Jeff asked me to carry this, since his blog is off the radar since he announced his retirement. It took an RC moment to change that. – Anthony
Wrong is Wrong – A reply to the Real Noise at Real Climate
Posted by Jeff Id on February 7, 2011
I knew this was coming and based on Ryan’s personality that it would be a bit of a rocket. Actually that knowledge helped me not blog on the RC post. Steig hasn’t figured out several issues with our work or the fact that his result near Byrd was essentially random. The post below is long and fun, but more importantly accurate, and contains what should be a nice little surprise for readers. I’m still ticked that even my small critique wasn’t allowed at RC. The scientists of RC are unqualified to judge what I write, the censorship is nonsense and they should read my comments as carefully as anything from their peers. What happens when you realize that you understand better than the alleged professionals? – you get bored — maybe you even quit blogging!
Anyway, Ryan ODonnell is a little tired of it as well and has just added another 14 pages to the unbelievable 88 page review. Read on and you’ll see what I mean.- Jeff
Steve McIntyre has a duplicate of this at his site.
————–
ERIC STEIG’S CRITQUE – By Ryan ODonnell
Some of you may have noticed that Eric Steig has a new post on our paper at RealClimate. In the past when I have wished to challenge Eric on something, I generally have responded at RealClimate. In this case, a more detailed response is required, and a simple post at RC would be insufficient. Based on the content, it would not have made it past moderation anyway. [Jeff’s bold]
Lest the following be entirely one-sided, I should note that most of my experiences with Eric in the past have been positive. He was professional and helpful when I was asking questions about how exactly his reconstruction was performed and how his verification statistics were obtained. My communication with him following acceptance of our paper was likewise friendly. While some of the public comments he has made about our paper have fallen far short of being glowing recommendations, Eric has every right to argue his point of view and I do not begrudge his doing so. I should also note that over the past week I was contacted by an editor from National Geographic, who mentioned in passing that he was referred to me by Eric. This was quite gracious of Eric, and I honestly appreciated the gesture.
However, once Eric puts on his RealClimate hat, his demeanor is something else entirely. Again, he has every right to blog about why he feels our paper is something other than how we have characterized it (just as we have every right to disagree). However, what he does not have the right to do is to defend his point of view by intentionally and grossly misrepresenting facts.
In other words, in his latest post, Eric crossed the line.
Let us examine how (with the best, of course, saved for last).
***
The first salient point is that Eric still doesn’t get it. The whole purpose of our paper was to demonstrate that if you properly use the data that S09 used, then the answer changes in a significant fashion. This is different than claiming that a method whereby satellite data and ground station data are used together in RegEM that the resulting answer is a more accurate representation of the [unknown] truth than other methods. We have not (and will not) make such a claim. The only claim we make is – given the data and regression method used by S09 – that the answer is different when the method is properly employed. Period.
Unfortunately, Eric does not seem to understand. He wishes to continue comparing our results to other methods and data sets (such as NECP, ERA-40, Monaghan’s kriging method, and boreholes). We did not use those sets or methods, and we make no comment on whether analyses conducted using those sets and methods are more likely to give better results. Yet Eric insists on using such comparisons to cast doubt on our methodological criticisms of the S09 method.
While such comparisons are, indeed, important for determining what might be the true temperature history of Antarctica, they have absolutely nothing to do with the methodological criticisms – which were the whole point of our paper. Zero. Nilch. Nada. Note how Eric has refrained from talking about those criticisms directly. I can only assume that this is because he has little to say, as the criticisms are spot-on.
Instead, what Eric would prefer to do is look at other products and say, “See! Our West Antarctic trends at Byrd Station are closer than O’Donnell’s! We were right!” While it may be a true statement that the S09 results at Byrd Station prove to be more accurate as better and better analyses are performed, if so, it was sheer luck (as I will demonstrate, once again). The S09 analysis does not have the necessary geographic resolution nor the proper calibration method necessary to independently demonstrate this accuracy.
I could write a chapter in the Farmer’s Almanac explaining how the global temperature will drop by 0.5 degrees by 2020 and base my analysis on the alignment of the planets and the decline in popularity of the name “Al”. If the global temperature drops by 0.5 degrees by 2020, does that validate my method – and, by extension, invalidate the criticisms against my method? Eric, apparently, would like to think so.
The question about whether the proper use of the AVHRR and station data sets yield an accurate representation of the temperature history of Antarctica is an entirely separate topic. To be sure, it is an important one, and it is a legitimate course of scientific inquiry for Eric to argue that our West Antarctic results are incorrect based on independent analyses. What is entirely, wholly, and completely not legitimate is to use those same arguments to defend the method of his paper, as the former makes no statement on the latter.
If he wishes to argue that our results are incorrect, that’s fine. But if he wishes to defend his method, then it is time for him to begin advancing mathematically correct arguments why his method was better (or why our criticisms were not accurate). Otherwise, it is time for Eric to stop playing the carnival prognosticator’s game of using the end result to imply that an inappropriate use of information was somehow “the right way”.
***
The second salient point relates to the evidence Eric presents that our reconstruction is less accurate. When it comes to differences between the reconstruction and ground data, Eric focuses primarily on Byrd station. While his discussion seems reasonable at first glance, it is quite misleading. Let us examine Eric’s comments on Byrd in detail.
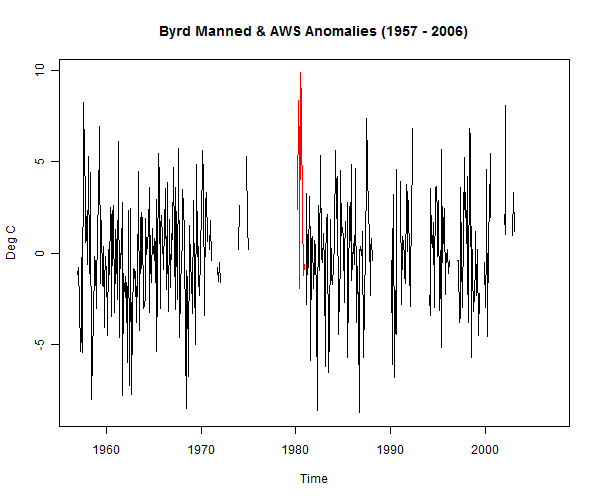
Eric first presents a plot where he displays a trendline of 0.38 +/- 0.2 Deg C / decade (Raw data) for 1957 – 2006. He claims that this is the ground data (in annual anomalies) for Byrd station. While there is not much untrue about this statement, there is certainly a lie of omission. To see this lie, we only need look at the raw data from Byrd over this period:

Pay close attention to the post-2000 timeframe. Notice how the winter months are absent? Now what do we suppose might happen if we fit a trend line to this data? One might go so far as to say that the conclusion is foregone.
So . . . would Eric Steig really do this? Of course not. A professional scientist would know better.
Trend check on the above plot: 0.38 Deg C / decade.
Hm.
By the way, the trend uncertainty when the trend is calculated this way is +/- 0.32, and, if one corrects for the serial correlation in the residuals, it jumps to +/- 0.86. But since neither of those tell the right story, I suppose the best option is to simply copy over the +/- 0.2 from the Monaghan reconstruction trend.
When calculated properly, the 50-year Byrd trend is 0.25 +/- 0.15 (corrected for serial correlation). This is still considerably higher than the Byrd location in our reconstruction, and is very close to the trend in the S09 reconstruction. However, we’ve yet to address the fact that the pre-1980 data comes from an entirely different sensor than the post-1980 data.
Eric notes this fact, and says:
Note that caution is in order in simply splicing these together, because sensor calibration issues could means that the 1°C difference is an overestimate (or an underestimate).
He then proceeds to splice them together anyway. His justification is that there is about a 1oC difference in the raw temperatures, and then goes on to state that there is independent evidence from a talk given at the AGU conference about a borehole measurement from the West Antarctic Ice Sheet Divide. This would be quite interesting, except that the first half of the statement is completely untrue.
If you look at the raw temperatures (which was how he computed his trend, so one might assume that he would compare raw temperatures here as well), the manned Byrd station shows a mean of -27.249 Deg C. The AWS station shows a mean of -27.149 . . . or a 0.1 Deg C difference. Perhaps he missed a decimal point.
However, since computing the trend using the raw data is unacceptable due to an uneven distribution of months for which data is present, computing the difference in temperature using the raw data is likewise unacceptable. The difference in temperature should be computed using anomalies to remove the annual cycle. If the calculation is done this (the proper) way, the manned Byrd station shows an average anomaly of -0.28 Deg C and the AWS station shows an average of 0.27 Deg C. This yields a difference of 0.55 Deg C . . . which is still not 1 Deg C.
Maybe he’s rounding up?
Seriously, Eric . . . are we playing horseshoes?
Of course, of this 0.55 Deg C difference, fully one-third is due to a single year (1980), which occurred 30 years ago:
Without 1980 – which occurs at the very beginning of the AWS record – the difference between the manned station anomalies and the AWS anomalies is 0.37 Deg C.
Furthermore, even if there were a 1 degree difference in the manned station and AWS values, this still doesn’t tell the story Eric wants it to.
The original Byrd station was located at 119 deg 24’ 14” W. The AWS station is located at 119 deg 32’ W. Seems like almost the same spot, right? The difference is only about 2.5 km. This is the same distance as that between McMurdo (elev. 32m) and Scott Base (elev. 20m). So if one can willy-nilly splice the Byrd station together, one would expect that the same could be done for McMurdo and Scott Base. So let’s look at the mean temperatures and trends for those two stations (both of which have nearly complete records).
McMurdo: -16.899 Deg. C (mean)
Scott Base: -19.850 Deg. C (mean)
That’s a 3 degree difference for stations at a similar elevation and a linear separation of 2.5 km . . . just like Byrd manned and Byrd AWS.
So what would the trend be if we spliced the first half of Scott Base with the second half of McMurdo?
1.05 +/- 0.19 Deg C / decade.
OMG . . . it is SO much worse than we thought!
Microclimate matters. Sensor differences matter. The fact that AWS stations are likely to show a warming bias compared to manned stations (as the distance between the sensor and the snow surface tends to decrease over time, and Antarctica shows a strong temperature gradient between the nominal 3m sensor height and the snow surface) matters. All of these are ignored by Eric, and he should know better.
Eric goes on to state that this meant we somehow used less available station data than he did:
On top of that, O’Donnell et al. do not appear to have used all of the information available from the weather stations. Byrd is actually composed of two different records, the occupied Byrd Station, which stops in 1980, and the Byrd AWS station which has episodically recorded temperatures at Byrd since then. O’Donnell et al. treat these as two independent data sets, and because their calculations (like ours) remove the mean of each record, O’Donnell et al. have removed information that might be rather important. namely, that the average temperatures in the AWS record (post 1980) are warmer — by about 1 Deg C — than the pre-1980 manned weather station record.
In reality, the situation is quite the opposite of what Eric implies. We have no a priori knowledge on how the two Byrd stations should be combined. We used the relationships between the two Byrd stations and the remainder of the Antarctic stations (with Scott Base and McMurdo –which show strong trends of 0.21 and 0.25 Deg C / decade – dominating the regression coefficients) to determine how far the two stations should be offset. By simply combining the two stations without considering how they relate to any other stations, it was Eric who threw this information away.
