Guest Post by Willis Eschenbach
I’ve been looking at the surface temperature results from the 42 CMIP5 models used in the IPCC reports. It’s a bit of a game to download them from the outstanding KNMI site. To get around that, I’ve collated them into an Excel workbook so that everyone can investigate them. Here’s the kind of thing that you can do with them …

You can see why folks are saying that the models have been going off the rails …
So for your greater scientific pleasure, the model results are in an Excel workbook called “Willis’s Collation CMIP5 Models” (5.8 Mb file) The results are from models running the RCP45 scenario. There are five sheets in the workbook, all of which show the surface air temperature. They are Global, Northern Hemisphere, Southern Hemisphere, Land, and Ocean temperatures. They cover the period from 1861 to 2100, showing monthly results. Enjoy.
Best to all,
w.
[UPDATE] The data in the spreadsheets is 108 individual runs from 42 models. Some models have only one run, while others are the average of two or more runs. I just downloaded the 42 individual runs data. The one-run-per-model data is here in a 1.2 Mb file called “CMIP5 Models Air Temp One Member.xlsx”. -w.
[UPDATE 2] I realized I hadn’t put up the absolute values of the HadCRUT4 data. It’s here, also as an Excel spreadsheet, for the globe, and the northern and southern hemispheres as well.
[UPDATE 3]
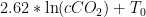 for a suitable reference temperature/concentration, accurate across all of HadCRUT4 to within around 0.1 C. In that case, forget RCP-whatever. Dial in what you expect CO_2 concentration to be in some particular year. Plug it into this formula. Congratulations! You now know the probable temperature that year if your guess as to the CO_2 concentration was correct to within about 0.1 C.
for a suitable reference temperature/concentration, accurate across all of HadCRUT4 to within around 0.1 C. In that case, forget RCP-whatever. Dial in what you expect CO_2 concentration to be in some particular year. Plug it into this formula. Congratulations! You now know the probable temperature that year if your guess as to the CO_2 concentration was correct to within about 0.1 C.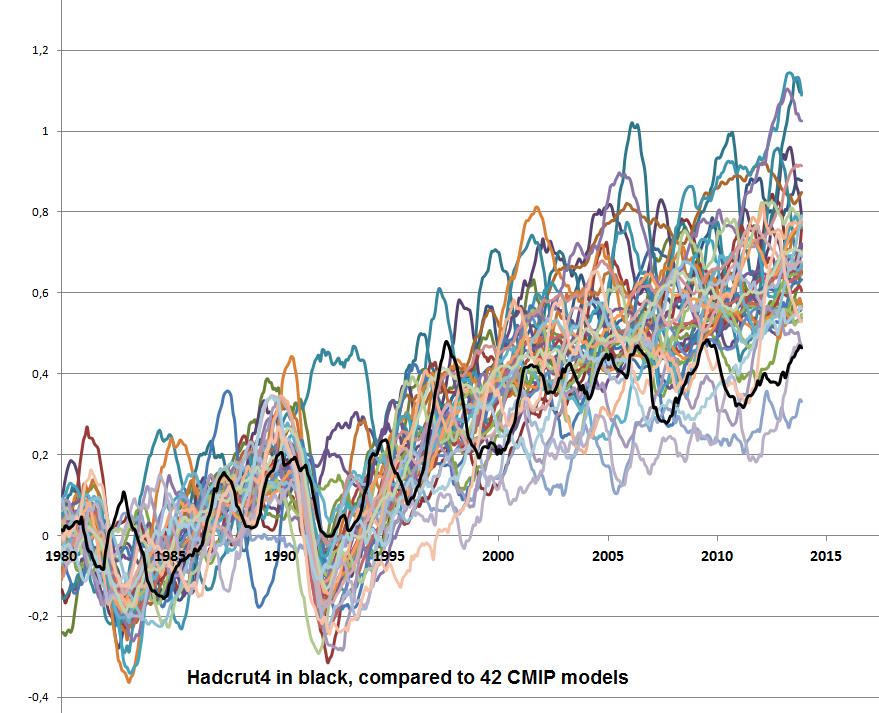
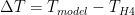 and compare it to a zero-centered symmetric Gaussian. If the model is at least a reasonable candidate, one ought to be able to assert some reasonable limits on the number of “independent samples” in 164 years of data and turn it into a p-value at least for the assertion “this model has zero bias”. I think that one will instantly reject nearly all of the models in CMIP5 all by itself.
