Guest essay by Larry Hamlin
In a clear discrediting of NOAA’s and the media’s recent overhyped and flawed global temperature claim that “July 2021 was the hottest month ever recorded” (with this hype promoted by NOAA climate alarmist “scientists”) updated data from all major global temperature anomaly measurement systems (including NOAA as discussed below) proves that NOAA’s claim was exaggerated, deceptive and distorted.

The 4 major global temperature measurement systems including satellite systems UAH and RSS and surface measurement systems GISS and HadCRUT revealed that NOAA was an isolated outlier in making their exaggerated claim that was so ridiculously overhyped by the climate alarmist media as clearly demonstrated by the headline and picture shown in the above article by the AP’s decades long biased climate alarmist activist Seth Borenstein.
The combined land and sea global surface temperature monthly anomaly data are available for each of the 5 major global temperature measurement systems at HadCRUT5, UAH6.LT, GISSlo, RSS TLT V4 and NOAAlo as discussed (with links) in the information provided below.
The UAH, RSS, GISS and HadCRUT global temperature monthly anomaly measurement systems showed that the highest July occurred in years 1998, 2020, 2019 and 2019 respectively and not year 2021 as claimed by NOAA.
Furthermore, NOAA’s “July hottest month ever” claim was both exaggerated and deceptive because it was based on a trivial and miniscule 0.01 degrees C above the prior July NOAA peak monthly anomaly measurements which occurred in years 2020, 2019 and 2016.
The NOAA July 2021 global monthly temperature anomaly measurement 95% confidence level (accuracy range) is +/- 0.19 C which is nearly 20 times greater than the miniscule 0.01 degrees C temperature anomaly difference between July 2021 and July 2020, 2019, and 2016 meaning that the difference between these July temperature anomaly measurements is scientifically insignificant and unnoteworthy.
Further adding to NOAA’s and the media’s deception that the July 2021 global temperature anomaly “hottest month ever” hype is the fact that this week (9/14/21) NOAA reduced its July 2021 temperature anomaly value by 0.01 degrees C as a part of its August 2021 global temperature anomaly system update meaning that July 2021 is not the “hottest month ever” but tied with July year 2019 with years 2020 and 2016 July anomalies just 0.01 degrees C lower.
Where are the climate alarmist media headlines announcing NOAA’s embarrassing reduction in its prior reported July 2021 temperature anomaly “hottest month ever” hype and acknowledging this change in the public press? Don’t hold your breath waiting for the NOAA and media alarmist correction announcement.
The highest peak global monthly temperature anomaly for all 5 temperature measurement systems including the UAH, RSS, GISS, HadCRUT and NOAA measurement systems occurred over 5 years ago in year 2016 during the months of February and March.
More significantly the media’s ignorant and misguided “July hottest month” exaggeration and deception deliberately tried to grossly distort the global monthly temperature measurement anomaly record by concealing the fact that global monthly temperature anomaly declines have been underway since peak year 2016 as clearly reflected in all 5 global temperature anomaly measurement systems data records as shown below in the UAH, RSS, HadCRUT, GISS and NOAA data records respectively.


The graph below shows the HadCRUT4 data. HadCRUT5 data has about 14% higher values. The February 2016 peak anomaly for HadCRUT5 data is 1.22 C
versus about 1.1 C for HadCRUT4.



Of course, there will be no news article blaring headlines or climate science ignorant (yet incredibly arrogant) TV broadcasters in the biased climate alarmist media acknowledging the erroneously flawed hype of the “July 2021 hottest month ever” scam that was nothing but politically motivated climate “science” alarmist propaganda consistent with the usual alarmism and media shenanigans built upon climate hype dishonesty through use of exaggeration, deception and distortion.
The declining global monthly temperature anomaly data trends for all 5 major temperature measurement systems over the last 5+ years as shown above clearly establish that there is no climate emergency.
Additionally, the U.S. and EU who have been driving the UN IPCC climate alarmism political campaign for over 30 years have now completely lost the ability to control global energy and emissions outcomes through the IPCC’s flawed climate model contrived schemes.
In 1990 the year of the first UN IPCC climate report the world’s developed nations led by the U.S. and EU were accountable for nearly 58% of all global energy use and 55% of all global emissions. But that dominance in global energy use and emissions by the developed nations changed dramatically and completely disappeared over the next 15-year period.
The world’s developing nations led by China and India took command of total global energy use in 2007 (controlling more than 50% of all global energy use) after dominating total global emissions in 2003 (controlling more than 50% of global emissions).
In year 2020 the developing nations controlled 61% of all global energy use and 2/3rds of all global emissions with these nations clearly on a path to further increase these commanding percentages in the future. The developing nations have no interest in crippling their economies by kowtowing to the western nation’s flawed model driven climate alarmism political propaganda campaign with the developing nations having announced to the world that they are fully committed to increased use of coal and other fossil fuels.
In year 2020 the developing nations consumed 82% of all global coal use with China alone consuming 54% of the world’s coal. China was the only nation in the world that increased both energy use and emissions in pandemic year 2020.
The U.S. and EU have not contributed to the increasing level of global emissions over the last 15 years. In fact, these nations reduced emissions during this time period by many billions of metric tons. Yet global emissions have continued to dramatically climb ever higher by many more billions of tons driven exclusively by the increased use and unstoppable growth of fossil fuel energy by the world’s developing nations.
Assertions by U.S. and EU politicians that massively costly, horrendously onerous and bureaucratically driven reductions of emissions will “fight climate change” along with bizarre claims of supporting a “net zero” future are ludicrous, disingenuous and represent nothing less than completely fraudulent proposed schemes.
It’s time for the developed nations to stop their scientifically incompetent, globally irrelevant, real world inept and purely politically driven flawed climate model alarmist propaganda campaign.
NOAA reported that July 2021 was the hottest month ever because July is the hottest month of the year and it was the hottest July on record, not because the anomaly for July was the highest anomaly ever recorded.
WHAT? Are you whitewashing?
You can’t read, why ever.
The confusion is strong in you.
Just looking up the UAH record, we have a couple of Julys warmer than this years.
1998 +0.38
2010 +0.20
2016 +0.26
2019 +0.25
2020 +0.30
2021 +0.20
I think it is obvious that the NOAA is referring to their own temperature index, here, not to UAH.
NOAA’s index might be worth looking at if NOAA had no preconceived idea of what it should be.
Then not only does its own temperature reading not confirm what others are saying, its allowing the media to hype up a none event, your efforts would be better spent talking to noaa and the media, let me know how you get on.
UAH6 is the only Temperature data set that matches SST data closely.
LINK
I’m not sure what you’re trying to show – you need to place everything on the same baseline to compare, like this.I would hope that HadCRUT is consistent with HadSST since HadSST is the SST component of HadCRUT.
You made an off set adjustment for two data sets to match up which changed its true starting point downward.
You manipulated the numbers, shame on you.
HadCrut starts at about -.175C in 1979
UAH6 starts at about -.45C in 1979.
LINK
My friend, the original link that you provided had the HadSST series offset to place it on the same baseline as the UAH series. HadSST and HadCRUT are on the same baseline, so you should have shifted both, or neither. If you want to claim that changing the baseline is “manipulation,” then this is what you get, and by your logic UAH doesn’t match the SSTs at all.
And, again, I will point out that HadSST is the SST component of the HadCRUT dataset, so there is no question whatsoever that both series are consistent.
Ahh I missed that, you are correct.
But even then the SST and Hadcrut don’t match up either, requires an offset to line them up together.
That is because the oceans are warming more slowly than the land (in no small part because water has a higher heat capacity than land surfaces do). So it isn’t an offset but a difference in trend.
How does your comment reconcile with this post?
https://wattsupwiththat.com/2021/09/12/surface-radiation-balance/
The bottom line is, July was NOT any hotter than any other in recent years! Anyone who was born before 1990 already knows this. If the only number we could go by were from the past 20-30 years, then, MAYBE, it might have seemed hotter. I remember all the way back to the late 1940’s and believe me, it was MIGHTY hot then, too! I hate it when these Johnny-come-lately kids try to blow smoke up everyone’s az!
At least in North America, Hansen said the year 1934, was 0.5C warmer than 1998. I assume there was a pretty hot July in 1934, although I don’t have the exact numbers, and may never have the exact numbers considering how the temperature record was bastardized.
But Hansen had a colleague who wrote to Hansen and said his estimate of the difference between 1934 and 1998, of 0.5C was consistent with his figures. This communication is enshrined in the Climategate emails.
https://www.ncdc.noaa.gov/cag/national/time-series/110/tavg/12/12/1930-2000?base_prd=true&begbaseyear=1901&endbaseyear=2000
Oh, wow! 1998 was hotter than 1934 by 2 one hundredths of a degree. Maw, fetch me my micrometer.
That was in the US Only.
So what?
What a hideous travesty! A hideous, expensive travesty. Thanks for the graphic example of the Big Lie, told by promoters of Human-caused Climate Change.
The Hockey Stick charts are computer-generated science fiction.
Real temperature charts from around the world tell a completely different story. They say we have nothing to fear from CO2, and they say today is not the hottest time in human history.
That’s the lie told by the Hockey Stick charts and their creators.
Wasn’t it Gavin Schmidt that essentially said climate is only important where you live? And, given all the temperature recordings’ problems and adjustments, the world has only warmed an estimated approximately 1.0 C in 220 years. Maw, go fetch me my speedo.
That’s after adjustments. After the temperatures stopped climbing in 1998, the Data Manipulators started cooling the recent past to make the present look warmer.
About 2007, Hansen was still saying 1934 was warmer than 1998, but they whittled the difference down in their computers in coming years to the point where they were showing 1934 as cooler than 1998. It’s all a scam.
Below is an analysis I did comparing unadjusted data (black line) to the major temperature indices from NASA and others. The raw data show that 1998 was much warmer than 1934 globally.
I personally don’t have confidence that the “unadjusted data” isn’t adjusted. As an example, the weather for Cape G. Missouri was originally missing for 3/2/2021, but was later “fixed.” Issue is that the high temperature weather now recorded for that day is about 20 warmer than what the weather reports were for that date. There’s also issues with weather stations over that period of time, such as ones located near airport runways. Could anything have changed at airports since WWII that would an local increase in temps unrelated to green house gasses?
You provide further proof that the governments cool the past and warm the present and near-present. Without the recent Super El Nino there would be no significant warming in the late 20th and early 21st Centuries. UAH6 shows what is actually happening in the atmosphere and ARGO does likewise for the oceans. They both show minimal 21st Century warming, with UAH6 showing an almost 19-year halt in warming before the recent Super El Nino. The governments’ data, however, show what the politicians want to show us.
The radiosonde, satellite and ARGO observations during the decade of the 2020s and early 2030s will tell the tale, one way or another. With China, India & etc. pumping out CO2, anything other than a steep increase in global warming will put the final nail in the UN IPCC CliSciFi models’ coffins.
“With China, India & etc. pumping out CO2, anything other than a steep increase in global warming will put the final nail in the UN IPCC CliSciFi models’ coffins.”
That’s right.
Back before everyone had AC hot was just another summer day, now people hibernate inside in climate control and when they go out it feels horrible to them. This I think is the biggest reason people actually believe that it is hotter today then it was 50 years ago. Even if you believe the BS numbers that show it is a little hotter today then back then the data shows the difference is very small and its all at night, but ask any true believer and they will tell you they can feel how much hotter it is now then back in the day. This is evidence of the strong brain washing that is going on today and, worse, how ridiculously susceptible to it it people have become.
You manipulated the numbers, shame on you.
HadCrut starts at about -.175C in 1979
UAH6 starts at about -.45C in 1979.
Of course they have different values, they have different baselines! Hadcrut is the temperature compared to the 30 year average Jan 1961 – Dec 1990, UAH6’s baseline is Jan 1981 – Dec 2010. As the Hadcrut baseline is earlier and temperatures have risen of course it’s anomalies are ‘warmer’. If you want to compare anomalies with different baseline periods you have to apply an offset so all are being compared to a common average. This is all spelt out in the woodfortrees documentation where they give the required offsets to align with UAH6 as
GISTEMP 0.43
HADCRUT4 0.29
RSS 0.13
UAH 0.00
So the correct 1979 Hadcrut4 value to compare with UAH6 is (-.175 – 0.29 =) -0.46.
https://woodfortrees.org/notes#baselines
Comparing raw anomalies with different baselines and no offset is like comparing the heights of two people while one is standing on a box.
UAH says land is warming 50% faster than the ocean so that fact that UAH’s global trend matches the SST trend is pretty odd.
Land temperatures are whatever the governments say they are. Actual long term atmospheric temperature trends should mimic long term SST trends. IIRC, studies show the ocean temperatures drive atmospheric temperatures. The UAH6 trend just confirms that.
Are you saying the government told UAH what to report?
NOAA engages in data tampering if the US data.
In what way?
By systematically altering historical and new data to change temperature trends … https://www.youtube.com/watch?v=Pvuhxv1Ywd4
That video seems to be Heller making his same old errors. He doesn’t grid the data, which creates huge biases in his averages, and he doesn’t apply any adjustment for ToBs, which creates moderate bias in his temperature graphs, and a huge bias in his graphs of “% of days above x temperature.” He also seems continually confused (or at least wants his viewers to be confused) about why the NOAA performs infilling. Do you have a better source?
The “source” is the difference between the Raw and the Altered data. The “altered” data is in essence manufactured miss-information — not data. Like they say — if the data doesn’t fit the theory — change the data.
The data aren’t being altered – they’re being used in an analytical product, which must account for imhomogeneities in the station records. For NOAA, whose approach requires continuous records, this means doing infilling using nearby stations. Otherwise, you’re inserting the global average in for the missing value, which you certainly don’t want to be doing when you have better information. Of course, there’s no need to infill if you use gridded anomalies, which Heller could do, but then he’d get the same answer as the NOAA.
Explain why USHCN (US Historical Climatology Network) station observations prior to 2008 received cooling temperature adjustments and those after 2008 received warming adjustments … https://www.youtube.com/watch?v=vnmzOeG_N64
This video commits all of Heller’s usual fallacies.
You seem to be fascinated with the word Heller. I don’t care what he did or does, I only care why are tax monies are being used to alter good data. So, again, explain why USHCN (US Historical Climatology Network) station observations prior to 2008 received cooling temperature adjustments and those after 2008 received warming adjustments.
You linked to another of Heller’s video as a source for your argument. I’m pointing out that there is no evidence of nefarious data tampering. The big differences Heller finds in the raw vs. adjusted data are coming from his own analysis errors. There is nothing in the video suggesting that temperatures were cooled prior to 2008 and warmed after, and you’ve provided no other evidence of this, so there’s nothing for me to address there.
With over 37 million views, isn’t it interesting that no one has yet found Tony’s USHCN analyses in error? Have you ever looked at the data?
Are you kidding? Heller has been debunked time and time again.
Here’s one – it makes much the same points as weekly_rise.
http://rankexploits.com/musings/2014/how-not-to-calculate-temperature/
That link does not answer the core question … why (on average) were the USHCN station “raw” data cooled before 2008 and warmed after 2008?
You do understand that “no evidence” is not a proof that nothing occured don’t you? You can’t say there is no evidence of rain inside my house therefore it is not raining.
The fact that I don’t see fairies dancing in my living room also isn’t proof that fairies don’t exist, but absent any evidence of their presence I have no reason to believe they exist.
The problem you overlook is that you also have no reason to believe they don’t exist. I’ll say it again the lack of evidence proves nothing. What you believe in that case is based purely on faith. Since faith is the basis, you can not denigrate someone who chooses the opposite. An argument asserting wrongness is facetious from the get go.
If you approach me and say, “explain why there are fairies in my back garden.” I would reply, “you haven’t shown any evidence that there are fairies in your back garden, so there is nothing for me to explain.” That’s no me asserting that you are wrong, that’s me asserting that the burden of proof has not yet left your shoulders. John demands that I explain why adjustments before 2008 are cooling the trend and adjustments after 2008 are warming it, but he’s provided no evidence that this is actually occurring, so there’s nothing to explain.
A more important point might be that the raw data is not saved by NOAA, but only the adjusted and rewritten data.
The “Raw” and the “Edited” data are publicly available for download. NOAA does not make it easy to find — but it’s there — and it better be because our taxes paid for it.
Infilling is not creating measured data. It is creating an artificial metric that may or may not be useful.
Take your grids and find the trends. You’ll never find enough grids with hot enough values to offset the areas with little or no warming and areas with cooling.
Unless you have a thermometer covering every single point on Earth’s surface, you are performing infilling whether you want to or not – the values you do have are providing estimates of all the values you don’t have. If you choose not to use nearby stations to estimate the missing values, then you’re using every point on the planet to estimate the missing values. I’m not sure about you, but I don’t think the best estimate of temperatures in Death Valley are the temperatures in Antarctica or Tibet.
You do the *exact* same thing when you use anomalies. When you combine the anomaly from Denver with the anomaly from New Orleans exactly what are you doing? You don’t know what caused the anomaly in either location so how can the best estimate of temperature be based on anomalies?
If you can not have temps from every point on earth, why do you worry about trying to invent a fake metric that has no meaning anyway? You do understand that GAT describes no place on earth accurately, right?
It GAT accurately represented every point on earth, you really would only need one thermometer to determine what is happening. The fact that you need to create pseudo-temperatures through infilling amply demonstrates that GAT is a made up metric with no meaning. It is like finding the average height of a herd of half Clydesdale and half Shetland horses. Exactly what good is that metric? It describes nothing accurately.
Knowing the planetary mean surface temperature is quite handy if you want to go and visit that planet and are wondering what clothes to pack, wouldn’t you say? Mars is a much colder planet than earth, for instance. But how can I make such a claim?
Mean surface temperature is clearly a useful metric to calculate and to track – changes in the mean surface temperature are directly correlated with changes in climatological variables like ice volume and sea level.
The mean surface temperature of Mercury would be totally useless.
Excellent point.
If we observed a long term change in the mean surface temperature of Mercury that would indeed be valuable information, agree or disagree?
“Valuable” in what context?
If you were visiting Earth from Mars would the GAT tell you what clothes to pack? What if you landed Miami vs San Diego? Or Port Barrow vs Mexico City?
The GAT doesn’t tell you the variance of the temperature profile at any specific location. And it is that variance that is of the most importance in deciding what clothes to wear. GAT is an almost useless metric .
Changes in mean surface temperature will *NOT* tell you anything about what is happening with climate. Again, climate is the entire temperature profile at a location and the GAT loses all that data in its calculation.
Think of it this way. If it is MINIMUM temps going up that raises the GAT then that minimum temp has to raise far enough to change the volume of the oceans and to change the melting rate. If the sea level is determined by max temp then min temps going up won’t change seal level much if at all. If the temp on a glacier changes from -10C to -9C how much extra melting will occur since both temps are far below the melting point of 0C?
There *are* other factors that are the real drivers of all of this. But the climate models ignore them all. As Freeman Dyson pointed out years ago, climate models are *not* holistic models of the environment and only a holistic model can truly tell you what is going on with the environment. The current climate models were useless in predicting the greening of the earth that has happened since 1980. Why is that? Ans – because the GAT doesn’t even begin to address that piece of the holistic model. Instead we are told that the GAT going up means the Earth is turning into a cinder and crops are going to fail and deserts will overtake the planet. Each claim totally unsupported by the GAT because the GAT can’t tell you what is happening on the Earth.
My answer was tongue in cheek – but you realize that there is a difference in the mean surface temperature of the planets, and you realize that the mean surface temperature of the earth indicates something about the state of the climate system (if the mean temperature is going up ice sheets will be retreating, going down they’ll be advancing, etc.). If the mean annual temperature is rising then we don’t much care if it is max or min daily temperature – the mean of both must be rising.
We don’t actually think there is a family in the US consisting of 3.15 persons, but the average family size in the US is unquestionably a useful metric to track.
Absolutely. The average family size is a useful metric to track. So is the average height of people. BTW…the Gorman’s think that given a ±1 cm on height measurements that the uncertainty of the mean of 1,000,000 people is given by root sum square or sqrt(1^2 * 1000000) = ±1000 cm. So if the average height is 168 cm they think the 95% CI on that is -1832 to 2168 cm. And if you measure a million more people the uncertainty of the mean increases even more they say. Even as absurd as that is they refuse to budge on their position regarding the uncertainty of the mean and continue to claim that it is actually statistics texts, expert statisticians, scientists, and everyone else that are all wrong.
I confess that I am utterly bewildered by Tim/Jim’s position on this. I’ve read as much of the debate between them and Bellman as I care to and their position is nonsensical. They literally seem to be saying that the larger your sample size the less certain you can be about the population mean.
That is exactly what their argument is. I’ve gone around with them several times as well myself. Bellman has the patience of Job.
I’ve generally found that I agree with Gorman’s opinion. However, I can’t speak for him. On the other hand, I believe you are misrepresenting what he has said. How about actually providing a quote instead of your interpretation of what you think he said?
The Standard Error of the Mean can be improved generally by taking multiple measurements of a stationary or fixed parameter. On the other hand, with non-stationary data, that is a time-series with a trend, both the mean and the standard deviation will change over time. If it is a positive trend, both the mean and standard deviation will increase over time. It makes no sense to claim that taking more measurements will improve the accuracy or precision when both are a moving target.
“But the uncertainty of the mean is the RSS of the individual uncertainties. You do not divide by N like you do when calculating the average. It’s just RSS. And the uncertainty of the mean is the RSS.” from here. That is not the only post like that though.
“On the other hand, with non-stationary data, that is a time-series with a trend, both the mean and the standard deviation will change over time.”
The inconvenient truth they all try to sweep under the carpet.
We aren’t discussing a timeseries of monthly anomalies or the uncertainty of a trend thereof. We are discussing the uncertainty on a single monthly global mean temperature anomaly only. The mean does not change over time. In other words, the mean for August isn’t any different because it is now September. Likewise the mean for 2020 isn’t any different because it is now 2021.
The Gorman’s say the uncertainty of the average of all grid cells in the global mesh is Utotal = sqrt(Ui^2 * N) where Un is the uncertainty of each individual grid cell. Statistics texts, expert statisticians, and everyone else says it is Utotal = Ui/sqrt(N). This can also be demonstrated via a monte carlo simulation.
You have just demonstrated that you don’t understand the problem. The current July is being compared with previous Julys. That is equivalent to sub-sampling to once a year, with July being the month for comparison. Thus, it becomes a time-series of Julys where the monthly average and the trend are generally increasing.
Comparing two or more monthly values is a completely different topic; one which would undoubtedly come with its own challenges by contrarians. But before you can even compare monthly values you must first produce the monthly values and provide an uncertainty for each one. The challenge being made on a single monthly value basis is that the uncertainty is not Utotal = Ui/sqrt(N), but Utotal = sqrt(Ui^2 * N) where Ui is the uncertainty on individual grid cells and N is the number grid cells. And its actually even more fundamental than that even. Some contrarians on here think the uncertainty of the mean of any set of values is described by the RSS as opposed to the SEM. That is the core issue being debated. And at its very core actually has nothing to do with comparing two or more means or even temperatures at all.
We can’t tell if the July average is increasing, becasue the mean keeps increasing. Is that what you are saying?
I’m basically saying that because the mean is changing during any month, and over a period of years, the standard error of the mean cannot be used to justify a higher precision than any individual reading. Therefore, with low precision, one cannot distinguish a 0.01 deg C difference.
Increases in precision can only be justified with stationary data, when the variations from reading to reading are random and normally distributed.
https://wattsupwiththat.com/2021/02/24/crowd-sourcing-a-crucible/#comment-3193339
Me:
Tim Gorman:
Of course, he then goes on to explain at great length about the uncertainty of the sum, without ever mentioning the average.
So, if an extraterrestrial alien decides to visit Earth, and lands in Antarctica in the Winter, or the Sahara in Summer, he/she/it will have adequate clothing for the environment based on the average temperature? No way! What is important is the range of seasonal temperature extremes, or the likely local temperature for the locality for landing. However, it is typically extreme temperatures that kill any organism, so it would still be more useful to know the range than to know the mean.
“they’re being used in an analytical product, which must account for imhomogeneities in the station records”.
Lmao, how many times have you bought the Brooklyn bridge? people are so ridiculously easy to fool these days.
Quiz: I want to take the average height of two people, so measure each of their heights from the floor to the tops of their heads. I see that one person is barefoot, the other is wearing 6″ platform heels.
Should I:
a. take the average exactly as-is, because data tampering is a sin and the word “inhomogenous” sounds like something Satan would say?
b. subtract the height of the platform heels before taking the average?
In this case, wouldn’t “account for imhomogeneities” be a subjective judgement of the person doing the “accounting”?
In other words these computer temperature adjustments are based on personal opinions of the adjuster. A biased person could easily insert his bias into the calculation.
I don’t buy the adjustments, especially those before the satellite era. Instead, we should stick with the unmodified, regional temperature charts to guide our path, and they tell us we have nothing to fear from CO2 because it’s not any warmer today than it was in decades past, so CO2 has not added any additional warmth to the picture, at least not enough to measure, or see.
The unmodified, regional surface temperature charts were made by people who had no climate change bias or agenda. They just recorded the temperatues as they saw them. So to eliminate the bias in the temperture record, let’s go with an unbiased source, the regional surface temperature charts.
That’s what I’m doing.
You don’t really need to do any adjustments at all, below is what the raw data (black line) look like compared to the adjusted datasets for the global land surface – you can see that the effect of adjustments is quite small:
As long as you’re accounting for station distribution (e.g. by gridding) and using the anomalies there isn’t much to worry about.
Nearby stations, nice! What is the NOAA infilled value for the two endpoints of the highlighted line between Hiawatha and Salina? Do you think NOAA would end up with a lower temp than the two endpoints?
Also, look at the variance (range) in temps over a small area. Do you think a range of 7 – 10 degrees in a small area can be adequately handled by an algorithm? With what uncertainty? I’ll bet it is a lot more than the 0.001 degree claimed precision. You will end up with something like 0.001 ± 1 degree.
“Also, look at the variance (range) in temps over a small area. Do you think a range of 7 – 10 degrees in a small area can be adequately handled by an algorithm? ”
You have just highlighted another excellent reason to use anomalies rather than absolute temperatures, spatial correlation is a lot better.
“An anomaly is the change in temperature relative to a baseline which usually the pre-industrial period, or a more recent climatology (1951-1980, or 1980-1999 etc.). With very few exceptions the changes are almost never shown in terms of absolute temperatures. So why is that?
There are two main reasons. First of all, the observed changes in global mean temperatures are more easily calculated in terms of anomalies (since anomalies have much greater spatial correlation than absolute temperatures). The details are described in the previous link, but the basic issue is that temperature anomalies have a much greater correlation scale (100’s of miles) than absolute temperatures – i.e. if the monthly anomaly in upstate New York is a 2ºC, that is a good estimate for the anomaly from Ohio to Maine, and from Quebec to Maryland, while the absolute temperature would vary far more. That means you need fewer data points to make a good estimate of the global value. The uncertainty in the global mean anomaly on a yearly basis (with the current network of stations) is around 0.1ºC in contrast that to the estimated uncertainty in the absolute temperature of about 0.5ºC (Jones et al, 1999).
https://www.realclimate.org/index.php/archives/2014/12/absolute-temperatures-and-relative-anomalies/
The problem with anomalies is no different than the problems with actual temps. The locations with higher values of anomalies will bias the total and increase the variance.
If you doubt this, when was the last time you saw a variance quoted with any anomaly average?
“… the observed changes in global mean temperatures are more easily calculated in terms of anomalies …”
Are you kidding? Do you really think that a computer has a big problem calculating numbers like 30 degrees vs anomalies like 2 degrees?
You have yet to show how any average of Tmax and Tmin over any time period shows what is actually changing. IOW, is Tmax increasing/falling, is Tmin increasing/falling, or some combination of both?
Somehow a metric derived from averages of averages of averages of averages has been assumed to be the correct depiction of what is happening everywhere globally. Averaging summer/winter, land/SST, coastal/inland, etc. simply can not tell you what is happening and where.
As evidence, I’ll give you a GAT of anomaly of 1.5 degrees C. You tell me where and how the temperature at any given location has changed. If you can’t, the metric has little or no value to anyone other than allowing propaganda to be propagated.
Anomalies lets one show a graph that shows a 5% increase in “temperature” rather than the 0.3% change in actual temperature. How scary!
For sure, this is why anomalies are much better to use. But surely you recognize that infilling a missing values from nearby stations is better than infilling the value with the mean of all the stations in the entire region for which you’re creating an average. Because that is what you’re doing if you leave the values as NULL.
NOAA is still altering data
In 2010 the anamoly for year 2010 was 0,62C, but in 2020 the anamoly for year 2010 was 0,72C (falsely adjusted)
Whoops! You didn’t get an answer, did you? Maybe he overlooked your question.
NOAA has to adjust the temperatures upwards so they can keep claiming we are experiencing the “hottest year evah!”
They have been doing it for years and getting away with it.
Why would you adjust a 10 year old year upwards in order to claim the current year was the hottest ever? And if their intention is to show every year is the hottest ever, why are so many years not the hottest ever?
Well, quite a few years are shown incorrectly as the “hottest year evah! by NOAA.
https://www.noaa.gov/news/2020-was-earth-s-2nd-hottest-year-just-behind-2016
“The world’s seven-warmest years have all occurred since 2014, with 10 of the warmest years occurring since 2005.”
end excerpt
Now reconcile the NOAA statement above with the UAH satellite chart (below). If you look at the UAH satellite chart, you could not say that any year between 1998 and 2016/2020, was “the hottest year evah!”, yet NOAA claims 10 of those years were the “hottest year evah!”
NOAA is putting out climate change propaganda. They are trying to scare people with their manipulated charts.
Look for yourself:
““The world’s seven-warmest years have all occurred since 2014, …” As you can see from the above, it is caused by a Super El Nino occurring at the end of their series beginning at 2014, something they don’t tell the plebs.
It is adjusted upward just enough to show the rate of warming that the UN IPCC CliSciFi models need (still not enough) but not hot enough to ruin the latest hottest year evah meme. It also might ruin the meme if somebody explained the difference between the energy required to raise the atmospheric temperature 1 C at the Antarctic vs the tropics. I’ve never done the calculations.
[And could someone explain to me what the difference to the globe a change of 0.01 (or even 0.001) C might be?]
Yes, warming the past. Must be an error!
Heller is always open to debate..try him….
He is happy to debate people (and I have engaged him in the past), but continues repeating the same incorrect things regardless. Smarter people than me have directly and clearly pointed out his errors to him many times over the years and nothing has changed, not one iota. Wasn’t he barred from contributing to this very blog because Anthony got fed up with this behavior?
(Tony Heller can post here as he has on occasion) SUNMOD
You’re wrong. Look at the analyses of Time of Obs bias – There should be as many biases from morning as afternoon data. The stations without TOB show different statistics from those that have it. Besides, those corrections should be very minor.
NOAA screws with the data. See Dr. Humlum’s analyses as well.
ToBs adjustments make up about half of the magnitude of adjustments to the USHCN data. And they make a very substantial difference when your metric is “number of days with x temperature.” You’re literally talking about counts of days at a given temperature, which highly depends on the time of day that measurements are being taken (a hot day will be counted twice with an afternoon reading, a cold day counted twice with a morning reading). His approach makes it completely impossible to parse climate trends out of trends resulting from changes in the station network composition or observing practices. And he knows this, it’s been painstakingly pointed out to him innumerable times.
Most temperature monitors had(have) min/max recorded temperature for the 24h. I think the argument was originally about the time of reset. This is all red herring and Heller envy. He’s got you on the run.
You are correct – if I reset the thermometer at the hottest part of the day, and the next day is colder than the day the thermometer was reset, then the max temperature recorded for the “next day” will actually be the max of the previous day. You’re double counting warm days. Vice versa for cool days.
If there is a gradual shift over many decades from volunteers taking readings in the afternoon to taking readings in the morning, which there was, it will impart a spurious cooling trend into the network that is not a climatic effect.
None are so blind as those who will not see! The readIngs, min max are recorded for the day and reset for the following day. The readings, min max are each for the date of interest.
Not always. That is what Weekly_rise is trying to explain. Obviously this is not an issue with MMTS instruments, but its definitely an issue with LiG instruments.
TOBS is only necessary if you are trying to create a population of similar things. It is one reason that trends from local and regional locations do not add up to the GAT. Which is more important? The local and regional temps!
“Wasn’t he barred from contributing to this very blog because Anthony got fed up with this behavior?”
I see you are desperate. Anthony didn’t get fed up with anything that had to do with the temperature record. The controversy was about whether CO2 could freeze out solid in Antarctica or not. Get your facts straight.
What other facts don’t you have straight?
Very good point Tom — thanks for that note.
That certainly seemed to be a part of the reason Anthony gave him the boot. But, as Anthony said in a comment on a another blog some years ago, it was Heller’s overall pattern of dishonest behavior, including refusal to admit to his many errors on USHCN, that drove the banning:
I don’t see anything there where Anthony says Heller is dishonest. One can be stubborn, argumentative, and even wrong, while at the same time not being dishonest. If you believe what you say, you are not being dishonest, even if you are wrong.
I guess that “dishonest” characterization is yours, not Anthony’s.
Seems not:
From Judith Curry’s Blog CE:
Nick Stokes | June 29, 2014 at 8:52 pm |
omanuel | June 29, 2014 at 8:25 pm |
“Steven Goddard aka Tony Heller has issued an open invitation to debate those who disagree with him.”
I remember an earlier invitation
“Again, I am happy to debate and humiliate anyone who disagrees with this basic mathematics.”
I’ve tried. His motto seems to be “never explain, never apologize”. And his basic mathematics is hopeless.
As hopeless as your grammar?
That is Nick Stokes’s “grammar”
Unless you mean “From Judith Curry’s Blog CE” ?
So I will just assume a sad denizen desperate to get in a disparaging dig at someone that they cannot counter with anything else.
Bless.
I’m guessing Carlo, Monte mistakenly thinks the word mathematics is plural.
http://rankexploits.com/musings/2014/how-not-to-calculate-temperature/
Heller, unkindly, also publishes the official charts showing how warm it was in the 1930s.
And backs those charts with headlines from the period.
Government is “cooking” the books to promote fear.
On a subject that only government can fix.
First, his “official charts” are his own – compiled using raw station data without taking into account the uneven spatial distribution of surface stations (i.e. gridding or any other weighting scheme). His results arise because of his incorrect methodology, not because anyone is nefariously fiddling the data. The black line in the graph linked below is the raw GHCN station data, with no adjustments applied whatsoever, but gridded to avoid oversampling the areas with the highest station density:
The trend is almost indistinguishable from the major indices from NASA, Berkeley Earth, and the CRU.
Second, the 1930s were quite warm in the contiguous US, so it is hardly surprising that Heller can find lots of newspaper clippings from the time saying so. This does not suggest that the US, or the globe, was warmer in the 1930s than it is today.
“and he doesn’t apply any adjustment for ToBs,”
Heller says ToBs are unnecessary and then goes on to demonstrate it.
ToBs are personal opinions, when it comes to the historical temperature record. Personal opinions and interpretations, and psychoanalysis of those who recorded the historic temperature readings so many decades ago, are not data.
He goes on to “demonstrate” that ToBs adjustments are unnecessary by using the same data containing all the other inhomogeneities he ignores. ToB is not a personal opinion – it is well documented that volunteers shifted from an afternoon read time to a morning read time over the course of the 20th century in response to a directive to improve precipitation measurements. The bias that this imparts into the historical trends is also not an opinion. This bias is especially prevalent in the analyses Heller presents showing “percentage of days above 90 degrees.” If you double count warm days in the past and gradually shift to double counting cool days instead, you’re going to produce a downward trend in the number of days above 90 degrees that has nothing to do with the climate. This will be a much bigger bias than even the bias in the daily mean temperature trend.
“it is well documented”
So you claim.
“Heller says TOBs are unnecessary and then goes on to demonstrate it.”
And Heller is plainly wrong.
It’s intuitively obvious that if you record the daily max on the evening of a hot day (and v importantly RESET the thermometer at the same time), then if a change to a cooler airmass occurs overnight it will result in the previous days high temperature at 9pm that day still being on the max thermo – so the previous hot day is recorded twice when the second day may be several degrees cooler.
Recording the max at 9am (and resetting) stops that.
This is Nick Stokes’ analysis ….
https://moyhu.blogspot.com/2014/05/the-necessity-of-tobs.html
“Because evening TOB has a warm bias, through double counting very warm afternoons, the change to 9am has a cooling effect. Here is a histogram of the putative effects for the 190 stations of changing from 5pm observing time to 9am. Positive effect indicates (in °C) the bias that has to be subtracted from temperatures before the change.”
