 This is one of those times I’m really glad WiFi has been installed on passenger aircraft. After reviewing this paper at Nic Lewis’ home prior to that extraordinary meeting with climate scientists I mentioned, and expecting a leisurely writeup in about a week, Nic sends me this email which I get on the plane:
This is one of those times I’m really glad WiFi has been installed on passenger aircraft. After reviewing this paper at Nic Lewis’ home prior to that extraordinary meeting with climate scientists I mentioned, and expecting a leisurely writeup in about a week, Nic sends me this email which I get on the plane:
Anthony, Climate Dynamics has released my paper nearly a week earlier than they said!!
This is a significant paper. As I once read on Climate Audit:
This will set the cat amongst the pigeons
Here is the paper at Climate Dynamics: http://link.springer.com/article/10.1007/s00382-014-2342-y
The implications for climate sensitivity of AR5 forcing and heat uptake estimates
Abstract
Energy budget estimates of equilibrium climate sensitivity (ECS) and transient climate response (TCR) are derived using the comprehensive 1750–2011 time series and the uncertainty ranges for forcing components provided in the Intergovernmental Panel on Climate Change Fifth Assessment Working Group I Report, along with its estimates of heat accumulation in the climate system. The resulting estimates are less dependent on global climate models and allow more realistically for forcing uncertainties than similar estimates based on forcings diagnosed from simulations by such models. Base and final periods are selected that have well matched volcanic activity and influence from internal variability. Using 1859–1882 for the base period and 1995–2011 for the final period, thus avoiding major volcanic activity, median estimates are derived for ECS of 1.64 K and for TCR of 1.33 K. ECS 17–83 and 5–95 % uncertainty ranges are 1.25–2.45 and 1.05–4.05 K; the corresponding TCR ranges are 1.05–1.80 and 0.90–2.50 K. Results using alternative well-matched base and final periods provide similar best estimates but give wider uncertainty ranges, principally reflecting smaller changes in average forcing. Uncertainty in aerosol forcing is the dominant contribution to the ECS and TCR uncertainty ranges.
A PDF file of a reformatted version of the final revised manuscript titled ‘The implications for climate sensitivity of AR5 forcing and heat uptake estimates’, with minor editing corrections, is available here: Lewis&Curry_AR5 energy budget climate sensitivity_Clim Dyn2014_accepted (reformatted, edited). This work was accepted for publication by Climate Dynamics on 13 September 2014.
A compressed zip file containing data and computer code that will generate the results in the paper is available here: AR5-EB-LewisCurry-ClimDyn-2342
Nic is preparing a discussion about the paper to post at Climate Audit, I’ll add it when it is ready – Anthony (somewhere over Canada)
UPDATE: The CA post is up at http://climateaudit.org/2014/09/24/the-implications-for-climate-sensitivity-of-ar5-forcing-and-heat-uptake-estimates-2/
EXCERPT:
When the Lewis & Crok report “A Sensitive Matter” about climate sensitivity in the IPCC Fifth Assessment Working Group 1 report (AR5) was published by the GWPF in March, various people criticised it for not being peer-reviewed. But peer review is for research papers, not for lengthy, wide-ranging review reports. The Lewis & Crok report placed considerable weight on energy budget sensitivity estimates based on the carefully considered AR5 forcing and heat uptake data, but those had been published too recently for any peer reviewed sensitivity estimates based on them to exist.
I am very pleased to say that the position has now changed. Lewis N and Curry J A: The implications for climate sensitivity of AR5 forcing and heat uptake estimates, Climate Dynamics (2014), has just been published, here. A non-paywalled version of the paper is available here, along with data and code. The paper’s results show the best (median) estimates and ‘likely’ (17–83% probability) ranges for equilibrium/effective climate sensitivity (ECS) and transient climate response (TCR) given in the Lewis & Crok report to have been slightly on the high side.
Our paper derives ECS and TCR estimates using the AR5 forcing and heat uptake estimates and uncertainty ranges. The analysis uses a global energy budget model that links ECS and TCR to changes in global mean surface temperature (GMST), radiative forcing and the rate of ocean etc. heat uptake between a base and a final period. The resulting estimates are less dependent on global climate models and allow more realistically for forcing uncertainties than similar estimates, such as those from the Otto et al (2013) paper.
Base and final periods were selected that have well matched volcanic activity and influence from internal variability, and reasonable agreement between ocean heat content datasets. The preferred pairing is 1859–1882 with 1995–2011, the longest early and late periods free of significant volcanic activity, which provide the largest change in forcing and hence the narrowest uncertainty ranges.
Table 1 gives the ECS and TCR estimates for the four base period – final period combinations used.
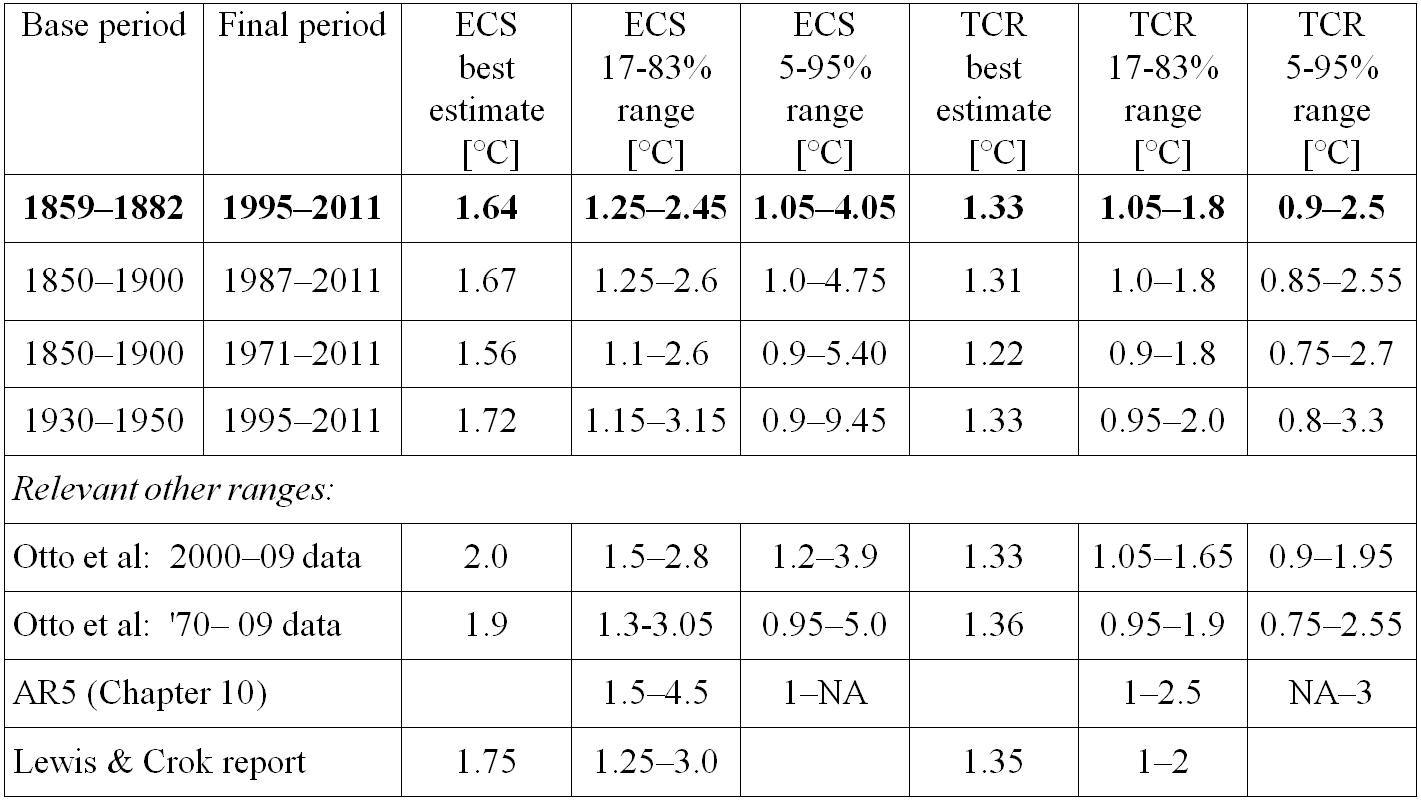 Table 1: Best estimates are medians (50% probability points). Ranges are to the nearest 0.05°C
Table 1: Best estimates are medians (50% probability points). Ranges are to the nearest 0.05°C
AR5 does not give a 95% bound for ECS, but its 90% bound of 6°C is double that of 3.0°C for our study, based on the preferred 1859–1882 and 1995–2011 periods.