and compare it to a zero-centered symmetric Gaussian. If the model is at least a reasonable candidate, one ought to be able to assert some reasonable limits on the number of “independent samples” in 164 years of data and turn it into a p-value at least for the assertion “this model has zero bias”. I think that one will instantly reject nearly all of the models in CMIP5 all by itself.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
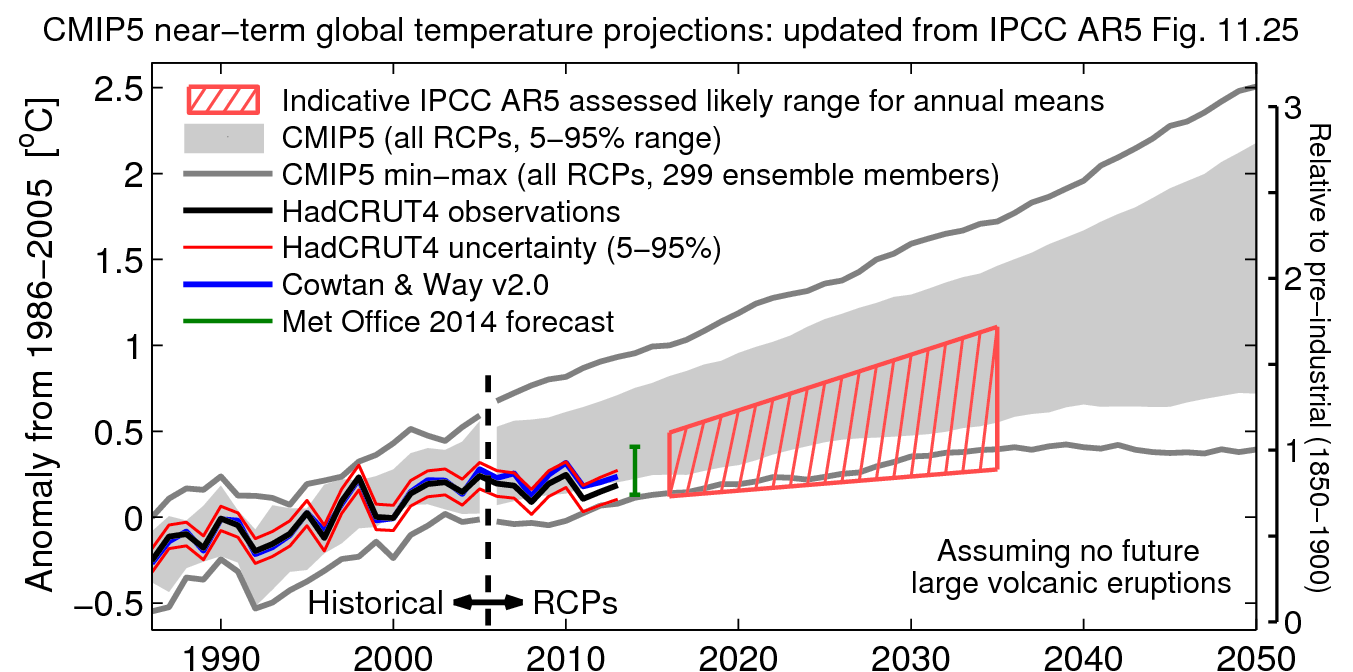{kind=link}
{kind=link}
For your further amusement, I’ve put the RCP 4.5 forcing results into an Excel workbook here. The data is from IIASA, but they only give it for every 5-10 year span, so I’ve splined it to give annual forcing values.
Best wishes,
w.