Since these all use opposite hemisphere data, winter vs summer, one needs to know the other statistical parameters associated with the mean. Tell us what the variance, skewness, and kurtosis parameters are. If these aren’t available, your GAT is meaningless.
The only thing they care about is division by the square root of N.
Look at the difference between 1998 and 2016 on the UAH satellite chart (below), and you will see that 2016 shows to be 0.1C warmer than 1998. The 0.1C figure is within the margin of error for the measuring instrument so 1998, and 2016, are basically tied for the warmest period in the last few decades.
Then, look at the NOAA chart, at the difference between 1998 and 2016. The NOAA chart shows that 2016 is about 0.4C warmer than 1998, so the NOAA chart is showing a big difference between 1998 and 2016, and it certainly doesn’t show they are tied for the warmest temperatures in the recent past.
How do you explain this discrepancy?
To me, this discrepancy is a transparent effort to manipulate the temperature record so NOAA can proclaim year after year as the “Hottest year evah!” and thus scare people into believing in the Human-caused climate change scam.
NOAA couldn’t be proclaiming any “hottest year evah!” using the UAH satellite chart because it shows there are no hotter years than 1998 until we reach the year 2016.
NOAA’s data manipulation of the temperature record is pure climate change propaganda.
The “discrepancy” is explained by the fact that these are different temperature estimates made using very different instrumentation, at different grains, and compiled using different methodologies. the NOAA is using surface (0-2 meter) temperature measurements taken by thermometer after steps to homogenize the station network, while UAH is using lower troposphere (0-10km) measurements made using MSU instruments on satellites, converted to temperature estimates after applying adjustments for drift, orbital decay, sensor calibration, etc.
The discrepancy is a red flag for the significant difference between 2 adjacent measurements. In addition to data altering, are you aware of the station location management activities of NOAA?
It is not a red flag at all to people who recognize a difference between satellites and weather stations. It is also worth noting that UAH does not even agree on the difference between 1998 and 2016 with other satellite-derived temperature estimates. It is the dataset of choice amongst those doubtful of global warming, but it is the singular outlier amongst its peers. Perhaps the discrepancy you note is actually suggestive of a flaw in the UAH methodology.
I guess we’ll all have to suffer under our red-flag climate … https://www.youtube.com/watch?v=p7WsUECyDkc
I posted a rebuttal to your UAH being the outlier somewhere. Maybe farther down in this thread. I’ll look for it.
Roy Spencer says the other data bases are the real outliers because they are using satellite data in their output where Roy says the particular satellite they are using is trending towards being too warm, and Roy dropped it out of his data, but NOAA and the rest are still using this “hotter” data which causes them to register higher temperatures than the UAH satellite.
I just found the rebuttal a few comments below this one.
Mears adjusted RSS in response to the pressure he was getting from CliSciFi practitioners that his results were being used to discredit their memes by the ‘denier’ crowd
IIRC, NOAA’s satellite data and the reanalysis datasets are both closer to UAH6.
Two different years almost two decades apart have average global temperatures recorded using two different methods. The difference in temperature between the the two years using method A (0.1 C uncertainty) is 0.1 C, meaning there is no statistical difference in the temperatures over the period of almost two decades. The difference in temperature between the two years using method B (unknown uncertainty due to wildly varying measuring conditions) is 0.4 C, meaning the measurements are useless because we can’t estimate its accuracy. Lets go with method A since method B is worthless.
The above implies we should use pre-radiosonde, pre-satellite and pre-ARGO temperature measurements only to reveal general temperature movements. For scientific work, only radiosonde, satellite and ARGO data should be utilized.
Somebody prove my analysis is incorrect.
Additionally, anybody screaming “hottest year evah” is an ideologue, not a scientist. Any organization that publishes reports to the public about “hottest year evah” without clear explanation of uncertainties is politically corrupt.
“I think it is obvious that the NOAA is referring to their own temperature index”
NOAA’s “temperature index” is not in Kelvin or Celsius degrees???
Temperature “index”??? Is the SI temperature scale not good enough?
Is NOAA doing science or is it doing hokus-pokus???
Or Abracadabra.
I saw the Steve Miller Band play at the Punchbowl in Hawaii. They flew the band in by helicopter. My buddy met the love of his life that day at the concert.
Yep. Larry hasn’t grasped even the basics of the topic he is writing about.
The irony is strong in this one.
Larry is also reporting HADCRUT for July 2021 before it has been released.
“New versions were published in December 2020: HadCRUT5, CRUTEM5 and HadSST4 (see papers). These are the recommended versions because of the improvements in data and processing methods over the previous versions.
They are updated every couple of months and currently have data up to June 2021”
https://crudata.uea.ac.uk/cru/data/temperature/
People less kind than myself could be forgiven for concluding Larry is a bit clueless.
That is a very slow process they run on, all other sets have already published, why so slow John?
Why did Larry say they had reported, when they haven’t?
Seems a more relevant question, in the context. 😉
Probably a mistake in his assuming that a large data set would have been updated weeks ago?
You still haven’t explained why they are over 1 1/2 months late in updating just a single month of data, very easy to do on the computers they have.
Why the long delay John?
This question in this context is completely irrelevant. Furthermore, John has no obligation to answer this question at all. He’s just pointed out that the July 2021 result is not published yet.
Translation: I don’t have an answer to offer on it either.
Cheers
No. The correct translation: you just tried to change topic (with insisting on getting answer to an irrelevant question) when it became obvious you were wrong.
Probably a mistake
A mistake which combined with his feeble grasp on anomalies invalidates the entire piece.
Keep trying.
I personally think all traditional datasets should delay reporting for 3 months. It takes about that long for the majority of already digitized records to make into the observational repositories. By updating so quickly we’re really only getting preliminary results that then change often significantly within the next few months. There’s still the issue of slow upload streams that are delayed longer than a few months and the even more onerous problem of handwritten records that often take years to get digitized and uploaded, but usually within 3 months the vast majority of the observations are available so I think it is a reasonable compromise. Just my $0.02…
It takes that long to decide what the readings should be, yes
Assuming that was a serious post I’m not sure what you mean. The issue is with the timing of the upload; not what the readings actually are. Other datasets like reanalysis which have rigid assimilation windows that can be as little as 1-2 hours in some cases that are often hard cutoffs such that if the data isn’t delivered in the specified window then it is not incorporated with some exceptions. As a result these datasets are generally available within a few days of the end of the month and are mostly locked in at that point. For example, NCAR is lagged by about 1 day. Copernicus reporting is lagged about 1 week. Of course, reanalysis assimilates more observations in a single month than these traditional datasets have over their entire periods so it’s not really comparing apples-to-apples.
And suitable news window.
I tend to agree, or at least they should put big health warnings that any reported data is likely to change slightly over the net few weeks and months.
The problem I think is that people have become a bit too obsessed over every monthly release (myself included), rather than looking at the big picture.
Yeah. I’m always eager for the monthly updates too. Maybe just better communication to the general public that observations continue to roll in and that the published figures will change as the later updates incorporate them. Of course, the argument is that if you’re seriously analyzing these datasets you should already be aware of the timing of uploads. I guess what I’m saying is that for those truly familiar with these datasets its rather obvious already.
The first thing the marxists ALWAYS do is manipulate numbers, from temp data to COVID deaths to election results.
It really is amazing how alarmists actually believe they understand the science.
As the article pointed out, only NOAA came to the conclusion that July was the hottest, the other 4 didn’t. Are you in the habit of only choosing the data set that shows what you want to see?
Beyond that, the claimed “record” was so far below the confidence level as to be completely meaningless. Only clueless trolls would try to tout a 0.01C increase as meaningful.
And, it was only a temporary “conclusion” that they then corrected downward.
But it got the headline.
The correction didn’t.
Political Science.
Leave them with the desired impression.
That’s all that matters.
“Only clueless trolls would try to tout a 0.01C increase as meaningful.”
In the NASA data July 2021 is only 0.02C cooler than July 2019. Must both be the warmest month on record, by that logic. 😉
You don’t understand anything about confidence intervals, do you.
How about you? 🙂 As far as I know you don’t have any tertiary education, and I seriously doubt you’ve learnt anything about statistics in high school. Regarding John, he seems to know what he’s talking about.
Hmm, so you’re saying anyone who didn’t go to university is thick. Well you certainly disprove the notion that university education is a sign of intelligence
Well, anyone who didn’t go to uni has problems with “confidence intervals”. For that matter, most of those who did go has this problem too 🙂 Anyway, MarkW was bullshiting about confidence intervals as if he knew what he was talking about when it was obvious he had no idea.
Exactly, like Rory or some other guys here. But the thing is there’s a strong correlation. Rory is an outlier.
Anyone who thinks you can take 21 students in an electrical engineering lab, have them build 21 circuits, individually measure the amplifies, and think you can combine the results to get a true value simply hasn’t learned about uncertainty (i.e. confidence intervals). It doesn’t matter how precisely you calculate the average of the 21 results, the uncertainty in the average will remain the uncertainty associated with the elements used to build the amplifiers and the uncertainties associated with the measuring devices.
You don’t seem to understand this basic fact of physical science. And yet you are willing to state that those of us that *do* understand physical science actually don’t. Heal thyself, physician.
🙂 Yeah, for sure. How do you think they measured gravitational waves with displacements like the diameter of a proton? Did they have a single instrument with uncertainty less than that? A very good ruler? And a good eyeball? Why does it take weeks to get the result? (Hint: postprocessing,”precisely calculating”).
“How do you think they measured gravitational waves with displacements like the diameter of a proton? Did they have a single instrument with uncertainty less than that? A very good ruler? And a good eyeball? Why does it take weeks to get the result? (Hint: postprocessing,”precisely calculating”).”
Because they were taking multiple measurements of the same measurand using the same instrument. Thus forming a probability distribution around the true value. By analyzing that probability distribution they could close in on the true value.
When you are measuring DIFFERENT MEASURANDS there is *NO* probability distribution formed.
It would be like averaging the gravity of Mercury, Venus, Earth, Mars, and Jupiter. Calculate the average to the millionth decimal place. YOU STILL WON’T HAVE THE TRUE VALUE FOR GRAVITY. And you will not have reduced the uncertainty associated with that mean by one iota. That’s because those independent, random measurements of different things don’t form a probability distribution.
It’s no different than measuring the temp at noon and at midnight and expecting the average of the two to have a lower uncertainty than each individual temperature. That average is not a true value of *anything* and the two measurements do not form a probability distribution that can be analyzed statistically.
🙂 Somehow you think here it is possible.
Change subjects much you.
You are treating temperature results as pure numbers whose precision is determined solely by the size of a floating variable in a computer. The same with confidence limits. You don’t even know the difference between numbers and MEASUREMENTS!
Measurements have their own confidence levels for each and every measurement. These confidence levels are described by the uncertainty in measuring a value. The uncertainties carry through to the final calculations. Most of the temps in the 1st half or more in the 20th century were measured in integers. That controls the ultimate precision of calculations on temperature measurements.
The fact that you and others continue to quote unwarranted confidence levels for temperature averages simply points out that you are ignorant of physical science and the necessity of proper treatment of measurements.
A classic example I’ve seen in an introductory statistics text for regressing two variables is the yield of corn per acre of farmland. What isn’t discussed much at all are the assumptions made for the analysis. First, the bushels of corn from a field is basically an integer, and the field size is a known number that doesn’t change (probably a land survey measurement). In other words, both the X and Y data are treated as being without error.
The analysis is done for a single growing season, so there is no time dependence. The sample population is all the fields in a single county, which means there are minimal spatial variations.
As a result, it is justified to say that the standard deviation (or variance) of the regression is the uncertainty of the bushels per acre result. If multiple regressions are done over multiple seasons and/or counties, the uncertainty must increase. All of the individual variances must be accounted for.
I think you are underestimating MarkW.
The honest confidence intervals, if they are honest would be at least + or – 5 C.
Actually, Phishlips, accounting for statistical uncertainty, 4 years in the last 6 could be in the running for the warmest July on record, 2016 and the last 3 are all statistically tied.
That’s what makes NOAA so dishonest – in their announcement they don’t admit that they really don’t know the global average temperature accurately enough to make such a claim based on such TINY differences between years.
But the warmest July was 1934. Not? That is surely the nub of all the argumentation here. Heller’s point is, I think, individual, reliable records prove that it was.
No.
It has generally been warming for the past approximately 300 years. Man started to get interested about 150 years ago. In the intervening time it has been warming and cooling in multi-decadal-long cycles, with a generally warming trend. Accordingly, the most recent decadal-long temperature recordings will be greater than those of previous decadal-long periods.
IIRC, the temperature differences between each decadal period have been reducing, indicating that increasing temperature trends have been plateauing. 21st Century data from all sources confirm that as a fact. CO2 does not significantly drive overall global temperatures, although it theoretically has some minor impact. Use long-term data to prove me wrong.
0.01ºC
ROTFLMAO……..
That’s a second to second temperature variable, not a global average, quite apart from being impossible to physically measure.
I’m just pointing out an error in the article. Do you agree or disagree with the comment above? You’re taking an adversarial tone, but I don’t think I’ve said anything controversial.
Of course you have. When the uncertainty interval is wider than the increment you have calculated you truly have no idea what actually happened. July 2021 could have been 0.1C LOWER and still been within the uncertainty interval!
Why does NOAA and the media never include the uncertainty interval? They include it for political polling. Isn’t temperature measurement as important?
It’s not, that’s the reason. You’re inability to understand this is really hilarious.
“your” instead of “you’re”
Hilarious you haven’t figured out there’s an ‘edit’ function on this blog.
… with a time limit.
Yeah, I know, and it’s only usable for a few minutes after posting. Apparently you haven’t figured out this.
In other words you can’t refute anything I asserted. All you have is the argumentative fallacy of Argument by Dismissal. Why am I not surprised that all you have is an argumentative fallacy?
No need for that, this is science, please read and understand at last the textbooks. Furthermore, the other guys here have refuted your assertions 100 times already.
You are *STILL* using an argumentative fallacy. This one is named Appeal to Authority. No actual refutation provided, just an appeal to authority.
If you can actually refute what I asserted then do so. If you can’t then stop using argumentative fallacies in a vain attempt to make yourself look smarter than you actually are.
You would lose a middle school debate using these tactics.
yep, science is THE authority.
So say’s political science (except when it comes to biology).
Yet somehow, scientists always claim “its worse than we thought”
Are you saying that the uncertainty interval is less than +/- 0.01 degrees?
Only fools think the can produce a world temperature number that would have any basis in reality. Satellite measure can be the only thing that might tell you something but the satellites have their own set of problems. The truth of the matter we might have the technology to do what we are trying to do today but more than that it is like we never will. The variables will eat you up and you cannot correct for them if you do not understand what they are. We are where we were, when our elites were discussing how many Angels can fit on the head of a pin, the argument is the same there is no answer. It to bad the politicians are using this BS to pick my pocket.
Do you have a reading comprehension problem, or is your short-term memory failing?
Whether or not there were later revisions that changed the anomaly for July 2021, my point about why NOAA reported it as the warmest month on record stands. Yourself and others in the comments are trying to argue with me over things I have not said.
You are defending the initial claim after NOAA revised the anomaly downward. Larry makes the point that there have been no media retractions.
Furthermore, when the uncertainty is +/- 0.19, a claim of +0.01 is meaningless.
I’m not defending any claim, I’m pointing out an error in the article. Despite all the downvotes, no one in this thread has actually tried to dispute my point. I am also fairly certain that the NOAA does not run all the world’s media, so they are hardly to blame for any retractions or lack thereof.
Yes they hav,e but you just carry on ,making ever more stupid comments
NOAA did, in fact, “run to all the world’s media” when it made its announcement in alarming terms. When NOAA revised the number, it did not, in fact, make the same sort of widespread announcement about the downward revision. It is a propaganda machine, not a neutral arbiter of science news.
The NOAA did not “make the announcement in alarming terms.” This is hyperbole. They made the announcement in their July 2021 Global Climate Report, using exactly the same language they use every other month (literally – the reports use the same template each month and the NOAA just updates the numeric values). As far as I’m aware, those reports are “snapshots” that are not revised or updated.
Why does NOAA never quote their uncertainty level when describing these values. Do you not understand that the measurement of 0.01 has no scientific significance! Rather than promoting a “hotter” than ever record they should be saying this value has no scientific significance.
“… using exactly the same language they use every other month (literally – the reports use the same template each month and the NOAA just updates the numeric values). So every month they report that the current month is the hottest, coldest, whatever since …? You know damned well that NOAA hypes the “good” (bad) news to us plebs.
That was a simple statement of fact which garnered 11 minuses (so far); thanks clapping monkeys.
The downvotes were for the assumption that if NOAA says it’s the warmest, then it is definitely the warmest. Who cares what the other data sets show.
An “anomaly” is your tattered attempt to articulate an explanation…
What you are stating here is a trivial and non-substantial fact. It is trivial in the sense that it does not add any understanding of the matter discussed in the article you are commenting, and non-substantial in that it is widely known that the “global mean temperature rise” is in fact primarily a rise in minimum temperatures.
The point made in the article you comment on is that the difference in this years anomaly and any previously recorded anomaly to the same average is less than the uncertainty range for the aggregate anomaly in question. The argument is correct that you cannot in any sensible way distinguish between July of 2021 and several previous July records.
https://www.noaa.gov/news/its-official-july-2021-was-earths-hottest-month-on-record
NOAA is still claiming there is a 0.01 °C difference as if it has any meaning. Given the nature of these measurements and the actual data we cannot tell whether July 2021 was hotter, colder or the same as previous Julys. Within the margin of uncertainty its can be any of those, and it is very misleading to say it is THE hottest. The only thing one can say is that it might be among the hottest.
Does anyone know how the confidence level is calculated? What sources of error are left out?
0.19 for NOAA’s measurements seems very small to me for a world wide measurement.
It is way too small, and ignores any and all instrumentation uncertainties.
Very likely it is just the standard deviation of the average of the average for July, multiplied by 2.
Exactly. It’s just the standard deviation of the “sample average.” They completely ignore uncertainty. These are PhDs mind you, making a mistake that would get you flunked in High School Chemistry.
That’s what I suspected. But, as you indicate, the error seems so obvious that I wondered what I was missing.
Climate “scientists” believe that by subtracting their holy anomalies, error is canceled. Very rarely will any of them admit this, but it is the elephant inside the tent.
You have nailed it. It is the standard deviation of the sample means average. Too many “scientists” and folks here treat it as how accurate or precise the mean is. They need to go back to school and learn statistics.
SIGMApopulation = SIGMAsample • √N
SIGMApopulation is what they should be using for a minimum uncertainty.
Do you mean Σ or σ? Either way I can’t figure out how you get that equation.
Confidence level is usually something like the RMS deviation from the final average of all the individual measurements that went into the final average.
Only in Climate “Science” are meteorological temperatures reported to 2 decimal places.
In any case the very concept of a global temperature is absurd, as is that of a global climate.
NOAA assumes all errors are random and cancel, without evidence, like all of the other climate frauds, which is the only way to get down to ±0.19C. It’s utterly absurd to have a temperature record from the 1800s with glass thermometers and then pretend you can torture this data and end up with an averages that let you distinguish between 5th hottest and 6th hottest years which are statistically indistinguishable. It’s all fraud.
Uncertainty for individual, independent, random measurements grows as you add more and more data points. It adds by root-sum-square. It is *not* the precision with which you calculate the average value of those independent, individual, random measurements — which actually tells you nothing about physical reality.
Daily maximum and minimum temp values are combined to produce a daily MID-RANGE value (which is *not* the average temperature value). These daily mid-range values are then averaged to produce a monthly average. Those monthly averages are then averaged once again to get an annual average. With each average you lose data which is needed to tell you what is actually happening. Then when you use thousands of annual averages to create the Global Average Temperature you totally lose what is happening physically in the thermodynamic system we call Earth.
If the uncertainties were calculated at each stage of this process you would wind up with an uncertainty for the GAT that would actually make it unusable. And, again, the precision with which the averages are calculated has nothing to do with the total uncertainty of the average being calculated.
Just think about the uncertainty of the mid-range value. If each measurement has a +/- 0.6C uncertainty then their “average” would have an uncertainty of sqrt(0.6^2 + 0.6^2) = 0.8. You already have an uncertainty wider than the anomaly of 0.01C that NOAA is stating. Nothing you can do by combining individual, independent, random measurements will ever reduce that uncertainty to a level that justifies stating a 0.01C anomaly difference.
I like how the average human has 1 testicle 🤔
..and one ovary and half a uterus.
Not sure about the half a uterus, but one Mann comes to mind that probably has half a …… never mind.
(But he does keep using the courts to scr*w people that disagree with him and never quite succeeds.)
Actually, the average human has no testicles. I believe there are very slightly more women than men, and some men have only one, and some none at all.
The average human certainly has less than two arms and two legs, and almost certainly one head.
After reading Derg’s post, I knew somebody would push it too far! 😉
Actually no. Less than 1. There are more women (slightly), and not every man has two testicles. Like you.
Do you treat people you encounter in real life like this?
No. Maybe this was unjustified. “To err is human, but it feels divine”.
Short version of your (excellent) post: averaging temperatures is as meaningful as averaging telephone numbers.
As far as mid-range values are concerned there are only two values being used. Therefore you get *no* cancellation of plus and minus values that you might get in a large number of data points (which is why you use root-sum-square). For just two values the uncertainties should probably be added directly, e.g. 0.6 + 0.6, giving an uncertainty for the daily mid-range value of +/- 1.2C. Averaging multiple mid-range values will *never* decrease the uncertainty below that +/- 1.2C interval. I don’t care how precisely you calculate the average of those multiple mid-range values, that average will always have a minimum uncertainty of +/- 1.2C.
If you can’t identify a difference greater than the uncertainty interval then you don’t really know if you have an actual difference or not!
As the General said when informed his weather forecasts were wildly inaccurate, he responded with “I know that, but I need them for planning purposes.” When planning for multi-trillion dollar spending, however, one needs more accuracy for climate predictions. And UN IPCC CliSciFi global climate models have proven to be massive failures.
NOAA is trustworthy—in the sense one can be assured they are playing politics with their reporting.
They have one clear objective = promote the AGW by any means,as the Allah of globalcommunism can never have enough believers.
I have predicted a bunch of new ultimate never seen before all time records already at the beginning of July though i believe in the ice age scare.
The secret of my prophecy?
The summer was supercold in many parts of the world including massive snowfalls in superhot regions.
To counterbalance reality they were forced to come up with some really scary nonsense following the 2nd commandment of communism “The bigger the gap between reality and official reality the bigger the lie must become”
As communism is nothing without fear reality needs some serious adjustments from time to time to maintain the illusion of the perfect utopia.(a reality check for reality itself)
Wether these adjustments are called Holdomor,Nazino affair(what lovely names they give their own attrocities)Lysenkoism(special scare and subjugation tactics against experts)or the destruction of the four olds in China,
is irrelevant.Relevant is the impact,be it mentally or physically.
And from now on its only getting worse and worse the closer we get to (agenda)as some radical changes will come and people won’t accept them without the necessary AGW, Covid,Terrorism- fear.
I think you’re seeing the writing on the wall, so to speak, but I suggest it’s not really enthusiasm for “communism” that is behind it. It’s enthusiasm for controlled society, and the underlying “ideology” is essentially just good old elitism.
The “rule by consent of the governed” movement that sprang up a few centuries ago presented some serious problems for the “Globalists” (elitists), and the vilification of that movement (and the societies/peoples which flourished since it took root among them) became a high priority recently.
Ideologies that have proven effective in the past for vilifying and undermining established societal orders, were “customized” and “deployed/funded” to aid in the “taking down” of what is often referred to as “the West”. (or Whiteness if you prefer ; )
The NOAA shows that in America, it wasn’t even close with 26 Julys hotter than the July of this year,
LINK
You’ve plotted the maximum temperature, to be comparable you should plot the mean.
LOL
That would just pollute the “hottest evah” meme.
Haven’t you been reading the thread? There is no such thing as the “mean”. At best it should be called a midrange temperature. A mean temperature would require taking a large number of periodic measurements throughout the day and then finding the mean.
As to the earth getting hotter, what do you think would best show us burning up, high temps during the day or low temps at night? Why would increasing nighttime temps and unchanging daytime temps cause a big stir among people?
With the hottest July in sine 1896, i.e., July 1936 much hotter than July 2021 by 3.18°F.
No. The maximum temperature in July 1936 was 3.18F warmer than the maximum temperature in July 2021. That’s what I was getting at. Plotting the right variable makes a difference.
The average temperature – which correlates to the mean quoted by NOAA – was warmer but by a more modest 1.4F.
https://www.ncdc.noaa.gov/cag/national/time-series/110/tavg/1/7/1895-2021?base_prd=true&begbaseyear=1901&endbaseyear=2000
And why wouldn’t it, in a overall slightly warming world. It is not, however, proof that maximum temperatures are increasing to record-breaking levels as the CliSciFi alarmists insist in their propaganda.
June on the other hand …
https://www.ncdc.noaa.gov/cag/national/time-series/110/tavg/1/6/1895-2021?base_prd=true&begbaseyear=1901&endbaseyear=2000
Hottest evah 🤓
Boooooosted by Russsssiaaa no doubt.
Also showing minor warming occurring on a cyclic basis with statistically expected excursions.
The graph shows an undeniable cyclic trend.
claim was exaggerated, deceptive and distorted
Just what the narrative driven media demand. Unbridled alarm.
“July was the world’s hottest month ever recorded, a US federal scientific and regulatory agency has reported.
The data shows that the combined land and ocean-surface temperature was 0.93C (1.68F) above the 20th Century average of 15.8C (60.4F).
It is the highest temperature since record-keeping began 142 years ago. The previous record, set in July 2016, was equalled in 2019 and 2020.
Experts believe this is due to the long-term impact of climate change.”
https://www.bbc.co.uk/news/world-us-canada-58208792
“July was world’s hottest month ever recorded, US scientists confirm
Confirmation of the record July heat follows the release of a landmark Intergovernmental Panel on Climate Change (IPCC) report on Monday “
https://www.theguardian.com/environment/2021/aug/13/july-worlds-hottest-month-ever-recorded-us-scientists
So, who are these US scientists? In the end it doesn’t matter, what matters is that this fake fact followed the release of the, er, landmark Intergovernmental Panel on Climate Change (IPCC) report. Timing is everything – ask a comedian or a musician.
No media outlet will publish a correction to this, so July was still the hottest month evah.
“No media outlet will publish a correction to this, so July was still the hottest month evah.”
What would a correction say? July 2021 is an insignificant 0.02C below July 2019 in the NASA data, HADCRUT – contrary to Larry’s ramblings – is not out yet, and the satellites measure a different quantity.
So what needs correcting?
What would a correction say?
How about the truth?
All 5 Global Temperature Measurement Systems Reject NOAA’s July 2021 “hottest month ever” Claims
NOAA could publicly admit it…
But they won’t, because it’s about the narrative, not science, not fact.
-1
Definitely over the target.
And now it’s back to 0
That’s what I call confidence.
The truth? You still haven’t stated what needs correcting, just copied Larry’s mistake.
How can 5 datasets reject anything when only 4 have reported?
And in the surface dataset that has reported 2019 and 2021 are joint warmest with an insignificant 0.02C difference. Not enough to ‘reject’ anything.
“You still haven’t stated what needs correcting”
What needs correcting is they should be using the UAH satellite charts as the official temperature record.
If they used the UAH satellite record, they would show July of 1998 as being warmer than any subsequent July. See the list of hottest July’s listed above for the UAH satellite chart.
Using the other charts, which have been manipulated for political purposes, is just simply pushing climate change propaganda. It’s scaremongering, plain and simple.
Correction would also say that July 2021 was not the hottest July on record. Doubt we’ll see anyone in the MSM publishing that.
Correction would also say that July 2021 was not the hottest July on record.
It is the hottest in the NOAA data.
In the NASA data, 2021 and 2019 are joint hottest.
HADCRUT is not out yet.
UAH and RSS don’t measure the surface.
Yes – alert the media!
http://www.drroyspencer.com/2019/04/uah-rss-noaa-uw-which-satellite-dataset-should-we-believe/
“Despite the most obvious explanation that the NOAA-14 MSU was no longer usable, RSS, NOAA, and UW continue to use all of the NOAA-14 data through its entire lifetime and treat it as just as accurate as NOAA-15 AMSU data. Since NOAA-14 was warming significantly relative to NOAA-15, this puts a stronger warming trend into their satellite datasets, raising the temperature of all subsequent satellites’ measurements after about 2000. . .”
“Clearly, the RSS, NOAA, and UW satellite datasets are the outliers when it comes to comparisons to radiosondes and reanalyses, having too much warming compared to independent data.
But you might ask, why do those 3 satellite datasets agree so well with each other? Mainly because UW and NOAA have largely followed the RSS lead… using NOAA-14 data even when its calibration was drifting, and using similar strategies for diurnal drift adjustments. Thus, NOAA and UW are, to a first approximation, slightly altered versions of the RSS dataset.”
end excerpts
Here’s one reason the UAH satellite chart should be the official temperature record.
If we must have an ‘official’ record, it should be one that measures the temperature at the surface, rather than the lower atmosphere. (Why do we need an ‘official’ temp record? Surely the more the better?)
It comes as no great surprise that Dr Roy thinks Dr Roy’s product is the best. I remember how people used to favour RSS when it showed the least warming, then it was revised and UAH is now the new favourite and Dr Mears of RSS is the antichrist 😉
The basic issue is that the satellites measure a different quantity to the surface datasets. Technically they don’t measure temperature at all, but brightness in the lower troposphere. This quantity is then converted to temperature using – yes – a model plus a whole raft of adjustments for correct for orbital drift, different instruments on different platforms etc.
Nobody lives 5km up in the air so while it is a useful metric for comparison it is arguably less relevant than the surface measurements for questions about GW. It is surely not valid to claim a lack of a record in the satellite data invalidates a record at the surface. One difference is that the troposphere exhibits a stronger response to el Nino and La Nina than occurs on the surface. This is why the record highs in the satellite data tend to be in El Nino years.
Your holy averages of averages are not climate, why is this so hard to understand?
“If we must have an ‘official’ record, it should be one that measures the temperature at the surface”
You guys keep bringing this up like it eliminates the UAH satellite from the competition.
On the UAH satellite website it says “The satellite-based instruments measure the temperature of the atmosphere from the surface up to an altitude of about eight kilometers above sea level.”
So you better talk to Roy Spencer because he says the measurements do measure from the surface.
https://www.uah.edu/essc/weather-products/global-temperature-report
Yes, but you wouldn’t expect a time series of temperatures from 0-8000m to match exactly one of temperatures at 2m. Therefore, the fact that July 2021 is not a record month in the UAH data does not ‘reject’ the fact that it is in the surface data, contrary to the OP.
Actually with the lapse rate it is pretty easy to get the surface temp. However, I don’t think the satellite actually measures the temperature at 5 km.
Also, anomalies and GAT is supposed to be a metric that shows temperature change. Satellite measures are no different! They show a metric where the temperature changes in a systematic way. Their advantage is better coverage of the whole earth.
“Actually with the lapse rate it is pretty easy to get the surface temp. However, I don’t think the satellite actually measures the temperature at 5 km.”
No, it was a flippant example. The published figure is a weighted average across multiple altitudes. Not sure if you could easily derive a meaningful surface temperature from that – and that is not what gets published and plotted is it?
“Their advantage is better coverage of the whole earth.”
Different anyway. The satellites’ orbits mean they can only scan from 85S to 85N. The excluded area is only a few % of the total, however it is at the poles which are amongst the fastest warming parts of the globe. They also have problems with mountainous areas of elevation over around 1500m. Doubtless this is all taken care of in the many adjustments.
The surface datasets also have coverage challenges however Berkeley Earth now claims to include 99.9% of the globe.
“Here’s one reason the UAH satellite chart should be the official temperature record.”
Yes, those “disputing” climate scientists would prefer that for the following reason.
And obviously why that cannot be the case.
At the very least a mean of data should be used and not the outlier.
Also satellite temp data of a broad depth of the atmosphere is not what we are experiencing at the surface, and for which the science is aimed at.
It misses the greater trend in AGW for a start, which is warming of minima under nocturnal inversions over land.
It is the outlier in being the coldest of all the series ….
https://ametsoc.net/sotc2020/State_of_the_Climate_in_2020_LowRes96.pdf
Table 2.3. Temperature trends (°C decade−1) for near-global lower tropospheric temperature (LTT) and tropical tropospheric temperature (TTT) over 1958–2020 and 1979–2020.
LTT (90°S–90°N) TTT (20°S–20°N)
Start Year 1958 1979 1958 1979
Radiosonde
NOAA/RATPACvA2 0.19 0.21 0.16 0.17
RAOBCOREv1.7 0.18 0.19 0.15 0.15
RICHv1.7 0.20 0.21 0.17 0.19
Satellite
UAHv6.0 — 0.14* — 0.13
RSS v4.0 — 0.22 — 0.18
UWv1.0 — — — 0.18
NOAA STAR v4.1 — — — 0.23
Reanalyses
ERA5 — 0.18 — 0.16
JRA-55 0.17 0.19 0.16 0.15
NASA/MERRA-2 — 0.19 — 0.19
Median 0.19 0.19 0.16 0.18
*The vertical sampling in UAH LTT is slightly different from other datasets and results in temperature
trends that are approximately 0.01°C decade−1 smaller than other datasets.
It wont format but UAH v6 is running at 0.14 C/dec since inception and the median is 0.19 C/dec
“… but the world is not warming like the UN IPCC CliSciFi models said it would” should be appended to every piece of propaganda produced by our government.
Win one for the grifter. Biden is trying to get over the finish line with Bernie’s $3.5 T spending bonanza with borrowed money before SS and Medicare trust funds are exhausted. Climate spending is part of the trillions in the grab bag. No wonder the EU is starting to look for more security independence. I would too.
Hamlin obviously doesn’t understand the difference between absolute temperatures and temperature anomalies.
Have you ever seen a relevant absolute temperature published somewhere ?
Or isn’t it fact, that only anomalies are published and base for all publications and comparisions ?
From NOAA:
July 2021 by the numbers
Around the globe: the combined land and ocean-surface temperature was 1.67 degrees F (0.93 of a degree C) above the 20th-century average of 60.4 degrees F (15.8 degrees C), making it the hottest July since records began 142 years ago. It was 0.02 of a degree F (0.01 of a degree C) higher than the previous record set in July 2016, which was then tied in 2019 and 2020.
https://www.noaa.gov/news/its-official-july-2021-was-earths-hottest-month-on-record
Do you see any absolute temperature your unbased critics refer to ?
NOAA changes their anamoly almost every year. The anamoly for 2010 went from 0.62C (1.12F) to 0.72C (1.30F) in only ten years.
They don’t care about science and logic
My thermometer measures to .001
It may do that but when was the last time it was calibrated?
With what uncertainty?
Ron I need some help with this comment.
When you said “absolute temperatures” were you talking kelvin temperatures? If so should you not have said absolute temperature anomalies?
And if we are comparing anomalies as changes from an agreed number isn’t a larger anomaly higher in that number than a lower anomaly?
Can you be specific in what is incorrect?
“Temperature anomaly” IS NOT a physical magnitude. Check the list of physical magnitudes and respective units of measurement in the SI system (“SI” for “Système International, which is the system of units used in modern science): it does not include any “temperature anomaly”.
“Temperature anomaly” is ambiguous: it is the result of calculating the difference between a temperature and a certain (arbitrary) value of temperature.
“Absolute Temperature” is another name for the magnitude “temperature” of the SI system. It is measured in Kelvin and has an absolute zero. “Absolute” meaning that it is not established by a human convention, but as a result of the laws of physics.
Measurements in other temperature scales (ºF, ºC, etc.) can be easily converted to their SI (K) values.
Ronald Stein did not use the right words, though for what I have seen of his writings along the years I believe he is not confused about the subject. He used ambiguously “absolute” to refer to “measured” temperatures, i.e., temperatures expressed in relation to the (conventional) zero of their respective scales, NOT to any other arbitrary value.
Temperature measures the hotness state of bodies. “Temperature anomalies” DO NOT measure anything physicaly meaningful, because of the dependence of the arbitrary temperature relative to which “anomalies” (differences) are calculated.
“In climate change studies, temperature anomalies are more important than absolute temperature. A temperature anomaly is the difference from an average, or baseline, temperature. The baseline temperature is typically computed by averaging 30 or more years of temperature data. A positive anomaly indicates the observed temperature was warmer than the baseline, while a negative anomaly indicates the observed temperature was cooler than the baseline.
When calculating an average of absolute temperatures, things like station location or elevation will have an effect on the data (ex. higher elevations tend to be cooler than lower elevations and urban areas tend to be warmer than rural areas). However, when looking at anomalies, those factors are less critical. For example, a summer month over an area may be cooler than average, both at a mountain top and in a nearby valley, but the absolute temperatures will be quite different at the two locations.”.
https://www.ncdc.noaa.gov/monitoring-references/dyk/anomalies-vs-temperature
I wish they wouldn’t use the term ‘absolute’ for the actual measured temperature, as it can be confused with the absolute (Kelvin) scale. However anomalies are immensely useful and pretty much how climatic temperatures are nearly always expressed.