With this being said, combining the two station records without regard to how they relate to other stations does change our results. So if Eric could somehow justify doing so, our West Antarctic trend would increase from 0.10 Deg C / decade to 0.16 Deg C / decade, and the area of statistically significant trends would grow to cover the WAIS divide, yielding statistically significant warming over 56% (instead of 33%) of West Antarctica. However, to do so, Eric must justify why it is okay to allow RegEM to determine offsets for every other infilled point in Antarctica except Byrd, and furthermore must propose and justify a specific value for the offset. If RegEM cannot properly combine the Byrd stations via infilling missing values, then what confidence can we have that it can properly infill anything else? And if we have no confidence in RegEM’s ability to infill, then the entire S09 reconstruction – and, by extension, ours – are nothing more than mathematical artifacts.
However, to guard against this possibility (unlike S09), we used an alternative method to determine offsets as a check against RegEM (credit Jeff Id for this idea and the implementation). Rather than doing any infilling, we determined how far to offset non-overlapping stations by comparing mean temperatures between stations that were physically close, and using these relationships to provide the offsets. This method yielded patterns of temperature change that were nearly identical to the RegEM-infilled reconstructions, with a resulting West Antarctic trend of 0.12 Deg C / decade.
Lastly, Eric implies that his use of Byrd as a single station somehow makes his method more accurate. This is hardly true. Whether you use Byrd as a single station or two separate stations, the S09 answer changes by a mere 0.01 Deg C / decade in West Antarctica and 0.005 Deg C / decade at the Byrd location. The characteristic of being entirely impervious to changes in the “most critical” weather station data is a rather odd result for a method that is supposed to better utilize the station data.
Interestingly, if you pre-combine the Byrd data like Eric does and perform the reconstruction exactly like S09, the resulting infilled ground station trend at Byrd is 0.13 Deg C / Decade (fairly close to our gridded result). The S09 gridded result, however, is 0.25 Deg C / Decade – or almost double the ground station trend from their own RegEM infilling, and closer to our gridded result than to Eric’s.
(Weird. Didn’t Eric say their reconstruction better captures the ground station data from Byrd? Hm.)
Stranger yet, if you add a 0.1 Deg C / decade trend to the Peninsula stations, the S09 West Antarctic trend increases from 0.20 to 0.25 – with most of the increase occurring 2,500 km away from the Peninsula on the Ross Ice Shelf – the East Antarctic trend increases from 0.10 to 0.13 . . . but the Peninsula trend only increases from 0.13 to 0.15. So changes in trends at the Peninsula stations result in bigger changes in West and East Antarctica than in the Peninsula! Nor is this an artifact of retaining the satellite data (sorry, Eric, but I’m going to nip that potential arm-flailing argument in the bud). Using the modeled PCs instead of the raw PCs in the satellite era, the West trend goes from 0.16 to 0.22, East goes from 0.08 to 0.12, and the Peninsula only goes from 0.11 to 0.14.
(Weird. Didn’t Eric say their reconstruction better captures the ground station data from Byrd? Hm.)
And (nope, still not done with this game) EVEN STRANGER YET, if you add a whopping 0.5 Deg C / decade trend to Byrd (or five times what we added to the Peninsula), the S09 West Antarctic trend changes by . . . well . . . a mere 0.02 Deg C / decade, and the gridded trend at Byrd station rises massively from 0.25 to . . . well . . . 0.29. The Byrd station trend used to produce this result, however, clocks in at a rather respectable 0.75 Deg C / decade. Again, this is not an artifact of retaining the satellite data. If you use the modeled PCs, the West trend increases by 0.03 and the gridded trend at Byrd increases to only 0.26.
(Weird. Didn’t Eric say their reconstruction better captures the ground station data from Byrd? Hm.)
Now, what happens to our reconstruction if you add a 0.1 Deg C / decade trend to the Peninsula stations? Our East Antarctic trends go from 0.02 to . . . 0.02. Our West Antarctic trends go from 0.10 to 0.16, with all of the increase in Ellsworth Land (adjacent to the Peninsula). And the Peninsula trend goes from 0.35 to 0.45 . . . or the same 0.1 Deg C / decade we added to the Peninsula stations.
And what happens if you add a 0.5 Deg C / decade trend to Byrd? Why, the West Antarctic trend increases 260% from 0.10 to 0.26 Deg C / decade, and the gridded trend at Byrd Station increases to 0.59 Deg C / decade . . . with the East Antarctic trends increasing by a mere 0.01 and the Peninsula trends increasing by 0.02.
(Weird. Didn’t Eric say their reconstruction better captures the ground station data from Byrd? Hm.)
You see, Eric, the nice thing about getting the method right is that if the data changes – or more data becomes available (like, say, a better way to offset Byrd station than using the relationships to other stations), then the answer will change in response. So if someone uses our method with better data, they will get a better answer. If someone uses your method with better data, well, they will get the same answer . . . or they will get garbage. This is why I find this comment by you to be particularly ironic:
At some point, yes. It’s not very inspiring work, since the answer doesn’t change, but i suppose it has to get done. I had hoped O’Donnell et al. would simply get it right, and we’d be done with the ‘debate’, but unfortunately not.—eric
Eric’s claims that his reconstruction better capture the information from the station data are wholly and demonstrably false. With about 30 minutes of effort he could have proven this to himself . . . not only for his reconstruction, but also for ours. On that note, I found this comment by Eric to be particularly infuriating:
If you can get their code to work properly, let me know. It’s not exactly user friendly, as it is all in one file, and it takes some work to separate the modules.
Here’s how you do it, Eric:
- Go to CRAN (http://cran.r-project.org/) and download the latest version of R.
- Download our code here: http://www.climateaudit.info/data/odonnell
- Open up R.
- Open up our code in Notepad.
- Put your cursor at the very top of our code.
- Go all the way to the end of the code and SHIFT-CLICK.
- Press CTRL-C.
- Go to R.
- Press CTRL-V.
- Wait about 17 minutes for the reconstructions to compute.
Easy-peasy. You didn’t even try.
I am sick of arm-waving arguments, unsubstantiated claims, and uncalled-for snark. Did you think I wouldn’t check? I would have thought you would have learned quite the opposite from your experience reviewing our paper.
Oops.
Did I let something slip?
***
I mentioned at the beginning that I was planning to save the best for last.
I have known that Eric was, indeed, Reviewer A since early December. I knew this because I asked him. When I asked, I promised that I would keep the information in confidence, as I was merely curious if my guess that I had originally posted on tAV had been correct.
Throughout all of the questioning on Climate Audit, tAV, and Andy Revkin’s blog, I kept my mouth shut. When Dr. Thomas Crowley became interested in this, I kept my mouth shut. When Eric asked for a copy of our paper (which, of course, he already had) I kept my mouth shut. I had every intention of keeping my promise . . . and were it not for Eric’s latest post on RC, I would have continued to keep my mouth shut.
However, when someone makes a suggestion during review that we take and then later attempts to use that very same suggestion to disparage our paper, my obligation to keep my mouth shut ends.
(Note to Eric: unsubstantiated arm-waving may frustrate me, but duplicity is intolerable.)
Part of Eric’s post is spent on the choice to use individual ridge regression (iRidge) instead of TTLS for our main results. He makes the following comment:
Second, in their main reconstruction, O’Donnell et al. choose to use a routine from Tapio Schneider’s ‘RegEM’ code known as ‘iridge’ (individual ridge regression). This implementation of RegEM has the advantage of having a built-in cross validation function, which is supposed to provide a datapoint-by-datapoint optimization of the truncation parameters used in the least-squares calibrations. Yet at least two independent groups who have tested the performance of RegEM with iridge have found that it is prone to the underestimation of trends, given sparse and noisy data (e.g. Mann et al, 2007a, Mann et al., 2007b, Smerdon and Kaplan, 2007) and this is precisely why more recent work has favored the use of TTLS, rather than iridge, as the regularization method in RegEM in such situations. It is not surprising that O’Donnell et al (2010), by using iridge, do indeed appear to have dramatically underestimated long-term trends—the Byrd comparison leaves no other possible conclusion.
The first – and by far the biggest – problem that I have with this is that our original submission relied on TTLS. Eric questioned the choice of the truncation parameter, and we presented the work Nic and Jeff had done (using ridge regression, direct RLS with no infilling, and the nearest-station reconstructions) that all gave nearly identical results.
What was Eric’s recommendation during review?
My recommendation is that the editor insist that results showing the ‘mostly likely’ West Antarctic trends be shown in place of Figure 3. [these were the ridge regression results] While the written text does acknowledge that the rate of warming in West Antarctica is probably greater than shown, it is the figures that provide the main visual ‘take home message’ that most readers will come away with. I am not suggesting here that kgnd = 5 will necessarily provide the best estimate, as I had thought was implied in the earlier version of the text. Perhaps, as the authors suggest, kgnd should not be used at all, but the results from the ‘iridge’ infilling should be used instead. . . . I recognize that these results are relatively new – since they evidently result from suggestions made in my previous review [uh, no, not really, bud . . . we’d done those months previously . . . but thanks for the vanity check] – but this is not a compelling reason to leave this ‘future work’.
(emphasis and bracketed comment added by me)
And after we replaced the TTLS versions with the iRidge versions (which were virtually identical to the TTLS ones), what was Eric’s response?
The use of the ‘iridge’ procedure makes sense to me, and I suspect it really does give the best results. But O’Donnell et al. do not address the issue with this procedure raised by Mann et al., 2008, which Steig et al. cite as being the reason for using ttls in the regem algorithm. The reason given in Mann et al., is not computational efficiency — as O’Donnell et al state — but rather a bias that results when extrapolating (‘reconstruction’) rather than infilling is done. Mann et al. are very clear that better results are obtained when the data set is first reduced by taking the first M eigenvalues. O’Donnell et al. simply ignore this earlier work. At least a couple of sentences justifying that would seem appropriate. (emphasis added by me)
So Eric recommends that we replace our TTLS results with the ridge regression ones (which required a major rewrite of both the paper and the SI) and then agrees with us that the iRidge results are likely to be better . . . and promptly attempts to turn his own recommendation against us.
There are not enough vulgar words in the English language to properly articulate my disgust at his blatant dishonesty and duplicity.
The second infuriating aspect of this comment is that he tries to again misrepresent the Mann article to support his claim when he already knew otherwise. How do I know he knew otherwise? Because I told him so in the review response:
We have two topics to discuss here. First, reducing the data set (in this case, the AVHRR data) to the first M eigenvalues is irrelevant insofar as the choice of infilling algorithm is concerned. One could just as easily infill the missing portion of the selected PCs using ridge regression as TTLS, though some modifications would need to be made to extract modeled estimates for ridge. Since S09 did not use modeled estimates anyway, this is certainly not a distinguishing characteristic.
