Eric Worrall writes;
Mike Whitehorn, chair of analytics at Dundee University, has written a fascinating article on The Register, about why data analysis is always contaminated by the value judgements of whoever is doing the analysis.
According to Whitehorn; “Evidence-based decision making is so clearly sensible because the alternative — making random decisions based on no evidence — is so clearly ludicrous. The “evidence” that we often use is in the form of information that we extract from raw data, often by data mining. Sadly, there has been an upsurge in the number people who move from the perfectly sensible premise of “basing decisions on data” to the erroneous conclusion that “the answer is therefore always in the data”.
All you have to do is to look hard enough for it. This strange leap of non-logic seems to apply particularly to big data; clearly the bigger the data set the more information it must contain.” http://www.theregister.co.uk/2014/10/20/sanity_now_ending_the_madness_of_data_completism/
The article is not about climate change, but it is an excellent explanation of why some data analysis tasks are impossible, using clear examples to illustrate his points, such as a thought experiment of some of the issues you would face if you tried to predict the winner of the next World Cup. One thing Whitehorn is clear about, is that the test of a system is whether it has predictive skill – something which climate models sadly lack. Or as Whitehorn puts it, “WS Brown in Introducing Econometrics defines data mining as: “An unethical econometric practice of massaging and manipulating the data to obtain the desired results.”
And the easiest person to fool is yourself.
Substituting computer powered correlation calculations merely generates more theories of lower value (that might be sheer coincidence).
But it’s consistent with a modern world where indoctrination of the many takes precedence over education of the few.
“LIKE” on those first two comments.
Humans and value judgments from Naomi Oreskes.
Wow – it appears the somewhere along the way that woman has been corrupted, since apparently at one point she understood the problem. Maybe it’s selective amnesia. Or maybe it’s selective financing.
Hmmm…so Naomi has just explained why climate models are useless; i.e.: if they’re impossible to validate, why have them?
Her approach to data (not to mention people who disagree with her) is just nuts; this ranks a couple pegs lower than “dog ate my homework”.
Again –
The Lady Oreskes.
I suggest a reasonable response to any post of the Lady Oreskes may be:
‘Hullo. Welcome to my world. Which world may you be from?”
If you want to add something about data, repeatability, transparency, please do so.
Auto
Jimbo;
Naomi Oreskes is now at Harvard and despite her earlier papers, one of which you cite in your post, she has now become a true believer in the AGW thesis and considers “deniers” a bunch of illiterate, stupid, neanderthals that deserve to be shunned and ignored, if not tossed in jail.
Look her up
I’ve made that mistake myself when trying to handicap horse races. Searching through scores of possible relationships between starting horses and race results, one is practically GUARANTEED to find data significant at the 5% level, or 1% level, purely by chance. Conclusions resulting from data mining are no more reliable then conclusions resulting from a college dorm bull session. The only RELIABLE conclusion is that the data may indicate that an independent study may be worthwhile.
After the data mining, you’ve got to run a new study on completely independent data to see if your hypotheses hold up.
The example about flipping coins, even imagining an unbiased flipping mechanism, is right on. And it’s the example that alarmists try to use against reality.
The example explains that in 100 coin flips, on average 50 will be heads, and 50 will be tails. However, you probably won’t get 50-50 because there are more possibilities for other numbers. As you increase the number of flips you start getting a result that is closer to the expected average. And the warmists like to tell you that, while they can’t predict this year’s weather, GCMs create a useful long-term approximation, and averaging the ensemble of all of them should be even more accurate.
The entire point of the coin flip is that it has to be an unbiased flipping mechanism before the greater number of flips creates an average that is meaningful. And climate “scientists” and alarmists and the IPCC don’t have any sort of unbiased mechanism. The only way to tell that an individual is unbiased when discussing climate is by observing how calm they are about the future. More calm = less biased, because in this reality there is absolutely no reason to think anything bad is happening.
