Robert Balic writes:
I recently read the Willis Eschenbach article Argo, Temperature, and OHC (http://wattsupwiththat.com/2014/03/02/argo-temperature-and-ohc/) which reported the trend in the global ocean temperatures as 0.022 ± 0.002 deg C /decade and Steven Casey asked
“Can we believe we have that much precision to 0.002 deg C/decade? And we have not yet measured a full decade.”
Also, there was a reply to a comment of mine on The Conversation mentioning the uncertainty which stated “The temperatures in the Argo profiles are accurate to ± 0.005°C http://www.argo.ucsd.edu/FAQ.html#accurate“.
I checked the website http://www.argo.ucsd.edu/How_Argo_floats.html and found that
“The SBE temperature/salinity sensor suites is now used almost exclusively. In the beginning, the FSI sensor was also used. The temperature data are accurate to a few millidegrees over the float lifetime,” and “The temperatures in the Argo profiles are accurate to ± 0.002°C”.
The temperature profiles might be accurate to ± 0.002°C now, but weren’t the measurements made to the nearest 0.1°C previously? I looked up the accuracy of their thermistors earlier this year and it was written as 0.1°C. A high precision commercial instrument usually has a claimed ± 0.05°C accuracy so they most likely did record to the nearest 0.1°C until they installed the new units. They can’t now insist that the smaller error in the previous trend remains uncorrected because they have new instruments this year.
Why is it relevant that the temperature measurements were taken to the nearest 0.1°C if they looked at the average of over 100 measurements? Well if you take my height for example and measure me to the nearest centimeter 100 times, then the average would probably come out to be 183cm with a standard deviation of 0. Perfect!
If you had recorded my height to the nearest millimeter having taken 50 measurements of 1825mm and 50 measurements of 1835mm, you would get an average of 1830mm with a standard deviation of 5mm or 0.5cm. A random spread of measurements over that range would bring the SD down to about a quarter of a centimeter and the error estimate is usually twice this value.
The rule of thumb that I was once taught is that your minimum error is plus or minus the value of the increment that the measurements were made with (eg. 1 cm) where the number of measurements are a few, or half this value when there are a large number of measurements (eg.± 0.5cm). So if the Argo floats only measured in increments of 0.1°C then the uncertainty in the mean of many measurements is at least ± 0.05°C. Hence, a trend of 0.02°C/decade measured over less than a decade is utterly meaningless.
Someone should also have a word in the ears of those at The University of Washington.
“Because total Arctic sea ice volume from PIOMAS is computed as an average over many grid points, the random error (scatter in above figures) doesn’t affect the uncertainty in the total ice volume and trend very much.”
This is the excuse to ignore the large errors implied by this plot.
![Fig2[1]](https://wattsupwiththat.files.wordpress.com/2014/10/fig21.png?resize=609%2C630)
Where the model predicts a 4m thickness the submarine data is spread evenly between 2.5 and 6 m. The range is nearly 0 to almost 3.5m where the estimate from the model is 1m, that is over 100% uncertainty in the thickness yet they are absolutely sure that the ice is in a death spiral.
Something to do with past satellite records of Arctic and Antarctic sea iice. Enjoy..
NIMBUS: Recovering the Past: http://youtu.be/bvGIE1y3cXA
https://mobile.twitter.com/NJSnowFan/status/520446647038644225
See the IPCC 1990 graph.
http://stevengoddard.wordpress.com/2014/10/08/monthly-serreze-propaganda-update/
“The temperature profiles might be accurate to ± 0.002°C now, but weren’t the measurements made to the nearest 0.1°C previously?”
They aren’t saying that the temperatures are accurate to ± 0.002°C. They are quoting at trend with statistical error ± 0.002°C/decade. Different units, for a start.
They arren’t measuring the trend with a thermistor; they are calculating the trend, which is a weighted average over time and many observations, and reporting the population-based standard error of that average.
So let’s say at time 0 the reading is 10.0C and it’s 10.1C after ten years. They could say the rate was 0.01 per year +/- 0.002? Is there enough precision to conclude this?
“They could say the rate was 0.01 per year +/- 0.002?”
There you see the units issue. It was ± 0.002°C/decade, or ± 0.0002°C/yr, or ± 0.02°C/cen. So how many °C?
Nick, are you actually claiming that the accuracy of the length of a meter decreases over time? Your reasoning and logic is backwards.
If they measured over a century a rate of 0.02°C/decade then you would have a difference over that time of 0.2°C and an error of ± 0.05°C would mean that there was a significant trend (if the data was smooth and no further error due to sampling).
I don’t doubt the manufacturers claim as it should be possible to build such an instrument, its the previous FSI instrument that wouldn’t have recorded the temperatures with enough precision to make the trend meaningful.
Yes they are. That is exactly what they are saying: “The temperatures in the Argo profiles are accurate to ± 0.002°C …”
No they aren’t. They are stating the accuracy of the recorded temperatures. They do not say “0.002°C/decade”, they say “0.002°C.” This is because they are not talking about temperature trends, they are talking about temperatures.
Yes, you are using different units than those stated. Should have been your first clue that you were talking out of your ass.
That should have been your second clue. They don’t say “The temperature trends calculated from the ARGO profiles are accurate to ± 0.002°C/decade.” They say “The temperatures in the Argo profiles are accurate to ± 0.002°C …”
You are correct, JJ. Nick is wrong.
JJ, meet the incorrigible Nick Stokes.
What really gets me is that nine times out of ten the raw data doesn’t show a trend and has to be ‘adjusted’ for one to become visible. Doesn’t this basically prove the measurement error is greater then the trend?
Indeed, JJ, you are right and I was wrong. I saw the mention of 0.022 ± 0.002 deg C /decade in the first para, with Stephen Casey’s question featured, and didn’t notice the later reference to 0.002°C as quoted accuracy. My apologies to the author.
Kudos to Nick Stokes for manning up and admitting that he was wrong.
I’ve had my differences with Nick, and that will continue until he sees that I’m right.☺
I mention this only because it is so extremely rare for anyone on the alarmist side to ever admit they were wrong about anything — when we know they’re wrong about everything. Well, as far as their alarming predictions go, anyway.
Well, I do have to add that the 0.002 °C is the manufacturer’s claim..
Maybe I misunderstand. Are you implying – but not saying – that with 1000 thermometer readings, each one accurate to ± 1°C, you can get a weighted average accurate to ± 0.001°C? If temperatures at the start of a decade and at the end of a decade are both known with an accuracy not exceeding ± 0.002°C, what is the accuracy of a trend?
Puhleeeze! Real scientists know how significant figures work. Witch doctors don’t.
That scatter plot is interesting since it indicates that PIOMAS consistently overestimates the thickness of thin ice and underestimates thick ice. Note that there is almost no dots below the green line for thicknesses below 1.5 meters (5 feet) and almost none above it over 4 meters (13 feet). Incidentally this implies that PIOMAS systematically underestimates the amount of multi-year ice.
Shhhh…. don’t give a hint to the climate obsessed. Watching them looking for the missing melt will be more fun than watching them look for the missing heat.
On Arctic sea ice thickness. Here is a small sample.
Co2, the trace time traveller.
Oh boy, they sure could sound alarmist back in the day. I thought it was just a modern phenomenon.
Oh boy is right, Jumbo. You should write up a study on this, or someone should.
@#!!&^*!! autocorrect Read Jimbo above
If that happened today we would have a headline of “Walrus dental record of climate change found at the North Pole”.
That’s a very interesting, and telling, observation. Thanks for pointing this out!
rip
A line of best fit would probably intercept the y-axis at 1m so its overestimating but for earlier estimates as well as later ones. I’m not sure what that means for the death spiral. Does it make it much steeper?
The only use for a plus minus 0005c of the worlds oceans is for the GREENS to cry ” we are going to die, the oceans are evaporating “
It’s a little worse than that. Even if you stayed in the same stadium in NY, if you’re not measuring the same 1,000 people they the law of large numbers still doesn’t apply. It could only work if the float followed the same volume of water wherever it went. Since this can never happen, you’re SOL.
Um, haven’t you forgotten something. Firstly ice doesn’t melt all year, and at some places it may never melt so you can’t average over the whole of the arctic to find the energy requirement, nor is it uniform there is much greater ice loss at the higher latitudes. If you take this into account you find out that you need 10-20 W per square meter over a much smaller time and space to account for the ice loss “Where it’s actually occuring” and 10-20W per square meter is at least 15 times the amount of energy imbalance supposedly generated by CO2 and its supposed feedbacks. This means that ice loss is NOT being caused by CO2.
“10-20W per square meter is at least 15 times the amount of energy imbalance supposedly generated by CO2 and its supposed feedbacks. This means that ice loss is NOT being caused by CO2.”
Not necessarily. The alleged energy imbalance caused by CO2 is a global imbalance. Wind and water could (and are by some thought to) be collecting energy in consequence of that imbalance and transporting it to the poles, thereby concentrating its action at the poles on the process of melting ice.
But the larger issue is spatial coverage, and the fact that the ARGO buoys are free floating.
Even if many measurements are averaged, they are not measuring the temperature at the same place twice. Every measurement made is taken at a diiferent place, where it may not be surprising to see small differences in temperatures.
If I was to measure the average height of a 1000 people in a football stadium New York, and then next month measure the height of a 1000 people in a hospital in Washington, the following month in a school in Seattle, the following month in the streets of Paris, the following month in a restaurant in Brussels, the following month in a park in Berlin, the following month in a concert Hamburg, the following month in a market in Cairo, etc. does the law of large numbers apply with the same veracity?