Considerable care was taken to allow for all relevant uncertainties. One reviewer applauded “the very thorough analysis that has been done and the attempt at clearly and carefully accounting for uncertainties”, whilst another commented that the paper provides “a state of the art update of the energy balance estimates including a comprehensive treatment of the AR5 data and assessments”.
Full report here: http://climateaudit.org/2014/09/24/the-implications-for-climate-sensitivity-of-ar5-forcing-and-heat-uptake-estimates-2/
UPDATE2: Judith Curry weighs in. More details on the paper at
http://judithcurry.com/2014/09/24/lewis-and-curry-climate-sensitivity-uncertainty/
Nicely timed science as an antidote to Tuesday’s Circus.
Nice!
For many of us, it seems quite obvious that climate temperature is less sensitive to CO2 than other variables. Additionally, the notion that positive feedbacks will push temperatures higher despite the fact that temperatures aren’t outside the range of natural variability is a difficult pill to swallow.
This means that many of us doubt that the climate will ever warm to catastrophic levels. It simply doesn’t make any sense. Why would runaway global warming occur now despite the fact that temperatures have been this warm many times in the past? Why now, and why do people think that the earth’s climate system is so unstable? Earth’s climate system definitely seems stable to me.
The climate has to be unstable and fragile to back up their contentions that we are on the brink of disaster if we don’t act NOW. somehow the world must be convinced of this. They will continue sabatoging the economy regardless, but it would be so much easier is they could scare us don’t you know.
So we’re down to roughly 1.64 C TCS (but with a long tail), which suggests that feedback from all sources is nearly neutral as this is easily with the error estimates of CO_2-only forcing. It is also solidly less than 2 C, almost a full degree less than the claims in the first drafts of AR5.
And this is not yet finished. Every year that the climate remains essentially neutral forces a recomputation of this number, by forcing a recomputation of the fraction of any observed past warming that was likely to be natural instead of CO_2 linked. TCS is still in freefall and will remain there until the climate decides to actually warm some more. At the moment, its pace in the 2000s is well under a single degree C extrapolated to 2100. If there are any nonlinear caps in the climate system — strong negative feedbacks that kick in once temperatures exceed some value — we could already have reached one.
Or not. All that this result fundamentally shows is that we don’t really have a very good idea of what the TCS is likely to be. Otherwise, it wouldn’t keep changing as we get more data. It is likely very premature to conclude anything at all about it, either way.
But yeah, a cat among the pigeons. Especially coming out right now, with climate marches and UN inspector-generals complaining that nobody takes the climate seriously any more (maybe because more people are dying because of amelioration every year than have ever died from “climate change” itself? ya think?).
For that very reason, I predict that it will not be covered by any of the mainstream media. There will not be any headlines such as “GLOBAL WARMING MAY BE A FULL DEGREE LESS THAN PREVIOUSLY EXPECTED” or “MISCHIEF MANAGED: CLIMATE CATASTROPHE NOW APPEARS UNLIKELY, BUT ONLY AFTER SPENDING HUNDREDS OF BILLIONS `PREVENTING’ IT”
rgb
This study, like all climate sensitivity studies, assumes that the late warming trend circa 1977-97 is due to CO2. That seems to be a very big assumption when it is considered that studies have shown that the late trend was due to increased insolation via reduced cloud albedo. Taking this fully into account, only the warming trend circa 1920–40 can be assumed attributable to CO2. Still, it is only an assumption. Please be aware that “climate sensitivity” is the very whole of the issue. Any calculation of climate sensitivity involves the assumption that all warming of the past century and a half is attributable to anthropogenic CO2. This is a very big assumption that ignores any possibility of natural processes. Climate “science” is based on such unverifiable assumptions as is this study.
Mpainter,
I agree with your comment. I have a question for all the big brains on this site. Increasing CO2 will clearly cause the altitude at which Outgoing Long-Wave IR is released to space to increase, which will cause the temperature at which this radiation is released to space to be lower, which will produce more of the dreaded “back-radiation.” I cannot understand how an increase in “back-radiation” could increase Surface temperature!
Is it not true that “back-radiation” will be absorbed and re-transmitted high in the troposphere, but absorbed and “thermalized” more and more as it gets lower and lower in the troposphere, with essentially zero reaching the surface? This would increase temperatures mid-troposphere, but does this actually produce a change at the surface? No mechanism capable of this effect is obvious to me.
Spending billions based on an unverifiable assumption such as that 1977-1997 warming was 100% attributable to CO2 should make us question the bona fides of every institution of higher learning with faculty who confirm this assumption. The universities have become havens for socialists, even in our capitalist extremely successful nation, who let the dogs in???
Michael,
Read: https://docs.google.com/document/d/1WPeBO_Ra9mkhWjv0J0SNmyRzHFVE9zPP8xRDUpR08jc/edit?usp=sharing
This should give you a better understanding of the process. Getting caught up in the details of a complex process, without having all of the facts straight can be misleading. The analysis leads to a simple net effect of the process, and clarifies the critical issues. It should be noted that changes in storage (ocean heat), movement of large long period currents, changes in aerosols and clouds, changes in solar activity and secondary effects (UV, magnetic fields, not just average intensity), etc., make the final net result of the changes in CO2 not able to be sorted out. However, the basic atmospheric greenhouse effect, and approximate gross warming from all causes can be better understood.
Weinstein,
I found that completely incomprehensible. As a degreed mechanical engineer I have plenty of understanding of thermodynamics, heat transfer, dipole moments, and the relationship between frequency and temperature, but that was clear as mud.
Once again, is there a way for “back-radiation” to reach the surface from the tropopause without being thermalized in the mid-troposphere?
Your essay Leonard reminds me of something I saw at scienceodoom.com
Plus the assumption that CO2 actually does effect temperature, and not vica versa.
vice versa
You only get one “a”. Where to you want it?
Ack. Typo, Muphry’s law strikes!
“where do you …”
Latecomer, it works in both directions. If CO2 concentration increases due to our activities (ie making cement, burning coal) the greenhouse effect of CO2 increases temperature. If the ocean temperature changes due to orbital forcings, solar effects, volcanoes, or shifting continents the temperature change can cause ocean release or absorption of CO2, these phenomena also change plant behavior and activity, which also changes the co2 content, therefore we can say it works both ways.
Hey Brian H – Another typo – That should be “Murphy’s law,” not “Murphry’s.” Sorry, but I’m a Murphy. I’m sure you understand…
Brian H you also missed “effect temperature”.
Also agree. The Null rules; natural variation MUST be first assumption, and it is unscathed.
Actually, it doesn’t. That part of its beauty.