The proper reference for this is Mann et al. (2007), not (2008). This may seem trivial, but it is important to note that the procedure in the 2008 paper specifically mentions that dimensionality reduction was not performed for the predictors, and states that dimensionality reduction was performed in past studies to guard against collinearity, not – as the reviewer states – out of any claim of improved performance in the absence of collinear predictors. Of the two algorithms – TTLS and ridge – only ridge regression incorporates an automatic check to ensure against collinearity of predictors. TTLS relies on the operator to select an appropriate truncation parameter. Therefore, this would suggest a reason to prefer ridge over TTLS, not the other way around, contrary to the implications of both the reviewer and Mann et al. (2008).
The second topic concerns the bias. The bias issue (which is also mentioned in the Mann et al. 2007 JGR paper, not the 2008 PNAS paper) is attributed to a personal communication from Dr. Lee (2006) and is not elaborated beyond mentioning that it relates to the standardization method of Mann et al. (2005). Smerdon and Kaplan (2007) showed that the standardization bias between Rutherford et al. (2005) and Mann et al. (2005) results from sensitivity due to use of precalibration data during standardization. This is only a concern for pseudoproxy studies or test data studies, as precalibration data is not available in practice (and is certainly unavailable with respect to our reconstruction and S09).
In practice, the standardization sensitivity cannot be a reason for choosing ridge over TTLS unless one has access to the very data one is trying to reconstruct. This is a separate issue from whether TTLS is more accurate than ridge, which is what the reviewer seems to be implying by the term “bias” – perhaps meaning that the ridge estimator is not a variance-unbiased estimator. While true, the TTLS estimator is not variance-unbiased either, so this interpretation does not provide a reason for selecting TTLS over ridge. It should be clear that Mann et al. (2007) was referring to the standardization bias – which, as we have pointed out, depends on precalibration data being available, and is not an indicator of which method is more accurate.
More to [what we believe to be] the reviewer’s point, though Mann et al. (2005) did show in the Supporting Information where TTLS demonstrated improved performance compared to ridge, this was by example only, and cannot therefore be considered a general result. By contrast, Christiansen et al. (2009) demonstrated worse performance for TTLS in pseudoproxy studies when stochasticity is considered – confirming that the Mann et al. (2005) result is unlikely to be a general one. Indeed, our own study shows ridge to outperform TTLS (and to significantly outperform the S09 implementation of TTLS), providing additional confirmation that any general claims of increased TTLS accuracy over ridge is rather suspect.
We therefore chose to mention the only consideration that actually applies in this case, which is computational efficiency. While the other considerations mentioned in Mann et al. (2007) are certainly interesting, discussing them is extratopical and would require much more space than a single article would allow – certainly more than a few sentences.
Note some curious changes from Eric’s review comment and his RC post. In his review comment, he refers to Mann 2008. I correct him, and let him know that the proper reference is Mann 2007. He also makes no mention of Smerdon’s paper. I do. I also took the time to explain, in excruciating detail, that the “bias” referred to in both papers is standardization bias, not variance bias in the predicted values.
So what does Eric do? Why, he changes the references to the ones I provided (notably, excluding the Christiansen paper) and proceeds to misrepresent them in exactly the same fashion that he tried during the review process! Wow. What honesty.
And by the way, in case anyone (including Eric) is wondering if I am the one who is misrepresenting Jason Smerdon’s paper, fear not. Nic and I contacted him by email to ensure our description was accurate.
But the B.S. piles even deeper. Eric implies that the reason the Byrd trends are lower is due to variance loss associated with iRidge. He apparently did not bother to check that his reconstruction shows a 16.5% variance loss (on average) in the pre-satellite era when compared to ours. The reason for choosing the pre-satellite era is that the satellite era in S09 is entirely AVHRR data, and is thus not dependent on the regression method. We also pointed this out during the review . . . specifically with respect to the Byrd station data. Variance loss due to regularization bias has absolutely NOTHING to do with the lower West Antarctic trends in our reconstruction . . . and Eric knows it.
This knowledge, of course, does not seem to stop him from implying the opposite.
Then Eric moves on to the TTLS reconstructions from the SI, grabs the kgnd = 6 reconstruction, and says, “See? Overfitting!” without, of course, providing any evidence that this is the case. He goes on to surmise that the reason for the overfitting is that our cross-validation procedure selected the improper number of modes to retain – yet again without providing any evidence that this is the case (other than it better matches his reconstruction).
So if Eric is right, then using kgnd = 6 should better capture the Byrd trends than kgnd = 7, right? Let’s see if that happens, shall we?
If we perform our same test as before (combining the two Byrd stations and adding a 0.5 Deg C trend), we get:
Infilled trend (kgnd = 6): 0.45 Deg C / decade
Infilled trend (kgnd = 7): 0.52 Deg C / decade
Weird. It looks as if the kgnd = 7 option better captures the Byrd trend . . . didn’t Eric say the opposite? Hm.
These translate into reconstruction trends at the Byrd location of 0.42 and 0.45 Deg C / decade, respectively (you can try other, more reasonable trends if you want . . . it doesn’t matter). I also note that the TTLS reconstructions do a poorer job of capturing the Byrd ground station trend than the iRidge reconstructions, which is the opposite behavior suggested by Eric (and this was noted during the review process as well).
Perhaps Eric meant that we overfit the “data rich” area of the Peninsula? Fear not, dear Reader, we also have a test for that! Let’s add our 0.1 Deg C / decade trend to the Peninsula stations, shall we, and see what results:
Recon trend increase (kgnd = 6): Peninsula +0.08, West +0.02, East +0.02
Recon trend increase (kgnd = 7): Peninsula + 0.11, West +0.03, East +0.01
Weird. It looks as if the kgnd = 7 option better captures the Peninsula trend with a similar effect on the East or West trends . . . didn’t Eric say the opposite? Hm.
By the way, Eric also fails to note that the kgnd = 5 and 6 Peninsula trends, when compared to the corresponding station trends, are outside the 95% CIs for the stations. I guess that’s okay, though, since the only station that really matters in all of Antarctica is Byrd (even though his own reconstruction is entirely immune to changes at Byrd).
As far as the other misrepresentations go in his post, I’m done with the games. These were all brought up by Eric during the review. Rather than go into detail here, I have simply made all of the versions of our paper, the reviews, and the responses available at http://www.climateaudit.info/data/odonnell.
***
My final comment is that this is not the first time.
At the end of his post, Eric suggests that the interested Reader see his post “On Overfitting”. I suggest the interested Reader do exactly that. In fact, I suggest the interested Reader spend a good deal of time on the “On Overfitting” post to fully absorb what Eric was saying about PC retention. Following this, I suggest that the interested Reader examine my posts in that thread.
Once this is completed, the interested Reader may find Review A rather . . . well . . . interesting when the Reader comes to the part where Eric talks about PC retention.
Fool me once, shame on you. But twice isn’t going to happen, bud.
Well done Ryan. The dishonesty Steig, as an individual isn’t that surprising. The group dishonesty implied by these revelations are far reaching. I wonder which part of the replication process is tripping up these mental midgets? Maybe keyboard shortcuts are too tricky for them……….. alternate method! Right click, move cursor down to “paste”. Left click…….haahahaha
Can I be the first to say:”Lies, damn lies and statistics.”
This strikes me as just another example of Mannian Maths being employed by Eric.
Most of us don’t understand the intricacies of advanced statistics – a sad fact we unfortunately share with the all those practicioners of ‘climate science’.
So here is a rare example of where the ordinary sceptic and the typical ‘climate scientist’ have something in common.
“Based on the content, it would not have made it past moderation anyway.”
Which content in particular? Can you point to any specific portions that you believe RC would reject?
Bravo!
Wow! Official reprimands need to be issued for such behavior. A big apology is in order here, as well. You should be ashamed of yourself, Eric Steig.
It wou,d take me days to read the papers and posts, then look at the references, and bone up on the statistical methods used to analyse the data, in order to make up my mind on who is right in this controversy about the analysis of Antarctic temperature data. It is clear that the scientists on both sides, who have done the work on this, have invested a lot of time and energy in it. I don’t have the time to do that. What I have gleaned from this exchange is that the Antarctic region has a shortage of data, and what is really going on is hard to reconstruct.
My impression is that ice core data shows that in the past, Antarctica and Greenland have had temperature changes which opposed each other due to ocean current oscillations.
http://www.geotimes.org/nov06/WebExtra111006.html
The findings suggest that as Antarctica gradually warms, Greenland cools. Likewise, as soon as Greenland’s temperature starts warming up, temperatures in Antarctica start to fall. And that’s not just the case with temperature spikes, Fischer says. “Even the smaller wiggles are directly related,” he says. This change is “astoundingly regular.”
Climate models suggest that the roughly inverse relationship the EPICA team observed is the result of a large change in heat in the Atlantic, Fischer says. The global pattern of currents known as the ocean conveyor belt shuttles warm, salty water northward from the Southern Hemisphere up along the coast of North America and around Europe, keeping the climate mild in these areas. As it carries heat northward to the North Atlantic, it depletes the South Atlantic of heat, thus warming Greenland and cooling Antarctica. Similarly, a slowdown in the strength of the currents could also cause a so-called positive feedback in the Southern Hemisphere: Instead of the warm water moving northward, it would stay in the south and warm up Antarctica.
Crickets chirping at RC, for the nonce.
shameful
Sister Michael Joseph in 3rd grade used to lecture us about the necessity of “avoiding bad companions.” I’ve seen Dr. Steig make a number of honest, genuine, off-the-cuff remarks both here and in other forums. Somehow, when he hangs out at RC, he becomes someone else. Do you suppose Sister was right?
I have to say, I absolutely love the writing style here. Very well toned, yet sharp and to the point, and eloquently so! Makes reading such dense, deep material particularly easy, as well as even fun.
Fascinating turn of events. I saw the RC post earlier myself and was taken by it, so seeing this response holds a lot of meaning to me.
Keep up the good fight for integrity and honesty in science; without which we cease to be scientists and become politicians.
It appears to me that Eric Steig is simply extremely jealous that someone “from the outside” dared to criticize and improve upon work done by one of the “climate elites”.
He is waging a war of utter pettiness, and will apparently not stop until he is vindicated and O’Donnell et al are vanquished.
I know from observation that this behavior is widespread in climate science, but I wonder if this sort of manic personality trait is also exhibited in other areas of science…
Wow!
Their reputations, careers and livelihoods depends on continuing the CAGW charade.
They will stop at nothing to preserve the charade. Nothing.
Atlas Shrugged.
I absolutely cannot believe that the journal allowed Eric Steig to referee the O’Donnell et al paper. For the same reason a publisher does not seek colleagues of the author as reviewers, it does not seek reviewers who’s papers are being challenged by the authors. That the journal sought Steig as a reviewer was an obvious bias and conflict of interest that both the publisher and Steig knew full well.
That Steig now criticizes the very changes he recommended in review is very revealing. He either intended to pull the wool over the eyes of the editor (who likely didn’t have the subject matter expertise to catch the ruse) in order to flame the paper after publication or he now grabs at straws, and apparently the wrong straws, to criticize the paper after the fact to save face. I personally believe the latter as the former would be a high risk gamble I don’t think Steig’s cohorts (ghost reviewers) would advise in favor of. Good on Jeff to break silence and expose the shoddy practices of the journal and self serving behavior of Steig.