You’d expect someone writing on this topic to have a basic grasp, but hey ho.
Another example is the constant whining about who Mann made the original hockey stick graph with (climate) modelling.
“how” instead of “who”
No kidding, Mann was a fraud
Was? Is? …
Did you get it? There was no climate modelling in that result.
Real data don’t produce a hockestick 😀
A very nice piece of jargon pretending to be a scientific explanation. As many people do, I evaluate the quality of the writings (and of the authors) by analysing the accuracy of usage of technical terms — or the stringency of their translation into the common language of lay people. Your citation did not pass that test.
Furthermore, you conflate “usefulness” with “truth”: that operation has no place in the realm of science.
Rewriting for correction and additions:
A very nice piece of jargon pretending to be a scientific explanation. As many people do, I evaluate the quality of the writings (and of the authors) by analysing the accuracy of usage of technical terms — or the stringency of their translation into the common language of lay people. Your citation did not pass that test.
Furthermore, you conflate “usefulness” with “truth”: that operation has no place in the realm of science.
And more: can you explain us how do you measure warming (or cooling) using “temperature anomalies”? It seems, if I grasped what your citations may mean, that the said “anomalies” are localized, i.e., what they call “baseline temperature” is not really a “baseline”, because it changes from place to place. How “useful” for a rigorous work in physics!… If in the good old days of NASA they worked with concepts like those, Armstrong would never get his walk on the Moon.
Well, João, you have made it 100% clear you can’t understand such an extremely simple thing. Congratulations! This is the “you can’t make it up” level. Yes, the local baseline is subtracted from the values because we want to see the fcukin local variation. Because local variations are comparable to each other, you genius. Anomalies are an extremely simple method to make data usable. Again, to the rest: we are struggling with a simple, entry level thing here, barely the first step to understand anything. Actually, anything in any STEM field.
Because the baseline is made up of data with an uncertainty of at least +/- 1.2C the anomalies also have the same uncertainty.
Unless the local variations are greater than +/- 1.2C any calculated anomaly is useless to determine a trend. The trend could be up, down, or sideways and there is no way to tell.
Hm, no one claimed otherwise. This is just a simple trick, we don’t lose anything. Actually, anomalies treat constant bias much better.
Tim, Tim, you never learn…
Of course you lose something. Can you tell me the max and min temps at Location A and the max and min temps at Location B, that both generated the exact same anomaly?
If you can’t then the anomaly tells you NOTHING about the climate at either location. You won’t know if max temps are going up generating a rising anomaly, if min temps are going up generating a rising anomaly, or if it is a combination of both.
All you will know is that something changed, you won’t know what and you won’t know how. In other words you will know nothing about the physical reality of Earth making the whole exercise useless.
If you calculate the mid-range value using one measurement with an uncertainty of +/- 0.6C and a second measurement with an uncertainty of +/- 0.6C exactly what uncertainty do *YOU* expect the mid-range value to have?
The maximum uncertainty value will be if both are off in the positive direction or both are off in the negative direction.
Positive direction: u_t = 0.6 + 0.6 = 1.2
Negative direction: u_t = -0.6 – 0.6 = -1.2.
The uncertainty interval thus becomes +/- 1.2
Don’t throw another argumentative fallacy at me. That will just prove you have no idea of how physical uncertainty works.
Show me where my math is wrong using your own math!
“The maximum uncertainty value will be if both are off in the positive direction or both are off in the negative direction.”
And what is the likelihood of that? Assuming independent measurements, even if all errors are maximum, there’s still a 50% chance that they will cancel out. Then what happens if you take 30 daily readings to get a monthly value, the chances that they all go in the same direction is insignificant. And that’s just for one instrument for one month.
This Gorman guy is hopeless, he’s unable to understand this.
I know. I’ve been going round in circles with him for months now. I doubt he’ll ever acknowledge his misunderstandings – but I’ve learnt a lot trying to explain why he’s wrong.
There is no misunderstanding on my part. Just your misreading of Taylor so as to support your view that an uncertainty interval of an independent, random measurement is some kind of a probability distribution. It isn’t. Statistical tools can’t be used on something that isn’t a probability distribution.
More argument by authority, except in this case as far as I can see you never actually quote Taylor to support your claim, and ignore all the times I’ve pointed out where Taylor says the opposite of what you claim.
So I’ll ask again, provide a quote from Taylor saying an uncertainty interval does not have a probability distribution. And then explain why Taylor says you can use RSS to to calculate the the uncertainty of a sum of uncertain independent measurements if there is no probability distribution.
“More argument by authority, except in this case as far as I can see you never actually quote Taylor to support your claim, and ignore all the times I’ve pointed out where Taylor says the opposite of what you claim.”
He’s not alone. There’s a whole support group here that props each other up with these instatistacies.
True. Though I have noticed few are prepared to acctualy state that they agree with Tim’s wilder statements. They usually try to divert the argument in some other direction
Square Root Of N Bellman declares Victory!
Hurray!
Thanks for your contribution. I’ll be sure to give it all the consideration it deserves.
“Instastatistics allows you to see everyone’s realtime follower count from Instagram. You can also see someone’s following count, how many posts they have and much more…”
Whatever are you blathering about now, Blob? Haven’t seen anyone post anything about Instagram.
There is no chance when there is no probability distribution. And an uncertainty interval does not define a probability distribution. What do *YOU* think the probability is for each data value in the interval 10 +/- 5?
Then what happens if you take 30 daily readings to get a monthly value, the chances that they all go in the same direction is insignificant.
Well, quite. For a random instrumental error taking N measurements reduces the uncertainty in inverse proportion to the square root of N.
Does anyone think climatologists have not thought about these issues?
The random error in a single thermometer reading is about 0.2C [Folland et al., 2001]; the monthly average will be based on at least two readings a day throughout the month, giving 60 or more values contributing to the mean. So the error in the monthly average will be at most 0.2/ SQRT(60) = 0.03C and this will be uncorrelated with the value for any other station or the value for any other month.
Brohan et al 2006
Unfortunately, a lot here, especially Tim Gorman, think the uncertainty in the mean increases by the square root of N.
It does increase by the sqrt of N.
If you take one measurement of the gravity of Mercury, Venus, Earth, Mars, and Jupiter and then average the measurements what do you get for a mean? Is that mean the true value for *gravity*?
What is the uncertainty associated with that mean? It is *not* how precisely you calculate the mean. It is the propagation of the uncertainties in each measurement, typically done using root-sum-square. It is certainly *not* the sum of each measurement uncertainty divided by 5! Not even divided by the sqrt(5)!.
Those measurements do *NOT* form a probability distribution for the value of “gravity”. If they don’t form a probability distribution for “gravity’ then you can’t use statistical methods to reduce the uncertainty associated with the mean.
Why is this so hard to understand? Measuring the gravity of those five different measurands is no different than measuring two different temperatures at two different times even at the same location using the same instrument. They are independent and random measurements of different measurands. They do not form a probability distribution around a true value. There is *no* true value associated with such a data set.
The mean is a much better (smaller error) approximation of the true mean value of the gravity of the planets. The mean of daily temperature measurements is a good approximation of the true daily mean with an error of 0.026C if the individual error is 0.2C and we have 60 measurements. We don’t make individual measurements more accurate with this. BTW the daily mean is calculated from all the measurements on a day, not by averaging the daily maximum and minimum, you genius.
nyolci:The mean is a much better (smaller error) approximation of the true mean value of the gravity of the planets.
The “true mean” is *NOT* the true value when uncertainties exist in the component values. Nor is the mean of the measurements of the five planets the true value for “gravity”!
“The mean of daily temperature measurements is a good approximation of the true daily mean with an error of 0.026C if the individual error is 0.2C and we have 60 measurements. “
What on Earth, or any planet, do you mean by *gravity*? Are you trying to determine the gravitational constant, or acceleration due to gravity? Assuming the latter are you interested in the average g of those specific 5 planets, or of all planets in the solar system, or the universe?
You’re good at coming up with examples of how not to use statistics. If you could apply that skill to understanding how statistics actually work, we might get somewhere.
He’s trying to get you to see that each and every individual temperature measurement is a SEPARATE population.
You apparently refuse to admit this because it would collapse your entire narrative.
Yes. And we keep sayin that measurement mean has a much narrower error approximating the “true” mean of the “separate” populations.
By blinding applying inappropriate formulae incorrectly.
The error of the mean is how precisely you can calculate that mean. It is *NOT* the same thing as the uncertainty associated with the mean. The uncertainty associated with the mean is a direct result of the uncertainty of the component data. When that data is independent and random, i.e. generated from single measurements of different measurands, the data does not define a probability distribution around a true value. Therefore you can’t reduce the uncertainty associated with that mean no matter how precisely you calculate that mean.
Is that what he’s doing? Thanks for the translation. Now if you could only explain what he means by that.
Of course, you could look at an individual measurement as a sample from a population of size 1, but that doesn’t stop it being a sample from a much larger or infinite population. Just as you might declare yourself to be a population of 1, whilst simultaneously being part of a larger population.
“but that doesn’t stop it being a sample from a much larger or infinite population.”
Of course it does! Just as the gravitational acceleration of each of five different planets is its own sample population of one, so is temperature measurements taken at different points in time.
Multiple measurements of the same measurand *does* represent a population of N measurements. Multiple measurements of different measurands does *NOT* represent a population of N measurements of the same thing, you wind up with N populations of size 1.
You have to treat the two different situations differently!
“Of course it does! Just as the gravitational acceleration of each of five different planets is its own sample population of one, so is temperature measurements taken at different points in time.”
Yet a few days ago you were defending the use of the UAH temperature trend in order to derive a pause. How do you think UAH produce a global monthly average except by taking lots of independent measurements around the globe?
Sorry, check your memory banks. I was *not* defending the use of UAH. I was defending against your charge of cherry picking a start date for an analysis of the UAH data.
UAH has its own problems. How measurements widely separated in time can define the climate at a location is magical thinking. It’s the same thinking that the use of anomalies can tell you what is happening. Those anomalies are based on means of independent, random temperature measurements that themselves tell you nothing about the actual climate.
The whole kit and kaboodle is a useless metric. It’s why I have always advocated for using degree-days based on the integration of the temperature profile. *THAT* actually tells you something about the actual climate. It’s why professional engineers use degree-days to size HVAC systems.
“Sorry, check your memory banks. I was *not* defending the use of UAH. I was defending against your charge of cherry picking a start date for an analysis of the UAH data.”
OK, the conversation was going down a lot of surreal rabbit holes – but the question remains, why defend a specific start date for a pause if you think all the monthly anomalies are meaningless?
I explained my view of UAH in excruciating detail. Apparently you didn’t even bother to read my post!
That’s a far different thing than defending a cherry-picking accusation.
No! You can never measure that temperature again!
The only way you can employ statistical sampling is by making multiple simultaneous measurements of a single spatial point.
But no one does this because measurement system costs increase with the number of sensors.
Who said anything about measuring the same temperature again? The idea is to measure different temperatures at different locations or times in order to estimate a specific mean.
“The only way you can employ statistical sampling is by making multiple simultaneous measurements of a single spatial point.?”
How is that even possible, and what would be the point? You’d only know the temperature at one place and one point in time. Lets say I have a digital thermometer that tells me the temperature in a room, by repeatedly sampling the temperature and giving me the average over the last few seconds. Is that a meaningless value becasue the samples weren’t taking simultaneously?
“Who said anything about measuring the same temperature again? The idea is to measure different temperatures at different locations or times in order to estimate a specific mean.”
If you are measuring different measurands then you are not forming a probability distribution around a true value. That means you can’t use statistical analysis on the the measurements to find their uncertainty.
As with the five planets, the mean you derive from such measurements is useless. There is no guarantee that you can find a measurand that actually matches the mean. If you have a mean that doesn’t exist then what kind of probability distribution do you have?
The true value is the mean. Each measurement has a probability of being a certain distance from the mean because there’s a probability distribution. If by measurand you mean the specific sample temperatures, I do not need to find one that matches the mean for the mean to exist.
If I throw a die multiple times, the mean will probably be close to 3.5, no individual roll will be 3.5. The probability distribution is uniform..
“The true value is the mean.”
Sorry, no. Not for multiple single measurements of independent, random measurands.
“Each measurement has a probability of being a certain distance from the mean because there’s a probability distribution”
Again, not for multiple single measurements of independent, random measurands. The uncertainty interval is *NOT* a probability distribution.
” If by measurand you mean the specific sample temperatures, I do not need to find one that matches the mean for the mean to exist.”
You keep mixing up definitions. The mean is not a true value. If nothing in the data set matches the mean then how do you have a probability distribution? Especially a gaussian distribution where the mean is supposed to be the most likely value?
Take a piece of paper out and write 100 times:
The mean is not a true value for independent, random, multiple measurands.
The fact that a mean can be calculated doesn’t mean that it exists in the physical reality we live in.
“If I throw a die multiple times, the mean will probably be close to 3.5, no individual roll will be 3.5. The probability distribution is uniform..”
I’ll tell you what. I’ll take you to a crap table in Las Vegas and you bet that you can roll a 3.5 and I’ll bet against you. Guess who’ll take home the most money at the end of the night?
Again, if the mean doesn’t physically exist, e.g. the average of the gravitational acceleration of five random planets, then it is useless.
The same thing applies to a die. You can calculate a mean of 3.5 but what use is that in the physical world? I’ll just take all your money while you try to roll a 3.5 on the crap table!
Me: “If I throw a die multiple times, the mean will probably be close to 3.5, no individual roll will be 3.5. The probability distribution is uniform..”
TG: “I’ll tell you what. I’ll take you to a crap table in Las Vegas and you bet that you can roll a 3.5 and I’ll bet against you. Guess who’ll take home the most money at the end of the night?”
Very good, now let’s try this with the average roll. I’ll bet that a hundred rolls will average close to 3.5, and you can bet that it will be closer to 4, as the true mean has to be an integer in order to exist.
“You can calculate a mean of 3.5 but what use is that in the physical world? I’ll just take all your money while you try to roll a 3.5 on the crap table!”
What do you think the average of 2 dice will be. If I know the average of one dies is 3.5, I can say the average of 2 will be 7. Do you allow that 7 is a true average as it’s an integer?
“Very good, now let’s try this with the average roll. I’ll bet that a hundred rolls will average close to 3.5, and you can bet that it will be closer to 4, as the true mean has to be an integer in order to exist.”
“be close”? What does that mean? And you would still lose all your money at the crap table. So that average of 3.5 is useless in the real, physical world. Just as it is with any data set created from independent, random measurements of different things.
“What do you think the average of 2 dice will be. If I know the average of one dies is 3.5, I can say the average of 2 will be 7. Do you allow that 7 is a true average as it’s an integer?
With two dice you have 36 possible outcomes. If you add up all the values for all 36 possible outcomes you get 242. 242/36 = 6.7222…..
The average value for rolling two dice is, again, not realizable in the physical world. It is *NOT* 7.
Close should be closer.
I’d double check your sums if I were you. The average of rolling two dice should be 7.
You are right. the sum is 252, not 242. So what? That wasn’t the assertion you made that we were discussing. You just did the argumentative fallacy of Equivocation – changing the definition of the issue.
I wasn’t continuing the argument, just correct my spelling and pointing out a trivial error.
“So what? That wasn’t the assertion you made that we were discussing.”
It seemed to regard it as important when you said
“The average value for rolling two dice is, again, not realizable in the physical world. It is *NOT* 7.”
If the average is 7, then it clearly is realizable in the physical world.
“So that average of 3.5 is useless in the real, physical world.”
So lets be clear about the game I was proposing. We will roll a large number of dice and average the score. Before we do that we will each take a guess as to what the average will be. Whoever is closer will win. I’ll choose 3.5, what will you choose?
Go back to Eq. 1 in the GUM and start there…
Even then you have to allow for different uncertainties associated with the multiple sensors. They are not all guaranteed to be accurate or even have the same uncertainty, not in the field anyway.
Exactly. You have to quantify the uncertainty for each sensor!
I tried to tell him he has to start with eg. 1 in the GUM and fill it out with whatever processing is done and then work through the partial derivatives, but he didn’t want any part of this.
Yep!
You really should read Brohan. For calculating the mean uncertainty sensors are assumed to have a fixed uncertainty of 0.2C.
The argument that you can reduce measurement uncertainty by taking multiple readings of the same value assumes a random distribution of errors around the true value (some will be positive, some negative).
Why would this randomness magically disappear in subsequent measurements of different temperatures by the same sensor – remembering fixed uncertainty?
You should read the Federal Meteorology Handbook No. 1. Especially the table describing the standards for federal temperature measuring stations. It shows +/- 0.6C as the acceptable standard.
I agree with you about the random distribution of readings associated with multiple readings of the same thing, with just a few caveats. Basically you need to be sure that the measurement device doesn’t change over the measurement interval. If it does you can get a skewed distribution where the mean is *not* the actual true value. This is especially true for field stations that cannot be calibrated over the entire measurement interval. (Think of a micrometer whose measurement is dependent on the pressure applied to the measurand. If that pressure changes because of environment changes, e.g. metal expansion, or because of wear on the measuring head then you will get a skewed distribution)
“Why would this randomness magically disappear in subsequent measurements of different temperatures by the same sensor – remembering fixed uncertainty?”
Because you are measuring different things each time. That does *not* build up a random distribution of measurements around a true value. There is no true value for a data set consisting of single measurements of different things.
Let’s assume you are building a deck on the back of your house. You go out and buy ten 2′ 2″x4″ boards and twenty 10′ 2″x4″ boards. You can certainly measure each of those boards and have an uncertainty interval for each one. You can certainly calculate a mean for a combined data set of the boards. Does that mean represent a “true value”? Do the measurements represent a random distribution around a “true value”?
You used the very same measuring tape to measure each one. Does that give you some cancellation in the individual uncertainties? It may very well do so. That is why you add the uncertainties using root-sum-square instead a direct addition. The direct addition will give you an upper bound on the overall uncertainty. The root-sum-square addition will give you a lower bound.
Consider the variances for independent, random variables being combined into a data set. When you combine the populations you add variances, you don’t divide by the new population size to get the new variance. You just do a direct addition. Uncertainty intervals are very similar to variances. You treat them the same. When you have different measurands, each measurand represents an independent, random variable with a population size of one and the uncertainty interval is the “variance” associated with each of the independent, random variables. Those uncertainty intervals add just like variances add. Root-sum-square gets introduced because *some* of the uncertainty may cancel but only *some*, not all.
Your assumption is a complete fantasy, the true value is not knowable; you are arguing that it is knowable, which means you are dwelling in a fantasy world.
The true value is unknowable; for temperature measurements, it is impossible to take “multiple readings of the same value”.
Of course I’m talking about the separate gravitational acceleration for each planet.
Don’t think it goes unnoticed that you refuse to accept that the average of those gravitational accelerations is meaningless for anything in the physical world. You can’t use their average to plot a course from the Earth to Mars or for the return, let alone estimate the fuel requirements for landing and taking off in the two different environments.
“You’re good at coming up with examples of how not to use statistics. If you could apply that skill to understanding how statistics actually work, we might get somewhere.”
Statistics are just one more tool for analyzing the real world. Just as a hammer is not useful for installing a lag screw, statistics are not always useful in analyzing every situation. Just as the average of the gravitational accelerations for five different planets is useless in the physical world the average of measurements of five different independent, random temperature measurements is useless in the real world. Since different climates can produce the same mid-range temperature value, the mid-range temperature is not a definitive metric for climate.
The reason I’m so good at coming up with examples where statistics don’t work is because there are so MANY situations where they don’t work. If you actually understood that we might get somewhere.
“Don’t think it goes unnoticed that you refuse to accept that the average of those gravitational accelerations is meaningless for anything in the physical world.”
Of course it’s meaningless, that’s why I asked you to clarify what value you were trying to measure. It doesn’t mean that all other averages are equally meaningless. Your arguments amount to saying that as there’s no point in adding the number of days in March to the size of the Eiffel Tower we should abandon the concept of addition.
If the average of those gravitational accelerations are useless then why would the average of independent, random, uncorrelated temperatures be any different?
No one is saying that *all* means are equally useless. The mean of multiple measurements of the same thing can get you closer to the true value of that “same thing”. Of course that assumes that the multiple measurements create a gaussian distribution. That is not always the case, e.g. a measurement sensor that wears away as it makes the measurements or a measurement sensor that depends on pressure against a measurand to make the measurement. In these cases you may very well get a skewed distribution and the mean may not be the true value at all.
All you can see is that you have a hammer and everything looks like a nail. You seem to be unable to accept that not everything is a nail. If the average of gravitational accelerations for different planets is meaningless then the average of temperatures taken at different times is meaningless as well. There is *no* difference.
“If the average of those gravitational accelerations are useless then why would the average of independent, random, uncorrelated temperatures be any different?”
Because what you are trying to measure has some utility and some meaning. Why do you want to know the average of anything? One common reason is to compare it to over means, to see if they are different or have changed over time.
There may be uses to the mean of different planets, but you would need to be clear about what hypothesis you were testing. For example, if you wanted to test the idea that large planets had a stronger gravity than small ones, you could test this by taking a random sample of small planets and a random sample of large ones. But you insisted on taking the mean of all sizes of planets, and I’m not sure what you think you are going to use the average for.
“The mean of multiple measurements of the same thing can get you closer to the true value of that “same thing. Of course that assumes that the multiple measurements create a gaussian distribution.”
It really doesn’t.
“All you can see is that you have a hammer and everything looks like a nail.”
An ironic cliche for someone who’d repeated it on just about every comment he’s made.
“Because what you are trying to measure has some utility and some meaning.”
Something that doesn’t exist physically has utility and meaning? A mean is not measured data. It is a calculated metric. It is of no utility if it doesn’t exist physically and therefore it has no meaning.
Didn’t the planet exercise prove this to you?
“Why do you want to know the average of anything? One common reason is to compare it to over means, to see if they are different or have changed over time.”
I want to know the average of multiple, dependent measurements of the same measurand in order to more accurately determine the true value, at least as long as the measurements represent a probability distribution that can be properly analyzed, e.g. a gaussian distribution.
“One common reason is to compare it to over means, to see if they are different or have changed over time.”
Knowing the mean changed over time is, again, useless if you don’t know what the cause of the change is. And you can’t determine changes in a temperature profile by calculating a mid-range value for the daily temperature. Too many different temperature profiles can result in the same mid-range value.
In this case what you *should* be analyzing is the data that makes up the temperature profile to actually see what is changing. Then you can make an informed judgement as to the cause and decide if any action needs to be taken. That’s the usefulness of degree-days. You can decide if you need to increase the size of your heating infrastructure or increase the size of your air conditioning infrastructure.
“There may be uses to the mean of different planets, but you would need to be clear about what hypothesis you were testing. “
“May be”? When you can think of one use come back and let me know!
” For example, if you wanted to test the idea that large planets had a stronger gravity than small ones, you could test this by taking a random sample of small planets and a random sample of large ones.”
You are changing the populations now. The issue is combining *all* measurements into one data set and calculating the mean. Why don’t you suggest doing the same with temperature measurements? E.g. combine all T_min’s and separately combine all T_max’s and compare them? See if the T_max’s are going up or the T_miin’s are going up?
“But you insisted on taking the mean of all sizes of planets, and I’m not sure what you think you are going to use the average for.”
You are the one saying to do the exact same thing for the temp measurements, taking the mean of all different sized temperatures. What are *you* going to do with that average that tells you nothing about the real world. Where do you go to measure that GAT? Heal thyself, physician.
“It really doesn’t.”
And now you really *are* arguing for the sake of arguing.
I don’t purport to analyze multiple measurements of the same thing and multiple measurements of different things the same way. You want to use the same hammer for nails *and* bolts. Not me.
“Well, quite. For a random instrumental error taking N measurements reduces the uncertainty in inverse proportion to the square root of N.”
Only if you are measuring the same measurand. Then the measurements form a normal distribution around the true value and you can reduce the uncertainty using the square root of N.
Independent, random measurements of different things simply don’t follow this rule. There is no probability distribution telling you the true value. All you can do is directly propagate the uncertainties since they are not probability distributions susceptible to statistical analysis.
When you measure the maximum temperature at Location A you are measuring a different measurand than when you measure the minimum temperature at that same location. The measurements do not create a probability distribution around a true value and are, therefore, not subject to the sqrt(N) reduction.
These dishonest characters refuse to see this.
Read the paragraph again. The quantity being estimated is the monthly mean, the element of the uncertainty from random instrumental or reading error most definitely is reduced by increasing the number of measurements.
How many populations are being sampled?
“The quantity being estimated is the monthly mean, the element of the uncertainty from random instrumental or reading error most definitely is reduced by increasing the number of measurements.”
The uncertainty from random instrumental or reading error can only be reduced IF YOU ARE MEASURING THE SAME THING. Then those number of measurements produce a probability distribution around the true value of the single measurand. Analyzing that probability will allow you to get closer and closer to the true value as you increase the number of measurements.
That is simply not true for independent, random measurements of multiple measurands. In this case there is NO TRUE VALUE. Therefore there is no probability distribution around a true value. If I have ten 2′ 2″x4″ boards and twenty 10′ 2″x4″ boards I can certainly calculate a mean (average value) for that data set. But that mean will not be measurable for any board in the data set. A board of that length simply won’t exist. And you can add any number of 2′ and 10′ boards you want along with their measurements and you *still* won’t be able to find a board in the data set that is of the length calculated as the mean.
You can calculate that mean of the board lengths out to as many decimal points you want, it won’t matter.
And the exact same logic applies for the uncertainty of that mean. The uncertainty of that mean *must* be propagated from the components of that data set. And that propagation formula is either a direct addition of the uncertainties or a root-sum-square calculation. Since you don’t have a probability distribution around a true value you can’t reduce that uncertainty. There is no probability distribution conducive to statistical analysis.
This was all beaten into me in my electrical engineering labs in the 60’s and 70’s. You can’t have 20 students build 20 different circuits with output uncertainties for each based on component tolerances and with 20 different measurement devices and expect to average the measurements and come up with a true value. Increasing the number of amplifiers won’t help. You just add to the uncertainty each time.
It’s exactly the same concept of adding the variances of two independent, random variables when you combine them. The variances add directly. You don’t reduce that value by dividing by N or sqrt(N). If you have a variance of 49 and a variance of 25 then when you combine the populations you get a variance of 74.
The usual climastrologer magic wand to reduce uncertainty…
Yawn, it’s still wrong regardless of how many times you dance on top of this pin.
You really don’t understand uncertainty intervals at all, do you? The true value can be *ANYWHERE* in the interval, including at each end. Uncertainty intervals are *not* probability distributions. There is *NO* “likelihood” of the true value being anywhere in the interval. It’s not a normal distribution or a Poisson distribution or a rectangular distribution or any other distributiion. (Technically, the true value has a probability of 1 and all the other values in the interval have a probability of zero. The problem is you don’t know the true value. If you did there wouldn’t be an uncertainty interval!)
With only two values the uncertainty interval in which the true value can exist is +/- (u1 + u2). There is no cancelling when you only have two independent, random variables. Since the uncertainty interval is not a probability distribution there is no way to evaluate any possible cancellation.
Say you have one independent, random measurement whose variance is 49 (i.e. uncertainty) and a second independent, random measurement whose variance uncertainty) is 25. What do you get for an overall variance when you combine those two independent, random variables? You get 49 + 25. The variances add directly.
What do you think an uncertainty interval is other than the total possible variance of the true value?
The so-called standard deviation (since the uncertainty interval is not a probability distribution there really isn’t a standard deviation but let’s pretend) of the first independent, random measurement is 7 and of the second 5 (sqrt of the variance). The combined standard deviation is sqrt(49+25) = 8.6. This is greater than the standard deviation of either. Both the standard deviation and the variance grow. And for every additional independent, random measurement you add into the data set the variance and standard deviation will grow.
If you have *multiple* independent, random measurements (i.e. measurement of different things using different devices) *then* you can assume you might see some cancellation among the data members. But *not* total cancellation like you would see with dependent, random measurements (i.e. multiple measurements of the same thing using the same device). This is why root-sum-square is used to calculate the resulting uncertainty for multiple independent, random data members, similar to what you would do with variances and standard deviations. But, again, uncertainty intervals have no standard deviation, no variance, and no “confidence interval” because those are statistical descriptors of a probability distribution and the uncertainty interval is not a probability distribution, you cannot assign a probability to any specific value in the interval. You just do *NOT* know any such information.
This is why the mid-range value for a specific location has a larger uncertainty than that for each measurement. And when you average multiples of those uncertain mid-range values the uncertainty propagates right along with the calculations. It doesn’t matter how precisely you calculate the mean, the mean will always carry along the uncertainty propagated upward from the individual members of the data set.
“You really don’t understand uncertainty intervals at all, do you? The true value can be *ANYWHERE* in the interval, including at each end. Uncertainty intervals are *not* probability distributions.”
How do you reconcile the last sentence to the rest of that quote. If the true value can be anywhere within an uncertainty interval it follows that a measured value can be anywhere within the uncertainty interval of the true value. Hence there has to be a probability distribution. Even if values could only occur in a few places within the interval there still has to be a probability distribution.
“There is *NO* “likelihood” of the true value being anywhere in the interval. It’s not a normal distribution or a Poisson distribution or a rectangular distribution or any other distributiion.”
This may be where you are missing the point. The probability distribution is of the measured or sampled values, not of the true value. If you measure a piece of wood or whatever, your measurement will be different to the true value by a certain value, i.e. the error. If the errors are independent then each measurement will have a random error following a probability distribution and using that you can take multiple measurements to get a more precise estimate of the true value.
This is exactly the same as taking a random sample of different things in order to estimate the true mean of a population. Each sample will differ from the true mean by a certain error. These errors follow the probability distribution of the population, and you can take multiple samples to improve the estimate of the true mean.
“With only two values the uncertainty interval in which the true value can exist is +/- (u1 + u2). There is no cancelling when you only have two independent, random variables.”
Again that’s the opposite of the truth, as Taylor explains. If you have two independent random values the uncertainty of the sum can use RSS. It’s dependent values where you have to add the uncertainties. I really don’t understand why you get so confused about the difference.
“The variances add directly.”
All you have to do is run a simple experiment to show that this is not the case.
“What do you think an uncertainty interval is other than the total possible variance of the true value?”
Err, as you’ve already said the true value has no variance.
“The so-called standard deviation (since the uncertainty interval is not a probability distribution there really isn’t a standard deviation but let’s pretend)”
You are disagreeing with the GUM now.
“The combined standard deviation is sqrt(49+25) = 8.6. This is greater than the standard deviation of either.”
Yes, that’s the uncertainty of the sum. And as I’m sure you know by now, when you take the average you divide the uncertainty by 2 to get 4.3. Which is less than either of the two standard deviations.
“But *not* total cancellation like you would see with dependent, random measurements (i.e. multiple measurements of the same thing using the same device).”
You still don;t understand what dependent means, do you?
“And when you average multiples of those uncertain mid-range values the uncertainty propagates right along with the calculations. It doesn’t matter how precisely you calculate the mean, the mean will always carry along the uncertainty propagated upward from the individual members of the data set.”
Point me to any source saying that.
“How do you reconcile the last sentence to the rest of that quote. If the true value can be anywhere within an uncertainty interval it follows that a measured value can be anywhere within the uncertainty interval of the true value. Hence there has to be a probability distribution. Even if values could only occur in a few places within the interval there still has to be a probability distribution.”
The uncertainty interval is not defined by the true value. You don’t *know* the true value. The measured value is associated with an uncertainty interval within which the true value will lie.
Exactly what kind of a probability distribution do you think is defined by the uncertainty interval? It can’t be a normal distribution, a Poisson distribution, or a rectangular distribution. So what kind of distribution is it?
As I’ve stated before, the true value has a probability of 1 of being the true value. All other values in the interval have a 0 probability of being the true value. The issue is that if you don’t know the true value then how do you assign a value in the interval a probability of 1?
“The uncertainty interval is not defined by the true value. You don’t *know* the true value. The measured value is associated with an uncertainty interval within which the true value will lie.”
You have a measurement with a known uncertainty interval, meaning the true value is probably within the uncertainty interval of the measurement. Correct? Now what do you think that means for the measurement? If I take a measurement of a measurand with unknown true value, doesn’t the measurement probably lie within half the uncertainty interval of the true value? Now what happens if I take a second measurement. This is different from the first but will also probably within half an uncertainty of the true value. Then I take a whole series of measurements all different values all lying within an interval the same size as the measurements uncertainty interval. How do you think the measurements will be distributed?
“Exactly what kind of a probability distribution do you think is defined by the uncertainty interval? It can’t be a normal distribution, a Poisson distribution, or a rectangular distribution. So what kind of distribution is it?”
What makes you think it cannot be any of those distributions, or any other? Look at section 4.4 of the GUM, figures 1 and 2. They show normal, uniform and triangular distributions
“Now what happens if I take a second measurement.”
It is impossible to make a second measurement!
I think Bellman believes in time machines!
Alternative explanations are becoming fewer by the second! I don’t get it.
“If I take a measurement of a measurand with unknown true value, doesn’t the measurement probably lie within half the uncertainty interval of the true value?”
No. The true value can be anywhere in the interval. You are *still* trying to view the uncertainty interval as a probability distribution, probably a gaussian distribution. It isn’t.
Take out a piece of paper and write 100 times:
“The uncertainty interval is not a probability distribution”
“Now what do you think that means for the measurement?”
It means nothing because the assumption you start from is not true.
“Now what happens if I take a second measurement.”
How do you take a second measurement of a temperature? It is a time function. Unless you own a time machine you can’t go back and take a second measurement of the same temperature measurand!
“This is different from the first but will also probably within half an uncertainty of the true value.”
First, you can’t take a second measurement. That moment has passed, never to be seen again. Second, the uncertainty interval is not a probability distribution. The true value can be ANYWHERE in the interval, you simply don’t know!!
“Then I take a whole series of measurements all different values all lying within an interval the same size as the measurements uncertainty interval.”
DO you own a time machine?
“How do you think the measurements will be distributed?”
Since you can’t make subsequent measurements who knows?
“What makes you think it cannot be any of those distributions, or any other? Look at section 4.4 of the GUM, figures 1 and 2. They show normal, uniform and triangular distributions”
As I’ve tried to tell you, the probability of the true value being the true value is 1. The probability of all other values being the true value is 0. The issue is that you don’t know what the true value is. It could be anywhere in the interval.
Does one value having a probability of 1 and all other values having a probability of zero sound like a gaussian, rectangular, or Poisson distribution?
Those sections in the GUM address how to handle multiple measurements of the same measurand. Since you can’t have multiple measurements of a moment in time, that section of the GUM doesn’t apply!
Again, DO you have a time machine?
You keep trying to force temperature measurements into being multiple measurements of the same thing. They aren’t. They are single measurements of different measurands. You can’t force the uncertainties of those single measurements of different measurands into being a random distribution of some kind around a true value. THERE IS NO TRUE VALUE for single measurements of different things. Just like there is no true value for the data set made up of the gravitational accelerations of five random planets. There is a mean. But that mean does not represent a true value in any way, shape, or form. Neither does a data set made up of single measurements of temperatures created from different measurands.
Put your hammer away. You are trying to use it on a bolt. And you keep trying to make the bolt into a nail.
“No. The true value can be anywhere in the interval.”
Not the question I asked. I’m asking where a given measurement can be within an interval centered on the true value. It’s a basic question about the symmetry of metric spaces. If the true value is within a certain distance of a measurement, it must follow that the measurement is within the same distance of the true value.
“You are *still* trying to view the uncertainty interval as a probability distribution, probably a gaussian distribution. It isn’t.”
I’m saying there’s a probability distribution associated with the uncertainty, not necessarily gaussian. It follows from the idea that an uncertain measurement is a random distance from the true value.
“How do you take a second measurement of a temperature?”
Who said this was a measurement of a temperature? I’m talking about the general idea of uncertainty intervals.
“Unless you own a time machine you can’t go back and take a second measurement of the same temperature measurand!”
No, but then you;d have to regard the measurand as being the average temperature over that period.
“Since you can’t make subsequent measurements who knows?”
Look again at example 4.4. They have 20 measurements of temperature and they form a distribution.
“Does one value having a probability of 1 and all other values having a probability of zero sound like a gaussian, rectangular, or Poisson distribution?”