Climate issues aside, this is an IT (MIS) issue that I’ve had to deal with for years. Clients always seem to be under the illusion that more data will automatically result in greater accuracy or more information, without regard to the quality of the data. And, by the way, it was dealing with this fact and watching the “adjustments” made to real-world data that made me understand just how faulty (and thus, wrong) the entire climate industry is.
I developed 20 distinct models to calculate 15+15.
The answers ranged, in an almost perfect normal distribution , betwixt 425 and 435.
So, taking the average we CLEARLY see that 15+15= 430, and if you refuse to believe this , well, you are a DENIER !!!!
One problem with comparing the coin flip with climate change is that the coin flip is a simple system for which we happen to know all the rules – namely that there is a precise 50% chance of heads and a precise 50% chance of tails. So yes, more samples yield greater accuracy. But in a more complex system for which we do not know all the rules, it does not necessarily follow that more samples will yield greater accuracy. If you happen to be measuring the wrong things, failing to measure the right things, or weighing some factor incorrectly, more samples might just skew the results more dramatically.
I had a economics professor that once told our class ” We use figures to justify what we’re going to do any way”
In re prediction and big-data; N. N. Taleb cautions against the prophesies of seers without skin-in-the-game, doxastic commitment, and so does Karl Popper, though not in so few words.
No news to me, I’m on my second (or even third, depending on how you count) startup company providing high end predictive modelling services based on big data. Getting paid — once you convince somebody that you can build a model for them that could be of value when model building is black magic as far as most middle managers is concerned — involves building a model with predictive skill, which in turn involves discovering patterns, often high-dimensional patterns, in the data that have real, robust predictive skill at a level that can beat random chance or the product of trivial one dimensional logistic models or basic clustering.
In building the models, one actually has to be very suspicious when the model you build works “too” well! Often, if not usually, it means that the data contains a “shadow” variable of the actual answer that new representatives would not have, for example identifying people who are likely to get cancer from a medical database the model may seize on the results of a particular test as being very predictive, because only people who actually have cancer ever get the test. Bayesian reasoning both ways has to constantly be employed and there ain’t no such thing as a free lunch.
rgb
Dare I ask if the first two start ups are still going, or if they succumbed to flaws in the model building?
The first succumbed to two things:
a) The dotcom collapse. We were not a dotcom, but our product was viewed as “elective” by managers tightening belts in the economic depression and gloom surrounding the disappearance of a half-trillion or so from the economy as it emerged that all the internet hardware and access companies were pretending they were banks and effectively loaning dotcom startups unlimited resources on good looks and a smile.
b) It was my first company, and several mistakes were made. Partnered in a complete a-hole, for example, who promised many marketing contacts but as it turned out, everybody hated him. Split our business focus and leveraged our stretch of profitability into 2/3 of a second product that, sadly, relied on a third party to make happen the rest of the way and they proved completely unreliable, when we should have been building a more robust stable of clients. Borrowed against our line of credit to stay afloat and keep our employees alive even after the dotcom collapse thinking we could still turn things around.
I lost actual money paying back the LOC. But there was never any question about whether or not the models I built with the software I developed to build high-dimensional models worked — they not only worked, they worked phenomenally well and our principle customer (a bank) went from marginally profitable to so profitable that they were acquired by a large bank, one that sadly already had its modeling being done in-house (and that has struggled some ever since — I don’t think to this day that they realize how important we were to the success of their acquisition). The VP we did business with tested us head to head against e.g. logistic models and we literally blew them out of the water.
I still have/own the software. It is still damn powerful. I’ve thought about customizing it to try to solve the climate problem in an entirely unique way. But there’s no profit in it, and I’ve got other potentially profitable irons in the fire. There is also the common problem, faced by all of the climate models or predictive models of nearly any sort, of:
i) Training the model on a subset of actual data. The climate modellers will sometimes tell you that the models have no adjustable parameters, but of course they lie. The models are in fact trained and parameters are in fact adjusted, against a reference period clearly marked in figure 9.8a in AR5.
ii) Testing the model on a secondary trial data set, a held out subset of the training data. This is where you see if the model has predictive skill, sort of. Building a model to match the training data alone is so enormously dangerous it isn’t worth considering. Building an optimized interpolating polynomial to some data is far too easy and can be done on top of many (linear algebra) bases — building a function that extrapolates to predict data outside of the fit range is very, very difficult.