With the above said, the fact that O’Donnell et al passed review in the face of such an antagonistic review process is a testimony to the soundness of the paper and, in my opinion, further underscores the soundness of methodology of the paper.
Before this gets too out of hand, I’ve said before (and I will stand by this statement) that the journal and editor did a commendable job of sorting through everything. An additional reviewer was, indeed, added in the middle of the process to arbitrate, and I believe that Journal of Climate and Dr. Anthony Broccoli did a fine job with this situation.
I would ask that people refrain from criticizing JoC or Dr. Anthony Broccoli.
Ryan,
Sorry but could you please clarify something. When you said that you asked Eric if he was Reviwer A, what was his actual response? Did he agree with you and say he was Reviwer A? Its not clear from your paragraph what his response was.
Id like to know this for certain before I start wading in to a few alarmists who dismissed the idea that Reviwer A was someone from “The Team”.
Regards
Mailman
This is quite shocking. In some ways it shouldn’t be as in the past I have met some very strange people for whom the elitism of the academic meritocracy must be upheld at all cost, and so convinced are they of their own merit that they are willing to subvert others’ participation to stay ahead.
Eric Steig must be a very insecure person.
Just a thought – is it possible that it is not the real Eric Steig you are dealing with at Real Climate but someone impersonating him (who therefore does not know the contents of the review process)? This sounds like the normal ‘games’ at RC. Surely ES would have the wit to realise you would call him on this. Either way RC does not come out of this well.
In my field (medical research), as I suppose other science fields, there are the manic personalities that will fight unfairly and indeed unscrupulously to rise to the top. But I think it fair to say that more mature science fields have a much broader scope of players who have an interest in exposing such behavior. Indeed, in my field the clinical review process culls out such individuals rather unceremoniously. The manic individuals are usually discredited and sent to flipping hamburgers for a living where they can argue with patrons wanting to have it their way. I think where climate science differs is grant funding is preconditioned on keeping the CAGW train on the track as there is little to no money to be made over climate as usual. The pool of independent scientists who’s interests would be served by promoting the science rather than the politics is not sufficiently large enough to police the ranks [yet].
Ryan:
Impressive stuff. So much work to clean up a mess not of your own making. Please keep us informed of Eric’s responses, if any.
Noelle:
I assume that you have not tried to make substantive criticisms at RC, let alone lengthy substantive criticisms.
Verity,
I doubt the clowns over at RC and the clowns that read their dross really care about how things look. All they care about is circling the wagons and protecting the received wisdom of Mann Made Global Warming ™.
Regards
Mailman
” Zero. Nilch. Nada.”I/i>
I believe the proper term is “Zilch.”
Bravo on the balance of the post!
This pretty much summarizes everything that’s wrong with ‘mainstream’ climate science in one place.
‘Correct’ results matter more than honest method, and no outsiders need apply.
Thanks again to Ryan, Jeff, and all the rest prepared to take up the cause.
This sort of nonsense is so bush-league – what embarassing behavior from a scientist. Unfortunately, it’s all that surprising, given the shenanigans from the Hockey Team over the past 5 years. But a shame. It would be great if Curry and other scientists with some integrity will publicly blast this sort of behavior in an effort to put their own house back in order.
Notwithstanding Ryan’s gracious words with respect to the journal in question but…..
Is it at all normal – in any field – to have a reviewer who is also the author of the paper being challenged? I realize Ryan is happy with how it was handled – which is good to hear – but how out of the ordinary is this scenerio in the science publishing landscape in the first place?
well written and documented, the inclusion of the reviewer was a mistake that the editors need to answer for.
Again a well written rebuttal allthough I don’t think he needed the brass knuckles….
with data as sketchy as this how can anyone try to divine any meanigful information from it ?
everyone is guessing based on incomplete and shifting data …
“when there are 2 distinctly different cures for the same illness neither doctor “knows” what the problem actually is …”
eadler says:
February 7, 2011 at 11:27 am
It wou,d take me days to read the papers and posts,……… in order to make up my mind on who is right in this controversy about the analysis of Antarctic temperature data.
========================================================
eadler, that’s all you took from the posting????? I think this post substantially moves the conversation from arguing a point of triviality to many other more significant topics.
Ryan O’Donnell says:
February 7, 2011 at 12:16 pm
“I would ask that people refrain from criticizing JoC or Dr. Anthony Broccoli.”
Ryan, the genie is out of the bottle. In deference to you, I’ll refrain, at this moment. But this leaves some very specific questions that should be asked and answered.
@ Noelle says:
February 7, 2011 at 11:19 am
“Which content in particular? Can you point to any specific portions that you believe RC would reject?”
The text that starts with “However, once Eric puts on his RealClimate hat,……” and ends with “………Fool me once, shame on you. But twice isn’t going to happen, bud.”
Noelle, if you read RC very often, you should know most of the skeptical comments don’t get through. It doesn’t matter how one words it,(polite or sharp) they simply will not allow a point they cannot immediately counter to come through. It doesn’t happen. Its why I quit bothering to read the garbage.
Verity Jones says:
February 7, 2011 at 12:28 pm
Surely ES would have the wit ………
=========================================================
I’m not sure, apparently he had difficulty with the “download, copy and paste” trick so……….
I am most taken aback by this whole affair. RC and Steig should be ashamed. I just read O’Donnell’s post at CA and then came here. I can can understand Id’s motivation. This is one example of why I refuse to even visit RC. Little on it can be trusted. Steig and most of the others at RC have long ago lost the privilege of using the name scientist. To call oneself a scientist not only implies some educational background but demands adherence to the philosophical principles of science as defined by Popper and others. Steig has failed to live up.
Eadler: “It wou,d take me days to read the papers and posts, then look at the references, and bone up on the statistical methods used to analyse the data, in order to make up my mind on who is right in this controversy about the analysis of Antarctic temperature data. It is clear that the scientists on both sides, who have done the work on this, have invested a lot of time and energy in it. I don’t have the time to do that. What I have gleaned from this exchange is that the Antarctic region has a shortage of data, and what is really going on is hard to reconstruct.
My impression is that ice core data shows that in the past, Antarctica and Greenland have had temperature changes which opposed each other due to ocean current oscillations.”
+++
Next time Ryan should consult with you perhaps… LOL
Any other Oracle?
This is much more damning than “climategate”…
More vocabulary – I believe what Eric Steig is engaged in is called carping.
carping (n) – persistent petty and unjustified criticism; faultfinding;
TomRude says:
February 7, 2011 at 1:33 pm
This is much more damning than “climategate”…
My words exactly in an email informing Mr Hill of this event. Nothing here has to be guessed at or put together. I’m not even talking about the fact that Eric reviewed Ryan et al’s paper, I am speaking of him having him change the paper to what he thought of as a better method and then getting on RC and criticizing that change. It’s dishonest to an amazing extent.
Whilst I share the frustration with having to deal with a hostile reviewer, I’m not sure about the wisdom of outing & shouting at them.
I would have thought that it would have been better to go through the editorial panel first with the complaint of deliberate misinterpretation of which he seems to have amassed a lot of evidence.
Sadly, one of the problems of peer review in a very select study area is that you are likely to get reviewed by someone is competing with you for recognition is the same space.
The temptation, as seen in Climategate, to sit on any new upstarts must be very real.
The answer?
Battle it out in the Blogs?
Are they to become a sort of lower house?
Its a possibility but the signal to noise ratio is low
One has to wonder exactly what RC’s strategy is. Or whether they are just too lacking in mental horsepower to have one.
Because if what they are doing is the tangible result of their conscious thought they shouldn’t be placed in charge of a whelk stall, let alone ‘real climate from real climate scientists’. First Schmidt and his cronies can;t make their minds up whether or not they think the science is settled, now Steig appears to have dropped both b.ll…s bigtime.
Not so long ago they considered themselves to be masters of the universe. Now they give the impression that they couldn’t reliably tell the time with their Micky Mouse watches.
Nice work, gentlemen. It is a black eye for science if a reviewer of a rebuttal paper is the author of the paper being rebutted. Yes, Stieg should be allowed to respond, but to review?
Darkinbad the Brightdayler says:
February 7, 2011 at 1:42 pm
I’m not going to quite your whole text but um, I think you missed the whole point. He wasn’t “competing” with Ryan, he was reviewing a paper that was a rebuttal to his own work. This is far and away a big no-no. Again, that isn’t even the biggest problem. The problem was the deceit Eric went through afterward. He asked Ryan to change a rather important method, then got on RC to rip him for making a change he himself as a review asked for. That isn’t something that a publication is going to be able to deal with at all. We aren’t talking about Eric misrepresenting the findings of Ryan, we are talking about Eric deliberately misrepresenting his own review.
AJ Abrams, how about misconduct? In the private sector that would get you fired with cause…
Noelle, the only time I had comments accepted in full (if at all) at RC was when I and others were parallel posting the full comments at Bishophill simultaneously as submitting them to RC. Even then the dialogue is very one-sided, with some posts being arbitrarily cut for no apparent reason while the most fatuous and snarky comments from pro-AGW cheerleaders always go through unscathed.
If Ryan had posted at RC it would either have not been allowed, or parts of ti would be cut so as use statements out of context. Its pretty pointless. Contrast RC behaviour with say WUWT where articles from all sides are encouraged and, apart from downright unpleasant remarks, little is moderated and there is no censorship.
Its pretty depressing to think that RC is supposedly the pinnacle of understanding in climate science and explanation run by the very high profile scientists such as Mann, Schmidt, Steig etc and yet they have to resort to censorship and bizarre rebuttals to keep everything on message. They more they carry on the more their collective credibility ebbs away until they will eventually be talking just to themselves. What the RC crowd seem to overlook is that people such as McKintyre, JeffID, RyanO, Willis Eschenbach and many others really do know what they are talking about and they are very tenacious, persitent, rarely make mistakes and when they do they have the grace to correct them. As was once attributed to Maynard Keynes, when asked what he would do if he was shown to be wrong, he is said to have replied “When the facts change, I change my mind – what do you do, sir?”.
Backstabbing and professional jealousy is as old as mankind. As much as we’d like to imagine practitioners in all fields of science as fundamentally “seeking truth”, the reality is that science is, as often as not, a competitive instrument of personal ambition and self-aggrandizement with the long knives flashing and slashing, for the most part, under the table.
I find it hugely entertaining to see someone like ODonnell lift the table and give us a glimpse of those flashing and slashing knives.
TomRude says:
February 7, 2011 at 1:54 pm
AJ Abrams, how about misconduct? In the private sector that would get you fired with cause…
We could go down that route, but we’ve already proven time and again that there is no way theses guys are going to be fired from anything, ever. Hell they might give him another cover of Time.
This is outrageous. Steig may very well be in violation of any academic code of conduct that his school has in effect. I emailed the department head to refer me to the code so I can review it.
Darkinbad the Brightdayler says:
February 7, 2011 at 1:42 pm
The answer?
========================================================
Honesty, character, and integrity. I know, it’s a revolutionary thought, but it is still the answer. But then, were climate science to have these characteristics as representative of the whole, the climate changing would not be an issue discussed on a daily basis.
