to destroy the integrity the data to save its usefulness’.
Another Vietnam type quote… that data is not operative.
It has often struck me as odd that most of the data discussed here seems to originate from US sources , although I realise that the experimental work may often have been a global cooperative both in terms of funding and in personnel.
So I took just 4 pages from the WUWT reference section and looked at the sources of the data:
1: Atmosphere page : All US source except compilations from Oslo(prof Humlum) and ECMWF (EU)
2: Sea Ice page: US + Norway, Denmark, Japan
3: Ocean page ; US + ECMWF(EU), BOM (Aus)
4: Global temperature: US + BOM(Aus), Denmark, Humlum again, Hadley(UK) and UEA(UK)
Now some of the sources are repeats of information elsewhere but the general impression is that the US is leading the dissemination of data relating to climate change , perhaps because it has the financial resources to do so , and a large number of skilled scientists and technicians , not to mention decades of satellite experience.
However to some extent that is also true of China , India, France, Russia, Why do I not see datasets , on say Arctic sea ice and temperatures from Russia, CO2 levels from Chinese measurements , global temperatures by satellite from India? They all have that capability , their scientists are the equal , and some might say better, than those in the West and they all have satellite building and launching capability .
Do they have useful data to compare wuth US/Hadley data , but are reluctant to reveal it for political or military reasons or are they not bothering to collect climate data and are happy to sit back and watch the US , UK ,EU weave the rope that will hang them in Paris in December?
?? political will ??
Mikewaite,
There is old Data for the years1961-1990 on the WMO site here-
http://data.un.org/Explorer.aspx?d=CLINO
Don’t know where they get it from or whether it’s ‘Raw’ or ‘Cooked’.
mikewaite:
You ask
There is a procedure known as ‘keeping your powder dry’; i.e. don’t spoil your chances before an engagement starts.
In 2009 the US, UK and EU thought they had woven the rope that would hang Russia, China and India in Copenhagen. But the US, UK and EU are now weaving a new rope because China destroyed their previous rope in Copenhagen.
Richard
Again, what will it be ten years from now?
===
dunno….but we will have to wait at least 10 years to even know what todays temp is
Which makes the point that they can’t claim no pause….because no one knows what today’s temp is
“I only started downloading GISS data in 2008, plus I picked up a few older uploads back to 2005 from the “Wayback Machine”.”
It would be handy if they published their data every year and kept it there available.
Are we now allowed to use the ‘f’ word ending in ‘d’? Please change the filter here.
[no, there’s a reason for it. – mod]
I am sure there is a reason for it as the laws can be a real problem “free speech” or not. However, it would be a nice thing to have a list someplace of words we are not allowed to use. Topics also. A complete list.
There was a German site years ago that I visited often that concerned a distribution of Linux. There were certain words and certain topics that could not be mentioned because of German law. It was weird. I made an off hand reference to the Holocaust and nearly got banned — on a programming site no less.
Anyway, a list of “don’t go there” words and topics might make the moderators life easier and help the commenter stay away from moderation.
Possible?
I note trying to access the Sea Ice pages here I get a request for a logon and password to the ssmi ftp data. Someone else trying to hide their data?
[We have seen that as well. Cryosphere data links still require no login permissions. .mod]
The impact of these changes is to demonstrate how easy it is to corrupt an field of science.
The “information” on the GISS pages can not be independently verified. Over the years, a few people have been watching the GISS “data” change with time. Such as
https://stevengoddard.wordpress.com/data-tampering-at-ushcngiss/
In 2008 I saved a sample of station reports to see if old data changed. Every month about 10 percent of GISS stations showed some temperature adjustments. Eventually my sample size increased to 30 stations. I don’t know the number of total GISS stations, but of those 30 randomly chosen stations, I saw temp data change every month for some data of some stations. The next month, a different set of 3 or 4 stations showed changes to old data.
At the end of 2012 there was a clear jump in number of stations with large adjustments. Almost every change in old data results in a cooling of the past.