The claimed for errors in climate data are unrealistic, period.
There are lots of BIG errors in climate science without resorting to small ones.
Exactly! Now I don’t have to say it!
True. I omitted a bit about this being the uncertainty in height for one person. What they are doing is like measuring samples of 3000 people in NY to find the trend in heights of adults over a decade.
Climate scientists can generate very accurate figures from what appears (to non climate scientists) to be garbage, or at best low-resolution / imprecise data. They use “gut feeling”, “adjustments”, “infilling”, “homogenization” and good old-fashioned “making stuff up” to ensure the results are “on message”. When the reality doesn’t match their theory the assume reality is wrong.
How else can you possibly explain their absolute certainty, to tiny fractions of a degree – based on things like tree-rings, lake sediments or ice cores. It’s nonsense.
+10. Yes, the old fashioned ways of fooling people seem to work well.
You missed “Kriging”.
One observation about measuring your height vs measuring buoy temperatures.
When you measure your height with many observations the height (ideally) is unchanging — so you are making many observations of a constant.
The measurement of temperature at a point in time and space on a buoy could be considered an independent observation of “something” — which has essentially nothing to do with the last “something” — or the next. Does the CLT (etc.)apply in this case? Considering the drift on the buoy, and that each measurement is independent, I am not sure that we can say that the stated accuracy is achieved. Just curious.
Actually, height IS changing. It varies during the day. Getting up in the morning, people are at their tallest height.
Height gradually shrinks during the day thanks to gravity compressing the padding in people’s joints.
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1545095/pdf/archdisch00801-0068.pdf
CLimate change driven?
Bill_W
Yes, during our nighttime horizontal climate we lengthen as the padding rebounds, however when we change to our usual daytime vertical climate we slowly shrink. I have thought about graphing it but then I realized I would need to do an IRB before performing and publishing such a graph and decided it isn’t worth the paperwork.
Besides, unlike normal climate science, I would want to include all the confounding variables like whether the subject was standing or sitting most of the day or what the effects of an afternoon nap may have. Then there is the problem of figuring out what minimum sample size would be needed to accurately represent the universe of people at an appropriate standard error would be. Then there are the unknown unknowns that would throw a monkey wrench into the whole thing. [only partly sarc]
So if i go to antartica i will be taller?
In reply to Bob Boder.
http://curious.astro.cornell.edu/question.php?number=310
The strength of gravity is about 0.3% less at the equator than at the poles, so you would be an infinitesimal amount shorter at the poles.
With NO gravity, astronauts are about 3% taller than on earth.
http://www.space.com/19116-astronauts-taller-space-spines.html
WillR
CLT or Central Limit Theorem is time independent – so convergence to errors that follow a normal distribution could take 1 week or 50 years (i.e beyond the lifetime of the sensor). Real sensors often show discontinuous drift when measured against more accurate devices something that keeps many employed in various national standards agencies. So we can’t just assume that CLT applies. We need to regularly calibrate devices and most important make sure we have consistency of measurement method. Change how you measure something and it increases the error.
The overall problem here is that the accuracy of the measuring device is not just the error; there is also the changing environment, the drift in the sensor and other things. As a rule of thumb a good thermocouple or thermistor would give you ± 0.5 °C but more likely ±1 °C. And that’s in a lab environment with good thermal contact and placement.
The other thing is that your accuracy is only as good as the calibration device. So if your national standards agency (NIST, NPL etc) cannot produce 0.002°C/decade then your sensor cannot claim that accuracy.
On the other hand you could just use a bunch of assumptions and forget to remind people that you’ve done that. Now where have I seen that done before I wonder?
…”so you are making many observations of a constant.” Lately I have been growing taller then my hair!
The major problem with virtually all long term climate data is the lack of random replicated samples. Nearly every other branch of field science requires both random sampling and replication in each set to define the size of errors. Climate science generally appears to think it jolly to take ONE sample and then proceed to perform all of the statistical analysis as if the variance of ONE sample was not equal to infinity. Has ALWAYS been garbage in and garbage out, to the closest infinity.
When you give a highly precise computer to somebody totally ignorant of metrology, you get pearls of wisdom such as “They arren’t measuring the trend with a thermistor; they are calculating the trend”.
Discerning minds will understand the pearl to mean the “trend” be a value with only tenuous connections to reality.
IOW why spend money on a measurement system if you don’t measure something with it, instead of asking the proverbial electromechanical ass aka a computer.
As one of the people who ran a maritime mobile weather station in the 60’s and 70’s I call bullshit on this whole sorry tale. We took air and sea temperatures to the nearest half degree by mark one eyeball. When you listen to these computer brained prats snivelling about 1000ths of a degree you just have to laugh at the stupidity on show. 0.7 degree rise in atmospheric temperature in 150 years based on random observations, almost none in the southern hemisphere, made to the nearest 1/2 degree. Give it a break.
Ivor – I remember reading about a guy who worked In Alaska back in the 50s/60s. He said often they did not go out to read the temps, just filled in off the top of his head. He said in those days no one thought that these figures would become so important in the future.
This account of the Sources of 20th Century Ocean Temperatures by the late Dr Robert Stevenson, chimes perfectly with your comments.
“Yes, the Ocean Has Warmed; No, It’s Not “Global Warming” by Dr. Robert E. Stevenson
http://www.21stcenturysciencetech.com/articles/ocean.html
“Surface water samples were taken routinely, however, with buckets from the deck and the ship’s engine-water intake valve. Most of the thermometers were calibrated into 1/4-degrees Fahrenheit.
They came from the U.S. Navy. Galvanized iron buckets were preferred, mainly because they lasted longer than the wood and canvas. But, they had the disadvantage of cooling quickly in the winds, so that
the temperature readings needed to be taken quickly.
I would guess that any bucket-temperature measurement that was closer to the actual temperature by better than 0.5° was an accident, or a good guess. But then, no one ever knew whether or not it was good or bad. Everyone always considered whatever reading was made to be precise, and they still do today.
The archived data used by Levitus, and a plethora of other oceanographers, were taken by me, and a whole cadre of students, post-docs, and seagoing technicians around the world. Those of us who obtained the data, are not going to be snowed by the claims of the great precision of “historical data found stored in some musty archives.”
from the same paper:
“It sometimes seems as if I’m living in a “time-warp” in which some people, and scientists, are unaware that rational life existed before their birth—or before they got out of the sixth grade. Yet, we marine scientists did not enter the second half of the 20th century without a fair bit of understanding of the thermal ocean.”
also from the same paper:
In 1991, when the IUGG and its associations met in Vienna for their General Assembly, the presidents and the secretaries-general of the four associations I’ve mentioned, discussed the program we would propose to forward to the International Commission of Scientific Unions (ICSU) for consideration at the 1992 Rio de Janeiro Conference. We all decided not to prepare any programs!
In our joint statement, which I paraphrase here, we noted that “To single out one variable, namely radiation through the atmosphere and the associated ‘greenhouse effect,’ as being the primary driving force of atmospheric and oceanic climate, is a simplistic and absurd way to view the complex interaction of forces between the land, ocean, atmosphere, and outer space.”
Furthermore, we stated, “climate modelling has been concentrated on the atmosphere with only a primitive representation of the ocean.” Actually, some of the early models depict the oceans as nearly stagnant. The logical approach would have been to model the oceans first (there were some reasonable ocean models at the time), then adding the atmospheric factors.
Well, no one in ICSU nor the United Nations Environment Program/World Meteorological Organization was ecstatic about our suggestion. Rather, they simply proceeded to evolve climate models from early weather models. That has imposed an entirely atmospheric perspective on processes which are actually heavily dominated by the ocean.
I would say that as the arctic ice is affected by oceanic movements (e.g. the warm Gulf Stream water ends up near the extremes of winter ice to the north of Norway), it is probably sensible not to make definitive judgements on how ice behaves until one has observed its behaviour for somewhere between 50 and 100 years. That would suggest that 2030 at earliest is probably the first meaningful datapoint for analysis of 1979 – 2028 satellite data.
This assumes that satellite data is all absolutely accurate when compared to manual measurement methods (I’m assuming that this is so, but experts can no doubt correct me).
Assuming that both arctic and antarctic measurements are equally accurate, currently the total sea ice is above the 30 year mean, which is hardly death throes…..
My take after reading many articles and posts on this is the cliamte science is so dominated by so-called global warming bias that even basic processes like homogenization end up corrupted. In real science homogenization yields more data and identifies underlying trends better. In climate science homogenization is used to hide trends and destroys data.
I agree with you. My local National Weather Service office at Pleasant Hill Missouri has a systematic bias built into its daily average temperature calculations. All averages are rounded up. At first blush, it looks reasonable and consistent. However, these averages are used to calculate heating and cooling degree days, with the result that, at the end of a month or season, heating degree days tend to be understated and cooling degree days tend to be overstated. This makes any time period appear to be warmer than it actually was, if one only looks at this parameter.
I note that the daily averages are not used to calculate monthly or seasonal averages.
The often-hyped “Arctic death spiral” is a very much simplified, very clever – but very false – piece of pure propaganda.
From August 22 through March 22, every extra sq meter of sea ice around the Antarctic reflects more energy back into space than the loss of a sq meter of sea ice in the Arctic can gain.
It is only in those five fleeting months of April, May, June, July and August that even a little bit of “arctic warming” occurs if sea ice is lost.
And even that statement compares only heat absorbed to heat energy reflected from the ocean surface to an ice-covered surface. When sea ice is lost in the arctic from today’s conditions, more heat is lost by increased evaporation, conduction, and convection, and LW radiation from the now-open surface than is lost when ice is present. Add those increased losses into the equation, and open ocean in the Arctic
Net effect?