If one does a rigorous, honest, thoughtful job of training the model and honestly testing it against a broad enough set of trial data, and don’t just turn the second step into a kind of additional training step on your parameters (defeating the purpose of validating the model building process altogether), you can end up with a model that might have legitimate predictive value in that it can beat random chance and/or other simple extrapolatory models.
Now here’s the rub. One MUST MUST MUST use data for both training and trial sets that SPANS THE RANGE OF VARIABILITY OF THE SYSTEM</b or one is going to have a very sad experience. If all of the data in your possession goes up and down and bounces around, but you train on a small segment of the data where it happens to be going up, most model building processes are going to conclude that there is a simple monotonic process driving the data up and incorporate it by any means available into its output as an easy path to a successful fit. If you omit comparison to a trial set held out as close to blindly as possible — that is, randomly selected by software if at all possible to ELIMINATE your opportunity for bias — you are asking for double trouble — a spurious fit to a monotonic model that cannot represent the true nonlinear variability of the underlying processes and never looking to note that your model doesn’t even fit the data you already have in your possession, so why would it somehow have great predictive virtue for future data yet unseen?
GCMs are doubly hoist on both accounts. The reference period was the single stretch in the last 75 years where the planet actually warmed, and failed to represent or train on any of the periods of substantial warming and cooling visible in the climate record (granting that our knowledge of the actual state of the global climate from proxies sucks and is difficult to train on, the models need to be able to at least qualitatively reproduce similar variance) over the last N years for pretty much any value of N. The models constructed after fitting to the reference period utterly failed to hindcast the major variations visible in the first half of the 20th century (as a reasonable trial set) and have utterly failed to predict the future after the training set — so far. Their error is precisely what one would expect from such a flawed model building process — they run consistently too hot, and they consistently underestimate systematic natural variability while producing actual microtrajectories with far too much variability and variability with the wrong time spectrum (that is, the wrong autocorrelation times, relaxation times, and fluctuation-dissipation times).
rgb
I tried forming a similar company to RGB’s to offer model building services to organizations in the non-profit sector including universities, None of my prospective clients displayed the slightest degree of interest. A professor at a world renowned research university suggested that I had gotten nowhere in trying to peddle my services at his university because the professors were “set in their ways.”
A kind of Gresham’s law seems to be operative in scientific institutions wherein bad model building practices drive out good ones. This phenomenon is driven, I think, by sloppy work on the part of the agencies that fund research. They perennially fail to require the use of best practices in building models and receive cheap but dysfunctional models in return.
rgb,
It’s worse that that, they’re training (dollars to donuts) on GAT data which uses similar theory to fill in the missing data.
Because when you sum the daily difference in Max temps since 1940 for 95 million records you get 0.0766F (-7.20F for Min temps).
All of the infilling they all do is worthless trash that does not represent actual measurements. And when you look at min temps regionally, they all change independently.
In building the models, one actually has to be very suspicious when the model you build works “too” well!
That happened to me once – I accidentally embedded part of the solution to the previous iteration of the algorithm into the inputs for the next iteration. Unfortunately it looked good enough that it passed release testing, and actually did some damage before it was pulled.
Hi What are: “often high-dimensional patterns”?. Do they depend on many variables — if so and if the problem cannot be reduced to a few renormalized variables — how does one avoid the “fitting an elephant” problem? Turning to General Circulation Models (or other relevant models) to predict the “global temperature anomaly” — I would truly like to know how many fitting parameters are typically used and what they are ? Of course, a fudge factor of three is already close to an elephant — maybe its a donkey.