Anyone can do this, download about 10 stations of data. After 2 months, download the same stations. Compare old vs new and you will see changes in several stations. Usually the changes are small, but sometimes there are much larger changes.
Walter, this new zip file does not contain a single file summarizing all the others (which you included in your first zip file in your post of a week or two ago and which made it very easy for users). Can you supply?
I’m not familiar enough with WordPress to do the update, and I don’t know if I even have the necessary permissions, as a guest poster. I’ve got the file ready and I’ve forwarded it to a moderator to replace the current zip file. The new one also contains the CSV and a short readme.txt in addition to the other files.
Link within the article and here;
https://wattsupwiththat.files.wordpress.com/2010/08/data-3.zip
updated accordingly.
Well, another fine mess. (h/t Laurel and Hardy)
If the standard theory of the alarmists was correct, then they would be able to show that correct theory by looking at data without having to fiddle with it. The “adjustments” scandals are mentioned in blogs all over the place. It is well and truly amazing that these government agencies can be caught red handed fiddling with the data to suit their desire to show warming and nothing ever comes of it.
Nothing much came of the climate-gate mess either. Nothing much ever comes of catching these clowns on anything.
Besides the raw political ramifications of the duplicity of these agencies helping enact ruinous legislation, there is the problem that the scientific method needs real, honest data to confirm or falsify theories. How the heck can real science be done in a duplicitous environment?
The GWPF team of independent scientists looking at the adjustments to the temperature records are aware of this study I assume?
Note to the author: If you are truly paranoid you hash checksum your data to make sure any new copies are not modified. I then save the results publicly and in a safe private location.
for example I run this command on Linux:
sha512sum gisstempdata/* > sha512sumdata.txt
(sha512 is about as secure as you can be until quantum computers take off)
Can somebody tell me what was the annually-averaged temperature in 1997 and 2014?
becouse NOAA say that in 1997 was 62.45 F (http://www.ncdc.noaa.gov/sotc/global/199713) and in 2014 (the “warmest” year ever) was 58.24F (http://www.ncdc.noaa.gov/sotc/global/2014/13)
As of June 2016 data, including “Pause Buster” adjustments, here are the averages by year, 1997-2014 for GISS and NOAA
YEAR GISS NOAA
1997 0.48 0.52
1998 0.63 0.64
1999 0.42 0.44
2000 0.42 0.43
2001 0.55 0.55
2002 0.63 0.61
2003 0.62 0.62
2004 0.55 0.58
2005 0.69 0.66
2006 0.64 0.62
2007 0.66 0.61
2008 0.54 0.54
2009 0.65 0.64
2010 0.71 0.70
2011 0.60 0.58
2012 0.63 0.62
2013 0.66 0.67
2014 0.75 0.74
Oops, that’s annual average anomaly, aginst their base temperature.
Since the trend only changes slightly with these alterations* I think most of the hubbub is about max temperature records.
I just started ignoring max temperatures once I found out the distribution of those are arcsine. They happen ALL THE TIME and that is normal. It’s also trivially easy to generate new ones by very small manipulations of the record that don’t affect the trend much. It’s terrible innumeracy that new max records get used by the warmists, it’s certainly science denial to do so. We are engaging in innumeracy by debating about tiny changes here in fact…
Peter.