More open ocean in the arctic cools the planet nine months of the year.
More ice around Antarctica cools the planet every month of the year.
The death spiral is up there with the hockey stick: Simple to understand, deceptive as heck.
I think the cooling period is longer than this. Once the angle of incident get over about 75 degrees, smooth water has the about the same albedo as ice. So only for the last month or so of NH summer does the angle get smaller than this, but since the Earth is a ball, a few hours east and west of the Sun line, that too ends up with a AoI larger than 75-80 degrees. So for lets say 6 hours a day, a single location would be net energy positive, but the rest of the day it’s net negative. When you calculate cooling rates with S-B between open water and very cold clear skies, the water is dumping more heat to space than it’s collecting.
There will be no death spiral, what we are seeing is built in temperature regulation, since the last time this happened was in the 30’s and 40’s, it took about 70 years for a complete heating/cooling cycle.
Don’t forget the insulation effect that sea ice has in the Antarctic/Arctic . The more sea ice you have, the less heat the warm water underneath the ice loses.
+/- 0.002 degrees ain’t even noise – no matter what you are using to measure the temperature.
A fish burp within 500 feet of the sensor would cause more of a change than that.
+/- 0.002 degrees is what you do when you are looking for any signs of heat. It is a desperate, desperate measure [no pun intended].
Its always funny to see the claims for accuracy greater than an instruments is capable of given due to the application maths. Yes you can do averages etc but the reality remains if you can only accurately measure to one decimal place you can only give accurate measurements to one decimal place . After that its intelligent guesswork.
Or in some cases UNINTELLIGENT guesses.
I agreed entirely with every word until you got to, “After that its intelligent guesswork.”
Please define “intelligent”.
Intelligent guesswork: A statistical method designed to extract money from politicians and free PR from reporters. In Climate Disruption™ “science” it usually involves a complete and total disregard of the mathematics of reality and relies on the misapplication of statistical manipulations to create a wholly fictional result. The desired end result is another 1 to 3 years at the public trough working diligently to create and publish said fiction in order to get to the next round of grant money. Kind of like politicians having to campaign every 2, 4 or 6 years to get elected… but with far less honesty.
Or motivated spinning.
It’s common to hear quotes of system accuracy, when they really mean measurement resolution.
They might be able to resolve a relative change of 0.002°C, but an absolute accuracy of 0.002°C? Yikes!
How do you calibrated a device to that kind of absolute accuracy?
PK
+10, you hit the nail on the head. The age old confusion between “precision” and “accuracy”. The fact that they can read a precise figure of 15.632 C on one buoy does not mean that it is necessarily the same temperature as the equally precise reading of 15.632 C on a different buoy. You need to know how accurate they are, that is how well calibrated against a known standard – or more importantly when calculating a trend (rather than a spot figure) how well calibrated they are against each other .
Also important is the temporal stability of that reading. Is a reading of 15.632 C in June 2012 the same temperature as a reading from the same buoy of 15.632 C in 2014?
Having said all that, statistical sampling to calculate a trend is all about the number of readings before and after. Once you get over 2000 data points (2000 before and 2000 after) errors in a discernable trend decline dramatically. Individual buoys may not be particularly accurate, or even very precise, but if the average of 2000 readings after is 0.2C higher than 2000 readings before, then the error bars on that 0.2C become vanishingly small.
Caution: This assumes that there in not a systemic problem with the sensors that means that their readings all rise by the same amount in a given time even if the temperature has not changed. I think the chances of that being the case is pretty remote!
It also assumes that the buoys are reasonably randomly distributed and that they cover the same area of ocean before and after. It does not really matter if, for instance, they do not sample the southern ocean at all, you just have to caveat your observation.
What is usually missing is the caveats. So, for example, if there is a calculated trend of 0.2C a decade excluding the southern ocean then you just have to say “excluding the southern ocean” – something climate scientists rarely do! They prefer to use questionable extrapolation techniques to fill the gaps.
Example
I use a Leica Disto laser distance measurement device in my job. It is “precise” to 1 mm in 50 metres. The marketing blurb says it is “accurate” to 1mm in 50 as well, although I have no way of testing that independently. Let us say I am measuring two walls roughly 10 metres apart. However, my hand is not that steady, the wall I am holding it against may be bumpy and I do not always hold it perfectly level or target exactly the same spot on the other wall. One measurement is never enough. I usually repeat two or three times and take the average because individual readings will often be up to 5mm out over 10 metres. I also know that if I took 2000 readings as precisely as I could on one one day and 2000 readings of the same spots on the walls the next, the chances of the average of each day’s measurements being more than 1mm different would be almost zero. I also know that if I took the same readings 2 years apart and the average of the second set were 5mm larger then I could be pretty certain that one of the walls was falling over! This is the case even though my “error bars” on an individual reading are plus or minus 5mm.
Upshot
The Argo float temperature system takes tens of thousands of readings every year. The trend is probably very accurate (repeat – the trend, not the absolute temperature!) and I can believe that the error bars on the trend might be +/- 0.002 C for the reasons stated above. It probably has nothing to do with the accuracy or precision of the individual temperature sensors at all, just the sheer number of samples taken. I think this is probably either a failure in communication or a failure in understanding – probably a bit of each. I would certainly trust the temperature trend from the Argo floats rather more than I would from our surface stations!
Good explanation TLM. However, you say
“… I can believe that the error bars on the trend might be +/- 0.002 C for the reasons stated above.”
A trend is a rate, correct? So the units on a trend variable should be deg C/[unit of time] e.g. deg C / year, and not just deg C. Minor point, but stating error in the proper units would go a long way towards avoiding the obviously erroneous claims of +/-0.002 deg C error for Argo temperatures.
“Caution: This assumes that there in not a systemic problem with the sensors that means that their readings all rise by the same amount in a given time even if the temperature has not changed. I think the chances of that being the case is pretty remote!”
should actually be:
“Caution: This assumes that there in not a systemic problem with the sensors that means that the readings of a majority of them change by some amount in the same direction in a given time even if the temperature has not changed. I think the chances of that being the case is quitr high!”
It is called “sensor drift”
A an accuracy of 0.002degC does seem quite unbelievable to me also and yet that is what is claimed by the company that manufactures (Seabird) many of the Argo probes. One such example is the SBE 41CP CTD. If you open this link http://www.seabird.com/sbe41-argo-ctd and click on the specifications page the initial accuracy is given as +/-0.002degC. They don’t state whether this is typical or maximum.
I would be very interested to know (a) what equipment they use to calibrate to this accuracy and (b) what method of temperature measurement they use. If they do use thermistors, as mentioned in the article above, then in my experience the best ‘Interchangeable’ types have an accuracy of 0.1degC. It is possible I suppose that Seabird could individually calibrate each thermistor in a controlled environment. However, even if the spec of the thermistor was 0.002degC then this does not take into account other errors. For example, the thermistor must be powered, often by a constant current source and the corresponding voltage then measured by an ADC. The current source and ADC also need to be calibrated and their errors included. Other factors such as temperature and temporal drift and variation of power supply can affect the reading. I note also that the probes ascend and take measurements. How long do they wait at a certain depth before taking a reading (i.e. what is the settling time of the float)?
There are many other questions about the float data quality. This paper http://onlinelibrary.wiley.com/doi/10.1002/rog.20022/full makes a good job at addressing many of the issues.
TTY
I don’t argue that there may some drift in individual sensors in individual buoys, but there would need to be roughly the same magnitude of drift – and in the same direction – for all of the sensors in order for there to be a systemic error of this magnitude.
Is that really possible? Surely if drift does occur it would be random? If it were so predictably uniform then the manufacturer is bound to know and could easily incorporate adjustment mechanisms into the read-out.
I would be gobsmacked if the operators and manufacturers of the buoys have not tested for such inherent and uniform errors and that they could occur without the operators knowledge. Or are you suggesting that they deliberately ignore the errors because the results suit their agenda?
I am sceptical of some of the claims of the scientists but I am not a cynic. Argo is a genuinely and massively impressive engineering and monitoring project – a real achievement that should be celebrated. The reality, or otherwise, of AGW will only become apparent with long term studies of this type. More satellites, more and better monitoring all round. Ignoring or casting doubt on this kind of project will just leave a space of ignorance for politicians and media pundits to fill with alarm and/or denial.
Scepticsm, a thirst for knowledge and curiosity are all part of the scientific process and the enemy of the alarmists and sky dragon slayers of this world.
This is so very incorrect that it is difficult to know how to begin. Or rather, it might be correct but is very probably not terribly useful.
Take a look at (for example) HADCRUT4. See how it jigs up and jigs down? Those jigs are the result of doing precisely what you suggest leads to meaningful before and after comparisons. It samples far more than 2000 inputs for each output. Each and every output is different from the one before, usually right about at the bounds of the claimed statistical accuracy. Are these changes representative of a discernible trend?
Don’t be absurd! Of course not. They are noise.
In order to make any sort of statements about significance of a linear trend in a timeseries you have to do far more work than this, and the actual statistical accuracy/significance of your claim is probably and order of magnitude smaller than you might think it would be if you do the analysis carelessly. It also depends on an assumption literally unprovable from the data itself — that there exists a linear trend in the data to be statistically extracted in the first place in the only context that matters — one that is extrapolable as a prediction of the future. That is what “trend” analysis is all about — it isn’t just fitting a linear curve to some data series, it is fitting the linear curve to the data series because it has some meaning.