It just takes the IPCC’s own AR5 estimates for T, Q, and F to compute a TCR and ECS much lower that the CMIP5 climate models. A falsification as powerful as the pause, using different means.
mpainter – re “a very big assumption”: The paper is not direct science, it is an exercise in indirection (using something to point to something else). What it does is to take all the assumptions in the IPCC report to see where they lead. It tells us nothing about climate, nothing about Climate sensitivity, nothing real, but it does tell us that the IPCC report and the climate models are wildly inaccurate based on their own assumptions.
Hoist on their own petard, do mean?
Who needs a CS study to see that models are wildly inaccurate?
A model incorporating this study’s cs figure would be only less inaccurate.A dubious virtue.
Howsoever derived and by whosoever, the same assumptions are inherent in this study as are found in all derivations of climate sensitivity:
That increasing temperature trends are due only CO2 and natural variation is dismissed
I’m certainly not going to complain about this result, but surely if the recent heat was magically going into the deep oceans instead of the atmosphere then surely it would not be possible to compare warming rates for the 2 periods? So wouldn’t one predictable rebuttal of this be along those lines?
One thing I have wondered about if recent heat had been going in the deep oceans wouldn’t we see a increase in rate of sea level rise? I haven’t seen any data that indicates that.
If one were to discard the second law, anyone could reason that the heat went deep and is waiting to spring out at us when we least expect it….lions and tigers and bears oh my!
Kazinsk, sea level IS rising. The rate is very low. The thermal expansion effect can be masked by temperature changes in the last hundreds or even thousands of years. Don’t forget a temperature change at the surface creates a transient (like a moving ripple) which can take thousands of years to spread through the world’s oceans. It’s possible the temperature pulse from the medieval warm period is still moving through the deep ocean. Superimposed on that is the little ice age pulse in the opposite direction, and now we are seeing a series of pulses which barely got started.
Well folks, if you take the time you can see for yourselves exactly at what rate sea level rises. And that rate, according to data kindly furnished by the NOAA is…
0.00 mm / year. Surprised?
Go see NOAA mean sea level data calculated from the gauge for the west coast, the Gulf coast, and the east coast, as far north as Chesapeake Bay.
These show a steady sea level for the last 15-20 years. How about that?
Chesapeake Bay shows a rise but in fact this is the well known subsidence of that area that is being recorded.
Bottom line: the sea level trends that show rising SL are being fabricated. Surprised again? Then you have yet to take the measure of these enterprising and inventive global warmers.
This paper as usual fails to take into effect the lingering effect of the last little ice age. When this is considered, only a minor fraction of the temperature rise is attributable to increasing CO2, hence the sensitivity should be in the lower end of the range, ESR and TSR being one degree C or less.
My sceptics hat remains firmly in place lenbilen. There’s something nonsensical and simplistic about CO2 sensitivity analysis.
It appears to appeal to “luke-warmers” and those wanting to squeeze into the corridor of acceptability
Great!…..so global warming is over
With adjustments and algorithms…..we’re already there
More details on the paper at
http://judithcurry.com/2014/09/24/lewis-and-curry-climate-sensitivity-uncertainty/
curryja,
You are in the mix of an intensifying TCS and ECS debate and that is where the action is. Nice.
John
So to sum up RFK jr. Is a moron.
I’m sorry, was there some doubt about that?
You’re right. No there wasn’t.
He’s worse than that. Read his bio.
Thus ends the great Global Warming scare.
First the climate wouldn’t cooperate, the signature troposphere hot spot wouldn’t materialize, now the models are revised based on real world data, and it turns out that we’ve already had more than half the warming expected. So far I’d say the result has been a net positive, and we may well be glad to have that warming in the next couple of decades if there is solar minimum related cooling we have to deal with.
Also just out, a PNAS/NOAA (!) study finding no anthro influence on West Coast weather. CO2 not involved. http://www.pnas.org/content/early/2014/09/16/1318371111.abstract “Very surprising” to the Believer authors.
Good and interesting citation, but where does it say “very surprising”? I don’t see that.
Such quotes are usually in the press release and later reported in the media.
The scare isn’t over. I may be jailed and sent to The Hague as a war criminal if Mr Kennedy’s proposal gains traction in the future. This thing has become like a religious crusade backed by people with political clout. And then there’s the effect of subsidies on my electric bill. Or that lady Norgaard who wrote I should be sent to the mental ward because I won’t accept Dr Mann as my saviour and have refused the official TCR range….this is quite scary.
Nobody is skeptical of this paper?
I am climate sensitivity to CO2 is zero. So I am skeptical of this paper.
Should have been “I am. Climate….
Well they cut it basically from 2 to 1 I would say they are half way there.
cant be zero.
Can so. ☺
It may not be constant.
Which puts into question the criticality of climate sensitivity to CO2 in the first place.
– – – – – – – –
Steven Mosher,
Unless nature, in the course of things, shows us that it is zero. Then as a science focused person you would agree that nature is right, right?
John
I am. I take this as just a standard argument tactic. “Even if we believe that highly adjusted temperature history and we believe that this rise is 100% due to man, then sensitivity is still much lower than previously estimated”.
I am. I think the net effect of adding CO2 to the atmosphere is negative (cooling) when convection is factored in. The idea that 400PPM of CO2 is a magic warming gas when it has little thermal mass (compared to water) is laughable. A few milliseconds of delay in outgoing CO2 resonant wavelengths can’t do anything useful. Where’s the lab experiment that shows otherwise?
Could be below zero…
I agree
Agreed.
mpainter has clearly stated the problem with the basic assumption in this paper. There is no reason to assume that the 77 -97 rise is due to anything other than an approach to a peak in the 1000 year solar “activity” periodicity. The IPCC models are inherently useless as forecasting tools. For a complete discussion of this and an updated forecast of the possible coming cooling based on the natural 1000 year and 60 year periodicities in the temperature data see
http://climatesense.norpag.blogspot.com
As to climate sensitivity we have no good ideas of what it is -. This is in fact the IPCC position.
By AR5 – WG1 the IPCC itself is saying: (Section 9.7.3.3)
“The assessed literature suggests that the range of climate sensitivities and transient responses covered by CMIP3/5 cannot be narrowed significantly by constraining the models with observations of the mean climate and variability, consistent with the difficulty of constraining the cloud feedbacks from observations ”
In plain English, this means that the IPCC contributors have no idea what the climate sensitivity is. Therefore, there is no credible basis for the WG 2 and 3 reports, and the Government policy makers have no empirical scientific basis for the entire UNFCCC process and their economically destructive climate and energy policies.
The whole idea of a climate sensitivity to CO2 (i.e., that we could dial up a chosen temperature by setting CO2 levels at some calculated level) is simply bizarre because the response of the temperature to Anthropogenic CO2 is simply not a constant, and will vary depending, as it does, on the state of the system as a whole at the time of the CO2 introduction.
Sorry the link is
http://climatesense-norpag.blogspot.com
Yeah, once allowed outside their ’79-’99 training playground, hind or fore, the models have “no skill”.
Dr Page, the climate sensitivity was selected arbitrarily to be the temperature response to doubling CO2. The actual answer depends on the pathway. But the estimate is rough, therefore it is polite not to complain about the fact that response isn’t constant. I see it as a simple number we can use to think about the problem.
So Norm, I realize most skeptics likely didn’t bother to waste time listening to Obama deliver his Climate Change mendacity on Monday to UN GA, they have better things to do than listen to his lies I realize. For myself, I certainly had better things Monday to do, like work, or straighten out my sock drawer, pick lint out of my navel etc than listen to Obama.
You see though, we’re fighting the good SCIENTIFIC fight here at WUWT, discussing ECS or TCR, radiative forcings, you know all that stuff warmists Climate Scientists once studied too.
But Obama and his sycophantic followers, they’ve moved-on (pun intended) in the Climate Wars. Science is no longer needed.