As you keep pointing pout, we don’t know what the true value is. Therefore it’s pointless to say the probability of the true value being the true value is 1. All we know is we have an uncertain measurement, with a known uncertainty interval. We don;t know where the true value lies in the uncertainty interval, but we can derive a probability distribution of where the true value is likely to reside. If all we know is the uncertainty interval then the best we can do is assume it’s equally likely the true value will reside at any point in the interval, and hence we have a uniform distribution.
If we know the uncertainty in the measurement has some other distribution, then we can apply that distribution to the question of where the true value may be. It’s more likely that our measurement was close to the true value than a long way from it, therefore it’s more likely that the true value will be closer to our measured value than far from it.
“Since you can’t have multiple measurements of a moment in time, that section of the GUM doesn’t apply!”
There’s no indication that the hypothetical measurements were all made at the same time. If they were all made at the same time in the same place they must have been using dodgy thermometers, given they differ by up to 6°C.
“You can’t force the uncertainties of those single measurements of different measurands into being a random distribution of some kind around a true value.”
You need to be clearer about when you are talking about the same or different things – I’ve been assuming here we were talking about measuring the same thing.
If you are talking about sampling to get a mean value, you need to be clear on what you mean by the true value. That has to be the true mean value of the population, and the measurements are actually sampling from the population. And that, of course, has a probability distribution.
“Not the question I asked. I’m asking where a given measurement can be within an interval centered on the true value.”
You’ve got it backwards as usual. A given measurement has an uncertainty interval in which the true value can lie. The true value can be anywhere in that interval.
The uncertainty interval is *NOT* centered on the true value. The uncertainty interval is centered on the measured value.
“I’m saying there’s a probability distribution associated with the uncertainty, not necessarily gaussian. It follows from the idea that an uncertain measurement is a random distance from the true value.”
There is *NOT* a probability distribution associated with the uncertainty. You are still looking at this backwards in the faint hope you can rationalize using your hammer on a bolt.
“Who said this was a measurement of a temperature? I’m talking about the general idea of uncertainty intervals.”
The general idea of uncertainty intervals have to be divided into two scenarios – 1. multiple measurements of the same measurand, and 2. single measurments of multiple measurands.
You keep on trying to say that they are the same and you can use the same statistical tools for all scenarios. I.e. Everything is a nail you can use your hammer on.
Sadly you are only deluding yourself.
“No, but then you;d have to regard the measurand as being the average temperature over that period.”
ROFL!! Have you looked up the definition of a measurand? It is something you can MEASURE. An average is a calculated value, it is *NOT* a measurand. You don’t go out in the lumber yard and measure an “average” board!
“Look again at example 4.4. They have 20 measurements of temperature and they form a distribution.”
Look at the “Principal Definitions and Equations of Chapter 4” on page 109.
“Suppose we make N measurements, x1, x2, …,xn of the same quantity x, all using the same method. (bolding mine, tpg)
I keep telling you that you have to read Taylor for understanding. I’m pretty sure you just flip through it “cherry-picking” things you think might allow you to treat independent, random measurements of different things in the same manner that you treat dependent, random measurements of the same thing.
STOP IT! You are only deluding yourself!
“As you keep pointing pout, we don’t know what the true value is. Therefore it’s pointless to say the probability of the true value being the true value is 1.”
ROFL! Nope. It is useless to say “the true value is” since we don’t know it. But it is *not* useless to say the probability of the true value being the true value is 1. You are *really* digging yourself a hole. Stop digging!
“We don;t know where the true value lies in the uncertainty interval, but we can derive a probability distribution of where the true value is likely to reside”
No, you can’t. If you know the probabilities associated with the values inside the interval then you also KNOW THE TRUE VALUE. But the whole concept of an uncertainty interval is that you do *NOT* know the true value!
” If all we know is the uncertainty interval then the best we can do is assume it’s equally likely the true value will reside at any point in the interval, and hence we have a uniform distribution.”
No! You do not have a uniform distribution. In a uniform distribution all values have the same probability. The uniform distribution is the rectangular distribution I mentioned above. Not all values in the uncertainty interval have the same probability. One has a probability of 1 and all the rest have a probability of zero. That is *NOT* a uniform or rectangular probability distribution. The issue remains that you simply don’t know which value has the probability of 1.
“f we know the uncertainty in the measurement has some other distribution, then we can apply that distribution to the question of where the true value may be”
No. The uncertainty interval is *NOT* a probability distribution. If it was you would *KNOW* the true value. By definition you do *NOT* know the true value, therefore you can’t have a probability distribution.
” therefore it’s more likely that the true value will be closer to our measured value than far from it.”
NO! You do *not* know any such thing. The true value can be ANYWHERE in the uncertainty interval. Again, there is no probability distribution associated with the uncertainty interval that allows you to say that!
YOU ARE STILL TRYING TO RATIONALIZE YOUR HAMMER INTO APPLYING IN ALL SITUATIONS.
Put the hammer away!
“You need to be clearer about when you are talking about the same or different things “
tim: “single measurements of different measurands”
I don’t know how I can be any clearer. I think the problem is your reading ability, not how clear I am.
“If you are talking about sampling to get a mean value, you need to be clear on what you mean by the true value. That has to be the true mean value of the population, and the measurements are actually sampling from the population. And that, of course, has a probability distribution.”
The true value of a group of single, independent, random measurements of different measurands doesn’t exist. I thought we clarified that with the average of the gravitational accelerations of random, independent planets.
You are apparently now trying to use the argumentative fallacy of Equivocation. Trying to change the definition of the issue from single measurements of multiple measurands to one of multiple measurements of the same measurand.
I’ve been crystal clear in this whole thread that temperature measurements consist of single measurements of independent, random measurands. And thus the uncertainties do *NOT* get diminished by N or sqrt(N). Adding more and more measurements of independent, random measurands only *increases* the uncertainty of the calculated mean, either directly or by RSS.
There is simply no way you could have misunderstood this. I stated over and over and over again, ad infinitum!
“You’ve got it backwards as usual. A given measurement has an uncertainty interval in which the true value can lie. The true value can be anywhere in that interval.
The uncertainty interval is *NOT* centered on the true value. The uncertainty interval is centered on the measured value. ”
Not saying it is. My point is there’s a symmetry between the the two. If the true value is within 1cm of the measured value, it must also be true that the measured value is within 1cm of the true value.
“Sadly you are only deluding yourself.”
Sadly, you are still failing to provide any evidence that the statistics they use in measuring single things don’t apply to finding the mean of multiple things.
“ROFL!! Have you looked up the definition of a measurand? It is something you can MEASURE. An average is a calculated value, it is *NOT* a measurand.”
Have you looked at the definition. Many things described as measurands are calculated values. That’s the whole point of talking about propagation of uncertainty – you are measuring multiple things and calculating the measurand from it.
““Suppose we make N measurements, x1, x2, …,xn of the same quantity x, all using the same method. (bolding mine, tpg)”
Supposing something doesn’t mean you cannot do other things. If you make multiple measures of the same thing and calculate the mean, you have a mean. If measure multiple different things and calculate the mean you have a mean.
“ It is useless to say “the true value is” since we don’t know it. But it is *not* useless to say the probability of the true value being the true value is 1.”
What exactly do you think the point of taking an uncertain measurement is? I measure something as 100 ± 1cm. Am I allowed to say the true value is probably between 99 and 101cm or can I only say it’s unknown, but if I did know it it would have probability 1.
“No. The uncertainty interval is *NOT* a probability distribution. If it was you would *KNOW* the true value.”
The uncertainty interval is not a probability distribution, but there exists a probability distribution that allows you to derive the uncertainty.
“NO! You do *not* know any such thing. The true value can be ANYWHERE in the uncertainty interval.”
It could also be outside the uncertainty interval, so you have literally no way of knowing what the true value is, and any attempt to measure anything is a waste of time.
“The true value of a group of single, independent, random measurements of different measurands doesn’t exist.”
Yet when you were talking about measuring different things you still kept going on about the true value, hence my confusion.
” I thought we clarified that with the average of the gravitational accelerations of random, independent planets. ”
I said the average was meaningless, I didn’t say it didn’t exist.
“You are apparently now trying to use the argumentative fallacy of Equivocation. Trying to change the definition of the issue from single measurements of multiple measurands to one of multiple measurements of the same measurand
I’ve been crystal clear in this whole thread that temperature measurements consist of single measurements of independent, random measurands. And thus the uncertainties do *NOT* get diminished by N or sqrt(N). Adding more and more measurements of independent, random measurands only *increases* the uncertainty of the calculated mean, either directly or by RSS.”
Is the issue the uncertainty of the individual measurements or the uncertainty of the mean? You might think you are being crystal clear but I’m still confused. Is the issue the uncertainty of single measurements of individual measurands or is it the uncertainty of the mean. You still haven’t provided a single piece of evidence or explanation as to why you think the uncertainty of the mean doesn’t reduce with sqrt N.
“There is simply no way you could have misunderstood this. I stated over and over and over again, ad infinitum!”
You post hundreds of length comments, which for some reason I decide to spend all day replying to. Sorry if I lost the sense of the thread. When I have time I’ll go back over it and see if it makes any more sense.
“Not saying it is. My point is there’s a symmetry between the the two.”
If you don’t know the true value then how do you know there is a symmetry. You keep on making unfounded assumptions.
“Sadly, you are still failing to provide any evidence that the statistics they use in measuring single things don’t apply to finding the mean of multiple things.”
All you have to do is look at Taylor’s treatise. Chapter 3 covers independent, random measurements of different things. Chapter 4 covers dependent, random measurements of the same thing. He states this specifically in his book. I’ve given you the direct quotes. But, as usual, you just blow them off because they don’t comport with your delusion.
“Have you looked at the definition. Many things described as measurands are calculated values. That’s the whole point of talking about propagation of uncertainty – you are measuring multiple things and calculating the measurand from it.”
MALARKY! The root of the word measurand is measure! It is *NOT* “calculate”.
“upposing something doesn’t mean you cannot do other things. If you make multiple measures of the same thing and calculate the mean, you have a mean. If measure multiple different things and calculate the mean you have a mean.”
Jeesh Bellman! You look at the direct evidence and refuse to see it. The entire chapter 4 is about how to analyze multiple measurements of the same thing. The calculation of the mean has nothing to do with the uncertainty associated with the mean. The precision with which you calculate the mean does *not* determine the uncertainty of the mean.
“What exactly do you think the point of taking an uncertain measurement is? I measure something as 100 ± 1cm. Am I allowed to say the true value is probably between 99 and 101cm or can I only say it’s unknown, but if I did know it it would have probability 1.”
Why are you being so obtuse? Stating a measured value with its uncertainty interval how measurements are specified! And not knowing the true value and saying that its probability is 1 is totally valid.
“The uncertainty interval is not a probability distribution, but there exists a probability distribution that allows you to derive the uncertainty.”
EXACTLY what is that probability distribution? If you can know the probability distribution ahead of time then why is it necessary to make measurements at all? You can determine the true value from the probability distribution!
“It could also be outside the uncertainty interval, so you have literally no way of knowing what the true value is, and any attempt to measure anything is a waste of time.”
Part of this is actually a true statement. The uncertainty interval is nothing more than an informed judgement. As such it is not categorically correct in all cases. The true value could lie outside the stated uncertainty interval. But that doesn’t make measurements a waste of time. It’s why making multiple measurements of the same thing is so important. it’s also why it is important to understand that the sum of independent, random measurements of different things have the uncertainty of the sum grow right along with the sum.
“I said the average was meaningless, I didn’t say it didn’t exist.”
And I said the same thing. The mean can always be calculated. That doesn’t make it mean anything. The average of the planets gravity constant is no different than the average of independent, random temperature measurements of different things, Both can be calculated but they are both meaningless!
“Is the issue the uncertainty of the individual measurements or the uncertainty of the mean? “
Both. With multiple measurements of the same thing the uncertainty of the mean decreases with more measurements. With multiple measurements of different things the uncertainty of the mean grows, either directly or by RSS. You have to be able to differentiate between how precisely you can calculate the mean in the case of multiple measurements of different things and how uncertain the mean is for multiple measurements of different things. They *are* different. If the additional data points aren’t part of a probability distribution around a true value, i.e. the case of multiple measurements of different things then those additional data points only make the mean more uncertain!
“You might think you are being crystal clear but I’m still confused. Is the issue the uncertainty of single measurements of individual measurands or is it the uncertainty of the mean. You still haven’t provided a single piece of evidence or explanation as to why you think the uncertainty of the mean doesn’t reduce with sqrt N.”
Again, read Chapter 3 of Taylor. it’s all in there whether you like it or not!
“If you don’t know the true value then how do you know there is a symmetry. You keep on making unfounded assumptions.”
It’s an axiom of metric spaces, and pretty self evident. If I’m 2000km from you, you are also 2000k from me. I don;t have to know where you are to know that’s true.
“He states this specifically in his book. I’ve given you the direct quotes. But, as usual, you just blow them off because they don’t comport with your delusion.”
I haven’t seen any quote from you to this effect. It’s a very specific claim – the formula for calculating the standard error of the mean is different, and works in the opposite direction, if you are measuring different things. You’d think Taylor would put a very big warning in his book, and alert all statisticians to the this new found theory.
“MALARKY! The root of the word measurand is measure! It is *NOT* “calculate”.”
I’ve given you the quote from the GUM (4.4.1) where they say “In most cases a measurand Y is not measured directly, but is determined from N other quantities through a functional relationship f”
Why do you think there are rules for propagating uncertainties if you cannot calculate a measurand?
“It’s an axiom of metric spaces, and pretty self evident. If I’m 2000km from you, you are also 2000k from me. I don;t have to know where you are to know that’s true.”
The problem is that you do *NOT* know what the distance *is*. The metric space is undefined. It is unknown. Assuming symmetry is an unfounded symmetry!
“I haven’t seen any quote from you to this effect.”
I’ve given it to you at least twice in this thread. Don’t tell me you haven’t seen it. You’ve replied to the posts containing the quote.
“You’d think Taylor would put a very big warning in his book, and alert all statisticians to the this new found theory.”
It’s not a new found theory. The only new found theory is yours – that uncertainty propagated by multiple measurements of different things can be diminished by dividing by the number of individual, random measurements. Your theory violates the rules for adding variances when combining populations of independent, random variables and you can’t bring yourself to admit it. You would rather just claim the entire world is wrong and you are right!
““In most cases a measurand Y is not measured directly, but is determined from N other quantities through a functional relationship f””
ROFL!! Y is a *calculated* value if it can’t be measured directly. You MEASURE other quantities to calculate the value. Why do you have such a problem with simple, common sense reading?
From the Free Dictionary: measurand -any quantity subject to measurement
from https://sisu.ut.ee/measurement/91-measurand-model-sources-uncertainty: “The measurand definition is the most basic step of any measurement. In this step it is defined what is actually measured and this definition is also the basis for the measurement procedure and model equation.”
from https://www.sciencedirect.com/topics/engineering/measurand: “Measurand – In the science of metrology, the measurand is the thing you are trying to measure.”
————————————–
From the GUM, Annex D:
D.1 The measurand
D.1.1 The first step in making a measurement is to specify the measurand — the quantity to be measured; the measurand cannot be specified by a value but only by a description of a quantity. However, in principle, a measurand cannot be completely described without an infinite amount of information. Thus, to the extent that it leaves room for interpretation, incomplete definition of the measurand introduces into the uncertainty of the result of a measurement a component of uncertainty that may or may not be significant relative to the accuracy required of the measurement.
———————————————-
“The quantity to be measured. *NOT* the quantity to be calculated from measurements.
“The problem is that you do *NOT* know what the distance *is*.”
Not a problem as I don’t need to know what the distance is, just that it will be the same.
“The metric space is undefined. It is unknown. Assuming symmetry is an unfounded symmetry!”
By metric space I just meant the standard Euclidean space. It’s a metric space, it is symmetrical. If you think Euclidean space, or any metric space isn’t symmetrical, give me a counter example.
“I’ve given it to you at least twice in this thread. Don’t tell me you haven’t seen it. You’ve replied to the posts containing the quote.”
And each time I’ve replied by pointing out it doesn’t support your argument.
“ROFL!! Y is a *calculated* value if it can’t be measured directly. You MEASURE other quantities to calculate the value. Why do you have such a problem with simple, common sense reading?”
My problem is in understanding why you think a measurand cannot be a calculated value when the quote clearly says it can be. Maybe you missed the wording that clearly describes Y as a measurand.
“By metric space I just meant the standard Euclidean space. It’s a metric space, it is symmetrical. If you think Euclidean space, or any metric space isn’t symmetrical, give me a counter example.”
I know what you mean. But M +/- u is a different metric space than m +/- u. Distances can only be the same in two different metric spaces if they are congruent. That would imply that M = m. And that implies, in turn, that you know what the true value is and that it is equal to M *and* m both.In other words u = 0.
If M +/- u and m +/- u are different metric spaces then there is guarantee of symmetry. It is even possible for some m – u or m + u to not exist in the M +/- u metric space. So how can there be symmetry?
“And each time I’ve replied by pointing out it doesn’t support your argument.”
The evidence doesn’t fit into your delusional world view you mean. You’ve even had to resort to saying Taylor is wrong in his analysis of uncertainties in order to maintain your delusional worldview.
I gave you a quote from the GUM that contradicts your quote. So which one is correct? I’ll go with all the other definitions I provided you. Ones which state that a measurand is something to be measured. If it can’t be measured then it is not a measurand. For instance, how do you measure the half-life of a radioactive isotope? Answer: you can’t. You have to measure something else that is measurable and then calculate half-life from the results gained from the physical measurand.
He apparently thinks measurand is the true value, as far as I can tell.
Sorry if I’m not using the correct definitions. Looking at the GUM they say not to talk of a true value of the measurand as it’s redundant
“I know what you mean. But M +/- u is a different metric space than m +/- u.”
I’m not sure you do if you think I’m talking about two different metric spaces. As I said it’s just the standard Euclidean space.
If we are measuring length and the uncertainty is 2cm, and we measure a measurand as 10cm, the measurand probably lies in the uncertainty interval [8,12]. wherever the measurand lies the measurement is likely to be within 2cm of it. That’s all I’m saying.
“You’ve even had to resort to saying Taylor is wrong in his analysis of uncertainties in order to maintain your delusional worldview.”
I’ve never said he’s wrong. All I’ve said is that if he was saying what you claimed he would be wrong. But why would it be so outrageous if someone was wrong, and to point out when he was wrong?
“I gave you a quote from the GUM that contradicts your quote.”
So know you are saying the GUM is wrong in at least one place. That seems possible, it’s not the clearest text, in keeping with most standards documents.
“If it can’t be measured then it is not a measurand”
That’s good. Does it mean I can ignore all that whining about going back to equation 1?
Outside of performing multiple measurements on a special reference specimen for which the true value is known (or defined), this is quite impossible.
How can you center an interval on something that isn’t known?
Do you understand how maths works. I’m not saying you know where the interval is, just that the measure will lie inside it.
centered
If it is centered, then you know what the value is!
Bingo!
No. You know it is centred, you don’t know where that center is.
I’m not sure how much clearer I can make this
1. There exists a measurand with a value, M, which you do not know.
2. You take a measure m, with a known uncertainty ±u.
3. This means that we still don’t know the value of M, but we know it lies between m – u and m + u.
4. This also means that m lies between the values M – u and M + u. We do not know what that interval is, we just know it exists and that m lies in it.
Nothing about anything being “centered” in steps 1,2,3,4….
3) actually, you expect the true value to be within the uncertainty interval, but you still don’t know with certainty.
4) follows from 3), so is also false.
“Nothing about anything being “centered” in steps 1,2,3,4….”
What do you think M – u and M + u implies. Where do you think M is in relation to those two points?
“actually, you expect the true value to be within the uncertainty interval, but you still don’t know with certainty.”
Yes, I should have said is likely to be within the uncertainty interval.
Your terminology is bizarre. As best I can see what you are calling a measurand is really the true value, but this is your own esoteric definition.
I let you in on a secret—outside of primary standards-level national laboratories, no one doing real measurement work cares about true values.
“No. You know it is centred, you don’t know where that center is”
If the true value is at either end of the uncertainty interval then how can you say the uncertainty interval is centered on the true value? How can it be centered on anything except the stated value? That’s what SV +/- u *means*. It is centered on the Stated Value (SV).
“This also means that m lies between the values M – u and M + u”
It does NOT mean,however, that M is centered in the interval. The only way for that to happen is if m = M which implies that you know the true value. In fact, if M is at the positive interval boundary then M+ u lies outside the uncertainty interval. How then can m always be between M+u and M-u since m is bounded by m+u and can’t go outside that boundary?
“how can you say the uncertainty interval is centered on the true value?”
I didn’t. The interval centered on the true value is not the uncertainty interval of the measurement. It’s a different interval that has the same size as the measurment uncertainty interval.
“It does NOT mean,however, that M is centered in the interval.”
If the interval is defined as [M – u, M + u], how can M not be at the center?
“I didn’t. The interval centered on the true value is not the uncertainty interval of the measurement. It’s a different interval that has the same size as the measurment uncertainty interval.”
Which like I said, implies that that M+u (or M-u) can include values not within the m +/- u interval. Which, in turn, implies that the whole concept of SV +/- u is meaningless.
I think you are going to find all kinds of opposition to such a delusional viewpoint. The concept of uncertainty is pretty much ingrained into our methods and protocols for physical science.
“If the interval is defined as [M – u, M + u], how can M not be at the center?”
You are creating a metric space totally separate from the physical reality of physical measurement. Saying that M is at the center of that created metric space is meaningless.
It is downright bizarre, where does he get these notions?
“Which like I said, implies that that M+u (or M-u) can include values not within the m +/- u interval.”
Of course they will, there two different intervals. If say the unknown value of a measurand was 9cm, and we measured it with an uncertainty of 2cm and got a result of 10cm, the uncertainty interval of the measurement would be [8,12] and the range (unknown to us) the measurement was likely to come from would be [7, 11].
“I think you are going to find all kinds of opposition to such a delusional viewpoint.”
I didn’t think I was saying anything controversial, it just seemed the most obvious way to think of what an uncertain measurement meant, and to explain why the measurement had to come from a probability distribution. I’m certainly not proposing it as a new theorem.
“Saying that M is at the center of that created metric space is meaningless.”
Who said anything about it being the center of a metric space?
“This may be where you are missing the point. The probability distribution is of the measured or sampled values, not of the true value.”
You are missing the point. If the true value can be anywhere in the uncertainty interval for ONE measurement then how do you diminish this uncertainty interval when you combine multiple measurements? The uncertainty interval will always grow in such a case. The only thing you have to answer is whether you do a direct addition of the uncertainty intervals or whether you do a root-sum-square addition.
It’s exactly the same thing as when you combine two independent random variables – the variances add. They don’t subtract, they don’t divide by N, they don’t divide by the sqrt(N). They ADD! Just like uncertainty intervals add.
“You are missing the point. If the true value can be anywhere in the uncertainty interval for ONE measurement then how do you diminish this uncertainty interval when you combine multiple measurements?”
In the way Taylor describes, in the way the GUM describes, and I expect every other text on Metrology describes. By averaging the measurements.
I’m puzzled why you keep arguing this point whilst elsewhere saying this does work for measurements of the same thing.
But YOU ARE NOT MEASURING THE SAME THINGS!
It doesn’t matter, but in the comment I was responding to, Tim Gorman was measuring the same thing.
The multiple measurements I was talking about was MULTIPLE INDEPENDENT, RANDOM MEASUREMENTS OF DIFFERENT THINGS! Not multiple measurements of the same thing!
Are you being deliberately obtuse?
Sorry if I misunderstood. I’m puzzled then how you were talking about the true value if you don;t think there can be a true value for a mean.
When you are using multiple single, independent, random measurements there is *NO* true value. The mean is not a true value. It may not exist physically. Go back to the planet and gravitational acceleration example. The mean of those random planet is *NOT* a true value for anything. It is useless for plotting a course in space. There is no place to go in space to actually measure that mean. it doesn’t physically exist.
That is *NOT* the same as saying the mean can’t be calculated. It can be calculated. It is just meaningless in the physical world. If you can’t go measure it then it is useless for physical science. And climatology is supposed to be a physical science, not a metaphysical science.
You are STILL trying to make temperature measurements of different measurands into multiple measurements of the same measurand. You are trying to use your hammer on a bolt by stubbornly clinging to the delusion that a bolt is a nail!
You don’t have multiple measurements of the same thing. You have single measurements of different things. Each of those measurements form a population of one. An independent, random measurement of different things. When you combine independent, random variables you add their variances. The same thing applies to uncertainty intervals. Combining them using root-sum-square is a nod to the fact that there might be some partial cancellation just from coincidence.
Put your hammer in its holster and look at the real world.
“If you measure a piece of wood or whatever, your measurement will be different to the true value by a certain value, i.e. the error.”
You’ve been told this over and over yet never seem to be able to grasp it. Once again, take out a sheet of paper and write :
“Error is not uncertainty, uncertainty is not error”
I did not say uncertainty is error. I said the error us the difference between a measured value and the true value. You expect this error to probably be within the uncertainty interval.
“I did not say uncertainty is error.”
That is *exactly* what you said.
“If you measure a piece of wood or whatever, your measurement will be different to the true value by a certain value, i.e. the error.”
Uncertainty is *NOT* error. Take the common ruler marked in sixteenths of an inch. When you measure something with it you are left with uncertainty because of having to estimate between the markings. That doesn’t mean you made an *error* in measurement, it just means that you can’t determine the actual true value with the measuring tool you have. There is uncertainty in the measurement but that is not the same as misreading the ruler, i.e. error.
It’s the same for a thermometer. If you are taking eyesight readings you have to estimate the reading based on the markings on the thermometer. That doesn’t mean you made an error in reading the temperature, the reading just has an uncertainty.
This applies even to digital sensors. You don’t know exactly how the field sensor has drifted since the last calibration and even the sensor has a resolution limit based on the number of bits allowed for reading and storing the measurement. These are uncertainties, not errors. They are really no different than eyesight reading of a manual thermometer.
Gross calibration problems can always be rectified but unless you are taking measurements in a calibration lab there will always be some uncertainty associated with the measurement. You simply don’t know if the measuring station has been invaded by wasps or been covered in soot from airplane exhausts at an airport. So there will always be some uncertainty associated with the measurements.
Me: “I did not say uncertainty is error.”
TG: “That is *exactly* what you said.”
Me: “If you measure a piece of wood or whatever, your measurement will be different to the true value by a certain value, i.e. the error.””
Where in that quote do I say uncertainty is error?
“Take the common ruler marked in sixteenths of an inch. When you measure something with it you are left with uncertainty because of having to estimate between the markings. That doesn’t mean you made an *error* in measurement,”
Yes it does. Maybe you are misunderstanding the word error in this context. It doesn’t necessarily mean you made a mistake. It just means the difference between the measured value and the true value.
MV – TV = error
Uncertainty is the estimation of an interval within which the (unknown) TV is expected to lie. It is a quantification of the reliability of a MV.
Exactly what I’ve been trying to explain to Tim.
“your measurement will be different to the true value by a certain value, i.e. the error.””
“Where in that quote do I say uncertainty is error?”
You don’t know what that “certain value” is so how can it define an “error”. You *still* are confused between uncertainty and error.
Nope. Error is not uncertainty. Uncertainty is not error.
Since you don’t know the difference between the measured value and the true value when you have independent, random measurements of different measurands then how can you have error? For all you know your stated value *is* the true value for a single, independent, random measurand. But how do you know?
Like the non-existent mean, you are trying to say something that doesn’t exist *does* exist. You are arguing for the sake of arguing.
“You don’t know what that “certain value” is so how can it define an “error”. You *still* are confused between uncertainty and error.”
You don;t know what it is, but you know it exists, just as you don;t know what the true value is but you know it exists.
“Nope. Error is not uncertainty. Uncertainty is not error.”
Correct, as I keep saying and you never seem to register.
“Since you don’t know the difference between the measured value and the true value when you have independent, random measurements of different measurands then how can you have error?”
If you cannot have error than there is no uncertainty and all measurements are correct.
“For all you know your stated value *is* the true value for a single, independent, random measurand. But how do you know?”
You don’t. That’s why there’s uncertainty.
“Like the non-existent mean, you are trying to say something that doesn’t exist *does* exist. You are arguing for the sake of arguing.”
I fear we are heading for an “is maths real” debate.
“This is exactly the same as taking a random sample of different things in order to estimate the true mean of a population.”
The mean of independent, random measurements, i.e. multiple measurements of different things, is meaningless in the physical world. It is *NOT* a true value of anything.
If you measure the heights of 1000 people, there is no guarantee that the mean of the heights will actually be found anywhere in the population. If the probability of the mean is zero, exactly what kind of probability distribution do you have?
You keep saying this as if it’s a problem. The mean of a population does not have to be the same as any individual value. In many cases it cannot be, e.g. average family size. It is not a problem with the idea of an average, it’s a problem with your understanding of a mean.
“Again that’s the opposite of the truth, as Taylor explains.”
Nope. It is *exactly* what Taylor explains. You have to read Taylor for what he says, not what you wish he says.
Rule 3.4, page 50
If several quantities x,…,w are measured with uncertainties delta_x,…delta_w, and the measured values are used to compute
q = x + … +z – (u + … +w),
then the uncertainty in the computed value q is the sum,
delta_q (approx) = delta_x + … delta_z + delta_u + … + delta_w
He then goes on to talk about adding the independent and random uncertainties in quadrature on Page 57 in order to allow for *some* cancellation (not total cancellation).
He then goes on to state on Pages 58/59
“Because expression (3.13) for the uncertainty in q = x + y is always smaller than (3.14) you should always use (3.13) when it is applicable. It is, however, not always applicable. ”
He then goes on to discuss the subject further.
The only one here that is confused is *YOU*.
My comment was in response to you claiming that
“With only two values the uncertainty interval in which the true value can exist is +/- (u1 + u2). There is no cancelling when you only have two independent, random variables.”
and my full response was
“Again that’s the opposite of the truth, as Taylor explains. If you have two independent random values the uncertainty of the sum can use RSS. It’s dependent values where you have to add the uncertainties. I really don’t understand why you get so confused about the difference.”
You admit here that Taylor says
“He then goes on to talk about adding the independent and random uncertainties in quadrature on Page 57 in order to allow for *some* cancellation (not total cancellation).”
Which is just what I said. When the values are independent you add in quadrature (i.e. RSS). Your equation is correct for dependent but not independent values – as I say, the opposite of what you claim.
You *must* be kidding! Assuming you have cancellation with only two independent, random measurements of different things means you know something about where the true value lies in each of the uncertainty intervals.
It’s why Taylor also said, which I quoted to you, that you have to be careful as to when you use the RSS method of adding uncertainties.
When the values are independent and random a direct addition represents the UPPER bound of the combined uncertainty. The RSS value represents a LOWER bound for the combined uncertainties. You have to be careful which one you use. Something you don’t seem to be ale to distinguish.
How do *YOU* know that you will have cancellation with only two uncertainty intervals involved? Do *YOU* know something about where the true values lie in those uncertainty intervals that even Taylor and Bevington don’t know?
My equation is correct. As Taylor points out in excruciating detail.
“You *must* be kidding! Assuming you have cancellation with only two independent, random measurements of different things means you know something about where the true value lies in each of the uncertainty intervals.”
No, it just means assuming it’s as likely that one measurement is too high and one to low as it is that both are too high or both are too low.
“It’s why Taylor also said, which I quoted to you, that you have to be careful as to when you use the RSS method of adding uncertainties.”
Yes, you have to be careful that the measurements are truly independent. His example is measuring two lengths with the same tape measure, which might be affected by the temperature. The two measurements are not independent, so less likely to cancel.
It really must occur to you at some point that you are using the word independent wrongly.
“How do *YOU* know that you will have cancellation with only two uncertainty intervals involved?”
You don’t it’s just less likely that both errors will be at the upper edge in the same direction. The fact still remains, that your claim was that with two independent random values the uncertainties must be added and cannot cancel – Taylor disagrees.
“My equation is correct. As Taylor points out in excruciating detail.”
Taylor’s exact words on your equation is
“No, it just means assuming it’s as likely that one measurement is too high and one to low as it is that both are too high or both are too low.”
“likely“? You are back to assuming the uncertainty interval defines a probability distribution. It doesn’t. The word “likely” doesn’t even apply!
“Yes, you have to be careful that the measurements are truly independent. His example is measuring two lengths with the same tape measure, which might be affected by the temperature. The two measurements are not independent, so less likely to cancel.”
You also have to ASSUME that you will encounter some random cancellations. And if you are measuring TWO lengths then they *are* independent. The uncertainty associated with the measuring tool might be affected by the temperature so that one length has a wider uncertainty range than the other. But that doesn’t affect how the uncertainties add when you have two independent, random measurands.
“It really must occur to you at some point that you are using the word independent wrongly.”
Nope. I’m using correctly. You just wish it was incorrect so you could use your hammer on a bolt! Taylor on Page 57 speaks to uncertainties that are INDEPENDENT and RANDOM. Exactly what happens with two different temperature measurements. They are independent and random and so are their uncertainties.
“You don’t it’s just less likely”
Again with the word “likely”. If you don’t know you will have cancellation then how do you assume you will? Your assumption is based on the uncertainty interval being defined by a probability distribution. IT ISN’T.
“The fact still remains, that your claim was that with two independent random values the uncertainties must be added and cannot cancel – Taylor disagrees.”
Nope. Taylor doesn’t disagree. I even quoted to you where he says you have to be careful with assuming cancellation! Did you forget so quickly or is it just willful ignorance?
“To see why this formula is likely to overestimate https://s0.wp.com/latex.php?latex=%5Cdelta_q&bg=ffffff&fg=000&s=0&c=20201002 [the sum of the two uncertainties], let us consider how the actual value of q could equal the highest extreme (3.12). Obviously, this occurs if we have underestimated x by the full amount https://s0.wp.com/latex.php?latex=%5Cdelta_x&bg=ffffff&fg=000&s=0&c=20201002 and underestimated y by the full https://s0.wp.com/latex.php?latex=%5Cdelta_y&bg=ffffff&fg=000&s=0&c=20201002, obviously, a fairly unlikely event.”
Once again you show that you simply do not understand what you are reading. That is his justification for using quadrature addition. But, as I quoted, he also said that you have to be careful in making such an assumption!
You are still cherry-picking hoping to find a rationalization for using your hammer on a bolt. STOP IT.
““likely“? You are back to assuming the uncertainty interval defines a probability distribution. It doesn’t. The word “likely” doesn’t even apply!”
It’s how Taylor describes it. “Clearly then, the probability that we will underestimate both and y bu the full extent is very small.” and “if x and y are measured independently and our errors are random in nature, we have a 50% chance that an underestimate in x is accompanied by an overestimate in y and vice versa.”
“Nope. I’m using correctly. You just wish it was incorrect so you could use your hammer on a bolt! ”
You really must stop fantasizing about my hammer, it’s getting a little tedious.
“Taylor on Page 57 speaks to uncertainties that are INDEPENDENT and RANDOM. Exactly what happens with two different temperature measurements.”
You’re focusing on the wrong bit there. It isn’t the fact that you are measuring different things that make them independent. Two measurements of the same thing can be independent, two measurements of different things might not be independent.
“Once again you show that you simply do not understand what you are reading. That is his justification for using quadrature addition. But, as I quoted, he also said that you have to be careful in making such an assumption!”
Good grief this is getting dense even for you. You say if you add two measurements you have to add the uncertainties. You then point to Taylor saying if the measurements are independent that will give you an overestimate and you can use RSS, but points out you have to be careful. You then claim his advice that on being careful means he agrees with you that you have to add the uncertainties and cannot use RSS.
“All you have to do is run a simple experiment to show that this is not the case.”
go here: https://socratic.org/statistics/random-variables/addition-rules-for-variances
It’s telling that you didn’t actually give any details on your so-called “experiment”.
Your link talks about summing two standard deviations. It makes no mention of averaging them. This seems to be a real blind spot for you.
tim: “What do you think an uncertainty interval is other than the total possible variance of the true value?”
“Err, as you’ve already said the true value has no variance.”
You’ve got to be kidding me! Did you *really* mean this? You don’t *know* what the true value is. You only know an uncertainty interval in which it can lie.
You whiffed on this one.
Read what you said. You talked about the uncertainty as being the total possible variance of the true value. But the true value has no variance. I assume you meant the total possible variance of measurements of the measurand, but you keep changing your argument so it’s difficult to be sure.
“You are disagreeing with the GUM now.”
No, I’m not. Most of the GUM is about how you handle uncertainty with multiple measurements of the same thing, not the propagation of uncertainty with independent, random measurements of different things.
It’s quite telling that you can’t seem to differentiate between the two. You treat *everything* as you have DEPENDENT, random measurements of the same thing.
The GUM is a text on measuring things, it’s not a statistical text, but I cannot find anywhere where it defines a measurand as only being one physical thing. The definition is just “particular quantity subject to measurement”.