One avoids the “fitting the elephant” problem through reduction of the count of the parameters. Reduction down to 1 is possible using available technology..The value of this parameter is set to maximize the information that is available for the purpose of controlling the associated system.
Let me explain just a teeny bit about the scaling of serious real-world problems. First of all, the models I build tend to have many inputs — 30 is a small model, the method works well with up to hundreds of inputs. Depending on how you build the model, each input can be one of several kinds of variable — binary, natural number, integer, floating point — and can have a restricted range or an unrestricted range. Things like natural numbers may represent data (like “colors”) that have no intrinsic ordinal relationship, or they can represent data (like “age”) that do.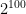 distinct cells, each cell representing a unique constellation of values.
distinct cells, each cell representing a unique constellation of values. 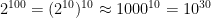 . If every molecule in your body was a statistical sample, and if the distribution was completely uniform, you’d have just about enough samples to associate every cell with one whole sample. That is, you will never have a statistically smooth sampling of the underlying space and be able to systematically build a good approximation to the true multivariate joint probability distribution.
. If every molecule in your body was a statistical sample, and if the distribution was completely uniform, you’d have just about enough samples to associate every cell with one whole sample. That is, you will never have a statistically smooth sampling of the underlying space and be able to systematically build a good approximation to the true multivariate joint probability distribution.
So here’s how scaling works. Let’s assume a 100 dimensional model, and assume that all 100 variables are strictly binary and have only two values, 0 or 1. You are or are not a smoker. You are or are not over 50 years or age.
The space you are building models on top of now has
This is sometimes called the “curse of dimensionality” for that reason. However, all is not lost! That’s because the data is usually not uniformly distributed on all 100 dimensions! Some dimensions have a lot more predictive value than others. Just “being a smoker vs not being a smoker” has a lot of predictive value in terms of determining probability of getting cancer.
One approach to multivariate distributions is to create the outer product of one dimensional models that treats each dimension as producing an indepedent contribution to the probability of whatever it is you are trying to model. This works well when it is true, and utterly fails when it is not. Sadly, there is no good way to tell a priori when it fails, one has to try and compare (once the data exceeds a very small number of heuristically graspable dimensions). The point is that the data itself “knows” about correlations that may not fit into your heuristic outer-product guesstimate. To beat “separable” models, one has to fully engage with a nonlinear multivariate representation that can handle things like “exclusive-or” combinations in the in output probability distribution, asymmetric double humps in the double binary distribution. Only it needs to handle them in 20, 30, or more dimensions, and let the model building process discover them as the rules are now beyond any human’s ability to perceive or heuristically guess.
Using a generalized nonlinear function approximator that can handle multivariate complexity is the solution, but it comes at a price. For one, the model now has thousands of parameters that have to be optimized against the data to build a maximum likelihood estimator (for example). Simply finding an optimum becomes a serious mathematical problem! Second, the model is not too powerful and can easily memorize the data instead of learning to smoothly interpolate the most predictive features in the underlying probability distribution in such a way that it can recognize similar (new) cases that aren’t an exact match and extrapolate to new cases that aren’t even a very good match at a level exceeding random chance.
Here is where honesty, experience, and a broad, deep data set are all key. You will never properly overcome the curse of dimensionality, but certain kinds of models and build methods can self-adapt to deliberately blur their predictive power, avoid overtraining (fitting the elephant), and end up with something that can differentiate mice from elephants given only partial, blurry pictures and not just recognize the one actual elephant in the training data any time they see that actual elephant while failing to recognize any other elephants as anything but mice.
I’ll be frank — building a really good model is at least part art, not science. This goes all the way down to the simplest linear regression models. Yes, one can write linear regression, feed it a data set, and get a best fit, but determining whether or not that fit has any meaning whatsoever is not so simple, not so simple at all. And when one is doing nonlinear regression on a complex landscape in high dimensionality, solving a maze becomes easy in comparison.