See my remarks elsewhere in this thread about reading Briggs’ articles on the dangers of fitting linear trends to timeseries data. On the one hand, one can, as you say, make statements like the following: The HADCRUT4 temperature in June of whatever was warmer/cooler than it was in June of whatever else, with a difference larger than the claimed error bar. That is a statement of fact. But it does not suffice to establish this as a linear trend, as if you could fit a line between these two points and it would be a good predictor of all of the data in between, or any of the data preceding or following the two points.
Sigh.
One day, if everybody studies this stuff, we can actually progress to where we start talking about relaxation rates and autocorrelation and fluctuation-dissipation. This is still well shy of where we can talk about them in a chaotic nonlinear problem, but at least we can start to understand what they are in linear stochastic problems, things like Langevin equations with delta correlated noise.
rgb
rgbatduke. Your comments are so misleading I don’t know where to begin. All I will say is that of course all the wiggles are noise, that is why we all do moving averages, linear regression, polynomials and all the other analysis of time series. These are not “fitting linear trends”, who said a trend had to be linear? Who said it only has to be between two points?
Maybe “trend” is the wrong word. Perhaps “track” would be a better one. All you can ever get from the data is how it has changed in the past. Seeing the signal through the noise is what it is all about. Of course this is no predictor of the future, only the stupid and ignorant would extrapolate a linear trend, or any trend for that matter and expect it to be right.
How the data changes helps us to understand how the climate changes over time. All science ever does is make a “hypothesiss” (model) and test that hypothesis with real world data. If the data does not fit or prove the model then the model is wrong.
How can we ever know whether the model is right or wrong if we don’t collect the data? Argo is the best data we have on sub-surface ocean temperatures. I would argue that it is very high quality data and well worth collecting and can tell us a huge amount about how the ocean and atmosphere are linked.
How would you measure sub-surface ocean temperatures? How much would it cost?
An excellent question. If you care to look at the answer:
http://wmbriggs.com/blog/?p=5107
http://wmbriggs.com/blog/?p=5172
etc. Look, neither I nor Briggs are suggesting that linear trend analysis is without any merit at all. However, it is a tool that is so heavily abused as to be instantly suspect whenever it is invoked to “prove” something in climate science. Read these articles, seriously. One doesn’t need to fit anything to see that datapoint x is higher than datapoint y in a timeseries. The only reason to fit anything is to make claims of some sort of connection between the form being fit and the presumed underlying hidden, unknown dynamics that gave rise to the time series. And the only way we should give such a fit the slightest credence is if the fit proves to have predictive skill outside of the range being fit, and then only with the direst of conditionals appended to the conclusion, especially when one is dealing with a process that is manifestly non-stationary.
Look if you like, you can go debate the issue with HenryP, who lurks on these pages, and who has built a dataset for “global temperature” that can be fit with a quadratic function with a negative slope to a few zillion digits and hence will swear up down and sideways that he can confidently predict global cooling. Me, personally I’m planning to read the entrails of the next chicken I see, as it is as likely to give the right answer.
I am on my second company founded upon predictive modeling. I have been doing it professionally and as a hobby (odd as that might sound) for almost 20 years at this point. I can cite you chapter and verse on training sets, trial sets, pattern recognition, regression linear and nonlinear, in hard problems where people will pay you a lot of money to get it right. Even a little bit right, just beating random chance. So by all means, fit anything you want and assert that the result is “significant”. Bet your own personal fortune on it.
Just don’t bet mine.
rgb
TLM, I used the example of my height to point out that the actual SD (from more precise measurements) can be greater than than that calculated when the these are rounded to a larger increment or the instrument records to a larger increment (the resolution). I don’t know which is the case for the Argo buoys.
While that was one measurement and not a trend, there is a similar problem when the trend is 0.02°C/decade calculated from data measured over less than a decade. If it was over a century then there are still other problems.
Don’t you know it is IEEE inspired?
That’s Imagine, Estimate, Exaggerate, Extrapolate
The GASTA anomaly due to the late 20th century warming is something like 0.8c. If global warming has caused less than 1 degree of warming in the air, how much would it cause in the oceans? My guess, a lot less than 0.02C. In other words, undetectable with current precision.
You know, NIST and CIPM have very nice guidelines on measurement uncertainty and error propagation. I’ve seen very few (there are some) discussions of the full meaning of those. With a few examples, it would probably become very easy to show that the estimated trend lines in most things in climatology (as in other fields) are not meaningful, even if statistically significant (at least at the lazy statistics level).
Also, saying that an instrument is good to whatever is generally not acceptable without the right calibration traceability documentation. We don’t know the linearity bounds on the sensors, the hysteresis, or many other things. I don’t know. Since doing some instrumentation and data quality work, I have a hard time trusting any but bulk assessments of things or direct measurements with lots of documentation. When people start doing math with things, they very, very rarely move their uncertainties forward.
At least with ocean sensors the linearity range only needs to extend from about -3C to about 33C. I doubt there will be any ocean readings outside that range anywhere in the world, but if someone knows of hotter or colder water somewhere I am ready to be educated by the data.
The Argo network is the best climate instrument system we have.
The coverage and number of floaters in use is large enough to give us reliable numbers over a period of a few years.
And the network is showing us that the oceans are not warming as fast as the theory predicts and is, in fact, a very low rate indicating global warming will not be a problem.
Compare the Argo system to the NCDC data-hiders-adjusters and one should understand how lucky climate science is to have Argo.
I like your comment better than the top post, truthfully. This:
is what we should be talking about, not measurement error.
Take the recent Josh Ellis paper, from the abstract:
What gives? Last time I checked the claims were for a heck of a lot greater an energy imbalance than 0.64 Wm-2. Wasn’t the claim 1.7 Wm-2 (net) in AR5?
” Wasn’t the claim 1.7 Wm-2 (net) in AR5?”
I think you’re thinking of the 1.7 Wm-2 extra forcing since 1750 due to C)2 (2.3 to all anthro). That’s different. That forcing causes warming, which increases outward IR. The difference (0.64) represents the amount of forcing that is not balanced by temperature rise since 1750.
The extra human induced forcing since 1750 is +2.3 W/m2 (not 1.7 W/m2) and, on top of that, there should have been an additional +1.8 W/m2 in feedback forcing apparent given the temperature increase.
And from 2005 to 2013, the net energy imbalance is 0.535 W/m2, not 0.64 W/m2.
If you run all those numbers backwards and forwards, all one gets is 1.5C per doubling of CO2 as equilibrium sensitivity.
Thanks Nick. I don’t really understand, but maybe the fault is mine. What do you mean by forcing that is not balanced by temperature rise?
Hey, btw, I’m not arguing anything yet. I’m honestly asking what this is all about. Hopefully Nick can ‘esplain it to me.
Nick, are you saying that the 0.8C warming we’ve seen since 1750 partially balances part of the 1.7 Wm-2 forcing imbalance (because forcings cause temps to rise, driving the system back towards equilibrium and driving the imbalance down towards zero) that there’s effectively a 0.64 Wm-2 imbalance right now?
I have no quarrel with this, and if I understand this properly it’s consistent with Hansen et al..
As I understand it, we’re still missing some heat. I’ll get back to this after I dig a bit, it’s been awhile. 🙂
This article is misleading. If you have N statistically independent observations, each with a standard deviation of sigma, the standard deviation of the mean will be sigma divided by the square root of N. If you know a little programming, it can be quite instructive to try this yourself. I just generated one million quasi-random numbers between 0 and 1 (with 16 decimals) and computed the mean as 0.4996796058936124. I then rounded each of the 1 million values of to only ONE decimal. The mean of the highly inaccurate one-decimal numbers was 0.4996611, so correct to 4 decimals…
N statistically independent observations that are as identical as possible.
That means using the same equipment with the same calibration to make the same measurement N times.
For example, using a laser rangefinder to measure the distance between the two same points N times.
However, systematic errors such as changes in air density between the two points and instrumental drift will eventually dominate.
In the case of the ARGO buoys one is averaging measurements made at different changing positions by different buoys. One is not making N repeated identical measurements. Even with simple averaging, the systematic errors will dominate: calibration, instrument drift, etc.
I’ll make it a little clearer. If the resolution of the instrument is 0.1°C ie, temperature calculated from a mean of voltage measurements over a few seconds and then recorded to the nearest 0.1°C, you can’t treat it as if it was exactly 0.1°C.
The North Pole is warming up. Air temperature to blame, women and children assisted first.
Deja Vu! As I have said before, as a young student of civil/structural engineering at Kingston-Upon-Thames College in the very early 80s, the Swiss made Wilt (pronounced Vilt) T2 Total Survey Station was the state-of-the-art gismo in the surveying world. There were only two in existence in the UK at the time, the then Greater London Council had one, the college had the other, at £20,000 a pop back then! The advertising claims were that this pice of kit measured angles to within 1 second of arc accuracy. It’s then Japanese equivalent also made the same claim. However, the Japanese version had its lenses ground to within 1 second of arc, but the Swiss T2 had its lenses ground to only 3 seconds of arc! It’s all in the tolerances, folks! 😉
“Wilt” or “Wild”? I recall vaguely some Wild instruments but please don’t embarrass me by asking what.
Ian M
It’s “Wild”. They have been making precision photogrammetric and surveying equipment for a long time. There is a (true) story about an extremely senior officer inspecting No 1. P.R.U. (Photographic Reconnaissance Unit) of the RAF during WW 2, and seeing a number of folders labelled “Wild plans” remarked: “You wouldn’t like to show me those, I suppose”
even in 1938 in the Arctic it wasn’t so cold.
http://trove.nla.gov.au/ndp/de…
“NORTH POLE NOTSO VERY COLD.