I have been thinking how badly the warmists are losing the scientific position now, and I wondered how the Liar-in-Chief would tell half-truths and mis-directions at the UN to avoid admitting the losing position they are in.
Here is the URL link to the WH site that has the text of Obama’s UN address Monday.
http://www.whitehouse.gov/the-press-office/2014/09/23/remarks-president-un-climate-change-summit
In his UN Speech, Obama uses the word “carbon” 12 times, five as “carbon emissions”, and 7 as “carbon pollution.” He never utters the phrase “carbon dioxide,” or “CO2.” Maybe later he can claim he was talking about “carbon soot?” Maybe Methane? Maybe sucrose? Who knows? He gave himself specious wiggle-room for the future to claim he didn’t actually say “carbon dioxide causes warming”. He never uses the word “temperature”, as in rising temperatures, but he mentions “hottest” twice.
And NO WHERE in it does he mention “global warming”.
He does make this early statement:
“In America, the past decade has been our hottest on record. Along our eastern coast, the city of Miami now floods at high tide. In our west, wildfire season now stretches most of the year. In our heartland, farms have been parched by the worst drought in generations, and drenched by the wettest spring in our history. A hurricane left parts of this great city dark and underwater. And some nations already live with far worse. Worldwide, this summer was the hottest ever recorded — with global carbon emissions still on the rise.”
So the “worst drought in generations”? That is a tacit admission there were even worse droughts though in the past, before man’s CO2 could have had an effect.
Miami, isn’t that coastal subsidence? “Wettest spring in our history”? That choice of words hides the fact there was no major flooding from the big rivers. Farmers love wet springs. And the great floods of all the major US rivers were far worse in the past, which is a truer indication of a wet spring and wet winter.
And does anyone doubt “some nations already live far worse” than the USA? Was an asinine statement. He probably wrote that himself over the objections of his speechwriter, since he’s a better speech writer than them.
His reference to Hurricane Sandy, a weak Cat 1 at landfall (at best), during the Atlantic hurricane season. It coincided with a high tide and a full moon. Hardly anthropogenic factors at work.
Then he makes the non sequitur, “– with global carbon emissions on the rise.”
I go through this exercise to demonstrate that the Left, President Obama, Mike Mann, (and NASA’s GISS in all likelihood too) have abandoned any real references to global warming effects of CO2. They make non sequitur about “carbon emissions.”
The point is, they don’t care if ECS or TCR is -100, 0, or a gazillion. They don’t really care. It is now a mind set, not about Global warming effects of CO2, but about eliminating carbon emissions no matter what the cost to humanity. Obama’s mind is made up. The only thing left for these idiots is vote the Progressive climate morons out of office so a new administration can clean house at NASA, NOAA, GISS, LLNL, DOE, DOS, EPA, FWS, IRS, etc.
I agree that there seems to be no way TCR or ECS can be anything but well under 1 deg C or even 0.0 deg C, given the hiatus. BUT what happens to the ECS calculations if an undeniable cooling period sets in (as you suggest on your website)? Sure the science says ECS or TCR doesn’t matter at that point as it is in the nose of dynamical variability and other forcings (solar).
The only thing at this point that will change Obama’s idiotic course and thus the US government and NASA’s weather data fabrications is either the President is removed, or public opinion (which is the only thing he considers when his mind is made up) becomes so overwhelming that he is politically forced to capitulate the Climate argument. (like he had to with deciding to bomb ISIS in Syria).
For that we need 2 or 3 very hard winters to come to US, I hate to say.
There are two DOE’s to clean out. Department of Energy and Department of Education… just needed to improve your list of cleaning… In fact, there’s nothing that doesn’t need cleaning out in this federal government. DHS is obviously screwed too.
I am working on a project with the research scientist, we are developing a new product (capitalism type stuff). She is using all the tools a scientist should use to lead us in a sound direction and allow us to develop a business plan, issue a risk analysis and engineer a manufacturing process. Her science skill will make the project a success, why is it so damned hard to get the same quality from the IPCC and our political class?
The answer is simple: Your scientist wants to make money by getting the science right. The IPCC will lose money if they get the science right- their funding would end if they told the truth.
We need a new label: “Catastrophe funding”?
The problem is a lot more complex and they are missing data to plug into the models. Then there’s the IPCC architecture. Their whole approach is a messy affair.
Also, Munich Re and other insurers support warmism. (But they will switch to New Ice Age scare the moment that works better to increase premiums)
This is what the actual data says – a relatively low climate sensitivity.
It also says the feedbacks have to be greatly overstated in the science given that the ECS and TCS are relatively similar figures, and the ECS estimate is not much different than the calculated impact of CO2 alone with no feedbacks.
Not to be picky but it’s …the Cat amongst the Canaries, I believe!:]
It (the cat) would probably drown – there’s a fair distance between the Islands 😉
GREAT WORK, thanks Nick and Judith!
I have long thought that Climate Sensitivity, both the Transient (TCS) and Equilibrium (ECS) versions are closer to 1°C than to the ~3°C assumed by the IPCC using “adjusted” (biased) thermometer data, and their strong desire to “cook the books” to remain in the catastrophe business.
That is, I think the Official Hockey Team is off by a factor of 2 or 3.
The central estimates in the new Lewis and Curry paper are TCS = 1.33°C and ECS = 1.64°C, which is about half the IPCC levels, or a factor of 2, a very good start.
I look forward to further solid research that justifies my earlier estimates.
I predict that the “real” central estimates will turn out to be TCS = 0.8°C and ECS = 1.1°C.
Ira Glickstein
Is 0.0°C close enough?
Brian H: Well, IMHO your 0.0 C is closer than the IPCC’s 3.0 C to what will ultimately be found to be the “truth”. However, I think my estimate of about 1.0 C will be closer still.
Just because the official climate team is distorting the science of the “greenhouse” effect by exaggerating TCS and ECS, does not give responsible skeptics license to distort it in the opposite direction.
I have no doubt that atmospheric CO2 and H2O are responsible for absorbing long-wave IR radiation from the earth and re-emitting some of it back, raising the surface temperatures above what they would be in an atmospheric absent these gases. If any WUWT reader does not accept that basic science, I recommend reading my series here on Visualizing the Atmospheric “Greenhouse” Effect, or the views of Willis Eschenbach and Anthony Watts himself.
Ira Glickstein
100% agree with IRA. A reasonable person would assume as a first guess that since our climate has been relatively stable…. the net feed-backs would likely be net negative. Thus a value for TCS is most likely <1.1C. It could be higher than 1.1C, but likely NOT. So far, based on data and recent lack of warming (especially based on the data requiring the fewest adjustments – satellites and weather balloons) the TCS is low.
I amwith Brian H
about 0 degC looks close enough.
Don’t forget that these estimates are based upon temp data, the correctness of which is moot.
How much of the ‘observed’ warming, used in their study, is down to temperature adjustments, past cooler, recent warmer?
If there is no temperature rise through to 2020, then what will climate sensitivity be?
Many Scientists are predicting that there will be no warming before 2030, if that is so, what will climate sensitivity be?
This is all make believe/guestimates.
Acheson: THANKS. Great minds think alike. Ira
Oops. Sorry Alcheson – the spell check changed your name in my previous comment. Ira
I don’t agree that a reasonable person would assume that our climate has been relatively stable. Over what time periods? Our own life times are but a blip in the scheme of things, and yet we can see swings between warming and cooling trends every 30 years since the end of the LIA. With the heat capacity of the oceans dwarfing that of the atmosphere, I don’t think we have a clue other than to try and capture patterns and project them into the future. But other than the recent observations of the various ocean oscillations that go in sync with these 30 year swings, we still have very little empirical knowledge of what is driving them. And the 164 years since the supposed end of the LIA is but a brief snapshot of what is taking place.