The best metaphor is this. Suppose you wanted to find the highest point on Earth above sea level, but every sample was “expensive” and the only way you could take them was by picking a point on the surface and then being given back the height above the surface of that point only! What algorithm for selecting points should you use to get the best estimate for the maximum height as a function of the number of sample points? Which algorithms will (eventually) actually find the highest point?
Hard, hard problems.
rgb
Please excuse me if I get my replies out of order — I don’t know how to use the reply function for a specific person. My background is in mathematical inverse scattering problems. This is a highly idealized situation with “perfect data” assumed. However, the problem of say determining an object from scattering data is in general “ill-posed” . Thus one must always introduce explicit assumptions about the answer to get any estimate at all for the answer. For example, we may assume that the answer must have certain “smoothness conditions”. RGB’s problem of finding the maximum height of a point on the earth is an example. If there is no “smoothness” one could have a point that is one micron in size and 20 miles high. You would never find it. Part of the art of inverse data analysis is to explicitly list all of the a priori assumptions that you used to fix the ill-posedness. I have no idea what to do when you have thousands of variables. Do you then require a high constrained model of the answer before you use the data?
To find an answer to a problem by making assumptions is the approach that I call “the method of heuristics.” Information theoretic optimization is an available alternative to this method. The former finds an answer. The latter finds the best possible answer.
About information theoretic methods. I had a discussion on this topic with Ed Jaynes about 20 years ago. We were discussing what were then called “maximum entropy methods” for finding the most likely answer. I think the unresolved problem came down to this — you have to have some exact solution for estimating the state space over which entropy is calculated. Otherwise, you have to use explicit assumptions (of unknown validity) to estimate the entropy. This just puts you back into the soup. Once again, I think alll you can do is explicitly list all assumptions so that the next guy can tell what you did..
Jim Rose:
In information theoretic optimization state spaces are of three kinds. The elements of the first are limiting relative frequencies. The elements of the second are conditions of events while the elements of the third are outcomes of the same events. The definitions of the outcomes are determined by the nature of the decision problem being solved. The definitions of the conditions minimize the conditional entropy making of these conditions “patterns.” The values assigned to the probabilities of the limiting relative frequencies maximize the entropy of the way in which the limiting frequency of a condition or conditional outcome will occur under constraints expressing the available information. A result from this argument is an optimization that is a bear to solve. Solve it we can thou approximate solutions are often needed.
Though Ed Jaynes was a pioneer in applying entropy maximization I don’t believe that he ever used entropy minimization. The latter is a necessity for logic to reduce to the classical logic when the missing information is nil.
RGB, I’d like to communicate with you more about your modeling experience and software. There may be a way we could do some business together. I’m part of a startup in the energy industry that is in part leveraging data to bring costs down for operators. Could you send me an email: jnieuwsma @ gorigger dot net
Prof. Whitehorn is excessivly pessimistic. Information theoretic optimization provides us with an alternative to contamination by value judgements.
Also, predictive skill is not the sole measure of a model or even the most important one. Most important is the missing information per event in each inference that is made by this model, the so-called entropy. The importance of this measure lies in its crucial role in information theoretic optimization.
I have considerable training in econometrics. We were taught from the git-go that data mining was abhorrent. That didn’t stop the instructor from later admitting that econometrics is partly an art form. A lot of econometric models don’t have a lot of predictive power either.
GP Hanner commented
IMO this has a lot to do with the data, and data quality. And yes most data, even data that the owner thinks is “good” data, usually isn’t, especially when you start getting into a large quantity of data (this is likely just an artifact of the origin of the data I work with).
In regards to surface station data, I think there is useful info in it, and I’ve worked to extract what I think is something of value. But I also think that the various published GAT series are fatality flawed, and either the creators are clueless, or they intentionally publish made up data that is basically just wrong.
That’s a common problem in modelling. In all too many cases, the data you have to build a model is useless. Or the pattern you are trying to discern simply isn’t there. Or a pattern is there, but it is a spurious pattern, the result of random chance, and not meaningful.