If measurand can only refer to a single thing and not an average of different things, then all your references metrological texts are irrelevant and you need to consult a statistical text book.
Most of the GUM is a treatise on handling multiple measurements of the SAME THING. It tells you how to make the measurements and handle the uncertainty associated with such.
What does “particular quantity” mean if it doesn’t mean the same thing? You measure gravitational acceleration – the SAME THING. You measure the diameter of a wire – the SAME THING. You measure the resistance of a substance – the SAME THING.
“If measurand can only refer to a single thing and not an average of different things, then all your references metrological texts are irrelevant and you need to consult a statistical text book.”
How does an average all of a sudden turn into a measurand? Especially when the average value may not even exist? How do you measure something that doesn’t exist?
If you have a universe of ten 2′ 2″x4″ boards and 20 10′ 2″x4″ boards will the average value become a measurand? How does that happen? Does a board of the “average” length just magically appear so it can become a measurand?
I don’t need to consult anything. You’ve already proved that you understand that the average gravitational acceleration of five random planets doesn’t actually mean anything. You can’t quantify fuel requirements for travel in space using the average value. Why you can’t extend this understanding to the measurement of five independent, random items is just beyond me. It truly appears that you are delusional when it comes to this subject!
“What does “particular quantity” mean if it doesn’t mean the same thing? You measure gravitational acceleration – the SAME THING. You measure the diameter of a wire – the SAME THING. You measure the resistance of a substance – the SAME THING.”
But you don’t think, global average temperature – the SAME THING, or average temperature over a year – the SAME THING.
“How does an average all of a sudden turn into a measurand? ”
That’s the question I’m asking you, the expert on metrology. Can an average value be a measurand or not? If it can we can apply the formulae in the GUM to calculating the uncertainty of a mean value, if it can’t then the GUM is of no use to this discussion and we will have to rely on the same formulae in statistical texts.
The GUM does not give you equations that can be pulled off the shelf and plugged into, you have to do the analysis yourself.
“But you don’t think, global average temperature – the SAME THING, or average temperature over a year – the SAME THING.”
All of these are CALCULATED values, not MEASURED values. Where do you go to measure the GAT or the average temperature over a year?
Did you miss the words “You measure“?
“hat’s the question I’m asking you, the expert on metrology. Can an average value be a measurand or not? If it can we can apply the formulae in the GUM to calculating the uncertainty of a mean value, if it can’t then the GUM is of no use to this discussion and we will have to rely on the same formulae in statistical texts.”
Again, a calculated value is *NOT* a measurand. The root of the word “measureand” is MEASURE. How do you measure a calculated value?
I’ve told you at least TWICE that the GUM only addresses multiple measurements of the same thing. It is *NOT* a good reference for addressing multiple measurements of different things. There *are* some formulas in the GUM that can be used with multiple measurements of different things but you have to be able to differentiate between the two situations in order to make proper use of them!
statistical texts typically only address the issue of multiple measurements of the same thing resulting in a probability distribution around a true value. I gave you a link to a statistical web page that addresses how to handle combining populations of independent, random populations but, as usual, you just blew it off because it doesn’t fit with your delusions. When you combine independent, random variables you *add* their variances. You don’t divide by N or sqrt(N). You just directly add them. Since independent, random temperature measurements of different things represent populations of size one, you treat their uncertainties the same way – you add them.
Root-sum-square is just a recognition that some uncertainties can cancel, not all but *some*. But you *have* to use judgement as to when this is a valid assumption to make.
You don’t seem to be able to apply *any* kind of judgement at all when it comes to propagating uncertainty. You continue to confuse how precisely you can calculate the mean with the fact that uncertainty propagates to the mean from the individual uncertainties of the component members of the data set when they are independent, random variables of population size one.
Until you can shed yourself of this delusion that everything is a nail I will never want to drive over a bridge you design or fly on an airplane you have a hand in designing or anything else that represents a possibility of personal injury.
“All of these are CALCULATED values, not MEASURED values. Where do you go to measure the GAT or the average temperature over a year?”
How do you measure the density of a piece of metal, the volume of a sphere, or the speed of sound?
“Again, a calculated value is *NOT* a measurand. The root of the word “measureand” is MEASURE. How do you measure a calculated value?”
As I understand it from Carlo Monte, you start with equation 1. Found just under the bit where it says that in most cases you do not measure a measurand directly, but determine it from N other quantities via a functional relationship – equation 1.
“It is *NOT* a good reference for addressing multiple measurements of different things.”
Fine. Then use a text that is a good reference for measurements of different things.
“I gave you a link to a statistical web page that addresses how to handle combining populations of independent, random populations but, as usual, you just blew it off because it doesn’t fit with your delusions.”
No, I pointed out several times that it doesn’t address how to calculate the uncertainty of a mean. If you think it does and I’m just ignoring it, give me an exact quote.
“When you combine independent, random variables you *add* their variances. You don’t divide by N or sqrt(N).”
And what do you do to those combined uncertainties when you divide by a constant?
“Since independent, random temperature measurements of different things represent populations of size one, you treat their uncertainties the same way – you add them.”
Except if they are independent values you can use RSS just as Taylor says.
“Root-sum-square is just a recognition that some uncertainties can cancel, not all but *some*”
I don;t know why you keep making this point. Nobody’s said that all uncertainties cancel out. If they did there would be no uncertainty.
“You don’t seem to be able to apply *any* kind of judgement at all when it comes to propagating uncertainty”
I’m not making any real world calculation. I’m just trying to get you to accept that in principle uncertainty of the mean decreases with the sqrt of sample size rather than increases.
Completely and totally wrong, the title is: Guide to the Expression of Uncertainty in Measurement.
It tells you a standard way of expressing uncertainty, and along the way uses lots of statistics.
“Yes, that’s the uncertainty of the sum. And as I’m sure you know by now, when you take the average you divide the uncertainty by 2 to get 4.3. Which is less than either of the two standard deviations.”
You still haven’t figured out the difference between how precisely you can calculate the mean (which is dependent on the number os data points) and the uncertainty of the mean caused by the uncertainty of the data points.
The uncertainty of the mean does *NOT* get divided by anything. It is either a direct sum of the individual uncertainties or the root-sum-square of the individual uncertainties.
You *only* get closer to the true value when you have dependent, random measurements and you can reduce the uncertainty based on the number of dependent, random measurements, i.e. measurements which define a gaussian distribution.
That simply doesn’t apply when you have independent, random measurements of different things.
Can you see the difference between the two bolded words above?
Rather than keep repeating this could you for once and for all provide some evidence for the claim that statistics work differently when averaging different measurements of the same thing and averaging different things. A quote from a statistics text book, or from any of your authorities, or an experimental or theoretical result for example.
Did you bother to look at the link I gave you? When combining independent, random variables the variances add. No “N” or sqrt(N). Why would uncertainty intervals be any different?
This is in response to me asking for evidence to your claim that
“The uncertainty of the mean does *NOT* get divided by anything. It is either a direct sum of the individual uncertainties or the root-sum-square of the individual uncertainties.”
You ask me to look at a link, I presume this one. Which as I already said, has nothing to say about calculating the mean. It’s about “Addition Rules for Variances”.
So, I’m still looking for you to provide some evidence that the uncertainty of the mean is obtained by directly summing or RSSing the individual uncertainties, without dividing by anything.
OMG! You can’t extend adding variances for combining independent, random populations to combining uncertainty intervals for independent, random populations? Each separate independent, random measurement of different things represent a population of one. When you combine the uncertainty of those how do you do it? You do it similarly to how you add variances! Using RSS instead of direct addition is *assuming* you have some (not total) cancellation in uncertainty among the multiple measurements of different things. But you *have* to exercise judgement when assuming this! It is *not* always true.
“Each separate independent, random measurement of different things represent a population of one. When you combine the uncertainty of those how do you do it?”
The same way you do any sampling. Each individual value is different to the mean, taking the mean of a large sample gives you a value that is more likely to be closer to the population mean. The uncertainty of the measurements is likely to be insignificant compared with the sampling uncertainties, but both get reduced by the sample size.
“You do it similarly to how you add variances! Using RSS instead of direct addition is *assuming* you have some (not total) cancellation in uncertainty among the multiple measurements of different things.”
Yes, assuming the samples are independent you do that and divide by the sample size. In other words, divide the sample standard deviation by the square-root of the sample size, gives you the standard error of the mean.
“But you *have* to exercise judgement when assuming this! It is *not* always true.”
Agreed, there’s a lot more to determining the uncertainty of the mean. For example it’s not easy to get a true random sample, and data usually has to be adjusted to allow for this. And something like determining a global average temperature is very different from just getting a random sample.
“The same way you do any sampling. Each individual value is different to the mean, taking the mean of a large sample gives you a value that is more likely to be closer to the population mean. The uncertainty of the measurements is likely to be insignificant compared with the sampling uncertainties, but both get reduced by the sample size.”
Once again you are trying to introduce the SAME statistical analysis procedure for multiple measurements of the same thing and multiple measurements of different things. Until you can admit that they are TOTALLY different situations and must be analyzed differently you are going to remain stuck in the same delusion.
You do *NOT* divide the uncertainty sum by N or sqrt(N) for multiple measurements of different measurands!
“Yes, assuming the samples are independent you do that and divide by the sample size.”
I gave you a link showing how to handle variance for combining two indpendent, random variables. You do *NOT* divide by N or sqrt(N). You just directly add the variances. Is your memory truly that bad?
“Agreed, there’s a lot more to determining the uncertainty of the mean. For example it’s not easy to get a true random sample, and data usually has to be adjusted to allow for this. And something like determining a global average temperature is very different from just getting a random sample.”
And we are back to you not differentiating between multiple measurements of the same thing and multiple measurements of different things. Did you forget your meds?
“Once again you are trying to introduce the SAME statistical analysis procedure for multiple measurements of the same thing and multiple measurements of different things.”
Yes because they work for both cases.
“Until you can admit that they are TOTALLY different situations and must be analyzed differently you are going to remain stuck in the same delusion. ”
Until you can produce some evidence that they have to be treated differently then this conversation will remain stuck.
“You do *NOT* divide the uncertainty sum by N or sqrt(N) for multiple measurements of different measurands!”
To be crystal clear, are you talking about the uncertainty of the mean at this point. If so, I’m still waiting for you to produce some evidence.
“I gave you a link showing how to handle variance for combining two indpendent, random variables. You do *NOT* divide by N or sqrt(N). You just directly add the variances. Is your memory truly that bad?”
Yes and as I’ve explained twice to you that link says nothing about the uncertainty of the mean.
“And we are back to you not differentiating between multiple measurements of the same thing and multiple measurements of different things. Did you forget your meds?”
And you are back to asserting that a differentiation has to be made, but still providing no evidence. And throwing in the usual petty insults as an alternative to justifying your claim.
“Yes because they work for both cases.”
They don’t. That’s why Taylor has Chapter 3 *and* Chapter 4. Multiple measurements of different things is covered in Chapter 3 and multiple measurements of different things is covered in Chapter 4.
Once again you see what you want to see when you read, not what is actually written!
“Until you can produce some evidence that they have to be treated differently then this conversation will remain stuck.”
Like I said, that’s why Taylor has two different chapters on this. chapter 3 to cover independent, random measurements of different things and Chapter 4 to cover dependent, random measurements of the same thing. You can’t even seem to recognize the difference in the two chapters. I can only ascribe it to willful ignorance.
“To be crystal clear, are you talking about the uncertainty of the mean at this point. If so, I’m still waiting for you to produce some evidence.”
To be crystal clear, how precisely you can calculate the mean has nothing whatsoever to do with the uncertainty propagated to the mean from the individual components in the data set when you have multiple measurements of different things.
it doesn’t matter how precisely you can calculate the mean for the gravitational acceleration of five different random planets. The uncertainty associated with that mean is the sum of the uncertainties of the gravitational acceleration of the each individual planet. No dividing by anything!
Calculate the mean out to the millionth digit, it won’t lessen the uncertainty of that calculated value. Each component is an independent, random variable of population size one. Just like variances the uncertainties add – no dividing!
“Yes and as I’ve explained twice to you that link says nothing about the uncertainty of the mean.”
Now you are back to the argumentative fallacy of Equivocation. Changing the definition of the issue being discussed. Do you *really* think a middle school debater would let you get away with that?
It simply doesn’t matter how precisely you calculate the mean. That doesn’t change the fact that the value you calculate for the mean has an uncertainty inherited from the individual components of the data set when the data set is made up of individual, random, measurements of different things. Similar to variances adding the uncertainties add. That’s the whole point of Chapter 3 in Taylor. Where in Chapter 3 does Taylor even mention uncertainty of the mean?
You want to skip right over Chapter 3 and assume that Chapter 4 applies to *all* situations when Taylor specifically says it only applies to multiple measurements of the same thing!
“And you are back to asserting that a differentiation has to be made, but still providing no evidence. And throwing in the usual petty insults as an alternative to justifying your claim.”
The evidence is right there in Taylor’s treatise. You just refuse to read it for meaning. And I will admit it is getting ever more tiresome trying to disabuse you of your delusion that Chapter 4 in Taylor applies to all situations. It doesn’t. And Taylor specifically says that in Chapter 4.
“Now you are back to the argumentative fallacy of Equivocation. Changing the definition of the issue being discussed. Do you *really* think a middle school debater would let you get away with that?”
The issue being discussed was how you calculate the uncertainty of the mean, and whether you had any evidence for the claim that you never divide the uncertainty when calculating the mean You’ve produced one link as evidence that for your claim, and seem to think it’s fallacious for me to point out it doesn’t address the question of whether you divide the uncertainty when you calculate the mean.
“it doesn’t matter how precisely you can calculate the mean for the gravitational acceleration of five different random planets.”
I’m not sure why you’re so obsessed with this example. The standard error of the mean is going to be huge in this case. A sample size of just 5 and huge differences in the samples.
“The uncertainty associated with that mean is the sum of the uncertainties of the gravitational acceleration of the each individual planet. No dividing by anything! ”
And again you simply assert this as is the assertion was evidence. But who cares? The uncertainties from the SD of the small sample is enourmous compared with any uncertainty in the calculation of the gravity of each planet.
“I’m not sure why you’re so obsessed with this example.”
Why are you so obsessed with trying to disprove what the example shows? You actually admitted, in a moment of weakness I suppose, that the mean calculated in that example is meaningless. Yet you continue to try and claim that it is some kind of outlier in the realm of physical science and measurement.
“The standard error of the mean is going to be huge in this case. A sample size of just 5 and huge differences in the samples.”
Make it fifty planets. Make it a thousand planets. Include planets around other stars. Include the sun itself. Will that change the meaningless of the mean you so precisely calculate?
There are HUGE differences in the temperatures used to formulate the GAT. Why do you consider that population to be ok but not one involving the gravity constant for different planets? Your assertions are hypocritical and inconsistent.
“And again you simply assert this as is the assertion was evidence. But who cares? The uncertainties from the SD of the small sample is enourmous compared with any uncertainty in the calculation of the gravity of each planet.”
I’ve given you the evidence for the assertion, variances add when combining independent, random variables just like uncertainties add. You just keep dismissing it because it doesn’t support your delusion. As I said, add however many planets you want to the example. It won’t change the meaningless of the mean you so precisely calculate. It will remain meaningless and useless in the physical world. The uncertainty associated with that mean will just keep on growing as you add independent, random planets with their own uncertainties. Just like the GAT.
“Why are you so obsessed with trying to disprove what the example shows?”
What does it prove. Rather than take the average of the gravity you could just add up the mass of each planet. Would that be a useful thing to do? If not does that mean adding is meaningless?
“Make it fifty planets. Make it a thousand planets. Include planets around other stars. ”
You need to revisit what you are trying to do. What I first asked you the objective you said you wanted to know the mean gravity of those 5 planets, now you are happy to include a much larger sample. If the objective is to find the average gravity on all planets throughout the universe then maybe that could be useful. But now you have the problem of a biased sample, limited to planets in this solar system, which may not be typical of all systems.
“There are HUGE differences in the temperatures used to formulate the GAT.”
All the data sets use anomalies not temperatures.
“Why do you consider that population to be ok but not one involving the gravity constant for different planets?”
Because, as I’ve a;ready explained, it’s a useful metric. This is the problem with your dumb examples. You think the problem is in the averaging but are using the meaningless of the result as justification. There’s nothing wrong in principle with averaging different things, but there has to be some point to doing it.
“I’ve given you the evidence for the assertion, variances add when combining independent, random variables just like uncertainties add.”
You keep doing this – quoting me asking for evidence without quoting the thing I’m asking evidence for. In this case it was “The uncertainty associated with that mean is the sum of the uncertainties of the gravitational acceleration of the each individual planet. No dividing by anything!”. I want evidence that you do not divide the uncertainty when calculating the average, the evidence you keep insisting you’ve given me is only talking about adding to values not dividing to obtain an average.
This really shouldn’t be difficult – you’ve asserted the claim sop many times I have to imagine you actually have a reason for making that claim, so surely in one of the many texts there is a sentence somewhere saying “don’t divide the uncertainty when calculating an average” Yet you fail to produce such a sentence.
“What does it prove. Rather than take the average of the gravity you could just add up the mass of each planet. Would that be a useful thing to do? If not does that mean adding is meaningless?”
Like I said, you are obsessed. It’s not the adding that is meaningless. It is the *mean* that is meaningless!
“If the objective is to find the average gravity on all planets throughout the universe then maybe that could be useful.”
How would it be useful? Would it help you navigate among the stars or planets? Would it help you calculate fuel loads for landing and taking off on any specific planet? Someone mentioned the number of angels on the head of a pin. The average gravity of a large number of planets is quite similar to trying to calculate the number of angels on the head of a pin. Perhaps an interesting metaphysical exercise but quite useless in the real, physical world.
“All the data sets use anomalies not temperatures.”
Anomalies carry along with them the very same uncertainties as the absolutes from which they are calculated. So what’s your point? Another delusion?
“This is the problem with your dumb examples. You think the problem is in the averaging but are using the meaningless of the result as justification. “
There is no problem with calculating an average. The problem is not the averaging itself. The problem is believing the average tells you something useful when it is calculated from independent, random measurements of different things.
You seem to have a problem with my examples – even though the represent real, physical situations in the reality we live in. They are only “dumb” to you because they don’t comport with your delusion.
“ I want evidence that you do not divide the uncertainty when calculating the average, the evidence you keep insisting you’ve given me is only talking about adding to values not dividing to obtain an average.”
I’ve given you the evidence. From Taylor’s treatise as well as the Socrates web site. You simply refuse to acknowledge the evidence because it lies outside the bounds of your delusion!
“so surely in one of the many texts there is a sentence somewhere saying “don’t divide the uncertainty when calculating an average” Yet you fail to produce such a sentence.”
Meaning you haven’t actually studied Taylor’s Chapter 3. You’ve just cherry-picked it for things you think support your delusion. You haven’t bothered to read the Socrates web sight for how to handle variances of independent, random variables when combining them. None of them show dividing the variances (read uncertainty) when combining the populations. You would expect that if you were to do that at least one of the references would show that being done.
I can give you all kinds of references.
go here: https://www.khanacademy.org/math/ap-statistics/random-variables-ap/combining-random-variables/a/combining-random-variables-article
————————————-
Here’s a few important facts about combining variances:
—————————————-
From http://www.biloxischools.net:
In general, the variance of the sum of several independent random variables is the sum of their variances. Remember that you can add variances only if the two random variables are independent, and that you can NEVER add standard deviations!
—————————————
I don’t know why I persist in giving you evidence. You just ignore it, dismiss, and refuse to admit it exists. You just stay snug and warm in your delusion.
“Like I said, you are obsessed. It’s not the adding that is meaningless. It is the *mean* that is meaningless!”
You’ve brought up the 5 planet average in just about every post, often multiple times, and claim it proves you cannot get a global temeprature average. I try to point out that’s a dumb argument, and you claim I’m obsessed.
So, what does adding up the mass of those 5 planets tell you? Can you use it to pilot a ship? Does it have any real word physical use? Can you build safer bridges with it?
“You’ve brought up the 5 planet average in just about every post, often multiple times, and claim it proves you cannot get a global temeprature average. I try to point out that’s a dumb argument, and you claim I’m obsessed.”
You CAN’T get a legitimate global temperature average. The uncertainty of that average is wider than the value of the average itself. You simply don’t know where the average value actually lies within that uncertainty interval. If you calculate an average global temp of 15C but the uncertainty is +/- 20C then how do you actually know the average is a true value? The true value of the global average temperature could be anywhere from -5C to +35C.
And it doesn’t matter how precisely you calculate the average, the uncertainty remains!
“So, what does adding up the mass of those 5 planets tell you? Can you use it to pilot a ship? Does it have any real word physical use? Can you build safer bridges with it?”
I asked *YOU* that. You never responded.
“The true value of the global average temperature could be anywhere from -5C to +35C.
And it doesn’t matter how precisely you calculate the average, the uncertainty remains!”
I’m really curious as to where you think this uncertainty comes from. If I can make N random independent observations of the the globe, each with a measurement uncertainty of ±0.5°C, and can calculate the mean temperature as precise as I want, say with large enough N I calculate it to ±0.1°C, then why is the actual uncertainty so large, ±20°C? The accuracy of the mean is made up of precision and trueness, the precision is narrow, so the only explanation is the trueness may be off by 20°C. This would imply a systematic error in every thermometer in the same direction of 20°C. This would also mean the measurements were not independent.
I kn ow you’ll say that uncertainty has nothing to do with error, and it’s some mystical property divorced from reality. But we’ve already established that if you say the uncertainty interval is [-5,35] that means the true value could be anywhere within the interval and we have no way of knowing where it lies. It must therefore be possible that you think the true value of the global average really could be -5°C, and somehow when we took 1000 or so independent measurements we managed to get an average of +15°C, so you have to think it’s physically possible for this to happen, and I just want to know how?
Do the partial derivatives, the answer will be revealed.
If your mathematical model leads to this sort of absurdity it is either wrong or you are using it wrong. Show me how you use partial derivatives to go from using a large sample of thermometers with an uncertainty of 0.5°C, and end up with a measurement uncertainty of the mean of 20°C and I’ll try to figure out where your mistake is.
It’s not my model, it is the method in the GUM.
First you have to sit down and write out Eq. 1 for this calculation.
“I’m really curious as to where you think this uncertainty comes from.”
That’s because you simply don’t understand the propagation of uncertainty. You’ve never done anything except cherry-pick Taylor or any of the other sources you’ve been given.
Most temperature stations are assumed to have a +/- 0.6C uncertainty, even the Argo floats. When you calculate a mid-range daily temperature you are combining two independent, random measurements of different things. Therefore the uncertainty associated with that mid-range temp is either a direct addition of the individual uncertainties (+/- 1.2C), an upper bound, or a root-mean-square addition, about +/- 0.8C, the lower bound. This already gives you a wider uncertainty range than the differences ngo’s like NOAA like to claim, e.g. 0.01C.
Now, what happens when you combine that supposedly independent, random single measurement at location A with a similar one at location B? Once again teh uncertainties add, either direct or root-sum-square. With every additional data point you include the individual uncertainties continue to add. Just like you add variances when you combine independent, random populations. As you add more data points the additions should tend to gravitate to root-sum-square because of possible cancellations.
Now, as Taylor points out in his Chapter 3, multiplication by a constant doesn’t change the uncertainty calculation since the uncertainty of a constant is 0. If q = Bx (like the calculation of an average). B can be anywhere on the number line as long as it is a constant. Then delta-q = delta-B + delta-x. See Page 54 in Taylor’s text. Since delta-B is zero the uncertainty in q becomes the uncertainty in x. As the uncertainty in x grows from adding more and more uncertainty into the sum the uncertainty in q grows right along with it. This happens whether you are using fractional uncertainties or direct uncertainties.
So if you start off with each individual component having an uncertainty of +/- 0.8C and you combine 1000 components, e.g. q = x1 + x2 + …. + xn, you wind up with an overall uncertainty of 0.8C times 1000 or an uncertainty of +/- 800C. That is, of course, a very high number. That doesn’t mean it is wrong, it just means you should have stopped adding data points early in the process. In fact, the uncertainty in just one mid-range value is already higher than the differences the climate alarmists like to trumpet, differences in the hundreths digit.
I’m sure someone is going to bring up anomalies. The issue there is that even with subtraction the uncertainties in the different quantities still add. It doesn’t matter if you have q = x1 + x2 or q = x1 – x2. The uncertainty in q is still the addition of the uncertainties in x1 and x2. Any baseline “average” (x1) is going to have at least the uncertainty that is carried along with calculation of that “average” (which we just discussed above). When combined with the daily mid-range value (x2) the total uncertainty, i.e. the uncertainty in the anomaly, becomes the addition of the individual uncertainties. Therefore you cannot reduce the uncertainty by calculating an anomaly.
The entire edifice of the climate “studies* today is rotten to the core. None of these people seem to have any knowledge of the propagation of uncertainty in physical science. They are just like you and think they can use the hammer of the central limit theory on the bolt of combining individual, random populations. They totally ignore the very simple rule that when you combine independent, random populations the variances of the populations add. A rule that *should* be covered in university today but apparently isn’t any longer.
From “Probability and Statistics for Engineers and Scientists”, 2nd Edition, Anthony Hayter:
———————————————
“Also, in general,
Var(X1 + X2) = Var(X1) + Var(X2) + 2Cov(X1,X2)
Notice that if the two random variables are independent so that their covariance is zero, then the variance of their sum is equal to the sum of their two variances.
—————————————-
(This was not my text in university but rather my son’s. Copyright 2002. My textbook would have had a copyright in the 60’s. But what they teach is exactly the same. )
Tmax and Tmin are certainly independent and random, neither depend on the other. They may both depend on the season but that doesn’t make each dependent on each other.
If you consider variance to be at least somewhat similar to uncertainty then adding uncertainties is perfectly justified. How you add them might be debated but addition is still the standard.
Note carefully that Var(X1+X2) is *NOT* equal to [Var(X1) + Var(X2)]/N (or sqrt(N).
From the same text the precision of the mean *is* dependent on the number of data points but that is absolutely not the same thing as the uncertainty (variance) associated with the combination of independent random data points.
——————————————————–
From the same text:
A special case of this result concerns the situation in which interest is focused toward the average X_bar of a set of independent, identically distributed N(u,s^2) random variables.
….the result above implies that X_bar is normally distributed with mean and variance
E(X_bar) = u and Var(X_bar) = s^^2/n
———————————
Averaging reduces the variance of the mean to s^2/n so that the average X_bar has a tendency to be closer to the mean than the mean of the individual independent, random variables.
The issue is that the standard deviation of the mean is *NOT* the same thing as the standard deviation of the population – which is derived from the variance and is similar to the uncertainty interval.
When combining independent, random variables the variance grows by addition, Simarly, the uncertainty of combined independent, random variables grow as well by addition.
So it simply doesn’t matter how much you reduce the standard deviation of the mean, it doesn’t affect the standard deviation or variance of the combined population – and uncertainty follows the same rule.
You can argue till you are blue in the face that the standard deviation of the mean is also the uncertainty of the population but but it isn’t true. It’s just your delusion causing you to be blind.
And this doesn’t even *begin* to address the problem that the populations of independent, random variables need to be at least somewhat similar in order to combine them. Daytime temps are *not* a similar population to nighttime temps. Trying to combine them violate the rule of similarity. It’s like what you alluded to with the planet example. Each of the planets represent a vastly different population thus combining them makes the combination questionable from the very start. It’s like measuring the heights of pygmies and Watusis, combining them, and trying to say the mean actually tells you anything. Just like the ten 2′ and twenty 10′ boards. The mean tells you nothing about the physical world. Since daytime temps and nighttime temps are such different populations, trying to combine them gives you nothing but meaningless values. And combining meaingless values into higher level averages makes the higher level values just as meaningess.
I know I’ve gone on and on here. I have no expectation of shaking you out of your delusion. I can only suggest you read this dissertation for MEANING and then go back to your statistics texts and verify everything I’ve asserted (which is backed up by quotes from accepted engineering textbooks).
Standard deviation of the mean is *NOT* the same thing as standard deviation of the population. And it is the standard deviation of the population which determines the uncertainty of the mean. It is truly that simple.
“That’s because you simply don’t understand the propagation of uncertainty. ”
Quite possibly you know a lot more about it than me. That’s why I’m asking you where the uncertainty comes from. Just repeating you add uncertainties isn’t what I’m after. I don;t want to know what the theory says, I want to know where the uncertainty is coming from in the real world.
I’ll take your first example to illustrate my concern. You have a thermometer with uncertainty 0.6°C. You use it to measure the minimum and maximum temperatures on a specific day. Let’s say they are 10.0°C and 20.0°C. As the uncertainty on each measure is ±0.06°C, that means the uncertainty interval for the minimum is [9.4, 10.6] and for the maximum it’s [19.4, 20.6]. That means the true minimum for example could have been anywhere from 9.4°C to 10.6°C. (You don’t say what type of uncertainty it is, so this might be a 95% confidence interval and it’s just possible the true min was outside the interval, but to keep this simple I’ll just assume the real value is always going to be inside the interval.)
So now you say, correctly, that we can add the uncertainties to find the uncertainty of the sum of max and min. Our measured sum is 30°C and the uncertainty is 1.2°C. This means the sum of the true min and max could be as low as 28.8°C or as high as 31.2°C, this would be the case if the true value was at the max distance in the uncertainty interval and both were in the same direction. (We could use RSS to get a slightly better interval, but as we are using the same thermometer it may not be the case that the errors are independent, so I’ll go with just adding the uncertainties.)
So far so good, and no disagreement. But now you say that if we take the average of min and max to get the mean, or if you prefer mid-point value, you say the uncertainty of the average will be the same as that for the sum. So we have a measured mid point value of 15°C with an uncertainty of 1.2°C. Meaning the true mid point value could be anywhere in the interval [13.8, 16.2]. But how. What if the true mid point value was 13.8°C. This would require that the true min and max average to 13.8°C, but we’ve already established that the true min wasn’t less than 9.4°C and the max wasn’t less than 19.4°C, which means the average of the min and max couldn’t be less than 14.4°C.
The only way the true mean could be 1.2°C below or above the measure mean is if at least one of the true values was at least 1.2°C below the measured value, but if that was the case the original uncertainty values were wrong as the true value was far outside the uncertainty interval.
“hat’s why I’m asking you where the uncertainty comes from.”
Where doesn’t it come from? In old thermometers where they used wine as the display medium varying alcohol content in different thermometers would give different readings. Uncertainty.
In more modern thermometers using mercury, imperfections in the glass tube would cause different readings between thermometers as well as for different temps measured by the same thermometer. Uncertainty.
For modern measurement stations, things like water flow being interfered with in an Argo float can cause different readings at different times and between different floats. Same for land based stations, bugs and leaves and whatever can block air intakes and outflow. Uncertainty.
Even in modern thermistor sensors, different manufacturing runs can result in different calibration, drift rates, etc. Uncertainty.
Yes, they are all uncertainties in individual readings. Your claim is that they increase with sample size.
This is one of the problems with using the mid-range value in a bimodal distribution. You get screwy numbers. You should only combine similar populations.
I am headed out for the night. Will be busy tomorrow. I’ll try and get back to this.
“Now, as Taylor points out in his Chapter 3, multiplication by a constant doesn’t change the uncertainty calculation since the uncertainty of a constant is 0.”
Which is as far as it’s worth reading your lengthy screed. You are still intent on making incorrect statements, however clearly written, by Taylor, despite having gone through this in excruciating detail. Either you are incapable of understanding the simple equation Taylor presents, showing that multiplication by a constant multiplies the uncertainty by the same constant, or you are deliberately trying to mislead.
“Then delta-q = delta-B + delta-x. See Page 54 in Taylor’s text. Since delta-B is zero the uncertainty in q becomes the uncertainty in x.”
Page 54
See the final equation labelled (3.9). Does it say what you’ve just said?
“Which is as far as it’s worth reading your lengthy screed. You are still intent on making incorrect statements, however clearly written, by Taylor, despite having gone through this in excruciating detail. Either you are incapable of understanding the simple equation Taylor presents, showing that multiplication by a constant multiplies the uncertainty by the same constant, or you are deliberately trying to mislead.”
I just despair of you *ever* understanding this.
The TOTAL uncertainty in q is the individual uncertainty delta-x multiplied by the number of individual elements. This assumes a uniform uncertainty for each element.
In his example delta-x is the uncertainty of each sheet of paper. The total uncertainty of a stack of 200 sheets is thus |B|(delta-x) where B=200!
Thus if you measure the the total stack and allocate the overall uncertainty uniformly to each individual element in the stack of 200 you get delta-x = u_total/|B|
QED!
Why is this concept so hard to understand?
“Why is this concept so hard to understand?”
Because you keep contradicting yourself.
Statement 1 from you.
“Now, as Taylor points out in his Chapter 3, multiplication by a constant doesn’t change the uncertainty calculation since the uncertainty of a constant is 0.”
Statement 2
“In his example delta-x is the uncertainty of each sheet of paper. The total uncertainty of a stack of 200 sheets is thus |B|(delta-x) where B=200!”
In the second statement you have literally multiplied the quantity by a constant and multiplied the uncertainty by the same constant, when in statement 1 you say multiplication by a constant doesn’t change the uncertainty calculation.
“The accuracy of the mean is made up of precision and trueness, the precision is narrow, so the only explanation is the trueness may be off by 20°C. “
You are getting closer! Keep it up!
“This would imply a systematic error in every thermometer in the same direction of 20°C”
No, it implies that uncertainties add. Using root-sum-square for the addition allows for *some* of the uncertainties to cancel.
“if you say the uncertainty interval is [-5,35] that means the true value could be anywhere within the interval and we have no way of knowing where it lies”
That is correct. And it doesn’t matter how small you make the standard deviation of your mean calculation. That mean can still lie in the -5C, 35C interval.
“It must therefore be possible that you think the true value of the global average really could be -5°C, and somehow when we took 1000 or so independent measurements we managed to get an average of +15°C, so you have to think it’s physically possible for this to happen, and I just want to know how?”
Because the standard deviation of the mean is *NOT* the same thing as the standard deviation of the population (i.e. the uncertainty).
You *still* haven’t grasped the difference between the two yet. Keep trying!
“No, it implies that uncertainties add. Using root-sum-square for the addition allows for *some* of the uncertainties to cancel.”
The point is that if adding uncertainties leads to impossible claims about the uncertainty, there is either something wrong with the theory, or much more likely with your interpretation of it. When I say an uncertainty of 20°C would require a systematic error of that size, you reject that by still insist that uncertainties add without division and therefore that is the correct uncertainty. Theory triumphing of reason.
“That mean can still lie in the -5C, 35C interval. ”
Of course it can lie in that interval, it can lie in any interval that is bigger than that as well. But are you saying it could lie anywhere in the interval. Could it say lie between -5°C and 0°C? or between 25°C and 35°C?
“Because the standard deviation of the mean is *NOT* the same thing as the standard deviation of the population (i.e. the uncertainty). ”
And there’s your problem. You think that when we talk about the uncertainty of the mean, we are actually talking about the uncertainty of individual elements. The standard deviation of the population just tells us where any random sample is likely to be, it isn’t telling us where the true mean may lie. But that still wouldn’t explain why you think the standard deviation of the population will increase with sample size.
“The point is that if adding uncertainties leads to impossible claims about the uncertainty, there is either something wrong with the theory, or much more likely with your interpretation of it”
Just because the uncertainties get large that doesn’t mean they are impossible. They are legitimate if you follow the techniques of propagating uncertainty. As I pointed out the problem is that you should have stopped adding data points when the uncertainty became larger than the effect you are trying to measure.
If the uncertainty associated with combining two independent, random measurements of different things, e.g. two temperatures, is larger than what you are looking for, then STOP. You are only fooling yourself by going any further.
If the uncertainty in combining two temperatures is +/- 0.8C and you are trying to identify differences of +/- 0.01C you are pursuing a lost cause. JUST STOP at that point.
“When I say an uncertainty of 20°C would require a systematic error of that size, you reject that by still insist that uncertainties add without division and therefore that is the correct uncertainty. Theory triumphing of reason.”
They *do* add without division. You keep wanting to define the standard error of the mean as the uncertainty of the mean. They *are* two different things. Learn it, love it, live it!
“Of course it can lie in that interval, it can lie in any interval that is bigger than that as well.”
Of course it can. But if you have done a professional job of estimating your uncertainty interval, it is not likely.
“But are you saying it could lie anywhere in the interval. Could it say lie between -5°C and 0°C? or between 25°C and 35°C?”
It could lie anywhere in the uncertainty interval.