* (0.01degC/decade over the entire record set, 0.03degC/decade since 1950, see thread above. Compare this to the debate about whether which prediction is correct: 1degC/century versus 3degC/century)
It is not so much the trend since 1950 that is the issue but whether or not we have a pause since 1997. For RSS, the slope is 0 since 1997. However for GISS, the already badly diverging slope of 0.0092/year in May jumped to an even worse 0.0124/year in June. See:
http://www.woodfortrees.org/plot/rss/from:1997/plot/rss/from:1997/trend/plot/gistemp/from:1997/plot/gistemp/from:1997/trend
This awful tampering of data is making El Nino’s look like they have no influence with global temperatures using GISS. The GISS data doesn’t look like data from this planet and would give very poor impression to any would be scientists studying how ENSO behaves with global temperatures. I am disgraced how this data has been treated and the best place for it is in the dust bin. The RSS data nicely represents how the global temperatures behave with changes in ENSO with the strongest events shown nicely over the period. The GISS data shows years with barely a El Nino no different from hardly any others and it is such a shambles. It has clearly been ruined and looks nothing like data sets previously. This time they have gone too far and there is now with RSS a 0.6 c between recently and the peak in 1997/98, yet GISS shows recently no difference and even a little warmer than 1997/98 peak. For global temperatures to show precision over 0.6 c difference between the two, shows nothing other than tampering. A 0.6 c difference is huge and way too large for it just to be caused by usual human error.