Weather observations broadcast fromthe North Pole since June 17 show that this is certainly not the coldestspot in the world. In fact, some of the temperatures recorded are only a fewdegrees below those taken during the early morning in parts of England.
The Soviet . scientists at the Pole havetraced a warm current of water thatflows far below- the polar ice, ‘making the area warmer than had – ever been thought.There are much, colder spots in theinterior of Greenland, where the temperature falls far below zero in the middle of the Arctic summer, while North Central Siberia has had temperatures of 95 degrees below zero Large expanses of open sea in the vicinity of the North Pole are mainly -responsible for keeping up the temperature, But they also cause Ionsperiods of dense fog and showers ofice-laden rain..”
H/T real science.
this link will work.
http://trove.nla.gov.au/ndp/del/article/146229328?searchTerm=north%20pole%20warmer&searchLimits=dateFrom=1938-01-01
I apologize if this observation has already been made … and I certainly have noticed comments around this issue … but the statement “reported the trend in the global ocean temperatures as 0.022 ± 0.002 deg C /decade” SHOULD go to the statistical issues of population variability and sampling error. For the proponent of the statement to be talking about measurement accuracy is about as disingenuous as you can get.
back to 1923-
http://trove.nla.gov.au/ndp/del/article/87532315?searchTerm=arctic%20thaw&searchLimits=
ARCTIC ICE THAWlNG.
AN ISLAND DISCOVERED.
LONDON, September. 1.
The Norwegian explorer, Captain Wiktor
Arensen, who has just returned from the
Arctic, claims to discovered an island
twelve miles in circumference near Franz
Joseph ,Island, in latitude, 80.40. It was
previously hidden by an, iceberg between
70 and 80 ft. high, which has melted. This
shows the exceptional nature of the recent
thawing in the Arctic Ocean.
Several folks have pointed out the fallacy of equating measuring the same thing many time with measuring many different things once each; then averaging.
Less obvious is the fact that an average of temperatures is not in any way a temperature. Just isn’t. So those Global Average Temperatures (air or water) are no such thing. The trends in them are NOT the trends in temperatures. They are only the trends in an average of a bunch of “stuff”, from denity changes to entrophy changes to precipitation effects to intrument drift to….
Temperature is an intrinsic property. As such, it can only be specific to a single thing, and an average of temperatures is void of meaning AS a temperature. (Since the needed specific heat, mass, phase change, etc. are all missing…)
http://chiefio.wordpress.com/2011/07/01/intrinsic-extrinsic-intensive-extensive/
The whole charade of using an average of temperatures is a lie on the face of it.
The author raises a very interesting and complex question, often neglected, overlooked, whitewashed over, and simply ignored in modern scientific endeavor. I’m not sure that he states it very clearly but the problem is roughly defined as “What to do about original measurement error?” and a follow-on question: “Do our mathematical results showing effects smaller than original measurement error actually mean anything at all?”
It is perfectly clear that the math is correct — all that division and averaging and probabilities, etc. [Almost] No one disputes that.
The claim/belief that measurement error always averages out thus we can ignore it in the end is a very dubious proposition. Claiming very precise accuracy over imprecise original measurement is simply a trick of mathematics.
A carpenters example goes something like this: One is building a house and needs 2x4s precisely 8 feet long for the walls. A supplier is offering 8 ft 2x4s at a steep discount — and guarantees accurate length to 1/8th of an inch — 0.125 inches — just accurate enough for house carpentry. The carpenter buys a truckload of these 2x4s and finds that they range from 7 1/2 feet to 8 1/2 feet in length — utter useless for his purposes. In the resultant civil lawsuit, the supplier brings in a statistician, who orders measurement of every 2×4 in the lot sold, then proves to the jury that his claim of “accurate length to 0.125 inches” is perfectly statistically correct — even though the original measurement error was +/- 6 inches.
Statistical result of great accuracy are not the same as real world results.
This article is well worth reading.
http://earthobservatory.nasa.gov/Features/OceanCooling/page1.php
here are the money quotes for me:
““I was aware that they were not seeing this huge cooling that we were seeing in the ocean,” says Willis. “In fact, every body was telling me I was wrong. And there were always doubts,” says Willis. “After all, it was a very surprising result. As a scientist, its part of my job to turn over every leaf. So I was constantly going back over the data and looking for problems.””
…
“Basically, I used the sea level data as a bridge to the in situ [ocean-based] data,” explains Willis, comparing them to one another figuring out where they didn’t agree. “First, I identified some new Argo floats that were giving bad data; they were too cool compared to other sources of data during the time period. It wasn’t a large number of floats, but the data were bad enough, so that when I tossed them, most of the cooling went away. But there was still a little bit, so I kept digging and digging.”
…
““So the new Argo data were too cold, and the older XBT data were too warm, and together, they made it seem like the ocean had cooled,” says Willis. The February evening he discovered the mistake, he says, is “burned into my memory.” He was supposed to fly to Colorado that weekend to give a talk on “ocean cooling” to prominent climate researchers. Instead, he’d be talking about how it was all a mistake.”
==============
the other possibility is that Argo and the XBT’s were correct, but because they didn’t match expectations of warming, they were adjusted because “every body was telling me I was wrong”.
In any case, removing floats after the fact is no different than removing tree ring samples because they don’t match thermometers. It is statistically invalid, because the assumption in statistics is that the sample is randomly selected.
As soon as you remove readings you have violated the assumption or random selection and you cannot rely on the statistics to give an accurate result. Formally it is called selection on the dependent variable.
The floats that appear to be running too hot or too cold are telling you that the floats are less accurate than you think. this does not give you license to remove them from the sample and claim that the sample is now more statistically accurate. it is a statistical nonsense.
You say truly. Unless one can demonstrate that a particular data (or data source) is faulty he is guilty of “selection bias if he rejects it. What is true for tree rings is true elsewhere.
In any sample there will always be outliers. floats that appear too hot or too cold. however, you are not allowed to remove them from the sample and then claim the sample is statistically random. And if the sample is not random, then your claim to statistical accuracy if false.
I agree that the article at the top is misleading and makes several mistakes, but the problem he points out is real. There are a few thousand ARGO buoys. We’ve had that many only for a decade or so. Before that we relied on scattered soundings. The ocean being sampled covers 70% of the Earth’s surface, and is not homogeneous.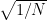 where
where  is the number of independent, identically distributed samples drawn from the distribution.
is the number of independent, identically distributed samples drawn from the distribution.
The issue isn’t just with the putative accuracy of the thermal measurements made by the buoys, although yes, comparing results obtained with an insanely sparse handful of measurements made with comparatively inaccurate instrumentation to the results obtained from an still insanely sparse handful of instruments with much better putative accuracy is problematic. It is with the insanely sparse bit. I very much doubt that I could measure a mean temperature in Durham county from 3000 perfectly accurate thermometers to within millidegrees. If I were to attempt it, I would have to start by eliminating bias. This would involve taking a map of Durham county, using a random number generator to select 3000 specific three dimensional locations in the air volume I’m trying to measure, positioning the thermometers at those locations precisely, making a single measurement at a randomly selected time, and cumulating the results. Oh, and these would have to be magic transparent zero-heat-capacity thermometers that do not change the temperature they measure.
How accurate the result is at reflecting the true average temperature is not, then, determined by the precision of my magic transparent perfectly accurate thermometers. It is determined by the spatiotemporal variance of the actual time dependent thermal distribution of temperatures in the measured volume of Durham county.
I can estimate that, at least. In my own back yard, the spatial variance in air temperature is between 1 and 4 C across maybe 20 meters — all one has to do is walk under a tree, or onto the driveway, or out over the grass, or sit up on the roof — and get very, very different results. The temporal variance at these locations is similarly easily degrees per hour — both systematically (with significant cumulation diurnally and with the seasons) and randomly, as today is sunny and tomorrow it is cloudy and rainy, this morning it is humid and warm and later today a cold front moves through and it cools and dries. Monte Carlo eliminates bias, but nothing can eliminate the need to sample the distribution itself, as the standard deviation is expected to scale like
Even this, however, is insufficient as a statistical treatment, because there is nothing that says that the underlying distribution is stationary and all of my assumptions used to effectively sample the distribution and thereby compute its variance and standard deviation in the hope that the central limit theorem kicks so that the mean of my observations will be normally distributed around the true mean (what I’m trying to measure require that the distribution being sampled be stationary. Among other things. None of which are particularly likely to be true for the climate, and indeed the whole point of the exercise is to infer the non- stationarity of the underlying distribution so that the cause of its motion can be attributed to a correlate.
This brings us full circle back to Briggs’ lovely posts on the sheer idiocy of fitting linear trends to timeseries data drawn from arbitrary (probably non-stationary) distributions:
http://wmbriggs.com/blog/?p=5172
(and more — he writes extensively on this subject). That is, there is no need for a sloppy treatment of this subject. Climate science is already rife with those. What I want to see is the slightest bit of self-consistent evidence that 3000 (say) ARGO buoys with perfect thermometry can measure the average temperature field of the ocean itself to within 0.001C ever, anywhere, long before we start monkeying around with the usual idiocy of fitting a time series as if the linear trend we extract is not only meaningful, but is accurate to this sort of scale over decades!
Puh-leeze.