“You think that when we talk about the uncertainty of the mean, we are actually talking about the uncertainty of individual elements. “
No, I am not. I’ve given you the math from a statistics book on this. Why do you ignore it? How precisely you calculate the mean from the stated values is measured by the standard deviation of the mean (disregarding the rules for significant digits). The more observations you have the smaller the interval in which the calculated mean will lie. That is *NOT* the uncertainty of the mean itself. The TOTAL uncertainty of the mean *is* determined by the uncertainty of the individual components in the population. But that TOTAL uncertainty is not the same thing as the individual uncertainty of each component!
“No, I am not. I’ve given you the math from a statistics book on this. Why do you ignore it?”
Possibly because you post so much that it’s impossible to keep up. Looking back I assume you are referring to this:
As usual, all of this is correct. None of it supports your claim. It’s about what happens when you add independent variables, not when you take their mean.
Again, the important word is “sum”.
(Can’t find the actual page this comes from, it’s just a link to a school web site.)
It would help if you gave me some evidence pertinent to your claims.
“I asked *YOU* that. You never responded.”
Funny that, what a strange coincidence. But I think I did answer you, I said the average gravity of 5 planets was meaningless and useless and so I think the answer to all those questions would be no.
So your turn, is there any use in adding up the mass of those 5 planets. Or for that matter adding up the g of those 5 planets?
It is meaningless because combining non-similar populations violates the rules of combining independent, random populations. It’s like combining the population representing the heights of giraffes with the population representing the heights of horses. Dissimilar populations. It’s the same with combining nighttime temps with daytime temps. Two different populations representing different things. The heights of the giraffes and horses can both be measured in inches. That doesn’t make them similar populatons. Daytime and nighttime temps can be measured in C or F or what-have-you. It doesn’t make them similar populations.
It’s why I keep advocating for degree-days. You are comparing similar populations. It’s why I think the models should focus on projecting daytime temps *and* nighttime temps. Similar populations. You would get far more information abut the global climate that the meaningless GAT.
“Where in Chapter 3 does Taylor even mention uncertainty of the mean?”
He doesn’t, but you can deduce it from other parts parts. Equation 3.16 shows adding uncertainties in quadrature for independent uncertainties. Equation 3.9 shows how uncertainties scale when you scale the quantity. Apply these to adding independent measurements and then dividing by the sample size and what do you get?
“He doesn’t, but you can deduce it from other parts parts.”
ROFL! In other words you know more about the subject than Taylor himself! What hubris.
“Equation 3.16 shows adding uncertainties in quadrature for independent uncertainties.”
But it doesn’t show reducing the resulting uncertainty by dividing by the number of measurements!
“Equation 3.9 shows how uncertainties scale when you scale the quantity”
But it doesn’t show dividing by the number of observations to reduce the total uncertainty!
“Apply these to adding independent measurements and then dividing by the sample size and what do you get?”
You get no reduction in the overall uncertainty. You get a more precisely calculated mean that is useless and meaningless, just like the example of the planets.
You speak of my obsessions and yet you are somehow obsessed with the idea that calculating the mean of independent, random measurements of different things ever more precisely somehow lessens the uncertainty associated with that mean. And no amount of evidence can penetrate that delusion. No amount of evidence will *ever* penetrate that delusion.
It’s why you should *never* be involved with the engineering of anything affecting the safety of the general public.
“ROFL! In other words you know more about the subject than Taylor himself! What hubris.”
No, I think I understand Taylor’s maths better than you do.
But thanks for playing the argument by authority game.
Me: “Equation 3.9 shows how uncertainties scale when you scale the quantity”
TG: “But it doesn’t show dividing by the number of observations to reduce the total uncertainty!”
Yes it does, and given we’ve been over this so many times, I really can’t understand why you fail to understand such a simple concept. If you multiply a quantity by a constant you can also multiply the uncertainty by the same constant. That constant does not have to be greater than 1. So if I want to divide a quantity by, say 200, that’s equivalent to multiplying by 0.005. I can therefore multiply the uncertainty by 0.005, which is equivalent to dividing by 200.
And, as we’ve discussed numerous times before, Taylor specifically uses the example of measuring a stack of 200 sheets of paper, dividing by 200 to get the thickness of a single sheet of paper, and also dividing the uncertainty by 200.
“You speak of my obsessions and yet you are somehow obsessed with the idea that calculating the mean of independent, random measurements of different things ever more precisely somehow lessens the uncertainty associated with that mean.”
If by more precise you mean that the standard error is smaller, then yes that’s exactly what reducing the uncertainty means. Again, we are talking about independent measurements, and assuming no systematic errors.
“And no amount of evidence can penetrate that delusion. No amount of evidence will *ever* penetrate that delusion.”
There’s one way to test that hypothesis. Give me some evidence.
“No, I think I understand Taylor’s maths better than you do.
But thanks for playing the argument by authority game.”
“Yes it does, and given we’ve been over this so many times, I really can’t understand why you fail to understand such a simple concept. “
Only because you won’t believe what is laid out in front of you. If you take 200 sheets of paper and measure the height with a uncertainty interval then you can get the *average” height of one sheet and the *average” size of the uncertainty for one sheet by dividing by 200. What you continue to refuse to understand is that you get the OVERALL uncertainty FIRST in this case and then scale it to each individual member. That is the SAME THING as taking the individual uncertainty for each sheet and adding them all together. u_total = u_1 + u_2 + …. + u_200. There is no dividing the sum by the number of sheets. You don’t do (u_1 + u_2 + … u_200)/ 200 to get u_total. Assuming all the uncertainties for each individual sheet is equal dividing the sum of the uncertainties by 200 just gets you right back to the individual uncertainty for each of the members of the data set.
When you stack the papers you are ADDING them. It’s a sum. The total uncertainty is also the sum of the uncertainties. Finding u_total first doesn’t change that in any way, shape, or form.
“If you multiply a quantity by a constant you can also multiply the uncertainty by the same constant.”
Multiplication is nothing more than repetitive addition – i.e. a sum. If you add multiple, equal uncertainties together that is the same thing as multiplying. You are undercutting your own assertion about how uncertainty is handled!
“That constant does not have to be greater than 1. So if I want to divide a quantity by, say 200, that’s equivalent to multiplying by 0.005. I can therefore multiply the uncertainty by 0.005, which is equivalent to dividing by 200.”
When you divide u_total by 200 you are doing nothing but calculating the individual uncertainty for each of the 200 members in the data set. You are *not* diminishing u_total in any way, shape, or form! u_total still remains u_individual * 200 – A SUM OF THE INDIVIDUAL UNCERTAINTITES.
This is simple third grade math – at least that is where I learned about multiplication being addition. You apparently haven’t learned that simple fact yet!
“If by more precise you mean that the standard error is smaller, then yes that’s exactly what reducing the uncertainty means. Again, we are talking about independent measurements, and assuming no systematic errors.”
But that does *NOT* mean you have reduced the associated uncertainty of that mean propagated from the individual uncertainties of the members of the data set. It just means you have calculated the mean more precisely.
If your data set is comprised of 100 individual, random members from different things, each with an uncertainty of 0.2, then the overall uncertainty of the mean will be either the direct addition (i.e. 0.2 * 100) as an upper bound or the root-sum-square [0.2 * sqrt(100)) as a lower bound. That’s 20 for an upper bound and 2 for a lower bound. It will *NOT* be 20/100 or 2/100. Those figures only tell you how precisely you have calculated the mean. They do *not* tell you the overall uncertainty interval in which that mean will lie. That will remain somewhere between 2 and 20.
“What you continue to refuse to understand is that you get the OVERALL uncertainty FIRST in this case and then scale it to each individual member. That is the SAME THING as taking the individual uncertainty for each sheet and adding them all together. u_total = u_1 + u_2 + …. + u_200.”
No it isn’t. In this case the sheets are measured as a block, and the uncertainty is that from measuring something that size with that particular ruler. When you divide by 200 you get the uncertainty for each sheet which is much more certain then you could have got by measuring an individual sheet with the same ruler. You should know that the uncertainty of an individual sheet of paper makes no sense. It isn’t the measurand that has the uncertainty, it’s the measurement.
Now in the case of taking the mean of multiple measurements of individual items, the process is a little different as we are first adding all the values together and using the rules for propagation of uncertainty to determine the uncertainty of the sum. But if the measurements are random and independent we can use RSS rather than just add the uncertainties. Then, just as for the stack of paper, when we divide by N to get the average, we can divide the total uncertainty by N to get the uncertainty of the average. If we added using RSS this will be less than the individual uncertainties. Even if we add all the uncertainties, we will still end up with an uncertainty that is the same as the average of the uncertainties.
Now to correct myself, this isn’t the same as calculating the standard error of the mean, though the concept is the same. Here we are only talking about the measurement uncertainties, and what this is telling us is that as the sample size increases the uncertainty in the mean from the uncertainty in the individual measurements decreases. But the uncertainty in the mean, that is the standard error of the mean is a different story as that uncertainty comes mostly from the uncertainty in the sampling. Hence in determining the standard error, it is the total variance that is used.
You can look at this as saying each sample is a measurement of the mean, that has an uncertainty equal to the standard deviation of the population. Applying that logic to the above two equations leads you to the formula for the standard error of the mean.
“No it isn’t. In this case the sheets are measured as a block, and the uncertainty is that from measuring something that size with that particular ruler. When you divide by 200 you get the uncertainty for each sheet which is much more certain then you could have got by measuring an individual sheet with the same ruler. “
You HAVE to be kidding me, right? Who says you have to measure individual sheets using a ruler? If I measured each sheet with a micrometer to get a state value +/- uncertainty, then the final uncertainty of 200 sheets would still be 200 * u.
The point Taylor was making is not that different measurement tools can give different uncertainties but that uncertainties ADD!
There are none so blind as those who will not see!
“You should know that the uncertainty of an individual sheet of paper makes no sense. It isn’t the measurand that has the uncertainty, it’s the measurement.”
I’m not sure what point you are making here. The uncertainty is actually a function of the measurement DEVICE, not the measurement itself. And of course the uncertainty in the thickness of a sheet of *anything* makes sense. A sheet of gold used for overlays, a sheet of FEP used in a 3D resin printer, the thickness of a piece of calibrating sheet used in a 3D filament printer, the thickness of a sheet of thin steel used to form a box, etc!
You *have* to know the uncertainty associated with the stated value of the measurement in order to judge if the sheet of whatever meets the tolerance requirements for the application it is being used for!
You don’t always have the luxury of measuring a stack of gold overlay sheets. Or a stack of FEP film. Or a stack of thin steel plates.
.
“Who says you have to measure individual sheets using a ruler? If I measured each sheet with a micrometer to get a state value +/- uncertainty, then the final uncertainty of 200 sheets would still be 200 * u.”
The whole point of the example was to show you don’t need an expensive measuring device to get a precise value for an individual sheet.
And you are wrong. If you know the uncertainty of an individual sheet using an accurate device, the uncertainty of the stack would be sqrt(200) * u.
“The uncertainty is actually a function of the measurement DEVICE, not the measurement itself.”
That was the point I was making.
“The whole point of the example was to show you don’t need an expensive measuring device to get a precise value for an individual sheet.”
So what? The final uncertainty is *still* the sum of all the individual uncertainties.
“And you are wrong. If you know the uncertainty of an individual sheet using an accurate device, the uncertainty of the stack would be sqrt(200) * u.”
Then how can the final uncertainty be u_total and the individual uncertainties be u_total/200?
U_total/200 is not equal to sqrt(200) * u
Uncertainties add in this situation. Root-sum-square is what you are trying imply should be used. Taylor is assuming that the uncertainties are common for each member of the population and there is no cancellation.
You *still* have not grasped the propagation of uncertainty yet.
“So what? The final uncertainty is *still* the sum of all the individual uncertainties.”
Only because the individual uncertainties were derived by dividing the total uncertainty by the number of sheets. Big news, if you divide a number by 200 and then multiply the result by 200 you get the original figure.
“Then how can the final uncertainty be u_total and the individual uncertainties be u_total/200?”
Because you are not measuring a single sheet of paper and determining the uncertainty, and then using that uncertainty to determine the uncertainty of the stack. Propagation of uncertainties depend on what uncertainties you are propagating.
On reflection I think it may or may not be appropriate to use RSS when adding the sheets of paper. It depends on exactly what has been measured. If you used a fine instrument to measure a single sheet of paper and found it was 0.0065 ± 0.0005 inches, and then used that to estimate how thick a stack of 200 sheets would be, you should not use RSS. Your assuming all sheets have the same thickness, but that thickness is only estimated with a single measurement. Hence there are no independent errors and all you can do is add all the uncertainties – i.e. multiply the uncertainty by 200. This is just reversing the exercise.
If on th other hand, for some obscure reason you measured each sheet and then added all the thicknesses together to estimate the stack of paper, you could use RSS on the uncertainties. You could also then divide the sum of the thicknesses by 200 to get an even more accurate thickness of an average sheet.
“Only because the individual uncertainties were derived by dividing the total uncertainty by the number of sheets. Big news, if you divide a number by 200 and then multiply the result by 200 you get the original figure.”
Judas H. Priest! That’s what Taylor and I have been trying to tell you for more than a month!
“Because you are not measuring a single sheet of paper and determining the uncertainty, and then using that uncertainty to determine the uncertainty of the stack. Propagation of uncertainties depend on what uncertainties you are propagating.”
And does it matter how you determine those individual uncertainties? You are not making any sense. If you want to argue that individual sheets could have different uncertainties I will agree with you. If you want to argue that directly scaling the overall uncertainty to each individual element is not reasonable, I will agree with you. I would only point out that this is a simplified example being used to teach basic principles – i.e. uncertainties add. And, in the real world the uncertainty propagated from each individual sheet has to add up to the total uncertainty of the stack. Some may have an uncertainty of .0006 and some .0004, but when you add them all up you come up with the same total.
“This is just reversing the exercise.”
You got it!
“If on th other hand, for some obscure reason you measured each sheet and then added all the thicknesses together to estimate the stack of paper, you could use RSS on the uncertainties.”
Probably correct. But how would those 200 stacked sheets come up with the same stated value for the total thickness and total uncertainty?
“Judas H. Priest! That’s what Taylor and I have been trying to tell you for more than a month!”
Was that before or after you were trying to tell me that Taylor says you don’t scale uncertainties when you scale a quantity?
“Now in the case of taking the mean of multiple measurements of individual items, the process is a little different as we are first adding all the values together and using the rules for propagation of uncertainty to determine the uncertainty of the sum. But if the measurements are random and independent we can use RSS rather than just add the uncertainties.”
You state this as if it is a hard and fast rule. It isn’t. As Taylor cautions, RSS is not always the best way to propagate uncertainty. Sometimes direct addition is best. You have to understand the process in order to make the judgement.
“Then, just as for the stack of paper, when we divide by N to get the average, we can divide the total uncertainty by N to get the uncertainty of the average”
But for independent, random measurements of different things how precisely you calculate the mean is meaningless. For that is what the term “uncertainty of the mean” actually means. It’s how precisely you calculate the mean. If that mean has an associated uncertainty propagated from the individual components of the data set then as long as your calculation lies within that uncertainty interval then refining it is basically an exercise in futility. It doesn’t *mean* anything. Again, if your first order attempt at the mean is 10 +/- 20 then why does it matter if you further your precision to 10.1 +/- 20? And that is the problem with the GAT. The uncertainty of that calculated mean is wider than the calculated mean itself!
“You state this as if it is a hard and fast rule. It isn’t. As Taylor cautions, RSS is not always the best way to propagate uncertainty.”
And what are the conditions that makes you think RSS is not the best way here. This all started with you insisting that if you added 100 thermometer readings with an uncertainty of ±0.5°C the uncertainty in the sum would be ±5.0°C, because of RSS.
But even if you don;t use RSS, the uncertainty of the mean is the same as the uncertainty of the individual measurements, not as you claim increasing as sample size increases.
“And what are the conditions that makes you think RSS is not the best way here.”
Because the assumption that the uncertainties of TWO separate populations will cancel is an unwarranted assumption. If you have a large number of uncertainties you will likely see some cancellation, at least for similar populations so the cancellation assumption can at least be justified on a common sense basis.
The word “some* is also the operative word. You cannot assume that all will cancel like you can with a random population derived from measuring the same thing multiple times. Even with multiple measurements of the same thing you may not get complete cancellation, i.e. you may not wind up with a gaussian distribution of values. This can happen if the sensor wears, the environment changes over time, or if the sensor drifts over time. This is especially important with field measuring stations that cannot be continuously calibrated between measurements.
“ uncertainty in the mean from the uncertainty in the individual measurements decreases.”
In other words you can calculate a mean more and more precisely. Do you know the difference between precision and accuracy/
Yes and I just mentioned it in a different comment. You claim the measurements are independent and can give a precise measure of the mean, so for the result to be inaccurate we need it not to be true, but that’s unlikely given all the measurements were independent. If there’s a systematic error the measurements were not independent.
You are still confusing precision and accuracy. Just because something is precise it doesn’t mean it is accurate. Just as the mean can be calculated with precision doesn’t mean it is accurate. The mean is no more accurate than the sum of the uncertainties of the individual elements.
I don’t think I am confusing the terms I just don’t see how you can use a possible lack of accuracy (or trueness if you prefer) to justify your claims about propagation of uncertainties.
The accuracy of a measurement or mean in this case consists of two things, the precision and the trueness (or accuracy if you prefer). Precision is how close different measurements are, and in the case of the mean how close different calculations of the mean would be. Trueness is how far the average of an infinite number of measurements would be from the true value. Precision relates to random independent errors, trueness relates to systematic errors.
Now lets apply this to the original example. We have 100 independent temperature readings each with a measurement uncertainty of 0.5°C, and we want to know the uncertainty of the mean. (For this example I’m assuming we only want the mean of these 100 readings, we are not looking on them as a sample of a population but are only interested in the uncertainty caused by the measurements).
So you say the uncertainty of the mean increases with the squarer-root of N and the uncertainty will therefore be ±5°C. I say it decreases by the square root of N, so the uncertainty of the mean should be 0.05°C.
Now you seem to accept that the larger N is the more precise the mean will be, and so I assume accept 0.05 as a measure of the precision of the mean. But you are now suggesting there might be a systematic error that makes the mean precise but less accurate. This could be the case if there is a systematic error in the temperature readings. If for example all 100 read 5°C too hot.
This may be true, but the problem is it has nothing to do with your assertions about uncertainty propagation.
Firstly, you’ve already said the uncertainty of the thermometers is 0.5°C. If there’s a known systematic error it should already have been compensated for, and any remaining uncertainty included in your 0.5°C value, and if you are worried about unknown uncertainties why haven’t you included that in your uncertainty value? You can’t quote an uncertainty value for each thermometer, then after the calculations have been done suddenly say that we have to change the uncertainty by 100 fold just in case there’s an unknown systematic error.
Secondly, your uncertainty analyis has nothing to do with any systematic error. If it was, it would not be increasing as you increase sample size. If every reading is 5°C too hot, the average of one reading will be 5°C too hot, so will the average of 2 readings, of 10, of 100, of 1000000. The systematic error is not going to get worse the more readings you take, but your calculations do.
“an uncertainty equal to the standard deviation of the population”
How do you get a standard deviation from a population that is not a probability distribution or that even approaches a gaussian?
I take you back to the example of ten 2′ 2″x4″ boards and twenty 10′ 2″x4″ boards. This does *not* give you a center mean that has any physical relationship to a gaussian probability distribution. In such a distribution the mean should occur with the highest frequency in the population. In this example there are *NO* boards that are the length of the mean. So it can’t be a gaussian distribution. So of what use is it to calculate out the mean to an arbitrary preciseness? You can add as many 2′ or 10′ boards you want to the population, you’ll never change the distribution of the population to anything approaching a normal one.
*I* can tell you the uncertainty interval around that mean by propagating the individual uncertainties. What can *you* tell me? That you calculated the mean to the millionth decimal place?
“How do you get a standard deviation from a population that is not a probability distribution or that even approaches a gaussian?”
You estimate the population standard deviation from the sample standard deviation. I’ve no idea why you would think the population doesn’t have a probability distribution. And it doesn’t have to be gaussian if your sample size is large enough.
“In such a distribution the mean should occur with the highest frequency in the population.”
Your confusing the mean average with the modal average.
“So it can’t be a gaussian distribution”
Of course it’s not a gaussian distribution, it’s bipolar .
“*I* can tell you the uncertainty interval around that mean by propagating the individual uncertainties. What can *you* tell me?”
It’s an odd example as you haven’t even mentioned the measurement uncertainties, just given me an exact number of boards of an exact length (albeit in some weird ancient measurement system). Are we meant to be randomly sampling the boards or should I just tell you the average is 6′ 2″ X 4″?
“You estimate the population standard deviation from the sample standard deviation. “
Pull out a sample of the 2′ and 10′ boards. What does that tell you about the standard deviation when the resulting sample is not any kind of normal distribution?
Again, the mean is supposed to be the value that occurs most often in a normal population. If that mean value NEVER appears in the population then how do you build a standard deviation around it?
Standard deviation for a skewed population gives you no information about the asymmetry in the population.
“And it doesn’t have to be gaussian if your sample size is large enough.”
If you are calculating the standard deviation of the mean, not if you are calculating the uncertainty of the mean.
Look at a graph of the incomes in the US. It is highly skewed to the lower incomes. Yet the few high incomes increase both the mean and the standard deviation around that mean (and the standard deviation is no symmetric around the mean) – something that really distorts analyzing the situation. You are far better off using the *median* value or the modal value in analyzing the skewed distribution.
As with the planets, you have a skewed distribution -Jupiter really misplaces the mean and gives a big asymmetry to the standard deviation.
The same thing occurs with temperatures on the earth. You get really skewed distributions when you combine temperatures. High temps significantly raise the mean and extends the standard deviation compared to low temperatures.
“Of course it’s not a gaussian distribution, it’s bipolar .”
I assume you mean bimodal distribution. What is the prime rule for analyzing bimodal or multi-modal distributions? Ans: BREAK THEM UP AND ANALYZE THEM SEPARATELY.
This is the *exact* situation with daytime temps and nighttime temps. They represent a bimodal distribution. Instead of calculating a mean (actually a mid-range) value which tells you nothing about the distribution they should be analyzed separately. That’s one more reason why degree-days should be used for analysis of temperatures on the Earth or why separate daytime/nighttime models should be developed to analyze global climate.
“It’s an odd example as you haven’t even mentioned the measurement uncertainties, just given me an exact number of boards of an exact length (albeit in some weird ancient measurement system). Are we meant to be randomly sampling the boards or should I just tell you the average is 6′ 2″ X 4″?”
The point is that the mean and the standard deviation of the mean and the standard deviation of the population are useless measures of the population. Break it into short boards and long boards and then do the analysis!
“Pull out a sample of the 2′ and 10′ boards. What does that tell you about the standard deviation when the resulting sample is not any kind of normal distribution?”
Standard deviation is not the same as a specific distribution. The standard deviation is simple the expected deviation from the norm. In the case of your boards, assuming there were an equal number of each the population standard deviation would be 4′.
Now,m if the distribution is normal, there’s useful things the standard deviation tells you, such as the probability of getting a sample within the bounds of the deviation.
“Again, the mean is supposed to be the value that occurs most often in a normal population.”
No it isn’t. I really don’t know where you get that idea from. Even if the distribution is roughly normal, there’s still no guarantee that any value will be equal to the mean.
“If that mean value NEVER appears in the population then how do you build a standard deviation around it?”
See the example of those two boards. The mean is 6′. It doesn’t matter if a 6′ board doesn’t exist, you can still say how far each board is from the mean.
“You are far better off using the *median* value or the modal value in analyzing the skewed distribution.”
In some cases. But that’s nothing to do with the uncertainty of the mean.
“I assume you mean bimodal distribution”
Yes, sorry.
“What is the prime rule for analyzing bimodal or multi-modal distributions? Ans: BREAK THEM UP AND ANALYZE THEM SEPARATELY.”
Depends, I would imagine, on what you are trying to do.
“This is the *exact* situation with daytime temps and nighttime temps.”
Once again, just because you have the mean, doesn’t stop you looking in more detail. And this has nothing to do with your claim uncertainty increases with sample size. What do you think will give you a more accurate daily mean temperature, 2 readings, or 1000 readings taken throughout the day?
Absolutely false, statements like this one demonstrate that your knowledge of metrology and uncertainty analysis is totally lacking; if you have indeed read through the GUM you certainly have not understood it (alternatively, you don’t like what it says so you silently reject it).
All of your hand-waving is vain, it has no technical basis.
It’s an example from Taylor (page 55). If he’s wrong you’d better let Tim know.
This is just a simple example that ignores other uncertainty sources, especially the spacing between sheets.
Again, if you don’t start with Eq. 1 of the GUM, your arguments are nothing but hand-waving.
YOU HAVE TO DO YOUR OWN UNCERTAINTY ANALYSIS.
All of this has been hand waving. No one here is trying calculate an actual global anomaly, and I’m not interested in doing a full uncertainty analysis. All we are trying to do is figure out whether, in general, increasing sample size increases uncertainty or not.
If you refuse to do a proper UA, then don’t be surprised when people laugh at your claimed impossibly small values of uncertainty for these global averages.
All this starts with Tim Gorman saying that if you take an average of independent thermometer readings, each with a measurement uncertainty of 0.5C the uncertainty will increase with the square root of the sample size. I think it will decrease with the sample size, you and Tim think it will increase, citing the general formula using partial derivatives as evidence. Demanding I work through it, but never doing it yourselves.
OK let me try. Feel free to explain why I’m wrong and show your own workings.
Equation 1 of the GUM says we can have a measurand Y which is calculated from a number of different measurements using a functional relation f.
Here f is the mean function so
with a corresponding estimate of Y given by
Part 2:
These are independent uncertainties, so we can use equation 10 to determine the combined standard uncertainty
Where f is the mean function. So,
Hence
and as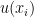 is the same for all
is the same for all  , say
, say 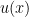 , we have
, we have
and taking the square roots of both side
Which is just what I was saying.
Now point out why I’m wrong, and show your own workings that leads to
This is all fine and dandy, except for one small little point: if x_i is temperature, you are not averaging independent measurements of the same quantity. Every microsecond that elapses, the temperature at a single location changes, it cannot be considered constant.
In addition, one unique measurement system is not being used to obtain all the data set, there are thousands of them.
Which means you have to find other ways to combine the u(x_i) values into a combined uncertainty.
This is what Tim has been trying to show you.
You keep begging me to go to Equation 1 of the GUM, you insist that of I worked out the partial derivatives all will be revealed. Yet when I do that and show I get the same result, you suddenly say I’m not allowed to use that as I’m not measuring the same quantity.
Equation 1 of the GUM is about combining different measurements to derive a new measurand. They do not have to be measuring the same thing. Look at the example in that section – it’s calculating the measurand from a variety of different measurements. No suggestion that they all have to measuring the same quantity.
Another simple example:
Suppose you have two results, X1 and X2, that you need to average. One has an uncertainty of 0.1%, while the other is considerably larger, 0.7%. What is the uncertainty of the average?
Dividing either value by sqrt(2) to get the combined uncertainty makes no sense; something else is needed. How does the uncertainty of one affect the other?
In that case you couldn’t use the short cut of dividing the uncertainty by sqrt(N), you would have to add in quadrature and divide by 2. Though if you are using fractional uncertainty, I’m not sure of hand exactly how you would calculate it.
Why would you divide by two? These are two indpendent, random populations of size one. You wouldn’t divide the sum of the two variances for two independent, random variables by two to get the total variance for their combination. Why would you do that for uncertainty?
Adding in quadrature is supposed to take care of any cancellation that might occur. Dividing by two is what you would do to get the mean, it is *not* what you do to determine total uncertainty.
Because of those partial derivatives you insisted I use. The function f is the mean function, the partial derivative is 1/2. I don’t care if you call them two different populations or two samples from the same population, the point was simply to go from the blessed equation 1, and work out the general formula for propagating uncertainties.
“You wouldn’t divide the sum of the two variances for two independent, random variables by two to get the total variance for their combination.”
What sort of combination are you talking about?
“Adding in quadrature is supposed to take care of any cancellation that might occur.”
Yes,for the sum. Now divide by the sample size to get the average.
In the GUM presentation of Type A uncertainty, 4.2, please read:
4.2.1 In most cases, the best available estimate of the expectation or expected value μ_q of a quantity q that varies randomly [a random variable (C.2.2)], and for which n independent observations q_k have been obtained under the same conditions of measurement (see B.2.15), is the arithmetic mean or average q (C.2.19) of the n observations [Eq. 3]
As I’ve tried to point out before, this condition is not true for global air temperature measurements. If you don’t see this, you will never get out of this rut of incorrect thinking.
Note that if the bolded condition is true, all the independent observations will have the same uncertainty. Temperature data cannot meet this requirement.
Note the formal definition of random variable:
C.2.2
random variable
variate
a variable that may take any of the values of a specified set of values and with which is associated a probability distribution
This is decidedly not true of history temperature records, thus treating means as though they are random variables is not valid.
The condition is reiterated in Sec. B for the definition of experimental S.D.:
B.2.17
experimental standard deviation
for a series of n measurements of the same measurand, the quantity s(q_k) characterizing the dispersion of the results and given by the formula:
In reality, the GUM does not tell you how to combine differing observations with differing uncertainties.
Also the formal definition of uncertainty:
B.2.18
uncertainty (of measurement)
parameter, associated with the result of a measurement, that characterizes the dispersion of the values that could reasonably be attributed to the measurand
NOTE 1 The parameter may be, for example, a standard deviation (or a given multiple of it), or the half-width of an interval having a stated level of confidence.
NOTE 2 Uncertainty of measurement comprises, in general, many components. Some of these components may be evaluated from the statistical distribution of the results of series of measurements and can be characterized by experimental standard deviations. The other components, which can also be characterized by standard deviations, are evaluated from assumed probability distributions based on experience or other information.
NOTE 3 It is understood that the result of the measurement is the best estimate of the value of the measurand, and that all components of uncertainty, including those arising from systematic effects, such as components associated with corrections and reference standards, contribute to the dispersion.
Yes 4.2.1 is explaining that the best measurement of a single quantity if the mean. But I’m not trying to do that using equation 1. I’m calculating a mean value from multiple separate measurements and then applying the general equation for propagation of uncertainties to show you get the expected formula. This is as per your request, and to avoid all these silly arguments about whether something is the same thing or not.
And as I keep telling TG, just because you say you can use a mean to determine a best measurement of something by repeatedly measuring it under the same conditions, does not mean that you cannot use the same idea for calculating any other mean. Metrology does not own statistics.
“Note that if the bolded condition is true, all the independent observations will have the same uncertainty. Temperature data cannot meet this requirement.”
The example I was given assumed all the uncertainties are the same. If they are different you can still use equation 10, it just doesn’t have such a simple closed form. In any case the uncertainty does not increase with sample size.
“This is decidedly not true of history temperature records,”
Nobodies said anything about historical temperature records, but your wrong, any temperature is a random variable.
Re: B.2.17. In using equation 1 as you requested, I’m taking the measurand Y to be the mean of the sample.
“In reality, the GUM does not tell you how to combine differing observations with differing uncertainties.”
Isn’t that what equation 10 is doing? each observation can have a different uncertainty, that’s what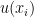 is, the uncertainty for each individual observation.
is, the uncertainty for each individual observation.
You are utterly beyond hope.
Very likely, but what do you think of my argument?
By the way, have you done your analysis using partial derivatives yet? The one that explains how the uncertainty of the mean can be much greater than the uncertainty of any individual measurement.
Until I see the exact numeric procedure used to produce these GAT charts, this is impossible.
We’re not talking about any actual temperature question of reconstruction, just the general question of whether uncertainty increases of decreases with sample size. It doesn’t even have to be about temperature. If I take the hight of ten men at random, each with an measurement uncertainty of 1cm, how much uncertainty will there be in the average of those ten men’s height? What about 1 million.
If you and T Goman are correct and uncertainty increases with the square root of the sample size the uncertainty for a million men should be 1000 x 1cm = 10m. All I want is for you to demonstrate using the equations in the GUM how that works.
What is the histogram of the data set you want to average?
What data set? It’s a hypothetical question about what happens to the measurement uncertainty when you take the mean.
This is just getting sad. You and TG have spent ages saying I have to go back to equation (1), do the partial derivatives, go back to first principles, and I’d see that the uncertainties increase with sample size. When I finally get round to doing that, and by my calculations it turns out that as expected, the uncertainties don’t increase, and ask you to show your own workings, you suddenly start saying you need more details. Nothing in the equations depend upon the actual data, it’s just about how the measurement uncertainties propagate.
This:
The distribution matters!
It doesn’t. Not for this example. We are just using the general formula in the GUM, starting at equation 1, to determine what the measurement uncertainty is when deriving a mean from a series of individual measures. If it was possible for you to show this leads to an uncertainty that scales with the square root of N, you would have done that by now, choosing any distribution you want.
But if you like, say the distribution of the men’s heights is normal, centered on 1.8m with a standard deviation of 0.2m. And take the uncertainty of 1cm to be the standard uncertainty, based on a normal distribution.
Note that in this exercise we are not trying to work out the uncertainty in the mean, just the measurement uncertainty. If you want the uncertainty in the mean use the standard formula for the standard error of the mean.
4.2.2 The individual observations q_k differ in value because of random variations in the influence quantities, or random effects (see 3.2.2). The experimental variance of the observations, which estimates the variance σ2 of the probability distribution of q, is given by…
Only if the data represents random samplings, i.e. has a Gaussian distribution, can the variance of the mean (square of the uncertainty) be quantified as σ2/N.
In neither of your examples, a bunch of boards or a month of temperature measurements, does the data have a Gaussian distribution. I can prove this for temperature data.
4.2.2 is talking about type A evaluation of uncertainty. I’m assuming the uncertainty of each measurement is type B. But if you prefer, assume the standard uncertainty was derived from repeated measurements of each person.
Also, 4.2.2 does not require a Gaussian distribution, it’s just the standard formula for calculating the standard deviation.
Here is month of one-minute temperature data (44640 points) from Golden, CO; the histogram conclusively shows there is no Gaussian distribution. The S.D. is 7.4°C, by your method the uncertainty of the mean is 7.4 / 211 = 0.04°C.
This is absurdly small. If anything, the uncertainty of the mean should be at least as large as the standard deviation.
Also, what exactly does the mean value here indicate? Where is it? You can’t even tell me this.
So I take it you aren’t going to do as you insisted I had to, and start with Equation 1 of the GUM, and work it out using the partial derivatives. Or you have done and found you’re wrong.
In answer to this particular question I doubt you can say the standard error f the mean is 0.04°C as using observations every minute with the same thermometer is not going to be 44640 independent measurements. If the thermometer is out by 0.5°C one minute it’s likely to be out by the same amount the next minute.
But I see no reason to assume your uncertainty of 7.4°C is realistic. If the thermometer is out by +0.5°C every minute the mean will still be only out by +0.5°C. Your talking about the SD of the monthly record, but this is just for one station. It isn’t a sample so apart from any uncertainty in the measurements you’ve got an exact record of temperature in that one place and the mean should be an exact mean of what that station recorded. The SD during that month isn’t relevant. If you want to use that one station as a sample for the the entire planet, then it won’t mean much – you can’t have a sample standard deviation with just one sample.
Do you understand what a Gaussian function is?
And, 24 h/day * 60 min/h * 31 days =
44640 minutes.
Are you going to show how the uncertainty of a mean increase with the square root of N, or are you just going to bring up more distractions.
I’ve really no idea why you working out how many minutes there are in a month. In case you didn’t get the point I was making 44640 observations taken every minute by the same thermometer are not going to be independent.
No I am not because it depends on many things, like the measurement system and how the data is used.
In UA, One Size Does Not Fit All.
And BTW, I never said the “uncertainty of a mean increase[s] with the square root of N“.
This is irrelevant because temperature anomalies are calculated from monthly averages, and it is you claim the uncertainty of the these averages is vanishing small.
If the data set is not normal, then the standard deviation of the mean does not decrease as you assert. You are blindly applying equations without understanding them.
This is why I asked you if you knew what a Gaussian function was (which you avoided answering). This is not a distraction, it is vitally important here.
“No I am not because it depends on many things, like the measurement system and how the data is used.”
Well isn’t that convenient! All this time you’ve been urging me to use equation 1 of the GUM and use the partial derivatives – when I asked how a global average could be out by 20°C, you said
“Do the partial derivatives, the answer will be revealed.”
Yet now I ask you to do the same and it’s impossible because it depends on too many things.
So how did you know that the global average could be out by 20°C if you don’t know enough to work it out from first principles? It’s a hypothetical problem, you can make the assumptions anything you want.
“And BTW, I never said the “uncertainty of a mean increase[s] with the square root of N“.”
Then we agree on that at least. But maybe you should have made that clear all the time you were attacking me and defending Tim Gorman. Did you ever explain to him he was wrong?
“This is irrelevant because temperature anomalies are calculated from monthly averages, and it is you [that] claim the uncertainty of the these averages is vanishing small.”