I agree that the published estimates of the global average surface temperature anomaly (which is even more subtle than the GAT per se, which even the publishers acknowledge isn’t known to within a whole degree C) are generally clueless and misleading and the result of any number of questionable practices. But the biggest problem I have with them is that they are almost invariably presented without any sort of meaning error analysis, let alone error estimate.
It’s one thing to draw HADCRUT4 (say) with error bars around 0.2 to 0.4C wide in the present — probably a fair estimate given that HADCRUT4 doesn’t even try to correct for UHI, undersamples the ocean just like everybody else, infills and patches over missing data in a selective way, etc, with error bars increasing systematically as one extends into the past. The problem with them doing that is that it immediately becomes apparent that we barely can resolve the fact that systematic warming has happened at all in the last 150 years.
In a few decades, of course, the quality and quantity of data will be much better and perhaps we can start to resolve things, at least if we deal with the systematic biases like UHI. Satellite data is a lot harder to screw up and at this point is a pretty hard limit on what they can do with the thermometric records, at least as long as Spencer and Christie are alive. Once they retire and/or die, of course, look for the establishment to replace them with somebody more “open” to the fact that the troposphere has in fact been warming all along because the ground record must be right if anybody is to continue to get funding.
rgb
And I plan on doing everything in my power to prove the surface record doesn’t show what we’ve been led to believe it does (ie warming where to the limits of the data we have doesn’t show warming at all).
First I ask is that really a premise of the presented argument? And, even if it is assessed as being a premise, is it the only premise in the argument. Further, is there a more fundamental premise that that posited premise is dependent on?
. . . thinking . . .
John
rgbatduke October 21, 2014 at 1:55 pm
That’s a common problem in modelling. In all too many cases, the data you have to build a model is useless.
In climate science, where the ‘data’ is too often the output from another model, does that mean the problem is squared or is it worse than that?
@RGB:
I urge you to contact IBM about your product. It’s just what they are looking for. They could market it to lots of customers. They could provide the manpower to polish and support it. They would give you a fair shake.
Thanks, Roger,
Perhaps, eventually. At the moment I’m more interested in trying one last time to salvage my patent on a Bayesian method of inference on privacy restricted datasets that doesn’t violate things like HIPAA or the GLBA. The real, serious problem one encounters in this arena is that patent examiners tend to be lawyers, and no matter how bright they are — as lawyers — they are really remarkably clueless about high end statistics and methods. Of course, that’s the problem with marketing this sort of thing as well. On the one hand, you have the customers who want you to squeeze statistical blood from a turnip — you can’t find patterns in data if they aren’t there, or if the data is dirty, or if the data is corrupt, or if there isn’t enough data to support the dimensionality of the pattern you are trying to infer. On the other hand, you have customers who simply have no idea what predictive modelling really is and why the margins they generate (relative to blind squirrel random chance) are often the difference between marginal (un)profitability and really making money. Or discovering the next cure for cancer. Or whatever.
All human knowledge is little more than inferred patterns, pattern recognition, models that we believe to the extent that they seem to work, so far. But statistics is the course in college that nearly everybody hated and sucked at, even scientists who know enough math that they should understand its importance. But all too often even scientists get through the CLT and t-tests and so on and then swear never to think about statistics again if they can help it, certainly at no greater a level than needed to process some simple experimental data and fit a straight, or (if greatly daring) curved line through it.
rgb
Thanks for the info. Another company you should go to if and when the patent issue is straightened out, especially if IBM already has an offering that is in the same space as yours, is EMC. They’re an opportunistic buyer of good tech companies.
A classic example of manipulation of data is the homogenisation of weather records in Australia where calculated values have replaced actual on-site measurements.This has lead to some cooling trends being changed into warming trends, so the reliability of information is questionable particularly when one is looking at temperatures of a tenth of a degree.
RGB said:
“In building the models, one actually has to be very suspicious when the model you build works “too” well! Often, if not usually, it means that the data contains a “shadow” variable of the actual answer that new representatives would not have, for example identifying people who are likely to get cancer from a medical database the model may seize on the results of a particular test as being very predictive, because only people who actually have cancer ever get the test.”