And while we are at it, we can work on physical models for transporting oceanic heat downwards from the surface and estimate a few of the time constants of the transport processes contributing to that — ones that work right on through strong stratification. What were those time scales, again? Even if we are — astoundingly, IMO — observing a trend that isn’t pure noise amplified by the judicious application of confirmation bias, is the physical cause of the trend the warming of the surface back during the dust bowl years in the 1930s, just now making its way to depth, or is it some sort of response to the warming that happened in the 1980s and 1990s, in the single double ENSO burst of warming visible in the last 70 years, or is there a fast process that is somehow warming the depths now even though the surface is not, actually warming at all?
Note that if one wishes to assert the latter, one has a very serious problem. If the relaxation time of the deep ocean is only decadal, why isn’t almost the entire ocean at 288 K? Oh, right, because in fact it is not decadal, it is millennial. We are probably still warming the ocean from the last glacial episode! The warm and cool waters that emerge and sink in the thermohaline circulation carry a pattern of temperature change imposed centuries ago, adding nicely to the chaotic tumble of surface climate changes — nothing like lagged nonlinear feedback in an oscillator to keep it on its chaotic toes, right?
rgb
Note that about 10 % of the ocean is never measured by Argo, and those 10 % is very non-random.
Amen rgb! To the immense thermo flywheel of the oceans, 10K years is a short time. Assuming .002C per decade is realistic (a trend which I have zero confidence in), 10K years would yield a 2C rise in average ocean temperature. Given that the last ice age provided 90K years of cooling, even 2C seems much too great.
Oops. Should have been .022 per decade yielding 22C rise which is not credible. So if .022 per decade is true, it would be a much higher rate than the rate of ocean warming averaged over the Holocene. What am I saying? Just that .022C per decade doesn’t make common sense.
“I agree that the article at the top is misleading and makes several mistakes, but the problem he points out is real. There are a few thousand ARGO buoys. We’ve had that many only for a decade or so. Before that we relied on scattered soundings. The ocean being sampled covers 70% of the Earth’s surface, and is not homogeneous.”
1. Homogeneous is ASSUMED to do the “averaging” calculations.
2. You actually have to test to prove that it’s NOT homogeneous.
3. In recent work, folks have shown that the homogeneous assumption was wrong. The SH ocean
is actually warmer than estimated from the assumption of homogeneity.
Given the data, Given an assumption of homogeneous field ( ie, the unsampled locations can be estimated
in an unbiased manner from the known locations), the algorithms generate an estimate of temperature.
This is commonly referred to as an “average”, but it is really not an average. It is, quite literally, the best estimate of the temperature at locations where no measurement was taken using the know data and an
assumption.
This prediction can of course be tested, by either holding out data or by increasing coverage
Again, what matters is whether or not the unsampled areas are homogeneous with the sampled.
Since they are UNSAMPLED and UNOBSERVED one can’t simply assert that they are non homogeneous. One can assume the unsampled is homogeneous and calculate a result. Then one can test this result.
My experience is that the homogeneous assumption hold up fairly well both for air and for SST.
The bias introduced by the assumption has, in fact, underestimated the warming. That is as we get more
coverage or recover old records we consistently find that we have underestimated the warming.
That is, previously un measured locations are warmer on average than the homogeneous assumption.
The bias is small, so the assumption is not without merit.
I wanted to write something that wasn’t too frivolous but
You can’t find the middle of a dart board to the nearest mm with a million thrown darts if you only know where the darts hit to the nearest 1m. Your precision of throws can be 1m off, but you need to know the position to the nearest 1mm.
If your noise level exceeds 1m then 1 million thrown darts would give you 1/sqrt(1M) = 1mm resolution. For example, if 620,000 samples fall on 2m marker and 380,000 samples fall on 1m marker, then you know the center was at about 1.620 meters. (I probably did the math wrong, but it’s the general idea).
This is the same principle all modern audio equipment uses (delta-sigma converter, though they shape the noise to get better results than 1/(sqrt(n)).
Of course, the accuracy might be terrible if the noise has any skewness, or isn’t sampled at the same point, or the sensors drift over that sample due to natural decay of all semiconductor based systems… all of which apply to the ARGO network.
As mentioned elsewhere in this most excellent discussion, accuracy and precision are two different things. Oversampling will get your great precision but accuracy is limited by many other factors.
RGB
I’d like to thank you for managing to explain simply, complex stuff I have always struggled to understand.
Along with other commentators in WUWT, Leif as well, over the years I have been reading WUWT my understanding and knowledge has increased, along with my library, due to your ability to put into clear simple form complex processes.
Thanks to Anthony and the Moderators also for providing a forum where this can happen
Had Argo showed warming instead of cooling, would anyone have removed any of the floats from the sample? If not, then how is this not confirmation bias?
The oceans were showing warming – lots of warming – up until Argo was installed. Then suddenly ocean temperatures leveled. What an amazing co-incidence. One could argue much too amazing.
Oh, I forgot to add one more comment. Most of the Argo buoys are free floating. As far as I know, none of their locations was determined by Monte Carlo and fixed on that basis alone (or varied on that basis alone). That means that the samples drawn by the buoys are neither independent nor unbiased. They violate the first principles of sampling theory for even simple, stationary distributions — and then they have to krige them.
All I can do is shake my head.
Look, there isn’t the slightest reason to believe that floating buoys are going to sample the entire ocean at all. A glance at the reasonably current map:
http://w3.jcommops.org/FTPRoot/Argo/Maps/status.png
Shows that they do not. Don’t let the size of the dots fool you. Each dot is the width of Florida — oh wait, it is a Mercator projection, so it is the width of Florida at Florida, and about twice that wide near the equator and the single dot at the top probably covers a football field or two at the North Pole. It looks uniform on a Mercator, which means that it is nowhere near uniform on the globe — some places are horribly oversampled, others nearly completely undersampled. The buoys all belong to different countries (introducing a nifty source of additional error, BTW).
At second glance, the buoys aren’t even close to uniform. They string together, swept into — could it be — currents? And what are currents, exactly? Warmed water heading towards cooler water! On the surface, anyway. Deeper, it is cooled water being displaced by warmed water as it cools, in enormous thermohaline convective rolls that both wind all over the planet and that form eddies — dead spots like the Sargasso — at the topological defects in the curl field. Some places don’t have any buoys at all, probably because they’d be a shipping hazard. Others — check out Japan! — seem to have so many they are running into each other randomly.
Each buoy (assuming that they all descend to 2 km — not all do), on average, is sampling a handful of points that have to represent the temperature of roughly 200,000 cubic kilometers of water. To put it into perspective, Durham county is roughly 800 square kilometers. If I distributed 3000 thermometers on it (say, by mounting most of them on cars, as this is the moral equivalent of the floating buoy confined to the ocean currents) each buoy would have to sample aproximately maybe a quarter of a square kilometer — a chunk half a kilometer square. The temperature reading of a single car would have to represent all of that volume/area and at the same time sample the spatiotemporal distribution often enough to eliminate the natural variance to the point where the sample mean is in correspondence with the true mean reliably over time (which is the thing that is basically impossible with a non-stationary distribution) accurately enough that when I come back to fit a linear trend to the timeseries of sample means I’m not just seeing the fact that yeah, the distribution isn’t stationary and isn’t statistically resolved both, I’m seeing an actual linear trend that has some meaning.
Over the decade or so that the buoys have been in place in adequate numbers, assuming that there are no other biases or sources of error, assuming that sampling in the hot city streets gives the same thing that a true Monte Carlo of sample locations and times would have given. Probably assuming a few more things. Every one a Bayesian prior that strictly reduces the confidence we can place in the final answer!
rgb
Well put, the map is most enlightening.
I’m actually quite disappointed in the quality of the ARGO network. It’s most disheartening.
So I counter with “It’s better than nothing”. Yes, data can be abused by putting too much confidence on it. Or by ignoring how it actually works.
But at least we see something now. The currents thing may be able to be determined more accurately by the tendency of these buys to line up. That would be of interest.
At least they are really measuring something.
Wow, you and rgbatduke are hard to please! Yes there isn’t a sensor on every square metre of the ocean – but Argo is quite simply an astounding achievement and hellishly expensive.
rgbatduke produces some very valid reasons why Argo is not accurately measuring the average temperature of the oceans. But how could it possibly do that? You would need a thermometer on every water molecule!
He is totally missing the point! What Argo is endeavouring to do is measure the change in temperatures over time which is why they only ever quote variance and not actual temperature. To do that it simply needs to do enough measurements to average out the random fluctuations. The map looks like a pretty random distribution to me. The only alternative would be to anchor each buoy to the ocean floor – imagine the cost of that!!!.
Using the current system, the longer the period of measurement and the more data points the more apparent any trend would become. Even if you bin the outliers (which is stupid of course), if the ocean is cooling or warming then it will show up in the remaining buoys in time. The Willis guy thought he was binning only data from faulty buoys and that newer buoys were much more accurate. He can only do that once – from then on by his own standards the newer buoys have to be right – or his whole argument falls down.
So what alternative system would you suggest that could get anything like this kind of coverage of temperatures at all levels of the ocean?
Or are you both suggesting we do nothing, because nothing is perfect, and we all seek perfection do we not?
TLM says;
Who proposed we just do nothing? We just ask that confirmation bias driven dubious statistical methods be excoriated by the science community. 0.022 ± 0.002 deg C /decade determined from a such a short time period is scientifically simply not credible.
To: TLM
October 10, 2014 at 9:15 am
Hmmmn.
So, you are satisfied if the ARGO buoys measure (report) only the “change” in ocean temperatures over time.
OK.
So, how do you accurately decide what the “change” in oceans are over time if these scattered bouys randomly floating around the Pacific and Atlantic Oceans go in and out of the Japanese currents and Gulf Stream? See, because the Gulf Stream and strong regional currents like those across the north Pacific wander themselves and vary in location and density and width and eddies and speeds. you cannot use even a simple approximation like “The Mississippi and Missouri rivers are always in the same location, so I can store data against the latest buoy internal GPS location, because the river will be here next spring, last fall, and last decade.”