The issue is about how much the uncertainty of the measurement of individual thermometers causes uncertainty in a mean of several thermometer readings. And in particular if it goes up or down as sample size increases.
As I’ve tried to point out a few times, any effects of measurement uncertainty is small compared with that of the sampling. But in both cases the uncertainty reduces as sample size increases, provided you have a random sample of independent measurements. This has little of course to do with the actual uncertainty in real world temperature estimates, which is a much more complicated affair.
I don’t claim the monthly temperature uncertainties are vanishingly small, just that the uncertainties for having thermometers with an uncertainty of 0.5°C become irrelevant when you are talking about a 1000 or so readings taken every day, averaged over a month.
Your example with a thermometer taking readings every minute is irrelevant to the real world data as they are usually based on just two readings a day, and the uncertainty of the daily value for any one station will be much greater than your single station.
“If the data set is not normal, then the standard deviation of the mean does not decrease as you assert. You are blindly applying equations without understanding them.”
And now you are doing the same thing as TG and simply asserting this claim with no evidence. The distribution does not have to be remotely Gaussian to calculate the standard error of the mean and for this decreases with sample size. Even Jim Gorman has posted videos explaining this.
https://www.khanacademy.org/math/ap-statistics/sampling-distribution-ap/sampling-distribution-mean/v/standard-error-of-the-mean
You are not taking random samples of the temperature data sets, instead are using the entire set!
What is the uncertainty of the mean of my example?
You have to understand the assumptions Taylor is making in his example.
He is trying to show that uncertainties add. Some of the unsaid assumptions are uniform sheets, uniform stacking, uniform uncertainties, etc. The example is not meant to be a complete, real world example, but merely an example to foster learning. Something which Bellman has yet to master!
Yes. UA is not easy nor cut-and-dried, except for simple cases. It is essential to understand the entire measurement process, end-to-end!
“He is trying to show that uncertainties add.”
If that’s what he’s trying to do in that example he has an odd way of going about it.
He starts by showing that the uncertainty of a quantity scales if you scale that quantity, then points out that this is especially useful when you want to measure something inconveniently small but available many times over, such as the thickness of a sheet of paper or a rapidly spinning wheel.
Then he illustrates this by measuring a stack of 200 sheets of paper with a single measure then dividing it and the uncertainty by 200 to get the thickness of a single sheet of paper (assuming all the paper is of the same thickness), and obtains a reduced uncertainty of 0.0005 inches.
Finally he explains that this technique allows you to measure something that would otherwise require sophisticated equipment and gives a remarkable small uncertainty.
Somehow he completely forgets to mention that what he’s really trying to show is that uncertainties add, despite having mentioned that several times in previous sections.
Tim might think he’s learning something from Taylor, but it seems he has a blind spot to anything that contradicts his faith, such as the conviction that you never ever divide an uncertainty.
Step back and re-read what you wrote.
“gives a remarkable small uncertainty.”
In Taylor’s example, the individual uncertainties *do* work out to be small? What is the issue with that? Why are those remarkably small?
There is simply no doubt in my mind that you have never had a job in the physical world that depends on metrology. You’ve never engineered *anything*, from an amplifier circuit to crankshaft journals in an engine.
A .0005 uncertainty in measurements with a micrometer that reads to the .001 is not remarkable at all. However, if you don’t have a micrometer available what are you supposed to do? Just assume no uncertainty at all? Or do you use a different measuring technique to determine macro effects which can be scaled down?
From your reply it seems you would just throw up your hands and call it quits – an impossible task to accomplish. That isn’t, however, what a professional in physical science and engineering would do.
Suppose you need to know the thickness of copper plate being glued to a circuit board substrate so you can calculate the capacitance between the top and bottom plates but you don’t have a tool adequate to measure individual pieces of the copper plate. You would do *exactly* what Taylor lays out. Stack sheets together until you have a thickness you can measure, estimate your uncertainty and then scale down the thickness and uncertainty! QED!
Regardless of what you are trying to imply, this is a legitimate technique that is used every day in every way around the world for all kinds of things. Get out of your basement and get some real world experience!
What a weird comment. You seem to think I’m disagreeing with Taylor, and this example. Not at all. I’ve been constantly pointing to it to explain to you that you can divide uncertainties, something you keep insisting you never do. In a different comment you’ve just said “Now, as Taylor points out in his Chapter 3, multiplication by a constant doesn’t change the uncertainty calculation since the uncertainty of a constant is 0.” This example shows that Taylor doesn’t agree with that. When you multiply the size of the stack by 1/200 you also multiply the uncertainty by 1/200.
When I’ve pointed out this example before you keep insisting that what he’s actually doing is showing uncertainties add, and imply he’s actually multiply the uncertainty of a single sheet of paper to get the uncertainty of the stack. Now you say
“You would do *exactly* what Taylor lays out. Stack sheets together until you have a thickness you can measure, estimate your uncertainty and then scale down the thickness and uncertainty! QED!”
Great, we are finally in agreement on something But I can’t help feeling that in a minute or two you’ll be back to insisting you never divide uncertainties, and that’s exactly what Taylor says.
“’ve been constantly pointing to it to explain to you that you can divide uncertainties, something you keep insisting you never do.”
You can divide the total uncertainty to scale down to individual uncertainties (with a lot of caveats). But you can’t divide total uncertainty in order to DIMINISH the total uncertainty. Adding more indpendent, random data points only increases the uncertainty, it doesn’t diminish it!
But as I keep having to repeat, I’m not looking for the uncertainty of the total, I’m looking for the uncertainty of the mean.
If I know the sum of a number of different things and the associated uncertainty, and I divide the sum by the number of things in order to find the mean, should I or should I not divide the uncertainty of the sum in order to find the uncertainty of the mean? You keep saying I should not, but never giving any evidence as to why I shouldn’t.
“This is simple third grade math – at least that is where I learned about multiplication being addition. You apparently haven’t learned that simple fact yet!”
Maybe you should have continued beyond the 3rd grade. Multiplication is more than repeated addition. What do you think 0.25 X 0.75 means?
“When you divide u_total by 200 you are doing nothing but calculating the individual uncertainty for each of the 200 members in the data set. You are *not* diminishing u_total in any way, shape, or form!”
You still don;t seem to understand that we are not interested in u_total, but in u_mean.
“Maybe you should have continued beyond the 3rd grade. Multiplication is more than repeated addition. What do you think 0.25 X 0.75 means?”
You are kidding me, right? You’ve apparently never tutored the new math or the even newer math. .25 is 25 x 10^^-2. 0.75 is 75 x 10^^-2. So you add 25 to itself 75 times and then divide by 100 (i.e. 10^^-2).
Unfreaking believable.
“You still don;t seem to understand that we are not interested in u_total, but in u_mean.”
Of course we are interested in u_total! How much wrapping do you need to wrap a ream of paper sized at 200 sheets? You darn well better know the uncertainty associated with that ream or you will waste packaging material!
You just continue to amaze me with your clear separation from how the real world works!
“.25 is 25 x 10^^-2. 0.75 is 75 x 10^^-2. So you add 25 to itself 75 times and then divide by 100 (i.e. 10^^-2).”
That’s a way of calculating it using repeated addition, but it doesn’t mean that multiplying fractions is repeated addition.
“Of course we are interested in u_total!”
Nice diversion. OK, you might be interested in u_total, but if you want to know the uncertainty of the mean it won;t be the same as the uncertainty of the total.
“That’s a way of calculating it using repeated addition, but it doesn’t mean that multiplying fractions is repeated addition.”
ROFL!! “It’s repeated addition but it isn’t repeated addition”?
That’s called “having your cake and eating too”!
You should really talk to a math teacher familiar with current methods of teaching!
“Nice diversion. OK, you might be interested in u_total, but if you want to know the uncertainty of the mean it won;t be the same as the uncertainty of the total.”
HALLELUJA! You are perhaps finally beginning to see the light!
The uncertainty of the total *is* the uncertainty of the mean. It is not the standard deviation of the mean which only has to do with how precisely you can calculate the mean. If you use significant figure rules then there is no need to calculate the mean any more precisely than what allows you to round up to the same number of significant figures in the individual elements. There is no need to calculate the mean to an interval of .0001 if the elements of the population are only measured to .1. Adding more data points to get to .0001 is just wasted effort.
This isn’t really an argument worth having here, and not one I have particularly strong feeling on. But just because it’s how you introduce children to multiplication by calling it repeated addition, doesn’t mean that’s what multiplication is. You can use techniques to multiply fractions by repeated addition, but it isn’t what the multiplication is doing. You are not adding 0.75 to itself 0.5 times.
Then what about irrational numbers, negative numbers, complex numbers. How do you even multiply something by zero?
Show your work—where is Eq. 1 for the entire process you do, and the partial derivatives necessary to compute the combined uncertainty.
Unless and until you have done a formal uncertainty analysis, you are just hand-waving.
I don’t think Bellman knows that the general formula for uncertainty propagation even includes partial derivatives. He doesn’t know what an integral is, how could he know what a partial derivative is?
Just what I was thinking, he never mentions anything about the partial derivatives and combined uncertainty.
“You want to skip right over Chapter 3 and assume that Chapter 4 applies to *all* situations when Taylor specifically says it only applies to multiple measurements of the same thing!”
I can’t find where Taylor specifically says it only applies to the same thing, but if he did, he’s wrong.
“I can’t find where Taylor specifically says it only applies to the same thing, but if he did, he’s wrong.”
That’s because you’ve never actually read Taylor for understanding and worked out any of the chapter problems. You only cherry-pick things that you believe support your delusion.
I gave you the quote from Taylor on Chapter 4 that applies. Like usual you just blew it off and now you are asserting that you know more about the subject than Taylor. Not only are you deluded about the uncertainty associated with the mean from independent, random measurements of different things you have delusions of grandeur that you know more than Taylor!
Chapter 4, Page 93
“Section 4.2 introduces, without formal justification, two important definitions related to a series of measured values x_1, …, x_n, all of some single quantity x.
I know you will just ignore this because it doesn’t fit your delusion. You’ll just claim that Taylor is wrong.
So sad.
“I gave you the quote from Taylor on Chapter 4 that applies”
And as I pointed out it doesn’t support your claim. He says suppose you measure the same thing several times, we can use the standard error of the mean to show this will be a more precise result. You seem to think that this means you cannot use the standard error of the mean to get a more precise mean when measuring different things.
“and now you are asserting that you know more about the subject than Taylor.”
No I’m saying if Taylor didn’t say that, but if he had said it he’d have been wrong. And I’m not saying it because I know more about it than him, but because every statistician over the past hundred or so years has said it.
“And as I pointed out it doesn’t support your claim”
Delusional. That’s the only word to describe your views.
A more precise mean doesn’t mean that there is less uncertainty is the mean you calculate! Precision and accuracy are two different things!
“No I’m saying if Taylor didn’t say that, but if he had said it he’d have been wrong.”
I gave you the exact quote of what he said. And you are claiming he didn’t say that? Delusion piled upon delusion.
“Delusional. That’s the only word to describe your views.”
I just did a monte carlo simulation…again. Shocker…It still decisively showed that the standard error of the mean adequately estimates the uncertainty even when the measurements were of different things.
As I’ve pointed out to you before, your monte carlo simulation is worthless when considering multiple measurements of different things.
As Bevington points out in his treatise, monte carlo techniques are used to evaluate multidimensional integrals through numerical integration. Those integrals must be of variables with probability distributions amenable to evaluating their integrals.
In other words monte carlo techniques are not used to calculate uncertainty. They are used to test the statistical significance of data using simple calculations.
There are two main issues here. First, a data set of multiple measurements of different things is not guaranteed to generate a distribution of values amenable to evaluation. If the mean doesn’t exist physically then it can’t be the most populous value in the data set. This means no Guassian distribution around a true value. Second, the monte carlo program must generate events with the same parameters predicted by the theoretical principle being tested an with the same boundary conditions as those imposed by the actual experimental equipment being used.
How do you meet these two restrictions in your simulation? The fact is that you can’t. You are generating a probability distribution that has no relationship to the physical world and you don’t restrict your events based on any boundary conditions.
In other words you are doing exactly what the climate scientists are doing. You are creating a model that gives you the output you want. Whether it means anything in reality is of no concern to you.
GUM Eq. 1: start there, and then get to work.
“You still don;t understand what dependent means, do you?”
You have DEPENDENT measurements when you are measuring the same thing multiple times. The measurements all depend on the item you measuring.
You have INDEPENDENT measurements when you are measuring different things one time each. Each single measurement has no dependence on any prior measurement and does not create any dependence of future measurements on the current measurement.
My guess is that it is YOU that doesn’t understand what dependent means.
“Point me to any source saying that.”
Taylor, Pages 58-60. I’ve even quoted these pages above for you to read and hopefully understand. See especially Equations 3.13 and 3.14 on Page 58.
Since the mean is calculated from a sum q = x1 + x2 + … + xn
the uncertainties in x1 … xn add, either directly or in quadrature.
delta-q = delta-x1 + …. + delta-xn or
delta-q = sqrt( delta_x1^2 + …. + delta-xn^2)
In neither case does the uncertainty of the mean, which is propagated from the individual components, get divided by N or sqrt(N).
In that case delta-q would be:
delta-q = (delta_x1 + …. + delta_xn)/ N
delta-q = (delta_x1 + … + delta_xn)/sqrt(N)
delta-q = [sqrt(delta-x1^2 + … + delta-xn^2)])/N
delta-q = (sqrt(delta-x1^2 + … + delta-xn^2)]/sqrt(N)
You will not find that anywhere in Taylor or Bevington for independent, random measurements of different measurands.
Where is the “a piece” in temperature data? There are multiple millions of pieces!
The piece you are measuring if you want to call it that, is the mean temperature for the particular mean you are interested in, global, regional, daily, monthly, or whatever.
Do you think I erase the original measurements?
It tells me about climate CHANGE, in an easily comparable way, you genius. This is the whole thing.
I think we are approaching DreamTime.
Do you have the original measurements? If so then show us the trends for Global Maximum Temperature and for Global Minimum Temperature. If you don’t have them then admit you don’t and admit you have no idea what is causing the GAT to go up.
What does the GAT tell you about climate change? Be exact. Tell us what is happening to the Global Max Temp and the Global Min Temp.
My guess is that you don’t have a clue and are just assuming that if the GAT is going up that it means the maximum temps are going up as the cause of the change. Just like Greta!
The way these people stomp their feet during their temper tantrums reminds me a lot of Greta.
Jesus H Christ, you are really strange. The average is NOT calculated from the min and max. Of course they can calculate global min and max, that would be useless, they don’t do that.
He knows a whole lot more about real temperature data than you do, Noci the Nasty.
Have you tried looking at BEST data? They give figures for global min and max. As far as I recall both are going up
Your averages of averages are NOT climate, they tell you absolutely NOTHING, Nochi the Nasty.
Hm, who is talking about the average of averages here? Gorman was unable to calculate the average in a very simple case, he thinks that comes from the average of min and max which is clearly wrong.
Tim, if that simple exercise will not work, perhaps you will need to make a sketch…
Nocy the Nasty digs deep in teh bag o’tricks and comes up with — Attack the Messenger.
Yawn.
Cool! I got two of them to agree with me!
“… the local baseline is subtracted from the values because we want to see the fcukin local variation. Because local variations are comparable to each other …”
… and then you take the collection of fuckin local variations and call it fuckin global, you super-genius!…
“Again, to the rest: we are struggling with a simple, entry level thing here, barely the first step to understand anything. Actually, anything in any STEM field.”
… but apparently the science is settled, in spite of being, as you hyper-STEM-genius say, at ‘barely the first step‘, which, as everyone knows, is enough to justify enormous, even irreversible, changes to economy, peoples life and welfare, etc.!… Perhaps what you, super-hyper-STEM-genius need is a bit less STEM and a bit more of classical culture. Some lights of history and philosophy. Go for it, if your brains can stand such a terrible burden!
Yes. If we have all the local anomalies, we can have the global anomaly. A total value to show how much warming has happened. Your inability to understand this simple thing is truly hilarious.
Anomalies are NOT data. They are a metric that looks scary when plotted on a graph. They also fool people into thinking that the GAT is happening the same everywhere on the globe! They are why you and a way too many scientists use the GAT to say this pond, or that valley, or some local area is experiencing “climate change” without cctully cheking local temperature records. It is way too easy to say an anomaly change of 0.2 is a 20% increase, when in reality of actual temps it is only 0.6%!
Well yes, clearly you need a baseline for whatever region you’re measuring, whether it is the globe, the hemispheres, a continent… right down to individual stations.
You can measure warming (or cooling) using anomalies or absolute temperatures for a particular region, but if you are interested in comparing the trend in summer versus winter at a particular location for example, or comparing trends across different locations, anomalies make such comparison far easier and clearer, which is one reason why they are so widely used, most people find them extraordinarily useful.
Absolute estimates of global average surface temperature are difficult to compile for several reasons. Some regions have few temperature measurement stations (e.g., the Sahara Desert) and interpolation must be made over large, data-sparse regions. In mountainous areas, most observations come from the inhabited valleys, so the effect of elevation on a region’s average temperature must be considered as well.
For example, a summer month over an area may be cooler than average, both at a mountain top and in a nearby valley, but the absolute temperatures will be quite different at the two locations. The use of anomalies in this case will show that temperatures for both locations were below average.
Using reference values computed on smaller [more local] scales over the same time period establishes a baseline from which anomalies are calculated. This effectively normalizes the data so they can be compared and combined to more accurately represent temperature patterns with respect to what is normal for different places within a region.
For these reasons, large-area summaries incorporate anomalies, not the temperature itself. Anomalies more accurately describe climate variability over larger areas than absolute temperatures do, and they give a frame of reference that allows more meaningful comparisons between locations and more accurate calculations of temperature trends.
https://www.ncdc.noaa.gov/monitoring-references/faq/anomalies.php
“… but if you are interested in comparing the trend …”
It is very difficult to explain in a way that someone like you will understand… You know (you know?), science does not work or progress using “trends” or “concensuses”: it works with “causality”. But to grasp that idea you must have some knowledge of what others have already thought, observed and discovered… try starting with Aristotle: many of the common mistakes made nowadays by scientists, researchers and engineers were already discussed and demonstrated by him…
“trend” here is the mathematical trend in a series (as in “trendline”). A terminus technicus of this field.
The fundamental laws of Physics are empirical (ie. observational) laws, and these, by their definition, are laws of consensus. (Eg. Energy was always conserved when we took care to observe it, so we postulate that Energy is always conserved.) So there definitely IS legitimate use of “consensus” in science. Furthermore, most of the calculations in (the mathematical theory of) Physics are approximate in nature (including climate modelling, an approximate solution to a very complicated differential equation system), and there is a broad consensus (supported by extensive statistical analyses) that these approximations are good enough. Actually, the overwhelming majority of engineering calculations are in this category. So please spare the bullshit.
In the realm of science, usefulness is not an operation. Something can clearly be better as a mathematical tool, anomalies make temperatures comparable. What you wrote looks like an empty rant.
Who said that “usefulness” is an “operation”? Your diseased mind, perhaps…
An “operation” is the action of conflating “usefulness” with “truth”.
Get a life, you have exhausted my patience!
You. I admit that what you wrote is so convoluted I don’t really know what you’re talking about here:
We didn’t conflate [mathematical] usefulness with the “truth”. I don’t know what you want to say here.
Tell us *exactly* who anomalies make temperatures comparable? If you don’t know what is causing the anomaly to be the value it is then how do you compare it with another anomaly?
They use anomalies, partially, to hide the fact that the average global temperature varies by 3C between the UN IPCC CliSciFi models. Can’t have the rubes believe water freezes at 3C.
Again, anomalies are a way to make temp changes look larger than what they actually are. Since you have a baseline, add the anomaly to the base and report it. Wouldn’t look so scary would it?
Anomalies are basically a way to get smaller values so that on a graph they look like HUGE increases, when in reality, the percent change is very, very small.
Yes, I know that; it is “they” who don’t know that. They cannot understand that a deviation, say, of 1 C at 35 C is differente from an equal one degree deviation at 10 C; or at -5 C. Different in its biological consequences, but also in physics: the maximum amount of water contained in a certain amount of air changes, not linearly, with temperature (because of that both absolute and relative humidity do not change proportionally to temperature). Also, around 0 C you can have change of state of water, but not at 25 C. And those idiots “sum” anomalies to get a “total anomaly“…
This is why they simply refuse to use enthalpy instead of temperature. Temperature is a poor, poor proxy for enthalpy.
Since newer temperature stations measure humidity and pressure calculation of enthalpy should be able to be done.
“to use enthalpy instead of temperature”
Yes, Tim! Thermodynamics is not a strong point for me, but I can understand that this simple assertion of yours is the key! Thank you for having shown it to me!
You are welcome. When this comes up think of the old adage about “dry heat” in Phoenix being less oppressive than the same temperature in San Antonio. The enthalpy is different because of the pressure and humidity differences. The *climates* in each location are different. But you will never capture that by using temperature as a metric.
That information is available. See Schuckmann 2020 for a full energy analysis since 1960. ERA also provides this information every 6 hours since 1979.
Does any U.S. governmental agency make that data public in a readable and understandable manner? You know, graphs?
There is a pretty simple graph in Schuckmann 2020 that boils it down to the total energy accumulated over time.

Absolute temperatures? I don’t need no stinkin’ absolute temperatures!
a so called “Global Temperature”, that’s not measured but calculated, can’t be a absolute one, never ever.
Seems your understanding of the subject is expandable.
Averaging desert temperature anomalies with those from the tropics is a chump’s game. And don’t get me started averaging ocean temperatures with land!
Hamlin obviously doesn’t understand the difference between absolute temperatures and temperature anomalies.
And he hasn’t spotted that the Hadley July data is not published yet (check the graph above)
Apart from those
glaring errorsminor issues – great article!How do these people measure ‘global’ temperatures, from the Arctic to Antarctica and Ecuador to Brunei and all (c. 200) countries North, South, East and West of the Equator??
For me this summer (in the UK) rates as being one of the worst I can remember for a long time (and my daily (analogue) temperature and pluvio readings will surely substantiate that). That said this has not stopped the grass from getting more lush and greener for our horses nor a great crop of courgettes and (greenhouse grown) tomatoes this year! Oh well, ‘𝑒𝑣𝑒𝑟𝑦 𝒄𝒍𝒐𝒖𝒅 ℎ𝑎𝑠 𝑎 𝑠𝑖𝑙𝑣𝑒𝑟 𝑙𝑖𝑛𝑖𝑛𝑔’.
Agree it would have been better to say that in NOAA’s data set July 2021 was statistically tied for hottest month, but I’m not sure how 5 data sets reject this. GISSTEMP was 0.02 below 2019, another statistical tie. UAH and RSS are measuring atmospheric temperatures which behave differently under different ENSO conditions, and HadCRUT hasn’t released their data for July yet.
ENSO conditions are the same for all measurements
Actually, no. The satellites measure (indirectly) the temperature of the lower troposphere, HADCRUT and GISTEMP are surface based (2m) stations and sea surface temperatures. It is well known that the troposphere reacts more strongly to ENSO perturbations than the surface. Here’s the 1998 El Nino in the UAH and NASA data
“the NASA data”
What a joke!
“sea surface temperatures” as if we have an real idea what happen in the sea. Yes they make nice graphs and tell what the temperature is, yet it mostly conjecture.
Trends, trends, trends; its always long-term trends that should line up considering any measurement from 2m above surface to mid-troposphere. If they don’t, one series is off.
“I’m not sure how 5 data sets reject this. “
Surely that’s “I’m not sure how 1 iffy data set trumps 5 other data sets”?
As weekly_rise pointed out in the first comment, NOAA announced that July 2021 was the warmest month in their data.
Monthly temperatures are communicated as anomalies, that is, the result of subtracting the average for that month over a common baseline period from the measured and averaged value. This enables us to compare January temperatures with July temperatures at a location or Hawaii temperature trends with Alaska trends (say), even though the actual numerical values are very different.
NOAA announced that the July 2021 temperature was the warmest measured average value on the record (sometimes called the absolute value) – not the largest anomaly. (So Larry’s pointing out larger February and March anomalies in the past makes no sense, February is unlikely to be warmer than July).
NOAA is a surface dataset so the satellite datasets are not really comparable. HADCRUT’s July 2021 data has not been released and in the NASA data July 2021 is effectively a tie – joint warmest with July 2019.
So Bellman is right, the ‘five datasets’ do not actually reject the NOAA claim.
Christ, you hate being wrong, don’t you. It happens to us all at some point.
Dust yourself down and chin up.
I’m not wrong.
“NOAA announced that the July 2021 temperature was the warmest measured average value on the record (sometimes called the absolute value).
You sure about that phillips?
The average global land and ocean surface temperature for January–July 2021 was 0.81°C (1.46°F) above the 20th century average of 13.8°C (56.9°F), tying with 2018 as the sixth warmest such period on record.
So not the 2armest after all.
NOAA correctly claimed July was the warmest month, not six months.
Then you clearly have no understanding how noaa get there temperature values ,yet you clearly contradic your self,
“Monthly temperatures are communicated as anomalies, that is, the result of subtracting the average for that month over a common baseline period from the measured and averaged value. This enables us to compare January temperatures with July temperatures ” which is exactly what I reproduced above .
Taken from noaa web site its clear noaa say this July is the 6th warmest not the hottest ever.
“the ten warmest years on record: 2016 (1st), 2020 (2nd), 2019 (3rd), 2015 (4th), 2017 (5th), 2018 (6th), 2014 (7th), 2010 (8th), 2013 (9th), and 2005 (10th).”
Yet again phillips I’ve caught you lying, contradicting yourself and mis leading people.
No idea where you got that quote (link?) but it seems to be talking about whole years. It doesn’t mention 2021 at all.
NOAA actually wrote:
That is the global average for July 2021 was 16.73C (anomaly of .93 added to baseline of 15.8) which was the highest absolute temperature on record.
They were not claiming it was the biggest monthly anomaly ever (it wasn’t), just the largest July anomaly – and as July is typically the warmest month the anomaly plus the baseline was enough to set a record.
The methodology is described in full here
I am not wrong.
Get real phillips
“This graphic compares the year-to-date temperature anomalies for 2021 (black line) to what were ultimately the ten warmest years on record: 2016 (1st), 2020 (2nd), 2019 (3rd), 2015 (4th), 2017 (5th), 2018 (6th), 2014 (7th), 2010 (8th), 2013 (9th), and 2005 (10th). Each month along each trace represents the year-to-date average temperature anomaly. In other words, the January value is the January average temperature anomaly, the February value is the average anomaly of both January and February, and so on.
The average global land and ocean surface temperature for January–July 2021 was 0.81°C (1.46°F) above the 20th century average of 13.8°C (56.9°F), tying with 2018 as the sixth warmest such period on record.
The anomalies themselves represent departures from the 20th century average temperature. The graph zooms into the warmest part of the entire history.”
Notice 2021 at the beginning, who said it was the biggest anomaly 2021 is only the 6th warmest, do your research phillips all this is on the noaa web site.
“ In other words, the January value is the January average temperature anomaly, the February value is the average anomaly of both January and February, and so on.“
So the number for July is the average of January to July, anomalies. It is not for July only and it is not the absolute value.
Completely irrelevant to the topic being discussed.
https://www.ncdc.noaa.gov/sotc/global/202107/supplemental/
So 2021 is the 6th warmest month on month not the warmest ever , how can you claim July is the hottest ever on one hand and then say “its not out yet ” on the other the data I’ve provided
Which you didn’t even knew existed must have a July stand alone figure otherwise they could not say its only the 6th warmest .
You seem a tad confused.
The graph and text you quoted was about year to date, so at the moment the July figure is the average of the anomalies from January to July. Compared with previous years this average is indeed 6th warmest.
But the NOAA stated the July absolute value – so anomaly plus baseline – was the hottest single month in their data.
So the ranking of YTD anomalies is doubly irrelevant.
The data that is not out yet is the July 2021 figure from HADCRUT, which does not reflect well on the author’s attention to detail.
January to July is 7 months.
We are talking of July only.
July being the hottest month of any year.
Even in the southern hemisphere?
He and you aren’t
Look here, what NOAA published:
My point was that there are only 3 other data sets being used. HadCRUT is mentioned, but hasn’t been updated to July yet.
Funny how the “iffy” data set is always the one showing the warmest month. It’s usually GISS that is described as iffy, but because this time it’s 0.02°C below the record it’s now considered more reliable than NOAA.
Iffy data is funny data
The hallmark of the NOAA
Especially when it is actually comparing smashed guacamole to shot from cannons puffed rice to ground peanut butter to baked mixed vegetables to roasted mystery vegetables to a well tested and verified satellite measurement.
Besides the irregular matching of separate uniquely contrived temperature measurements, most of the alleged temperature sets are maladjusted into submission.
Then these arrogant presumptive data sets calculate anomalies with out calculating error ranges. Each ignoring that every “adjusted” temperature datum increases the error range, not diminish errors.
One of these temperature sets is not like the others, and that one is validated and verified by weather balloon measurements.
Radiosondes from 1958, satellites since 1979 and ARGO since 2004 are the only data sets that are of sufficient quality for scientific-level studies. Land surface measurements with wildly varying methods and SST measurements from buckets, engine intakes and expendable sinking probes give a dog’s breakfast of numbers, even before the insane combining of ocean and land temperatures.
Where is the graph of natural change or the graph of anthropogenic change?
Actual = natural + anthropogenic.
Oh I get it, you want to claim all change is anthropogenic, and if you release the natural change people will ask why its has flat lined.
I can get even more ludicrous than NOAA.
Assuming atmospheric CO2 is the problem; judging by mankind’s contribution to the atmosphere and temperature variations since 1850, for mankind to raise global temperature by 2ºC would take some 20,000+ years, at a rate of ~0.0001°C per year.
Blame Mother Nature, it’s all her fault!
It is a curious coincidence with NOAA’s data set that so many recent July’s have all had almost identical temperatures.
“0.92” is not a temperature.
Sorry, I should have said temperature anomaly. But as this is comparing the same calendar month, the relative differences will be the same.
So, what does that suggest to you? Perhaps that the temperature anomalies (not temperatures) indicate that Summer high temperatures have stopped rising? Or that the measurement uncertainty (“The NOAA July 2021 global monthly temperature anomaly measurement 95% confidence level (accuracy range) is +/- 0.19 C …”) obscures any real trend?
It doesn’t suggest anything to me. I just noted that it it was a coincidence. Other data sets show more variety for July Anomalies – it’s just the way the dice fall.
What it does show is that there isn’t much point in obsessing over which year was warmer than another. Records tell you little without the context.
Here are all of NOAA’s July Anomalies. If you want to look at just the last 7 years you could say they’ve stopped rising, but it also shows those last 7 years have been the 7 warmest in the set.
If you shorten the x axis and stretch the y axis, this graph will look even more terrifying.
Feel free to submit your own graphs in your favorite aspect ratio.
It goes without saying that whenever a time series has a positive trend, one can expect that the most recent measurements will be at least among the largest, if not the largest. Pointing out the obvious suggests an attempt to influence people with something that is not really important. It is redundant, because it is a consequence of how a time series behaves, and probably only worth noting if the most recent measurements don’t actually reflect the general trend.
This is akin to Monckton pointing out that the monthly temperatures for the last 6+ years are not showing a statistically significant positive trend. While that is not a guarantee it will continue indefinitely, it is noteworthy because it is anomalous behavior in the context of recent history and may (one of the favorite weasel words of alarmists) be indicative of a climate regime change.
It doesn’t go without saying at all. There’s a lot of year to year variation, especially when looking at individual months. Look how long it was before the 1998 record was broken.
It’s interesting that we have had a longish run of the hot July’s precisely because it doesn’t happen so often. I’m not suggesting this “proves” warming has happened, the prove of that is in the continuing long term trend.
“…and probably only worth noting if the most recent measurements don’t actually reflect the general trend.”
You’re right, they don’t reflect the general trend, 6 out of the last seven years have all been above the trend.
You fail to recognize that if the last 6 years had not been essentially flat (no trend!), the slope of the trend would be steeper.
And if they’d dropped down to 2014 levels the trend would be shallower. What exactly is your point?.
What happened to the 18-year period between 1997 and 2014? Did the then-current CMIP5 models reflect what actually happened? Did the CO2 forcing cease to act?
Why do you think this graph represents climate?
What is the trend of the UN IPCC CliSciFi CMIP6 models? How about CMIP5’s? Compared to the UAH6 trend? Get real, CliSciFi practitioners obfuscate, mislead and outright lie for the cause. Read the U.S. National Climate Assessments and tell me they represent neutral science.
And the same characters fly off the handle every time he points this out with the same irrational nonsense.
And any single year is weather, not climate. However, 5 years out of 6 begins to look like climate.
Not sure if you think that’s a good or bad thing. I mean, if you think the last 6 years are the current climate for July, there’s clearly been a big change since 2015.
I’m not making a subjective value judgement on what is happening. I’m only pointing out that there does appear to be at least a short-term change. The difference between the highs and lows has changed over time, and it isn’t obvious whether that is a processing artifact or if it actually is indicative of some physical process(es) that we don’t understand.
As Willis has pointed out more than once, there appear to be emergent phenomena that limit temperatures, at least in the tropics. Perhaps the climate is banging its head on a water vapor ceilings. Then there is the controversial role of reduced solar activity. Therefore, there are a number of things that could affect the climate, and a half-dozen years of highs with questionable uncertainties just might be a harbinger.
It is important to keep an open mind and not start running around in circles flailing one’s arms because a particular month reaches a claimed high of questionable statistical significance.
“It is important to keep an open mind and not start running around in circles flailing one’s arms because a particular month reaches a claimed high of questionable statistical significance.”
Yes, that’s what I keep saying. One month or even a few years don’t tell you much. An unexpected jump in temperatures might be an indication of some change, but until you have enough evidence it’s better to assume it’s just chance. Same with “the pause”, it’s always possible that something has happened that has caused a change in the rate of warming, but it’s more likely just to be an artifact of natural variation, and it’s best to wait till you have evidence that a change has actually happened.
There was no jump in July 2021! The initial claim of 0.01 deg (subsequently retracted) was not justified as being significant in light of the much larger uncertainty.
However, that is not what NOAA did! They are making it look like they have an agenda.
“There was no jump in July 2021!”
The jump I had in mind was the one in 2015, which has mostly carried on through to 2021.
“However, that is not what NOAA did!”
What exactly did NOAA do? I think their news article was badly worded, but as far as I can see they did not draw any conclusions based on one month, they give the figures and put it in the context of a warming world.
They’ve been publishing monthly news articles since March this year, despite none of the other months being the hottest month on record. They report August as the 6th warmest August on record. They don;t mention that it’s only 0.01°C below 5th place, or 0.02°C below 3rd. Or that it’s not significantly different from being the warmest on record.
Not seeing much sign of a slow down in the rise in July temperatures.
Last 50 years: 0.18°C / decade
Last 40 years: 0.19°C / decade
Last 30 years: 0.22°C / decade
Last 20 years: 0.21°C / decade
Last 10 years: 0.29°C / decade
The uncertainty of individual monthly measurements is not obscuring the trend. All of these trends are significant (not accounting for auto-correlation admittedly).
On what basis do you claim statistical significance for decadal changes when Larry claimed that the annual uncertainty is similar to the decadal changes.
That’s the annual uncertainty of individual years. I’m talking about the significance of the trend.
You are giving the impression that a trend does not have an associated uncertainty, which is not the case. The larger the uncertainty in the individual years, the larger the uncertainty in the decadal trend.
If you think about it, the trend is not going to be reliable if the magnitude of the trend is the same as the annual uncertainty! For the trend to have any value of prediction, the slope of the trend will have to be much larger than the uncertainty of the individual measurements from which the slope is derived.
“You are giving the impression that a trend does not have an associated uncertainty, which is not the case.”
All the graphs I’ve posted today show the uncertainty in the trend. Admittedly this is not taking into account auto-correlation and such like.
“The larger the uncertainty in the individual years, the larger the uncertainty in the decadal trend.”
This is true, but only to the extent that large uncertainty increases variation. This is already taken into account in the standard error of the trend.
“If you think about it, the trend is not going to be reliable if the magnitude of the trend is the same as the annual uncertainty!”
I’ve thought about it, and you are wrong. If you have enough data points the uncertainty of individual points average out, just as all sources of variance in the data.
“For the trend to have any value of prediction,…”
Who said anything about prediction?
“f you have enough data points the uncertainty of individual points average out, just as all sources of variance in the data.”
How do you *know* the uncertainties average out? Uncertainty intervals are not probability distributions so how can you determine whether or not they cancel? These uncertainties are not random variations around a true value forming a normal distribution (or any other kind of distribution)!