The differences from just other data sets only a few years ago is astounding.
If so large changes can happen over just a few years, just think what could have happened to data many decades ago with less people keeping an eye.
The GISS data doesn’t look like data from this planet and would give very poor impression to any would be scientists studying how ENSO behaves with global temperatures.
The tool to best see interesting events over time is the wavelet transform. I haven’t gotten there yet… but I will. Part of my “reteach myself matlab” exercise I’ve been working on
Peter
Paul Homewood has an interesting post on his blog dated July 20 here
https://notalotofpeopleknowthat.wordpress.com/2015/07/20/noaa-tampering-exposed/
“Last month, NOAA caused a lot of controversy by adjusting historic global temperature data to show that the pause had never happened. This has been well covered by WUWT and others, but what is less well known is that NOAA have been making similar but subtle adjustments year by year for a while now.
When they do this, the old versions are never archived, and they do not publically announce what they have done. Instead, the new figures simply replace the old version.
Fortunately, however, Walter Dnes has been archiving the old data each month since January 2010. His results were published at WUWT last week.
I have used his data to show in a simple fashion what the total effect of these changes since 2009 has been.”
Read on his blog what these effects are. A good complement to Walter Dnes’s posts here.
“When they do this, the old versions are never archived, and they do not publically announce what they have done”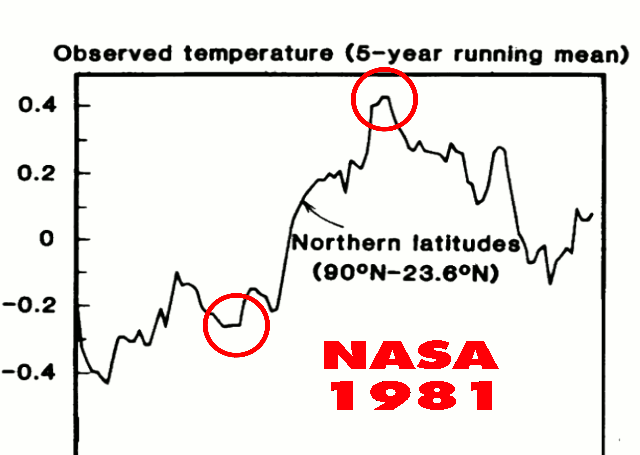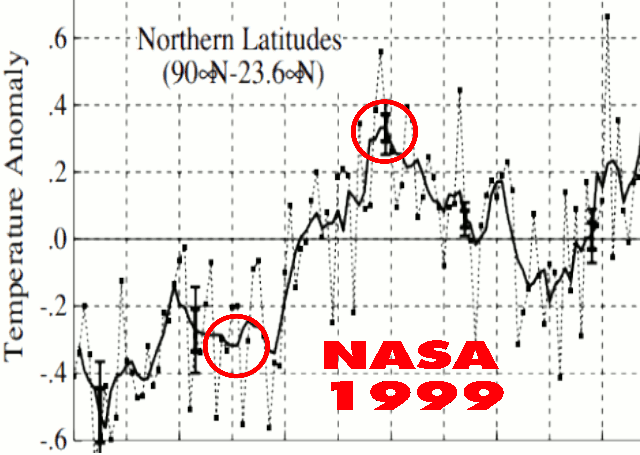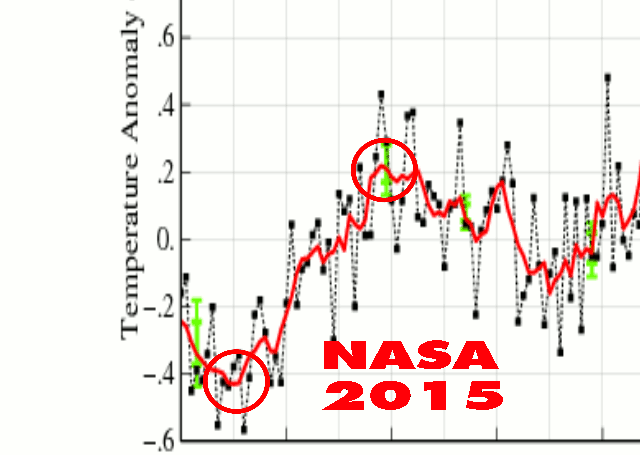
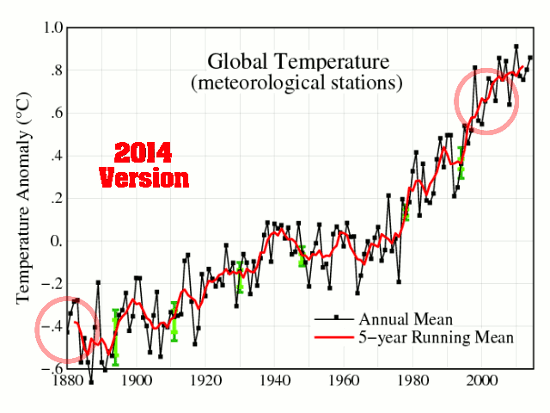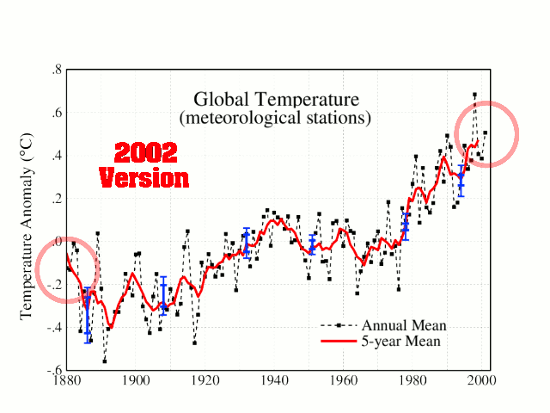
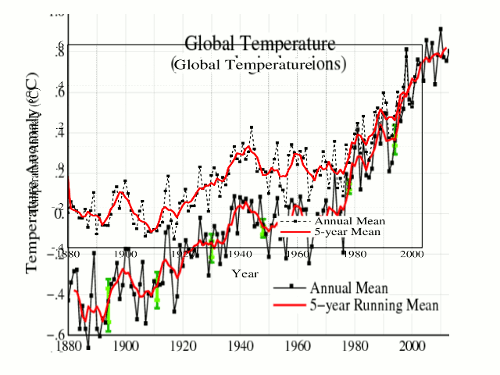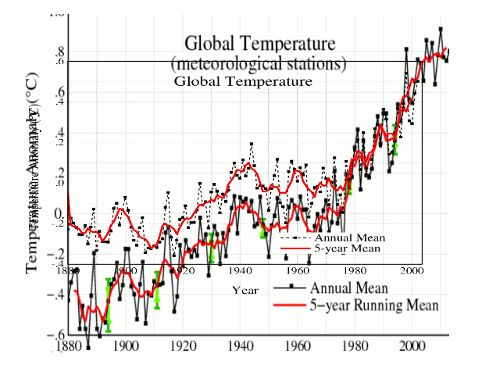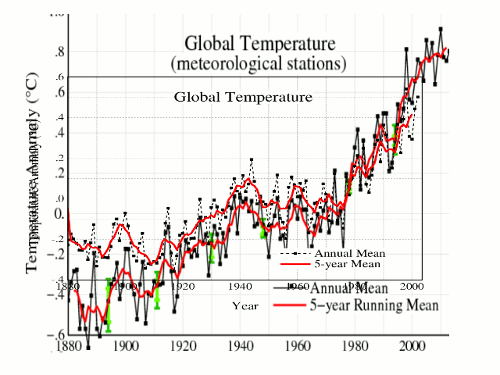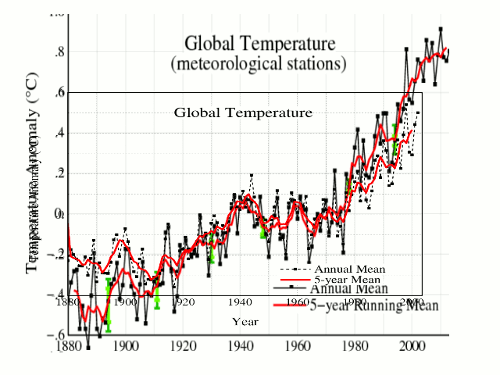
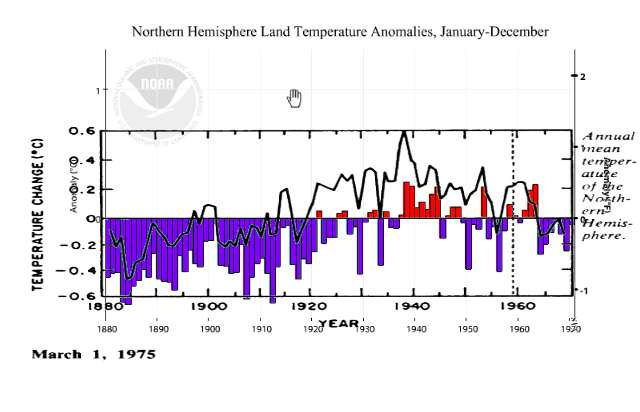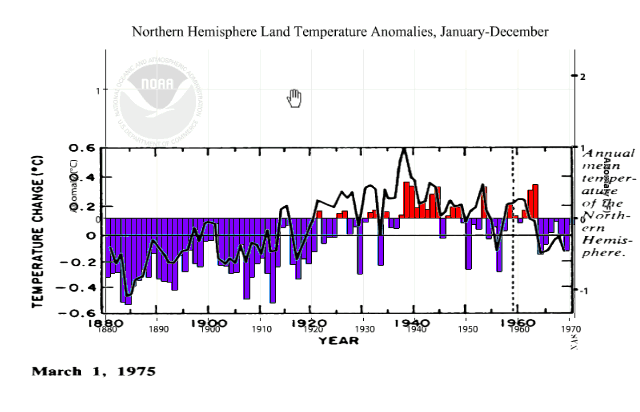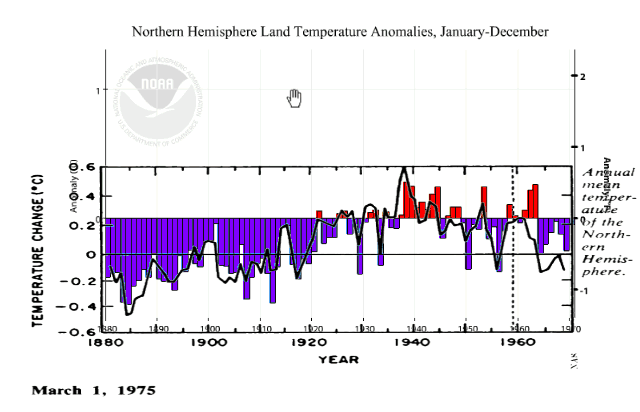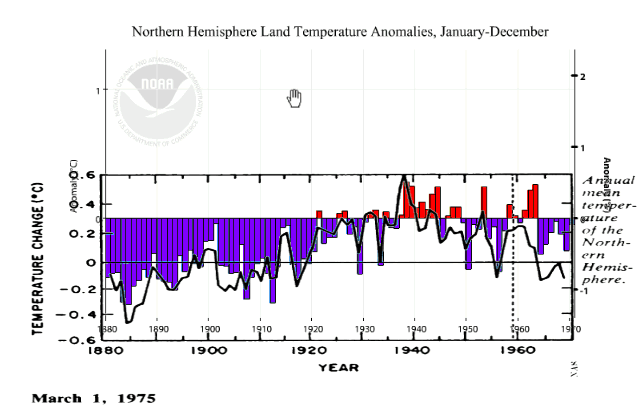
 ?w=700
?w=700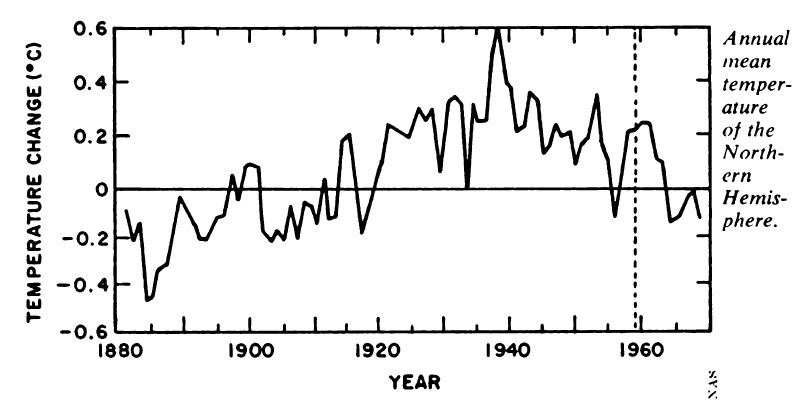
================================
Exactly. See this Bill illis post here. http://wattsupwiththat.com/2015/03/06/can-adjustments-right-a-wrong/#comment-1877173
Here are the changes made to GISS temperatures on just one day this February. Yellow is the new temperature assumption and strikeout is the previous number. Almost every single monthly temperature record from 1880 to 1950 was adjusted down by 0.01C.
I mean every freaking month is history suddenly got 0.01C colder. What the heck changed that made the records in 1880 0.01C colder. Did the old thermometer readers screw up that bad?
http://s2.postimg.org/eclux0yl5/GISS_Global_Adjustments_Feb_14_2015.png