I’m still struggling to find the relevance of any warming in Antarctica given for example the raw Byrd data shown above. We seem to be discussing tenths of one degree Centigrade per decade when seasonal temperature changes are in the order of 25 degrees and even the warmest temperatures are still a good 15 degrees below freezing! It’s still friggin’ cold, folks!!
Frank K. says:
February 7, 2011 at 1:41 pm
More vocabulary – I believe what Eric Steig is engaged in is called carping.
carping (n) – persistent petty and unjustified criticism; faultfinding;
========================================================
I think you’re being very generous. If he knowingly demanded a change in the paper, and then went to RC to criticize the change, ……….. I’m not sure what you call that?? I’ve never heard of anything like that being done………maybe he’ll live in infamy with a new word………. he tried to steig O’Donnall’s paper!!!
Eric Steig is under the spell of Gavin “Darth Vader” Schmidt.
Had to go and look at the comments at RC. Liked this simple, innocent question:
42 Vernon says:
5 Feb 2011 at 8:34 PM
Why are responses from one of the co-authors not being posted? That seems counter productive.
To which the slap-down reply is:
[Response: If said co-author could stick to the point at hand, said co-author would get listened to.–eric]
In other words, we are only going to discuss what Eric wants to discuss at RC. Hey Eric – why don’t you go and debate this at ClimateAudit.org? At least then we will all know the comments are not being censored.
@ Darkinbad the Brightdayler:
As already mentioned, the review process itself was part of the problem. When the process doesn’t work anymore, I say let the truth be known for all to see. Getting mired in pointless procedural correctness is one of the problems in the first place.
Bravo to Jeff for standing up and calling them out. Its a scathing review.
It would appear we need a review of the scientific method … LOL
Just… wow.
Some 30 years ago, a friend of mine graduated in Marine Biology but because there was no money in it he became a banker. Now, of course, there is ample funding for marine biologists, as long as they promote AGW. Scientific research has become corrupted by the theory of AGW to the point where research is being treated with cynicism by lay people and scientists who claim record-breaking cold is caused by AGW are being laughed at. Fortunately, scientists are not yet held in the same contempt as bankers, but the greed of the peddlers of AGW porn is making them blind to the perfidious path they tread. Historians of science will be savage when they come to write about the disingenuous conspiricies surrounding AGW and its proponents, especially if they’re having to write by candlelight in the freezing cold because the wind isn’t blowing.
An excellent example of why journals are leary about publishing outsiders whose reputation and livliehood does not depend on “good relations in the community”. They won’t take being knifed in the back in such a manner with a thin smile and a mental note to return the favor likewise some day down the road.
Instead they go and cause a public nuisance that embarrasses everyone. . .
At least I suspect that is how it will be seen by “the Club”.
Statistically, about 1 in 100 lawyers are thrown out of their profession during their careers, about 1 in 100 doctors, etc. Fortunately, no climatologist has ever been disciplined.
Q. Why is it that climatologists are so much better than the other professional classes?
A. All climatologists have been exonerated by 3 independent inquiries (at a minimum).
This brings graphically to life the intention to abuse the peer review process outlined by The Team in the Climategate emails
Snipped from the newest post made at realclimate.org:
The html tags did not work. Here is the post from Realclimate that I was trying to cite:
RE: Vernon at 42 says:
““Why are responses from one of the co-authors not being posted? That seems counter productive.”
Two of the authors RyanO and JeffID are posting at ClimateAudit.org and Wattsupwiththat.com
Hey Eric – why don’t you go and debate this at ClimateAudit.org? At least then we will all know the comments are not being censored.[edit for insulting remarks].
[Response:Know what? I have a day job. And those guys know perfectly well I do not read those sites without a good reason to, and telling me I have ‘explaining to do’ doesn’t rise to that level. If they have scientific points to make, they should make them here.–eric]
Comment by ThinkingScientist — 7 Feb 2011 @ 5:24 PM”
After climategate none of this surprises me. I’ve experienced RC censorship as described above. Snide comments from Gavin and buddies when they don’t agree with you, and any further postings you try and make showing evidence for your position are blocked. They are like little children, hiding behind their mommies skirts, darting out to throw rocks when the other kids on the block walk by. What is shows is RealScience = JunkScience. Like countries that use “democratic” in their name, if they need to use “Real” in their name, you can be sure they anything but.
I’ve never used “R” before. Following the above instructions I installed it on win 7×64, cut and pasted “RO10Code.txt” into “R” and after churning away for awhile up popped a screen with 3 graphs, showing Deg C, Variance, and # Eff Parameters. It’s still churning away so maybe more will happen?
> main.gnd = emFn(Yo, maxiter = 500, tol = 0.0005, type = “iridge”, plt = c(T, 1), DoFL = 12)
10: Relative: 1.78244; RMS: 0.054; Stagnation: 0.03029.
20: Relative: 1.93936; RMS: 0.01585; Stagnation: 0.00817.
30: Relative: 1.97744; RMS: 0.00709; Stagnation: 0.00359.
40: Relative: 1.99406; RMS: 0.00434; Stagnation: 0.00218.
50: Relative: 2.00321; RMS: 0.00296; Stagnation: 0.00148.
60: Relative: 2.00888; RMS: 0.00219; Stagnation: 0.00109.
70: Relative: 2.01275; RMS: 0.00171; Stagnation: 0.00085.
80: Relative: 2.01564; RMS: 0.00142; Stagnation: 7e-04.
90: Relative: 2.0179; RMS: 0.00129; Stagnation: 0.00064.
100: Relative: 2.02002; RMS: 0.00297; Stagnation: 0.00147.
Thank you Jeff.
geoo50, from what I remember, I think it will converge after 141 iterations. 😉
http://www.youtube.com/user/TheAtheistAntidote#p/search/0/WftNsz1Nhz8
This expresses my thoughts on the boys at RC
RE GeorgeGR
The “[edit for insulting remarks]” can be seen in full cross-posted at Bishophill where I cross-post whenever posting at RC. Its as telling see what is left out as reading the RC replies. For convenience, the edited “insulting remarks” I made were:
“And judging by the comments of RyanO at CA, which we all know you will have read by now, you have some serious explaining to do. Try doing that without RC moderation to hide behind.”
geoo50, I found your comment extremely amusing. Good one. Now can anyone get their granny to do it, it would be hilarious.
It converged and is now infilling AVHRR PC 1,2…124,125, and the graphs are cycling as this happens. Sort of like watching a Chinese movie. Things are happening on the screen, but I haven’t got a clue what they mean. Oh, I’ve now moved on to “RLS using 126 satellite spatial eigenvectors.” Don’t tell me the ending I don’t want to spoil it.
Looks like I got an error near the end:
Error in getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, :
binary operation on non-conformable arrays
>
here is more detail:
> ### Calculate stats for just 1982 – 2006
>
> eigen.stats.57.82 = getStats(grid.orig[301:600, ], eigen.grid[301:600, ], idx[301:600, ])[[1]]
> rls.stats.57.82 = getStats(grid.orig[301:600, ], rls.grid[301:600, ], idx[301:600, ])[[1]]
> S09.stats.57.82 = getStats(grid.orig[301:600, ], S09.grid[301:600, ], idx[301:600, ])[[1]]
> avhrr.stats = getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, ])[[1]]
Error in getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, :
binary operation on non-conformable arrays
>
>
> ###==============================================
> ### EIGEN AND RLS SATELLITE STATS FOR COMPARISON
> ###==============================================
>
> ### Compare EIGEN and RLS vs. satellite
>
> eigen.sat.stats = getStats(makeAnom(all.avhrr), window(recon.eigen[[1]], start = 1982))
> rls.sat.stats = getStats(makeAnom(all.avhrr), window(recon.rls[[1]], start = 1982))
>
> ### Compare S09 unspliced solution vs. satellite
>
> S09.sat.stats = getStats(makeAnom(all.avhrr), window(recon.S09[[1]], start = 1982))
>
>
> ################################################################################
> ###################### END VERIFICATION ######################
> ################################################################################
>
>
>
[Response:Know what? I have a day job. And those guys know perfectly well I do not read those sites without a good reason to, and telling me I have ‘explaining to do’ doesn’t rise to that level. If they have scientific points to make, they should make them here.–eric]
+++
LOL, that’s keeping with the character exposed… digging deeper!
Ryan, I appreciate your respect for how the Journal handled the situation and I am pleased that they brought in an additional reviewer as they should have. It is to their credit for doing so. However, bringing Steig onboard as a reviewer is difficult for me to reconcile in the context of my personal experience with clinical peer review.
Putting that concern aside, the behavior of Steig recommending a change in methodology during review under the anonymity of a blind review process then publicly criticizing the change after publication (and now exposed) throws more than just his own reputation under the bus. I would hope that the Journal will make inquiry (as any other journal would) as it appears he has abused his position as a reviewer for self interests.
Ryan – As I said over on CA, I rarely post, but making an exception today. I wanted to personally thank you for all your clear , concise work and for your efforts in getting your work published after facing what you did. You have a respect from me that I cannot put easily into words. Thank you so much for your work and today’s clearing of the air.
geoo50, depending on the amount of memory you have, you may have run out of memory during the recon.eigen computation. I’ve got a quad-core with 4 GB of RAM, and it ran just fine. Crashed at a similar spot on my laptop (1GB, single-processor) though.
🙁
Sorry . . . the operations are quite memory intensive.
At http://noconsensus.wordpress.com/2010/12/01/doing-it-ourselves/ JeffID posted the following:
“The review process unfortunately took longer than expected, primarily due to one reviewer in particular. The total number of pages dedicated by just that reviewer alone and our subsequent responses – was 88 single-spaced pages, or more than 10 times the length of the paper.”
Was that Reviewer A, aka Steig?
ge0050 says:
February 7, 2011 at 3:23 pm
Looks like I got an error near the end:
========================================================
Was the R downloaded made for use by Win 7 64 bit?
ThinkingScientist: Yes.
Well????
Doesnt it feél comfortable and safe that these are the guys the worlds leader is having as consultants and advisors?.
“The worlds leading climate scientists” makes you wonder whats the bad ones are like? And I really wonder how our governments is so skillfull in picking out just the rutten eggs from the scientific basket.
Is there a secret code within science that all the noogooders gets the political assignments and the goood ones have market value?
Jeff you really exposed the RC gang för what they are.And I thank you for that.No wonder RCs members is hiding in thier bunker and I cant feel sorry for them as the co2 level increases with every hatchet they close.
ge0050
At the console before you run type Sys.info()
http://stat.ethz.ch/R-manual/R-patched/library/base/html/Sys.info.html
Also sessionInfo()
http://stat.ethz.ch/R-manual/R-patched/library/utils/html/sessionInfo.html
Then run the program.
If it fails, Type in traceback()
C&P all the previous and send to ryan
That should give enough detail for Ryan to track down the issue.
@James Sexton
> Was the R downloaded made for use by Win 7 64 bit?
It ran OK on my 32-bit Win/XP R installation (with 3GB ram).