Thanks IRA. Now Spren, if we look at the temperature/CO2 history over the past 500 million years, we see the temperature has only varied about +/-5C from an average value of about 17C. I would say that is quite remarkably stable, even though CO2 was in the thousands of PPMs at times. There was never runaway global warming.
No one has a clue what the changes in clouds or global water vapour were over the study period. Without these data along with SST or OHC data (which also is missing over study period) how can anything but speculation about sensitivity emerge?
Which makes all this complex work seem ridiculous to me. Anything that suggests that ECS uncertainties are higher than the IPCC has pretended is a step forward but I can’t help feel like this exercise is angels dancing on a pinhead. Or is there something I’m missing?
Dave You are quite right. Curry is unable to break away from the group think approach of the academic establishment – for a different approach check my corrected link just above.
You may be missing the fact that they don’t challenge most established climatology theoretical basis. They set loose an idea which is like a liter of miscible fluid falling in a bathtub full of water. The miscibility is the key. The work is solid, and it can slow down the panic. This is very useful because it allows a much better planning effort to respond to the problem. And if the problem is minor, at least we wasted less money and effort.
Dave, are you into tax law?
Do you know Mike?
Some Canadians might get the reference – nothing to do with Mann!
https://www.facebook.com/groups/30579496309/
Posted this info here…..wonder what they’ll make of it….;-)
Good work by Lewis and Curry!
We learn (yet again) that the sky isn’t falling, overheating, or being destroyed by man.
At the same time, the ‘climate crisis’ meme continues to be exploited ruthlessly at the highest levels of government. We learn today that Our Dear Leader has ‘taken executive action on climate change’, as he described in his recent speech at the UN.
Obama Announces Executive Actions to Fight Climate Change at UN
President Obama announced a series of executive actions to fight climate change on Tuesday, during a speech to the United Nations Climate Summit in New York City.
Obama ordered all federal agencies to begin factoring “climate resilience” into all of their international development programs and investments.
The action is expected to complement efforts by the federal government to reduce greenhouse gas emissions, according to the White House.
Obama is also expected to release climate monitoring data used by the federal government to developing nations.
The NOAA will also begin developing “extreme-weather risk outlooks” for as long as 30 days in advance to help local communities to prepare for damaging weather and prevent “loss of life and property,” partnering with private companies to monitor and predict climate change.
What the hell is ‘climate resilience’? And how do you ‘factor it into international development programs and investments’?
Similarly, isn’t a 30 day weather outlook a ‘weather forecast’? When did weather forecasts become ‘predictions of climate change’?
In Cairo Illinois climate resilience means having 20 thousand empty gunny sacks and piles of sand to fill them if the river is approaching flood stage.
“The NOAA will also begin developing “extreme-weather risk outlooks” for as long as 30 days in advance to help local communities to prepare for damaging weather and prevent “loss of life and property,”
So we have our 2 coldest Winters since the 1970’s (2009/10 and 2013/14) in most of the US and Obama is shutting down power/electricity producing coal fired plants that were essential last Winter for electricity/residential heating when the extreme cold hit.
This plan will guarantee black outs. If not this Winter, then in some Winters in the near future.
http://www.wallstreetdaily.com/2014/09/02/coal-burning-power-plants/
What if, instead, we have more heat waves as promised by this administration because of human caused climate change(but are not happening)?.
Shutting down coal plants used to generate power/electricity for air conditioning would make things worse.
The US has 200+ years worth of coal to generate electricity/power. To become more energy independent, why are we shutting down coal fired plants?
This makes about as much sense as turning off your sprinkler/irrigation system to help your lawn/farm because of a drought.
Or a doctor telling a patient suffering from dehydration to drink less fluids.
Or to cut back on emissions of CO2 because farmers don’t have enough storage space for the record smashing crops and production caused by CO2’s atmospheric fertilizer effect on all plants.
.
Now, I hope people can see
1. There is a debate, You just have to JOIN IT.
2. You can get published.
3. Providing a better answer is always welcomed. Straight up crazy denial… well, nobody important listens to that.
important, how ?
your drive-by advice carries the exact same weight.
Maybe Mosh amuses himself better than he amuses other readers, but his point about the ‘crazy denial’ commenters should be repeatedly made. Some of it is pretty lightweight/frothy and yes, it does devalue an excellent blog in the eyes of the outside world.
Mosh makes a solid point.
Steven Mosher, meanwhile back at Eli’s I run into my old friends who continue to call me a denier and get upset when I mention the science isn’t settled. This morning I was so upset after watching Mr. Kennedy threaten to send me to jail I wrote a post saying I was going underground…..but I may decide to stay and just keep using this name.
Steve Mosher says: “Straight up crazy denial…”
Denial of what? Can you not be specific?
It is published.
Mosh, yes you can get published NOW. Indeed the Team in shock has quietened down in the publishing sphere both in preparing new papers and in gatekeeping and intimidation of editors. We’re getting stuff from them published now about climate change depression and crying jags. What kind of debate is that? The As a lukewarmer, surely you, yourself weren’t impressed by the premier published scientists at IPCC estimates of future warming 4-6C. It is indeed skeptics like Nick Lewis that have caused the IPCC to trim their ECS estimates. I don’t think there can be any doubt that hundreds of billions were simply wasted on non-science before sceptics got a critical mass together. If the cats were still away, the mice would still be playing. Even with the lighter commenters, WUWT is the most important thing to have happened in climate science. With the thankless battle against global, large, establishment, rent-seeker science, journalism and politicians, it is also no wonder that many sceptics may have become a bit cynical. Hey, the establishment refuses to debate anyway and no one needs to teach them anything about mockery and jeering.
mosher, you’re really slumming now, showing up at WUWT.
that you would grace us with your thoughts is truly some kind of an honor.
the memories might last for……seconds
Mosh says:
“There is a debate, You just have to JOIN IT.
Straight up crazy denial… well, nobody important listens to that”
I think your last point is what has driven so many away from the “debate” in frustration. Not being listened to and being generalized by insults.
If the the news is any indication, “nobody important” listens to well-reasoned arguments and data either.
ps Do I really need to publish the fact that for nearly a generation CO2 and temperatures show no relation? Isn’t this true whether I publish it or not? The fact that “important” people ignore this and leverage the climate change meme for their own gain while others fall silent serves as a discouraging counterpoint to your latest drive-by.
As opposed to hand-waving, crazy pronouncements of doom that constantly need to be revised because we should already be doomed by now. Is there a difference between denial and skepticism? What about the old canard “show me.” If you are claiming something, then prove it. It isn’t up to me to disprove your claim. And so far, warmists are batting zero. Why is my refusal to believe their nonsense counterproductive compared to their complete failure to substantiate their claims?
Well, Mosher does get an acknowledgement at the end of the Lewis and Curry paper for providing helpful comments. It seems like he goes back and forth on that.
TCR is defined as temperature change at the end of a 70 years long period while CO₂ is increasing at a steady 1% annual rate. However, actual rate is less than 0.5% (0.43% in the last 55 years), therefore a TCR of 1.3°C implies 0.56°C (1°F) change by 2084, provided CO₂ keeps increasing at the same rate (so it would be ~540 ppmv by that time).
However, safe and abundant nuclear energy will be available sooner than that and atmospheric CO₂ will become the default raw material of molecular manufacturing based on programmable self replicating assemblers, so catastrophic CO₂ depletion is a more imminent danger, killing all plant life off, to be followed by mass starvation. It could be replenished any time using limestone, but huge quantities of lime milk, as a byproduct, could lead to dangerous ocean basification.
It is only prudent to preload the atmosphere with the stuff as much as practicable while we can afford it.