Seems to me that this is the fault of climate models. Build in an assumption that carbon dioxide absorbs low frequency energy and is transparent to high frequency energy, and another that solar radiant energy is high frequency and terrestrial radiant energy is low frequency. You then are building into the model the answer to the question, what happens to temperature if the earth receives high frequency energy from the some and retransmits it at low frequency?
Or have I got this wrong?
If CO2 is a proxy of temperature, then the shadow variable example would very much apply to climate modelling – it would explain why it is possible to create a model which correlates CO2 and temperature, but has no predictive skill.
big data is nothing more than a marketing hoax by hardware and software vendors … this assumption that there is always a signal in the data and that more data allows you to find this signal is almost always flawed … a small amount of real data that is an actual accurate measurement of a real world process is much more valid and useful … gathering alot of rotten data is like mixing dog poop into a gallon of ice cream … adding 20 more gallons of ice cream into the mix won’t change the fact that you’ll still have dog poop ice cream …
I don’t think that is entirely the case. As Feynman said in one of his lectures, a scientific breakthrough starts with a guess. Its only when you try to validate your model by using it to predict observations that you learn whether your guess was right.
I like some of the examples out of Freakonomics – the author in each case started with an educated guess, then attempted to find patterns in the data which matched the guess, then attempted to independently verify the result, to validate the pattern.
For example, the author was asked to detect teachers who help students cheat on exams, so he chose several metrics based on guesswork. He assumed that teachers who gave their students illicit help would have anomalously high grades, but that the students would likely revert to mean in their next year, when taught by a different teacher. He also guessed that teachers who adjusted the exam results afterwards would use templates – they would answer high score questions near the end of the exam, possibly missing earlier questions – and all the answers would be identical for an anomalously high number of papers from students taught by particular teachers.
He validated these guesses by identifying teachers with suspicious result patterns, and by having the Education Department investigate the potential cases he identified.
My point is big data and guesswork can work, making value judgements is valid – but you have to remain aware that your model is a set of value judgements, that it has not been validated, until it can be proven via independent testing of its predictions.
Very fine commentary. It occurs to me to wonder if there is any way of mitigating the risk of bias in selecting a test pool of data after the fact — after the model has begun to issue predictions.
We’re currently collect over 3 million surface station sample per year now, there’s lots of room to pick whatever you want for a trend from your out of band samples.
The article is not entirely fair to data mining as a practice, but data mining and analysis has been done so poorly by so many people in the Internet age althat I understand the sentiment. But to say that data mining “never” is reliable, as the article claims, is untrue.
I’m a little concerned about the GISS global temperature data set. It seams NOAA announces a highest temperature ever recorded a lot more often than the other three data sets, Hadley, UAH, RSS. I hope NOAA doesn’t have an agenda to make 2014 the hottest year ever, so they can claim global warming has not ended.
Reblogged this on gottadobetterthanthis and commented:
–
Good points, and some very good comments below the main article.
RGB’s contributions are both impressive and illuminating, particularly his caveats, but I have a couple of questions for him. Does he assume that each variable input is independent of another? Or does he allow for correlation? If he allows for correlation how does he allow for the possibility that a single variable may act as a switch for one or more of the other variables, particularly if that single variable would usually have little or negligible weight in the model?
I remember being part of a small team analysing and testing a relatively simple stochastic model which back tested well and which predicted accurately for the more than two years that we studied it before publishing. One of our team had reservations as to whether the mathematical assumptions underlying the model were sound and, despite two other professors of statistics vouching for them, published a minority report. Shortly after the report went to press, an event, which had no precedent and for which the assumptions on which the model was based did not allow, occurred. The model, for which we had vouched, failed utterly.
Since then I have always been wary of the predictive powers attached to any linear or multi-linear model. Climate, in particular, requires complex dynamic modelling and there are far too many parameters and far too little accurate historical data available for any such models to be able to make reliable long term predictions