You might make the assumption that there is *some* cancellation, that is why uncertainties are propagated using root-sum-square instead of direct addition. But TOTAL cancellation? That is a totally unwarranted assumption for independent, random measurements.
Besides, variances do not cancel. They add. Variances grow just like standard deviations grow when you add two data sets together.
To be fair, you didn’t say anything about prediction. However, the point of doing a linear regression is to determine the relationship between an independent variable (in this case time) and a dependent variable such as temperature. Generally the reason for developing the relationship is so that one can predict how the dependent variable changes with time, i.e. prediction! The correlation coefficient between the two variables, when squared, provides an estimate of the amount of variance explained, or predicted, by r^2.
Not so! If you look at the graph you provided above, the uncertainty range has the typical bow-tie appearance because the end points are used to estimate the slope of the regression line uncertainty envelope. The greater the uncertainty of the dependent variable measurements, the wider the bow-tie will be at the ends. Incidentally, it appears that NOAA is using an uncertainty of about 0.06 deg C. Where did that number come from? What is the justification?
While we are on the topic, you claimed above that the decadal trend lines are statistically significant. What that means is that the null hypothesis, that there is no trend, is rejected and it can be said that there is probably a real change in y for a change in x. However, that doesn’t tell us anything about the uncertainty in the slope of the lines, or how the correlation coefficient changes with the slope of the uncertainty envelope. Again, the statistics are not rigorous, and do not completely characterize the relationships.
I think there’s some misunderstanding here. The uncertainty range in the graphs is the Confidence Interval; the range that the true trend line is likely to occupy. It has a bow-tie shape because the slope pivots about the central point. What you are talking about is the Prediction Interval – the interval any given sample is likely to occupy. This will be wider and straighter than the confidence interval.
I’m not sure how useful a prediction interval would be for a time series, as the samples have already happened. If you want to predict future anomalies, assuming a linear trend will continue, the confidence interval will give you the likely range of the average temperature, whereas the prediction interval will give you the likely range of any specific monthly value.
Why do you throw the measurement uncertainty into the rubbish bin, Herr Doktor?
Hmmmm…. Can you tell us *exactly* what caused the differences in those anomalies? Why are the anomaly values trending up?
Is it because maximum temps are going up? Is it because minimum temps are going up? Is it a combination of both? And *exactly* where are these changes happening? Land? Land where? Ocean? Ocean where?
If you can’t explain why they are changing then do the changes actually mean anything?
No I cannot say “exactly” what causes the differences in the anomalies. I could hazard a guess as to some of the reasons why it is trending up, but that isn’t necessary to my point, which is that there is an upward trend regardless of what caused it.
“Is it because maximum temps are going up? Is it because minimum temps are going up? Is it a combination of both? And *exactly* where are these changes happening? Land? Land where? Ocean? Ocean where?”
Has it ever occurred to you to download the data yourself and try to answer your questions for yourself?
NOAA has an interactive chart that will let you look at the trends over different regions.
For example, according to NOAA the trend for July since 1971 globally is +0.18°C / decade. For ocean it’s +0.15°C / decade. For land it’s +0.27°C / decade. For land in Europe it’s +0.47°C / decade.
For the USA, the mean temperature rise was +0.42°F (0.23°C) / decade, max temperature was +0.34°F (0.19°C) / decade, minimum +0.50°F (0.28°C) / decade.
Useless for him. He thinks the mean is calculated by averaging the daily max and min.
“Useless for him. He thinks the mean is calculated by averaging the daily max and min.”
Exactly how do *you* think the daily mid-range temp is determined?
If you don’t know the mid-range temp then how do you calculate an anomaly?
If you don’t mind I’m not going to hold my breath waiting for an actual answer from you. I’m sure it will just be one more argumentative fallacy.
Averaging the measurements. Not just the min and max.
From the local average over a fixed period as a baseline. Please note that I’m not talking about averaging the averages. Actually taking the average is not straightforward here because we have missing values, we have stations moved around etc. Anyway, this can be done and it is done with very good resulting statistical properties.
You mean dividing by the square root of N?
Hahahahahahahahaahahah!
No.
It is much more complex than you suggest. For a very long time, only the daily max and min were reported, and the mid-range value was used to derive weekly and monthly arithmetic means of the mid-range values. It is less clear how annual means were obtained, and may not be the same for every agency.
If modern automatic stations are actually computing daily arithmetic means, then they aren’t strictly comparable with the historical data. Any way you care to cut it, there are issues with the data processing that raise questions about the fitness for purpose.
That may explain why rigorous statements of uncertainty so rarely accompany the nominal reported measurements.
Yes, that’s why it’s done by scientists not amateurs bullshiting in a blog.
Stations don’t compute anything. Their data is collected, and processed in a non trivial way (eg. homogenized etc.). That is the main reason why you have a 2-3 month lag in reporting. Even the data collection may take time, some remote stations may report only a few times a month. Anyway, the result is comparable with historical data with very well known error properties. What you see in the reports is usually some digest from this.
Noci the Nasty digs deep into the Projection bag.
Are you speaking about yourself?
“No I cannot say “exactly” what causes the differences in the anomalies. I could hazard a guess as to some of the reasons why it is trending up, but that isn’t necessary to my point, which is that there is an upward trend regardless of what caused it.”
Have you seen the TV ads with “Captain Obvious”? My guess is that he looks a lot like you.
“Has it ever occurred to you to download the data yourself and try to answer your questions for yourself?”
What makes you think I haven’t? I *know* what is causing the GAT to trend upwards. And it isn’t because the Earth is going to turn into a cinder.
You keep quoting trend results with absolutely nothing to offer as to what is causing the averages to go up. If you don’t know then how does knowing the trend is up help generate any solutions, assuming of course that an upward trend is bad.
“What makes you think I haven’t?”
Because you keep asking lots of questions implying there’s no way to know if warming has been caused by maximum or minimum, ocean or land etc.
“And it isn’t because the Earth is going to turn into a cinder.”
That’s a relief, though until you mentioned it, it had never occurred to me that the world might turn into a cinder – at least not through global warming.
“If you don’t know then how does knowing the trend is up help generate any solutions, assuming of course that an upward trend is bad.”
I’m not a scientist and I’m not trying to solve anything. All I’m doing is trying to point out how i see the data. Lots of people here insist that either there’s been no warming, or there has been warming but it’s now stopped, and I like to look at the data to see if that’s true, and then sometimes explain why it isn’t true. I don’t think you have to know the cause of a trend to be interested in it, but my own limited “research” suggests that rising CO2 is a plausible cause, whereas most of the alternative theories proposed here don’t seem to be as plausible. I don’t assume this is necessarily going to be bad, but I’m not sure I want to take the chance that it won’t be.
I *KNOW* what is happening locally. Nighttime minimum temps are going up and daytime maximum temps are going down. There are articles all over the internet about various states seeing the same thing, such as IA.
“That’s a relief, though until you mentioned it, it had never occurred to me that the world might turn into a cinder – at least not through global warming.”
Really? You live in a cave with no outside news source?
“All I’m doing is trying to point out how i see the data. “
What data? GAT? GAT simply isn’t sufficient to determine anything. The trends are basically a joke. First off they depend on the assumption that temperature is a good proxy for enthalpy. But it is *NOT* a good proxy for that. Pressure and humidity are totally ignored. When you combine temperatures from Denver at 5000ft altitude with temperatures from Phoenix at 1000 ft altitude and temperatures from New Orleans at 5ft altitude you get an average which is meaningless just based on physical attributes let alone the measurement uncertainties!
” I don’t think you have to know the cause of a trend to be interested in it, but my own limited “research” suggests that rising CO2 is a plausible cause”
If that interest doesn’t result in being able to formulate a solution to a problem then it is nothing except mental masturbation.
What is “rising CO2” a plausible case *OF*? If it is rising minimum temperatures then why would you want to “solve” that? It means more food, fewer cold deaths, fewer traffic accidents, lower fuel costs, etc. All GOOD things for the environment. Meaning that lowering CO2 is BAD!
If NOAA isn’t also providing the uncertainty for the slopes of the trends, then they aren’t providing all the data. This is one of the continuing criticisms of both NOAA and NASA; they act as though the numbers they present are exact and have no associated uncertainties. This is either carelessness, incompetence, or fraud.
And UAH, but nobody seems to criticize their graphs showing no uncertainty.
They should *all* show their uncertainties. How else do you make an informed judgement concerning their data?
It seems to be an affliction shared by everyone who considers themselves to be a climatologist. Those of use with different academic backgrounds are not pleased with the cavalier attitude towards precision and uncertainty.
“Is it because maximum temps are going up? Is it because minimum temps are going up? Is it a combination of both? And *exactly* where are these changes happening? Land? Land where? Ocean? Ocean where?”
It’s a combination of both – but the main contribution is from rising minima over land.
The cause of that is that under nocturnal inversions the reduction of cooling to space is stored in a narrow vertical depth of the atmosphere, whereas during the day it is spread aloft by convention.
Gorman, the genius thinks that the daily mean is calculated by averaging the daily (point) maximum and minimum. That’s why he’s is constantly masturbating around it. My guess is that he thinks any increase in the mean is just an artifact of something around the extremes. Or some bs along these lines.
“Noci the Nasty digs deep into the Projection bag.”
That is how it has always been done. Even current methods try to simulate that as closely as possible in order to make their data match with older measurements.
Satellites of course don’t do that. But their measurements don’t tell what is happening with the climate either. They only get snapshots when the satellite is in the measurement window. And then they track whether the snapshots are going up or down in value.
If the mean is *NOT* determined by the extremes of the temperature profile then those means ARE absolutely useless for measuring climate. Climate is the ENTIRE temperature profile at a location. That is why degree-day values are used by professional engineers to size HVAC systems. The degree-day values tell you directly what is happening with the climate! Climate scientists should convert to doing the same thing!
Yes. The mean is a value, not climate.
Yes. No one claimed otherwise. And it has nothing to do with how you calculate mean.
And if the mean doesn’t describe the climate then of what use is it in the real world?
None, outside of propaganda used to scare people.
No spaghetti graph today, Banton?
And while I’m here, you still have not defined exactly what you mean by “insolation”…the crickets are getting louder.
That explanation is garbage. Nothing explained
Very good! And why are all the greenies on here wanting to LOWER minimum temps? It means less food, more deaths, higher fuel costs, etc!
Standard deviations of your averages of averages are NOT uncertainty.
I fail to see any climate change, especially if you drop off the last short period that ends on a Super El Nino. If you believe in the power of small changes, the last 20 years shows a slowdown in temperature changes from the prior 30-year trend.
The full-period of 42 years for the current (08/21) UAH6 shows a trend of only 0.13 C/decade. In any case, other trends are approximately 2 C/century. Not alarming in the slightest. The short trend ending on a Super El Nino must be ignored for scientific purposes.
Just stick with radiosondes, satellites and ARGO and you might be able to do some real scientific work.
Also, the last 40 years is supposed to be the period where global temperatures were rising the fastest, along with significantly rising atmospheric CO2 concentrations. A trend of less than 2 C/century doesn’t seem so alarming.
Your case is stronger than you present. Positive individual measurement correlation would reduce the standard error of the trend. Negative individual measurement correlation is impossible in this evaluation.
Who cares what these “trends” are?
That reporting these numbers to the hundredths isn’t justified.
Is it when UAH do it?
“UAH Global Temperature Update for August, 2021:+0.17 deg. C.“
https://www.drroyspencer.com/2021/09/uah-global-temperature-update-for-august-20210-17-deg-c/
They may be because the procedure for measuring is very different from reading a thermometer twice a day.
I agree. I think that reporting to 0.1 degrees may be pushing it. If Larry’s claim is correct, then the temperatures should be reported as X.X +/- 0.2 deg.
If these anomalies are calculated using mid-range land temperatures then they should be stated as X +/- 1C. Daily mid-range temps have an an uncertainty of +/- 1.2C. Round that down to +/- 1C and any anomaly calculated using those mid-range values will also have an uncertainty of +/- 1C.
If the historical temperatures were recorded to the nearest degree, then the implied uncertainty is +/- 0.5 deg.
+/- 0.5deg is the *reading* uncertainty. To that must be added the instrument uncertainty. Most thermometer readings in the past, at least as far as I know,are assumed to have a +/- 0.6C uncertainty. That is the current federal standard for any temperature station in use today as documented in the Federal Meteorological Handbook No. 1. FMH 3 gives a similar value for weather balloon sensors.
That means when you calculate the uncertainty of a mid-range value it should be 0.6 + 0.6, giving an interval of +/- 1.2C.
Should they be added in quadrature?
For just two measurements? I don’t think so. It would be quite an assumption that there would be cancellation with just two data points. That would almost require you to have some knowledge of where the true value would lie in the uncertainty interval.
You could always do the direct addition like I did and also add them in quadrature. And then state that the uncertainty is between the two points. The direct addition would be an upper bound, the quadrature addition would be a lower bound.
A down vote on my statement? Somebody is showing that they aren’t familiar with precision and the proper use of significant figures!
Well, if the average has gone up a degree in a century, it sounds remarkably like someone just read the trendline as being .01 degrees higher this July than last July.….A couple of 10 year smoothings and fourier reconstruvtions can even confirm that, yes, that is how averages and trendlines work….
The Klimate Kooks will be all over this one, already see two pontificating.
The choice of photo in “the OCR” (Orange County Register??) signals the entire article is mean to be propaganda. Why not just use an artist’s conception of hell, that probably has more relevance to the global warming scam.
NOAA and NASA change hundreds of their monthly entries all the way back to 1880 every month. This month NASA made 217 changes to their Land Ocean Temperature Index
No matter what it was a lie. All one needs to do is plot the USHCN temperature data, as Tony Heller has to see that.
Ditto. I wonder if they also tamper with non-US data.
Here is the lunatic that wrote that press release. Send him a note and CC your senator.
john.jones-bateman
john.jones-bateman@noaa.gov
It is called propaganda when they use single weather events or a month long temperature data to push their climate misinformation agenda.
Warmist/alarmists used to say 30 years is the minimum time frame now it is down to a single day weather event as part of the climate emergency propaganda drive.
They lie and distort the reality because they have a climate emergency ideology to sell.
I’m not holding my breath…
Wrong number?
“<i> The UAH, RSS, GISS and HadCRUT global temperature monthly anomaly measurement systems showed that the highest July occurred in years 1998, 2020, 2019 and 2019 respectively and not year 2021 as claimed by NOAA.</i>”
Should the 2nd ‘2019’ be 2016?
Facts not obeying to models???
Urgent to dismiss those facts and appoint new ones!
Great report. I had Perry Mason check it out — and he agreed … https://www.youtube.com/watch?v=hqIqC5en8aY
“Hottest evuh” claims are of course often lies, but unfortunately they are lies that a lot of people want to believe.
And have no reason to disbelieve if retractions are not published.
July was hot? Where? Not where I live!!! mid to low 60s daytime, with one or two days in the 70s, low 50s at night, and that’s supposed to be “hottest month ever”??????”
Are those people just plain nuts???
They are educated by those who educated Greta — ignore the data — you must only believe.
AH– I should have known that the notorious LIAR Seth Borenstein was behind this fraudulent AP news story. I have seen Seth Borenstein’s fabrications for decades now, and he is the best climate FICTION writer in the business.
I’m too old to witness this, but I have a Funny Feeling that we will never see 2016 again as the Holocene takes charge.
It is typical of the media to hype individual events during a cool year. If this were a El Nino year and the average global temperature through July was a record, they would have hyped that instead. Since the 2021 global temperature is well below any possible record, they instead hype one month. This type of cherry picking is actually even more dishonest than the whether it was or was not a record.
It is hilarious to see the anti-science trolls try to justify the headlines when the bigger problem is the obvious cherry picking and ignoring this is a cooler year. The lack of honesty by the media is disgusting and anyone who is interested in science would admit it. Not our trolls however. They once again proved to the world they have no interest in science.
NOAA uses surface weather observation locations for global temperature (and other) data – see attached image. Note the data density of US stations. When creating daily or monthly global averages, does anyone know if NOAA performs a common average (regardless of location), or is an area-weighting function used to account for spatial distribution differences?
It’s area weighted on a 5×5 lat/lon grid. I’ve never heard of any dataset using a common average. I don’t even know how that would be possible.
https://journals.ametsoc.org/view/journals/bams/93/11/bams-d-11-00241.1.xml
Of course it’s possible. Just take the average of available data reporting stations. Problem is, in high-density regions, NOAA does not use all the data and even subjectively removes some. They’ve turned a simple procedure into a complex process.
That’s just a trivial average though. The goal is to determine the global mean. I don’t how you would project a trivial average onto a spherical shape and have it adequately resemble the spherical mean. The procedure is complex for a bunch of reasons. And it’s not just NOAA using a complex process. It’s everyone. In fact, NOAA’s process is among the simplest.
And I’m not sure what you mean by “NOAA does not use all of the data and even subjectively removes some”. And to be frank I’m surprised you say it only because you didn’t know how NOAA is doing it so I question how you could possibly know one way or another on the point above. And I say that with due respect because you’re smart guy who is clearly very knowledgeable in the atmospheric sciences and especially sounding analysis. I’ve even email you to get support on RAOB. You were prompt and super helpful.
“NOAA does not use all of the data and even subjectively removes some” is explained in their well documented temperature processing literature … https://www.ncdc.noaa.gov/monitoring-references/faq/temperature-monitoring.php Even though NOAA engages in complex temperature data processing, I just have one simple question … why, on average, are the USHCN “raw” data temperatures cooled prior to 2008 and why are they warmed after 2008?
NOAA does not use USHCN for their global temperature dataset. They use the GHCN repository. The stations that comprise USHCN are contained within GHCN as well. In fact, USHCN is just a subset of GHCN. One of the design goals of USHCN was to be as consistent as possible. That means they try to keep the same 1219 stations. Stations are constantly being commissioned in the US. These stations are omitted because they don’t comply with the stated goals of USHCN. There have been occasions when a station of long record gets decommissioned. In that case I believe they replace it with a nearby station to keep the station count as close to 1219 as possible. Note that recently commissioned stations are added to the GHCN repository though. In fact, stations are added to GHCN constantly. This includes station records that are years and even decades old as those records get digitized. Digitization projects are still ongoing.
The webpage you linked to explains the adjustments. The most onerous is the time-of-observation bias. The bias is a result of the gradual shift from PM to AM observations. The bias propagates into analyzed trends so it must be corrected. Station moves, instrument changes, etc. also contaminate the record with biases as well. These biases are corrected with pairwise homogenization which has no subjective elements to it though it does use the HOMR database for clues regarding the bias inducing changepoints.
And although USHCN isn’t used for NOAA’s global mean temperature dataset the USCRN dataset confirms that USHCN is a pretty accurate depiction of US temperatures and that the pairwise homogenization corrections are doing their jobs. Actually, USCRN indicates that USHCN is still biased a bit too low though the difference is relatively small.
Why were the USHCN temperatures cooled prior to 2008 and warmed after 2008?
What are the impacts of any UHI adjustments. CONUS and global?
I just have one simple question … why, on average, are the USHCN “raw” data temperatures cooled prior to 2008 and why are they warmed after 2008.
I think bdgwx covered this (multiply-asked) question better than I could, but I do have a question for you, if I may?
Why do you care about USHCN?
Despite the name it ceased being the US dataset of record over 7 years ago. It’s 1200-odd stations were superceded by the 10,000-odd of nClimDiv.
“The USCRN serves, as its name and original intent imply, as a reference network for operational estimates of national-scale temperature. NCDC builds its current operational contiguous U.S. (CONUS) temperature from a divisional dataset based on 5-km resolution gridded temperature data. This dataset, called nClimDiv, replaced the previous operational dataset, the U.S. Historical Climatology Network (USHCN), in March 2014.
Compared to USHCN, nClimDiv uses a much larger set of stations—over 10,000—and a different computational approach known as climatologically aided interpolation, which helps address topographic variability. ”
https://www.ncdc.noaa.gov/temp-and-precip/national-temperature-index/background
Similarly GISTEMP stopped using USHCN in 2011. Although it is maintained as a legacy product, as far as I am aware no significant published dataset continues to use it.
So why the burning curiosity?
Why were the raw USHCN temperatures cooled prior to 2008 and warmed after 2008?
It’s been answered multiple times on this thread on other threads, by Nick Stokes on Moyhu, and on their website.
That many denizens refuse to read and understand enough to overcome their ideological motivated conspiracy ideation is not going to be changed by doing so again.
Your problem and it’s seemingly not going to be fixed by the scientific logic that homogenisation is.
Six times – the same question about an obsolete dataset that nobody uses.
And yet no reply to why he wants to know.
Weird.
I understand how that works for milk — and then the entire milk batch comes out the same temperature — but not for USHCN data. But doesn’t anyone know why the raw USHCN temperatures are cooled prior to 2008 and warmed after 2008?
The adjustments are explained on your own link. Did you read it?
I’m not sure I’m understanding your statement that USHCN is cooled prior and warmed after 2008. Where are you seeing that?
Here are some publications I want you to wade through.
Smith 2005 and Smith 2008 – NOAA GlobalTemp methods
Menne 2009 – Pairwise Homogenization Algorithm
Hausfather 2016 – Evaluation of PHA via USCRN overlap period
I had responded earlier but my post is pending approval. Let me try it again with DOI numbers instead of hyperlinks.
The adjustments are explained on your own link. Did you read it?
I’m not sure I’m understanding your statement that USHCN is cooled prior and warmed after 2008. Where are you seeing that?
Here are some publications I want you to wade through.
Smith 2005 (10.1175/JCLI3362.1) – NOAA GlobalTemp methods
Smith 2006 (10.1175/2007JCLI2100.1) – NOAA GlobalTemp methods
Menne 2009 (10.1175/2008JCLI2263.1) – Pairwise Homogenization Algorithm
Hausfather 2016 (10.1002/2015GL067640) – Evaluation of PHA via USCRN overlap period
See Figure 1 … the “final-raw” black line. Why are the older data made colder and the newer data made warmer? https://wattsupwiththat.com/2020/11/03/recent-ushcn-final-v-raw-temperature-differences/
I cant see that they did !
“Figure 5. Impact of adjustments on U.S. temperatures relative to the 1900-1910 period, following the approach used in creating the old USHCN v1 adjustment plot.”
http://berkeleyearth.org/wp-content/uploads/2015/04/Figure5.png
From: https://cdiac.ess-dive.lbl.gov/epubs/ndp/ushcn/monthly_doc.html
“Table 1. Differences between USHCN version 2.0 and version 2.5”
“VERSION 2.0: The temperature data were last homogenized by the PHA algorithm in May 2008. Since May 2008, more recent data have been added to the homogenized database using the monthly values computed from GHCN-Daily (but without re-homogenizing the dataset).”
“VERSION 2.5: The raw database is routinely reconstructed using the latest version of GHCN-Daily, usually each day. The full period of record monthly values are re-homogenized whenever the raw database is re-constructed (usually once per day)”
See Figure 1 … the “final-raw” black line. Why are the older data made colder and the newer data made warmer? https://wattsupwiththat.com/2020/11/03/recent-ushcn-final-v-raw-temperature-differences/
I don’t see your beef about 2008 specifically other than they introduced V2.0 then … irrelevant as has been defunct since 2014.
Read the contributions by Steven Mosher and Nick Stokes on that thread …. they are the only ones who know what they are talking about.
Of course the USHCN data is defunct, that’s why the data is updated and modified annually with our tax monies. I have about 1 million questions — and they increase each year. But let’s take one at a time. Let’s start with USH Station #17366, Selma, AL. The mean July 1920 “raw” temperature was 32.55 and the altered temperature was 33.23 C. Explain the reason for that change.
What did your own link say about this?
Make sure you read the comments in that WUWT blog post. There are some really good ones that explain what is going on.
Reminder…this is all moot because NOAA GlobalTemp does NOT use USHCN.
Of course they’re not used, that’s why the USHCN data is updated and modified annually with our tax monies. I have about 1 million questions — and they increase each year. But let’s take one at a time. Let’s start with USH Station #17366, Selma, AL. The mean July 1920 “raw” temperature was 32.55 and the altered temperature was 33.23 C. Explain the reason for that change.
Again…station moves, instrument changes, and time-of-observation changes. There are 13 documented changepoints for this station. It is very likely there were many undocumented changepoints as was common especially prior to WWII. The difference between unadjusted and adjusted is the result of the PHA processing. Read the literature I linked to above. Side note…where are you seeing 32.55 and 33.23? I’m seeing 27.39 vs 27.84 in GHCN-M.
Now you’ve done it. You got ahead of me and prematurely exposed the other 1 million questions. So now, I have to ask you 2 questions about the same station. Remember, my initial question (and all my comments) have been about the USHCN data — which is the core long-term temperature history of the US. So first, explain how the USHCN data was altered, and then second, explain how that same station reflects different data for the GHCN-M file.
1) Pairwise Homogenization Algorithm – Menne 2009.
2) I think I see the problem. You didn’t pull tavg; you pulled tmax. I just verified that USHCN matches GHCN-M for station 17366.
BTW…USHCN isn’t the core long term history of the US. It is only a long term history of the US. nClimDiv is the core long term history of the US. USHCN has a maximum of 1220 stations by design. nClimDiv has about 10000. Note that nClimDiv and USHCN-adj are nearly identical. Doubly note that USCRN is nearly identical suggesting that PHA is an effective bias correction technique.
Question…what are the 6 general steps of the PHA?
Have a look at temperature.global for another data set, no warming for 5 years.
Thanks for the note. The comment … “Temperature.Global calculates the current global temperature of the Earth. It uses unadjusted surface temperatures.” is especially refreshing — since it supports Tony’s work — and better reflects the UAH satellite data. Glad I brought my snow shovel to Florida.
They use area weighting, but my bitch is that a degree C in the Arctic does not have the energy associated with a degree C in the Tropics. Its the humidity not the temperature, as the old saying goes.
And … they don’t use all the data reporting stations for the averages. I want a refund of my tax monies.
They use all of the stations in the GHCN-M repository which I believe is more than 27,000 the last time I looked.
the claim of hottest month ever is based on precision in measurements that does NOT EXIST, it is not possible to assign a single temperature of the entire earth with the precision they claim = they are LYING to us
“It is not possible to assign a single temperature of the entire earth.” Period. End of sentence.
The UAH, RSS, GISS and HadCRUT global temperature monthly anomaly measurement systems showed that the highest July occurred in years 1998, 2020, 2019 and 2019 respectively and not year 2021 as claimed by NOAA.
Why is 2019 repeated?
They probably meant 2016. After all, 2016 was the “hottest year evah!”.
ZEKE 2014 Changing the Past?
Diligent observers of NCDC’s temperature record have noted that many of the
values change by small amounts on a daily basis. This includes not only
recent temperatures but those in the distant past as well, and has created
some confusion about why, exactly, the recorded temperatures in 1917 should
change day-to-day. The explanation is relatively straightforward. NCDC
assumes that the current set of instruments recording temperature is
accurate, so any time of observation changes or PHA-adjustments are done
relative to current temperatures. Because breakpoints are detected through
pair-wise comparisons, new data coming in may slightly change the magnitude
of recent adjustments by providing a more comprehensive difference series
between neighboring stations.
When breakpoints are removed, the entire record prior to the breakpoint is
adjusted up or down depending on the size and direction of the breakpoint.
This means that slight modifications of recent breakpoints will impact all
past temperatures at the station in question though a constant offset. The
alternative to this would be to assume that the original data is accurate,
and adjusted any new data relative to the old data (e.g. adjust everything
in front of breakpoints rather than behind them). From the perspective of
calculating trends over time, these two approaches are identical, and its
not clear that there is necessarily a preferred option.
Nick Stokes used to give a valuable monthly temperature update [on sabbatical at present]
He would also give a James Hansen update in his lnks.
The GISS V4 land/ocean temperature anomaly was 0.85°C in June 2021, up from 0.79°C in May. This small rise is similar to the 0.01°C increase (now 0.03°C) reported for TempLS. Jim Hansen’s report is here.
What I found in Hansen’s report was that the July anomalies are the lowest for all the months. So even if a record was broken it is actually less of an anomaly increase than for other months.
We are still on track for a much lower year than in recent years ? equal the highest at the moment with 4 months that we can only hope get lower .
N o one can keep up a fraud of global warming if we do get cool years.
Conversely if it was to keep going up ??
JMA differs with me and actually gives a figure for the month to date!
Amazing.
The monthly anomaly of the global average surface temperature in August 2021 (i.e. the average of the near-surface air temperature over land and the SST) was +0.27°C above the 1991-2020 average (+0.81°C above the 20th century average), and was the 4th warmest since 1891
So when a scientist starts to write up a new paper with temperature as one variable, does he use the version from today, yesterday, a month ago, a year ago?
Also, the scientist who wrote a paper 20 years ago, using versions available then, needs to either recalculate using the latest version, or retract the original because the temperature data were wrong.
Silly effects arise when people choose to modify basic scientific concepts that have stood the tests of time. Like inventing home made ways to calculate uncertainty and using temperature anomalies instead of real, measured temperatures and like using subjective adjustments like TOBS.
It just comes through as crooked science, or anti-science.
Geoff S
“It just comes through as crooked science, or anti-science.”
It does to me.
What I also find annoying is when location names are changed to be politically correct. When I’m looking to find an old mine, I can never be certain it is the correct location. The probability is high for most name changes, but there is no certainty.
It always amazes me that scientists use simple regression to try and find a “trend” in the temperature data statistical analysis results.
Everything I have researched tells me that temperature for sure is a periodic function composed of a number of underlying oscillations. This cries out for some kind of frequency/time based analysis rather than trying to do averages and find a trend via statistics.
People talk about cherry picking, but that is what you get when you try to chose a starting point on a periodic function. Do you start at the bottom of a cycle or the top of a cycle? Should you be using annual averages or monthly or daily temps in order to identify the cycle?
I don’t think many scientists or mathematicians have ever studied periodic functions and done Fourier or wavelet analysis of complex periodic functions. The predominate people who have studied this are engineers and physicists. Is it a coincidence that you see few of these people as authors of climate papers.
https://xkcd.com/793/
The hubris here is almost unbelievable. Dunning-Kruger.
What is your background in metrology?
None. I have no academic credentials in either metrology or climate science. I am but a layman in these matters and most defer to those smarter than I for knowledge and understanding.
The interesting thing about the comment section for this article was a tag team of three or four relatively skillful commenters completely highjacking the comment section by doing pretty much everything except address and refute the main point of the article. They sounded kind of like they were or might eventually or were working their way around to it. But really it was just a bombardment of non sequiturs and red herrings. Curious.
But they couldn’t have done it nearly so effectively without the participation of those being led astray.
I suppose you could have jumped in early and pointed out to those being led astray what the proper response should have been. I don’t have a lot of respect for Monday Morning Quarterbacks.
“everything except address and refute the main point of the article”
Disagree. The main point of the article was that NOAA’s announcement of a record hot month in July was ‘rejected’ by ‘all 5 major datasets’
One objection is that one of those 5 had not reported, and the author plotted the graph for June apparently without noticing. A sloppy error that does not speak of attention to detail by the author or proof-reading by the site (if any).
But the principal objection is that Hamlin does not seem to have grasped the concept of an anomaly. NOAA reported the hottest month because it was the hottest in absolute terms, (that is baseline + anomaly, just pointing out this basic truth is enough to earn massive downvotes, so it goes). The anomaly measures the difference from the average for the month so when Hamlin plotted anomaly graphs or quoted larger anomalies in March and February he is achieving no more than embarrassing himself.
NOAA is a surface dataset, Hadley July data is not yet available, the NASA data showed July 2021 joint warmest with 2019. After the August update NOAA show the same thing. UAH and RSS have different warmest months, but they are not measuring the same quantity as NOAA.
The ‘
54 datasets’ have changed nothing of significance.Hamlin is misunderstanding a lot of things here. One thing not mentioned yet in the comment section is his claim that the “95% confidence level (accuracy range)” is ±0.19C for July 2021. He arrives at this by taking the sum of the high frequency, low frequency, and bias variances of 0.004934, 0.000002, and 0.004130 respectively as reported for that month and transforming them via 2*sqrt(Vh+Vl+Vb). NOAA’s variance reporting is different than the other datasets. Vose et al. 2012 says it best when they say the error variances when presented as confidence intervals is “a broad depiction of historical noise rather than as a precise time series of exact error estimates.” This makes sense since the NOAA reconstruction employs a decadal low frequency analysis with the high frequency component being the residual of the detrended anomalies. That’s not to say that the ±0.19C confidence interval is incorrect. It just needs to be interpreted with context. Arguez 2013 has a pretty good summary of how to calculate the probability of the rankings and a more applicable uncertainty estimate for the task at hand. If Hamlin is aware of any of this he isn’t letting on his article.
You describe variance reporting using high freq, low freq, and bias components. I’m sorry but these are not frequency components, they are statistical results derived from periodic functions. The term “variance” is a dead give away as to the type of analysis.
I know you want to sound educated but you are simply a mathematician with an apparent lack of knowledge about time and frequency analysis. This type of analysis would have trig functions, not probability and variance.
Another give away is your reference to “noise”. Noise in a signal is extraneous information that is not signal but when demodulated look like a signal component. Temperature data does NOT have noise components, temperature data IS the signal. What you describe as noise is nothing more that the variance obscuring the “trend” you are looking for. Spoken by a real mathematician not a physical scientist.
Would you mind explaining NOAA’s reconstruction method and how those variances are calculated and what they mean in your own words?
We are all dumber after this Thread.
If you think about it the earth “floats” in a vast void and infinite heat sink (space) with an ultimate temperature of 3 degrees kelvin above absolute zero and the only true heat source ,apart from man’s measly input , is the sun.
And in 4.5 billion years of existence there is no evidence of there ever being an example of a runaway greenhouse effect (during the biological earth stages to today) , which is what many Climate scientists fear.
Despite there being over the ages vast and numerous sources of CO2 fluctuating the levels in the atmosphere over a wide range .
Taking this into account isn’t it far more likely that the earth will ‘lean” toward cooling more than heating since heating (the sun) only heats , ignoring the Northern and Southern parts of the globe , say 10 degrees below both , about 40% of the earths surface less clouds , the other 60% is just radiating heat into the cold of space .
As an example the Sahara desert can be 40-45 oC during the day but drop to -5 oC at night with no clouds and low humidity .
The Sun’s luminosity increases by 1% every 120 million years (Gough 1981).
It is widely accepted among climate scientists that a runaway greenhouse is not possible on Earth due to the Simpson–Nakajima. A moist greenhouse may be technically achievable, but it would require substantial forcing likely beyond what is anthropogenically possible. (Goldblatt 2012).
It is widely accepted among climate scientists that a runaway greenhouse is not possible on Earth
That certainly isn’t the impression that’s given to the general public by the media. I’ve seen concerns from “scientists” expressing exactly that fear “if we don’t fix it now”.
Along with the “tipping point” fearmongering.
I’ve seen the media and others hype the hypothesis as well. It’s pretty clear that the hype comes with a lack of understanding of the radiation limits in effect on Earth. BTW…I meant to say both the Komabayashi–Ingersoll and Simpson–Nakajima limits in my post above. The KI limit is about 75C. I don’t know exactly what the SN limit is, but I believe it is a bit lower than that. Even then I believe those require a completely GHG saturated atmosphere which obviously isn’t realistic. The evidence seems to suggest that 50C is probably the upper limit even in the most wildly unlikely scenarios which obviously is no where close to a runaway greenhouse effect. If someone knows of another figure for the upper bound on Earth’s temperature please post it.
“The evidence seems to suggest that 50C is probably the upper limit even in the most wildly unlikely scenarios which obviously is no where close to a runaway greenhouse effect.”
I think if THAT were what’s being communicated, it would be a lot easier to discuss among the general public. But then, they couldn’t keep people in panic mode, could they?
How much relief do you think the climate “stressed” (as posted here recently) would feel knowing that? How much despair would be relieved?
Some comments noted that the HadCRUT5 measurement system has not yet updated its official data record for July 2021. HadCRUT5 is now two months behind the other 4 global monthly temperature anomaly systems which have reported monthly anomaly data for both July and August 2021.
The HadCRUT5 monthly global temperature anomaly data records for years 2020 and 2021 are shown below.
Each of the HadCRUT5 years 2020 and 2021 starts with January then February, March etc.
2020 1.069, 1.113, 1.094, 1.063, 0.908, 0.825, 0.816, 0.801, 0.867, 0.811, 1.013, 0.693 Average 0.923
2021 0.701, 0.565, 0.726, 0.760, 0.706, 0.712,
Every HadCRUT5 monthly 2021 global temperature anomaly is significantly below every monthly 2020 global temperature anomaly as the recorded data shows.
This consistent trend supports that the HadCRUT5 July 2021 anomaly will also likely be below year 2020 and also even further below the HadCRUT5 highest peak July global temperature anomaly of 0.857 in year 2019.