Add Bob’s work on estimating oceanic/atmospheric teleconnected recharge/discharge chaos combined with overturning circulation, and all the added heat is likely natural. On to the next thing watermelons can jump on. They can use the same signs, posters, and banners. Just white out whatever they were warning us about and put something else in there. Good to go.
The only thing that would prove elevated CO2 is effecting temperature is if it bumped us out of the current ice age, which isn’t due to end until Antarctica moves off the South Pole, Panama sinks and the Arctic Ocean opens up. THEN, I’d believe it.
This is a “destructive” paper, and none the worse for that.
If the analysis stands up, and I’m not qualified to audit it, then all it actually demonstrates is that, BASED ON THE IPCC’s OWN ASSUMPTIONS, CO2 sensitivity is very modest, and anthropogenic CO2 is nothing to fear. Of course, most of the criticisms seen in this blog above criticise the underlying (IPCC) assumptions, but that’s not fair as it doesn’t pretend to address those questions. As far as it goes, excellent. It isn’t the last word, but it ought to get substantial coverage, though I doubt that it will reach the headlines..
Is that a fair summary?
Pretty good, moth catcher. So, is your avitar a bat? My most favorite opera is Die Fledermous.
So climate is always changing; even now they all scream at us.
So just when will we reach climate equilibrium, that this paper mentions??
Earth rotates, therefore weather is never in equilibrium. Climate is the integral of weather.
Ergo, climate is never in equilibrium.
Any system in thermal equilibrium, must be isothermal. That’s a three dollar word for ” all at the same Temperature.”
Take a look at the recent post at unrealclimate. Its about methane and come to think of it I’ve seen quite a number of recent articles regarding the catastrophic consequences when methane gets released from thawing tundra or from clathrates at the bottom of the sea.
I predict that what we are seeing is a pivot away from the dependence of climate catastrophe’s on the concentration of CO2. Methane has far greater “greenhouse” potential than co2 and the increase of 1-2C will be the “trigger” for huge releases in methane that will be the tipping point for large increases in temperature not achievable by co2 alone.
Does this paper take into account all the heat that the Koch brothers have been hiding deep in the ocean?
We should have a poll on what value of ECS people think is correct.
Exactly. And whatever the majority of people think will be “settled science.” Wasn’t “science” a by-product of the enlightenment whose purpose was to move beyond religion and philosophy as a theory of knowledge by demonstrating through empirical evidence and observations facts that could stand on their own? I see very little “science” in the current state of climatology. I commend the efforts of this study to use the warmists own facts against their stated conclusions, but I agree with others in this thread that the study does little to advance the actual science.
rgbatduke – re: press coverage – not sure you are right. David Rose of the UK’s Daily Mail was at Nic Lewis’s dinner party with Anthony, plus David Whitehouse of GWPF. The Australian carried Steve Koonin’s WSJ piece too. I think this will get some traction.
“The preferred pairing is 1859–1882 with 1995–2011, the longest early and late periods free of significant volcanic activity, which provide the largest change in forcing and hence the narrowest uncertainty ranges.”
I understand the power of using the IPCC’s own data to chop the estimates, but I’m wondering what those estimates would be if we hadn’t added on at least 0.3-0.5C to the 100 year warming by pushing down the temps of the first half and jacking up those of the second half. Yeah, I know all about TOBS etc and the rationale, but definitely every 0.1C that could be added (or subtracted from the early part) without setting off alarm bells, to tilt the temperature curve upwards WOULD be done. You can be sure every metric that supports the meme would be pushed in the desired direction. It is human nature. Indeed, in the corporate sphere, anti-trust laws ARE violated if two or more companies had an opportunity to collude!!! If the not-so-big-these-days 3 auto makers’ presidents were seen together having a drink on their holidays in Palm Springs, or sharing a taxi, or even being in the same hotel, or on the golf course, you wouldn’t need any tape recording. They would be automatically guilty of unfair trade practices. This is equally true for the ‘clime syndicate’ (thanks Mark Steyn) who depend on cash flow from gov. Too bad anti-trust can’t be invoked for the syndicate – they wouldn’t even deign to meet in such a shabby place as Palm Springs.
Without wading through the paper, does this imply that we now sufficiently understand atmospheric processes such that it is no longer a “travesty” that we can’t explain the lack of warming over the past 2 decades, despite more than 1/3 of all man’s CO2 being pumped into the atmosphere over that period?
first, read the paper. It is free, so no excuses.
Second, not it does not answer the question you pose. It only provides one partial rational. It very specifically tries to eliminate natural variability to the extent it can.
Congratulations, Dr. Stokes and Dr, Curry.
This looks like a very solid paper, once again pointing to lower climate sensitivity.
Sorry, I meant Dr. Lewis.
Stokes would be having a stroke if he wrote anything that wasn’t alarmist.
mothcatcher
September 24, 2014 at 1:37 pm
“Maybe Mosh amuses himself better than he amuses other readers, but his point about the ‘crazy denial’ commenters should be repeatedly made. Some of it is pretty lightweight/frothy and yes, it does devalue an excellent blog in the eyes of the outside world.”
===========
Gottya, less is more.
Must not upset the “outside world” view.
I can get even frothier if you want, just say go.
For anyone who missed it, read this comment:
Rud Istvan September 24, 2014 at 12:42 pm
in response to this comment:
mpainter September 24, 2014 at 9:43 am
Lewis and Curry use IPCC’s own data, assumptions and estimates to shoot down the AR5 conclusions. As Mr Istvan says: “A falsification as powerful as the pause, using different means.” The name of this article also gives you a great big hint: “…lowers the range of climate sensitivity using data from IPCC AR5”.
Interesting.
I merely used this for the same point. Anyone seen this before or know of a newer version?
http://cosmoscon.files.wordpress.com/2011/12/co2-vs-temp.jpg
I guess grabbing the tables off woodfortrees and displaying them myself would do the job.
As goes climate sensitivity, It seems basically linear.
http://www.nebulousresearch.org/other/archibald/archibald-33.jpg
The steepness of the linearity is erm, Lets say flatlined.
A hockey stick! (inverted)
Congratulations to both Nic Lewis & Judith Curry on this landmark publication. Wow. Hot stuff!
Steven E. Koonin (https://en.wikipedia.org/wiki/Steven_E._Koonin) remarked, in his recent WSJ essay
http://online.wsj.com/articles/climate-science-is-not-settled-1411143565 “Climate Science Is Not Settled,” that
“Today’s best estimate of the [climate] sensitivity (between 2.7 degrees Fahrenheit and 8.1 degrees Fahrenheit) is no different, and no more certain, than it was 30 years ago. And this is despite an heroic research effort costing billions of dollars.”
Good to see Lewis & Curry resolving this conundrum, and on a considerably lower budget!
1. Climate sensitivity is not a constant across all climactic states. It is the sum total of numerous forcings and feedback mechanisms, which themselves are not constant across climactic states (e.g. ice albedo feedback.) It should be no surprise that climate sensitivity estimates derived using recent observations should differ from those derived from paleo data (e.g. the last glacial retreat.)
2. Antarctic ice extent (particularly it’s anomalous expansion despite warming temperatures) may explain the difference between model estimates of climate sensitivity and recent observations. I don’t believe any models predicted that warming would result in expanding ice coverage and therefore negative ice albedo feedback for the southern hemisphere.
They were very good OTOH at predicting positive albedo feedback for decreasing arctic ice.
BTW it is not a negative feedback. A positive feedback amplifies its cause; a negative feedback dampens it.
So, the feedback of growing sea ice is a positive feedback even when it works to reduce temperatures. It works in both directions in an amplifying, i.e. “positive” manner, in feedback-lingo.