Comment: [Response:Know what? I have a day job. And those guys know perfectly well I do not read those sites without a good reason to, and telling me I have ‘explaining to do’ doesn’t rise to that level. If they have scientific points to make, they should make them here.–eric]
Translation: [Whaaaaaaaaaaaah. Mommeeeeeeee!! Ryan and Jeff are being MEAN too me. Make them stop! Whaaaaaaaaaaah!]
@MattH i think the relevance of warming in the antarctic however small was that it meant that antarctica finally came in from the cold and became part of the global warming world. this obviously was very important to them.cant have a whole continent disagreeing with the team
MattH at 2:07 pm sez:
We seem to be discussing tenths of one degree Centigrade per decade when seasonal temperature changes are in the order of 25 degrees and even the warmest temperatures are still a good 15 degrees below freezing! It’s still friggin’ cold, folks!!
Agreed, exactly. The anomaly could be 100 times greater (1/10th times 100 = ten degrees) and STILL the biggest chunk of ice on the planet –two kilometers thick and 15 million square kilometers in diameter — would be 5 degrees below the “melting” point; and STILL would have heat of fusion to suck up before it started to liquify.
The torch on the Statue of Liberty will not be underwater this century due to this scale of climate change — DVD covers to the contrary.
By the way, remind me to discuss how 37 degrees centigrade (plus or minus over one degree) became “ninety-eight-point-six” (F) when the German medical journals were translated into American English. Also how the German instruments were biased warm by over one degree C. Tenths of a degree, people, are difficult to measure. And we can’t do “stats” on measurements this way. We just can’t.
Dr. ODonnel,
seems as I was the first who tried to run “R010 Code.txt” to under Unix. Trying to do so ends with R not finding tir_lons.txt and tir_lats.txt within local filesystem. See patch below.
Best
diff -u a/RO10 Code.txt b/RO10 Code.txt
— a/RO10 Code.txt 2011-02-08 01:16:39.000000000 +0100
+++ b/RO10 Code.txt 2011-02-08 01:41:12.000000000 +0100
@@ -1272,8 +1272,8 @@
rm(grid)
### Load longitude/latitude coordinates
– lon = read.table(“tir_lons.txt”)
– lat = read.table(“tir_lats.txt”)
+ lon = read.table(“Tir_lons.txt”)
+ lat = read.table(“Tir_lats.txt”)
sat.coord = cbind(lon,lat)
### Load S09 recon
James Sexton says:
February 7, 2011 at 1:13 pm
eadler says:
February 7, 2011 at 11:27 am
It would take me days to read the papers and posts,……… in order to make up my mind on who is right in this controversy about the analysis of Antarctic temperature data.
========================================================
eadler, that’s all you took from the posting????? I think this post substantially moves the conversation from arguing a point of triviality to many other more significant topics.
To me this seems a difference of opinion about how to use the sparse weather station data on the Antarctic to fill in the temperature record, using statistical techniques. There also is an element of personal rivalry, which is not uncommon in the world of scientific research. Exactly what is happening in the Antarctic is really uncertain, and it will take more studies and time to figure it out.
http://en.wikipedia.org/wiki/Antarctica_cooling_controversy#cite_note-3
http://pubs.giss.nasa.gov/docs/2004/2004_Shindell_Schmidt.pdf
The West Antarctic Peninsula, which is a narrow waist extending into the ocean, is an exception because its average temperature is only slightly below freezing, and the disappearance of sea ice will have a great effect on it.
http://www.coolantarctica.com/Antarctica%20fact%20file/science/global_warming.htm
The Antarctic Peninsula, particularly the West coast of the Peninsula is warming at a rate about 10 times faster than the global average. This has received a great deal of publicity in recent years and of course is where the Larsen B ice shelf (see above) is situated. The average annual temperature of this region has increased by nearly 3°C in the last 50 years.
However, data on temperatures in Antarctica only really go back about 50 years, anything beyond that is surmised from ice cores or other sources and so we don’t really know how the temperatures vary over even the medium term in Antarctica.
The Antarctic Peninsula also represents only about 4% of the whole continent, the other 96% appears to have had a stable temperature over the last 40 years to the extent where the most remarkable aspect is the stability compared to other parts of the world.
What are the significant topics that you see arising from this?
David M says:
February 7, 2011 at 1:07 pm
Notwithstanding Ryan’s gracious words with respect to the journal in question but…..
Is it at all normal – in any field – to have a reviewer who is also the author of the paper being challenged? I realize Ryan is happy with how it was handled – which is good to hear – but how out of the ordinary is this scenerio in the science publishing landscape in the first place?
========================================================
Those of us who sit on corporate or volunteer boards recuse ourselves from discussion and leave the room when items that we “MIGHT” have an interest in are discussed. However, as an engineer, I have been asked to review other peoples work from time to time to give and opinion on the substance and validity of the work. In those cases, one is normally bound to advise the other party that they have been asked to review the work. This is not unusual and in fact when I was a consultant, we were often asked to represent an owner as an expert to review the work of other engineers on a project. But everyone knew that the reviews were taking place and who was doing what. However, it did sometimes result in studies of studies of studies when there was a disagreement on approach. It can be hard to get off that kind of Merry Go Round.
There were comments # 63 and 64 at RC that referred to my text without quoting it.
Here are the comments that were at RC. They weren’t there long, and they initially published my name and IP address, although those were quickly deleted.
#63
cagw_skeptic99 says:
7 Feb 2011 at 7:02 PM
[Edit. Resorting to threats of personal intimidation against scientists eh? Was only a matter of time frankly. Thanks for including your name in your email address.–Jim]
#64
cagw_skeptic99 says:
7 Feb 2011 at 7:33 PM
If suggesting that you will have issues testifying under oath is a threat of personal intimidation, why don’t you have the guts to publish what I said? Your house of cards is crumbling, and I am enjoying the process. You wouldn’t have perceived the suggestion that you would need to take the fifth amendment as a threat if you and your cronies weren’t quivering in your boots while waiting for your subpoenas.
cagw_skeptic99
Here is the ‘threatening’ text that they commented on, but didn’t publish, before they deleted the comments altogether:
Eric, It seems that the authors have both scientific and ethical points that have been very well made on the referenced blog posts. I am one of many who are eagerly awaiting your response, although we have no expectation that you will actually choose to do so. Your “Team” will be changing the subject, creating straw men, ducking and weaving, and hiding behind moderation on this site.
There is a pretty good chance that you and your Team will get invitations from the new House committees which investigate matters like this. I wonder if your moderation works in front of a CSPAN camera? I wonder if you will speak openly or take the fifth?
I rarely read RC these days – they have a reputation of producing sententious nonsesne.
However, in reading through the link o JeffID, there is something of the behaviour of the ugly sisters at RC.
Science cannot be conducted with schoolboy attitude and arrogance.
Sorry all you RC folk
Tried to run the R-code as described, but got the error (after some run-time and lots of graphs):
Error: object ‘recon.rls’ not found
It never used more than 1G memory. Seems like Eric might have a valid point.
> Sys.info()
sysname release
“Windows” “7 x64”
version nodename
“build 7601, Service Pack 1” “X52”
machine login
“x86” “—”
user
“—”
>
> sessionInfo()
R version 2.12.1 (2010-12-16)
Platform: i386-pc-mingw32/i386 (32-bit)
locale:
[1] LC_COLLATE=English_United States.1252
[2] LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
>
>
Hugo,
Thanks. In PC-world, filenames are not case sensitive. Easy enough to change.
Pax,
Would need to see more details (also posted at CA). You didn’t, by chance, ever hit the escape key while it was running, did you?
just wow
cagw_skeptic99 says:
February 7, 2011 at 4:53 pm
[Edit. Resorting to threats of personal intimidation against scientists eh? Was only a matter of time frankly. Thanks for including your name in your email address.–Jim]
Are you SURE they didn’t confuse you with Ben Santer???
Maybe on RC Steig’s more interested in the overall message rather than the science, the antarctic is warming.
To my mind there is absolutely no sense in trying to carry on a dialogue at RC.
Either a site permits open discussion (censorship for language and personal insult aside) or it doesn’t.
And in the latter case they ought be boycotted.
I smell an FOI in Steig’s near future… I wonder if they will be scrambling to say this is all taken out of context too? It certainly adds weight to the argument that the ClimateGate interpretations made by skeptics are spot on, these chaps have the form and it has been revealed elegantly by Mr Id. Thank you sir, and may I add that I admire your restraint (though I imagine some colourful language was uttered throughout this ordeal).
I got the same error as ge0050 (February 7, 2011 at 3:23 pm), but traceback() isn’t of much help here:
[…]
[[9]]: Unspliced reconstruction [[10]]: Spliced reconstruction
[[1]] [[1]]
[[2]] [[2]]
[[3]] [[3]]
[[4]] [[4]]
=================================================================
Fehler in getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, :
binäre Operation auf nicht passenden Arrays
> traceback()
4: getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600,
])
3: eval.with.vis(expr, envir, enclos)
2: eval.with.vis(ei, envir)
1: source(“R010Code.txt”)
> sessionInfo()
R version 2.12.1 (2010-12-16)
Platform: x86_64-pc-linux-gnu (64-bit)
I thought I would post this here before RC dumps the borehole.
Retrieved from the Real Climate Borehole
Jeff Id says:
2 Feb 2011 at 4:09 PM
Eric,
Some of the differences are real and correct. You took the example of a single station in your article. This is what I was referring to, you can’t really look at that small of a scale with 7 pc’s and expect a perfect match. The stations information may very easily be shifted nearby the point being examined and can also be reasonably well weighted. The number of PC’s determines the resolution.
On larger regions the patterns will average out if the math is correct but an arbitrary boundary may or may not have perfect representation. I believe that the Ross issue is something that Ryan and Nic would have more expertise with than myself but again if you look at the area weighted and our reconstruction, the similarities are quite evident. We aren’t far off from the actual station data (I have confirmed this with several methods), but IMHO the station position is a more reliable indicator of where the information should be than correlation with noisy and highly spatially correlated sat data. Again, the simple methods are also is difficult to disagree with and if you check them out they may make your case better than you think.
If you take a look at the area weighted link, you can see that some of the trends are more muted, but represent a very similar pattern to what our paper revealed – and IMO a very different one from your original. Just be careful when looking at a truncated least squares method when analysing patterns, especially when the sampling is not spatially even. [edit -keep on trying to sneak in off-topic snark like this, and all of your stuff will go straight to the borehole from now on–understood?]
From the Antarctic is still warming thread:
59
sHx says:
7 Feb 2011 at 3:45 PM
It seems Ryan O’Donnell disagrees with Eric Steig.
[Response: Gee, I’m so surprised. Ryan knows full well (as does Jeff) is welcome to comment here is he avoid the kind of inflammatory language that some of his coauthors use.–eric]
Ryan O’Donnell & Jeff I’d,
Thank you for having this part of your dialog with Eric Steig in an open venue like WUWT and CA.
Your approach to open science confirms the ideal of a scientific self-correction process.
The climate science renaissance is alive and thriving; replacing the biased science of the IPCC consensus.
John
I believe that Journal of Climate and Dr. Anthony Broccoli did a fine job with this situation – Ryan
I wonder how Dr. Broccoli feels about this now?