I actually think you are missing the point. Today I’m driving my car through Durham. Its thermometer reads (at the instant I happen to look at it) 24C to a single degree. Ten minutes later I’ve driven out of the city and glance at the thermometer. Now it reads 22C (I’m out of the UHI of the city, and these numbers are realistic). I park. When I get into the car in my driveway an hour later it reads 28C — south facing concrete driveway, parked in the sun. When I go out the next day to drive away, it’s the end of the night, the same driveway is cooler than the grass nearby as it radiates heat away faster.
The only anomaly I am recording if I average that over a handful of cars all being driven on city streets is the anomaly associated with the paths cars are likely to take. Even if I include the measurements of a hundred million cars, averaged over the entire continental United States, it won’t give me the thing you’d like to consider the anomaly, even of the surface temperature of the United States. My samples are not random. They are not independent. They are not drawn in an unbiased way (look at the distribution of roadways in the US). And finally, they are drawn from a distribution that we believe is fundamentally non-stationary — this is the bit that you just don’t get. I cannot distinguish statistical error from the movement of the non-stationary distribution at the same time! They both appear the same, as an anomaly in the data! I can measure the temperatures of staggering numbers of cars, reduce the standard deviation of all of those measurements to nearly zero, and still have no idea what the actual temperature anomaly of the US is, let alone its linear trend!
To even think of justifying an estimate, one has to do lots of things. Stop measuring on the roads, for example. Select truly random measurement sites. Sorry, but that’s just how it is in Monte Carlo. If you select sites through any non-random means, you are asking for trouble, especially when the system you are samping has non-random internal structure! You are advocating no-black-swan statistics. People who lived in Europe performed a long running, very thorough experiment. They looked at swans, and everywhere they looked, the swans were white! They sampled in England, they sampled in France, they sampled in the Americas, they sampled in Asia. No black swans to be found. Not unreasonably, they concluded that they had proven to (fill in some huge number of zeros before the first 1) that there were no black swans to be found anywhere in the world Today, of course, they would call this kriging the data or infilling missing data by interpolating existing samples as that makes it sound ever so much more math-y and official.
And then they visited Australia…
Note that if they had used Monte Carlo to answer the question, Australia is around 1.5% of the Earth’s surface area (and of course maybe 5% of its land surface area). If they’d sampled the neighborhood of a few hundred randomly selected sites on the surface they could not have missed the black swans.
This is, of course, not a perfect metaphor for ARGO, and actually I love ARGO and think it is a great idea if still inadequate by an easy order of magnitude or three to achieve its actual goal. But the point still bears repeating. I’d trust a much smaller network of buoys that were dropped at places that are literally randomly selected from water over 2km deep, used to produce a single set of data, hauled out of the water, and dropped in at the next location at an equally randomly selected time. The axioms of statistics call for iid samples for a reason, and if you fail to respect this reason you must use Bayesian methods to correct for your bias (if you can!) and you have to consequently degrade your expected statistical precision by the uncertainty in your assumptions.
To return to the Black Swan problem, the erroneous assumption was that because swans fly, the global swan population was in some sense sufficiently homogeneous that it exhibited a kind of ergodicity. If you sit anywhere that swans are to be found and wait, if black swans exist one will come swanning along, sooner or later. You don’t even have to go looking lots of places. We don’t go looking for mosquitoes — they find us! Looking lots of places simply confirmed our prior biases and beliefs. But as it happened, the Black Swans of Australia just don’t fly over to Europe, much.
The same thing is true inside the US. If I looked at my squirrel population, I would conclude “no black squirrels”. After all, the US is still multiply connected by forest (with a few places where one has to run a highway gauntlet that squirrels never seem to hesitate to run). If there were black squirrels in, say, Detroit, there would be black squirrels in my neighborhood because I can’t imagine evolution selecting against black squirrelness enough to prevent squirrel diffusion.
Sadly, my wife is from Detroit, and Detroit is full of black squirrels.
This is directly related to ARGO sampling problem. Leaving the buoys adrift in the currents is cheap and easy. However, it without question biases their trajectories and biases the coverage of the sampling. Perhaps we can assume that the ocean in between, where the currents do not carry them, is homogeneous structurally with the ocean where the currents pick them up and concentrate them. Obviously, whether or not we can, we do. But that doesn’t mean that the assumption is true, and that has to be reflected as a degradation of the reported error in ARGO’s averages.
The same thing is true in the temporal direction. Because we do not really know the deep ocean dynamics governing heat transport, we don’t have any good way of knowing a priori what the distribution of temperature anomalies is over any extended period of time, or how rapidly it changes, or how it changes. Over time, ARGO might tell us some of those things, which is good. In the meantime, we cannot attach any particular meaning to any trend we observe in the possibly biased, error underreported data. It could be pure statistical noise, that we are treating like signal! We won’t know until after we understand the data.
The simplest thing to do is what Briggs recommends. Don’t fit (linear or other) functions to timeseries data and then use the function you fit as a replacement for the data itself!
Gads, how hard is this to understand? I don’t need somebody to draw a line through HADCRUT4 or ARGO data in order to see what the data does — it is nothing more than a guide to the eye, usually a guide drawn by somebody who wants to sell you something if that something is nothing more than a favored belief. I can see the data itself. By looking directly at the data, I can get some sort of feel for how much of what I’m seeing is probably noise, and how much might or might not be signal, although even this is fraught with peril the minute I try to mentally extrapolate what I see as a trend. It is a classroom example to make timeseries that has a known nonlinear form (plus noise), fit a short segment of it, and see how incredibly wrong you can be about the meaning of the linear trend you fit. There’s a lovely paper by Koutsoyiannis in which he illustrates the problem, which is happens all the time in climate science, basically every single time somebody tries to linearize something as the climate is a non-stationary process
That doesn’t mean one cannot analyze it, only that the analysis is hard and one ends up much more uncertain of the results of the analysis. And don’t presume that the results of your analysis have much predictive value, especially on timescales long compared to the scale you examine and analyze.
rgb
OK, one more example and then I have to clean my kitchen and go teach. One thing I’ve spent far too much of my life doing is importance sampling Monte Carlo. In it, one applies a Markov process to a system in such a way that it moves from an arbitrary initial state into an (average) state of detailed balance with the correct statistical weights and then ergodically sample the phase space in the vicinity of this “equilibrium” volume of phase space.
Obviously, one assumes ergodicity — but my stat mech teacher was Richard Palmer, who made a name for himself studying broken ergodicity in physics. So let’s simply note that one cannot assume ergodicity, only profoundly hope for it unless you are studying a comparatively simple system.
I was studying a comparatively simple system, and even near the critical temperatures I was studying I could count on it, subject to something called critical slowing down. One of many things I was looking at was indeed the critical slowing down itself — the dynamical critical exponents of the system. Those are found by looking at the dynamical scaling of the autocorrelation time(s) of the system near/at the critical point.
However, the autocorrelation time one obtains has a problem. The Markov process one uses doesn’t generate independent samples! Each timestep in the series is strongly correlated to the previous one, and it takes many steps to end up with “independent” samples. I was faced with the question: How many?
The answer was — run the process a very long time and compute the variance of the distribution of sample results. Now use the same data and compute the standard deviation which is related to this variance by the square root of the number of effectively independent samples. Compute the actual scaling of the variance to the standard deviation and from the result, infer the number of independent samples relative to the number of timesteps.
Only then could I actually make accurate error estimates of the quantities I was sampling! The sample standard deviation one computed from keeping every timestep as if it were an independent sample was much greater than the number of actually independent samples being drawn from the system. Using it one would get error estimates that were absurdly low, and be tempted to make many a false conclusion from the data — like (just as an example) asserting that this was statistically significantly larger than that, or worse, trying to fit curves through the data with nonlinear regression to extract critical exponents when the error bars you were feeding the regression code were themselves an order of magnitude too small.
Note also that I couldn’t do this sort of correction analysis on any short span of the data, because I had to have enough data that the variance itself was correctly estimated. This wasn’t a chaotic problem with multiple attractors (although it was a critical problem where a second attractor was emergent), but with critical slowing down this was at best a self-consistent process. If there really were multiple attractors with broken short-run ergodicity between them, I would have been open to serious black swan error — only sampling the neighborhood of whatever attractor I happened to be near or that happened to be most likely. To help protect against that, naturally I did a gazillion runs with different random number seeds and different starting conditions, but of course for truly complex problems there is no real solution, as they are non-ergodic and often nearly disconnected. In high dimensionality you may never even hit the place that determines their macroscopic behavior even with simple Monte Carlo in any reasonable amount of time (which is why importance sampling MC and why genetic algorithms and why simulated annealing and why hard problems are hard — they often appear to be NP complete).
To put this again into the context of ARGO, we have a tiny, tiny segment of data. What is it now, ten or fifteen years? It doesn’t even constitute a single point of data on the timescale most often quoted for climate, and the whole point of ARGO is to determine things like the autocorrelation times, the important transport processes, and so on — or that would be the point if they hadn’t been subverted into a way to prove anthropogenic global warming instead. In a few decades of patient observation, we’ll eventually accumulate enough data to begin to make some first, tentative statements about relaxation times and autocorrelations on decadal timescales, which is the only thing that matters.