DirkH is right. Looking at the interaction between negative and positive feedbacks is the only [way] to understand a dissipative complex nonlinear system such as climate. If we lose the ability to even correctly define and talk about positive and negative feedback then any remaining chance of understanding climate goes out of the window. This is instead the beginning of a retreat from symbolic language and the unevolution of sentience.
ook ook
[? One of those is definitely misspelled, but I can’t figure out which one. .mod]
OK, so try to make a “clear and concise” “feedback” term for the following:
Increasing Arctic sea ice loss during a time of assumed Arctic warming increases heat loss and cools the planet.
Increasing Antarctic sea ice gain during a period of measured cooling Antarctic air temperatures cools the planet.
There is a suggestion that the IPCC could have done this had they wanted to. Any idea who didn’t want to?
=============
all of them?
Real simple. The lead authors. Look again at the official published WG1 excuse for not providing an AR5 best estimate. Something about reality not agreeing with the CMIP5 models they relied on.
HUGE.
But they’re still 95% confident in whatever they are saying, or not saying:) Or is it now 97%?
Thanks, Rud.
==========
Estimates of climate sensitivity: “are derived using the … uncertainty ranges for forcing components provided in [AR5].”
AR5’s forcing estimates assume that no mechanism of “solar amplification” is at work and the error bars on the AR5 solar forcing estimates do not include any estimate of the possibility that other solar forcings besides TSI could be at work, despite the overwhelming evidence for SOME solar driver of climate more powerful than TSI.
Nic and Judith acknowledge this omission at the bottom of page 6 of their PDF:
Their exercise proceeds in accordance with the IPCCs assumption that most late 20th century warming was caused by CO2 and notes how, even on this assumption, the lack of 21st century warming causes the estimated warming effect of CO2 (in the form of the estimated climate sensitivity) to be reduced considerably.
If it turns out that some powerful non-TSI solar driver is in play and that 20th century warming was largely caused by the high level of solar activity from 1920-2000 (Usoskin’s “grand maximum” dating), then the warming that is left to attribute to CO2 becomes that much smaller still. It is very much in prospect that the actual climate sensitivity is substantially less than one (negative feedback).
Great, so it turns out there was no problem after all. We can all now go home. Thanks for the great job Anthony. Last person to exist the web site please turn off the server.
I can’t tell if you are kidding or not.
It would however have been a great waste of time, money, and scientific talent.
Except for the data collected.
Which is not to say another scare story won’t be coming down the pipeline.
Might wanna keep the server warmed up 🙂
ECS with the highest probability in the plot is about 1.25 deg. Perhaps even lower with a proper temperature data set.
They still haven’t taken solar cycles into consideration.
I said it was 1.25 degrees over 5 years ago
markstoval
September 24, 2014 at 11:40 am
“To be “cured” against one’s will and cured of states which we may not regard as disease is to be put on a level of those who have not yet reached the age of reason or those who never will; to be classed with infants, imbeciles, and domestic animals.” ― C.S. Lewis
The ideo_logues understand this well. That is why first they enter professions and seek office in institutions that will dumb down the populace, even (or especially) in the lefty progression of university teaching such that they will make infants, imbeciles and domestic animals out of them. They take over NGOs, the environmental portfolio because these already are full of zealots and and an endless supply of ready-to-serve useful idjits.
This fight is far from over. But nature will eventually settle the debate one way or another no matter how many times politicians and climate scientists may suggest that the debate is over.
However, this paper does show the problems facing AR6.
If there is no warming between now and 2018, and if the data comprising the second period is extended out to 2018 rather than being cut at 2011, and if there are no volcanos through to 2018, AR6 will have to fess up that climate sensitivity is far lower than previously suggested.
Couple that problem to the fact that. if there is no warming between now and 2018, all models will be out of the 95% confidence band, and AR6 is looking like it will be a very difficult report to write.
The 2015 climate conference really might be the last gasp because the potents looking ahead are not good from those in the warmist camp.
Richard, never mind AR6. It is Paris 2015, and “OBummer” that is the present political fight. Please enlist.
No, you are missing the real point here. The missing heat has gone even deeper into the depths of the oceans than we had at first thought.
I do not believe that the IPCC will ever climb down from its position that climate model projections are correct. In my view this organization is in the grip of persons who are dedicated to a cause, not to scientific verity. It will only change when such persons are removed from their positions of influence.
OT: I have improved the photo of the Bath-dinner and would like to email it to Anthony/WUWT. Is there an email address that I can use for this? David Greene. My email address: 301parkave at gmail dot com
FYI for those wanting to run Lewis’ code – found a minor problem.
Paths weren’t coded properly / were hardcoded with Lewis’ PC’s directory structure.
Lines 217 & 218 should be replaced with:
AR5hc= matrix(scan(paste(path.heat, ‘/heat_ascii_v6.txt’, sep=””), skip=1, quiet=TRUE), ncol=13, byrow=TRUE)
colnames(AR5hc)= scan(paste(path.heat, ‘/heat_ascii_v6.txt’, sep=””), what=’character’, nlines=1)
First of all congratulations to Nic and Judy for getting this (C)AGW busting paper into the literature.
Now, as others have mentioned this paper assumes all warming is caused by CO2. Several analysis I’ve seen limit the CO2 warming to a maximum of 60% (probably less). That would reduce the real TCR to 1.33*.6 = .8C.
This would indicate either negative feed-backs are in place or there are some errors in the way CO2 warming is specified in the literature. Probably both.
I recall that within the last few months Dr. Curry on her blog suggested that about 50% of the warming appeared to be due to natural variation (predominantly ocean cyclyes).
When you take that into account, and when you consider the implication of the many adjustments that have been made to the temperature record that have made the past coler and the present warmer, when you account for station drop outs, and pollution by UHI, it is probably that the TCR is very much less than the figure you suggest.
I am with Brian H, that when all is done and dusted, say in 20 years time, it will probably be seen to be approximately 0 degC, or at any rate, so small that the signal cannot be measured using our best measuring equipment. It will probably all be seen to be lost in the noise of natural variability.
Come on, all you do is stir the pot here, now you feel put upon ?
I thought you had a funny story.
Among “Climate Scientists” Richard Lindzen and Judith Curry stand out.
Richard has the “Gravitas” to address august bodies such as the British “House of Parliament”.
Judith Curry engages with the general public better than anyone. Not even the redoubtable Anthony Watts can match the volume of comments that Judith’s posts attract.
That said I am disappointed that Richard and Judith imagine that there is some validity to the 1896 hypothesis by Svante Arrhenius that says:
“The selective absorption of the atmosphere is……………..not exerted by the chief mass of the air, but in a high degree by aqueous vapor and carbonic acid, which are present in the air in small quantities.”
The Arrhenius hypothesis is nonsense but it lingers on because the CO2 concentration in the atmosphere has correlated with global temperatures over the last 800,000 years.
Thanks to ice cores we have a precise record of temperature and [CO2]. These records show that the correlation is a consequence of Henry’s law rather than the Arrhenius hypothesis:
http://diggingintheclay.wordpress.com/2013/05/04/the-dog-that-did-not-bark/
Arrhenius was first refuted by Wood (1909), whose experiments/results are easily repeatable. Unlike Arrhenius and those who follow in his footsteps who can’t be bothered to do actual experiments or stuff like that. Here’s a thorough discussion:
http://greenhouse.geologist-1011.net/
Arrhenius has been refuted so completely, it’s really a joke that his “Greenhouse Effect” is taken seriously by climate ‘scientists’. Obviously, these guys have never had a real greenhouse so don’t have a clue how it actually does what it does.
Thanks for that! So any scientist should know that CO2 is not the dominant driver of climate that Arrhenius claimed.