The RC “borehole” is truly fascinating. It certainly reveals alot about the mindset over there and is actually a far more interesting read than the main pages which are so sterile as to be largely useless. In many ways it reveals the areas of climate “orthodoxy” that the team would most like to avoid having a debate about!
It begs the question however – why have comments switched on at all at RC if the only purpose is to parrot the views of the posters and a smattering of sycophancy ?
My bet is that the borehole will soon disappear because it’ll be attracting more views than the posts themselves. It’s certainly the first feature over there that attracts me on a regular basis!
cagw_skeptic99, looks like your #63 at RC has been removed.
Many thanks to Ryan and Jeff for all your work and for exposing such unethical conduct.
Eric Steig is exposed for all to see. He should have done the right and honorable action in refusing to review O’Donnell et al. (2010) in the first place. The fact that he did not do so is particularly telling.
Ah! For you guys that are getting this error:
Error in getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, :
binary operation on non-conformable arrays
Guess what? You’re already WELL past the reconstruction phase. That portion of the code is to calculate average explained variance between the ground stations and the AVHRR data, and is not relevant to the reconstructions. I’m at present unsure why you are getting the error (I do not get the error), but I will figure it out.
Anyway, to see plots of the reconstructions you made, try this command:
plotMap(recon.rls[[3]][[2]], rng=0.6) <–gives the RLS 1957-2006 trends
plotMap(recon.eigen[[3]][[2]], rng=0.6) <–gives the E-W 1957-2006 trends
To see the tabulated comparisons, type:
recon.rls[[16]]
recon.eigen[[16]]
If I can figure out why the AVHRR explained variance routine isn't working, I will let you know.
Oops . . . make that:
plotMap(recon.rls[[5]][[2]], rng=0.6) <–gives the RLS 1957-2006 trends
plotMap(recon.eigen[[5]][[2]], rng=0.6) <–gives the E-W 1957-2006 trends
Too many #'s to remember. Haha!
> ################################################################################
> ###################### END VERIFICATION ######################
> ################################################################################
>
> traceback()
1: getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600,
])
>
Jeff,
Nothing here has changed my opinion of Steig. He may have been cordial and polite in private communications, but he has always shown his true colors in his online comments. He is nothing but a baby that got spanked, and now he has gone on to solidify that glaring reality.
The best punishment these jokers can receive is public embarrassment when their fraud is exposed.
Mark
“Of course, of this 0.55 Deg C difference, fully one-third is due to a single year (1980), which occurred 30 years ago”
You comment here echos a question I have raised without satisfactory response with Schmidt et al: what does the effect have of a regional anomaly have on the global averages? This is significant. The NH and the SH have large insolation, albedo and temperature range differences. Then we have the season-to-season and year-to-year differences on a regional scale – like the Arctic. At what point does a regional change distort a global “average” such that the Hansen et al global temperature anomalies mean nothing globally?
You also mention the prognositicator’s ploy of using positive results to justify bad causation factors. I refer you to RealClimate Jan11/2010, in which I (and RC) complained that the historical temperature data, shown by Schmidt to say what a wonderful job Hansen did in 1988, correlated better with Scenario C than the one offered by Schmidt, Scenario B. “C” was dismissed by Mr. S. as it was based on a non-emissions after Y2000, and therefore was not a “useful” comparison. RC and I contended that the correlation to “C” was, in fact, significant as it showed that incorrect or non-world algorithms in the place of real-world attempts at CO2 forcings must have matched in up and down error what was going on. Scenario B, as it was also off – and noticeably “warm”, had been a poorer prognosticator. Just because we understood the math of “B” did not mean that we should say it was a “better” or more useful effort at forecasting. In this case the prognosticator was arbitrarily saying the closest match was worse because he didn’t understand it, and the further match was useful … because it came closer to general understanding predictions! Nice, circular logic.
Check out RealClimate Jan11/2011, the Comparison of the record to the 1988 predictions of Hansesn. In essence the predictions should not have changed. Just the details. But the determination to deny error is so strong than virtually nothing other than glacial masses advancing from Washington Heights is going to get the RealClimate people to admit they have some rethinking to do.
“”Frank K. says:
February 7, 2011 at 4:30 pm
Comment: [Response:Know what? I have a day job. And those guys know perfectly well I do not read those sites without a good reason to, and telling me I have ‘explaining to do’ doesn’t rise to that level. If they have scientific points to make, they should make them here.–eric]
Translation: [Whaaaaaaaaaaaah. Mommeeeeeeee!! Ryan and Jeff are being MEAN too me. Make them stop! Whaaaaaaaaaaah!]””
_______________
Frank…YOU”RE KILLING ME! Almost [trimmed] my pants! I had a brief mental image of the Grinch (Jim Carrey version) on the jet sled. BWAHAHAHAHAHAHAHAH!!!
On a more serious note…many thanks Ryan, great post! I agree with many above: “WOW” and, “this is worse than climategate”
This, in my opinion, is worse than Climategate. This is simply out and out bald-faced lying. If it is not lying, then it is incompetence to a degree which should disqualify Steig from any further research on the subject until he receives an education.
Sad
Yup, I had the same results!
…
> eigen.stats.57.82 = getStats(grid.orig[301:600, ], eigen.grid[301:600, ], idx[301:600, ])[[1]]
> rls.stats.57.82 = getStats(grid.orig[301:600, ], rls.grid[301:600, ], idx[301:600, ])[[1]]
> S09.stats.57.82 = getStats(grid.orig[301:600, ], S09.grid[301:600, ], idx[301:600, ])[[1]]
> avhrr.stats = getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, ])[[1]]
Error in getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, :
binary operation on non-conformable arrays
…..
This is what TRUE science is all about. Can others reproduce your results?
Obviously a minor software problem and will be fixed soon, but tonight is an example of how science should be done. It is amazing what can happen when hundreds of people get involved.
Well done!
> plotMap(recon.rls[[5]][[2]], rng=0.6) <–gives the RLS 1957-2006 trends
Error: unexpected input in "plotMap(recon.rls[[5]][[2]], rng=0.6) plotMap(recon.rls[[5]][[2]], rng=0.6)
Error in library(mapproj) : there is no package called ‘mapproj’
Steve,
You’ll need to download package “mapproj” from CRAN. Then it will work. 😉
Please provide a link to “mapproj” since I can not locate it.
To reproduce the results, I am following the instructions to the letter….
I am using 64 bit Windows 7and using the R x64 2.12.1 GUI software.
I located “mapproj” at this website location:
http://cran.opensourceresources.org/bin/windows/contrib/r-release/mapproj_1.1-8.3.zip
Will try to run the software once again.
eadler says:
February 7, 2011 at 4:50 pm
James Sexton says:
February 7, 2011 at 1:13 pm
eadler says:
February 7, 2011 at 11:27 am
“What are the significant topics that you see arising from this?”
=======================================================
Oh, I dunno, howbout, something like honesty?
Truly, if one cannot trust the persons speaking, what validity can you give them? Steig isn’t the only person whose character comes into question here. Why does the journal allow/invite Steig to review the paper? Did the RC team know this? What of the journal? Did this ever happen before? What validity do you hold for such a venture in that they intentionally deceive people?
And the truest question………why would I engage with a person that refuses to accept the disingenuous nature of these people………..
The answer is ………so others can see. I thank you.
Steve,
I believe you will also need to download the maps_2.1-5.zip package. When I loaded the mapproj package R listed this as required.
Gaylon says:
February 7, 2011 at 7:10 pm
With my experience as a father as my guide, I was simply noting the very close similarity of the behavior of people like Eric Steig to little children at a playground… :^)
There’s another vocabulary word that seems apt here for Mr. Steig:
pet·u·lant –adjective
1. moved to or showing sudden, impatient irritation, especially over some trifling annoyance.
2. insolent or rude in speech or behavior.
3. characterized by temporary or capricious ill humor : peevish.
Stephen John:
Thanks for helping, but I am calling it a night. Obviously there is much more involved to get this software to run than the simple instructions posted at the start of this topic.
Science is all about the ability to reproduce the results and this has been a fantastic teaching tool for everyone involved tonight.
When “complete” instructions are posted on how to install everything required to run this software, then I will try it once again.
Anyway, it was fun watching the graphs, as the algorithm converged to an answer.
Keep up the good work!
Eadler: “To me this seems a difference of opinion about how to use the sparse weather station data on the Antarctic to fill in the temperature record, using statistical techniques. ”
+++
Fortunately you are referencing wikipedia therefore you must be an authority on the subject…
Comments at RC appear to have been closed – last one is #63. When this happened before it seemed to me that all the major players at RC got together to review the offending piece and settle on a going forward policy. I suspect they are all reading through Ryan’s piece and figuring out how to salvage Steig. I expect Gavin to step forward and take the heat – or at least that is what has happened before.
For those having problem installing the right bits of ‘R’ – installing software isn’t really much to do with reproducing the calculations.
It is clear from the comments here that people who know very little about R can reproduce the bulk of the calculations following the simple cut and paste directions provided.
If you have an older or different version of ‘R’, or can’t immediately determine from the error messages what to do to resolve ‘R’ problems – Google is your friend…
Ryan,
Usually at the start of all my code I put in an install packages section.
First a defined function that returns if you have already installed the packages.
Then some code to install packages if they have not been installed.
(also and example of how to check for a version number of a package)
is.installed <- function(mypkg) is.element(mypkg, installed.packages()[,1])
Animation <- "animation"
raster <- "raster"
if(!is.installed(Animation))install.packages(Animation)
if (packageDescription('raster')$Version < "1.5-8") { install.packages(raster) }
library("animation")
library("raster")
Eric & company are going to play their cards till the cows come home. They have no interest in correctness, their breatherin will save them. Till the cows come home.
This relates to me like the argument about creationism. Try http://www.scientificamerican.com/article.cfm?id=bad-science-and-false-fac. Go back and forth a hundred times and there is no answer. The Alarmists know this, their “climate scientists” know this. It will not stop until people wake up and I’m afraid that is a long, cold way away. Maybe ten or twenty years or more.
It’l happen.
RyanO or JeffId or anyone who knows how and is willing, I would LOVE to see the results of a FOI request of anyone associated with this issue who was likely to have be discussing it on the Steig/Mann/”The Team” side of things. I don’t recall where Steig works, but considering the behavior of those folks evidenced in Climategate, I’d be willing to bet that these folks are emailing each other during working hours and from their work computers about this very issue – and that they also did so when the paper was first submitted for review to the journal or first came to the attention of ANY one of those folks. Heck knows if a FOI would actually be honored and be able to pry that correspondence into the public eye, but it sure would be lovely to see…
As others here have also commented, I’m utterly appalled at the idea that a journal would possibly use the author of a paper being rebutted as a peer reviewer of the rebutting paper. That sure seems entirely rotten to me. Calling in a third reviewer hardly mitigates that gaffe (to put it nicely).