Here are some old official data. The changes, small or large, together are major.
Here is an earlier global NH north of 23 degrees. (NASA 1981 vs 1990)
Here is GISS global, (2002 vs 2014)
Here is global 1981, vs 2014
NCDC has dramatically cooled pre-1963 Northern Hemisphere temperatures since the 1975 National Academy of Sciences report.
Some more global for you..
The NH anomaly drop from the 1940s blip (the one in climate gate they were trying and eventually succeeding to eliminate) was at one time .6 degrees C
The current surface record is F.U.B.A.R.
With the new GISS adjustments, 1998 is in a 3 way tie for 8th!
This is what is so deceptive about the anomaly method as well. Picking an anomaly relative to a certain base is , well relative and an anomaly. Especially when both are ever changing,
The question is do either UAH or RSS show any year close to as warm as 1998. The answer is no, they do not. Both show 2014and 2015 as nowhere near 1998, and both show 1998 as the “warmest year ever” to quote the CAGW phrase.
Both UAH and RSS are ballpark .3 degrees below 1998. Both show 2010 and other years as at least this much 0R MORE warmer then 2014. Schmitt proclaimed a what, 34% chance that 2014 was the hottest year ever based on what .04 degrees? By that measure there is a 100 percent chance that RSS and UAH show that 1998 was the “warmest year ever”.
Correction to second sentence in last paragraph…Both RSS and UAH show 2010. 2014, 2015 and other years as at least this much 0R MORE cooler then 1998. (Read before submitting, urgg)