So why are governments around the world trying to reduce CO2 emissions when they should know it will have no detectable effect on global temperature?
gallopingcamel September 25, 2014 at 6:43 pm
They should. And I find it hard to believe that any of them don’t know it. Therefore:
The perpetrators of CAGW never intended to do science. And they have not. They simply provided a plausible cover story for a political agenda, then shouted down, intimidated and silenced anyone who objected. The agenda isn’t about global temperatures or saving Gaia or the polar bears. It’s not even about CO2. It’s about control and power. The same pig, new lipstick.
I too believe, as others have aluded to, that ECS and TCR are not only a function of the doubling of CO2 but also a function of ([H2Osolid],[H2O liquid],[H2Ogas]) in the atmosphere. Unfortunately these concentration vary so widely over short, medium and long terms and spatially across the planet that an “average” of these values over a 70 year period would be meaningless. The strongest function affecting the local influence of CO2 is how much water(liquid) is present in the atmosphere. There is no way that these calculated numbers can be constants! Why? Because CO2 is scrubbed from the atmosphere by liquid water. Because warming up liquid water in the oceans raises the local CO2 concentration. Because, in the presence of high humidity, CO2 plays practically no role whatsoever in the green house effect. Because on any given day, or during any given month, or even over several years the cloudiness of any given location (or the snowiness) drastically affects the reflection of heat back into space regardless of the local CO2 concentration. And because in the few locations on planet earth where [H2O] is low enough for CO2 to actually have a green house effect, the local temperature swings widely from mid-day to darkest night! Face it, measuring CO2 at one spot on the planet where there is minimal influence of water vapor and then believing that your measured value can somehow CAUSE a fixed effect on the overall temperature of the planet is simply too naive – IMHO. CO2 is denser than water vapor. Water vapor can get higher into the atmosphere at higher concentrations and can condense and fall back to earth carrying CO2 with it. To try to get an estimate of these two “constants” by comparing a perceived period when the inflence of CO2 should have been “low” and when it should be “high” assumes of course that the [CO2] in the atmosphere was accurately measured during these two time periods – the world over! So call me skeptical. To show any single variable affect of a doubling of CO2 where CO2 is actually CAUSING the effect, and not be effected by the actual cause, you will need to show me similar calculated results from more than just two 70 year periods where the numbers actually agree with each other. More importantly, the cause -> effect needs to be demonstrably CONSISTENT. . . . ie. where one variable [CO2] is consistently rising, the other should also be consistently rising!!! At the very least someone should perfom these same three calculations at three distinct time periods that are separated along the curve where there is a measureable difference of CO2 and where the temperature was also measured AT THAT SAME SITE. In my humble opinion, even though the use of their own data showed just how improbable IPECACs predictions are, this paper still uses their data – “garbage in”. . . . . and we all know of course GI=GO.
PG,
As you are a Climate Activist lawyer, it is likely you are more attuned to the PR side of Climate Change than to the science-side anyway.
So I ask “what happens to Obama and his Climate Change dogma when the US goes through a brutal winter(or two)?” When temperatures winter temps plummet worse than last winter, and the GL’s freeze over even earlier? When people are freezing in their homes because his oil, gas, and electricity brought on by bad Obama energy policies?
Obama is an ideologue. He doesn’t recognize other opinions when his mind is set. But he does understand the politics of public opinion. Will he be forced to change his mind (like he had to on bombing Syria)? If you had asked Joe Biden or Obama 2 years ago what they thought the odds of them ordering US bombing (especially non government rebels) inside Syria, they’d have said “zero chance”. Biden was admamant that we were done with combat ops in Iraq.
Things change. and so will this fever called “climate Change.” Where will Climate Activist lawyers be then? In the bread-lines with the McKibben-ites, I hope.
Sorry I just can’t get my head around all this climate sensitivity stuff when my city of Adelaide shows this kind of min/max temperature forecast for various suburbs of the greater metro area-
Adelaide 9 21
Elizabeth 7 21
Glenelg 9 19
Noarlunga 11 20
Mt Barker 7 20
C’mon Big Climate modellers and BOM cheer squads. Surely if you can homogenise and mangle thermometers hundreds of kilometres apart you can manipulate one small city lot better than that?
http://www.bom.gov.au/sa/forecasts/adelaide.shtml
Most likely TCR = 1.33 C. The world has already warmed by at least 1 C since 1750. So expect 0.33 C warming when CO2 reached 560 ppm. Is that catastrophic? Unless the global warming since 1750 is not due to CO2. If so, it’s all natural climate change.
Is it Nicholas Stern AGW, warmist extraordinaire, the cause of such unwarranted hilarity?
It would have helped if we had had a thermometer in the middle of the Sahara, the Gobi, and Death Valley and recorded the nighttime temperature over the past 100 or so years.
Anyway, to include the natural variation part the period should cover enough time for an even number of hot/cold PDO/AMO regimes. In the last century we seem to have had two where el nino dominated and only one where la nina did. We’re in the 4th cooling period now-except we’re not cooling (yet, anyway).
But, whatever, we’ll continually refine the figures hopefully. And people will pay attention. Not so hopefully.
What I like about the paper is that Lewis and Curry have chosen different periods to compare …
… including 2 periods which are probably the very best to use in that volcanoes and the AMO cycles would not be expected to have a substantive impact on the results (1859-1882 versus 2005-2011).
The pro-AGW climate scientists are unlikely to have published the data using these two periods although they might have calculated it. But when they saw the results of this calculation, they would have just moved on to two other periods where cherrypicking would produce high numbers. But then, this is what they do
As important as this paper is, I want to take Nic and Judith to task a bit for not emphasizing how AR5, and by extension their own analysis, ignores the uncertainty in solar forcing. As I commented above, they do note that they are ignoring possible forcing effects from UV shift and any other mechanism of “solar amplification” (solar effects other than changes in total electromagnetic radiation, or TSI), but then in their discussion of remaining uncertainties they omit mention of this omitted variable.
This pattern appears both at the end of their abstract:
And at the end of their conclusion:
Aerosol forcing might be the most important uncertainty amongst the included uncertainties, and there are unknown unknowns that the authors cannot be faulted for omitting, but there is a huge known unknown — the magnitude of non-TSI solar forcing effects, that MUST be mentioned. As it stands, the paper’s summary conclusion about the sources of remaining uncertainty is just wrong.
I seem to recollect that in at least one his earlier climate sensitivity posts here at WUWT Nic Lewis was careful to note that any increase in the amount of 20th century warming that can be attributed to high solar activity would decrease the warming that can be attributed to CO2, which would decrease the implied climate sensitivity. Did this important proviso get jettisoned by the peer review process? If so, I think the details of that should be made public.
An entirely different approach described at http://agwunveiled.blogspot.com has a 95% correlation and determines climate sensitivity of zero.
The Lewis and Curry research is well done and provides encouraging results. But one question: given that the work is predicated on global conservation of energy, what is the uncertainty of the findings that results from the uncertainty in the global energy balance?
My question is prompted by my experience and the results of a fairly sophisticated energy balance measurement for a sizeable industrial melting furnace that showed an ~3% discrepancy between input and output energy. For me, intuitively, this suggests that the global energy balance is likely not very well known or accurate.
If this uncertainty was covered in the paper, and I missed it, please point me to the appropriate section of the paper.
Thanks
Dan
A quick run of the MODTRAN calculator shows us doubling CO2 shows a 2.78 Centigrade rise. What the calculation ignores is night time. So halve it and what do we get… 1.39 Centigrade.. Am I close enough when we consider the height of the stratosphere which gives a shorter night, will up that number around an eighth to ~1.6 Centigrade per doubling? 😉
Where’s the evidence that CO2 has ever caused warming?
Why has there been no warming for the past decade?
All evidence suggests CO2 changes are a result of temperature changes, NOT a cause.