And, as many others here have also noted, I too have had my comments ‘disappeared’ over at RC – the few I made when I first became aware of the site and had NO clue that they behaved in such a despicable fashion. Those comments were perfectly civil, relevant to the topic, but skeptical in the “if xyz supporting AGW is correct, then how is abc accounted for?” After having a few comments like that appear, only to disappear again almost immediately, I quit even trying to post at RC and not long after that stopped bothering to read it either. The site has zero credibility, and the moderators are just snide, petulant, arrogant, and downright rude. It also burns my buns that these people are running that site on the taxpayer’s dollar, during working hours, while neglecting the work they are being payed to do. This disgusting trend seems to be appearing all over government sites these days – but RC takes the cake in this regard.
Jeff Id,
many people thought Steig and a couple of other team members were more gentlemanly than is turning out. When you lay down with pigs you probably are one!! That applies to the whole team!!
They apparently have decided to brazen this fraud out!! It is beginning to look like the media and Politicians will help them. I keep wondering why this is so important to them!
Wow.
Ryan and Jeff et al – thanks for putting up with the flagrant fraud and twelve-year-old tantrums from the … cant finish that.
I wonder if MSM will pick this up (won’t hold my breath), if they do, then I wonder what kind of spin they will put on it to support the AGW case? A few ideas:
Perfectly normal for Scientists in specialized fields to have papers reviewed by those that disagree with their views?
This specific area of Science is so socialistic that there are very few Scientists qualified to review a paper such as this?
There is no cover up, this is a perfectly normal peer review process?
Don’t forget get that another reviewer was called in for arbitration, perfectly transparent process?
This has little bearing on the consensus of the world’s leading climate Scientists?
The IPCC were unavailable for comment?
This is just some bitching on the blogosphere, net cranks, deniers, nothing to worry about?
I am starting to sound like the BBC, I’d better shut up.
I wonder if Steig is the source of this statement
“Indeed, over the past 50 years, the Antarctic Peninsula has warmed by an alarming 2.8C, faster than any other part of the world. So, if this warming was to continue unabated, could an emerald Antarctica be reborn?”
made on “Secrets of Antarctica’s fossilised forests” here
http://www.bbc.co.uk/news/science-environment-12378934 today 8/2/11 on BBC’s Web site.
“One hundred million years ago, the Earth was in the grip of an extreme Greenhouse Effect.
The polar ice caps had all but melted and rainforests inhabited by dinosaurs existed in their place.
These Antarctic ecosystems were adapted to the long months of winter darkness that occur at the poles, and were truly bizarre.
But if global warming continues unabated, could these ancient forests be a taste of things to come?”
“However, other fossils show that truly subtropical forests existed on Antarctica during even earlier times. This was during the “age of the dinosaurs” when much higher CO2 levels triggered a phase of extreme global warming.”
I wonder what came first; CO2 or warmth? I am sure that “The Team” know for sure that CO2 came first from dinosaur SUVs.
This again illustrates the “Peer (Pal) Review” process in Climate “Science” as it was clearly exposed in the Climategate mails.
Looking at the bad experiences of Editors who dared to publish stuff critical to the Mainstream’s belief (Climategate, again), it needed considerable courage by the Editor to bring in a 4th Reviewer to unlock the paper from “Reviewer A”.
There is an interesting comment at Bishop Hill
http://bishophill.squarespace.com/blog/2011/2/8/steig-snippets.html
“I would say that RealClimate now has a serious credibility problem. Mendaciousness on this level is going to be hard to ignore.”
Just to make sure I have this right:
Steig is “Reviewer A”. “Reviewer A” make several comments/suggestions. You incorporate suggestions. Stieg now give you grief for doing anything “Reviewer A” says.
You cannot possibly make stuff up that good….
Firstly, thanks to Ryan and Jeff for this rebuttal (and for the work going into this).
While I had my suspicions about ‘reviewer A’ when this was posted last year at tAV, it is good to now know. The point isn’t so much that Steig was asked to review the rebuttal of his paper – the point is that he obviously tried to prevent this paper being published in the first instance (88 pages of review???). Again, this is something which has been used in the past, see the story of how M&M’s rebuttal was made to not get published.
What is extraordinary is that the reviewer then openly criticises the authors for adopting a method he himself proposed.
This surely must count as abuse of the pal review system?
As for using RC to publicly criticise the paper – I think this goes towards showing, yet again, that the arrogance of The Team is influencing their thought processes … they are numpties …
Shorter Id;-
You may be right but your methods are wrong.
(And if our methods are wrong its because you told us to use them.)
Philip Finck wrote:
“Noell, you are dishonest, and attempt to distract from the issue.”
I think you owe me an apology.
The front page of Nature got a lot of attention in the press, about ‘global warming’
Look at the Nature Cover at the time:
Antartica Warming
http://www.nature.com/nature/journal/v457/n7228/covers/
“A new reconstruction of Antarctic surface temperature trends for 1957–2006, reported this week by Steig et al., suggests that overall the continent is warming by about 0.1 °C per decade. The cover illustrates the geographic extent of warming, with the ‘hotspot’ peninsula and West Antarctica shown red against the white ice-covered ocean. [Cover image: NASA Goddard Space Flight Center/University of Washington/USGS]”
Has anybody heard anything from the co0-authors?
http://pubs.giss.nasa.gov/abstracts/2009/Steig_etal.html
Eric J. Steig1, David P. Schneider2, Scott D. Rutherford3, Michael E. Mann4, Josefino C. Comiso5 & Drew T. Shindell6
Congratulations to Ryan, Jeff, and company on their fine contribution to scientific knowledge. I’m in no position to evaluate the competing claims, but they certainly make for a colorful example of the adversarial nature of science. Stick to your guns, lads, stick to your guns!
I wouldn’t be at all surprised if Dr. Broccoli and those at JoC responsible for publication review try to wave all this off with “Hey, we published it. No harm, no foul.” They may even go so far as to twist Stieg’s private acknowledgment as an attempt to deal with the conflict of interest.
But how do you explain criticizing the very approach you, yourself suggest? Eric Stieg must have learned something! Again, well done.
Dr. O’Donnel,
on my system, it appears as if “est” as a paraemeter to getStats(orig,est,idx) does not conform with “idx”. I put a print(dim(p)) for each parameter into getStats(), got a long list for each call to getStats() and observed that “est” normally conforms to “idx” for both dimensions, except in the offfending line:
“getStats:dim(orig) =” 300 87, “getStats:dim(est) =” 300 5509,”getStats:dim(cal.idx) =300 87
Fehler in getStats(grid.orig[301:600, ], makeAnom(all.avhrr), idx[301:600, :
By pointing to the much-fragmented Byrd station “record,” Steig is clutching at straws, of course, to support his “discovery” of West Antarctic “warming.” But there are more fundamental problems in estimating continent-wide trends from sparse and short station records obtained under adverse conditions. They tend to be spatially incoherent at the low frequencies, which are not adequately captured in records of brief duration. Thus the apparent “trends” can be inconsistent even at close-by stations, such as McMurdo and Scott Base, with the former showing .18C/decade and the latter only .11C/decade for 1957-2006. In any event, whatever the true trend for that particular period (other Antarctic stations show comparable NEGATIVE values), it should never be mistaken for a SECULAR trend. Multi-decadal trends prove to be an unstable metric under natural temperature variability at the low (multi-decadal) frequencies. Only in the next century will we have a reliable indication of what the secular trends are in Antarctica.
Note to all who have attempted to run the code:
The pesky line has been removed. Should work fine now. 😉
What does it say about Steig’s abilities when mere amatuers can get the code to run
and he can’t.
Steig once invited Ryan to take a matlab class from Him.
Looks like eric got schooled
It has been a truly wonderful experience to watch the “skeptic” process evolve and integrate into the field of global climate science. Here above, we see the result of years of learning, reverse engineering, research, methodology development and testing. This then had to be coupled with patient and indomitable engagement with the established science authorities. And now finally (in 2011 no less), specific individuals and groups have been able to take on the scientists, their science and the peer review process to fully and completely rebut not just their specious claims but also their methods and their peer review processes. Climategate gave us snippets that had to be reconstructed like a jigsaw puzzle making it difficult to convey the full picture to the average layman. But above entire story of the development and publishing of just one paper, the disingenuous review followed by a blow by blow recounting of the sordid details makes for very compelling and persuasive reading indeed – bravo!
More shine off their halos. In time there’ll be none left. Then they’ll look pretty silly.
Rational Debate says:
February 7, 2011 at 11:00 pm
Steig is s on the faculty at UW
http://earthweb.ess.washington.edu/~steig/
In this age of blackberries, i-pods, droids etc., it is unlikely that Team members email each other on work computers. Surely they learned SOMETHING from Climategate.
And, interestingly, the email field on Steig’s UW home page is blank.
re post by: Duke C. says: February 9, 2011 at 6:36 am
One never knows! Old habits are hard to break – plus, its all too easy to be on one “safe” subject in work emails with someone you regularly correspond with, and then have it bleed over into another subject also considered to be reasonable (by those corresponding at the time) – or to bleed into a little kvetching with a collegue – all things that after the fact turns out not to be so reasonable or not to look so reasonable to outside eyes.
You would think that they’d’ve learned from Climategate, and I’m sure that at least to some extent they have – but didn’t “The Team” wind up leaving some stuff on a public FTP server after having been caught out that way once before? Humans are humans. The only way to know in this case would be to do an FOI and see what turns up – assuming that the FOI’s managed to pry info out of the various institutions (for Steig, Mann, and any others who could conceivably have been debating the paper amongst themselves) and weren’t just utterly stonewalled.
Heck, if nothing else, if the FOI’s were properly responded to and came up negative, it’d still be interesting just to see that they had apparently at least partially (or at some times, for some subjects) learned their lessons! 😉 Even that of course wouldn’t prove that they were always infallible, but would show that they’d at least partially learned something from climategate.
‘Rational Debate’, you’re clueless about so many matters re: academic science, it’s not funny, except when it is. Let me address one:
Certainly the editor would know that Steig was an author of the work being critiqued by O’Donnell et al. It can be ENTIRELY appropriate for that author to be a reviewer. Whether it is in a given case, is the editor’s call. O’Donnell et al. were likely also free to put Steig on a list of authors they would prefer NOT to be reviewers; again, it is the editor’s call whether or not to honor that request.
It appears Steig was a reviewer on three drafts of the paper, at which point (according to Steig) his comments were deemed no longer helpful, and he was not a reviewer of the draft that got published, which was (again according to Steig) significantly different from the ones he’d seen. This explains his later public requests to see a copy of the paper, which you baying jackals here in your echo chamber seemed to find so damning.
Apparently a retraction of at least some of Mr. O’Donnell’s inflammatory misinformed outbursts is in the works (says Steig). We shall see.
Steven Sullivan says:
February 9, 2011 at 3:29 pm
“”It appears Steig was a reviewer on three drafts of the paper, at which point (according to Steig) his comments were deemed no longer helpful.””
——–
Steven Sullivan,
You appear to have been closely following the Steig situation regarding the reviewing of O’Donnell et al. Perhaps you have a source of info not generally available to others.
Do you have any additional detail about why Steig’s comments were no longer deemed helpful?
John
patrioticduo says:
February 8, 2011 at 2:33 pm
——–
patrioticduo,
Wonderful comment.
Your comment is worthy of framing and putting on my study wall.
Moderators, can that comment be a quote of the week candidate?
John