So right now we don’t even have one real sample based on our best estimates of probable autocorrelation times and fluctuation times, but you are already fitting linear trends to the data, to absurd precision, without really knowing the variance of the system you are studying and hence unable to differentiate the sampling error from the autocorrelation trend and without any hope whatsoever of correctly ascribing a cause to the time constants you don’t even know yet.
Arrgh.
rgb
Oops, “greater” –>> “smaller”. The number of Monte Carlo samples is much greater than the number of iid samples inferred from the variance, so that the sd evaluated with the former as if they are independent is far, far too small.
rgb
The whole point of Argo buoys is a measurement of temperature and salinity in different depths. You are free to interpret that data any way you like. If it is insufficient to measure autocorrelation times, that’s just too bad.
rgbatduke, fantastic analysis. Makes me think ARGO is measuring the temperature of eddies, since that’s where stuff tends to collect. At least we’ll know the temperature of the Pacific Garbage Patch!
As I noted above, about 10 % of the ocean is not sampled at all. This includes e. g. the Arctic Ocean, the Sea of Okhotsk and the Banda sea to take just three very different areas.
How about making the ~3000 buoys fixed so that each covers about 120,000 square kilometers of ocean? Of course much of the ocean isn’t 2000 meters deep, so the floats would need to move up and down. Better than drifting, IMO.
See comments above. Fixed grids are OK, but are most useful if they are fixed and adaptive double the grid resolution a couple of times and see whether or if your measurements are converging. Or jackknife the grid you’ve got to the same end.
This is actually one of the better ways to get at the probable actual error, or at least to learn something about the internal consistency of what your data predicts as its own error.
I like Monte Carlo. iid is iid, not a grid, and not adrift in the internally structured soup you are measuring. No way to even detect a systematic bias in buoy sampling due to the fact that they tend to accumulate where the currents push them, which could be (for example) where heat tends to accumulate.
Think about it — upwelling cold currents push “away” from a surface defect. Buoys are actively repelled from the defect unless they reach it underwater. They are actively pulled towards places in the thermohaline circulation where there is downwelling surface water creating a net inflow. To correct for this requires a detailed knowledge of the thermohaline flow, the resulting temperature inhomogeneity, and more. ARGO might tell us about these things in a few decades. In the meantime, all we can reasonably guess is that there is almost certainly bias in the measurement due to the currents.
rgb
More decades of non-random sampling by drifting buoys might indeed produce data useful in some applications. Maybe over time the coverage area per float could be halved from roughly the size of PA to that of WV.
The overall R value is terrible (as visual inspection of the data clearly show).
Furthermore, there appears to be an even lower correlation at the higher observed values where the prediction tends to systematically underestimate the actual values. This means that (apparently) the predicted values may show an increasing error at increasing sea ice levels. It is clearly the ideal model for climate terrorism.
If the 3,000 ARGO buoys moved at 5 mph (I don’t think they come close), they could measure ~43% of the ocean’s cubic miles of water ( have it as ~303.4 Million cubic miles).
They don’t really swim; they move vertically, and their horizontal movement is a result of ocean currents. So they tend to stay in the same body of water, unless currents vary with different depths.
I looked at the maps of a couple and came to the conclusion that it wasn’t even close to 5 mph. It just goes to show what a small % of the oceans are even sampled, then read rgbatduke to see how worthless even that small % is.
Robert Brown didn’t seem to mention precision but a good summary as usual.
Even “precision” takes on different meanings if not very clearly stated what it is to mean. An instrument stated with a 0.002 precision many times means the readings have a display of 0.00x three decimals with x being in this case always in even values in the last digit. Or it could mean repeatability within a time period like two readings taken 20 minutes apart are guaranteed to have the difference between the two off by no more than ±0.002 from actual.
Then you have “accuracy”. You can have a very precise but totally inaccurate readings!
Other commenters above have spoken on the calibration issue but what of drift? The manufacturer may be able to guarantee that over the lets say five year lifetime of the instrument it will not drift more than 0.0x (accuracy) and that due to precise calibration it’s absolute accuracy is also within that range but if you ever have any common drift (in this case maybe caused in common by barnacles, salt deposition, single salt molecule infiltration into the electronics, water related, etc) that all instruments naturally have in common then even ‘trends’ over long time periods of time could be up to two times the stamped accuracy off from the actual trend and if those are in common even great numbers of instruments or a great number of readings will never average out or removes that factor, all without going out of stamped specs.
So a trends to 0.002 °C/decade? Pure hogwash… served up to us courtesy of the global climate scientist community, but thats their job and pay of late.
Wrong Robert. He writes a lot better and is more knowledgeable.
Please, it is not “5 x 1021 Joules” . Use “5 x 10^21” where ‘^’ stands for ‘to the exponent of’ or “5 x 10E21” where “E” stands for ‘to the exponent of’ or ‘5 x 10**21’ with the same meaning. They are all standard while 5 x 1021 Joules is just confusing.
Well said.
Also, it’s joules, not Joules, if you write it out and J not j for the symbol (capital for the symbol if the unit is named after a person – in this case James Joule). Case is important but clear with the SI system.
In the arctic most of the ice melts as it is moved by currents out of the arctic. So you must add, not a temperature measurement, but a metric to account for the energy to move the ice, which varies greatly, and has far more to do with cyclical ocean changes.
Robert Balic’s statements regarding precision are valid for statistical errors that are independent and identically distributed. I have argued for some time now that ARGO data does not necessarily conform to this ideal. In the world of manufacturing we have the iron-clad rule of stack up error, which is that stack up error equals or is less than sum of absolute value of errors. I think ARGO data might have rather large errors as the environment in which the data are collected is not stationary. Moreover, the conditions under which researchers established sensor precision and drift is not the open ocean.
Another thing to ponder: how exact and stable are the ARGO pressure transducers? The measurements occurs at preset pressures. If the pressure sensors aren’t absolutely stable then the measurement depths will change over time.
In tropical waters there is typically about 20 degrees difference between the surface and 2000 meters depth, i. e. 1 degree per 100 m. A change of 0.002 degrees is consequently equivalent to 0.2 meters (about 8 inches). Actually it is worse because at the termocline the temperature gradient is about four times as steep, so there you need precision on the order of. ± 1 inch
Anyone want to bet that Argo pressure transducers are stable enough to measure depth with a ± 1 inch repeatibility over a 4 to 6 years life?
+1. Astute. Vertical rate of change in temperature is high in the upper 200 m and not always monotonic.
From Nic Lewis 5/10/13 at 1:33 pm in Layers of Meaning in Levitus
@ Curious George 10/10 at 10:14 am
Are you implying – but not saying – that with 1000 thermometer readings, each one accurate to ± 1°C, you can get a weighted average accurate to ± 0.001°C
No. If it is as you state, the standard error of the mean is ± 1°C/sqrt(1000) or about ± 0.03 °C
ARGO’s might have a precision of ± 0.002 °C they have also been measured to have a drift of more than ± 0.001 °C of per year, which is a at best a systematic error for each instrument.
Statistically, we must not forget that these precise thermometers are trying to measure the temperature of a body that has a range of – 1°C to ~ 31°C with 90% of the body from 2 °C to 7 °C in a 3D shape that moves and evolves and is hard to predict. That’s why we need to measure it.
Much of the sampling discussion above relates back to three subjects discussed in Decimals of Precision Those subjects are:
Ari Tai (Flight behavior; are floats heat seeking?)
Martin A (spatial Autocorrelation)
George E. Smith (Nyquist sampling)
Plus my support (at Feb. 3, 2012 at 1:21 pm, same thread) of
_ _1. possible heat seeking behavior leading to non-random sampling from float tracks behavior and
_ _ 2. Nyquist underesampling issues sampling in 6 dimensions: 3 spatial and 3 temporal (diurnal, seasonal, climatological)
It is worth repeating the paragraph from rgbatduke 10/10 at 7:36 am
Is the ARGO dataset sampled enough to confidently interpret the space between reading to the vaunted 0.002 deg precision? Well let’s test it. Take the dataset for any 10-day period. Do several 50% bootstrap tessellations to interpolate between ARGO profile vertices. Now interpolate the temperature at all x,y z points of the volume according to that tessellation net. Repeat the bootstrap. resample the control point, reconfigure the tessellations, interpolate the new temperature field. Repeat at least 9 times.. At each x,y,z poin in the volume, you now have N different interpolations, from N different combinations of ARGO data used (that probably reported several days apart!). What is the scatter of interpolated temperatures for eacy x,y,z (and it probably varies a lot with shallow z)? What is the mean uncertainty?
The precision of the ARGO is vanishing small compared to the interpolation error between ARGO profiles.
Which is almost certainly vanishingly small compared to systematic errors due to non-stationarity and bias even in the ARGO profiles. But who cares? The precision of a buoy is tremendous, maybe. So we can be certain that the ocean is warming, especially if we throw out any data that looks “too cold”.
rgb
I don’t think that I pointed out my problem with the Argo data. I highlighted one of many problems with just simply assuming that many measurements would mean each measurement need not be precise, just accurate. One is that the resolution of the instrument is not the mean and standard deviation of many precise measurements varying about an increment that you can just throw into the soup. There are other problems that are more important. I just wanted to highlight that one.
The problem with the PIOMAS data is different but I was just questioning whether you can white wash any concerns with “a lot of measurements were made”.
Everybody forgets…
……
……
http://www.resacorp.com/images/slrund073.gif
…
….
As n approaches infinity, SE becomes exact.
How does the Balic discussion in the sixth paragraph apply to satellite measurements of SLR? I seem to recall that Jason and Topex were on the order of 25mm or more, but claims have been made for just over 3mm per year. I’m not an expert on this; is there a difference?